
SiamHAS: Siamese Tracker with Hierarchical Attention Strategy for Aerial Tracking


Abstract
:1. Introduction
- We propose a target tracker with the strategy of hierarchical attention. After comparing with several state-of-the-art Siamese trackers, our SiamHAS reaps more stable robustness and precision in challenging scenes such as target occlusion, especially in various challenges in aerial scenarios, and achieves the desired goal.
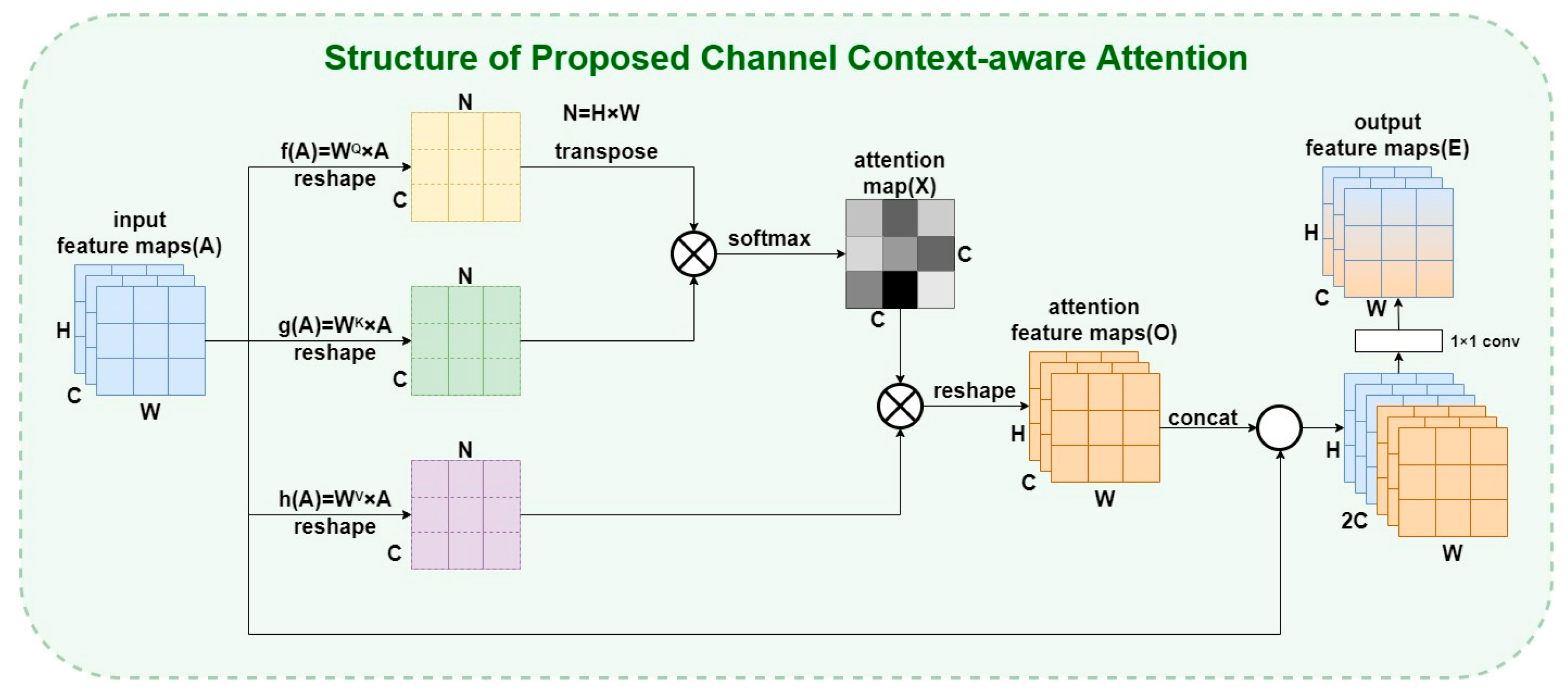
- In the feature fusion sub-network, a feature enhancement method integrating multiple attention strategies is introduced in this paper. With the channel context-aware mechanism, global context information can be included among different channels, which achieves feature enhancement in the channel dimension. The introduction of multiple modified Transformer encoders enhances the saliency of deeper features in each branch and effectively improves performance.
- Extensive comparative experiments on our proposed SiamHAS are conducted on many benchmarks with complex and challenging scenarios. The experiments demonstrate that our algorithm obtains high robustness in challenging scenarios, and the hierarchical attention mechanism and Transformer module can strongly improve the performance of the Siamese network-based tracker.
2. Related Work
2.1. Siamese Trackers
2.2. Attention Mechanism
2.2.1. Introduction to Attention Mechanism
2.2.2. Typical Attention Mechanisms in Computer Vision
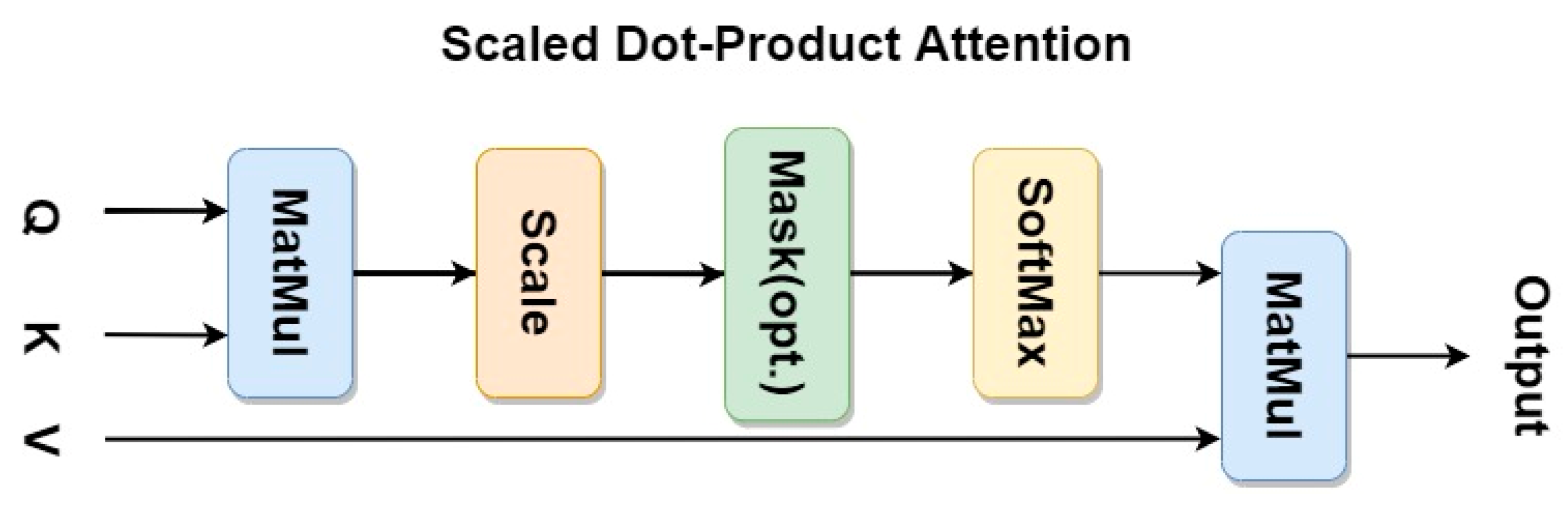
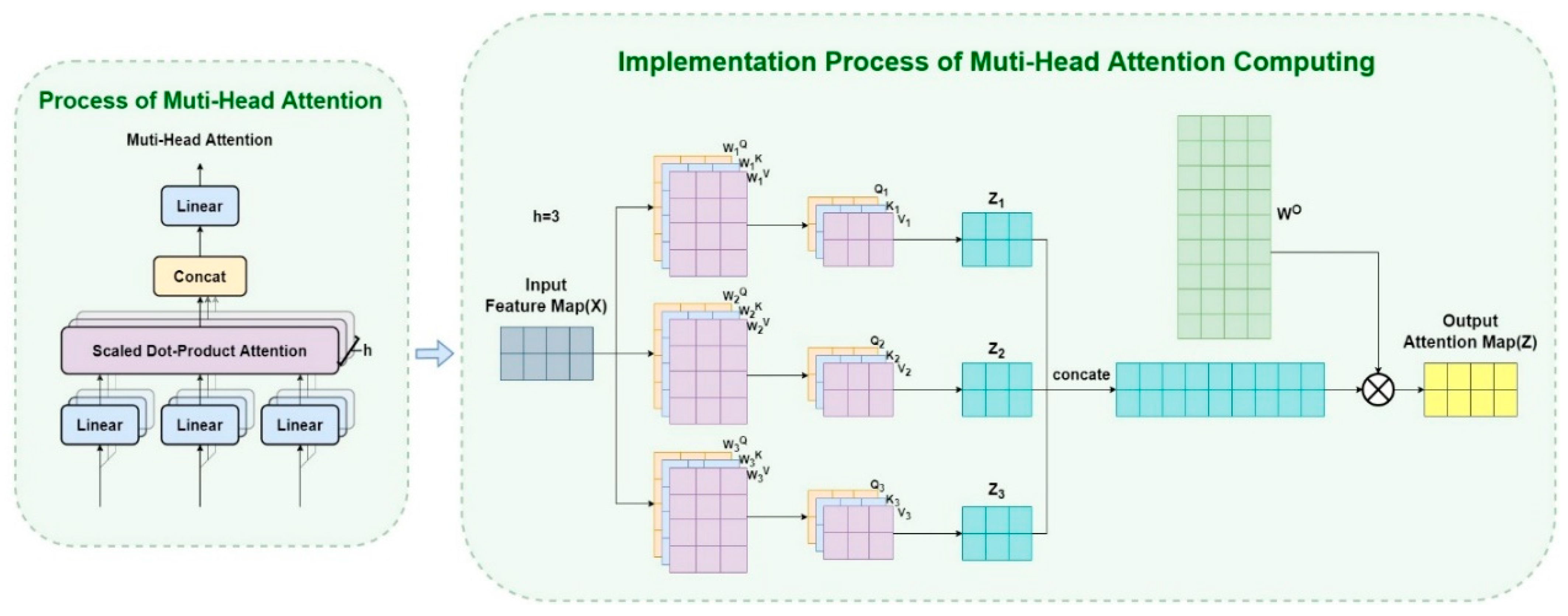
2.3. Transformer and Multi-Head Attention
3. Proposed Approach
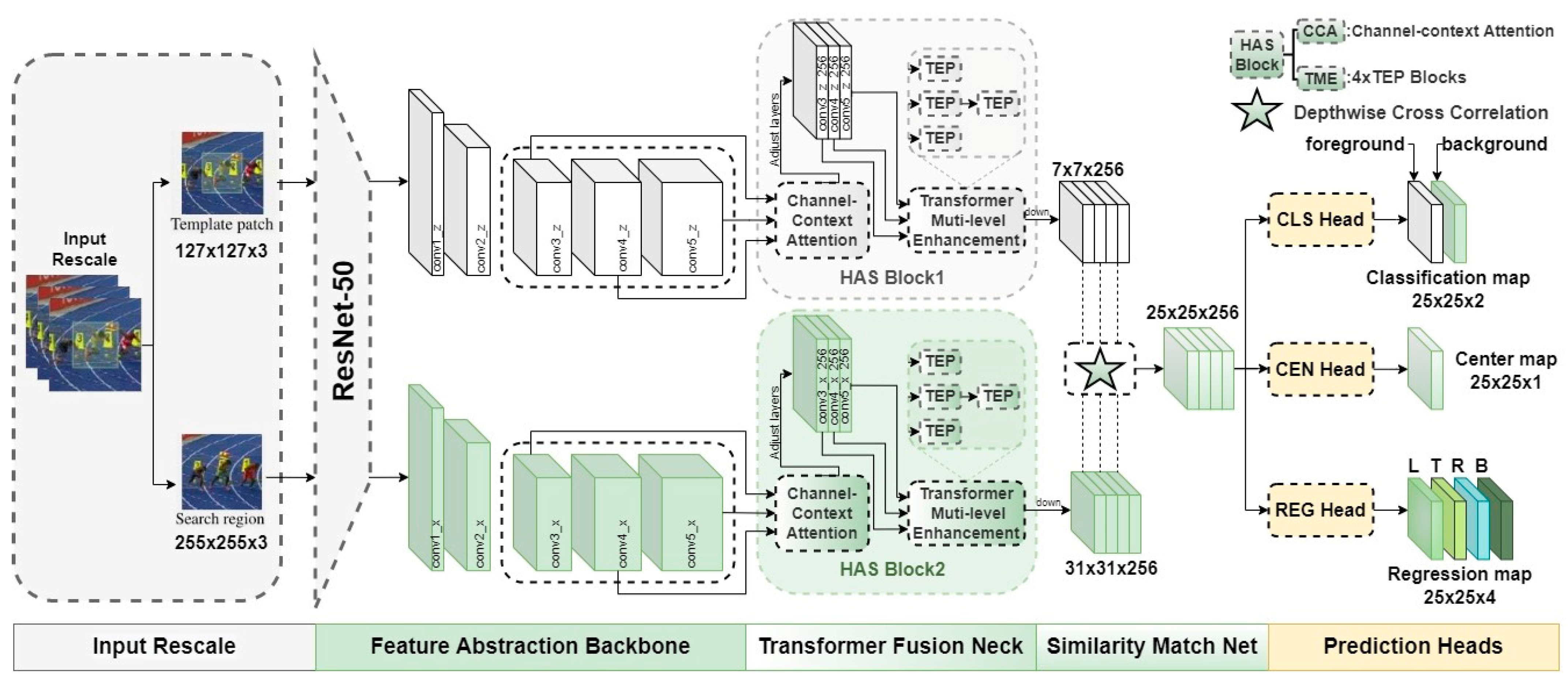
3.1. The Overall Structure of SiamHAS
3.1.1. The Proposed CCA Module: Channel Context-Aware Attention
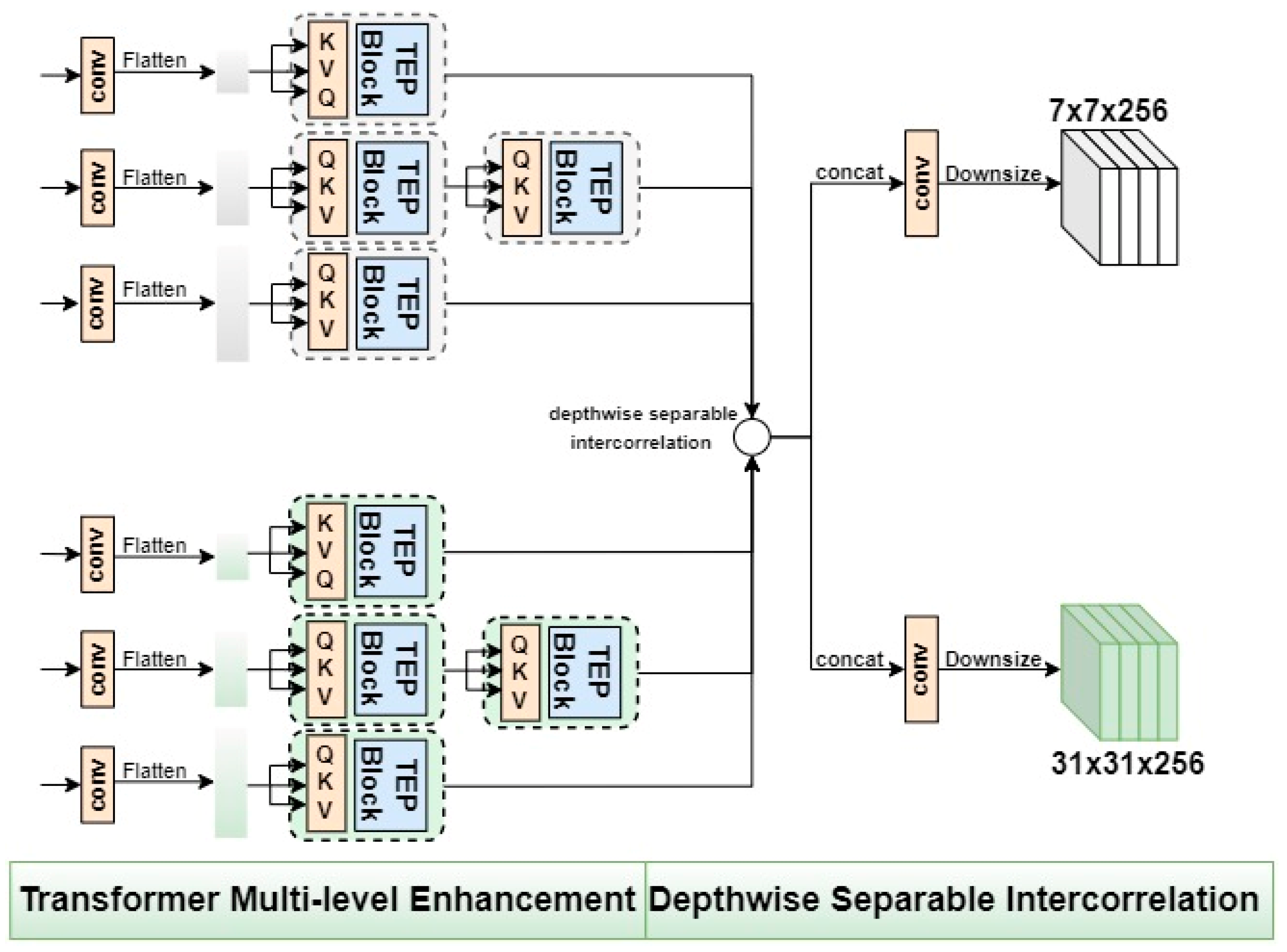
3.1.2. The Proposed TME Module: Transformer Multi-Level Enhancement
3.1.3. The Similarity Matching Net and Downsize Feature Fusion
3.1.4. The Prediction Heads
3.1.5. The Loss Function
4. Experiments and Discussion
4.1. Experiments Settings
4.1.1. Experiments Environment and Parameter Settings
4.1.2. Datasets and Pretreatment
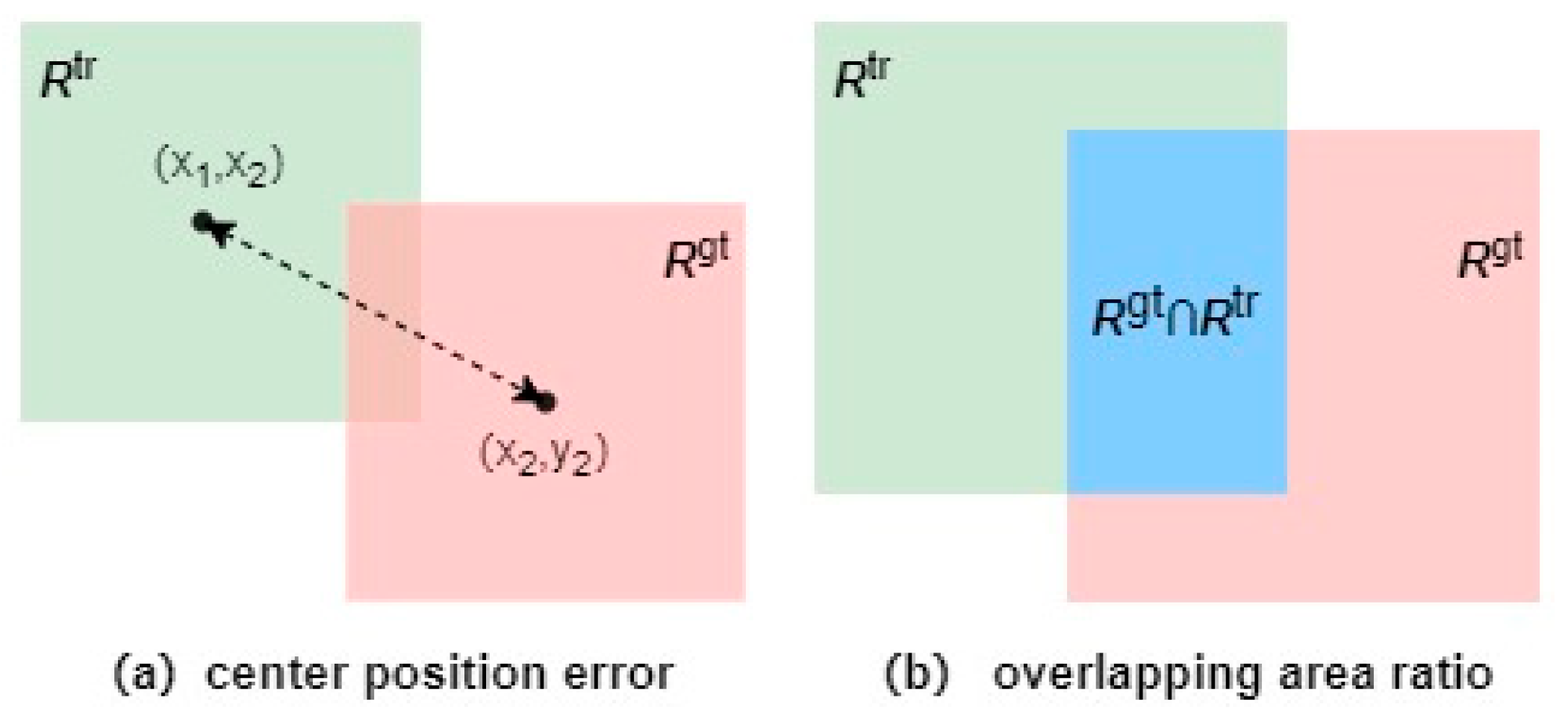
4.2. Evaluation Metrics
4.2.1. Precision
4.2.2. Success Rate
4.3. Performance Comparison
4.3.1. UAV123 Benchmark
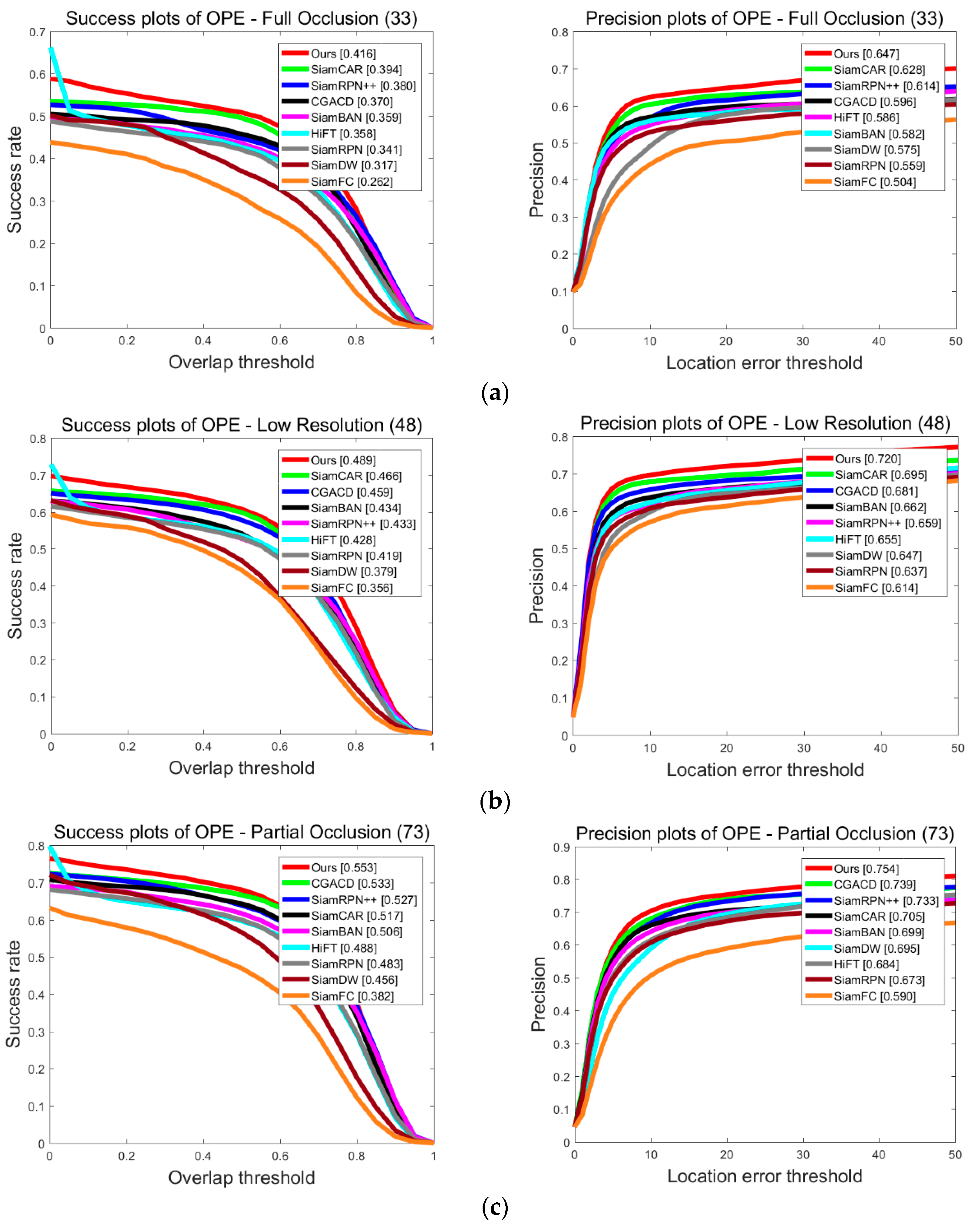
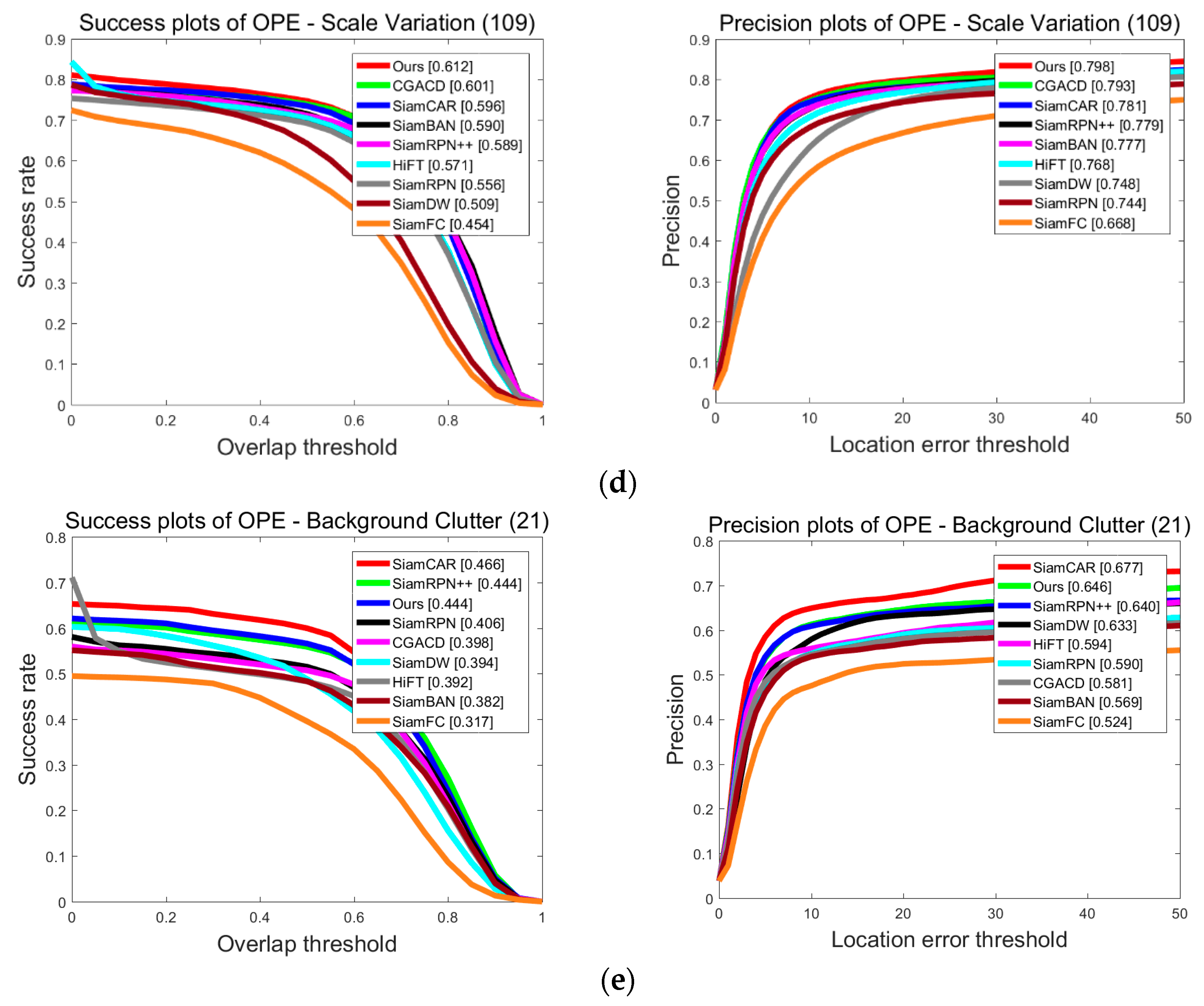
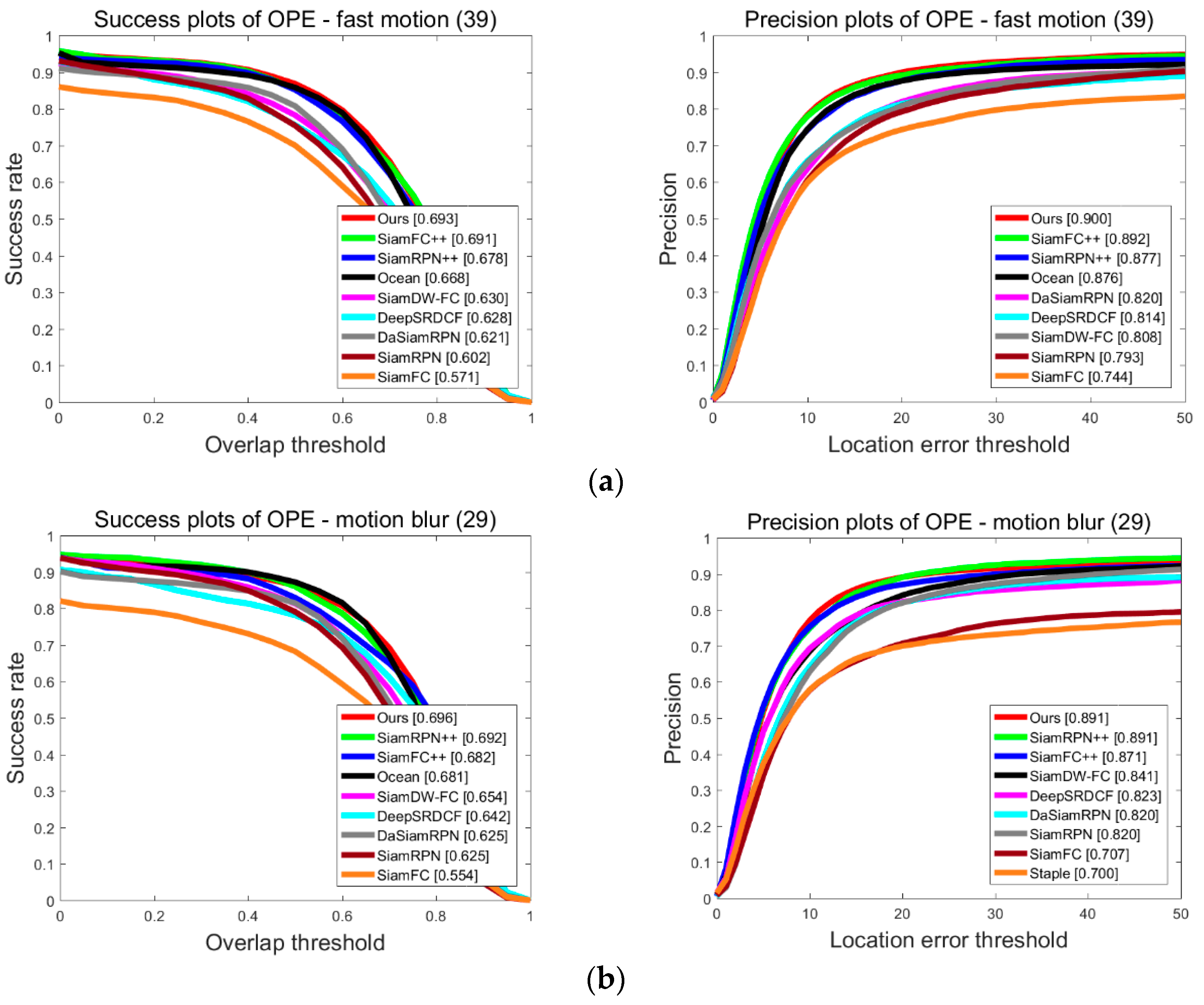
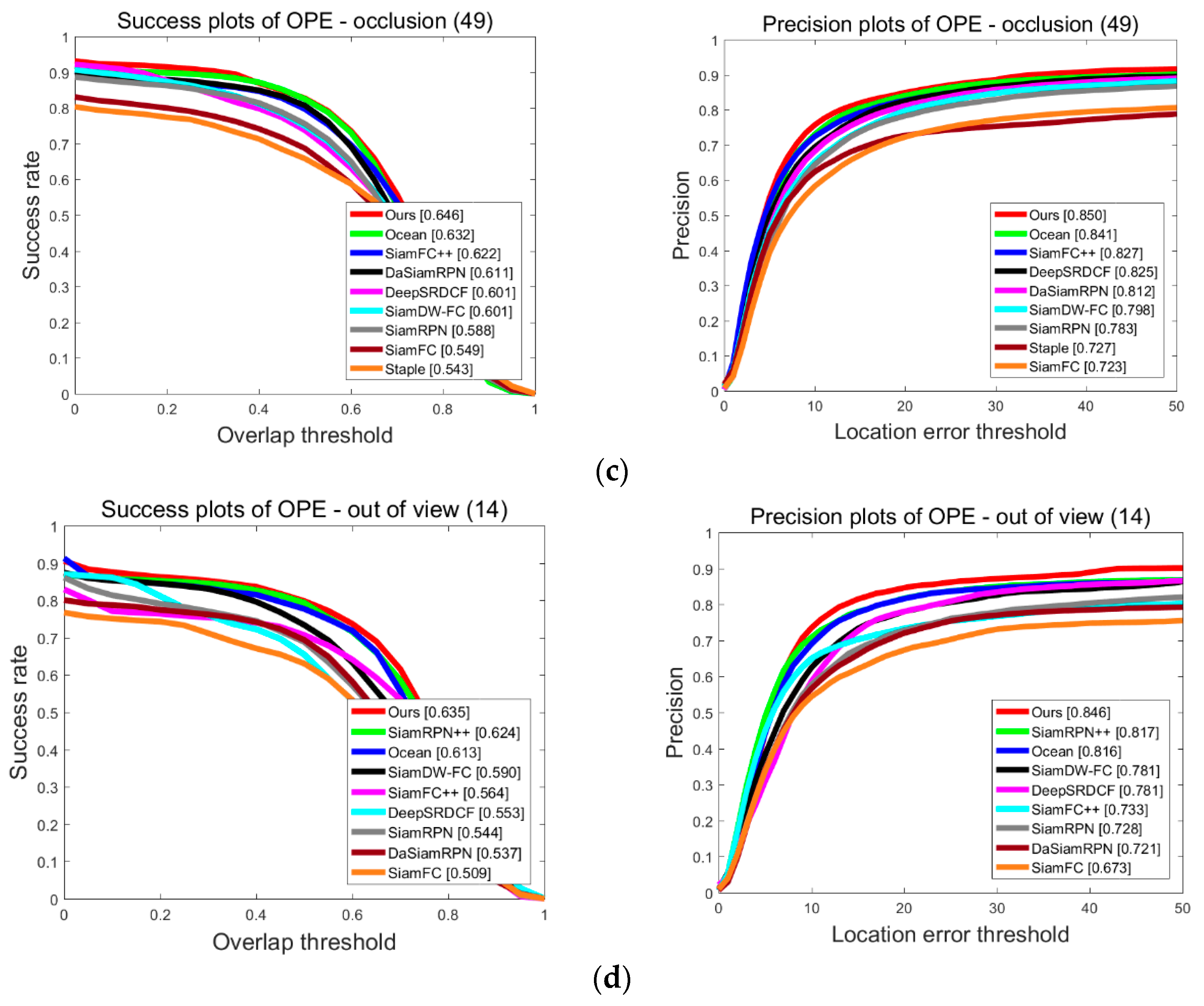
4.3.2. Attribute-Based Discussion on UAV123
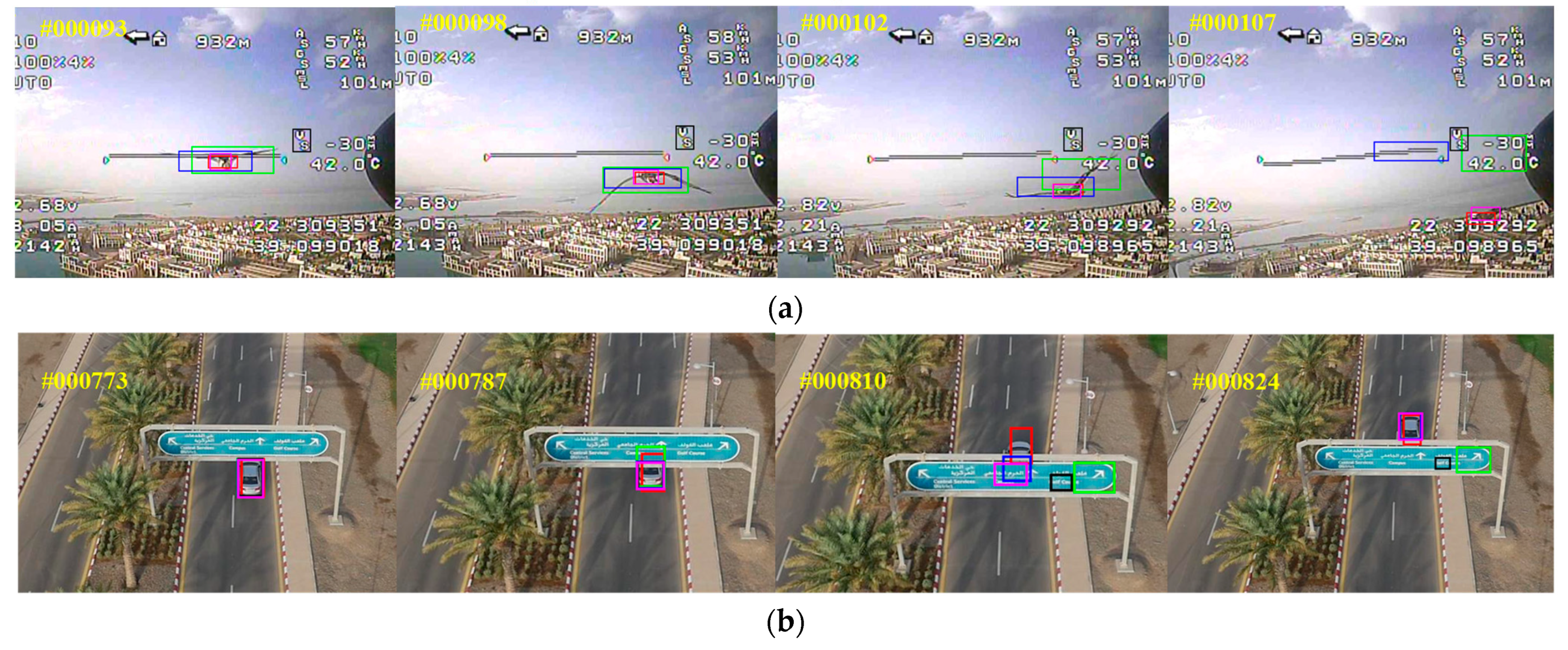
4.3.3. Case Visual Comparison on UAV123
4.3.4. UAV20L Benchmark
4.4. Quantitative Analysis
4.5. Discussion and Ablation Studies
4.5.1. Case Discussion on OTB100
4.5.2. Heat Map Experiment
4.5.3. Modules Ablation Experiment
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zuo, C.; Qian, J.; Feng, S.; Yin, W.; Li, Y.; Fan, P.; Han, J.; Qian, K. Deep learning in optical metrology: A review. Light Sci. Appl. 2022, 11, 39. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Jiang, S.; Song, L.; Peng, P.; Mu, F.; Li, H.; Jiang, P.; Xu, T. Automated optical inspection of FAST’s reflector surface using drones and computer vision. Light Adv. Manuf. 2023, 4, 1. [Google Scholar] [CrossRef]
- Huang, L.; Luo, R.; Liu, X.; Hao, X. Spectral imaging with deep learning. Light Sci. Appl. 2022, 11, 61. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Liu, T.; Singh, M.; Çetintaş, E.; Luo, Y.; Rivenson, Y.; Larin, K.V.; Ozcan, A. Neural network-based image reconstruction in swept-source optical coherence tomography using undersampled spectral data. Light Sci. Appl. 2021, 10, 155. [Google Scholar] [CrossRef]
- Kim, J.S.; Yeom, D.H.; Joo, Y.H. Fast and robust algorithm of tracking multiple moving objects for intelligent video surveillance systems. IEEE Trans. Consum. Electron. 2011, 57, 1165–1170. [Google Scholar] [CrossRef]
- Wang, S.; Jiang, F.; Zhang, B.; Ma, R.; Hao, Q. Development of UAV-based target tracking and recognition systems. IEEE Trans. Intell. Transp. Syst. 2019, 21, 3409–3422. [Google Scholar] [CrossRef]
- Cao, J.; Song, C.; Song, S.; Xiao, F.; Zhang, X.; Liu, Z.; Ang, M.H., Jr. Robust Object Tracking Algorithm for Autonomous Vehicles in Complex Scenes. Remote Sens. 2021, 13, 3234. [Google Scholar] [CrossRef]
- Wu, H.; Zhou, J. Privacy Leakage of SIFT Features via Deep Generative Model Based Image Reconstruction. IEEE Trans. Inf. Forensics Secur. 2021, 16, 2973–2985. [Google Scholar] [CrossRef]
- Nakada, S.; Meguro, T.; Zhao, Q. An Improved Approach for Generative Model-Based Product Image Anomaly Detection. In Proceedings of the 2022 IEEE International Conference on Consumer Electronics-Asia (ICCE-Asia), Yeosu, Republic of Korea, 26–28 October 2022; pp. 1–4. [Google Scholar]
- Lei, Y.; Ding, X.; Wang, S. Visual Tracker Using Sequential Bayesian Learning: Discriminative, Generative, and Hybrid. IEEE Trans. Syst. Man Cybern. Part B 2008, 38, 1578–1591. [Google Scholar]
- Jiang, N.; Su, H.; Liu, W.; Wu, Y. Discriminative Metric Preservation for Tracking Low-Resolution Targets. IEEE Trans. Image Process. 2012, 21, 1284–1297. [Google Scholar] [CrossRef]
- Shi, J.; Tomasi. Good features to track. In Proceedings of the 1994 IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 21–23 June 1994; pp. 593–600. [Google Scholar]
- Comaniciu, D.; Ramesh, V.; Meer, P. Real-time tracking of non-rigid objects using mean shift. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. CVPR 2000 (Cat. No. PR00662), Hilton Head, SC, USA, 15 June 2000; Volume 2, pp. 142–149. [Google Scholar]
- Bolme, D.S.; Beveridge, J.R.; Draper, B.A.; Lui, Y.M. Visual Object Tracking Using Adaptive Correlation Filters. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2544–2550. [Google Scholar]
- Du, F.; Liu, P.; Zhao, W.; Tang, X. Correlation-guided attention for corner detection based visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2020, Seattle, WA, USA, 13–19 June 2020; pp. 6836–6845. [Google Scholar]
- Nishimura, H.; Nagai, Y.; Tasaka, K.; Yanagihara, H. Object tracking by branched correlation filters and particle filter. In Proceedings of the 2017 4th IAPR Asian Conference on Pattern Recognition (ACPR), Nanjing, China, 26–29 November 2017. [Google Scholar]
- Su, Y.; Liu, J.; Xu, F.; Zhang, X.; Zuo, Y. A Novel Anti-Drift Visual Object Tracking Algorithm Based on Sparse Response and Adaptive Spatial-Temporal Context-Aware. Remote Sens. 2021, 13, 4672. [Google Scholar] [CrossRef]
- Nam, H.; Han, B. Learning Multi-Domain Convolutional Neural Networks for Visual Tracking. In Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4293–4302. [Google Scholar]
- Zhu, K.; Zhang, X.; Chen, G.; Tan, X.; Liao, P.; Wu, H.; Cui, X.; Zuo, Y.; Lv, Z. Single object tracking in satellite videos: Deep Siamese network incorporating an interframe difference centroid inertia motion model. Remote Sens. 2021, 13, 1298. [Google Scholar] [CrossRef]
- Huang, B.; Xu, T.; Shen, Z.; Jiang, S.; Zhao, B.; Bian, Z. SiamATL: Online Update of Siamese Tracking Network via Attentional Transfer Learning. IEEE Trans. Cybern. 2021, 52, 7527–7540. [Google Scholar] [CrossRef] [PubMed]
- Deng, A.; Liu, J.; Chen, Q.; Wang, X.; Zuo, Y. Visual Tracking with FPN Based on Transformer and Response Map Enhancement. Appl. Sci. 2022, 12, 6551. [Google Scholar] [CrossRef]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-Speed Tracking with Kernelized Correlation Filters. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 583–596. [Google Scholar] [CrossRef]
- He, A.; Luo, C.; Tian, X.; Zeng, W. Towards a better match in siamese network based visual object tracker. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops 2018, Munich, Germany, 8–14 September 2018. [Google Scholar]
- An, N.; Yan, W.Q. Multitarget tracking using Siamese neural networks. ACM Trans. Multimid. Comput. Commun. Appl. 2021, 17, 75. [Google Scholar] [CrossRef]
- Cheng, S.; Zhong, B.; Li, G.; Liu, X.; Tang, Z.; Li, X.; Wang, J. Learning to filter: Siamese relation network for robust tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2021, Nashville, TN, USA, 21–24 June 2021; pp. 4421–4431. [Google Scholar]
- Guo, Q.; Feng, W.; Zhou, C.; Huang, R.; Wan, L.; Wang, S. Learning dynamic siamese network for visual object tracking. In Proceedings of the IEEE International Conference on Computer Vision 2017, Venice, Italy, 22–29 October 2017; pp. 1763–1771. [Google Scholar]
- Tao, R.; Gavves, E.; Smeulders, A.W.M. Siamese instance search for tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1420–1429. [Google Scholar]
- Wang, L.; Ouyang, W.; Wang, X.; Lu, H. Visual tracking with fully convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision 2015, Santiago, Chile, 11–18 December 2015; pp. 3119–3127. [Google Scholar]
- Zhang, Z.; Peng, H. Deeper and wider siamese networks for realtime visual tracking. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4591–4600. [Google Scholar]
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High performance visual tracking with siamese region proposal network. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Xu, Y.; Wang, Z.; Li, Z.; Yuan, Y.; Yu, G. Siamfc++: Towards robust and accurate visual tracking with target estimation guidelines. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12549–12556. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Fan, H.; Ling, H. Siamese cascaded region proposal networks for real-time visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2019, Long Beach, CA, USA, 15–21 June 2019; pp. 7952–7961. [Google Scholar]
- Zhu, Z.; Wang, Q.; Li, B.; Wu, W.; Yan, J.; Hu, W. Distractor-aware siamese networks for visual object tracking. In Proceedings of the European Conference on Computer Vision (ECCV) 2018, Munich, Germany, 8–14 September 2018; pp. 101–117. [Google Scholar]
- Li, B.; Wu, W.; Wang, Q.; Zhang, F.; Xing, J.; Yan, J.S. Evolution of siamese visual tracking with very deep networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 16–20. [Google Scholar]
- Cao, Z.; Fu, C.; Ye, J.; Li, B.; Li, Y. HiFT: Hierarchical Feature Transformer for Aerial Tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 15457–15466. [Google Scholar]
- Chen, Z.; Zhong, B.; Li, G.; Zhang, S.; Ji, R. Siamese box adaptive network for visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2020, Seattle, WA, USA, 16–18 June 2020; pp. 6668–6677. [Google Scholar]
- Guo, D.; Wang, J.; Cui, Y.; Wang, Z.; Chen, S. SiamCAR: Siamese fully convolutional classification and regression for visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2020, Seattle, WA, USA, 16–18 June 2020; pp. 6269–6277. [Google Scholar]
- Zhang, Z.; Peng, H.; Fu, J.; Li, B.; Hu, W. Ocean: Object-aware anchor-free tracking. In Computer Vision–ECCV 2020, Proceedings of the 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 771–787. [Google Scholar]
- Niu, Z.; Zhong, G.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Guo, M.H.; Xu, T.X.; Liu, J.J.; Liu, Z.N.; Jiang, P.T.; Mu, T.J.; Zhang, S.-H.; Martin, R.R.; Cheng, M.-M.; Hu, S.M. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Brauwers, G.; Frasincar, F. A general survey on attention mechanisms in deep learning. IEEE Trans. Knowl. Data Eng. 2021, 35, 3279–3298. [Google Scholar] [CrossRef]
- Yang, B.; Wang, L.; Wong, D.; Chao, L.S.; Tu, Z. Convolutional self-attention networks. arXiv 2019, arXiv:1904.03107. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European conference on computer vision (ECCV) 2018, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2019, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Zhang, D.; Zhang, H.; Tang, J.; Wang, M.; Hua, X.; Sun, Q. Feature pyramid transformer. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 323–339. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Xing, D.; Evangeliou, N.; Tsoukalas, A.; Tzes, A. Siamese transformer pyramid networks for real-time UAV tracking. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision 2022, Waikoloa, HI, USA, 3–8 January 2022; pp. 2139–2148. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.-F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Computer Vision–ECCV 2014, Proceedings of the 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Huang, L.; Zhao, X.; Huang, K. Got-10k: A large high-diversity benchmark for generic object tracking in the wild. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1562–1577. [Google Scholar] [CrossRef] [PubMed]
- Mueller, M.; Smith, N.; Ghanem, B. A benchmark and simulator for uav tracking. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 445–461. [Google Scholar]
- Wu, Y.; Lim, J.; Yang, M.H. Online object tracking: A benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2411–2418. [Google Scholar]
- Cao, Z.; Fu, C.; Ye, J.; Li, B.; Li, Y. SiamAPN++: Siamese attentional aggregation network for real-time UAV tracking. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 3086–3092. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tracker | Ours | CGACD | SiamCAR | SiamRPN++ | SiamBAN | HiFT | SiamDW | SiamRPN | SiamFC |
|---|---|---|---|---|---|---|---|---|---|
| Success | 0.627 | 0.620 | 0.615 | 0.611 | 0.604 | 0.589 | 0.582 | 0.536 | 0.478 |
| Precision | 0.820 | 0.815 | 0.804 | 0.804 | 0.795 | 0.787 | 0.776 | 0.772 | 0.697 |
| Tracker | Ours | SiamAPN++ | HiFT | SiamAPN | SiamFC++ | SiamRPN | DaSiamRPN | SiamFC |
|---|---|---|---|---|---|---|---|---|
| Success | 0.573 | 0.560 | 0.553 | 0.539 | 0.533 | 0.528 | 0.547 | 0.423 |
| Precision | 0.745 | 0.736 | 0.736 | 0.721 | 0.695 | 0.696 | 0.676 | 0.629 |
| NO. | CCA | TME | Success-U | PRE-U | Success-O | PRE-O | FPS |
|---|---|---|---|---|---|---|---|
| 1 | × | × | 0.599 | 0.773 | 0.676 | 0.879 | 51 |
| 2 | √ | × | 0.601 | 0.789 | 0.681 | 0.881 | 49 |
| 3 | × | √ | 0.615 | 0.804 | 0.686 | 0.887 | 47 |
| 4 | √ | √ | 0.627 | 0.820 | 0.693 | 0.896 | 45 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, F.; Liu, J.; Chen, Q.; Wang, X.; Liu, C. SiamHAS: Siamese Tracker with Hierarchical Attention Strategy for Aerial Tracking. Micromachines 2023, 14, 893. https://doi.org/10.3390/mi14040893
Liu F, Liu J, Chen Q, Wang X, Liu C. SiamHAS: Siamese Tracker with Hierarchical Attention Strategy for Aerial Tracking. Micromachines. 2023; 14(4):893. https://doi.org/10.3390/mi14040893
Chicago/Turabian StyleLiu, Faxue, Jinghong Liu, Qiqi Chen, Xuan Wang, and Chenglong Liu. 2023. "SiamHAS: Siamese Tracker with Hierarchical Attention Strategy for Aerial Tracking" Micromachines 14, no. 4: 893. https://doi.org/10.3390/mi14040893