
A Deep Learning Approach for Predicting Multiple Sclerosis
 ,
,  , ,
, ,  , and
, and
Abstract
:1. Introduction
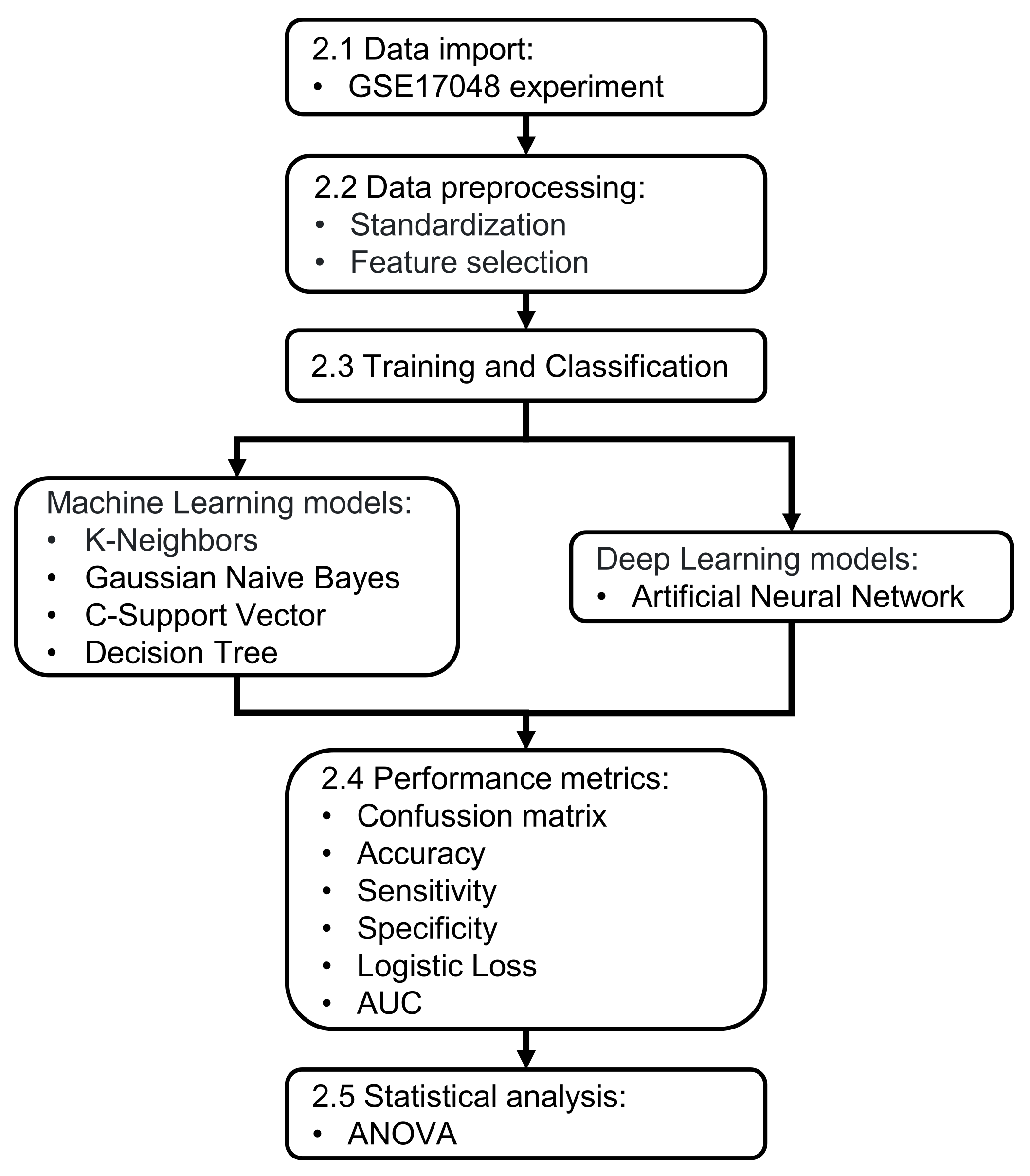
2. Materials and Methods
2.1. Data Import
2.2. Data Preprocessing
- Standardization: this technique normalizes the features by removing the mean and scaling to unit variance [11]. Overfitting is a common problem in ML and DL, where a model works well on the training data but not on the testing data, i.e., the model is too complex with a high variance [22]. To avoid overfitting, the input data are divided into 80% training () and 20% testing (), based on Pareto analysis [23]. Additionally, the output labels are separated into 80% and 20% for validation. After dividing the dataset, and are standardized.
- Feature selection: in linear models, the target value is modeled as a linear combination of the features [24]. After standardizing the training data, the dimensionality reduction technique: recursive feature elimination (RFE) with cross-validation is used to select the most important features [16]. Given an external estimator that assigns weights to features (for example, the coefficients of a linear model), the RFE goal is to select features recursively, considering smaller and smaller sets of them. First, the estimator is trained on the initial set of features. The importance of each one is obtained either through any specific attribute, such as coefficients value (weights assigned to the features, coef_) or feature importances (the impurity-based feature importances, feature_importances_). Then, the least important features are pruned from the current set. That procedure is recursively repeated on the pruned set until the desired number of elements to select is eventually reached. RFE with cross-validation (RFECV) performs RFE in a cross-validation loop to find the optimal number of features. The scoring strategy ”accuracy” optimizes the proportion of correctly classified samples.
2.3. Training and Classification
- Machine learning models: The K-Neighbors (KN) [25], Gaussian Naive Bayes (GNB) [26], C-Support Vector (CSV) [27], and Decision Tree (DT) [28] techniques are trained with the most relevant genetic features selected by RFECV method. The Anaconda 3 2021.05 (Python 3.8.8 64-bit) software and the open-source development internet application Jupyter Notebook are used to generate the pseudo codes that are executed on a personal computer with Windows 10 Home, 11th Gen Intel Core i5-1135G7 2.4 GHz processor, 8 GB memory, and 500 GB hard disk. Hyperparameters are the settings that can be arbitrarily configured before starting the training process to optimize the model performance, e.g., in Random Forest-based algorithms, the number of estimators (number of decision trees) and the criterion or impurity measure. In contrast, model parameters, such as weights in neural networks, are learned during the model training process [29]. The hyperparameters of the four ML techniques are set by default.
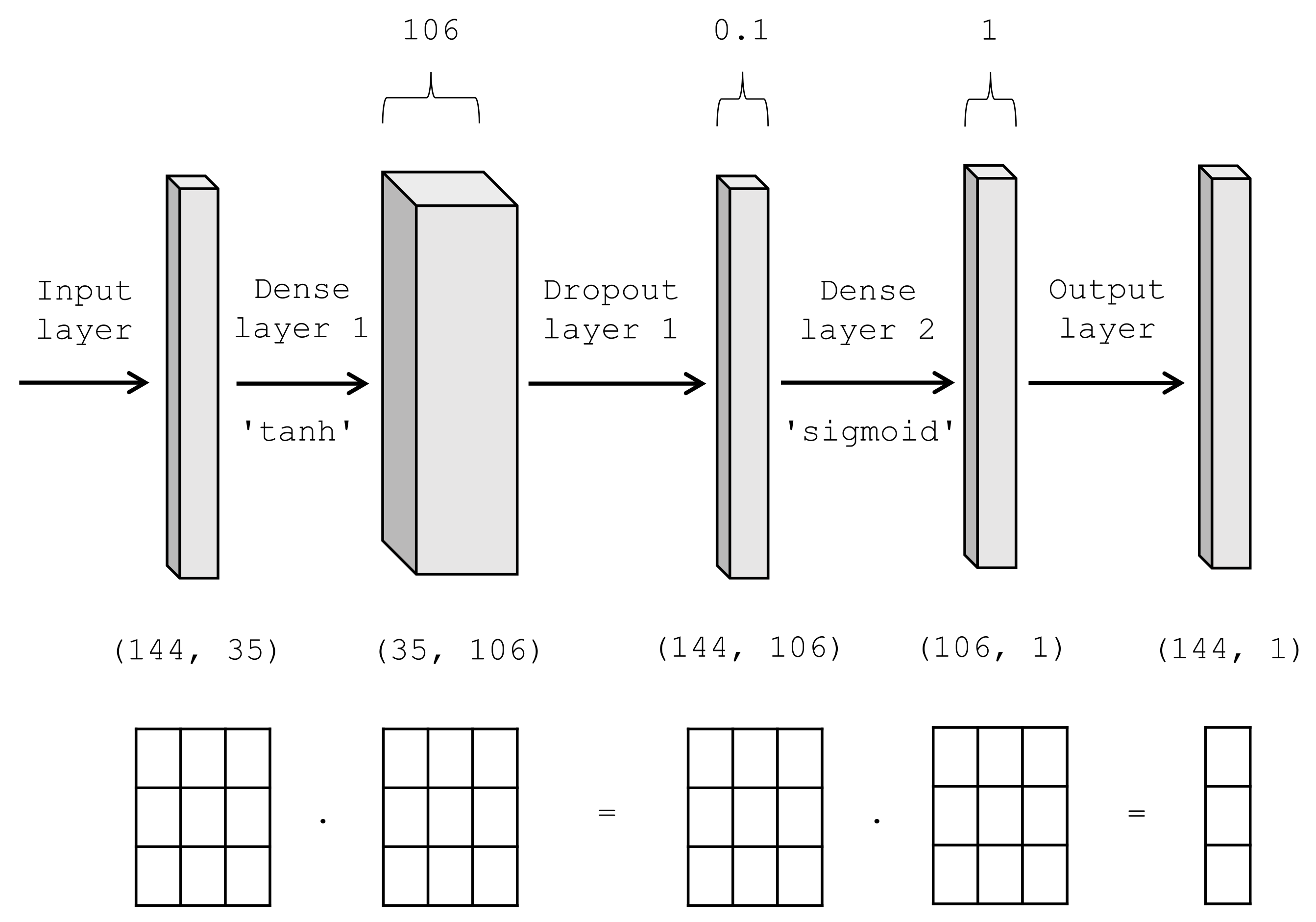
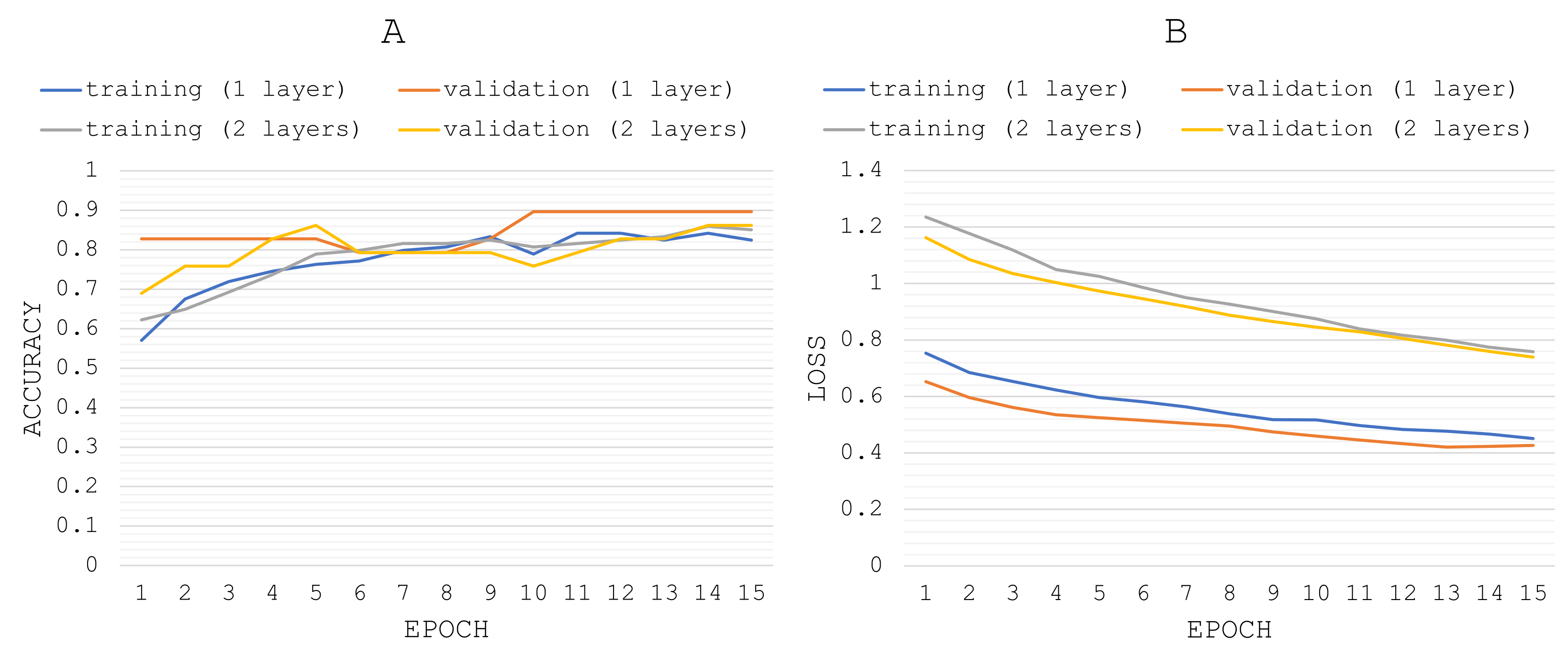
- Deep learning models: at the core of DP are neural networks, mathematical entities capable of representing complex functions through a composition of simple functions. The basic building block of these complex functions is the neuron. It is a linear transformation of the input (for example, multiplying the input by a number, the weight, and adding a constant, the bias) followed by applying a fixed nonlinear function, the activation function [30]. Mathematically, the neuron output can be expressed as , with x as the input, w as the weight or scaling factor, and b as the bias or offset. f is the activation function, commonly set to hyperbolic tangent. A multi-layer neural network is a composition of functions such as Equations (1)–(4).The output of a layer of neurons is used as an input for the following layer. Between the input, and the output layer, there can be one or more non-linear layer, called hidden layers. The leftmost layer or input layer, consists of a set of neurons representing the input features. The output layer receives the values from the last hidden layer and transforms them into output values.The number of hidden neurons can be determined by Equation (5),where is the number of input neurons, the number of input samples, and L the number of hidden layers [31].The proposed ANN architecture is presented in Figure 2, where 144 is the number of individuals, 35 is the number of input neurons (features selected by RFECV method), 106 is the number of computed hidden neurons of a single dense-type hidden layer with ’tanh’ as the activation function, followed by a dropout-type layer with 0.1 frequency. The second dense layer with ’sigmoid’ as activation function receives the values from the dropout layer and transforms them into output predictions (healthy/MS). The number of hidden layers is set to one for comparison purposes. An extra model is conformed by adding a second hidden layer to the network structure, in order to analyze whether a network with two hidden layers and fewer hidden neurons (53 units) than a single hidden layer (106 units) achieves higher performance and lower validation loss [32].In addition, the dense layer includes a kernel regularizer argument (kernel_regularizer = l2 with learning rate, lr = 0.01), which implements a regularizer function applied to the kernel weights matrix. The l2 regularization prevents overfitting and reduces model complexity.
2.4. Performance Metrics
2.5. Statistical Analysis
3. Results
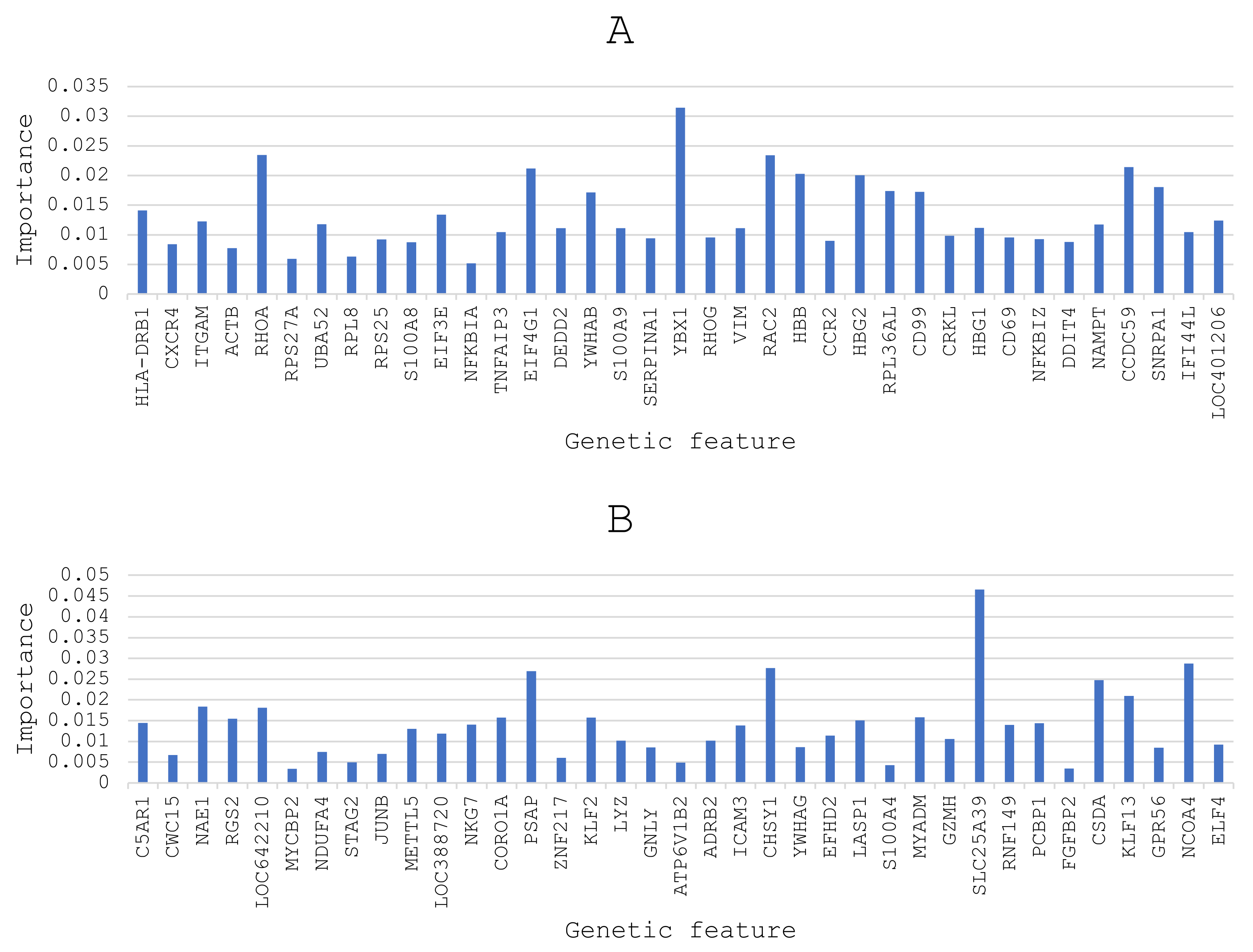
3.1. Feature Selection
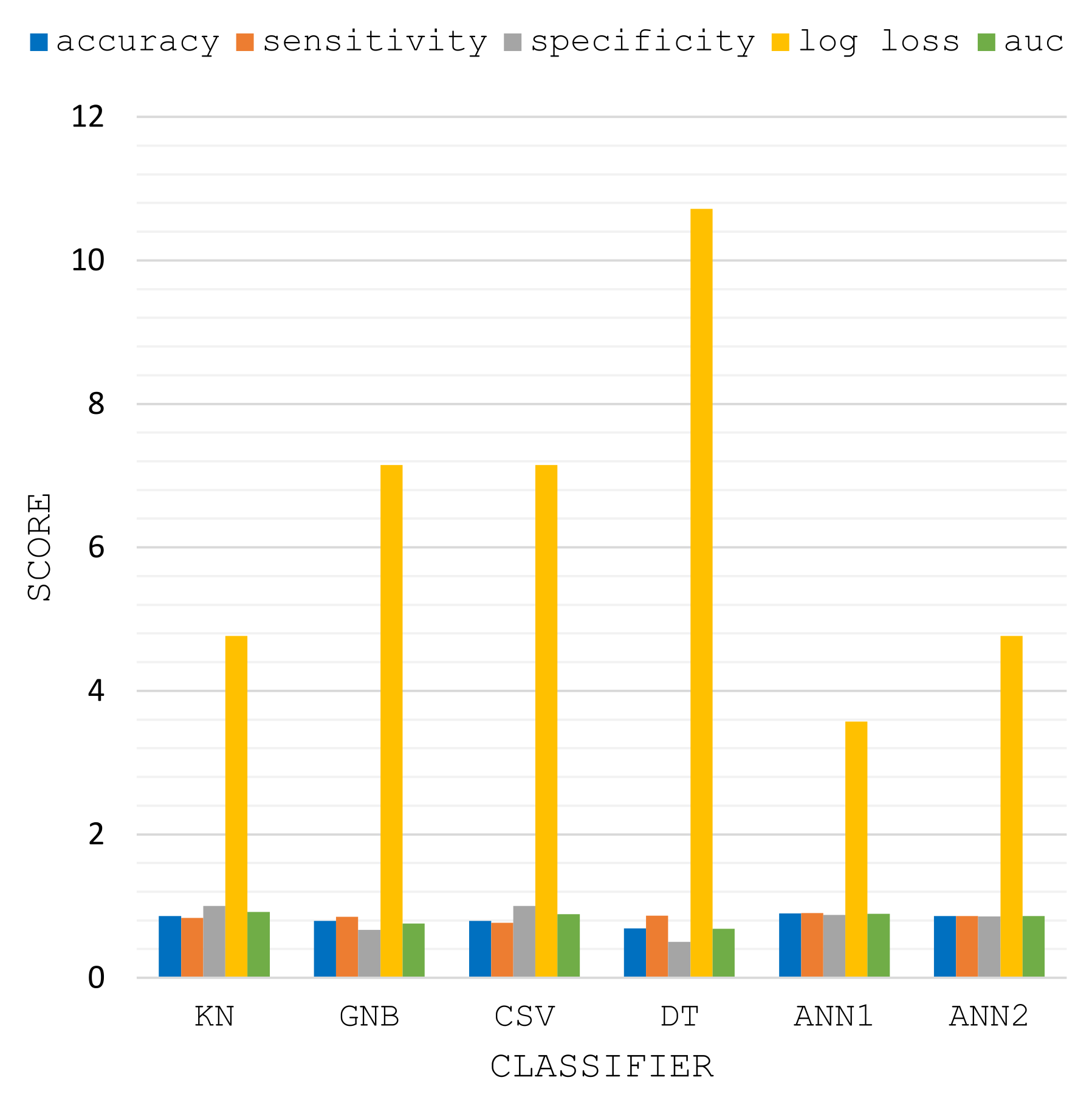
3.2. Performance Comparison
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Milo, R.; Miller, A. Revised diagnostic criteria of multiple sclerosis. Autoimmun. Rev. 2014, 13, 518–524. [Google Scholar] [CrossRef] [PubMed]
- Murgia, F.; Lorefice, L.; Poddighe, S.; Fenu, G.; Secci, M.A.; Marrosu, M.G.; Cocco, E.; Atzori, L. Multi-platform characterization of cerebrospinal fluid and serum metabolome of patients affected by relapsing–Remitting and primary progressive multiple sclerosis. J. Clin. Med. 2020, 9, 863. [Google Scholar] [CrossRef] [Green Version]
- Tarlinton, R.E.; Khaibullin, T.; Granatov, E.; Martynova, E.; Rizvanov, A.; Khaiboullina, S. The interaction between viral and environmental risk factors in the pathogenesis of multiple sclerosis. Int. J. Mol. Sci. 2019, 20, 303. [Google Scholar] [CrossRef] [Green Version]
- Goodin, D.S. Genetic and environmental susceptibility to multiple sclerosis. Med Res. Arch. 2021, 9. [Google Scholar] [CrossRef]
- da Silva Bernardes, M.; Paiva, C.L.A.; Paradela, E.R.; Alvarenga, M.P.; Pereira, F.F.; Vasconcelos, C.C.; Alvarenga, R.M.P. Familial multiple sclerosis in a Brazilian sample: Is HLA-DR15 involved in susceptibility to the disease? J. Neuroimmunol. 2019, 330, 74–80. [Google Scholar] [CrossRef] [PubMed]
- Hamet, P.; Tremblay, J. Artificial intelligence in medicine. Metabolism 2017, 69, S36–S40. [Google Scholar] [CrossRef]
- Law, M.T.; Traboulsee, A.L.; Li, D.K.; Carruthers, R.L.; Freedman, M.S.; Kolind, S.H.; Tam, R. Machine learning in secondary progressive multiple sclerosis: An improved predictive model for short-term disability progression. Mult. Scler. J.-Exp. Transl. Clin. 2019, 5, 2055217319885983. [Google Scholar] [CrossRef] [PubMed]
- Macin, G.; Tasci, B.; Tasci, I.; Faust, O.; Barua, P.D.; Dogan, S.; Tuncer, T.; Tan, R.S.; Acharya, U.R. An accurate multiple sclerosis detection model based on exemplar multiple parameters local phase quantization: ExMPLPQ. Appl. Sci. 2022, 12, 4920. [Google Scholar] [CrossRef]
- Nabizadeh, F.; Masrouri, S.; Ramezannezhad, E.; Ghaderi, A.; Sharafi, A.M.; Soraneh, S.; Moghadasi, A.N. Artificial intelligence in the diagnosis of multiple sclerosis: A systematic review. Mult. Scler. Relat. Disord. 2022, 59, 103673. [Google Scholar] [CrossRef]
- Goyal, M.; Khanna, D.; Rana, P.S.; Khaibullin, T.; Martynova, E.; Rizvanov, A.A.; Khaiboullina, S.F.; Baranwal, M. Computational Intelligence Technique for Prediction of Multiple Sclerosis Based on Serum Cytokines. Front. Neurol. 2019, 10, 781. [Google Scholar] [CrossRef] [Green Version]
- Casalino, G.; Castellano, G.; Consiglio, A.; Nuzziello, N.; Vessio, G. MicroRNA expression classification for pediatric multiple sclerosis identification. J. Ambient. Intell. Humaniz. Comput. 2021. [Google Scholar] [CrossRef]
- Chen, X.; Hou, H.; Qiao, H.; Fan, H.; Zhao, T.; Dong, M. Identification of blood-derived candidate gene markers and a new 7-gene diagnostic model for multiple sclerosis. Biol. Res. 2021, 54, 12. [Google Scholar] [CrossRef] [PubMed]
- Fagone, P.; Mazzon, E.; Mammana, S.; Di Marco, R.; Spinasanta, F.; Basile, M.S.; Petralia, M.C.; Bramanti, P.; Nicoletti, F.; Mangano, K. Identification of CD4+ T cell biomarkers for predicting the response of patients with relapsing-remitting multiple sclerosis to natalizumab treatment. Mol. Med. Rep. 2019, 20, 678–684. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tao, J.; Wang, C.; Tian, S. Feature selection based on differentially correlated gene pairs reveals the mechanism of IFN-therapy for multiple sclerosis. Bioinform. Genom. 2020, 8, e8812. [Google Scholar] [CrossRef]
- Ren, Z.; Ren, G.; Wu, D. Deep Learning Based Feature Selection Algorithm for Small Targets Based on mRMR. Micromachines 2022, 13, 1765. [Google Scholar] [CrossRef]
- Artur, M. Review the performance of the Bernoulli Naïve Bayes Classifier in Intrusion Detection Systems using Recursive Feature Elimination with Cross-validated selection of the best number of features. Procedia Comput. Sci. 2021, 190, 564–570. [Google Scholar] [CrossRef]
- Aviles, M.; Sánchez-Reyes, L.M.; Fuentes-Aguilar, R.Q.; Toledo-Pérez, D.C.; Rodríguez-Reséndiz, J. A Novel Methodology for Classifying EMG Movements Based on SVM and Genetic Algorithms. Micromachines 2022, 13, 2108. [Google Scholar] [CrossRef]
- Bovet, D.P.; Crescenzi, P.; Bovet, D. Introduction to the Theory of Complexity; Prentice Hall: London, UK, 1994; Volume 7. [Google Scholar]
- Achache, M. Complexity analysis and numerical implementation of a short-step primal-dual algorithm for linear complementarity problems. Appl. Math. Comput. 2010, 216, 1889–1895. [Google Scholar] [CrossRef]
- Salamai, A.A.; El-kenawy, E.S.M.; Abdelhameed, I. Dynamic voting classifier for risk identification in supply chain 4.0. CMC-Comput. Mater. Contin. 2021, 69, 3749–3766. [Google Scholar] [CrossRef]
- National Center for Biotechnology Information (NCBI)—Gene Expression Omnibus (GEO) Database. 2010. Available online: https://www.ncbi.nlm.nih.gov/geo/geo2r (accessed on 25 August 2022).
- Mirjalili, V.; Raschka, S. Python Machine Learning; Marcombo: Barcelona, Spain, 2020. [Google Scholar]
- Roccetti, M.; Delnevo, G.; Casini, L.; Mirri, S. An alternative approach to dimension reduction for pareto distributed data: A case study. J. Big Data 2021, 8, 39. [Google Scholar] [CrossRef]
- Kaufmann, K.; Maryanovsky, D.; Mellor, W.M.; Zhu, C.; Rosengarten, A.S.; Harrington, T.J.; Oses, C.; Toher, C.; Curtarolo, S.; Vecchio, K.S. Discovery of high-entropy ceramics via machine learning. Npj Comput. Mater. 2020, 6, 42. [Google Scholar] [CrossRef]
- Sarker, I.H. Machine learning: Algorithms, real-world applications and research directions. SN Comput. Sci. 2021, 2, 160. [Google Scholar] [CrossRef] [PubMed]
- Ontivero-Ortega, M.; Lage-Castellanos, A.; Valente, G.; Goebel, R.; Valdes-Sosa, M. Fast Gaussian Naïve Bayes for searchlight classification analysis. Neuroimage 2017, 163, 471–479. [Google Scholar] [CrossRef] [PubMed]
- Montolío, A.; Martín-Gallego, A.; Cegoñino, J.; Orduna, E.; Vilades, E.; Garcia-Martin, E.; Del Palomar, A.P. Machine learning in diagnosis and disability prediction of multiple sclerosis using optical coherence tomography. Comput. Biol. Med. 2021, 133, 104416. [Google Scholar] [CrossRef] [PubMed]
- Kotsiantis, S.B. Decision trees: A recent overview. Artif. Intell. Rev. 2013, 39, 261–283. [Google Scholar] [CrossRef]
- Villegas-Mier, C.G.; Rodriguez-Resendiz, J.; Álvarez-Alvarado, J.M.; Jiménez-Hernández, H.; Odry, Á. Optimized Random Forest for Solar Radiation Prediction Using Sunshine Hours. Micromachines 2022, 13, 1406. [Google Scholar] [CrossRef]
- Stevens, E.; Antiga, L.; Viehmann, T. Deep Learning with PyTorch; Manning Publications: Shelter Island, NY, USA, 2020. [Google Scholar]
- Madhiarasan, M.; Deepa, S. A novel criterion to select hidden neuron numbers in improved back propagation networks for wind speed forecasting. Appl. Intell. 2016, 44, 878–893. [Google Scholar] [CrossRef]
- Han, W.; Nan, L.; Su, M.; Chen, Y.; Li, R.; Zhang, X. Research on the prediction method of centrifugal pump performance based on a double hidden layer BP neural network. Energies 2019, 12, 2709. [Google Scholar] [CrossRef] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # | Selected Feature | Importance |
|---|---|---|
| 1 | SLC25A39 | 0.046594 |
| 2 | YBX1 | 0.031416 |
| 3 | NCOA4 | 0.028775 |
| 4 | CHSY1 | 0.027680 |
| 5 | PSAP | 0.026925 |
| 6 | CSDA | 0.024730 |
| 7 | RHOA | 0.023475 |
| 8 | RAC2 | 0.023392 |
| 9 | CCDC59 | 0.021414 |
| 10 | EIF4G1 | 0.021162 |
| 11 | KLF13 | 0.020960 |
| 12 | HBB | 0.020262 |
| 13 | HBG2 | 0.020044 |
| 14 | NAE1 | 0.018367 |
| 15 | LOC642210 | 0.018103 |
| 16 | SNRPA1 | 0.018043 |
| 17 | RPL36AL | 0.017384 |
| 18 | CD99 | 0.017245 |
| 19 | YWHAB | 0.017153 |
| 20 | MYADM | 0.015812 |
| 21 | KLF2 | 0.015753 |
| 22 | CORO1A | 0.015732 |
| 23 | RGS2 | 0.015477 |
| 24 | LASP1 | 0.015034 |
| 25 | C5AR1 | 0.014447 |
| 26 | PCBP1 | 0.014407 |
| 27 | HLA-DRB1 | 0.014128 |
| 28 | NKG7 | 0.014030 |
| 29 | RNF149 | 0.013935 |
| 30 | ICAM3 | 0.013826 |
| 31 | EIF3E | 0.013390 |
| 32 | METTL5 | 0.013029 |
| 33 | LOC401206 | 0.012424 |
| 34 | ITGAM | 0.012246 |
| 35 | LOC388720 | 0.011856 |
| Classifier | Runtime without FS/with FS | Memory without FS/with FS | Program Size |
|---|---|---|---|
| KN | 2 ms/1 ms | 109 KB/55 KB | 2.53 KB |
| GNB | 2 ms/1 ms | 109 KB/55 KB | 2.49 KB |
| CSV | 3 ms/2 ms | 109 KB/55 KB | 2.47 KB |
| DT | 3 ms/2 ms | 109 KB/55 KB | 2.5 KB |
| ANN1 | 18 ms by step/14 ms by step | 109 KB/55 KB | 5.56 KB |
| ANN2 | 28 ms by step/19 ms by step | 109 KB/55 KB | 5.58 KB |
| Classifier | Accuracy without FS/with FS | Sensitivity | Specificity | Log_LOSS | auc |
|---|---|---|---|---|---|
| KN | 0.6896/0.8620 | 0.8333 | 1.0 | 4.764 | 0.9166 |
| GNB | 0.7931/0.7931 | 0.85 | 0.6666 | 7.146 | 0.7583 |
| CSV | 0.7586/0.7931 | 0.7692 | 1.0 | 7.1461 | 0.8846 |
| DT | 0.6551/0.6896 | 0.8666 | 0.5 | 10.7189 | 0.6833 |
| ANN1 | 0.7931/0.8965 | 0.9047 | 0.8750 | 3.573 | 0.8898 |
| ANN2 | 0.7241/0.8620 | 0.8636 | 0.8571 | 4.764 | 0.8603 |
| KN | GNB | CSV | DT | ANN1 | ANN2 | |
|---|---|---|---|---|---|---|
| Number of samples | 29 | 29 | 29 | 29 | 29 | 29 |
| Mean | 0.8275 | 0.6896 | 0.8965 | 0.5172 | 0.7241 | 0.7586 |
| Std. Deviation | 0.3777 | 0.4626 | 0.3045 | 0.4997 | 0.4469 | 0.4279 |
| Std. Error of Mean | 0.0713 | 0.0874 | 0.0575 | 0.0944 | 0.0844 | 0.0808 |
| Source | SS | DF | MS | F(DFn, DFd) | p-Value |
|---|---|---|---|---|---|
| Between | 2.4597 | 5 | 0.4919 | 2.7279 | 0.0213 |
| Within | 30.2972 | 168 | 0.1803 | - | - |
| Total | 32.7570 | 173 | - | - | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ponce de Leon-Sanchez, E.R.; Dominguez-Ramirez, O.A.; Herrera-Navarro, A.M.; Rodriguez-Resendiz, J.; Paredes-Orta, C.; Mendiola-Santibañez, J.D. A Deep Learning Approach for Predicting Multiple Sclerosis. Micromachines 2023, 14, 749. https://doi.org/10.3390/mi14040749
Ponce de Leon-Sanchez ER, Dominguez-Ramirez OA, Herrera-Navarro AM, Rodriguez-Resendiz J, Paredes-Orta C, Mendiola-Santibañez JD. A Deep Learning Approach for Predicting Multiple Sclerosis. Micromachines. 2023; 14(4):749. https://doi.org/10.3390/mi14040749
Chicago/Turabian StylePonce de Leon-Sanchez, Edgar Rafael, Omar Arturo Dominguez-Ramirez, Ana Marcela Herrera-Navarro, Juvenal Rodriguez-Resendiz, Carlos Paredes-Orta, and Jorge Domingo Mendiola-Santibañez. 2023. "A Deep Learning Approach for Predicting Multiple Sclerosis" Micromachines 14, no. 4: 749. https://doi.org/10.3390/mi14040749