
A Multi-Label Detection Deep Learning Model with Attention-Guided Image Enhancement for Retinal Images

Abstract
:1. Introduction
2. Related Work
2.1. Fundus Image Classification
2.2. Data Enhancement
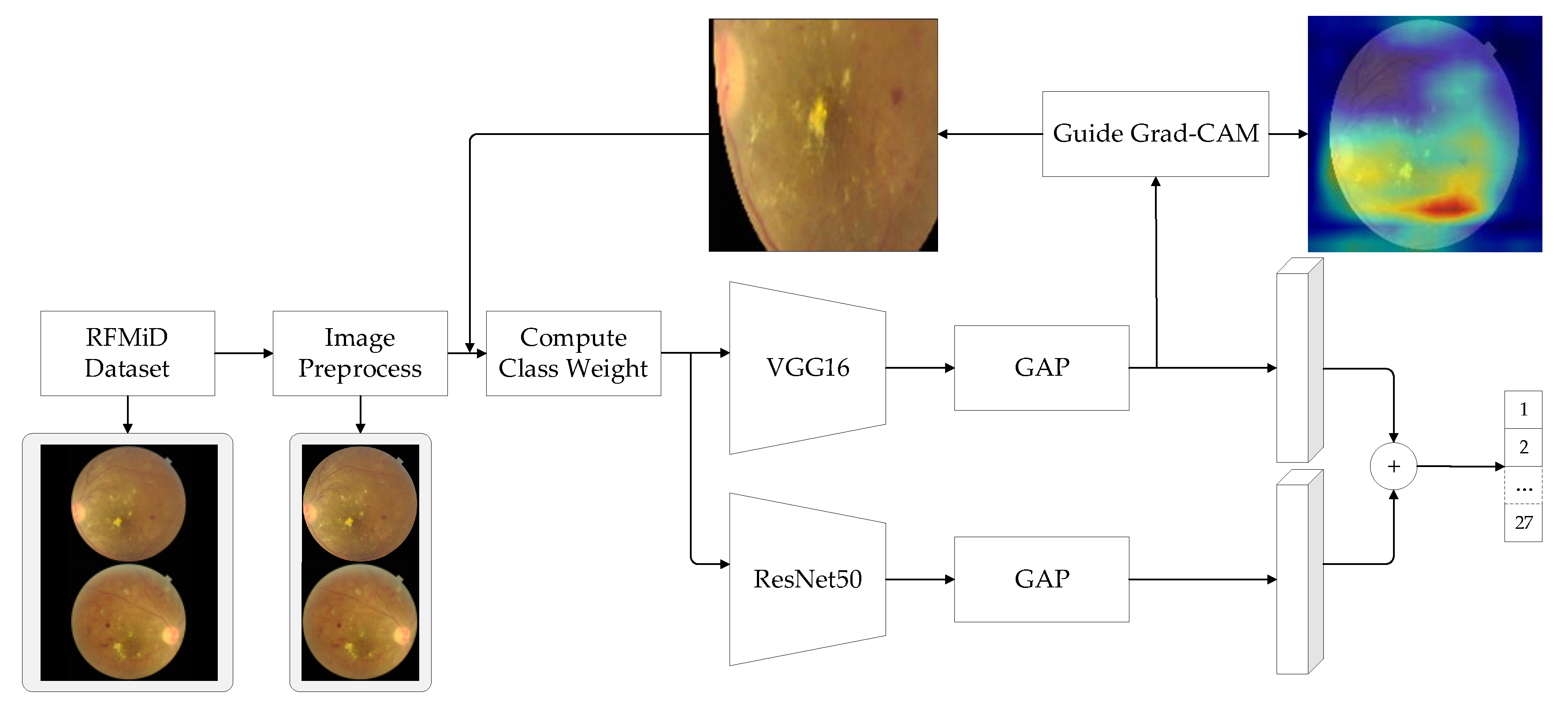
3. Methodology
3.1. Data Enhancement
3.2. Feature Fusion
3.3. Loss Function Design
4. Experimental Results and Analysis
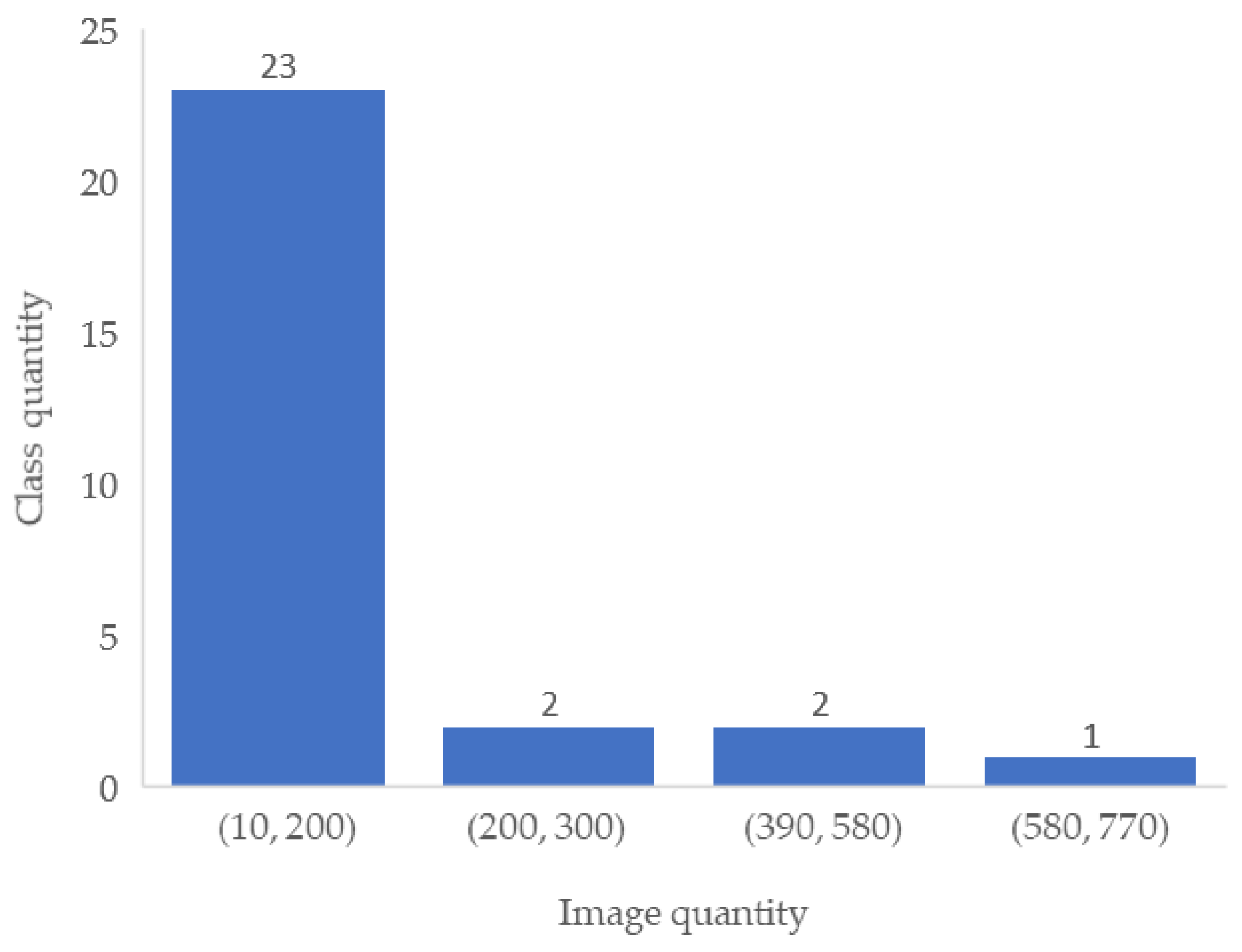
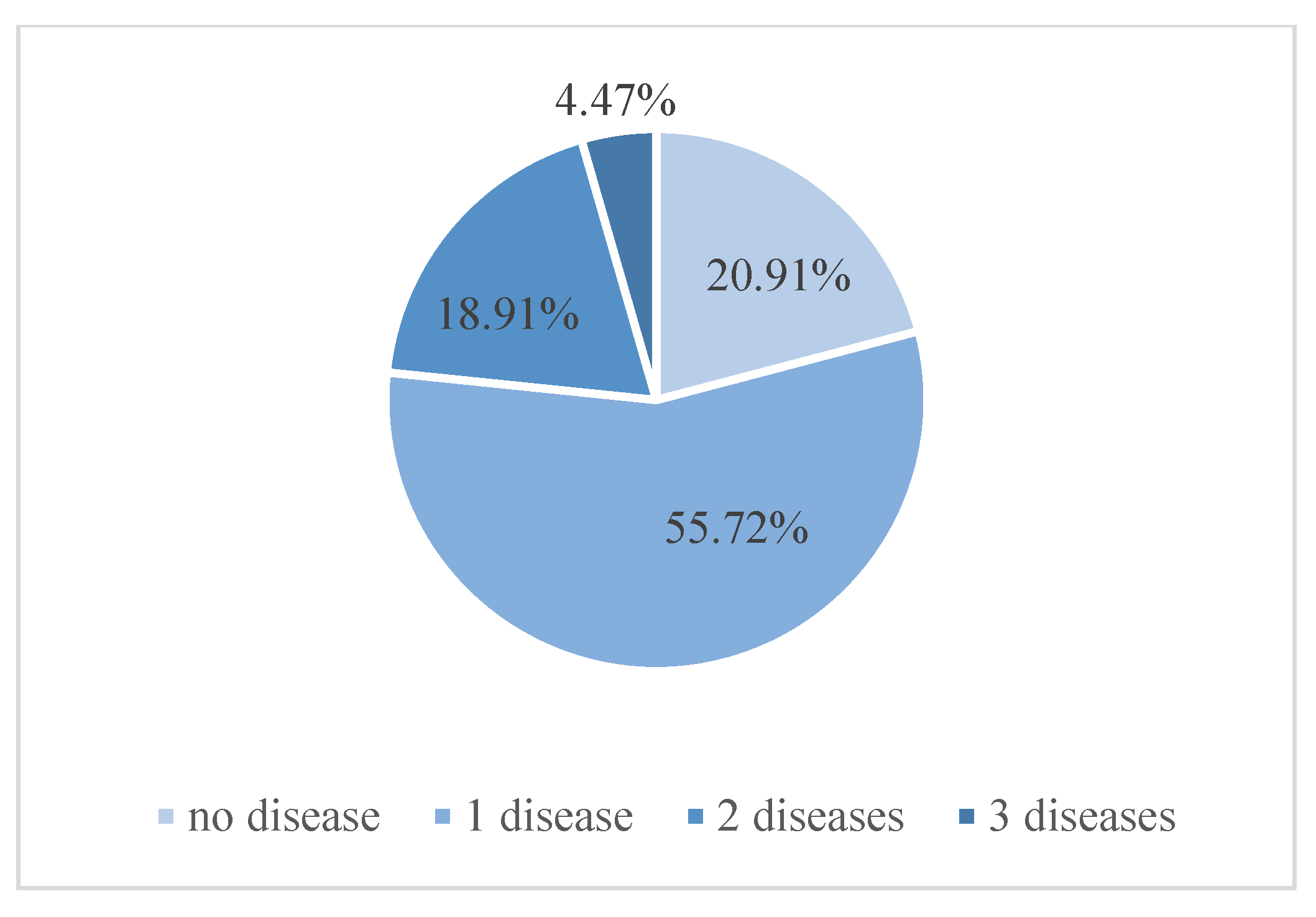
4.1. Experimental Datasets
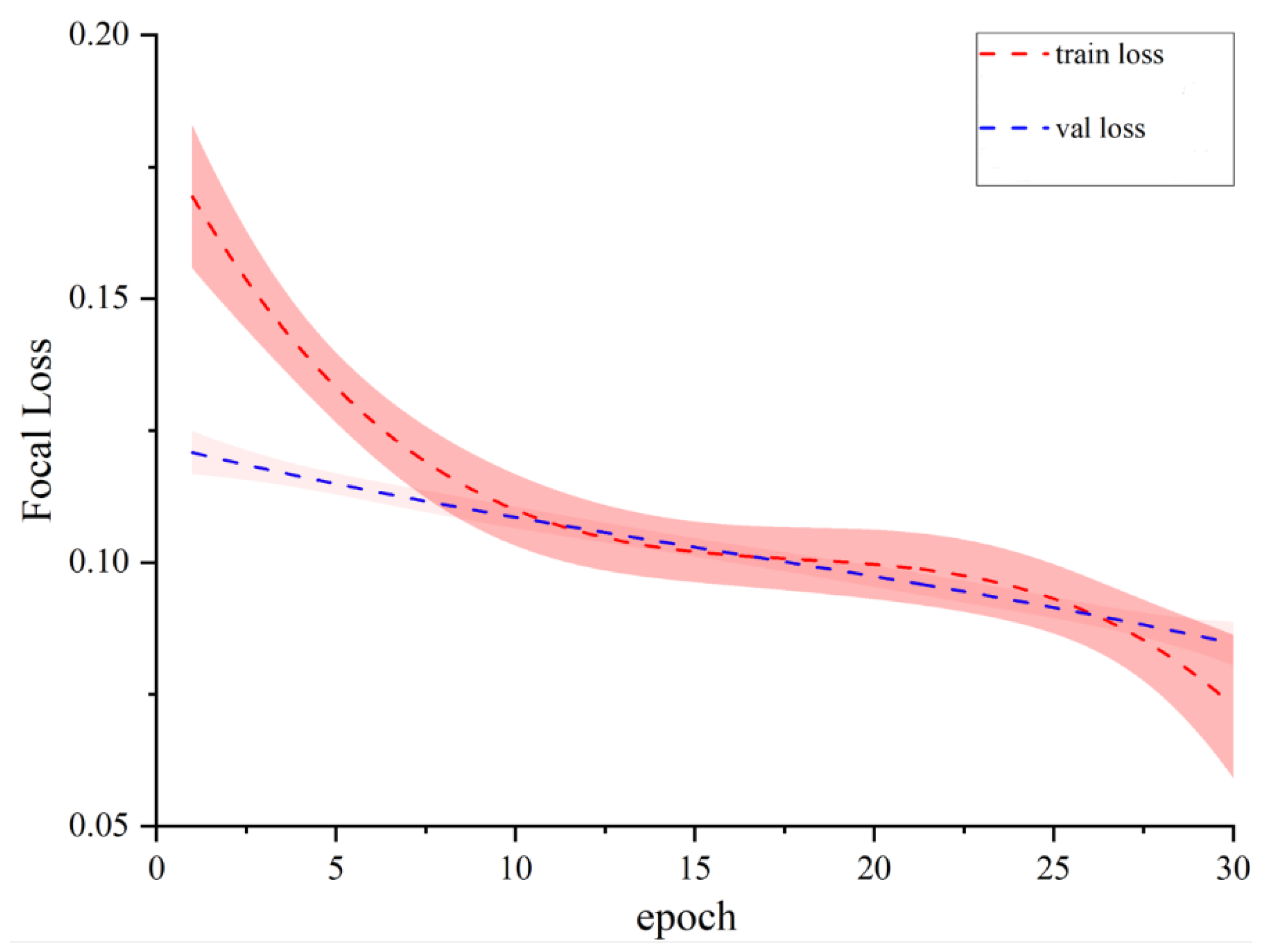
4.2. Experimental Parameter Setting
4.3. Experimental Results
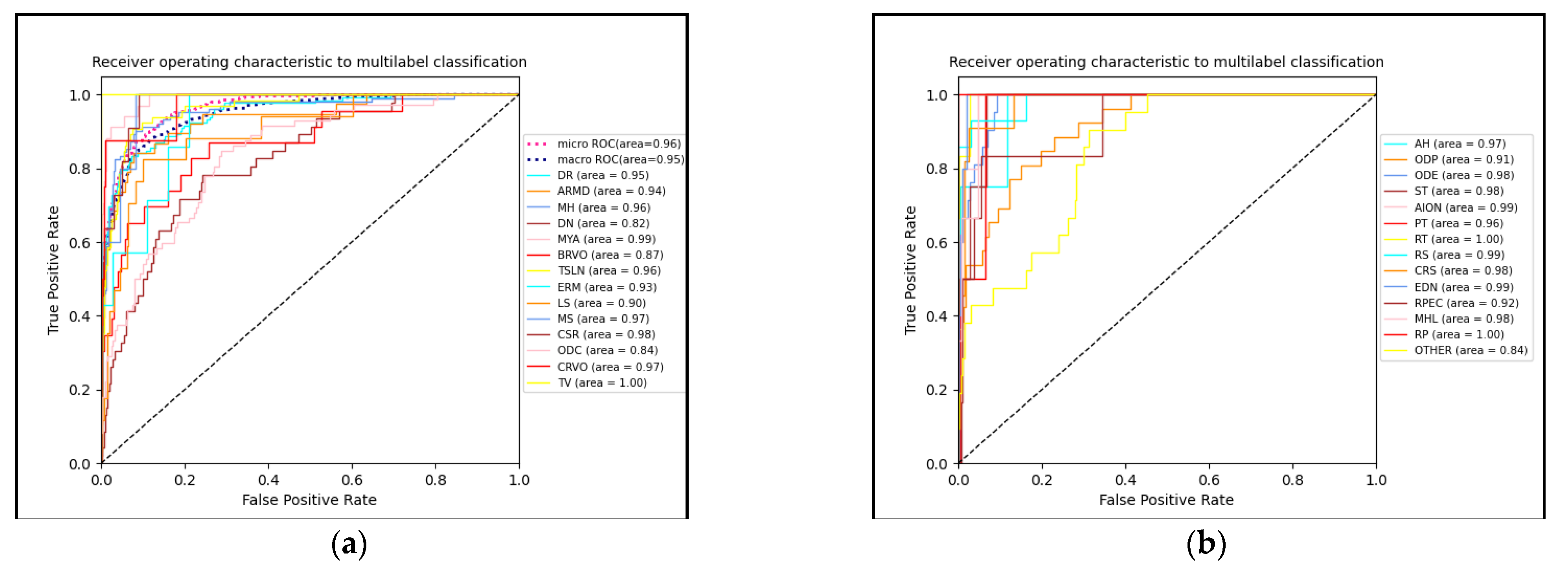
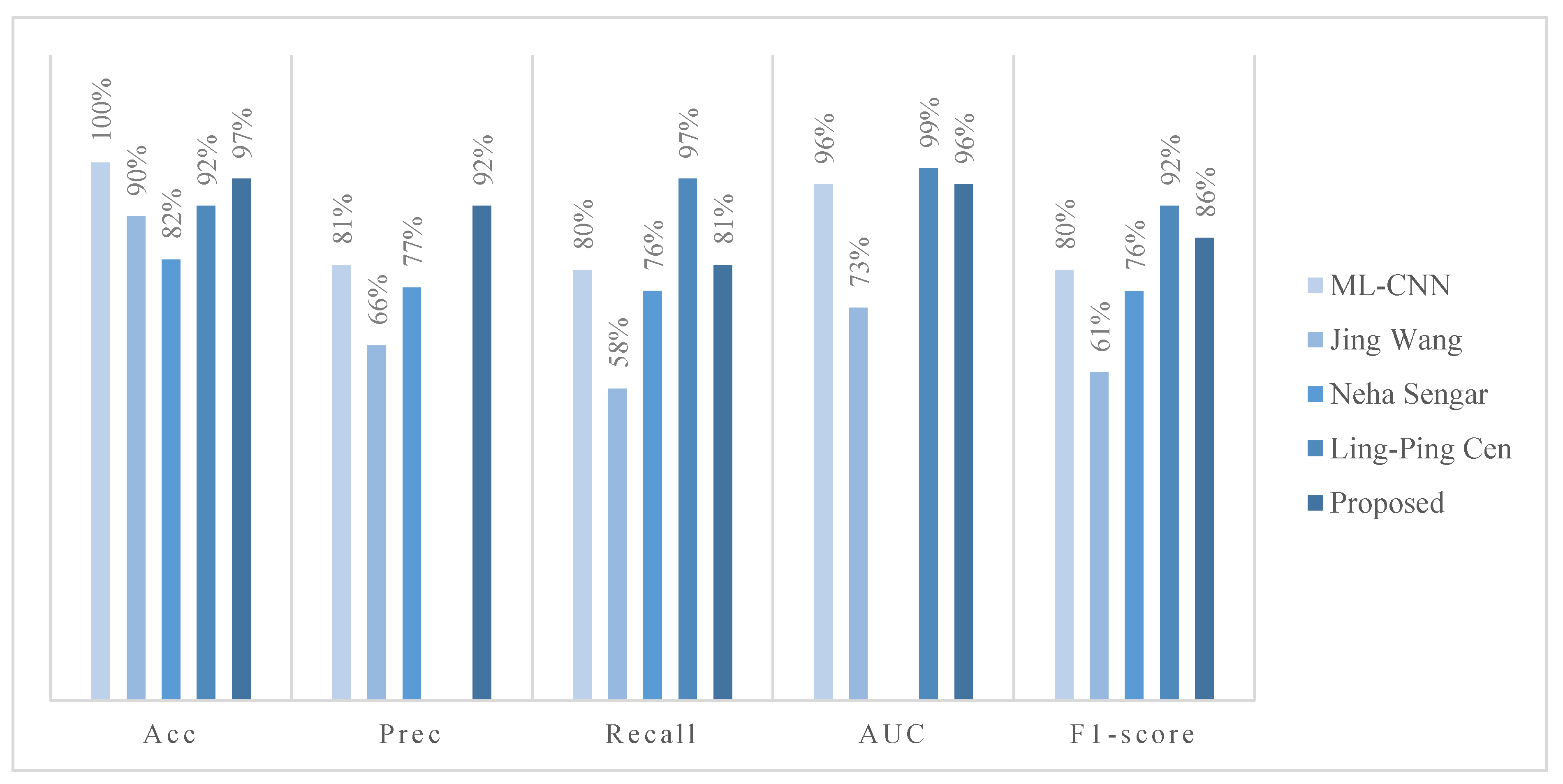
4.3.1. Classification Performance Evaluation
4.3.2. Module Comparison Experiment
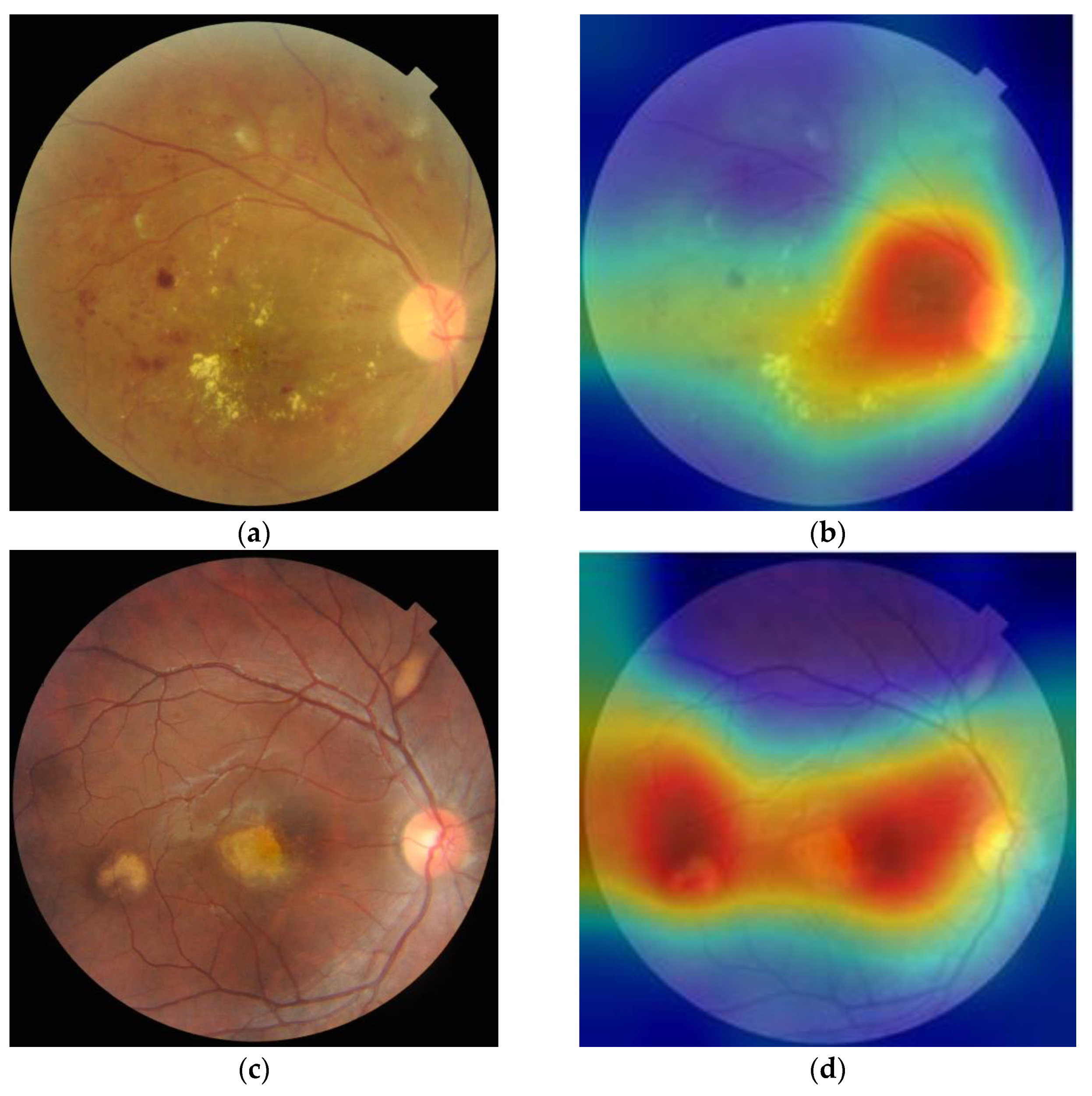
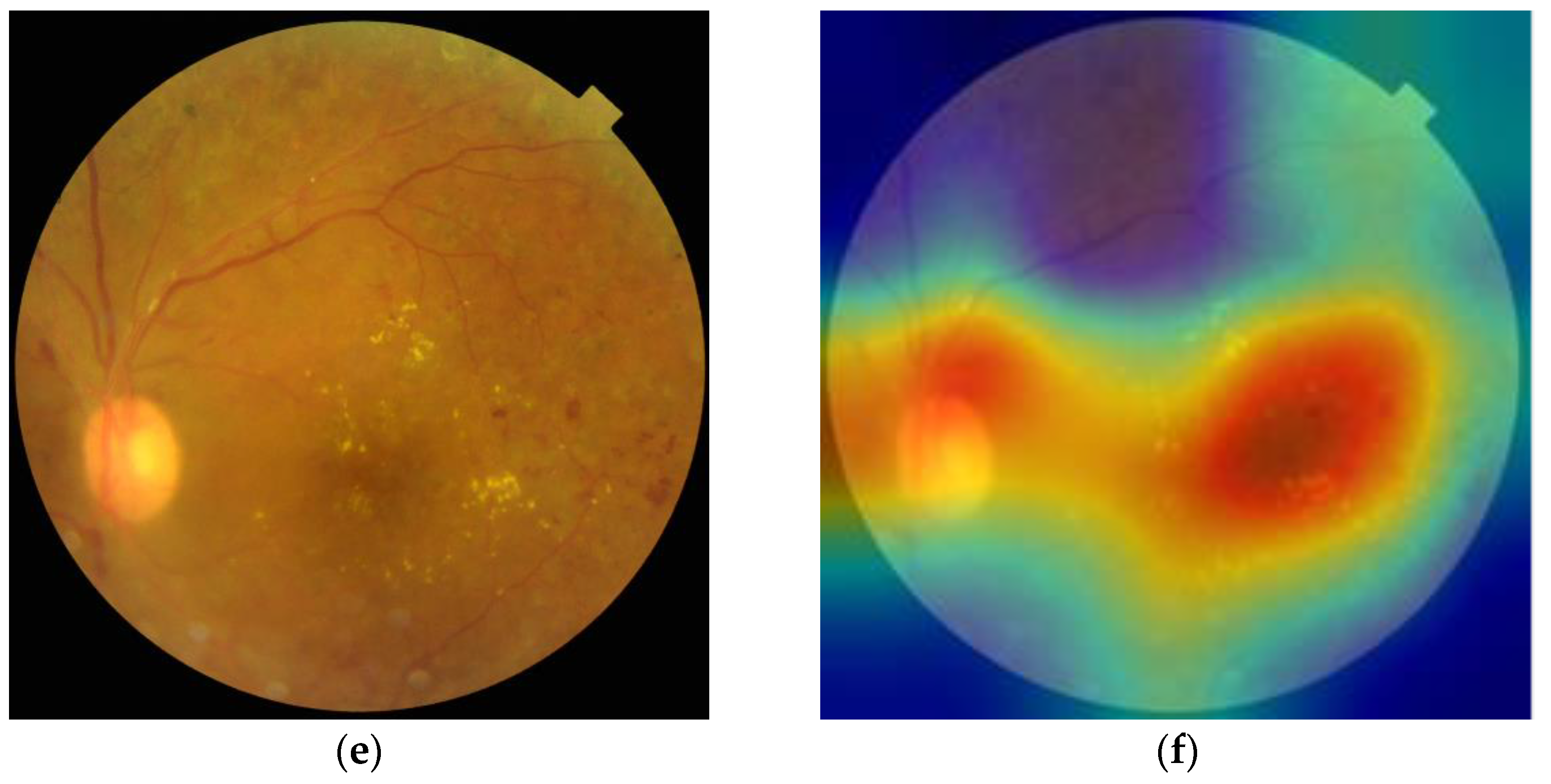
4.3.3. Visual Analytics
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Klein, R.; Klein, B.E.K. The prevalence of age-related eye diseases and visual impairment in aging: Current estimates. Investig. Ophthalmol. Vis. Sci. 2013, 54, ORSF5–ORSF13. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wong, W.L.; Su, X.; Li, X.; Cheung, C.M.G.; Klein, R.; Cheng, C.Y.; Wong, T.Y. Global prevalence of age-related macular degeneration and disease burden projection for 2020 and 2040: A systematic review and meta-analysis. Lancet Glob. Health 2014, 2, e106–e116. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Jia, M.; Yang, X.; Xu, M. Blood Vessel Segmentation of Retinal Image Based on Dense-U-Net Network. Micromachines 2021, 12, 1478. [Google Scholar] [CrossRef]
- He, J.; Li, C.; Ye, J.; Wang, S.; Qiao, Y.; Gu, L. Classification of Ocular Diseases Employing Attention-Based Unilateral and Bilateral Feature Weighting and Fusion. In Proceedings of the 2020 IEEE 17th International Symposium on Biomedical Imaging (ISBI), Iowa City, IA, USA, 3–7 April 2020; pp. 1258–1261. [Google Scholar]
- Kha, Q.H.; Tran, T.O.; Nguyen, T.T.; Nguyen, V.N.; Than, K.; Le, N.Q.K. An interpretable deep learning model for classifying adaptor protein complexes from sequence information. Methods 2022, 207, 90–96. [Google Scholar] [CrossRef] [PubMed]
- Le, N.Q.K. Potential of deep representative learning features to interpret the sequence information in proteomics. Proteomics 2022, 22, e2100232. [Google Scholar] [CrossRef] [PubMed]
- Nneji, G.U.; Cai, J.; Deng, J.; Monday, H.N.; Hossin, M.A.; Nahar, S. Identification of Diabetic Retinopathy Using Weighted Fusion Deep Learning Based on Dual-Channel Fundus Scans. Diagnostics 2022, 12, 540. [Google Scholar] [CrossRef]
- Pham, Q.T.; Ahn, S.; Shin, J.; Song, S.J. Generating future fundus images for early age-related macular degeneration based on generative adversarial networks. Comput. Methods Programs Biomed. 2022, 216, 106648. [Google Scholar] [CrossRef]
- David, D.S.; Selvi, S.A.M.; Sivaprakash, S.; Raja, P.V.; Sharma, D.K.; Dadheech, P.; Sengan, S. Enhanced Detection of Glaucoma on Ensemble Convolutional Neural Network for Clinical Informatics. Comput. Mater. Contin. 2022, 70, 2563–2579. [Google Scholar]
- Quellec, G. Automatic Image Analysis Method for Automatically Recognising at Least One Rare Characteristic. U.S. Patent Application No. 17/610,098, 19 November 2020. [Google Scholar]
- Choi, J.Y.; Yoo, T.K.; Seo, J.G.; Kwak, J.; Um, T.T.; Rim, T.H. Multi-categorical deep learning neural network to classify retinal images: A pilot study employing small database. PLoS ONE 2017, 12, e0187336. [Google Scholar] [CrossRef] [Green Version]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning Deep Features for Discriminative Localization. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Pittsburgh, PA, USA, 27–30 June 2016. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Chattopadhay, A.; Sarkar, A.; Howlader, P.; Balasubramanian, V.N. Grad-CAM++: Improved Visual Explanations for Deep Convolutional Networks. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the CVPR, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Peng, Y.; Dharssi, S.; Chen, Q.; Keenan, T.D.; Agrón, E.; Wong, W.T.; Chew, E.Y.; Lu, Z. Deepseenet: A deep learning model for automated classification of patient-based age-related macular degeneration severity from color fundus photographs. Ophthalmology 2018, 125, 1199–1206. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, X.; Peng, C.; Xue, X.; Sun, J. Exfuse: Enhancing feature fusion for semantic segmentation. In Proceedings of the ECCV, Munich, Germany, 8–14 September 2018; pp. 1–15. [Google Scholar]
- Xu, X.; Guan, Y.; Li, J.; Ma, Z.; Zhang, L.; Li, L. Automatic glaucoma detection based on transfer induced attention network. BioMed Eng. OnLine 2021, 20, 1–19. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; Xu, M.; Wang, X.; Jiang, L.; Liu, H. Attention Based Glaucoma Detection: A Large-Scale Database and CNN Model. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 10563–10572. [Google Scholar] [CrossRef] [Green Version]
- Lin, Z.; Guo, R.; Wang, Y.; Wu, B.; Chen, T.; Wang, W.; Chen, D.Z.; Wu, J. A Framework for Identifying Diabetic Retinopathy Based on Anti-noise Detection and Attention-Based Fusion. In Medical Image Computing and Computer Assisted Intervention—MICCAI 2018. MICCAI 2018; Frangi, A., Schnabel, J., Davatzikos, C., Alberola-López, C., Fichtinger, G., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; Volume 11071. [Google Scholar] [CrossRef]
- Lu, J.; Wu, W. Fine-grained image classification based on attention-guided image enhancement. J. Phys. Conf. Ser. 2021, 1754, 012189. [Google Scholar] [CrossRef]
- Hu, T.; Qi, H.; Huang, Q.; Lu, Y. See Better before Looking Closer: Weakly Supervised Data Augmentation Network for Fine-Grained Visual Classification. Available online: https://arxiv.org/abs/1901.09891 (accessed on 19 October 2020).
- Guo, W.; Wang, Y. Class Activation Mapping Guided Data Augmentation for Fine-Grained Visual Classification. J. Comput.-Aided Des. Comput. Graph. 2021, 33, 1698–1704. [Google Scholar] [CrossRef]
- Gao, K.; Shen, H.; Liu, Y.; Zeng, L.; Hu, D. Dense-CAM: Visualize the Gender of Brains with MRI Images. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S.C. Network in Network. Available online: https://arxiv.org/abs/1312.4400 (accessed on 19 October 2020).
- Müller, D.; Soto-Rey, I.; Kramer, F. Multi-Disease Detection in Retinal Imaging based on Ensembling Heterogeneous Deep Learning Models. In German Medical Data Sciences 2021: Digital Medicine: Recognize–Understand–Heal; IOS Press: Frankfurt, Germany, 2021. [Google Scholar] [CrossRef]
- Li, Z.; Xu, M.; Yang, X.; Han, Y. Multi-Label Fundus Image Classification Using Attention Mechanisms and Feature Fusion. Micromachines 2022, 13, 947. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the ECCV, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Guo, F.; Li, W.; Zhao, X.; Zou, B. Glaucoma Screening Method Based on Semantic Feature Map Guidance. J. Comput. Des. Comput. Graph. 2021, 33, 363–375. [Google Scholar] [CrossRef]
- Wu, X.; Song, X.; Gao, S. Convolution Neural Network Based on Data Enhancement for Fire Identification. Sci. Technol. Eng. 2020, 20, 1113–1117. [Google Scholar]
- Tan, R.; Tan, W.; Liu, Y. Fine-Grained Image Classification Combining Dual Semantic Data Augmentation and Target Location. Comput. Eng. 2022, 48, 237–242+249. [Google Scholar] [CrossRef]
- Xu, X.; Li, J.; Guan, Y.; Zhao, L.; Zhao, Q.; Zhang, L.; Li, L. GLA-Net: A global-local attention network for automatic cataract classification. J. Biomed. Inform. 2021, 124, 103939. [Google Scholar] [CrossRef]
- Lin, M.; Chen, Q.; Yan, S. Network In Network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Ouda, O.; AbdelMaksoud, E.; El-Aziz, A.A.A.; Elmogy, M. Multiple Ocular Disease Diagnosis Using Fundus Images Based on Multi-Label Deep Learning Classification. Electronics 2022, 11, 1966. [Google Scholar] [CrossRef]
- Wang, J.; Yang, L.; Huo, Z.; He, W.; Luo, J. Multi-Label Classification of Fundus Images With EfficientNet. IEEE Access 2020, 8, 212499–212508. [Google Scholar] [CrossRef]
- Sengar, N.; Joshi, R.C.; Dutta, M.K.; Burget, R. EyeDeep-Net: A multi-class diagnosis of retinal diseases using deep neural network. Neural Comput. Appl. 2023. [Google Scholar] [CrossRef]
- Cen, L.-P.; Ji, J.; Lin, J.-W.; Ju, S.-T.; Lin, H.-J.; Li, T.-P.; Wang, Y.; Yang, J.-F.; Liu, Y.-F.; Tan, S.; et al. Automatic detection of 39 fundus diseases and conditions in retinal photographs using deep neural networks. Nat. Commun. 2021, 12, 4828. [Google Scholar] [CrossRef] [PubMed]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Disease Type | Image Quantity | Disease Type | Image Quantity | Disease Type | Image Quantity |
|---|---|---|---|---|---|
| DR | 376 | CSR | 37 | RS | 43 |
| ARMD | 100 | ODC | 282 | CRS | 32 |
| MH | 317 | CRVO | 28 | EDN | 15 |
| DN | 138 | TV | 6 | RPEC | 22 |
| MYA | 101 | AH | 16 | MHL | 11 |
| BRVO | 73 | ODP | 65 | RP | 6 |
| TSLN | 186 | ST | 5 | Others | 34 |
| ERM | 14 | AION | 17 | ODE | 58 |
| LS | 47 | PT | 11 | ||
| MS | 15 | RT | 14 |
| Model | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| VGG16 | 0.8969 | 0.7292 | 0.7955 | 0.7609 |
| ResNet50 | 0.9156 | 0.7308 | 0.7451 | 0.7378 |
| Ensemble model | 0.9172 | 0.7762 | 0.8409 | 0.8072 |
| Ensemble model + Image enhance | 0.9737 | 0.9167 | 0.8083 | 0.8590 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Xu, M.; Yang, X.; Han, Y.; Wang, J. A Multi-Label Detection Deep Learning Model with Attention-Guided Image Enhancement for Retinal Images. Micromachines 2023, 14, 705. https://doi.org/10.3390/mi14030705
Li Z, Xu M, Yang X, Han Y, Wang J. A Multi-Label Detection Deep Learning Model with Attention-Guided Image Enhancement for Retinal Images. Micromachines. 2023; 14(3):705. https://doi.org/10.3390/mi14030705
Chicago/Turabian StyleLi, Zhenwei, Mengying Xu, Xiaoli Yang, Yanqi Han, and Jiawen Wang. 2023. "A Multi-Label Detection Deep Learning Model with Attention-Guided Image Enhancement for Retinal Images" Micromachines 14, no. 3: 705. https://doi.org/10.3390/mi14030705