
How to Implement Automotive Fault Diagnosis Using Artificial Intelligence Scheme

Abstract
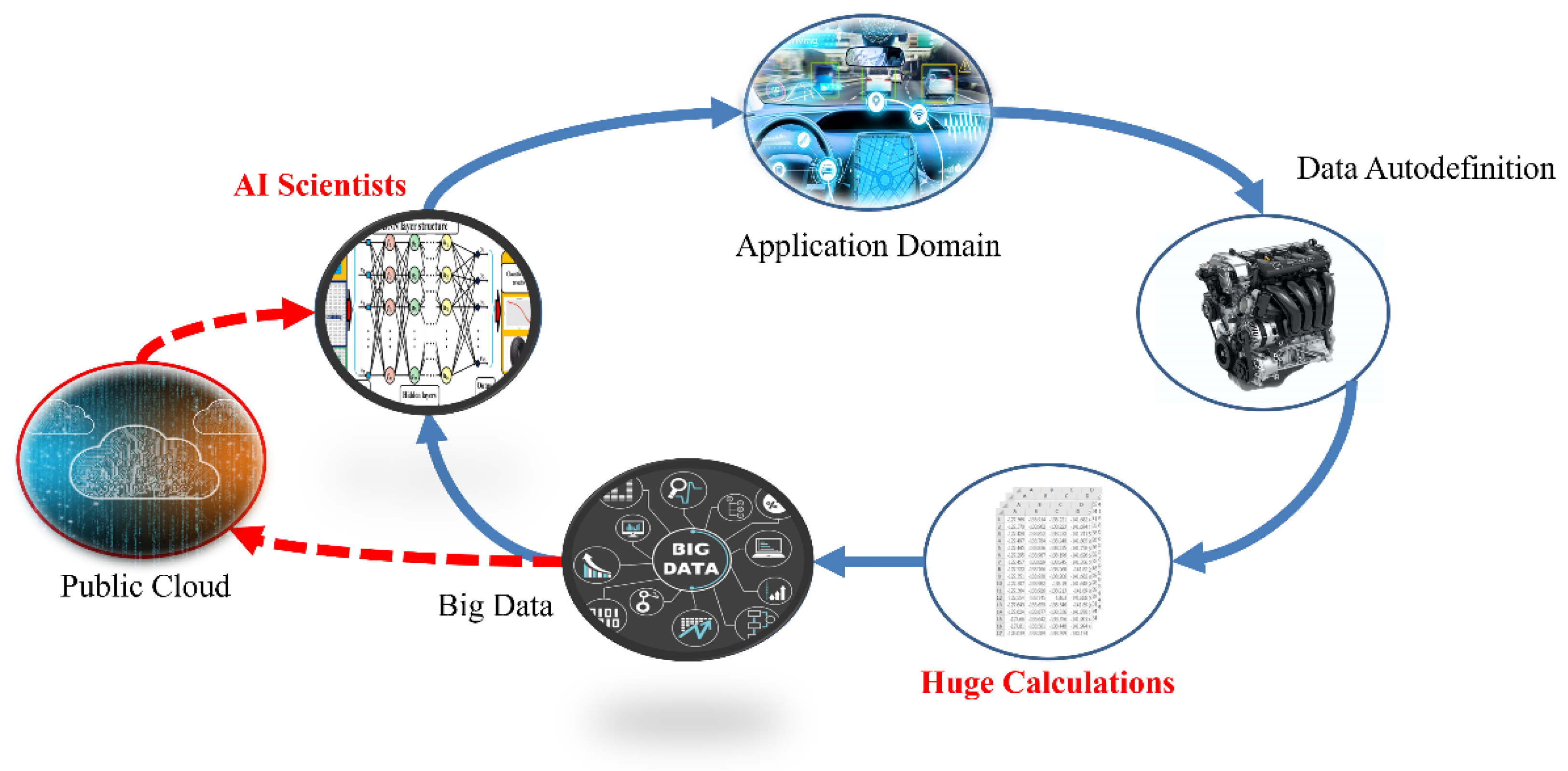
:1. Introduction
2. Overview of Machine and Deep Learning Methods
2.1. Unsupervised Learning
2.1.1. K-Means
2.1.2. PCA (Principal Component Analysis, PCA)
2.1.3. GANs (Generative Adversarial Networks)
2.2. Supervised Learning
2.2.1. Linear Regression
2.2.2. Decision Tree
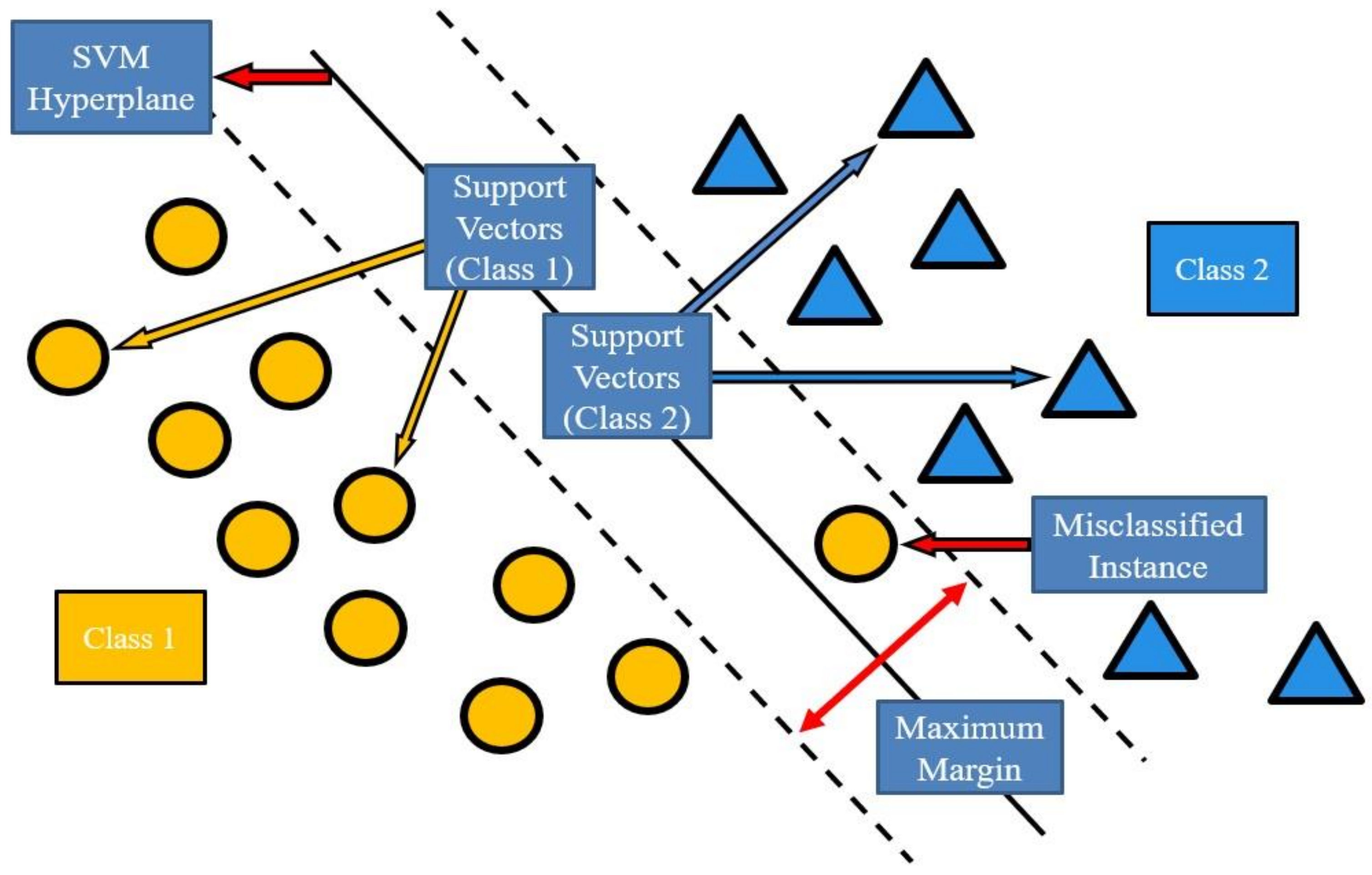
2.2.3. SVM (Support Vector Machine)
2.2.4. Neural Network
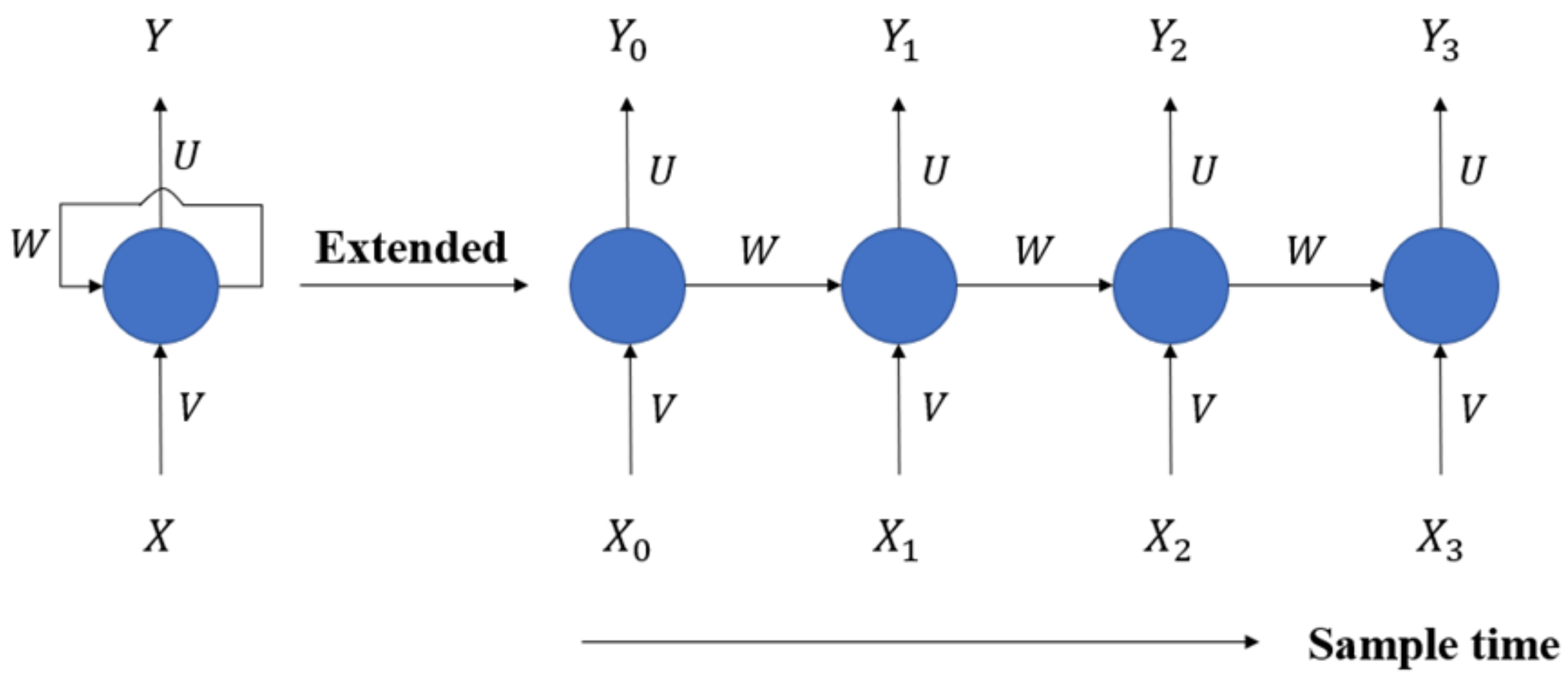
2.2.5. LSTM (Long Short-Term Memory)
2.3. Reinforcement Learning
2.3.1. Monte Carlo Learning
2.3.2. Q-Learning
2.3.3. SARSA (State–Action–Reward–State–Action)
3. Realizing In-Vehicle Fault Diagnosis
3.1. Unsupervised Learning
3.1.1. K-Means
3.1.2. PCA (Principal Component Analysis)
3.1.3. GAN (Generative Adversarial Network)

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Method | Main Application |
|---|---|---|
| [44] | K-means PCA | A research study on unsupervised machine learning algorithms for early fault detection in predictive maintenance |
| [26] | K-means PCA | Fault class prediction in unsupervised learning using model-based clustering approach |
| [39] | GAN | Vehicle trajectory prediction based on social generative adversarial network for self-driving car applications |
| [40] | GAN | Automotive radar interference mitigation based on a generative adversarial network |
| [50] | GAN | Simulated intensity rendering of 3D LiDAR using generative adversarial network |
| [51] | GAN | Intelligent fault diagnosis under small sample size conditions via bidirectional InfoMax GAN with unsupervised representation learning |
| [56] | GAN | KfreqGAN: unsupervised detection of sequence anomaly with adversarial learning and frequency domain information |
| [47] | PCA | A quick self-compensation method of resistance simulation system in vehicle chassis dynamometer based on kernel PCA |
| [22] | GAN | A generative-adversarial-network-enabled deep distributional reinforcement learning for transmission scheduling in the Internet of Vehicles |
| [57] | GAN | SA-SGAN: a vehicle trajectory prediction model based on generative adversarial networks |
3.2. Supervised Learning
3.2.1. SVM (Support Vector Machine)
| Ref. | Method | Main Application |
|---|---|---|
| [55] | SVM | Fault diagnosis of an autonomous vehicle with an improved SVM algorithm subject to unbalanced datasets |
| [56] | SVM | Safety cruise control of connected vehicles using radar and vehicle-to-vehicle communication |
| [64] | LSTM | Vehicle driving behavior predicting and judging using LSTM and statistics methods |
| [61] | Decision tree (random forest) | Multiple-instance learning with random forest for event log analysis and predictive maintenance in ship electric propulsion system |
| [57] | SVM | Acoustic-based and machine-learning-driven methods for vehicle fault classification |
| [58] | DNN SVM | Implementation of machine learning for fault classification on vehicle power transmission system |
| [59] | SVM | Prediction of driver intention to lane change by augmenting sensor information using machine learning techniques |
| [62] | Decision tree (random forest) | Predicting the need for vehicle compressor repairs using maintenance records and logged vehicle data |
| [60] | SVM | SemiBoost: boosting for semisupervised learning |
| [63] | Decision tree (random forest) | Decision approach for maintenance of urban rail transit based on equipment supervision data mining |
| [65] | LSTM | Multivariate deep learning approach for electric vehicle speed forecasting |
| [66] | LSTM | Identification of driver braking intention based on long short-term memory (LSTM) network |
| [67] | Linear regression | Modeling vehicle-merging position selection behaviors based on a finite mixture of linear regression models |
| [68] | Linear regression | Measurement-based VLC channel characterization for I2V communications in a real urban scenario |
| [69] | Neural network | A multimodality fusion deep neural network and safety test strategy for intelligent vehicles |
| [70] | Neural network | Battery thermal runaway fault prognosis in electric vehicles based on abnormal heat generation and deep learning algorithms |
| [71] | Neural network | Object classification using CNN-based fusion of vision and LIDAR in autonomous vehicle environment |
3.2.2. Decision Tree
3.2.3. LSTM (Long Short-Term Memory)
3.2.4. Linear Regression
3.2.5. Neural Network
3.3. Reinforcement Learning
3.3.1. Q-Learning
3.3.2. Monte Carlo Learning
| Ref. | Method | Main Application |
|---|---|---|
| [75] | DQN | Lane change of vehicles based on DQN |
| [76] | DQN | Decision-making for oncoming traffic-overtaking scenario using double DQN |
| [77] | DQN | Integration of electric vehicles in smart grid using deep reinforcement learning |
| [78] | DQN | ES-DQN: a learning method for vehicle intelligent speed control strategy under uncertain cut-in scenario |
| [79] | Monte Carlo learning | Safe reinforcement learning for autonomous vehicle using Monte Carlo tree search |
| [80] | Monte Carlo learning | Combining planning and deep reinforcement learning in tactical decision making for autonomous driving |
| [84] | Monte Carlo learning | Simulation of supercavitating vehicle steady motion |
| [9] | SARSA | Autonomous RL: autonomous vehicle obstacle avoidance in a dynamic environment using MLP-SARSA reinforcement learning |
| [85] | SARSA | Power management strategy of hybrid vehicles using SARSA method |
| [86] | SARSA | A path-planning algorithm based on RRT and SARSA (Ȝ) in unknown and complex conditions |
3.3.3. SARSA (State–Action–Reward–State–Action)
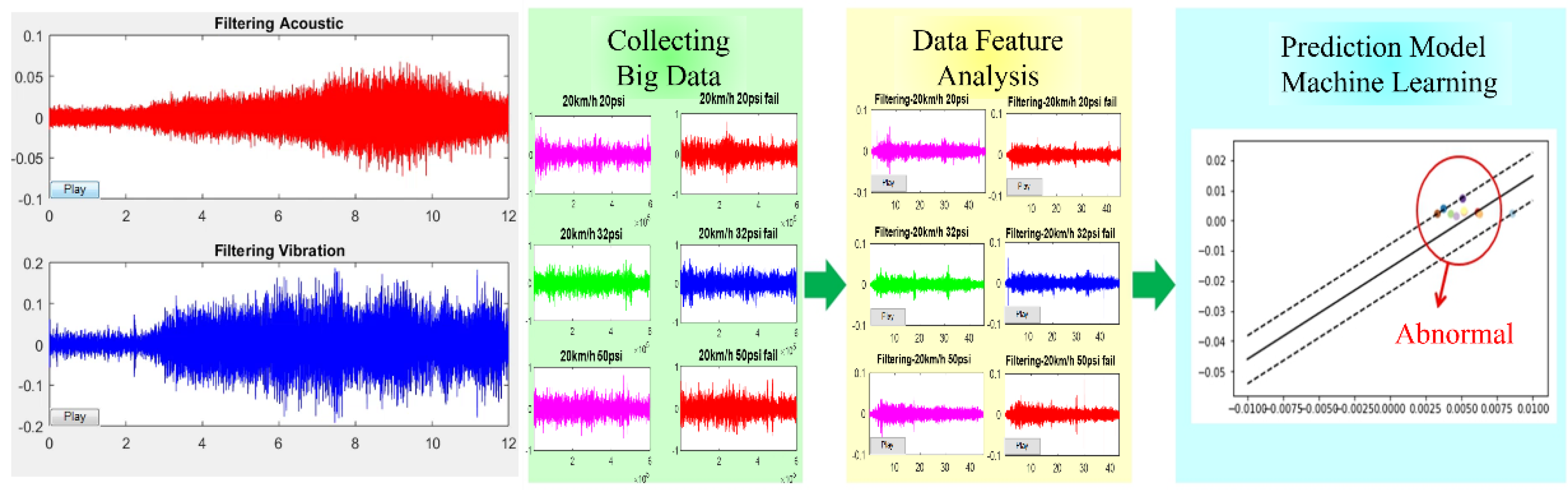
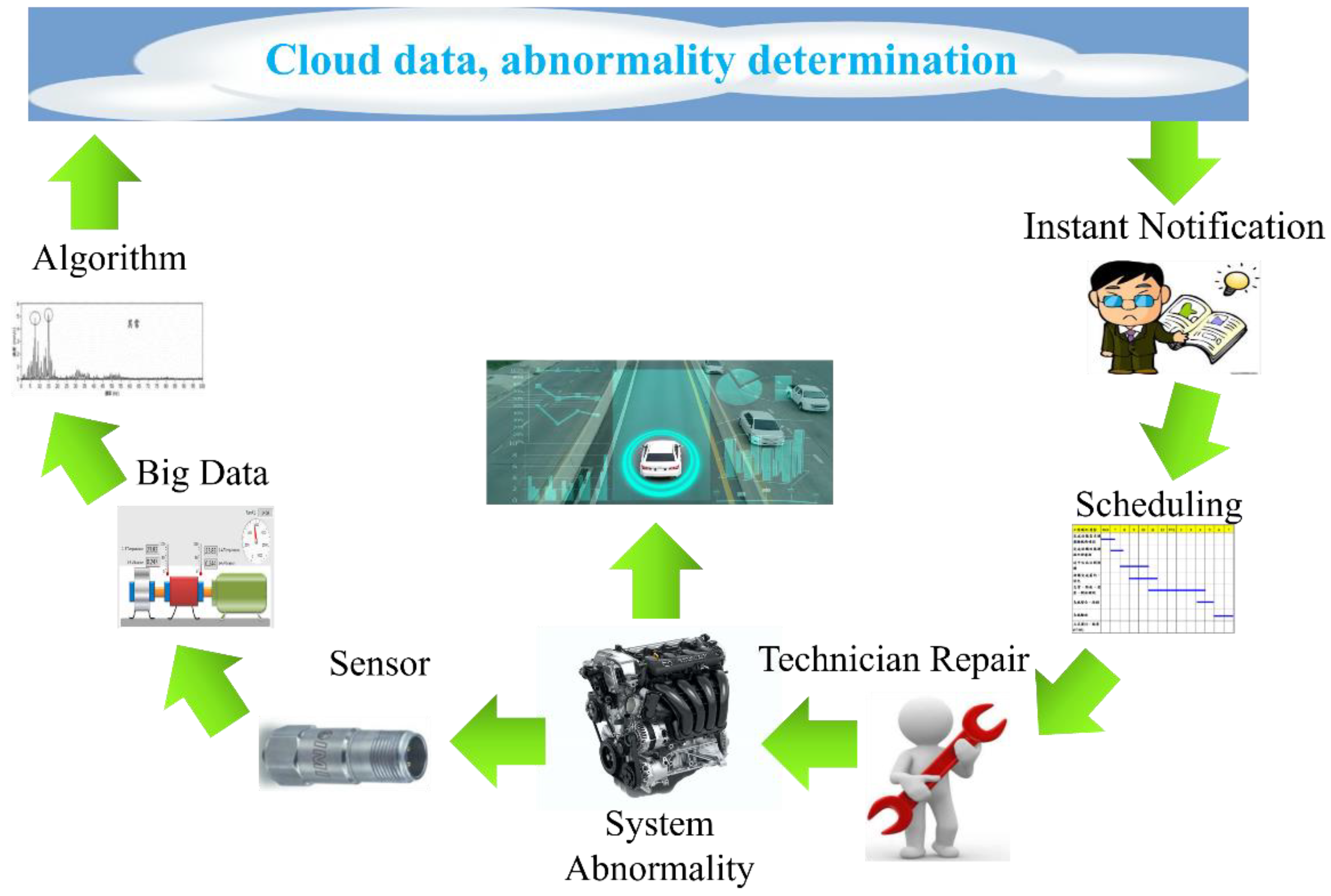
4. Overview of the Application of Vehicle Fault Diagnosis to the Internet of Vehicles (Using Acoustic Signals to Achieve Fault Prediction as an Example)
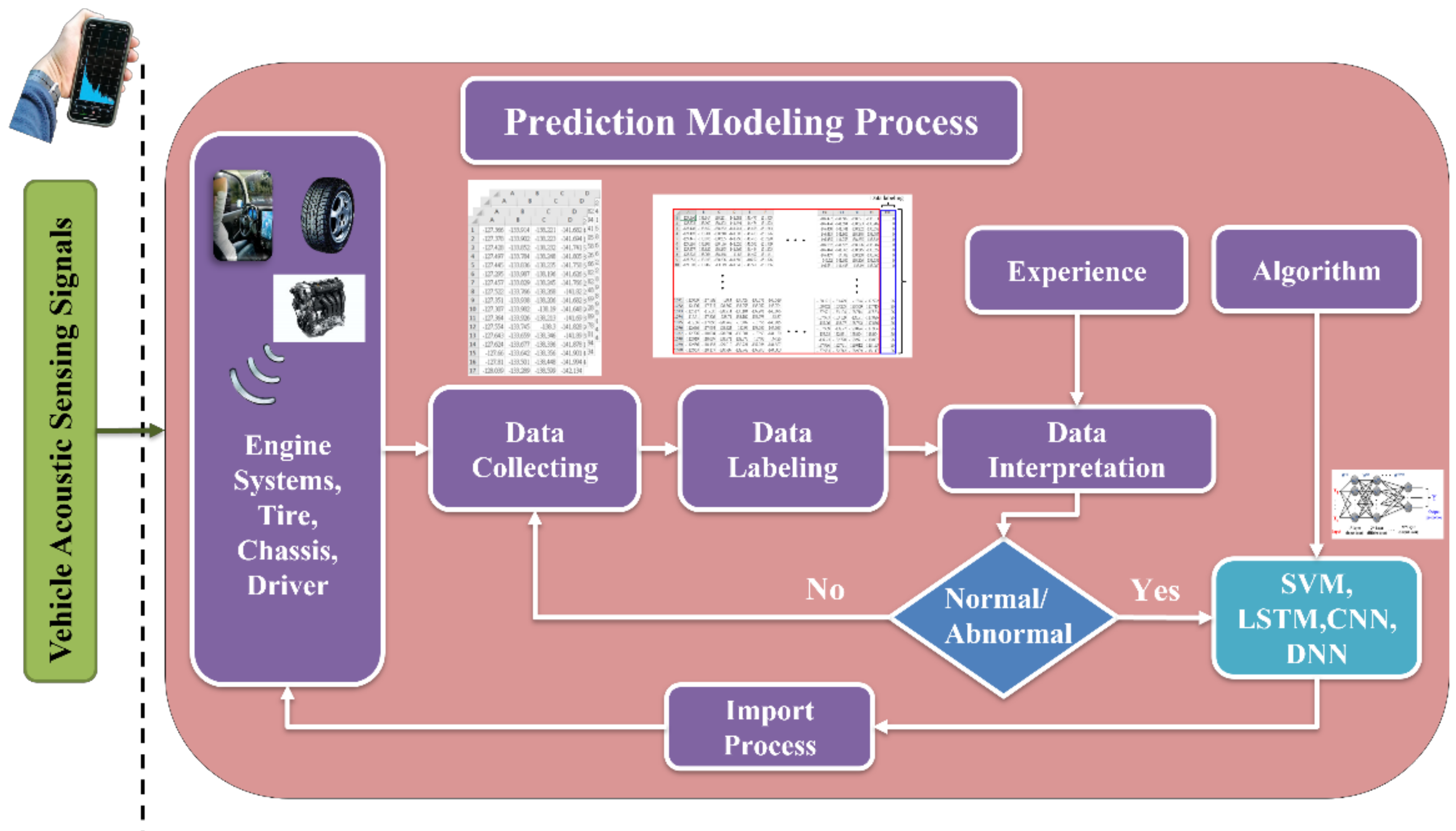
4.1. Overview of Vehicle Transmission Acoustic Signal Processing
4.2. Establishment of Fault Diagnosis Model
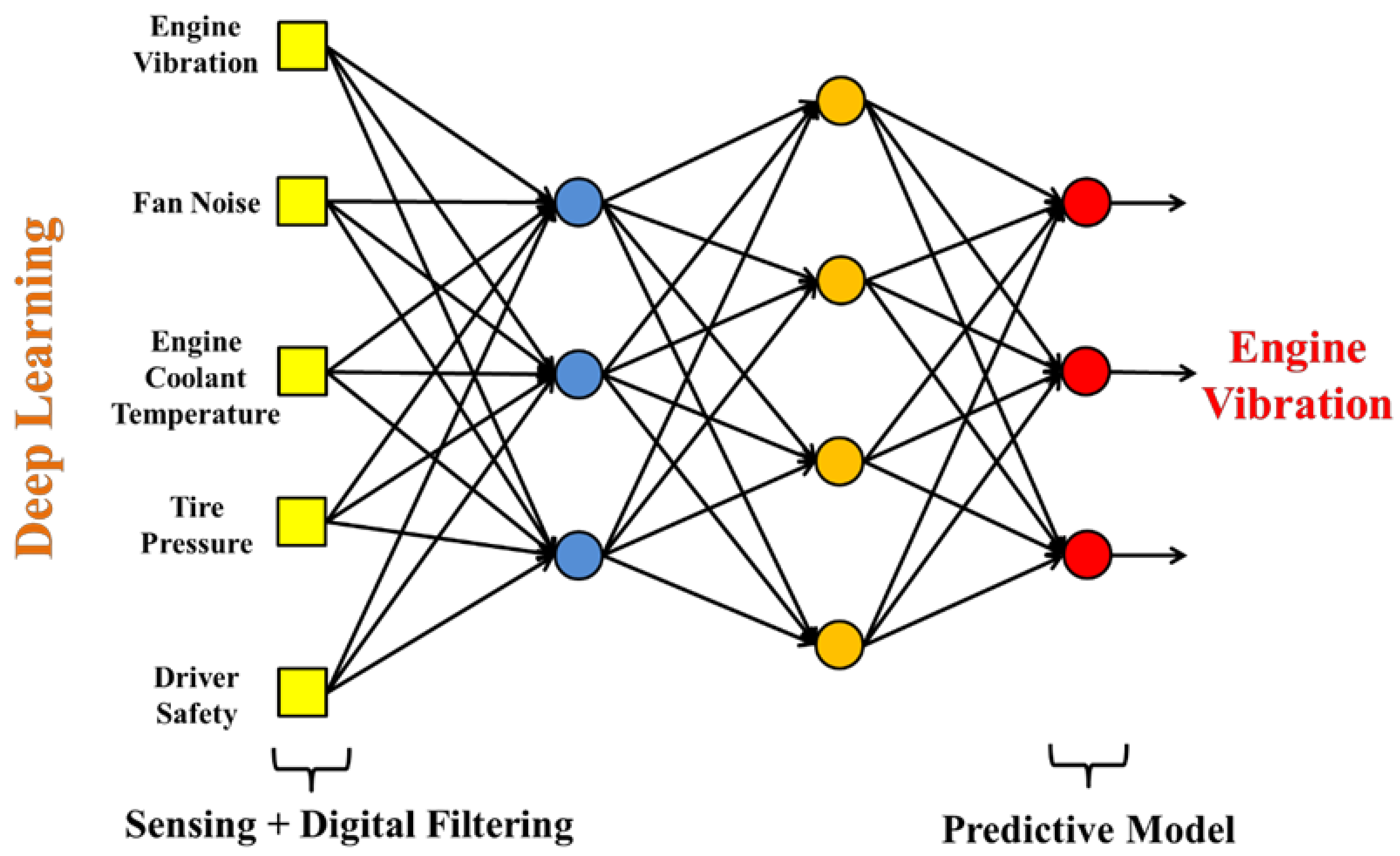
4.3. Multiple Data Source Input Architecture
5. Discussion and Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| 2-DOF | Two-degree-of-freedom |
| ACC | Adaptive cruise control |
| ADAS | Advanced driver assistance system |
| AHG | Abnormal heat generation |
| AI | Artificial intelligence |
| ANN | Artificial neural network |
| AR | Autoregressive |
| CART | Classification and regression tree algorithm |
| CCC | Connected cruise control |
| CNN | Convolutional neural network |
| DNN | Deep neural network |
| DDQN | Double-deep Q-learning |
| DQN | Deep Q-learning network |
| ES-DQN | Experience selection deep Q-learning network |
| FMCW/CS | Frequency-modulated continuous wave/chirp sequence |
| FNN | Feedforward neural network |
| GAN | Generative adversarial network |
| GPS | Global positioning system |
| IDM | Intelligent driver model |
| IMF-DNN | Integrated multimodality fusion deep neural network |
| I2V | Infrastructure-to-vehicle |
| IoT | Internet of Things |
| IoV | Internet of Vehicles |
| LPC | Linear predictive coding |
| LSTM | Long short-term memory |
| MCTS | Monte Carlo tree search |
| MDP | Markov decision process |
| MEMS | Microelectromechanical system |
| MFCC | Mel-frequency cepstral coefficient |
| ML | Machine learning |
| MLP | Multilayer perceptron |
| MOBIL | Minimizing overall braking induced by lane |
| MS | Model-based scheme |
| MSE | Mean square error |
| PCA | Principal components analysis |
| PdM | Predictive maintenance |
| PER | Prioritized experience replay |
| RAOM | Random adjacent optimization method |
| RBF | Radial basis function |
| RFFT | Real fast Fourier transform |
| RL | Reinforcement learning |
| RL-RRT | Reinforcement learning rapidly exploring random tree |
| RNN | Recurrent neural network |
| RRT | Rapidly exploring random tree |
| SARSA | State–action–reward–state–action |
| SA-SGAN | Self-attention social generative adversarial network |
| SDN | Software-defined network |
| SSE | Sum of square error |
| SVM | Support vector machine |
| SVM-RFE | Support vector machine–recursive feature elimination |
| SUMO | Simulation of urban mobility |
| UDDS | Urban dynamometer driving schedule |
| URT | Urban rail transit |
| V2G | Vehicle-to-grid |
| VFDD | Vehicle fault detection and diagnosis |
| VLC | Visible light communication |
| WT | Wavelet transform |
References
- Lin, Y.W.; Hsiao, C.K.; Liu, J.M.; Li, S.Q.; Chiu, H.Y.; Liu, Y.E.; Su, C.H.S.; Gong, C.S.A. Artificial Intelligence Applied in Prediction for Dynamic Tire Set of Vehicle. In Proceedings of the 2020 International Conference on Information Management (ICIM 2020), Chiayi, Taiwan, 13–14 August 2020. [Google Scholar]
- Billings, R.M.; Michaels, A.J. Real-Time Mask Recognition. IoT 2021, 2, 688–716. [Google Scholar] [CrossRef]
- Arthurs, P.; Gillam, L.; Krause, P.; Wang, N.; Halder, K.; Mouzakitis, A. A Taxonomy and Survey of Edge Cloud Computing for Intelligent Transportation Systems and Connected Vehicles. IEEE Trans. Intell. Transp. Syst. 2022, 23, 7. [Google Scholar] [CrossRef]
- Liu, S.; Liu, L.; Tang, J.; Yu, B.; Wang, Y.; Shi, W. Edge Computing for Autonomous Driving: Opportunities and Challenges. Proc. IEEE 2019, 107, 1697–1716. [Google Scholar] [CrossRef]
- Sharma, P.; Saraswat, N. Diagnosis of motor faults using sound signature analysis. Int. J. Innov. Res. Electr. 2015, 3, 529–551. [Google Scholar]
- Singh, D.; Singh, M. Internet of vehicles for smart and safe driving. In Proceedings of the International Conference on Connected Vehicles and Expo (ICCVE), Shenzhen, China, 19–23 October 2015. [Google Scholar]
- Saibannavar, D.; Math, M.M.; Kulkarni, U. A Survey on On-Board Diagnostic in Vehicles. In Proceedings of the International Conference on Mobile Computing and Sustainable Informatics, Lalitpur, Nepal, 23 January 2020; Springer: Cham, Switzerland, 2020; pp. 49–60. [Google Scholar]
- Khamoudj, C.E.; Tayeb, F.B.; Benatchba, K.; Benbouzid, M. Classical mechanics-inspired optimization metaheuristic for induction machines bearing failures detection and diagnosis. In Proceedings of the IECON 2017-43rd Annual Conference of the IEEE Industrial Electronics Society, Beijing, China, 29 October–1 November 2017. [Google Scholar]
- Tinga, T.; Loendersloot, R. Physical model-based prognostics and health monitoring to enable predictive maintenance. In Predictive Maintenance in Dynamic Systems; Springer: Cham, Switzerland, 2019; pp. 313–353. [Google Scholar]
- Zhou, Y.; Zhu, L.; Yi, J.; Luan, T.H.; Li, C. On Vehicle Fault Diagnosis: A Low Complexity Onboard Method. In Proceedings of the GLOBECOM 2020—2020 IEEE Global Communications Conference, Taipei, Taiwan, 7–11 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Zhao, Y.; Liu, P.; Wang, Z.; Hong, J. Electric vehicle battery fault diagnosis based on statistical method. Energy Procedia 2017, 105, 2366–2371. [Google Scholar] [CrossRef]
- Shen, D.; Wu, L.; Kang, G.; Guan, Y.; Peng, Z. A novel online method for predicting the remaining useful life of lithium-ion batteries considering random variable discharge current. Energy 2021, 218, 119490. [Google Scholar] [CrossRef]
- Liu, Y.H.; Yu, W.J.; Dillon, T.; Rahayu, W.; Li, M. Empowering IoT Predictive Maintenance Solutions With AI: A Distributed System for Manufacturing Plant-Wide Monitoring. IEEE Trans. Ind. Inform. 2022, 18, 1345–1354. [Google Scholar] [CrossRef]
- Tang, S.; Yuan, S.; Zhu, Y. Data preprocessing techniques in convolutional neural network based on fault diagnosis towards rotating machinery. IEEE Access 2020, 8, 149487–149496. [Google Scholar] [CrossRef]
- Metwally, M.; Moustafa, H.M.; Hassaan, G. Diagnosis of rotating machines faults using artificial intelligence based on preprocessing for input data. In Proceedings of the Conference of Open Innovations Association (FRUCT), Yaroslavl, Russia, 20–24 April 2020. [Google Scholar]
- Amruthnath, N.; Gupta, T. A Research Study on Unsupervised Machine Learning Algorithms for Early Fault Detection in Predictive Maintenance. In Proceedings of the International Conference on Industrial Engineering and Applications (ICIEA), Singapore, 26–28 April 2018. [Google Scholar]
- Amruthnath, N.; Gupta, T. Fault class prediction in unsupervised learning using model-based clustering approach. In Proceedings of the 2018 International Conference on Information and Computer Technologies (ICICT), DeKalb, IL, USA, 23–25 March 2018. [Google Scholar]
- Kang, L.W.; Hsu, C.C.; Wang, I.S.; Liu, T.L.; Chen, S.Y.; Chang, C.Y. Vehicle Trajectory Prediction based on Social Generative Adversarial Network for Self-Driving Car Applications. In Proceedings of the International Symposium on Computer, Consumer and Control (IS3C), Taichung, China, 13–16 November 2020. [Google Scholar]
- Chen, S.; Shangguan, W.; Taghia, J.; Kühnau, U.; Martin, R. Automotive Radar Interference Mitigation Based on a Generative Adversarial Network. In Proceedings of the IEEE Asia-Pacific Microwave Conference (APMC), Hong Kong, China, 8–11 December 2020. [Google Scholar]
- Mok, S.; Kim, G. Simulated Intensity Rendering of 3D LiDAR using Generative Adversarial Network. In Proceedings of the IEEE International Conference on Big Data and Smart Computing (BigComp), Jeju Island, Korea, 17–20 January 2021. [Google Scholar]
- Liu, S.; Chen, J.; He, S.; Xu, E.; Lv, H.; Zhou, Z. Intelligent fault diagnosis under small sample size conditions via Bidirectional InfoMax GAN with unsupervised representation learning. Knowl. -Based Syst. 2021, 232, 107488. [Google Scholar] [CrossRef]
- Yao, Y.; Ma, J.; Ye, Y. KfreqGAN: Unsupervised detection of sequence anomaly with adversarial learning and frequency domain information. Knowl. -Based Syst. 2021, 236, 107757. [Google Scholar] [CrossRef]
- Guo, L.; Wang, Y. A quick self-compensation method of resistance simulation system in vehicle chassis dynamometer based on kernel PCA. In Proceedings of the 2010 8th World Congress on Intelligent Control and Automation, Jinan, China, 7–9 July 2010. [Google Scholar]
- Naeem, F.; Seifollahi, S.; Zhou, Z.; Tariq, M. A Generative Adversarial Network Enabled Deep Distributional Reinforcement Learning for Transmission Scheduling in Internet of Vehicles. IEEE Trans. Intell. Transp. Syst. 2020, 22, 4550–4559. [Google Scholar] [CrossRef]
- Zhou, D.; Wang, H.; Li, W.; Zhou, Y.; Cheng, N.; Lu, N. SA-SGAN: A Vehicle Trajectory Prediction Model Based on Generative Adversarial Networks. In Proceedings of the 2021 IEEE 94th Vehicular Technology Conference (VTC2021-Fall), Norman, OK, USA, 27–30 September 2021. [Google Scholar]
- Shi, Q.; Zhang, H. Fault Diagnosis of an Autonomous Vehicle with an Improved SVM Algorithm Subject to Unbalanced Datasets. IEEE Trans. Ind. Electron. 2020, 68, 6248–6256. [Google Scholar] [CrossRef]
- Ma, Z.; Huo, Q.; Yang, X.; Zhao, X. Safety Cruise Control of Connected Vehicles Using Radar and Vehicle-to-Vehicle Communication. IEEE Syst. J. 2020, 14, 4602–4613. [Google Scholar] [CrossRef]
- Zhang, C.; Che, G.; Gao, B. Vehicle driving behavior predicting and judging using LSTM and statistics methods. In Proceedings of the 2020 4th CAA International Conference on Vehicular Control and Intelligence (CVCI), Hangzhou, China, 18–20 December 2020. [Google Scholar]
- Bakdi, A.; Kristensen, N.B.; Stakkeland, M. Multiple Instance Learning with Random Forest for Event-Logs Analysis and Predictive Maintenance in Ship Electric Propulsion System. IEEE Trans. Ind. Inform. 2022. [Google Scholar] [CrossRef]
- Chao, K.W.; Chen, Y.H.; Ho, Y.Y.; Guu, D.Y.; Luo, L.B.; Tseng, C.W.; Su, C.S.; Gong, C.A.; Huang, Q.Y.; Lee, I.E.; et al. Feature-Driven Fault Classification for Vehicle Driving Health based on Supervised Learning. In Proceedings of the 26th National Conference on Vehicle Engineering, Taiwan, China, 12 November 2021. [Google Scholar]
- Gong, C.S.A.; Su, C.S.S.; Tseng, K.H. Implementation of Machine Learning for Fault Classification on Vehicle Power Transmission System. IEEE Sens. J. 2020, 20, 15163–15176. [Google Scholar] [CrossRef]
- Kim, I.H.; Bong, J.H.; Park, J.; Park, S. Prediction of Driver’s Intention of Lane Change by Augmenting Sensor Information using Machine Learning Techniques. Sensors 2017, 17, 1350. [Google Scholar] [CrossRef]
- Prytz, R.; Nowaczyk, S.; Rognvaldsson, T.; Byttner, S. Predicting the need for vehicle compressor repairs using maintenance records and logged vehicle data. Eng. Appl. Artif. Intell. 2015, 41, 139–150. [Google Scholar] [CrossRef]
- Mallapragada, P.K.; Jin, R.; Jain, A.K.; Liu, Y. SemiBoost: Boosting for Semi-Supervised Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 31, 2000–2014. [Google Scholar] [CrossRef]
- Zhang, M. Decision approach of maintenance for urban rail transit based on equipment supervision data mining. In Proceedings of the 2015 IEEE 8th International Conference on Intelligent Data Acquisition and Advanced Computing Systems: Technology and Applications (IDAACS), Warsaw, Poland, 24–26 September 2015. [Google Scholar]
- Malek, Y.N.; Najib, M.; Bakhouya, M.; Essaaidi, M. Multivariate deep learning approach for electric vehicle speed forecasting. Big Data Min. Anal. 2021, 4, 56–64. [Google Scholar] [CrossRef]
- Wang, S.; Zhao, X.; Yu, Q.; Yuan, T. Identification of Driver Braking Intention Based on Long Short-Term Memory (LSTM) Network. IEEE Access 2020, 8, 180422–180432. [Google Scholar] [CrossRef]
- Li, G.; Pan, Y.; Yang, Z.; Ma, J. Modeling Vehicle Merging Position Selection Behaviors Based on a Finite Mixture of Linear Regression Models. IEEE Access 2019, 7, 158445–158458. [Google Scholar] [CrossRef]
- Caputo, S.; Mucchi, L.; Cataliotti, F.; Seminara, M.; Nawaz, T.; Catani, J. Measurement-based VLC channel characterization for I2V communications in a real urban scenario. Veh. Commun. 2020, 28, 100305. [Google Scholar] [CrossRef]
- Nie, J.; Yan, J.; Yin, H.; Ren, L.; Meng, Q. A Multimodality Fusion Deep Neural Network and Safety Test Strategy for Intelligent Vehicles. IEEE Trans. Intell. Veh. 2020, 6, 310–322. [Google Scholar] [CrossRef]
- The Mercedes Star Diagnosis Compact 3. Available online: http://www.cardiagnostics.be/-now/DAS-WIS.htm#The_Mercedes_Star_Diagnosis_compact_3 (accessed on 7 August 2022).
- Nissan Service Information. Available online: https://www.nissan-techinfo.com/dept.aspx?dept_id=25 (accessed on 7 August 2022).
- Tech-One Toyota Specialists-Independent Garage Based on in Sidcup MOT Tech One. Available online: https://www.tech-one.co.uk (accessed on 7 August 2022).
- Li, D.; Liu, P.; Zhang, Z.; Zhang, L.; Deng, J.; Wang, Z.; Dorrell, D.G.; Li, W.; Sauer, D.U. Battery Thermal Runaway Fault Prognosis in Electric Vehicles Based on Abnormal Heat Generation and Deep Learning Algorithms. IEEE Trans. Power Electron. 2022, 37, 8513–8525. [Google Scholar] [CrossRef]
- Gao, H.; Cheng, B.; Wang, J.; Li, K.; Zhao, J.; Li, D. Object Classification Using CNN-Based Fusion of Vision and LIDAR in Autonomous Vehicle Environment. IEEE Trans. Ind. Inform. 2018, 14, 4224–4231. [Google Scholar] [CrossRef]
- Yi, L.M. Lane Change of Vehicles Based on DQN. In Proceedings of the 2020 5th International Conference on Information Science, Computer Technology and Transportation (ISCTT), Shenyang, China, 13–15 November 2020. [Google Scholar]
- Mo, S.J.; Pei, X.F.; Chen, Z. Decision-Making for Oncoming Traffic Overtaking Scenario using Double DQN. In Proceedings of the 2019 3rd Conference on Vehicle Control and Intelligence (CVCI), Hefei, China, 21–22 September 2019. [Google Scholar]
- Kiaee, F. Integration of Electric Vehicles in Smart Grid using Deep Reinforcement Learning. In Proceedings of the 2020 11th International Conference on Information and Knowledge Technology (IKT), Tehran, Iran, 22–23 December 2020. [Google Scholar]
- Chen, Q.Y.; Zhao, W.Z.; Li, L.; Wang, C.Y.; Chen, F. ES-DQN: A Learning Method for Vehicle Intelligent Speed Control Strategy Under Uncertain Cut-In Scenario. IEEE Trans. Veh. Technol. 2022, 71, 2472–2484. [Google Scholar] [CrossRef]
- Mo, S.J.; Pei, X.F.; Wu, C.X. Safe Reinforcement Learning for Autonomous Vehicle Using Monte Carlo Tree Search. IEEE Trans. Intell. Transp. Syst. 2021, 23, 6766–6773. [Google Scholar] [CrossRef]
- Hoel, C.J.; Campbell, K.D.; Wolff, K.; Laine, L.; Kochenderfer, M.J. Combining Planning and Deep Reinforcement Learning in Tactical Decision Making for Autonomous Driving. IEEE Trans. Intell. Veh. 2019, 5, 294–305. [Google Scholar] [CrossRef]
- Tian, G.P.; An, W.G.; Zhou, L. Simulation of supercavitating vehicle steady motion. In Proceedings of the 2008 International Conference on Machine Learning and Cybernetics, Kunming, China, 12–15 July 2008. [Google Scholar]
- Arvind, C.S.; Senthilnath, J. Autonomous RL: Autonomous Vehicle Obstacle Avoidance in a Dynamic Environment using MLP-SARSA Reinforcement Learning. In Proceedings of the 2019 IEEE 5th International Conference on Mechatronics System and Robots (ICMSR), Singapore, 3–5 May 2019. [Google Scholar]
- Biyouki, S.A.K.; Javareshk, S.M.A.N.; Noori, A.; Hassanehgheh, F.J. Power Management Strategy of Hybrid Vehicles Using Sarsa Method. In Proceedings of the Electrical Engineering (ICEE), Iranian Conference, Mashhad, Iran, 8–10 May 2018. [Google Scholar]
- Zou, Q.; Zhang, Y.; Liu, S.H. A path planning algorithm based on RRT and SARSA in unknown and complex conditions. In Proceedings of the 2020 Chinese Control and Decision Conference (CCDC), Hefei, China, 22–24 August 2020. [Google Scholar]
- Dandare, S.N.; Dudul, S.V. Support vector machine based multiple fault detection in an automobile engine using sound signal. J. Electron. Electr. Eng. 2012, 3, 59–63. [Google Scholar]
- Li, K.; Zhang, R.; Li, F.; Su, L.; Wang, H.; Chen, P. A new rotation machinery fault diagnosis method based on deep structure and sparse least squares support vector machine. IEEE Access 2019, 7, 26571–26580. [Google Scholar] [CrossRef]
- Raschka, S.; Mirjalili, V. Python Machine Learning; Packt Publishing: Birmingham, UK, 2017. [Google Scholar]
- Aggarwal, C.C. Neural Networks and Deep Learning; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Gong, C.S.A.; Su, C.S.; Chao, K.W.; Chao, Y.C.; Su, C.K.; Chiu, W.H. Exploiting deep neural network and long short-term memory method-ologies in bioacoustic classification of LPC-based features. PLoS ONE 2021, 16, e0259140. [Google Scholar] [CrossRef]
- Dreyfus, G. Neural Networks: Methodology and Applications; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Farbiz, F.; Miaolong, Y.; Zhou, Y. A Cognitive Analytics based Approach for Machine Health Monitoring, Anomaly Detection, and Predictive Maintenance. In Proceedings of the 2020 15th IEEE Conference on Industrial Electronics and Applications (ICIEA), Kristiansand, Norway, 9–13 November 2020. [Google Scholar]
- Shen, H.; Duan, Z. Application research of Clustering algorithm based on K-means in data mining. In Proceedings of the 2020 International Conference on Computer Information and Big Data Applications (CIBDA), Guiyang, China, 17–19 April 2020. [Google Scholar]
- Kim, H.G.; Yoon, H.S.; Yoo, J.H.; Yoon, H.I.; Han, S.S. Development of Predictive Maintenance Technology for Wafer Transfer Robot using Clustering Algorithm. In Proceedings of the 2019 International Conference on Electronics, Information, and Communication (ICEIC), Auckland, New Zealand, 22–25 January 2019. [Google Scholar]
- Kiangala, K.S.; Wang, Z. An Effective Predictive Maintenance Framework for Conveyor Motors Using Dual Time-Series Imaging and Convolutional Neural Network in an Industry 4.0 Environment. IEEE Access 2020, 8, 121033–121049. [Google Scholar] [CrossRef]
- Pearson, K. On Lines and Planes of Closest Fit to Systems of Points in Space. Lond. Edinb. Dublin Philos. Mag. J. Sci. 1901, 2, 559–572. [Google Scholar] [CrossRef]
- Pei, Y. Linear Principal Component Discriminant Analysis. In Proceedings of the 2015 IEEE International Conference on Systems, Man, and Cybernetics, Hong Kong, China, 9–12 October 2015. [Google Scholar]
- Shaw, P.J.A. Multivariate Statistics for the Environmental Sciences; Hodder-Arnold: London, UK, 2003; ISBN 978-0-340-80763-7. [Google Scholar]
- Xu, G.; Zhang, S.; Liang, Y. Using Linear Regression Analysis for Face Recognition Based on PCA and LDA. In Proceedings of the International Conference Computational Intelligence and Software Engineering (CiSE), Wuhan, China, 11–13 December 2009. [Google Scholar]
- Rashid, T. Make Your First GAN with Pytorch; Independently Published: New York, NY, USA, 2020. [Google Scholar]
- Mitrofanov, S.; Semenkin, E. An Approach to Training Decision Trees with the Relearning of Nodes. In Proceedings of the 2021 International Conference on Information Technologies (InfoTech), Varna, Bulgaria, 16–17 September 2021. [Google Scholar]
- Jolliffe, I.T. Principal Component Analysis; Springer: New York, NY, USA, 2002. [Google Scholar]
- Smith, L.I. A tutorial on Principal Components Analysis. arXiv 2014, arXiv:1404.1100. [Google Scholar]
- Gupta, A.; Johnson, J.; Li, F.-F.; Savarese, S.; Alahi, A. Social GAN: Socially acceptable trajectories with generative adversarial networks. In Proceedings of the IEEE Conference Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 17–19 June 2018. [Google Scholar]
- Pathak, D.; Krähenbühl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context encoders: Feature learning by inpainting. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; IEEE Computer Society: Piscataway, NJ, USA, 2016; pp. 2536–2544. [Google Scholar]
- Yeh, R.A.; Chen, C.; Lim, T.; Schwing, A.G.; Hasegawa-Johnson, M.N. Do, Semantic image inpainting with deep generative models. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; IEEE Computer Society: Piscataway, NJ, USA, 2017; pp. 6882–6890. [Google Scholar]
- Mogren, O. C-RNN-gan: Continuous recurrent neural networks with adversarial training. arXiv 2016, arXiv:1611.09904. [Google Scholar]
- Esteban, C.; Hyland, S.L.; Rätsch, G. Real-valued (medical) time series generation with recurrent conditional GANs. arXiv 2017, arXiv:1706.02633. [Google Scholar]
- Michon, J.A. A critical view of driver behavior models: What do we know, what should we do? In Human Behavior and Traffic Safety; Evans, L., Schwing, R.C., Eds.; Springer: Boston, MA, USA, 1985; pp. 485–524. [Google Scholar]
- Torres, R.D.D.; Molina, M.; Campoy, P. Survey of Bayesian networks applications on unmanned intelligent autonomous vehicles. arXiv 2019, arXiv:1901.05517. [Google Scholar]
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; et al. Mastering the game of Go without human knowledge. Nature 2017, 550, 354–359. [Google Scholar] [CrossRef]
- Hoel, C.J.; Wolff, K.; Laine, L. Automated speed and lane change decision making using deep reinforcement learning. arXiv 2018, arXiv:1803.10056. [Google Scholar]
- Xu, G.; Liu, M.; Wang, J.; Ma, Y.; Wang, J.; Li, F.; Shen, W. Data-driven fault diagnostics and prognostics for predictive maintenance: A brief overview. In Proceedings of the 2019 IEEE 15th International Conference on Automation Science and Engineering (CASE), Vancouver, BC, Canada, 22–26 August 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 103–108. [Google Scholar]
- Theissler, A.; Pérez-Velázquez, J.; Kettelgerdes, M.; Elger, G. Predictive maintenance enabled by machine learning: Use cases and challenges in the automotive industry. Reliab. Eng. Syst. Saf. 2021, 215, 107864. [Google Scholar] [CrossRef]
- Sorte, R.G.; Ram, P. Vibration based blind identification of bearing failures in rotating machinery. Int. J. Sci. Res. 2015, 4, 199–207. [Google Scholar]
- Liu, H.; Liu, S.; Shkel, A.A.; Tang, Y.; Kim, E.S. Multi-Band MEMS Resonant Microphone Array for Continuous Lung-Sound Monitoring and Classification. In Proceedings of the 2020 IEEE 33rd International Conference on Micro Electro Mechanical Systems (MEMS), Vancouver, BC, Canada, 18–22 January 2020. [Google Scholar]
- Mbo’o, C.P.; Hameyer, K. Fault Diagnosis of Bearing Damage by Means of the Linear Discriminant Analysis of Stator Current Features From the Frequency Selection. IEEE Trans. Ind. Appl. 2016, 52, 3861–3868. [Google Scholar] [CrossRef]
- Hasan, M.M.; Ali, H.; Hossain, M.F.; Abujar, S. Preprocessing of Continuous Bengali Speech for Feature Extraction. In Proceedings of the 2020 11th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kharagpur, India, 1–3 July 2020. [Google Scholar]
- Arena, F.; Collotta, M.; Luca, L.; Ruggieri, M.; Termine, F.G. Predictive Maintenance in the Automotive Sector: A Literature Review. Math. Comput. Appl. 2021, 27, 2. [Google Scholar] [CrossRef]
- Bekar, E.T.; Nyqvist, P.; Skoogh, A. An intelligent approach for data pre-processing and analysis in predictive maintenance with an industrial case study. Adv. Mech. Eng. Dec. 2020, 12, 1687814020919207. [Google Scholar] [CrossRef]
- Liu, Y.E. Implementation of Artificial Intelligence in Sound Recognition of Automotive Driving Status. Master’s Thesis, Chang Gung University, Taiwan, China, 16 September 2021. [Google Scholar]








Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gong, C.-S.A.; Su, C.-H.S.; Chen, Y.-H.; Guu, D.-Y. How to Implement Automotive Fault Diagnosis Using Artificial Intelligence Scheme. Micromachines 2022, 13, 1380. https://doi.org/10.3390/mi13091380
Gong C-SA, Su C-HS, Chen Y-H, Guu D-Y. How to Implement Automotive Fault Diagnosis Using Artificial Intelligence Scheme. Micromachines. 2022; 13(9):1380. https://doi.org/10.3390/mi13091380
Chicago/Turabian StyleGong, Cihun-Siyong Alex, Chih-Hui Simon Su, Yu-Hua Chen, and De-Yu Guu. 2022. "How to Implement Automotive Fault Diagnosis Using Artificial Intelligence Scheme" Micromachines 13, no. 9: 1380. https://doi.org/10.3390/mi13091380