
Deep Learning for Clothing Style Recognition Using YOLOv5

Abstract
:1. Introduction
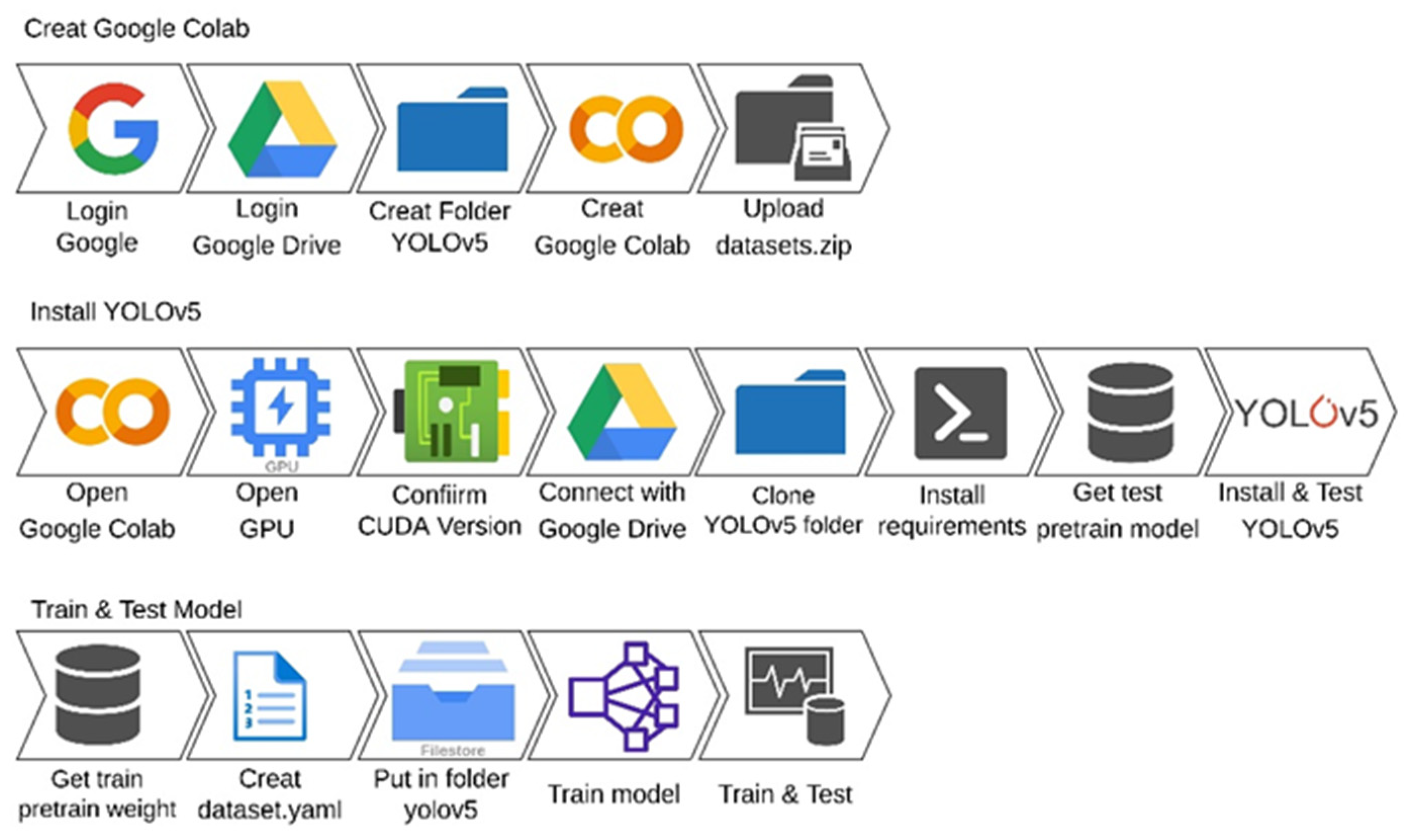
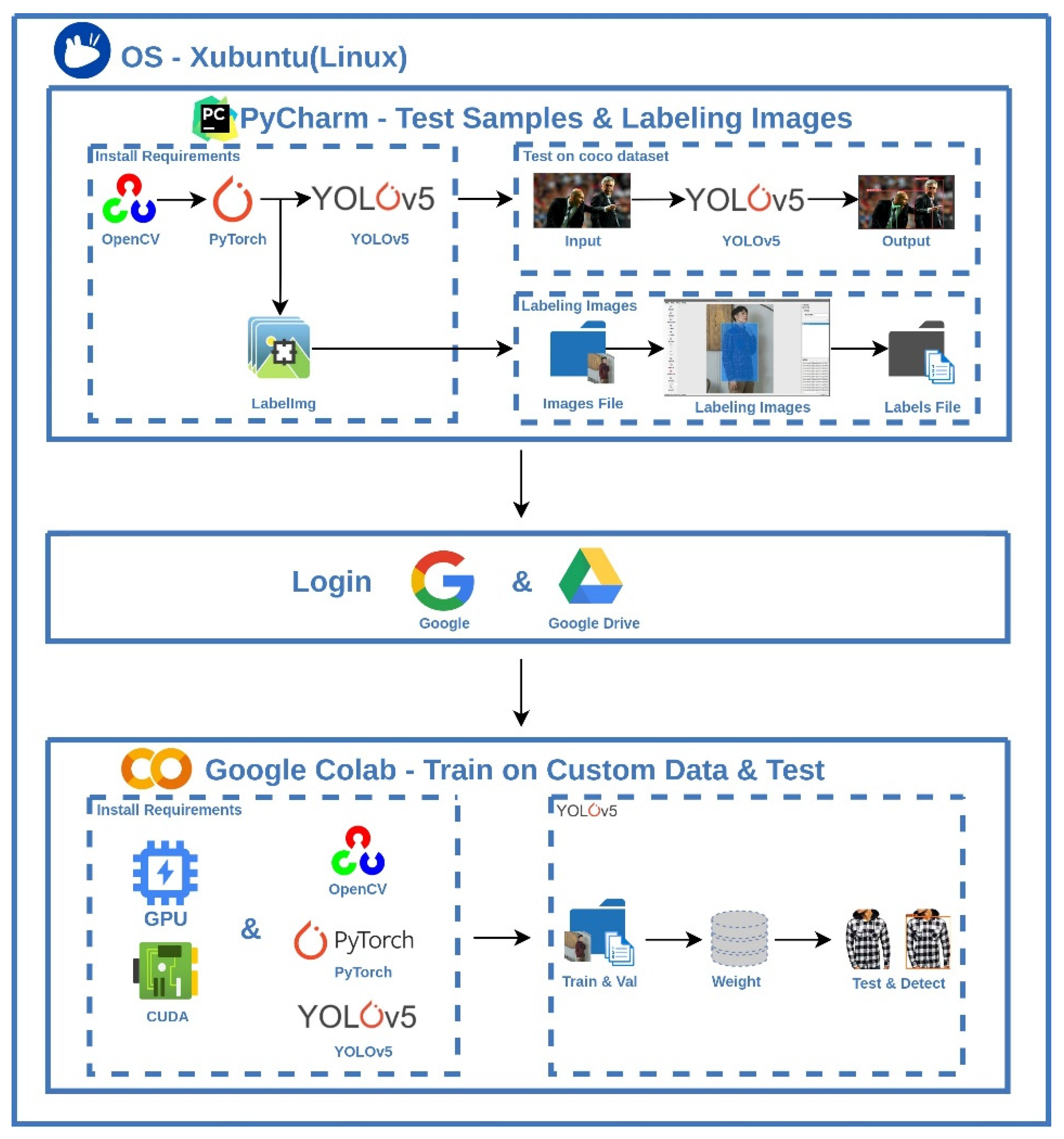
- The process of building an integrated environment based on Google Colab is concisely explained so that those interested in deep learning can easily get involved in the study, especially for beginners who lack their own powerful GPU computer;
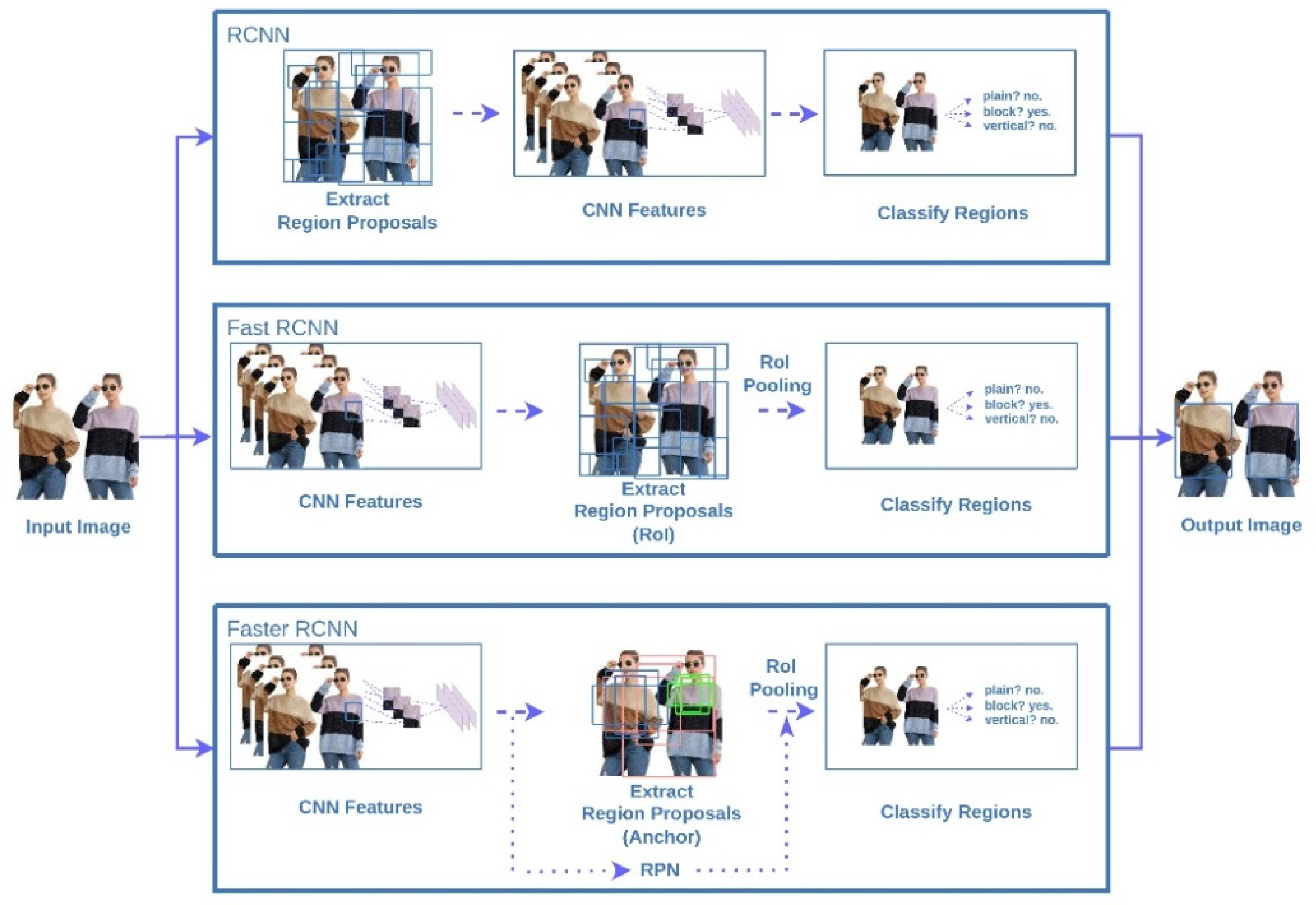
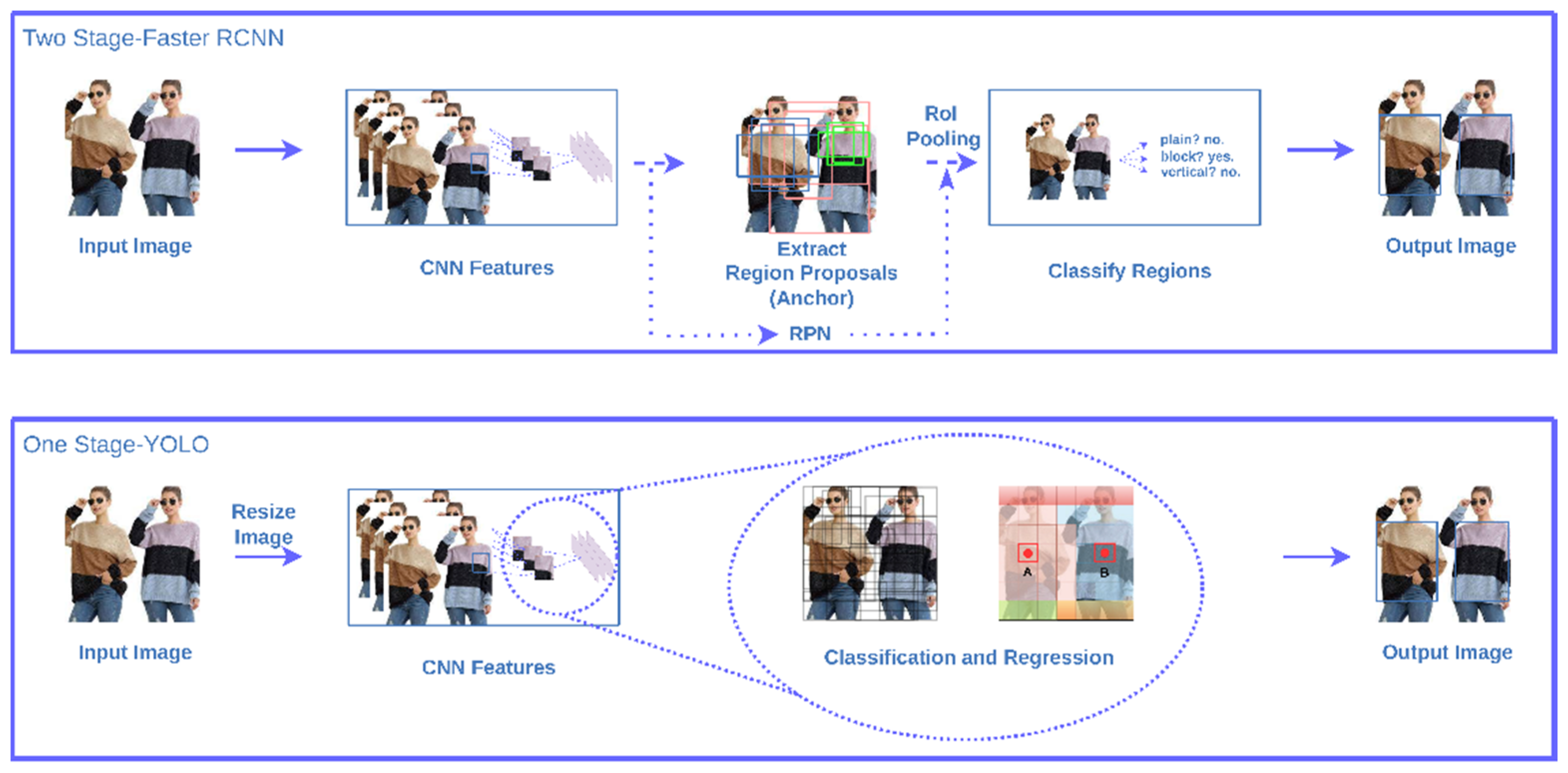
- The crucial differences among R-CNN, Fast R-CNN, and Faster R-CNN are explained concisely such that readers can have easier access to the key concepts of typical two-stage algorithms;
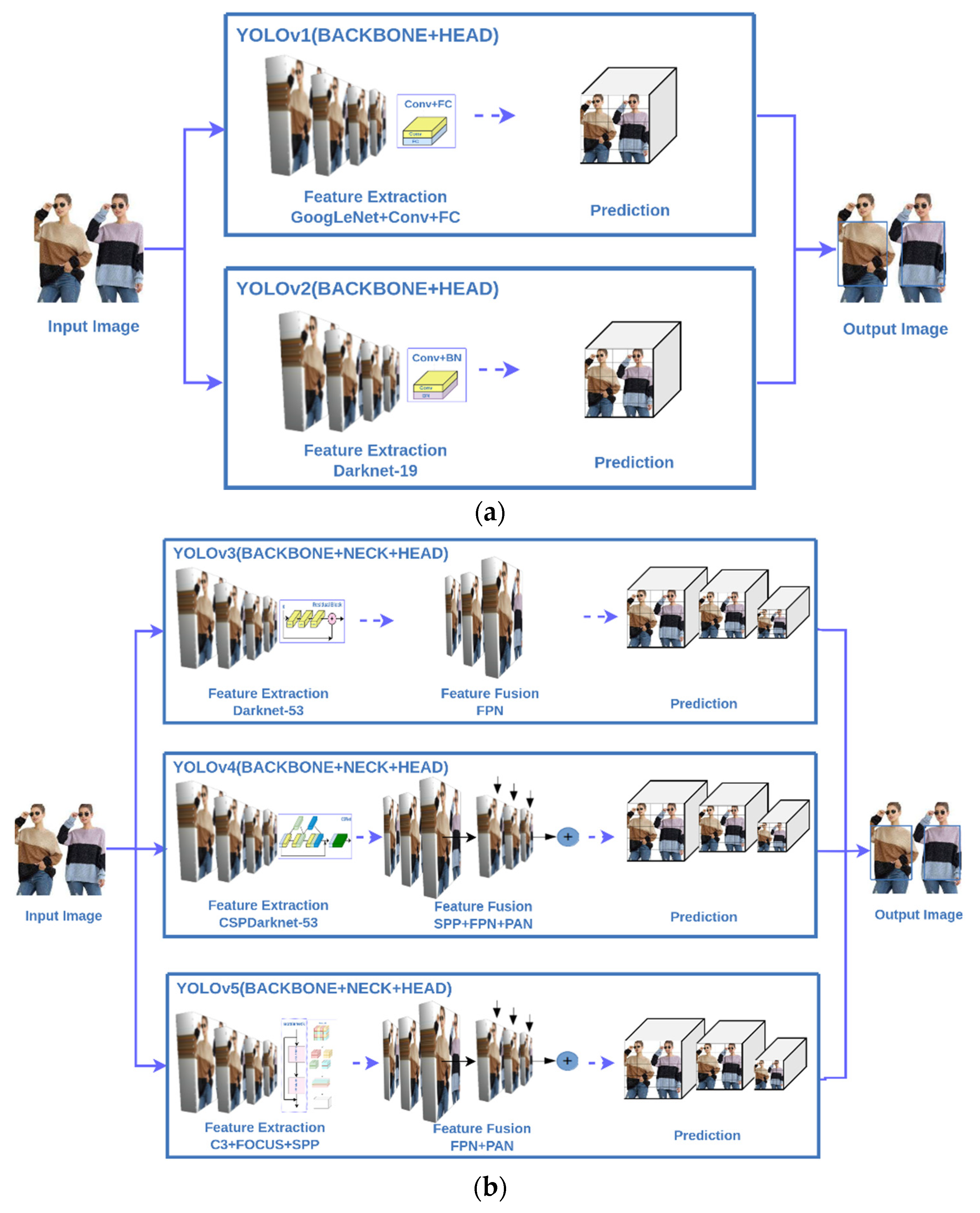
- The essential modifications in the development of the YOLO series are succinctly explained such that the readers will know better about the cores of each generation of one-stage YOLOs;
- Experimental results about the recognition of clothing styles are provided along with each essential step. Furthermore, the integration of experimental outcomes are given for performance validations. The indexes of average precision (AP), mean average precision (mAP), recall, F1-score, model size, and frames per second (FPS) are investigated.
2. Materials and Methods
2.1. Object Detection
2.1.1. Two-Stage
2.1.2. One-Stage
2.2. Implementation of Deep Learning Framework
System Built with Google Colab
2.3. YOLO Algorithms
3. Results
3.1. Integrated Develepmental Environment
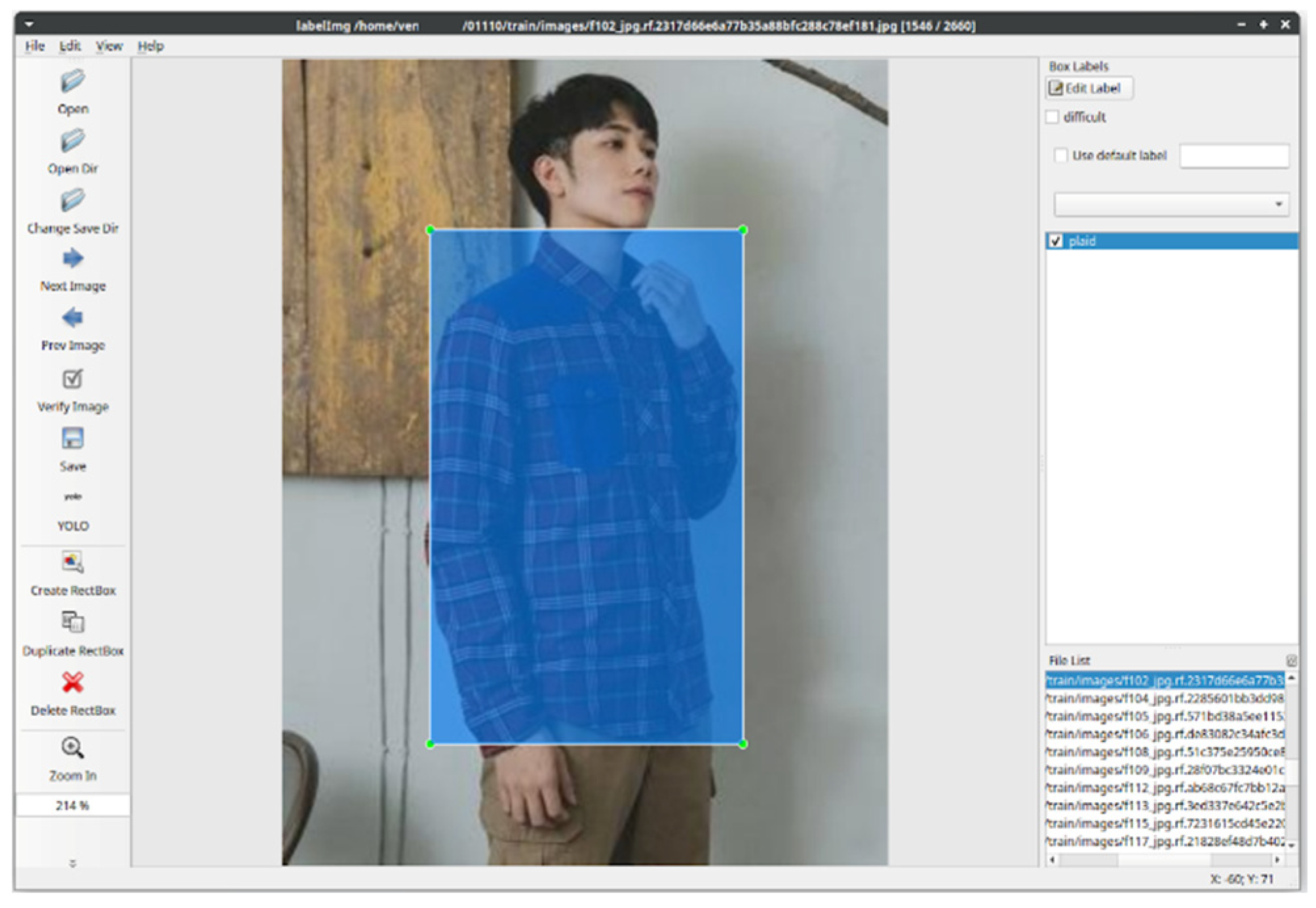
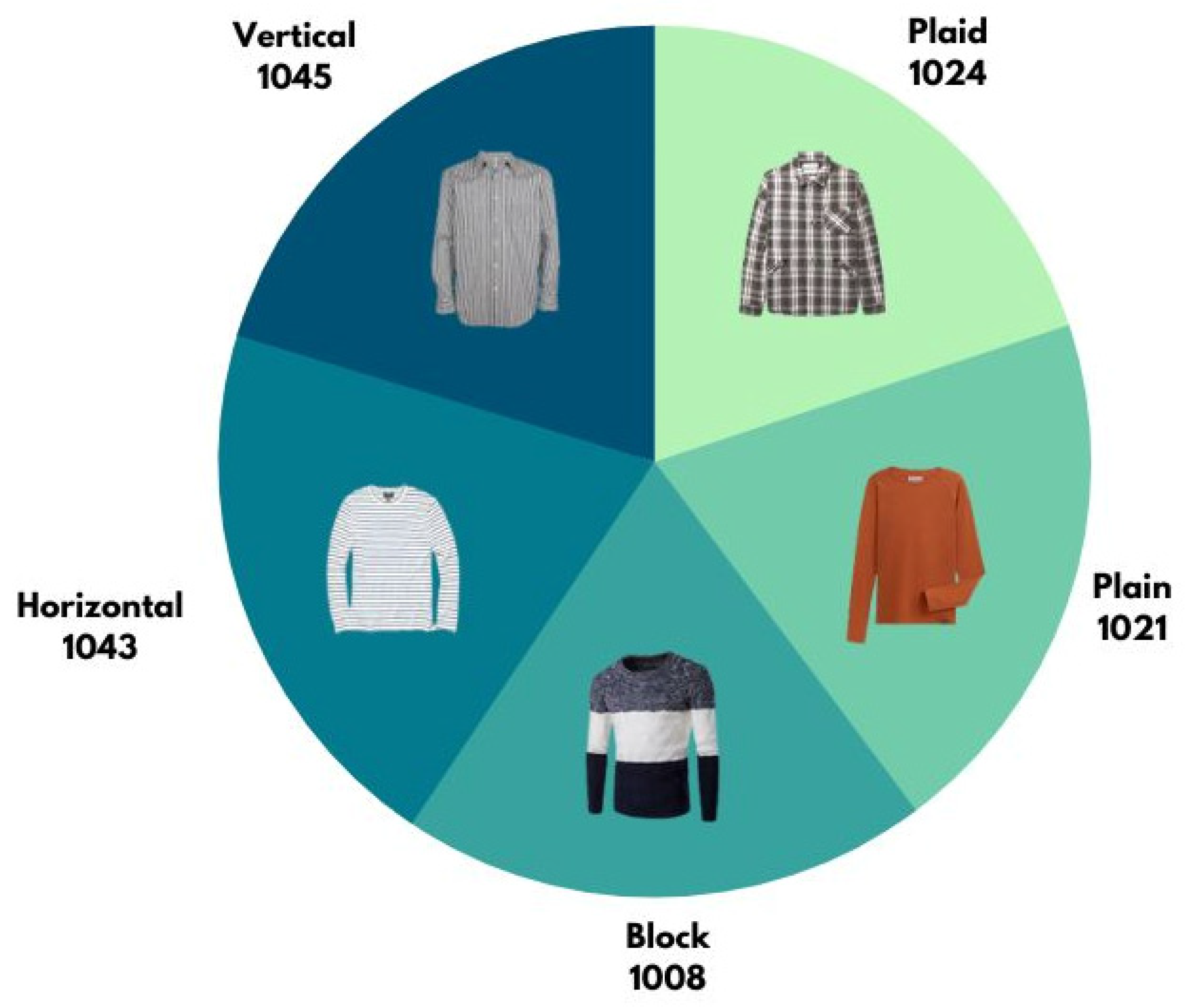
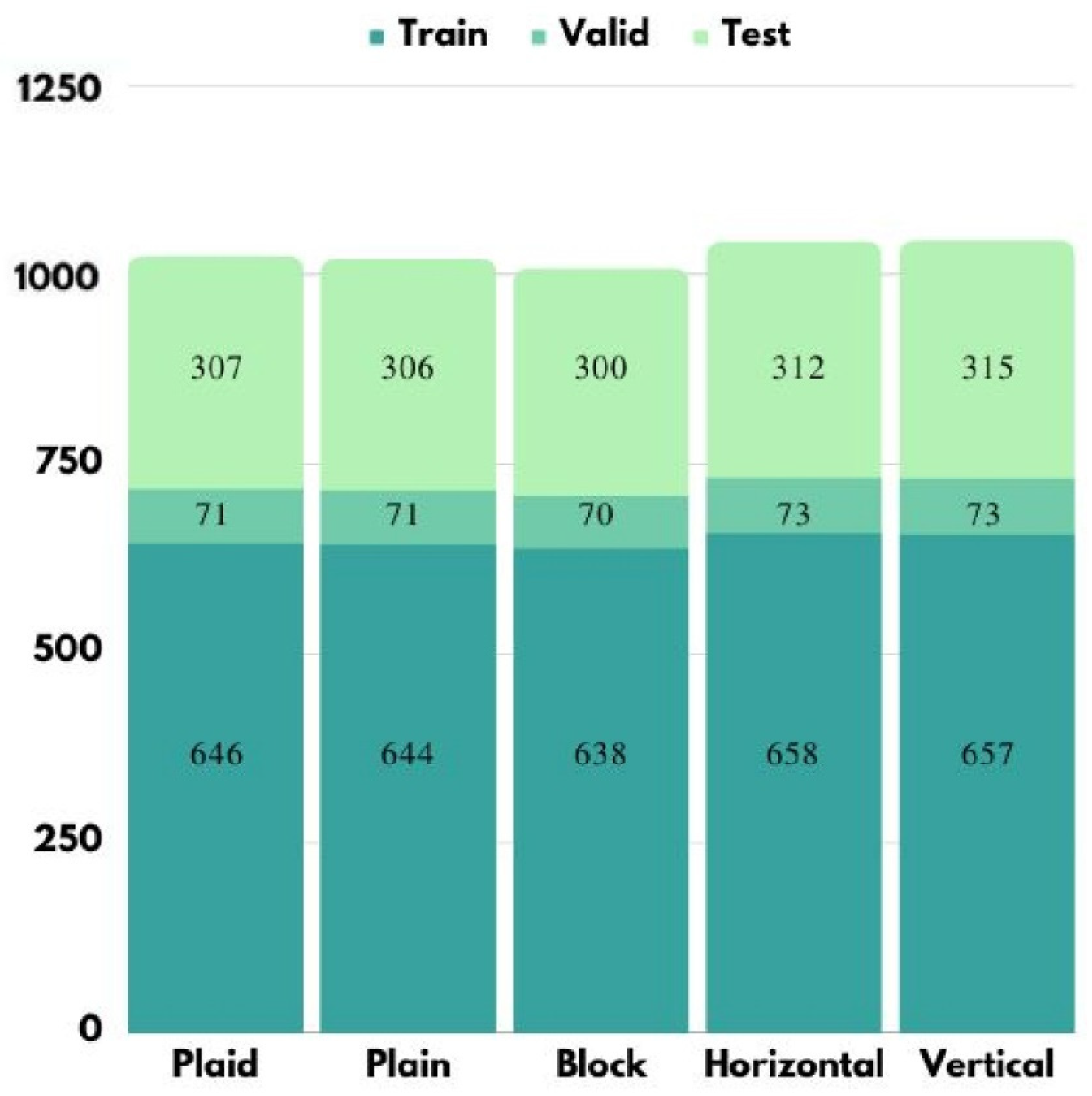
3.2. Dataset
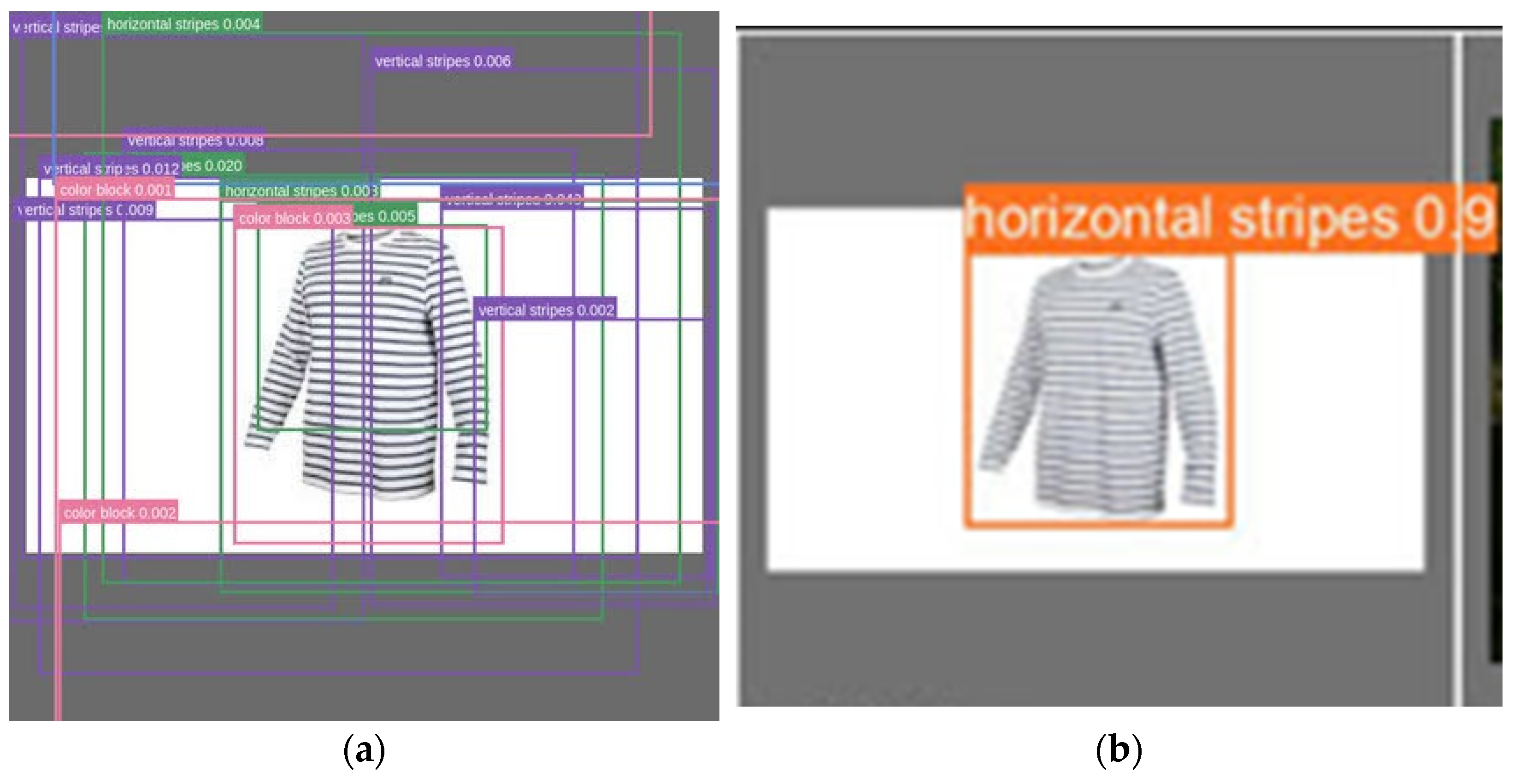
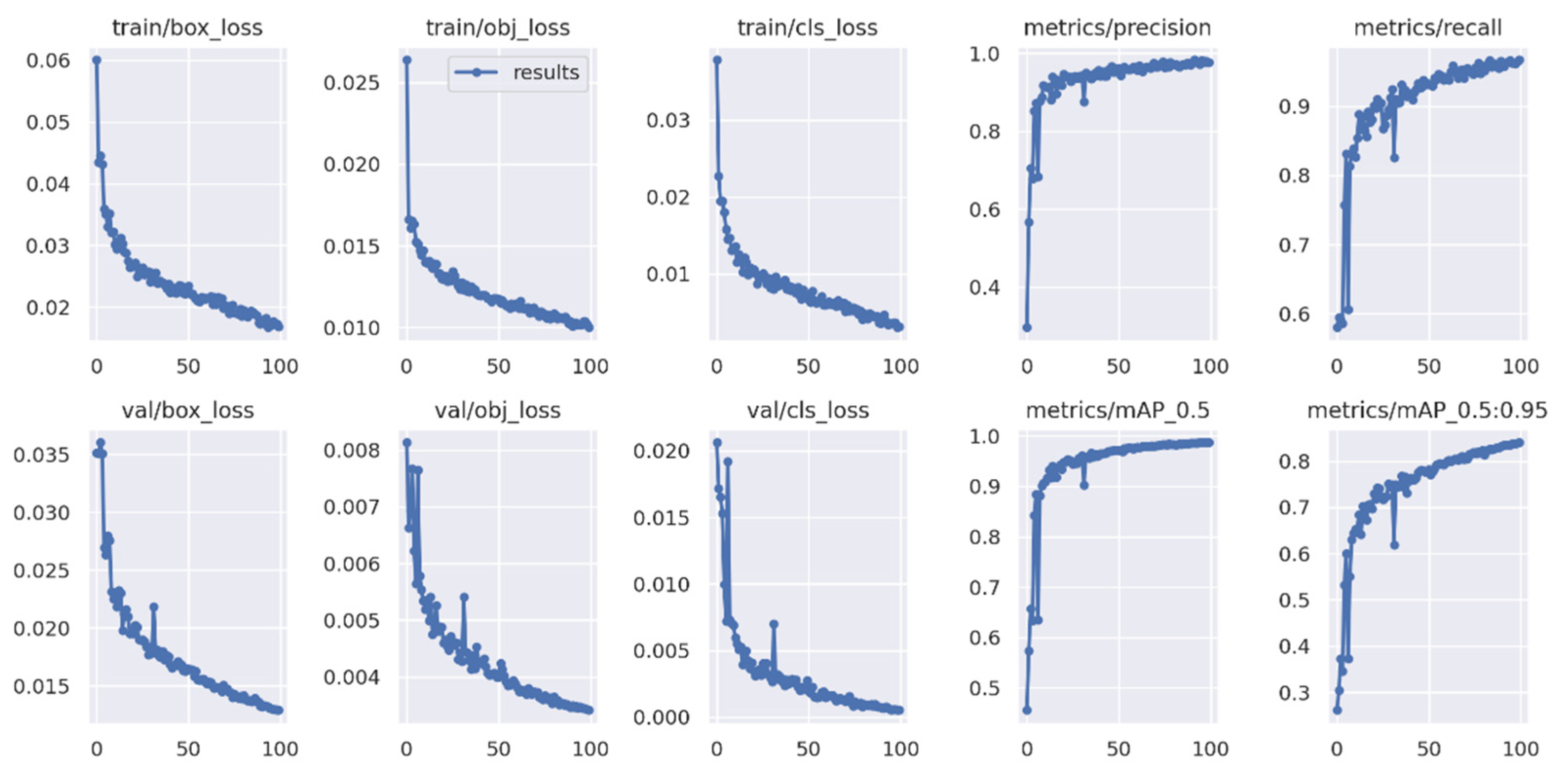
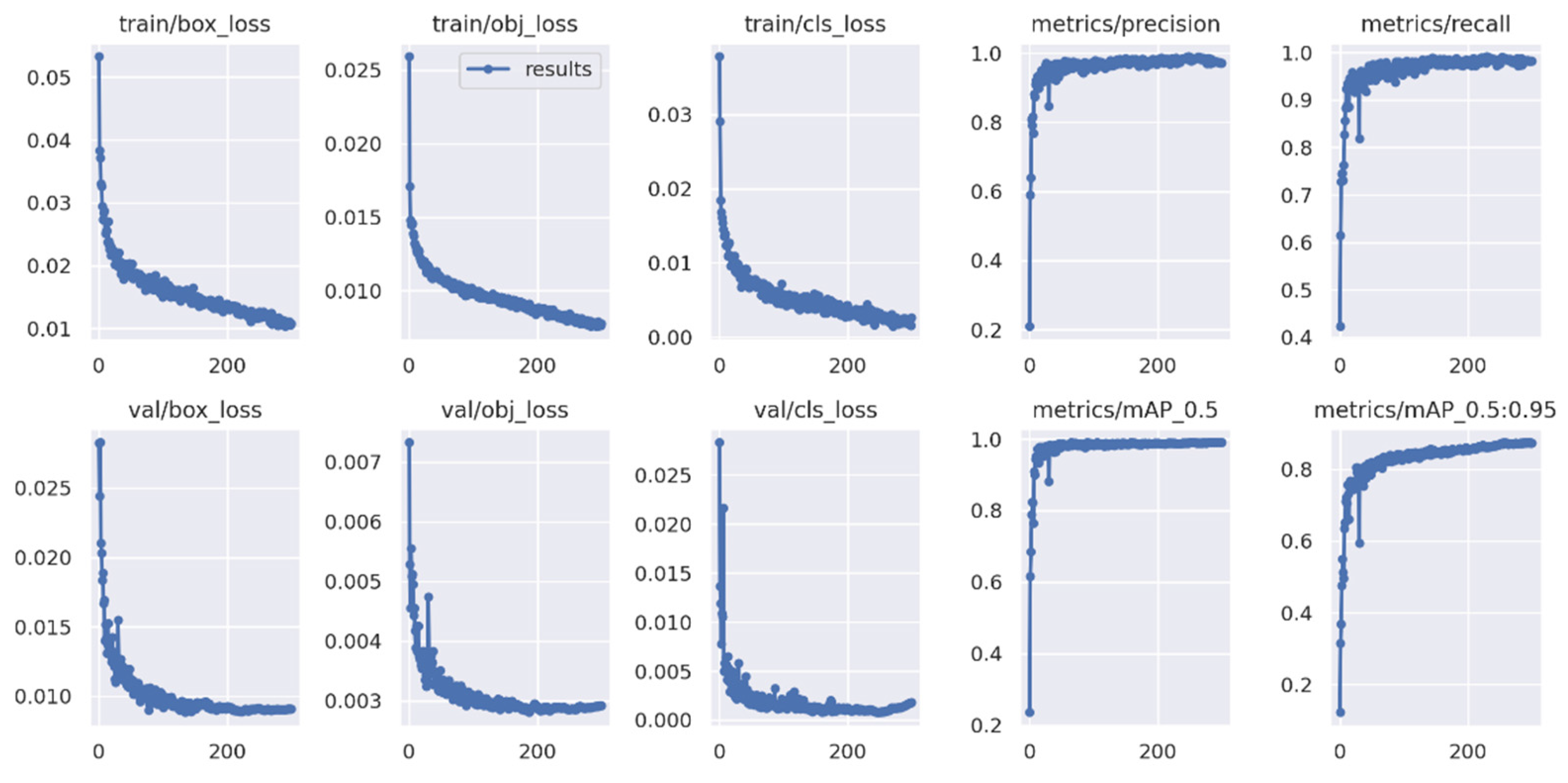
3.3. Integration Testing Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Joshua, J.; Hendryli, J.; Herwindiati, D.E. Automatic License Plate Recognition for Parking System Using Convolutional Neural Networks. In Proceedings of the 2020 International Conference on Information Management and Technology (ICIMTech), Bandung, Indonesia, 13–14 August 2020; pp. 71–74. [Google Scholar]
- Latha, R.S.; Sreekanth, G.R.; Rajadevi, R.; Nivetha, S.K.; Kumar, K.A.; Akash, V.; Bhuvanesh, S.; Anbarasu, P. Fruits and Vegetables Recognition Using YOLO. In Proceedings of the 2022 International Conference on Computer Communication and Informatics (ICCCI), Coimbatore, India, 25 January 2022; pp. 1–6. [Google Scholar]
- Jia, D. Intelligent Clothing Matching Based on Feature Analysis. In Proceedings of the 2022 14th International Conference on Measuring Technology and Mechatronics Automation (ICMTMA), Changsha, China, 15–16 January 2022; pp. 653–656. [Google Scholar]
- Sozzi, M.; Cantalamessa, S.; Cogato, A.; Kayad, A.; Marinello, F. Automatic Bunch Detection in White Grape Varieties Using YOLOv3, YOLOv4, and YOLOv5 Deep Learning Algorithms. Agronomy 2022, 12, 319. [Google Scholar] [CrossRef]
- Han, W.; Jiang, F.; Zhu, Z. Detection of Cherry Quality Using YOLOV5 Model Based on Flood Filling Algorithm. Foods 2022, 11, 1127. [Google Scholar] [CrossRef] [PubMed]
- Fan, Y.; Zhang, S.; Feng, K.; Qian, K.; Wang, Y.; Qin, S. Strawberry Maturity Recognition Algorithm Combining Dark Channel Enhancement and YOLOv5. Sensors 2022, 22, 419. [Google Scholar] [CrossRef] [PubMed]
- Mathew, M.P.; Mahesh, T.Y. Leaf-Based Disease Detection in Bell Pepper Plant Using YOLO V5. Signal Image Video Process. 2022, 16, 841–847. [Google Scholar] [CrossRef]
- Safonova, A.; Hamad, Y.; Alekhina, A.; Kaplun, D. Detection of Norway Spruce Trees (Picea Abies) Infested by Bark Beetle in UAV Images Using YOLOs Architectures. IEEE Access 2022, 10, 10384–10392. [Google Scholar] [CrossRef]
- Qi, J.; Liu, X.; Liu, K.; Xu, F.; Guo, H.; Tian, X.; Li, M.; Bao, Z.; Li, Y. An Improved YOLOv5 Model Based on Visual Attention Mechanism: Application to Recognition of Tomato Virus Disease. Comput. Electron. Agric. 2022, 194, 106780. [Google Scholar] [CrossRef]
- Qi, X.; Dong, J.; Lan, Y.; Zhu, H. Method for Identifying Litchi Picking Position Based on YOLOv5 and PSPNet. Remote Sens. 2022, 14, 2004. [Google Scholar] [CrossRef]
- Yan, B.; Fan, P.; Lei, X.; Liu, Z.; Yang, F. A Real-Time Apple Targets Detection Method for Picking Robot Based on Improved YOLOv5. Remote Sens. 2021, 13, 1619. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision–ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2016; Volume 9905, pp. 21–37. ISBN 978-3-319-46447-3. [Google Scholar]
- Ontor, M.Z.H.; Ali, M.M.; Hossain, S.S.; Nayer, M.; Ahmed, K.; Bui, F.M. YOLO_CC: Deep Learning Based Approach for Early Stage Detection of Cervical Cancer from Cervix Images Using YOLOv5s Model. In Proceedings of the 2022 Second International Conference on Advances in Electrical, Computing, Communication and Sustainable Technologies (ICAECT), Bhilai, India, 21 April 2022; pp. 1–5. [Google Scholar]
- Shah, R.; Shastri, J.; Bohara, M.H.; Panchal, B.Y.; Goel, P. Detection of Different Types of Blood Cells: A Comparative Analysis. In Proceedings of the 2022 IEEE International Conference on Distributed Computing and Electrical Circuits and Electronics (ICDCECE), Ballari, India, 23 April 2022; pp. 1–5. [Google Scholar]
- Reddy, J.S.C.; Venkatesh, C.; Sinha, S.; Mazumdar, S. Real Time Automatic Polyp Detection in White Light Endoscopy Videos Using a Combination of YOLO and DeepSORT. In Proceedings of the 2022 1st International Conference on the Paradigm Shifts in Communication, Embedded Systems, Machine Learning and Signal Processing (PCEMS), Nagpur, India, 6 May 2022; pp. 104–106. [Google Scholar]
- Sha, M.; Wang, H.; Lin, G.; Long, Y.; Zeng, Y.; Guo, S. Design of Multi-Sensor Vein Data Fusion Blood Sampling Robot Based on Deep Learning. In Proceedings of the 2022 2nd International Conference on Computer, Control and Robotics (ICCCR), Shanghai, China, 18 March 2022; pp. 46–51. [Google Scholar]
- Gupta, S.; Chakraborti, S.; Yogitha, R.; Mathivanan, G. Object Detection with Audio Comments Using YOLO V3. In Proceedings of the 2022 International Conference on Applied Artificial Intelligence and Computing (ICAAIC), Salem, India, 9 May 2022; pp. 903–909. [Google Scholar]
- Htet, S.M.; Aung, S.T.; Aye, B. Real-Time Myanmar Sign Language Recognition Using Deep Learning. In Proceedings of the 2022 International Conference on Industrial Engineering, Applications and Manufacturing (ICIEAM), Sochi, Russian, 16 May 2022; pp. 847–853. [Google Scholar]
- Youssry, N.; Khattab, A. Accurate Real-Time Face Mask Detection Framework Using YOLOv5. In Proceedings of the 2022 IEEE International Conference on Design & Test of Integrated Micro & Nano-Systems (DTS), Cairo, Egypt, 6 June 2022; pp. 1–6. [Google Scholar]
- Liu, C.-C.; Fuh, S.-C.; Lin, C.-J.; Huang, T.-H. A Novel Facial Mask Detection Using Fast-YOLO Algorithm. In Proceedings of the 2022 8th International Conference on Applied System Innovation (ICASI), Nantou, Taiwan, 22 April 2022; pp. 144–146. [Google Scholar]
- Kolpe, R.; Ghogare, S.; Jawale, M.A.; William, P.; Pawar, A.B. Identification of Face Mask and Social Distancing Using YOLO Algorithm Based on Machine Learning Approach. In Proceedings of the 2022 6th International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 25 May 2022; pp. 1399–1403. [Google Scholar]
- Sharma, R.; Sharma, A.; Jain, R.; Sharma, S.; Singh, S. Face Mask Detection Using Artificial Intelligence for Workplaces. In Proceedings of the 2022 6th International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 25 May 2022; pp. 1003–1008. [Google Scholar]
- Priya, M.V.; Pankaj, D.S. 3DYOLO: Real-Time 3D Object Detection in 3D Point Clouds for Autonomous Driving. In Proceedings of the 2021 IEEE International India Geoscience and Remote Sensing Symposium (InGARSS), Ahmedabad, India, 6 December 2021; pp. 41–44. [Google Scholar]
- Mostafa, M.; Ghantous, M. A YOLO Based Approach for Traffic Light Recognition for ADAS Systems. In Proceedings of the 2022 2nd International Mobile, Intelligent, and Ubiquitous Computing Conference (MIUCC), Cairo, Egypt, 8 May 2022; pp. 225–229. [Google Scholar]
- Toheed, A.; Yousaf, M.H.; Rabnawaz; Javed, A. Physical Adversarial Attack Scheme on Object Detectors Using 3D Adversarial Object. In Proceedings of the 2022 2nd International Conference on Digital Futures and Transformative Technologies (ICoDT2), Rawalpindi, Pakistan, 24 May 2022; pp. 1–4. [Google Scholar]
- Amrouche, A.; Bentrcia, Y.; Abed, A.; Hezil, N. Vehicle Detection and Tracking in Real-Time Using YOLOv4-Tiny. In Proceedings of the 2022 7th International Conference on Image and Signal Processing and their Applications (ISPA), Mostaganem, Algeria, 8 May 2022; pp. 1–5. [Google Scholar]
- Miekkala, T.; Pyykonen, P.; Kutila, M.; Kyytinen, A. LiDAR System Benchmarking for VRU Detection in Heavy Goods Vehicle Blind Spots. In Proceedings of the 2021 IEEE 17th International Conference on Intelligent Computer Communication and Processing (ICCP), Cluj-Napoca, Romania, 28 October 2021; pp. 299–303. [Google Scholar]
- Athala, V.H.; Haris Rangkuti, A.; Luthfi, N.F.; Vikri Aditama, S.; Kerta, J.M. Improved Pattern Recognition of Various Traditional Clothes with Convolutional Neural Network. In Proceedings of the 2021 3rd International Symposium on Material and Electrical Engineering Conference (ISMEE), Bandung, Indonesia, 10 November 2021; pp. 15–20. [Google Scholar]
- Rangkuti, A.H.; Hasbi Athala, V.; Luthfi, N.F.; Vikri Aditama, S.; Aslamiah, A.H. Content-Based Traditional Clothes Pattern Retrieval Using Convolutional Neural Network. In Proceedings of the 2021 3rd International Symposium on Material and Electrical Engineering Conference (ISMEE), Bandung, Indonesia, 10 November 2021; pp. 9–14. [Google Scholar]
- Rizki, Y.; Medikawati Taufiq, R.; Mukhtar, H.; Apri Wenando, F.; Al Amien, J. Comparison between Faster R-CNN and CNN in Recognizing Weaving Patterns. In Proceedings of the 2020 International Conference on Informatics, Multimedia, Cyber and Information System (ICIMCIS), Jakarta, Indonesia, 19 November 2020; pp. 81–86. [Google Scholar]
- Shubathra, S.; Kalaivaani, P.; Santhoshkumar, S. Clothing Image Recognition Based on Multiple Features Using Deep Neural Networks. In Proceedings of the 2020 International Conference on Electronics and Sustainable Communication Systems (ICESC), Coimbatore, India, 2–4 July 2020; pp. 166–172. [Google Scholar]
- Li, Y.; He, Z.; Wang, S.; Wang, Z.; Huang, W. Multideep Feature Fusion Algorithm for Clothing Style Recognition. Wirel. Commun. Mob. Comput. 2021, 2021, 5577393. [Google Scholar] [CrossRef]
- Yang, M.; Yu, K. Real-Time Clothing Recognition in Surveillance Videos. In Proceedings of the 2011 18th IEEE International Conference on Image Processing, Brussels, Belgium, 11–14 September 2011; pp. 2937–2940. [Google Scholar]
- Bhatnagar, S.; Ghosal, D.; Kolekar, M.H. Classification of Fashion Article Images Using Convolutional Neural Networks. In Proceedings of the 2017 Fourth International Conference on Image Information Processing (ICIIP), Shimla, India, 21–23 December 2017; pp. 1–6. [Google Scholar]
- Xiang, J.; Dong, T.; Pan, R.; Gao, W. Clothing Attribute Recognition Based on RCNN Framework Using L-Softmax Loss. IEEE Access 2020, 8, 48299–48313. [Google Scholar] [CrossRef]
- Li, R.; Lu, W.; Liang, H.; Mao, Y.; Wang, X. Multiple Features with Extreme Learning Machines for Clothing Image Recognition. IEEE Access 2018, 6, 36283–36294. [Google Scholar] [CrossRef]
- Yue, X.; Zhang, C.; Fujita, H.; Lv, Y. Clothing Fashion Style Recognition with Design Issue Graph. Appl. Intell. 2021, 51, 3548–3560. [Google Scholar] [CrossRef]
- Tian, Q.; Chanda, S.; Kumar, K.C.A.; Gray, D. Improving Apparel Detection with Category Grouping and Multi-Grained Branches. Multimed. Tools Appl. 2021, 1–18. [Google Scholar] [CrossRef]
- Medina, A.; Méndez, J.; Ponce, P.; Peffer, T.; Meier, A.; Molina, A. Using Deep Learning in Real-Time for Clothing Classification with Connected Thermostats. Energies 2022, 15, 1811. [Google Scholar] [CrossRef]
- Hidayati, S.C.; You, C.-W.; Cheng, W.-H.; Hua, K.-L. Learning and Recognition of Clothing Genres From Full-Body Images. IEEE Trans. Cybern. 2018, 48, 1647–1659. [Google Scholar] [CrossRef] [PubMed]
- Dong, Q.; Gong, S.; Zhu, X. Imbalanced Deep Learning by Minority Class Incremental Rectification. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1367–1381. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jain, S.; Kumar, J. Garment Categorization Using Data Mining Techniques. Symmetry 2020, 12, 984. [Google Scholar] [CrossRef]
- Huang, F.-H.; Lu, H.-M.; Hsu, Y.-W. From Street Photos to Fashion Trends: Leveraging User-Provided Noisy Labels for Fashion Understanding. IEEE Access 2021, 9, 49189–49205. [Google Scholar] [CrossRef]
- Donati, L.; Iotti, E.; Mordonini, G.; Prati, A. Fashion Product Classification through Deep Learning and Computer Vision. Appl. Sci. 2019, 9, 1385. [Google Scholar] [CrossRef] [Green Version]
- Jo, J.; Lee, S.; Lee, C.; Lee, D.; Lim, H. Development of Fashion Product Retrieval and Recommendations Model Based on Deep Learning. Electronics 2020, 9, 508. [Google Scholar] [CrossRef]
- Vijayaraj, A.; Vasanth Raj, P.T.; Jebakumar, R.; Gururama Senthilvel, P.; Kumar, N.; Suresh Kumar, R.; Dhanagopal, R. Deep Learning Image Classification for Fashion Design. Wirel. Commun. Mob. Comput. 2022, 2022, 7549397. [Google Scholar] [CrossRef]
- Huang, C.-Q.; Chen, J.-K.; Pan, Y.; Lai, H.-J.; Lai, J.Y.; Huang, Q.-H. Clothing Landmark Detection Using Deep Networks With Prior of Key Point Associations. IEEE Trans. Cybern. 2019, 49, 3744–3754. [Google Scholar] [CrossRef]
- Chun, Y.; Wang, C.; He, M. A Novel Clothing Attribute Representation Network-Based Self-Attention Mechanism. IEEE Access 2020, 8, 201762–201769. [Google Scholar] [CrossRef]
- RCNN~YOLOv5. Available online: https://www.gushiciku.cn/dl/0aAQn/zh-tw (accessed on 21 May 2021).
- Lin, C.-T.; Huang, S.-W.; Wu, Y.-Y.; Lai, S.-H. GAN-Based Day-to-Night Image Style Transfer for Nighttime Vehicle Detection. IEEE Trans. Intell. Transp. Syst. 2021, 22, 951–963. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Zheng, J.; Sun, S.; Zhao, S. Fast Ship Detection Based on Lightweight YOLOv5 Network. IET Image Process. 2022, 16, 1585–1593. [Google Scholar] [CrossRef]
- Huang, Y.-S.; Chou, P.-R.; Chen, H.-M.; Chang, Y.-C.; Chang, R.-F. One-Stage Pulmonary Nodule Detection Using 3-D DCNN with Feature Fusion and Attention Mechanism in CT Image. Comput. Methods Programs Biomed. 2022, 220, 106786. [Google Scholar] [CrossRef]
- Yu, B.; Shin, J.; Kim, G.; Roh, S.; Sohn, K. Non-Anchor-Based Vehicle Detection for Traffic Surveillance Using Bounding Ellipses. IEEE Access 2021, 9, 123061–123074. [Google Scholar] [CrossRef]
- Xie, F.; Lin, B.; Liu, Y. Research on the Coordinate Attention Mechanism Fuse in a YOLOv5 Deep Learning Detector for the SAR Ship Detection Task. Sensors 2022, 22, 3370. [Google Scholar] [CrossRef]
- Vesth, T.; Lagesen, K.; Acar, Ö.; Ussery, D. CMG-Biotools, a Free Workbench for Basic Comparative Microbial Genomics. PLoS ONE 2013, 8, e60120. [Google Scholar] [CrossRef]
- Singh, A.P.; Agarwal, D. Webcam Motion Detection in Real-Time Using Python. In Proceedings of the 2022 International Mobile and Embedded Technology Conference (MECON), Noida, India, 10 March 2022; pp. 1–4. [Google Scholar]
- Alon, H.D.; Ligayo, M.A.D.; Misola, M.A.; Sandoval, A.A.; Fontanilla, M.V. Eye-Zheimer: A Deep Transfer Learning Approach of Dementia Detection and Classification from NeuroImaging. In Proceedings of the 2020 IEEE 7th International Conference on Engineering Technologies and Applied Sciences (ICETAS), Kuala Lumpur, Malaysia, 18 December 2020; pp. 1–4. [Google Scholar]
- Kaufmane, E.; Sudars, K.; Namatēvs, I.; Kalniņa, I.; Judvaitis, J.; Balašs, R.; Strautiņa, S. QuinceSet: Dataset of Annotated Japanese Quince Images for Object Detection. Data Brief 2022, 42, 108332. [Google Scholar] [CrossRef]
- Liu, Z.; Luo, P.; Qiu, S.; Wang, X.; Tang, X. DeepFashion: Powering Robust Clothes Recognition and Retrieval with Rich Annotations. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1096–1104. [Google Scholar]
- Ge, Y.; Zhang, R.; Wang, X.; Tang, X.; Luo, P. DeepFashion2: A Versatile Benchmark for Detection, Pose Estimation, Segmentation and Re-Identification of Clothing Images. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5332–5340. [Google Scholar]
- Liberatori, B.; Mami, C.A.; Santacatterina, G.; Zullich, M.; Pellegrino, F.A. YOLO-Based Face Mask Detection on Low-End Devices Using Pruning and Quantization. In Proceedings of the 2022 45th Jubilee International Convention on Information, Communication and Electronic Technology (MIPRO), Opatija, Croatia, 23 May 2022; pp. 900–905. [Google Scholar]
- Sharma, H.; Das, S.; Mandal, P.; Acharya, A.; Kumar, P.; Dasgupta, M.; Basak, R.; Pal, S.B. Visual Perception Through Smart Mirror. In Proceedings of the 2022 Interdisciplinary Research in Technology and Management (IRTM), Kolkata, India, 24 February 2022; pp. 1–5. [Google Scholar]
- Patil, H.D.; Ansari, N.F. Intrusion Detection and Repellent System for Wild Animals Using Artificial Intelligence of Things. In Proceedings of the 2022 International Conference on Computing, Communication and Power Technology (IC3P), Visakhapatnam, India, 7–8 January 2022; pp. 291–296. [Google Scholar]
- Miao, Y.; Shi, E.; Lei, M.; Sun, C.; Shen, X.; Liu, Y. Vehicle Control System Based on Dynamic Traffic Gesture Recognition. In Proceedings of the 2022 5th International Conference on Circuits, Systems and Simulation (ICCSS), Nanjing, China, 13 May 2022; pp. 196–201. [Google Scholar]
- Xu, X.; Zhang, X.; Zhang, T.; Shi, J.; Wei, S.; Li, J. On-Board Ship Detection in SAR Images Based on L-YOLO. In Proceedings of the 2022 IEEE Radar Conference (RadarConf22), New York, NY, USA, 21 March 2022; pp. 1–5. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | One-stage | YOLOv1~YOLOv5, SSD |
| Two-stage | R-CNN, Fast R-CNN, Faster R-CNN | |
| Anchor | Anchor-free | YOLOv1 |
| Anchor-based | YOLOv2~YOLOv5, SSD, Faster R-CNN | |
| Labelling | Regional proposal | R-CNN, Fast R-CNN, Faster R-CNN |
| Key point | YOLOv1 | |
| IoU | YOLOv2~YOLOv5, SSD, Faster R-CNN |
| AP (%) | mAP (%) | Model Size | FPS | |||||
|---|---|---|---|---|---|---|---|---|
| Plaid | Plain | Block | Horizon | Vertical | ||||
| Faster R-CNN | 87.0 | 93.3 | 100 | 85.9 | 85.7 | 90.3 | 175.5 | 7 |
| YOLOv3-tiny | 89.7 | 95.7 | 90.0 | 92.0 | 91.3 | 91.7 | 33.4 | 28.5 |
| YOLOv4-tiny | 98.9 | 98.0 | 94.1 | 93.0 | 97.0 | 96.2 | 23.1 | 24.5 |
| YOLOv5s (100 epochs) | 99.3 | 99.1 | 99.0 | 97.3 | 94.9 | 98.4 | 14 | 40 |
| YOLOv5s (300 epochs) | 98.5 | 99.4 | 99.3 | 99.4 | 96.6 | 99.1 | 14.4 | 40 |
| Precision | Recall | F1-Score | |
|---|---|---|---|
| Faster R-CNN | 0.91 | 0.89 | 0.90 |
| YOLOv3-tiny | 0.93 | 0.85 | 0.89 |
| YOLOv4-tiny | 0.90 | 0.95 | 0.93 |
| YOLOv5s (100 epochs) | 0.98 | 0.96 | 0.97 |
| YOLOv5s (300 epochs) | 0.97 | 0.98 | 0.97 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chang, Y.-H.; Zhang, Y.-Y. Deep Learning for Clothing Style Recognition Using YOLOv5. Micromachines 2022, 13, 1678. https://doi.org/10.3390/mi13101678
Chang Y-H, Zhang Y-Y. Deep Learning for Clothing Style Recognition Using YOLOv5. Micromachines. 2022; 13(10):1678. https://doi.org/10.3390/mi13101678
Chicago/Turabian StyleChang, Yeong-Hwa, and Ya-Ying Zhang. 2022. "Deep Learning for Clothing Style Recognition Using YOLOv5" Micromachines 13, no. 10: 1678. https://doi.org/10.3390/mi13101678