

State-Level Mapping of the Road Transport Network from Aerial Orthophotography: An End-to-End Road Extraction Solution Based on Deep Learning Models Trained for Recognition, Semantic Segmentation and Post-Processing with Conditional Generative Learning
 ,
,  ,
,  , and
, and
Abstract
:
1. Introduction
- A processing methodology that combines image classification, semantic segmentation, and post-processing operations with DL model components, which delivers considerably improved road surface area extraction results when compared to other state-of-the-art models trained for the same task, is proposed. To the best of our knowledge, this is the first time such an objective has been approached, and a large-scale production solution for road mapping has been applied in this manner.
- The proposed end-to-end road mapping solution was implemented and evaluated at a very large scale on the SROADEX dataset (containing image tiles of 256 × 256 pixels). The application of the methodology resulted in a maximum increase in the IoU score of 10.6% over the state-of-the-art U-Net [3]—Inception-ResNet-v2 [11] semantic segmentation model (in a metrical comparison on a test set of more than 12,500 unseen images).
- A large-scale, qualitative assessment of the capabilities was carried out on a single full, unseen orthoimage covering 532 km2 to identify the advantages and challenges posed by the proposed processing workflow, and future lines of work that could improve the results are discussed.
2. Related Work
2.1. Approaches Based on Convolutional Neural Networks
2.2. Approaches Based on Semantic Segmentation Models
2.3. Approaches Based on Unsupervised Learning
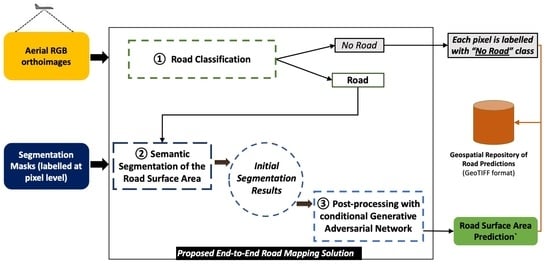
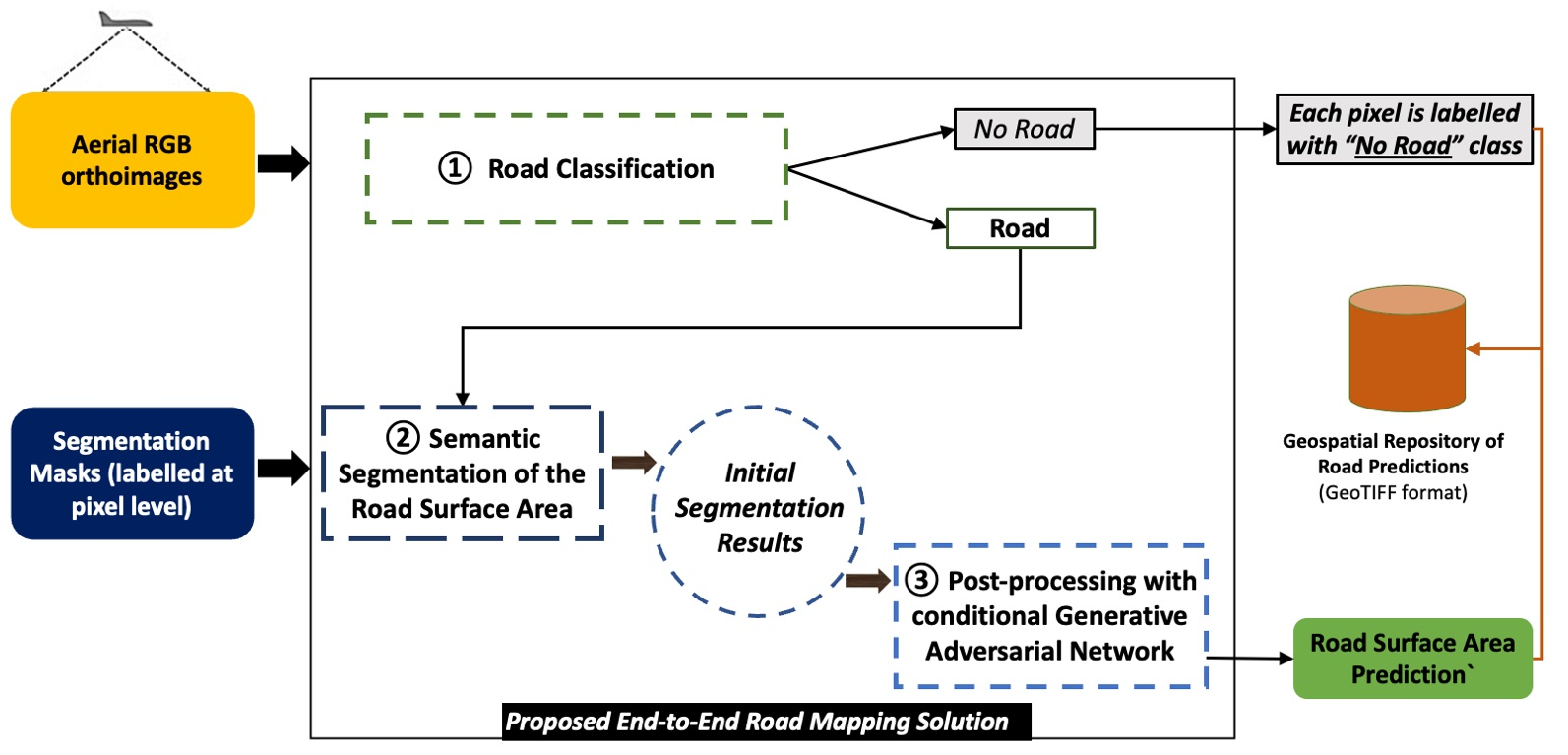
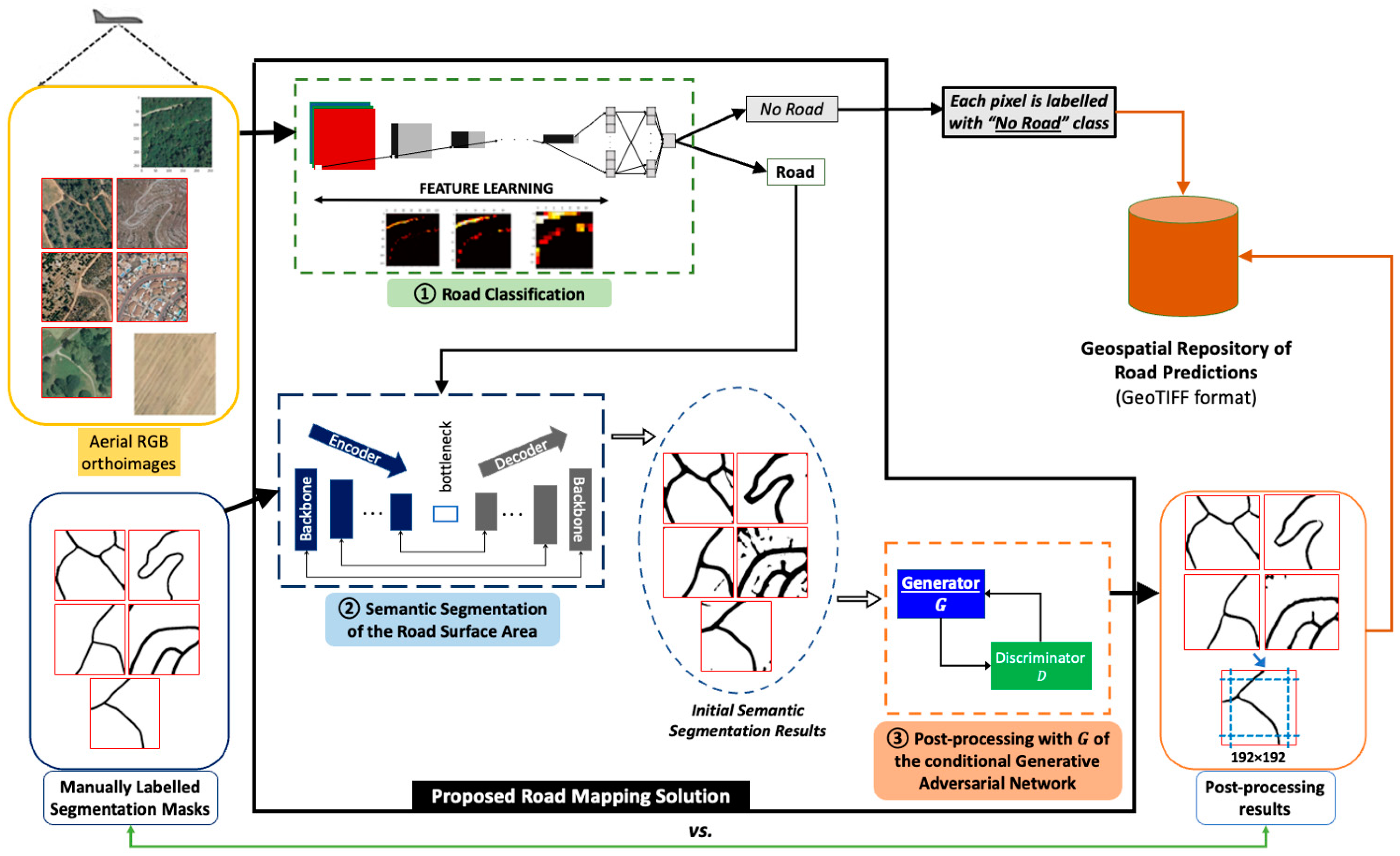
3. Methodology Proposal of an End-to-End Road Surface Area Mapping Solution Combining Classification, Semantic Segmentation, and Post-Processing with Conditional Generative Adversarial Learning
- The first step is the determination of the bounding box of the region to be processed as the most restrictive coordinates between the orthoimage and the theoretical coordinates for that orthoimage. This procedure is applied to avoid processing twice the additional geographic extent covered by the orthoimages in ECW format.
- From the obtained bounding box, the number of tiles (columns × rows) to be processed is determined, knowing that, for each 256 × 256-pixel tile, with resolution 0.5 m/pixel extracted, only the central 192 × 192 pixels will be considered in the final predictions. This reduces the problem of inaccurate extraction near the edges of the tiles displayed by segmentation networks.
- Before processing each tile, it is checked whether it is contained in, or overlaps with, national administrative boundaries, which allows to discard the processing tiles from sea, or ocean areas, and outside the country’s borders.
- The tile satisfying the criteria is processed with the binary classification model, trained for road recognition, to determine whether the tile contains road elements, or not (in operation ①). The pixels of the tiles not fulfilling these criteria will have a probability assigned. The training procedure of the road recognition DL component and the relation between its input and output are presented in Section 4.2.
- If the tile contains roads (prediction of road recognition model is higher than 0.5, ), it is processed with the semantic segmentation network (in operation ②) and stored as a georeferenced GeoTIFF image of a single band, containing the probability that the tile pixels belong to the “Road” class. The stored tile maintains the original size of 256 × 256 pixels. On the contrary, a will assigned to every pixel belonging to tiles tagged with the “No_Road” label.
- To subsequently evaluate the results, the probability that the tile contains a road (after passing through the recognition network) is stored in a PostgreSQL [62] with PostGIS [63] database, together with the associated rectangle with its coordinates. The training procedure of the DL component trained for the semantic segmentation of the road surface areas and the relation between the encoding and decoding of the input and output are presented in Section 4.3.
- The processing continues by binarizing the initial segmentation predictions with a decision limit of 0.5.
- Next, the binarized semantic segmentation predictions are evaluated with the generator of the cGAN network proposed in [59], trained on the SROADEX dataset (in operation ③), to obtain the post-processed, synthetic road predictions. The training procedure and the relation between the input and output of the DL component trained for the post-processing are presented in Section 4.4.
- The values obtained from the GAN network are binarized afterwards with the same threshold , with the final result being a binary image that contains the “Road”/“No_Road” labels, at pixel level. The file is stored as a single-band georeferenced image that contains only the central 192 × 192 pixels; adjacent tiles are processed with the corresponding overlap of 10% (to reduce the effect of prediction errors near image boundaries).
- Finally, after processing all the tiles organized in rows and columns of the orthoimage (approximately 59,000 tiles), a mosaic is constructed with the resulting post-processed predictions and stored in a GeoTIFF file containing the final road mapping predictions.
| Algorithm 1: Road Mapping Procedure |
| Input: ECW orthoimage file, national boundary and official grid division limits, road recognition model, semantic segmentation model, and cGAN model for postprocessing Output: extracted road surface areas (image format) |
| 1: Compute extension of image to process from ECW file and its grid division 2: Calculate #rows and #columns of 256 × 256 image to process 3: for in #rows do 4: for in #columns do 5: calculate boundary 6: if inside country boundary then 7: extract from ECW file and store in memory 8: evaluate with road recognition model → 9: if then 10: evaluate with semantic segmentation model → 11: store as GeoTIFF file using coordinates 12: else 13: store as GeoTIFF file 14: end if 15: end if 16: end for 17: end for 18: for each GeoTIFF image file stored do 19: read 20: binarize by applying threshold value 21: evaluate with postprocessing cGAN model → 22: infer class by thresholding with decision limit 23: store binarized overwriting GeoTIFF image file 24: end for each 25: mosaic all GeoTIFF image files → extracted road surface areas (image format) 26: clean intermediate files (GeoTIFF tiles) |
4. Implementation of the Proposed End-to-End Road Mapping Solution on the SROADEX Dataset
4.1. Data
4.2. Road Classification Operation
4.3. Semantic Segmentation of Road Surface Areas Operation
4.4. Post-Processing of the Initial Segmentation Masks with Conditional Generative Adversarial Learning
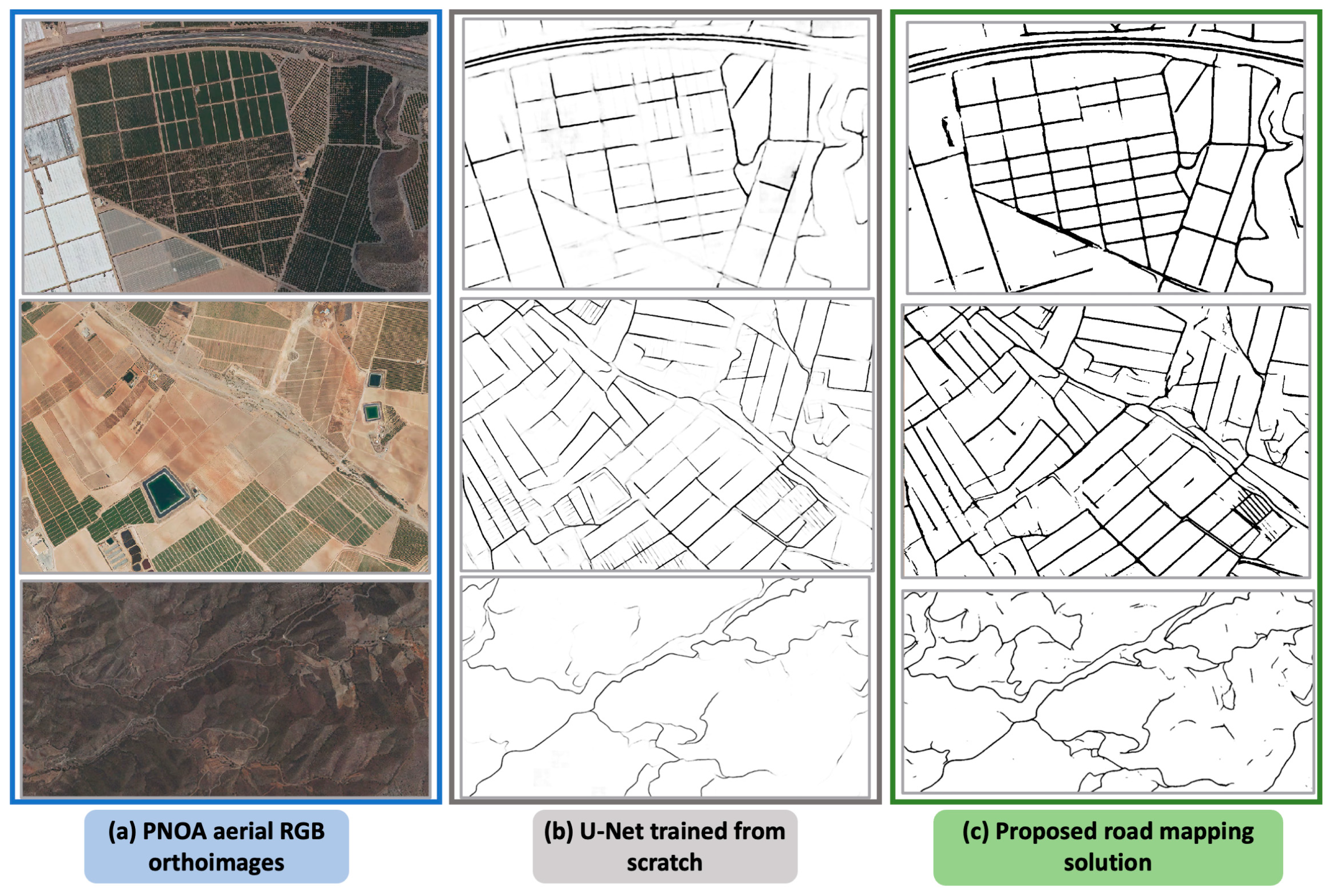
5. Evaluation of a Single, Unseen Orthoimage File Covering 532 km2
6. Discussion
6.1. Advantages of the Proposed Solution
6.2. Challenges Posed by the Proposed Solution
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Instituto Geográfico Nacional (Spain) Especificaciones de Producto de Redes e Infraestructuras del Transporte del Instituto Geográfico Nacional. Available online: http://www.ign.es/resources/IGR/Transporte/20160316_Espec_RT_V0.5.pdf (accessed on 22 March 2023).
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015; Conference Track Proceedings. Bengio, Y., LeCun, Y., Eds.; [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI, Munich, Germany, 5–9 October 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; IEEE Computer Society: Washington, DC, USA, 2017; pp. 5967–5976. [Google Scholar]
- Liu, Y.; Yao, J.; Lu, X.; Xia, M.; Wang, X.; Liu, Y. RoadNet: Learning to Comprehensively Analyze Road Networks in Complex Urban Scenes From High-Resolution Remotely Sensed Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 2043–2056. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, Q.; Wang, Y. Road Extraction by Deep Residual U-Net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef]
- Alshaikhli, T.; Liu, W.; Maruyama, Y. Automated Method of Road Extraction from Aerial Images Using a Deep Convolutional Neural Network. Appl. Sci. 2019, 9, 4825. [Google Scholar] [CrossRef]
- Xin, J.; Zhang, X.; Zhang, Z.; Fang, W. Road Extraction of High-Resolution Remote Sensing Images Derived from DenseUNet. Remote Sens. 2019, 11, 2499. [Google Scholar] [CrossRef]
- Cheng, G.; Wang, Y.; Xu, S.; Wang, H.; Xiang, S.; Pan, C. Automatic Road Detection and Centerline Extraction via Cascaded End-to-End Convolutional Neural Network. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3322–3337. [Google Scholar] [CrossRef]
- Manso-Callejo, M.A.; Cira, C.-I.; Alcarria, R.; Gonzalez Matesanz, F.J. First Dataset of Wind Turbine Data Created at National Level with Deep Learning Techniques from Aerial Orthophotographs with a Spatial Resolution of 0.5 m/Pixel. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 7968–7980. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Singh, S.P., Markovitch, S., Eds.; AAAI Press: Washington, DC, USA, 2017; pp. 4278–4284. [Google Scholar]
- Liu, J.; Qin, Q.; Li, J.; Li, Y. Rural Road Extraction from High-Resolution Remote Sensing Images Based on Geometric Feature Inference. ISPRS Int. J. Geo-Inf. 2017, 6, 314. [Google Scholar] [CrossRef]
- Mattyus, G.; Wang, S.; Fidler, S.; Urtasun, R. Enhancing Road Maps by Parsing Aerial Images Around the World. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 11–18 December 2015; IEEE Computer Society: Washington, DC, USA, 2015; pp. 1689–1697. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Wang, J.; Qin, Q.; Gao, Z.; Zhao, J.; Ye, X. A New Approach to Urban Road Extraction Using High-Resolution Aerial Image. IJGI 2016, 5, 114. [Google Scholar] [CrossRef]
- Hutchison, D.; Kanade, T.; Kittler, J.; Kleinberg, J.M.; Mattern, F.; Mitchell, J.C.; Naor, M.; Nierstrasz, O.; Pandu Rangan, C.; Steffen, B.; et al. Learning to Detect Roads in High-Resolution Aerial Images. In Computer Vision—ECCV 2010; Daniilidis, K., Maragos, P., Paragios, N., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6316, pp. 210–223. ISBN 978-3-642-15566-6. [Google Scholar]
- Dong, R.; Li, W.; Fu, H.; Gan, L.; Yu, L.; Zheng, J.; Xia, M. Oil Palm Plantation Mapping from High-Resolution Remote Sensing Images Using Deep Learning. Int. J. Remote Sens. 2020, 41, 2022–2046. [Google Scholar] [CrossRef]
- Panboonyuen, T.; Jitkajornwanich, K.; Lawawirojwong, S.; Srestasathiern, P.; Vateekul, P. Road Segmentation of Remotely-Sensed Images Using Deep Convolutional Neural Networks with Landscape Metrics and Conditional Random Fields. Remote Sens. 2017, 9, 680. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, X.; Sun, Y.; Zhang, P. Road Centerline Extraction from Very-High-Resolution Aerial Image and LiDAR Data Based on Road Connectivity. Remote Sens. 2018, 10, 1284. [Google Scholar] [CrossRef]
- Abdollahi, A.; Pradhan, B.; Shukla, N.; Chakraborty, S.; Alamri, A. Deep Learning Approaches Applied to Remote Sensing Datasets for Road Extraction: A State-Of-The-Art Review. Remote Sens. 2020, 12, 1444. [Google Scholar] [CrossRef]
- Zhong, Z.; Li, J.; Cui, W.; Jiang, H. Fully Convolutional Networks for Building and Road Extraction: Preliminary Results. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium, IGARSS 2016, Beijing, China, 10–15 July 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1591–1594. [Google Scholar]
- Mnih, V. Machine Learning for Aerial Image Labeling. Ph.D. Thesis, University of Toronto, Toronto, ON, Canada, 2013. [Google Scholar]
- Wei, Y.; Wang, Z.; Xu, M. Road Structure Refined CNN for Road Extraction in Aerial Image. IEEE Geosci. Remote Sens. Lett. 2017, 14, 709–713. [Google Scholar] [CrossRef]
- Wang, S.; Yang, H.; Wu, Q.; Zheng, Z.; Wu, Y.; Li, J. An Improved Method for Road Extraction from High-Resolution Remote-Sensing Images That Enhances Boundary Information. Sensors 2020, 20, 2064. [Google Scholar] [CrossRef]
- Alshehhi, R.; Marpu, P.R.; Woon, W.L.; Mura, M.D. Simultaneous Extraction of Roads and Buildings in Remote Sensing Imagery with Convolutional Neural Networks. ISPRS J. Photogramm. Remote Sens. 2017, 130, 139–149. [Google Scholar] [CrossRef]
- Li, P.; Zang, Y.; Wang, C.; Li, J.; Cheng, M.; Luo, L.; Yu, Y. Road Network Extraction via Deep Learning and Line Integral Convolution. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium, IGARSS 2016, Beijing, China, 10–15 July 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1599–1602. [Google Scholar]
- Gao, H.; Xiao, J.; Yin, Y.; Liu, T.; Shi, J. A Mutually Supervised Graph Attention Network for Few-Shot Segmentation: The Perspective of Fully Utilizing Limited Samples. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–13. [Google Scholar] [CrossRef]
- Li, Y.; Xu, L.; Rao, J.; Guo, L.; Yan, Z.; Jin, S. A Y-Net Deep Learning Method for Road Segmentation Using High-Resolution Visible Remote Sensing Images. Remote Sens. Lett. 2019, 10, 381–390. [Google Scholar] [CrossRef]
- Buslaev, A.; Seferbekov, S.S.; Iglovikov, V.; Shvets, A. Fully Convolutional Network for Automatic Road Extraction From Satellite Imagery. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition Workshops, CVPR Workshops 2018, Salt Lake City, UT, USA, 18–22 June 2018; IEEE Computer Society: Washington, DC, USA, 2018; pp. 207–210. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26–30 June 2016; IEEE: Las Vegas, NV, USA, 2016; pp. 770–778. [Google Scholar]
- Xu, Y.; Feng, Y.; Xie, Z.; Hu, A.; Zhang, X. A Research on Extracting Road Network from High Resolution Remote Sensing Imagery. In Proceedings of the 26th International Conference on Geoinformatics, Geoinformatics 2018, Kunming, China, 28–30 June 2018; Hu, S., Ye, X., Yang, K., Fan, H., Eds.; IEEE: Washington, DC, USA, 2018; pp. 1–4. [Google Scholar]
- Zhou, L.; Zhang, C.; Wu, M. D-LinkNet: LinkNet With Pretrained Encoder and Dilated Convolution for High Resolution Satellite Imagery Road Extraction. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition Workshops, CVPR Workshops 2018, Salt Lake City, UT, USA, 18–22 June 2018; IEEE Computer Society: Washington, DC, USA, 2018; pp. 182–186. [Google Scholar]
- Wang, Q.; Gao, J.; Yuan, Y. Embedding Structured Contour and Location Prior in Siamesed Fully Convolutional Networks for Road Detection. IEEE Trans. Intell. Transp. Syst. 2018, 19, 230–241. [Google Scholar] [CrossRef]
- Panboonyuen, T.; Vateekul, P.; Jitkajornwanich, K.; Lawawirojwong, S. An Enhanced Deep Convolutional Encoder-Decoder Network for Road Segmentation on Aerial Imagery. In Proceedings of the Recent Advances in Information and Communication Technology 2017—Proceedings of the 13th International Conference on Computing and Information Technology (IC2IT), Bangkok, Thailand, 6–7 July 2017; Meesad, P., Sodsee, S., Unger, H., Eds.; Springer: Berlin/Heidelberg, Germany, 2017; Volume 566, pp. 191–201. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Clevert, D.-A.; Unterthiner, T.; Hochreiter, S. Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs). In Proceedings of the 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, 2–4 May 2016; Conference Track Proceedings. Bengio, Y., LeCun, Y., Eds.; [Google Scholar]
- Doshi, J. Residual Inception Skip Network for Binary Segmentation. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition Workshops, CVPR Workshops 2018, Salt Lake City, UT, USA, 18–22 June 2018; IEEE Computer Society: Washington, DC, USA, 2018; pp. 216–219. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26–30 June 2016; IEEE: Las Vegas, NV, USA, 2016; pp. 2818–2826. [Google Scholar]
- He, H.; Yang, D.; Wang, S.; Wang, S.; Liu, X. Road Segmentation of Cross-Modal Remote Sensing Images Using Deep Segmentation Network and Transfer Learning. Ind. Robot 2019, 46, 384–390. [Google Scholar] [CrossRef]
- Xia, W.; Zhang, Y.-Z.; Liu, J.; Luo, L.; Yang, K. Road Extraction from High Resolution Image with Deep Convolution Network—A Case Study of GF-2 Image. Proceedings 2018, 2, 325. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Gao, L.; Song, W.; Dai, J.; Chen, Y. Road Extraction from High-Resolution Remote Sensing Imagery Using Refined Deep Residual Convolutional Neural Network. Remote Sens. 2019, 11, 552. [Google Scholar] [CrossRef]
- Xie, Y.; Miao, F.; Zhou, K.; Peng, J. HsgNet: A Road Extraction Network Based on Global Perception of High-Order Spatial Information. ISPRS Int. J. Geo Inf. 2019, 8, 571. [Google Scholar] [CrossRef]
- Chaurasia, A.; Culurciello, E. LinkNet: Exploiting Encoder Representations for Efficient Semantic Segmentation. In Proceedings of the 2017 IEEE Visual Communications and Image Processing (VCIP), St. Petersburg, FL, USA, 10–13 December 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Etten, A.V.; Lindenbaum, D.; Bacastow, T.M. SpaceNet: A Remote Sensing Dataset and Challenge Series. CoRR arXiv 2018, arXiv:1807.01232. [Google Scholar]
- Demir, I.; Koperski, K.; Lindenbaum, D.; Pang, G.; Huang, J.; Basu, S.; Hughes, F.; Tuia, D.; Raskar, R. DeepGlobe 2018: A Challenge to Parse the Earth Through Satellite Images. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition Workshops, CVPR Workshops 2018, Salt Lake City, UT, USA, 18–22 June 2018; IEEE Computer Society: Washington, DC, USA, 2018; pp. 172–181. [Google Scholar]
- Kestur, R.; Farooq, S.; Abdal, R.; Mehraj, E.; Narasipura, O.; Mudigere, M. UFCN: A Fully Convolutional Neural Network for Road Extraction in RGB Imagery Acquired by Remote Sensing from an Unmanned Aerial Vehicle. J. Appl. Remote Sens. 2018, 12, 016020. [Google Scholar] [CrossRef]
- Henry, C.; Azimi, S.M.; Merkle, N. Road Segmentation in SAR Satellite Images with Deep Fully-Convolutional Neural Networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1867–1871. [Google Scholar] [CrossRef]
- Manso-Callejo, M.-Á.; Cira, C.-I.; González-Jiménez, A.; Querol-Pascual, J.-J. Dataset Containing Orthoimages Tagged with Road Information Covering Approximately 8650 Km2 of the Spanish Territory (SROADEX). Data Brief 2022, 42, 108316. [Google Scholar] [CrossRef] [PubMed]
- Varia, N.; Dokania, A.; Jayavelu, S. DeepExt: A Convolution Neural Network for Road Extraction Using RGB Images Captured by UAV. In Proceedings of the IEEE Symposium Series on Computational Intelligence, SSCI 2018, Bangalore, India, 18–21 November 2018; IEEE: Boston, MA, USA, 2018; pp. 1890–1895. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; IEEE: Boston, MA, USA, 2015; pp. 3431–3440. [Google Scholar]
- Shi, Q.; Liu, X.; Li, X. Road Detection From Remote Sensing Images by Generative Adversarial Networks. IEEE Access 2018, 6, 25486–25494. [Google Scholar] [CrossRef]
- Yang, C.; Wang, Z. An Ensemble Wasserstein Generative Adversarial Network Method for Road Extraction From High Resolution Remote Sensing Images in Rural Areas. IEEE Access 2020, 8, 174317–174324. [Google Scholar] [CrossRef]
- Hartmann, S.; Weinmann, M.; Wessel, R.; Klein, R. StreetGAN: Towards Road Network Synthesis with Generative Adversarial Networks. In Proceedings of the International Conference on Computer Graphics, Visualization and Computer Vision, Marrakesh, Morocco, 23–25 May 2017. [Google Scholar]
- Costea, D.; Marcu, A.; Leordeanu, M.; Slusanschi, E. Creating Roadmaps in Aerial Images with Generative Adversarial Networks and Smoothing-Based Optimization. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops (ICCVW), Venice, Italy, 27–29 October 2017; IEEE: Venice, Italy, 2017; pp. 2100–2109. [Google Scholar]
- Zhang, Y.; Li, X.; Zhang, Q. Road Topology Refinement via a Multi-Conditional Generative Adversarial Network. Sensors 2019, 19, 1162. [Google Scholar] [CrossRef] [PubMed]
- Belli, D.; Kipf, T. Image-Conditioned Graph Generation for Road Network Extraction. CoRR arXiv 2019, arXiv:1910.14388. [Google Scholar]
- Liu, L.; Ma, H.; Chen, S.; Tang, X.; Xie, J.; Huang, G.; Mo, F. Image-Translation-Based Road Marking Extraction From Mobile Laser Point Clouds. IEEE Access 2020, 8, 64297–64309. [Google Scholar] [CrossRef]
- Cira, C.-I.; Manso-Callejo, M.-Á.; Alcarria, R.; Fernández Pareja, T.; Bordel Sánchez, B.; Serradilla, F. Generative Learning for Postprocessing Semantic Segmentation Predictions: A Lightweight Conditional Generative Adversarial Network Based on Pix2pix to Improve the Extraction of Road Surface Areas. Land 2021, 10, 79. [Google Scholar] [CrossRef]
- Cira, C.-I.; Kada, M.; Manso-Callejo, M.-Á.; Alcarria, R.; Bordel Sanchez, B.B. Improving Road Surface Area Extraction via Semantic Segmentation with Conditional Generative Learning for Deep Inpainting Operations. IJGI 2022, 11, 43. [Google Scholar] [CrossRef]
- Sirotkovic, J.; Dujmic, H.; Papic, V. Image Segmentation Based on Complexity Mining and Mean-Shift Algorithm. In Proceedings of the 2014 IEEE Symposium on Computers and Communications (ISCC), Funchal, Portugal, 23–26 June 2014; IEEE: Funchal, Madeira, Portugal, 2014; pp. 1–6. [Google Scholar]
- PostgreSQL: Documentation. Available online: https://www.postgresql.org/docs/ (accessed on 21 May 2022).
- Documentation|PostGIS. Available online: https://postgis.net/documentation/ (accessed on 21 May 2022).
- Cira, C.-I.; Alcarria, R.; Manso-Callejo, M.-Á.; Serradilla, F. A Framework Based on Nesting of Convolutional Neural Networks to Classify Secondary Roads in High Resolution Aerial Orthoimages. Remote Sens. 2020, 12, 765. [Google Scholar] [CrossRef]
- Cira, C.-I.; Alcarria, R.; Manso-Callejo, M.-Á.; Serradilla, F. A Deep Learning-Based Solution for Large-Scale Extraction of the Secondary Road Network from High-Resolution Aerial Orthoimagery. Appl. Sci. 2020, 10, 7272. [Google Scholar] [CrossRef]
- Manso-Callejo, Miguel Angel; Calimanut-Ionut, Cira SROADEX: Dataset for Binary Recognition and Semantic Segmentation of Road Surface Areas from High Resolution Aerial Orthoimages Covering Approximately 8650 km2 of the Spanish Territory Tagged with Road Information. Data Brief 2022, 42, 108316.
- Instituto Geográfico Nacional Plan Nacional de Ortofotografía Aérea. Available online: https://pnoa.ign.es/caracteristicas-tecnicas (accessed on 25 November 2019).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision, ICCV 2015, Santiago, Chile, 7–13 December 2015; IEEE Computer Society: Washington, DC, USA, 2015; pp. 1026–1034. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015; Conference Track Proceedings. Bengio, Y., LeCun, Y., Eds.; [Google Scholar]
- Yakubovskiy, P. Segmentation Models; GitHub, 2019. Available online: https://github.com/qubvel/segmentation_models (accessed on 14 April 2023).
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE: Salt Lake City, UT, USA, 2018; pp. 7132–7141. [Google Scholar]
- Instituto Geográfico Nacional Centro de Descargas del CNIG (IGN). Available online: http://centrodedescargas.cnig.es (accessed on 3 February 2020).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Performance Metric | VGG-v1 | VGG-v2 | VGGNet Trained from Scratch | ||||
|---|---|---|---|---|---|---|---|
| Validation | Test | Validation | Test | Validation | Test | ||
| Loss | M | 0.2536 | 0.2511 | 0.2550 | 0.2555 | 0.2622 | 0.2581 |
| SD | 0.0039 | 0.0023 | 0.0021 | 0.0033 | 0.0040 | 0.0046 | |
| Accuracy | M | 0.8956 | 0.8967 | 0.8946 | 0.8961 | 0.8928 | 0.8953 |
| SD | 0.0008 | 0.0007 | 0.0014 | 0.0018 | 0.0020 | 0.0017 | |
| Precision (weighted) | M | 0.8964 | 0.8974 | 0.8946 | 0.8961 | 0.8929 | 0.8953 |
| SD | 0.0006 | 0.0005 | 0.0015 | 0.0018 | 0.0019 | 0.0016 | |
| Recall (weighted) | M | 0.8956 | 0.8967 | 0.8946 | 0.8961 | 0.8928 | 0.8953 |
| SD | 0.0008 | 0.0007 | 0.0014 | 0.0018 | 0.0020 | 0.0017 | |
| F1 score (weighted) | M | 0.8957 | 0.8967 | 0.8946 | 0.8961 | 0.8928 | 0.8953 |
| SD | 0.0009 | 0.0007 | 0.0015 | 0.0018 | 0.0020 | 0.0017 | |
| AUC-ROC score | M | 0.9634 | 0.9640 | 0.9605 | 0.9608 | 0.9579 | 0.9590 |
| SD | 0.0003 | 0.0012 | 0.0008 | 0.0016 | 0.0004 | 0.0007 | |
| Performance Metric | U-Net (Trained from Scratch) | U-Net—SEResNeXt50 | U-Net—Inception-ResNet-v2 | ||||
|---|---|---|---|---|---|---|---|
| Validation | Test | Validation | Test | Validation | Test | ||
| Loss | M | 0.5527 | 0.5473 | 0.5170 | 0.5212 | 0.5057 | 0.5108 |
| SD | 0.0037 | 0.0212 | 0.0028 | 0.0027 | 0.0039 | 0.0040 | |
| IoU score (positive class) | M | 0.2941 | 0.2903 | 0.3197 | 0.3160 | 0.3470 | 0.3435 |
| SD | 0.0035 | 0.0034 | 0.0117 | 0.0115 | 0.0212 | 0.0214 | |
| IoU score (negative class) | M | 0.8674 | 0.8664 | 0.8798 | 0.8772 | 0.8887 | 0.8876 |
| SD | 0.0051 | 0.0055 | 0.0038 | 0.0042 | 0.0264 | 0.0274 | |
| IoU score | M | 0.5808 | 0.5784 | 0.5998 | 0.5966 | 0.6179 | 0.6155 |
| SD | 0.0027 | 0.0029 | 0.0043 | 0.0039 | 0.0210 | 0.0216 | |
| F1 score (positive class) | M | 0.4271 | 0.4223 | 0.4555 | 0.4511 | 0.4848 | 0.4805 |
| SD | 0.0042 | 0.0043 | 0.0128 | 0.0128 | 0.0222 | 0.0225 | |
| F1 score (negative class) | M | 0.9148 | 0.9150 | 0.9230 | 0.9215 | 0.9277 | 0.9273 |
| SD | 0.0057 | 0.0060 | 0.0045 | 0.0048 | 0.0222 | 0.0230 | |
| F1 score | M | 0.6709 | 0.6687 | 0.6893 | 0.6863 | 0.7062 | 0.7039 |
| SD | 0.0027 | 0.0029 | 0.0038 | 0.0042 | 0.0198 | 0.0203 | |
| Pixel accuracy | M | 0.8710 | 0.8701 | 0.8831 | 0.8806 | 0.8916 | 0.8907 |
| SD | 0.0051 | 0.0055 | 0.0038 | 0.0042 | 0.0262 | 0.0272 | |
| Precision (positive class) | M | 0.2986 | 0.2947 | 0.3242 | 0.3204 | 0.3527 | 0.3492 |
| SD | 0.0036 | 0.0035 | 0.0121 | 0.0120 | 0.0226 | 0.0229 | |
| Precision (negative class) | M | 0.9977 | 0.9976 | 0.9979 | 0.9980 | 0.9978 | 0.9979 |
| SD | 0.0001 | 0.0001 | 0.0001 | 0.0000 | 0.0003 | 0.0002 | |
| Precision | M | 0.6481 | 0.6462 | 0.6611 | 0.6592 | 0.6753 | 0.6735 |
| SD | 0.0018 | 0.0017 | 0.0061 | 0.0060 | 0.0112 | 0.0114 | |
| Recall (positive class) | M | 0.8597 | 0.8554 | 0.8695 | 0.8626 | 0.8662 | 0.8592 |
| SD | 0.0053 | 0.0013 | 0.0014 | 0.0008 | 0.0059 | 0.0064 | |
| Recall (negative class) | M | 0.8692 | 0.8682 | 0.8814 | 0.8788 | 0.8904 | 0.8893 |
| SD | 0.0051 | 0.0056 | 0.0038 | 0.0042 | 0.0265 | 0.0275 | |
| Recall | M | 0.8644 | 0.8618 | 0.8755 | 0.8707 | 0.8783 | 0.8743 |
| SD | 0.0044 | 0.0022 | 0.0024 | 0.0024 | 0.0123 | 0.0126 | |
| Performance Metric | Best Semantic Segmentation Model (*) | Post-Processing with the cGAN Proposed in [59] | |||
|---|---|---|---|---|---|
| Mean Value and Standard Deviation | Mean Percentage Difference (**) | Maximum Result | Maximum Improvement (***) | ||
| IoU score (positive class) | 0.3409 | 0.4959 ± 0.0053 | +15.50% | 0.5012 | +16.03% |
| IoU score (negative class) | 0.9118 | 0.9629 ± 0.0005 | +5.11% | 0.9628 | +5.10% |
| IoU score | 0.6264 | 0.7294 ± 0.0026 | +10.30% | 0.7320 | +10.57% |
| F1 score (positive class) | 0.4788 | 0.6118 ± 0.0051 | +13.30% | 0.6175 | +13.87% |
| F1 score (negative class) | 0.9476 | 0.9764 ± 0.0003 | +2.88% | 0.9763 | +2.87% |
| F1 score | 0.7132 | 0.7941 ± 0.0024 | +8.09% | 0.7969 | +8.37% |
| Pixel accuracy | 0.9149 | 0.9640 ± 0.0005 | +4.91% | 0.9639 | +4.90% |
| Precision (positive class) | 0.3463 | 0.6170 ± 0.0116 | +27.07% | 0.6088 | +26.25% |
| Precision (negative class) | 0.9980 | 0.9899 ± 0.0006 | −0.81% | 0.9904 | −0.76% |
| Precision | 0.6722 | 0.8034 ± 0.0056 | +13.13% | 0.7996 | +12.75% |
| Recall (positive class) | 0.8610 | 0.6592 ± 0.0190 | −20.18% | 0.6762 | −18.48% |
| Recall (negative class) | 0.9134 | 0.9725 ± 0.0010 | +5.91% | 0.9719 | +5.85% |
| Recall | 0.8872 | 0.8158 ± 0.0091 | −7.14% | 0.8241 | −6.32% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cira, C.-I.; Manso-Callejo, M.-Á.; Alcarria, R.; Bordel Sánchez, B.; González Matesanz, J. State-Level Mapping of the Road Transport Network from Aerial Orthophotography: An End-to-End Road Extraction Solution Based on Deep Learning Models Trained for Recognition, Semantic Segmentation and Post-Processing with Conditional Generative Learning. Remote Sens. 2023, 15, 2099. https://doi.org/10.3390/rs15082099
Cira C-I, Manso-Callejo M-Á, Alcarria R, Bordel Sánchez B, González Matesanz J. State-Level Mapping of the Road Transport Network from Aerial Orthophotography: An End-to-End Road Extraction Solution Based on Deep Learning Models Trained for Recognition, Semantic Segmentation and Post-Processing with Conditional Generative Learning. Remote Sensing. 2023; 15(8):2099. https://doi.org/10.3390/rs15082099
Chicago/Turabian StyleCira, Calimanut-Ionut, Miguel-Ángel Manso-Callejo, Ramón Alcarria, Borja Bordel Sánchez, and Javier González Matesanz. 2023. "State-Level Mapping of the Road Transport Network from Aerial Orthophotography: An End-to-End Road Extraction Solution Based on Deep Learning Models Trained for Recognition, Semantic Segmentation and Post-Processing with Conditional Generative Learning" Remote Sensing 15, no. 8: 2099. https://doi.org/10.3390/rs15082099