1. Introduction
In recent years, much attention has been devoted to and significant advances have been made in the application of deep learning (DL) techniques to the semantic segmentation of remote sensing imagery in general and the extraction of building footprints in particular [
1,
2,
3]. The obtained spatial information enables manifold applications in environmental and urban analysis and planning, but their manual acquisition is time-consuming and therefore costly. Challenges that are encountered in this area of research include the variety and semantics of visible objects, the spatiotemporal variability in their appearance, occlusions by other image contents, resulting difficulties in accurately separating objects and identifying their boundaries, highly imbalanced class distributions, and the availability of annotated training data [
3,
4,
5].
The extraction of building footprints is a task that is addressed frequently, and various innovative methods have been explored that tackle the described problems. While the application of DL for the semantic segmentation of building footprints in remote sensing images promises a cost-effective automation of a previously laborious manual process, effective training of DL models requires large amounts of annotated data, which by itself is costly and time-consuming to procure if labeling is performed manually. Solution approaches to reduce labeling costs focus either on improving training efficiency with the limited data available (model-centric) or on finding ways to cost-efficiently generate larger annotated datasets (data-centric), and in some cases a combination of both is investigated. In the former category, Kang et al. [
6] and Hua et al. [
7] propose semi-supervised learning methods where only a limited amount of the training data is labeled. In the latter category, several studies investigate the use of publicly available data (e.g., OpenStreetMap) to automatically generate large-scale datasets for training and evaluation of neural networks [
5,
8,
9,
10,
11,
12,
13]. Nevertheless, a prevalent weakness of these approaches is a certain misalignment between the derived labels and the remote sensing images.
As semantic segmentation of building footprints matures, researchers turn to the task of extracting even more detailed building information from aerial images. Some authors use classic computer vision approaches to identify individual roof segments and their orientation in aerial images [
14,
15]. To the best of our knowledge, three more recent publications apply semantic segmentation by means of DL for this task [
16,
17,
18]. A popular application of this information is solar potential analysis, but mapped roof segments and their orientation can be useful for other fields such as urban planning as well. However, a major barrier for DL approaches remains the availability of datasets.
Lee et al. [
16] introduced and first applied the manually labeled DeepRoof dataset. They distinguish sixteen azimuth classes for sloped segments in 22.5
bins and one class for flat segments. Krapf et al. [
17] also used the DeepRoof dataset and additionally explored the semantic segmentation of roof superstructures. In a subsequent work, Krapf et al. [
19] published RID (the roof information dataset), which includes labels for roof segments as well as roof superstructures. Li et al. [
18] used RID, designed a multi-task network architecture, and reduced the number of classes for sloped roof segments to four, based on the insight that sixteen classes disproportionately deteriorate model performance while four classes reduce this problem and are still sufficient for accurate solar potential estimation.
To the best of our knowledge, the only datasets for semantic segmentation of roof segments are the DeepRoof dataset [
16] and the RID [
19]. They feature 2274 and 1880 buildings with 4312 and >4500 manually labeled roof segments, respectively. In both cases, the labeled aerial images are sourced from small geographic regions and the diversity of roof geometries, building contexts, lighting conditions, and image quality is limited. The applicability of models trained on these rather homogeneous datasets to regions with different properties is therefore limited [
19]. A larger and more heterogeneous dataset comprising labeled imagery from diverse regions and settings could improve model performance and applicability, but, as in the case of building footprints and semantic segmentation datasets in general, such data is costly and time-consuming to produce manually [
20].
Accordingly and similar to the problem of building footprint extraction and training of artificial neural networks in general, the shortage of annotated training data hampers a further improvement of the models’ performance. Contrary to the case of building footprints, on the other hand, publicly available map data cannot be used to automatically generate large-scale training datasets because they do not contain information about roof segments. However, semantic 3D city models according to the CityGML standard [
21,
22] are today available for many towns and cities worldwide. In many cases, they are published by public authorities and are openly accessible free of charge [
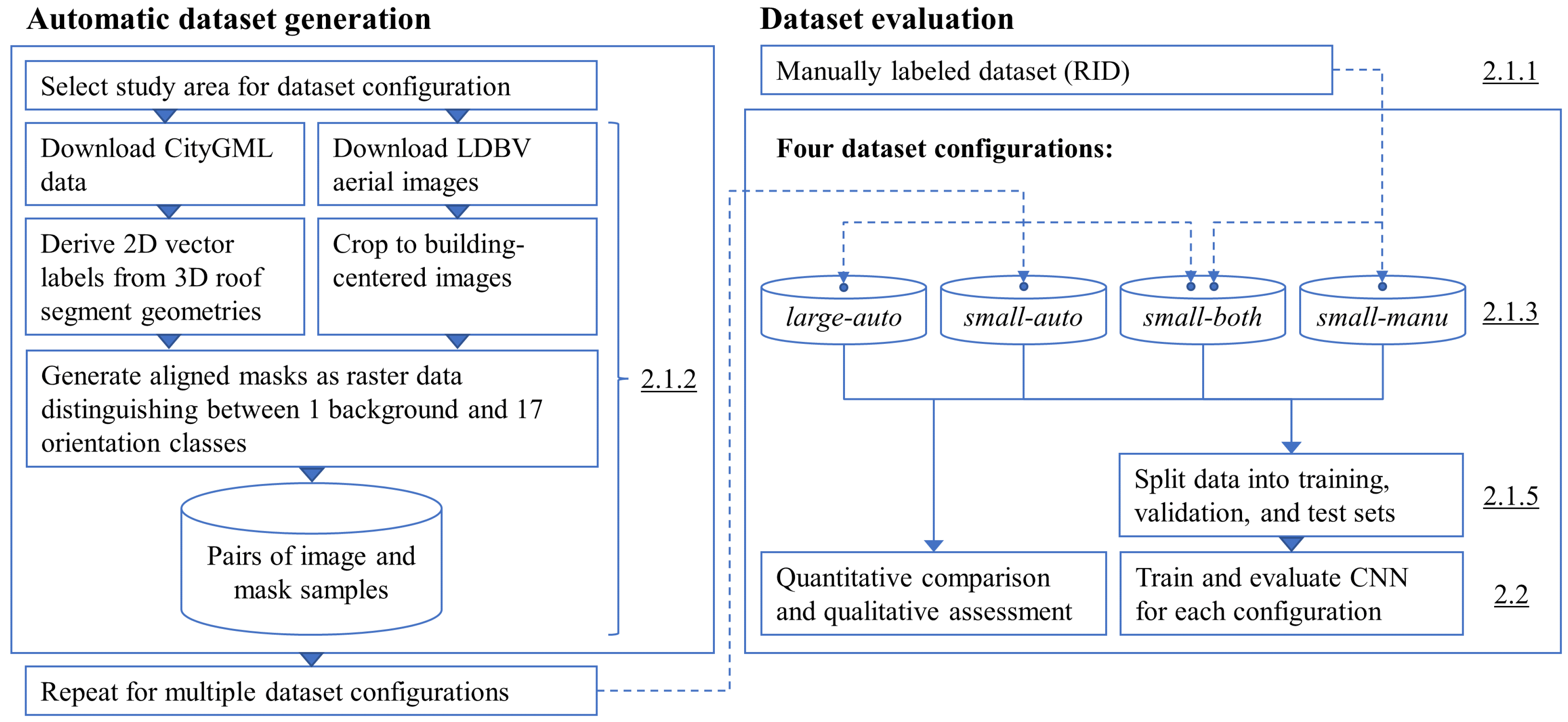
23]. They represent detailed building data with roof and wall surfaces described both semantically and geometrically, which could be used to derive roof segment labels for aerial images and, thus, to cost-efficiently generate more heterogeneous large-scale datasets featuring a wider variety of roof geometries and other properties. Based on this insight, this paper presents a novel approach for cost-effectively generating a versatile large-scale dataset for semantic segmentation of roof segments from aerial images using 3D city models, representing a wide range of geometrical and geographical conditions. To evaluate the dataset, this paper investigates the effectiveness of the automatically created large-scale dataset in comparison to the existing, manually labeled RID by training convolutional neural networks (CNNs) on both datasets.
The aims of the present study can be summarized into the following research questions, which are answered and discussed throughout this article:
- 1.
How can semantic 3D city models be used to generate heterogeneous large-scale datasets of roof segment labels for aerial images?
- 2.
Which label characteristics and potential inaccuracies must be expected when using such an approach?
- 3.
How does the segmentation performance of a convolutional neural network model differ when trained on small-scale, homogeneous, manually labeled data compared to large-scale, heterogeneous, automatically labeled data?
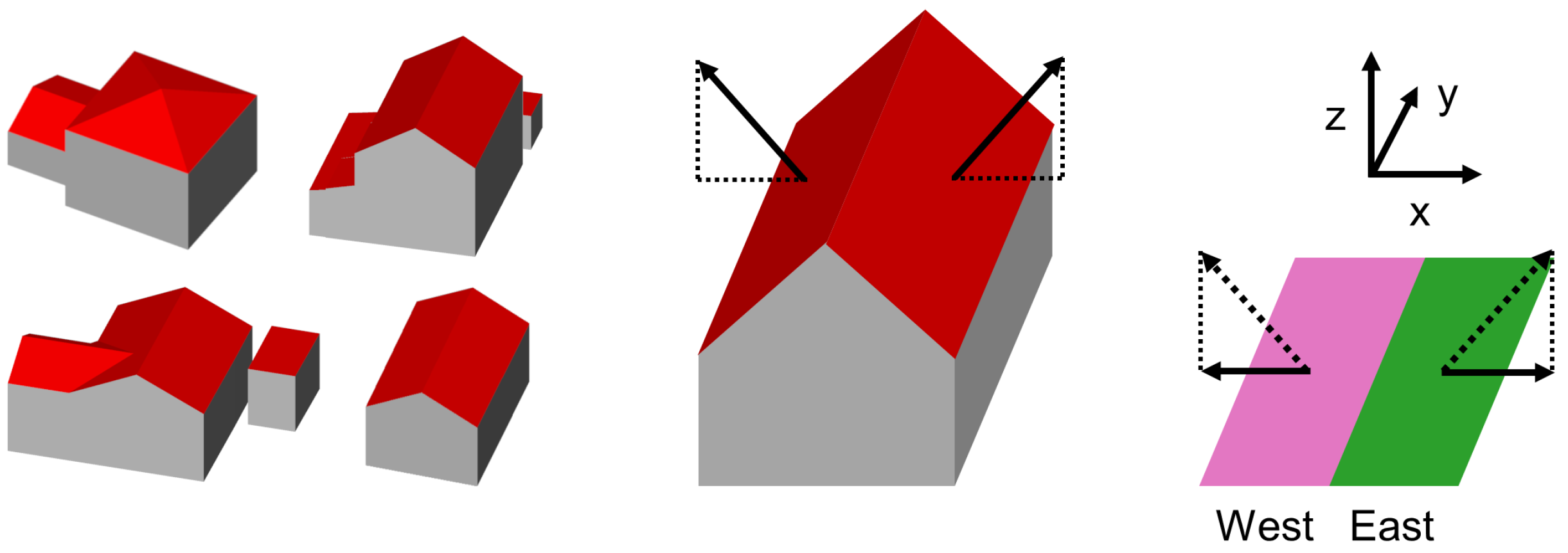
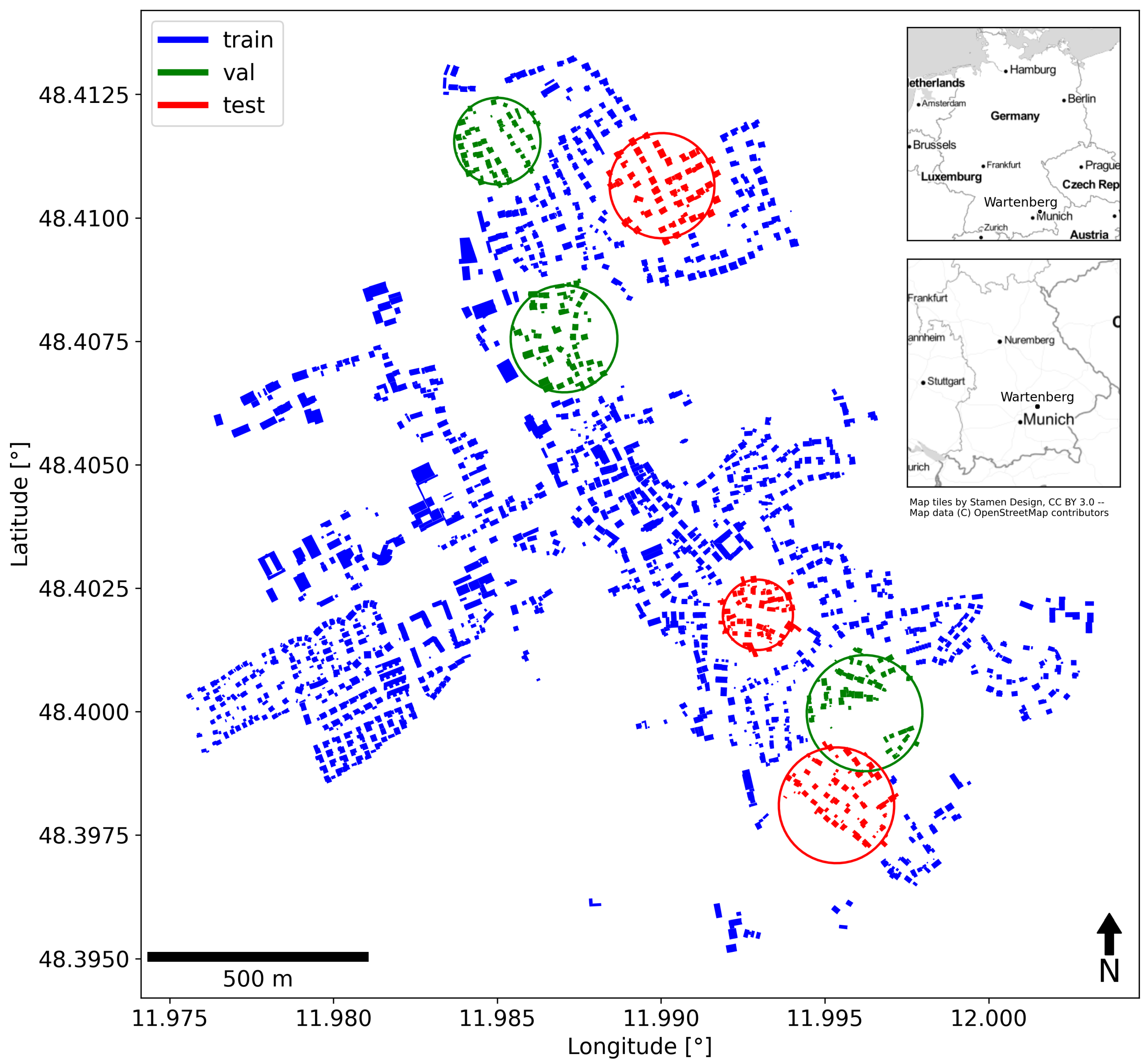
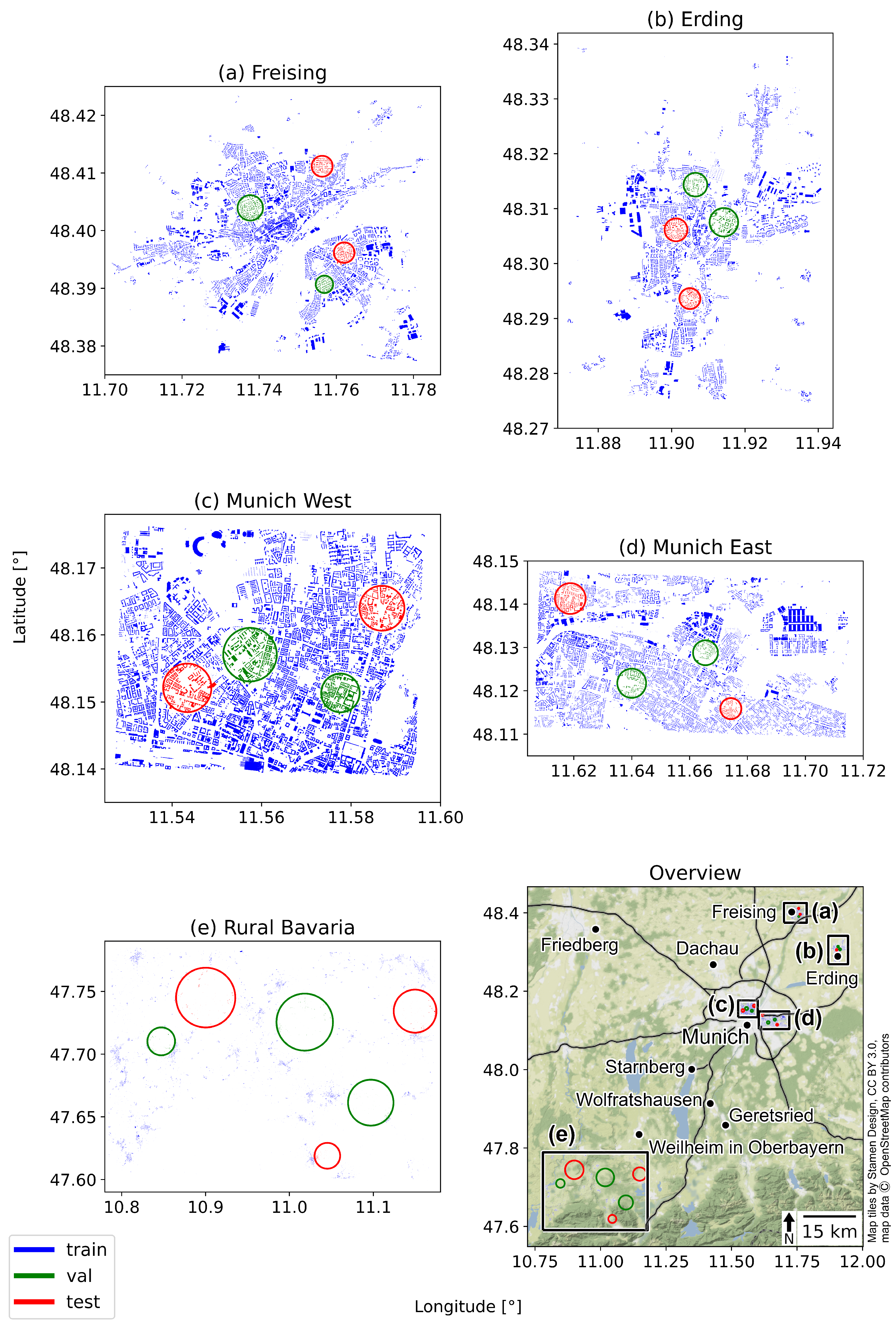
To this end, a set of study areas in southern Germany was selected that reflects diverse settlement conditions. Using a 3D city model, we created a large-scale training dataset in the form of digital orthophotos and roof segments masks reflecting 18 classes, similarly to DeepRoof [
16] and RID [
19]. Additionally, the manually labeled RID [
19] was recreated in an automated fashion using this study’s novel approach. Both the original and the recreated RID served as comparison to evaluate our large-scale dataset and the model that was trained on it. The datasets were split into subsets for training, validation, and testing with the aim to reduce the introduction of a spatial bias. With regard to research question 1, the approach to dataset generation and all configurations are described in
Section 2.1. A convolutional neural network adopting the U-Net architecture [
24] was trained on each of the datasets. Details about the hyperparameters, training procedure, and evaluation metrics are provided in
Section 2.2. The results comprise a detailed comparison between the manually and automatically generated datasets with respect to research question 2 (
Section 3.1). Furthermore, and in response to research question 3, an evaluation of the networks’ semantic segmentation performance (
Section 3.2) and exemplary model predictions are examined (
Section 3.3). The discussion (
Section 4) provides further answers to questions 2 and 3 by reviewing implications and limitations of the findings and giving suggestions for improvements as well as a comparison to the state of the art.
The contributions of this article include:
A novel approach for generating labeled datasets from 3D city models and aerial images for semantic segmentation of roof segments,
The exemplary generation of such a large-scale dataset that is more than 50 times as large as the state of the art,
A model that predicts roof segments and their orientation with a mean IoU of 0.70, which surpasses the state of the art, is capable of generalizing to a significantly larger variety of roofs, and distinguishes more orientation classes,
A discussion of opportunities and challenges in using 3D city models for automatically generating such datasets.
3. Results
The first section of the results chapter aims to answer research question 2 by identifying characteristics and potential inaccuracies of the generated roof segment labels. Following it, the results in terms of semantic segmentation performance are presented and illustrated with exemplary model predictions, which provide a comprehensive answer to research question 3.
3.1. Automatically Generated Labels and Their Quality
Because the samples of the two corresponding configurations
small-manu and
small-auto cover the same area around identical locations (the building centroids), it is possible to compare them with respect to their quality and consistency.
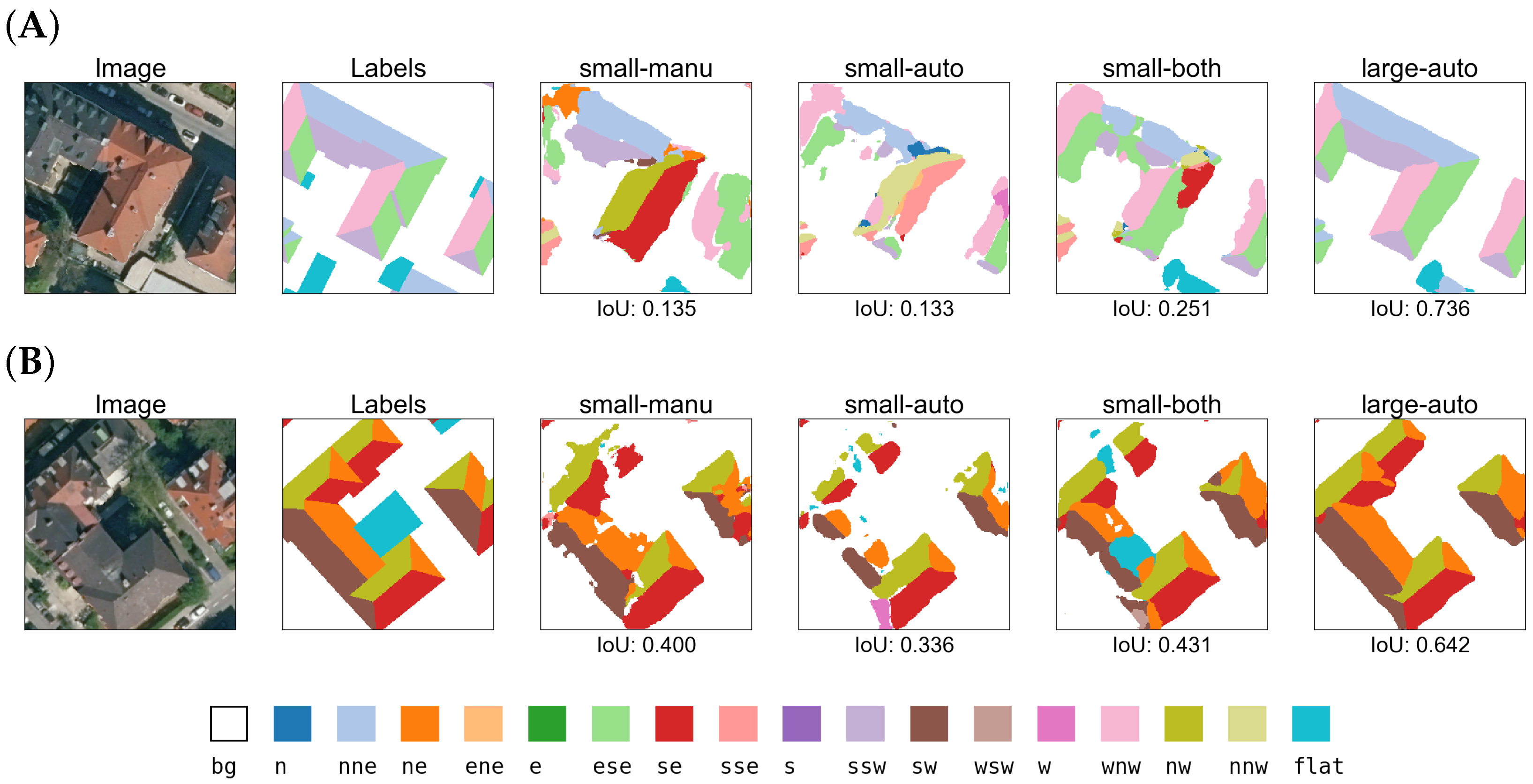
Figure 5 gives an exemplary graphical comparison showing two training samples from both datasets. Overall, the automatically generated labels are well aligned to the roofs as depicted in the aerial imagery, and their representation of the roof geometries is largely very accurate. This points to their suitability for the training of neural networks.
The manually labeled RID dataset is based on Google aerial imagery, while the automatically labeled datasets use LDBV true orthophotos to warrant congruence with the 3D city data. Hence, a certain degree of misalignment between the two is to be expected. To obtain a quantitative measure, their IoU was computed and found to be 0.49. While this indicates some degree of consistency, several sources for discrepancies between the two datasets and, thus, their labels can be identified. They are described in the following and can be observed in the samples shown in
Figure 5, which were selected to illustrate them.
For both datasets there are cases where one provides more detailed labels than the other; for instance, with respect to the individual delineation of dormers or their omission. Qualitative assessment of random samples indicates that, generally, dormers are more often delineated individually in the manual dataset. Furthermore, roof geometries in the LOD2 3D city model in some cases are simplified to an extent that leads to an incorrect representation of some roof parts in the derived labels, particularly for cross-gabled buildings with one or several wings. The manual dataset in general only has labels for visible roofs, while the automatically generated labels also cover roof areas that may be hidden underneath vegetation in the LDBV images.
Because the LOD2 3D city data used here do not model roof overhangs whereas they are of course visible in the aerial imagery, the automatic labels in many cases do not cover the depicted roofs completely, i.e., to their edges. The effect of this systematic inaccuracy on the performance of the models could, for instance, be investigated by labeling a certain amount of LDBV image samples manually including roof overhangs, training a model on these data, and comparing its results to those of a model trained on 3D-city-data-derived labels.
Finally, there are cases in which the assignment of an orientation class differs between the manual and automatic datasets. This occurs when a roof segment’s orientation is at the boundary between two classes. Then, the outcome of the manual labeling process may fall in one orientation class while the orientation computed from the segment’s normal vector in the 3D city data results in the other orientation class. Potential effects on segmentation performance are unclear and could be investigated separately in the future, but are considered likely to be negligible because of the small number of cases and the fact that, at the boundary between two classes, the orientation of a segment is not always unambiguous between the datasets due to small differences in angles. Therefore, the assignment of either class cannot with certainty be considered wrong taking into account the context of the underlying data. Similarly, either model output could be considered correct within the margins of uncertainty.
3.2. Semantic Segmentation Performance
3.2.1. Mean Intersection over Union
Table 5 lists the performance of all four models in terms of intersection over union as described in
Section 2.2.3, evaluated on each of the four configurations’ test sets. One finds a clear separation between the model trained on manually labeled samples and those trained on automatically labeled samples, but also between the small-scale models and the model trained on the large-scale dataset. The same holds true for the corresponding test datasets and the models’ results on these.
With an IoU of 0.603 and 0.602, respectively, the models small-manu and small-both are the best performers on the manually labeled dataset small-manu. The first was trained on this particular dataset and, therefore, can be expected to be specialized on it. The latter, which was trained on the combined small-scale datasets (both manually and automatically labeled), achieves practically equal, but not superior performance. Additional exposure to automatically labeled LDBV images during training seems not to have translated into an improvement in its ability to segment Google imagery, but also not to have impeded it. The large-scale model large-auto with an IoU of 0.504 scores higher than the model small-auto (0.369) only trained on the automatically labeled small-scale dataset, indicating an improvement from training on an extended LDBV image dataset when required to generalize to Google data with manual labels.
With respect to the dataset small-auto, the large-scale model large-auto scores highest at 0.700, again providing evidence for the benefit arising from dataset extension. The models small-both and small-auto, which were trained on automatically labeled data as well, achieve IoU values of 0.616 and 0.584, respectively. The first performs slightly better, which might be attributed to its exposure to additional, albeit manually labeled Google imagery during training. The worst performing model on the automatically labeled small-scale dataset unsurprisingly is the one that was not exposed to any corresponding training data, but only to manually labeled data: small-manu with an IoU of 0.425.
On the dataset small-both combining both the manually and automatically labeled small-scale datasets, the corresponding model that was trained on this exact dataset scores highest at 0.609. It is closely followed by the model large-auto with an IoU of 0.597. While this may at first glance appear to indicate that training on an extended, automatically labeled dataset also enhances segmentation performance on manually labeled data, the large-auto model’s results on the datasets small-manu and small-auto tell otherwise, where it performs rather poorly on the first and very good on the second. This illustrates the fact that evaluation on a combined dataset can be misleading, since the same mean IoU value may be achieved by different distributions of performance across the included image sources.
The evaluation results on the large-auto test dataset show the lowest IoU scores on average. This could be expected considering that it is the most challenging dataset with very heterogeneous data from rural and urban areas across Bavaria, where especially the urban parts differ significantly from the rural small-town area represented in the small-scale datasets. The model large-auto trained on the corresponding training data achieves the highest score at 0.635. Among the remaining three models, the one that was exposed to both manually and automatically labeled data in training (small-both) performs best at 0.467, again indicating a carryover effect from increased training data heterogeneity even if the source of the additional data is different. It is followed by the model small-auto, achieving an IoU of 0.411. Finally, the model small-manu, which was trained only on the small and manually labeled dataset, shows the poorest performance with an IoU of 0.366.
With respect to the main diagonal in
Table 5, which represents the evaluation of the four models on their own test datasets, it is noteworthy that the model
large-auto performs best, considering that it was both trained and tested on the most diverse, heterogeneous, and, therefore, challenging configuration.
Regarding the small-scale models and in view of the performance on the manually labeled test dataset small-manu, it appears that combining manually and automatically labeled training data does not translate into a performance improvement compared to training only with manually labeled data. Conversely, if evaluated on an automatically labeled dataset (small-auto or large-auto), a model that during training was exposed to both manually and automatically labeled data outperforms one that was trained exclusively on automatically labeled data. Overall, one can observe a significant degree of specialization among the models on the data used for training and only limited ability to generalize to data of different composition and quality, but also a clear improvement in model versatility from combining heterogeneous data during training.
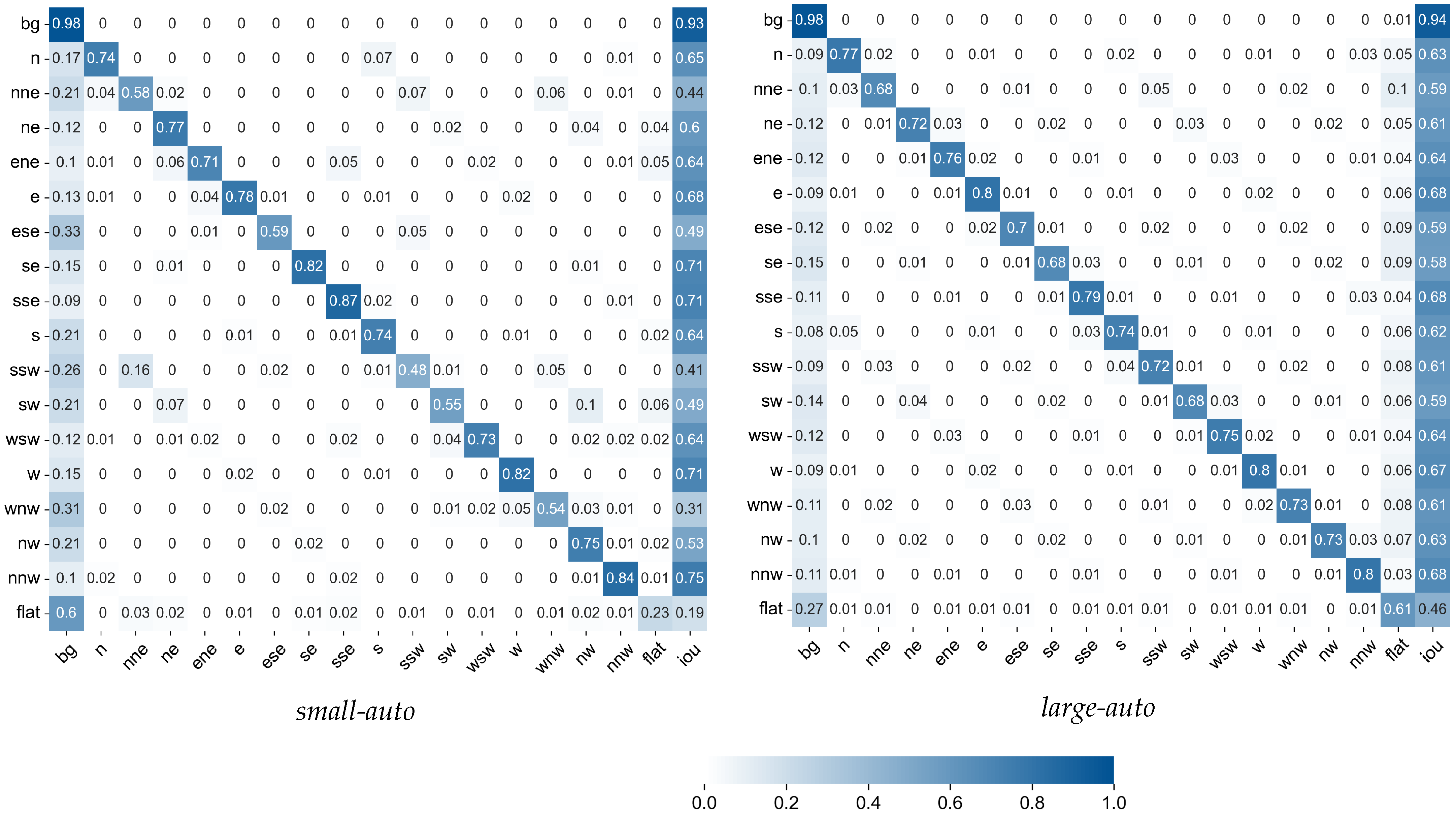
3.2.2. Confusion Matrices
Figure 6 compares confusion matrices of the models
small-auto and
large-auto evaluated on their own test sets. Several notable observations can be made: in both cases, the background class is the one that is identified most reliably, followed by the sloped roof segment classes. Flat roofs pose a challenge to both models, and the model
small-auto classifies the majority as background, which is reflected in a low class IoU of 0.19. The model
large-auto also has difficulties identifying flat roofs but performs significantly better.
While the background class is identified very well, it is also the one that is most frequently assigned falsely to pixels that belong to roof segments. This points to the problem arising from the highly imbalanced class distribution. Although a loss function suitable for such data was used in training, it nevertheless could not completely prevent the development of a model bias to predict the background class with higher frequency. Another observable pattern is that sloped roof segments are with some, however lesser, frequency classified as flat.
Both models have a slight tendency to confuse sloped roof segment classes with orthogonal azimuths. For example, while most north-facing roof segments are identified correctly, a certain number is also classified as facing east, south, or west. This is understandable considering that such roof segments would mainly differ by lighting, whereas any textures such as roof tile patterns would have a similar orientation.
Across all these characteristics, the model
small-auto shows a higher variability than the model
large-auto, which is mainly due to the small dataset in which not all classes are represented equally. Variability aside, the model
large-auto performs better overall, confirming the finding in terms of mean IoU described in
Section 3.2.1.
3.3. Model Prediction Examples
Figure 7 shows predictions of all four models when evaluated on samples from the manually and automatically labeled small-scale datasets at identical locations. They illustrate similarities and differences in model behavior and between the data sources. It is immediately apparent that the image quality differs, with the Google image crops being slightly sharper and higher in contrast compared to the LDBV imagery. A possible reason could be a post-processing of the Google images that enhances these attributes.
The samples from location (A) contain residential buildings with roofs predominantly sloped towards north and south. Manual and 3D-city-data-derived labels show good consistency overall, with the manual labels omitting a few small roof areas in the north-western part of the sample. The models small-manu and small-both perform best on the Google image (upper row), the first scoring slightly higher in terms of IoU. Both models trained solely on automatically labeled data score lower. The large-auto model’s prediction delivers better roof outlines, but a higher IoU score is hindered mainly by predictions of flat roofs that are not present in the labels and failure to accurately detect the roof structures at the north-western position.
Roof segments in the corresponding LDBV image (lower row) at the same location are predicted best by the large-scale model large-auto. It is the only one capable of correctly identifying and outlining several of the smaller roof structures in the picture. The models small-auto and small-both follow in this order sorted by performance, correlated inversely to the number of samples they were trained on. The model small-manu, trained exclusively on manually labeled Google images, clearly has difficulties interpreting the LDBV image, delivering largely inaccurate segment predictions, which is reflected in its IoU being the lowest among all examples from this location.
Location (B) contains two pyramid roofs, which generally pose a greater challenge to the networks due to their lower frequency in the training data. Comparison of the labels at the location reveals a roof that was falsely classified as flat in the manual data. The available two-dimensional information did not allow the labeling person to identify its gable geometry. The automatically generated labels, on the other hand, contain an additional gable roof where in the LDBV image only a parking lot is visible, possibly due to outdated data. Regarding predictions on the Google image (upper row), none of the models manages to deliver convincing results, in particular with respect to the pyramid roofs. Quantitatively, the models small-manu and large-auto score highest, but their predictions do not seem sufficient for practical application.
In view of the predictions on the LDBV image sample (lower row) at location (B), one can observe that three of the models underlie the same misinterpretation as the human labeler, classifying the roof in the south-eastern corner of the sample as flat. The pyramid roofs are outlined well by the models large-auto and small-both, while the other two have difficulties. The model small-manu, not exposed to automatically labeled LDBV images in training, manages to identify some segments but fails with many, which is reflected in the lowest IoU score. The discrepancy between the ground truth labels and the objects actually visible in the LDBV image crop leads to overall lower IoU values in this example.
These examples confirm the observation made in the overall results that there is significant specialization on the data source the models were trained on, and this is comprehensible considering the systematic differences in image and label quality. The results of the models small-both and large-auto illustrate that both a more diverse training dataset composed from both sources and an extended, purely automatically labeled dataset can lead to an improvement in segmentation performance on either data source.
Figure 8 provides predictions from all four models on two samples from the large-scale dataset
large-auto showing buildings from an urban residential environment in Munich, reflected in larger and more coherent roof structures. Since manually labeled samples are not available at these locations, a comparison between automatically and manually labeled samples as provided for the small-scale datasets is not possible here.
At both locations (A) and (B), the model large-auto scores highest by a significant margin, which meets the expectations considering that only this model was trained on data from similar environments. Qualitatively, it is capable of delivering very accurate outlines of the individual roof segments and of identifying their orientations correctly. The flat roofs that are present in the labels at the south-western corner of location (A) and centrally at location (B) are not predicted because they are hardly visible or covered by vegetation in the corresponding images, which also limits the maximum achievable IoU on these samples. The three models that were trained on the small-scale datasets largely fail to produce usable results. In many cases, they manage to identify correct orientations but fail to detect complete segments. Notably, the model small-both scores highest among the three in both examples, again indicating an improvement in capability to generalize from training on mixed data.
5. Conclusions
This study demonstrates that semantic 3D city models are a valuable resource for the generation of large-scale training datasets for the semantic segmentation of individual roof segments in aerial imagery. Further, evidence was presented showing that artificial neural networks trained on such datasets compare very favorably to models trained on smaller manually or automatically labeled datasets, but significant specialization on the training data source was found. In a first attempt to overcome this problem, data from both generation approaches were combined in training and the results point to an improvement in model versatility.
This paper exposes various starting points that call for further research. From a model-centric perspective, it appears worthwhile to explore loss functions that are even more suitable for semantic segmentation with highly imbalanced class distributions, such as generalized IoU loss functions [
42,
43], and to apply network architectures that are tailored more specifically to the problem at hand, such as successfully demonstrated by Li et al. [
18]. From a data-centric point of view, promising strategies include the combination of manually and automatically labeled data to improve the networks’ generalizability, either prior to training or in consecutive training steps. In addition, this publication’s approach can be applied in future work to generate even larger and more diverse datasets from 3D city data as their availability continues to improve (for instance, the state of Bavaria released all its LOD2 CityGML assets as open data as of 2023 [
57], comprising around 8.6 million semantically labeled building models; moreover, a comprehensive but not exhaustive list of openly available datasets can be found at [
23]). To improve comparability between the models trained on manually or automatically labeled data and to isolate any effects stemming from the characteristics of the 3D-city-data-derived labels, it will be pivotal to obtain a manually labeled dataset based on the same imagery as the automatically labeled data. These data could also serve to investigate the annotation agreement of human labels with the automated, 3D-city-data-based labels.
In recent years, semantic segmentation of building footprints from aerial images received a significant research interest. The maturity of the respective algorithms and the increased availability of high-resolution aerial images enable the extraction of even more detailed building information. To this end, this study contributes to the task of semantic segmentation of roof segments. The results can be used to better understand our built environment and to design more efficient, livable, and sustainable cities.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
