1. Introduction
The contiguous and rich spectral information captured by hyperspectral images (HSIs) reflects the most fundamental characteristics of composition of ground objects, providing capability to perform diagnostic identification of ground objects [
1]. Thus, HSIs are usually employed in various remote sensing applications related to recognition of different materials, such as environmental monitoring [
2], mineral exploration [
3] and land-cover classification [
4,
5]. One critical technique in these applications is HSI classification (HSIC) that is usually addressed in the framework of supervised learning [
6]. Recently, state-of-the-art (SOTA) performance of HSIC has been realized by the following deep learning (DL) methods, that make full use of spectral–spatial information: spectral–spatial residual network (SSRN) [
7], multiscale covariance maps with 2-D convolutional neural networks (CNNs) [
8], automatic CNN [
9], hybrid spectral CNN (HybridSN) [
10], spectral–spatial transformer network (SSTN) [
11], bole convolution with three-direction attention mechanism [
12] and Gabor ensemble filters [
13]. However, due to the curse of dimensionality, directly applying supervised classification to HSIs may require a huge number of labeled samples to gain satisfactory performance. Since scenes in practical hyperspectral remote sensing applications are usually varied, with complex types of surface materials, it is difficult to always obtain sufficient labeled samples for HSIC.
In order to circumvent the problem, the following research topics of HSIC developed: unsupervised feature extraction (UFE), unsupervised classification (clustering), semi-supervised learning, transfer learning and self-supervised learning (S2L). The UFE methods aim to transform HSI samples linearly, or non-linearly, to extract informative and distinguishable features, facilitating the subsequent training of classifiers. Like the above-mentioned DL methods, the dominant UFE methods, such as the following, exploit the information of the spatial context: superpixels or principal component analysis (PCA), such as superpixel PCA (SuperPCA) [
14], spectral–spatial and superpixelwise PCA (S3-PCA) [
15], PCA-based multiscale 2-D singular spectrum analysis [
16], flexible Gabor-based superpixel-level unsupervised linear discriminant analysis [
17]. Meanwhile, a few of the UFE methods achieve SOTA performance by applying sequential conventional feature extraction to form deep features. Specifically, and interestingly, random image patches have been successfully employed as convolutional kernels to extract deep features, such as random patches network [
18], spectral–spatial random patches network [
19] and random multiscale convolutional network [
20]. Furthermore, other UFE methods are derived from filter-based methods, such as PCA network-based multi-grained network (MugNet) [
21], etc. Unlike the above-mentioned UFE methods that use conventional feature extraction to generate deep features, autoencoder-based UFE methods learn deep features directly from data itself, such as 3D convolutional autoencoder [
22] and recursive autoencoder [
23].
Since HSI annotation usually requires extensive field data collection campaigns, that are costly and impractical when the HSI scene involves incooperative areas [
24], a few published works focus on unsupervised classification, i.e., clustering, that directly models the intrinsic characteristic of HSI samples to form several clusters [
25]. Typical HSI clustering methods include
k-means, fuzzy
c-means and
etc. Compared with supervised classification, clustering is more challenging and fundamental, due to spectral variability and the absence of a supervisory signal. Differing from unsupervised classification methods, semi-supervised classification makes use of unlabeled samples in the supervised process, such as Laplacian support vector machine [
26]. Indeed, the idea of clustering has been used in semi-supervised classification to exploit the characteristics of HSI samples. For instance, Wei et al. proposed a multitask network by integrating the intra-cluster similarity and inter-cluster dissimilarity of unlabeled HSI samples with supervised classification loss to boost the classification performance [
27], whereas Yao et al. proposed a two-step cluster–CNN method for HSIC [
28].
As a critical part of machine learning, transfer learning usually mitigates the information learned from the source domain to the target domain. In this way, the demand for labeled samples in the classification task of the target domain is decreased. Li et al. first proved that a network trained by supervision on partial classes can be used to extract discriminative features of other classes in one HSI [
29]. In this case, source and target domains correspond to different classes in the same HSI, where the domain divergence is smaller than is the case when two domains correspond to different HSIs, usually processed by domain adaptation techniques that aim to mitigate the supervisory signal from the source HSI to the target HSI [
30].
From the perspective of the classification task, the preceding S2L methods mainly work in extracting more discriminative features via pseudo-supervised or reconstructed information of unlabeled samples [
31,
32,
33,
34]. Recently, S2L methods in the literature concerning computer vision has shown their power to learn effective visual representations without any other supervision. Generally, these methods employ Siamese networks that are naturally suitable for comparing different views of one image [
35]. However, they use different strategies to prevent the network output from being a constant for all inputs, i.e.,
network collapsing. The method named momentum contrast (MoCo) constructs the Siamese networks with an encoder and the corresponding moving-averaged encoder that enables the building of a large and consistent queue on-the-fly [
36]. Starting from the network input of two different augmented views of one image, MoCo regards representations of the two encoders as positive pairs, whereas the representation of the encoder and the queue form negative pairs. Considering the memory cost of the queue in MoCo, the simple framework for contrastive learning representation (SimCLR) directly shares the weights of the Siamese networks and constructs negative pairs using different instances in each training batch [
37]. Benefiting from the strategy of discriminating between groups of similar images, instead of individual images, Caron et al. proposed to swap assignments between multiple views of the same image (SwAV), using a “swapped” prediction mechanism, where the code of a view computed by the trainable prototypes is predicted from the representation of another view [
38].
To eliminate the shortcomings of MoCo and SimCLR, that require either a memory bank or large batch-size to obtain accurate negative pairs, a novel method, namely bootstrap your own latent (BYOL), abandoned negative pairs and employed two neural networks, referred to as online and target networks, that interact and learn from each other [
39]. Along the lines of BYOL, the method named simple siamese (SimSiam) representation learning prevents collapsing with a stop-gradient operation of the target encoder, instead of the average-moving strategy [
35].
Figure 1 gives a comparison of the above-mentioned S2L methods and it is clear that BYOL surpassed other methods by large margins under the same evaluation protocol of the ImageNet dataset [
40].
Following the success of S2L in visual representation learning, the community of hyperspectral remote sensing has introduced self-supervised learning to HSIC [
42,
43,
44,
45] or clustering [
46]. Hu et al. used BYOL with the encoder backbone of a two-layer transformer for HSIC [
42], whereas Cao et al. treated features extracted by a variational autoencoder and an adversarial autoencoder as two views, instead of feeding two augmentations of each HSI sample [
43]. Derived from the framework of SimCLR [
37], Hou et al. paid more attention to the preprocessing of HSI samples and used Gaussian noise for augmentation [
44]. From the view of semantic feature extraction, Xu et al. proposed an end-to-end spectral–spatial network via the contrastive loss of two feature descriptions [
45]. Furthermore, Cai et al. first applied S2L to a scalable deep online clustering model, named spectral–spatial contrastive clustering, based on within cluster similarity and between-cluster redundancy [
46].
From the perspective of enhancing classification performance, techniques related to (semi-)supervised learning always require sufficient labeled samples as supervisory information, including supervision of the source domain in transfer learning. Meanwhile, although several works focus on clustering of HSIs, it is impossible to achieve performance superior to supervised classification by means of clustering techniques, due to spectral variations. Consequently, without the requirement of labeled samples, UFE and S2L that only make use of unlabeled samples naturally show the following merits. First, unlike a supervision process that has to be performed again with labeled samples updated, both UFE and S2L directly output extracted features or learned representations. Both UFE and S2L show more generalization for labeled samples in division of feature extraction and subsequent training of classifiers. Second, with the arrival of the era of big remote sensing data, both UFE and S2L can provide an automatic way of learning representation, and, thus, show more potential for future research of hyperspectral remote sensing. There is a conviction, held by the machine learning community, that S2L is a hot topic of future research. To summarize, UFE and S2L are more feasible when large amounts of HSI samples are to be processed. Note that S2L can be roughly regarded as a general concept of UFE.
The intrinsic merits and the practical success of S2L have accelerated its application to processing of HSIs, listed as the above-mentioned S2L-based methods for HSIC [
42,
43,
44,
45]. However, most of the methods that directly introduce S2L to HSIC are limited in the following two aspects. First, from the perspective of feature learning, the classification accuracy can be enhanced if more discriminative information of HSIs is exploited in the training process of S2L. However, this strategy has been neglected in S2L-based tasks of HSIC. Second, the computer vision community has proved that the success of S2L lies in learning visual representation not only for linear classification but also for downstream tasks. Specifically, the main merit of S2L on classification is that the learned visual representations from a relatively large dataset, such as ImageNet [
40], can be fine-tuned on small datasets. In this way, higher accuracy and faster convergence are more easily achieved than in training from scratch. However, since existing S2L-based methods of HSIC process only one HSI, without the involvement of fine-tuning from other HSIs, they hardly reflect the advantages of S2L.
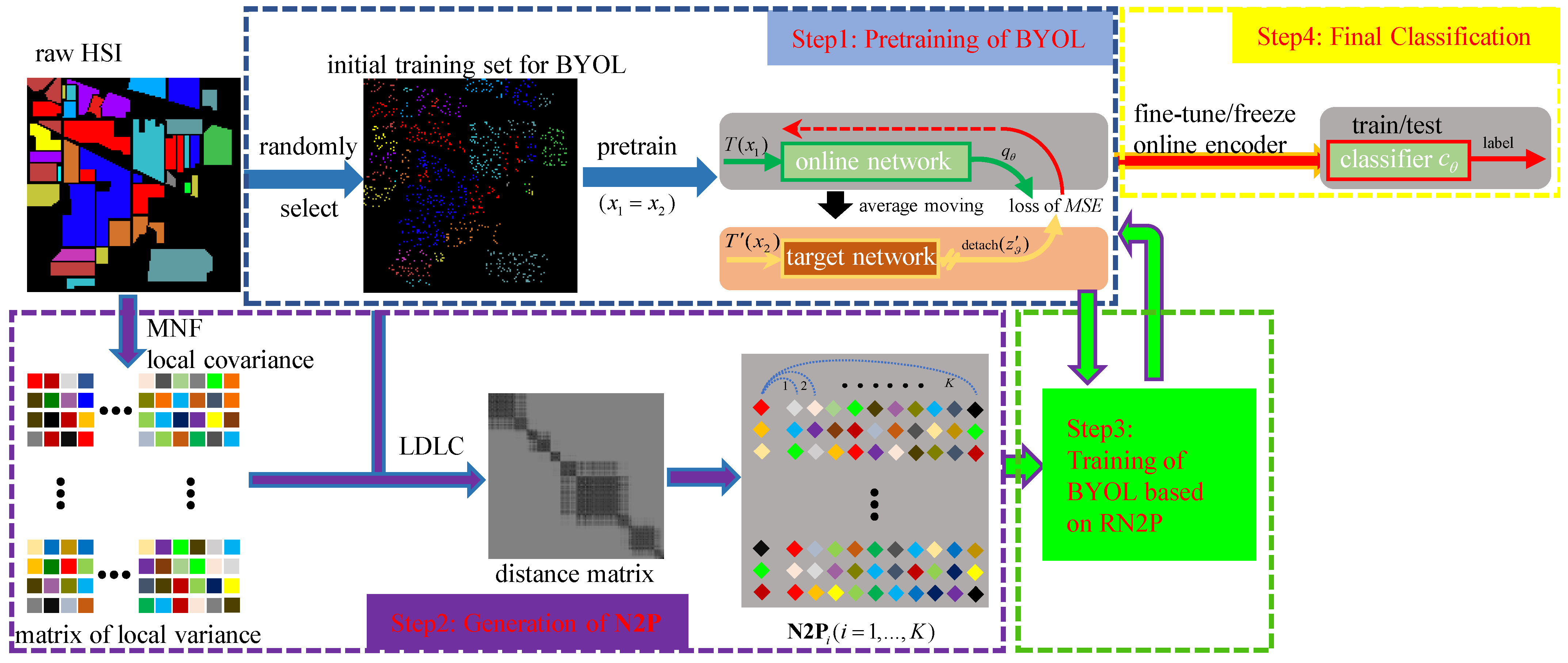
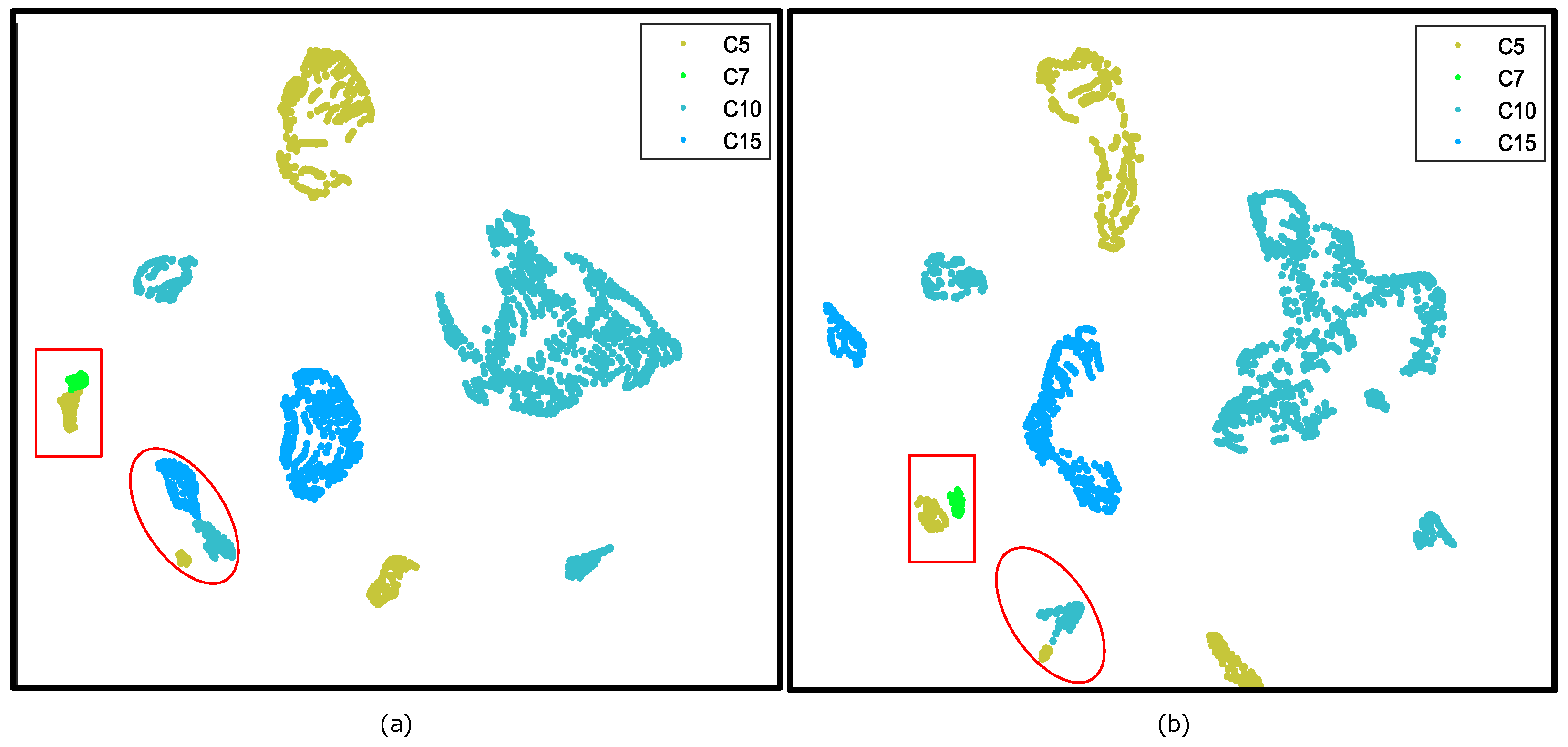
In this work, we, thus, tasked ourselves to find solutions to the above-mentioned two aspects, namely, exploiting discriminative information in the training process of S2L and fine-tuning from other HSIs. Aiming at the former aspect, we propose a n earest neighboring self-supervised learning (N2SSL) method for HSIC, based on the framework of BYOL and the well-known backbone of SSRN. To be specific, the proposed N2SSL method contains four main steps: pretraining of SSRN-based BYOL, generating nearest neighboring pairs (N2Ps) of samples derived from Log distance of local covariance (LDLC), training of BYOL based on reliable N2P (RN2P), final classification. First, a subset of all HSI samples is extracted as the initial training set to pretrain BYOL. Second, the affinity of these samples is generated by LDLC, and, thus, N2Ps can be easily constructed from each sample of the training set and one of its K-nearest neighboring samples. Third, extraction of RN2P and training of BYOL work in a collaborative way. In particular, N2P fed into BYOL with relatively smaller loss behave more similarly and, thus, can be treated as RN2P, whereas RN2P established by different samples are believed to help BYOL learn more discriminative representations and are, then, used to train BYOL. When the training process is finished, linear classification, based on frozen representation, is performed for final classification.
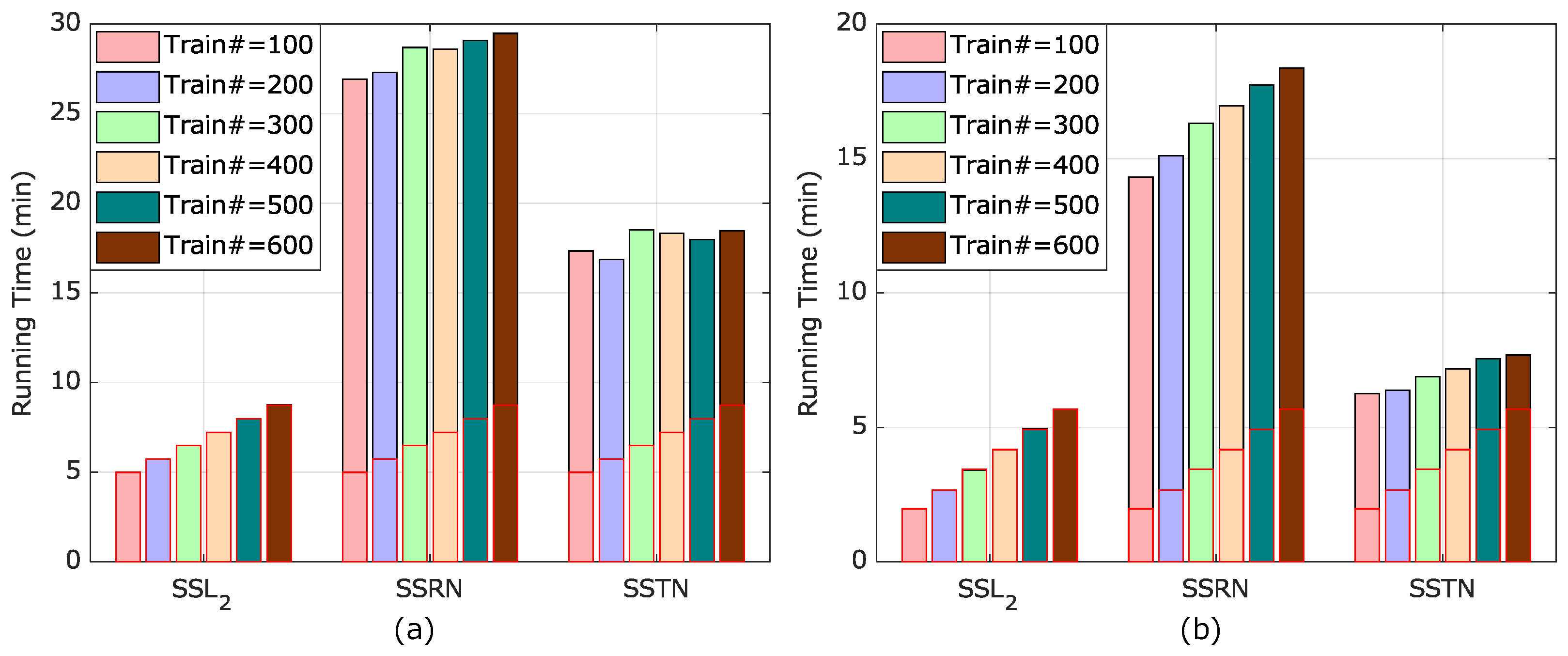
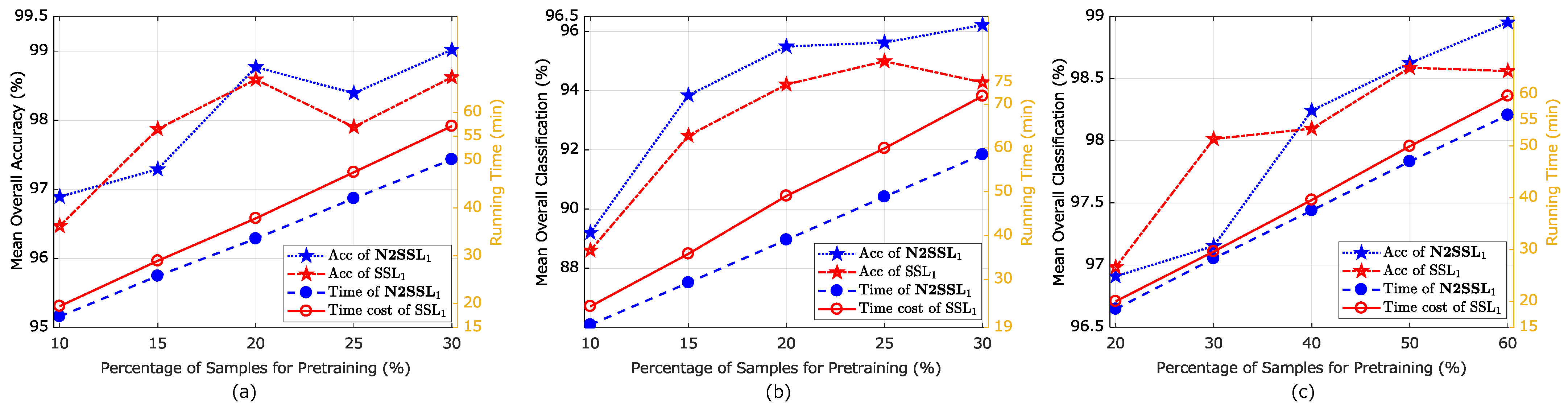
To understand the effect and importance of fine-tuning, we conducted an experimental study wherein N2SSL was performed on an unrelated HSI and then this was fine-tuned to another HSI; N2SSL was conducted on the Kennedy Space Center scene, but the learned network was then fine-tuned to University of Pavia and Indian Pines scenes. The classification accuracy and computational cost showed that the trained network from an unrelated HSI improved the efficiency.
The main contributions of our work are summarized as follows:
- (1)
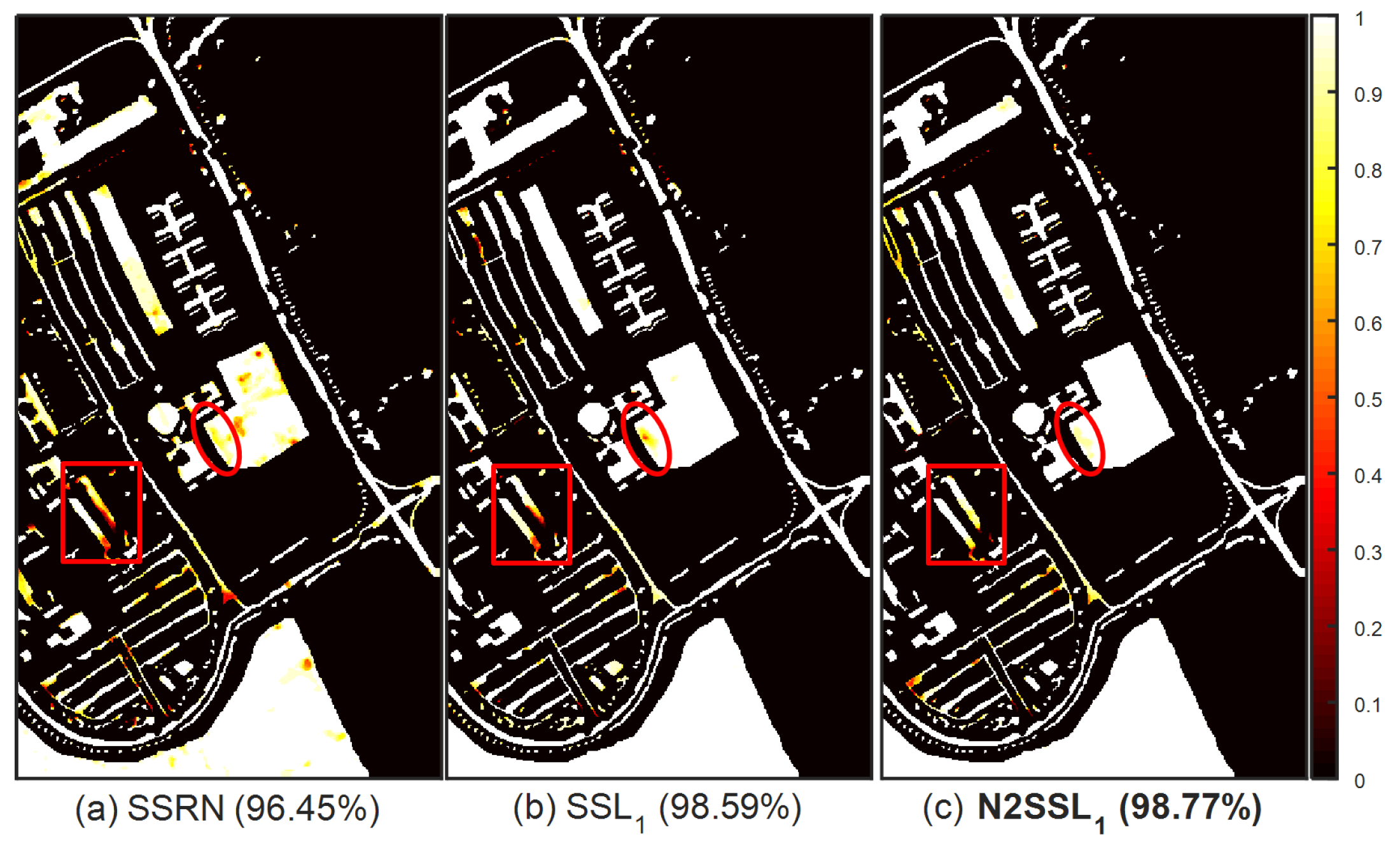
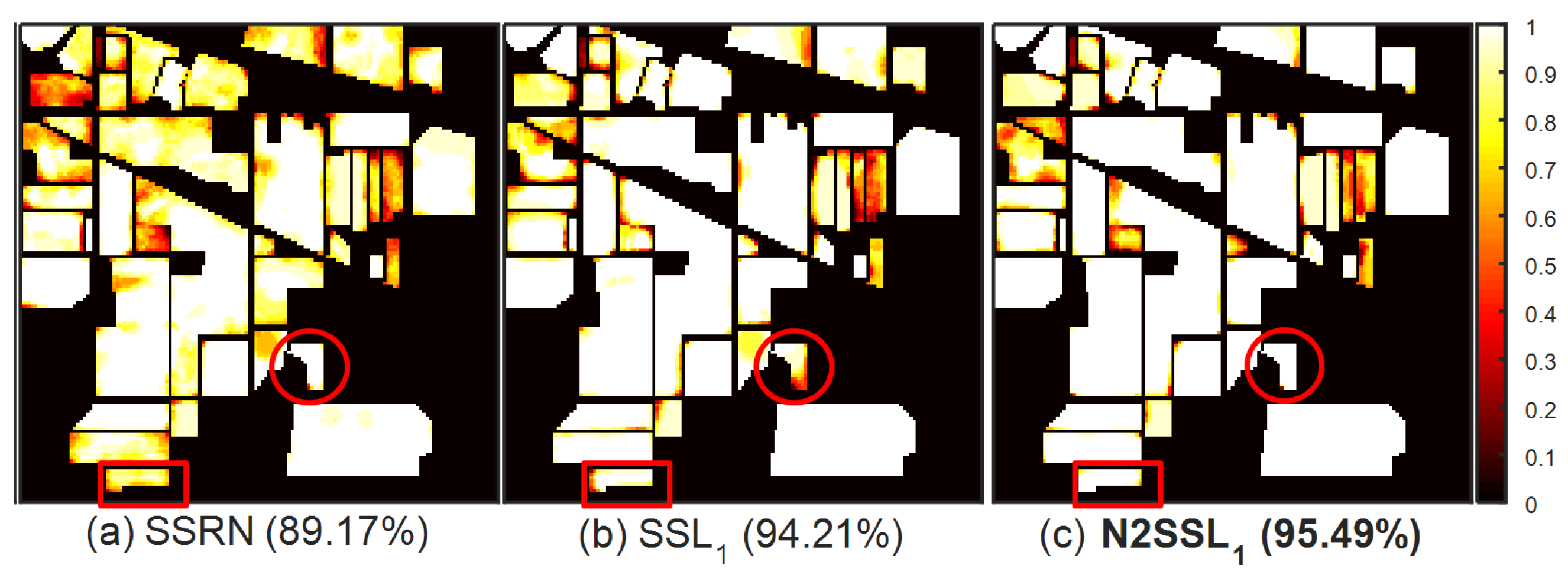
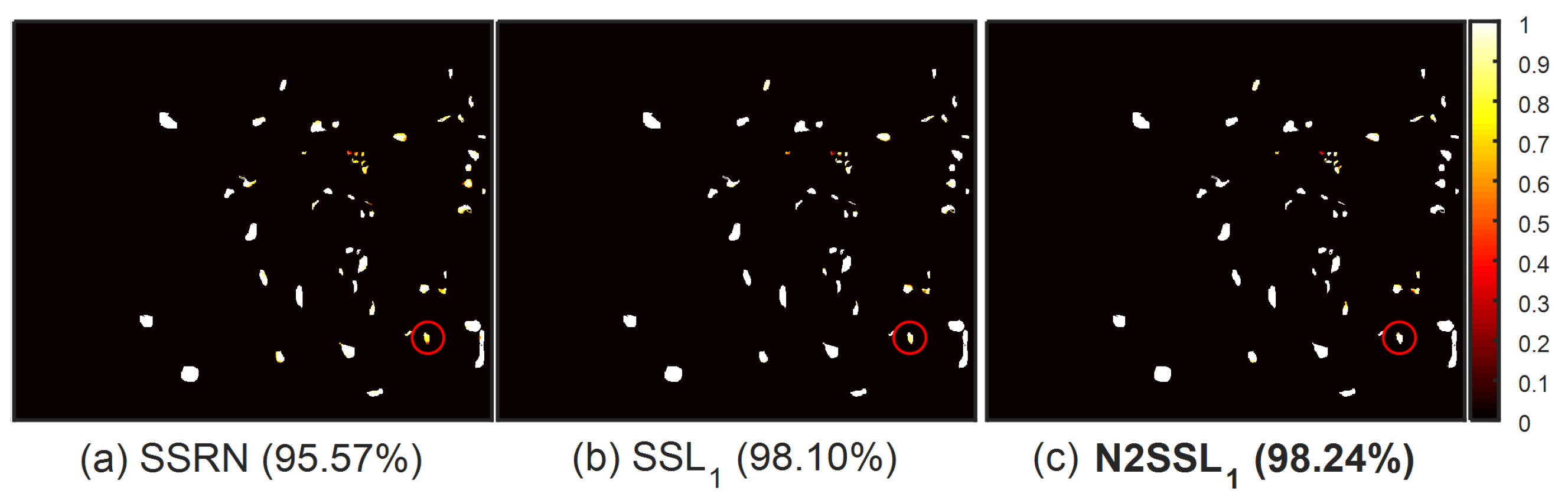
To the best knowledge of the authors, this is the first time that discriminative information, facilitating subsequent classification, is encoded by RN2P-based S2L. Comprehensive experiments on three benchmark HSIs were conducted to demonstrate the effectiveness of N2SSL, in terms of higher classification accuracy and less computational cost, compared to a standard framework of SSRN-based BYOL and other SOTA self-supervised methods designed for HSIC.
- (2)
Fine-tuning of trained networks by N2SSL from an unrelated HSI to other HSIs is validated for the first time, which may be a new research topic of deep learning-based HSIC.
- (3)
Since data augmentation (DA) plays a critical role in S2L, a comprehensive review of DA on HSI samples is illustrated in
Section 2, which can be referred to by future S2L-based research on HSIs.
The rest of the paper is organized as follows. The DA of HSI samples and framework of BYOL are reviewed in
Section 2. The proposed methodology of HSIC is presented in
Section 3.
Section 4 and
Section 5 describe the experimental setup and results, respectively.
Section 6 summarizes the research.
3. Proposed Methodology
As shown in
Figure 3, the proposed N2SSL method consists of four main steps: (i) pretraining of BYOL, (ii) generation of nearest neighboring pairs (N2Ps), (iii) training of BYOL based on reliable N2P (RN2P) and (iv) classification. First, given the considerable computational load of self-supervised learning on all samples of one HSI, a subset of all HSI samples is randomly selected as the initial training set, i.e.,
, which is used to pretrain BYOL by applying different augmentations to each sample. Herein, we opted for simplicity and adopted the main backbone of SSRN as the encoder. Second, since it is expected to encode the discriminative information of HSI samples in the training process of BYOL, to facilitate subsequent classification, N2P is generated by using the Log-Euclidean distance of local covariance (LDLC). When LDLC between samples of
TS is computed, each sample and one of its
K-nearest neighboring compose a pair. For better illustration, the
ith nearest neighboring samples and the corresponding HSI samples form the
ith subset of N2P, i.e., N2P
K). Third, since there failure in N2P may occur, i.e., pairs constructed by samples of different classes, the MSE-based loss of N2P, obtained by the pretrained BYOL is used to extract RN2P. Conversely, it is believed that training BYOL by RN2P can facilitate the learning discriminative information, as BYOL is forced to interact between augmentations of different, but similar, samples, instead of the same samples. Finally, linear classification, or fine-tuning-based labelling of samples is conducted. In the following, implementation details of the proposed method are described.
3.1. Pretraining of BYOL
Pretraining of BYOL is performed by learning on two augmentations of each sample in
TS. Specifically, the three components of the online network are the SSRN-based encoder
, two networks of multilayer perceptrons (MLPs) working as projector
and predictor
, respectively. The target encoder
and projector
share the same architecture as
and
, respectively.
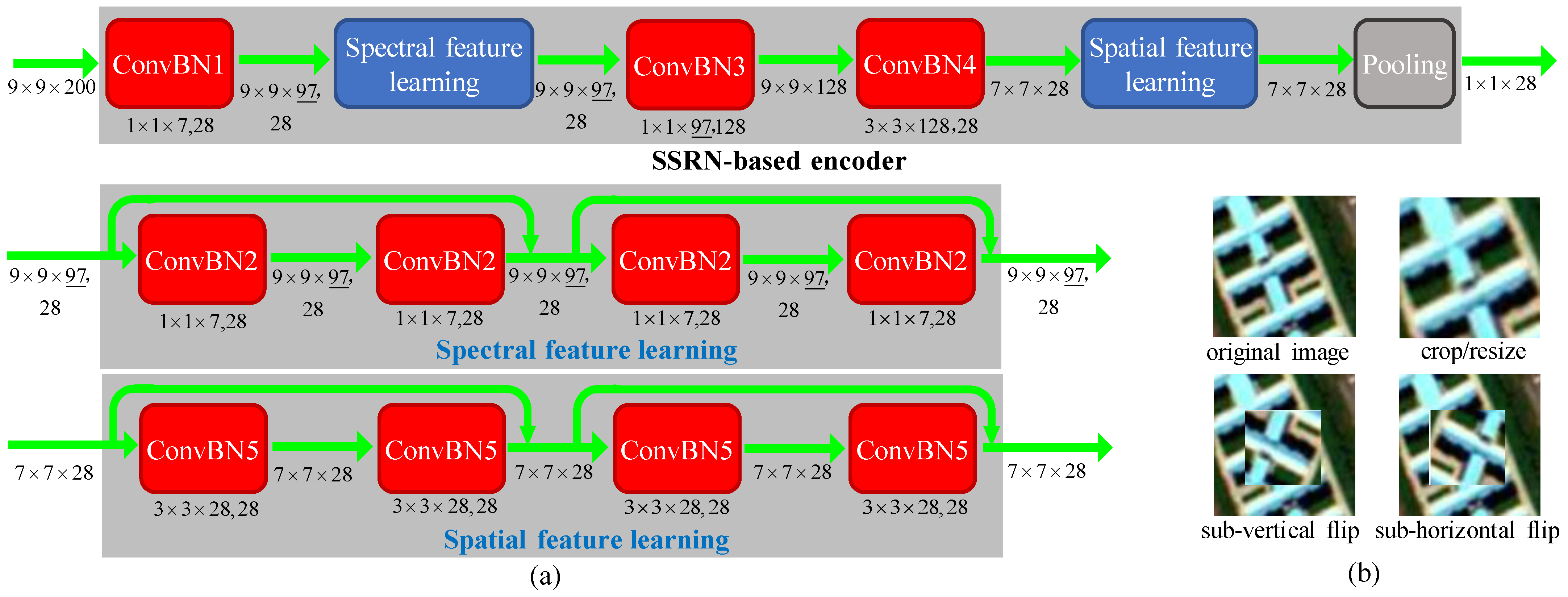
Figure 4a gives an example of an SSRN-based encoder that extracts deep features via two residual modules of spectral and spatial feature learning. Please refer to [
7] for details of SSRN. For simple illustration, we herein take a 3-D sample of the Indian Pines image with 200 bands as an example. The neighboring region of 9 × 9 pixels surrounding each pixel is considered to be the 3-D sample for the central pixel with the size of 9 × 9 × 200. The 3-D cube is first convolved by 281 × 1 × 7 spectral kernels (ConvBN1) with a subsampling stride of (1, 1, 2) to generate 289 × 9 × 97 cubes. Then, the module of spectral feature learning employs four convolutional layers (ConvBN2) and two identity mappings to learn the deep spectral features. All of the four convolution kernels share the same size of 281 × 1 × 7 with padding to keep the same size of output as input. Subsequently, two convolutional layers (ConvBN3 and ConvBN4) are employed to abstract spectral and spatial features, respectively. Following ConvBN4, the module of spatial feature learning uses four successive 3-D convolutional filter banks (ConvBN5), where the kernels have the same depth as the input 3-D feature volume. Similarly, the outputs of these filter banks keep the same size as the inputs of the feature cubes. Finally, an average pooling layer generates a 1 × 1 × 28 feature vector. When the size of input 3-D cube is fixed, the only parameter of the SSRN-based encoder is the kernel size of ConvBN3, i.e., the value of 97 underlined, which is determined by the number of bands. Furthermore, the sizes of MLP networks of the projectors (
and
) and predictor
were set to 28-512-128 and 128-512-128, respectively.
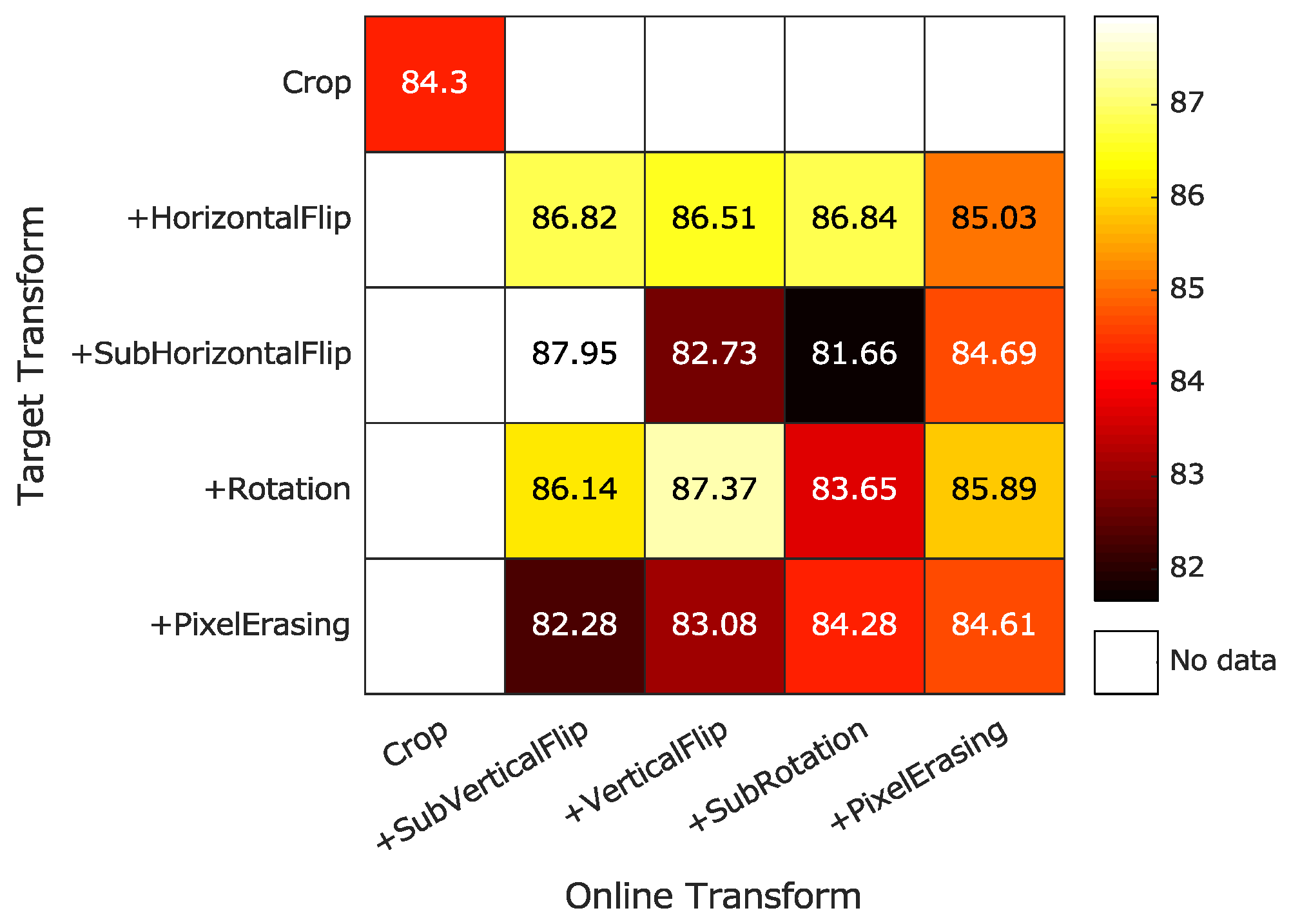
Regarding the augmentations used in BYOL, random cropping, followed by resizing back to the original size, was employed as it has proved to be effective in processing 3-D HSI samples. Empirically, we conducted experiments related to classification accuracy with respect to different augmentations. It was found that random cropping, followed by resizing with sub-vertical flip and with sub-horizontal flip, were enough for the online and target networks, respectively. Specifically, given one image pair of 9 × 9 × b, where b is the number of bands, a random spatial patch of each image was selected, with an area uniformly sampled between 8% and 100% of that of the original image, and an aspect ratio logarithmically sampled between
and
. This patch was then resized to the original size of 9 × 9
b using bicubic interpolation. For the optional sub-horizontal and sub-vertical flips, a sub-window surrounding the central pixel was randomly set to 3 × 3 to 7 × 7 pixels.
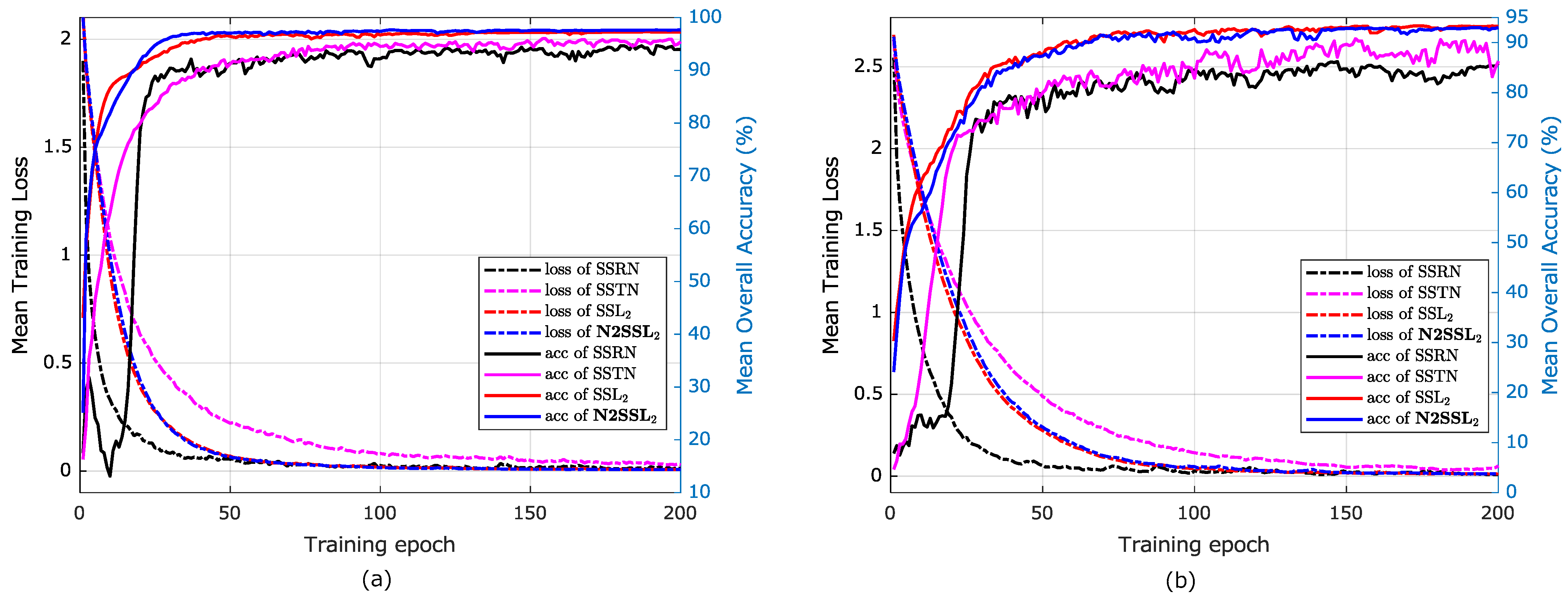
Figure 4b illustrates a conceptual example of these transforms. By applying MSE-based loss in Equation (
2) on augmented
TS, pretraining of BYOL was easily achieved in
epochs.
3.2. Generatation of N2P
As mentioned above, two samples from one pair are expected to belong to the same category for encoding discriminative information for BYOL training. Thus, metrics, or UFE methods, achieving SOTA performance of computing affinity between HSI samples are considered to be candidates for the generation of N2P. Among these methods, local covariance matrix representation, exploiting spectral–spatial information, has been successfully applied to both unsupervised and supervised HSIC [
24,
25,
69]. Compared with SAM and Euclidean distances, it exploited the similarities and variances of local samples and proved to be suitable for measuring distances between HSI samples. Consequently, we employed it for generation of N2P, which computed the Log-Euclidean distances of local covariance (LDLC) of similar samples.
Particularly, maximum noise fraction (MNF) was first applied to the original HSI to reduce the dimensionality and suppress noise. Given the window size
T, the SAD measure was used to find the
M-1 most similar neighboring samples of the central sample. Then, these
M samples were treated as a local set, i.e.,
P = {
}. Then, the covariance of
P was formulated as
where
denotes the mean of samples. As covariance matrices are symmetric positive definites, they lie on a Riemannian manifold and, thus, Euclidean distance is hardly suitable for them, whereas LDLC was proposed in [
70] to model the differences of covariance matrices. Given two sets
and
corresponding to samples
and
, the corresponding covariance matrices are denoted as
and
, respectively. The LDLC between the two samples is then defined as
where
var denotes the vector variance and
represents the vector of CM logarithm on the set
. The main parameters are the number of MNF components
L, the number of neighboring samples
M and the window size
T, which were set to 20, 25 and 220, respectively.
With the definition of LDLC, the distances among all samples in TS can be computed. Afterwards, each sample and one of its K-nearest neighboring samples formed the subset N2P K) and, thus, K pairs were generated.
3.3. Training of BYOL Based on RN2P
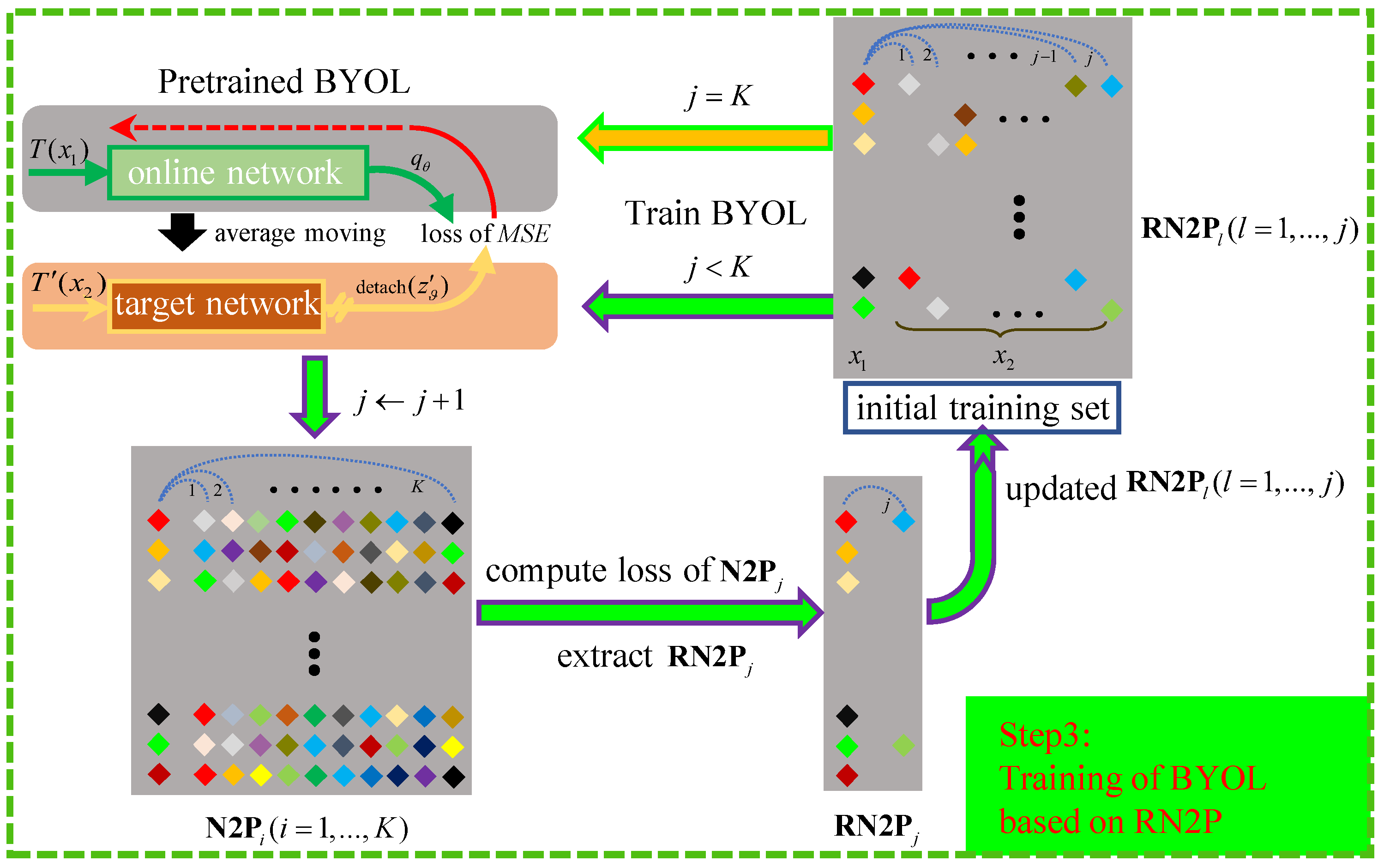
By learning between two views of one sample, pretrained BYOL is expected to learn the latent semantic representations of HSI samples. Therefore, when two views of different samples belonging to the same category are fed into BYOL, the corresponding MSE-based loss is expected to be relatively small. Based on this observation and the truth that the original N2P can hardly be accurate enough, pretrained BYOL can be used for further refinement of N2P, i.e., extraction of RN2P. Since N2P is obtained via LDLC-based distances between nearest neighboring samples, N2P is believed to be more reliable than N2P (). Thus, N2P ( K) was used to extract RN2P ( K) in order. Meanwhile, RN2P is naturally beneficial to extract RN2P () when it is used to train BYOL. The strategy is similar to the concept of evolving, i.e., the network learns semantic representation from easy pairs to hard pairs gradually, which has been applied to several applications, such as clustering of natural images. Consequently, extracted RN2P was added to TS to train BYOL for further extracting of RN2P. Once the extraction of RN2P finished, they were used to train BYOL for epochs.
In detail, as shown in
Figure 5, we constantly computed the MSE-based loss of N2P
and extracted pairs with the smallest losses as RN2P
, according to the ratio, i.e.,
. In this way, RN2P
contained
pairs and was added to the training set. Then, BYOL was trained by the new training set with
epochs and used for generation of RN2P
. Thus, when the iteration process finished, RN2P
K) containing
pairs were used to perform subsequent training of BYOL for
epochs. The implementation details of the proposed iterative process are illustrated in Algorithm 1.
| Algorithm 1: Training of BYOL based on RN2P. |
| Input: |
| pretrained networks and N2P, initial training set: TS, number of epochs: ne2, number of final epochs: ne3, ratio for extracting RN2P: . |
| 1: Repeats: |
| 2: Compute MSE-based loss of N2Pj. |
| 3: Extract RN2Pj according to η. |
| 4: Train BYOL using TS and RN2Pl (l = 1, …, j) for ne2 epochs. |
| 5: j ← j + 1. |
| 6: Until all N2Pj is processed. |
| 7: Train BYOL using RN2P for ne3 epochs. |
| Return: trained BYOL. |
3.4. Final Classification
When training of BYOL was over, only the online encoder
was kept to compute the latent representations of both labeled and unlabeled HSI samples. Then, the corresponding classifier was designed as an MLP network of 28-
C, where
C was the number of classes. We regularized the classifier by clipping the logits using a hyperbolic tangent function
where
is a positive scalar and
is the output of the classifier on labeled samples, and by adding a logit-regularization penalty term in the loss
where
is the cross-entropy function,
y denotes the labels of labeled samples, and
is the regularization parameter. We set
and
as [
39].
In the case of linear classification, the parameters of the online encoder are fixed and only the classifier is trained. Instead, both the online encoder and classifier are trained in the case of fine-tuning. Finally, the classification map was obtained by the inference of all samples of HSI.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}