
Arbitrary-Oriented Ship Detection Method Based on Long-Edge Decomposition Rotated Bounding Box Encoding in SAR Images

Abstract
:1. Introduction
2. Arbitrary-Oriented Ship Detection in SAR Images
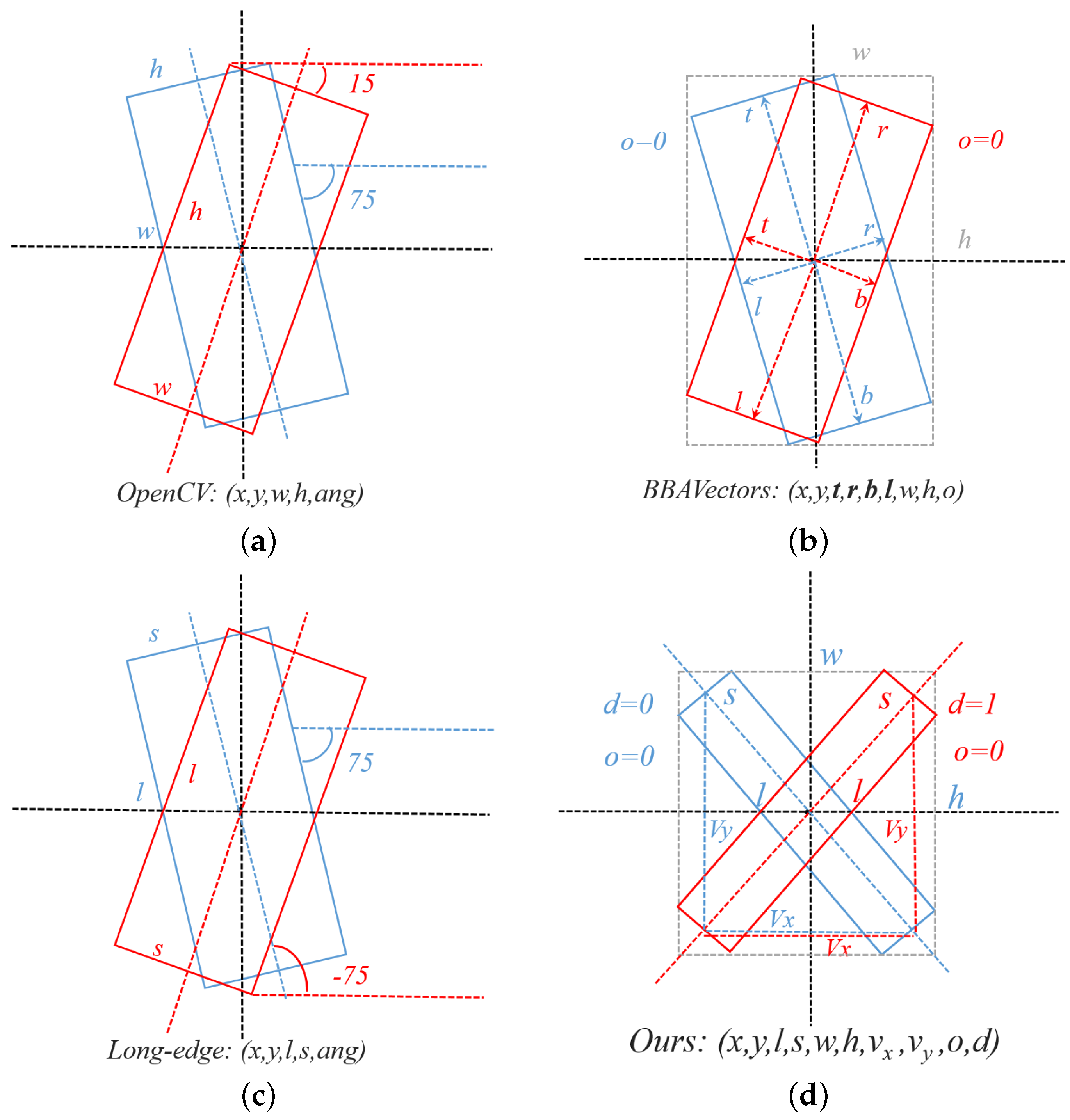
2.1. Classic RBB Encodings
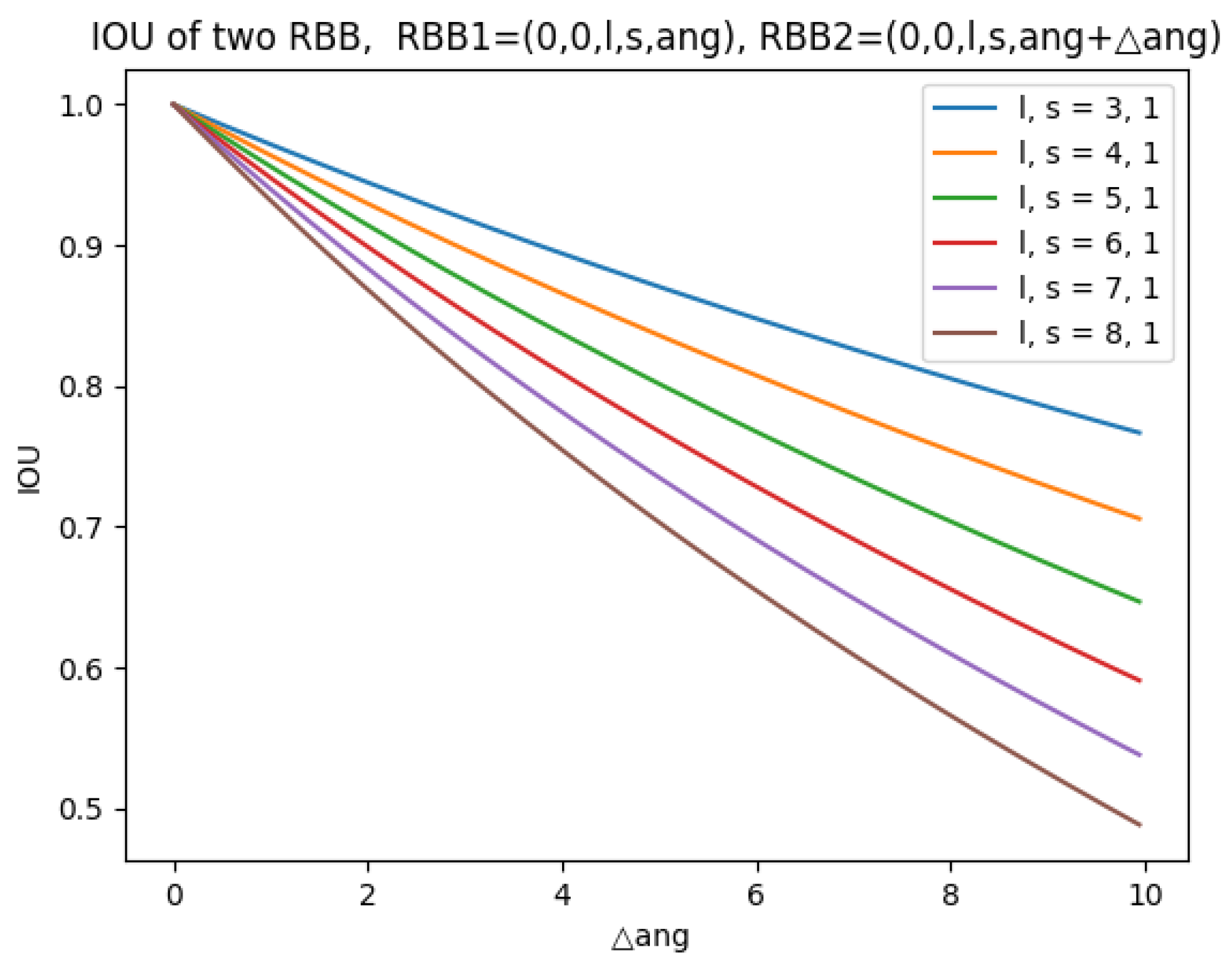
2.2. Long-Edge Decomposition RBB Encoding
| Algorithm 1 Encoding. |
| Input:, i = 1,2,3,4, the bottom, left, top, and right corner points of RBB Output:(x, y , l, s, w, h, , , o, d), code words of long-edge decomposition encoding
|
| Algorithm 2 Decoding. |
| Input: (, , , ), code words Output: , i = 1,2,3,4, coordinates of the bottom, left, top, and right corner points
|
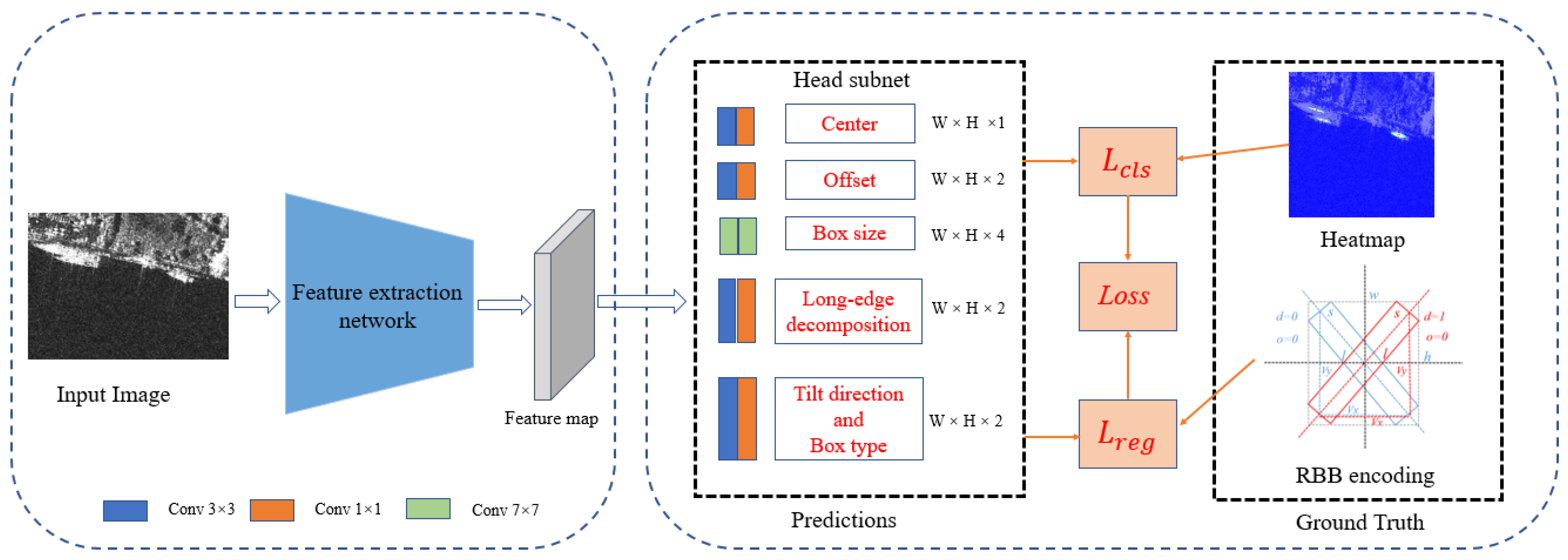
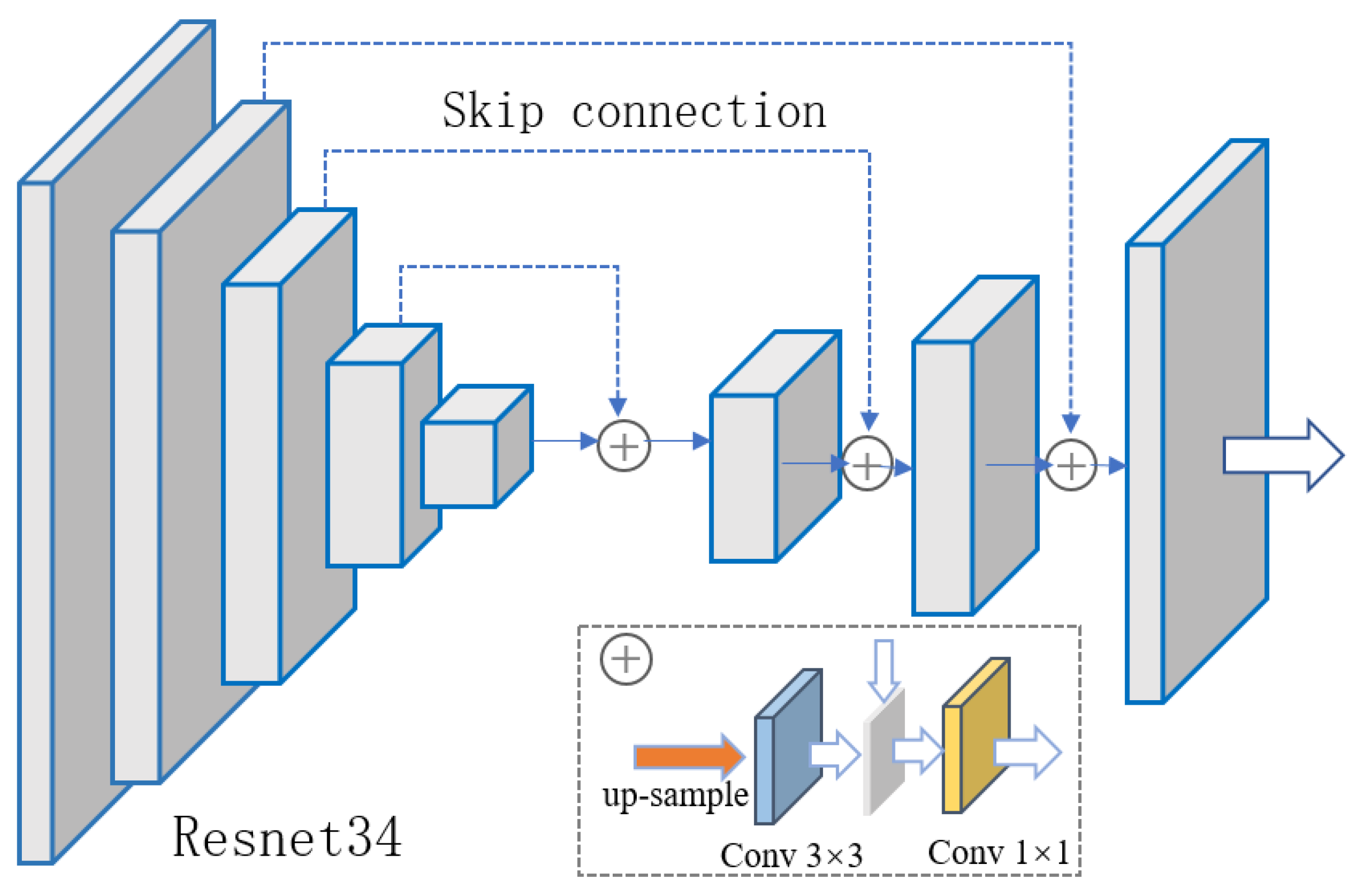
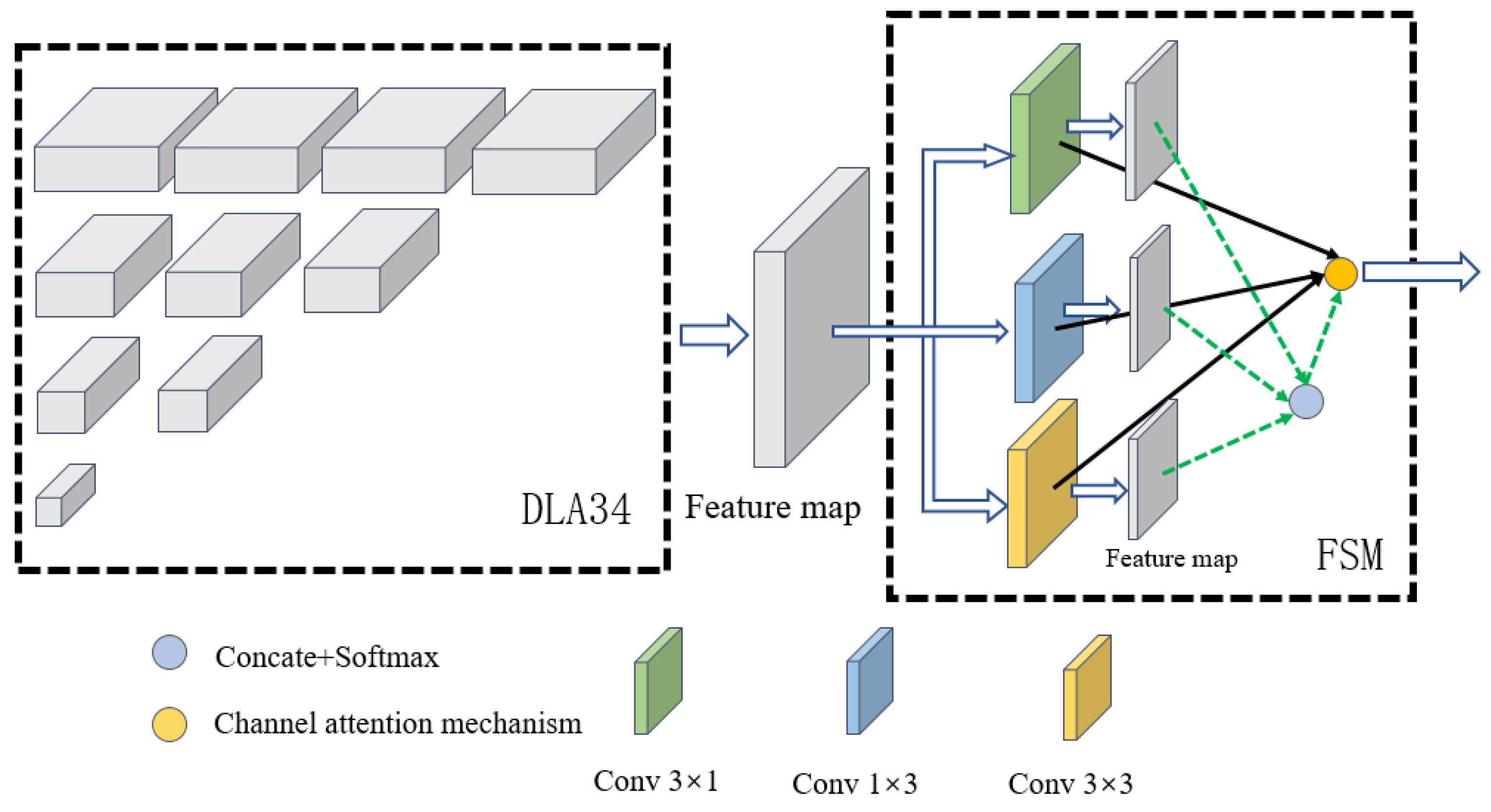
2.3. Model Structure
2.4. Multiscale Elliptical Gaussian Sample Balancing Strategy
2.5. Loss Function
3. Experiments and Discussion
3.1. Experimental Settings and Evaluation Metrics
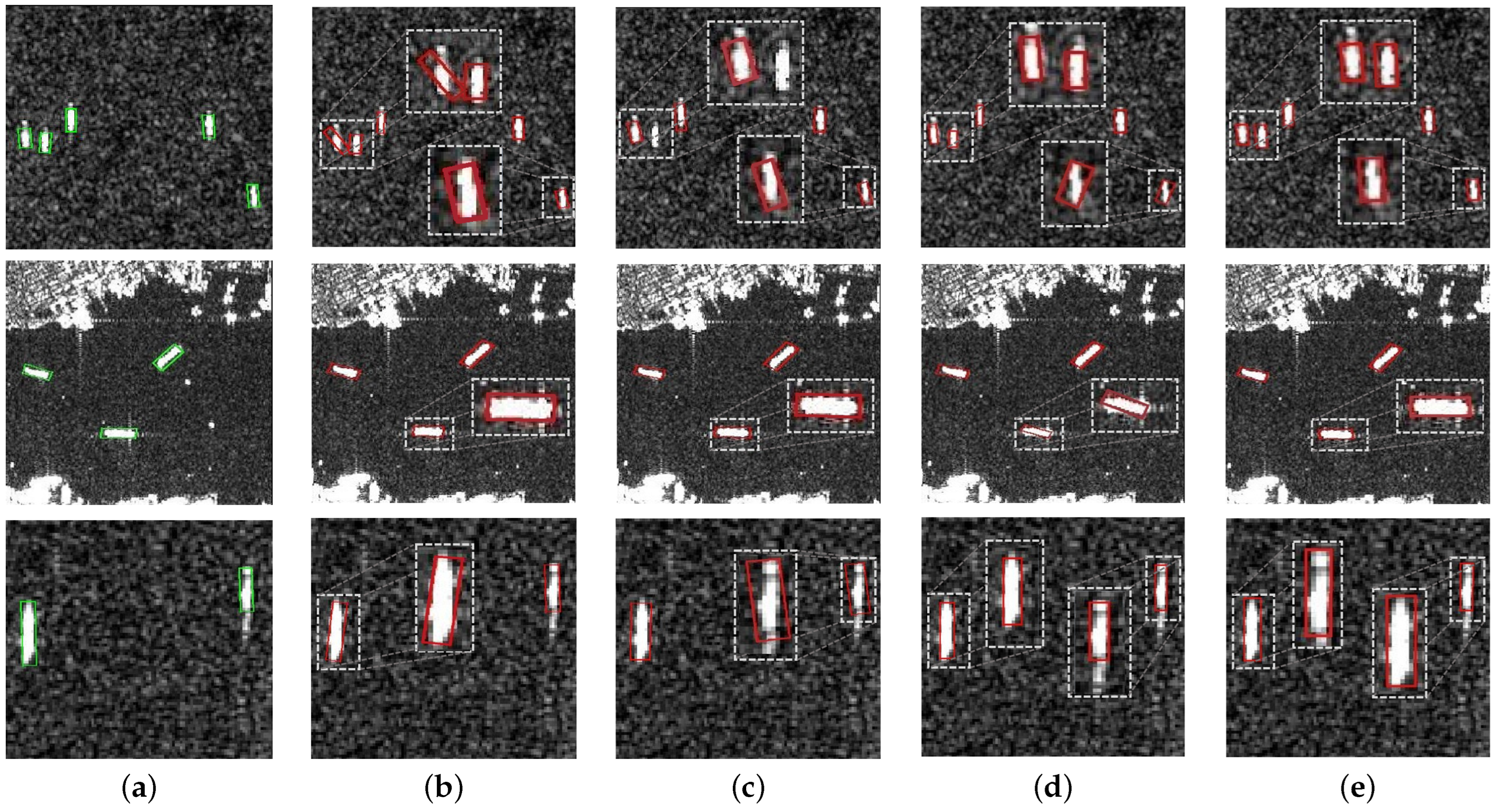
3.2. Comparison Experiments of Different Encodings
3.3. Experiments of the Multiscale Elliptical Gaussian Sample Balancing
3.4. Comparison Experiments with the Mainstream Detection Methods
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Xie, H.; An, D.; Huang, X.; Zhou, Z. Efficient raw signal generation based on equivalent scatterer and subaperture processing for one-stationary bistatic SAR including motion errors. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3360–3377. [Google Scholar] [CrossRef]
- Xie, H.; Shi, S.; An, D.; Wang, G.; Wang, G.; Xiao, H.; Huang, X.; Zhou, Z.; Xie, C.; Wang, F.; et al. Fast factorized backprojection algorithm for one-stationary bistatic spotlight circular SAR image formation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 1494–1510. [Google Scholar] [CrossRef]
- Xie, H.; Hu, J.; Duan, K.; Wang, G. High-efficiency and high-precision reconstruction strategy for P-band ultra-wideband bistatic synthetic aperture radar raw data including motion errors. IEEE Access 2020, 8, 31143–31158. [Google Scholar] [CrossRef]
- An, D.; Wang, W.; Zhou, Z. Refocusing of ground moving target in circular synthetic aperture radar. IEEE Sens. J. 2019, 19, 8668–8674. [Google Scholar] [CrossRef]
- Li, J.; An, D.; Wang, W.; Zhou, Z.; Chen, M. A novel method for single-channel CSAR ground moving target imaging. IEEE Sens. J. 2019, 19, 8642–8649. [Google Scholar] [CrossRef]
- Lang, H.; Xi, Y.; Zhang, X. Ship detection in high-resolution SAR images by clustering spatially enhanced pixel descriptor. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5407–5423. [Google Scholar] [CrossRef]
- Gao, G.; Liu, L.; Zhao, L.; Shi, G.; Kuang, G. An adaptive and fast CFAR algorithm based on automatic censoring for target detection in high-resolution SAR images. IEEE Trans. Geosci. Remote Sens. 2008, 47, 1685–1697. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Law, H.; Deng, J. CornerNet: Detecting objects as paired keypoints. Int. J. Comput. Vis. 2020, 128, 642–656. [Google Scholar] [CrossRef] [Green Version]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Li, J.; Qu, C.; Shao, J. Ship detection in SAR images based on an improved faster R-CNN. In Proceedings of the 2017 SAR in Big Data Era: Models, Methods and Applications (BIGSARDATA), Beijing, China, 13–14 November 2017; pp. 1–6. [Google Scholar]
- Xiaoling, Z.; Tianwen, Z.; Jun, S.; Shunjun, W. High-speed and high-accurate SAR ship detection based on a depthwise separable convolution neural network. J. Radars 2019, 8, 841–851. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Fu, J.; Sun, X.; Wang, Z.; Fu, K. An anchor-free method based on feature balancing and refinement network for multiscale ship detection in SAR images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 1331–1344. [Google Scholar] [CrossRef]
- Guo, H.; Yang, X.; Wang, N.; Gao, X. A CenterNet++ model for ship detection in SAR images. Pattern Recognit. 2021, 112, 107787. [Google Scholar] [CrossRef]
- An, Q.; Pan, Z.; Liu, L.; You, H. DRBox-v2: An improved detector with rotatable boxes for target detection in SAR images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8333–8349. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Yang, R.; Pan, Z.; Jia, X.; Zhang, L.; Deng, Y. A novel CNN-based detector for ship detection based on rotatable bounding box in SAR images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 1938–1958. [Google Scholar] [CrossRef]
- Yang, X.; Hou, L.; Zhou, Y.; Wang, W.; Yan, J. Dense label encoding for boundary discontinuity free rotation detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 15819–15829. [Google Scholar]
- Yang, X.; Yan, J. Arbitrary-oriented object detection with circular smooth label. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 677–694. [Google Scholar]
- Yi, J.; Wu, P.; Liu, B.; Huang, Q.; Qu, H.; Metaxas, D. Oriented object detection in aerial images with box boundary-aware vectors. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 2150–2159. [Google Scholar]
- He, Y.; Gao, F.; Wang, J.; Hussain, A.; Yang, E.; Zhou, H. Learning polar encodings for arbitrary-oriented ship detection in SAR images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 3846–3859. [Google Scholar] [CrossRef]
- Yang, X.; Yan, J.; Ming, Q.; Wang, W.; Zhang, X.; Tian, Q. Rethinking rotated object detection with gaussian wasserstein distance loss. arXiv 2022, arXiv:2101.11952. [Google Scholar]
- Yang, X.; Yang, X.; Yang, J.; Ming, Q.; Wang, W.; Tian, Q.; Yan, J. Learning high-precision bounding box for rotated object detection via kullback-leibler divergence. Adv. Neural Inf. Process. Syst. 2021, 34, 18381–18394. [Google Scholar]
- Shrivastava, A.; Gupta, A.; Girshick, R. Training region-based object detectors with online hard example mining. In Proceedings of the IEEE Conference on Computer Vision and Pattern recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 761–769. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhu, C.; Chen, F.; Shen, Z.; Savvides, M. Soft anchor-point object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 91–107. [Google Scholar]
- Shiqi, C.; Wei, W.; Ronghui, Z.; Jun, Z.; Shengqi, L. A lightweight, arbitrary-oriented SAR ship detector via feature map-based knowledge distillation. J. Radars 2022, 11, 1–14. [Google Scholar]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.S.; Lu, Q. Learning RoI transformer for oriented object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 2849–2858. [Google Scholar]
- Yu, F.; Wang, D.; Shelhamer, E.; Darrell, T. Deep layer aggregation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 2403–2412. [Google Scholar]
- Pan, X.; Ren, Y.; Sheng, K.; Dong, W.; Yuan, H.; Guo, X.; Ma, C.; Xu, C. Dynamic refinement network for oriented and densely packed object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11207–11216. [Google Scholar]
- Han, J.; Ding, J.; Xue, N.; Xia, G.S. Redet: A rotation-equivariant detector for aerial object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 2786–2795. [Google Scholar]
- Xie, X.; Cheng, G.; Wang, J.; Yao, X.; Han, J. Oriented R-CNN for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 3520–3529. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| RBB Encodings | ||||
|---|---|---|---|---|
| Opencv encoding | 0.938 | 0.901 | 0.886 | 0.919 |
| Long-edge encoding | 0.953 | 0.915 | 0.898 | 0.933 |
| BBAVectors encoding | 0.952 | 0.933 | 0.902 | 0.942 |
| Ours encoding | 0.952 | 0.939 | 0.908 | 0.945 |
| Strategies | ||||
|---|---|---|---|---|
| CGSBS (with NMS or not) | 0.952 | 0.939 | 0.908 | 0.945 |
| EGSBS (w/o NMS) | 0.848 | 0.961 | 0.872 | 0.901 |
| EGSBS (w NMS) | 0.917 | 0.961 | 0.916 | 0.938 |
| MEGSBS (w/o NMS) | 0.948 | 0.964 | 0.923 | 0.956 |
| MEGSBS (w NMS) | 0.955 | 0.964 | 0.930 | 0.960 |
| Metrics | Circular Gaussian | Elliptical Gaussian | Multiscale Elliptical Gaussian |
|---|---|---|---|
| Rd (Top 30 pc) | 0.914 | 0.928 | 0.934 |
| (Bttm 30 pc) | 1.014 | 1.418 | 1.034 |
| (Bttm 30 pc) | 0.941 | 1.362 | 1.013 |
| Detection Methods | Parameters Quantity (M) | ||||
|---|---|---|---|---|---|
| Rotated-Retinanet | 36.35 | 0.825 | 0.868 | 0.832 | 0.846 |
| ROItransformer | 55.25 | 0.905 | 0.921 | 0.913 | 0.913 |
| Rotated-FCOS | 51.11 | 0.891 | 0.925 | 0.911 | 0.908 |
| BBAVectors | 24.38 | 0.952 | 0.933 | 0.902 | 0.942 |
| Ours (Dla34 + FSM) | 20.72 | 0.949 | 0.955 | 0.925 | 0.952 |
| Ours (Res34 + FPN) | 24.45 | 0.948 | 0.964 | 0.923 | 0.956 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, X.; Xie, H.; Chen, J.; Zhang, J.; Wang, G.; Xie, K. Arbitrary-Oriented Ship Detection Method Based on Long-Edge Decomposition Rotated Bounding Box Encoding in SAR Images. Remote Sens. 2023, 15, 673. https://doi.org/10.3390/rs15030673
Jiang X, Xie H, Chen J, Zhang J, Wang G, Xie K. Arbitrary-Oriented Ship Detection Method Based on Long-Edge Decomposition Rotated Bounding Box Encoding in SAR Images. Remote Sensing. 2023; 15(3):673. https://doi.org/10.3390/rs15030673
Chicago/Turabian StyleJiang, Xinqiao, Hongtu Xie, Jiaxing Chen, Jian Zhang, Guoqian Wang, and Kai Xie. 2023. "Arbitrary-Oriented Ship Detection Method Based on Long-Edge Decomposition Rotated Bounding Box Encoding in SAR Images" Remote Sensing 15, no. 3: 673. https://doi.org/10.3390/rs15030673