


Automatic Damage Detection and Diagnosis for Hydraulic Structures Using Drones and Artificial Intelligence Techniques
Abstract
:1. Introduction
- (1)
- The Xception backbone-based crack automatic segmentation network achieves faster detection efficiency and few parameters because it uses depthwise separable convolution for its internal convolution kernel, and the hole rate of the convolution kernel can be set by itself.
- (2)
- The combination of the attention mechanism module and the Deeplab V3+ backbone network can significantly improve the accuracy of the model for identifying small-scale concrete cracks.
- (3)
- The proposed method shows strong crack pixel-level detection performance on a variety of different types and background roughness crack images.
2. Methodology and Materials
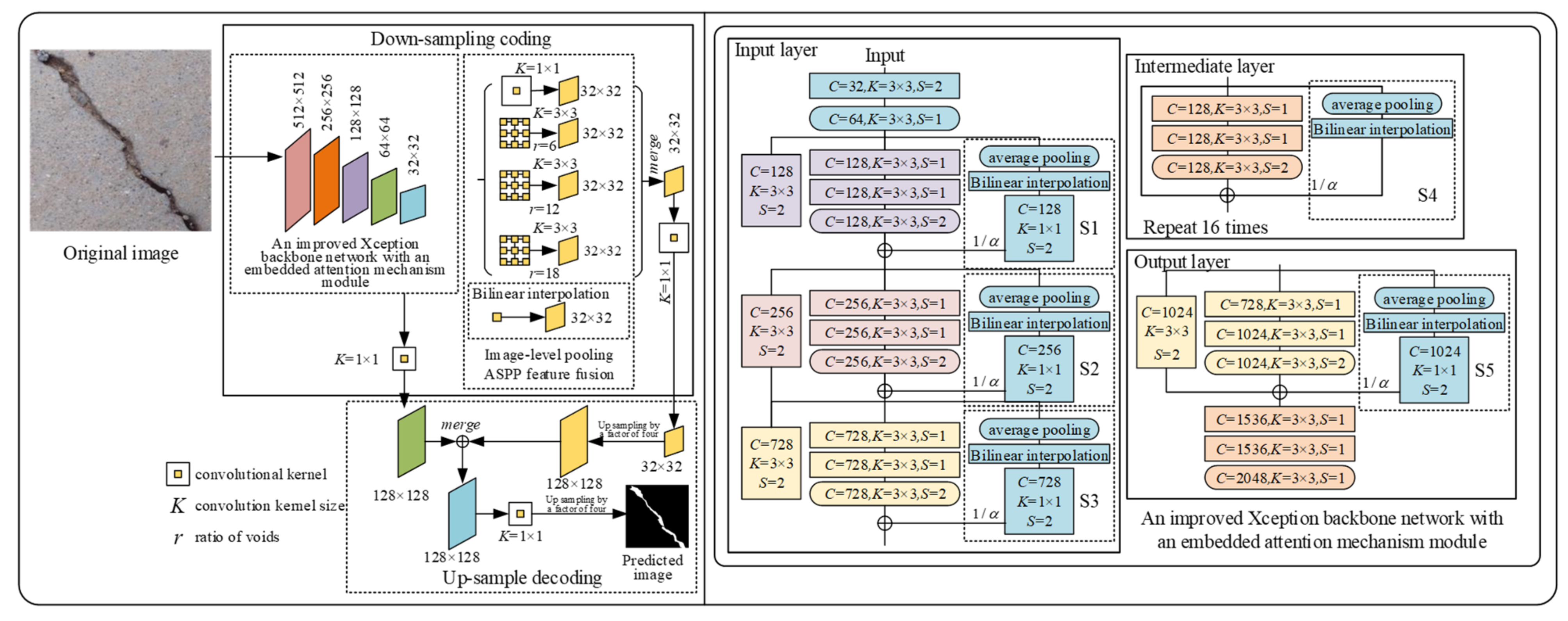
2.1. The Deeplabv3+ Semantic Segmentation Network
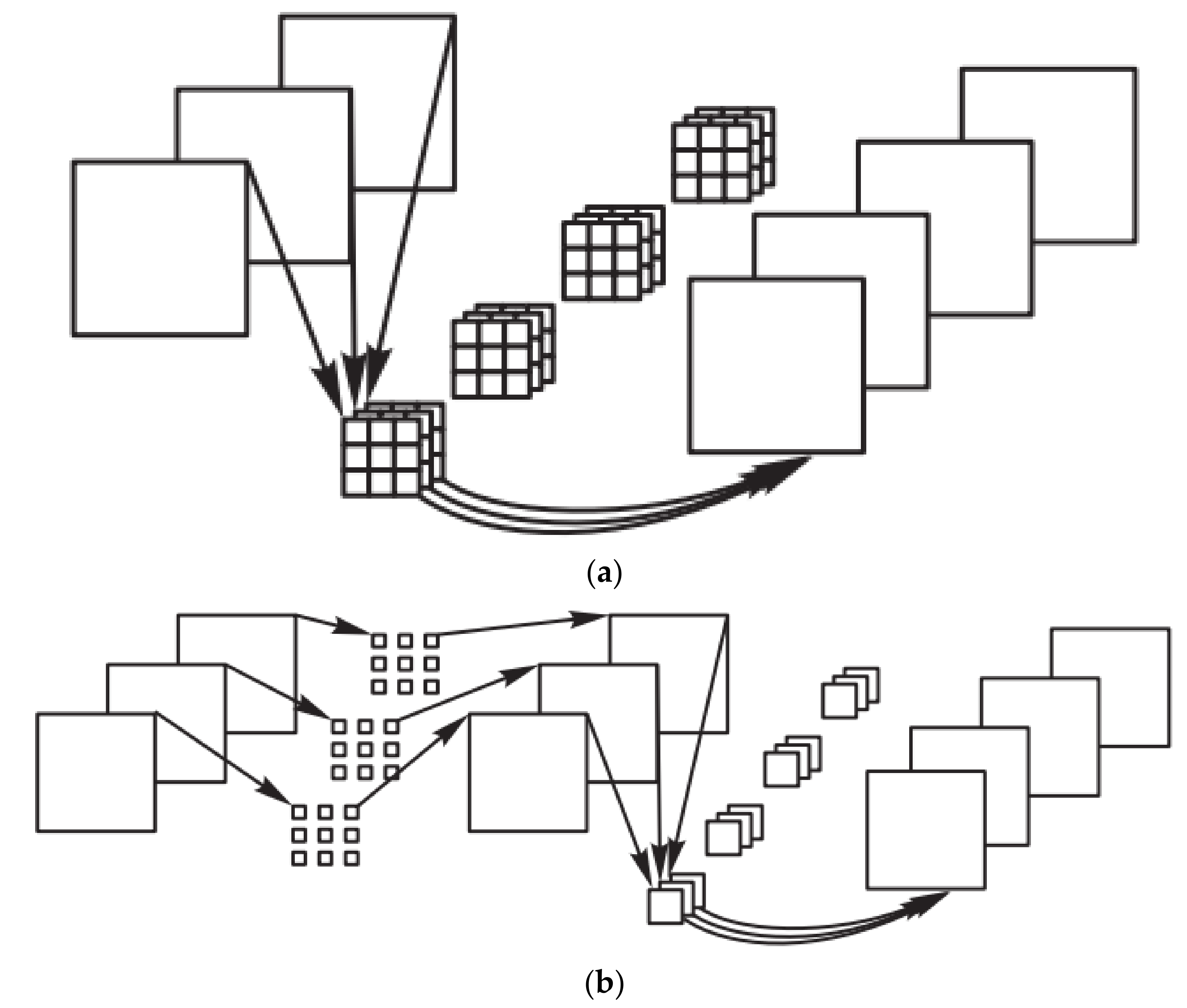
2.2. The Xception Backbone
2.3. The Adaptive Attention Mechanism
2.4. Evaluation Indicators
3. Experimental Setup
3.1. Project Description
3.2. Drone Inspection
3.3. Dataset Label and Generation
4. Result and Discussion
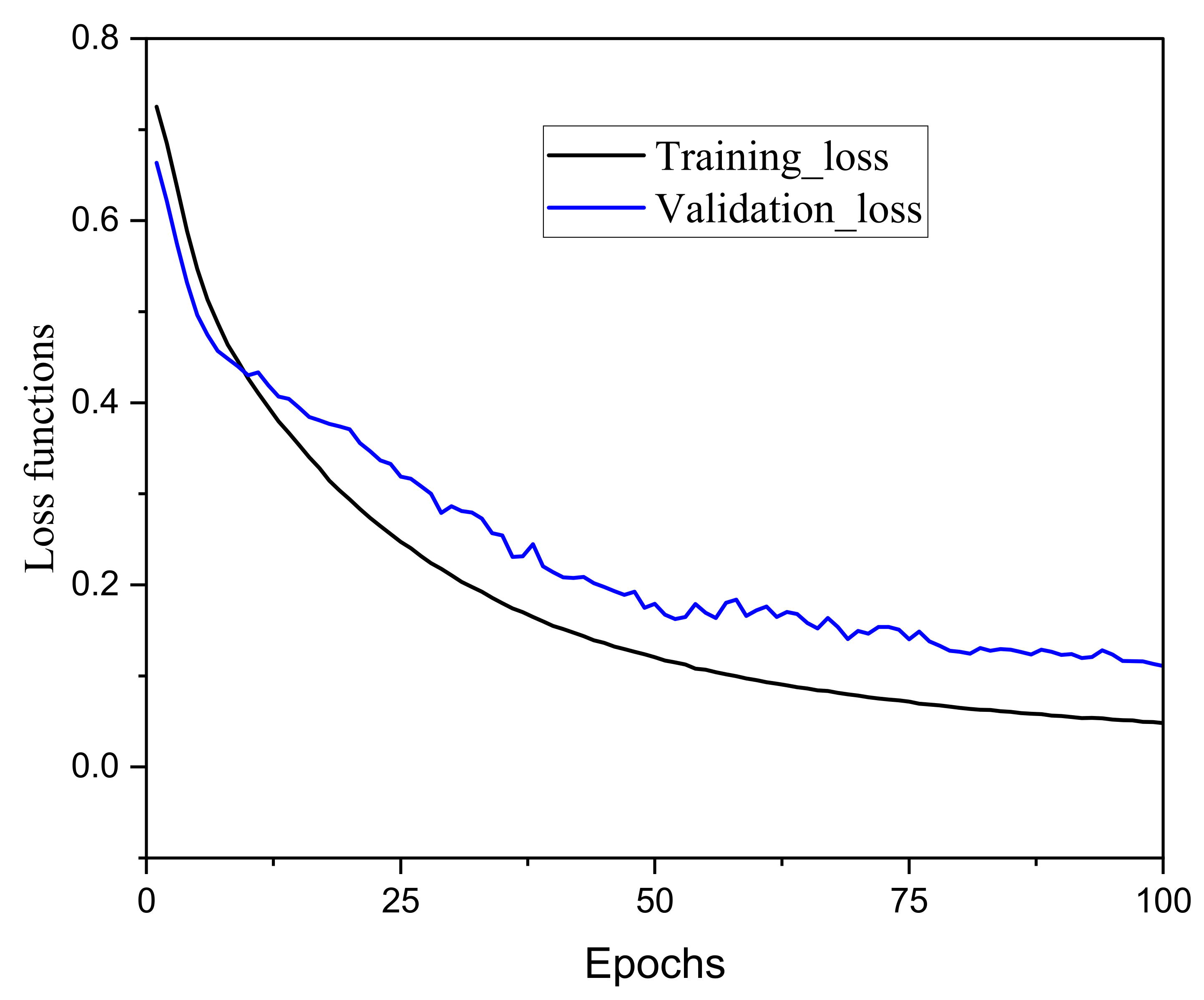
4.1. Model Training
4.2. Ablation Experiments
4.3. Model Comparison with Other Algorithms
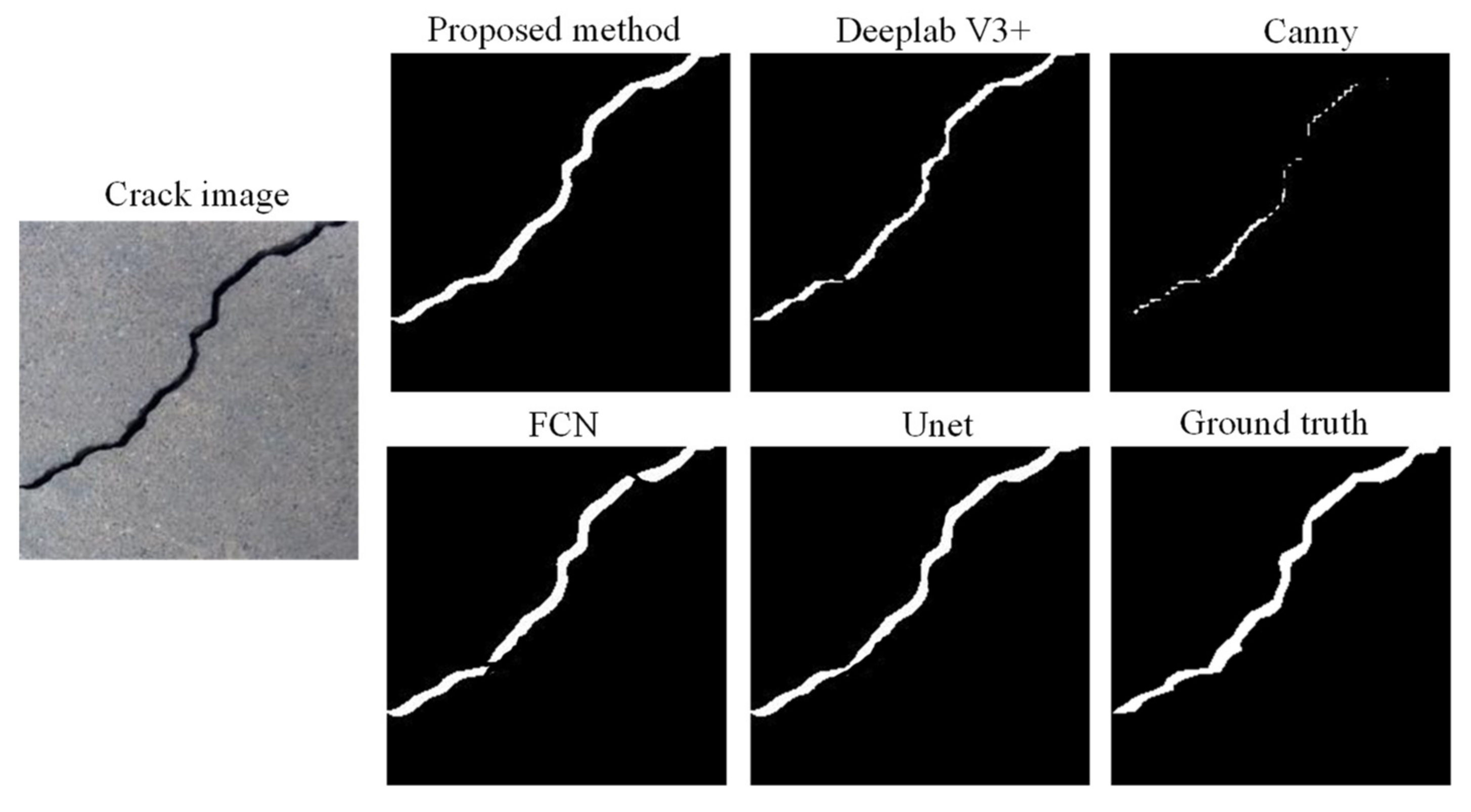
4.4. Test Result Visualization
5. Conclusions
- (a)
- The experimental results show that the proposed method can realize high-precision crack identification, and the identification results have been obtained in the test set, achieving 90.537 IOU, 91.227 precision, 91.301 recall, and 91.264 F1_score.
- (b)
- The fusion of a lightweight backbone network and attention mechanism can improve the accuracy of model crack identification and improve the speed of model crack detection.
- (c)
- The proposed method can effectively identify different types of s types of cracks in hydraulic concretes. It can be seen from the experimental results that the proposed method has a good recognition effect on wide, narrow, transverse, and longitudinal cracks.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhu, Y.; Niu, X.; Gu, C.; Yang, D.; Sun, Q.; Rodriguez, E.F. Using the DEMATEL-VIKOR Method in Dam Failure Path Identification. Int. J. Environ. Res. Public Health 2020, 17, 1480. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Niu, X. The First Stage of the Middle-Line South-to-North Water-Transfer Project. Engineering 2022, 16, 21–28. [Google Scholar] [CrossRef]
- Su, H.; Li, J.; Wen, Z.; Guo, Z.; Zhou, R. Integrated Certainty and Uncertainty Evaluation Approach for Seepage Control Effectiveness of a Gravity Dam. Appl. Math. Model. 2019, 65, 1–22. [Google Scholar] [CrossRef]
- Zoubir, H.; Rguig, M.; El Aroussi, M.; Chehri, A.; Saadane, R.; Jeon, G. Concrete Bridge Defects Identification and Localization Based on Classification Deep Convolutional Neural Networks and Transfer Learning. Remote Sens. 2022, 14, 4882. [Google Scholar] [CrossRef]
- Ren, Q.; Li, M.; Kong, T.; Ma, J. Multi-Sensor Real-Time Monitoring of Dam Behavior Using Self-Adaptive Online Sequential Learning. Autom. Constr. 2022, 140, 104365. [Google Scholar] [CrossRef]
- Li, Y.; Bao, T.; Shu, X.; Gao, Z.; Gong, J.; Zhang, K. Data-Driven Crack Behavior Anomaly Identification Method for Concrete Dams in Long-Term Service Using Offline and Online Change Point Detection. J. Civ. Struct. Health Monit. 2021, 11, 1449–1460. [Google Scholar] [CrossRef]
- Dai, B.; Gu, C.; Zhao, E.; Qin, X. Statistical Model Optimized Random Forest Regression Model for Concrete Dam Deformation Monitoring. Struct. Control. Health Monit. 2018, 25, e2170. [Google Scholar] [CrossRef]
- Zhu, Y.; Niu, X.; Gu, C.; Dai, B.; Huang, L. A Fuzzy Clustering Logic Life Loss Risk Evaluation Model for Dam-Break Floods. Complexity 2021, 2021, 7093256. [Google Scholar] [CrossRef]
- Liang, J.; Chen, B.; Shao, C.; Li, J.; Wu, B. Time Reverse Modeling of Damage Detection in Underwater Concrete Beams Using Piezoelectric Intelligent Modules. Sensors 2020, 20, 7318. [Google Scholar] [CrossRef]
- Dong, C.Z.; Catbas, F.N. A Review of Computer Vision–Based Structural Health Monitoring at Local and Global Levels. Struct. Health Monit. 2020, 20, 692–743. [Google Scholar] [CrossRef]
- Spencer, B.F.; Hoskere, V.; Narazaki, Y. Advances in Computer Vision-Based Civil Infrastructure Inspection and Monitoring. Engineering 2019, 5, 199–222. [Google Scholar] [CrossRef]
- Shin, D.; Jin, J.; Kim, J. Enhancing Railway Maintenance Safety Using Open-Source Computer Vision. J. Adv. Transp. 2021, 2021, 5575557. [Google Scholar] [CrossRef]
- Feroz, S.; Dabous, S.A. Uav-Based Remote Sensing Applications for Bridge Condition Assessment. Remote Sens. 2021, 13, 1809. [Google Scholar] [CrossRef]
- Yao, H.; Qin, R.; Chen, X. Unmanned Aerial Vehicle for Remote Sensing Applications—A Review. Remote Sens. 2019, 11, 1443. [Google Scholar] [CrossRef] [Green Version]
- González-deSantos, L.M.; Martínez-Sánchez, J.; González-Jorge, H.; Navarro-Medina, F.; Arias, P. UAV Payload with Collision Mitigation for Contact Inspection. Autom. Constr. 2020, 115, 103200. [Google Scholar] [CrossRef]
- Zhao, J.; Zhang, X.; Yan, J.; Qiu, X.; Yao, X.; Tian, Y.; Zhu, Y.; Cao, W. A Wheat Spike Detection Method in Uav Images Based on Improved Yolov5. Remote Sens. 2021, 13, 3095. [Google Scholar] [CrossRef]
- Bui, K.T.T.; Tien Bui, D.; Zou, J.; Van Doan, C.; Revhaug, I. A Novel Hybrid Artificial Intelligent Approach Based on Neural Fuzzy Inference Model and Particle Swarm Optimization for Horizontal Displacement Modeling of Hydropower Dam. Neural Comput. Appl. 2018, 29, 1495–1506. [Google Scholar] [CrossRef]
- Li, Y.; Wang, H.; Dang, L.M.; Nguyen, T.N.; Han, D.; Lee, A.; Jang, I.; Moon, H. A Deep Learning-Based Hybrid Framework for Object Detection and Recognition in Autonomous Driving. IEEE Access 2020, 8, 194228–194239. [Google Scholar] [CrossRef]
- Cha, Y.J.; Choi, W.; Büyüköztürk, O. Deep Learning-Based Crack Damage Detection Using Convolutional Neural Networks. Comput. Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Mohtasham Khani, M.; Vahidnia, S.; Ghasemzadeh, L.; Ozturk, Y.E.; Yuvalaklioglu, M.; Akin, S.; Ure, N.K. Deep-Learning-Based Crack Detection with Applications for the Structural Health Monitoring of Gas Turbines. Struct. Health Monit. 2020, 19, 1440–1452. [Google Scholar] [CrossRef]
- Kim, B.; Yuvaraj, N.; Sri Preethaa, K.R.; Arun Pandian, R. Surface Crack Detection Using Deep Learning with Shallow CNN Architecture for Enhanced Computation. Neural Comput. Appl. 2021, 33, 9289–9305. [Google Scholar] [CrossRef]
- Tang, W.; Zou, D.; Yang, S.; Shi, J.; Dan, J.; Song, G. A Two-Stage Approach for Automatic Liver Segmentation with Faster R-CNN and DeepLab. Neural Comput. Appl. 2020, 32, 6769–6778. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gopalakrishnan, K.; Gholami, H.; Vidyadharan, A.; Agrawal, A. Crack Damage Detection in Unmanned Aerial Vehicle Images of Civil Infrastructure Using Pre-Trained Deep Learning Model. Int. J. Traffic Transp. Eng. 2018, 8, 1–14. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Lin, M.; Chen, Q.; Yan, S. Network In Network: Original Paper. In Proceedings of the 2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, 14–16 April 2014; pp. 1–10. [Google Scholar]
- Zhong, H.; Li, H.; Ooi, E.T.; Song, C. Hydraulic Fracture at the Dam-Foundation Interface Using the Scaled Boundary Finite Element Method Coupled with the Cohesive Crack Model. Eng. Anal. Bound. Elem. 2018, 88, 41–53. [Google Scholar] [CrossRef]
- Zhang, L.; Shen, J.; Zhu, B. A Research on an Improved Unet-Based Concrete Crack Detection Algorithm. Struct. Health Monit. 2021, 20, 1864–1879. [Google Scholar] [CrossRef]
- Dung, C.V.; Anh, L.D.; Vu, C.; Duc, L.; Dung, C.V.; Anh, L.D. Autonomous Concrete Crack Detection Using Deep Fully Convolutional Neural Network. Autom. Constr. 2019, 99, 52–58. [Google Scholar] [CrossRef]
- Akagic, A.; Buza, E.; Omanovic, S.; Karabegovic, A. Pavement Crack Detection Using Otsu Thresholding for Image Segmentation. In Proceedings of the 41st International Convention on Information and Communication Technology, Electronics and Microelectronics, MIPRO 2018, Opatija, Croatia, 21–25 May 2018; pp. 1092–1097. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Values |
|---|---|
| weight | 570 g |
| size | 180 × 97 × 74 mm (fold); 183 × 253 × 77 mm (stretch) |
| flight time | 34 min |
| maximum ascent speed | 4 m/s |
| maximum descent speed | 3 m/s |
| maximum horizontal flight speed | 19 m/s |
| maximum flight altitude | 500 m |
| maximum wind resistance rating | Level 5 wind |
| maximum transmission distance | 10,000 m |
| maximum supported storage | 8 G (airborne memory) + 256 GB |
| camera pixels | 3840 × 2160 pixels |
| equivalent focal length | 24 mm |
| aperture | f/2.8 |
| angle of view | 84° |
| Lab Environment | Configuration Details |
|---|---|
| Hardware environment | CPU: Intel i7-12700KF |
| GPU: NVIDIA GeForce RTX 3070 | |
| Memory:32 GB | |
| Software environment | Window 10 system |
| Development environment | VS code |
| Model Computing Environment | Pytorch |
| Xception Backbone | The Adaptive Attention Mechanism Network | IOU | Precision | Recall | F1 |
|---|---|---|---|---|---|
| 74.820 | 84.350 | 82.170 | 83.246 | ||
| √ | 86.094 | 90.178 | 81.070 | 85.385 | |
| √ | 71.640 | 82.000 | 77.988 | 79.948 | |
| √ | √ | 90.537 | 91.227 | 91.301 | 91.264 |
| Models | IOU | Interference Speed/s |
|---|---|---|
| Proposed method | 90.537 | 0.0192 |
| Deeplabv3+ | 74.820 | 0.0224 |
| FCN | 78.204 | 0.0215 |
| UNet | 82.030 | 0.0201 |
| Canny | 69.242 | 0.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, Y.; Tang, H. Automatic Damage Detection and Diagnosis for Hydraulic Structures Using Drones and Artificial Intelligence Techniques. Remote Sens. 2023, 15, 615. https://doi.org/10.3390/rs15030615
Zhu Y, Tang H. Automatic Damage Detection and Diagnosis for Hydraulic Structures Using Drones and Artificial Intelligence Techniques. Remote Sensing. 2023; 15(3):615. https://doi.org/10.3390/rs15030615
Chicago/Turabian StyleZhu, Yantao, and Hongwu Tang. 2023. "Automatic Damage Detection and Diagnosis for Hydraulic Structures Using Drones and Artificial Intelligence Techniques" Remote Sensing 15, no. 3: 615. https://doi.org/10.3390/rs15030615