
YOLO-HR: Improved YOLOv5 for Object Detection in High-Resolution Optical Remote Sensing Images
Abstract
:1. Introduction
2. Related Work
2.1. Datasets of Optical Remote Sensing Image Object Detection
2.2. Attention Mechnishem
2.3. Object Detection Networks in Remote Sensing Image
3. Materials and Methods
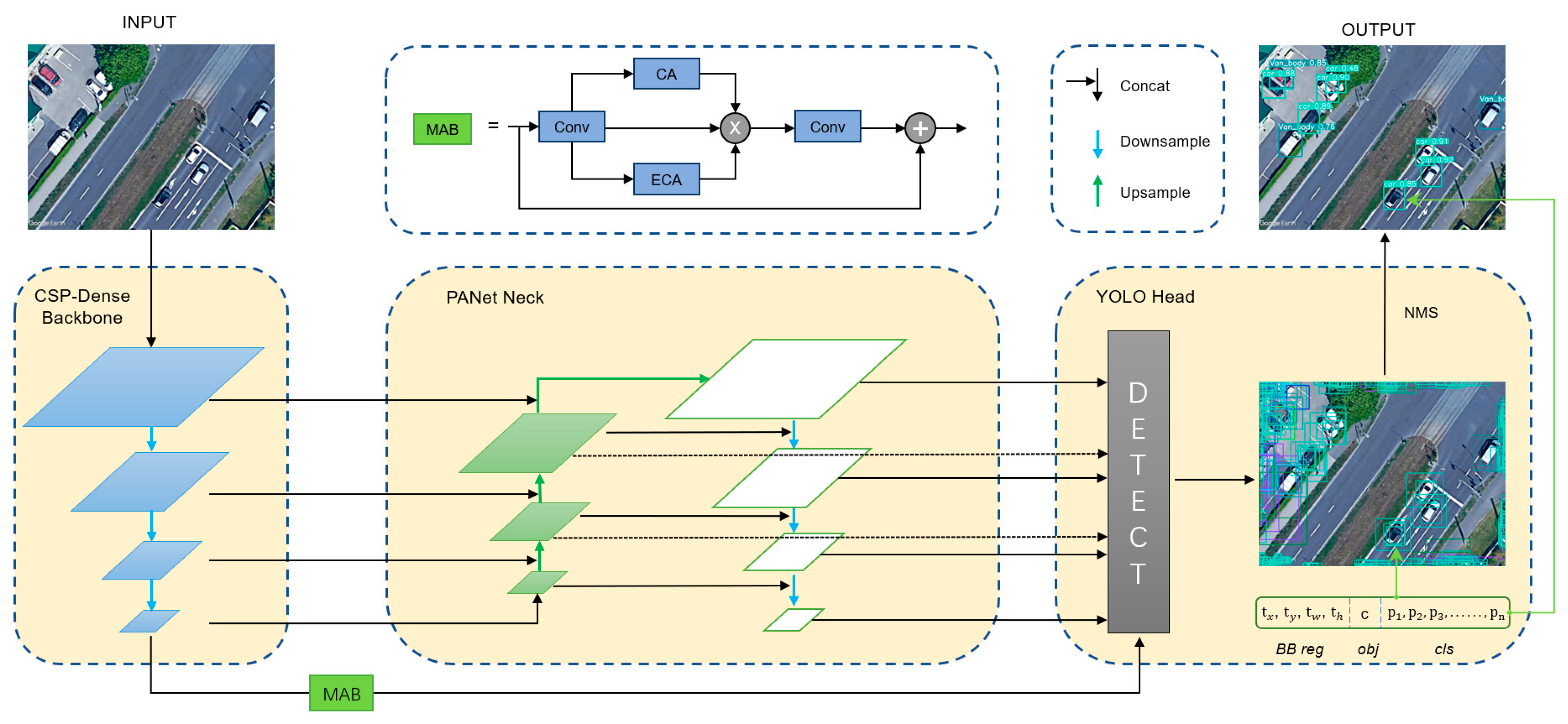
3.1. YOLO-HR
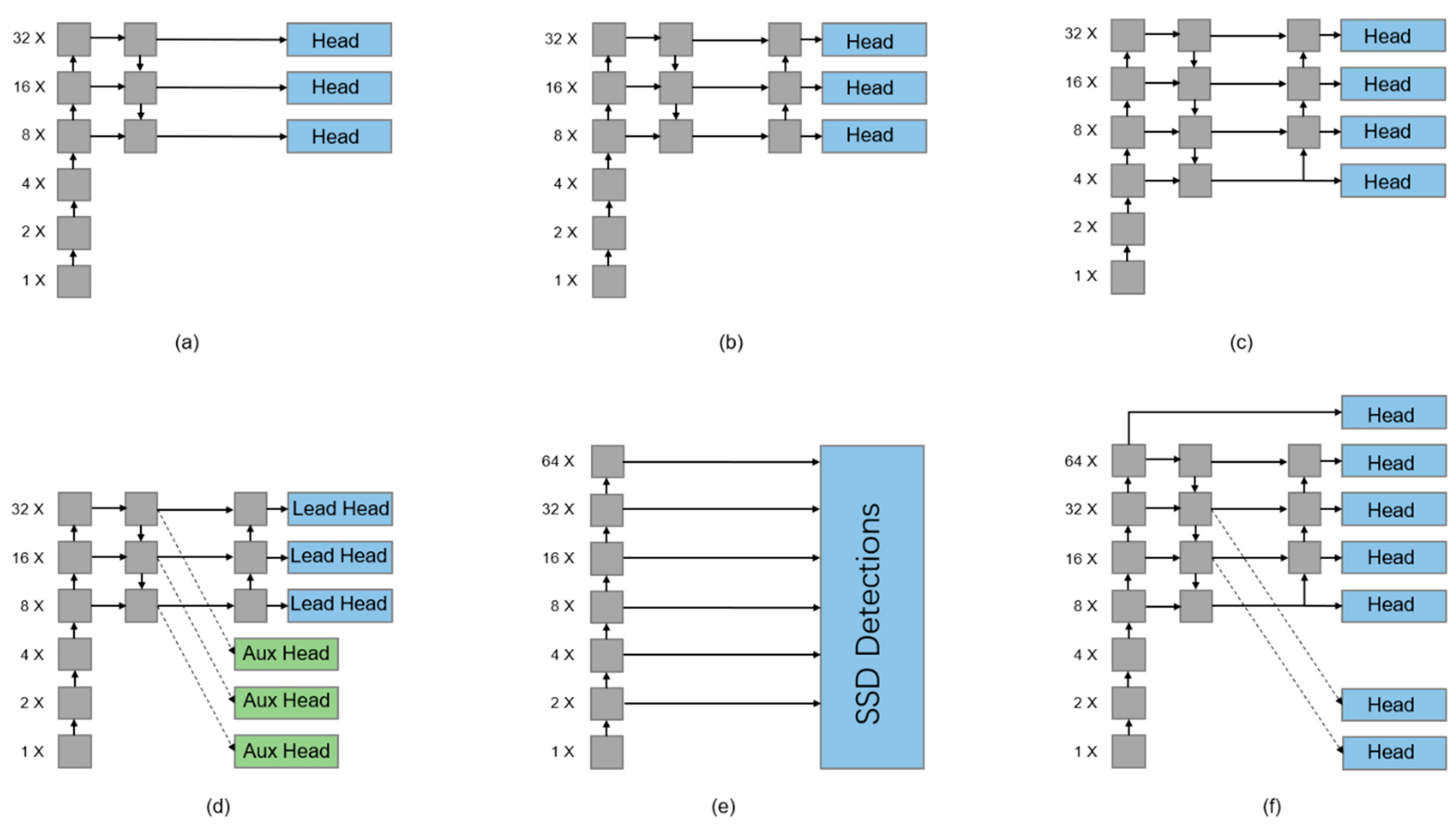
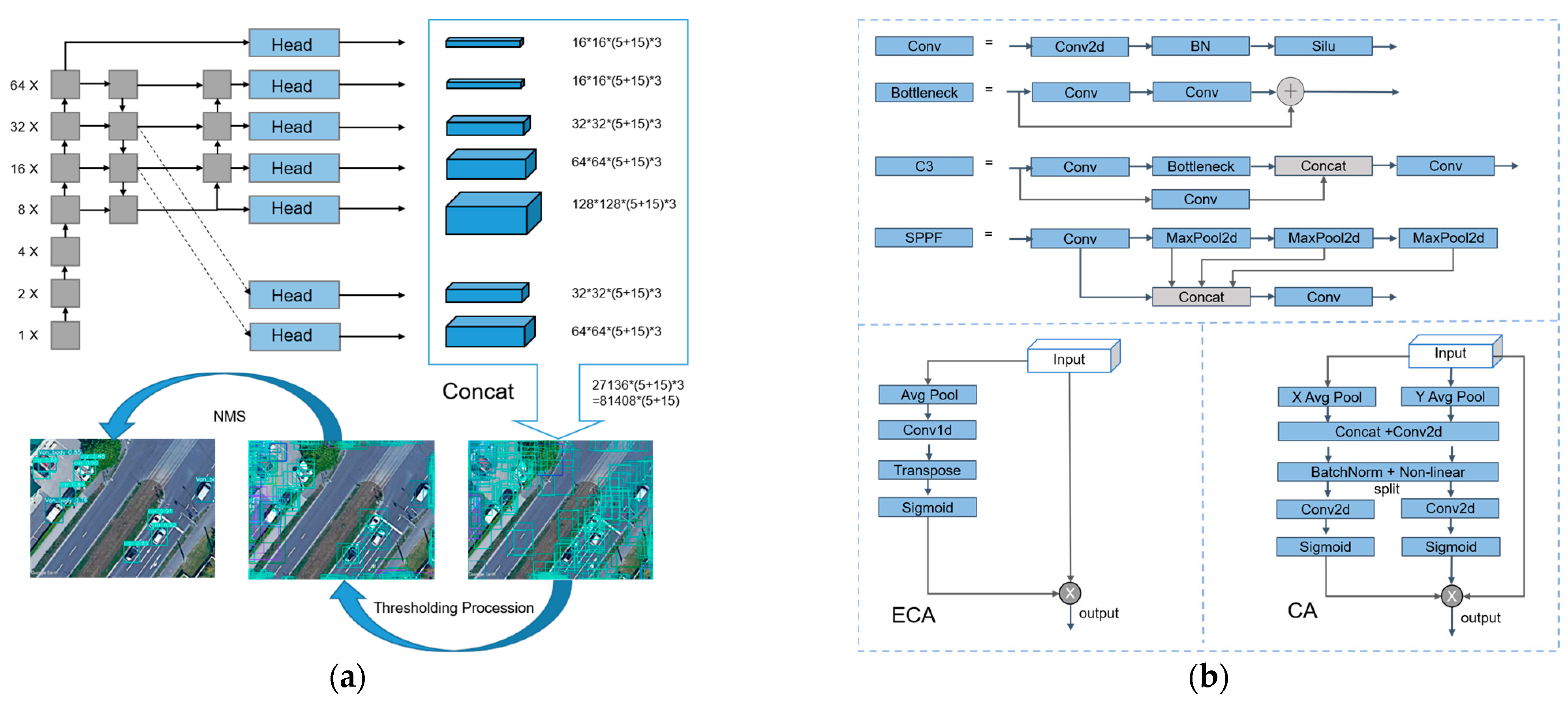
3.1.1. Comparison of Prediction Head
3.1.2. Overall Structure of YOLO-HR
3.2. Data Augmentation
3.3. Loss Function
4. Experiment
4.1. Experimental Platform and Related Indexes
4.1.1. Experimental Platform
4.1.2. Related Indexes
4.2. Experiments on SIMD
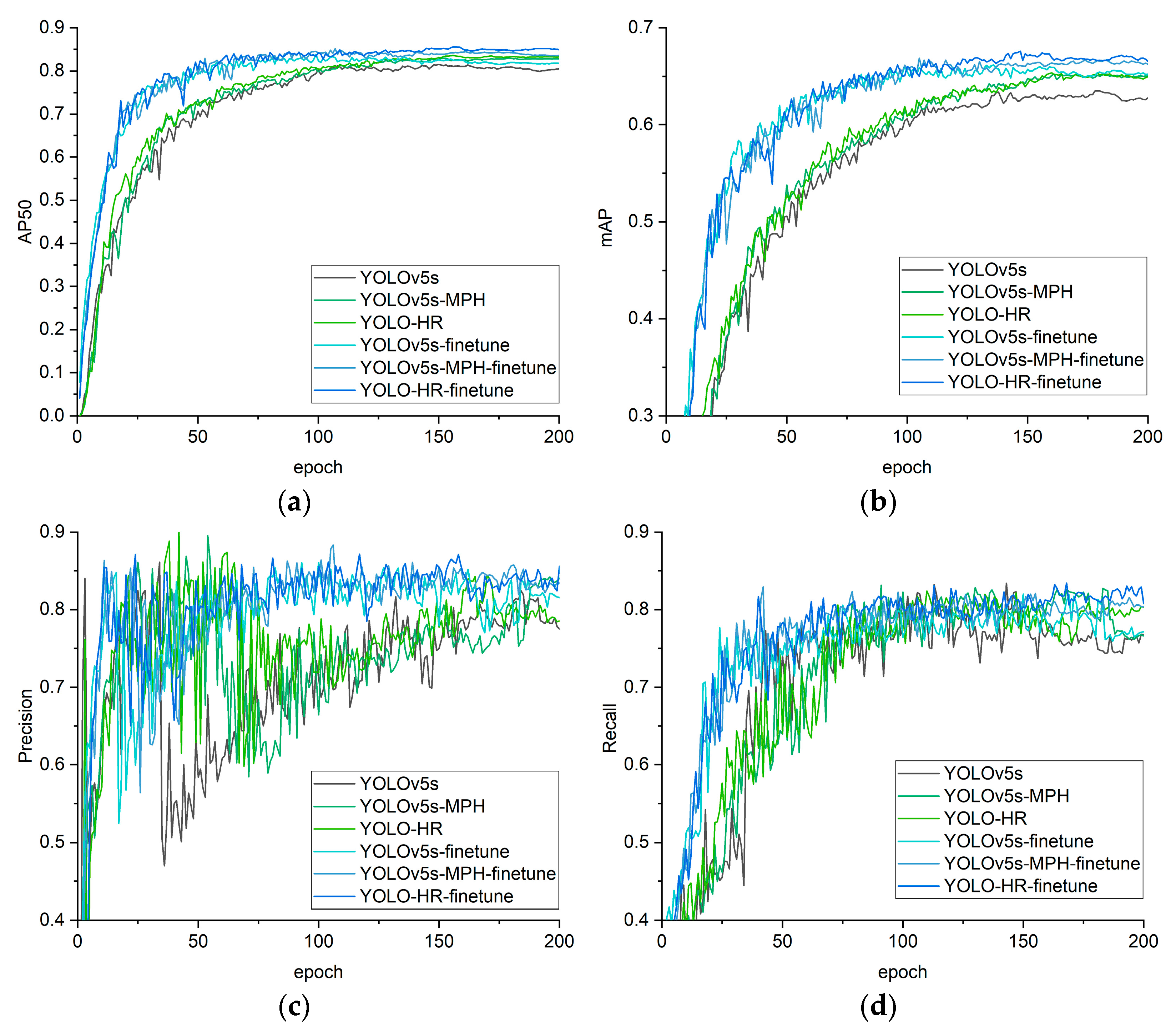
4.2.1. Ablation Test
4.2.2. Comparison Experiments
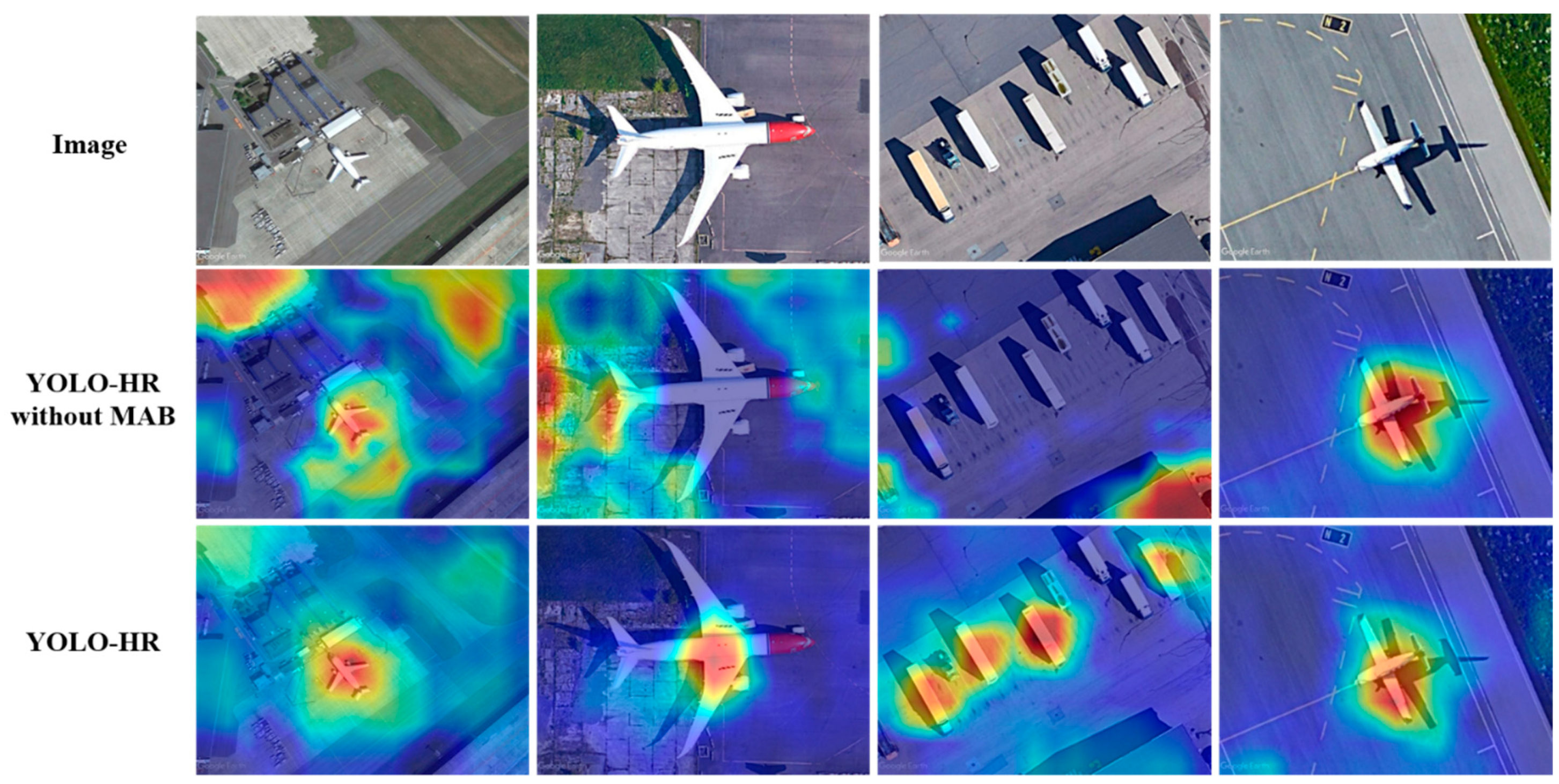
4.2.3. Qualitative Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object Detection in Optical Remote Sensing Images: A Survey and A New Benchmark 2019. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Bello, I.M.; Zhang, K.; Su, Y.; Wang, J.; Aslam, M.A. Densely Multiscale Framework for Segmentation of High Resolution Remote Sensing Imagery. Comput. Geosci. 2022, 167, 105196. [Google Scholar] [CrossRef]
- Wang, Y.; Gao, L.; Hong, D.; Sha, J.; Liu, L.; Zhang, B.; Rong, X.; Zhang, Y. Mask DeepLab: End-to-End Image Segmentation for Change Detection in High-Resolution Remote Sensing Images. Int. J. Appl. Earth Obs. Geoinf. 2021, 104, 102582. [Google Scholar] [CrossRef]
- Bonannella, C.; Chirici, G.; Travaglini, D.; Pecchi, M.; Vangi, E.; D’Amico, G.; Giannetti, F. Characterization of Wildfires and Harvesting Forest Disturbances and Recovery Using Landsat Time Series: A Case Study in Mediterranean Forests in Central Italy. Fire 2022, 5, 68. [Google Scholar] [CrossRef]
- Li, J.; Zhuang, Y.; Dong, S.; Gao, P.; Dong, H.; Chen, H.; Chen, L.; Li, L. Hierarchical Disentangling Network for Building Extraction from Very High Resolution Optical Remote Sensing Imagery. Remote Sens. 2022, 14, 1767. [Google Scholar] [CrossRef]
- Wu, D.; Song, H.; Fan, C. Object Tracking in Satellite Videos Based on Improved Kernel Correlation Filter Assisted by Road Information. Remote Sens. 2022, 14, 4215. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J. A Survey on Object Detection in Optical Remote Sensing Images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef] [Green Version]
- Li, C.; Cong, R.; Guo, C.; Li, H.; Zhang, C.; Zheng, F.; Zhao, Y. A Parallel Down-up Fusion Network for Salient Object Detection in Optical Remote Sensing Images. Neurocomputing 2020, 415, 411–420. [Google Scholar] [CrossRef]
- Yu, Y.; Wang, J.; Qiang, H.; Jiang, M.; Tang, E.; Yu, C.; Zhang, Y.; Li, J. Sparse Anchoring Guided High-Resolution Capsule Network for Geospatial Object Detection from Remote Sensing Imagery. Int. J. Appl. Earth Obs. Geoinf. 2021, 104, 102548. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Ding, P.; Zhang, Y.; Deng, W.-J.; Jia, P.; Kuijper, A. A Light and Faster Regional Convolutional Neural Network for Object Detection in Optical Remote Sensing Images. ISPRS J. Photogramm. Remote Sens. 2018, 141, 208–218. [Google Scholar] [CrossRef]
- Wang, P.; Chen, P.; Yuan, Y.; Liu, D.; Huang, Z.; Hou, X.; Cottrell, G. Understanding Convolution for Semantic Segmentation. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018. [Google Scholar]
- Training Region-Based Object Detectors with Online Hard Example Mining | IEEE Conference Publication | IEEE Xplore. Available online: https://ieeexplore.ieee.org/document/7780458 (accessed on 24 October 2022).
- Shivappriya, S.N.; Priyadarsini, M.J.P.; Stateczny, A.; Puttamadappa, C.; Parameshachari, B.D. Cascade Object Detection and Remote Sensing Object Detection Method Based on Trainable Activation Function. Remote Sens. 2021, 13, 200. [Google Scholar] [CrossRef]
- Wang, Y.; Xu, C.; Liu, C.; Li, Z. Context Information Refinement for Few-Shot Object Detection in Remote Sensing Images. Remote Sens. 2022, 14, 3255. [Google Scholar] [CrossRef]
- Wu, Z.-Z.; Wang, X.-F.; Zou, L.; Xu, L.-X.; Li, X.-L.; Weise, T. Hierarchical Object Detection for Very High-Resolution Satellite Images. Appl. Soft Comput. 2021, 113, 107885. [Google Scholar] [CrossRef]
- Weng, L.; Gao, J.; Xia, M.; Lin, H. MSNet: Multifunctional Feature-Sharing Network for Land-Cover Segmentation. Remote Sens. 2022, 14, 5209. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ultralytics/Yolov5. Available online: https://github.com/ultralytics/yolov5 (accessed on 15 September 2022).
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; Volume 9905, pp. 21–37. ISBN 978-3-319-46447-3. [Google Scholar]
- Fu, C.-Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. DSSD: Deconvolutional Single Shot Detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks 2019. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.-C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Liu, K.; Huang, J.; Li, X. Eagle-Eye-Inspired Attention for Object Detection in Remote Sensing. Remote Sens. 2022, 14, 1743. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Li, P.; Che, C. SeMo-YOLO: A Multiscale Object Detection Network in Satellite Remote Sensing Images. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; p. 8. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection 2018. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Wang, J.; Gong, Z.; Liu, X.; Guo, H.; Yu, D.; Ding, L. Object Detection Based on Adaptive Feature-Aware Method in Optical Remote Sensing Images. Remote Sens. 2022, 14, 3616. [Google Scholar] [CrossRef]
- Han, W.; Li, J.; Wang, S.; Wang, Y.; Yan, J.; Fan, R.; Zhang, X.; Wang, L. A Context-Scale-Aware Detector and a New Benchmark for Remote Sensing Small Weak Object Detection in Unmanned Aerial Vehicle Images. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102966. [Google Scholar] [CrossRef]
- Wang, Y.; Bashir, S.M.A.; Khan, M.; Ullah, Q.; Wang, R.; Song, Y.; Guo, Z.; Niu, Y. Remote Sensing Image Super-Resolution and Object Detection: Benchmark and State of the Art. Expert Syst. Appl. 2022, 197, 116793. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Multisized Object Detection Using Spaceborne Optical Imagery | IEEE Journals & Magazine | IEEE Xplore. Available online: https://ieeexplore.ieee.org/document/9109702 (accessed on 10 November 2022).
- Heitz, G.; Koller, D. Learning Spatial Context: Using Stuff to Find Things. In Proceedings of the Computer Vision—ECCV 2008; Forsyth, D., Torr, P., Zisserman, A., Eds.; Springer: Berlin, Heidelberg, 2008; pp. 30–43. [Google Scholar]
- MPLab Earth Observation. Available online: http://web.eee.sztaki.hu/remotesensing/building_benchmark.html (accessed on 1 November 2022).
- Learning Rotation-Invariant Convolutional Neural Networks for Object Detection in VHR Optical Remote Sensing Images | IEEE Journals & Magazine | IEEE Xplore. Available online: https://ieeexplore.ieee.org/document/7560644 (accessed on 1 November 2022).
- Razakarivony, S.; Jurie, F. Vehicle Detection in Aerial Imagery: A Small Target Detection Benchmark. J. Vis. Commun. Image Represent. 2016, 34, 187–203. [Google Scholar] [CrossRef] [Green Version]
- Zhu, H.; Chen, X.; Dai, W.; Fu, K.; Ye, Q.; Jiao, J. Orientation Robust Object Detection in Aerial Images Using Deep Convolutional Neural Network. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 3735–3739. [Google Scholar]
- DLR—Earth Observation Center—DLR Multi-Class Vehicle Detection and Orientation in Aerial Imagery (DLR-MVDA). Available online: https://www.dlr.de/eoc/en/desktopdefault.aspx/tabid-12760/22294_read-52777 (accessed on 1 November 2022).
- Liu, Z.; Yuan, L.; Weng, L.; Yiping, Y. A High Resolution Optical Satellite Image Dataset for Ship Recognition and Some New Baselines. In Proceedings of the 6th International Conference on Pattern Recognition Applications and Methods, Porto, Portugal, 24–26 February 2017. [Google Scholar] [CrossRef]
- Xia, G.-S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-Scale Dataset for Object Detection in Aerial Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Zou, Z.; Shi, Z. Random Access Memories: A New Paradigm for Target Detection in High Resolution Aerial Remote Sensing Images. IEEE Trans. Image Process. 2018, 27, 1100–1111. [Google Scholar] [CrossRef]
- ITCVD Dataset—University of Twente Research Information. Available online: https://research.utwente.nl/en/datasets/itcvd-dataset (accessed on 1 November 2022).
- Scottish Index of Multiple Deprivation 2020. Available online: https://www.gov.scot/collections/scottish-index-of-multiple-deprivation-2020/ (accessed on 2 September 2022).
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. arXiv 2020, arXiv:1910.03151. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Chen, S.; Tan, X.; Wang, B.; Hu, X. Reverse Attention for Salient Object Detection. In Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; Volume 11213, pp. 236–252. ISBN 978-3-030-01239-7. [Google Scholar]
- Lin, H.; Cheng, X.; Wu, X.; Yang, F.; Shen, D.; Wang, Z.; Song, Q.; Yuan, W. CAT: Cross Attention in Vision Transformer 2021. In Proceedings of the 2022 IEEE International Conference on Multimedia and Expo, Taipei City, Taiwan, 11–15 July 2022. [Google Scholar]
- Qingyun, F.; Zhaokui, W. Cross-Modality Attentive Feature Fusion for Object Detection in Multispectral Remote Sensing Imagery. Pattern Recognit. 2022, 130, 108786. [Google Scholar] [CrossRef]
- Hu, G.; Yao, P.; Wan, M.; Bao, W.; Zeng, W. Detection and Classification of Diseased Pine Trees with Different Levels of Severity from UAV Remote Sensing Images. Ecol. Inform. 2022, 72, 101844. [Google Scholar] [CrossRef]
- Song, C.; Zhang, F.; Li, J.; Xie, J.; Yang, C.; Zhou, H.; Zhang, J. Detection of Maize Tassels for UAV Remote Sensing Image with an Improved YOLOX Model. J. Integr. Agric. 2022, in press. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, J.; Yang, K.; Wang, L.; Su, F.; Chen, X. Semantic Segmentation of High-Resolution Remote Sensing Images Based on a Class Feature Attention Mechanism Fused with Deeplabv3+. Comput. Geosci. 2022, 158, 104969. [Google Scholar] [CrossRef]
- Lang, L.; Xu, K.; Zhang, Q.; Wang, D. Fast and Accurate Object Detection in Remote Sensing Images Based on Lightweight Deep Neural Network. Sensors 2021, 21, 5460. [Google Scholar] [CrossRef]
- Zhao, C.; Fu, X.; Dong, J.; Qin, R.; Chang, J.; Lang, P. SAR Ship Detection Based on End-to-End Morphological Feature Pyramid Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 4599–4611. [Google Scholar] [CrossRef]
- Zhou, K.; Zhang, M.; Wang, H.; Tan, J. Ship Detection in SAR Images Based on Multi-Scale Feature Extraction and Adaptive Feature Fusion. Remote Sens. 2022, 14, 755. [Google Scholar] [CrossRef]
- Han, P.; Liao, D.; Han, B.; Cheng, Z. SEAN: A Simple and Efficient Attention Network for Aircraft Detection in SAR Images. Remote Sens. 2022, 14, 4669. [Google Scholar] [CrossRef]
- Yu, W.; Wang, Z.; Li, J.; Luo, Y.; Yu, Z. A Lightweight Network Based on One-Level Feature for Ship Detection in SAR Images. Remote Sens. 2022, 14, 3321. [Google Scholar] [CrossRef]
- Peng, J.; Wang, D.; Liao, X.; Shao, Q.; Sun, Z.; Yue, H.; Ye, H. Wild Animal Survey Using UAS Imagery and Deep Learning: Modified Faster R-CNN for Kiang Detection in Tibetan Plateau. ISPRS J. Photogramm. Remote Sens. 2020, 169, 364–376. [Google Scholar] [CrossRef]
- Torney, C.J.; Lloyd-Jones, D.J.; Chevallier, M.; Moyer, D.C.; Maliti, H.T.; Mwita, M.; Kohi, E.M.; Hopcraft, G.C. A Comparison of Deep Learning and Citizen Science Techniques for Counting Wildlife in Aerial Survey Images. Methods Ecol. Evol. 2019, 10, 779–787. [Google Scholar] [CrossRef] [Green Version]
- Eikelboom, J.A.J.; Wind, J.; van de Ven, E.; Kenana, L.M.; Schroder, B.; de Knegt, H.J.; van Langevelde, F.; Prins, H.H.T. Improving the Precision and Accuracy of Animal Population Estimates with Aerial Image Object Detection. Methods Ecol. Evol. 2019, 10, 1875–1887. [Google Scholar] [CrossRef] [Green Version]
- Sun, X.; Wang, P.; Wang, C.; Liu, Y.; Fu, K. PBNet: Part-Based Convolutional Neural Network for Complex Composite Object Detection in Remote Sensing Imagery. ISPRS J. Photogramm. Remote Sens. 2021, 173, 50–65. [Google Scholar] [CrossRef]
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z.; Sun, X.; Fu, K. SCRDet: Towards More Robust Detection for Small, Cluttered and Rotated Objects. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8231–8240. [Google Scholar]
- Fu, K.; Chang, Z.; Zhang, Y.; Xu, G.; Zhang, K.; Sun, X. Rotation-Aware and Multi-Scale Convolutional Neural Network for Object Detection in Remote Sensing Images. ISPRS J. Photogramm. Remote Sens. 2020, 161, 294–308. [Google Scholar] [CrossRef]
- Wei, H.; Zhang, Y.; Chang, Z.; Li, H.; Wang, H.; Sun, X. Oriented Objects as Pairs of Middle Lines. ISPRS J. Photogramm. Remote Sens. 2020, 169, 268–279. [Google Scholar] [CrossRef]
- Wang, J.; Yang, W.; Li, H.-C.; Zhang, H.; Xia, G.-S. Learning Center Probability Map for Detecting Objects in Aerial Images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 4307–4323. [Google Scholar] [CrossRef]
- Zhang, G.; Lu, S.; Zhang, W. CAD-Net: A Context-Aware Detection Network for Objects in Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 10015–10024. [Google Scholar] [CrossRef]
- Zheng, X.; Zhang, W.; Huan, L.; Gong, J.; Zhang, H. AProNet: Detecting Objects with Precise Orientation from Aerial Images. ISPRS J. Photogramm. Remote Sens. 2021, 181, 99–112. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into High Quality Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as Points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Chen, Q.; Wang, Y.; Yang, T.; Zhang, X.; Cheng, J.; Sun, J. You Only Look One-Level Feature. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.-T.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar] [CrossRef]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-Captured Scenarios. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 10–17 October 2021. [Google Scholar]
- Kumar, A.; Kalia, A.; Kalia, A. ETL-YOLO v4: A Face Mask Detection Algorithm in Era of COVID-19 Pandemic. Optik 2022, 259, 169051. [Google Scholar] [CrossRef]
- Li, J.; Gu, J.; Huang, Z.; Wen, J. Application Research of Improved YOLO V3 Algorithm in PCB Electronic Component Detection. Appl. Sci. 2019, 9, 3750. [Google Scholar] [CrossRef] [Green Version]
- Gevorgyan, Z. SIoU Loss: More Powerful Learning for Bounding Box Regression. arXiv 2022, arXiv:2205.12740. [Google Scholar]
- Chen, D.; Miao, D. Control Distance IoU and Control Distance IoU Loss Function for Better Bounding Box Regression. arXiv 2021, arXiv:2103.11696. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. Int. J. Comput. Vis. 2020, 128, 336–359. [Google Scholar] [CrossRef]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open MMLab Detection Toolbox and Benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DataSet | Categories | Images | Instances | Year |
|---|---|---|---|---|
| TAS [42] | 1 | 30 | 1319 | 2008 |
| SZTAKI-INRIA [43] | 1 | 9 | 665 | 2012 |
| NWPU VHR-10 [44] | 10 | 800 | 3775 | 2014 |
| VEDAI [45] | 9 | 1210 | 3640 | 2015 |
| UCAS-AOD [46] | 2 | 910 | 6029 | 2015 |
| DLR-MVDA [47] | 2 | 20 | 14,235 | 2015 |
| HRSC-2016 [48] | 1 | 1070 | 2976 | 2016 |
| RSOD [1] | 4 | 976 | 6950 | 2017 |
| DOTA [49] | 15 | 2806 | 188,282 | 2017 |
| DIOR [1] | 20 | 23,463 | 192,472 | 2018 |
| LEVIR [50] | 3 | 21,952 | 10,069 | 2018 |
| ITCVD [51] | 1 | 173 | 29,088 | 2018 |
| SIMD [52] | 15 | 5000 | 45,303 | 2020 |
| ID | Module | From | N | Argvs | Output | Parameters |
|---|---|---|---|---|---|---|
| Input | 1024 × 1024 × 3 | |||||
| 0 | Conv | −1 | 1 | (3, 32, 6, 2, 2) | 512 × 512 × 32 | 3520 |
| 1 | Conv | −1 | 1 | (32, 64, 3, 2) | 256 × 256 × 64 | 18,560 |
| 2 | C3 | −1 | 1 | (64, 64, 1) | 256 × 256 × 64 | 18,816 |
| 3 | Conv | −1 | 1 | (64, 128, 3, 2) | 128 × 128 × 128 | 73,984 |
| 4 | C3 | −1 | 2 | (128, 128, 2) | 128 × 128 × 128 | 115,712 |
| 5 | Conv | −1 | 1 | (128, 256, 3, 2) | 64 × 64 × 256 | 295,454 |
| 6 | C3 | −1 | 3 | (256, 256, 3) | 64 × 64 × 256 | 625,152 |
| 7 | Conv | −1 | 1 | (256, 384, 3, 2) | 32 × 32 × 384 | 885,504 |
| 8 | C3 | −1 | 1 | (384, 384, 1) | 32 × 32 × 384 | 665,856 |
| 9 | Conv | −1 | 1 | (384, 512, 3, 2) | 16 × 16 × 512 | 1,770,496 |
| 10 | C3 | −1 | 1 | (512, 512, 1) | 16 × 16 × 512 | 1,182,720 |
| 11 | SPPF | −1 | 1 | (512, 512, 5) | 16 × 16 × 512 | 656,896 |
| 12 | Conv | −1 | 1 | (512, 384, 1, 1) | 16 × 16 × 374 | 197,376 |
| 13 | Upsample | −1 | 1 | (None, 2, ‘nearest’) | 32 × 32 × 384 | 0 |
| 14 | Concat | (−1, 8) | 1 | (1) | 32 × 32 × 768 | 0 |
| 15 | C3 | −1 | 1 | (768, 384, 1, False) | 32 × 32 × 384 | 813,312 |
| 16 | Conv | −1 | 1 | (384, 256, 1, 1) | 32 × 32 × 256 | 98,816 |
| 17 | Upsample | −1 | 1 | (None, 2, ‘nearest’) | 64 × 64 × 256 | 0 |
| 18 | Concat | (−1, 6) | 1 | (1] | 64 × 64 × 512 | 0 |
| 19 | C3 | −1 | 1 | (512, 256, 1, False) | 64 × 64 × 256 | 361,984 |
| 20 | Conv | −1 | 1 | (256, 128, 1, 1) | 64 × 64 × 128 | 33,024 |
| 21 | Upsample | −1 | 1 | (None, 2, ‘nearest’) | 128 × 128 × 128 | 0 |
| 22 | Concat | (−1, 4) | 1 | (1) | 128 × 128 × 256 | 0 |
| 23 | C3 | −1 | 1 | (256, 128, 1, False) | 128 × 128 × 128 | 90,880 |
| 24 | Conv | −1 | 1 | (128, 128, 3, 2) | 64 × 64 × 128 | 147,712 |
| 25 | Concat | (−1, 20) | 1 | (1) | 64 × 64 × 256 | 0 |
| 26 | C3 | −1 | 1 | (256, 256, 1, False) | 64 × 64 × 256 | 296,448 |
| 27 | Conv | −1 | 1 | (256, 256, 3, 2) | 32 × 32 × 256 | 590,336 |
| 28 | Concat | (−1, 16) | 1 | (1) | 32 × 32 × 512 | 0 |
| 29 | C3 | −1 | 1 | (512, 384, 1, False) | 32 × 32 × 384 | 715,008 |
| 30 | Conv | −1 | 1 | (384, 384, 3, 2) | 16 × 16 × 384 | 1,327,872 |
| 31 | Concat | (−1, 11) | 1 | (1) | 16 × 16 × 896 | 0 |
| 32 | C3 | −1 | 1 | (896, 512, 1, False) | 16 × 16 × 512 | 1,379,328 |
| 33 | MAB | 11 | 1 | (512, 512) | 16 × 16 × 512 | 1,361,477 |
| 34 | Detect | (23, 26, 20, 16, 29, 32, 33) | 81406 × (5 + 15) |
| Platform | Name |
|---|---|
| CPU | lntel(R) Core(TM) i9-12900K/32G |
| GPU | NVIDIA GeForce RTX 3090/24G |
| Disk capacity | SSD/500G + HDD/4T |
| The operating system | Windows 10 |
| Deep learning framework | Pytorch 1.7 |
| Name | Params (M) | FLOPS (G) | Speed (ms) | AP50 (%) | mAP (%) | P (%) | R (%) |
|---|---|---|---|---|---|---|---|
| YOLOv5s | 6.72 | 15.9 | 5.8 | 81.51 | 62.8 | 75.01 | 79.66 |
| YOLOv5s + Finetune | 6.72 | 15.9 | 5.8 | 83.85 | 66.05 | 83.10 | 79.65 |
| YOLOv5s +MPH | 11.9 | 16.3 | 6.5 | 82.96 | 65.12 | 80.73 | 79.40 |
| YOLOv5s + MPH + Finetune | 11.9 | 16.3 | 6.5 | 85.15 | 66.68 | 83.47 | 80.30 |
| YOLO-HR | 13.2 | 16.6 | 6.7 | 83.61 | 65.0 | 76.51 | 80.85 |
| YOLO-HR + Finetune | 13.2 | 16.6 | 6.7 | 85.59 | 67.31 | 85.95 | 81.28 |
| Name | AP50 (%) | mAP (%) | Params (M) | FLOPs (G) | Speed (ms) |
|---|---|---|---|---|---|
| YOLOv3-Tiny [32,34] | 77.23 | 54.53 | 8.3 | 12.9 | 4.3 |
| YOLOv5n [24] | 79.56 | 60.69 | 1.7 | 4.2 | 4.8 |
| YOLOv5s [24] | 83.85 | 66.05 | 6.72 | 15.9 | 5.8 |
| YOLO-HR-n | 83.01 | 64.04 | 3.34 | 4.4 | 6.3 |
| YOLO-HR-s | 85.59 | 67.31 | 13.2 | 16.6 | 6.7 |
| YOLOX-s [33] | 76.63 | 56.83 | 8.94 | 26.79 | 5.7 |
| YOLOv7s [25] | 83.80 | 66.55 | 8.92 | 26.8 | 6.3 |
| YOLOv7-tiny [25] | 82.08 | 64.16 | 5.77 | 13.1 | 5.2 |
| Faster RCNN [12] | 77.74 | - | 41.19 | 198.47 | 26.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wan, D.; Lu, R.; Wang, S.; Shen, S.; Xu, T.; Lang, X. YOLO-HR: Improved YOLOv5 for Object Detection in High-Resolution Optical Remote Sensing Images. Remote Sens. 2023, 15, 614. https://doi.org/10.3390/rs15030614
Wan D, Lu R, Wang S, Shen S, Xu T, Lang X. YOLO-HR: Improved YOLOv5 for Object Detection in High-Resolution Optical Remote Sensing Images. Remote Sensing. 2023; 15(3):614. https://doi.org/10.3390/rs15030614
Chicago/Turabian StyleWan, Dahang, Rongsheng Lu, Sailei Wang, Siyuan Shen, Ting Xu, and Xianli Lang. 2023. "YOLO-HR: Improved YOLOv5 for Object Detection in High-Resolution Optical Remote Sensing Images" Remote Sensing 15, no. 3: 614. https://doi.org/10.3390/rs15030614