1. Introduction
Image segmentation or semantic annotation is an exceptionally significant topic in remote sensing image interpretation and plays a key role in various real-world applications, such as geohazard monitoring [
1,
2], urban planning [
3,
4], site-specific crop management [
5,
6], autonomous driving systems [
7,
8], and land change detection [
9]. This task aims to segment and interpret a given image into different image regions associated with semantic categories.
Recently, deep learning methods represented by deep convolutional neural networks [
10] have demonstrated powerful feature extraction capabilities compared with traditional feature extraction methods, thereby sparking the interest of researchers and prompting a series of works [
11,
12,
13,
14,
15,
16]. Among these works, FCN [
11] is a pioneer in deep convolutional neural networks and has made great progress in the field of image segmentation. Its encoder–decoder architecture first employs several down-sampling layers in the encoder to reduce the spatial resolution of the feature map to extract features. Then, it uses several up-sampling layers in the decoder to restore the spatial resolution, and it exhibits many improvements in semantic segmentation. However, limited by the structure of the encoder–decoder, FCN suffers from inadequate contextual and detail information. On one hand, some of the detail information is usually dropped by the down-sampling operation. On the other hand, due to the inherent nature of convolution, FCN does not provide adequate contextual information. This task leaves plenty of room for improvement. The key to improving the performance of semantic segmentation is to obtain strong semantic representation with detail information (e.g., detailed target boundaries, location, etc.) [
17].
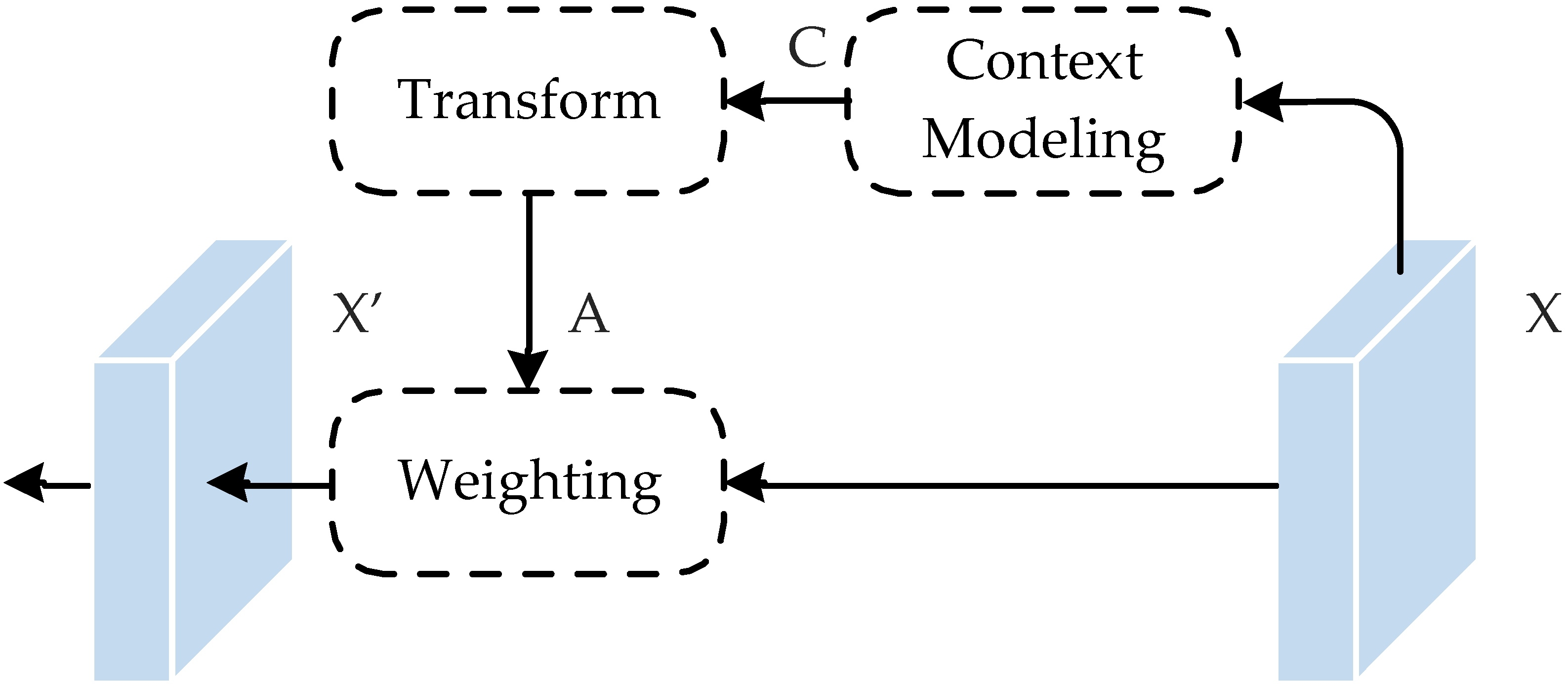
To restore detail information, several studies fuse features that come from encoder (low-level features) and decoder (high-level features) by long-range skip connections. FPN-based approaches [
18,
19,
20] employ a long-range lateral path to refine feature representations across layers iteratively. SFNet [
17] extracts location information from low-level features at a limited scope (e.g., 3 × 3 kernel size) and then applies it to calibrate the target boundaries of high-level features. Although impressive, these methods solely focus on harvesting contextual information from a local perspective (the local level) and do not aggregate contextual information from a more comprehensive perspective.
Furthermore, to improve the intra-class consistency of feature representation, some studies enhance feature representation by aggregating contextual information. Wang et al. [
21] proposed the self-attention mechanism, a long-range contextual relationship modeling approach that is used by the segmentation model [
22,
23,
24,
25] to aggregate contextual information across an image adaptively. EDFT [
26] designed the Depth-aware Self-attention (DSA) Module, which uses the self-attention mechanism to aggregate image-level contextual information to merge RGB features and depth features. Nevertheless, these approaches only focus on harvesting contextual information from the perspective of the whole image (the image level) without explicit guidance of prior context information [
27], and they suffer from high computational complexity
, where
is the input image size [
28]. In addition, OCRNet [
29], ACFNet [
30], and SCARF [
31] model the contextual relationships within a specific category region based on coarse segmentation (the semantic level). However, in some regions, the contextual information tends to be unbalanced (e.g., pixels in the border or small-scale object regions are susceptible to interference from another category), leading to the misclassification of these pixels. Moreover, ISNet [
32] models contextual information from the perspective of the image level and semantic level. HMANet [
33] designed a Class Augmented Attention (CAA) module to capture semantic-level context information and a Region Shuffle Attention (RSA) module to exploit region-wise image level context information. Although these methods improve the intra-class consistency of the feature representation, they still lack local detail information, resulting in lower classification accuracy in the object boundary region.
Several works have attempted to combine local-level and image-level contextual information to enhance the detail information and intra-class consistency of feature maps. MANet [
34] introduces the multi-scale context extraction module (MCM) to extract both local-level and image-level contextual information in low-resolution feature maps. Zhang et al. [
35] aggregate local-level contextual information in a high-resolution branch and harvest image-level contextual information in a low-resolution branch based on HRNet. HRCNet [
36] proposes a light-weight dual attention (LDA) module to obtain image-level contextual information, and then the feature enhancement feature pyramid (FEFP) module is designed to exploit the local-level and image-level contextual information in parallel structure. Although these methods harvest local-level and image-level contextual information within the single module or between different modules, they are still missing the contextual dependencies of distinct classes. This paper seeks to provide a solution to these issues by integrating different levels of contextual information efficiently to enhance feature representation.
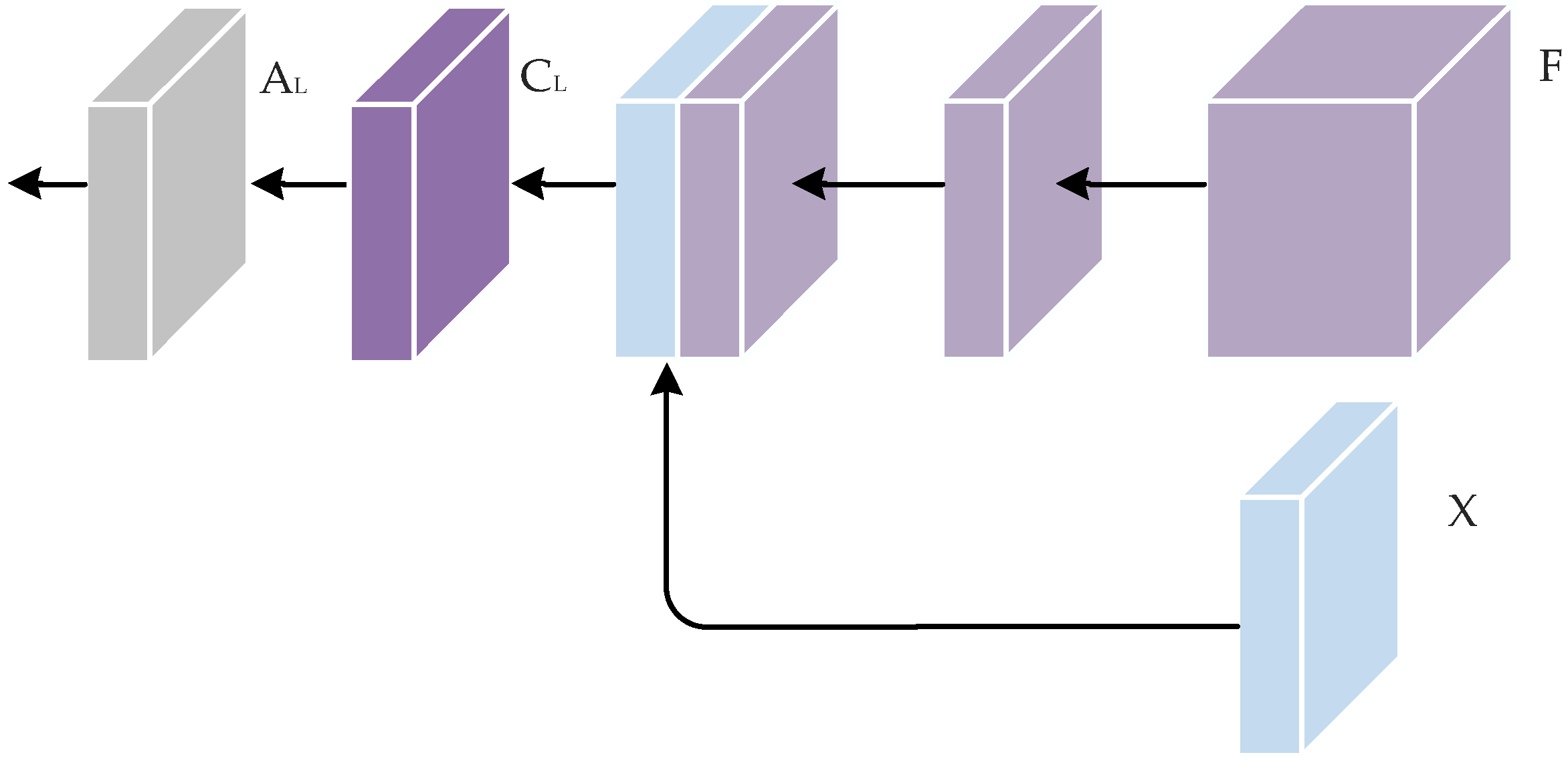
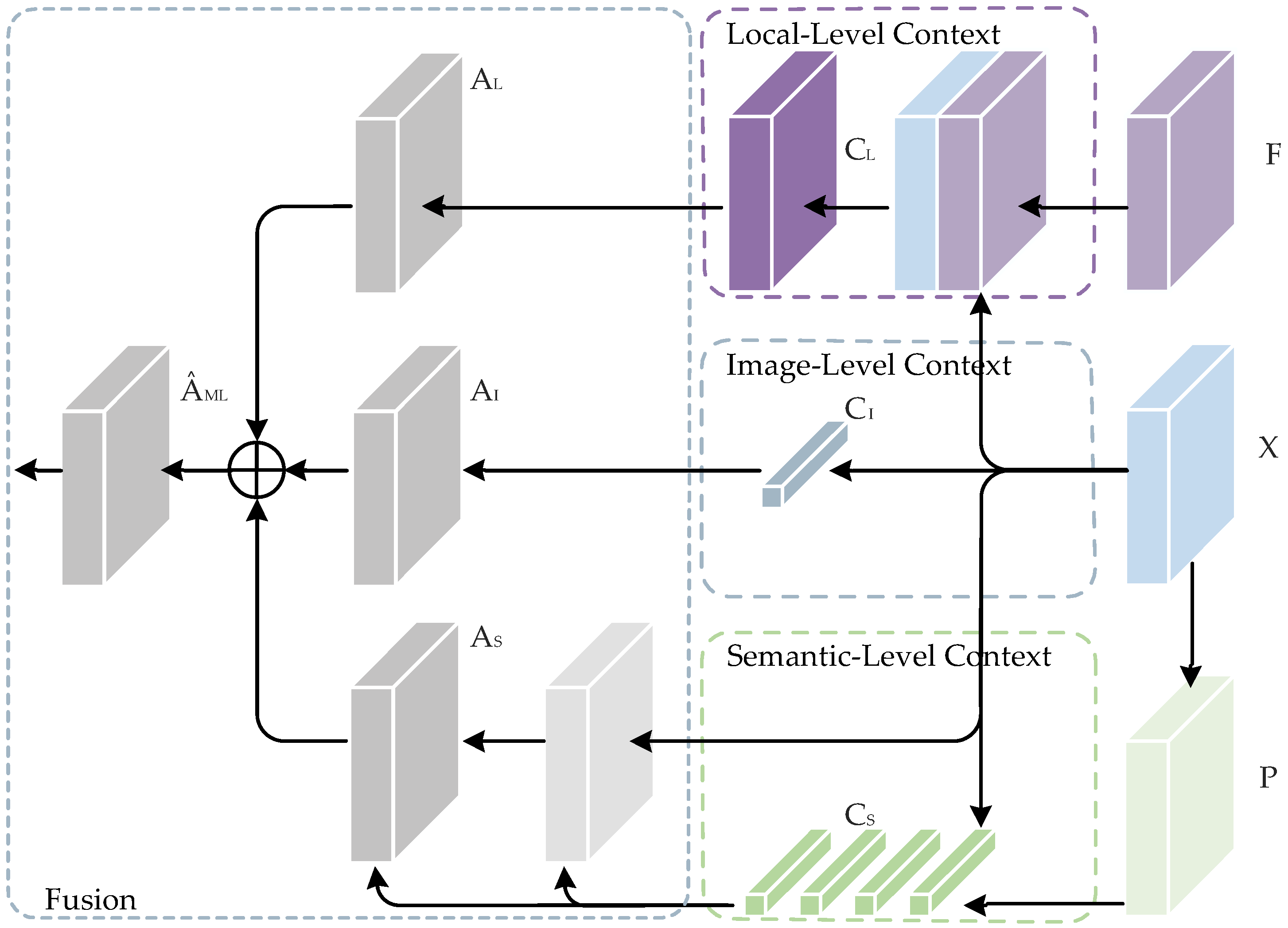
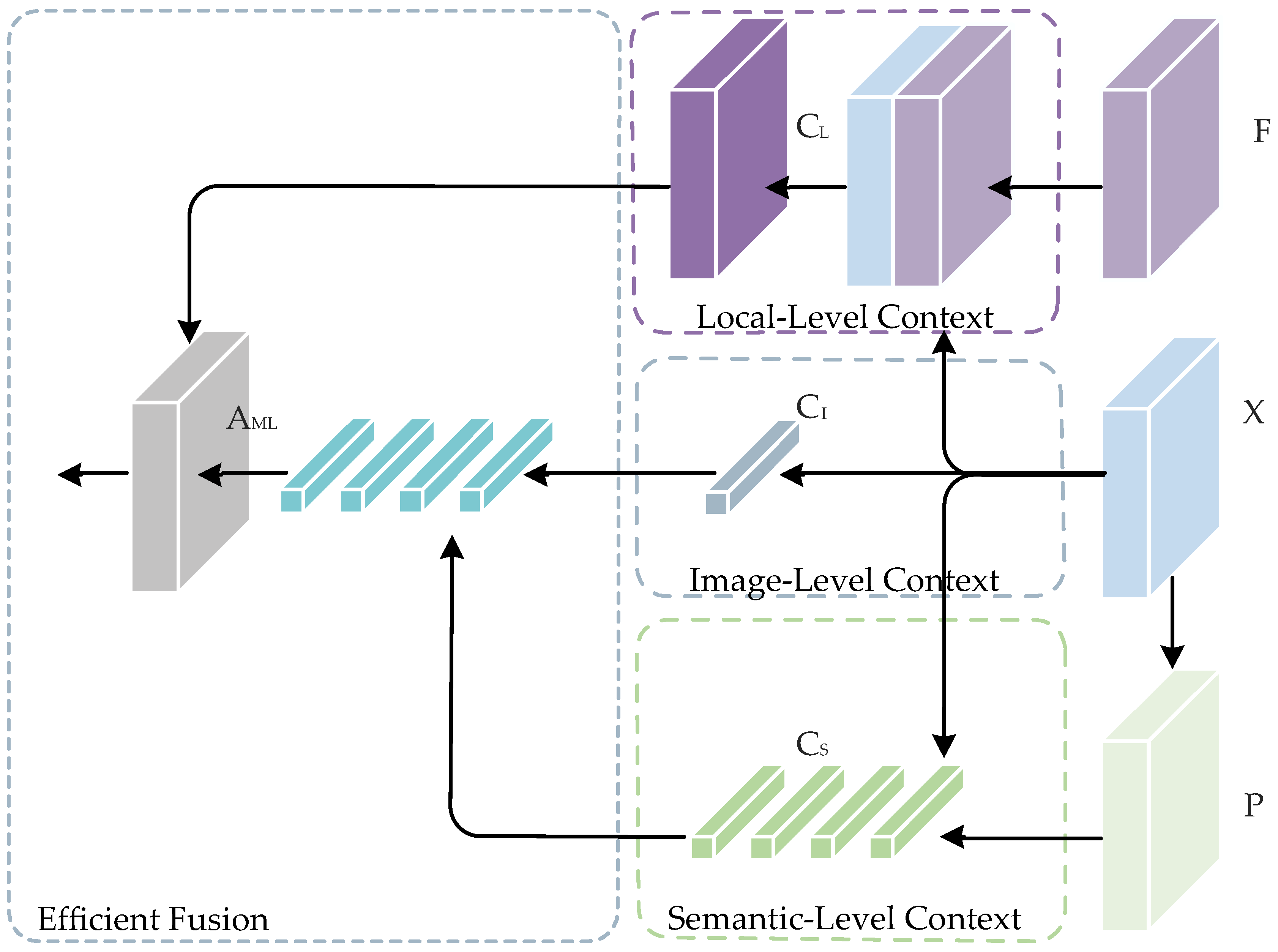
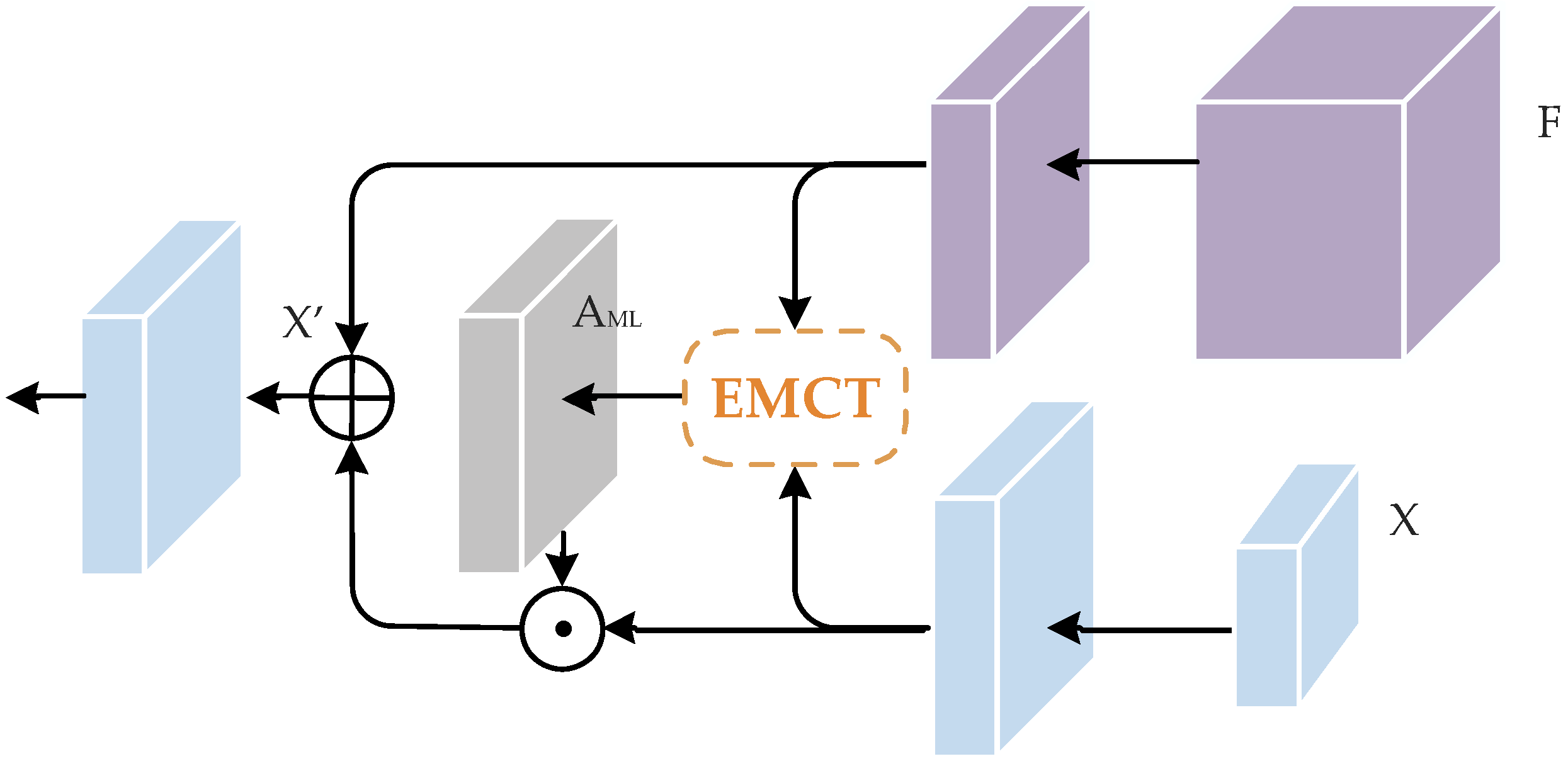
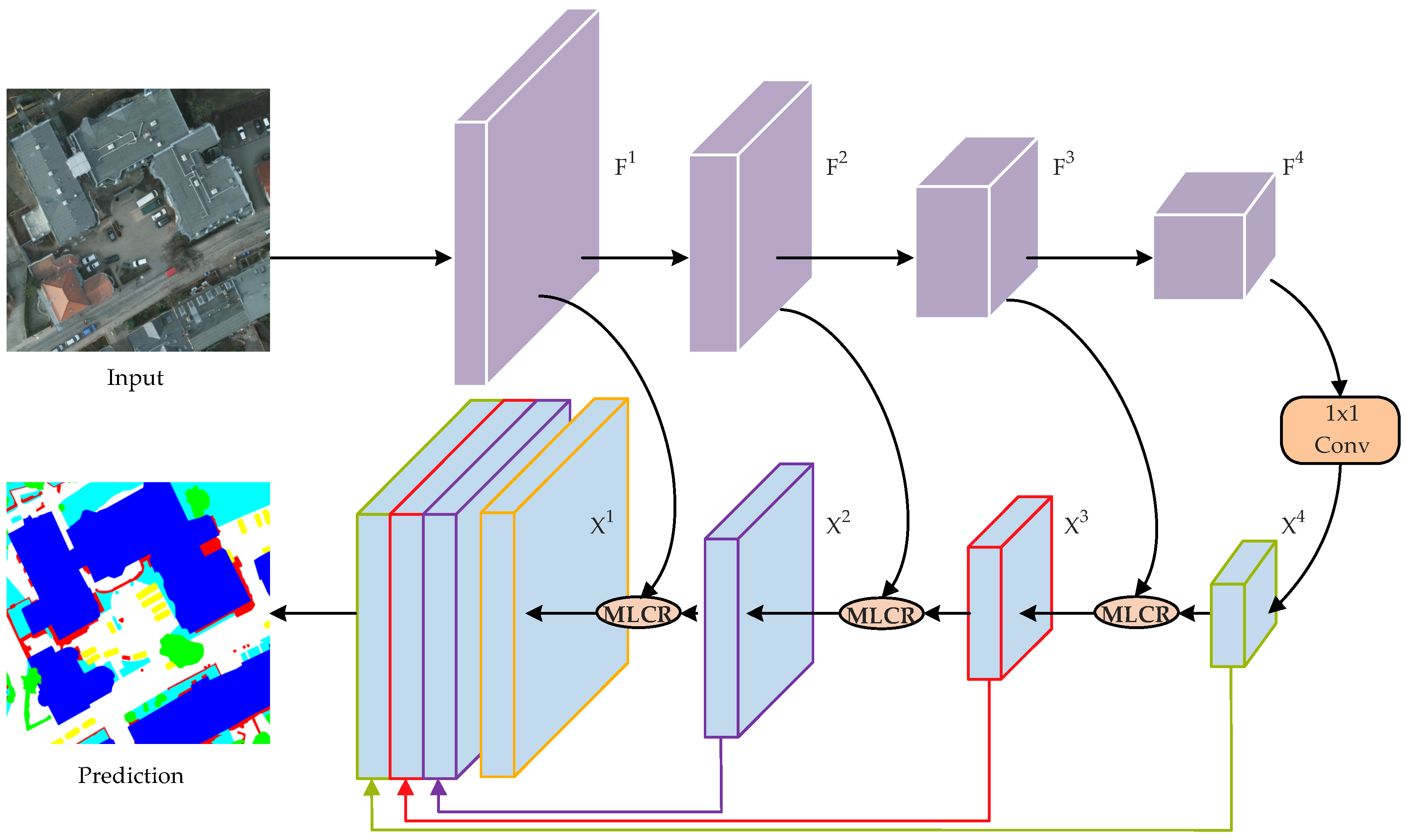
To this end, we propose a novel network called the multi-level context refinement network (MLCRNet) to harvest contextual information from a more comprehensive perspective efficiently. The basic idea is to embed local-level and image-level contextual information into semantic-level contextual relations to obtain more comprehensive and accurate contextual information to augment feature representation. Specifically, inspired by the flow alignment module in SFNet [
17], we first design a local-level context aggregation module, which discards the warp operation that demands extensive computation and enhances the feature representation with a local contextual relationship matrix directly. Then, we propose the multi-level context transform (MCT) module to integrate three levels of context, namely, local-level, image-level, and semantic-level, to capture contextual information from multiple aspects adaptively, which can improve model performance but dramatically increased GPU memory usage and inference time. Thus, an efficient MCT (EMCT) module is presented to address feature redundancy and to improve the efficiency of our MCT module. Subsequently, based on the EMCT block and FPN framework, we propose a multi-level context prior feature refinement module called the multi-level context refinement (MLCR) module to enhance feature representation by aggregating multi-level contextual information. Finally, our model refines the feature map iteratively across FPN [
18] decoder layers with MLCR.
In summary, our contribution falls into three aspects:
We propose a MCT module, which dynamically harvests contextual information from the semantic, image, and local perspectives.
The EMCT module is designed to address feature redundancy and improve the efficiency of our MCT module. Furthermore, a MLCR module is proposed on the basis of EMCT and FPN to enhance feature representation by aggregating multi-level contextual information.
We propose a novel MLCRNet based on the feature pyramid framework for accurate semantic segmentation.
5. Discussion
Previous studies have explored the importance of different levels of context and have made many improvements in semantic segmentation. However, these approaches tend to only focus on level-specific contextual relationships and do not harvest contextual information from a more holistic perspective. Consequently, these approaches are prone to suffer from a lack of contextual information (e.g., image-level context provides little improvement in identifying small targets). To this end, we aimed to seek an efficient and comprehensive approach that can model and transform contextual information.
Initially, we directly integrated local-level, image-level, and semantic-level contextual attention matrices, which improved model performance but dramatically increased GPU memory usage and inference time. We realize that these three levels of context are not orthogonal. Moreover, concatenating the three levels of contextual attention matrices directly suffers from the redundancy of contextual information. Hence, we designed the EMCT module to transform the three levels of contextual relationships into a contextual attention matrix effectively and efficiently. The experimental results suggest that our proposed method has three advantages over other methods. First, our proposed MLCR module has made progress in quantitative experimental results, and ablation experimental results on the Potsdam test set reveal the effectiveness of our proposed module, thereby lifting the mIoU by 1.9% compared with the Baseline and outperforming other state-of-the-art models. Second, the computational cost of our proposed MLCR module is less than those of other contextual aggregation methods. Relative to DANet, MLCRNet reduces the number of parameters by 46% and the FLOPs by 78%. Lastly, from the qualitative experimental results, our MLCR module increases the consistency of intra-class segmentation and object boundary accuracy, as shown in the first row of
Figure 10. MLCNet improves the quality of the car edges while solving the problem of misclassification of disturbed areas (e.g., areas between adjacent vehicles, areas obscured by building shadows). The second and third rows of
Figure 10 show the power of MLCRNet to improve the intra-class consistency of large objects (e.g., buildings, roads, grassy areas, etc.). Nevertheless, for future practical applications, we need to continue to improve accuracy.
6. Conclusions
In this paper, we designed a novel MLCRNet that dynamically harvests contextual information from the semantic, image, and local perspectives for aerial image semantic segmentation. Concretely, we first integrated three levels of context, namely, local level, image level, and semantic level, to capture contextual information from multiple aspects adaptively. Next, an efficient fusion block is presented to address feature redundancy and improve the efficiency of our multi-level context. Finally, our model refines the feature map iteratively across FPN layers with MLCR. Extensive evaluations on Potsdam and Vaihingen challenging datasets demonstrate that our model can gather the multi-level contextual information efficiently, thereby enhancing the structure reasoning of the model.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









