
Early-Season Crop Identification in the Shiyang River Basin Using a Deep Learning Algorithm and Time-Series Sentinel-2 Data


Abstract
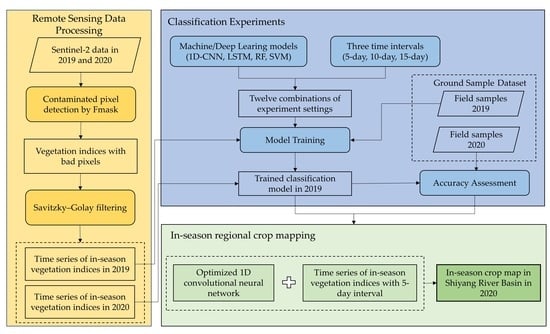
:
1. Introduction
- (1)
- Are the classification performances of deep-learning algorithms in early-season crop identification better than those of shallow machine-learning algorithms?
- (2)
- What is the smallest temporal interval of the image series required for accurate early-season crop identification (i.e., 5, 10, or 15 days)?
- (3)
- What is the earliest identification time of the major crops in the Shiyang River Basin?
2. Materials and Methods
2.1. Overview of the Study Area
2.2. Data and Processing
2.2.1. Sentinel-2 Data Products
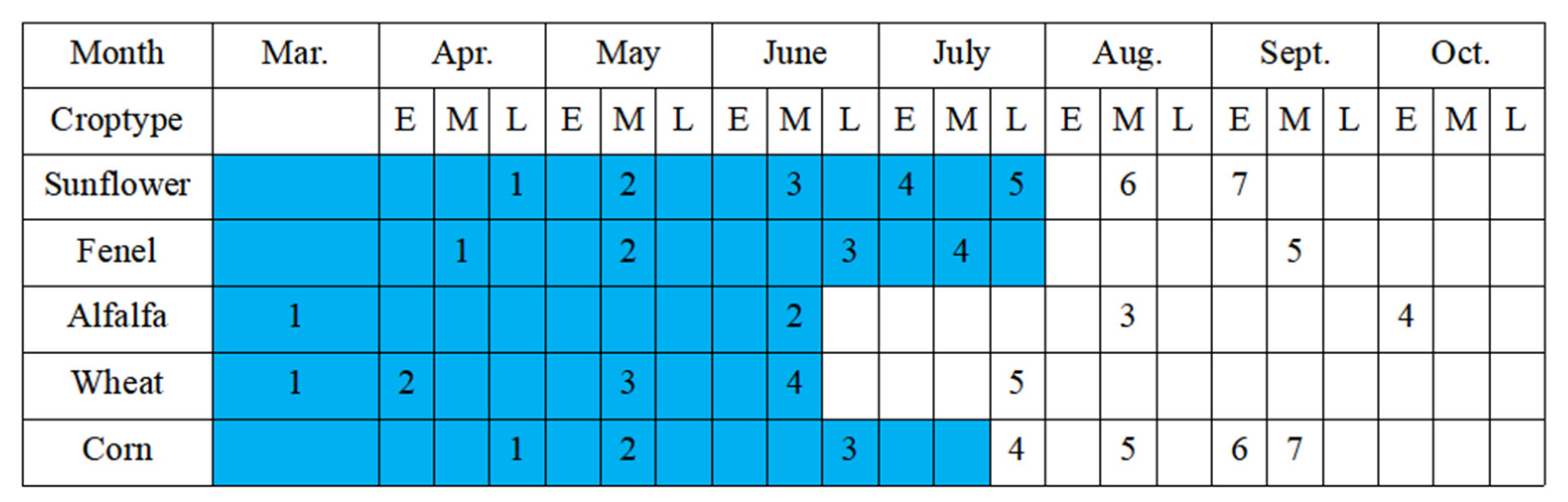
2.2.2. Ground Reference Data
2.2.3. Image Quality Control
2.2.4. Feature Construction
2.2.5. Data Interpolation and Smoothing
3. Methodology
3.1. Classifier
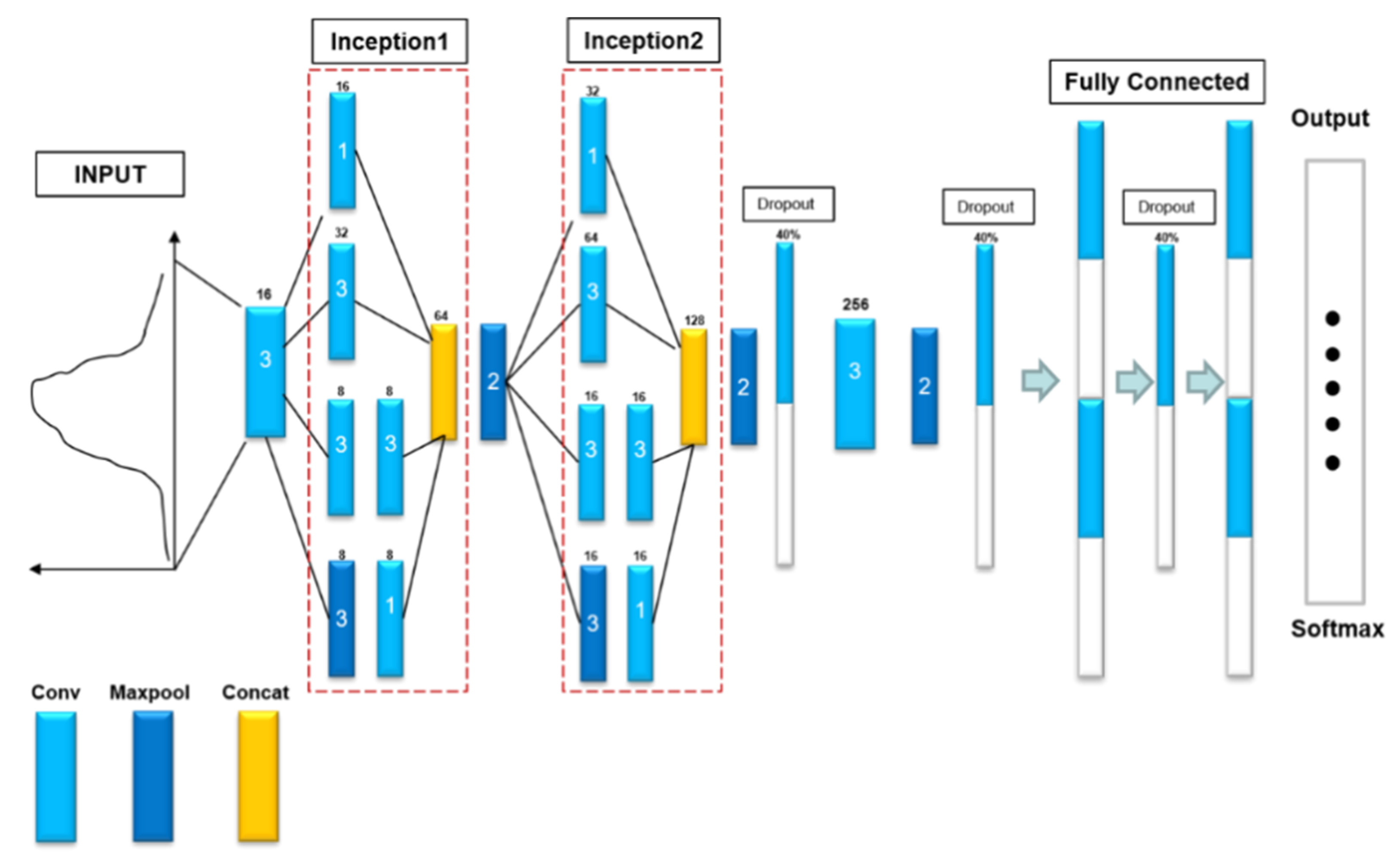
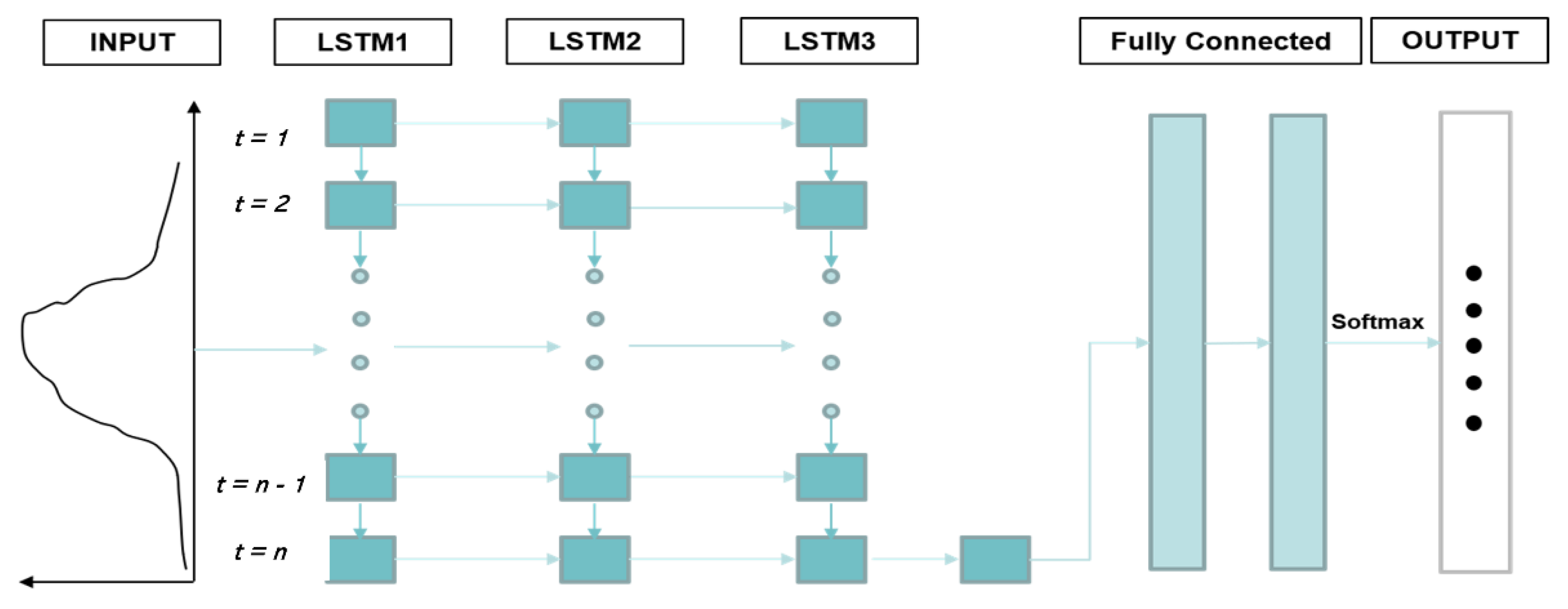
3.1.1. Deep Learning Models
3.1.2. Shallow Machine Learning Models
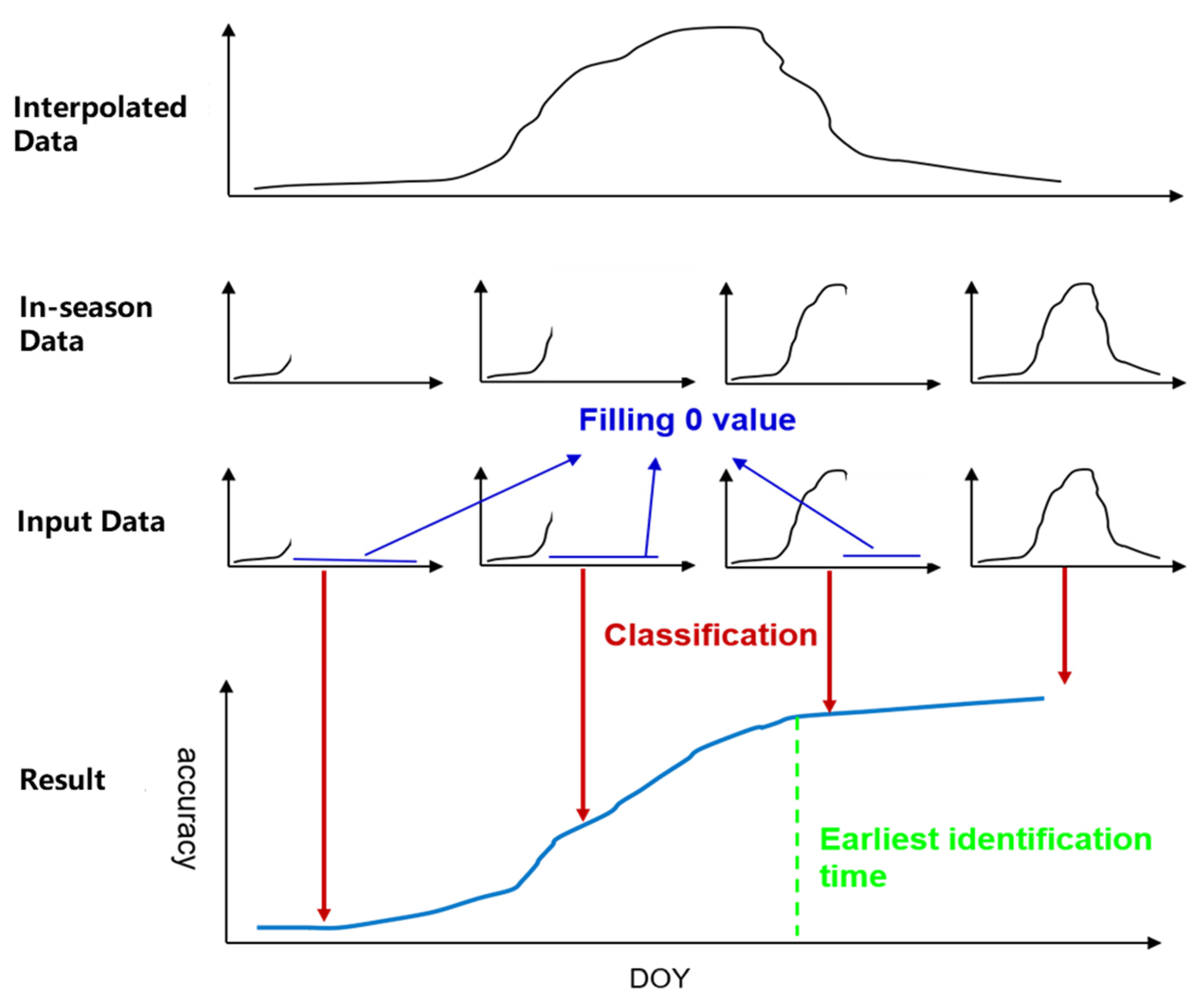
3.2. Experimental Design
3.3. Accuracy Assessment
4. Results
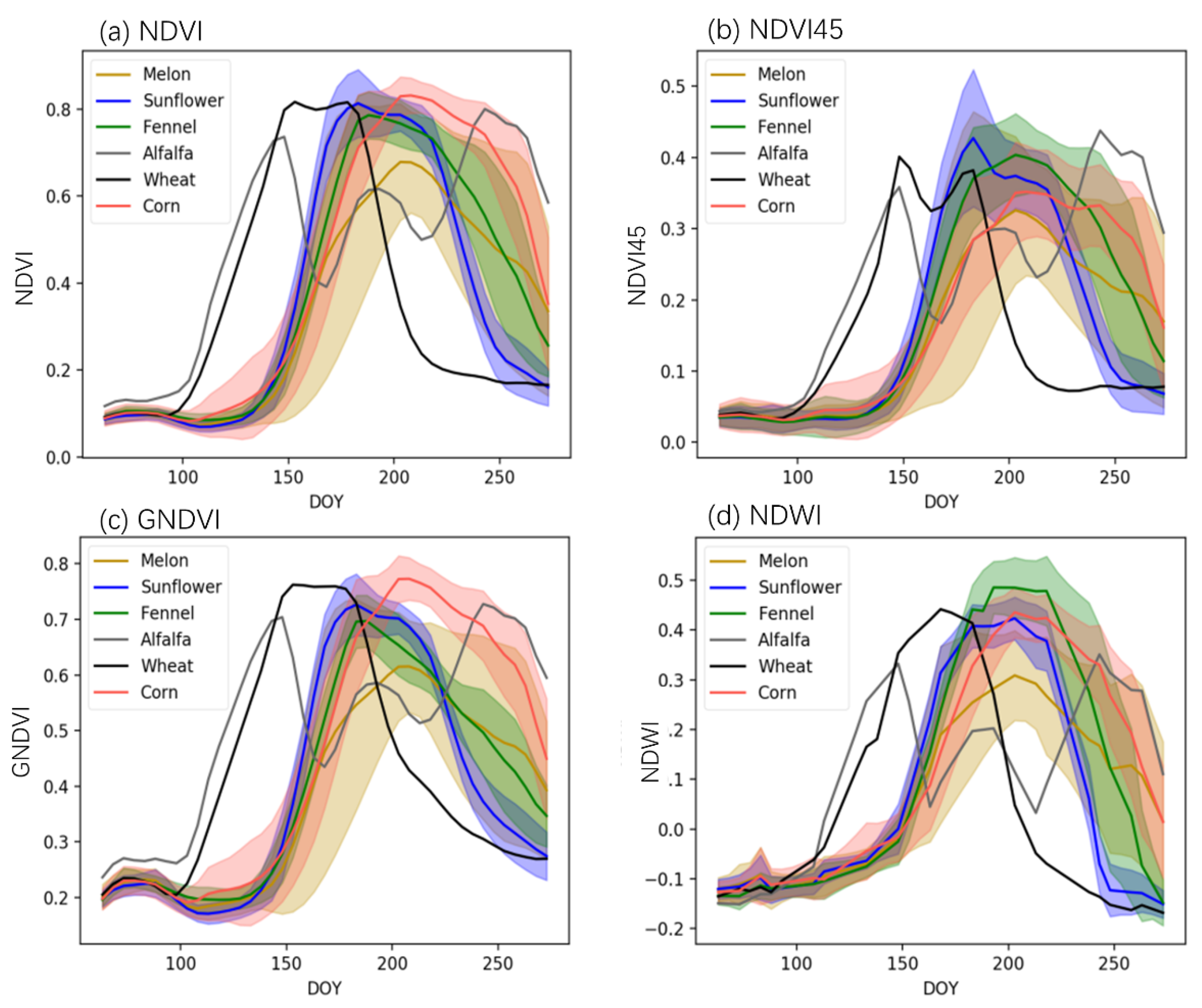
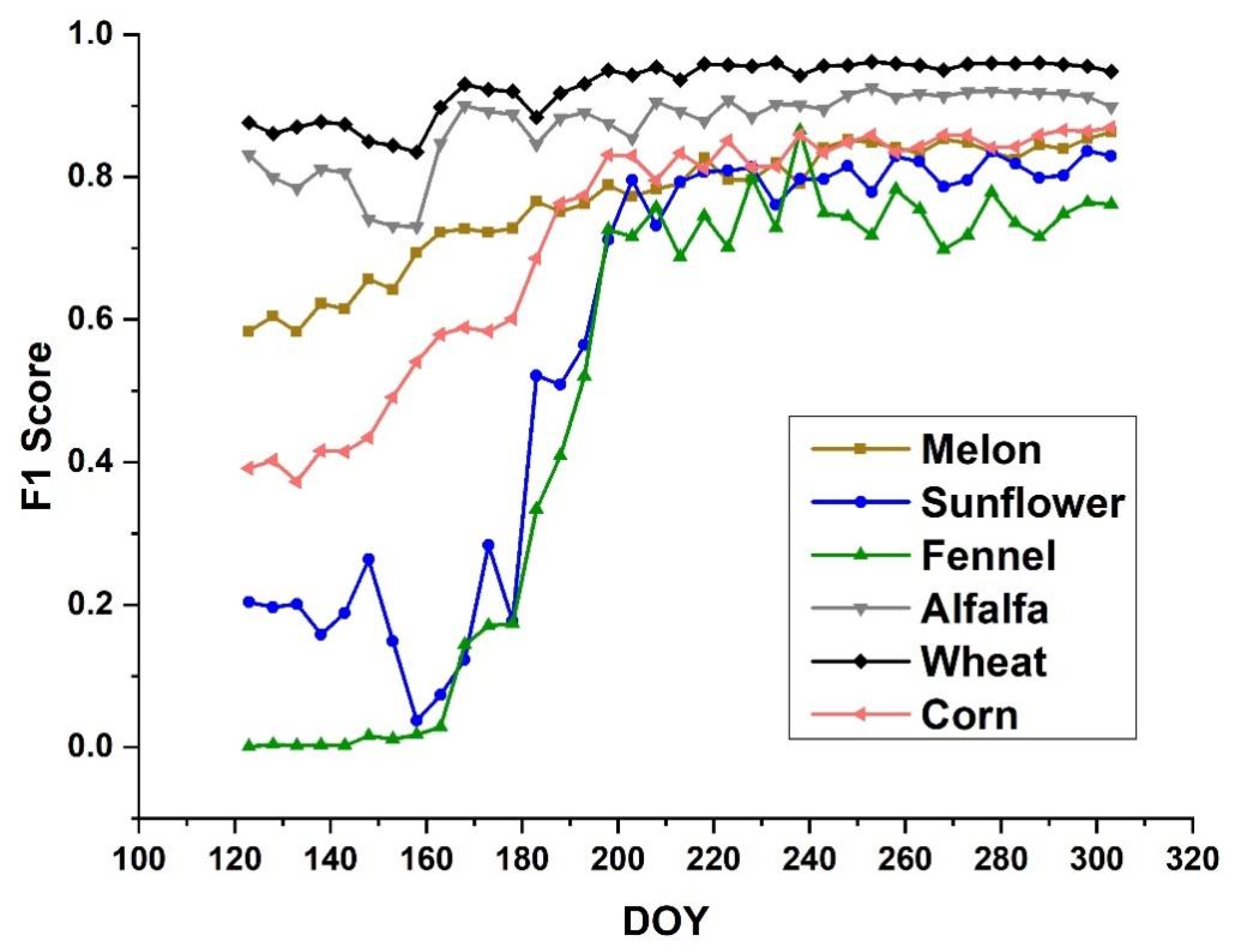
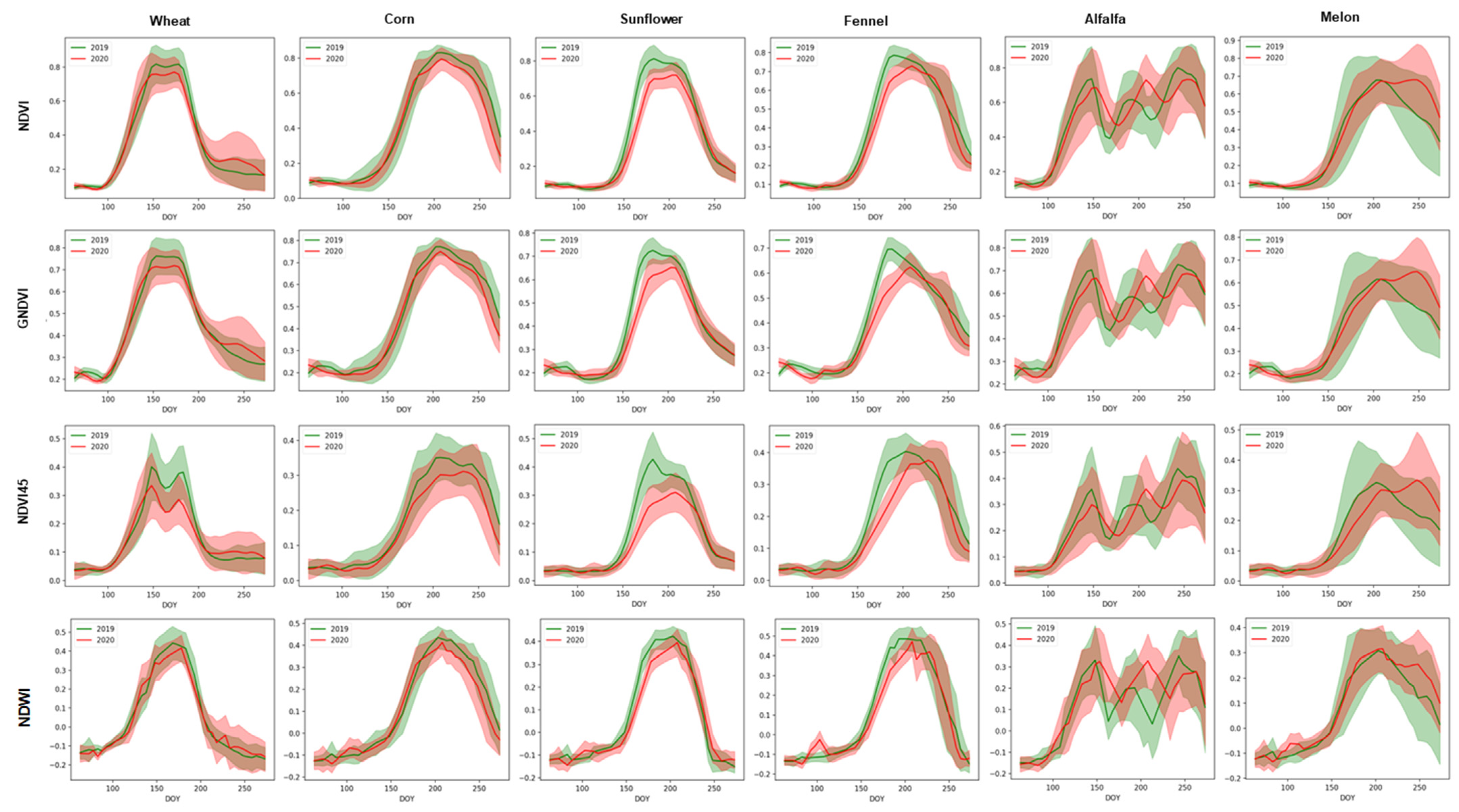
4.1. Crop Growth Characteristics
4.2. Classification Performances of the Different Combinations of Classification Strategies
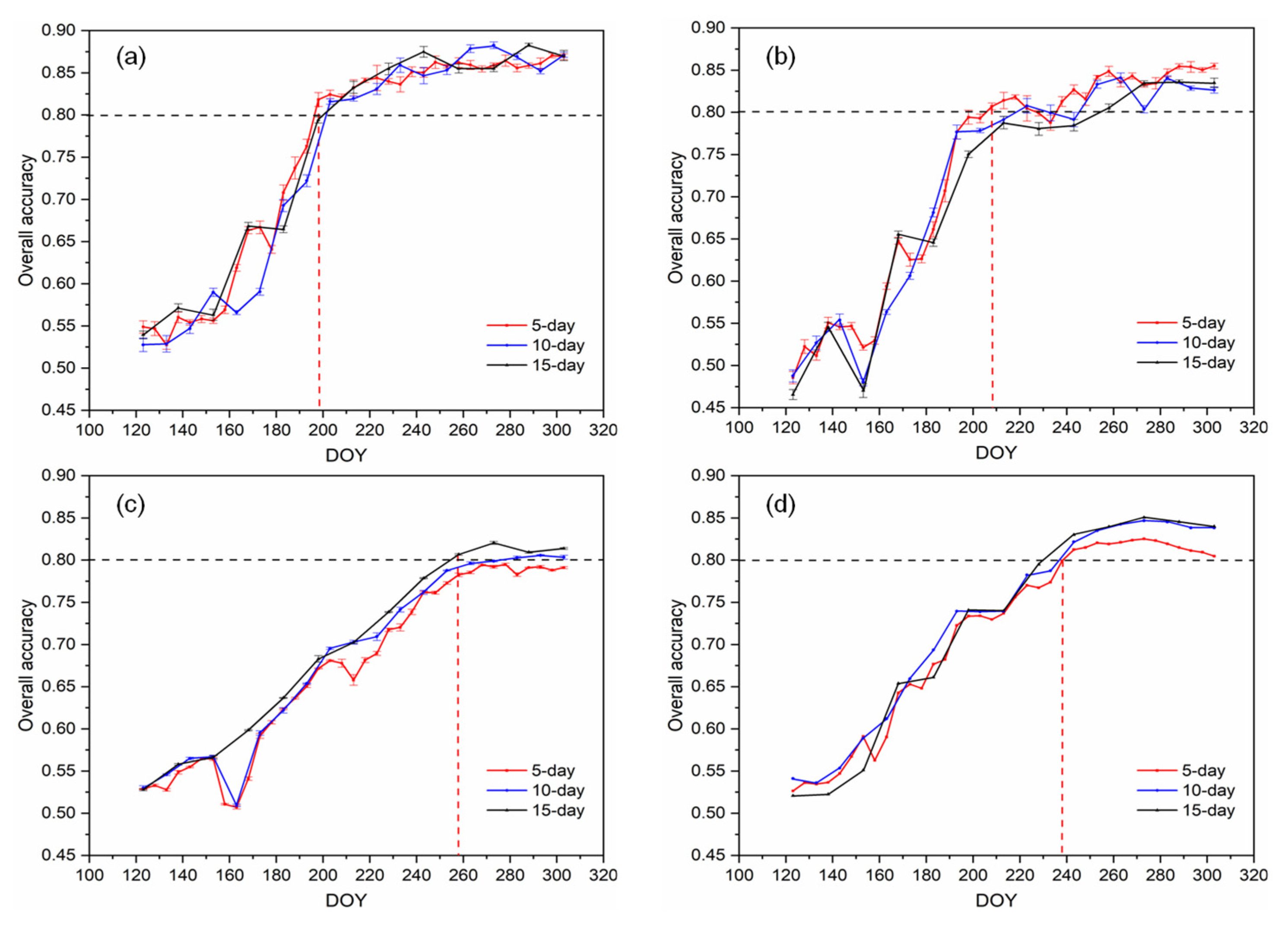
4.3. Early Identification Time for Each Crop
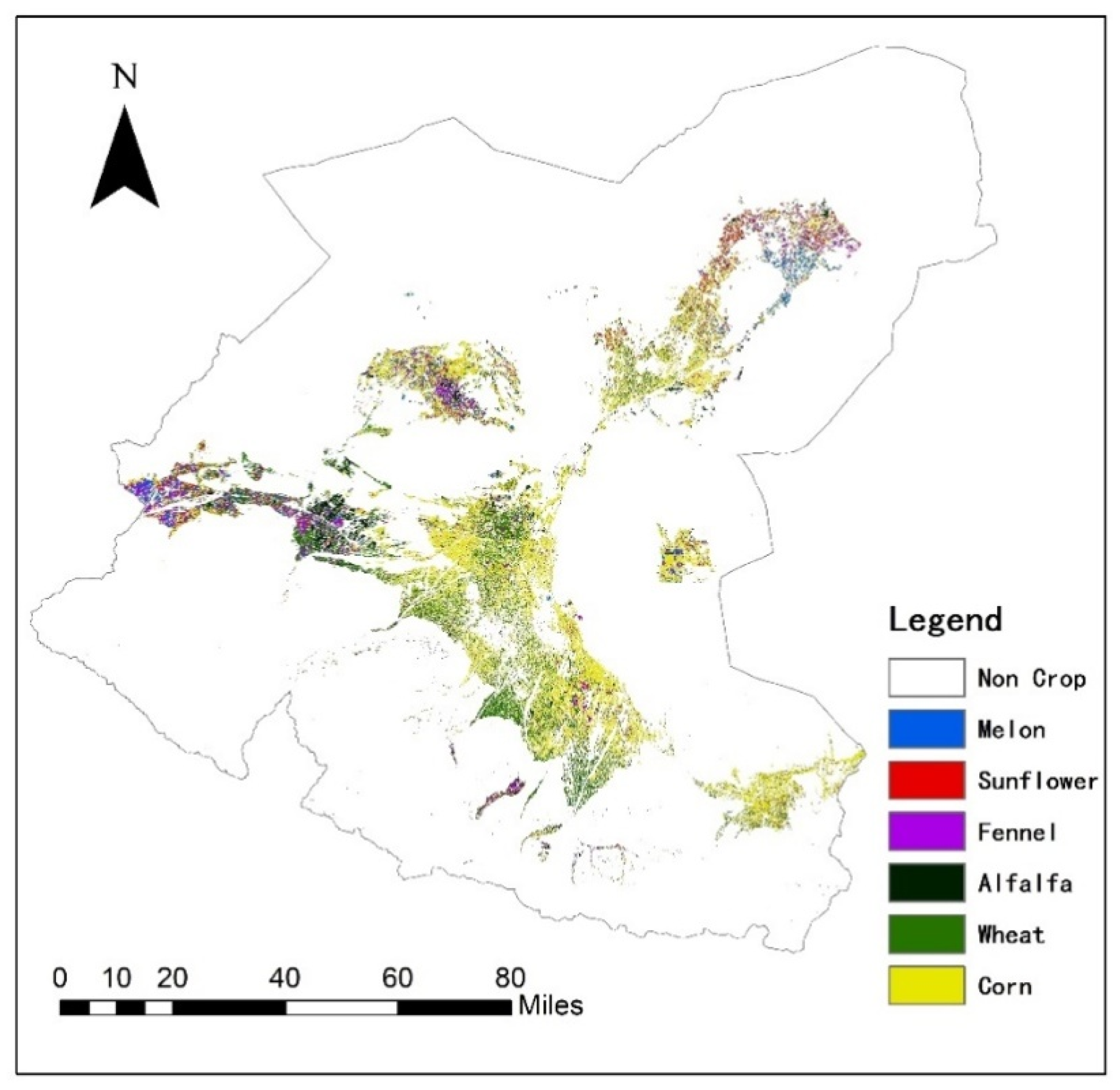
4.4. Early Crop Mapping in the Shiyang River Basin
5. Discussion
5.1. Influence of Crop Spectral and Phenological Characteristics on Early Identification Times
5.2. Factors Decreasing the Accuracy of the Early Crop Mapping
5.3. Limitations and Future Work
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ozdogan, M. The spatial distribution of crop types from modis data: Temporal unmixing using independent component analysis. Remote Sens. Environ. 2010, 114, 1190–1204. [Google Scholar] [CrossRef]
- See, L.; Fritz, S.; You, L.; Ramankutty, N.; Herrero, M.; Justice, C.; Becker-Reshef, I.; Thornton, P.; Erb, K.; Gong, P.; et al. Improved global cropland data as an essential ingredient for food security. Glob. Food Secur. 2015, 4, 37–45. [Google Scholar] [CrossRef]
- Franch, B.; Vermote, E.F.; Becker-Reshef, I.; Claverie, M.; Huang, J.; Zhang, J.; Justice, C.; Sobrino, J.A. Improving the timeliness of winter wheat production forecast in the united states of America, Ukraine and china using modis data and ncar growing degree day information. Remote Sens. Environ. 2015, 161, 131–148. [Google Scholar] [CrossRef]
- Wardlow, B.D.; Callahan, K. A multi-scale accuracy assessment of the modis irrigated agriculture data-set (mirad) for the state of nebraska, USA. GIScience Remote Sens. 2014, 51, 575–592. [Google Scholar] [CrossRef]
- Jia, K.; Wu, B.; Li, Q. Crop classification using hj satellite multispectral data in the north china plain. J. Appl. Remote Sens. 2013, 7, 073576. [Google Scholar] [CrossRef]
- Immitzer, M.; Vuolo, F.; Atzberger, C. First experience with sentinel-2 data for crop and tree species classifications in central europe. Remote Sens. 2016, 8, 166. [Google Scholar] [CrossRef]
- You, N.; Dong, J. Examining earliest identifiable timing of crops using all available sentinel 1/2 imagery and google earth engine. ISPRS J. Photogramm. Remote Sens. 2020, 161, 109–123. [Google Scholar]
- Hao, P.; Zhan, Y.; Wang, L.; Niu, Z.; Shakir, M. Feature selection of time series modis data for early crop classification using random forest: A case study in kansas, USA. Remote Sens. 2015, 7, 5347–5369. [Google Scholar] [CrossRef] [Green Version]
- Boryan, C.; Yang, Z.; Di, L. Deriving 2011 cultivated land cover data sets using usda national agricultural statistics service historic cropland data layers. In Proceedings of the 2012 IEEE International Geoscience and Remote Sensing Symposium, Munich, Germany, 22–27 July 2012; pp. 6297–6300. [Google Scholar]
- Boryan, C.; Yang, Z.; Mueller, R.; Craig, M. Monitoring us agriculture: The us department of agriculture, national agricultural statistics service, cropland data layer program. Geocato Int. 2011, 26, 341–358. [Google Scholar] [CrossRef]
- Fisette, T.; Davidson, A.; Daneshfar, B.; Rollin, P.; Aly, Z.; Campbell, L. Annual space-based crop inventory for Canada: 2009–2014. In Proceedings of the 2014 IEEE Geoscience and Remote Sensing Symposium, Quebec City, QC, Canada, 13–18 July 2014; pp. 5095–5098. [Google Scholar]
- Huang, X.; Huang, J.; Li, X.; Shen, Q.; Chen, Z. Early mapping of winter wheat in henan province of china using time series of sentinel-2 data. GIScience Remote Sens. 2022, 59, 1534–1549. [Google Scholar] [CrossRef]
- Hao, P.; Tang, H.; Chen, Z.; Meng, Q.; Kang, Y. Early-season crop type mapping using 30-m reference time series. J. Integr. Agric. 2020, 19, 1897–1911. [Google Scholar] [CrossRef]
- Al-Shammari, D.; Fuentes, I.; Whelan, B.M.; Filippi, P.; Bishop, T.F.A. Mapping of cotton fields within-season using phenology-based metrics derived from a time series of landsat imagery. Remote Sens. 2020, 12, 3038. [Google Scholar] [CrossRef]
- Johnson, D.M.; Mueller, R. Pre- and within-season crop type classification trained with archival land cover information. Remote Sens. Environ. 2021, 264, 112576. [Google Scholar] [CrossRef]
- Lin, Z.; Zhong, R.; Xiong, X.; Guo, C.; Xu, J.; Zhu, Y.; Xu, J.; Ying, Y.; Ting, K.C.; Huang, J.; et al. Large-scale rice mapping using multi-task spatiotemporal deep learning and sentinel-1 sar time series. Remote Sens. 2022, 14, 669. [Google Scholar] [CrossRef]
- Cai, Y.; Guan, K.; Peng, J.; Wang, S.; Seifert, C.; Wardlow, B.; Li, Z. A high-performance and in-season classification system of field-level crop types using time-series landsat data and a machine learning approach. Remote Sens. Environ. 2018, 210, 35–47. [Google Scholar] [CrossRef]
- Konduri, V.S.; Kumar, J.; Hargrove, W.W.; Hoffman, F.M.; Ganguly, A.R. Mapping crops within the growing season across the united states. Remote Sens. Environ. 2020, 251, 112048. [Google Scholar] [CrossRef]
- Yang, Y.; Ren, W.; Tao, B.; Ji, L.; Liang, L.; Ruane, A.C.; Fisher, J.B.; Liu, J.; Sama, M.; Li, Z.; et al. Characterizing spatiotemporal patterns of crop phenology across north america during 2000–2016 using satellite imagery and agricultural survey data. ISPRS J. Photogramm. Remote Sens. 2020, 170, 156–173. [Google Scholar] [CrossRef]
- Feng, S.; Zhao, J.; Liu, T.; Zhang, H.; Zhang, Z.; Guo, X. Crop type identification and mapping using machine learning algorithms and sentinel-2 time series data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 3295–3306. [Google Scholar] [CrossRef]
- Löw, F.; Michel, U.; Dech, S.; Conrad, C. Impact of feature selection on the accuracy and spatial uncertainty of per-field crop classification using support vector machines. ISPRS J. Photogramm. Remote Sens. 2013, 85, 102–119. [Google Scholar] [CrossRef]
- Massey, R.; Sankey, T.T.; Congalton, R.G.; Yadav, K.; Thenkabail, P.S.; Ozdogan, M.; Sánchez Meador, A.J. Modis phenology-derived, multi-year distribution of conterminous U.S. Crop types. Remote Sens. Environ. 2017, 198, 490–503. [Google Scholar] [CrossRef]
- Zhong, L.; Gong, P.; Biging, G.S. Phenology-based crop classification algorithm and its implications on agricultural water use assessments in california’s central valley. Photogramm. Eng. Rem. Sens. 2012, 78, 799–813. [Google Scholar] [CrossRef]
- Zhong, L.; Gong, P.; Biging, G.S. Efficient corn and soybean mapping with temporal extendability: A multi-year experiment using landsat imagery. Remote Sens. Environ. 2014, 140, 1–13. [Google Scholar] [CrossRef]
- Xu, J.; Zhu, Y.; Zhong, R.; Lin, Z.; Xu, J.; Jiang, H.; Huang, J.; Li, H.; Lin, T. Deepcropmapping: A multi-temporal deep learning approach with improved spatial generalizability for dynamic corn and soybean mapping. Remote Sens. Environ. 2020, 247, 111946. [Google Scholar] [CrossRef]
- Song, X.P.; Potapov, P.V.; Krylov, A.; King, L.; Di Bella, C.M.; Hudson, A.; Khan, A.; Adusei, B.; Stehman, S.V.; Hansen, M.C. National-scale soybean mapping and area estimation in the united states using medium resolution satellite imagery and field survey. Remote Sens. Environ. 2017, 190, 383–395. [Google Scholar] [CrossRef]
- Zhang, H.X.; Li, Q.Z.; Liu, J.G.; Shang, J.L.; Du, X.; Zhao, L.C.; Wang, N.; Dong, T.F. Crop classification and acreage estimation in north korea using phenology features. Giscience Remote Sens. 2017, 54, 381–406. [Google Scholar] [CrossRef]
- Zhao, S.; Liu, X.; Ding, C.; Liu, S.; Wu, C.; Wu, L. Mapping rice paddies in complex landscapes with convolutional neural networks and phenological metrics. Giscience Remote Sens. 2020, 57, 37–48. [Google Scholar] [CrossRef]
- Maponya, M.G.; Van Niekerk, A.; Mashimbye, Z.E. Pre-harvest classification of crop types using a sentinel-2 time-series and machine learning. Comput. Electron. Agr. 2020, 169, 105164. [Google Scholar] [CrossRef]
- Veloso, A.; Mermoz, S.; Bouvet, A.; Le Toan, T.; Planells, M.; Dejoux, J.-F.; Ceschia, E. Understanding the temporal behavior of crops using sentinel-1 and sentinel-2-like data for agricultural applications. Remote Sens. Environ. 2017, 199, 415–426. [Google Scholar] [CrossRef]
- Lin, C.; Zhong, L.; Song, X.-P.; Dong, J.; Lobell, D.B.; Jin, Z. Early- and in-season crop type mapping without current-year ground truth: Generating labels from historical information via a topology-based approach. Remote Sens. Environ. 2022, 274, 112994. [Google Scholar] [CrossRef]
- Marais Sicre, C.; Inglada, J.; Fieuzal, R.; Baup, F.; Valero, S.; Cros, J.; Huc, M.; Demarez, V. Early detection of summer crops using high spatial resolution optical image time series. Remote Sens. 2016, 8, 591. [Google Scholar] [CrossRef] [Green Version]
- Skakun, S.; Franch, B.; Vermote, E.; Roger, J.-C.; Becker-Reshef, I.; Justice, C.; Kussul, N. Early season large-area winter crop mapping using modis ndvi data, growing degree days information and a gaussian mixture model. Remote Sens. Environ. 2017, 195, 244–258. [Google Scholar] [CrossRef]
- D’andrimont, R.; Taymans, M.; Lemoine, G.; Ceglar, A.; Yordanov, M.; Van Der Velde, M. Detecting flowering phenology in oil seed rape parcels with sentinel-1 and-2 time series. Remote Sens. Environ. 2020, 239, 111660. [Google Scholar] [CrossRef] [PubMed]
- Hao, P.; Wu, M.; Niu, Z.; Wang, L.; Zhan, Y. Estimation of different data compositions for early-season crop type classification. PeerJ 2018, 6, e4834. [Google Scholar] [CrossRef] [PubMed]
- Pal, M.; Mather, P.M. An assessment of the effectiveness of decision tree methods for land cover classification. Remote Sens. Environ. 2003, 86, 554–565. [Google Scholar] [CrossRef]
- Pal, M.; Mather, P.M. Assessment of the effectiveness of support vector machines for hyperspectral data. Future Gener. Comp. Sy. 2004, 20, 1215–1225. [Google Scholar] [CrossRef]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Zhong, L.; Hu, L.; Zhou, H. Deep learning based multi-temporal crop classification. Remote Sens. Environ. 2019, 221, 430–443. [Google Scholar] [CrossRef]
- Hochreiter, S. The vanishing gradient problem during learning recurrent neural nets and problem solutions. Int. J. Uncertain. Fuzz 1998, 6, 107–116. [Google Scholar] [CrossRef] [Green Version]
- Mazzia, V.; Khaliq, A.; Chiaberge, M. Improvement in land cover and crop classification based on temporal features learning from sentinel-2 data using recurrent-convolutional neural network (r-cnn). Appl. Sci. 2020, 10, 238. [Google Scholar] [CrossRef] [Green Version]
- Qiu, S.; Zhu, Z.; He, B. Fmask 4.0: Improved cloud and cloud shadow detection in landsats 4–8 and sentinel-2 imagery. Remote Sens. Environ. 2019, 231, 111205. [Google Scholar] [CrossRef]
- Yi, Z.; Jia, L.; Chen, Q. Crop classification using multi-temporal Sentinel-2 data in the shiyang river basin of China. Remote Sens. 2020, 12, 4052. [Google Scholar] [CrossRef]
- Gitelson, A.A.; Kaufman, Y.J.; Merzlyak, M.N. Use of a green channel in remote sensing of global vegetation from eos-modis. Remote Sens. Environ. 1996, 58, 298. [Google Scholar] [CrossRef]
- Sun, Y.H.; Qin, Q.M.; Ren, H.Z.; Zhang, T.Y.; Chen, S.S. Red-edge band vegetation indices for leaf area index estimation from sentinel-2/msi imagery. IEEE Trans. Geosci. Remote Sens. 2020, 58, 826–840. [Google Scholar] [CrossRef]
- Hu, Q.; Wu, W.-B.; Song, Q.; Lu, M.; Chen, D.; Yu, Q.-Y.; Tang, H.-J. How do temporal and spectral features matter in crop classification in heilongjiang province, china? J. Integr. Agric. 2017, 16, 324–336. [Google Scholar] [CrossRef]
- Chen, J.; Jönsson, P.; Tamura, M.; Gu, Z.; Matsushita, B.; Eklundh, L. A simple method for reconstructing a high-quality ndvi time-series data set based on the savitzky–golay filter. Remote Sens. Environ. 2004, 91, 332–344. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. arXiv 2019, arXiv:1912.01703. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Carrão, H.; Gonçalves, P.; Caetano, M. Contribution of multispectral and multitemporal information from modis images to land cover classification. Remote Sens. Environ. 2008, 112, 986–997. [Google Scholar] [CrossRef]
- Shi, D.; Yang, X. An assessment of algorithmic parameters affecting image classification accuracy by random forests. Photogramm. Eng. Remote Sens. 2016, 82, 407–417. [Google Scholar] [CrossRef]
- Zhang, J.; Feng, L.; Yao, F. Improved maize cultivated area estimation over a large scale combining modis–evi time series data and crop phenological information. ISPRS J. Photogramm. Remote Sens. 2014, 94, 102–113. [Google Scholar] [CrossRef]
- Olofsson, P.; Foody, G.M.; Stehman, S.V.; Woodcock, C.E. Making better use of accuracy data in land change studies: Estimating accuracy and area and quantifying uncertainty using stratified estimation. Remote Sens. Environ. 2013, 129, 122–131. [Google Scholar] [CrossRef]
- Foody, G.M. Thematic map comparison: Evaluating the statistical significance of differences in classification accuracy. Photogramm. Eng. Remote Sens. 2004, 70, 627–633. [Google Scholar] [CrossRef]
- Vuolo, F.; Neuwirth, M.; Immitzer, M.; Atzberger, C.; Ng, W.-T. How much does multi-temporal sentinel-2 data improve crop type classification? Int. J. Appl. Earth Obs. Geoinf. 2018, 72, 122–130. [Google Scholar] [CrossRef]












{kind=link}
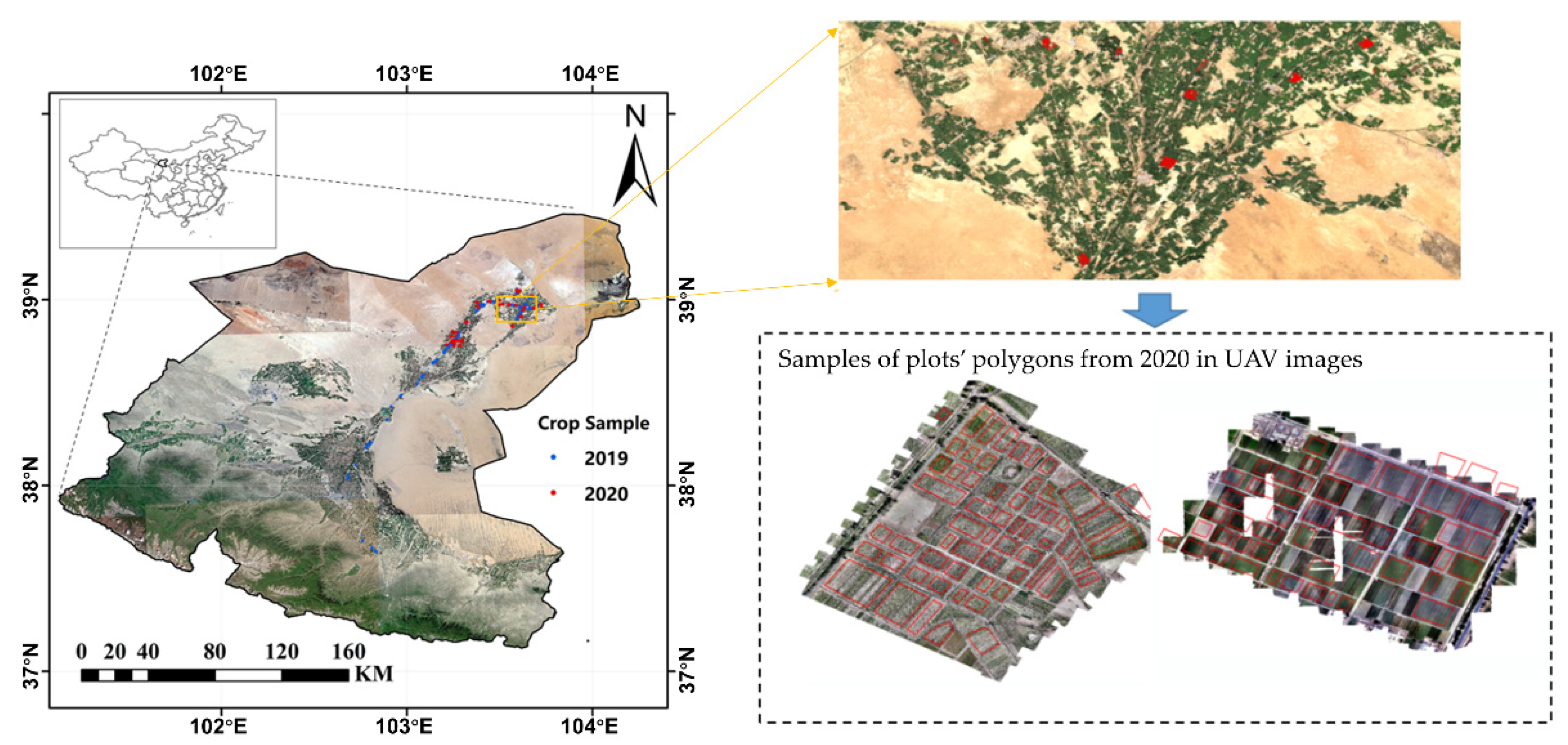{kind=link}
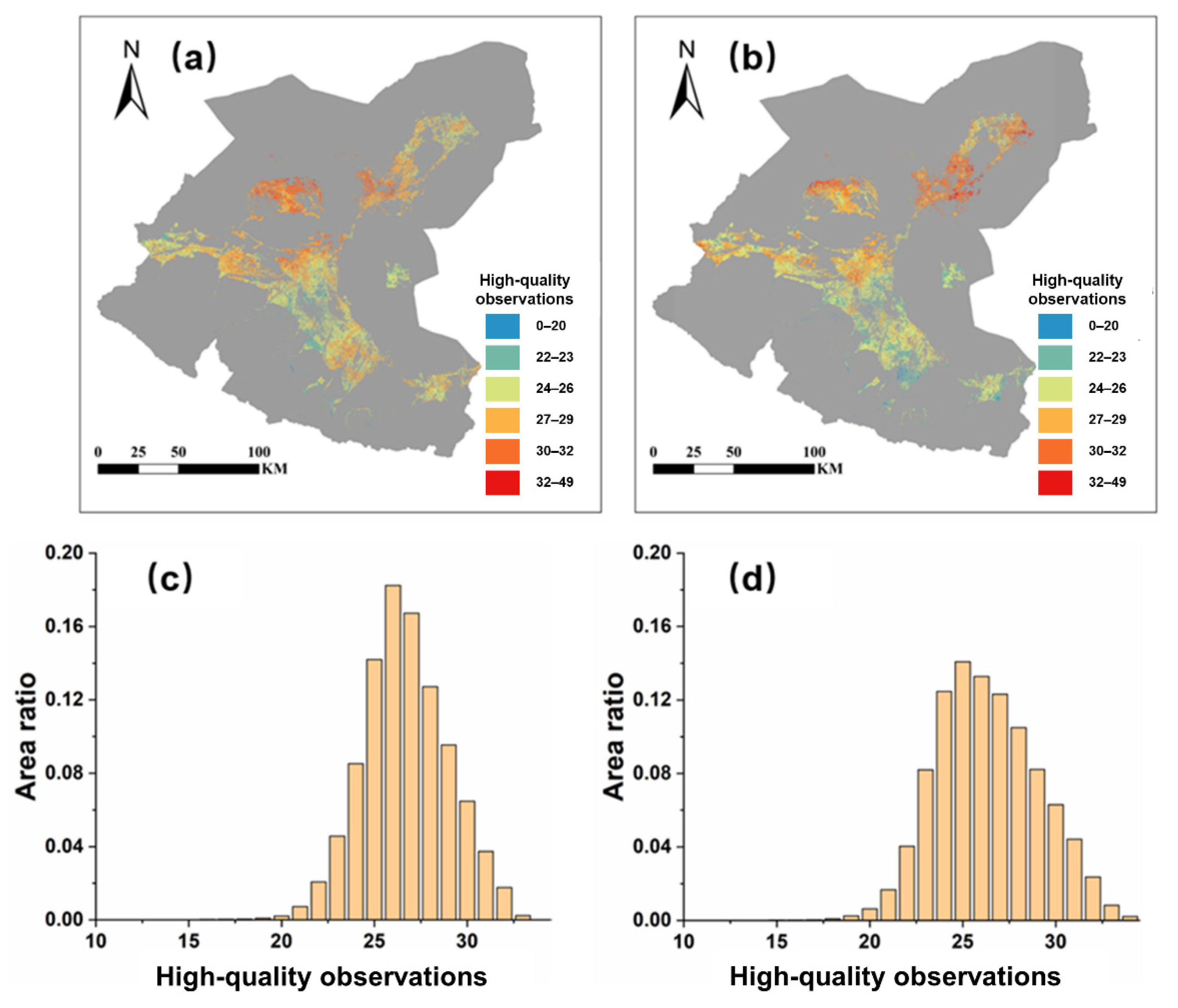{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Crop Type | Field-Plot Number | Pixel Number | ||
|---|---|---|---|---|
| 2019 | 2020 | 2019 | 2020 | |
| Wheat | 29 | 58 | 2636 | 4030 |
| Corn | 62 | 166 | 3702 | 5358 |
| Melon | 78 | 162 | 3562 | 6580 |
| Fennel | 30 | 77 | 1549 | 1626 |
| Sunflower | 39 | 159 | 2522 | 5352 |
| Alfalfa | 30 | 32 | 2909 | 4897 |
| Total | 268 | 654 | 16,880 | 27,843 |
| Classifiers | Hyper-Parameters | Optional Values | Selected Values |
|---|---|---|---|
| RF | n_estimators | 100, 200, 300, 400, 500 | 500 |
| max_depth | 5, 7, 9, 11, 13, None | 13 | |
| min_samples_split | 2, 5, 10, 15, 20 | 2 | |
| min_samples_leaf | 1, 2, 5, 10 | 1 | |
| max_features | log2, sqrt, none | sqrt | |
| SVM | C | 0.001, 0.01, 0.1, 1, 10, 100 | 1 |
| gamma | 0.01, 0.1, 1, 2, 10 | 2 |
| Actual Types | Predicted Types | Total | PA | |||||
|---|---|---|---|---|---|---|---|---|
| Melons | Sunflower | Fennel | Alfalfa | Wheat | Corn | |||
| Melons | 4843 | 328 | 353 | 150 | 159 | 747 | 6580 | 0.58 ± 0.09 |
| Sunflower | 484 | 3998 | 197 | 265 | 5 | 403 | 5352 | 0.51 ± 0.10 |
| Fennel | 159 | 70 | 1280 | 32 | 3 | 82 | 1626 | 0.76 ± 0.16 |
| Alfalfa | 223 | 150 | 60 | 4047 | 108 | 309 | 4897 | 0.78 ± 0.09 |
| Wheat | 50 | 6 | 5 | 68 | 3876 | 25 | 4030 | 0.98 ± 0.03 |
| Corn | 198 | 143 | 52 | 17 | 41 | 4907 | 5358 | 0.97 ± 0.02 |
| Total | 5957 | 4695 | 1947 | 4579 | 4192 | 6473 | 27,843 | |
| Proportion | 0.1267 | 0.0590 | 0.0428 | 0.1266 | 0.2108 | 0.4341 | 1 | |
| UA | 0.81 ± 0.06 | 0.85 ± 0.06 | 0.66 ± 0.11 | 0.88 ± 0.11 | 0.93 ± 0.07 | 0.76 ± 0.07 | ||
| OA | 0.81 ± 0.04 | Kappa | 0.79 | |||||
| HSES | HSFS | SFSMY | |||||||
|---|---|---|---|---|---|---|---|---|---|
| PA | UA | F1 Score | PA | UA | F1 Score | PA | UA | F1 Score | |
| Melons | 0.74 | 0.81 | 0.77 | 0.85 | 0.87 | 0.86 | 0.95 | 0.95 | 0.95 |
| Sunflower | 0.75 | 0.85 | 0.80 | 0.78 | 0.89 | 0.83 | 0.96 | 0.96 | 0.95 |
| Fennel | 0.78 | 0.64 | 0.70 | 0.95 | 0.66 | 0.78 | 0.94 | 0.94 | 0.94 |
| Alfalfa | 0.83 | 0.88 | 0.85 | 0.84 | 0.96 | 0.90 | 0.98 | 0.98 | 0.98 |
| Wheat | 0.96 | 0.93 | 0.94 | 0.95 | 0.95 | 0.95 | 0.97 | 0.99 | 0.97 |
| Corn | 0.92 | 0.76 | 0.83 | 0.93 | 0.82 | 0.87 | 0.96 | 0.96 | 0.96 |
| OA | 0.83 | 0.87 | 0.96 | ||||||
| Kappa | 0.79 | 0.84 | 0.95 | ||||||
| HSES vs. HSFS | HSFS vs. SFSMY | |||
|---|---|---|---|---|
| Z Value | Significant? | Z Value | Significant? | |
| Melons | 4.98 | YES, 5% | 1.76 | YES, 10% |
| Sunflower | 4.09 | YES, 5% | 1.99 | YES, 5% |
| Fennel | 2.92 | YES, 5% | 1.86 | YES, 10% |
| Alfalfa | 0.34 | NO | 1.33 | NO |
| Wheat | 0.13 | NO | 0.50 | NO |
| Corn | 1.98 | YES, 5% | 1.79 | YES, 10% |
| Total | 5.49 | YES, 5% | 2.54 | YES, 5% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yi, Z.; Jia, L.; Chen, Q.; Jiang, M.; Zhou, D.; Zeng, Y. Early-Season Crop Identification in the Shiyang River Basin Using a Deep Learning Algorithm and Time-Series Sentinel-2 Data. Remote Sens. 2022, 14, 5625. https://doi.org/10.3390/rs14215625
Yi Z, Jia L, Chen Q, Jiang M, Zhou D, Zeng Y. Early-Season Crop Identification in the Shiyang River Basin Using a Deep Learning Algorithm and Time-Series Sentinel-2 Data. Remote Sensing. 2022; 14(21):5625. https://doi.org/10.3390/rs14215625
Chicago/Turabian StyleYi, Zhiwei, Li Jia, Qiting Chen, Min Jiang, Dingwang Zhou, and Yelong Zeng. 2022. "Early-Season Crop Identification in the Shiyang River Basin Using a Deep Learning Algorithm and Time-Series Sentinel-2 Data" Remote Sensing 14, no. 21: 5625. https://doi.org/10.3390/rs14215625