
Pomelo Tree Detection Method Based on Attention Mechanism and Cross-Layer Feature Fusion

 , ,
, ,  and
and
Abstract
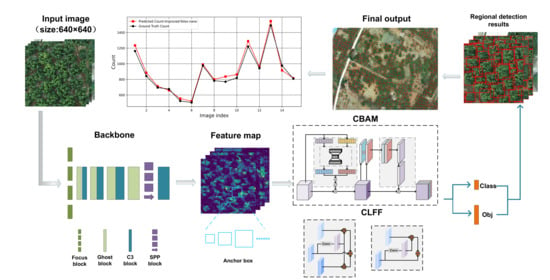
:
1. Introduction
- The two-stage algorithm has good performance in tree detection, but the algorithm is complex, leading to computational inefficiency and slow detection.
- The one-stage algorithm runs faster than the two-stage one, but the model size is still too large for real-time application. The lightweight version of the one-stage algorithm is fast enough, but the feature-extraction ability is limited.
- Some studies used an attention mechanism and a feature-fusion module to improve feature-extraction ability. However, they did not consider the advantage of the complimentary characteristics between different layers.
- A hybrid attention mechanism module weights the pixels of the feature map with channel attention and spatial attention to improve feature extraction and highlight pomelo tree regions in backgrounds;
- A feature-fusion module fuses the feature maps of different layers without greatly increasing computation, so it effectively aggregates feature maps;
- A Ghost module replaces the convolution module, reducing the number of parameters and the computational complexity of the deep network, so as to further improve the model-detection effect.
2. Materials and Methods
2.1. Materials
2.1.1. Image Data Collection
2.1.2. Image Annotation and Data Generation
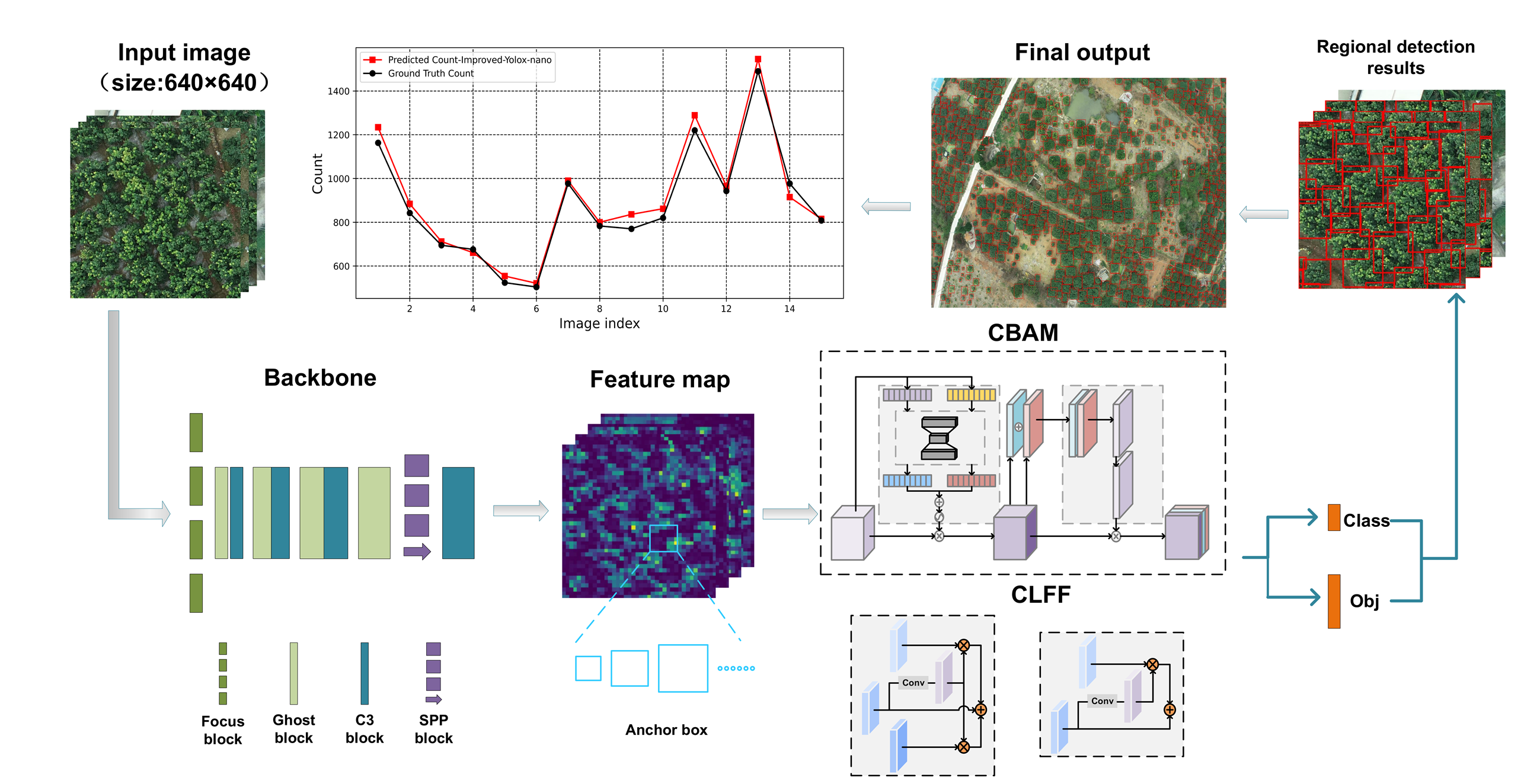
2.2. Proposed Method
2.2.1. Hybrid Attention Mechanism Module
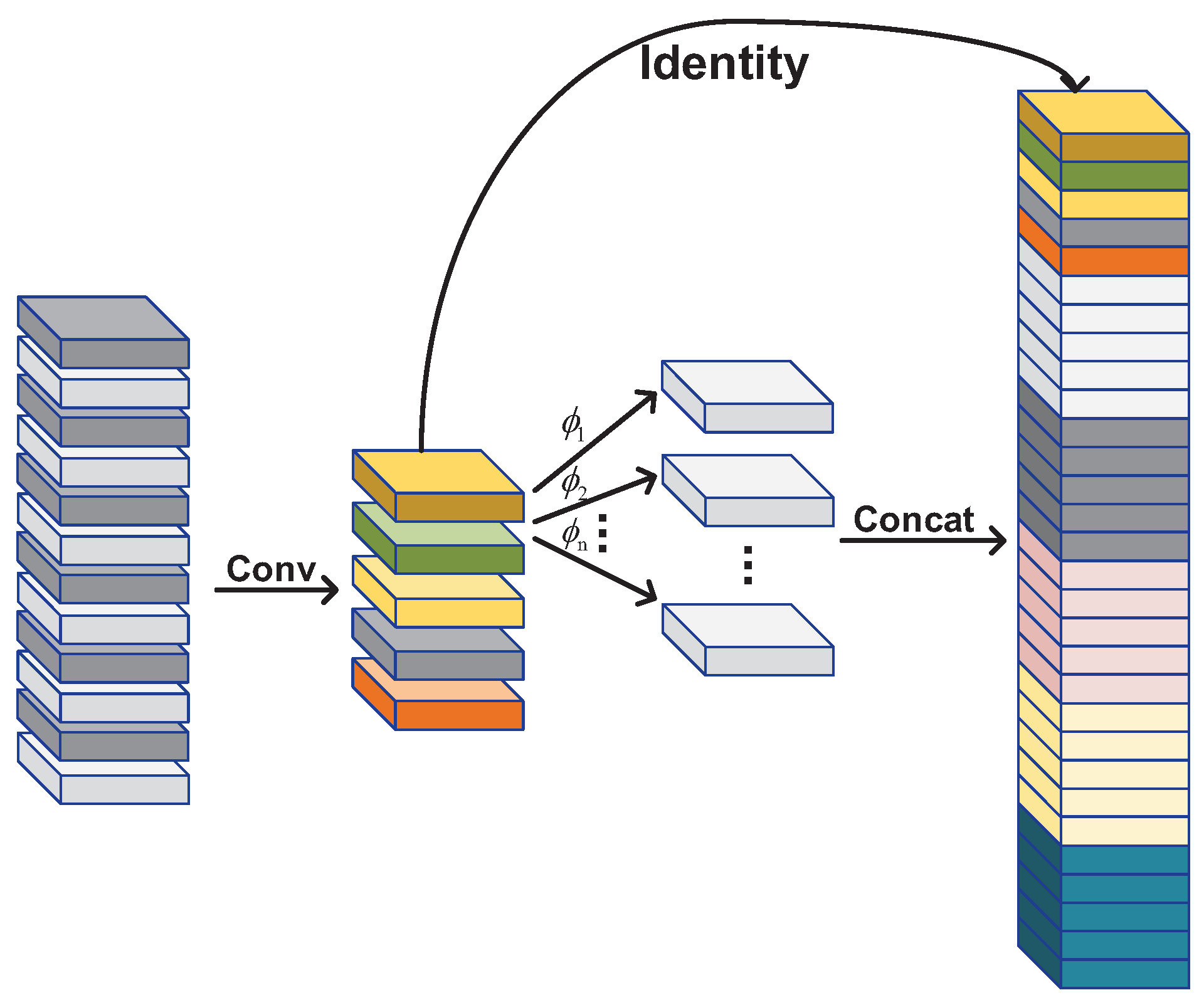
2.2.2. Cross-Layer Feature Fusion Pyramid
- 1.
- For the middle feature map , we generate the semantic mask using a convolution with a kernel;
- 2.
- We multiply the semantic mask and shallow-feature map , and the semantic mask and deep-feature map ;
- 3.
- We sum the above two results, and feed the sum to a convolution layer to obtain the output of the feature-fusion module.
2.2.3. Ghost Convolution Module
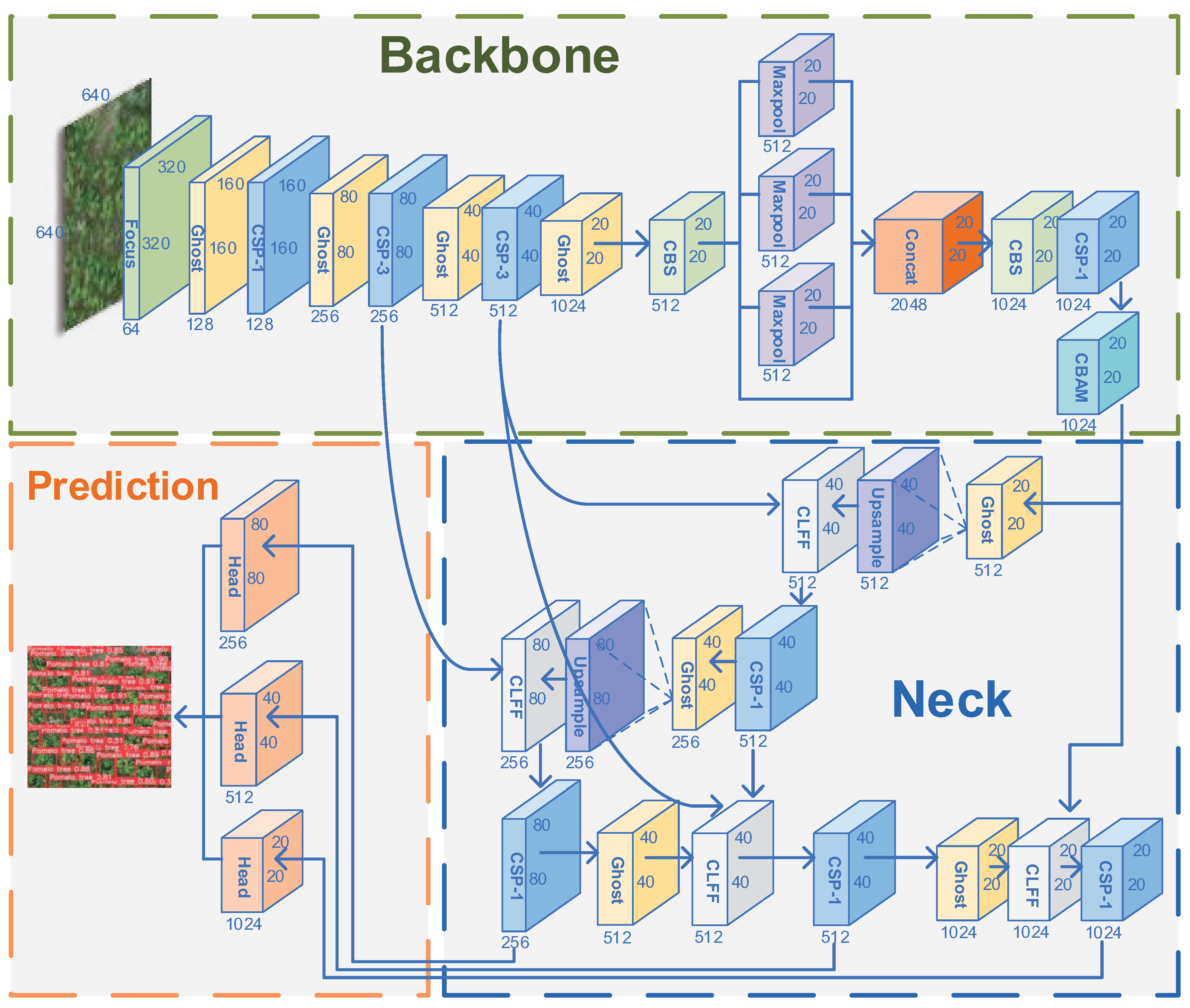
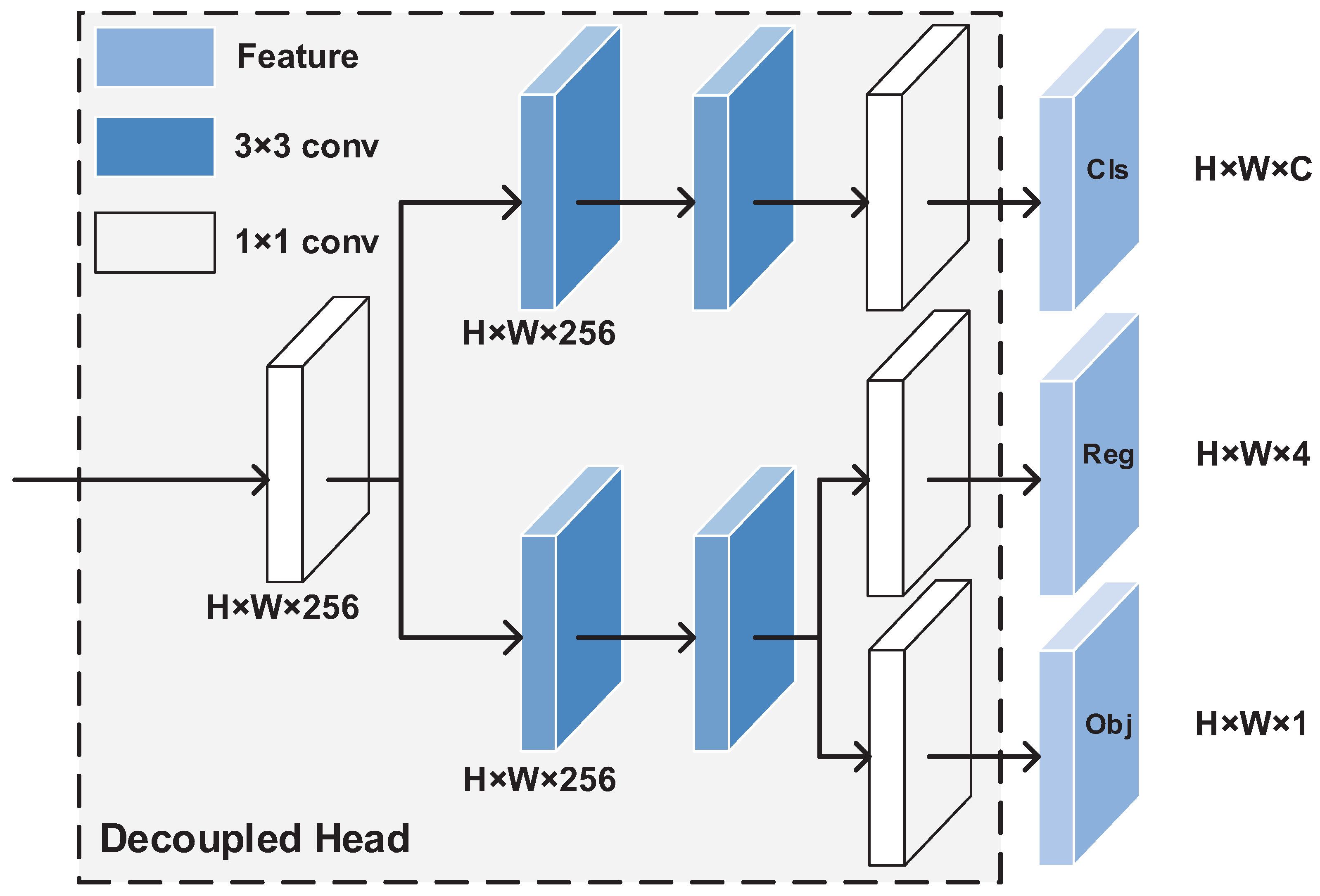
2.3. Pomelo Tree-Detection Network
- The Focus module uses a slicing operation to split a high-resolution feature map into multiple low-resolution feature maps. This module samples and splices the input feature maps in each column and obtains output feature maps by convolution operations, which can reduce information loss due to downsampling;
- The CBS structure consists of convolutional layers, normalization processing, and SiLU activation functions, which have the characteristics of no upper or lower bound, smoothness, and non-monotonicity, which can improve accuracy;
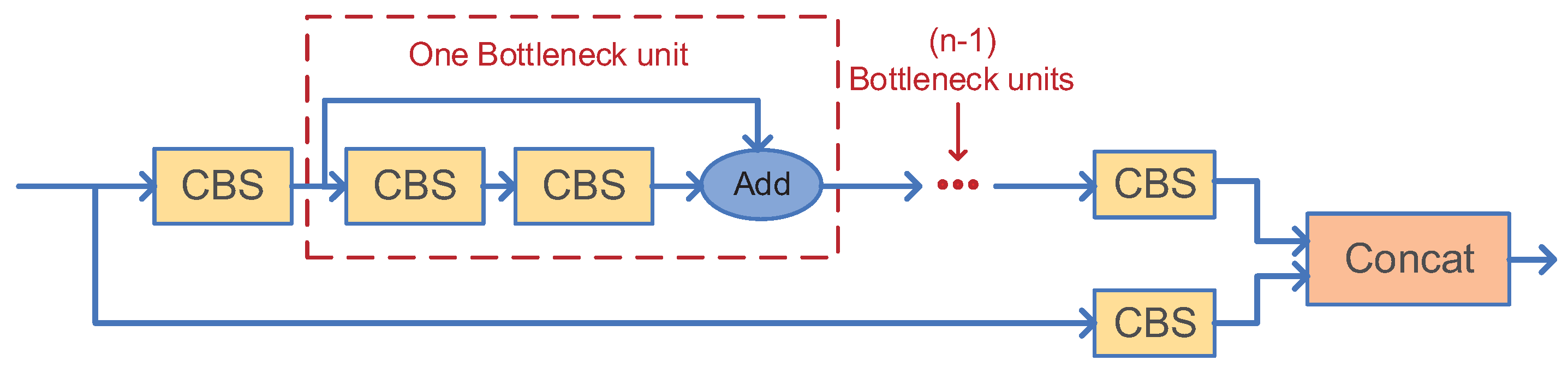
- The CSP structure consists of a standard convolutional structure and a bottleneck module, which reduces and then expands the number of channels, with the final number of input and output channels remaining the same. The input feature layer of the CSP has two branches, one with multi-bottleneck stacking and standard convolution, and the other with a basic convolution module, as shown in Figure 7. The feature maps of the two branches are aggregated by a concat operation. To reduce the model size, we only stack the bottleneck modules once in the CSP structure;
- The SPP module can realize the fusion of local and global features, which enriches the information of the feature map. It performs well in the case of large differences in target size.

3. Results
3.1. Standard of Performance Evaluation
3.2. Comparison to State-of-the-Art Object-Detection Algorithms
3.2.1. Comparison of Detection Performance
- Faster R-CNN had the lowest precision, with just 43.17% and 16.08%, respectively, in datasets 1 and 2, perhaps because of the complex background. Faster R-CNN does not build an image feature pyramid, and cannot effectively use shallow and small-scale features, resulting in a high number of false detections and low precision. In addition, this method appears to overfit, which resulted in much lower accuracy than other methods, indicating that this method is unsuitable for pomelo tree detection.
- SSD had an extremely low recall, with 58.23% and 30.06% in datasets 1 and 2, respectively, because SSD has no feature pyramid, the same as in Faster R-CNN. The recall rate of SSD was 1% to 4% lower than that of Faster R-CNN, which uses two-step detection. It first generates the region of interest, and then detects within it. Therefore, two-step detection could reduce the number of missed objects, and had a higher recall rate. However, the recall rates of SSD and Faster R-CNN were both lower than those of other methods owing to the lack of a feature pyramid.
- YOLOv3 had the highest precision of all methods, reaching over 93% in the first dataset and 91% in the second region. However, its recall was less than 80% and 50% in the two datasets, respectively. YOLOv3 is the most complex because it includes a large number of convolution modules, which incur more computational cost.
- YOLOv4-tiny had similar detection results to YOLOv3, as they are both single-stage detectors. Although YOLOx-nano is also a single-stage detector, it had about 6% to 25% higher recall than YOLOv4-tiny and YOLOv3 in both regions because it has two PANet structures that can constitute a bottom-up feature pyramid, which can enhance feature extraction. In addition, YOLOx-nano is anchor-free, which is better than an anchor-based detector for single-tree detection in remote-sensing images [59]. Because an anchor-based detector matches the object based on the anchor box’s size, it misses detection if the object’s size exceeds that of the anchor box. The anchor free detector efficiently eliminates the problem that the anchor box does not match the object size and lowers the possibility of missed detection.
- Libra and CCTD are both two-stage detectors and therefore have a high recall rate on both datasets, with about 87% in the first dataset and 80% in the second dataset. This result indicated that Libra and CCTD method had fewer missed detections. However, because Libra and CCTD are anchor-based method, their accuracy is limited, with only about 63% to 75% in the second dataset.
- Our method obtained the highest among all algorithms, which demonstrates its effectiveness. The precision was 92.41% and 87.18% in datasets 1 and 2, respectively, the recall was 87.07% and 75.35%, and the AP value was 93.74% and 87.81%. Among all compared methods, the value of ours was the highest. The outstanding performance of our method can be attributed to the attention mechanism, the cross-layer feature-fusion pyramid, and the Ghost module. The attention mechanism improves the capacity to extract feature information across space and channels, and provides enough feature suppression background information. The cross-layer feature-fusion pyramid combines semantic information from feature maps at different levels of layers, allowing it to learn rich information. Use of the Ghost module instead of convolution reduces the variance of the feature geometry, thus deepening the feature information association between deep and shallow feature maps.
- The model size of our proposed method was 7.8 MB only, which is 98% and 96% smaller than that of Libra and YOLOv3, respectively, and is just slightly more than that of YOLOx-nano. In addition, our method was the fastest of all methods. It is worth noting that the size of our proposed method is larger than YOLOx-nano, but it runs faster than YOLOx-nano. This is because the ghost module we used can reduce the computational complexity. In summary, our improvements make the model lighter and more computationally efficient.
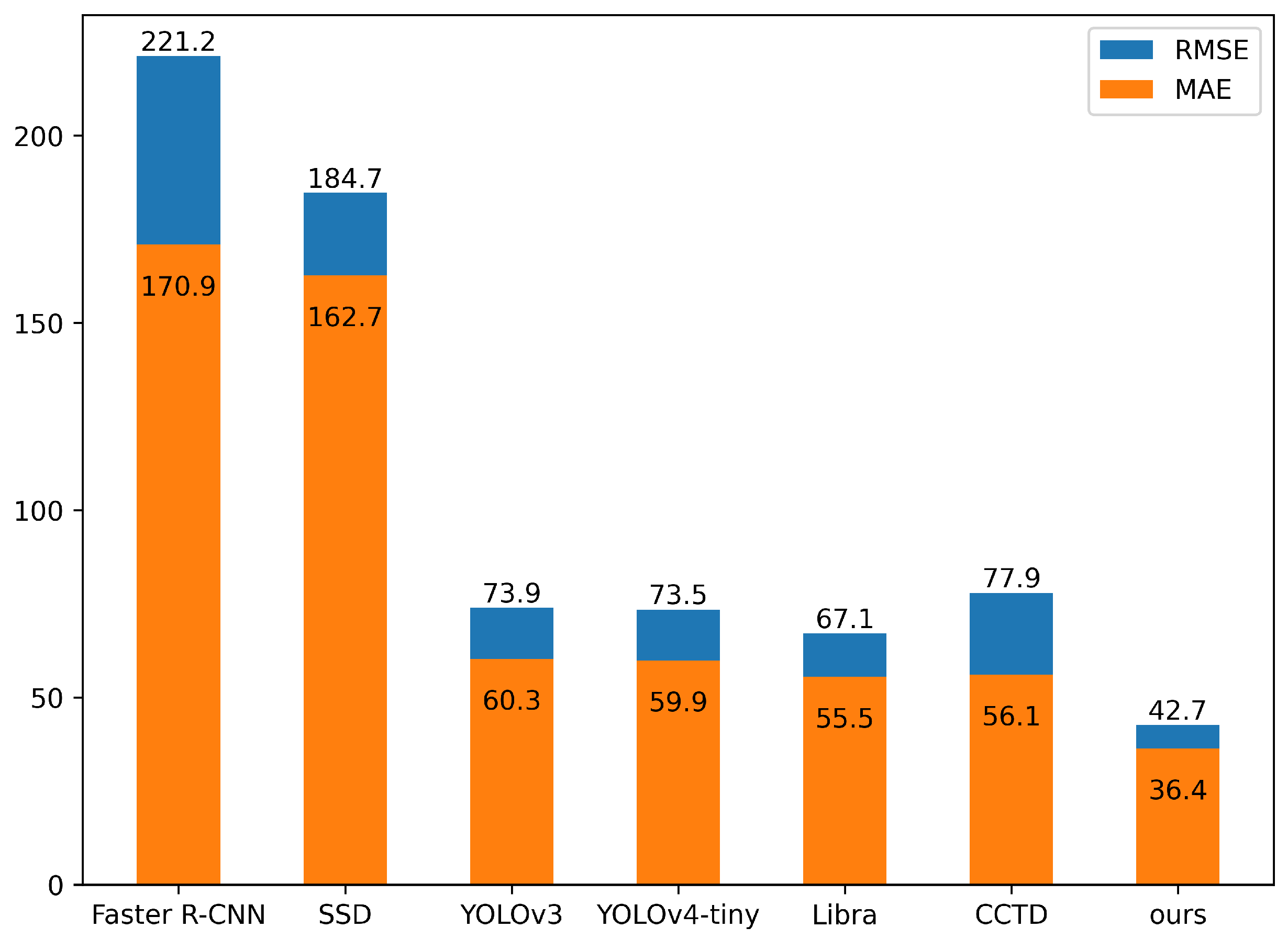
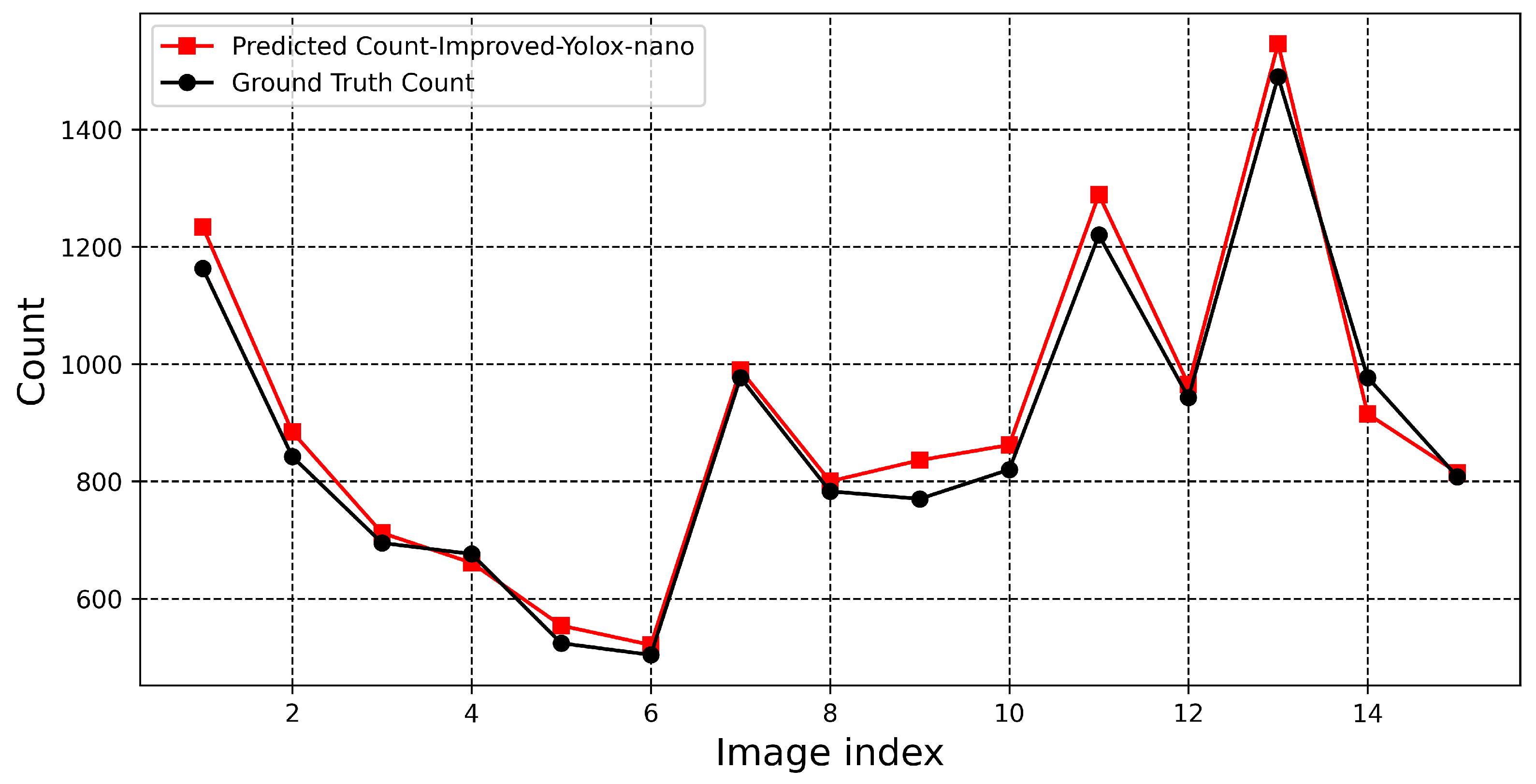
3.2.2. Counting Performance
3.3. Ablation Experiments
3.3.1. Attention Mechanism
3.3.2. Use of Cross-Layer Fusion Feature Pyramid
3.3.3. Use of Ghost Module
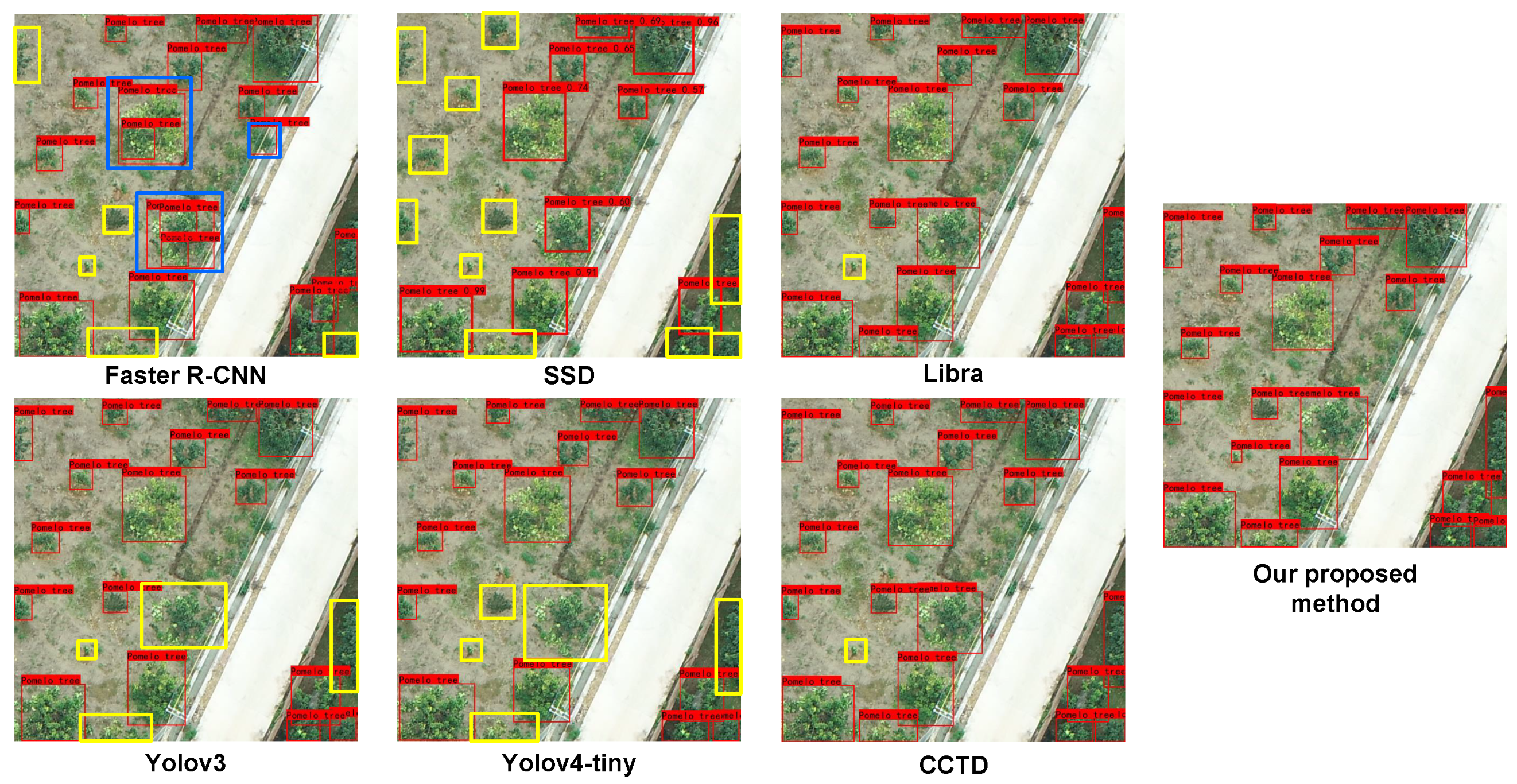
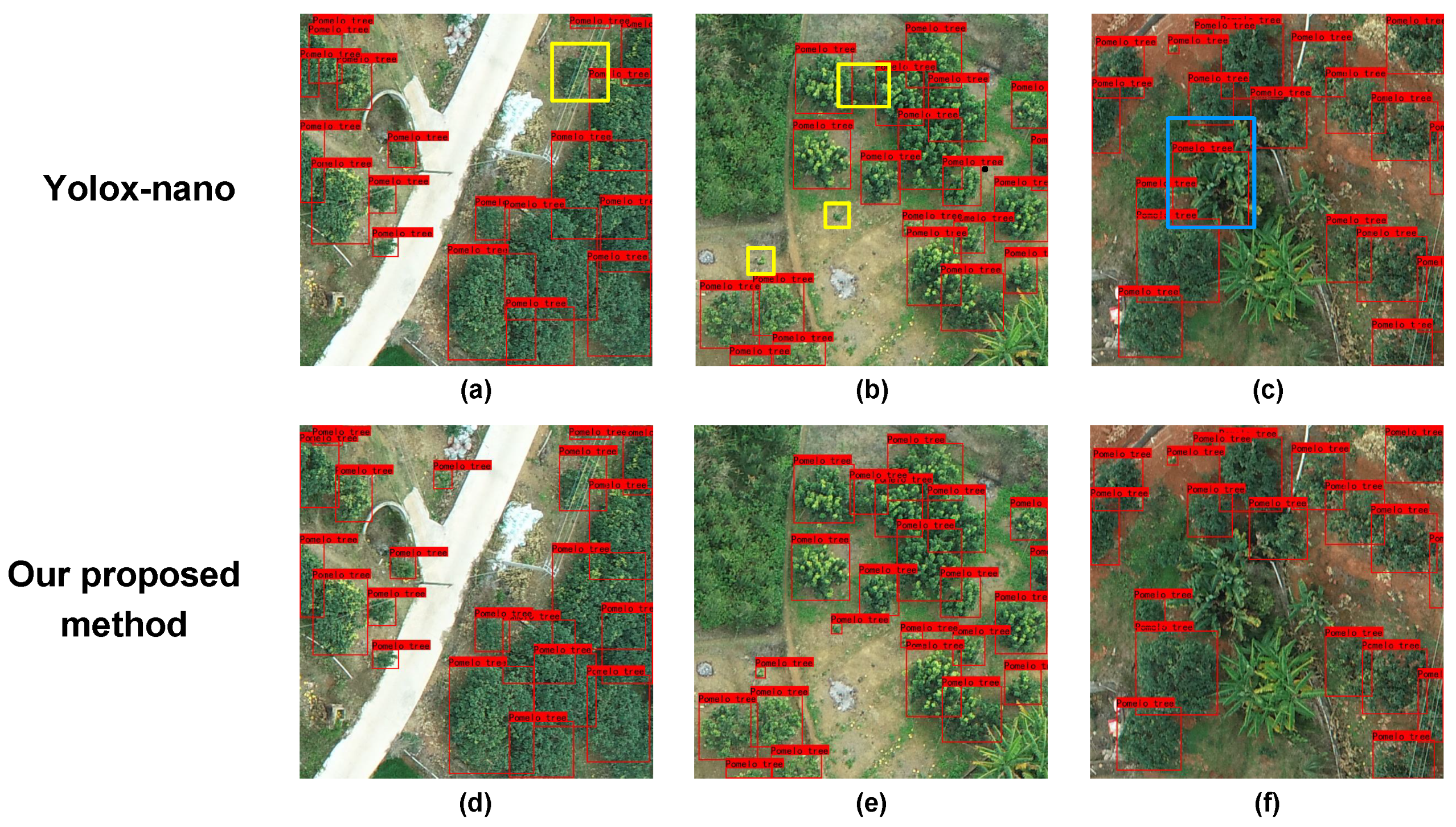
3.3.4. Visual Effect
4. Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| ACC | Accuracy |
| BiFPN | Bidirectional Feature Pyramid Network |
| CBMA | Convolutional Block Attention Module |
| CBS | Convolution, Batch normalization and SiLU activation |
| Complete-IoU | |
| CLFF | Cross-Layer Feature Fusion |
| CNNs | Convolutional Neural Networks |
| CSP | Cross-Stage Partial |
| Intersection Over Union | |
| FPN | Feature Pyramid Network |
| MAE | Mean Error |
| PANet | Path Aggregation Network |
| RMSE | Root Mean Square Error |
| RPN | Region Proposal Network |
| Correlation Coefficient | |
| SGD | Stochastic Gradient Descent |
| SiLU | Sigmoid Weighted Liner Unit |
| SPP | Spatial Pyramid Pooling |
| UAVs | Unmanned Aerial Vehicles |
References
- Morton, J.F. Fruits of Warm Climates; JF Morton: Miami, FL, USA, 1987. [Google Scholar]
- Jiménez-Brenes, F.M.; López-Granados, F.; De Castro, A.; Torres-Sánchez, J.; Serrano, N.; Peña, J. Quantifying pruning impacts on olive tree architecture and annual canopy growth by using UAV-based 3D modelling. Plant Methods 2017, 13, 55. [Google Scholar] [CrossRef] [PubMed]
- Castillo-Ruiz, F.J.; Jimenez-Jimenez, F.; Blanco-Roldán, G.L.; Sola-Guirado, R.R.; Agueera-Vega, J.; Castro-Garcia, S. Analysis of fruit and oil quantity and quality distribution in high-density olive trees in order to improve the mechanical harvesting process. Span. J. Agric. Res. 2015, 13, e0209. [Google Scholar] [CrossRef]
- Garcia-Ruiz, F.; Sankaran, S.; Maja, J.M.; Lee, W.S.; Rasmussen, J.; Ehsani, R. Comparison of two aerial imaging platforms for identification of Huanglongbing-infected citrus trees. Comput. Electron. Agric. 2013, 91, 106–115. [Google Scholar] [CrossRef]
- Zhang, C.; Valente, J.; Kooistra, L.; Guo, L.; Wang, W. Orchard management with small unmanned aerial vehicles: A survey of sensing and analysis approaches. Precis. Agric. 2021, 22, 2007–2052. [Google Scholar] [CrossRef]
- Barbagallo, S.; Consoli, S.; Russo, A. A one-layer satellite surface energy balance for estimating evapotranspiration rates and crop water stress indexes. Sensors 2009, 9, 1–21. [Google Scholar] [CrossRef] [PubMed]
- Salgadoe, A.S.A.; Robson, A.J.; Lamb, D.W.; Dann, E.K.; Searle, C. Quantifying the severity of phytophthora root rot disease in avocado trees using image analysis. Remote Sens. 2018, 10, 226. [Google Scholar] [CrossRef]
- Moran, M.S.; Inoue, Y.; Barnes, E. Opportunities and limitations for image-based remote sensing in precision crop management. Remote Sens. Environ. 1997, 61, 319–346. [Google Scholar] [CrossRef]
- Wal, T.; Abma, B.; Viguria, A.; Prévinaire, E.; Zarco-Tejada, P.J.; Serruys, P.; Valkengoed, E.V.; Voet, P. Fieldcopter: Unmanned aerial systems for crop monitoring services. In Precision Agriculture ’13; Wageningen Academic Publishers: Wageningen, The Netherlands, 2013; pp. 169–175. [Google Scholar]
- Ochoa, K.S.; Guo, Z. A framework for the management of agricultural resources with automated aerial imagery detection. Comput. Electron. Agric. 2019, 162, 53–69. [Google Scholar] [CrossRef]
- Swetnam, T.L.; Falk, D.A. Application of metabolic scaling theory to reduce error in local maxima tree segmentation from aerial LiDAR. For. Ecol. Manag. 2014, 323, 158–167. [Google Scholar] [CrossRef]
- Yang, J.; He, Y.; Caspersen, J.P.; Jones, T.A. Delineating individual tree crowns in an uneven-aged, mixed broadleaf forest using multispectral watershed segmentation and multiscale fitting. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 10, 1390–1401. [Google Scholar] [CrossRef]
- Jing, L.; Hu, B.; Noland, T.; Li, J. An individual tree crown delineation method based on multi-scale segmentation of imagery. ISPRS J. Photogramm. Remote Sens. 2012, 70, 88–98. [Google Scholar] [CrossRef]
- Srestasathiern, P.; Rakwatin, P. Oil palm tree detection with high resolution multi-spectral satellite imagery. Remote Sens. 2014, 6, 9749–9774. [Google Scholar] [CrossRef]
- Dos Santos, A.M.; Mitja, D.; Delaître, E.; Demagistri, L.; de Souza Miranda, I.; Libourel, T.; Petit, M. Estimating babassu palm density using automatic palm tree detection with very high spatial resolution satellite images. J. Environ. Manag. 2017, 193, 40–51. [Google Scholar] [CrossRef] [PubMed]
- Pu, R.; Landry, S. A comparative analysis of high spatial resolution IKONOS and WorldView-2 imagery for mapping urban tree species. Remote Sens. Environ. 2012, 124, 516–533. [Google Scholar] [CrossRef]
- Hung, C.; Bryson, M.; Sukkarieh, S. Multi-class predictive template for tree crown detection. ISPRS J. Photogramm. Remote Sens. 2012, 68, 170–183. [Google Scholar] [CrossRef]
- Dalponte, M.; Ørka, H.O.; Ene, L.T.; Gobakken, T.; Næsset, E. Tree crown delineation and tree species classification in boreal forests using hyperspectral and ALS data. Remote Sens. Environ. 2014, 140, 306–317. [Google Scholar] [CrossRef]
- López-López, M.; Calderón, R.; González-Dugo, V.; Zarco-Tejada, P.J.; Fereres, E. Early detection and quantification of almond red leaf blotch using high-resolution hyperspectral and thermal imagery. Remote Sens. 2016, 8, 276. [Google Scholar] [CrossRef]
- Nevalainen, O.; Honkavaara, E.; Tuominen, S.; Viljanen, N.; Hakala, T.; Yu, X.; Hyyppä, J.; Saari, H.; Pölönen, I.; Imai, N.N.; et al. Individual tree detection and classification with UAV-based photogrammetric point clouds and hyperspectral imaging. Remote Sens. 2017, 9, 185. [Google Scholar] [CrossRef]
- Wang, Y.; Zhu, X.; Wu, B. Automatic detection of individual oil palm trees from UAV images using HOG features and an SVM classifier. Int. J. Remote Sens. 2019, 40, 7356–7370. [Google Scholar] [CrossRef]
- Huang, K.K.; Ren, C.X.; Liu, H.; Lai, Z.R.; Yu, Y.F.; Dai, D.Q. Hyperspectral image classification via discriminant Gabor ensemble filter. IEEE Trans. Cybern. 2021, 52, 8352–8365. [Google Scholar] [CrossRef] [PubMed]
- Albetis, J.; Duthoit, S.; Guttler, F.; Jacquin, A.; Goulard, M.; Poilvé, H.; Féret, J.B.; Dedieu, G. Detection of Flavescence dorée grapevine disease using unmanned aerial vehicle (UAV) multispectral imagery. Remote Sens. 2017, 9, 308. [Google Scholar] [CrossRef]
- Lei, S.; Luo, J.; Tao, X.; Qiu, Z. Remote Sensing Detecting of Yellow Leaf Disease of Arecanut Based on UAV Multisource Sensors. Remote Sens. 2021, 13, 4562. [Google Scholar] [CrossRef]
- Zhang, Y.; Wa, S.; Liu, Y.; Zhou, X.; Sun, P.; Ma, Q. High-Accuracy Detection of Maize Leaf Diseases CNN Based on Multi-Pathway Activation Function Module. Remote Sens. 2021, 13, 4218. [Google Scholar] [CrossRef]
- Nofrizal, A.Y.; Sonobe, R.; Yamashita, H.; Seki, H.; Mihara, H.; Morita, A.; Ikka, T. Evaluation of a One-Dimensional Convolution Neural Network for Chlorophyll Content Estimation Using a Compact Spectrometer. Remote Sens. 2022, 14, 1997. [Google Scholar] [CrossRef]
- Milioto, A.; Lottes, P.; Stachniss, C. Real-time semantic segmentation of crop and weed for precision agriculture robots leveraging background knowledge in CNNs. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 2229–2235. [Google Scholar]
- Potena, C.; Nardi, D.; Pretto, A. Fast and accurate crop and weed identification with summarized train sets for precision agriculture. In Proceedings of the International Conference on Intelligent Autonomous Systems, Shanghai, China, 3–7 July 2016; pp. 105–121. [Google Scholar]
- Milella, A.; Marani, R.; Petitti, A.; Reina, G. In-field high throughput grapevine phenotyping with a consumer-grade depth camera. Comput. Electron. Agric. 2019, 156, 293–306. [Google Scholar] [CrossRef]
- Qi, X.; Dong, J.; Lan, Y.; Zhu, H. Method for Identifying Litchi Picking Position Based on YOLOv5 and PSPNet. Remote Sens. 2022, 14, 2004. [Google Scholar] [CrossRef]
- Huang, B.; Zhao, B.; Song, Y. Urban land-use mapping using a deep convolutional neural network with high spatial resolution multispectral remote-sensing imagery. Remote Sens. Environ. 2018, 214, 73–86. [Google Scholar] [CrossRef]
- Huang, K.K.; Ren, C.X.; Liu, H.; Lai, Z.R.; Yu, Y.F.; Dai, D.Q. Hyperspectral image classification via discriminative convolutional neural network with an improved triplet loss. Pattern Recognit. 2021, 112, 107744. [Google Scholar] [CrossRef]
- Li, W.; Fu, H.; Yu, L.; Cracknell, A. Deep learning based oil palm tree detection and counting for high-resolution remote-sensing images. Remote Sens. 2016, 9, 22. [Google Scholar] [CrossRef]
- Pibre, L.; Chaumon, M.; Subsol, G.; Lenco, D.; Derras, M. How to deal with multi-source data for tree detection based on deep learning. In Proceedings of the 2017 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Montreal, QC, Canada, 14–16 November 2017; pp. 1150–1154. [Google Scholar]
- Wu, J.; Yang, G.; Yang, H.; Zhu, Y.; Li, Z.; Lei, L.; Zhao, C. Extracting apple tree crown information from remote imagery using deep learning. Comput. Electron. Agric. 2020, 174, 105504. [Google Scholar] [CrossRef]
- Zheng, J.; Fu, H.; Li, W.; Wu, W.; Yu, L.; Yuan, S.; Tao, W.Y.W.; Pang, T.K.; Kanniah, K.D. Growing status observation for oil palm trees using Unmanned Aerial Vehicle (UAV) images. ISPRS J. Photogramm. Remote Sens. 2021, 173, 95–121. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed]
- Osco, L.P.; De Arruda, M.d.S.; Junior, J.M.; Da Silva, N.B.; Ramos, A.P.M.; Moryia, É.A.S.; Imai, N.N.; Pereira, D.R.; Creste, J.E.; Matsubara, E.T.; et al. A convolutional neural network approach for counting and geolocating citrus-trees in UAV multispectral imagery. ISPRS J. Photogramm. Remote Sens. 2020, 160, 97–106. [Google Scholar] [CrossRef]
- Zheng, J.; Wu, W.; Yu, L.; Fu, H. Coconut Trees Detection on the Tenarunga Using High-Resolution Satellite Images and Deep Learning. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 6512–6515. [Google Scholar]
- Zheng, J.; Wu, W.; Yuan, S.; Fu, H.; Li, W.; Yu, L. Multisource-domain generalization-based oil palm tree detection using very-high-resolution (vhr) satellite images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Zheng, J.; Fu, H.; Li, W.; Wu, W.; Zhao, Y.; Dong, R.; Yu, L. Cross-regional oil palm tree counting and detection via a multi-level attention domain adaptation network. ISPRS J. Photogramm. Remote Sens. 2020, 167, 154–177. [Google Scholar] [CrossRef]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra r-cnn: Towards balanced learning for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 821–830. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. Scaled-yolov4: Scaling cross stage partial network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13029–13038. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Liu, R.; Tao, F.; Liu, X.; Na, J.; Leng, H.; Wu, J.; Zhou, T. RAANet: A Residual ASPP with Attention Framework for Semantic Segmentation of High-Resolution Remote Sensing Images. Remote Sens. 2022, 14, 3109. [Google Scholar] [CrossRef]
- Han, Z.; Hu, W.; Peng, S.; Lin, H.; Zhang, J.; Zhou, J.; Wang, P.; Dian, Y. Detection of Standing Dead Trees after Pine Wilt Disease Outbreak with Airborne Remote Sensing Imagery by Multi-Scale Spatial Attention Deep Learning and Gaussian Kernel Approach. Remote Sens. 2022, 14, 3075. [Google Scholar] [CrossRef]
- Gong, H.; Mu, T.; Li, Q.; Dai, H.; Li, C.; He, Z.; Wang, W.; Han, F.; Tuniyazi, A.; Li, H.; et al. Swin-Transformer-Enabled YOLOv5 with Attention Mechanism for Small Object Detection on Satellite Images. Remote Sens. 2022, 14, 2861. [Google Scholar] [CrossRef]
- Li, X.; Pan, J.; Xie, F.; Zeng, J.; Li, Q.; Huang, X.; Liu, D.; Wang, X. Fast and accurate green pepper detection in complex backgrounds via an improved Yolov4-tiny model. Comput. Electron. Agric. 2021, 191, 106503. [Google Scholar] [CrossRef]
- Yu, J.; Wu, T.; Zhou, S.; Pan, H.; Zhang, X.; Zhang, W. An SAR Ship Object Detection Algorithm Based on Feature Information Efficient Representation Network. Remote Sens. 2022, 14, 3489. [Google Scholar] [CrossRef]
- Cheng, G.; Yang, C.; Yao, X.; Guo, L.; Han, J. When deep learning meets metric learning: Remote-sensing image scene classification via learning discriminative CNNs. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2811–2821. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 1580–1589. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Li, M.; Zhai, Y.M.; Luo, Y.W.; Ge, P.F.; Ren, C.X. Enhanced transport distance for unsupervised domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 13936–13944. [Google Scholar]
- Liu, J.J.; Hou, Q.; Cheng, M.M.; Feng, J.; Jiang, J. A simple pooling-based design for real-time salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3917–3926. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10781–10790. [Google Scholar]
- Zamboni, P.; Junior, J.M.; Silva, J.d.A.; Miyoshi, G.T.; Matsubara, E.T.; Nogueira, K.; Gonçalves, W.N. Benchmarking Anchor-Based and Anchor-Free State-of-the-Art Deep Learning Methods for Individual Tree Detection in RGB High-Resolution Images. Remote Sens. 2021, 13, 2482. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Configuration | Parameter |
|---|---|
| CPU | Intel Core i9-10900kes |
| GPU | 2 NVIDIA GeForce RTX 3090 |
| Accelerated environment | CUDA 11.3 CUDNN8.2.1 |
| Development | PyCharm2021.1.1 |
| Operating system | Ubantu 18.04 |
| Model frame | PyTorch 1.10 |
| Algorithm | Precision (%) | Recall (%) | AP (%) | F1-Score |
|---|---|---|---|---|
| Faster R-CNN | 43.17 | 63.99 | 53.98 | 0.52 |
| SSD | 82.56 | 58.23 | 68.92 | 0.68 |
| YOLOv3 | 93.64 | 79.24 | 91.74 | 0.86 |
| YOLOv4-tiny | 89.93 | 81.26 | 89.53 | 0.85 |
| YOLOx-nano | 90.99 | 86.43 | 93.08 | 0.89 |
| Libra | 87.12 | 87.85 | 89.25 | 0.87 |
| CCTD | 87.29 | 87.64 | 91.61 | 0.87 |
| ours | 92.41 | 87.07 | 93.74 | 0.90 |
| Algorithm | Precision (%) | Recall (%) | AP (%) | F1-Score |
|---|---|---|---|---|
| Faster R-CNN | 16.08 | 30.16 | 8.99 | 0.21 |
| SSD | 87.91 | 30.06 | 60.26 | 0.45 |
| YOLOv3 | 91.81 | 46.72 | 73.31 | 0.62 |
| YOLOv4-tiny | 84.73 | 62.37 | 79.09 | 0.72 |
| YOLOx-nano | 84.41 | 71.09 | 83.66 | 0.77 |
| Libra | 63.98 | 72.22 | 69.25 | 0.68 |
| CCTD | 76.67 | 83.84 | 84.72 | 0.80 |
| ours | 87.18 | 75.35 | 87.81 | 0.81 |
| Algorithms | Model Size | The Average | The Shortest |
|---|---|---|---|
| (MB) | Detection Time | Detection Time | |
| Faster R-CNN | 107.86 | 0.262 s | 0.248 s |
| SSD | 90.07 | 0.159 s | 0.125 s |
| YOLOv3 | 234.69 | 0.196 s | 0.174 s |
| YOLOv4-tiny | 22.41 | 0.133 s | 0.119 s |
| YOLOx-nano | 2.7 | 0.133 s | 0.121 s |
| Libra | 466 | 0.872 s | 0.828 s |
| CCTD | 315 | 0.615 s | 0.588 s |
| ours | 7.8 | 0.099 s | 0.091 s |
| Algorithm | MAE | RMSE | ACC (%) | |
|---|---|---|---|---|
| Faster R-CNN | 170.9 | 221.2 | 82.18 | 0.24 |
| SSD | 162.7 | 184.7 | 82.61 | 0.47 |
| YOLOv3 | 60.3 | 73.9 | 92.91 | 0.92 |
| YOLOv4-tiny | 59.9 | 73.5 | 93.12 | 0.92 |
| Libra | 55.5 | 67.1 | 92.97 | 0.93 |
| CCTD | 56.1 | 77.9 | 93.07 | 0.91 |
| ours | 36.4 | 42.7 | 95.93 | 0.97 |
| YOLOx-Nano | CBAM | CLFF | Ghost | .5 (%) | .5:.95 (%) |
|---|---|---|---|---|---|
| √ | 93.08 | 61.0 | |||
| √ | √ | 93.38 | 61.1 | ||
| √ | √ | 93.21 | 60.9 | ||
| √ | √ | 93.36 | 61.1 | ||
| √ | √ | √ | 93.53 | 61.3 | |
| √ | √ | √ | √ | 93.74 | 61.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, H.; Huang, K.; Ren, C.; Xiong, Y.; Duan, J.; Yang, Z. Pomelo Tree Detection Method Based on Attention Mechanism and Cross-Layer Feature Fusion. Remote Sens. 2022, 14, 3902. https://doi.org/10.3390/rs14163902
Yuan H, Huang K, Ren C, Xiong Y, Duan J, Yang Z. Pomelo Tree Detection Method Based on Attention Mechanism and Cross-Layer Feature Fusion. Remote Sensing. 2022; 14(16):3902. https://doi.org/10.3390/rs14163902
Chicago/Turabian StyleYuan, Haotian, Kekun Huang, Chuanxian Ren, Yongzhu Xiong, Jieli Duan, and Zhou Yang. 2022. "Pomelo Tree Detection Method Based on Attention Mechanism and Cross-Layer Feature Fusion" Remote Sensing 14, no. 16: 3902. https://doi.org/10.3390/rs14163902