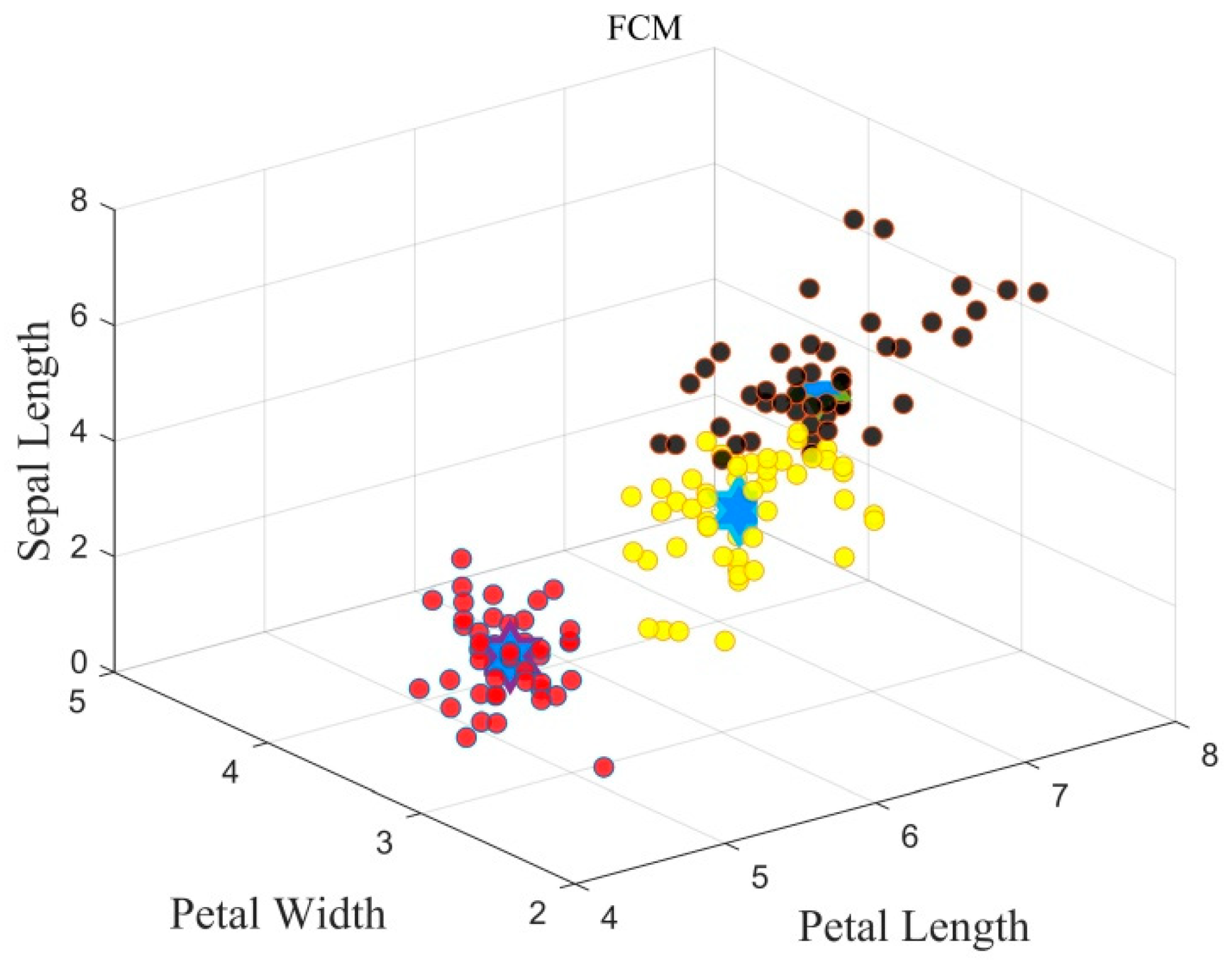
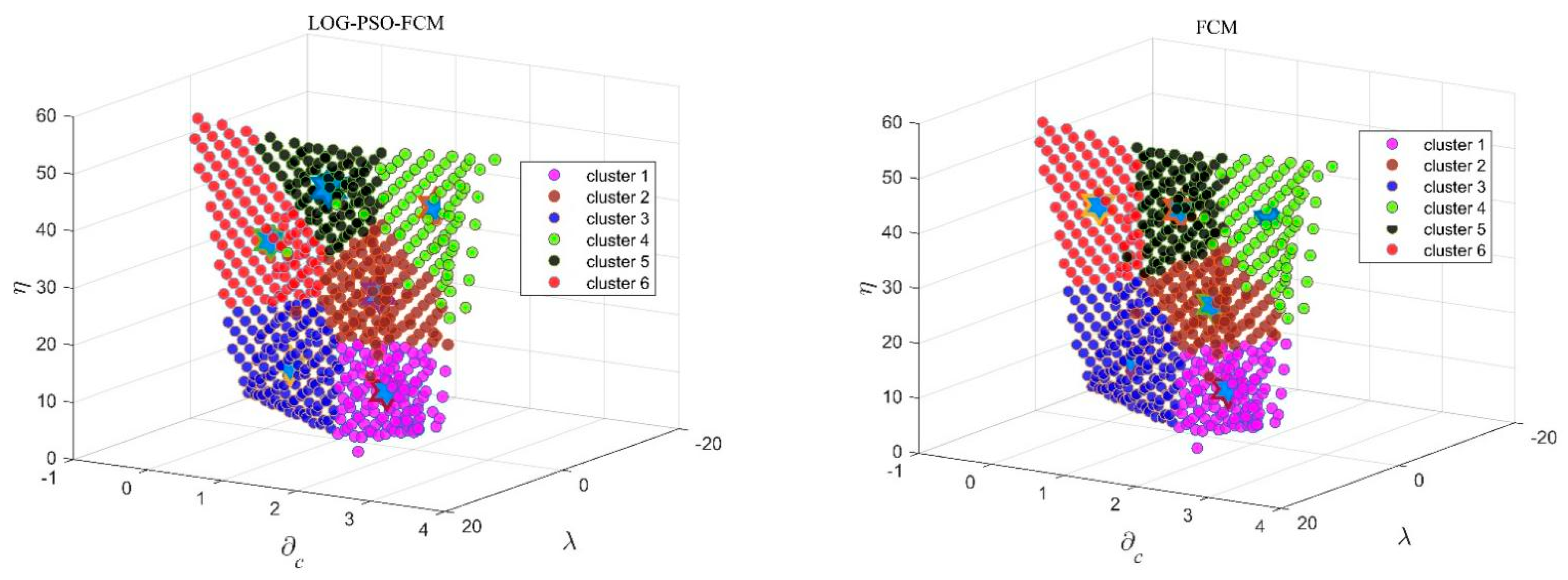
3.1. FCM Theory and Mathematic Basis
In the present paper, the dataset chosen artificially from triple-frequency combination observations of BDS-3 is defined as
of
objects indexed by
where each object is represented by its corresponding characteristic vector, i.e.,
. The characteristic vector is composed of
,
, and
. In order to eliminate the negative effects of the dimension, the raw dataset is manipulated by a Z-score calculator based on the mean value and standard deviation [
24,
25].
is defined as the amount of clusters. And is defined as the characteristic vector of the corresponding cluster center listed by . Note that the FCM is different from the hard cluster method (HCM) for the underlying idea of the fuzzy partition matrix , and is the important index that indicates the proportion of the object with cluster center. We define as the Euclidean distance between data and cluster center .
In the FCM, the fuzzy partition matrix is further added as follows
where
is the fuzzy weighting exponent ranging from 1 to 5, and it is regulated as 2 in this paper;
is the Euclidean distance between data
and cluster center
, i.e.,
. The constraint conditions are as follows
The FCM method falls into the category of iterative algorithms. In order to minimize the objective function, the cluster centers and fuzzy partition matrix are updated through the following equations based on the Lagrange method derived by rigorous mathematical proof.
During iteration, the cluster centers and fuzzy partition matrix are calculated. The process continues before the new cluster centers change within an error threshold, indicating that the prototypes of cluster centers are stabilized.
Additionally, before implementing the FCM method, the initialization should be finished. The random process is usually used to generate the fuzzy partition matrix and cluster center vectors, causing a severe convergence problem, i.e., falling into the local minimum trap.
3.2. Graph Theory
The clustering method falls into the unsupervised machine-learning algorithm, and there is no prior knowledge about the cluster structure of the dataset, including the number of clusters. Thus, the clustering algorithm executes random initiation conditions, leading to the non-convergence solution or falling into the local optimum.
Taking the selection of triple-frequency combination observations, for example, the first step is to generate a set of cluster centers before implementing the clustering method for almost all algorithms. Additionally, the number of clusters is also unknown, which will be determined by empirical rules or an artificial test. Usually, the maximum number of clusters is less than .
The present paper proposed a novel approach to calculate the number , called the graph theory model.
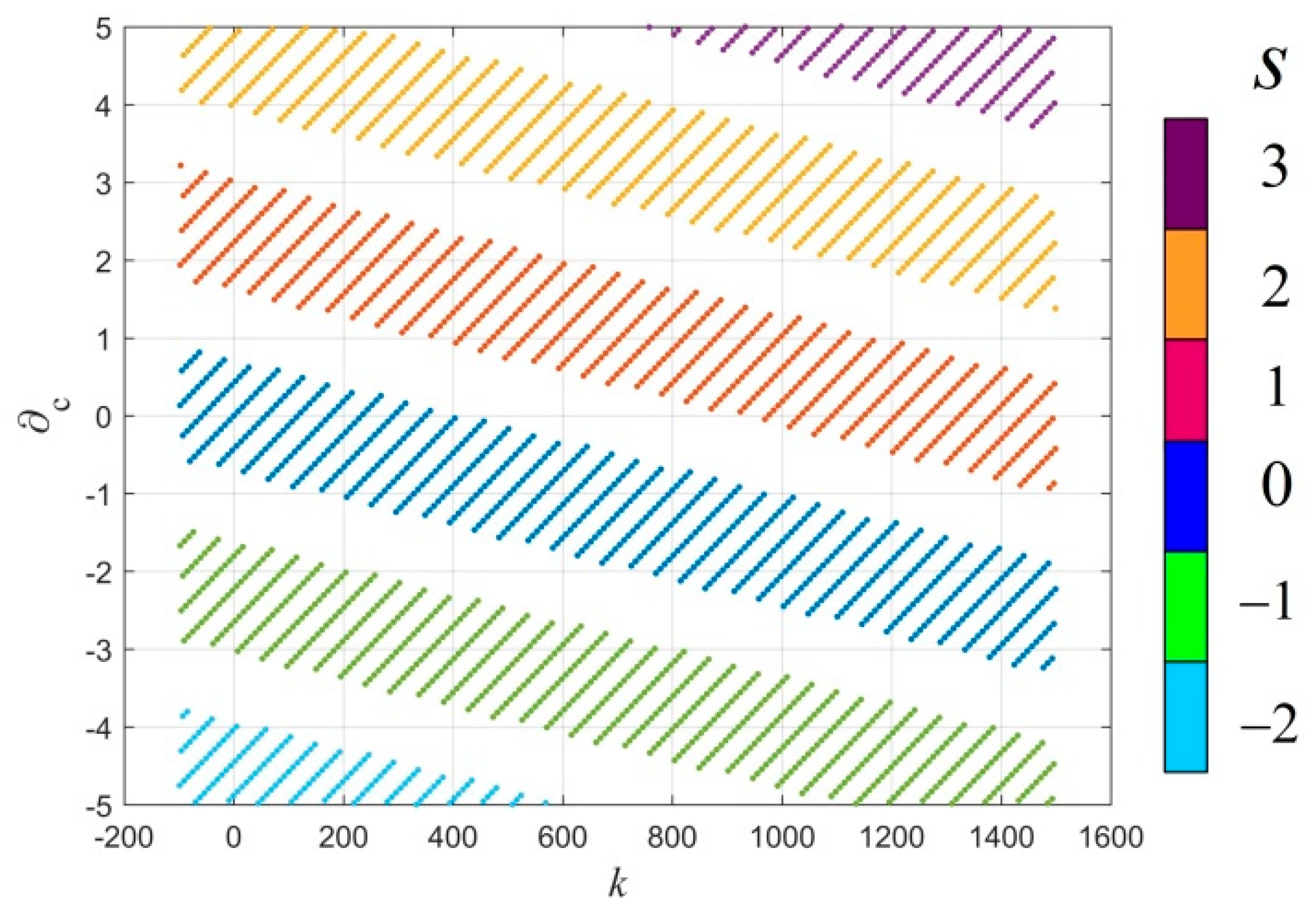
Imagine the different data vectors are points in hyper-dimension space. Under specific distance measurement, we determine the distance between any two points. Then, all the data points and the corresponding distance relationship can be treated as undirected weighted graph in graph theory.
A graph is a pair where is a set of vertices, and is a set of edges. The amount of vertices equals the number of data, while the number of edges is .
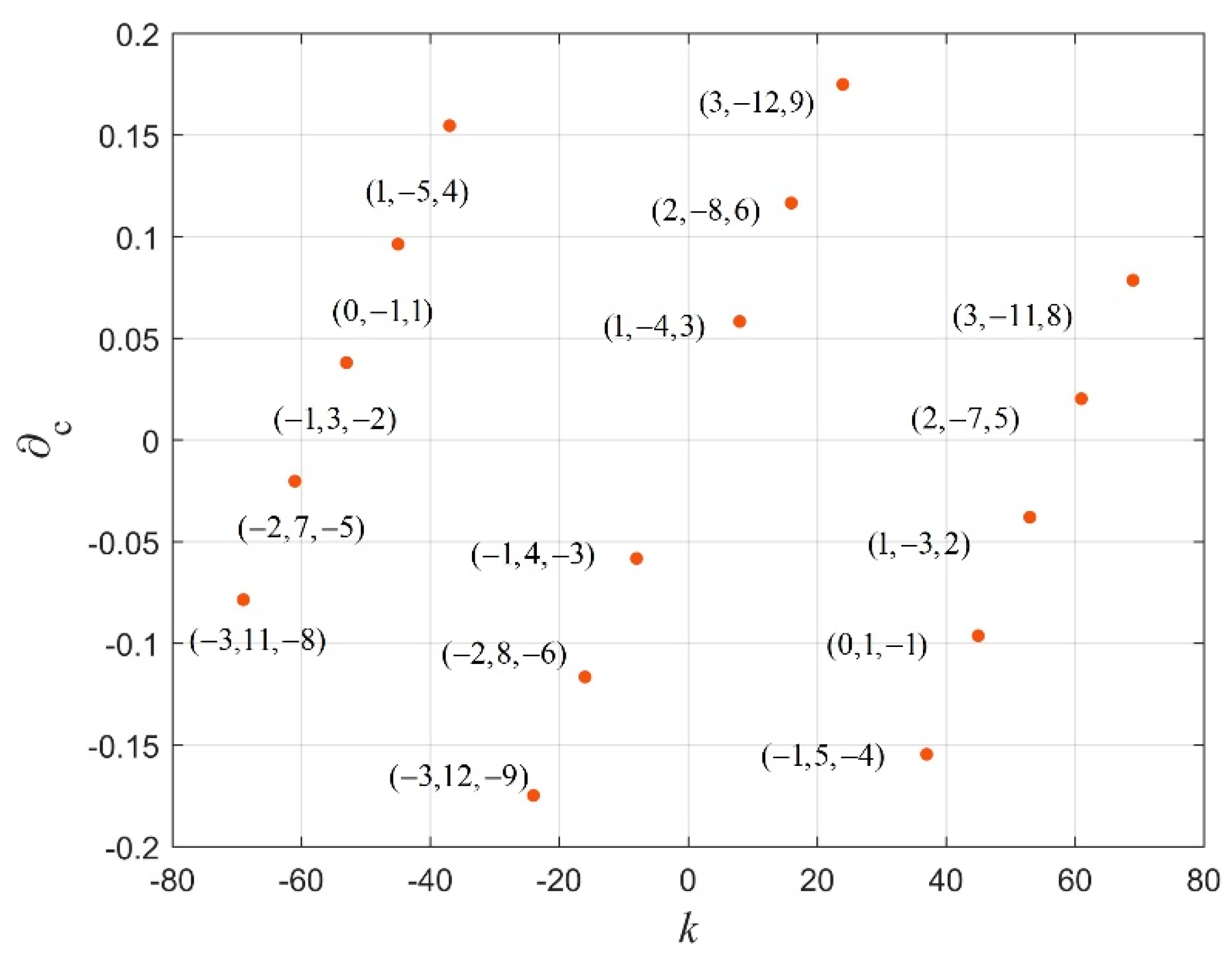
In order to analyze the relationship between every pair of vertices, the Chebyshev distance is the measurement of the different vertices. The definition of the Chebyshev distance is given as follows:
Further, we define the distance exponent ; edges with distance of more than will be eliminated, where the is the average distance for all the selected edges.
It is impossible and meaningless to incorporate all edges with the graph, especially the ones with too large a distance, which means that they are probably not similar. The underlying idea is to eliminate the extra edges with too large a distance, i.e., more than , and to save those edges with limited distance. Then, we can refer to some methods in graph theory, e.g., degree distribution, to analyze the cluster structure.
In graph theory, we can obtain a matrix denoting the relationship between adjacent vertices, called the adjacent matrix, which is given by
The degree of
is represented as
, which is actually the number of edges connected with the vertices The degree can be expressed as
where
is the diagonal element of matrix
.
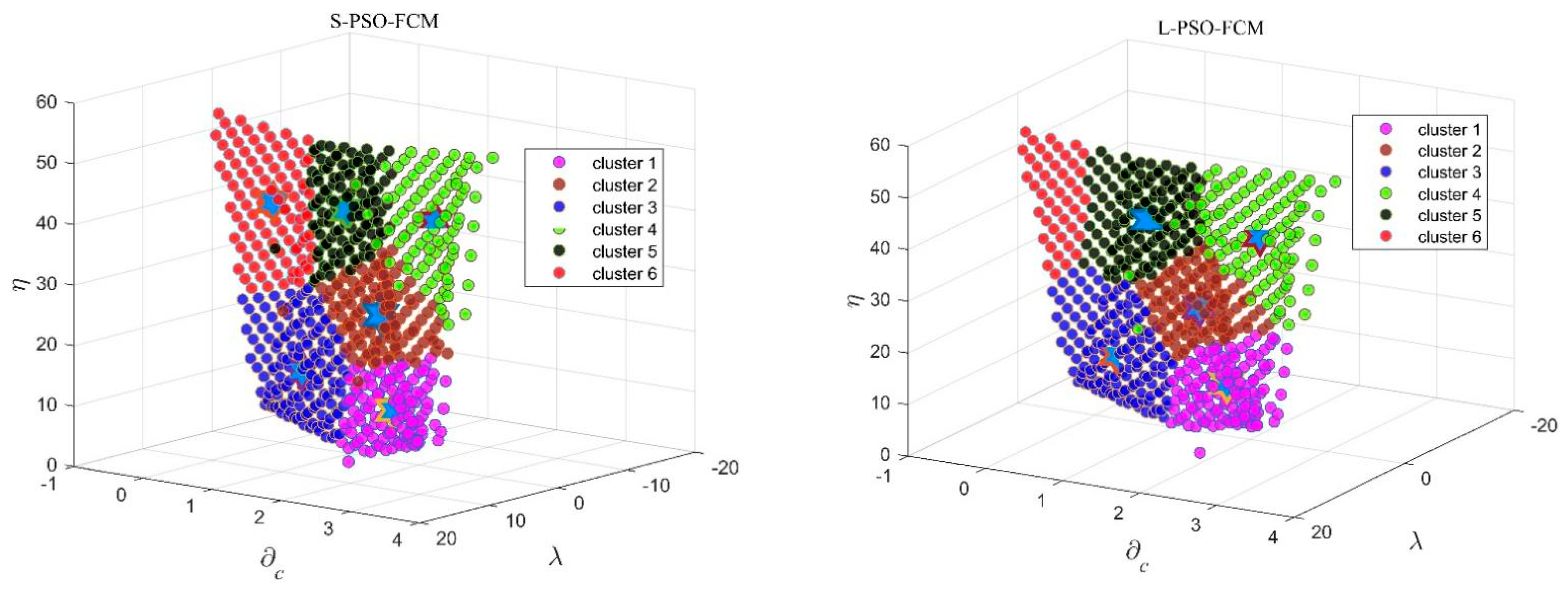
The vertices with a large degree, and the belonging vertices, will be considered as one cluster. The remaining vertices will update the degree distribution, and then, a similar process will be executed to determine the other cluster centers and their belonging vertices.
Step1: calculate the degree for all vertices.
Step2: reckon the one with the largest degree is the one of the cluster center and eliminate this vertex and its belonging edges.
Step3: calculate the amount of remaining vertices, judge whether the number is less than . If yes, then classify these vertices to the nearest cluster, and if not, return to Step 1.
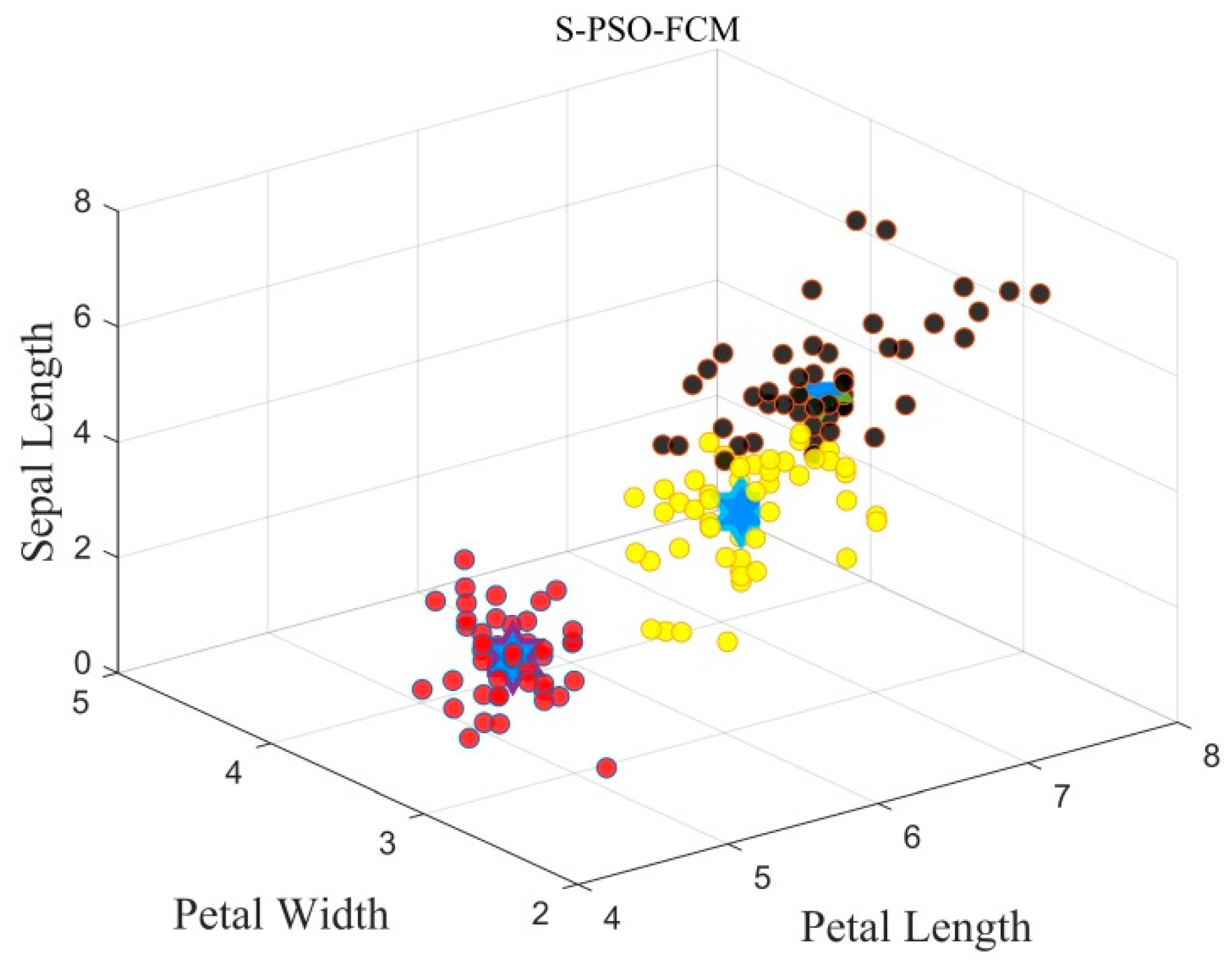
With the support of the graph theory, we are able to obtain the probable cluster center and the amount of classes . It is noted that the results are very coarse and merely serve as the initiation of the clustering algorithm. And the initiation results are much better than the random calculation.
3.4. Particle Swarm Optimization (PSO)
The traditional PSO algorithm runs in an intuitive and simple way where each particle utilizes the prior best solution itself and the other particle with global best solution [
27]. Ref. [
28] claims that the particle swarm technique is more efficient with respect to generic algorithms. Additionally, it was mentioned in ref. [
29] that PSO outperforms the differential evolution algorithm.
During the iteration, a certain number of particles are involved to find the best solution. Each particle owns two kinds of properties. One is solution property, referred to as the position matrix p, and the other is mutation property, referred to as the velocity matrix v. Parameters in the optimal control problem constitute the position vector, and every particle can be recognized as a possible solution. The velocity vector includes the information of each particle’s mutation, which helps the particle to find better solution.
Assume
to be the size of the swarm. The position vector and velocity vector can be formulated as
p and
v. For each particle, the previous best solution property in history will be remarked as
, while the global best solution is
. Obviously,
is of superiority with respect to
. The PSO follows the equation to search better solutions
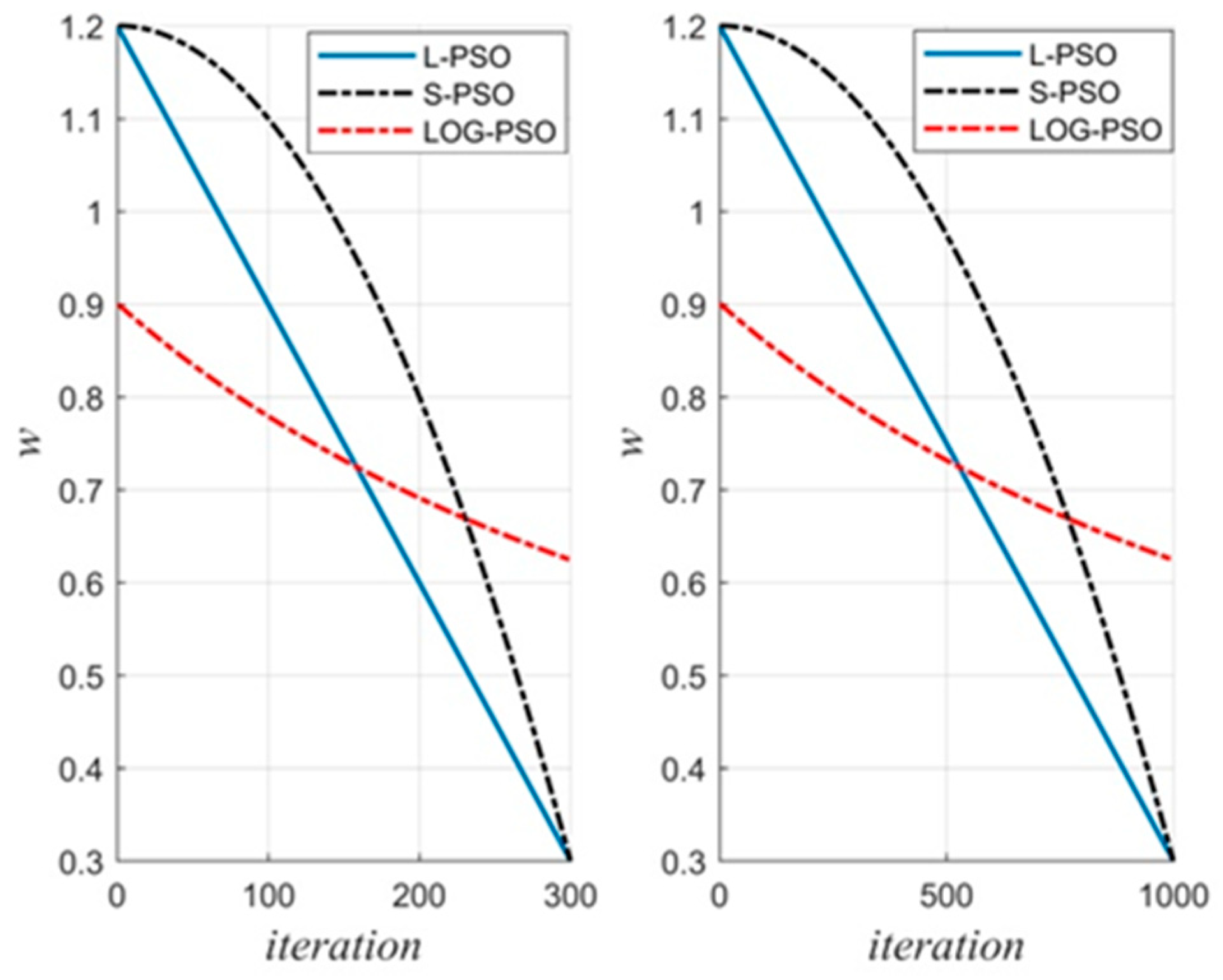
where
denotes the
particle’s mutation with regard to the parameter in the iteration;
is the inertial weight;
and
are acceleration coefficients;
are random numbers, which are uniformly distributed in the interval between 0 and 1. More details can be found in ref. [
27].
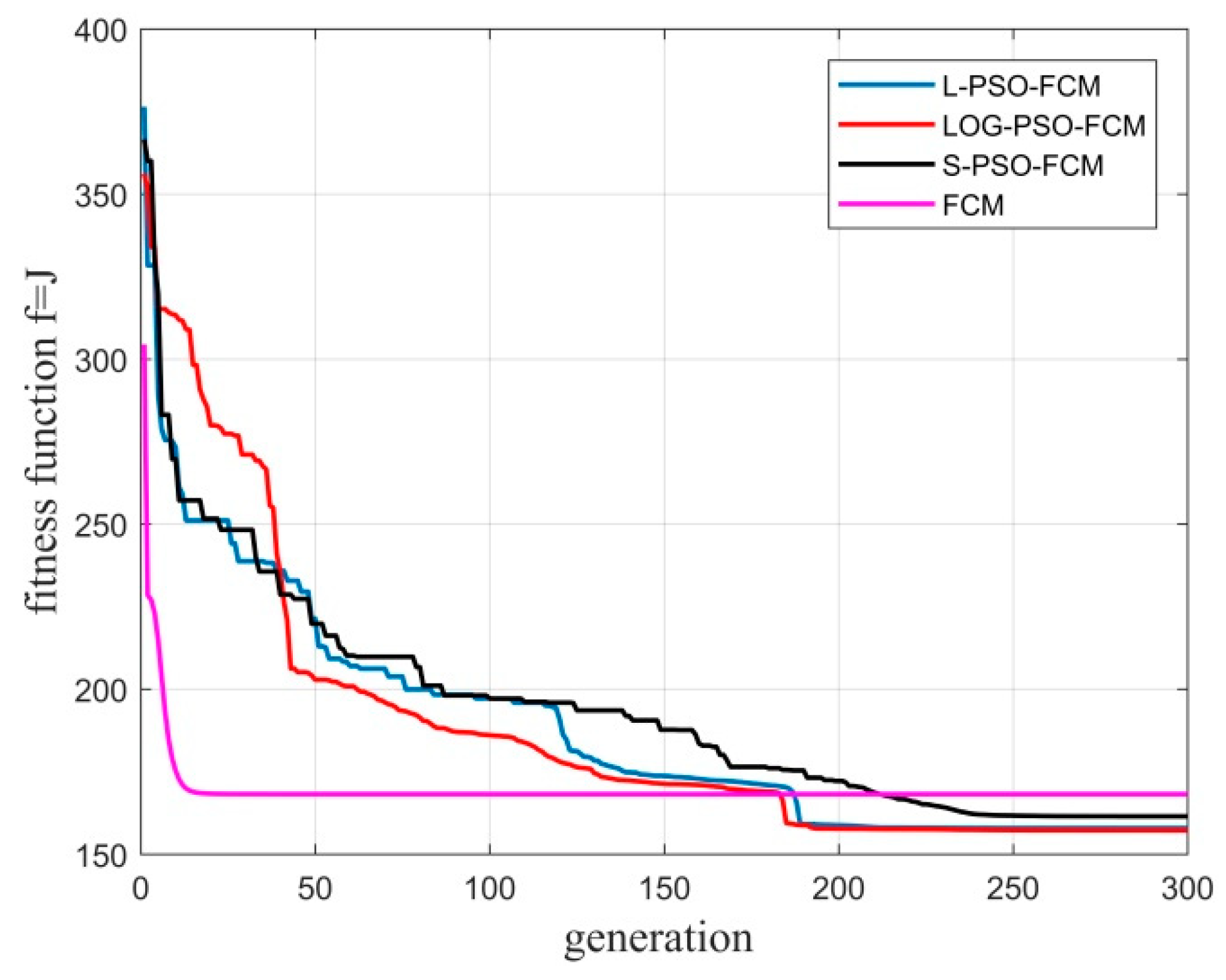
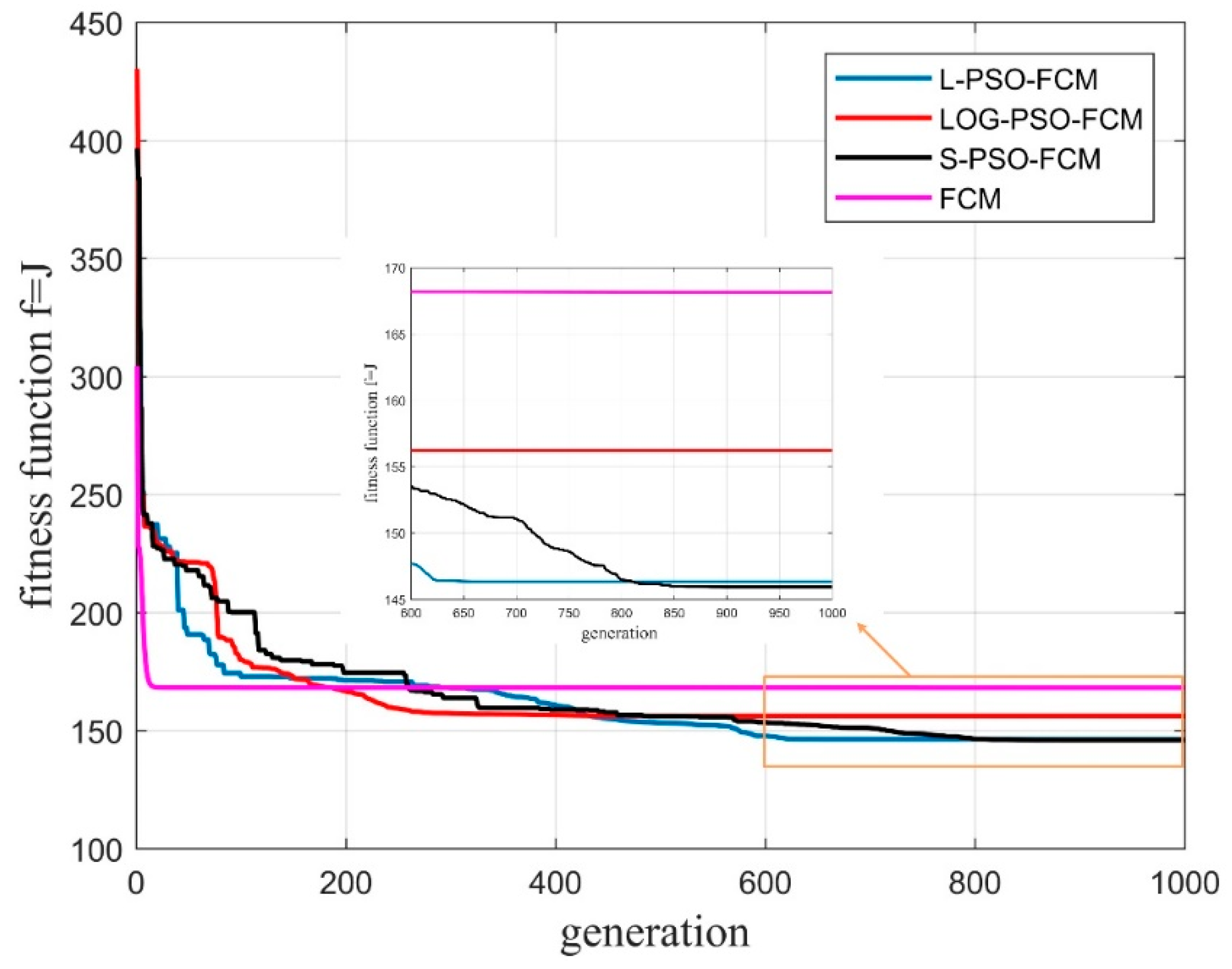
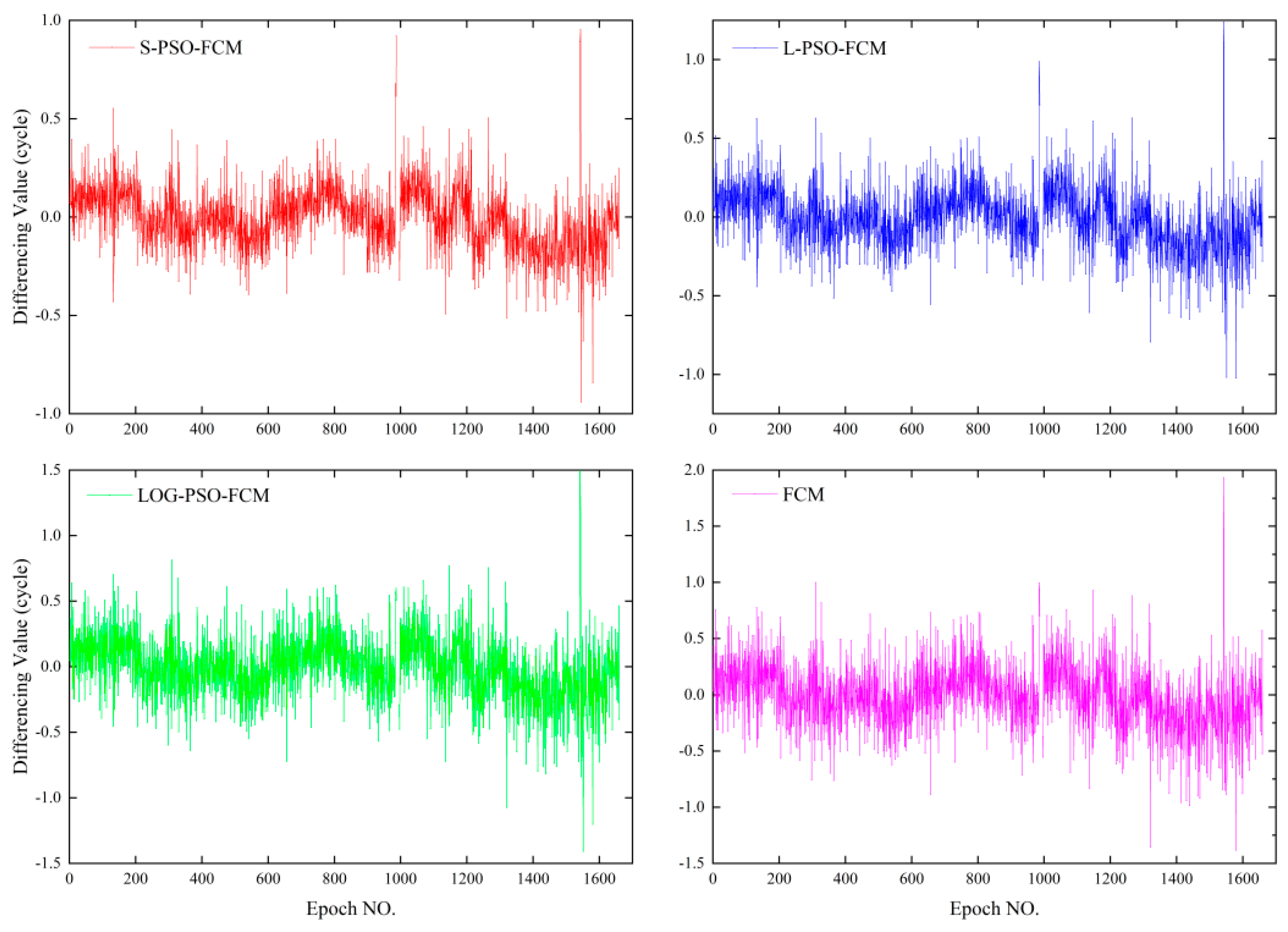
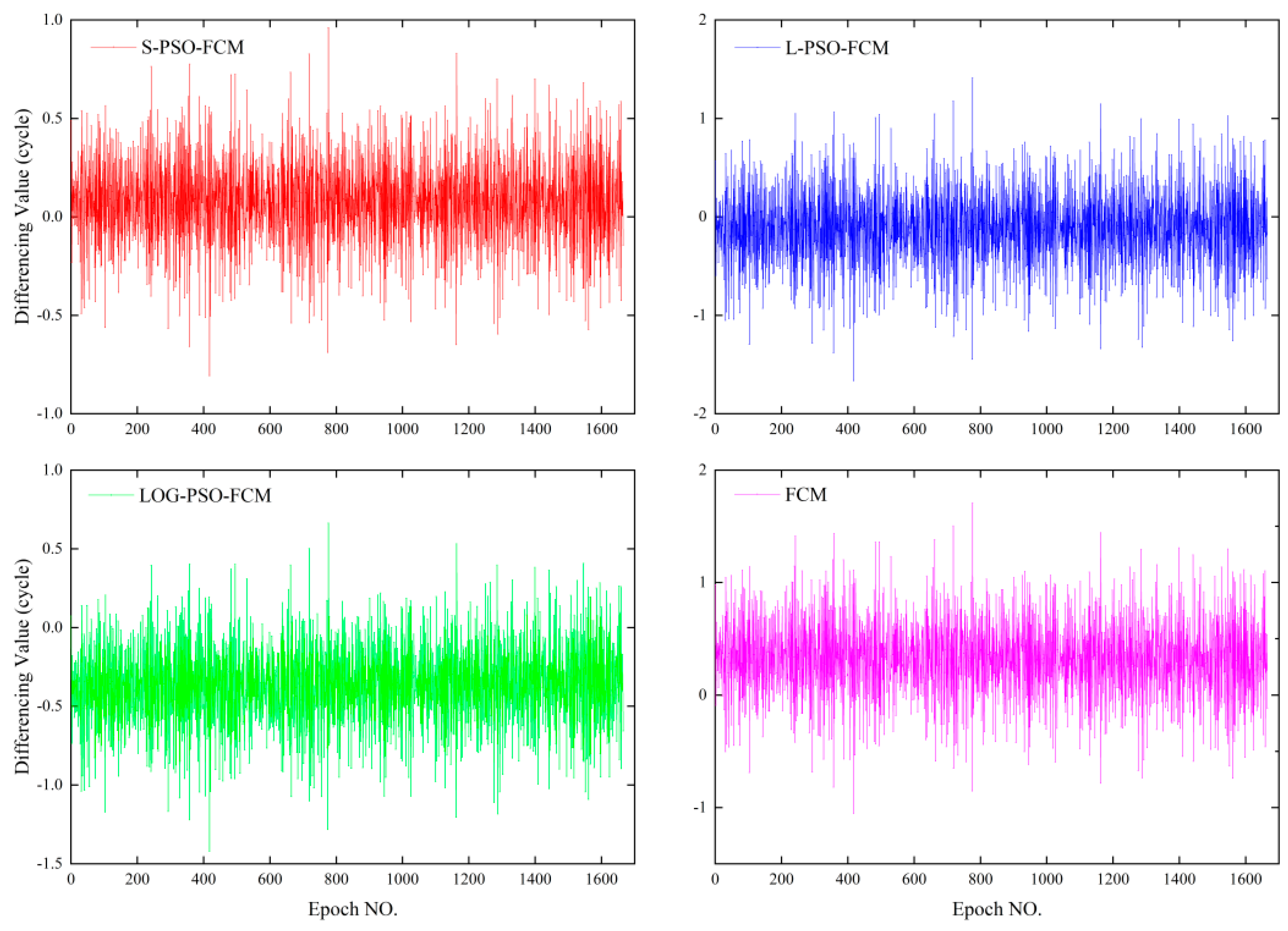
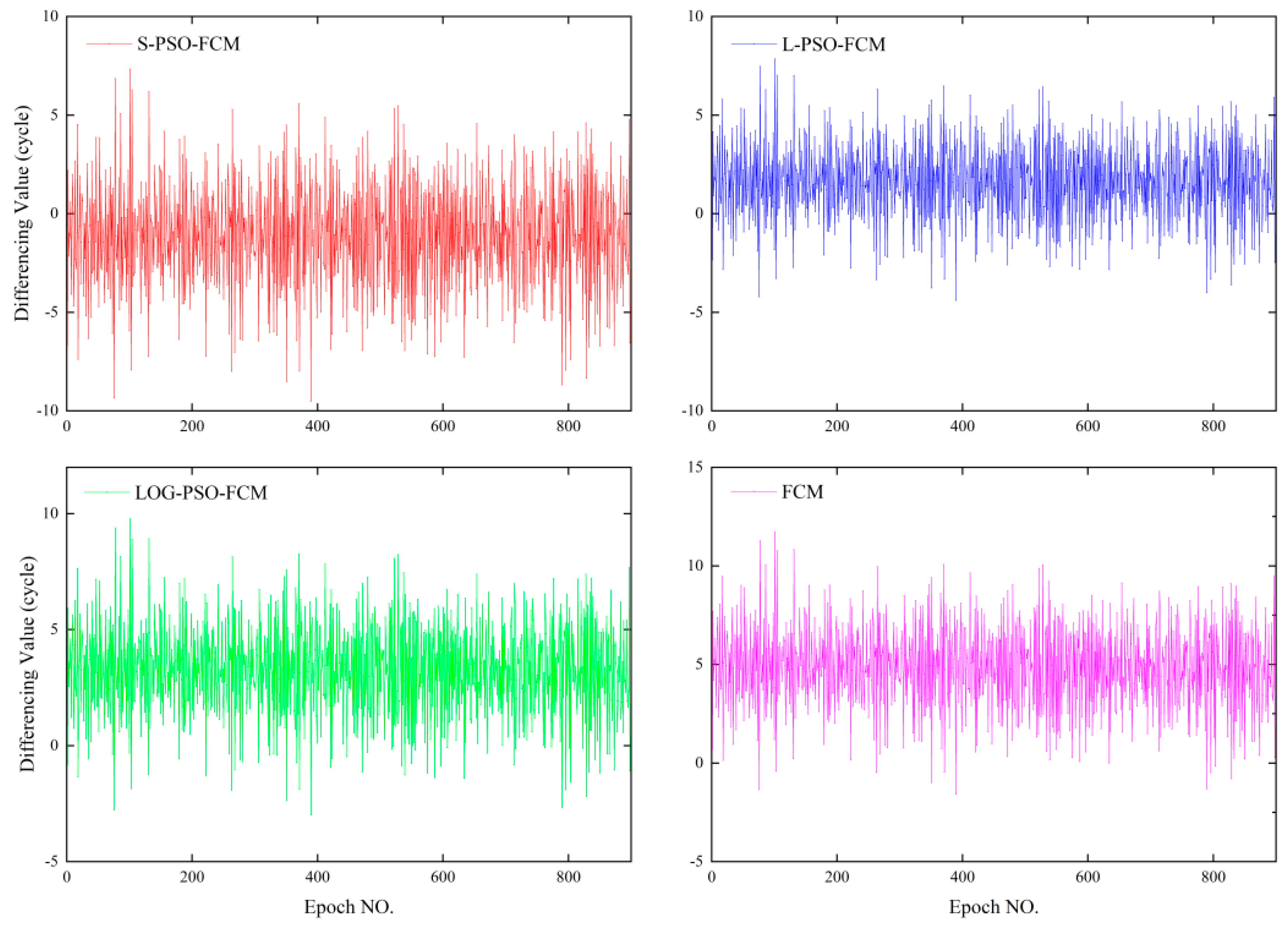
The fitness value is determined by the clustering validation function, according to which the PSO will repeat the application of Equation (29) until the iteration stops. Actually, the fitness function is the parameter that connects the FCM with the PSO method and will be discussed in the remainder of the present paper.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}