1. Introduction
Synthetic aperture radar (SAR) is an active microwave earth observation system that can stably provide high-resolution images in all weather conditions at any time of day. With the rapid development of SAR technology, the quantity and diversity (i.e., different resolutions, scenarios, imaging platforms, etc.) of SAR images are improving year by year, which promotes the research of SAR image interpretation algorithms [
1,
2,
3,
4]. Among the interpretation tasks of SAR images, ship detection is a fundamental task in marine monitoring and national defense. However, due to the complex background and resource-constrained onboard environments, real-time ship detection with high-resolution SAR images is still a challenging task.
Traditional ship detection methods are mainly based on prior knowledge, such as statistical models and hand-crafted features. One of the most representative methods is the constant false alarm rate (CFAR) [
5] detection algorithm, which models the background clutter using statistical distribution and computes an adaptive threshold to determine whether a pixel belongs to the target region. To deal with different sea conditions, researchers have designed many novel CFAR detectors by adopting different statistical models to fit complex sea clutter and designing new sliding window structures to estimate model parameters. However, the scattering-based CFAR heavily relies on sea conditions and cannot deal with multitarget situations and nonhomogeneous backgrounds. To solve this problem, other features are also utilized to detect ships, such as extended fractal features [
6], scale-invariant feature transform (SIFT) [
7], reflection symmetry properties [
8], and saliency information [
9]. The performance of these methods mainly depends on manually designed features and is not stable when ships are of various shapes or under different backgrounds. Moreover, sea–land segmentation is always required to decrease false alarms in inshore areas, which increases the complexity of the detection algorithm.
Object detection in optical images is one of the major tasks in computer vision and great breakthroughs have been made in recent years. Benefitting from their automatic learning ability and powerful feature extracting ability, convolutional neural networks (CNNs) can precisely locate targets in the image. According to the development process of CNN-based detectors, they can be roughly grouped into three categories: two-stage methods [
10,
11,
12], one-stage anchor-based methods [
13,
14,
15,
16,
17,
18], and one-stage anchor-free methods [
19,
20,
21]. In the recently presented YOLOX [
22], the YOLO network is integrated with an anchor-free mechanism and SimOTA label matching strategy, which achieves state-of-the-art performance.
The breakthrough in computer vision also promotes the rapid development of SAR image processing. Attracted by their simplicity and high accuracy, many scholars tried to introduce these CNN-based detectors to SAR image interpretation tasks [
2,
23,
24,
25,
26,
27]. However, certain problems remain to be solved for ship detection in SAR images. First, due to the active imaging mechanism of SAR, there inevitably exists coherent speckle noise, which is far from the noise in optical images and leads to a more complex background. Besides, despite the various image resolutions and ship sizes, most ships are small compared to the large-scene background, as shown in
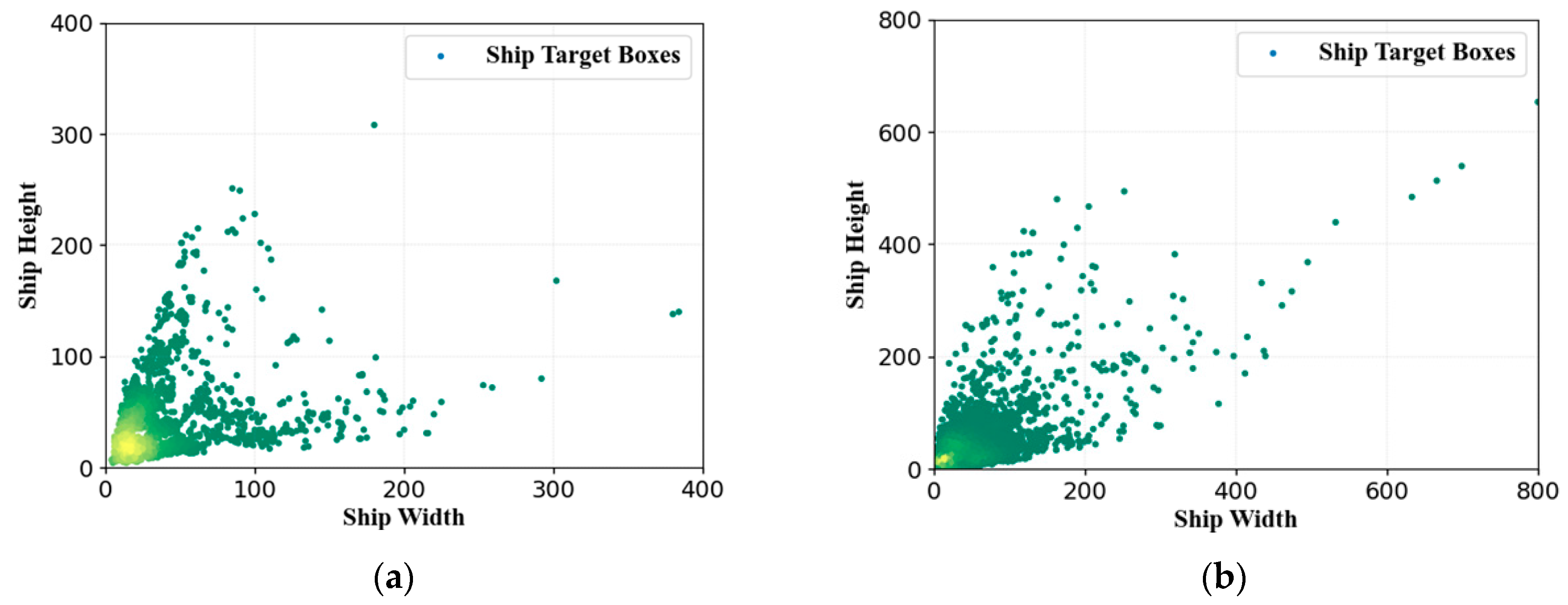
Figure 1a. Small ships take up only a few pixels in the image, making them more likely to be missed by the network. To address these problems, scholars have proposed many novel models to improve ship detection accuracy. Kang et al. [
28] combined three feature layers for region generation and proposed a contextual CNN detector. Jiao et al. [
29] densely connected all feature maps from top down to achieve multiscale and multiscene SAR ship detection. To detect multiscale ships with different directions, Zhao et al. [
30] designed an attention-receptive pyramid network. Fu et al. [
31] proposed level-based attention to better fuse features across different pyramidal levels. Zhang et al. [
32] integrated four unique FPNs to constitute the Quad-FPN and significantly boosted ship detection performance. Gao et al. [
33] replaced the path aggregation network (PANet) [
34] in YOLOv4 [
16] with the scale-equalizing pyramid convolution (SEPC) [
35] to better extract semantic characteristics of different scales. Among these methods, inserted modules, e.g., the attention mechanism, and a new feature fusion approach are common solutions to complex backgrounds and small target scales. However, the model parameter and computational complexity are also increased due to extra structures, causing a decline in detection speed.
In practical maritime surveillance, the timeliness of detection results is important in addition to accuracy. Since data transmitting between satellite and ground station could be time-consuming, it is of crucial importance to realize real-time on-satellite ship detection. However, the weight and volume of the processing system are limited due to the finite load of the satellite, leading to constrained computation resources. Therefore, lightness and efficiency of the detection model are critical to algorithm deployment and achieving real-time detection. For neural network-based detectors, the network architecture which decides how features are propagated and represented is of vital importance to the efficiency of detection algorithms. In consideration of this, some researchers have put forward novel lightweight models to improve detection speed. Zhang et al. [
37] proved that SAR ship detection is relatively easier than optical target detection by proposing “ShipDeNet-20”, which combines feature fusion, feature enhance and scale share feature pyramid modules to build a lightweight and precise model. To realize low-equipment-required real-time ship detection, Jiang et al. [
38] constructed an end-to-end detection network based on YOLOv4, achieving a smaller model size and higher detection speed. Feng et al. [
39] redesigned the backbone of YOLOX and proposed position-enhanced attention to improve the accuracy and speed of SAR ship detection from a more balanced perspective.
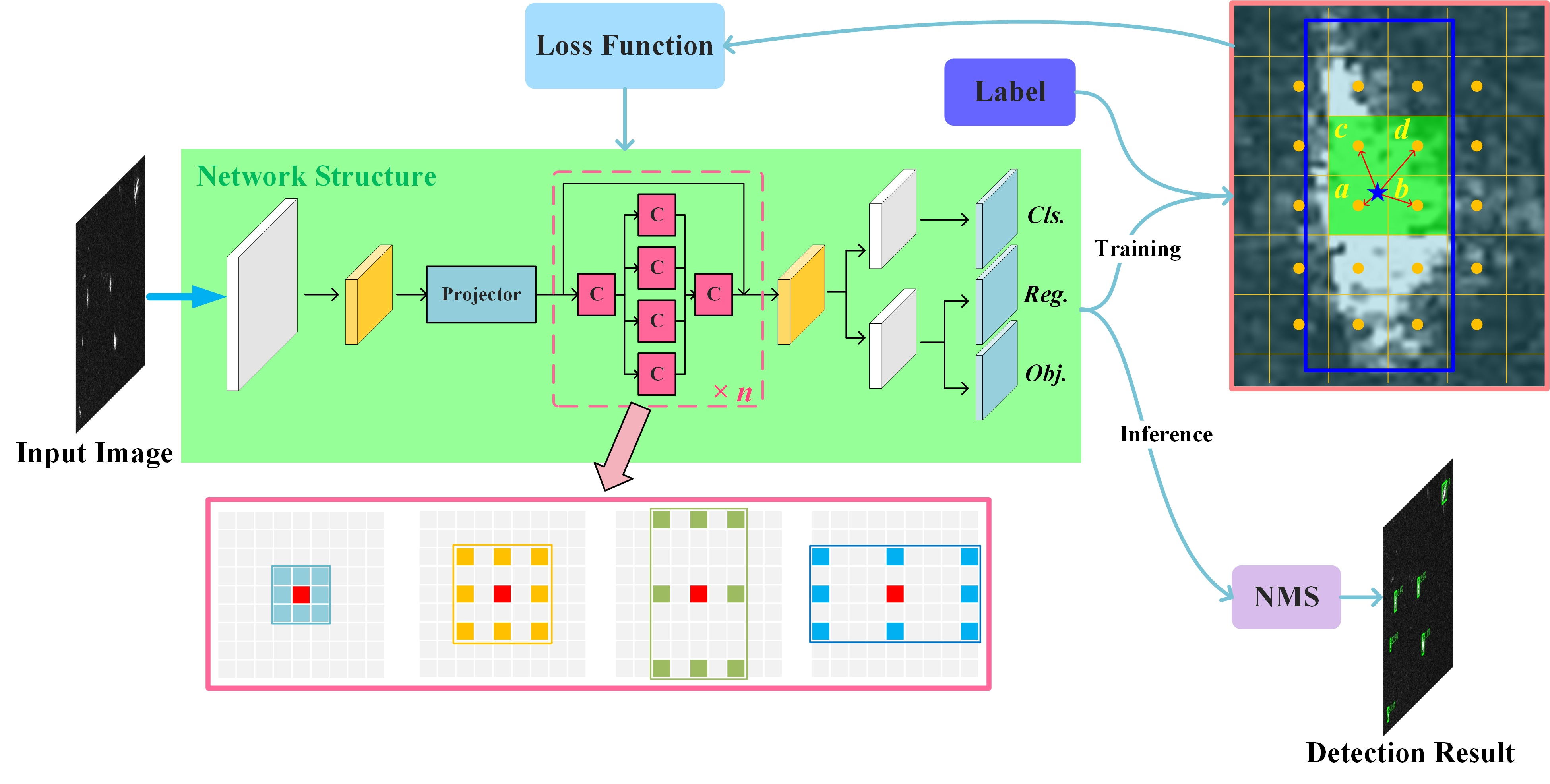
Moreover, general detection networks designed for optical images become redundant when they are directly applied to SAR ship detection. Compared to optical images, SAR images have a relatively low resolution as well as a low signal-to-noise ratio, which means the amplitude information of SAR images is not as incomprehensible as that of optical targets for CNN. Hence, there is room for the simplification of ship detection networks. For instance, the feature pyramid structure is widely adopted in recently developed detection networks [
22,
40,
41] to achieve multiscale detection. As shown in
Figure 2a, the key idea of such pyramidal structures is to combine semantically weak but spatially strong low-level feature maps with spatially coarse but semantically strong high-level feature maps to create a feature pyramid that has strong semantical information at all scales. In optical images with complex contexts, the target scale distribution is more even; therefore, the feature pyramid is essential for balancing targets of different scales. It can utilize multiple feature maps to split the optimization process of the complex detection problem into multiple subproblems according to object scales, thus improving detection efficiency. However, the situation is different for SAR ship detection. There are two main reasons. First, although the size of the ship target varies by ship type and imaging resolution, most ships are small and cover a few pixels in SAR images. Because the downsampling operation in CNNs loses detail information and is affected by speckle noise and background interference, these small ships tend to be more easily overlooked in high-level features. Intuitively, it is questionable whether a ship with a length and width of no more than 20 pixels retains valid target information after 32× downsampling. As a result, the fusion between high-level features and low-level features could be of little help to the latter. Second, compared to optical images containing multiple color channels, single-channel SAR images have a relatively low texture level. Therefore, the semantic information of SAR ship targets is not as complex as that of optical image targets, leading to a relative reduction in the required network depth [
36]. The semantic level in low-level features could be discriminative enough to distinguish between ships and interference, making the localization information in low-level features more important than the semantic information from high-level features. Therefore, feature pyramids are inefficient for SAR ship detection due to their equal focus on high-level features and low-level features. In summary, although the feature pyramid can deal with multiscale target problems, it is not efficient enough for fast ship detection.
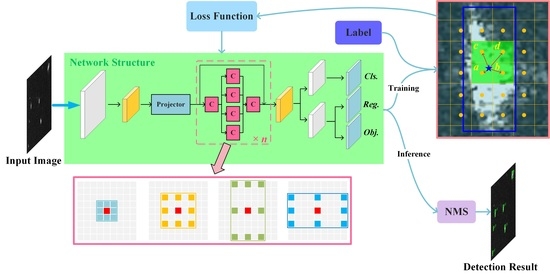
Based on the analysis above, a lightweight SAR ship detection method using a one-level feature is proposed. On account of the state-of-the-art performance, we chose the small version of YOLOX, i.e., YOLOX-s, as our baseline and further simplified the network structure. Different from current detection methods, the proposed network replaced the computationally heavy feature pyramid structure with neat convolution blocks and detect objects based on the one-level feature. It can be seen from
Figure 2b that the proposed network has a shallower depth and more simple structure, showing greater portability. Detailed contributions of this paper are summarized as follows:
- (1)
Inspired by the idea of utilizing a one-level feature in YOLOF [
42], the feature representation ability of one-level feature maps for ship detection in SAR images is verified and a novel ship detector is proposed. Different from mainstream ship detection methods, the proposed method offers an alternative option to complex pyramidal structures by detecting ships using a one-level feature, which is valid and efficient.
- (2)
In order to expand the receptive field and enrich semantic information of the one-level feature map, a residual asymmetric dilated convolution (RADC) block is proposed. By stacking convolutional blocks with four different dilated branches, ships with various shapes can be captured by the network efficiently.
- (3)
Since the proposed network detects objects on a single scale, large targets take up more pixels whereas small targets are easily ignored when calculating losses. To deal with this imbalance problem, center-based uniform matching, which assigns labels based on their center locations, is employed during the training stage.
To validate the effectiveness and robustness of the proposed method, extensive experiments on the SAR Ship Detection Dataset (SSDD) [
36] and High-Resolution SAR Images Dataset (HRSID) [
43] were conducted. The results show that the proposed method achieves comparative performance with baseline while requiring fewer model parameters and less computational cost, proving its high efficiency and reliability.
The rest of the paper is arranged as follows. In
Section 2, the overall structure and detailed improvements of the proposed method are described.
Section 3 provides the experiment results as well as corresponding analysis. Then, the experiment results are discussed and problems are analyzed in
Section 4. Lastly, the conclusion is drawn in
Section 5.
2. Materials and Methods
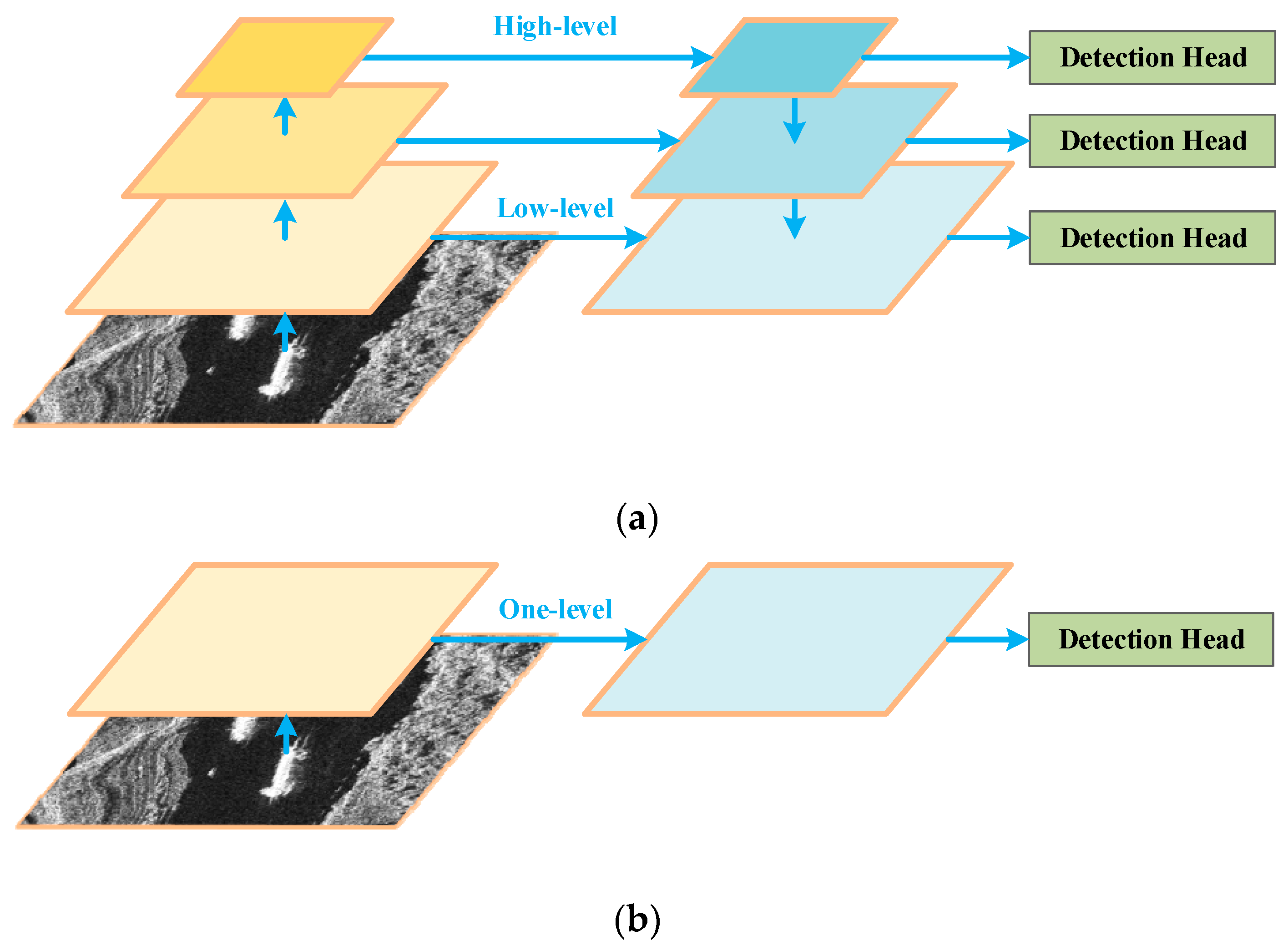
The proposed method can be mainly divided into four parts: a baseline network using a backbone for feature extraction, a neck constructed by a projector and stacking RADC modules, a decoupled head for final detection, and a label assignment strategy for model training. First of all, the overall framework, as well as the backbone of the proposed network, is described. Next, the structure of the proposed RADC block is illustrated. After that, the structure of the decoupled detection head is described. Then, drawbacks of traditional label assignment strategies on a single detection head are analyzed and center-based uniform matching is presented in detail. Finally, details of the output mapping and loss function calculation are given.
2.1. Overall Scheme of the Proposed Network
In recently developed one-stage detection networks, the most commonly used structure is the combination of backbone, neck, and head [
16]. Backbones, such as VGG [
44], ResNet [
45] and DenseNet [
46], are the key part for feature extracting. Following YOLOX, the Cross-Stage Partial Darknet (CSPDarknet) [
47] was adopted to construct our backbone. During the forward propagation process, the image is gradually subsampled through convolution layers with stride 2, and higher feature maps are obtained. The feature map after
l times of downsampling is denoted as
in this paper, where
W × H is the size of the input image,
cin is the channel number, and
is the corresponding downsampling rate of C
l. In order to validate the effectiveness of the one-level feature map for ship detection, we only adopted one feature map from the backbone, as shown in
Figure 3. Different from multilevel feature maps that require sequential resampling and fusion, the only feature map is enhanced by a streamlined neck. First, the feature map is adjusted by a projector which consists of a 1 × 1 convolution layer and a 3 × 3 convolution layer, where both convolutions are followed by a batch normalization (BN) operation. Additionally, the channel number of the feature map is changed to
cout. Then, the feature map is enhanced by
n consecutive RADC blocks. With multiple asymmetric dilation convolution branches, an RADC block can expand the receptive field and can efficiently discover strip-shaped ship targets. The processed feature P
l is transferred into detection output by a decoupled head. Finally, to generate the final detection results, non-maximum suppression (NMS) is used to remove repetitive predictions.
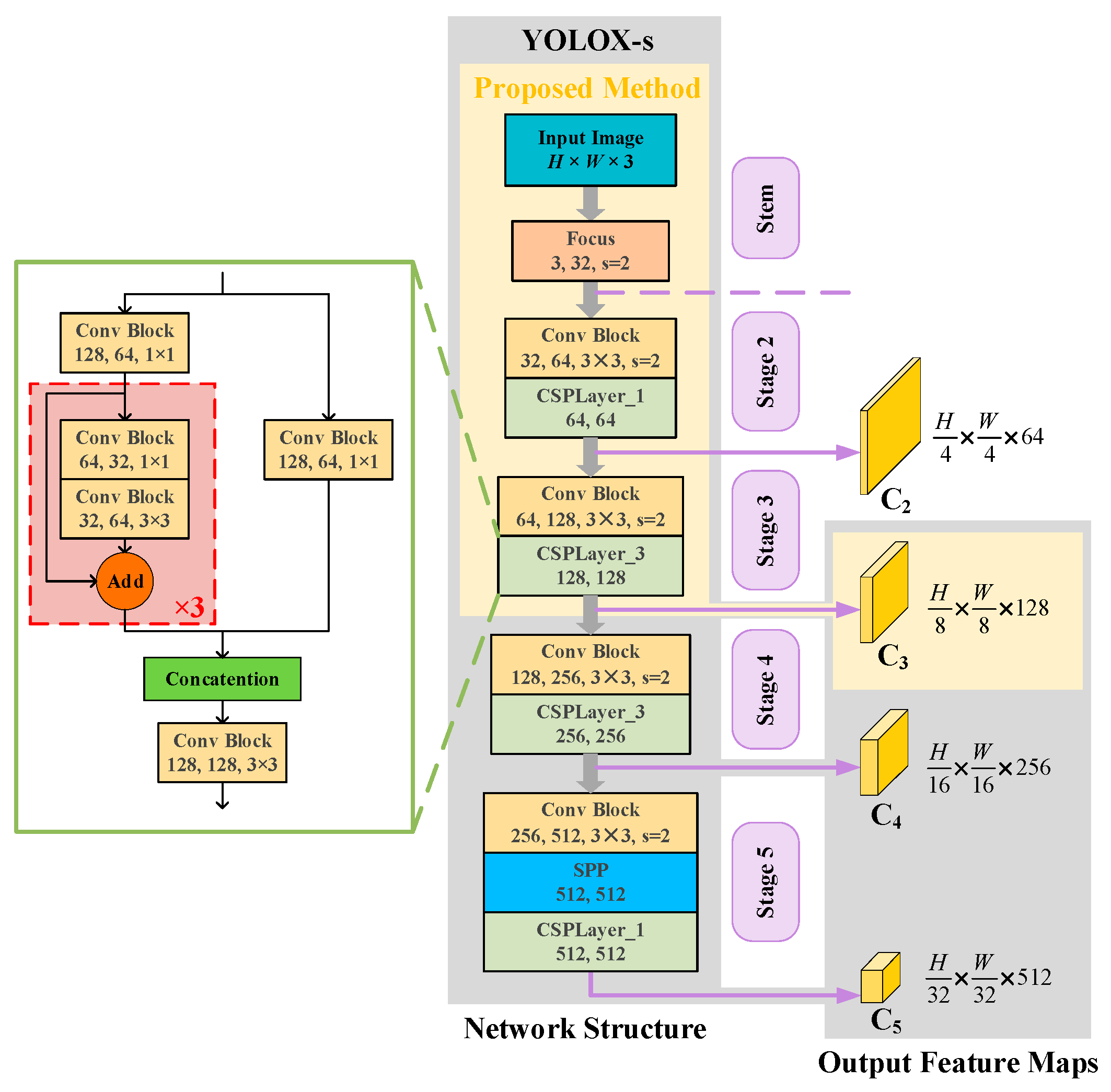
The structure of CSPDarknet, as well as the backbone of the proposed method, is shown in
Figure 4. As a note, Conv Block denotes a convolutional layer followed by a BN layer and a SiLU activation function. When the image is input into CSPDarknet, several feature maps with different downsampling rates are generated at specific stages, which are the input of the neck part. For mainstream detection networks, C
3, C
4, and C
5 are utilized to realize feature fusion across different scales, which is also the case of YOLOX-s. To verify the effectiveness of one-level features, an appropriate feature level associated with target characteristics is crucial. On account of the small size of ship targets and the influence of coherent noise, shallow feature maps with higher resolution tend to retain more efficient characteristics of small ship targets than deep feature maps. In view of this, some researchers additionally added a shallower level C
2 into their feature pyramid [
48,
49] to build an effective ship detector, which demonstrates the importance of shallow feature maps in SAR ship detection. Therefore, we set
l = 3 and chose C
3 as the only output of the backbone.
2.2. Residual Asymmetric Dilated Convolution Block
As the network goes deeper, high-level feature maps with large receptive fields contain stronger semantic information and are suitable for detecting large ships, whereas semantically weak but spatially strong low-level feature maps with small receptive fields are favorable to the detection of small ship targets. Thus, in addition to the fusion and enhancement of features, the other important role of multiscale detection is that the network has multiple receptive fields to detect targets of all scales. However, when it comes to the single-feature map situation, the receptive field of the output map is a constant, greatly limiting the network’s generalization ability. On one hand, if the scale of a ship target is much larger than this receptive field, it would be difficult for the network to fully extract target features and, thus, becomes problematic to detect. On the other hand, a ship that is significantly smaller than the receptive field can be easily ignored by the network, making it hard to be located precisely. To detect ships with different scales within a single-feature map, we were inspired by SC-EADNet [
50] and proposed the RADC block to expand the receptive field of the one-level feature and improve the network’s ability to detect ship targets of various scales.
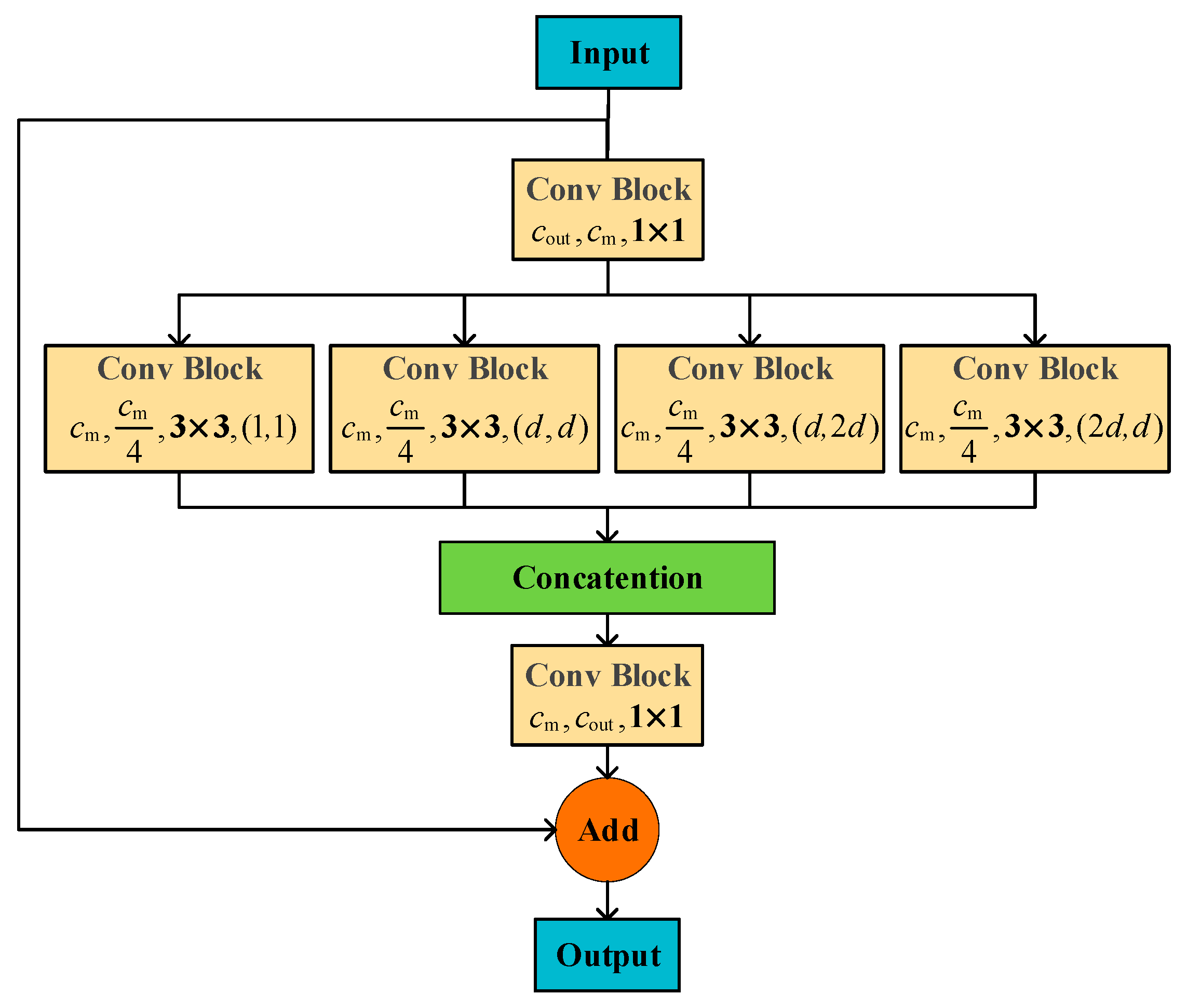
As shown in
Figure 5, four branches with different asymmetric dilation rates were used to enrich the receptive field of the one-level feature map. The input and output of the RADC block are of the same size, including both feature map scale and channel number. When the feature map with
cout channels is fed into the RADC block, the processing schedule can be divided into four steps. First, to reduce computational complexity, the channel number of the feature map is reduced to
cm by a convolution block with kernel size 1 × 1. Second, the compressed feature map is parallelly processed by four dilated convolution blocks with kernel size 3 × 3. Since dilated convolution can effectively enlarge receptive fields, the covered scale range of the feature map is also expanded. The output channel number of each branch is a quarter of
cm as there are four branches. Then, the four outputs are concatenated and followed by a 1 × 1 convolution to restore the channel number to
cout. Finally, we add the input feature to the processed feature by adding a residual connection, resulting in an output feature map with multiple receptive fields.
The dilation rates of these four branches are set as (1, 1), (d, d), (2 × d, d), and (d, 2 × d), respectively. The parameter d is a predefined base dilation rate that indicates the receptive field level of the RADC block, which is set as 2 in our method. Generally speaking, a larger d can greatly increase the receptive field. However, the 3 × 3 convolution may damage feature extraction if the dilation rate is too large, as those pixels far from the center are less likely to locate at the same target. To enhance the receptive field effectively, we stack identical RADC blocks to expand the receptive field gradually.
There are several benefits of applying the RADC block as a basic component in the neck part. (1) Dilated convolutions are used to enlarge the receptive field of the one-level feature map, which contributes to the detection of large-scale ship targets. Meanwhile, the residual connection can effectively preserve original information, generating a feature map with multiple receptive fields covering all object scales. (2) Considering the slender shape and arbitrary orientation of ship targets in SAR images, as shown in
Figure 6a, standard square dilation is not suitable for the convolution kernel to capture ship target features. Thus, there are two branches whose dilation rates are asymmetric in the RADC block, i.e., one horizontally longer and the other vertically longer. The receptive field of the RADC block is demonstrated in
Figure 6b, where it can be seen that ships with various shapes can be covered properly, contributing to the feature extraction of large targets. (3) Due to four parallel dilated convolution branches, the low-level feature from the backbone is refined and semantically reinforced with more context information while only a little computational burden is increased. By stacking RADC blocks, the receptive field and semantic level of C
l can be gradually enhanced.
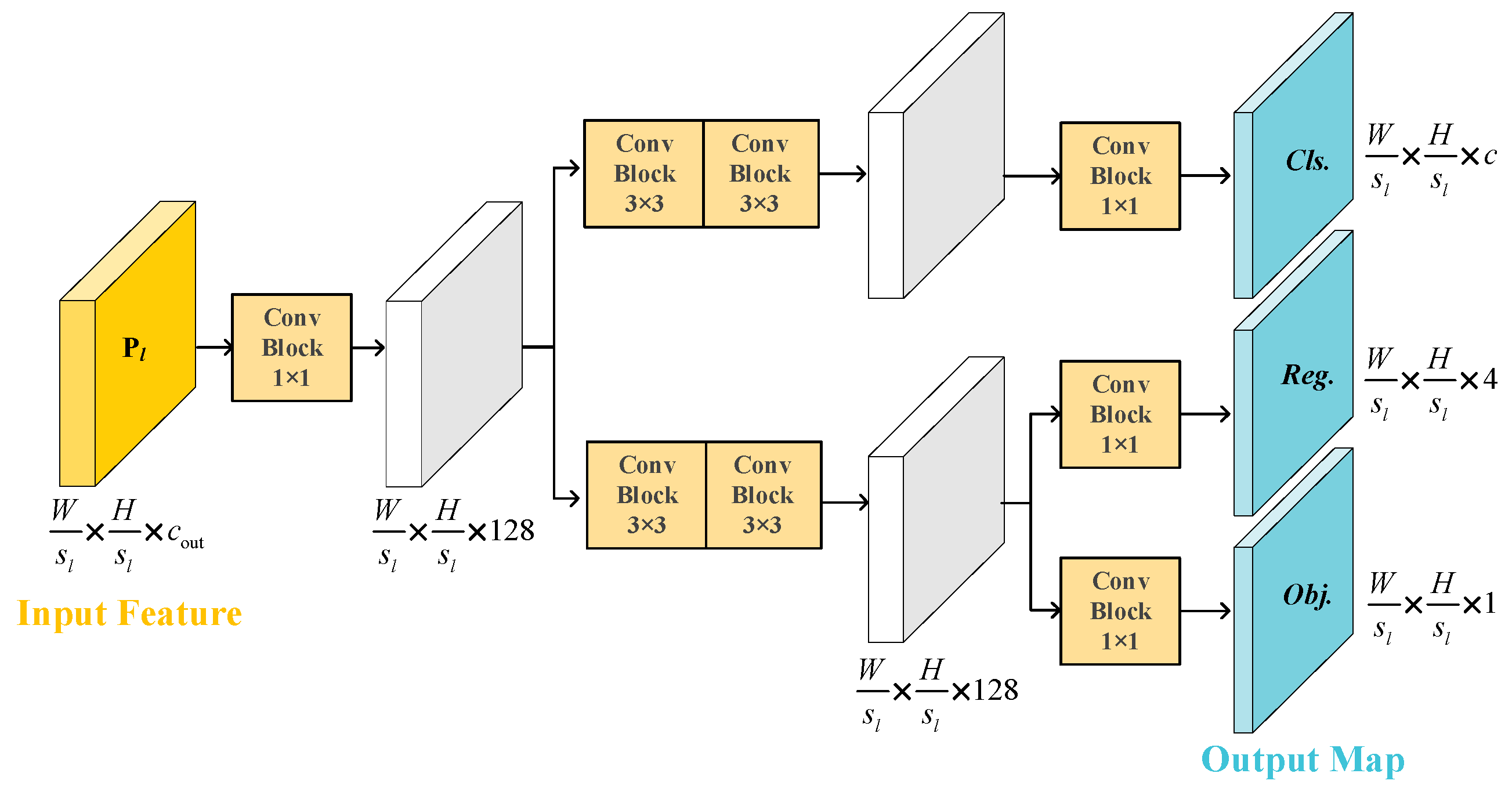
2.3. Decoupled Head
To make the proposed network simple and streamlined, we dealt with the feature map within the single scale and used only one detection head, which produces one output map
, where
c is the number of target categories. The structure of the decoupled head is shown in
Figure 7. The output of the RADC blocks, P
l, is sent into the detection head for final detection. The channel number of P
l is first changed to 128 through a 1 × 1 convolution block. After that, the feature map is divided into two branches with two convolution blocks, one for classification and the other for regression. The regression branch is further separated to predict the coordinate and quality of the predicted box, i.e., the coordinate branch and IoU (intersection over union) branch. At the end of each branch, a 1 × 1 convolution is performed to compress the channel dimension and form the output map.
2.4. Center-Based Uniform Matching
For CNN-based object detectors, dense prior settings (e.g., preset anchor boxes and grid points) are essential to cover as many potential targets as possible. Most of these prior settings are redundant and invalid for the final detection result. During the training process, the label assignment strategy determines which predictions are positive samples and which predictions are negative samples and is of great importance for the optimization of the network. To ensure the effectiveness of loss function, a good assignment strategy should consider the measurement of the similarity between label and prediction and have a universal rule to separate positive and negative samples. The IoU threshold was widely adopted as the assignment criterion and, since the arrival of anchor-free detectors, a lot of strategies that are based on the location of labels and predictions were presented [
20,
21]. To make the label assigning procedure more adaptive, scholars are also trying to design dynamic strategies to improve detection performance [
51,
52].
As for YOLOX, SimOTA can assign a different number of positive predictions with each ground truth based on their matching similarity, where higher similarity corresponds to more assignments. Such a dynamic mechanism is sensitive to the suitability of predictions for labels and can adaptively adjust positive samples. For multiscale situations in which targets at different scales are assigned with predictions at different scales, SimOTA is good at dividing positives and negatives. However, it cannot balance targets at different scales when all predictions are on the same scale. Larger targets tend to have a higher IoU with predictions and obtain more assignments, whereas small targets are easily neglected. Moreover, in the end stage of network training, too many positive samples are assigned, e.g., 6–8, for each target. The network might be misled by low-quality predictions, leading to a risk of a high false alarm rate.
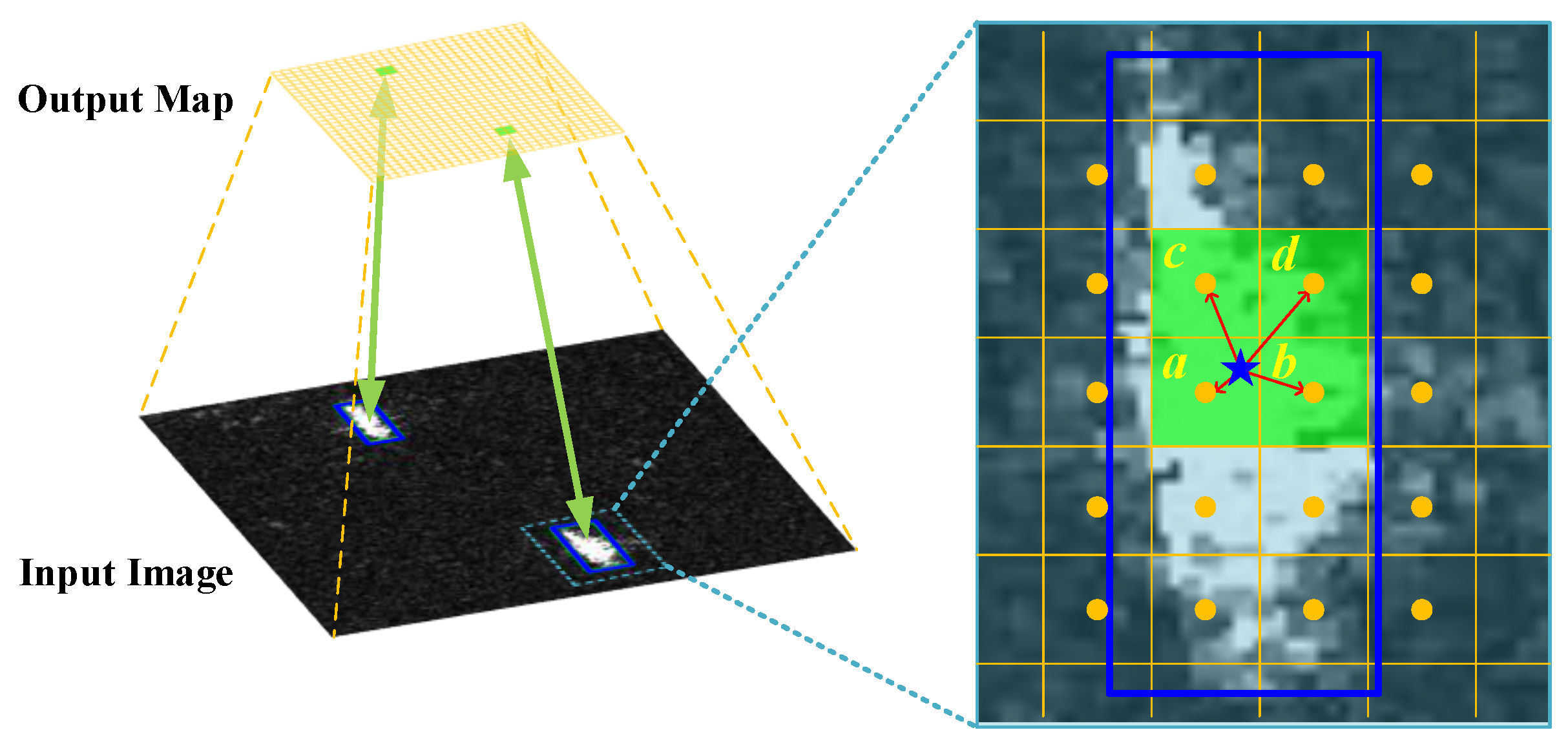
To deal with the problem of scale imbalance and low-quality matching, a plain matching strategy, namely, center-based uniform matching, is proposed in this paper. As the only output map is subsampled, every location of the output corresponds to a grid in the input image and represents the predicted result around the grid. Considering that CNN extracts the feature in a local manner, closer pixels in the output map are more representative of the target. Thus, according to the center location of the ground truth box, a fixed number of grids around the center point are selected as positive samples. The matching of the ground truth g
n and the grid that corresponds to pixel (
i,
j) in the output map can be summarized as follows:
where
represents the region of the
k nearest grids around the center point of target g
n and
k is a constant designed manually. The case of
k = 4 is shown in
Figure 8, where four nearest grids are selected as positive samples. It can be seen that the assigned positive pixels are distributed in the central region of the target, and the target can be properly covered by their receptive field. Additionally, if a pixel lies in the positive neighbor of multiple targets, it would be assigned to the target with the largest IoU.
The hyperparameter
k represents the number of positive samples for every target and determines the overall assignment level. When
k = 1, the center grid is assigned to the target, which is similar to CenterNet [
20]. Generally speaking, more positives can improve training efficiency while generating more low-quality predictions. Therefore, considering the small size of ship targets, we set
k = 4.
Center-based uniform matching assigns an equal number of positive samples to each ground truth regardless of their scale, which solves the imbalance problem of positive samples for a one-level feature map situation. Different from the uniform matching in [
41], the proposed method measures the distances between grids and labels with central locations and avoids the hyperparameter design required by the anchor mechanism. Since the location of all target boxes is determined, assigned positives and the optimization objective are invariable during the training process, which is more stable and prevents low-quality predictions caused by too many positive assignments.
2.5. Output Mapping and Loss Function
The proposed network is an anchor-free detector. It directly outputs the detection result and every pixel in the output map produces one predicted box. Concretely, for a pixel point located at position (
i,
j) (where
i = 0, 1, 2, …,
W/
sl − 1 and
j = 0, 1, 2, …,
H/
sl − 1) in the output map, its dimension (i.e., channel number of the output map) is 4 + 1 +
c, corresponding to four output coordinates
, the predicted confidence
, and classification result of this prediction
. Additionally, the coordinate of the predicted bounding box
can be obtained by decoding the output coordinates through:
where
is the center point coordinate of the predicted box and
is the corresponding width and height.
While training the network, the predicted boxes are first divided into positive targets and negative backgrounds using the proposed center-based uniform matching strategy. Then, for an image with
ship targets, the total loss function
can be calculated by:
where
Npos is the number of positive assignments,
α is a weighting parameter set as 5.0,
cn and
tn represent the category and bounding box of the
n-th target, respectively, and
is an indicator that equals to 1 when the prediction on (
i,
j) is assigned to the
n-th target; otherwise, it is 0. The classification loss
Lcls and objectiveness loss
Lobj adopt binary cross entropy with sigmoid normalization, and bounding box regression loss
Lreg adopts IoU loss.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}