
Self-Supervised Pre-Training with Bridge Neural Network for SAR-Optical Matching


Abstract
:
1. Introduction
- We propose a framework applying self-supervised learning to SAR-optical image matching, improving the feature learning ability of SAR and optical images.
- We take MoCo and BNN as one of the most representative works in self-supervised learning and multi-modal image matching to make the framework truly implemented.
- For the proposed framework, we conduct lots of experiments to confirm the feasibility and the effectiveness of the self-supervised learning transferred to optical-SAR image matching task, which would encourage further research in this field.
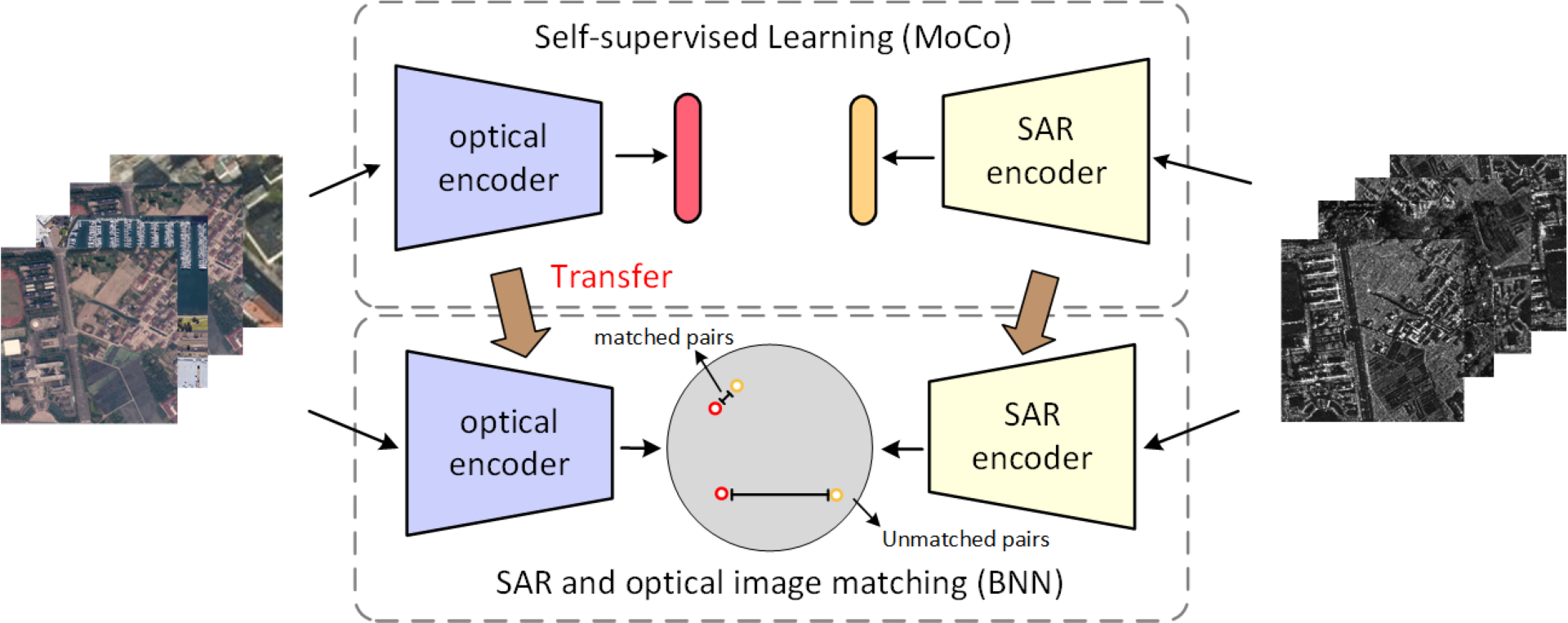
2. Method
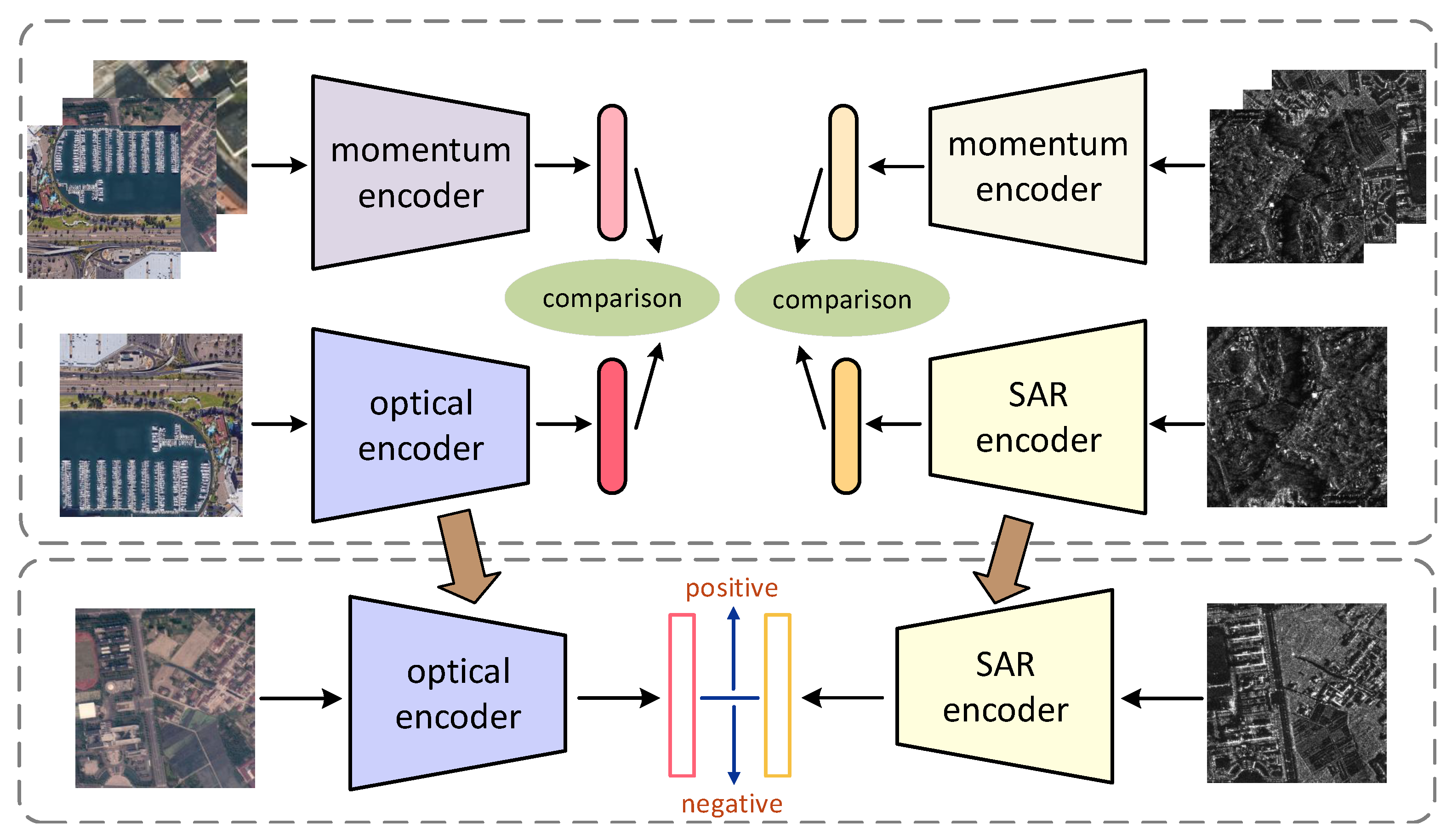
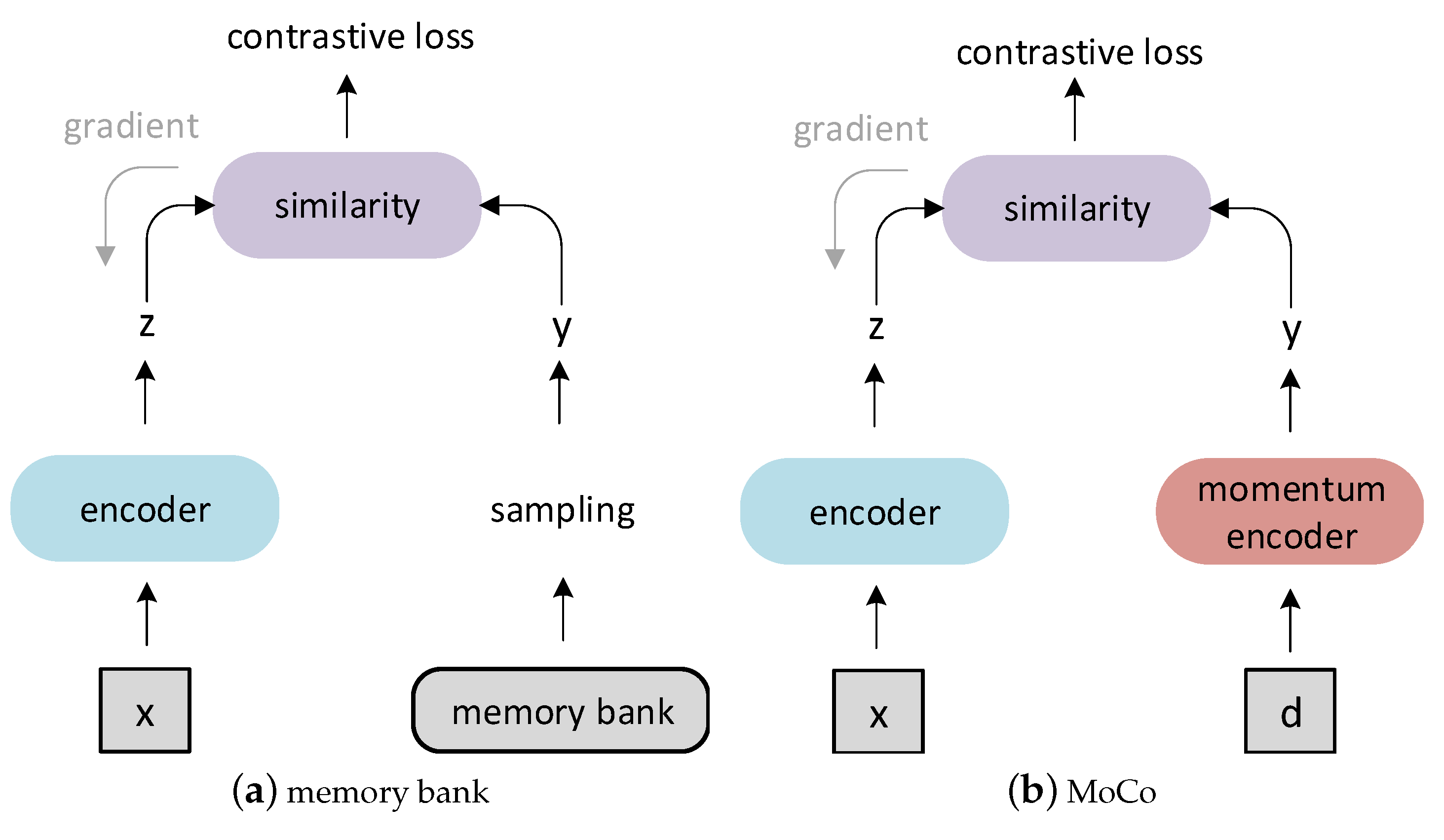
2.1. Momentum Contrast
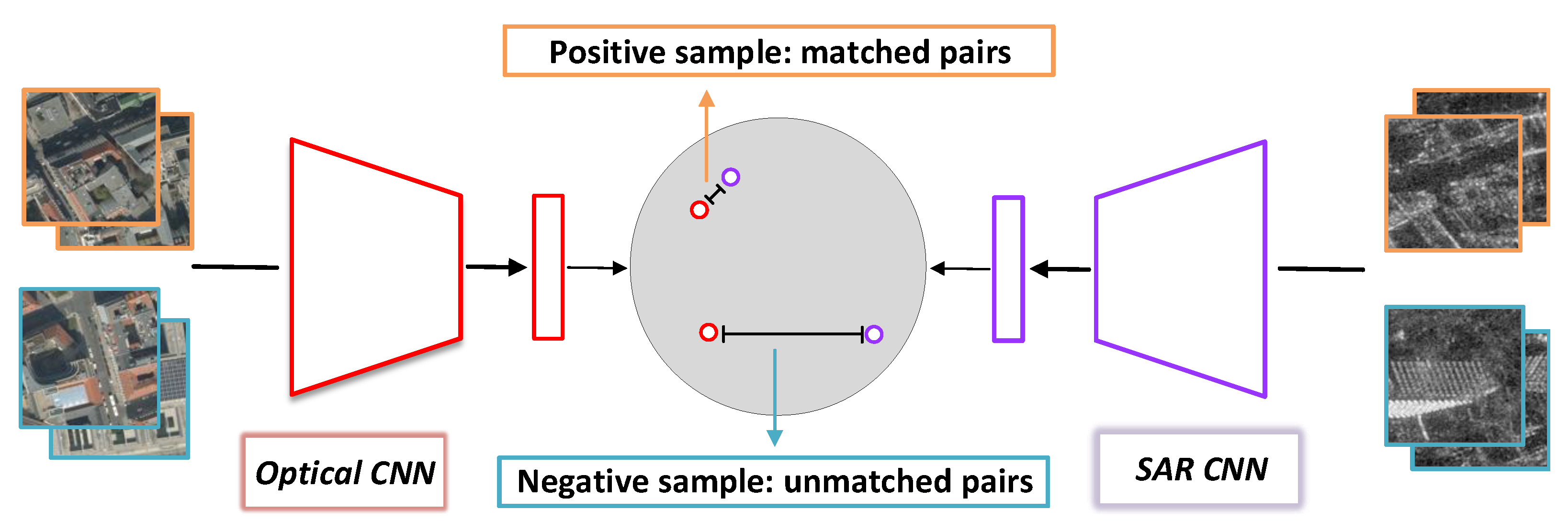
2.2. Bridge Neural Network
2.3. Transfer MoCo Pre-Trained Model to BNN
3. Experiments
3.1. Dataset
3.2. Implementation
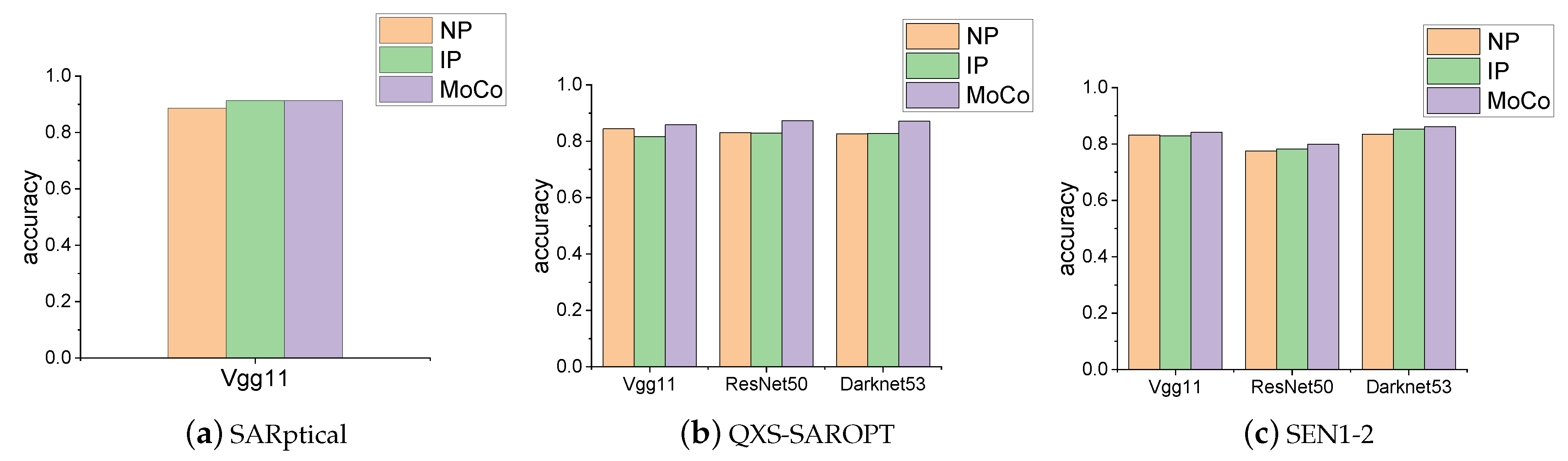
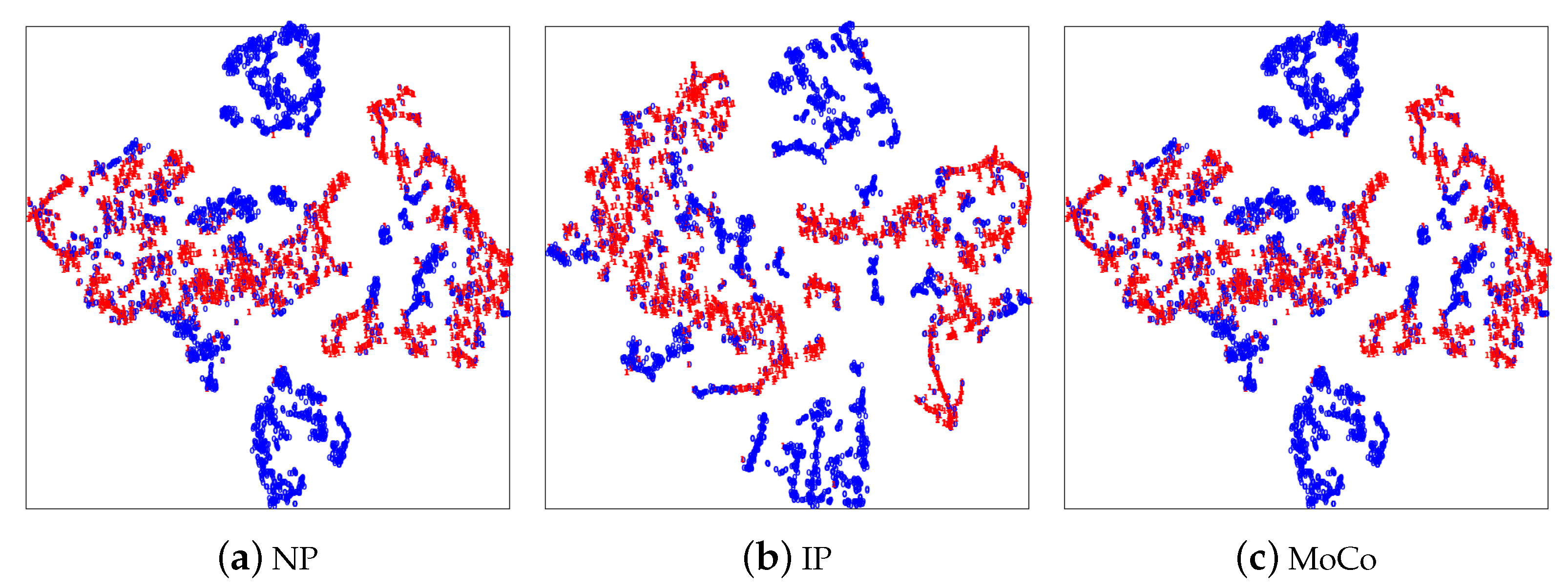
3.3. Results Analysis
4. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Burger, W.; Burge, M.J. Principles of Digital Image Processing: Core Algorithms; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Walters-Williams, J.; Li, Y. Estimation of mutual information: A survey. In Proceedings of the International Conference on Rough Sets and Knowledge Technology, Gold Coast, Australia, 14–16 July 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 389–396. [Google Scholar]
- Suri, S.; Reinartz, P. Mutual-information-based registration of TerraSAR-X and Ikonos imagery in urban areas. IEEE Trans. Geosci. Remote Sens. 2009, 48, 939–949. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Dellinger, F.; Delon, J.; Gousseau, Y.; Michel, J.; Tupin, F. SAR-SIFT: A SIFT-like algorithm for SAR images. IEEE Trans. Geosci. Remote Sens. 2014, 53, 453–466. [Google Scholar] [CrossRef] [Green Version]
- Ye, Y.; Shen, L. Hopc: A novel similarity metric based on geometric structural properties for multi-modal remote sensing image matching. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 3, 9. [Google Scholar] [CrossRef] [Green Version]
- Ye, Y.; Shan, J.; Bruzzone, L.; Shen, L. Robust registration of multimodal remote sensing images based on structural similarity. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2941–2958. [Google Scholar] [CrossRef]
- Zagoruyko, S.; Komodakis, N. Learning to compare image patches via convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4353–4361. [Google Scholar]
- Merkle, N.; Luo, W.; Auer, S.; Müller, R.; Urtasun, R. Exploiting deep matching and SAR data for the geo-localization accuracy improvement of optical satellite images. Remote Sens. 2017, 9, 586. [Google Scholar] [CrossRef] [Green Version]
- Mou, L.; Schmitt, M.; Wang, Y.; Zhu, X.X. A CNN for the identification of corresponding patches in SAR and optical imagery of urban scenes. In Proceedings of the 2017 Joint Urban Remote Sensing Event (JURSE), Dubai, United Arab Emirates, 6–8 March 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–4. [Google Scholar]
- Hughes, L.H.; Schmitt, M.; Mou, L.; Wang, Y.; Zhu, X.X. Identifying corresponding patches in SAR and optical images with a pseudo-Siamese CNN. IEEE Geosci. Remote Sens. Lett. 2018, 15, 784–788. [Google Scholar] [CrossRef] [Green Version]
- Xu, Y.; Xiang, X.; Huang, M. Task-Driven Common Representation Learning via Bridge Neural Network. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 5573–5580. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Girshick, R.; Dollár, P. Rethinking imagenet pre-training. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 4918–4927. [Google Scholar]
- Wu, Z.; Xiong, Y.; Yu, S.X.; Lin, D. Unsupervised feature learning via non-parametric instance discrimination. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3733–3742. [Google Scholar]
- Oord, A.v.d.; Li, Y.; Vinyals, O. Representation learning with contrastive predictive coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- Tian, Y.; Krishnan, D.; Isola, P. Contrastive multiview coding. arXiv 2019, arXiv:1906.05849. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, PMLR, Vienna, Austria, 12–18 July 2020; pp. 1597–1607. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- Caron, M.; Misra, I.; Mairal, J.; Goyal, P.; Bojanowski, P.; Joulin, A. Unsupervised learning of visual features by contrasting cluster assignments. arXiv 2020, arXiv:2006.09882. [Google Scholar]
- Zbontar, J.; Jing, L.; Misra, I.; LeCun, Y.; Deny, S. Barlow Twins: Self-Supervised Learning via Redundancy Reduction. arXiv 2021, arXiv:2103.03230. [Google Scholar]
- Henaff, O. Data-efficient image recognition with contrastive predictive coding. In Proceedings of the International Conference on Machine Learning, Vienna, Austria, 12–18 July 2020; pp. 4182–4192. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Wang, Y.; Zhu, X.X. The sarptical dataset for joint analysis of sar and optical image in dense urban area. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 6840–6843. [Google Scholar]
- Huang, M.; Xu, Y.; Qian, L.; Shi, W.; Zhang, Y.; Bao, W.; Wang, N.; Liu, X.; Xiang, X. The QXS-SAROPT Dataset for Deep Learning in SAR-Optical Data Fusion. arXiv 2021, arXiv:2103.08259. [Google Scholar]
- Schmitt, M.; Hughes, L.H.; Zhu, X.X. The SEN1-2 dataset for deep learning in SAR-optical data fusion. arXiv 2018, arXiv:1807.01569. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bao, W.; Huang, M.; Zhang, Y.; Xu, Y.; Liu, X.; Xiang, X. Boosting ship detection in SAR images with complementary pretraining techniques. arXiv 2021, arXiv:2103.08251. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Accuracy | Precision | Recall |
|---|---|---|---|
| NP-BNN | |||
| IP-BNN | |||
| MoCo-BNN(ours) |
| Backbone | Methods | Accuracy | Precision | Recall |
|---|---|---|---|---|
| Vgg11 | NP-BNN | |||
| IP-BNN | ||||
| MoCo-BNN(ours) | ||||
| ResNet50 | NP-BNN | |||
| IP-BNN [25,30] | ||||
| MoCo-BNN(ours) | ||||
| Darknet53 | NP-BNN | |||
| IP-BNN [25,30] | ||||
| MoCo-BNN(ours) |
| Backbone | Methods | Accuracy | Precision | Recall |
|---|---|---|---|---|
| Vgg11 | NP-BNN | |||
| IP-BNN | ||||
| MoCo-BNN(ours) | ||||
| ResNet50 | NP-BNN | |||
| IP-BNN | ||||
| MoCo-BNN(ours) | ||||
| Darknet53 | NP-BNN | |||
| IP-BNN | ||||
| MoCo-BNN(ours) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qian, L.; Liu, X.; Huang, M.; Xiang, X. Self-Supervised Pre-Training with Bridge Neural Network for SAR-Optical Matching. Remote Sens. 2022, 14, 2749. https://doi.org/10.3390/rs14122749
Qian L, Liu X, Huang M, Xiang X. Self-Supervised Pre-Training with Bridge Neural Network for SAR-Optical Matching. Remote Sensing. 2022; 14(12):2749. https://doi.org/10.3390/rs14122749
Chicago/Turabian StyleQian, Lixin, Xiaochun Liu, Meiyu Huang, and Xueshuang Xiang. 2022. "Self-Supervised Pre-Training with Bridge Neural Network for SAR-Optical Matching" Remote Sensing 14, no. 12: 2749. https://doi.org/10.3390/rs14122749