
Improving YOLOv5 with Attention Mechanism for Detecting Boulders from Planetary Images



Abstract
:1. Introduction
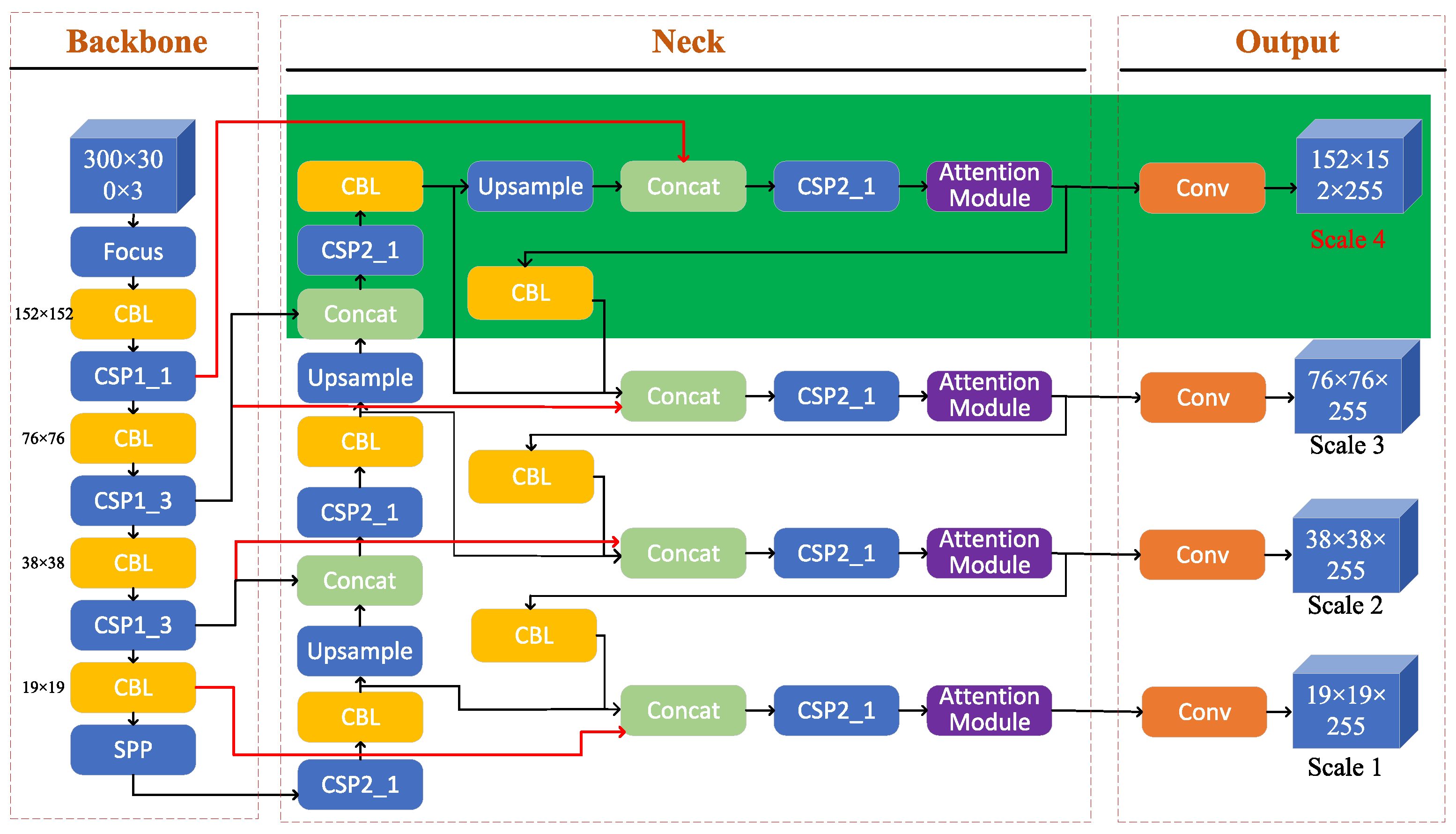
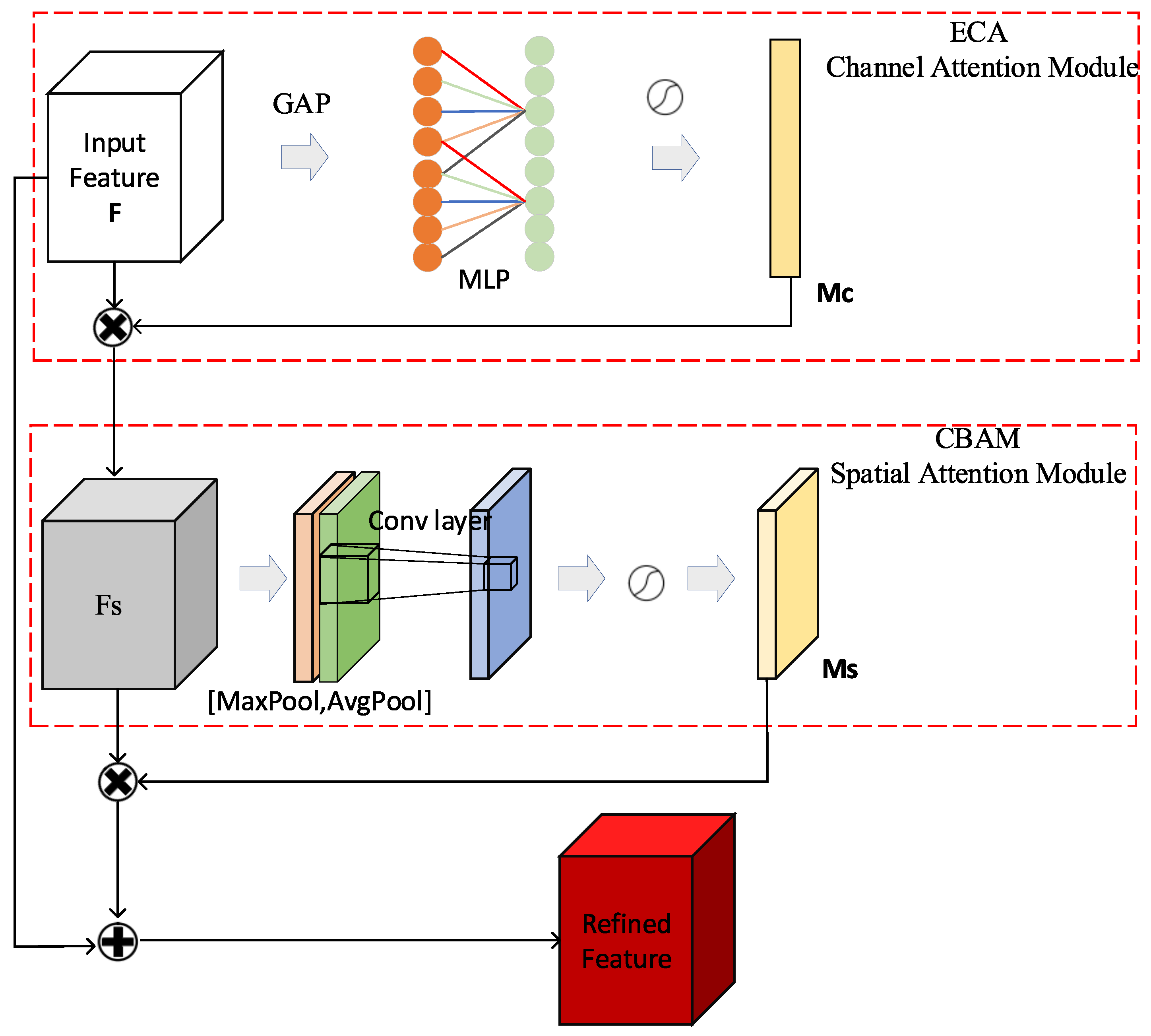
- The YOLOv5 detection methods are improved by applying the attention mechanism. Besides three feature fusion layers which aggregate the feature maps of different levels to obtain more contextual information, an additional shallow layer is added to obtain more feature information of the small boulders. In addition, inspired by the idea of residual networks, new connections have been added to bring feature information from backbone network into these feature fusion layers to further reduce the feature information loss of the small boulders. Moreover, the attention modules implemented by combining the CBAM [8] and ECA-Net [9] attention mechanisms have been added into each feature fusion layer to highlight the information that contributes to the boulder detection. The evaluations have shown that these improvements have increased the performance of YOLOv5 by 3.4% in precision.
- A pyramid based approach is designed to detect multi-scale boulders. From the input large image, the proposed approach obtains several layers of images with lower resolution through downsampling. Then, these layers of images are cut into small slices which are fed into the improved YOLOv5 detection methods for boulder detection. Afterwards, the detection results of different layers are relocated to the original large image, and the non-maximum value suppression (NMS) [10] is used to filter the duplicate results. We have applied the proposed boulder detection approach to detect the boulders on the Bennu asteroid. The distribution of the boulders on Bennu asteroid has been also analyzed and presented.
2. The Methods
2.1. The State of Art Object Detecting Methods Based on Deep Learning
2.2. The YOLOv5 Method
2.3. The Attention Mechanism
2.3.1. CBAM
2.3.2. ECA-Net
2.4. Improved YOLOv5 with Attention Mechanism
2.5. The Pyramid Based Approach Using Improved YOLOv5 for Detecting Boulders
3. The Datasets and Results
3.1. Datasets
3.2. The Implementations and Settings
3.3. The Comparison with Related Object Detection Methods
3.4. The Analysis of the Boulders on Bennu Asteroid
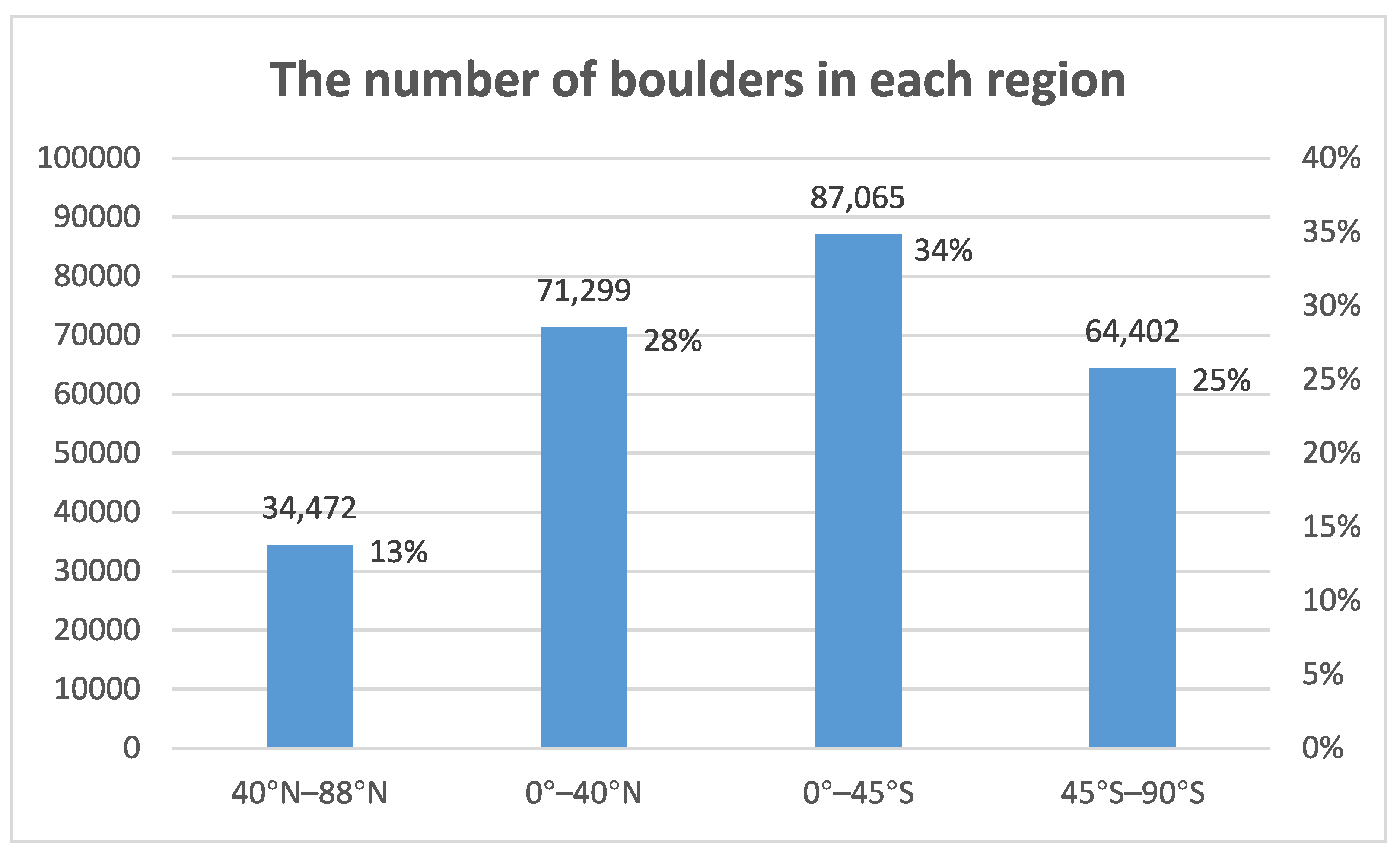
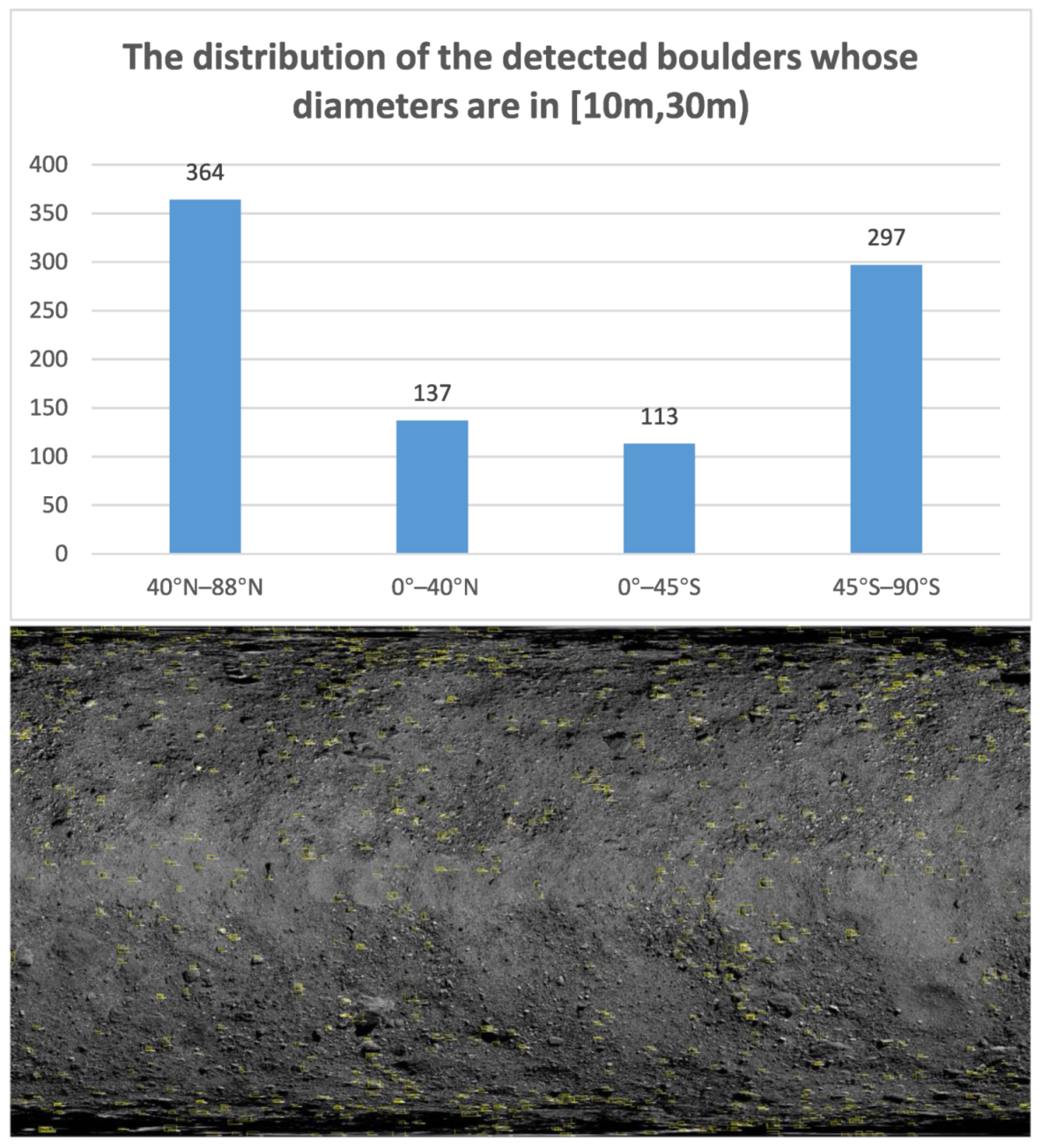
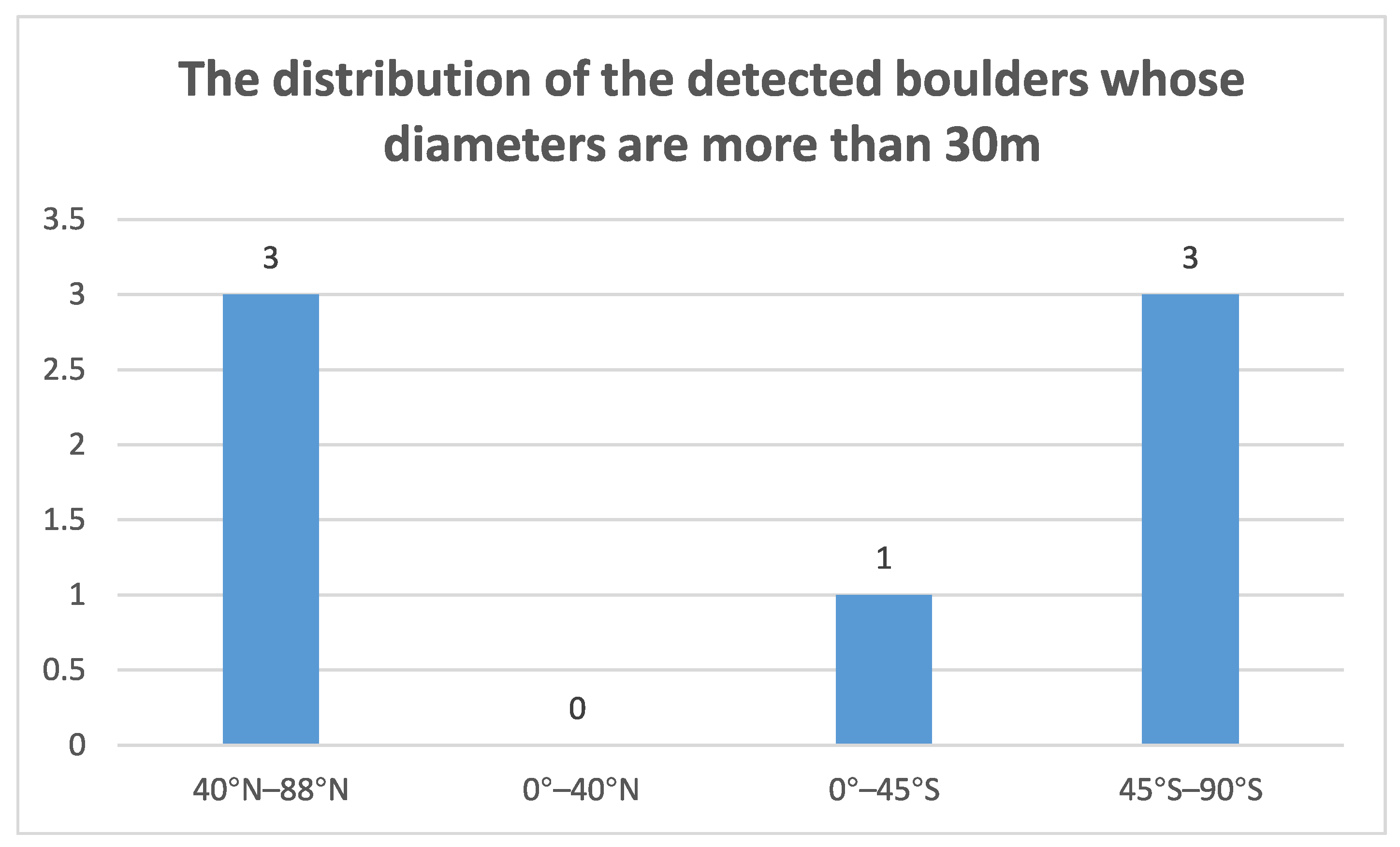
3.4.1. Statistics of the Number of Boulders
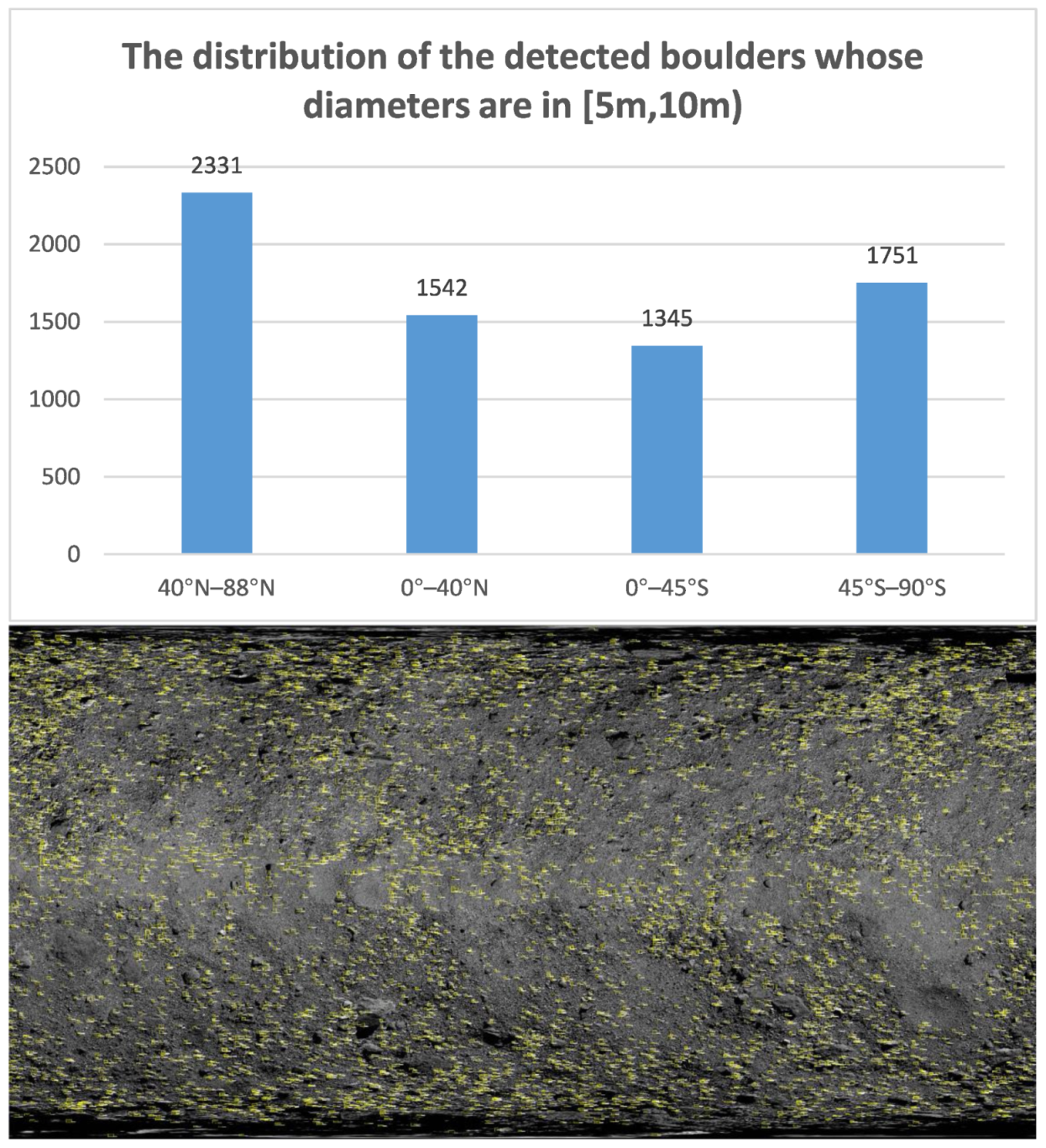
3.4.2. Boulder Distribution Statistics
4. Discussion
4.1. Applications and Limitations
4.2. Hyperparameter Exploration
4.3. The Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, H.; Jiang, J.; Zhang, G. CraterIDNet: An end-to-end fully convolutional neural network for crater detection and identification in remotely sensed planetary images. Remote Sens. 2018, 10, 1067. [Google Scholar] [CrossRef] [Green Version]
- Benedix, G.K.; Lagain, A.; Chai, K.; Meka, S.; Anderson, S.; Norman, C.; Bland, P.A.; Paxman, J.; Towner, M.C.; Tan, T. Deriving surface ages on Mars using automated crater counting. Earth Space Sci. 2020, 7, e2019EA001005. [Google Scholar] [CrossRef] [Green Version]
- Ding, M.; Cao, Y.F.; Wu, Q.X. Autonomous craters detection from planetary image. In Proceedings of the 2008 3rd International Conference on Innovative Computing Information and Control, Dalian, China, 18–20 June 2008; p. 443. [Google Scholar]
- Pajola, M.; Pozzobon, R.; Lucchetti, A.; Rossato, S.; Baratti, E.; Galluzzi, V.; Cremonese, G. Abundance and size-frequency distribution of boulders in Linné crater’s ejecta (Moon). Planet. Space Sci. 2019, 165, 99–109. [Google Scholar] [CrossRef]
- Walsh, K.J.; Jawin, E.R.; Ballouz, R.L.; Barnouin, O.S.; Bierhaus, E.B.; Connolly, H.C., Jr.; Molaro, J.L.; McCoy, T.J.; Delbo, M. Craters, boulders and regolith of (101955) Bennu indicative of an old and dynamic surface. Nat. Geosci. 2019, 12, 242–246. [Google Scholar] [CrossRef]
- Jawin, E.R.; Walsh, K.J.; Barnouin, O.S.; McCoy, T.J.; Ballouz, R.L.; DellaGiustina, D.N.; Connolly, H.C., Jr.; Marshall, J.; Beddingfield, C.; Nolan, M.C.; et al. Global patterns of recent mass movement on asteroid (101955) Bennu. J. Geophys. Res. Planets 2020, 125, e2020JE006475. [Google Scholar] [CrossRef]
- GitHub. YOLOV5-Master. 2021. Available online: https://github.com/ultralytics/yolov5.git/ (accessed on 1 March 2021).
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 6 October 2018; Springer: Munich, Germany, 2018; pp. 3–19. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14 June 2020. [Google Scholar]
- Neubeck, A.; Van Gool, L. Efficient non-maximum suppression. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; IEEE Computer Society: Hong Kong, China, 2006; Volume 3, pp. 850–855. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. ANIPS 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, Y.; Liu, Q. Convolutional neural networks with large-margin softmax loss function for cognitive load recognition. In Proceedings of the 2017 36th Chinese Control Conference (CCC), Dalian, China, 11 September 2017; pp. 4045–4049. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Amsterdam, The Netherlands, 2016; pp. 21–37. [Google Scholar]
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. Dssd: Deconvolutional single shot detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Zheng, L.; Fu, C.; Zhao, Y. Extend the shallow part of single shot multibox detector via convolutional neural network. In Proceedings of the Tenth International Conference on Digital Image Processing (ICDIP 2018), Shanghai, China, 11–14 May 2018; International Society for Optics and Photonics: Shanghai, China, 2018; Volume 10806, p. 1080613. [Google Scholar]
- Cui, L.; Ma, R.; Lv, P.; Jiang, X.; Gao, Z.; Zhou, B.; Xu, M. MDSSD: Multi-scale deconvolutional single shot detector for small objects. arXiv 2018, arXiv:1805.07009. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 12 December 2016; IEEE Computer Society: Las Vegas, NV, USA, 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Hawaii, HI, USA, 21–26 July 2017; IEEE Computer Society: Hawaii, HI, USA, 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Ma, J.; Shao, W.; Ye, H.; Wang, L.; Wang, H.; Zheng, Y.; Xue, X. Arbitrary-oriented scene text detection via rotation proposals. IEEE Trans. Multimed. 2018, 20, 3111–3122. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; IEEE Computer Society: Las Vegas, NV, USA, 2016; pp. 770–778. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; AAAI: New York, NY, USA, 2020; pp. 12993–13000. [Google Scholar]
- Wang, W.; Xie, E.; Song, X.; Zang, Y.; Wang, W.; Lu, T.; Yu, G.; Shen, C. Efficient and accurate arbitrary-shaped text detection with pixel aggregation network. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; IEEE: Seoul, Korea, 2019; pp. 8440–8449. [Google Scholar]
- Zeiler, M.D.; Taylor, G.W.; Fergus, R. Adaptive deconvolutional networks for mid and high level feature learning. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2018–2025. [Google Scholar]
- Mastromichalakis, S. ALReLU: A different approach on Leaky ReLU activation function to improve Neural Networks Performance. arXiv 2020, arXiv:2012.07564. [Google Scholar]
- Kim, D.; Park, S.; Kang, D.; Paik, J. Improved center and scale prediction-based pedestrian detection using convolutional block. In Proceedings of the 2019 IEEE 9th International Conference on Consumer Electronics (ICCE-Berlin), Berlin, Germany, 8–11 September 2019; pp. 418–419. [Google Scholar]
- Everingham, M.; Gool, L.V.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- 101955 Bennu. 2021. Available online: https://solarsystem.nasa.gov/asteroids-comets-and-meteors/asteroids/101955-bennu/in-depth/ (accessed on 1 April 2021).
- OSIRIS-REx Mission. 2020. Available online: https://www.asteroidmission.org/bennu_global_mosaic/ (accessed on 1 July 2020).
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Jiang, B.; Luo, R.; Mao, J.; Xiao, T.; Jiang, Y. Acquisition of localization confidence for accurate object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Springer: Munich, Germany, 2018; pp. 784–799. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Method | Backbone | Precision | FPS |
|---|---|---|---|---|
| Bennu | SSD | VGG-16 | 44.1% | 11 |
| ESSD | VGG-16 | 43.0% | 11 | |
| MDSSD | VGG-16 | 53.0% | 4 | |
| YOLOv3 | Darknet-53 | 59.4% | 33 | |
| YOLOv4 | CSPDarknet53 | 72.0% | 32 | |
| YOLOv5 | CSPDarknet53 | 73.2% | 30 | |
| Ours | CSPDarknet53 | 76.6% | 25 | |
| VOC2007 | SSD | VGG-16 | 77.5% | 46 |
| ESSD | VGG-16 | 79.4% | 25 | |
| MDSSD | VGG-16 | 78.6% | 28 | |
| YOLOv3 | Darknet-53 | 74.5% | 36 | |
| YOLOv4 | CSPDarknet53 | 78.1% | 35 | |
| YOLOv5 | CSPDarknet53 | 82.7% | 36 | |
| Ours | CSPDarknet53 | 84.2% | 28 |
| Layer | Layer Size | Slice Size | Slices Num | Boulders Num Detected | Result |
|---|---|---|---|---|---|
| First layer | 31,417 × 15,709 | 320 × 320 | 4802 | 276,431 | 257,238 |
| Second layer | 15,709 × 7855 | 320 × 327 | 1176 | 99,812 | |
| Third layer | 7855 × 3928 | 327 × 327 | 288 | 19,768 | |
| Fourth layer | 3928 × 1964 | 327 × 327 | 72 | 3562 | |
| Fifth layer | 1964 × 982 | 327 × 327 | 18 | 510 | |
| Sixth layer | 982 × 491 | 327 × 491 | 3 | 21 |
| Number | Img Size | Epochs | Batch Size | LR | Optimizer | Precision |
|---|---|---|---|---|---|---|
| exp1 | 640 | 300 | 16 | 0.01 | Adam | 72.0% |
| exp2 | 320 | 300 | 16 | 0.01 | SGD | 71.5% |
| exp3 | 320 | 300 | 16 | 0.001 | Adam | 71.7% |
| exp4 | 320 | 300 | 16 | 0.1 | Adam | 72.4% |
| exp5 | 320 | 300 | 8 | 0.01 | Adam | 72.1% |
| exp6 | 320 | 300 | 32 | 0.01 | Adam | 71.2% |
| exp7 | 320 | 300 | 64 | 0.01 | Adam | 70.1% |
| exp8 | 320 | 300 | 16 | 0.01 | Adam | 73.2% |
| Method | Scale4 Layer | New Connections | Attention Mechanism | Precision | ||
|---|---|---|---|---|---|---|
| ECA | CBAM | ECA+CBAM | ||||
| YOLOv5 | × | × | × | × | × | 73.2% |
| Improved YOLOv5 | ✓ | × | × | × | × | 75.1% |
| Improved YOLOv5 | ✓ | ✓ | × | × | × | 75.5% |
| Improved YOLOv5 | ✓ | ✓ | ✓ | × | × | 76.1% |
| Improved YOLOv5 | ✓ | ✓ | × | ✓ | × | 73.7% |
| Ours | ✓ | ✓ | × | × | ✓ | 76.6% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, L.; Geng, X.; Li, Z.; Liu, C. Improving YOLOv5 with Attention Mechanism for Detecting Boulders from Planetary Images. Remote Sens. 2021, 13, 3776. https://doi.org/10.3390/rs13183776
Zhu L, Geng X, Li Z, Liu C. Improving YOLOv5 with Attention Mechanism for Detecting Boulders from Planetary Images. Remote Sensing. 2021; 13(18):3776. https://doi.org/10.3390/rs13183776
Chicago/Turabian StyleZhu, Linlin, Xun Geng, Zheng Li, and Chun Liu. 2021. "Improving YOLOv5 with Attention Mechanism for Detecting Boulders from Planetary Images" Remote Sensing 13, no. 18: 3776. https://doi.org/10.3390/rs13183776