
Accuracy Assessment in Convolutional Neural Network-Based Deep Learning Remote Sensing Studies—Part 1: Literature Review


Abstract
:
1. Introduction
2. Background
2.1. Traditional Remote Sensing Accuracy Evaluation
2.2. The Purpose of Accuracy Assessment
2.2.1. Deep Learning Accuracy Assessment Example Use Cases
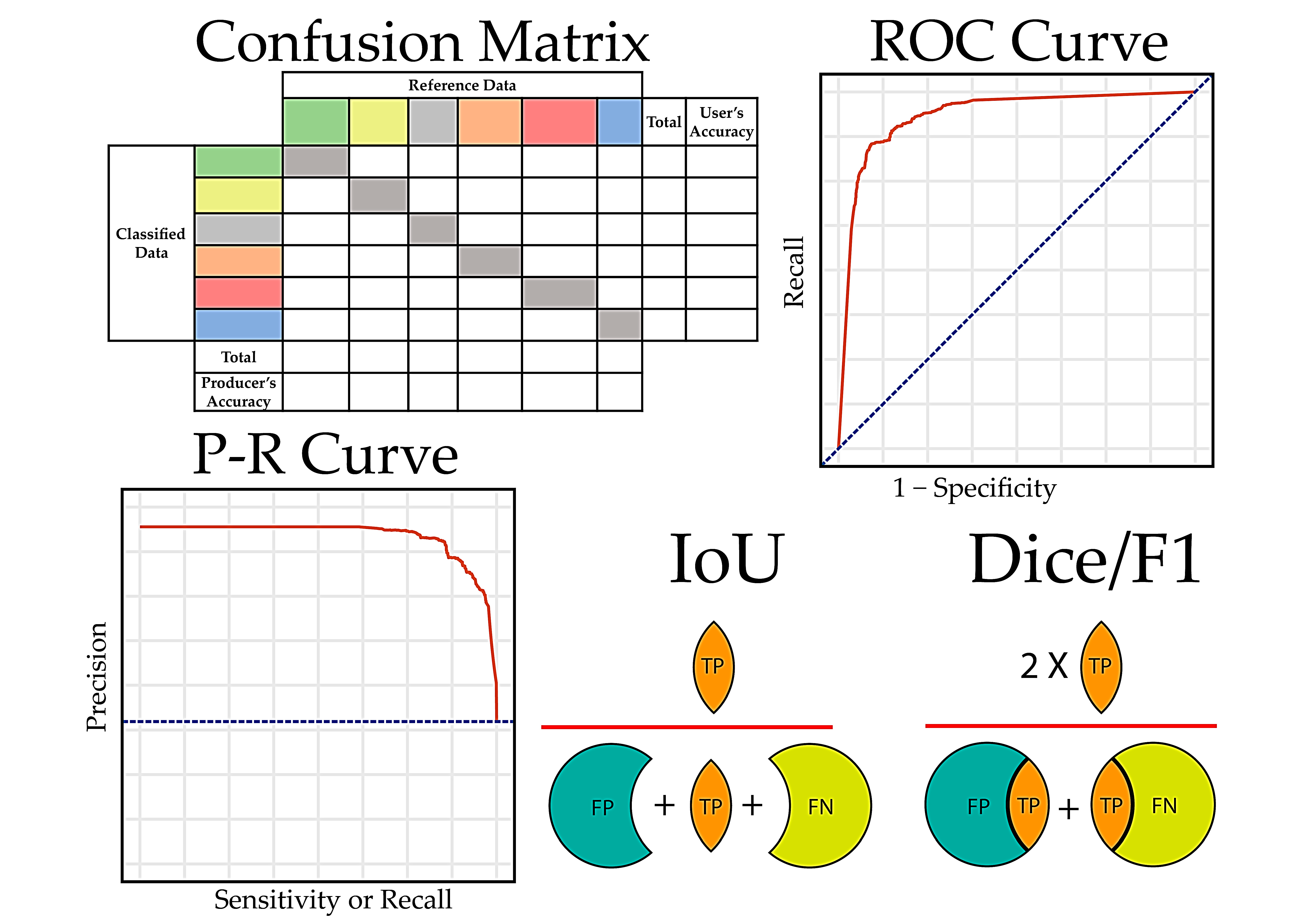
2.2.2. The Confusion Matrix
2.2.3. Summary Metrics Derived from Confusion Matrix
3. Literature Review Methods for Surveying Accuracy Evaluation of CNNs in Remote Sensing
AND ((SCENE CLASSIFICATION) OR (SCENE LABEL*) OR (OBJECT DETECTION)
OR (SEMANTIC SEGMENTATION) OR (INSTANCE SEGMENTATION)))
- Scene classification, sometimes referred to as scene labeling, involves classifying an entire image or image chip to a single category, or multiple categories, with no localized detection of features within the image. For example, an entire scene could be recognized as an example of a developed area or a developed area and woodlands [20,21,34,35].
- Instance segmentation differentiates and maps the boundaries of each unique occurrence of the classes of interest. For example, each building in an image could be detected as a separate instance of the “building” class. The outputs include bounding boxes for each instance, class probabilities, and pixel-level feature masks [24,25,97].
4. Accuracy Metrics Commonly Used in Remote Sensing CNN Classifications
4.1. The Confusion Matrix in RS CNN Studies
4.1.1. The Binary Confusion Matrix: True and False Positives and Negatives
4.1.2. The Multiclass DL CNN Confusion Matrix
4.1.3. The Sample vs. the Population Confusion Matrix
4.2. Accuracy Metrics Derived from the Confusion Matrix and Commonly used in CNN Applications
4.2.1. Overall Accuracy and Kappa
4.2.2. Recall and Precision
4.2.3. Specificity and Negative Predictive Value
4.2.4. False Positive Rate, False Negative Rate, False Discovery Rate
4.2.5. Balanced Accuracy and Matthews Correlation Coefficient
4.2.6. F1
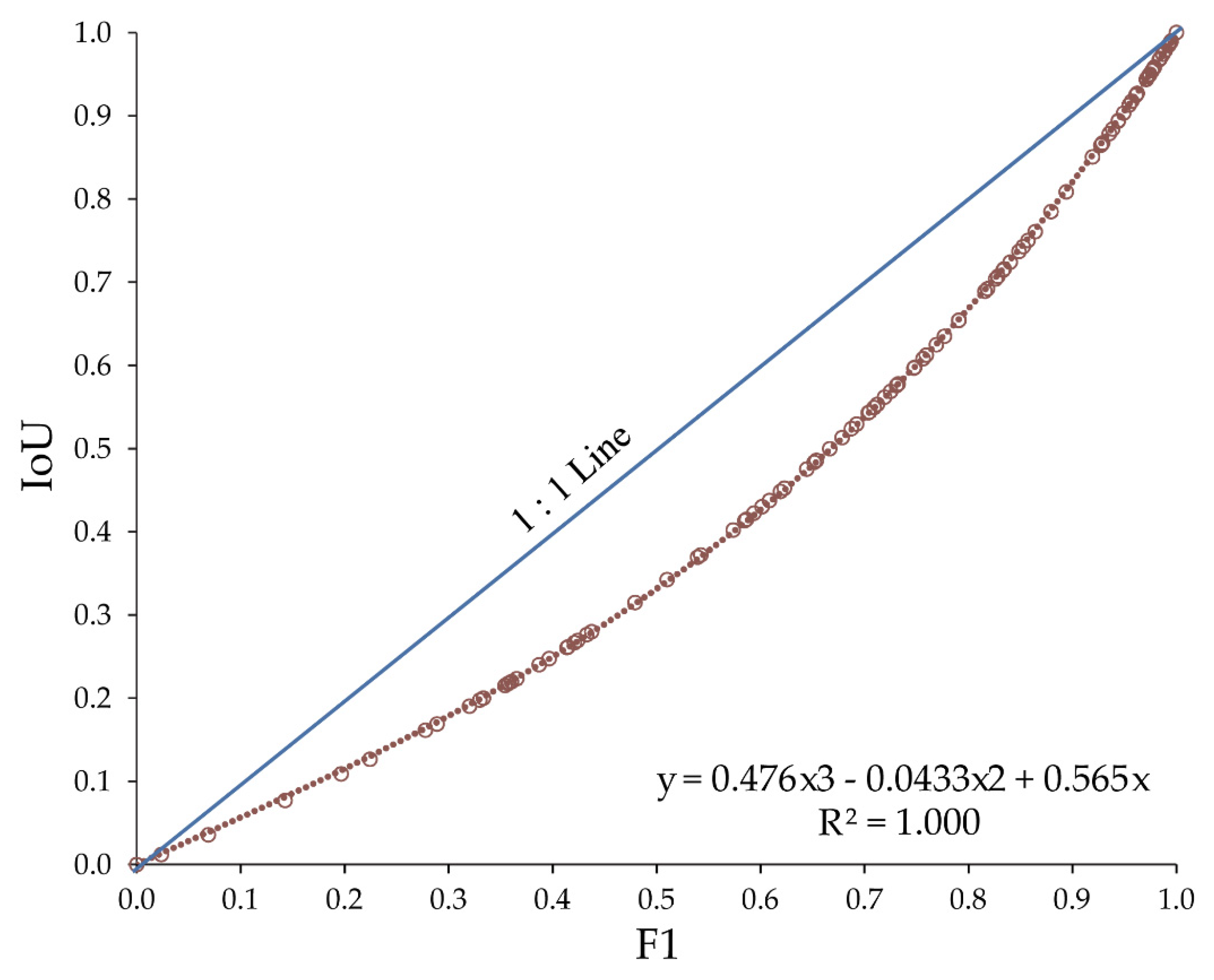
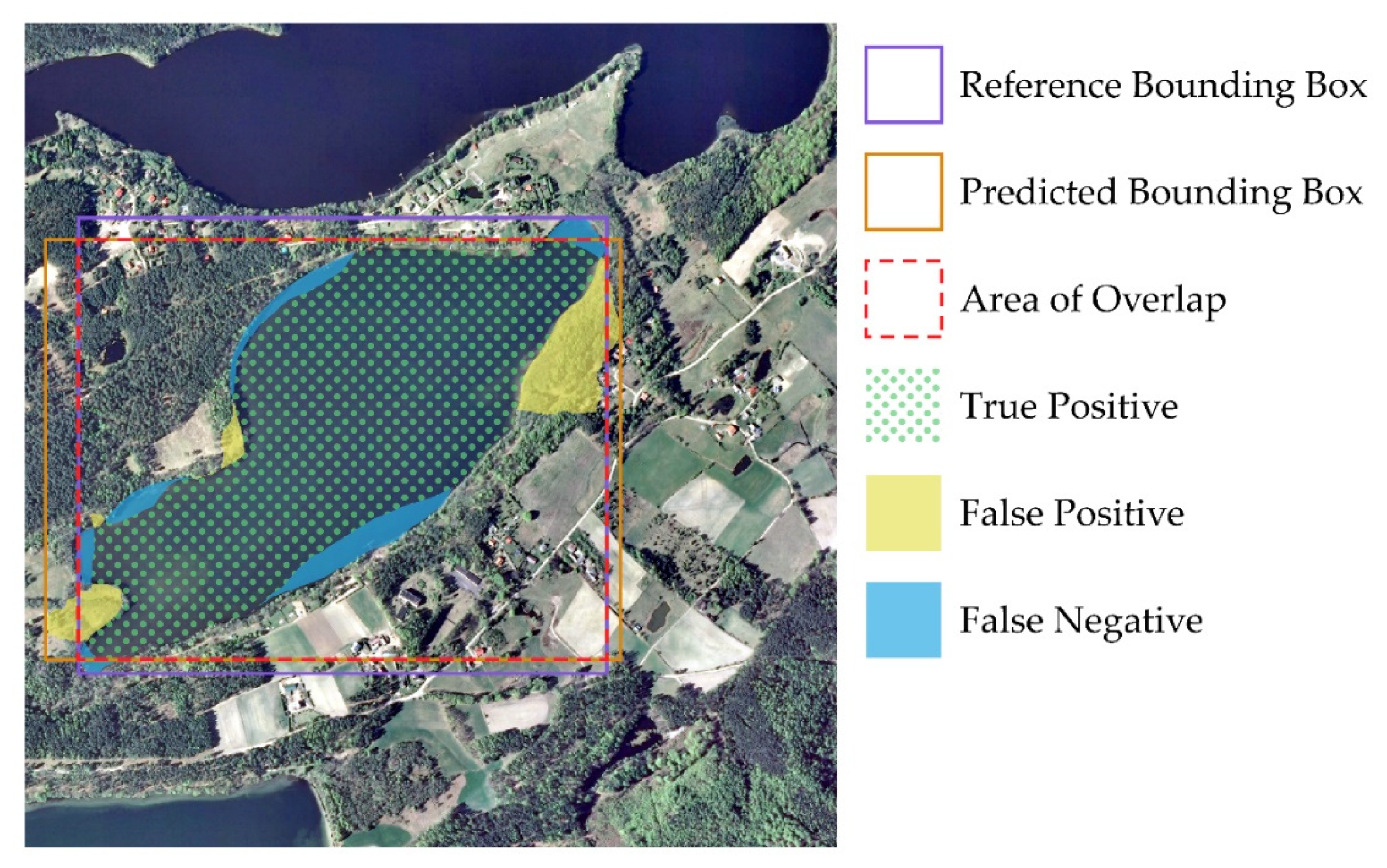
4.2.7. Intersection-Over-Union (IoU)
4.2.8. Combined Multiclass Metrics
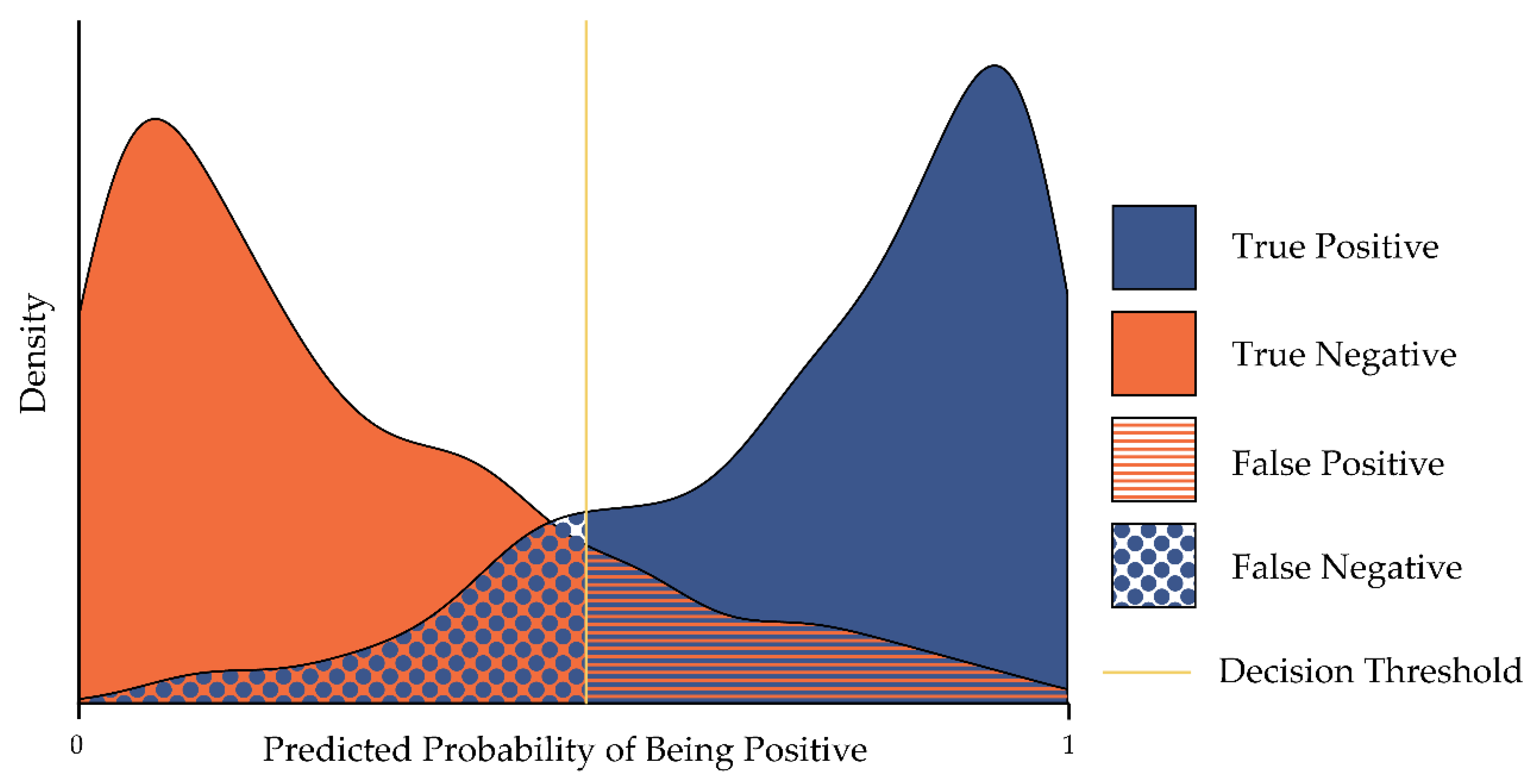
4.3. Metrics for CNN Classifications with Variable Decision Thresholds
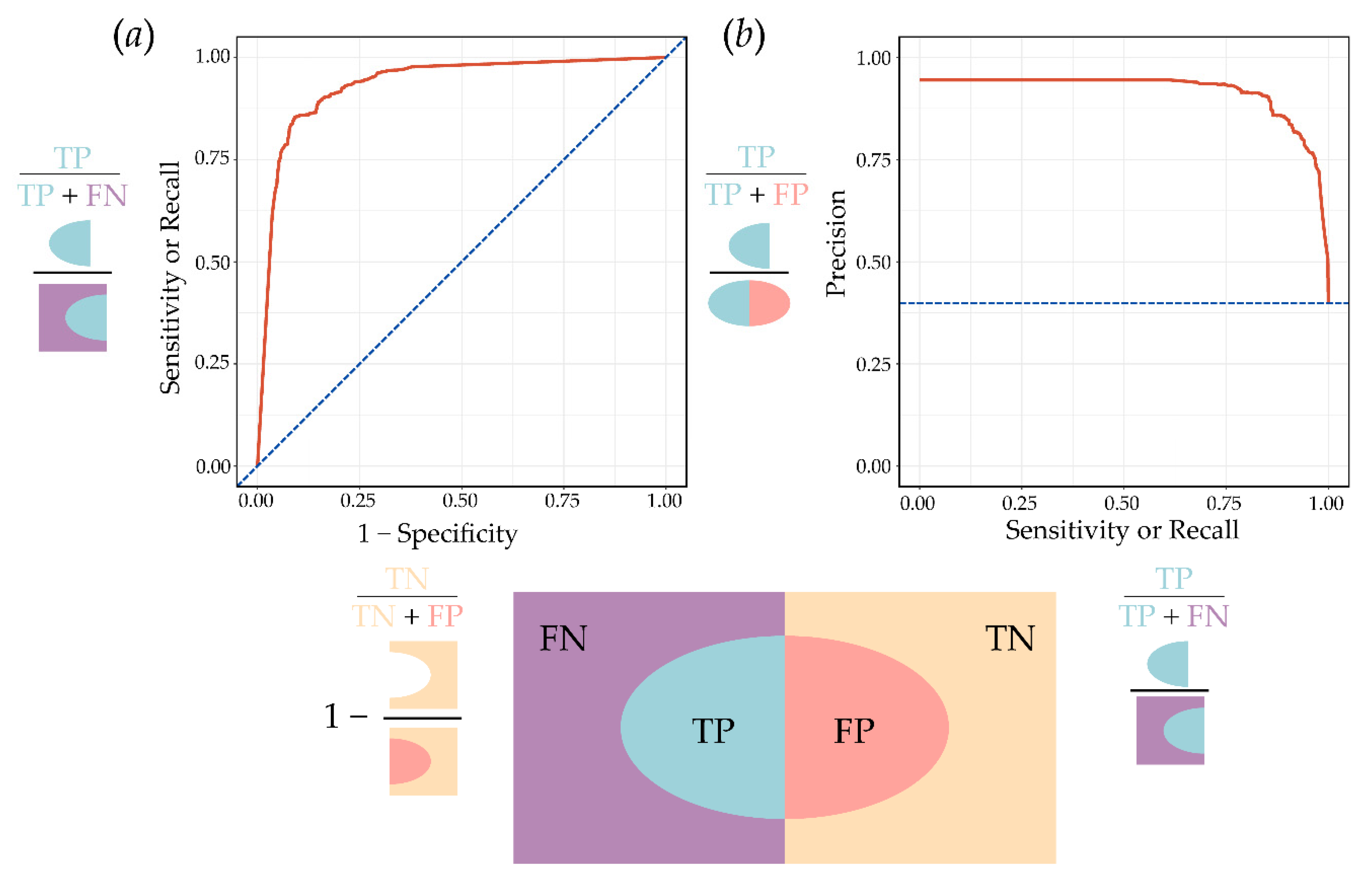
4.3.1. Receiver Operating Characteristic Curve (ROC) and Area under the Curve (AUC)
4.3.2. Precision-Recall Curve (P-R Curve), Average Precision, and Mean Average Precision
4.4. Note on Loss Metrics
5. Discussion and Recommendations
5.1. Comparison of DL and Traditional RS Approaches to Accuracy Assessment
5.2. Clarity in Terminology
5.3. Class Prevalence and Imbalance
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Congalton, R. Accuracy Assessment of Remotely Sensed Data: Future Needs and Directions. In Proceedings of the Pecora, Singapore, 31 August–2 September 1994; ASPRS: Bethesda, MD, USA, 1994; Volume 12, pp. 383–388. [Google Scholar]
- Congalton, R.G. A Review of Assessing the Accuracy of Classifications of Remotely Sensed Data. Remote Sens. Environ. 1991, 37, 35–46. [Google Scholar] [CrossRef]
- Congalton, R.G.; Green, K. Assessing the Accuracy of Remotely Sensed Data: Principles and Practices; CRC Press: Boca Raton, FL, USA, 2019. [Google Scholar]
- Congalton, R.G.; Oderwald, R.G.; Mead, R.A. Assessing Landsat Classification Accuracy Using Discrete Multivariate Analysis Statistical Techniques. Photogramm. Eng. Remote. Sens. 1983, 49, 1671–1678. [Google Scholar]
- Foody, G.M. Status of Land Cover Classification Accuracy Assessment. Remote Sens. Environ. 2002, 80, 185–201. [Google Scholar] [CrossRef]
- Foody, G.M. Harshness in Image Classification Accuracy Assessment. Int. J. Remote Sens. 2008, 29, 3137–3158. [Google Scholar] [CrossRef] [Green Version]
- Stehman, S. Statistical Rigor and Practical Utility in Thematic Map Accuracy Assessment. Photogramm. Eng. Remote Sens. 2001, 67, 727–734. [Google Scholar]
- Stehman, S.V.; Foody, G.M. Accuracy assessment. In The SAGE Handbook of Remote Sensing; Sage London: London, UK, 2009; pp. 297–309. [Google Scholar]
- Stehman, S.V. Selecting and Interpreting Measures of Thematic Classification Accuracy. Remote Sens. Environ. 1997, 62, 77–89. [Google Scholar] [CrossRef]
- Stehman, S.V.; Czaplewski, R.L. Design and Analysis for Thematic Map Accuracy Assessment: Fundamental Principles. Remote Sens. Environ. 1998, 64, 331–344. [Google Scholar] [CrossRef]
- Stehman, S.V.; Foody, G.M. Key Issues in Rigorous Accuracy Assessment of Land Cover Products. Remote Sens. Environ. 2019, 231, 111199. [Google Scholar] [CrossRef]
- Foody, G.M. Explaining the Unsuitability of the Kappa Coefficient in the Assessment and Comparison of the Accuracy of Thematic Maps Obtained by Image Classification. Remote Sens. Environ. 2020, 239, 111630. [Google Scholar] [CrossRef]
- Pontius, R.G.; Millones, M. Death to Kappa: Birth of Quantity Disagreement and Allocation Disagreement for Accuracy Assessment. Int. J. Remote Sens. 2011, 32, 4407–4429. [Google Scholar] [CrossRef]
- Clinton, N.; Holt, A.; Scarborough, J.; Yan, L.; Gong, P. Accuracy Assessment Measures for Object-Based Image Segmentation Goodness. Photogramm. Eng. Remote Sens. 2010, 76, 289–299. [Google Scholar] [CrossRef]
- Radoux, J.; Bogaert, P.; Fasbender, D.; Defourny, P. Thematic Accuracy Assessment of Geographic Object-Based Image Classification. Int. J. Geogr. Inf. Sci. 2011, 25, 895–911. [Google Scholar] [CrossRef]
- Radoux, J.; Bogaert, P. Accounting for the Area of Polygon Sampling Units for the Prediction of Primary Accuracy Assessment Indices. Remote Sens. Environ. 2014, 142, 9–19. [Google Scholar] [CrossRef]
- Radoux, J.; Bogaert, P. Good Practices for Object-Based Accuracy Assessment. Remote Sens. 2017, 9, 646. [Google Scholar] [CrossRef] [Green Version]
- Ye, S.; Pontius, R.G.; Rakshit, R. A Review of Accuracy Assessment for Object-Based Image Analysis: From per-Pixel to per-Polygon Approaches. ISPRS J. Photogramm. Remote Sens. 2018, 141, 137–147. [Google Scholar] [CrossRef]
- Warner, T.A.; Nellis, M.D.; Foody, G.M. The SAGE Handbook of Remote Sensing; SAGE: Newcastle upon Tyne, UK, 2009; ISBN 978-1-4462-0676-8. [Google Scholar]
- Zhang, L.; Zhang, L.; Du, B. Deep Learning for Remote Sens. Data: A Technical Tutorial on the State of the Art. IEEE Geosci. Remote Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep Learning in Remote Sens.: A Comprehensive Review and List of Resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef] [Green Version]
- Ball, J.E.; Anderson, D.T.; Sr, C.S.C. Comprehensive Survey of Deep Learning in Remote Sens.: Theories, Tools, and Challenges for the Community. J. Appl. Remote Sens. 2017, 11, 042609. [Google Scholar] [CrossRef] [Green Version]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep Learning in Remote Sens. Applications: A Meta-Analysis and Review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Hoeser, T.; Bachofer, F.; Kuenzer, C. Object Detection and Image Segmentation with Deep Learning on Earth Observation Data: A Review—Part II: Applications. Remote Sens. 2020, 12, 3053. [Google Scholar] [CrossRef]
- Hoeser, T.; Kuenzer, C. Object Detection and Image Segmentation with Deep Learning on Earth Observation Data: A Review-Part I: Evolution and Recent Trends. Remote Sens. 2020, 12, 1667. [Google Scholar] [CrossRef]
- Atkinson, P.M.; Tatnall, A.R.L. Introduction Neural Networks in Remote Sens. Int. J. Remote Sens. 1997, 18, 699–709. [Google Scholar] [CrossRef]
- Foody, G.M.; Arora, M.K. An Evaluation of Some Factors Affecting the Accuracy of Classification by an Artificial Neural Network. Int. J. Remote Sens. 1997, 18, 799–810. [Google Scholar] [CrossRef]
- Boguszewski, A.; Batorski, D.; Ziemba-Jankowska, N.; Zambrzycka, A.; Dziedzic, T. LandCover.Ai: Dataset for Automatic Mapping of Buildings, Woodlands and Water from Aerial Imagery. arXiv 2020, arXiv:2005.02264. [Google Scholar]
- Li, W.; Wang, Z.; Wang, Y.; Wu, J.; Wang, J.; Jia, Y.; Gui, G. Classification of High-Spatial-Resolution Remote Sens. Scenes Method Using Transfer Learning and Deep Convolutional Neural Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 1986–1995. [Google Scholar] [CrossRef]
- Zhang, W.; Witharana, C.; Liljedahl, A.K.; Kanevskiy, M. Deep Convolutional Neural Networks for Automated Characterization of Arctic Ice-Wedge Polygons in Very High Spatial Resolution Aerial Imagery. Remote Sens. 2018, 10, 1487. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- ImageNet. Available online: http://www.image-net.org/ (accessed on 8 January 2021).
- Carbonneau, P.E.; Dugdale, S.J.; Breckon, T.P.; Dietrich, J.T.; Fonstad, M.A.; Miyamoto, H.; Woodget, A.S. Adopting Deep Learning Methods for Airborne RGB Fluvial Scene Classification. Remote Sens. Environ. 2020, 251, 112107. [Google Scholar] [CrossRef]
- Basu, S.; Ganguly, S.; Mukhopadhyay, S.; DiBiano, R.; Karki, M.; Nemani, R. DeepSat: A Learning Framework for Satellite Imagery. In Proceedings of the 23rd SIGSPATIAL International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 3–6 November 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 1–10. [Google Scholar]
- Cheng, G.; Xie, X.; Han, J.; Guo, L.; Xia, G. Remote Sens. Image Scene Classification Meets Deep Learning: Challenges, Methods, Benchmarks, and Opportunities. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 3735–3756. [Google Scholar] [CrossRef]
- Jiao, L.; Huo, L.; Hu, C.; Tang, P. Refined UNet: UNet-Based Refinement Network for Cloud and Shadow Precise Segmentation. Remote Sens. 2020, 12, 2001. [Google Scholar] [CrossRef]
- Kerner, H.R.; Wagstaff, K.L.; Bue, B.D.; Gray, P.C.; Bell, J.F.; Amor, H.B. Toward Generalized Change Detection on Planetary Surfaces With Convolutional Autoencoders and Transfer Learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 3900–3918. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Bester, M.S.; Guillen, L.A.; Ramezan, C.A.; Carpinello, D.J.; Fan, Y.; Hartley, F.M.; Maynard, S.M.; Pyron, J.L. Semantic Segmentation Deep Learning for Extracting Surface Mine Extents from Historic Topographic Maps. Remote Sens. 2020, 12, 4145. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Pourmohammadi, P.; Poyner, J.D. Mapping the Topographic Features of Mining-Related Valley Fills Using Mask R-CNN Deep Learning and Digital Elevation Data. Remote Sens. 2020, 12, 547. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Han, L.; Han, L.; Zhu, L. How Well Do Deep Learning-Based Methods for Land Cover Classification and Object Detection Perform on High Resolution Remote Sens. Imagery? Remote Sens. 2020, 12, 417. [Google Scholar] [CrossRef] [Green Version]
- Zhang, W.; Liljedahl, A.K.; Kanevskiy, M.; Epstein, H.E.; Jones, B.M.; Jorgenson, M.T.; Kent, K. Transferability of the Deep Learning Mask R-CNN Model for Automated Mapping of Ice-Wedge Polygons in High-Resolution Satellite and UAV Images. Remote Sens. 2020, 12, 1085. [Google Scholar] [CrossRef] [Green Version]
- Yuan, Q.; Shen, H.; Li, T.; Li, Z.; Li, S.; Jiang, Y.; Xu, H.; Tan, W.; Yang, Q.; Wang, J.; et al. Deep Learning in Environmental Remote Sens.: Achievements and Challenges. Remote Sens. Environ. 2020, 241, 111716. [Google Scholar] [CrossRef]
- Lin, T.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C. Microsoft Coco: Common Objects in Context. In European Conference on Computer Vision; Springer: Cham, Germany, 2014; pp. 740–755. [Google Scholar]
- ENVI Deep Learning-Automate Analytics with Deep Learning. Available online: https://www.l3harrisgeospatial.com/Software-Technology/ENVI-Deep-Learning (accessed on 31 December 2020).
- Introduction to ENVI Deep Learning. Available online: https://www.l3harrisgeospatial.com/docs/deep_learning_Introduction.html (accessed on 31 December 2020).
- Machine Learning Deep Learning for Geospatial Applications. Available online: https://www.hexagongeospatial.com/white-papers/machine-learning-for-geospatial-applications (accessed on 31 December 2020).
- The World’s Preferred Remote Sens. Software Package. Available online: https://www.hexagongeospatial.com/products/power-portfolio/erdas-imagine (accessed on 31 December 2020).
- Keras: The Python Deep Learning API. Available online: https://keras.io/ (accessed on 31 December 2020).
- TensorFlow. Available online: https://www.tensorflow.org/ (accessed on 31 December 2020).
- Howard, J.; Gugger, S. Fastai: A Layered API for Deep Learning. Information 2020, 11, 108. [Google Scholar] [CrossRef] [Green Version]
- Huang, Z.; Wei, Y.; Wang, X.; Liu, W. A PyTorch Semantic Segmentation Toolbox. 2018. Available online: https://xinggangw.info/pubs/toolbox.pdf (accessed on 1 June 2021).
- PyTorch. Available online: https://www.pytorch.org (accessed on 31 December 2020).
- Maxwell, A.E.; Warner, T.A.; Fang, F. Implementation of Machine-Learning Classification in Remote Sens.: An Applied Review. Int. J. Remote Sens. 2018, 39, 2784–2817. [Google Scholar] [CrossRef] [Green Version]
- Aksoy, S.; Koperski, K.; Tusk, C.; Marchisio, G.; Tilton, J.C. Learning Bayesian Classifiers for Scene Classification with a Visual Grammar. IEEE Trans. Geosci. Remote Sens. 2005, 43, 581–589. [Google Scholar] [CrossRef] [Green Version]
- Warner, T.A.; McGraw, J.B.; Landenberger, R. Segmentation and Classification of High Resolution Imagery for Mapping Individual Species in a Closed Canopy, Deciduous Forest. Sci. China Ser. E Technol. Sci. 2006, 49, 128–139. [Google Scholar] [CrossRef]
- Brandtberg, T.; McGraw, J.B.; Warner, T.A.; Landenberger, R.E. Image Restoration Based on Multiscale Relationships of Image Structures. IEEE Trans. Geosci. Remote Sens. 2003, 41, 102–110. [Google Scholar] [CrossRef]
- Foody, G.M. Sample Size Determination for Image Classification Accuracy Assessment and Comparison. Int. J. Remote Sens. 2009, 30, 5273–5291. [Google Scholar] [CrossRef]
- Stehman, S.V. Thematic Map Accuracy Assessment from the Perspective of Finite Population Sampling. Int. J. Remote Sens. 1995, 16, 589–593. [Google Scholar] [CrossRef]
- Stehman, S.V. Comparison of Systematic and Random Sampling for Estimating the Accuracy of Maps Generated from Remotely Sensed Data. Photogramm. Eng. 1992, 8, 1343–1350. [Google Scholar]
- Stehman, S.V. Estimating the Kappa Coefficient and Its Variance under Stratified Random Sampling. Photogramm. Eng. Remote Sens. 1996, 7, 401–407. [Google Scholar]
- Stehman, S.V. Estimating Standard Errors of Accuracy Assessment Statistics under Cluster Sampling. Remote Sens. Environ. 1997, 60, 258–269. [Google Scholar] [CrossRef]
- Stehman, S.V. Basic Probability Sampling Designs for Thematic Map Accuracy Assessment. Int. J. Remote Sens. 1999, 20, 2423–2441. [Google Scholar] [CrossRef]
- Stehman, S.V. Practical Implications of Design-Based Sampling Inference for Thematic Map Accuracy Assessment. Remote Sens. Environ. 2000, 72, 35–45. [Google Scholar] [CrossRef]
- Stehman, S.V. Sampling Designs for Accuracy Assessment of Land Cover. Int. J. Remote Sens. 2009, 30, 5243–5272. [Google Scholar] [CrossRef]
- Stehman, S.V. Impact of Sample Size Allocation When Using Stratified Random Sampling to Estimate Accuracy and Area of Land-Cover Change. Remote Sens. Lett. 2012, 3, 111–120. [Google Scholar] [CrossRef]
- Stehman, S.V. Estimating Area and Map Accuracy for Stratified Random Sampling When the Strata Are Different from the Map Classes. Int. J. Remote Sens. 2014, 35, 4923–4939. [Google Scholar] [CrossRef]
- Stehman, S.V.; Wickham, J.D. Pixels, Blocks of Pixels, and Polygons: Choosing a Spatial Unit for Thematic Accuracy Assessment. Remote Sens. Environ. 2011, 115, 3044–3055. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Ke, X.; Zhan, X.; Shi, J.; Wei, S.; Pan, D.; Li, J.; Su, H.; Zhou, Y.; et al. LS-SSDD-v1.0: A Deep Learning Dataset Dedicated to Small Ship Detection from Large-Scale Sentinel-1 SAR Images. Remote Sens. 2020, 12, 2997. [Google Scholar] [CrossRef]
- Zhang, C.; Chen, Y.; Yang, X.; Gao, S.; Li, F.; Kong, A.; Zu, D.; Sun, L. Improved Remote Sens. Image Classification Based on Multi-Scale Feature Fusion. Remote Sens. 2020, 12, 213. [Google Scholar] [CrossRef] [Green Version]
- Pierdicca, R.; Paolanti, M.; Matrone, F.; Martini, M.; Morbidoni, C.; Malinverni, E.S.; Frontoni, E.; Lingua, A.M. Point Cloud Semantic Segmentation Using a Deep Learning Framework for Cultural Heritage. Remote Sens. 2020, 12, 1005. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. UNet++: Redesigning Skip Connections to Exploit Multiscale Features in Image Segmentation. IEEE Trans. Med. Imaging 2020, 39, 1856–1867. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sun, F.; Yang, G.; Zhang, A.; Zhang, Y. Circle-U-Net: An Efficient Architecture for Semantic Segmentation. Algorithms 2021, 14, 159. [Google Scholar] [CrossRef]
- Li, W.; Hsu, C.-Y. Automated Terrain Feature Identification from Remote Sens. Imagery: A Deep Learning Approach. Int. J. Geogr. Inf. Sci. 2020, 34, 637–660. [Google Scholar] [CrossRef]
- Bai, Y.; Wu, W.; Yang, Z.; Yu, J.; Zhao, B.; Liu, X.; Yang, H.; Mas, E.; Koshimura, S. Enhancement of Detecting Permanent Water and Temporary Water in Flood Disasters by Fusing Sentinel-1 and Sentinel-2 Imagery Using Deep Learning Algorithms: Demonstration of Sen1Floods11 Benchmark Datasets. Remote Sens. 2021, 13, 2220. [Google Scholar] [CrossRef]
- Panagiotou, E.; Chochlakis, G.; Grammatikopoulos, L.; Charou, E. Generating Elevation Surface from a Single RGB Remotely Sensed Image Using Deep Learning. Remote Sens. 2020, 12, 2002. [Google Scholar] [CrossRef]
- Park, J.H.; Inamori, T.; Hamaguchi, R.; Otsuki, K.; Kim, J.E.; Yamaoka, K. RGB Image Prioritization Using Convolutional Neural Network on a Microprocessor for Nanosatellites. Remote Sens. 2020, 12, 3941. [Google Scholar] [CrossRef]
- Abdalla, A.; Cen, H.; Abdel-Rahman, E.; Wan, L.; He, Y. Color Calibration of Proximal Sensing RGB Images of Oilseed Rape Canopy via Deep Learning Combined with K-Means Algorithm. Remote Sens. 2019, 11, 3001. [Google Scholar] [CrossRef] [Green Version]
- Yang, R.; Su, L.; Zhao, X.; Wan, H.; Sun, J. Representative Band Selection for Hyperspectral Image Classification. J. Vis. Commun. Image Represent. 2017, 48, 396–403. [Google Scholar] [CrossRef]
- Witharana, C.; Bhuiyan, M.A.E.; Liljedahl, A.K.; Kanevskiy, M.; Epstein, H.E.; Jones, B.M.; Daanen, R.; Griffin, C.G.; Kent, K.; Ward Jones, M.K. Understanding the Synergies of Deep Learning and Data Fusion of Multispectral and Panchromatic High Resolution Commercial Satellite Imagery for Automated Ice-Wedge Polygon Detection. ISPRS J. Photogramm. Remote Sens. 2020, 170, 174–191. [Google Scholar] [CrossRef]
- Zang, N.; Cao, Y.; Wang, Y.; Huang, B.; Zhang, L.; Mathiopoulos, P.T. Land-Use Mapping for High-Spatial Resolution Remote Sens. Image Via Deep Learning: A Review. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 5372–5391. [Google Scholar] [CrossRef]
- Sun, Y.; Huang, J.; Ao, Z.; Lao, D.; Xin, Q. Deep Learning Approaches for the Mapping of Tree Species Diversity in a Tropical Wetland Using Airborne LiDAR and High-Spatial-Resolution Remote Sens. Images. Forests 2019, 10, 1047. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Majumder, A.; Zhang, H.; Gopi, M. Optimized Multi-Spectral Filter Array Based Imaging of Natural Scenes. Sensors 2018, 18, 1172. [Google Scholar] [CrossRef] [Green Version]
- Bhuiyan, M.A.E.; Witharana, C.; Liljedahl, A.K.; Jones, B.M.; Daanen, R.; Epstein, H.E.; Kent, K.; Griffin, C.G.; Agnew, A. Understanding the Effects of Optimal Combination of Spectral Bands on Deep Learning Model Predictions: A Case Study Based on Permafrost Tundra Landform Mapping Using High Resolution Multispectral Satellite Imagery. J. Imaging 2020, 6, 97. [Google Scholar] [CrossRef]
- Cai, Y.; Huang, H.; Wang, K.; Zhang, C.; Fan, L.; Guo, F. Selecting Optimal Combination of Data Channels for Semantic Segmentation in City Information Modelling (CIM). Remote Sens. 2021, 13, 1367. [Google Scholar] [CrossRef]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Can Semantic Labeling Methods Generalize to Any City? The Inria Aerial Image Labeling Benchmark. In Proceedings of the 2017 IEEE International Geoscience and Remote Sens. Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 3226–3229. [Google Scholar]
- Robinson, C.; Hou, L.; Malkin, K.; Soobitsky, R.; Czawlytko, J.; Dilkina, B.; Jojic, N. Large Scale High-Resolution Land Cover Mapping With Multi-Resolution Data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 12726–12735. [Google Scholar]
- Stehman, S.V. A Critical Evaluation of the Normalized Error Matrix in Map Accuracy Assessment. Photogramm. Eng. Remote Sens. 2004, 70, 743–751. [Google Scholar] [CrossRef]
- Stehman, S.V. Estimating Area from an Accuracy Assessment Error Matrix. Remote Sens. Environ. 2013, 132, 202–211. [Google Scholar] [CrossRef]
- Chen, J.; Wan, L.; Zhu, J.; Xu, G.; Deng, M. Multi-Scale Spatial and Channel-Wise Attention for Improving Object Detection in Remote Sens. Imagery. IEEE Geosci. Remote Sens. Lett. 2019, 17, 681–685. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. arXiv 2018, arXiv:1802.02611. [Google Scholar]
- Liu, J.; Wang, Z.; Cheng, K. An Improved Algorithm for Semantic Segmentation of Remote Sens. Images Based on DeepLabv3+. In Proceedings of the 5th International Conference on Communication and Information Processing, Association for Computing Machinery, New York, NY, USA, 15–17 November 2019; pp. 124–128. [Google Scholar]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. UNet++: A Nested U-Net Architecture for Medical Image Segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Stoyanov, D., Taylor, Z., Carneiro, G., Syeda-Mahmood, T., Martel, A., Maier-Hein, L., Tavares, J.M.R.S., Bradley, A., Papa, J.P., Belagiannis, V., et al., Eds.; Springer International Publishing: Cham, Germany, 2018; pp. 3–11. [Google Scholar]
- Yurtkulu, S.C.; Şahin, Y.H.; Unal, G. Semantic Segmentation with Extended DeepLabv3 Architecture. In Proceedings of the 2019 27th Signal Processing and Communications Applications Conference (SIU), Sivas, Turkey, 24–26 April 2019; pp. 1–4. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Tharwat, A. Classification Assessment Methods. Appl. Comput. Inform. 2021, 17, 168–192. [Google Scholar] [CrossRef]
- Du, L.; McCarty, G.W.; Zhang, X.; Lang, M.W.; Vanderhoof, M.K.; Li, X.; Huang, C.; Lee, S.; Zou, Z. Mapping Forested Wetland Inundation in the Delmarva Peninsula, USA Using Deep Convolutional Neural Networks. Remote Sens. 2020, 12, 644. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Liu, G.; Zhang, C.; Atkinson, P.M.; Tan, X.; Jian, X.; Zhou, X.; Li, Y. Two-Phase Object-Based Deep Learning for Multi-Temporal SAR Image Change Detection. Remote Sens. 2020, 12, 548. [Google Scholar] [CrossRef] [Green Version]
- Bundzel, M.; Jaščur, M.; Kováč, M.; Lieskovský, T.; Sinčák, P.; Tkáčik, T. Semantic Segmentation of Airborne LiDAR Data in Maya Archaeology. Remote Sens. 2020, 12, 3685. [Google Scholar] [CrossRef]
- Zhang, Y.; Sheng, W.; Jiang, J.; Jing, N.; Wang, Q.; Mao, Z. Priority Branches for Ship Detection in Optical Remote Sens. Images. Remote Sens. 2020, 12, 1196. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Jiang, B.; Wang, S.; Shen, L.; Fu, Y. A Human–Computer Fusion Framework for Aircraft Recognition in Remote Sens. Images. IEEE Geosci. Remote Sens. Lett. 2019, 17, 297–301. [Google Scholar] [CrossRef]
- Waldner, F.; Diakogiannis, F.I. Deep Learning on Edge: Extracting Field Boundaries from Satellite Images with a Convolutional Neural Network. Remote Sens. Environ. 2020, 245, 111741. [Google Scholar] [CrossRef]
- Papp, A.; Pegoraro, J.; Bauer, D.; Taupe, P.; Wiesmeyr, C.; Kriechbaum-Zabini, A. Automatic Annotation of Hyperspectral Images and Spectral Signal Classification of People and Vehicles in Areas of Dense Vegetation with Deep Learning. Remote Sens. 2020, 12, 2111. [Google Scholar] [CrossRef]
- Xu, S.; Zhang, S.; Zeng, J.; Li, T.; Guo, Q.; Jin, S. A Framework for Land Use Scenes Classification Based on Landscape Photos. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 6124–6141. [Google Scholar] [CrossRef]
- Prakash, N.; Manconi, A.; Loew, S. Mapping Landslides on EO Data: Performance of Deep Learning Models vs. Traditional Machine Learning Models. Remote Sens. 2020, 12, 346. [Google Scholar] [CrossRef] [Green Version]
- Wang, M.; Zhang, H.; Sun, W.; Li, S.; Wang, F.; Yang, G. A Coarse-to-Fine Deep Learning Based Land Use Change Detection Method for High-Resolution Remote Sens. Images. Remote Sens. 2020, 12, 1933. [Google Scholar] [CrossRef]
- Soloy, A.; Turki, I.; Fournier, M.; Costa, S.; Peuziat, B.; Lecoq, N. A Deep Learning-Based Method for Quantifying and Mapping the Grain Size on Pebble Beaches. Remote Sens. 2020, 12, 3659. [Google Scholar] [CrossRef]
- Qiu, C.; Schmitt, M.; Geiß, C.; Chen, T.-H.K.; Zhu, X.X. A Framework for Large-Scale Mapping of Human Settlement Extent from Sentinel-2 Images via Fully Convolutional Neural Networks. ISPRS J. Photogramm. Remote Sens. 2020, 163, 152–170. [Google Scholar] [CrossRef]
- Veeranampalayam Sivakumar, A.N.; Li, J.; Scott, S.; Psota, E.J.; Jhala, A.; Luck, J.D.; Shi, Y. Comparison of Object Detection and Patch-Based Classification Deep Learning Models on Mid- to Late-Season Weed Detection in UAV Imagery. Remote Sens. 2020, 12, 2136. [Google Scholar] [CrossRef]
- Liu, J.; Chen, K.; Xu, G.; Sun, X.; Yan, M.; Diao, W.; Han, H. Convolutional Neural Network-Based Transfer Learning for Optical Aerial Images Change Detection. IEEE Geosci. Remote Sens. Lett. 2019, 17, 127–131. [Google Scholar] [CrossRef]
- Jin, S.; Su, Y.; Gao, S.; Wu, F.; Ma, Q.; Xu, K.; Hu, T.; Liu, J.; Pang, S.; Guan, H.; et al. Separating the Structural Components of Maize for Field Phenotyping Using Terrestrial Lidar Data and Deep Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2019, 58, 2644–2658. [Google Scholar] [CrossRef]
- Li, Y.; Chen, R.; Zhang, Y.; Zhang, M.; Chen, L. Multi-Label Remote Sens. Image Scene Classification by Combining a Convolutional Neural Network and a Graph Neural Network. Remote Sens. 2020, 12, 4003. [Google Scholar] [CrossRef]
- Rangnekar, A.; Mokashi, N.; Ientilucci, E.; Kanan, C.; Hoffman, M. Aerorit: A New Scene for Hyperspectral Image Analysis. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8116–8124. [Google Scholar] [CrossRef]
- Yang, M.-D.; Tseng, H.-H.; Hsu, Y.-C.; Tsai, H.P. Semantic Segmentation Using Deep Learning with Vegetation Indices for Rice Lodging Identification in Multi-Date UAV Visible Images. Remote Sens. 2020, 12, 633. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Ma, J.; Lv, X.; Chen, D. Hierarchical Weakly Supervised Learning for Residential Area Semantic Segmentation in Remote Sens. Images. IEEE Geosci. Remote Sens. Lett. 2019, 17, 117–121. [Google Scholar] [CrossRef]
- He, C.; Li, S.; Xiong, D.; Fang, P.; Liao, M. Remote Sens. Image Semantic Segmentation Based on Edge Information Guidance. Remote Sens. 2020, 12, 1501. [Google Scholar] [CrossRef]
- Qamar, F.; Dobler, G. Pixel-Wise Classification of High-Resolution Ground-Based Urban Hyperspectral Images with Convolutional Neural Networks. Remote Sens. 2020, 12, 2540. [Google Scholar] [CrossRef]
- Mou, L.; Hua, Y.; Zhu, X.X. Relation Matters: Relational Context-Aware Fully Convolutional Network for Semantic Segmentation of High-Resolution Aerial Images. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7557–7569. [Google Scholar] [CrossRef]
- Sun, X.; Shi, A.; Huang, H.; Mayer, H. BAS4 Net: Boundary-Aware Semi-Supervised Semantic Segmentation Network for Very High Resolution Remote Sens. Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5398–5413. [Google Scholar] [CrossRef]
- Singh, A.; Kalke, H.; Loewen, M.; Ray, N. River Ice Segmentation with Deep Learning. IEEE Trans. Geosci. and Remote Sens. 2020, 58, 7570–7579. [Google Scholar] [CrossRef] [Green Version]
- Cortes, C.; Mohri, M. Confidence Intervals for the Area Under the ROC Curve. Adv. Neural Inf. Process. Syst. 2005, 17, 305–312. [Google Scholar]
- Fan, J.; Upadhye, S.; Worster, A. Understanding Receiver Operating Characteristic (ROC) Curves. Can. J. Emerg. Med. 2006, 8, 19–20. [Google Scholar] [CrossRef]
- Lobo, J.M.; Jiménez-Valverde, A.; Real, R. AUC: A Misleading Measure of the Performance of Predictive Distribution Models. Glob. Ecol. Biogeogr. 2008, 17, 145–151. [Google Scholar] [CrossRef]
- McNeil, B.J.; Hanley, J.A. Statistical Approaches to the Analysis of Receiver Operating Characteristic (ROC) Curves. Med. Decis. Mak. 1984, 4, 137–150. [Google Scholar] [CrossRef]
- Wandishin, M.S.; Mullen, S.J. Multiclass ROC Analysis. Weather Forecast. 2009, 24, 530–547. [Google Scholar] [CrossRef]
- Saito, T.; Rehmsmeier, M. The Precision-Recall Plot Is More Informative than the ROC Plot When Evaluating Binary Classifiers on Imbalanced Datasets. PLoS ONE 2015, 10, e0118432. [Google Scholar] [CrossRef] [Green Version]
- Keilwagen, J.; Grosse, I.; Grau, J. Area under Precision-Recall Curves for Weighted and Unweighted Data. PLoS ONE 2014, 9, e92209. [Google Scholar] [CrossRef] [PubMed]
- Boyd, K.; Eng, K.H.; Page, C.D. Area under the Precision-Recall Curve: Point Estimates and Confidence Intervals. In Proceedings of the Machine Learning and Knowledge Discovery in Databases, Prague, Czech Republic, 23–27 September 2013; Blockeel, H., Kersting, K., Nijssen, S., Železný, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 451–466. [Google Scholar]
- Oh, S.; Chang, A.; Ashapure, A.; Jung, J.; Dube, N.; Maeda, M.; Gonzalez, D.; Landivar, J. Plant Counting of Cotton from UAS Imagery Using Deep Learning-Based Object Detection Framework. Remote Sens. 2020, 12, 2981. [Google Scholar] [CrossRef]
- COCO-Common Objects in Context. Available online: https://cocodataset.org/#detection-eval (accessed on 3 April 2021).
- 1Su, H.; Wei, S.; Liu, S.; Liang, J.; Wang, C.; Shi, J.; Zhang, X. HQ-ISNet: High-Quality Instance Segmentation for Remote Sensing Imagery. Remote Sens. 2020, 12, 989. [Google Scholar] [CrossRef] [Green Version]
- Ma, J.; Chen, J.; Ng, M.; Huang, R.; Li, Y.; Li, C.; Yang, X.; Martel, A.L. Loss Odyssey in Medical Image Segmentation. Med. Image Anal. 2021, 102035. [Google Scholar] [CrossRef] [PubMed]
- Ho, Y.; Wookey, S. The Real-World-Weight Cross-Entropy Loss Function: Modeling the Costs of Mislabeling. IEEE Access 2020, 8, 4806–4813. [Google Scholar] [CrossRef]
- Zhang, Z.; Sabuncu, M.R. Generalized Cross Entropy Loss for Training Deep Neural Networks with Noisy Labels. arXiv 2018, arXiv:1805.07836. [Google Scholar]
- Sudre, C.H.; Li, W.; Vercauteren, T.; Ourselin, S.; Jorge Cardoso, M. Generalised Dice Overlap as a Deep Learning Loss Function for Highly Unbalanced Segmentations. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Cardoso, M.J., Arbel, T., Carneiro, G., Syeda-Mahmood, T., Tavares, J.M.R.S., Moradi, M., Bradley, A., Greenspan, H., Papa, J.P., Madabhushi, A., et al., Eds.; Springer International Publishing: Cham, Germany, 2017; pp. 240–248. [Google Scholar]
- Li, X.; Sun, X.; Meng, Y.; Liang, J.; Wu, F.; Li, J. Dice Loss for Data-Imbalanced NLP Tasks. arXiv 2020, arXiv:1911.02855. [Google Scholar]
- Wang, P.; Chung, A.C.S. Focal Dice Loss and Image Dilation for Brain Tumor Segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Stoyanov, D., Taylor, Z., Carneiro, G., Syeda-Mahmood, T., Martel, A., Maier-Hein, L., Tavares, J.M.R.S., Bradley, A., Papa, J.P., Belagiannis, V., et al., Eds.; Springer International Publishing: Cham, Germany, 2018; pp. 119–127. [Google Scholar]
- Zhao, R.; Qian, B.; Zhang, X.; Li, Y.; Wei, R.; Liu, Y.; Pan, Y. Rethinking Dice Loss for Medical Image Segmentation. In Proceedings of the 2020 IEEE International Conference on Data Mining (ICDM), Sorrento, Italy, 17–20 November 2020; pp. 851–860. [Google Scholar]
- Salehi, S.S.M.; Erdogmus, D.; Gholipour, A. Tversky Loss Function for Image Segmentation Using 3D Fully Convolutional Deep Networks. arXiv 2017, arXiv:1706.05721. [Google Scholar]
- Abraham, N.; Khan, N.M. A Novel Focal Tversky Loss Function With Improved Attention U-Net for Lesion Segmentation. In Proceedings of the 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), Venice, Italy, 8–11 April 2019; pp. 683–687. [Google Scholar]
- Bertels, J.; Eelbode, T.; Berman, M.; Vandermeulen, D.; Maes, F.; Bisschops, R.; Blaschko, M.B. Optimizing the Dice Score and Jaccard Index for Medical Image Segmentation: Theory and Practice. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2019, Shenzhen, China, 13–17 October 2019; Shen, D., Liu, T., Peters, T.M., Staib, L.H., Essert, C., Zhou, S., Yap, P.-T., Khan, A., Eds.; Springer International Publishing: Cham, Germany, 2019; pp. 92–100. [Google Scholar]
- Bertels, J.; Robben, D.; Vandermeulen, D.; Suetens, P. Optimization with Soft Dice Can Lead to a Volumetric Bias. In Brainlesion: Glioma, Multiple Sclerosis, Stroke and Traumatic Brain Injuries; Crimi, A., Bakas, S., Eds.; Springer International Publishing: Cham, Germany, 2020; pp. 89–97. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Mukhoti, J.; Kulharia, V.; Sanyal, A.; Golodetz, S.; Torr, P.H.S.; Dokania, P.K. Calibrating Deep Neural Networks Using Focal Loss. arXiv 2020, arXiv:2002.09437. [Google Scholar]
- Yun, P.; Tai, L.; Wang, Y.; Liu, C.; Liu, M. Focal Loss in 3D Object Detection. IEEE Robot. Autom. Lett. 2019, 4, 1263–1270. [Google Scholar] [CrossRef] [Green Version]
- Wang, Q.; Wan, J.; Yuan, Y. Deep Metric Learning for Crowdedness Regression. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 2633–2643. [Google Scholar] [CrossRef]
- Wang, W.; Wang, Y.; Wu, Y.; Lin, T.; Li, S.; Chen, B. Quantification of Full Left Ventricular Metrics via Deep Regression Learning With Contour-Guidance. IEEE Access 2019, 7, 47918–47928. [Google Scholar] [CrossRef]
- Salomonson, V.V.; Appel, I. Estimating Fractional Snow Cover from MODIS Using the Normalized Difference Snow Index. Remote Sens. Environ. 2004, 89, 351–360. [Google Scholar] [CrossRef]
- Shi, Y.; Li, Q.; Zhu, X.X. Building Segmentation through a Gated Graph Convolutional Neural Network with Deep Structured Feature Embedding. ISPRS J. Photogramm. Remote Sens. 2020, 159, 184–197. [Google Scholar] [CrossRef] [PubMed]
- Luo, S.; Li, H.; Shen, H. Deeply Supervised Convolutional Neural Network for Shadow Detection Based on a Novel Aerial Shadow Imagery Dataset. ISPRS J. Photogramm. Remote Sens. 2020, 167, 443–457. [Google Scholar] [CrossRef]
- Qian, J.; Xia, M.; Zhang, Y.; Liu, J.; Xu, Y. TCDNet: Trilateral Change Detection Network for Google Earth Image. Remote Sens. 2020, 12, 2669. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | ||||||
|---|---|---|---|---|---|---|
| A | B | C | Row Total | UA | ||
| Classification | A | PAA | PAB | PAC | PA+ | PAA/PA+ |
| B | PBA | PBB | PBC | PB+ | PBB/PB+ | |
| C | PCA | PCB | PCC | PC+ | PCC/PC+ | |
| Column total | P+A | P+B | P+C | |||
| PA | PAA/P+A | PBB/P+B | PCC/P+C | |||
| Measure | Type of Measure | Equation |
|---|---|---|
| Overall Accuracy (OA) | Integrated summary | |
| Kappa | Integrated summary | |
| User’s Accuracy (UA) | Class-based | |
| Producer’s Accuracy (PA) | Class-based |
| CNN Classification Type | Number of Studies | ||
|---|---|---|---|
| Binary and Single Class Classifications | Multiclass Classifications | Total | |
| Scene Classification | 0 | 12 | 12 |
| Object Detection | 18 | 13 | 32 |
| Semantic Segmentation | 20 | 33 | 52 |
| Instance Segmentation | 3 | 4 | 7 |
| Total | 41 | 62 | 103 |
| Reference Data | |||
|---|---|---|---|
| Positive | Negative | ||
| Classification Result | Positive | TP | FP |
| Negative | FN | TN | |
| Type of Confusion Matrix | Number of Studies |
|---|---|
| Reference category values add to 100% | 11 |
| Predicted category values add to 100% | 2 |
| Values in entire table add to 100% (or values represent landscape proportions) | 4 |
| Total | 17 |
| Generally Accepted or Most Commonly Used Name of Measure in RS DL | Other Names Used in the RS DL Literature | Equation | Relation to Traditional RS Measures |
|---|---|---|---|
| Overall Accuracy (OA) [99] | Percent Correct Classification [100] Pixel Accuracy [101] | Overall Accuracy | |
| Recall [102] | Sensitivity [101] True Positive Rate (TPR) [101] Overall Accuracy [103] Detection Probability [68] Hit Rate [104] | PA for positives | |
| Precision [102] | Positive Predictive Value (PPV) [101] | UA for positives | |
| Specificity [105] | True Negative Rate (TNR) [101] | PA for negatives | |
| Negative Predictive Value (NPV) [101] | UA for negatives | ||
| False Positive Rate (FPR) [106] | Probability of False Detection [107] False Alarm Probability [100] | (PA for negatives) | |
| False Negative Rate (FNR) 1 | Missing Detection Probability [100] Missing Alarm [108] Misidentification Score [109] | (PA for positives) | |
| False Discovery Rate (FDR) 1 | False Alarm Probability [68] Commission Error [110] | (UA for positives) | |
| Balanced Accuracy [101] | (Recall + Specificity) | ||
| Matthews Correlation Coefficient (MCC) [101] | |||
| F1 [111] | F-measure [112] (Liu et al. 2020) F-score [113] Fβ Score [114] Sørensen–Dice Coefficient [115] | or | |
| Intersection-over-Union (IoU) [99] | Jaccard Index [115] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Maxwell, A.E.; Warner, T.A.; Guillén, L.A. Accuracy Assessment in Convolutional Neural Network-Based Deep Learning Remote Sensing Studies—Part 1: Literature Review. Remote Sens. 2021, 13, 2450. https://doi.org/10.3390/rs13132450
Maxwell AE, Warner TA, Guillén LA. Accuracy Assessment in Convolutional Neural Network-Based Deep Learning Remote Sensing Studies—Part 1: Literature Review. Remote Sensing. 2021; 13(13):2450. https://doi.org/10.3390/rs13132450
Chicago/Turabian StyleMaxwell, Aaron E., Timothy A. Warner, and Luis Andrés Guillén. 2021. "Accuracy Assessment in Convolutional Neural Network-Based Deep Learning Remote Sensing Studies—Part 1: Literature Review" Remote Sensing 13, no. 13: 2450. https://doi.org/10.3390/rs13132450