
Knowledge Retrieval Model Based on a Graph Database for Semantic Search in Equipment Purchase Order Specifications for Steel Plants

Abstract
:1. Introduction
1.1. Status of IT Technology and Data Usage
1.2. Transition of Manufacturing Plant to Revamping Model
2. Literature Review
2.1. Information Retrieval
2.2. Purchase Order
2.3. Knowledge Graph
3. A Preliminary Study
3.1. Survey as a Preliminary Study
3.2. Problem Statement and Research Objective
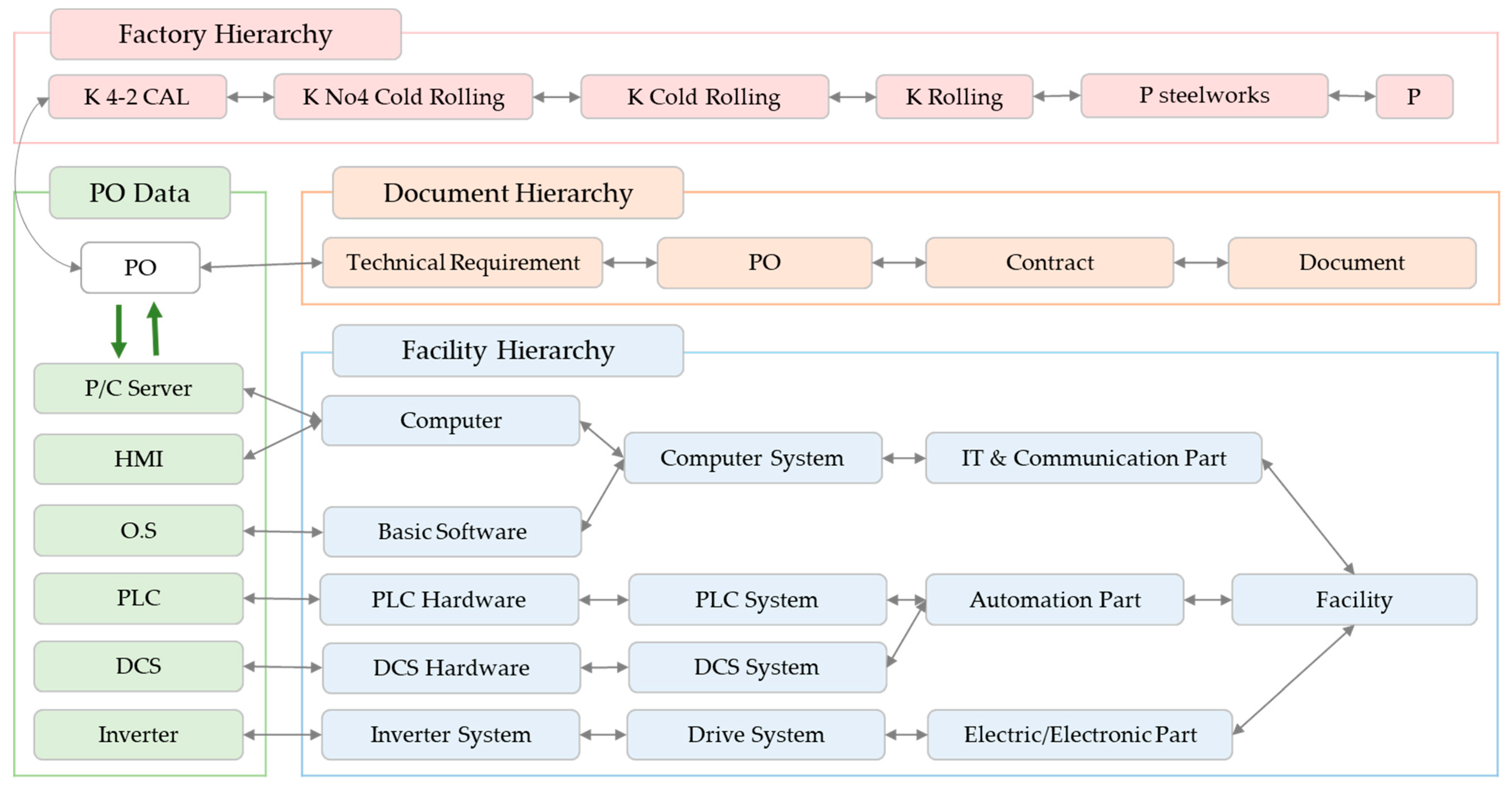
4. Research Framework and Model Overview
4.1. Research Framework
- Step 1. Definitions of data and hierarchical structures: Factory hierarchy, document hierarchy, facility classification hierarchy, and PO data were defined.
- Step 2. Data preprocessing: A CSV file was developed to create a number of nodes and relationships in the graph database.
- Step 3. Model development: The POKREM was developed using preprocessed CSV files and the reasoning function.
- Step 4. Platform development: A platform was developed for the system integration.
- Step 5. Test: The performance of the POKREM was tested through queries.
- Step 6. Validation: Semantic analysis was performed on the test results.
4.2. Modeling Process Overview
4.3. Selection of Target PO Data
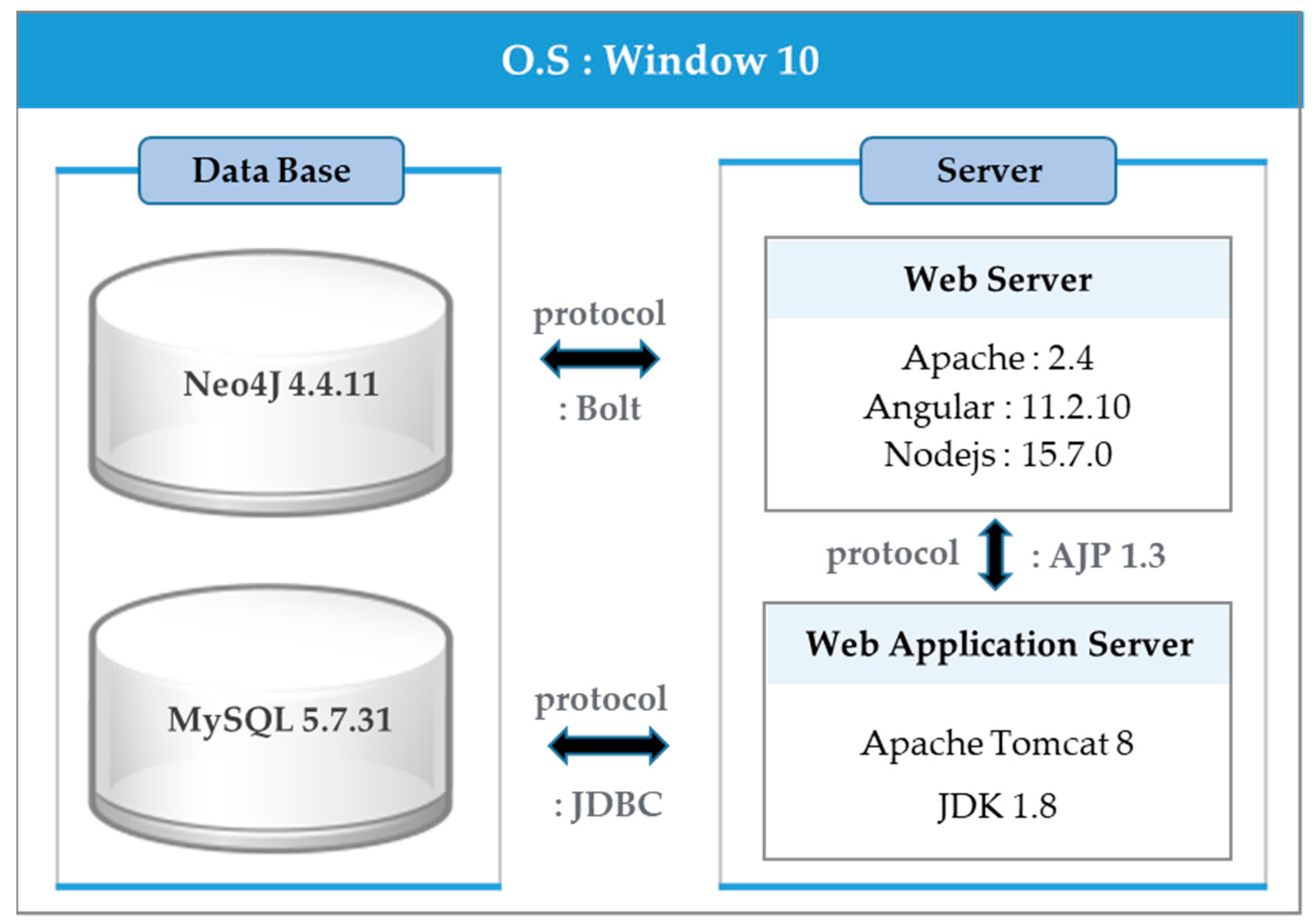
4.4. Development Environment of the POKREM
5. Definition of Data Hierarchy
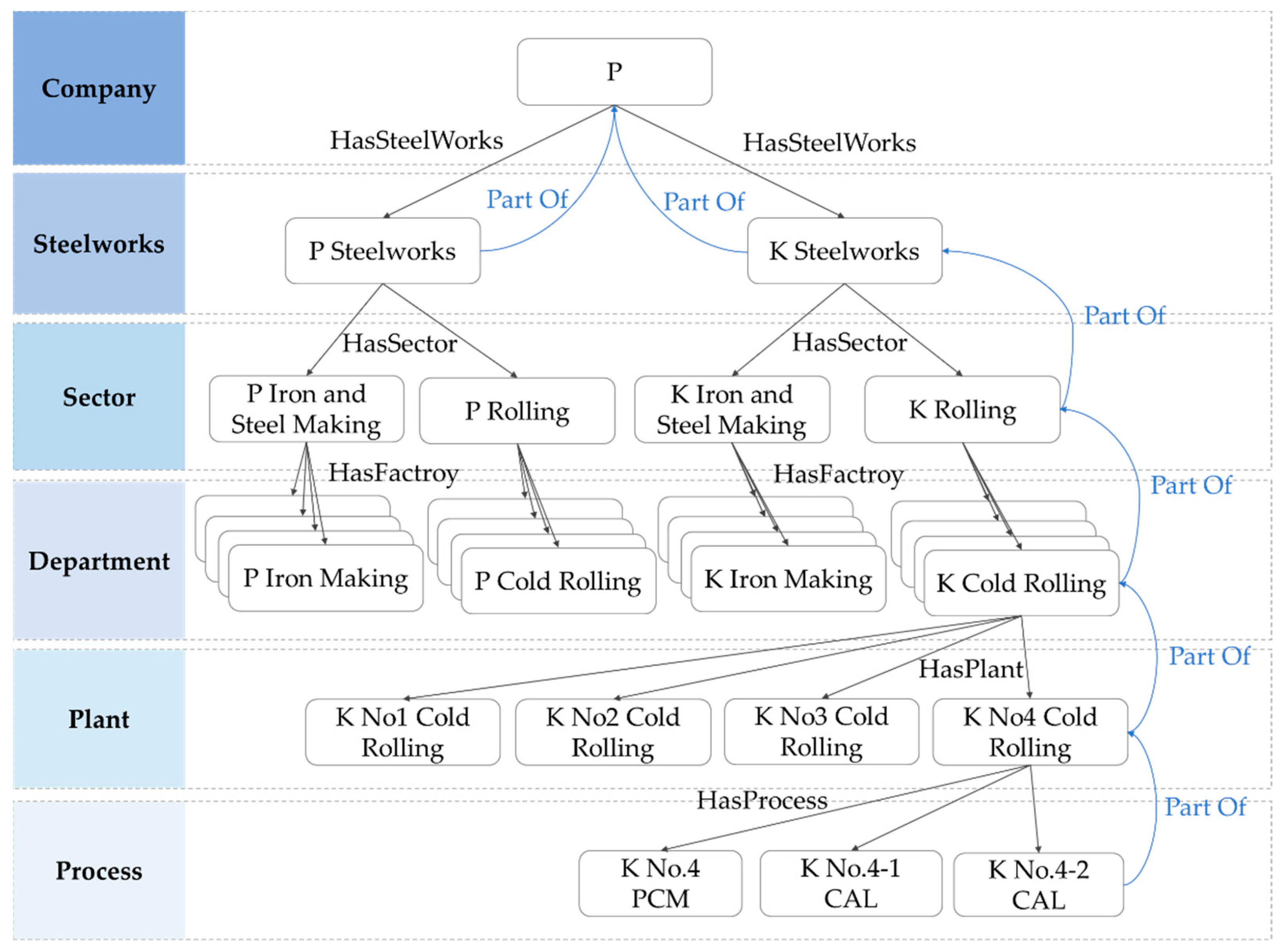
- Factory hierarchy was defined to classify POs by organization. The factory hierarchy consists of six tiers under “company,” ranging from the label of the highest tier to the label of the lowest tier.
- Document hierarchy was defined to classify various documents by type. The document hierarchy consists of four tiers from “document”, which is the node of the highest tier label, to “technical requirement” and “general provision”, which are the nodes of the lowest tier. It was assumed that documents of various categories can be added in the future using the document hierarchy.
- Facility classification hierarchy was defined to classify the items included in the Scope of Supply of POs according to the facility type. The facility classification hierarchy consists of four tiers.
- Definitions of PO data refer to the definitions of the POs of the plant owner, which is the target of this study and consists of the main information on each PO and the item information contained in the Scope of Supply.
5.1. Definition of Factory Hierarchy
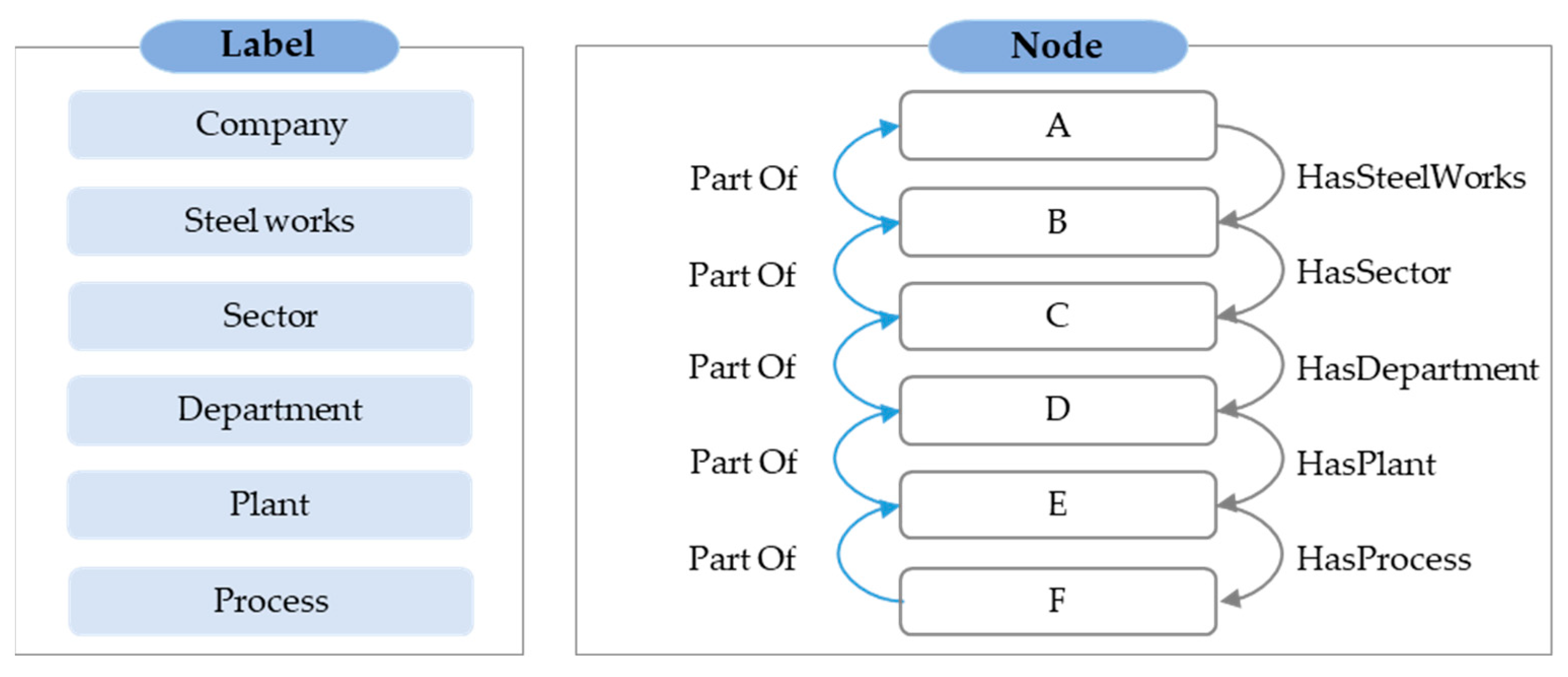
5.1.1. Hierarchical Structure
5.1.2. Node Relationship
5.1.3. Converting to Triple
5.2. Definition of Document Hierarchy
5.2.1. Hierarchical Structure
5.2.2. Node Relationship
5.2.3. Converting to Triple
5.3. Definition of Facility Classification Hierarchy
5.3.1. Hierarchical Structure
5.3.2. Node Relationship
5.3.3. Converting to Triple
5.4. PO Document and Data Definition
5.4.1. Data Structure
5.4.2. Node Relationship
5.4.3. Converting to Triple
6. Development of the POKREM
6.1. Data Preprocessing
6.2. CSV File Import Processing
6.3. Application of Rule-Based Reasoning
- If node A and node B have a relationship of “HasSteelworks”, “HasSector”, “HasDepartment”, “HasPlant”, “HasProcess”, “HasDocument”, or “HasItem”, then nodes A and B have a “Has” relationship.
- If there is a relationship of “Has” from node A to node B, then there is a relationship of “PartOf” from node B to node A.
- If there is a “PartOf” relationship from node A to node B, then there is a “Has” relationship from node B to node A.
- If node A has a “Has” relationship with node B, and node B has a “Has” relationship with node C, then nodes A and C have a “Has” relationship.
- If node A has a “PartOF” relationship with node B, and node B has a “PartOF” relationship with node C, then nodes A and C have a “PartOF” relationship.
- If node A has a “SubClassOf” relationship with node B, and node B has a “SubClassOf” relationship with node C, then nodes A and C have a “SubClassOf” relationship.
- If node A has a “Contain” relationship with node B, and node B has a “Contain” relationship with node C, then nodes A and C have a “Contain” relationship.
- If node A has a “SubGroupOf” relationship with node B, and node B has a “SubGroupOf” relationship with node C, then nodes A and C have a “SubGroupOf” relationship.
- If node A has an “Include” relationship with node B, and node B has an “Include” relationship with node C, then nodes A and C have an “Include” relationship.
6.4. System Integration of POKREM
6.4.1. Configuration and Flow of Web Server
- Process of the user accessing the server: When a user enters a URL and accesses the system, the web server displays the login screen to the user. Then, when the user inputs their ID and password on the login screen, the entered ID and password information is sent from the web server to the MySQL DBMS through the WAS. The login is either processed successfully or fails based on the operation of comparing to the actual ID and password.
- Process of handling a PO-related query: When the user inputs a query related to the PO in the query input window after logging in successfully, the web server passes the query to the Neo4J DBMS and receives and displays the processed result on the user’s screen.
- Process of saving a PO-related query: When the user writes a PO-related query and requests to save the query, the web server saves the query created in the MySQL DMBS through the WAS.
- Process of using a saved query: When the user queries a saved query, the web server displays the query saved in the MySQL DMBS on the user screen through WAS. When the user selects the saved query and requests processing, the web server passes the query to the Neo4j DBMS and upon receiving the processed result, displays it on the user screen.
6.4.2. Interface Example Using SI
7. Test and Validation
7.1. Test Data
7.2. Performance Evaluation Metrics for Testing
- True Positive (TP): The case of a correct answer that is included in the query result of the constructed POKREM.
- False Negative (FN): The case of a correct answer that is not included in the query result of the constructed POKREM.
- False Positive (FP): The case of an incorrect answer that is included in the query result of the constructed POKREM.
- True Negative (TN): The case of an incorrect answer that is not included in the query result of the constructed POKREM.
7.3. POKREM Modeling Accuracy Test
7.4. Validation for User’s System Applicability
7.5. Discussion
8. Conclusions and Future Works
8.1. Conclusions
8.2. Research Contributions
8.3. Limitations and Further Research
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AJP | Apache JServ Protocol |
| CAL | Continuous Annealing Line |
| CSV | Comma-separated Values |
| DB | Database |
| DBMS | Data Base Management System |
| DCS | Distributed Control Systems |
| DGC | Document-grounded Conversation |
| FGI | Focus Group Interview |
| ICT | Information and Communication Technologies |
| IIR | Interactive Information Retrieval |
| IR | Information Retrieval |
| IT | Information Technology |
| JDBC | Java Database Connectivity |
| JDK | Java Development Kit |
| KG | Knowledge Graph |
| POKREM | Purchase Order’s Knowledge Retrieval Model |
| MCC | Motor Control Centers |
| ML | Machine Learning |
| NLP | Natural Language Processing |
| OS | Operating System |
| PCM | Pickling and Tandem Rolling Coiling Mill |
| PLC | Programmable Logic Controllers |
| PO | Purchase Order |
| RCL | Recoiling Line |
| RDF | Resource Description Framework |
| RDFS | Resource Description Framework Schema |
| UPS | Uninterruptible Power Supply |
| URI | Uniform Resource Identifier |
| WAS | Web Application Server |
Appendix A. Triple Representation

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Subject | The Label of the Subject | Relationship | Object | The Label of the Object |
|---|---|---|---|---|
| Facility | fLevel0 | Include | Civil Machinery Part | fLevel1 |
| Facility | fLevel0 | Include | Instrumentation Part | fLevel1 |
| Facility | fLevel0 | Include | Electric and Electronic Part | fLevel1 |
| Facility | fLevel0 | Include | Automation Part | fLevel1 |
| Facility | fLevel0 | Include | IT and Communication Part | fLevel1 |
| Civil Machinery Part | fLevel1 | subGroupOf | Facility | fLevel0 |
| Instrumentation Part | fLevel1 | subGroupOf | Facility | fLevel0 |
| Electric and Electronic Part | fLevel1 | subGroupOf | Facility | fLevel0 |
| Automation Part | fLevel1 | subGroupOf | Facility | fLevel0 |
| IT and Communication Part | fLevel1 | subGroupOf | Facility | fLevel0 |
| Civil Machinery Part | fLevel1 | Include | Industrial Machinery | fLevel2 |
| Industrial Machinery | fLevel2 | subGroupOf | Civil Machinery Part | fLevel1 |
| Industrial Machinery | fLevel2 | Include | Crane Equipment | fLevel3 |
| Crane Equipment | fLevel3 | subGroupOf | Industrial Machinery | fLevel2 |
| Instrumentation Part | fLevel1 | Include | Field Instruments | fLevel2 |
| Field Instruments | fLevel2 | subGroupOf | Instrumentation Part | fLevel1 |
| Field Instruments | fLevel2 | Include | Flow Instruments | fLevel3 |
| Field Instruments | fLevel2 | Include | Level Instruments | fLevel3 |
| Field Instruments | fLevel2 | Include | Special Measuring Instruments | fLevel3 |
| Flow Instruments | fLevel3 | subGroupOf | Field Instruments | fLevel2 |
| Level Instruments | fLevel3 | subGroupOf | Field Instruments | fLevel2 |
| Special Measuring Instruments | fLevel3 | subGroupOf | Field Instruments | fLevel2 |
| Electric and Electronic Part | fLevel1 | Include | Power Distribution Panel | fLevel2 |
| Electric and Electronic Part | fLevel1 | Include | Transformer | fLevel2 |
| Electric and Electronic Part | fLevel1 | Include | Aux Equipments | fLevel2 |
| Electric and Electronic Part | fLevel1 | Include | Mortor & Brake | fLevel2 |
| Electric and Electronic Part | fLevel1 | Include | Drive System | fLevel2 |
| Electric and Electronic Part | fLevel1 | Include | Power Control Equipment | fLevel2 |
| Electric and Electronic Part | fLevel1 | Include | Operation Panel | fLevel2 |
| Electric and Electronic Part | fLevel1 | Include | Process Sensors | fLevel2 |
| Electric and Electronic Part | fLevel1 | Include | Spare Part | fLevel2 |
| Power Distribution Panel | fLevel2 | subGroupOf | Electric and Electronic Part | fLevel1 |
| Transformer | fLevel2 | subGroupOf | Electric and Electronic Part | fLevel1 |
| Aux Equipments | fLevel2 | subGroupOf | Electric and Electronic Part | fLevel1 |
| Mortor & Brake | fLevel2 | subGroupOf | Electric and Electronic Part | fLevel1 |
| Drive System | fLevel2 | subGroupOf | Electric and Electronic Part | fLevel1 |
| Emergency Power Supply | fLevel2 | subGroupOf | Electric and Electronic Part | fLevel1 |
| Power Control Equipment | fLevel2 | subGroupOf | Electric and Electronic Part | fLevel1 |
| Operation Panel | fLevel2 | subGroupOf | Electric and Electronic Part | fLevel1 |
| Process Sensors | fLevel2 | subGroupOf | Electric and Electronic Part | fLevel1 |
| Spare Part | fLevel2 | subGroupOf | Electric and Electronic Part | fLevel1 |
| Power Distribution Panel | fLevel2 | Include | High Voltage Panel | fLevel3 |
| Power Distribution Panel | fLevel2 | Include | Low Voltage Panel | fLevel3 |
| Power Distribution Panel | fLevel2 | Include | MCC | fLevel3 |
| High Voltage Panel | fLevel3 | subGroupOf | Power Distribution Panel | fLevel2 |
| Low Voltage Panel | fLevel3 | subGroupOf | Power Distribution Panel | fLevel2 |
| MCC | fLevel3 | subGroupOf | Power Distribution Panel | fLevel2 |
| Aux Equipments | fLevel2 | Include | Power Monitoring System | fLevel3 |
| Aux Equipments | fLevel2 | Include | Aux’ Panel and Box | fLevel3 |
| Aux Equipments | fLevel2 | Include | Air Conditioner | fLevel3 |
| Power Monitoring System | fLevel3 | subGroupOf | Aux Equipments | fLevel2 |
| Aux’ Panel and Box | fLevel3 | subGroupOf | Aux Equipments | fLevel2 |
| Air Conditioner | fLevel3 | subGroupOf | Aux Equipments | fLevel2 |
| Mortor & Brake | fLevel2 | Include | Motor | fLevel3 |
| Mortor & Brake | fLevel2 | Include | Brake and Control Unit | fLevel3 |
| Motor | fLevel3 | subGroupOf | Mortor & Brake | fLevel2 |
| Brake and Control Unit | fLevel3 | subGroupOf | Mortor & Brake | fLevel2 |
| Drive System | fLevel2 | Include | Converter System | fLevel3 |
| Drive System | fLevel2 | Include | Inverter System | fLevel3 |
| Converter System | fLevel3 | subGroupOf | Drive System | fLevel2 |
| Inverter System | fLevel3 | subGroupOf | Drive System | fLevel2 |
| Power Control Equipment | fLevel2 | Include | UPS System | fLevel3 |
| Power Control Equipment | fLevel2 | Include | Battery Charger System | fLevel3 |
| Power Control Equipment | fLevel2 | Include | Rectifier | fLevel3 |
| UPS System | fLevel3 | subGroupOf | Power Control Equipment | fLevel2 |
| Battery Charger System | fLevel3 | subGroupOf | Power Control Equipment | fLevel2 |
| Rectifier | fLevel3 | subGroupOf | Power Control Equipment | fLevel2 |
| Automation Part | fLevel1 | Include | PLC System | fLevel2 |
| Automation Part | fLevel1 | Include | DCS System | fLevel2 |
Appendix B. Code for KG Model Development
Appendix C. Query and Correct Answers for the Test
| No. | Sortation | Content |
|---|---|---|
| 1 | Query | How many PO’s are there for “K No3 Cold Rolling”? |
| Correct answer | 2 | |
| 2 | Query | What is the PO of “P No1 Cold Rolling”? |
| Correct answer | T36695, 356435, 729381, 743696 | |
| 3 | Query | Which group does the PO of “P No2 Cold Rolling” belong to in the document classification? |
| Correct answer | Technical Requirement | |
| 4 | Query | What is the name and quantity of items in the “K No3 Rolling” PO that are included in the “Computer Network Device”? |
| Correct answer | (Backbone Switch_474883, 1), (Local Switch_474883, 6) | |
| 5 | Query | Between the PO nodes of “K No3 Rolling”, what is the name of the PO that has the item included in the Computer Network Device? |
| Correct answer | 474883 | |
| 6 | Query | Between the PO nodes of “K No3 Rolling”, when is the delivery date of the PO with the item included in the Computer Network Device? |
| Correct answer | 2021-06-30 | |
| 7 | Query | Which PO has an item included in the facility classification “Computer”? |
| Correct answer | T36695, 356435, 743696, 739345, 474883, 569323 | |
| 8 | Query | Which PO has an item included in the facility classification “DCS System”? |
| Correct answer | T36695, 356435, 927386, 739345 | |
| 9 | Query | What is the project name and completion date of the PO with the items included in the facility classification “Air Conditioner”? |
| Correct answer | (Purchase Specifications of a Control System for No.1 RCL P Works, 2018-09-30), (Purchase Specifications of a Control System for No.3-1 RCL K Works, 2020-12-31) | |
| 10 | Query | What is the name and delivery date of the PO with the item included in the facility classification “Operation Panel”? |
| Correct answer | (356435, 2021-06-30), (743696, 2019-10-31), (739345, 2020-10-31), (T674271, 2019-10-31) | |
| 11 | Query | What is the name of the PO with the item included in the facility classification “UPS System” and what is name of the item, quantity of the item, and the unit of the quantity? |
| Correct answer | (729381, UPS_729381, 3, Set), (739345, UPS_739345, 1, Set) | |
| 12 | Query | Among the POs that have items included in the facility classification “UPS System”, what is the name of the PO whose date of delivery is after 2019? |
| Correct answer | 739345 | |
| 13 | Query | Among the “K No4 Cold Rolling” PO, what is the project title and completion date of the PO whose completion date is after January 2023? |
| Correct answer | (Purchase Specifications of a Control System for No.4-1 CAL K Works, 2023-06-30), (Purchase Specifications of a Control System for No.4-2 CAL K Works, 2023-07-31) | |
| 14 | Query | Among the “P No1 Cold Rolling” PO, what is the project title and target process, published date, date of delivery and completion date of the PO with delivery date before December 2019? |
| Correct answer | (Purchase Specifications of a Control System for No.1 RCL P Works, P 1RCL, 2018-04-04, 2018-07-31, 2018-09-30), (Purchase Specifications of a Control System for No.2 RCL P Works, P 2RCL, 2019-07-20, 2019-10-31, 2020-03-31) | |
| 15 | Query | Among the “P No1 Cold Rolling” PO, what is the project title and item of the PO whose completion date is after July 2020? |
| Correct answer | (Purchase Specifications of a Control System for No.1 PCM P Works, P/C Server_T36695, HMI_T36695) (Purchase Specifications of a Control System for No.1 PCM P Works, GUI Dev Studio_T36695) (Purchase Specifications of a Control System for No.1 PCM P Works, HMI_T36695) (Purchase Specifications of a Control System for No.1 PCM P Works, GUI Runtime_T36695) (Purchase Specifications of a Control System for No.1 PCM P Works, V Studio_T36695) (Purchase Specifications of a Control System for No.1 PCM P Works, VTS_T36695) (Purchase Specifications of a Control System for No.1 PCM P Works, Process Control Function_T36695) (Purchase Specifications of a Control System for No.1 PCM P Works, HMI Screen Function_T36695) (Purchase Specifications of a Control System for No.1 PCM P Works, DCS CPU Panel_T36695) (Purchase Specifications of a Control System for No.1 PCM P Works, PLC CPU Panel_T36695) (Purchase Specifications of a Process Computer System for No.1 PCM P Works, P/C Server_356435) (Purchase Specifications of a Process Computer System for No.1 PCM P Works, HMI_356435) (Purchase Specifications of a Process Computer System for No.1 PCM P Works, Process Control Function_356435) (Purchase Specifications of a Process Computer System for No.1 PCM P Works, DCS CPU Panel_356435) (Purchase Specifications of a Process Computer System for No.1 PCM P Works, PLC CPU Panel_356435) (Purchase Specifications of a Process Computer System for No.1 PCM P Works, Local Operation Panel_D_356435) (Purchase Specifications of a Process Computer System for No.1 PCM P Works, Local Operation Panel_W_356435) (Purchase Specifications of a Process Computer System for No.1 PCM P Works, Local Operation Panel_P_356435) (Purchase Specifications of a Process Computer System for No.1 PCM P Works, HMI Screen Function_356435) |
| No. | Sortation | Content |
|---|---|---|
| 1 | Query | Item “Process Control Function_740711” is part of which node? |
| Correct answer | P, K Steelworks, K Rolling, K Cold Rolling, K No4 Cold Rolling, K 4-2CAL, 740711 | |
| 2 | Query | Item “P/C Server_T36695” is part of which node? |
| Correct answer | P, P Steelworks, P Rolling, P Cold Rolling, P No1 Cold Rolling, P 1PCM, T36695 | |
| 3 | Query | What node does the node “P 2PCM” have? |
| Correct answer | 927386, iba IPC_927386, iba software package_927386, PLC CPU Panel_927386, DCS CPU Panel_927386, PLC Control Panel_927386 | |
| 4 | Query | What node does the node “K 4-2CAL” have? |
| Correct answer | 740711 | |
| 5 | Query | Item “PLC CPU Panel_927386” is subclass of which node? |
| Correct answer | Facility, Automation Part, PLC System, PLC Hardware | |
| 6 | Query | Item “Air Conditioner_739345” is subclass of which node? |
| Correct answer | Facility, Electric and Electronic Part, Aux Equipments, Air Conditioner | |
| 7 | Query | Which node does the node “PLC Hardware” include? |
| Correct answer | iba IPC_743696, PLC Control Panel_739345, iba IPC_927386, PLC CPU Panel_T36695, PLC CPU Panel_927386, PLC CPU Panel_743696, PLC Control Panel_743696, PLC CPU Panel_739345, PLC CPU Panel_356435, iba IPC_739345, PLC Control Panel_927386 | |
| 8 | Query | Which node does the node “Field Instrument” include? |
| Correct answer | Special Measuring Instruments, Flow Instruments, Level Instruments, Width Gauge_729381, Thickness Gauge_739345, Width Gauge_739345, Thickness Gauge_729381 | |
| 9 | Query | Which node does the node “Document” Contain? |
| Correct answer | Contract, PO, Technical Requirement, General Provision, T36695, 356435, 729381, 743696, 927386, 739345, 474883, T674271, 569323, 740711 | |
| 10 | Query | Which node does the node “Technical Requirement” Contain? |
| Correct answer | T36695, 356435, 729381, 743696, 927386, 739345, 474883, T674271, 569323, 740711 | |
| 11 | Query | PO “729381” is subclass of which node? |
| Correct answer | Technical Requirement, PO, Contract, Document | |
| 12 | Query | Node “General Provision” is subclass of which node? |
| Correct answer | Document, Contract, PO | |
| 13 | Query | What node does the node “P 1PCM” have? |
| Correct answer | P/C Server_T36695, HMI_T36695, GUI Dev Studio_T36695, GUI Runtime_T36695, V Studio_T36695, VTS_T36695, DCS CPU Panel_T36695, PLC CPU Panel_T36695, P/C Server_356435, HMI_356435, DCS CPU Panel_356435, PLC CPU Panel_356435, Local Operation Panel_D_356435, Local Operation Panel_W_356435, Local Operation Panel_P_356435, 356435, T36695 | |
| 14 | Query | Node “K 4-2CAL” is part of which node? |
| Correct answer | P, K Steelworks, K Rolling, K Cold Rolling, K No4 Cold Rolling | |
| 15 | Query | Node “P Steel Making” is part of which node? |
| Correct answer | P, P Steelworks, P Iron and Steel Making |
References
- Attaran, M. Information technology and business-process redesign. Bus. Process Manag. J. 2003, 9, 440–458. [Google Scholar] [CrossRef]
- Our World in Data. Interactive Charts on Internet. Available online: https://ourworldindata.org/internet#citation (accessed on 15 March 2023).
- Synergy Research Group. Hyperscale Data Center Count Reaches 541 in Mid-2020. Available online: https://www.srgresearch.com/articles/hyperscale-data-center-count-reaches-541-mid-2020-another-176-pipeline (accessed on 14 December 2022).
- Synergy Research Group. Huge Cloud Market Still Growing at 34% Per Year. Available online: https://www.srgresearch.com/articles/huge-cloud-market-is-still-growing-at-34-per-year-amazon-microsoft-and-google-now-account-for-65-of-all-cloud-revenues (accessed on 1 December 2022).
- Ministry of Science and ICT. Wireless Data Traffic. Available online: https://www.msit.go.kr/bbs/view.do?sCode=user&mId=99&mPid=74&bbsSeqNo=79&nttSeqNo=3173481 (accessed on 3 December 2022).
- Brynjolfsson, E.; Yang, S. Information technology and productivity: A review of the literature. Adv. Comput. 1996, 43, 179–214. [Google Scholar] [CrossRef] [Green Version]
- Dedrick, J.; Kraemer, K.L.; Shih, E. Information technology and productivity in developed and developing countries. J. Manag. Inf. Syst. 2013, 30, 97–122. [Google Scholar] [CrossRef] [Green Version]
- Duc, D.T.V.; Nguyen, P.V. The Nexus of ICT, Manufacturing Productivity and Economic Restructuring in Vietnam. J. Asian Financ. Econ. Bus. 2021, 8, 235–247. [Google Scholar] [CrossRef]
- Sanderson, M.; Croft, W.B. The history of information retrieval research. Proc. IEEE 2012, 100, 1444–1451. [Google Scholar] [CrossRef]
- Allemang, D.; Hendler, J.; Gandon, F. Semantic Web for the Working Ontologist: Effective Modeling for Linked Data, RDFS, and OWL, 3rd ed.; ACM Books: New York, NY, USA, 2020. [Google Scholar]
- Brennan, D. Process Industry Economics: Principles, Concepts and Applications, 2nd ed.; Elsevier Science: Amsterdam, The Netherlands, 2020; pp. 1–15,95–125. [Google Scholar]
- Kim, C.-Y.; Jeong, J.-G.; Choi, S.-W.; Lee, E.-B. An AI-Based Automatic Risks Detection Solution for Plant Owner’s Technical Requirements in Equipment Purchase Order. Sustainability 2022, 14, 10010. [Google Scholar] [CrossRef]
- Dobler, D.W.; Burt, D.N. Purchasing and Supply Management: Text and Cases, 6th ed.; McGraw-Hill: New York, NY, USA, 1996. [Google Scholar]
- Zobel, J. What we talk about when we talk about information retrieval. In Proceedings of the 41st Annual ACM SIGIR Conference on Research & Development on Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018; pp. 18–26. [Google Scholar]
- Cooper, W.S. A definition of relevance for information retrieval. Inform. Storage Ret. 1971, 7, 19–37. [Google Scholar] [CrossRef]
- Wong, S.K.M.; Ziarko, W.; Raghavan, V.V.; Wong, P.C. On modeling of information retrieval concepts in vector spaces. ACM Trans. Database Syst. 1987, 12, 299–321. [Google Scholar] [CrossRef]
- Wiesman, F.; Hasman, A.; Van den Herik, H. Information retrieval: An overview of system characteristics. Int. J. Med. Inform. 1997, 47, 5–26. [Google Scholar] [CrossRef]
- Rehma, A.A.; Awan, M.J.; Butt, I. Comparison and evaluation of information retrieval models. VFAST Trans. Softw. Eng. 2018, 6, 7–14. [Google Scholar] [CrossRef]
- Merrouni, Z.A.; Frikh, B.; Ouhbi, B. Toward contextual information retrieval: A review and trends. Procedia Comput. Sci. 2019, 148, 191–200. [Google Scholar] [CrossRef]
- Yu, B. Research on information retrieval model based on ontology. EURASIP J. Wirel. Commun. Netw. 2019, 2019, 1–8. [Google Scholar] [CrossRef]
- Azad, H.K.; Deepak, A. Query expansion techniques for information retrieval: A survey. Inf. Process Manag. 2019, 56, 1698–1735. [Google Scholar] [CrossRef] [Green Version]
- Bai, T.; Ge, Y.; Guo, S.; Zhang, Z.; Gong, L. Enhanced natural language interface for web-based information retrieval. IEEE Access 2020, 9, 4233–4241. [Google Scholar] [CrossRef]
- Angdresey, A.; Lamongi, M.A.; Munir, R. Information Retrieval System in the Bible. Cogito Smart J. 2021, 7, 111–120. [Google Scholar] [CrossRef]
- Sansone, C.; Sperlí, G. Legal Information Retrieval systems: State-of-the-art and open issues. Inf. Syst. 2022, 106, 101967. [Google Scholar] [CrossRef]
- Ibrihich, S.; Oussous, A.; Ibrihich, O.; Esghir, M. A Review on recent research in information retrieval. Procedia Comput. Sci. 2022, 201, 777–782. [Google Scholar] [CrossRef]
- Moe, W.W.; Fader, P.S. Fast-track: Article using advance purchase orders to forecast new product sales. Mark. Sci. 2002, 21, 347–364. [Google Scholar] [CrossRef] [Green Version]
- Wang, G.; Miller, S. Intelligent aggregation of purchase orders in e-procurement. In Proceedings of the 9th IEEE International EDOC Enterprise Computing Conference (EDOC’05), Enschede, The Netherlands, 19–23 September 2005; pp. 27–36. [Google Scholar]
- Li, Y. Process-focused risk analysis and management of purchase-order financing under logistic financing innovation. In Proceedings of the 2008 4th International Conference on Wireless Communications, Networking and Mobile Computing, Dalian, China, 12–14 October 2008; pp. 1–5. [Google Scholar]
- Baraka, R.S.; Al-Ashqar, Y.M. Building a SOA-Based Model for Purchase Order Management in E-Commerce Systems. In Proceedings of the 2013 Palestinian International Conference on Information and Communication Technology, Gaza, Palestine, 15–16 April 2013; pp. 107–114. [Google Scholar]
- Huang, Y.-S.; Ho, R.-S.; Fang, C.-C. Quantity discount coordination for allocation of purchase orders in supply chains with multiple suppliers. Int. J. Prod. Res. 2015, 53, 6653–6671. [Google Scholar] [CrossRef]
- Bock, S.; Isik, F. A new two-dimensional performance measure in purchase order sizing. Int. J. Prod. Res. 2015, 53, 4951–4962. [Google Scholar] [CrossRef]
- Yamanaka, S. Quantitative credit risk monitoring using purchase order information. JSIAM Lett. 2017, 9, 49–52. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Hwang, S.; Yund, W.; Boyle, L.N.; Banerjee, A.G. Predicting purchase orders delivery times using regression models with dimension reduction. In Proceedings of the International Design Engineering Technical Conferences and Computers and Information in Engineering Conference, Quebec, QC, Canada, 26–29 August 2018; p. V01BT02A034. [Google Scholar]
- Zou, X. A survey on application of knowledge graph. In Proceedings of the 4th International Conference on Control Engineering and Artificial Intelligence, Singapore, 17–19 January 2020; p. 012016. [Google Scholar]
- Berners-Lee, T.; Hendler, J.; Lassila, O. The Semantic Web. Sci. Am. 2001, 284, 34–43. Available online: https://www.jstor.org/stable/26059207 (accessed on 15 February 2023). [CrossRef]
- The Keyword. Introducing the Knowledge Graph. Available online: https://blog.google/products/search/introducing-knowledge-graph-things-not/ (accessed on 14 November 2022).
- Auer, S.; Mann, S. Towards an open research knowledge graph. Ser. Libr. 2019, 76, 35–41. [Google Scholar] [CrossRef] [Green Version]
- Auer, S.; Kovtun, V.; Prinz, M.; Kasprzik, A.; Stocker, M.; Vidal, M.E. Towards a knowledge graph for science. In Proceedings of the 8th International Conference on Web Intelligence, Mining and Semantics, Novi Sad, Serbia, 25–27 June 2018; pp. 1–6. [Google Scholar]
- Wang, R.; Yan, Y.; Wang, J.; Jia, Y.; Zhang, Y.; Zhang, W.; Wang, X. Acekg: A large-scale knowledge graph for academic data mining. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 1487–1490. [Google Scholar]
- Chen, Y.; Kuang, J.; Cheng, D.; Zheng, J.; Gao, M.; Zhou, A. AgriKG: An agricultural knowledge graph and its applications. In Proceedings of the 24th International Conference on Database Systems for Advanced Applications, Chiang Mai, Thailand, 22–25 April 2019; pp. 533–537. [Google Scholar]
- Noy, N.; Gao, Y.; Jain, A.; Narayanan, A.; Patterson, A.; Taylor, J. Industry-scale Knowledge Graphs: Lessons and Challenges: Five diverse technology companies show how it’s done. Queue 2019, 17, 48–75. [Google Scholar] [CrossRef]
- Guo, Q.; Zhuang, F.; Qin, C.; Zhu, H.; Xie, X.; Xiong, H.; He, Q. A survey on knowledge graph-based recommender systems. IEEE Trans. Knowl. Data Eng. 2020, 34, 3549–3568. [Google Scholar] [CrossRef]
- Chen, X.; Jia, S.; Xiang, Y. A review: Knowledge reasoning over knowledge graph. Expert. Syst. Appl. 2020, 141, 112948. [Google Scholar] [CrossRef]
- Huang, H.; Hong, Z.; Zhou, H.; Wu, J.; Jin, N. Knowledge graph construction and application of power grid equipment. Math. Probl. Eng. 2020, 2020, 8269082. [Google Scholar] [CrossRef]
- Liu, J.; Schmid, F.; Li, K.; Zheng, W. A knowledge graph-based approach for exploring railway operational accidents. Reliab. Eng. Syst. Saf. 2021, 207, 107352. [Google Scholar] [CrossRef]
- Kim, B.; Lee, D.; Kim, D.; Kim, H.; Kim, S.; Kwon, O.; Kim, H. Generative Model Using Knowledge Graph for Document-Grounded Conversations. Appl. Sci. 2022, 12, 3367. [Google Scholar] [CrossRef]
- S & P Global Commodity Insights. Winners 2022. Available online: https://www.spglobal.com/commodityinsights/global-metals-awards/winners (accessed on 16 March 2023).
- Microsoft. Windows 10. Available online: https://www.microsoft.com/ (accessed on 15 December 2022).
- Neo4j. Neo4j Graph Database. Available online: https://neo4j.com/product/neo4j-graph-database/ (accessed on 6 November 2022).
- DB-ENGINES. DB-Engines Ranking of Graph DBMS. Available online: https://db-engines.com/en/ranking/graph+dbms (accessed on 11 November 2022).
- Liu, P.; Huang, Y.; Wang, P.; Zhao, Q.; Nie, J.; Tang, Y.; Sun, L.; Wang, H.; Wu, X.; Li, W. Construction of typhoon disaster knowledge graph based on graph database Neo4j. In Proceedings of the 2020 32nd Chinese Control and Decision Conference (CCDC), Hefei, China, 22–24 August 2020; pp. 3612–3616. [Google Scholar]
- Chen, Z.; Wang, Y.; Zhao, B.; Cheng, J.; Zhao, X.; Duan, Z. Knowledge graph completion: A review. IEEE Access 2020, 8, 192435–192456. [Google Scholar] [CrossRef]
- MySQL. Database Design and Modeling. Available online: https://dev.mysql.com/doc/workbench/en/wb-data-modeling.html (accessed on 11 December 2022).
- APACHE. Apache HTTP Server Project. Available online: https://httpd.apache.org/ (accessed on 13 December 2022).
- Angular. The Web Development Framework for Building the Future. Available online: https://angular.io/ (accessed on 17 November 2022).
- Open JS Foundation. Node.js. Available online: https://nodejs.org/en/ (accessed on 20 November 2022).
- Apache Tomcat. Apache Tomcat. Available online: https://tomcat.apache.org/ (accessed on 26 December 2022).
- Oracle. Java Technical Details. Available online: https://www.oracle.com/java/technologies/ (accessed on 30 December 2022).
- Neo4j. Bolt Protocol. Available online: https://neo4j.com/docs/bolt/current/bolt/ (accessed on 9 December 2022).
- Oracle. Java JDBC API. Available online: https://docs.oracle.com/javase/8/docs/technotes/guides/jdbc/ (accessed on 12 December 2022).
- Apache Tomcat. The Apache Tomcat Connectors-AJP Protocol Reference. Available online: https://tomcat.apache.org/connectors-doc/ajp/ajpv13a.html (accessed on 17 November 2022).
- Paulheim, H. Knowledge graph refinement: A survey of approaches and evaluation methods. Semant. Web 2017, 8, 489–508. [Google Scholar] [CrossRef] [Green Version]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Lambert, S.D.; Loiselle, C.G. Combining individual interviews and focus groups to enhance data richness. J. Adv. Nurs. 2008, 62, 228–237. [Google Scholar] [CrossRef] [PubMed]











| Expert Code | Affiliation | Department | Year of Experience | Participant Rate (%) |
|---|---|---|---|---|
| A | P company | Procurement | Over 25 | 27.8 |
| B | P company | Engineering | ||
| C | P company | Engineering | ||
| D | P company | Procurement | ||
| E | P company | Bidding | ||
| F | P company | Engineering | 12–17 | 22.2 |
| G | P company | Procurement | ||
| H | P company | Bidding | ||
| I | P company | Engineering | ||
| J | P company | Engineering | 7–12 | 44.4 |
| K | P company | Bidding | ||
| L | P company | Bidding | ||
| M | P company | Procurement | ||
| N | P company | Engineering | ||
| O | P company | Engineering | ||
| P | P company | Procurement | ||
| Q | P company | Engineering | ||
| R | P company | Engineering | 3–7 | 5.6 |
| Composition | Applied Program |
|---|---|
| Operating System | Windows 10 |
| Graph DBMS | Neo4j |
| Query Language | Cypher |
| Relational DBMS | MySQL 5.7.31 |
| Web Server | Apache 2.4 |
| Web Server User InterfaceFramework | Angular 11.2.10 |
| Web Server TypeScript | Node.js |
| Web Application Server | Apache Tomcat 8/JDK 1.8 |
| Subject | The Label of the Subject | Relationship | Object | The Label of the Object |
|---|---|---|---|---|
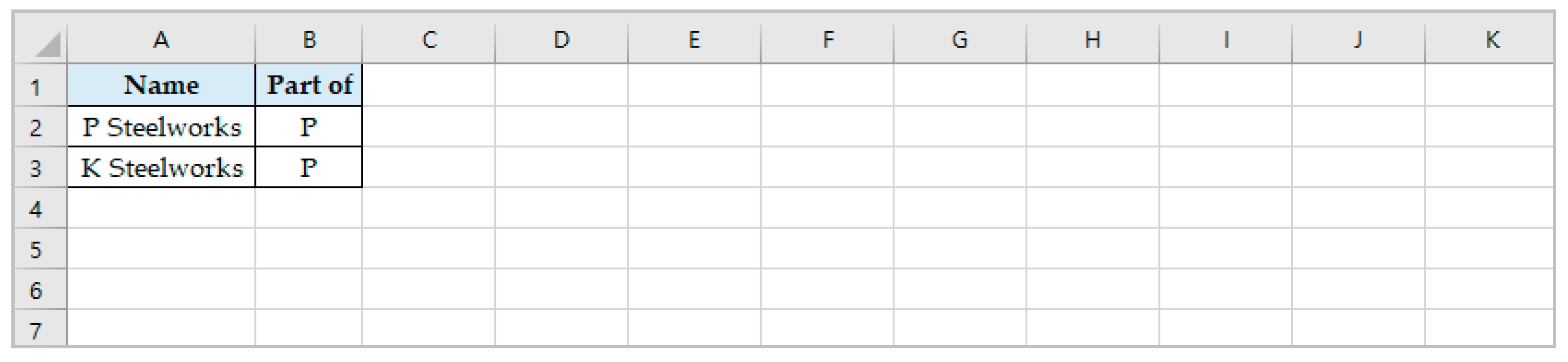
| P | Company | HasSteelworks | P steelworks | Steelworks |
| P | Company | HasSteelworks | K steelworks | Steelworks |
| P steelworks | Steelworks | PartOf | P | Company |
| K steelworks | Steelworks | PartOf | P | Company |
| P steelworks | Steelworks | HasSector | P Iron and Steel Making | Sector |
| P steelworks | Steelworks | HasSector | P Rolling | Sector |
| K steelworks | Steelworks | HasSector | K Iron and Steel Making | Sector |
| K steelworks | Steelworks | HasSector | K Rolling | Sector |
| P Iron and Steel Making | Sector | PartOf | P steelworks | Steelworks |
| P Rolling | Sector | PartOf | P steelworks | Steelworks |
| K Iron and Steel Making | Sector | PartOf | K steelworks | Steelworks |
| K Rolling | Sector | PartOf | K steelworks | Steelworks |
| P Iron and Steel Making | Sector | HasDepartment | P Iron Making | Department |
| P Rolling | Sector | HasDepartment | P Cold Rolling | Department |
| K Iron and Steel Making | Sector | HasDepartment | K Iron Making | Department |
| K Rolling | Sector | HasDepartment | K Cold Rolling | Department |
| P Iron Making | Department | PartOf | P Iron and Steel Making | Sector |
| P Cold Rolling | Department | PartOf | P Rolling | Sector |
| K Iron Making | Department | PartOf | K Iron and Steel Making | Sector |
| K Cold Rolling | Department | PartOf | K Rolling | Sector |
| K Cold Rolling | Department | HasPlant | K No1 Cold Rolling | Plant |
| K Cold Rolling | Department | HasPlant | K No2 Cold Rolling | Plant |
| K No1 Cold Rolling | Plant | PartOf | K Cold Rolling | Department |
| K No2 Cold Rolling | Plant | PartOf | K Cold Rolling | Department |
| K No4 Cold Rolling | Plant | HasProcess | K No4. PCM | Process |
| K No4 Cold Rolling | Plant | HasProcess | K No4-1 CAL | Process |
| K No4. PCM | Process | PartOf | K No4 Cold Rolling | Plant |
| K No4-1 CAL | Process | PartOf | K No4 Cold Rolling | Plant |
| K No4-2 CAL | Process | PartOf | K No4 Cold Rolling | Plant |
| Subject | The Label of the Subject | Relationship | Object | The Label of the Object |
|---|---|---|---|---|
| Document | dLevel0 | Contain | Contract | dLevel1 |
| Contract | dLevel1 | SubClassOf | Document | dLevel0 |
| Contract | dLevel1 | Contain | PO | dLevel2 |
| PO | dLevel2 | SubClassOf | Contract | dLevel1 |
| PO | dLevel2 | Contain | Technical Requirement | dLevel3 |
| PO | dLevel2 | Contain | General Provision | dLevel3 |
| Technical Requirement | dLevel3 | SubClassOf | PO | dLevel2 |
| General Provision | dLevel3 | SubClassOf | PO | dLevel2 |
| fLevel0 | fLevel1 | fLevel2 | fLevel3 |
|---|---|---|---|
| Facility | Civil Machinery Part | Industrial Machinery | Crane Equipment |
| Instrumentation Part | Field Instruments | Flow Instruments | |
| Level Instruments | |||
| Special Measuring Instruments | |||
| Electric and Electronic Part | Power Distribution Panel | High Voltage Panel | |
| Low Voltage Panel | |||
| MCC | |||
| Transformer | |||
| Aux Equipment | Power Monitoring System | ||
| Aux’ Panel and Box | |||
| Air Conditioner | |||
| Motor and Brake | Motor | ||
| Brake and Control Unit | |||
| Drive System | Converter System | ||
| Inverter System | |||
| Emergency Power Supply | |||
| Power Control Equipment | UPS System | ||
| Battery Charger System | |||
| Rectifier | |||
| Operation Panel | |||
| Process Sensors | |||
| Spare Part | |||
| Automation Part | PLC System | PLC Hardware | |
| PLC Basic Software | |||
| PLC Software Development | |||
| PLC Network Device | |||
| DCS System | DCS Hardware | ||
| DCS Basic Software | |||
| DCS Software Development | |||
| DCS Network Device | |||
| IT and Communication Part | Computer System | Computer | |
| Basic Software | |||
| Computer Software Development | |||
| Computer Network Device | |||
| Audiovisual System | Display Device | ||
| Audible Device |
| Contract Number | Project Title | Published Date | Date of Delivery | Completion Date | Target Process |
|---|---|---|---|---|---|
| T36695 | Purchase Specifications of a Control System for No.1 PCM P Works | 2020-03-17 | 2020-05-31 | 2020-10-31 | P 1PCM |
| 356435 | Purchase Specifications of a Process Computer System for No.1 PCM P Works | 2021-01-24 | 2021-06-30 | 2021-11-30 | P 1PCM |
| 729381 | Purchase Specifications of a Control System for No.1 RCL P Works | 2018-04-04 | 2018-07-31 | 2018-09-30 | P 1RCL |
| 743696 | Purchase Specifications of a Control System for No.2 RCL P Works | 2019-07-20 | 2019-10-31 | 2020-03-31 | P 2RCL |
| 927386 | Purchase Specifications of a Control System for No.2 PCM P Works | 2021-08-17 | 2021-12-31 | 2022-04-30 | P 2PCM |
| 739345 | Purchase Specifications of a Control System for No.3-1 RCL K Works | 2020-06-02 | 2020-10-31 | 2020-12-31 | K 3-1RCL |
| 474883 | Purchase Specifications of a Process Computer System for No.3-1 RCL K Works | 2021-02-17 | 2021-06-30 | 2021-11-30 | K 3-1RCL |
| T674271 | Purchase Specifications of a Control System for No.4 PCM K Works | 2019-05-30 | 2019-10-31 | 2020-02-28 | K 4PCM |
| 569323 | Purchase Specifications of a Control System for No.4-1 CAL K Works | 2022-09-05 | 2023-01-31 | 2023-06-30 | K 4-1CAL |
| 740711 | Purchase Specifications of a Control System for No.4-2 CAL K Works | 2022-11-02 | 2023-03-31 | 2023-07-31 | K 4-2CAL |
| Name | Type | Quantity | Quantity Unit | PO ID | Facility Type |
|---|---|---|---|---|---|
| P/C Server_T36695 | Window Server | 2 | Set | T36695 | Computer |
| HMI_T36695 | P.C | 4 | Set | T36695 | Computer |
| GUI Dev Studio_T36695 | Development | 1 | EA | T36695 | Basic Software |
| GUI Runtime_T36695 | Runtime | 3 | EA | T36695 | Basic Software |
| V Studio_T36695 | Development Tool | 2 | EA | T36695 | Basic Software |
| VTS_T36695 | Clustering Tool | 2 | EA | T36695 | Basic Software |
| Process Control Function_T36695 | Software Development | 1 | Lot | T36695 | Computer Software Development |
| HMI Screen Function_T36695 | Software Development | 1 | Lot | T36695 | Computer Software Development |
| DCS CPU Panel_T36695 | CPU Panel | 2 | Set | T36695 | DCS Hardware |
| PLC CPU Panel_T36695 | CPU Panel | 1 | Set | T36695 | PLC Hardware |
| Subject | The Label of the Subject | Relationship | Object | The Label of the Object |
|---|---|---|---|---|
| P 1PCM | Process | HasDocument | T36695 | Document |
| T36695 | Document | PartOF | P 1PCM | Process |
| T36695 | Document | HasItem | P/C Server_T36695 | Item |
| P/C Server_T36695 | Item | SupplyItemOf | T36695 | Document |
| P/C Server_T36695 | Item | PartOF | T36695 | Document |
| Computer | fLevel3 | Include | P/C Server_T36695 | Item |
| P/C Server_T36695 | Item | SubGroupOf | Computer | fLevel3 |
| CSV File Name | Label | Number of Nodes Included |
|---|---|---|
| steelworks | steelworks | 2 |
| sector | sector | 4 |
| department | department | 23 |
| plant | plant | 6 |
| process | process | 8 |
| f1 | fLevel1 | 5 |
| f2 | fLevel2 | 16 |
| f3 | fLevel3 | 31 |
| POID | Document | 10 |
| POItem | Item | 80 |
| No. | Sortation | Content |
|---|---|---|
| 1 | Query | What are P’s steelworks? |
| Correct answer | P Steelworks, K Steelworks | |
| 2 | Query | What department does “K Iron and Steel Making” sector have? |
| Correct answer | K Iron Making, K Chemical Conversion, K Steel Making, K Continuous Casting | |
| 3 | Query | What department does “P Rolling” sector have? |
| Correct answer | P Hot Rolling, P Thick Plate, P Material, P Wire Rod, P Electrical Steel, P Cold Rolling, P Galvanizing, P STS Rolling | |
| 4 | Query | How many Departments does the “P rolling” Sector have? |
| Correct answer | 8 | |
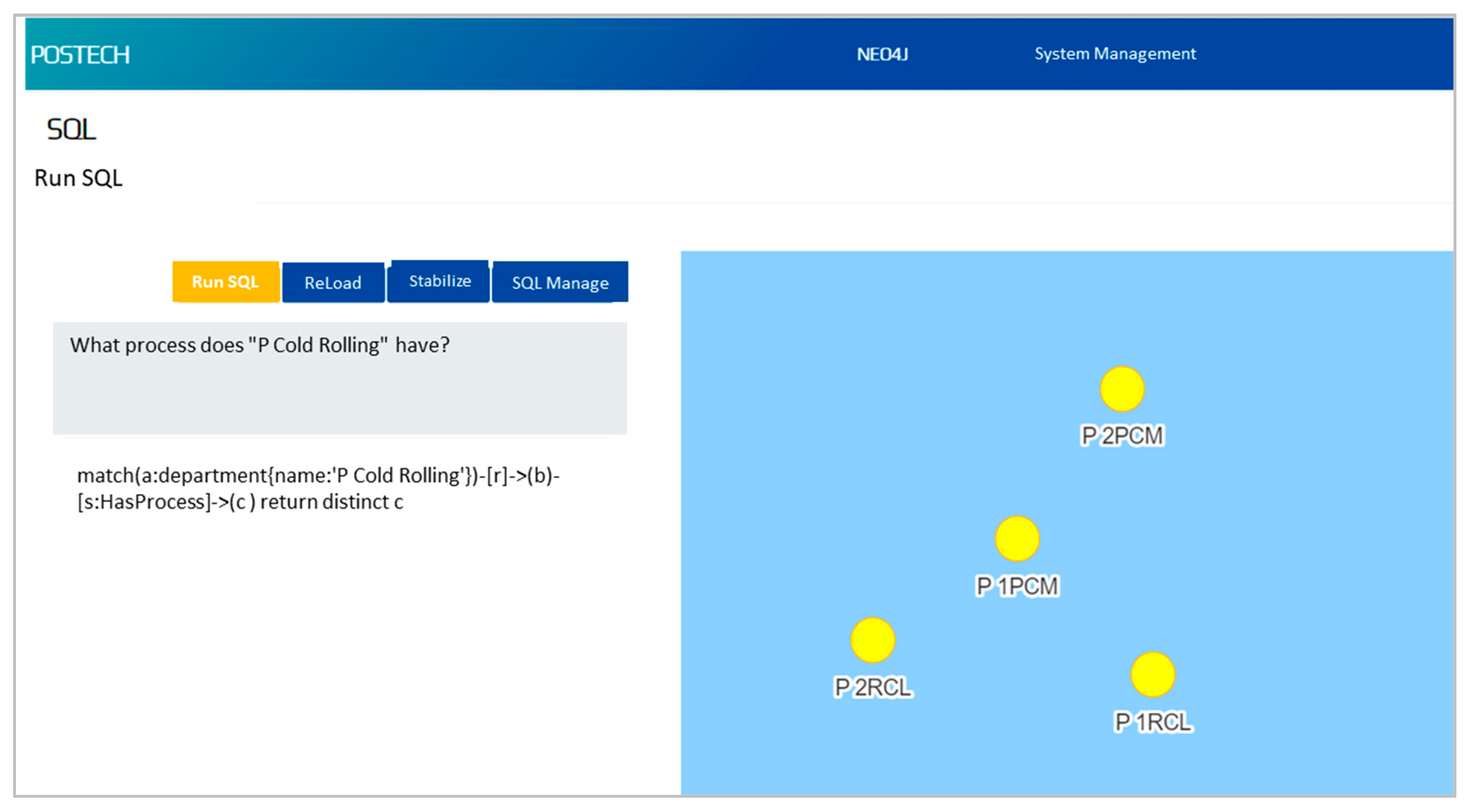
| 5 | Query | What process does “P Cold Rolling” have? |
| Correct answer | P 1PCM, P 1RCL, P 2RCL, P 2PCM | |
| 6 | Query | How many processes does “K Cold Rolling” have? |
| Correct answer | 4 | |
| 7 | Query | What process does “K No3 Cold Rolling” have? |
| Correct answer | K 3-1RCL | |
| 8 | Query | What sub-node does the PO node contain in the document classification? |
| Correct answer | Technical Requirement, General Provision | |
| 9 | Query | How many items does the PO “T36695” have? |
| Correct answer | 10 | |
| 10 | Query | How many items does the PO “356435” have? |
| Correct answer | 9 | |
| 11 | Query | What item does PO “927386” have? |
| Correct answer | DCS CPU Panel_927386, PLC CPU Panel_927386, PLC Control Panel_927386, iba software package_927386, iba IPC_927386, PLC Control Function_927386, DCS Control Function_927386 | |
| 12 | Query | What are the nodes of the fLevel1 label that the Facility node includes in the facility classification? |
| Correct answer | Civil Machinery Part, Instrument Part, Electric and Electronic Part, Automation Part, IT and Communication Part | |
| 13 | Query | What are the nodes of the fLevel2 label that the “Instrument Part” node includes in the facility classification? |
| Correct answer | field Instruments | |
| 14 | Query | What are the subgroup nodes of the “PLC System” node in the facility classification? |
| Correct answer | PLC Hardware, PLC Basic Software, PLC Software Development, PLC Network Device | |
| 15 | Query | What node is included in the “IT and Communication Part” node in the facility classification and is the upper group of the “Basic Software” node? |
| Correct answer | Computer System |
| Test Stage | Classification Elements of a Confusion Matrix | Performance Evaluation Metrics (%) | ||||||
|---|---|---|---|---|---|---|---|---|
| TP | TN | FP | FN | Accuracy | Precision | Recall | F1 Score | |
| 1 | 43 | 2062 | 0 | 0 | 100 | 100 | 100 | 100 |
| 2 | 52 | 1496 | 0 | 0 | 100 | 100 | 100 | 100 |
| 3 | 93 | 2755 | 17 | 0 | 99.4 | 84.5 | 100 | 91.6 |
| Total Performance | 99.7 | 91.7 | 100 | 95.7 | ||||
| Expert Code | Affiliation | Department | Year of Experience |
|---|---|---|---|
| A | P company | Procurement | Over 10 |
| B | P company | Engineering | |
| C | P company | Engineering | |
| D | P company | Procurement | |
| E | P company | Bidding | |
| F | P company | Engineering | |
| G | P company | Procurement |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cha, H.-J.; Choi, S.-W.; Lee, E.-B.; Lee, D.-M. Knowledge Retrieval Model Based on a Graph Database for Semantic Search in Equipment Purchase Order Specifications for Steel Plants. Sustainability 2023, 15, 6319. https://doi.org/10.3390/su15076319
Cha H-J, Choi S-W, Lee E-B, Lee D-M. Knowledge Retrieval Model Based on a Graph Database for Semantic Search in Equipment Purchase Order Specifications for Steel Plants. Sustainability. 2023; 15(7):6319. https://doi.org/10.3390/su15076319
Chicago/Turabian StyleCha, Ho-Jin, So-Won Choi, Eul-Bum Lee, and Duk-Man Lee. 2023. "Knowledge Retrieval Model Based on a Graph Database for Semantic Search in Equipment Purchase Order Specifications for Steel Plants" Sustainability 15, no. 7: 6319. https://doi.org/10.3390/su15076319