
An Integrated Method Based on Convolutional Neural Networks and Data Fusion for Assembled Structure State Recognition

Abstract
:1. Introduction
2. Methods
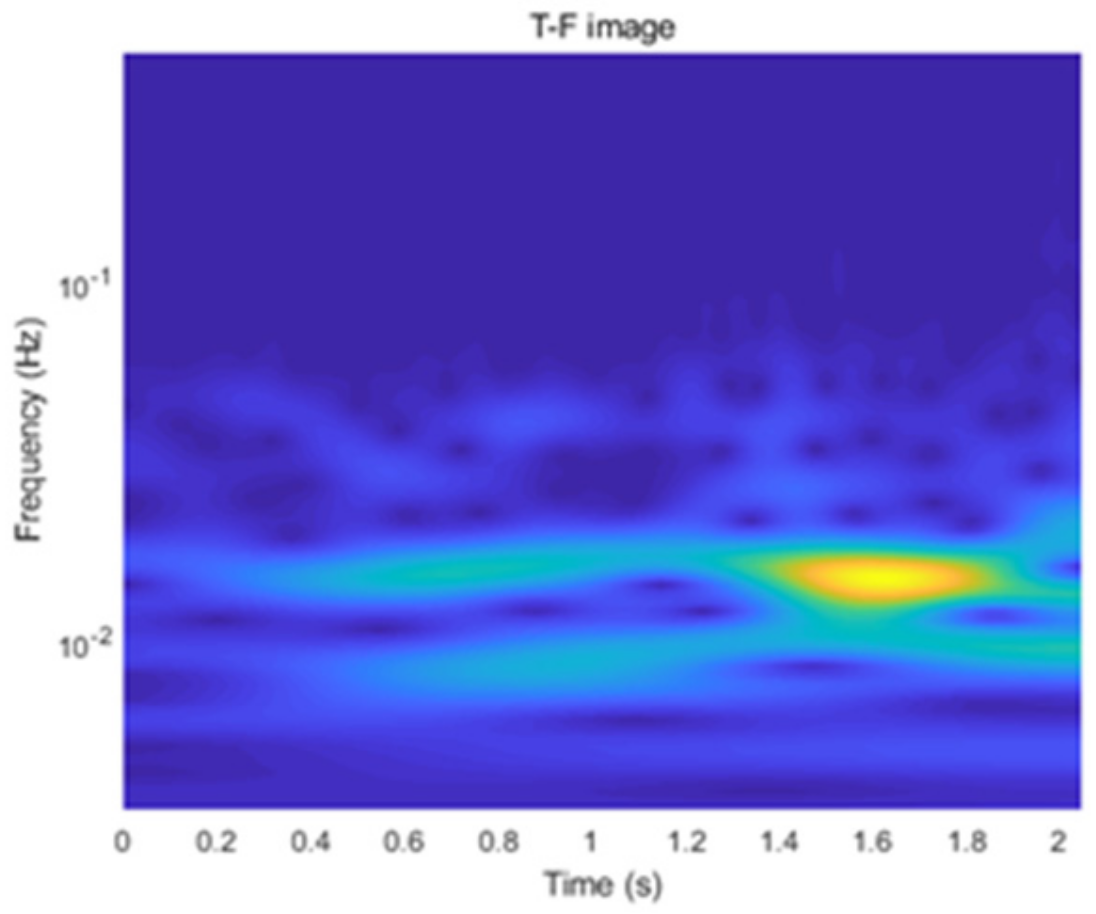
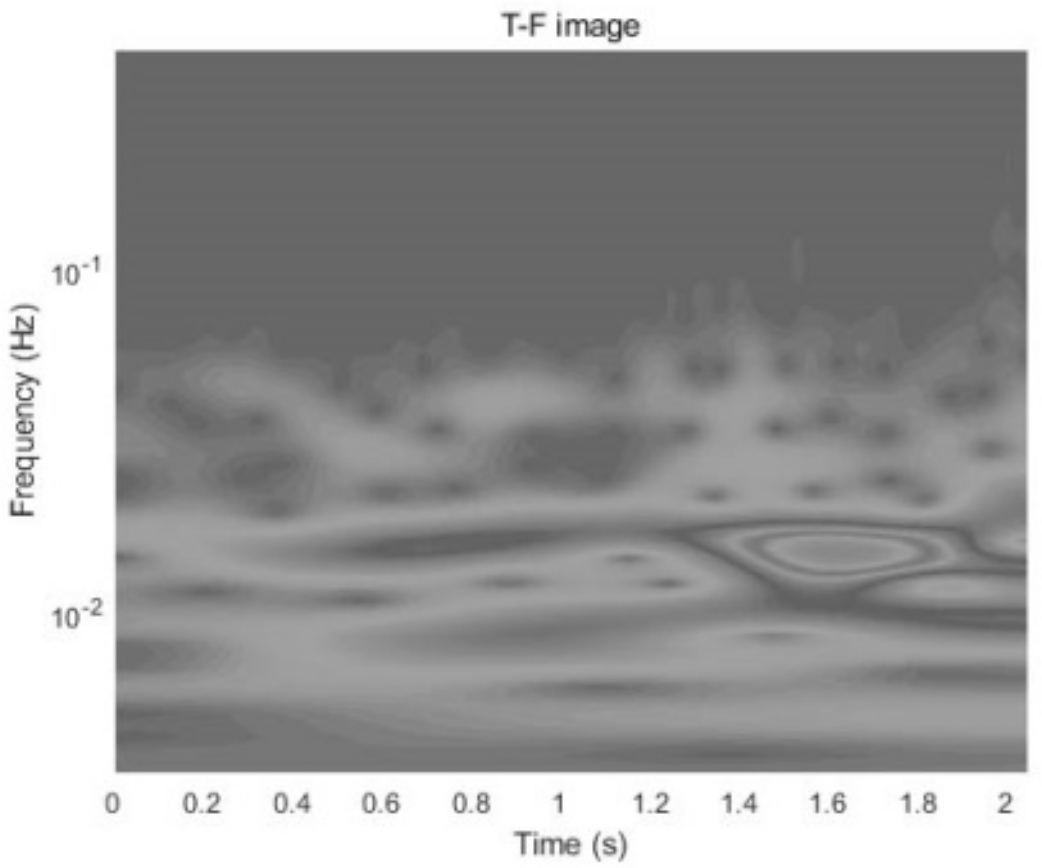
- The original acceleration signals are denoised using a median filtering method and are separated into segments. Then, the acceleration signal segments are processed through the Continuous Wavelet Transform (CWT) to generate Time-Frequency (T-F) images. These T-F images are stored as grayscale images and are labeled based on their dominant graphical features.
- The T-F images are used as input feature maps for CNNs to recognize the state of ASs.
- The final decision is obtained by fusing the preliminary recognition results using D-S evidence theory.
2.1. Data Preprocessing
2.2. CNN Decision
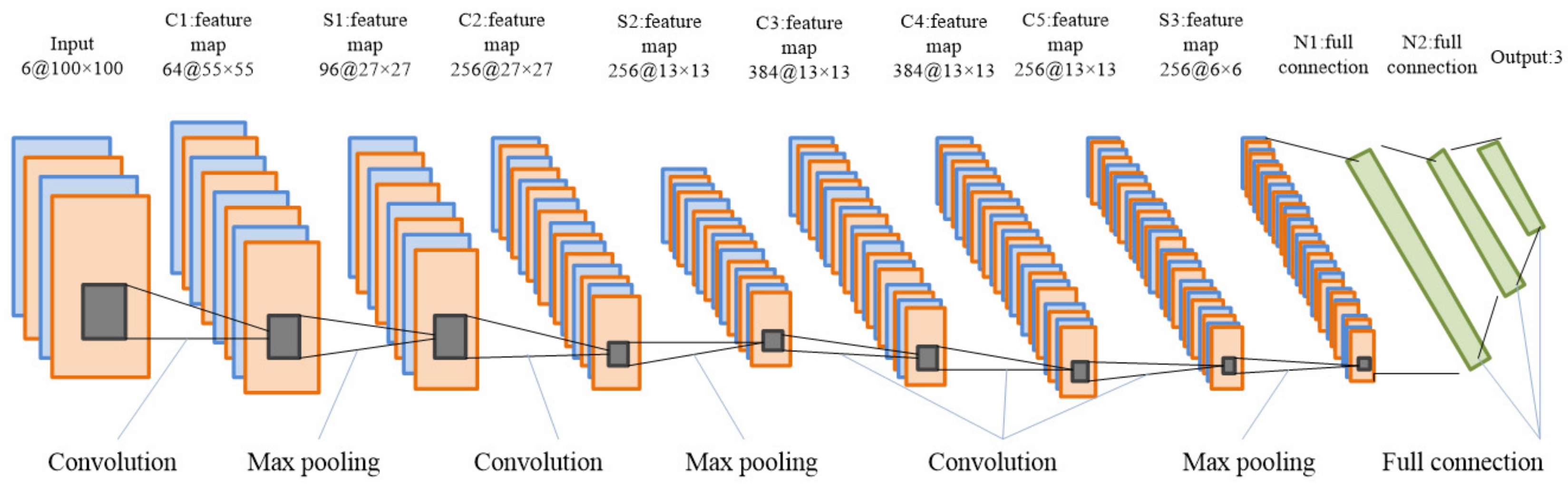
2.2.1. Architecture of the CNN Models
2.2.2. Illustration of CNNs
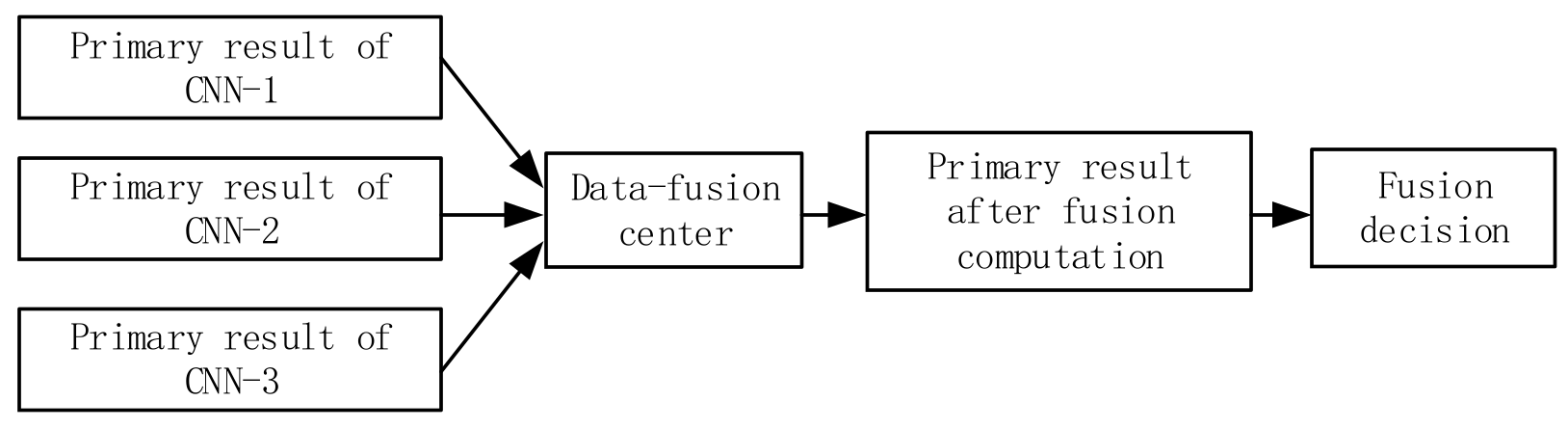
2.3. Data Fusion
3. Experimental Verification
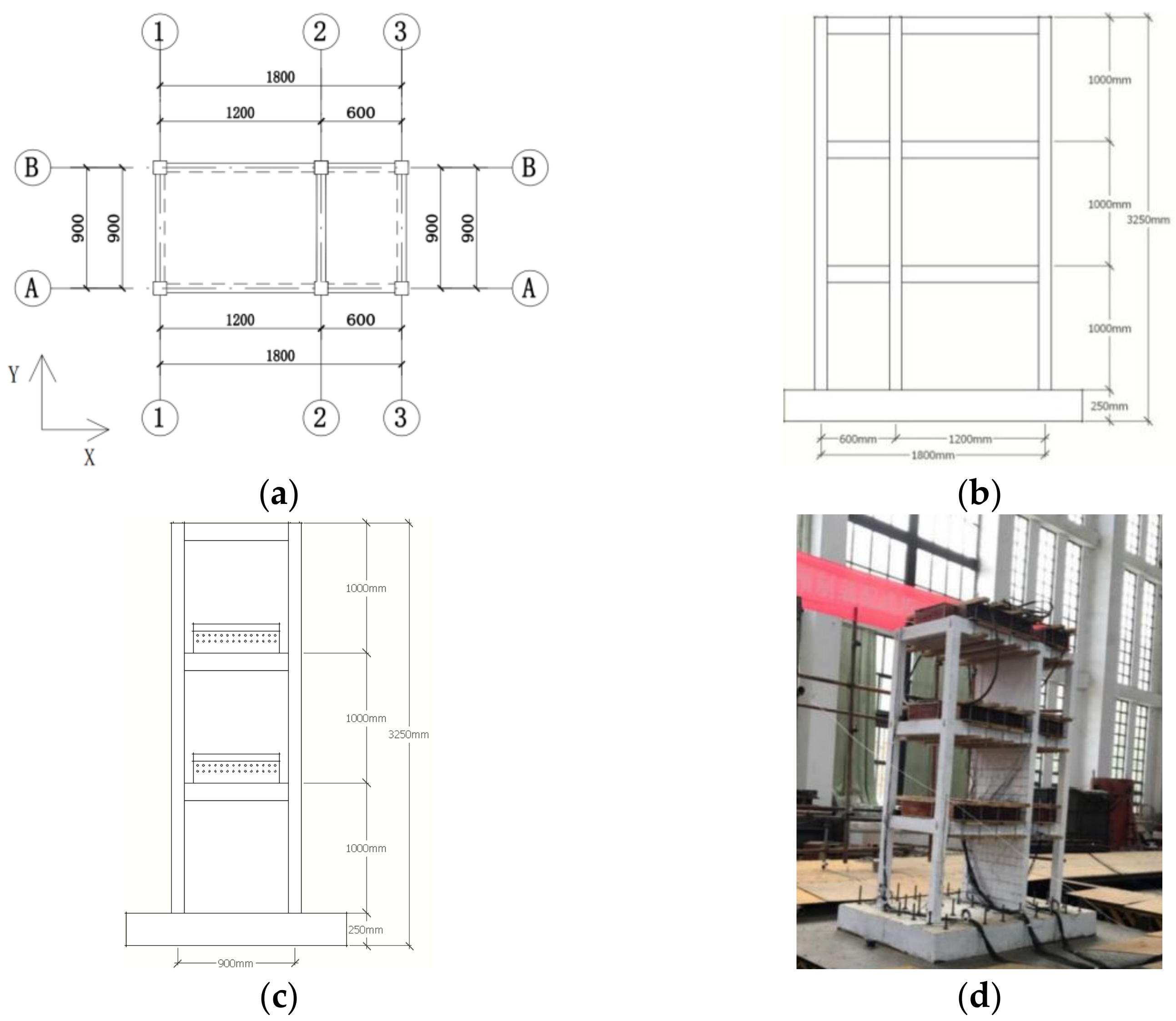
3.1. Example and Condition Description
3.2. Pattern Recognition of AS
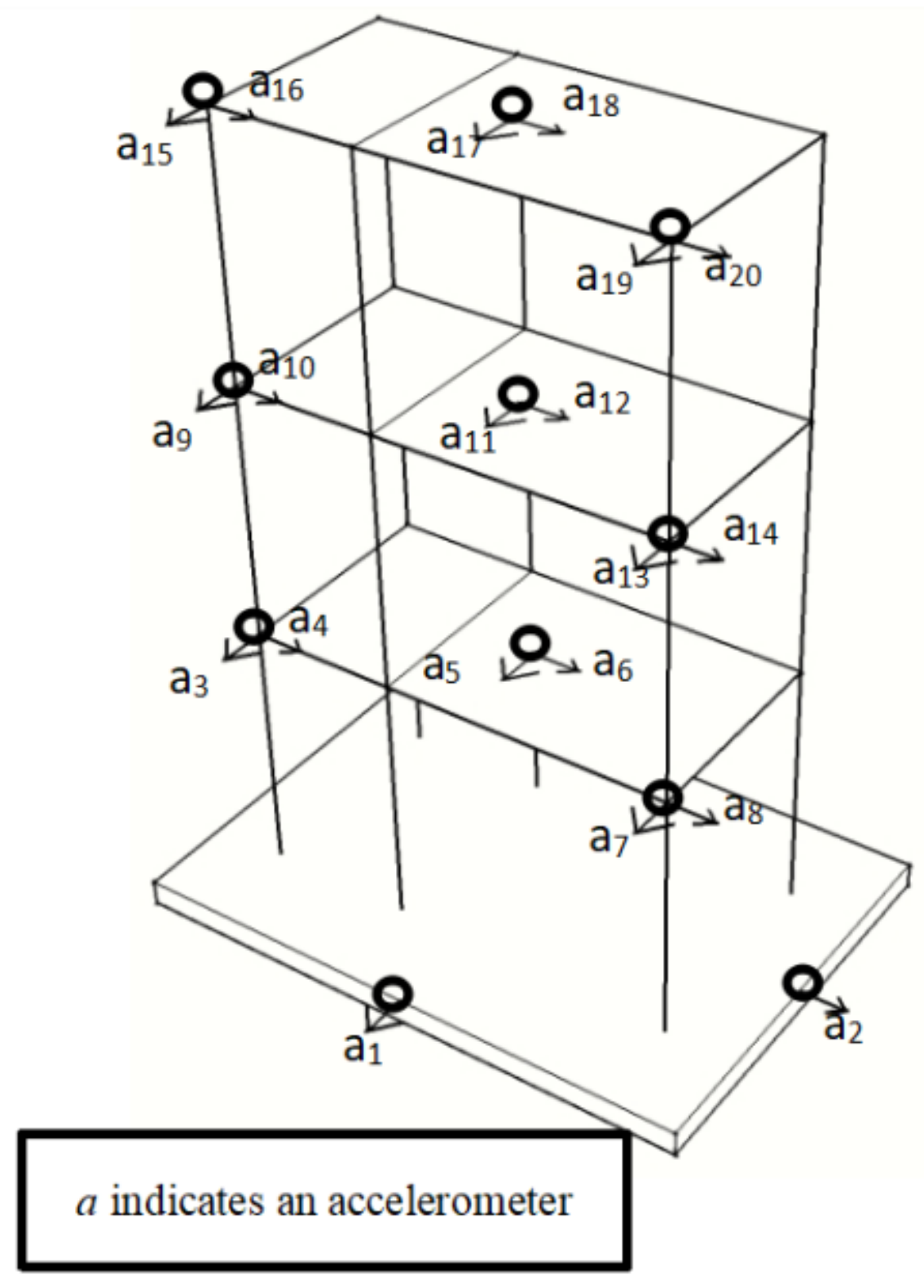
3.2.1. Signal Acquisition
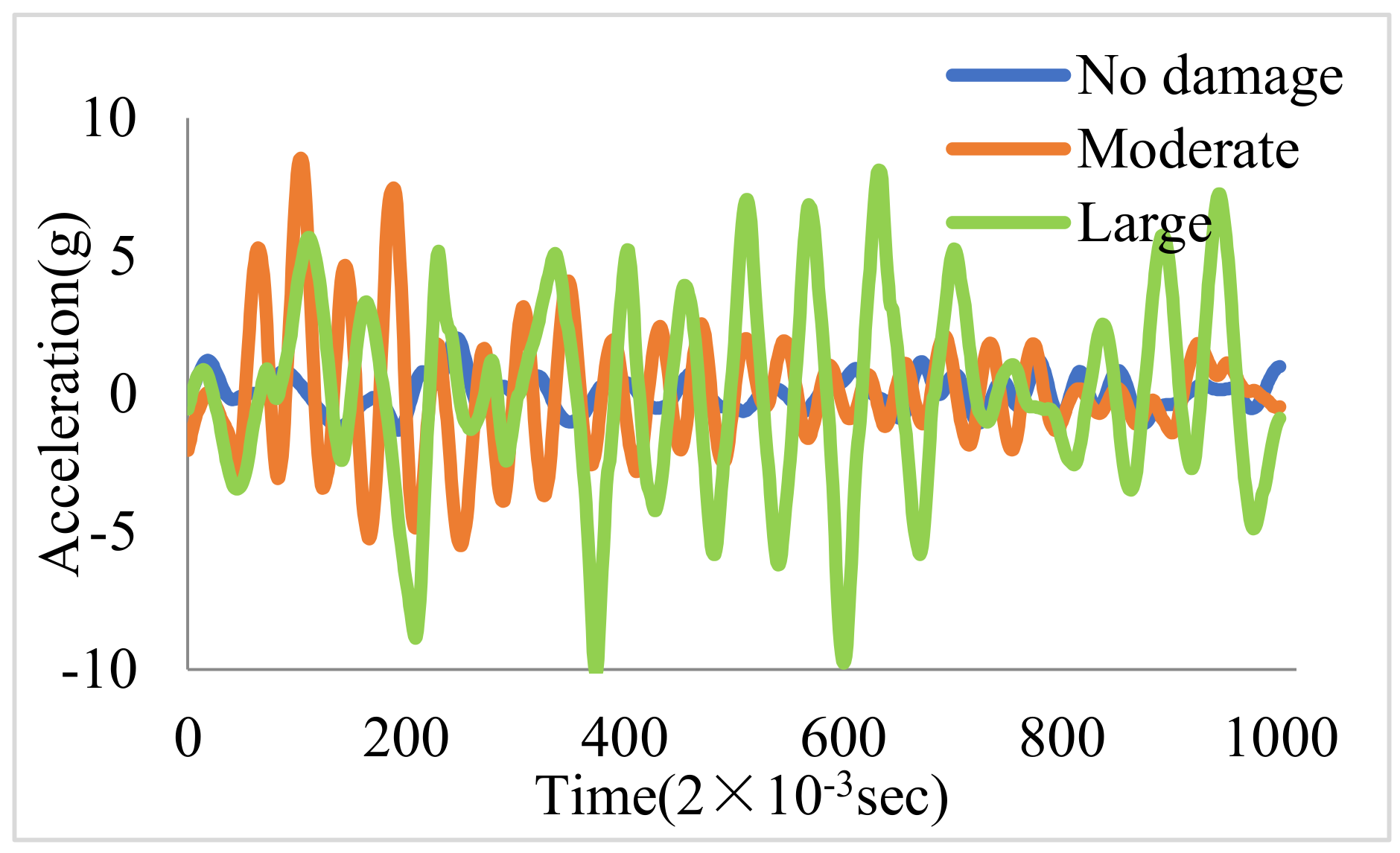
3.2.2. Data Processing
3.2.3. Single CNN Model
3.2.4. Data Fusion
3.3. Results and Discussion
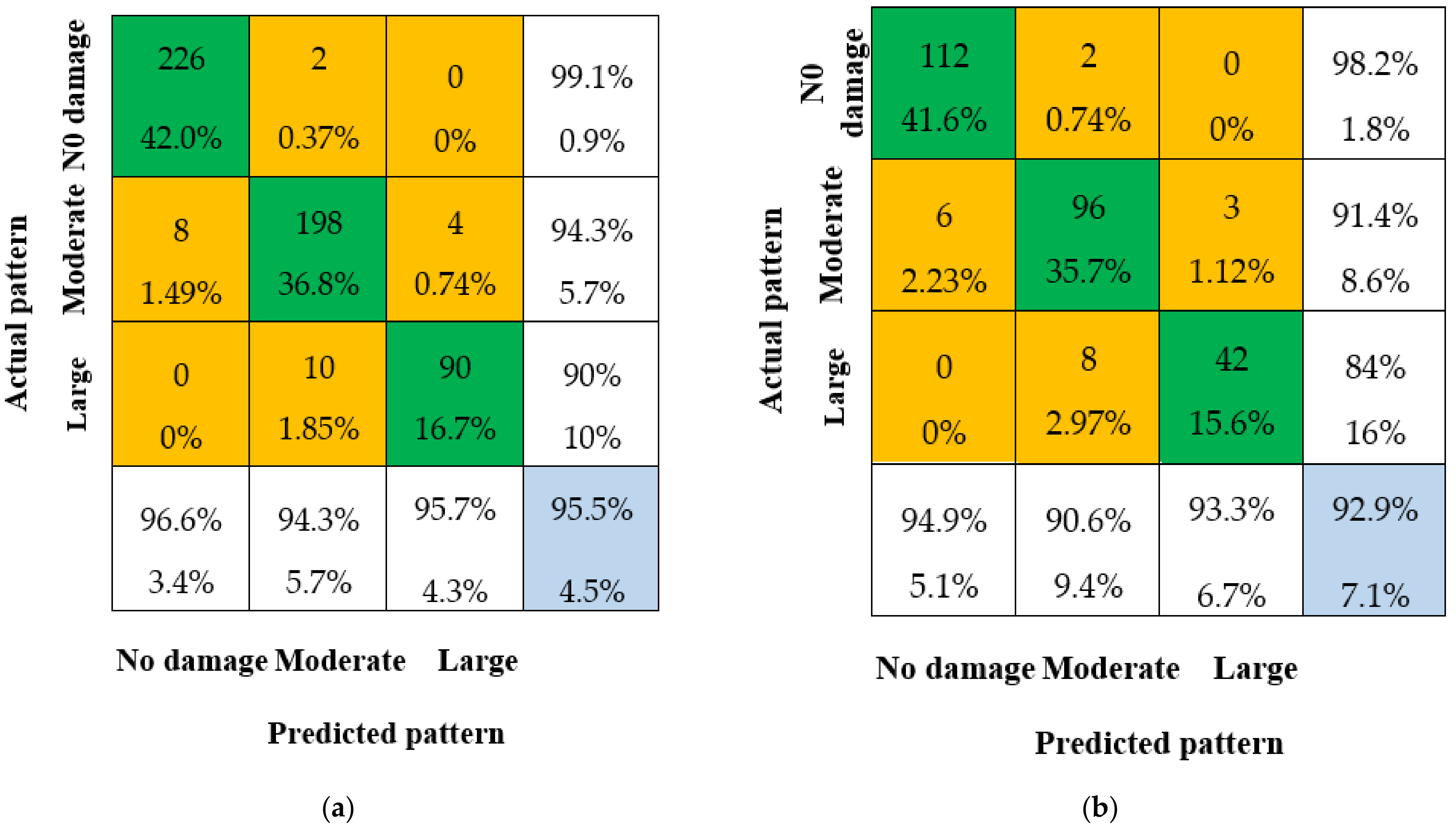
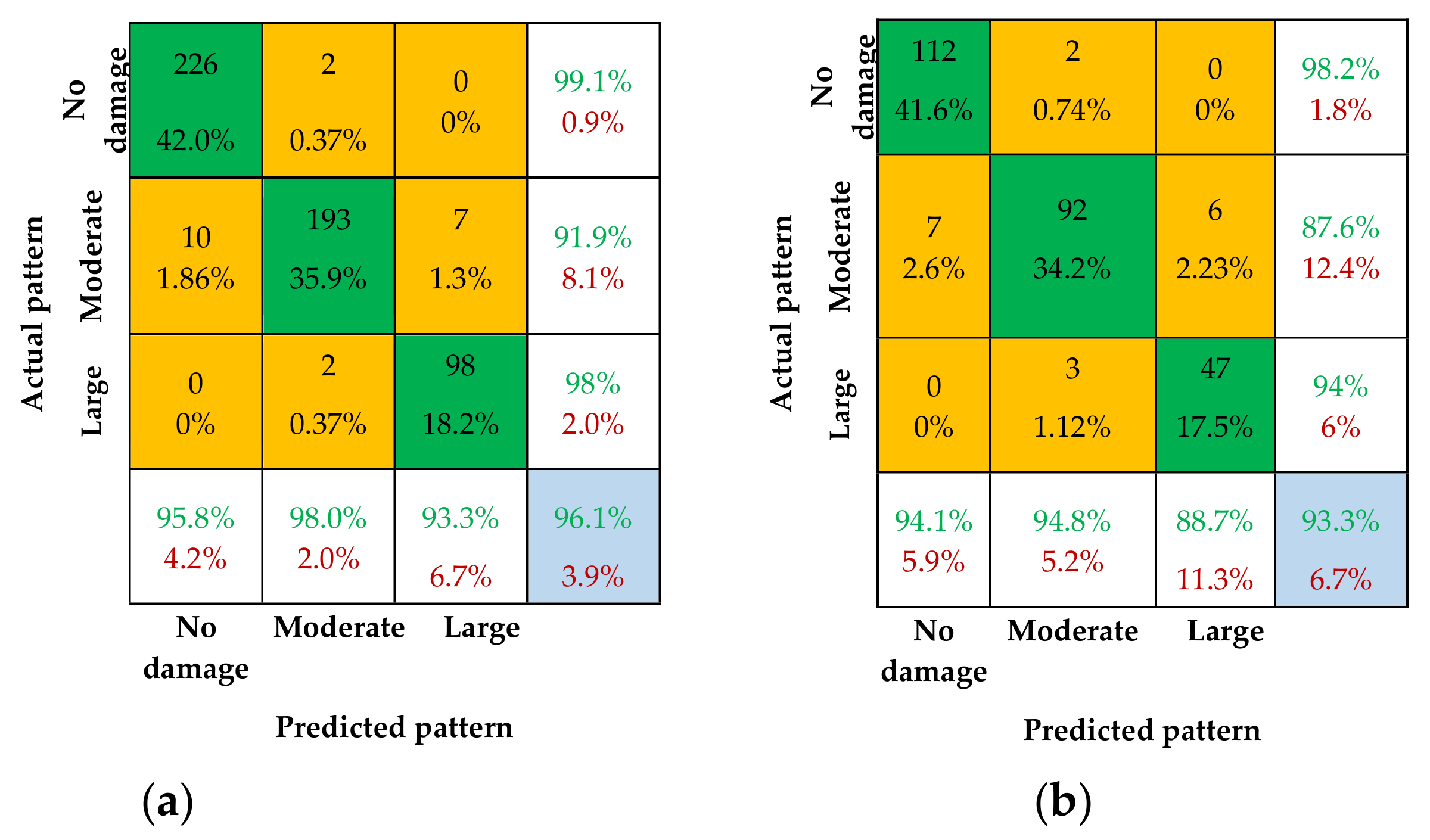
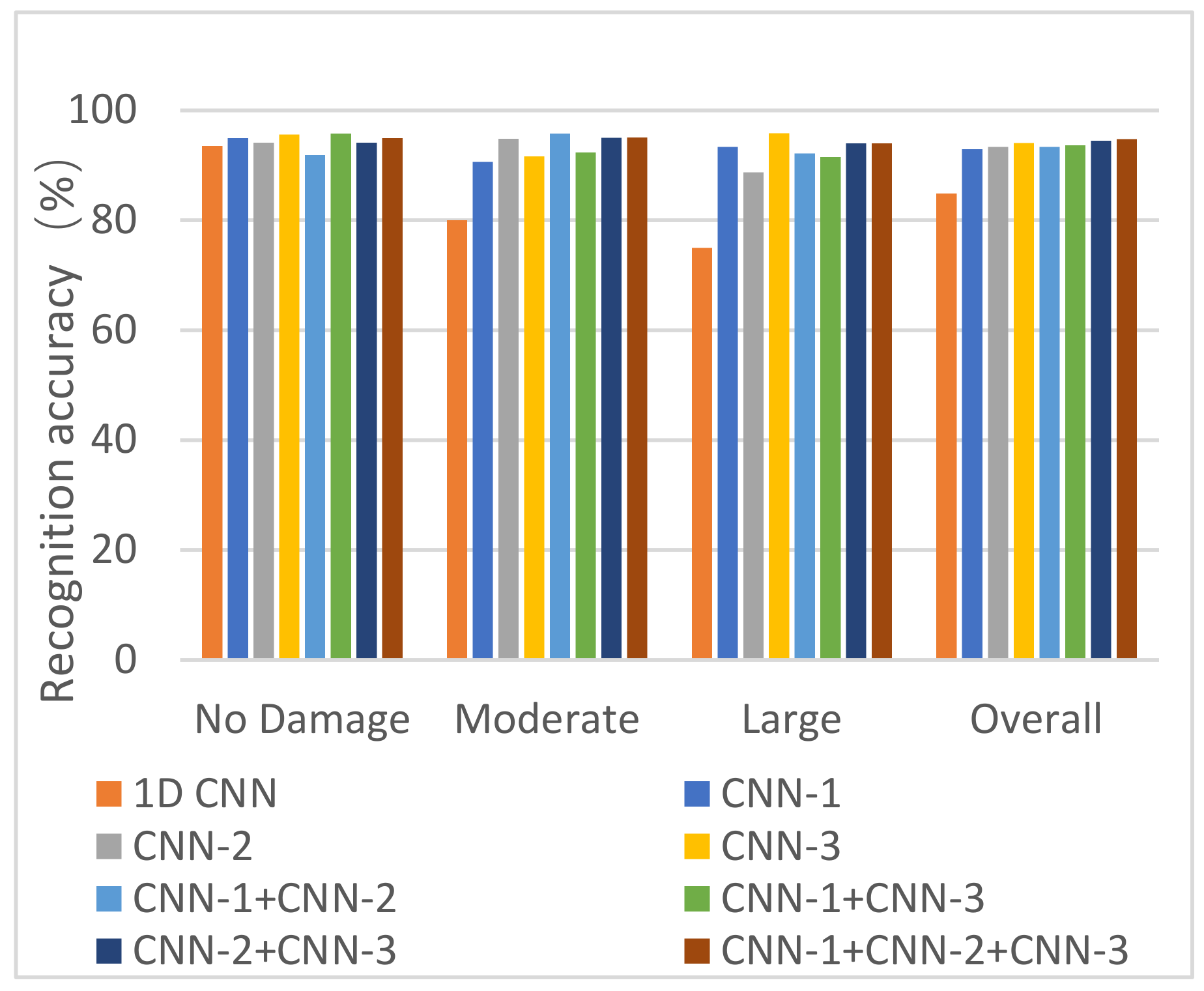
3.3.1. Single CNN Decision Results
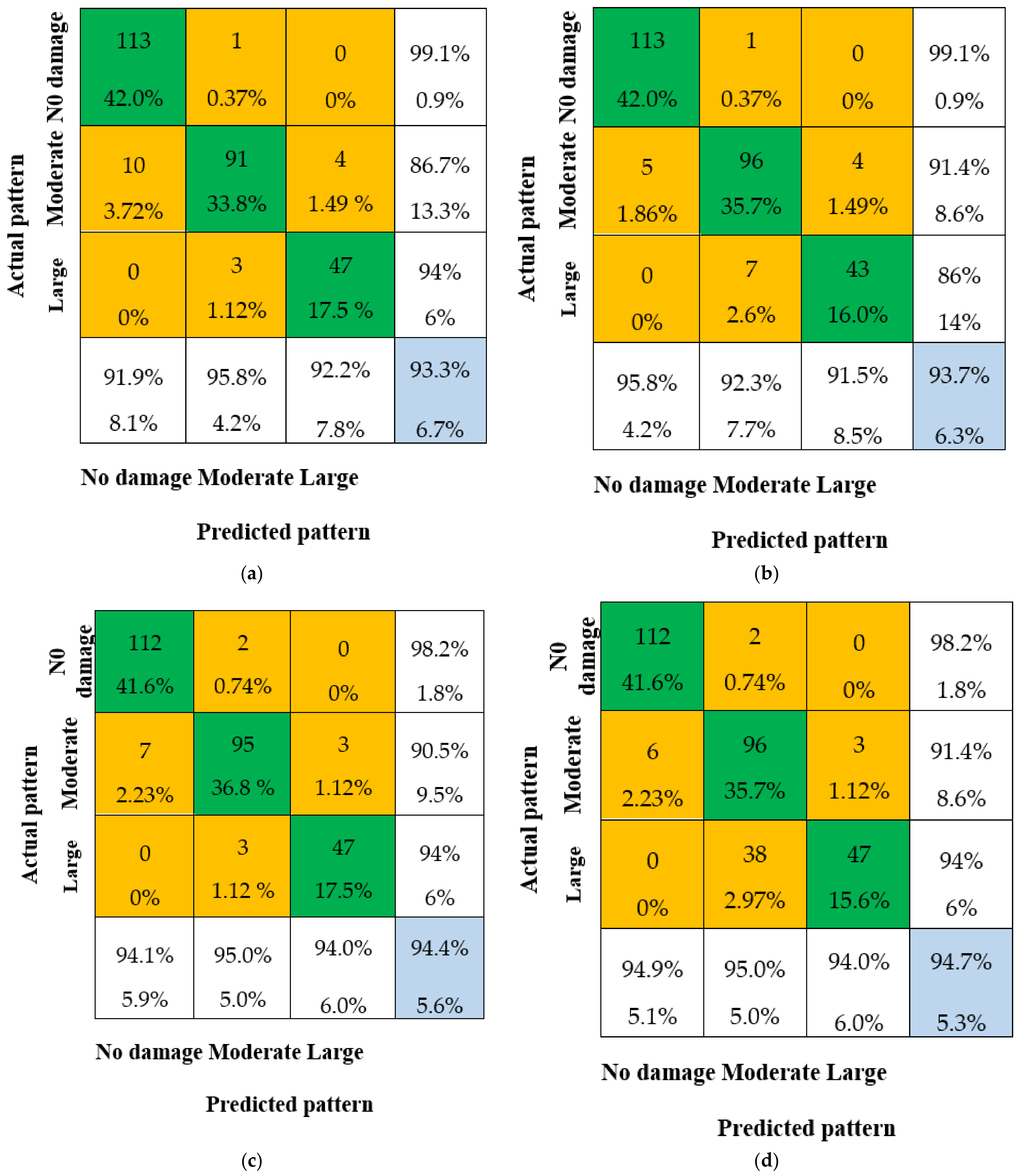
3.3.2. Fusion Decision Results
- The pattern recognition ability of the fusion methods is significantly improved compared to the single CNN decision. The overall IA is not less than 93.3% for all four fusion methods, which is much better than the overall IA of CNN-1 (92.9%). This demonstrates that the data fusion method has a higher IA than any single CNN model.
- The overall IA for the combination of CNN-1 and CNN-2, and the combination of CNN-1 and CNN-3, is 93.3% and 93.7%, respectively, which is lower than the overall IA for the combination of CNN-2 and CNN-3. This is due to the lower overall IA of single CNN-1 compared to CNN-2 and CNN-3, which results in a lower overall IA after data fusion.
- The overall IA for the combination of all three CNN models (CNN-1 + CNN-2 + CNN-3) is 2%, 1.6%, and 0.8% higher compared to CNN-1, CNN-2, and CNN-3, respectively. This indicates that multi-sensor data fusion has a better pattern recognition capacity than any single CNN model.
4. Discussion
4.1. Comparison with Other Methods
4.2. Recognition Ability with Different Input Images of the Same Patterns
4.3. Recognition Ability with Similar T-F Images from Different Patterns
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bo, Q. The ministry of housing and construction finalized eight key tasks in 2016. China Prospect Des. 2016, 1, 1–11. [Google Scholar]
- Ju, R.-S.; Lee, H.-J.; Chen, C.-C.; Tao, C.-C. Experimental study on separating reinforced concrete infill walls from steel moment frames. J. Constr. Steel Res. 2012, 71, 119–128. [Google Scholar] [CrossRef]
- Liu, X.; Bradford, M.A.; Lee, M.S.S. Behavior of High-Strength Friction-Grip Bolted Shear Connectors in Sustainable Composite Beams. J. Struct. Eng. 2015, 141, 04014149. [Google Scholar] [CrossRef]
- Ko, J.M.; Ni, Y.-Q.; Chan, H.-T.T. Dynamic monitoring of structural health in cable-supported bridges. Smart Struct. Mater. Smart Syst. Bridges Struct. Highw. 1999, 3671, 161–172. [Google Scholar] [CrossRef]
- Doebling, S.W.; Farrar, C.R. The State of the Art in Structural Identification of Constructed Facilities; Los Alamos National Laboratory: Santa Fe, NM, USA, 1999. [Google Scholar]
- Sohn, H.; Farrar, C.R.; Hemez, F.M.; Shunk, D.D.; Stinemates, D.W.; Nadler, B.R.; Czarnecki, J.J. A Review of Structural Health Monitoring Literature: 1996–2001; Los Alamos National Laboratory: Santa Fe, NM, USA, 2003; Volume 1, p. 16. [Google Scholar]
- Giordano, P.F.; Quqa, S.; Limongelli, M.P. The value of monitoring a structural health monitoring system. Struct. Saf. 2023, 100, 102280. [Google Scholar] [CrossRef]
- Avci, O.; Abdeljaber, O.; Kiranyaz, S.; Hussein, M.; Gabbouj, M.; Inman, D.J. A review of vibration-based damage detection in civil structures: From traditional methods to Machine Learning and Deep Learning applications. Mech. Syst. Signal Process. 2021, 147, 107077. [Google Scholar] [CrossRef]
- Homaei, F.; Shojaee, S.; Amiri, G. A direct damage detection method using ultiple damage localization index based on mode shapes criterion. Struct. Eng. Mech. 2014, 49, 183–202. [Google Scholar] [CrossRef]
- Abdeljaber, O.; Avci, O.; Kiranyaz, S.; Gabbouj, M.; Inman, D.J. Real-time vibration-based structural damage detection using one-dimensional convolutional neural networks. J. Sound Vib. 2017, 388, 154–170. [Google Scholar] [CrossRef]
- Hakim, S.J.S.; Irwan, M.J.; Ibrahim, M.H.W.; Ayop, S.S. Structural damage identification employing hybrid intelligence using artificial neural networks and vibration-based methods. J. Appl. Res. Technol. 2022, 20, 221–236. [Google Scholar] [CrossRef]
- Gomez-Cabrera, A.; Escamilla-Ambrosio, P.J. Review of Machine-Learning Techniques Applied to Structural Health Monitoring Systems for Building and Bridge Structures. Appl. Sci. 2022, 12, 10754. [Google Scholar] [CrossRef]
- Kiranyaz, S.; Waris, M.-A.; Ahmad, I.; Hamila, R.; Gabbouj, M. Face segmentation in thumbnail images by data-adaptive convolutional segmentation networks. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; IEEE: New York, NY, USA, 2016; pp. 2306–2310. [Google Scholar]
- Hien, H.T.; Akira, M. Damage detection method using support vector machine and first three natural frequencies for shear structures. Open J. Civ. Eng. 2013, 3, 104–112. [Google Scholar]
- Lu, N.; Wu, Y.; Feng, L.; Song, J. Deep learning for fall detection: 3d-cnn combined with lstm on video kinematic data. IEEE J. Biomed. Health Inform. 2018, 23, 314–323. [Google Scholar] [CrossRef] [PubMed]
- Cho, K.; Van Merrienboer, B.; Bahdanau, D.; Bengio, Y. On the properties of neural machine translation: Encoder-decoder approaches. Comput. Sci. 2014, 1409, 1259. [Google Scholar]
- Ma, X.; Yang, H.; Chen, Q.; Huang, D.; Wang, Y. Depaudionet: An efficient deep model for audio based depression classification. In Proceedings of the 6th International Workshop on Audio/Visual Emotion Challenge, New York, NY, USA, 16 October 2016; pp. 35–42. [Google Scholar]
- Schlosser, J.; Chow, C.K.; Kira, Z. Fusing LIDAR and images for pedestrian detection using convolutional neural networks. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 2198–2205. [Google Scholar]
- Ebesu, T.; Yi, F. Neural citation network for context-aware citation recommendation. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 1093–1096. [Google Scholar]
- Tang, Z.; Chen, Z.; Bao, Y.; Li, H. Convolutional neural network-based data anomaly detection method using multiple information for structural health monitoring. Struct. Control. Health Monit. 2018, 26, e2296. [Google Scholar] [CrossRef]
- Arnab, A.; Zheng, S.; Jayasumana, S.; Romera-Paredes, B.; Larsson, M.; Kirillov, A.; Savchynskyy, B.; Rother, C.; Kahl, F.; Torr, P.H. Conditional Random Fields Meet Deep Neural Networks for Semantic Segmentation: Combining Probabilistic Graphical Models with Deep Learning for Structured Prediction. IEEE Signal Process. Mag. 2018, 35, 37–52. [Google Scholar] [CrossRef]
- Kerdvibulvech, C.; Saito, H. Vision-Based Detection of Guitar Players’ Fingertips Without Markers. In Proceedings of the Computer Graphics, Imaging and Visualisation (CGIV 2007), Bangkok, Thailand, 14–17 August 2007; pp. 419–428. [Google Scholar]
- Gers, F.A.; Schmidhuber, E. LSTM recurrent networks learn simple context-free and context-sensitive languages. IEEE Trans. Neural Netw. 2001, 12, 1333–1340. [Google Scholar] [CrossRef]
- Klapper-Rybicka, M.; Schraudolph, N.N.; Schmidhuber, J. Unsupervised learning in LSTM recurrent neural networks. In Proceedings of the Artificial Neural Networks—ICANN 2001: International Conference, Vienna, Austria, 21–25 August 2001; Volume 11, pp. 684–691. [Google Scholar]
- Zhang, Y.; Miyamori, Y.; Mikami, S.; Saito, T. Vibration-based structural state identification by a 1-dimensional convolutional neural network. Comput. Civ. Infrastruct. Eng. 2019, 34, 822–839. [Google Scholar] [CrossRef]
- Khodabandehlou, H.; Pekcan, G.; Fadali, M.S. Vibration-based structural condition assessment using convolution neural networks. Struct. Control. Health Monit. 2019, 26, e2308. [Google Scholar] [CrossRef]
- Xu, Y.; Wei, S.; Bao, Y.; Li, H. Automatic seismic damage identification of reinforced concrete columns from images by a region-based deep convolutional neural network. Struct. Control Health Monit. 2019, 26, e2313. [Google Scholar] [CrossRef]
- Tang, Y.; Huang, Z.; Chen, Z.; Chen, M.; Zhou, H.; Zhang, H.; Sun, J. Novel visual crack width measurement based on backbone double-scale features for improved detection automation. Eng. Struct. 2023, 274, 115158. [Google Scholar] [CrossRef]
- Broer, A.A.R.; Benedictus, R.; Zarouchas, D. The Need for Multi-Sensor Data Fusion in Structural Health Monitoring of Composite Aircraft Structures. Aerospace 2022, 9, 183. [Google Scholar] [CrossRef]
- Kashinath, S.A.; Mostafa, S.A.; Mustapha, A.; Mahdin, H.; Lim, D.; Mahmoud, M.A.; Mohammed, M.A.; Al-Rimy, B.A.S.; Fudzee, M.F.M.; Yang, T.J. Review of Data Fusion Methods for Real-Time and Multi-Sensor Traffic Flow Analysis. IEEE Access 2021, 9, 51258–51276. [Google Scholar] [CrossRef]
- Zhou, Q.; Zhou, H.; Zhou, Q.; Yang, F.; Luo, L.; Li, T. Structural damage detection based on posteriori probability support vector machine and Dempster–Shafer evidence theory. Appl. Soft Comput. 2015, 36, 368–374. [Google Scholar] [CrossRef]
- Jiang, S.-F.; Fu, D.-B.; Ma, S.-L.; Fang, S.-E.; Wu, Z.-Q. Structural Novelty Detection Based on Adaptive Consensus Data Fusion Algorithm and Wavelet Analysis. Adv. Struct. Eng. 2013, 16, 189–205. [Google Scholar] [CrossRef]
- Wu, R.-T.; Jahanshahi, M.R. Data fusion approaches for structural health monitoring and system identification: Past, present, and future. Struct. Health Monit. 2020, 19, 552–586. [Google Scholar] [CrossRef]
- Li, H.; Bao, Y.; Ou, J. Structural damage identification based on integration of information fusion and shannon entropy. Mech. Syst. Signal Process. 2008, 22, 1427–1440. [Google Scholar] [CrossRef]
- Zhao, Q.; Zhang, L. ECG Feature Extraction and Classification Using Wavelet Transform and Support Vector Machines. In Proceedings of the 2005 International Conference on Neural Networks and Brain, Beijing, China, 13–15 October 2005; Volume 2, pp. 1089–1092. [Google Scholar]
- Chan, T.-H.; Jia, K.; Gao, S.; Lu, J.; Zeng, Z.; Ma, Y. PCANet: A Simple Deep Learning Baseline for Image Classification? IEEE Trans. Image Process. 2015, 24, 5017–5032. [Google Scholar] [CrossRef]
- Ye, F.; Chen, J.; Li, Y. Improvement of DS Evidence Theory for Multi-Sensor Conflicting Information. Symmetry 2017, 9, 69. [Google Scholar] [CrossRef]
- Gros, X.E. Applications of NDT Data Fusion; Kluwer Academic Publishers: Boston, MA, USA, 2001; pp. 20–23. [Google Scholar]
- Rahman, M.A.; Sritharan, S. Seismic response of precast, posttensioned concrete jointed wall systems designed for low-to midrise buildings using the direct displacement-based approach. PCI J. 2015, 60, 38–56. [Google Scholar] [CrossRef]
- Liu, Z. Shaking Table Test Study on Cast-In-Situ RC Frame-Assembled Dry-Connected Shear Wall Structure; Fuzhou University: Fuzhou, China, 2018. (In Chinese) [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Description | Peak Table Acceleration (g) | Damage Pattern |
|---|---|---|---|
| A1-W | White noise | 0.05 g | No damage |
| A1 | El-Centro | 0.1 g | |
| A2 | Taft | 0.1 g | |
| A3 | SHW2 | 0.1 g | |
| B1-W | White noise | 0.05 g | |
| B1 | El-Centro | 0.15 g | |
| B2 | Taft | 0.15 g | |
| B3 | SHW2 | 0.15 g | |
| C1-W | White noise | 0.05 g | |
| C1 | El-Centro | 0.2 g | |
| C2 | Taft | 0.2 g | |
| C3 | SHW2 | 0.2 g | |
| D1-W | White noise | 0.05 g | Moderate damage |
| D1 | El-Centro | 0.31 g | |
| D2 | Taft | 0.31 g | |
| D3 | SHW2 | 0.31 g | |
| E1-W | White noise | 0.05 g | |
| E1 | El-Centro | 0.4 g | |
| E2 | Taft | 0.4 g | |
| E3 | SHW2 | 0.4 g | |
| F1-W | White noise | 0.05 g | |
| F1 | El-Centro | 0.51 g | |
| F2 | Taft | 0.51 g | |
| F3 | SHW2 | 0.51 g | |
| G1-W | White noise | 0.05 g | Large damage |
| G1 | El-Centro | 0.62 g | |
| G2 | Taft | 0.62 g | |
| H1-W | White noise | 0.05 g | |
| H1 | El-Centro | 0.7 g | |
| H2 | Taft | 0.7 g | |
| I1-W | White noise | 0.05 g | |
| I1 | El-Centro | 0.8 g |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, J.; Jiang, S.; Zhao, J.; Zhang, Z. An Integrated Method Based on Convolutional Neural Networks and Data Fusion for Assembled Structure State Recognition. Sustainability 2023, 15, 6094. https://doi.org/10.3390/su15076094
Luo J, Jiang S, Zhao J, Zhang Z. An Integrated Method Based on Convolutional Neural Networks and Data Fusion for Assembled Structure State Recognition. Sustainability. 2023; 15(7):6094. https://doi.org/10.3390/su15076094
Chicago/Turabian StyleLuo, Jianbin, Shaofei Jiang, Jian Zhao, and Zhangrong Zhang. 2023. "An Integrated Method Based on Convolutional Neural Networks and Data Fusion for Assembled Structure State Recognition" Sustainability 15, no. 7: 6094. https://doi.org/10.3390/su15076094