
Optimization-Driven Machine Learning Approach for the Prediction of Hydrochar Properties from Municipal Solid Waste
 , , , ,
, , , ,  , and
, and
Abstract
:1. Introduction
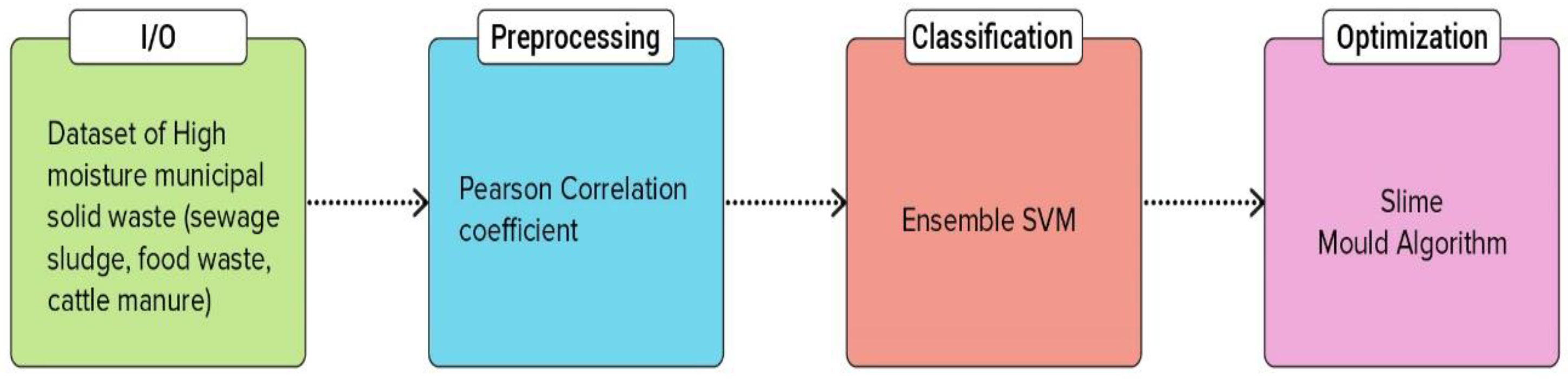
2. Materials and Methods
2.1. Dataset and Preprocessing
2.2. Data Preprocessing
2.3. Ensemble-SVM for Classification
2.4. Slime Mould Optimization
2.4.1. Approaching Food Algorithm
2.4.2. Warp Food Algorithm
2.5. Training and Evaluation
2.6. Analysis Method for Feature Importance
3. Results and Discussion
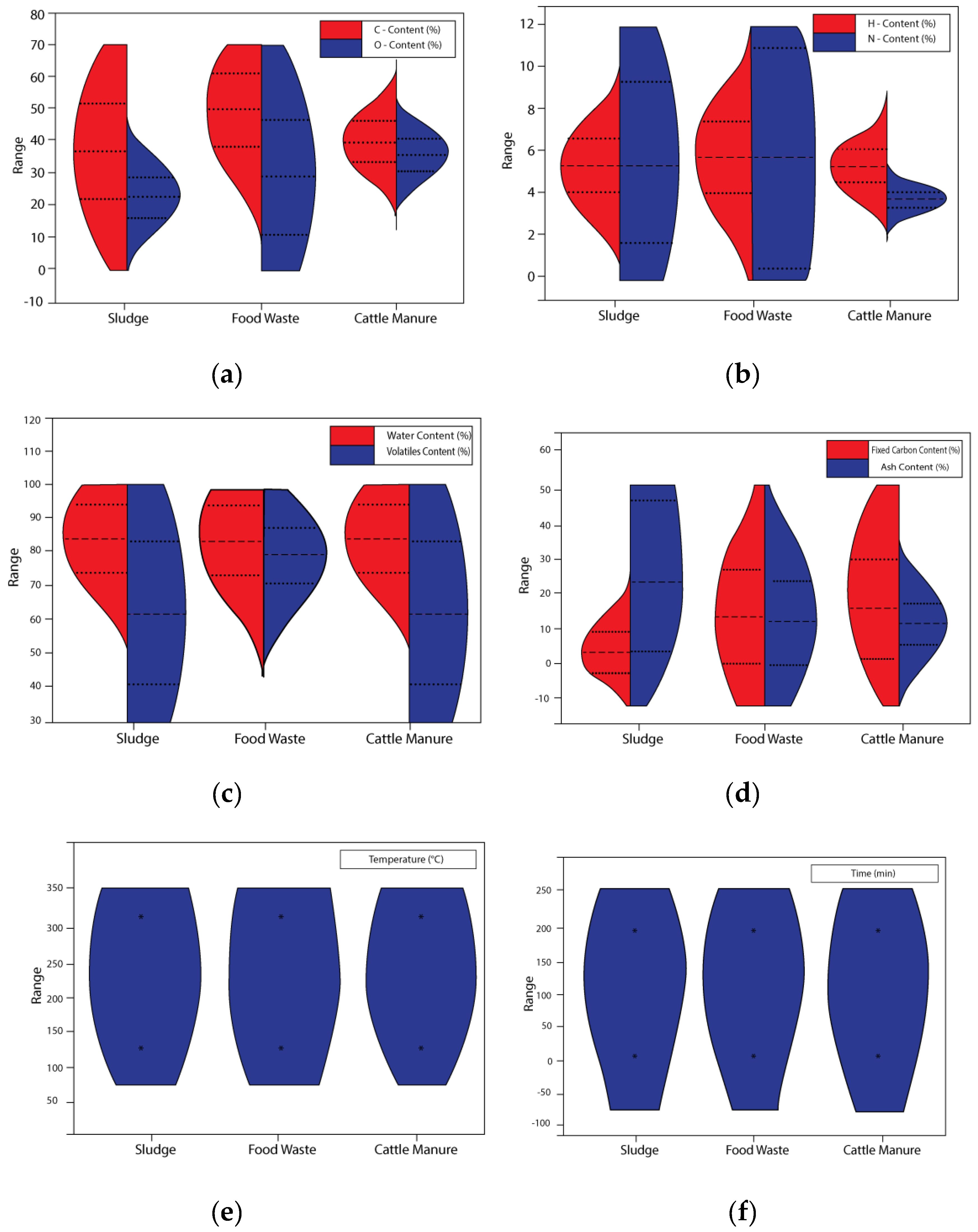
3.1. Statistical Analysis of Sewage Sludge, Food Waste, Cattle Manure, and Hydrochar Characteristics
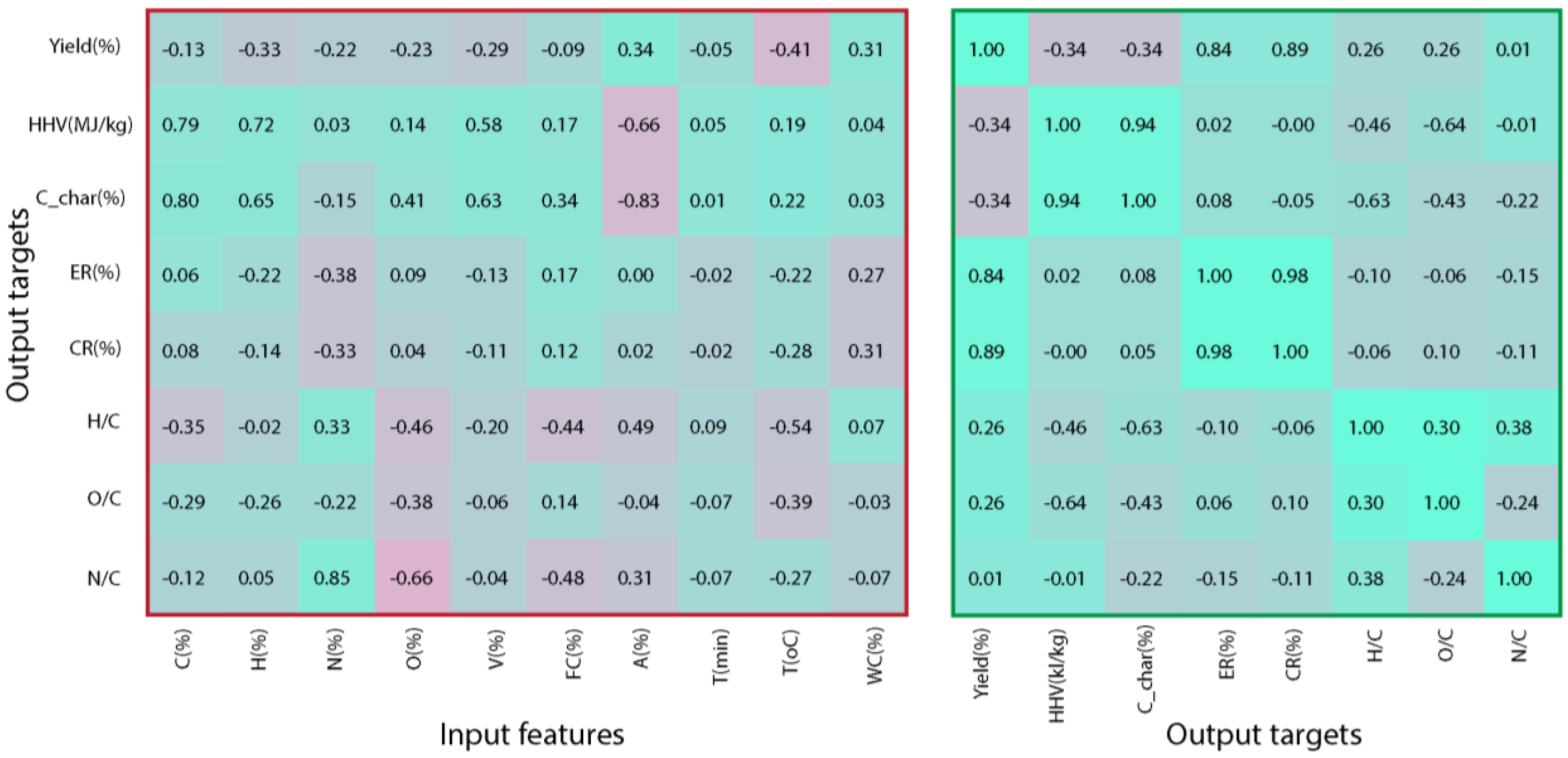
3.2. ML Model’s Hyperparameter Tuning and Variable Correlation
3.3. Evaluation of ML Model’s Optimization for Testing Dataset
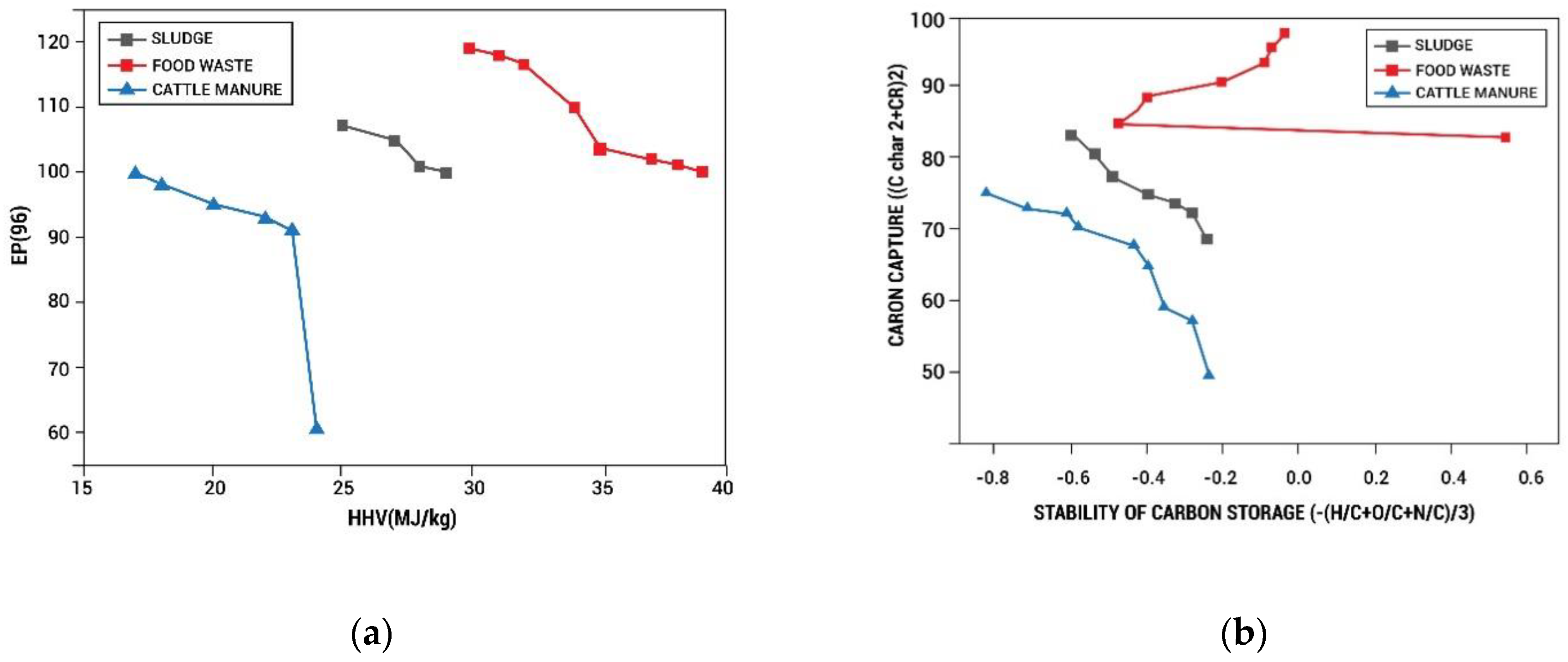
3.4. Slime Mould Algorithm Optimization of Hydrochar Properties Based on Ensemble SVM
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Multi-Task Prediction of Fuel Properties of Hydrochar Derived from Wet Municipal Wastes with Random Forest. Available online: https://www.researchgate.net/profile/jie-li-85/publication/343124219_multi-task_prediction_of_fuel_properties_of_hydrochar_derived_from_wet_municipal_wastes_with_random_forest/links/5f1799dda6fdcc9626a67c5a/multi-task-prediction-of-fuel-properties-of-hydrochar-derived-from-wet-municipal-wastes-with-random-forest.pdf (accessed on 20 June 2022).
- Birgen, C.; Magnanelli, E.; Carlsson, P.; Skreiberg, Ø.; Mosby, J.; Becidan, M. Machine learning based modelling for lower-Ju heating value prediction of municipal solid waste. Fuel 2020, 283, 118906. [Google Scholar] [CrossRef]
- AlZubi, A.A. IoT-based automated water pollution treatment using machine learning classifiers. Environ. Technol. 2022, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Liu, X.; Legros, R.; Bi, X.T.; Lim, C.J.; Sokhansanj, S. Pelletization of torrefied sawdust and properties of torrefied pellets. Appl. Energy 2012, 93, 680–685. [Google Scholar] [CrossRef]
- Liu, Z.; Quek, A.; Balasubramanian, R. Preparation and characterization of fuel pellets from woody biomass, agro-residues and their corresponding hydrochars. Appl. Energy 2014, 113, 1315–1322. [Google Scholar] [CrossRef]
- Xie, S.; Yu, G.; Li, C.; You, F.; Li, J.; Tian, R.; Wang, G.; Wang, Y. Dewaterability enhancement and heavy metals immobilization by pig manure biochar addition during hydrothermal treatment of sewage sludge. Environ. Sci. Pollut. Res. 2019, 26, 16537–16547. [Google Scholar] [CrossRef]
- Diggelman, C.; Ham, R.K. Household food waste to wastewater or to solid waste? That is the question. Waste Manag. Res. J. Sustain. Circ. Econ. 2003, 21, 501–514. [Google Scholar] [CrossRef]
- Leng, L.; Yuan, X.; Shao, J.; Huang, H.; Wang, H.; Li, H.; Chen, X.; Zeng, G. Study on demetalization of sewage sludge by sequential extraction before liquefaction for the production of cleaner bio-oil and bio-char. Bioresour. Technol. 2016, 200, 320–327. [Google Scholar] [CrossRef]
- Mau, V.; Gross, A. Energy conversion and gas emissions from production and combustion of poultry-litter-derived hydrochar and biochar. Appl. Energy 2018, 213, 510–519. [Google Scholar] [CrossRef]
- Tian, H.; Li, J.; Yan, M.; Tong, Y.W.; Wang, C.-H.; Wang, X. Organic waste to biohydrogen: A critical review from technological development and environmental impact analysis perspective. Appl. Energy 2019, 256, 113961. [Google Scholar] [CrossRef]
- Li, J.; Zhu, X.; Li, Y.; Tong, Y.W.; Ok, Y.S.; Wang, X. Multi-task prediction and optimization of hydrochar properties from high-moisture municipal solid waste: Application of machine learning on waste-to-resource. J. Clean. Prod. 2020, 278, 123928. [Google Scholar] [CrossRef]
- Hameed, Z.; Aslam, M.; Khan, Z.; Maqsood, K.; Atabani, A.; Ghauri, M.; Khurram, M.S.; Rehan, M.; Nizami, A.-S. Gasification of municipal solid waste blends with biomass for energy production and resources recovery: Current status, hybrid technologies and innovative prospects. Renew. Sustain. Energy Rev. 2020, 136, 110375. [Google Scholar] [CrossRef]
- Qian, X.; Lee, S.; Chandrasekaran, R.; Yang, Y.; Caballes, M.; Alamu, O.; Chen, G. Electricity Evaluation and Emission Characteristics of Poultry Litter Co-Combustion Process. Appl. Sci. 2019, 9, 4116. [Google Scholar] [CrossRef] [Green Version]
- Tasca, A.L.; Puccini, M.; Gori, R.; Corsi, I.; Galletti, A.M.R.; Vitolo, S. Hydrothermal carbonization of sewage sludge: A critical analysis of process severity, hydrochar properties and environmental implications. Waste Manag. 2019, 93, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; Flora, J.R.; Caicedo, J.M.; Berge, N.D. Investigating the role of feedstock properties and process conditions on products formed during the hydrothermal carbonization of organics using regression techniques. Bioresour. Technol. 2015, 187, 263–274. [Google Scholar] [CrossRef] [PubMed]
- Cao, H.; Xin, Y.; Yuan, Q. Prediction of biochar yield from cattle manure pyrolysis via least squares support vector machine intelligent approach. Bioresour. Technol. 2016, 202, 158–164. [Google Scholar] [CrossRef]
- Taki, M.; Rohani, A. Machine learning models for prediction the Higher Heating Value (HHV) of Municipal Solid Waste (MSW) for waste-to-energy evaluation. Case Stud. Therm. Eng. 2022, 31, 101823. [Google Scholar] [CrossRef]
- Jassim, M.S.; Coskuner, G.; Zontul, M. Comparative performance analysis of support vector regression and artificial neural network for prediction of municipal solid waste generation. Waste Manag. Res. J. Sustain. Circ. Econ. 2021, 40, 195–204. [Google Scholar] [CrossRef]
- Adeleke, O.; Akinlabi, S.; Jen, T.-C.; Dunmade, I. A machine learning approach for investigating the impact of seasonal variation on physical composition of municipal solid waste. J. Reliab. Intell. Environ. 2022, 1–20. [Google Scholar] [CrossRef]
- Riaz, A.R.; Gilani, S.M.M.; Naseer, S.; Alshmrany, S.; Shafiq, M.; Choi, J.G. Applying Adaptive Security Techniques for Risk Analysis of Internet of Things (IoT)-Based Smart Agriculture. Sustainability 2022, 14, 10964. [Google Scholar] [CrossRef]
- Ro, K.S.; Flora, J.R.V.; Bae, S.; Libra, J.A.; Berge, N.D.; Álvarez-Murillo, A.; Li, L. Properties of Animal-Manure-Based Hydrochars and Predictions Using Published Models. ACS Sustain. Chem. Eng. 2017, 5, 7317–7324. [Google Scholar] [CrossRef]
- Li, J.; Pan, L.; Suvarna, M.; Tong, Y.W.; Wang, X. Fuel properties of hydrochar and pyrochar: Prediction and exploration with machine learning. Appl. Energy 2020, 269, 115166. [Google Scholar] [CrossRef]
- Ma, J.; Chen, M.; Yang, T.; Liu, Z.; Jiao, W.; Li, D.; Gai, C. Gasification performance of the hydrochar derived from co-hydrothermal carbonization of sewage sludge and sawdust. Energy 2019, 173, 732–739. [Google Scholar] [CrossRef]
- Ismail, H.Y.; Shirazian, S.; Skoretska, I.; Mynko, O.; Ghanim, B.; Leahy, J.J.; Walker, G.M.; Kwapinski, W. ANN-Kriging hybrid model for predicting carbon and inorganic phosphorus recovery in hydrothermal carbonization. Waste Manag. 2019, 85, 242–252. [Google Scholar] [CrossRef] [PubMed]
- Bokhari, S.A.; Saqib, Z.; Amir, S.; Naseer, S.; Shafiq, M.; Ali, A.; Zaman-ul-Haq, M.; Irshad, A.; Hamam, H. Assessing land cover transformation for urban environmental sustainability through satellite sensing. Sustainability 2022, 14, 2810. [Google Scholar] [CrossRef]
- Kim, H.-C.; Pang, S.; Je, H.-M.; Kim, D.; Bang, S.Y. Constructing support vector machine ensemble. Pattern Recognit. 2003, 36, 2757–2767. [Google Scholar] [CrossRef]
- Li, S.; Chen, H.; Wang, M.; Heidari, A.A.; Mirjalili, S. Slime mould algorithm: A new method for stochastic optimization. Future Gener. Comput. Syst. 2020, 111, 300–323. [Google Scholar] [CrossRef]
- Patino-Ramirez, F.; Boussard, A.; Arson, C.; Dussutour, A. Substrate composition directs slime molds behavior. Sci. Rep. 2019, 9, 15444 . [Google Scholar] [CrossRef] [Green Version]
- Zubaidi, S.L.; Abdulkareem, I.H.; Hashim, K.S.; Al-Bugharbee, H.; Ridha, H.M.; Gharghan, S.K.; Al-Qaim, F.F.; Muradov, M.; Kot, P.; Al-Khaddar, R. Hybridised Artificial Neural Network Model with Slime Mould Algorithm: A Novel Methodology for Prediction of Urban Stochastic Water Demand. Water 2020, 12, 2692. [Google Scholar] [CrossRef]
- Kumar, C.; Raj, T.D.; Premkumar, M. A new stochastic slime mould optimization algorithm for the estimation of solar photovoltaic cell parameters. Optik 2020, 223, 165277. [Google Scholar] [CrossRef]
- Mostafa, M.; Rezk, H.; Aly, M.; Ahmed, E.M. A new strategy based on slime mould algorithm to extract the optimal model parameters of solar PV panel. Sustain. Energy Technol. Assess. 2020, 42, 100849. [Google Scholar] [CrossRef]
- Yin, C.-Y. Prediction of higher heating values of biomass from proximate and ultimate analyses. Fuel 2010, 90, 1128–1132. [Google Scholar] [CrossRef] [Green Version]
- Qian, X.; Lee, S.; Soto, A.-M.; Chen, G. Regression Model to Predict the Higher Heating Value of Poultry Waste from Proximate Analysis. Resources 2018, 7, 39. [Google Scholar] [CrossRef] [Green Version]
- Zhu, X.; Li, Y.; Wang, X. Machine learning prediction of biochar yield and carbon contents in biochar based on biomass characteristics and pyrolysis conditions. Bioresour. Technol. 2019, 288, 121527. [Google Scholar] [CrossRef]
- Wu, G.; Kechavarzi, C.; Li, X.; Wu, S.; Pollard, S.J.; Sui, H.; Coulon, F. Machine learning models for predicting PAHs bioavailability in compost amended soils. Chem. Eng. J. 2013, 223, 747–754. [Google Scholar] [CrossRef]
- Jiang, W.; Xing, X.; Li, S.; Zhang, X.; Wang, W. Synthesis, characterization and machine learning based performance prediction of straw activated carbon. J. Clean. Prod. 2018, 212, 1210–1223. [Google Scholar] [CrossRef]
- Cheng, F.; Porter, M.D.; Colosi, L.M. Is hydrothermal treatment coupled with carbon capture and storage an energy-producing negative emissions technology? Energy Convers. Manag. 2020, 203, 112252. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Content | Sewage Sludge | Food Waste | Cattle Manure | ||||
|---|---|---|---|---|---|---|---|
| LB | UB | LB | UB | LB | UB | ||
| Elemental Composition | C (%) | 22.2 | 51.9 | 38.92 | 46.2 | 33.92 | 46.2 |
| O (%) | 16.12 | 29 | 31.23 | 40.98 | 31.23 | 40.98 | |
| H (%) | 4.17 | 6.73 | 4.17 | 7.62 | 4.62 | 6.23 | |
| N (%) | 1.86 | 10.92 | 0.63 | 10.92 | 3.42 | 4.23 | |
| Proximate composition | Fc (%) | 0.02 | 9.87 | 0.82 | 25.86 | 1.21 | 29.26 |
| V (%) | 45.98 | 83.62 | 71.52 | 87.23 | 29.26 | 39.5 | |
| A (%) | 15.21 | 48.23 | 0.87 | 21.74 | 5.47 | 17.63 | |
| Operational conditions | T (°C) | 150 | 320 | 150 | 320 | 150 | 320 |
| T (min) | 9 | 220 | 8 | 220 | 5 | 220 | |
| WC (%) | 75.23 | 95.24 | 74.86 | 95.87 | 94.97 | 74.56 | |
| References | Process of Waste Conversion | Feedstock Types | Size of the Data Set | Machine Learning Model | Task Type | R2 Testing |
|---|---|---|---|---|---|---|
| Li et al. (2019) [22] | HTC | Organic wastes | 248 | Random Forest | Multi | 0.8–0.95 |
| Ismail et al. (2019) [24] | HTC | Poultry litter | 21 | NN | Multi | >0.90 |
| Jiang et al. (2019) [36] | HTC + pyrolysis | Straw | 30 | Linear Regression | Single | 0.098–0.99 |
| SVR | Single | 0.98–0.99 | ||||
| Li et al. (2020) [27] | HTC | Organic wastes | 649 | RF | Single | >0.90 |
| 475 | RF | Single | >0.90 | |||
| Cheng et al. (2020) [37] | Hydrothermal treatment | Microalgae, crops/forest residues, and organic wastes | 800 | Multiple linear regression | Multi | 0.16–0.60 |
| - | Regression tree | Multi | 0.29–0.75 | |||
| - | RF | Multi | 0.70–0.90 | |||
| Li, J., Zhu et al. (2020) [11] | HTC | Food waste, sludge, and manure | 248 | RF | Multi | 0.55–0.91 |
| SVR | Multi | 0.88–0.96 | ||||
| NN | Multi | 0.88–0.95 | ||||
| This Work | HTC | Sewage sludge, food waste, and cattle manure | 281 | Ensemble SVM | Multi | 0.89–0.97 |
| Properties | Maximum Fuel Properties of Pareto Solution | Maximum CCS Stability of Pareto Solution | ||||
|---|---|---|---|---|---|---|
| Sewage Sludge | Cattle Manure | Food Waste | Sewage Sludge | Cattle Manure | Food Waste | |
| C (%) | 50.98 | 48.40 | 63.87 | 50.98 | 48.40 | 63.87 |
| O (%) | 17.54 | 32.01 | 11.01 | 23.78 | 38.76 | 15.21 |
| H (%) | 4.31 | 5.09 | 3.25 | 4.31 | 5.09 | 3.25 |
| N (%) | 9.04 | 4.11 | 12.56 | 4.87 | 3.49 | 9.06 |
| Fc (%) | 11.02 | 13.23 | 15.26 | 8.04 | 13.11 | 12.01 |
| V (%) | 70.86 | 74.52 | 71.91 | 75.36 | 82.63 | 76.71 |
| A (%) | 20.32 | 13.65 | 11.87 | 14.32 | 6.31 | 13.44 |
| T (°C) | 223.00 | 205.42 | 285.65 | 297.93 | 328.98 | 327.78 |
| t (min) | 6.00 | 6.00 | 6.08 | 29.56 | 57.06 | 14.14 |
| WC (%) | 76.02 | 76.05 | 76.02 | 88.04 | 74.91 | 95.78 |
| HHV (MJ/kg) | 29.37 | 21.66 | 36.43 | 27.11 | 25.44 | 33.21 |
| YIELD (%) | 70.31 | 80.06 | 70.65 | 65.07 | 46.57 | 66.18 |
| ER (%) | 104.87 | 95.32 | 113.27 | 96.45 | 71.65 | 107.33 |
| CR (%) | 92.54 | 92.41 | 106.21 | 91.53 | 65.65 | 103.26 |
| C_char (%) | 66.98 | 53.27 | 82.74 | 67.61 | 66.46 | 84.71 |
| H/C | 0.82 | 2.02 | 0.21 | 0.62 | 0.95 | 0.12 |
| N/C | 0.23 | 0.08 | 0.23 | 0.08 | 0.1 | 0.07 |
| O/C | 0.01 | 0.57 | 0.01 | 0.03 | 0.18 | 0.01 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Velusamy, P.; Srinivasan, J.; Subramanian, N.; Mahendran, R.K.; Saleem, M.Q.; Ahmad, M.; Shafiq, M.; Choi, J.-G. Optimization-Driven Machine Learning Approach for the Prediction of Hydrochar Properties from Municipal Solid Waste. Sustainability 2023, 15, 6088. https://doi.org/10.3390/su15076088
Velusamy P, Srinivasan J, Subramanian N, Mahendran RK, Saleem MQ, Ahmad M, Shafiq M, Choi J-G. Optimization-Driven Machine Learning Approach for the Prediction of Hydrochar Properties from Municipal Solid Waste. Sustainability. 2023; 15(7):6088. https://doi.org/10.3390/su15076088
Chicago/Turabian StyleVelusamy, Parthasarathy, Jagadeesan Srinivasan, Nithyaselvakumari Subramanian, Rakesh Kumar Mahendran, Muhammad Qaiser Saleem, Maqbool Ahmad, Muhammad Shafiq, and Jin-Ghoo Choi. 2023. "Optimization-Driven Machine Learning Approach for the Prediction of Hydrochar Properties from Municipal Solid Waste" Sustainability 15, no. 7: 6088. https://doi.org/10.3390/su15076088