1. Introduction
With the development of the electronics industry, the electronics industry occupies an important position in the modern manufacturing industry. As an important electronic component, the printed circuit board (PCB) is a carrier connected to various electronic components that provides line connections and hardware support for the equipment. From small electronic watches and calculators to large computers, communication electronics, and military weapons systems, as long as there are electronic components such as integrated circuits, almost every electronic device needs a PCB [
1,
2,
3,
4]. However, the PCB manufacturing process is complex and prone to miss holes, mouse bites, open circuits, shorts, and other minor defects. To ensure the safety and reliability of electronic equipment, it is necessary to detect the surface defects of PCB.
Traditional manual inspection is easily disrupted by external environmental factors, which can affect the efficiency of defect detection. Additionally, the detection of tiny defects can cause visual fatigue and lead to misclassification [
5]. To solve the problems, some scholars have introduced machine learning into PCB detection and have made great progress. Wang et al. [
6] proposed an automatic detection algorithm for PCB pinholes by combining machine learning knowledge. Pinhole defects of 2 mm can be identified within 10 s. Yuk et al. [
7] implemented the detection of PCB defects using accelerated robust features and random forest algorithm. Weighted kernel density estimation (WKDE) mappings were generated with weighted probabilities by considering the density of features to achieve the detection of defect concentration regions. V et al. [
8] used similarity metrics for the detection of PCB surface defects. Experimental results demonstrated the effectiveness of this method in detecting and locating local defects in PCB images of complex component installations. Some scholars have also proposed PCB surface defect detection approaches based on machine learning, which are not real-time approaches [
9,
10]. Although machine learning-based methods can achieve recognition of PCB surface defects, most algorithms still require the artificial setting of image features through a priori knowledge, which results in the algorithms’ lack of generalization ability.
Traditional image processing-based defect detection methods achieve acceptable detection accuracy; however, they are time-consuming and sensitive to the environment and inferred images [
11]. With the development of deep learning (DL) and computer vision, DL and convolutional neural network (CNN) techniques are widely used in the detection of PCB defects. The existing deep learning target detection methods are mainly divided into the single-stage and the two-stage detection algorithm. The single-stage algorithm processes the entire input image in a single pass to detect objects. These algorithms typically use a single CNN to perform both the region proposal and object detection. The two-stage algorithm separates the object proposal from object detection. The first stage of a two-stage algorithm generates region proposals using a separate algorithm or network; then, the second stage performs object detection within those proposed regions. The two-stage detection algorithm is represented by R-CNN (regions with CNN features) [
12], Fast R-CNN (fast region-based CNN) [
13], and Faster R-CNN [
14]. These algorithms were used to generate candidate boxes and then classify each candidate box. The single-stage detection algorithm is represented by the YOLO (You Only Look Once) series [
15,
16,
17,
18] and SSD (Single Shot MultiBox Detector) [
19]. These algorithms directly generated the class probability and position coordinate values of the object while creating the candidate frame, and the final detection results can be directly obtained after a single detection. To address the problem that image uncertainty can limit PCB detection performance under uneven ambient light or unstable transmission channels, Yu et al. [
20] designed a novel collaborative learning classification model. Zhang et al. [
21] obtained a good detection effect by using a cost-sensitive residual convolutional neural network for PCB appearance defects; however, the model has high complexity and a large number of parameters. Wan et al. [
22] achieved the detection of PCB surface defects by using a few labeled samples based on semi-supervised learning (SSL) methods, which improved the detection efficiency with a detection mean average precision (mAP) of 98.4%. Ding et al. [
23] proposed TDD-net (tiny defect detection) based on Faster R-CNN for the detection of tiny target defects in PCB. The accuracy is high but the model size is too large to be used on embedded devices. Xuan et al. [
24] proposed a detection algorithm based on YOLOX and coordinate attention for PCB defects detection, which has good robustness; however, the size of the algorithm model is 379 MB. Wu et al. [
25] proposed the GSC YOLOv5, a deep learning detection method that incorporates lightweight networks and a dual-attention mechanism, to effectively solve the small target detection problem; however, the proposed attention mechanism is complex and slow. Zheng et al. [
26] implemented real-time detection of PCB surface defects based on MobileNet-V2. The mAP of four types of defects is only 92.86%, which needs to continue to improve. Yu et al. [
27] proposed the diagonal feature pyramid (DFP) to improve the performance of tiny defect detection. However, the model size is 69.3MB and still needs further quantification. Other scholars have also proposed a series of detection methods based on deep learning techniques, all of which have problems of large model size and poor real-time performance [
28,
29].
Deep learning-based detection algorithms have been able to achieve good accuracy in other defect detection fields. In industrial applications, as PCB surface defect detection requires high accuracy and real-time performance, the current PCB surface defect detection algorithm needs to be further improved in terms of detection accuracy and speed. Therefore, in order to further improve the model accuracy, a real-time detection network based on the YOLOv5 algorithm is designed, which provides theoretical support for the subsequent deployment of the embedded platform. Specific innovation points are as follows:
- (1)
The K-means ++ algorithm was used to obtain 12 new sets of anchors, which solves the problem that YOLOv5 preset anchors based on the COCO dataset are not applicable to the PCB dataset. Based on the new anchors, a new detection layer is added to obtain more information about the features of the target.
- (2)
A united attention mechanism is designed by combining the channel attention module and the spatial attention module. It pays better attention to the channel information and spatial information of the features.
- (3)
Combined with the Swin transformer and depth-wise separable convolution, a backbone network is designed for feature extraction. More spatial and channel information are obtained, and the analysis capability of the network is improved.
- (4)
During the training process, the CIoU(Complete-IoU) [
30] is replaced by the regression loss function EIoU(Efficient-IoU) [
31], which more clearly measures the differences in the overlap area, centroids, and edge lengths in the bounding box regression. The convergence speed of the model is accelerated and the model regression accuracy is improved.
The remainder of this paper is organized as follows.
Section 2 introduces the image preprocessing and dataset.
Section 3 presents the details of the proposed method.
Section 4 reports the experimental results and discussion.
Section 5 concludes this article and considers further work.
2. Image Preprocessing and Dataset
The original PCB defect dataset was obtained from the Intelligent Robot Development Laboratory of Peking University [
23]. For this dataset, the average pixel size of each image is 2777 × 2138, and the average pixel size of the six defects is 130 × 110. There are a total of 1386 images with six types of defects, which are short, spur, open circuit, mouse bite, spurious copper, missing hole, and various defects are shown in
Figure 1. Due to the small number of samples in the original dataset, problems such as low detection accuracy, low robustness, and overfitting are likely to occur in the training process. The problem of insufficient training samples can be effectively solved by appropriately enhancing the original image to increase the number of images [
32]. More and richer training data can be generated through various transformations of the image, which can effectively avoid overfitting and improve the generalization ability of the model. In this paper, the dataset was extended to 8316 images after the random flipping, rotation, cropping, and cutout operations in
Figure 2, where the ratio of the training set, validation set, and test set is 8:1:1, and the number of each defect image in the dataset is shown in
Table 1. A comparison of original and enhanced dataset is shown in
Table 2; the mAP is increased from 90.56% to 93.88%.
3. Description of Methodology
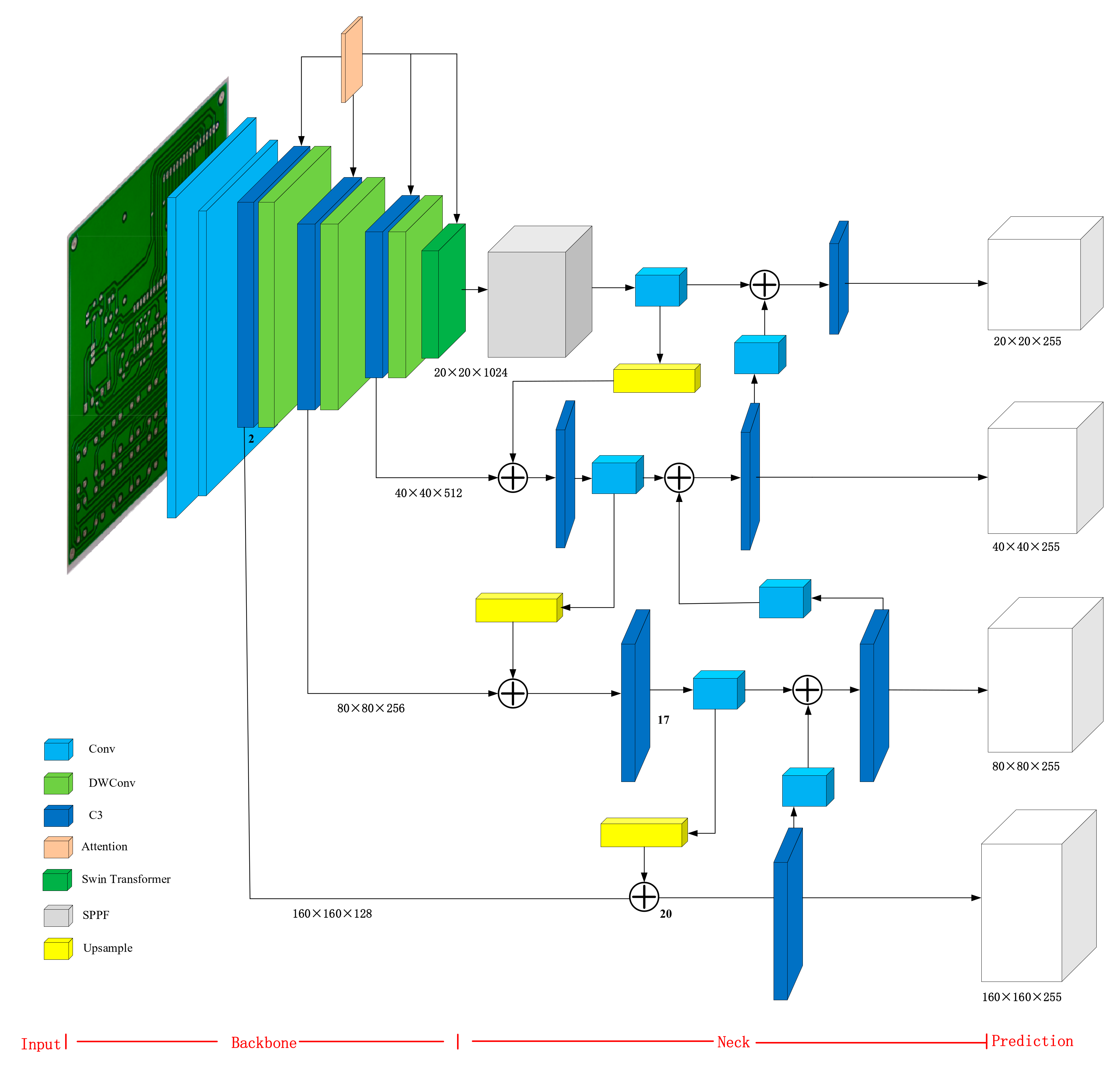
3.1. PCB-YOLO Network Structure
In this study, improvements are made based on the three basic structural frameworks of the spine, neck and head of YOLOv5. YOLOv5 extracts three networks with different levels of scale feature maps for detection, (80,80), (40,40), and (20,20). In order to obtain more information about the features of the small target to be detected, a new detection layer is added according to the new anchors obtained using the K-means++ algorithm.
Figure 3 shows that the PCB-YOLO network structure consists of four parts: input, backbone, neck, and prediction. In input, the image is adjusted to 640 × 640 × 3 and input to the backbone. The united attention mechanism and Swin transformer module are embedded in the backbone to improve the model’s ability to pay attention to channel information and spatial information. DwConv is used to compress the model, which not only guarantees the accuracy of the model but also greatly reduces the size of the model. The network at different levels of four scale feature maps are extracted for detection, which were (160,160), (80,80), (40,40), (20,20) respectively.
In the dataset, the average pixel size of each image is 2777 × 2138 and the pixels of the six defects are 130 × 110. According to the definition in the literature [
33], the types of detects of PCB with less than 1.23% of annotated pixels are small objects. In order to solve the problem of YOLOv5 preset anchors based on the COCO dataset not being applicable to PCB datasets, this paper uses the K-means++ algorithm to generate 12 new sets of anchors. A sample point is randomly selected from the uniformly distributed small target PCB dataset
as the first initial clustering center
. The shortest distance
is calculated from each sample
and the current clustering center
, to the probability
of each sample
being selected as the next clustering center is calculated,
is represented by Equation (1). The K = 12 clustering centers (
) are selected according to the roulette wheel method. The distance
is calculated from each sample
to K = 12 clustering centers in the PCB dataset
, and the sample
is divided into the category
corresponding to the clustering center with the smallest distance
. The clustering center
E is recalculated for each category
, and
E is represented by Equation (2), until the position of the clustering center
no longer changes. Equation (3) is the clustering means.
where
is PCB dataset,
is the cluster center,
is the probability of the cluster center, and
is the shortest distance from sample
x to the cluster center
.
is the new cluster center.
Finally, 12 new sets of anchors, (7,7) (11,11) (13,13) (11,18) (17,12) (16,16) (13,24) (24,13) (20,20) (35,13) (28,23) (36,34), are obtained using the K-means++ algorithm. A new small target detection layer is added according to the new anchors. In the new small target detection layer, the feature map 80 × 80 × 256 is up-sampled and further expanded to 160 × 160 × 128 by other processes. In addition, the feature map 160 × 160 × 128 in the bone network is concatenated and fused to obtain a larger feature map 160 × 160 × 255 for small target detection.
3.2. Bakbone Network
3.2.1. United Attention Mechanism
The attention mechanism essentially locates interesting information and suppresses useless information. The PCB dataset contains complex background information. After feature extraction of the convolutional layer, the defect information to be detected takes up a small proportion, while the background and non-detected object information takes up a large proportion. This non-interest region information will interfere with defect detection.
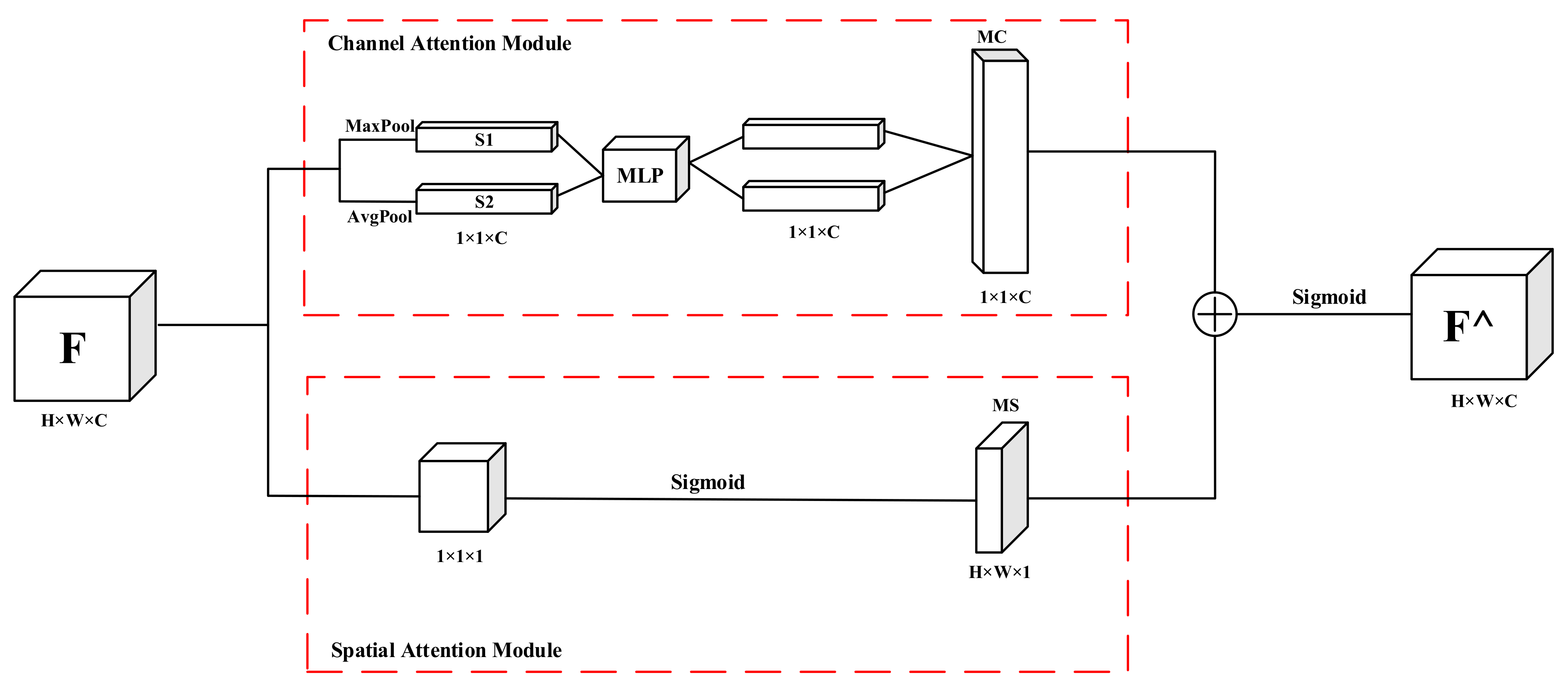
In order to focus on the defect target to be detected in the image and ignore the irrelevant object information, a united attention mechanism (UAM) is design based on the channel attention module (CAM) and spatial attention module (SAM) proposed by Woo et al. [
34]. The UAM consists of channel attention module and spatial attention module connected in parallel. Through the parallel structure, the feature map information about both spatial dimensions and channel dimensions is encoded simultaneously, which can make better use of the information between the channel and space of the feature map. The detailed structure of the UAM is shown in
Figure 4, where F is the input of the feature map, H and W are the height and width, respectively, and C is number of channels of the input of feature map. In CAM, the global space information of F is firstly compressed using max pool and avg pool to generate two feature maps S1 and S2 of size 1 × 1 × C. Then, two one-dimensional feature maps are obtained through multi-layer perception (MLP). The two one-dimensional feature maps are normalized to obtain the weighted feature map MC. In SAM, the result is input into the sigmoid function after F is activated by the 1 × 1 × 1 convolutional module to obtain the weight feature graph MS. The MC and MS are connected in parallel by element-by-element summation, and the output feature map F^ is obtained after the sigmoid activation function is executed.
3.2.2. Swin Transformer Module
The transformer is a model based on a self-attentive mechanism, which not only has strong modeling function in the global environment but also shows excellent transferability for downstream tasks under large-scale pre-training. VIT [
35] was the first transformer for computer vision, and its demonstrated powerful performance in image classification has driven the development of subsequent transformers for computer vision. The Swin transformer proposed by Liu et al. [
36] is the most popular hierarchical vision transformer that is able to compute attention within a local window without overlap, and allows cross-window computation by introducing shift windows. The Swin transformer overcomes the lack of connectivity between the windows generated by the conventional window partitioning strategy in VIT, which leads to higher efficiency and lower complexity.
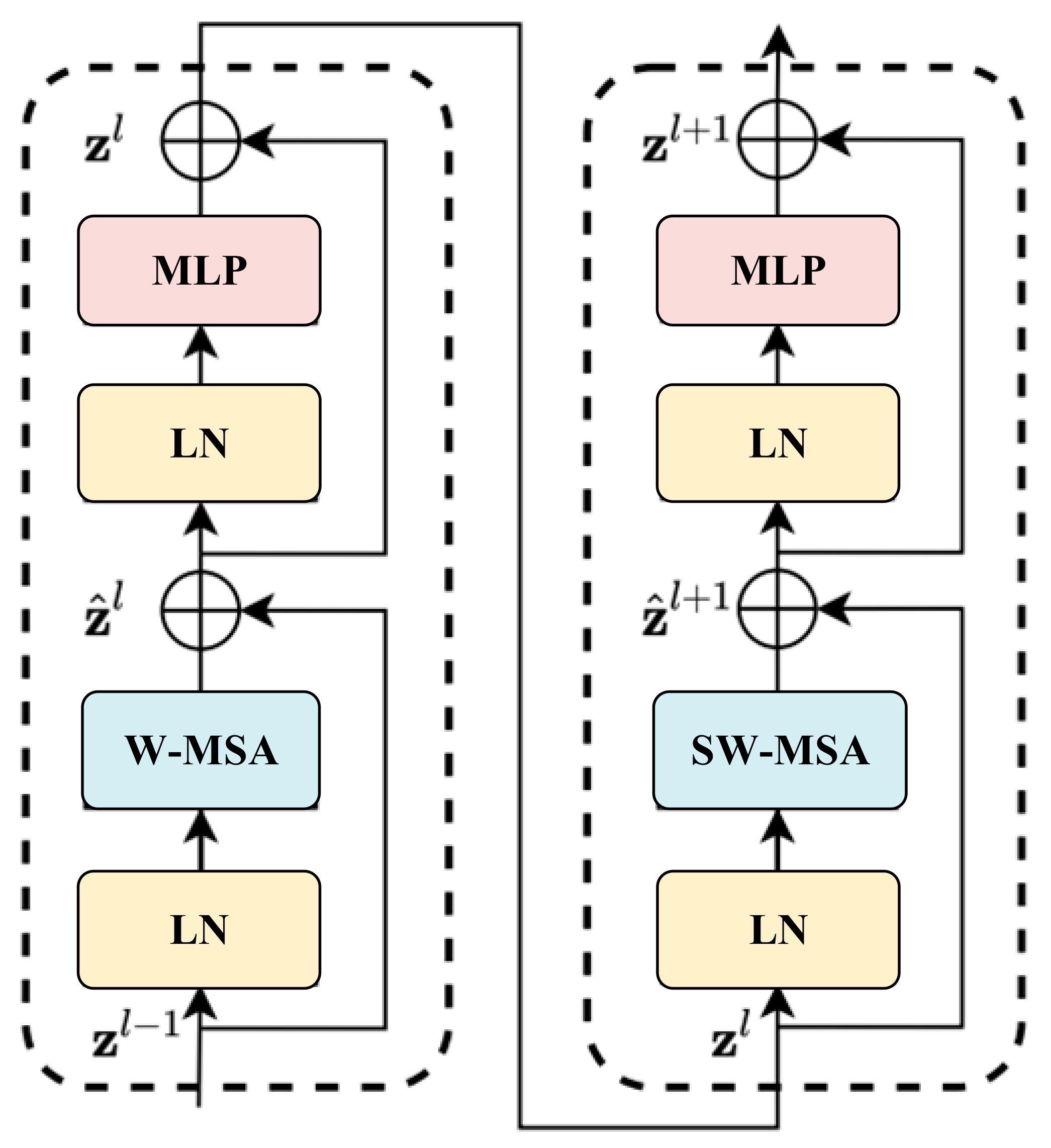
The structure of the Swin transformer is shown in
Figure 5, which consists of two shifted windowing-based self-attention mechanisms and two MLPs. Each self-attention mechanism module and MLP module is preceded by an LN (LayerNorm level normalization) layer, and the remaining connections are added after each module. Where W-MSA is multi-head self-attention modules with regular windowing configurations and SW-MSA is shifted windowing configurations, respectively.
The attention expressions of the Swin transformer are shown in Equations (4)–(7), where
and
are the feature outputs of (S)W-MSA and MLP in the
module, respectively, and
denotes the output features of the corresponding
layer.
3.2.3. Depth-Wise Separable Convolution
In 2017, the Google team proposed MobileNet, a lightweight neural network focused on mobile or embedded devices, where the basic unit of MobileNet is depth-wise separable convolution (DwConv) [
37]. As shown in
Figure 6, DwConv is constructed from depth-wise convolution and pointwise convolution. One convolutional kernel of the depth-wise convolution can control a channel in one direction. One channel can only be accessed by a single convolution. The process of the pointwise convolution is similar to the normal convolution process. The convolutional kernel has a size of 1 × 1 and is weighed in one direction corresponding to the previous map’s depth to generate the new feature map. The computational complexity of a regular convolution
is shown in Equation (8), and the computational complexity of a DwConv
is shown in Equation (9). The ratio of the computational cost of deep separable convolution to that of standard convolution is shown in Equation (10). Experiments [
32] show that the computational amount of the DwConv is eight-to-nine times lower than that of the normal convolution if the number of convolutional kernels in DwConv is 3 × 3.
3.3. Loss Function
The YOLOv5 algorithm uses CIoU to calculate the localization loss. The CIoU formula is shown in Equation (11), where α is the parameter of the trade-off and
is the parameter of measure the aspect ratio consistency. The
,
are defined as shown in Equations (12) and (13), respectively.
where
is CIoU localization loss, α is the parameter of the trade-off and
is the parameter of measure the aspect ratio consistency.
,
and
,
are side width and side length of the true box and the prediction box, respectively.
are the diagonals of the smallest outer rectangle of the real box and the predicted box, respectively.
Although the CIoU loss function takes into account the overlap area, centroid distance, and aspect ratio of the bounding box regression, the parameter in the formula reflects the difference in aspect ratio rather than the true difference between the aspect ratio and its confidence level. Therefore, the CIoU loss function sometimes prevents the model from optimizing the similarity effectively, and fails to achieve accurate positioning.
In this paper, the EIoU loss function is used to calculate the localization loss. Based on the penalty term of the CIoU, the penalty term of EIoU splits the influence factor of the aspect ratio to calculate the length and width of the target box and anchor box, respectively. In addition, the EIoU loss function consists of three parts: overlap loss, center distance loss, and width-height loss. The overlap loss and center distance loss continue the CIoU method. However, the width-height loss directly minimizes the difference between the width and height of the target box and the anchor box, which makes the convergence speed faster. By using the true difference between the length and width of the prediction box and the labeled box to supervise back-propagation process, the optimal solution of the loss function is obtained, and in this process the small target detection performance is improved by increasing the regression accuracy. The EIoU is defined as shown in Equation (14), where
,
,
and
,
,
are the centroid, side width, and side length of the true box and the prediction box, respectively.
,
,
are the diagonals, side widths, and side lengths of the smallest outer rectangle of the real box and the predicted box, respectively.
5. Conclusions
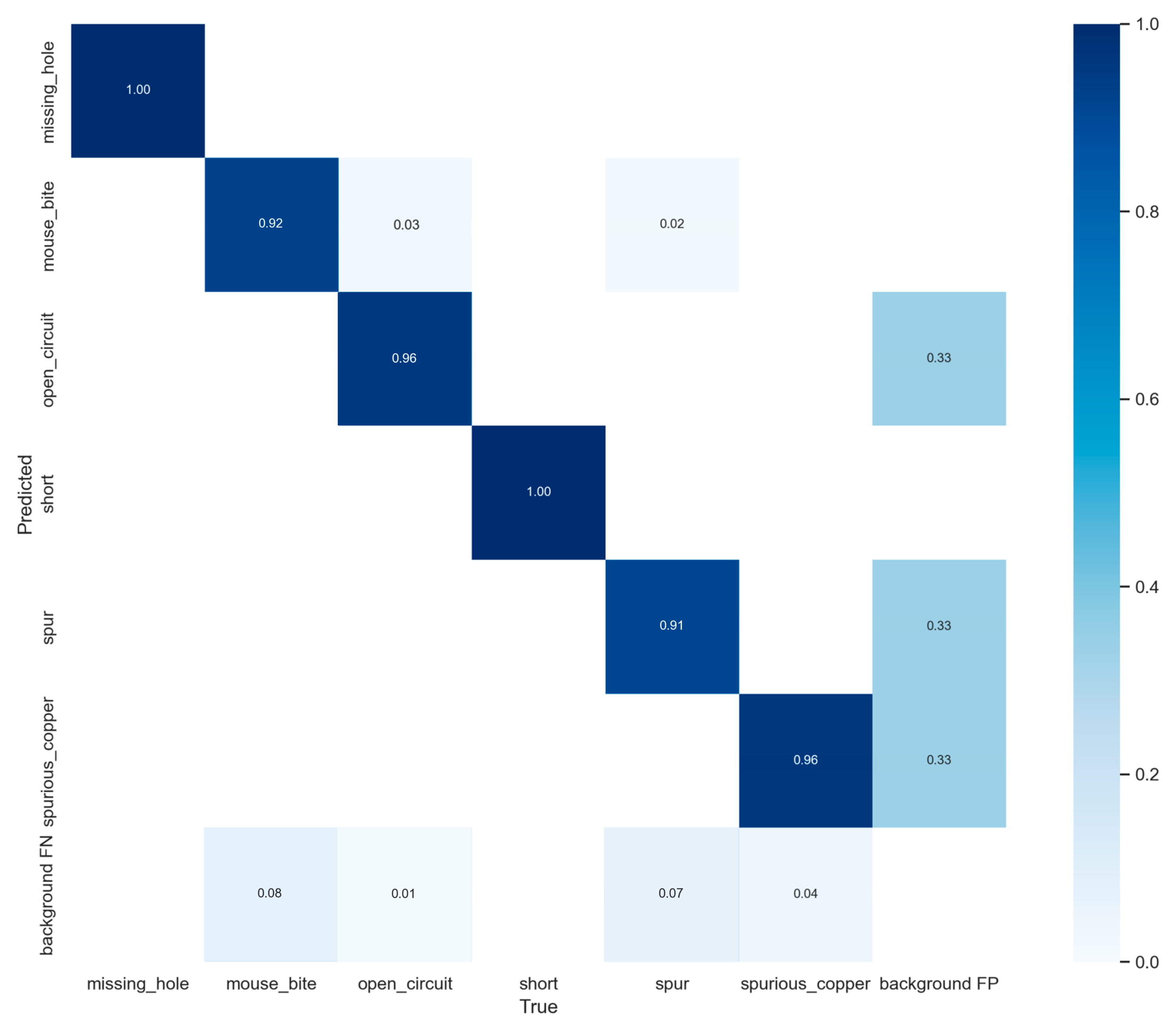
Surface defects in the PCB production process can directly affect the quality of PCBs, and should be effectively detected. In this paper, a PCB-YOLO detection network based on the improved YOLOv5 is presented. By preprocessing the images, the feature information of defects is enriched and overfitting is effectively avoided, and the mAP is improved by 3.32%. According to the new anchors obtained using the K-means ++ algorithm, a new small target detection layer is added the network to obtain more small target feature information for the detection and improve the detection ability of small targets. The ability of the model to analyze PCB defects is improved by using the united attention mechanism with the Swin transformer module. The DwConv significantly compresses the model size and improves the detection speed while ensuring the accuracy of the algorithm. The regression loss function EIoU improves the localization ability of the algorithm. Experiments show that when PCB-YOLO is compared to YOLOv5, the difference in model size is small; however, the mAP is improved by 5.86% to 95.97%, and the detection speed is 92.5 FPS, which can achieve real-time detection of PCB surface defects.
The detection model proposed in this paper provides a new idea for PCB surface defect detection. However, specific hardware configurations are required to achieve fast detection. In the future, we will continue to work on industrial inspection and deployment. Meanwhile, as there are many other PCB defects, such as breaking lines and wrong hole sizes, we will continue to strengthen the research on more PCB surface defect types and expand the scope of application. We believe we can make a great contribution to intelligent, sustainable, and automated industrial manufacturing.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}