

Aligning the Goals Hybrid Model for the Diagnosis of Mental Health Quality


 ,
,
Abstract
:1. Introduction
2. Problem Definition and Optimization Model
2.1. Machine Learning
2.1.1. Logistic Regression
2.1.2. Random Forest
2.1.3. Naïve Bayes
2.2. Analytic Hierarchy Process (AHP)
- (a)
- STRUCTURING: This deals with the formulation of the problem and the identification of objectives. This phase aims to identify, characterize, and organize the relevant factors in the decision-support process.
- (b)
- EVALUATION: This allows for the subdivision of a subphase partial evaluation of actions (alternatives) according to each point of view (criteria) and an overall evaluation subphase considering the various partial evaluations.
- (c)
- RECOMMENDATION: In this phase, sensitivity and robustness analyses are carried out to verify whether changes in the parameters of the evaluation model interfere with the final result. It is a fundamental phase that contributes to generating knowledge about the problem, increasing the confidence of the decision-maker in the obtained results.
2.2.1. Multi-Criteria Methodology
- It is easy to use for non-specialists, preferably transformed into a computer program that is as user-friendly as possible, featuring visual graphic resources;
- It constitutes a logical and transparent method;
- It enables freedom from ambiguity for input data interpretations;
- It encompasses both quantitative and qualitative criteria;
- It values judgments;
- It allows the decision-maker to have algorithms that enable the use of criteria that are independent of each other, such as algorithms that help in problems in which the evaluation criteria are interdependent, and, similarly, it can deal with alternatives that are independent of each other;
- It incorporates human behavior issues into decision-making processes.
- Considering the subjectivity of decision-makers, that is, the individual perceptions and envisioning involved in the aspects of problems, decision-makers find it most challenging to explain their perceptions;
- Structuring the problem according to the shared vision;
- Identifying common points of view;
- Knowing where decision-makers are inconsistent;
- Checking what can be changed and for what reason.
- Define and structure the problem;
- Define the set of criteria or attributes or both, that will be used to rank the alternatives;
- Choose whether to use discrete or continuous methods; in cases of opting for discrete methods (conceived to work with a finite number of alternatives), it must favor the use of methods either from the French School or the American School;
- Identify the preference system of the decision-makers;
- Choose the aggregation procedure.
- The choice of alternatives;
- The construction of criteria and information aggregation;
- The classification of the alternatives in which the dominance of the groups is identified;
- The ordering of a classification hierarchy among the alternatives.
- The structuring phase of a problem can be divided as follows [32]:
- The structure and composition of the components;
- The analysis;
- The synthesis of information.
2.2.2. The Classic Analytic Hierarchy Process (AHP) Method
2.2.3. Analytic Hierarchy Process (AHP)—Average of Normalized Values Method
- (a)
- Normalization by the sum of each column’s elements:
- (b)
- The sum of elements of each normalized line, divided by order of the matrix:
- (c)
- Calculation of the eigenvalue associated with the calculated vector in the previous item:
2.2.4. Analytic Hierarchy Process (AHP)—Geometric Mean Method
- (a)
- The product of the elements of each row raised to the inverse of the order of the matrix:
- (b)
- Normalizing the obtained priority vector and calculating the eigenvalue associated with the calculated vector will produce an identical result to the λmax of the average normalized values method.
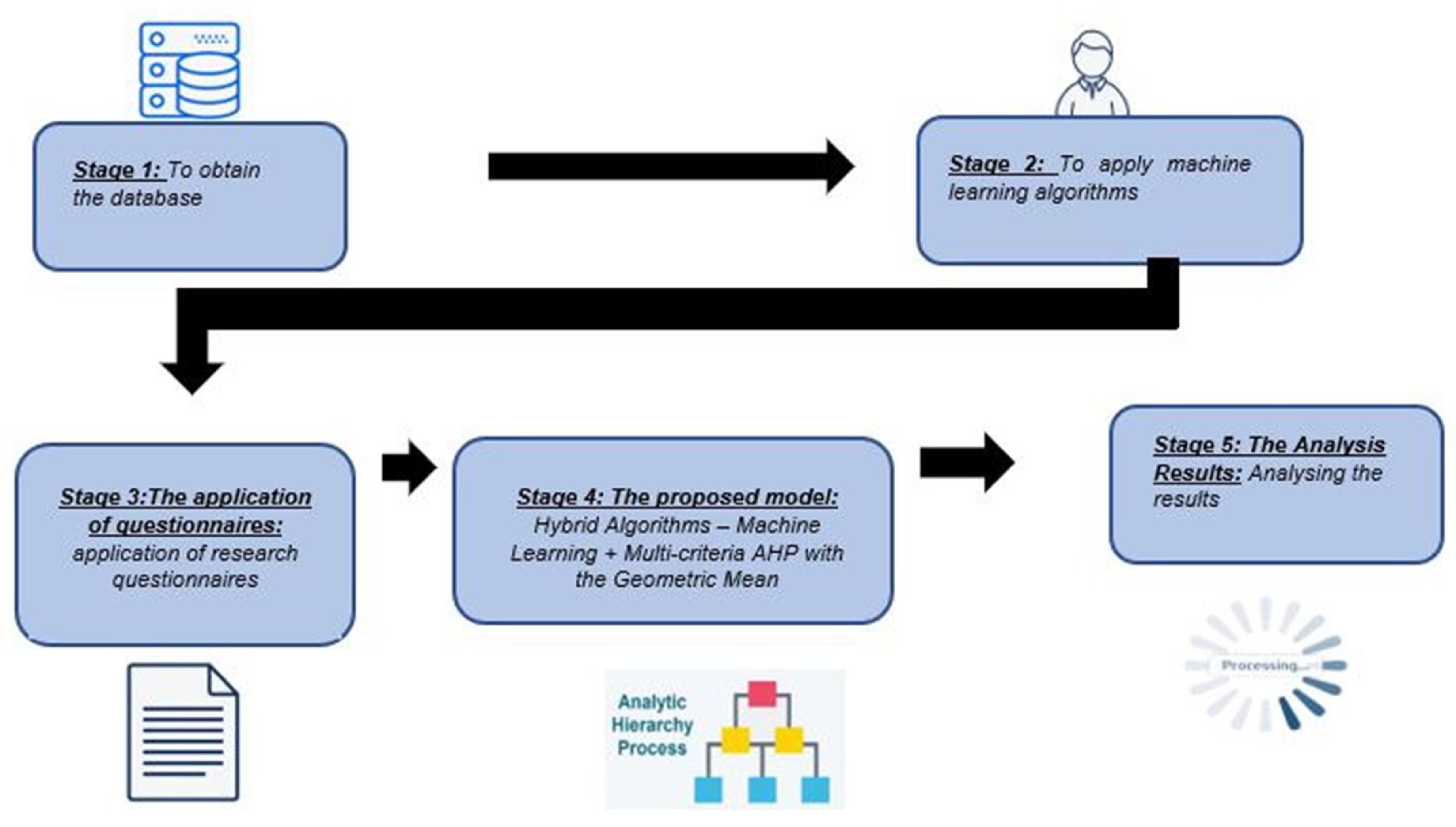
3. Results
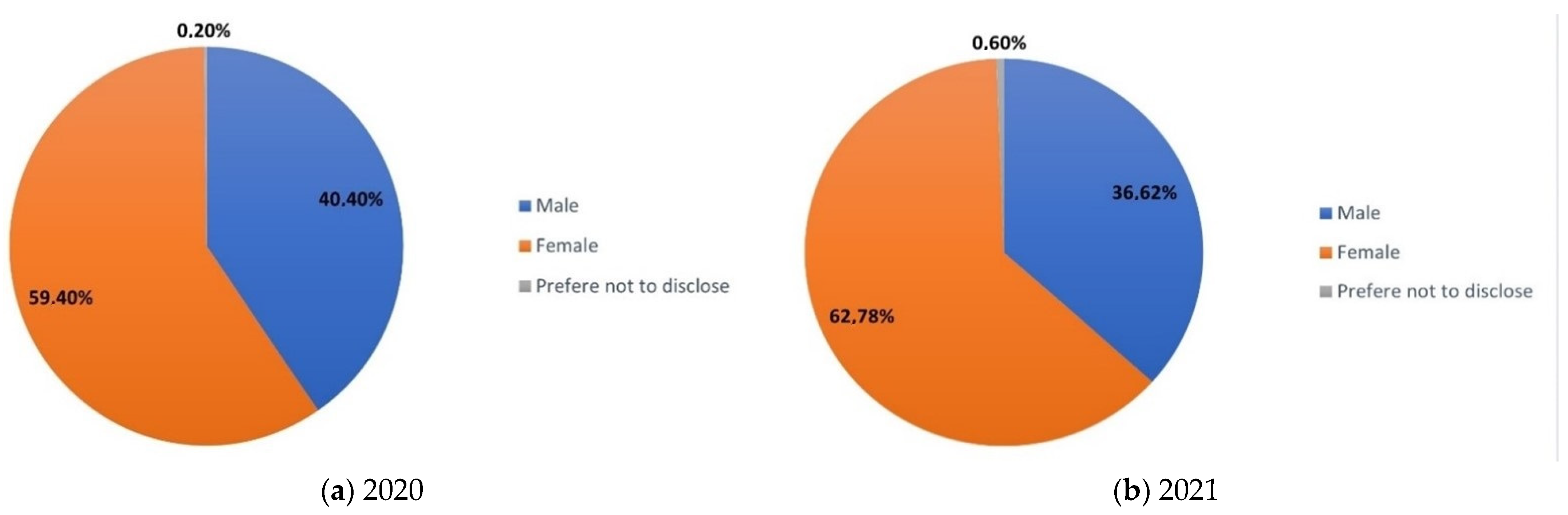
3.1. Method of Preparing the Database
- Your mood;
- Your self-confidence;
- Your interest in life;
- Your ability to endure difficult situations.
- Your eating habits;
- Your energy (willingness to do things);
- Your sleep;
- Your physical health (pain, tremors, malaise);
- Your sexuality (sexual satisfaction).
- Your coexistence with your family (the one you live with);
- Your coexistence with friends;
- Your coexistence with other people;
- Your financial conditions for family support.
- Your interest in working/studying;
- Your leisure activities (the things you like to do);
- Your ability to fulfill obligations;
- Your household tasks (cooking, cleaning the house, shopping, fixing things);
- Your interest in engaging in other activities.
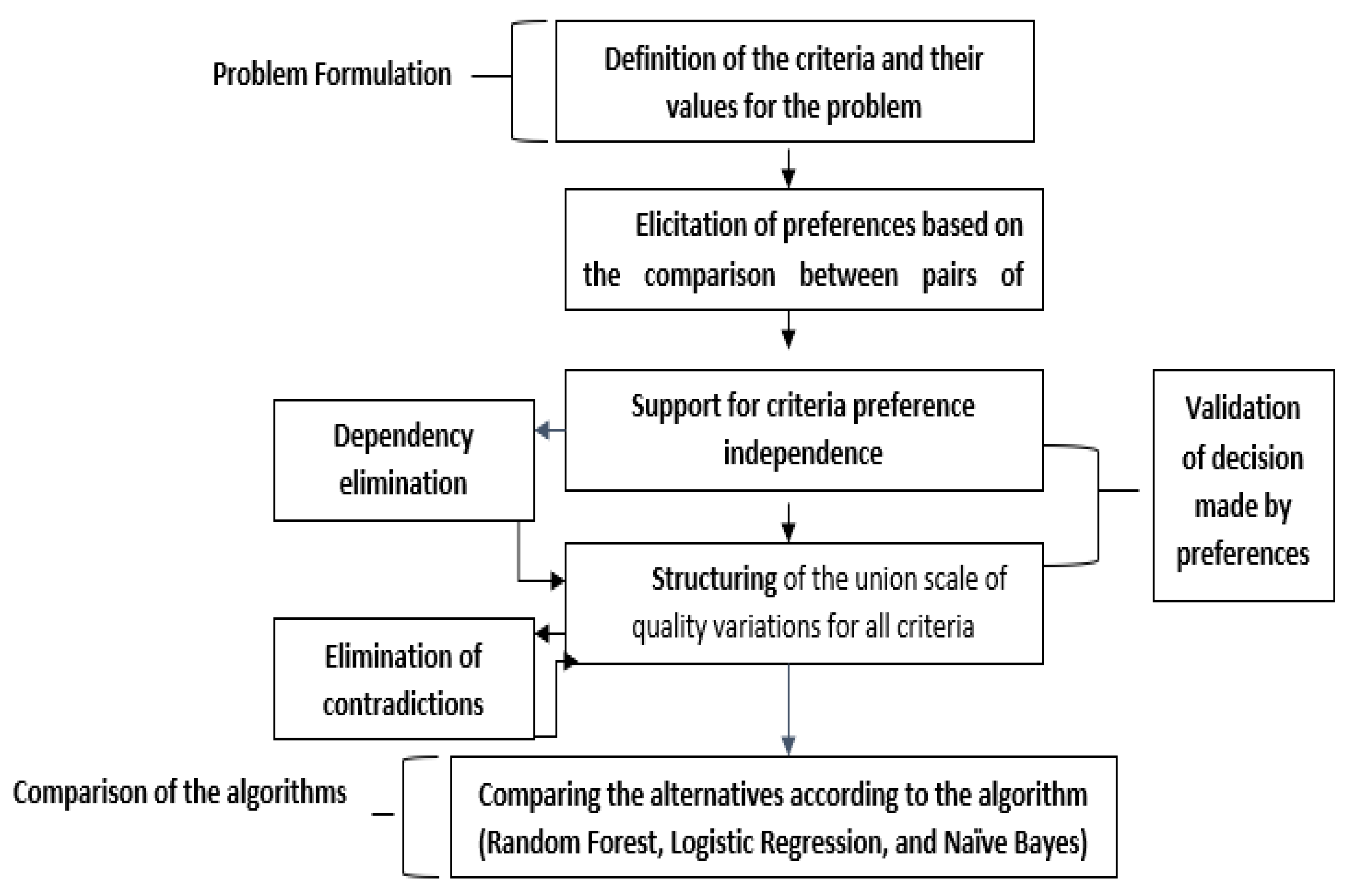
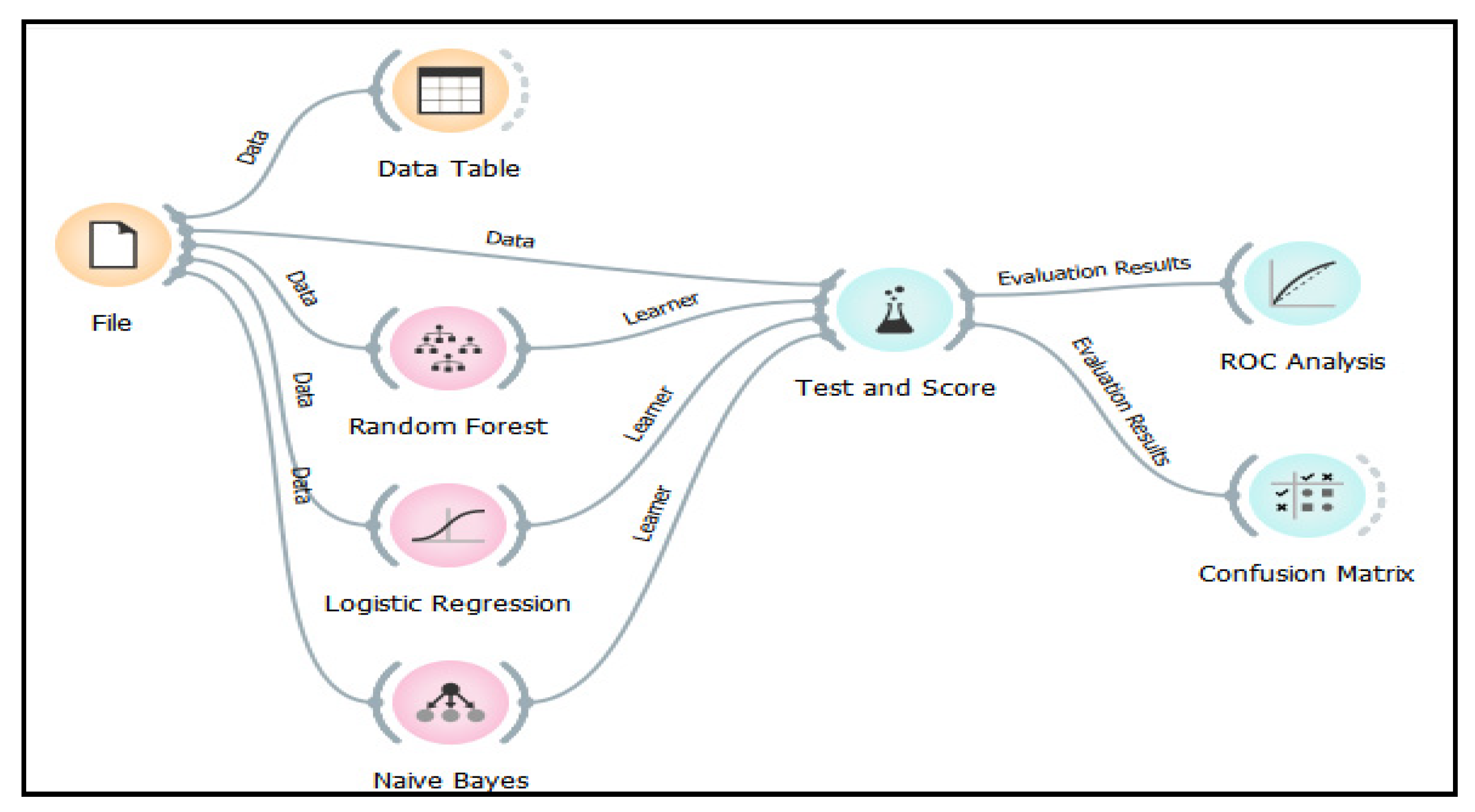
3.2. Description of the Proposed Hybrid Model Development
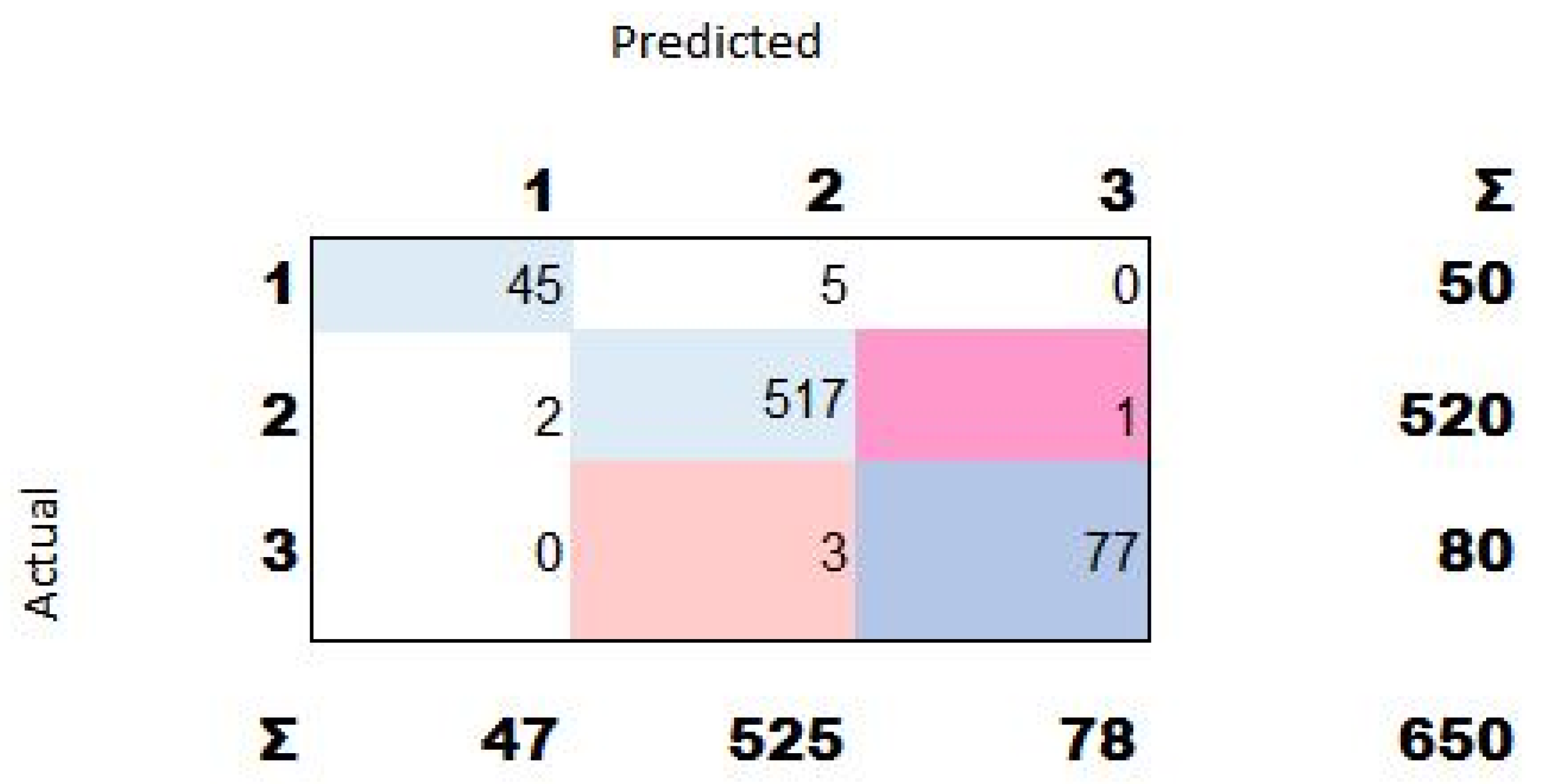
Hybrid Algorithms
4. Discussion
5. Conclusions and Future Studies
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Brooks, S.K.; Webster, R.K.; Smith, L.E.; Woodland, L.; Wessely, S.; Greenberg, N.; Rubin, G.J. The psychological impact of quarantine and how to reduce it: Rapid review of the evidence. Lancet 2020, 395, 912–920. [Google Scholar] [CrossRef] [PubMed]
- Ferguson, N.; Laydon, D.; Nedjati Gilani, G.; Imai, N.; Ainslie, K.; Baguelin, M.; Ghani, A. Report 9: Impact of Non-Pharmaceutical Interventions (NPIs) to Reduce COVID-19 Mortality and Healthcare Demand; Imperial College COVID-19 Response Team, Imperial College London: London, UK, 2020. [Google Scholar] [CrossRef]
- Melo, M.C.A.; Soares, D.S. Impact of social distancing on mental health during the COVID-19 pandemic: An urgent discussion. Int. J. Soc. Psychiatry 2020, 66, 625–626. [Google Scholar] [CrossRef]
- Cartilha Fiocruz. Available online: https://www.sbpsp.org.br/ (accessed on 28 March 2020).
- Sociedade Brasileira de Psicanálise de São Paulo. Available online: http://sbpsp.org.br/atividades/eventos-sbpsp/item/1725-escuta-psicanalitica-para-profissionais-de-saud.html (accessed on 29 March 2020).
- Saúde mental e Atenção Psicossocial na Pandemia COVID-19. Available online: https://www.fiocruzbrasilia.fiocruz.br/wp-content/uploads/2020/04/Sa%C3%BAde-Mental-e-Aten%C3%A7%C3%A3o-Psicossocial-na-Pandemia-Covid-19-recomenda%C3%A7%C3%B5es-gerais.pdf) (accessed on 30 March 2020).
- Inter-Agency Standing Committee. Como Lidar Com os Aspectos Psicossociais e de Saúde Mental Referentes ao Surto de COVID-19. Version 1.5, March 2020. Available online: https://interagencystandingcommittee.org/system/files/2020-03/IASC%20Interim%20Briefing%20Note%20on%20COVID-19%20Outbreak%20Readiness%20and%20Response%20Operations%20-%20MHPSS%20%28Portuguese%29.pdf (accessed on 25 April 2020).
- Van, H.E. Lockdown is the World’s Biggest Psychological Experiment—And We Will Pay the Price. Available online: https://www.weforum.org/agenda/2020/04/this-is-the-psychological-side-of-the-covid-19-pandemic-that-were-ignoring/ (accessed on 25 April 2020).
- IFPI. Portaria nº 853—Suspende as Aulas e Atendimento ao Público no IFPI e Outros Encaminhamentos, 2020. Available online: https://www.ifpi.edu.br/coronavirus/ifpi-2013-portarias-e-notas-tecnicas (accessed on 30 March 2020).
- Bouyssou, D.; Marchant, T.; Pirlot, M.; Perny, P.; Tsoukiás, A.; Vincke, P. Evaluation and Decision Models: A Critical Perspective; Kluwer Academic: Boston, MA, USA, 2000. [Google Scholar]
- Papathanasiou, J.; Ploskas, N. Multiple Criteria Decision Aid: Methods, Examples and Python Implementations, 1st ed.; Springer: Berlin/Heidelberg, Germany, 2018; ISBN 10 3319916467. [Google Scholar]
- Ozernoy, V.M. Choosing the “Best” multiple criteria decision-making method. INFOR 1998, 30, 159–171. [Google Scholar]
- Luciano, C.N. Um Modelo Híbrido para Apoio ao Diagnóstico de Transtornos Psicológicos. Master’s Thesis, Universidade de Fortaleza, Fortaleza, Brazil, 2010. [Google Scholar]
- Bana, E.; Costa, C.A.; Ensslin, L.; Correa, E.C.; Vansnick, J.C. Decision support systems in action: Integrates application in a multicriteria decision aid process. Eur. J. Oper. Res. 1999, 133, 315–335. [Google Scholar] [CrossRef]
- Hunink, M.M.; Weinstein, M.C.; Wittenberg, E.; Drummond, M.F.; Pliskin, J.S.; Wong, J.B.; Glasziou, P.P. Decision Making in Health and Medicine: Integrating Evidence and Values; Cambridge University Press: Cambridge, UK, 2001. [Google Scholar]
- Szolovits, P. How Can Computer Programs Reason. In Cardiostim 88; Futura Pub Co.: Milano, Italy, 1988. [Google Scholar]
- Gomes, L.A.M.; Gomes Carlos, F.S.; Almeida, A.T. Tomada de Decisão Gerencial: Enfoque Multicritério; Atlas: São Paulo, Brazil, 2002. [Google Scholar]
- Ackoff, R.L.; Sasieni, M.W. Pesquisa Operacional; Livros Técnicos e Científicos: Rio de Janeiro, Brazil, 1975. [Google Scholar]
- Oliveira, S.T.J.; de Moraes, L.F.R. Avaliação Multicritério de Projetos de Produção da Indústria de Petróleo no Brasil: Uma analise Comparativa dos Métodos Promethee e Todim. Master’s Thesis, Fluminense Federal University, Niterói, Brazil, 2003. [Google Scholar]
- Marins Cristiano, S.; Cozendey Manaara, I. A metodologia de multicritério como ferramenta para tomada de decisões gerenciais: Um estudo de caso. In 25º Encontro Nacional de Enegenharia de Produção; ENEGEP: Porto Alegre, Brazil, 2005. [Google Scholar]
- Roy, B. Decision-aid and decision-making. Eur. J. Oper. Res. 1990, 45, 324–331. [Google Scholar] [CrossRef]
- Roy Bouyssou, D. Aidemulticritère à la Décision: Méthodes et cas; Econômica: Paris, France, 1993. [Google Scholar]
- Romero, C. Teoría de la Decisión Multicriterio: Conceptos, Técnicas y Aplicaciones; Alianza: Madrid, Spain, 1993. [Google Scholar]
- Vincke, P.H. L’aid Emulticritère à Ladècision; Éditions de l’Université de Bruxelles: Bruxelles, Belgium, 1989. [Google Scholar]
- Almeida, C.; Ana Paula, C.S. Aplicações com Métodos Multicritério de Apoio à Decisão; Universitária da UFPE: Recife, Brazil, 2003. [Google Scholar]
- Gomes Araya, M.C.G.; Carignano, C. Tomada de Decisões em Cenários Complexos; Pioneira: São Paulo, Brazil, 2004. [Google Scholar]
- Quirino, M.G. Incorporação das Relações de Subordinação na Matriz de Ordenação—Roberts em MCDA Quando os Axiomas de Assimetria e Transitividade Negativa São Violados. Ph.D. Thesis, Federal University of Santa Catarina, Florianópolis, Brazil, 2002. [Google Scholar]
- Dutra, A. Elaboração de um Sistema de Avaliação de Desempenho dos Recursos Humanos da Secretaria de Estado da Administração—SEA à luz da Metodologia Multicritério de Apoio a Decisão. Master’s Thesis, Federal University of Santa Catarina. Florianópolis, Brazil, 1998; 415p. [Google Scholar]
- Zuffo, A.C. Seleção e Aplicação de Métodos Multicriteriais ao Planejamento Ambiental de Recursos Hídricos. Ph.D. Thesis, University of São Paulo, São Carlos, Brazil, 1998. [Google Scholar]
- Saaty, T.L. Fundamentals of Decision Making and Priority Theory: With the Analytic Hierarchy Process; RWS Publications: Pittsburgh, PA, USA, 1994. [Google Scholar]
- Carvalho, D.; Pinheiro, P.R.; Pinheiro, M.C.D. A Hybrid Model to Support the Early Diagnosis of Breast Cancer. Procedia Comput. Sci. 2016, 91, 927–934. [Google Scholar] [CrossRef]
- Morais, D.C. Modelagem Multicritério em Grupo para Planejamento Estratégico do Controle de Perdas no Abastecimento de Água. Ph.D. Thesis, Postgraduate Program in Production Engineering at the Federal University of Pernambuco, Recife, Brazil, 2006; p. 148. [Google Scholar]
- Mello, J.C.C.B.S.D.; Gomes, E.G.; Leta, F.R.; Pessolani, R.B.V. Conceitos Básicos do Apoio Multicritério à Decisão e sua Aplicação no Projeto Aerodesign. Engevista 2003, 5, 22–35. [Google Scholar]
- Vincke, P. Multicriteria Decision-Aid; John Wiley & Sons: Chichester, UK, 1992. [Google Scholar]
- Saaty, T.L. Método de Análise Hierárquica; Wainer, d.S.e.S., Translator; Makron Books do BrasilEditoraLtda: São Paulo, Brazil, 1991. [Google Scholar]
- Forman, E.H.; Selly, M.A. Decision by Objectives: How to Convince Others that You Are Right; World Scientific: Singapore, 2002; 402p, Available online: http://professorforman.com/DecisionByObjectives/Chapter1.PDF (accessed on 25 October 2021).
- Saaty, T.L. The Analytic Hierarchy Process; McGraw-Hill: New York, NY, USA, 1980. [Google Scholar]
- Bhushan, N.; Rai, K. Strategic Decision Making: Applying the Analytic Hierarchy Process; Springer: New York, NY, USA, 2004. [Google Scholar]
- Saaty, T.L. Theory and Applications of the Analytic Network Process: Decision Making with Benefits, Opportunities, Costs, and Risks; RWS Publications: Pittsburgh, PA, USA, 2005. [Google Scholar]
- Saaty, T.L. Relative Measurement and its Generalisation in Decision Making: Why Pairwise Comparisons are Central in Mathematics for the Measurement of Intangible Factors—The Analytic Hierarchy/Network Process. Rev. Real Acad. Cienc. Exactas Fis. Y Nat.-Ser. A Mat. 2008, 102, 251–318. Available online: http://www.rac.es/ficheros/doc/00576.PDF (accessed on 17 October 2014). [CrossRef]
- Costa, H.G. Auxílio Multricritério à Decisão: Método AHP; Abepro: Rio de Janeiro, Brazil, 2006. [Google Scholar]
- Hair, J.F., Jr.; Black, W.C.; Babin, B.J.; Anderson, R.E.; Tatham, R.L. Análise Multivariada de Dados, 5th ed.; Bookman: Porto Alegre, Brazil, 2005. [Google Scholar]
- Saaty, T.L. Decision Making for Leaders: The Analytic Hierarchy Process for Decisions in a Complex World; RWS Publications: Pittsburgh, PA, USA, 1990. [Google Scholar]
- Teodoro, M.L.M.; Alvares-Teodoro, J.; Peixoto, C.B.; Pereira, E.G.; Diniz, M.L.N.; de Freitas, S.K.P.; Ribeiro, P.C.C.; Gomes, C.M.A.; Mansur-Alves, M. Saúde Mental em Estudantes Universitários Durante a Pandemia de COVID-19. 2021. Available online: http://seer.uftm.edu.br/revistaeletronica/index.php/refacs/article/view/5409 (accessed on 30 March 2020).
- Hueniken, K.; Somé, N.H.; Abdelhack, M.; Taylor, G.; Marshall, T.E.; Wickens, C.M.; Hamilton, H.A.; Wells, S.; Felsky, D. Machine Learning–Based Predictive Modeling of Anxiety and Depressive Symptoms During 8 Months of the COVID-19 Global Pandemic: Repeated Cross-sectional Survey Study. JMIR Ment. Health 2021, 8, e32876. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning, 6th ed.; Springer: New York, 2015. [Google Scholar]
- Montgomery, D.; Peck, E.; Vining, G. Introduction to Linear Regression Analysis, 5th ed.; John Wiley & Sons: New York, NY, USA, 2012. [Google Scholar]
- Akaike, H. A New Look at the Statistical Model Identification. IEEE Trans. Autom. Control 1974, 19, 716–723. [Google Scholar] [CrossRef]
- Duarte, M.D.Q.; Santo, M.A.D.S.; Lima, C.P.; Giordani, J.P.; Trentini, C.M. COVID-19 e os impactos na saúde mental: Uma amostra do Rio Grande do Sul, Brasil. Ciência Saúde Coletiva 2020, 25, 3401–3411. [Google Scholar] [CrossRef] [PubMed]
- Silva CC, S.; dos Santos, G.M.; da Silva Pereira VC, L.; Dantas, D.V.; Barbosa MH, P.A.; Freire, R.P.; da Silva, J.A. Saúde mental e pandemia: Associação entre estresse, trabalho e Covid-19 em profissionais médicos. Res. Soc. Dev. 2022, 11, e41111831314. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Breiman, L. Bagging Predictors. Mach. Learn. 1996, 26, 123–140. [Google Scholar] [CrossRef]
- de Freitas Barbosa, V.A.; Gomes, J.C.; de Santana, M.A.; de Lima, C.L.; Calado, R.B.; Bertoldo Junior, C.R.; de Almeida Albuquerque, J.E.; de Souzam, R.G.; de Araújo, R.J.E.; Júnior, L.A.R.M.; et al. Covid-19 Rapid TEST by Combining a Random Forest-Based Web System and Blood Tests. J. Biomol. Struct. Dyn. 2022, 40, 11948–11967. [Google Scholar] [CrossRef] [PubMed]
- Waheed, A.; Goyal, M.; Gupta, D.; Khanna, A.; Al-Turjman, F.; Pinheiro, P.R. Covidgan: Data Augmentation Using Auxiliary Classifier Gan for Improved Covid-19 Detection. IEEE Access 2020, 8, 91916–91923. [Google Scholar] [CrossRef]
- Zhang, Z. Naive Bayes Classification in R. Ann. Transl. Med. 2016, 4, 241–245. [Google Scholar] [CrossRef]
- Qasrawi, R.; Amro, M.; VicunaPolo, S.; Abu Al-Halawa, D.; Agha, H.; Abu Seir, R.; Hoteit, M.; Hoteit, R.; Allehdan, S.; Behzad, N.; et al. Machine learning techniques for predicting depression and anxiety in pregnant and postpartum women during the COVID-19 pandemic: A cross-sectional regional study. F1000Research 2022, 11, 390. [Google Scholar] [CrossRef] [PubMed]
- Tartuce, T.J.A. Métodos de Pesquisa; UNICE—Higher Education: Fortaleza, Brazil, 2006. [Google Scholar]
- Cervo, A.L. Metodologia Científica, 6th ed; Pearson: São Paulo, Brazil, 2007. [Google Scholar]
- Gil, A.C. Como Elaborar Projetos de Pesquisa, 4th ed.; Atlas: São Paulo, Brazil, 2002. [Google Scholar]
- Hulley, S.B.; Cummings, S.R.; Brower, W.S. Delineando a Pesquisa Clínica, 4th ed.; Artmed: Porto Alegre, Brazil, 2015. [Google Scholar]
- Santos, A.R. Metodologia Científica: A Construção do Conhecimento; DP&A: Rio de Janeiro, Brazil, 1999. [Google Scholar]
- Fonseca, J.J.S. Metodologia da Pesquisa Científica; UEC: Fortaleza, Brazil, 2002. [Google Scholar]
- Luxburg, V.; Schölkopf, B. Statistical learning theory: Models, concepts, and results. arXiv 2008, arXiv:0810.475. [Google Scholar]
- De Andrade, E.C.; Pinheiro, L.I.C.C.; Pinheiro, P.R.; Nunes, L.C.; Pinheiro, M.C.D.; Pereira, M.L.D.; De Abreu, W.C.; Filho, R.H.; Simão Filho, M.; Pinheiro, P.G.C.D.; et al. Hybrid Model for Early Identification Post-Covid-19 Sequelae. J. Ambient. Intell. Humaniz. Comput. 2023, 1, 1–14. [Google Scholar] [CrossRef]
- Zanon, C.; Dellazzana-Zanon, L.L.; Wechsler, S.M.; Fabretti, R.R.; Rocha, K.N.D. COVID-19: Implicações e aplicações da Psicologia Positiva em tempos de pandemia. Estud. Psicol. Camp. 2020, 37. [Google Scholar] [CrossRef]
- Schmidt, B.; Crepaldi, M.A.; Bolze, S.D.A.; Neiva-Silva, L.; Demenech, L.M. Saúde mental e intervenções psicológicas diante da pandemia do novo coronavírus (COVID-19). Estud. Psicol. Camp. 2020, 37. [Google Scholar] [CrossRef]
- Tamanini, I.; de Castro, A.K.; Pinheiro, P.R.; Pinheiro, M.C.D. Towards an Applied Multicriteria Model to the Diagnosis of Alzheimer’S Disease: A Neuroimaging Study Case. In Proceedings of the 2009 IEEE International Conference on Intelligent Computing and Intelligent Systems, Shanghai, China, 20–22 November 2009; pp. 652–656. [Google Scholar]
- Jiang, X.; Deng, L.; Zhu, Y.; Ji, H.; Tao, L.; Liu, L.; Ji, W. Psychological crisis intervention during the outbreak period of new coronavirus pneumonia from experience in Shanghai. Psychiatry Res. 2020, 286, 112903. [Google Scholar] [CrossRef] [PubMed]
- Jung, S.J.; Jun, J.Y. Mental health and psychological intervention amid COVID-19 Outbreak: Perspectives from South Korea. Yonsei Med. J. 2020, 61, 271–272. [Google Scholar] [CrossRef]
- Bana Costa, C.A. Structuration, Construction et Exploitation dún Modèle Multicritère dAide à la Decision, Tese (Doutorado em Engenharia de Sistemas); Universidade Técnica de Lisboa, Instituto Superior Técnico: Lisboa, Portugal, 1992. [Google Scholar]
- Carvalho, d.A.E.; Rogerio, P.R.; de Paula, A.L.B.; Comin, L.; Dantas, P.P.G.C. Towards Machine Learning Algorithms in Predicting the Clinical Evolution of Patients Diagnosed with COVID-19. Appl. Sci. 2022, 12, 8939–8958. [Google Scholar]
- Andrade, E.; Portela, S.; Pinheiro, P.R.; Nunes, L.C.; Simão Filho, M.; Costa, W.S.; Pinheiro, M.C.D. A Protocol for the Diagnosis of Autism Spectrum Disorder Structured in Machine Learning and Verbal Decision Analysis. Comput. Math. Methods Med. 2021, 2021, 1–14. [Google Scholar] [CrossRef]
- Luana, P.I.C.C.; Pereira Maria Lúcia, D.; de Andrade Evandro, C.; Nunes Luciano, C.; Abreu Wilson, C.d.; Pinheiro Pedro Gabriel Calíope, D.; Holanda, F.; Pinheiro, P.R. An Intelligent Multicriteria Model for Diagnosing Dementia in People Infected with Human Immunodeficiency Virus. Appl. Sci. 2021, 11, 10457–10479. [Google Scholar]
- Pinheiro, P.R.; Tamanini, I.; Pinheiro, M.C.D.; De Albuquerque, V.H.C. Evaluation of the Alzheimer’s Disease Clinical Stages Under the Optics of Hybrid Approaches in Verbal Decision Analysis. Telemat. Inform. 2017, 35, 776–789. [Google Scholar] [CrossRef]
- Pinheiro, P.R.; Visvizi, A.; Lytras, M.D.; Pinheiro, M.C.D. Application and Decision-Making Implications of Novel Optimization Models in Public Health. Comput. Math. Methods Med. 2022, 2022, 9764895. [Google Scholar] [CrossRef]
- Frasquilho, D.; Matos, M.G.; Salonna, F.; Guerreiro, D.; Storti, C.C.; Gaspar, T.; Caldas-de-Almeida, J.M. Mental Hearth outcomes in a time of economic recession: A systematic literature review. RMC Public Health 2015, 16, 1154. [Google Scholar]
- Neria, Y.; Sullivan, G.M. Understanding the mental health effects of indirect exposure to mass trauma through the media. JAMA 2011, 3012, 1374–1375. [Google Scholar] [CrossRef] [PubMed]
- Thompson, R.R.; Jone, N.M.; Holman, F.A.; Silver, R.C. Media exposure to mass violence events can fuel e cycle of distress. Sci. Adv. 2019, 5, caav3502. [Google Scholar] [CrossRef] [PubMed]
- Castro, A.K.A.D.; Pinheiro, P.R.; Pinheiro, M.C.D.; Isabelle, T. Towards the Applied Hybrid Model in Decision Making: A Neuropsychological Diagnosis of Alzheimer’s Disease Study Case. Int. J. Comput. Int. Sys. 2011, 4, 89–99. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MCDM | MCDA |
|---|---|
| Existence of a well-defined set, A; the existence of a decision-maker, D | The border of A is diffuse and can be modified during the process. There is no decision-maker, D, but rather a set of actors participating in the decision-making process |
| Existence of a well-defined preference model in the mind of the decision-maker, D | Preferences are rarely well-defined, which are uncertainties, partial knowledge, conflict, and contradictions |
| Unambiguous data | It recognizes the data’s ambiguity, often inaccurately or arbitrarily defined |
| Existence of an optimal solution to a well-defined mathematical problem | It is impossible to determine whether a solution is good or bad by considering only the mathematical model since cultural, pedagogical, and situational aspects affect the decision |
| Criterion | Preference Structure | Description |
|---|---|---|
| True criterion | Complete preorder (traditional model) | Any difference implies a strict preference |
| Quasi-criterion | Semi-ordered (threshold model) | There is a constant indecision zone between indifference and strict preference |
| Interval criterion | Interval order (variable threshold model) | There is a variable indecision zone between indifference and strict preference over the scale |
| Pseudo-criterion | Pseudo-order (double threshold model) | A sudden shift from indifference to strict preference is avoided, with a hesitation zone represented by weak preference |
Criteria  | g1 | g2 | …………. | gJ | …………. | gm |
Limits  | q1, p1 | q2,p2 | …………. | qj, pj | …………. | qn, pn |
Alternatives  | ||||||
| A1 | a11 | a12 | …………. | a1j | …………. | a1n |
| A2 | a21 | a22 | …………. | a2j | …………. | a2n |
| ………… | …………. | …………. | …………. | …………. | …………. | …………. |
| Ai | ai1 | ai2 | …………. | aij | …………. | ain |
| ……….. | …………. | …………. | …………. | …………. | …………. | …………. |
| Am | am1 | am2 | …………. | amj | …………. | amn |
| A1 | a11 | a12 | …………. | a1j | …………. | a1n |
| A = | Criterion 1 | Criterion 1 | Criterion 2 |
| 1 | Numerical Evaluation | ||
| Criterion 2 | 1/numerical evaluation | 1 |
| Scale | Numerical Evaluation | Reciprocal |
|---|---|---|
| Extremely preferred | 9 | 1/9 |
| Between very strong and extremely | 8 | 1/8 |
| Very strongly preferred | 7 | 1/7 |
| Between strong and very strong | 6 | 1/6 |
| Strongly preferred | 5 | 1/5 |
| Between moderate and strong | 4 | 1/4 |
| Moderately preferred | 3 | 1/3 |
| Between equal and moderate | 2 | 1/2 |
| Equally preferred | 1 | 1 |
| Critérios | Definições dos Critérios |
|---|---|
| Cr1: Emotions and feelings | Related aspects to possible changes in emotions and feelings |
| Cr2: Physical health | Related aspects to possible changes in physical health |
| Cr3: Interpersonal relationships | Related aspects to possible changes in interpersonal relationships |
| Cr4: Routine | Related aspects to possible changes in daily behavioral routine |
| Alternatives |
|---|
| a1: Worse than before |
| a2: No change |
| a3: Better than before |
| AUTOVETOR 2020 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AHP Classic | AHP Normalized Values | AHP with Geometric Mean | ||||||||||
| CR1 | CR2 | CR3 | CR4 | CR1 | CR2 | CR3 | CR4 | CR1 | CR2 | CR3 | CR4 | |
| WORSE THAN BEFORE (%) | 0.30 | 0.28 | 0.32 | 0.34 | 0.32 | 0.28 | 0.32 | 0.34 | 0.28 | 0.32 | 0.34 | 0.34 |
| Same as BEFORE (%) | 0.48 | 0.42 | 0.44 | 0.46 | 0.46 | 0.42 | 0.44 | 0.46 | 0.42 | 0.44 | 0.46 | 0.43 |
| Better THAN BEFORE | 0.21 | 0.20 | 0.14 | 0.12 | 0.27 | 0.20 | 0.14 | 0.12 | 0.20 | 0.14 | 0.12 | 0.13 |
| Consistency Index Results—The Year 2020 | ||||
|---|---|---|---|---|
| Index/Alternatives | Criterion: CR1: Emotions and Feelings | Criterion: CR2: Physical Health | Criterion: CR3: Interpersonal Relationships | Criterion: CR4: Routine |
| IC | 0.18 | 0.22 | 0.29 | 0.33 |
| Eigenvector 2021 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AHP Classic | AHP Normalized Values | AHP with Geometric Mean | ||||||||||
| CR1 | CR2 | CR3 | CR4 | CR1 | CR2 | CR3 | CR4 | CR1 | CR2 | CR3 | CR4 | |
| WORSE THAN before (%) | 0.34 | 0.56 | 0.03 | 0.25 | 0.56 | 0.56 | 0.03 | 0.25 | 0.56 | 0.03 | 0.25 | 0.37 |
| SAME AS BEFORE (%) | 0.43 | 0.35 | 0.46 | 0.53 | 0.35 | 0.35 | 0.46 | 0.53 | 0.35 | 0.46 | 0.53 | 0.40 |
| Better THAN BEFORE | 0.13 | 0.06 | 0.09 | 0.10 | 0.06 | 0.06 | 0.09 | 0.10 | 0.06 | 0.09 | 0.10 | 0.14 |
| Consistency Index Results—The Year 2021 | ||||
|---|---|---|---|---|
| Index/Alternatives | Criterion: CR1: Emotions and Feelings | Criterion: CR2: Physical Health | Criterion: CR3: Interpersonal Relationships | Criterion: CR4: Routine |
| IC | 0.18 | 0.23 | 0.27 | 0.32 |
| Model | Train Time (s) | Test Time (s) | AUC | CA | F1 | Precision | Recall | Log Loss | Specificity |
|---|---|---|---|---|---|---|---|---|---|
| Random Forest | 0.034 | 0.004 | 0.999 | 0.980 | 0.970 | 0.980 | 0.960 | 0.044 | 0.990 |
| Naïve Bayes | 0.007 | 0.008 | 0.975 | 0.887 | 0.828 | 0.837 | 0.820 | 0.183 | 0.920 |
| Logistic Regression | 0.042 | 0.001 | 0.997 | 0.973 | 0.959 | 0.940 | 0.940 | 0.120 | 0.990 |
| Model | Train Time (s) | Test Time (s) | AUC | CA | F1 | Precision | Recall | Log Loss | Specificity |
|---|---|---|---|---|---|---|---|---|---|
| Random Forest | 0.028 | 0.004 | 1.000 | 0.995 | 0.995 | 0.995 | 0.995 | 0.044 | 0.990 |
| Naïve Bayes | 0.009 | 0.001 | 0.992 | 0.911 | 0.915 | 0.931 | 0.911 | 0.339 | 0.972 |
| Logistic Regression | 0.046 | 0.001 | 0.971 | 0.895 | 0.883 | 0.889 | 0.895 | 0.284 | 0.841 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Costa, W.S.; Pinheiro, P.R.; dos Santos, N.M.; Cabral, L.d.A.F. Aligning the Goals Hybrid Model for the Diagnosis of Mental Health Quality. Sustainability 2023, 15, 5938. https://doi.org/10.3390/su15075938
Costa WS, Pinheiro PR, dos Santos NM, Cabral LdAF. Aligning the Goals Hybrid Model for the Diagnosis of Mental Health Quality. Sustainability. 2023; 15(7):5938. https://doi.org/10.3390/su15075938
Chicago/Turabian StyleCosta, Wagner Silva, Plácido R. Pinheiro, Nádia M. dos Santos, and Lucídio dos A. F. Cabral. 2023. "Aligning the Goals Hybrid Model for the Diagnosis of Mental Health Quality" Sustainability 15, no. 7: 5938. https://doi.org/10.3390/su15075938