

A Study of CNN and Transfer Learning in Medical Imaging: Advantages, Challenges, Future Scope
 , , , and
, , , and
Abstract
:1. Introduction
- This review aids in the comprehension of CNN and transfer learning techniques among researchers and students.
- We simply describe the major issues of traditional ML and how DL-based techniques like CNN can come to the rescue and play an important role in diagnostic analysis.
- We describe in-depth the ideas, theories, and cutting-edge architectures of CNN, the most well-known deep learning technique.
- A literature review is provided in this paper to give an overview of related research work done on the use of CNN and TL techniques.
- We discuss the difficulties that deep learning-based techniques currently face, such as the scarcity of training data, overfitting, and vanishing gradient problems.
- The strategies for choosing the right TL-based technique for a problem are discussed.
- We also present a list of medical imaging modalities used in training the model, and we describe computational resources such as GPU, CPU, and TPU by contrasting how each tool affects deep learning algorithms.
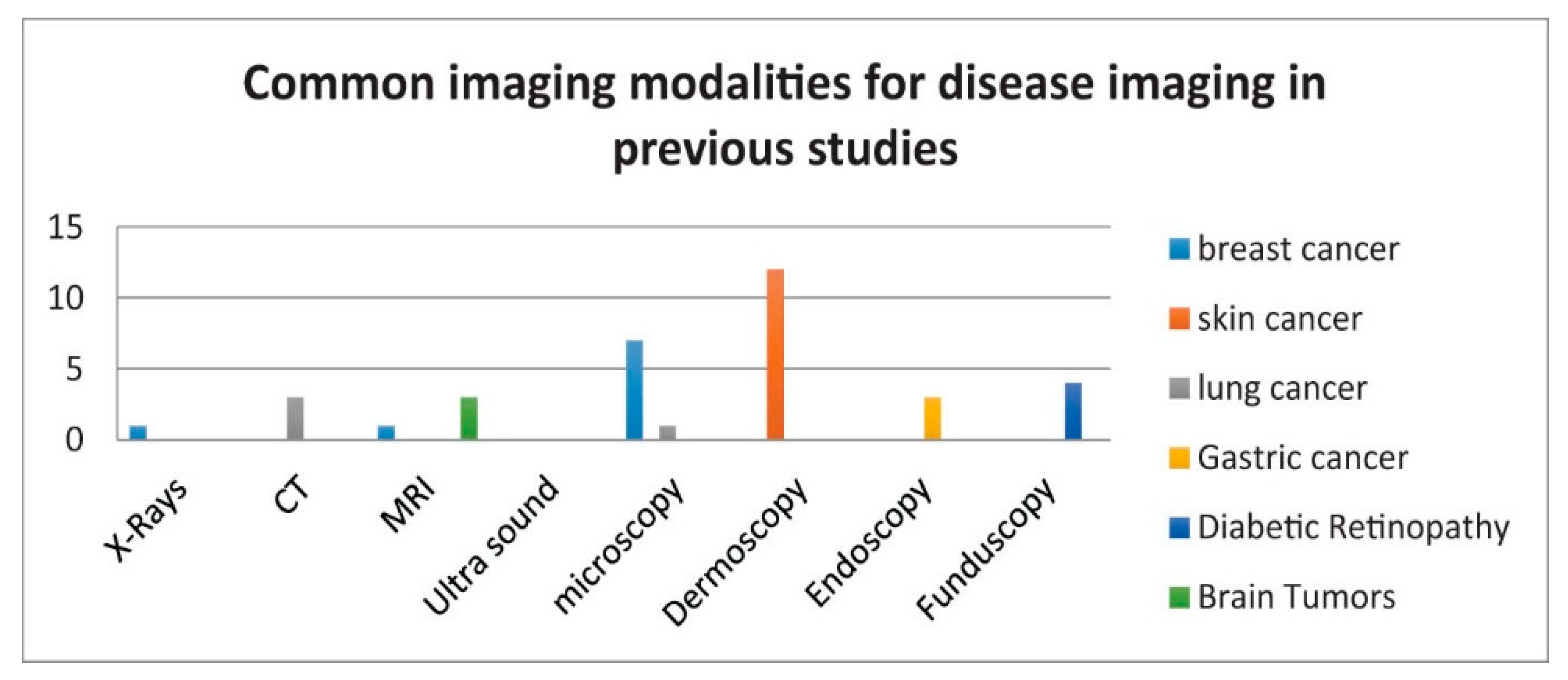
2. Imaging Modalities for Analytics and Diagnostics
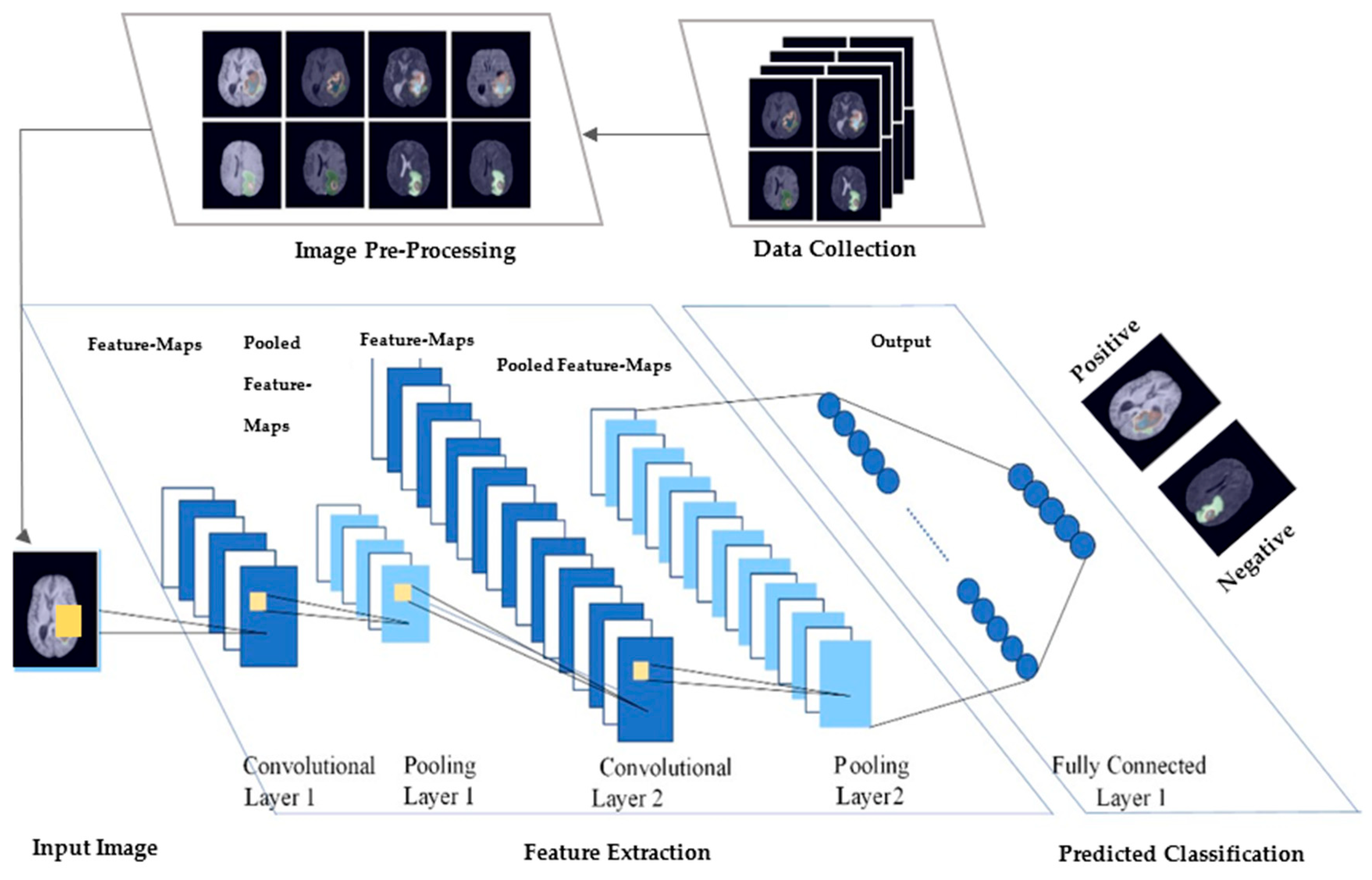
3. Convolutional Neural Network and its Background
- Forward propagation: To train a neural network, one must first provide it with an input, and then, in light of the outcomes of that processing, an output is produced.
- Backward propagation: Next, the model uses the backpropagation technique, such that the weights of the neural network are modified in response to the error that was obtained in the forward propagation.
3.1. Important Elements of CNN
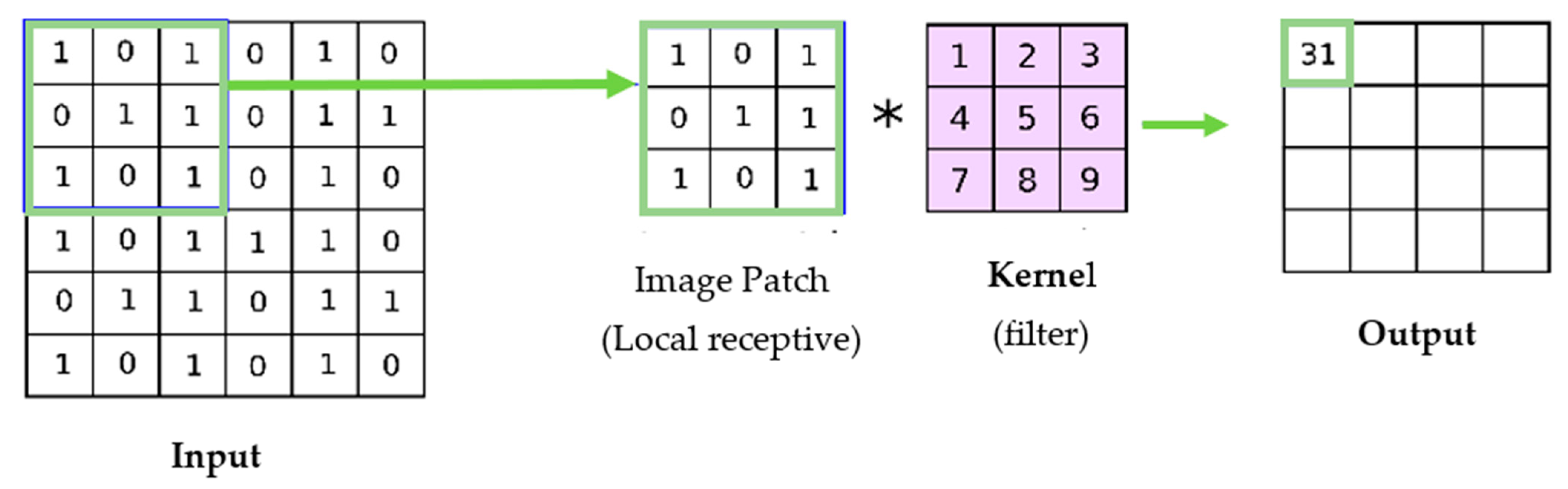
3.1.1. Convolutional Layer
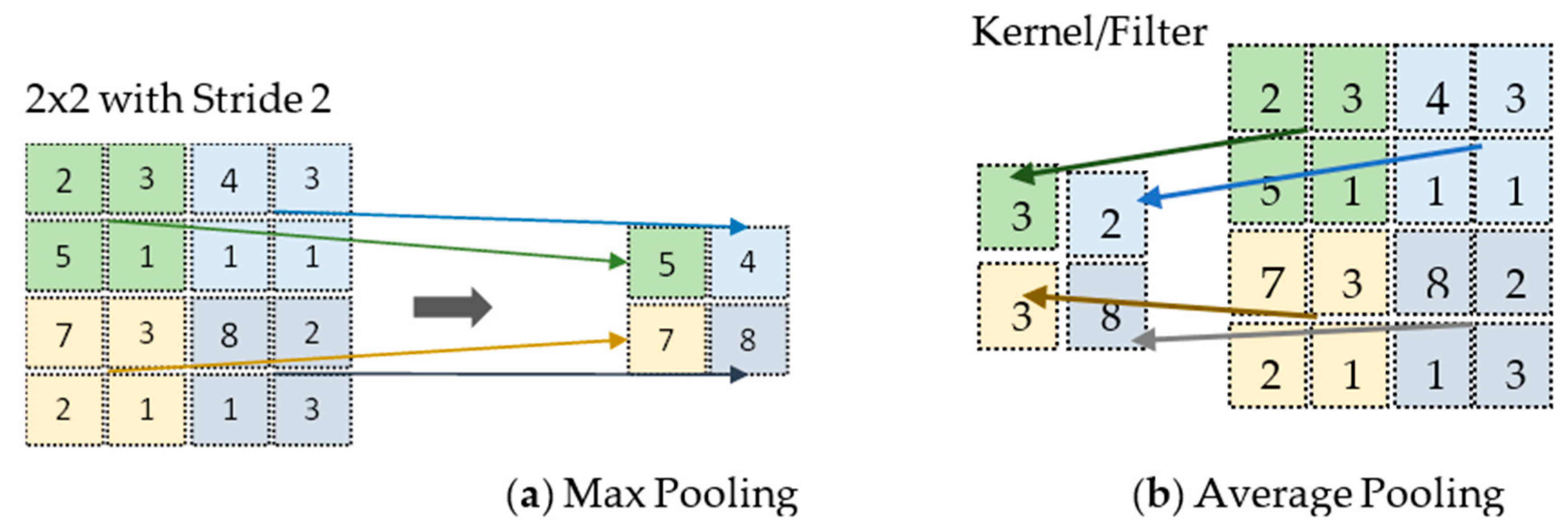
3.1.2. Pooling Layer
- (a)
- Average pooling: This is used when the average value is desired for each patch on the feature map.
- (b)
3.1.3. Fully Connected Layers
3.2. Important Parameters and Hyperparameters for Building CNN
- Kernels: The kernel is nothing but a matrix that is used to traverse over the input images to perform a dot product to extract features [32]. By using the stride value, the kernel can move by columns of pixels based on the number assigned to the stride.
- Biases: Before passing the output values through an activation function, the bias is used to adjust the scaled values. For example, in a neural network, the activation function receives an input ‘x’ which is multiplied by the ‘w’ weight. Therefore, adding a constant bias to the input will enable you to shift the activation function [33].
- Padding: When a kernel is used with image processing, the image is altered each time a convolution is carried out on the input data. The image shrinks and thus this can be done only a certain number of times before the input image completely disappears [34]. As a result, some of the information contained in the image can be lost. The problem is that when the kernel moves across the image there is a significant impact on the pixels in the outskirts of the image, which are much smaller when compared to the center pixels of the image [35]. Therefore, a more accurate analysis of the image can be achieved by the use of padding, which is added to the image’s outer frame to provide more room for the filter to cover the image.
- Stride: Stride is another so-called hyperparameter in the convolutional layer that specifies the pixel count the kernel shifts over the input image matrix. For instance, when two is set as the stride, then the filter or kernel moves two pixels at a time. When three is set as stride, then the filter moves three pixels at a time, and so on [36].
- Dropout for regularization: This is a powerful yet simple regularization technique for deep learning models [37], and CNNs usually have the habit of overfitting. When there are a large number of nodes or neurons in a full-connected layer, it is more likely that co-adaptation occurs. Co-adaption simply means when many neurons in a single layer extract very similar or the same hidden features from the given input data. This usually happens when two different neurons’ connection weights are identical [38]. This technique works based on selecting neurons randomly and ignoring them during training; they will lose their contribution for further processes.
- Learning Rate: The learning rate is a very important parameter in CNN which defines how swiftly a network updates its parameters during backpropagation [39]. Keeping the learning rate low makes the convergence smooth, but the learning process slows down. However, keeping the learning rate larger may speed up the process of learning, but may prevent convergence.
4. ConvNets over Traditional Machine Learning
4.1. The Problem with Traditional Neural Networks
4.2. Feature Extraction
4.3. Parameter Sharing
5. Literature Review
6. What is Transfer Learning?
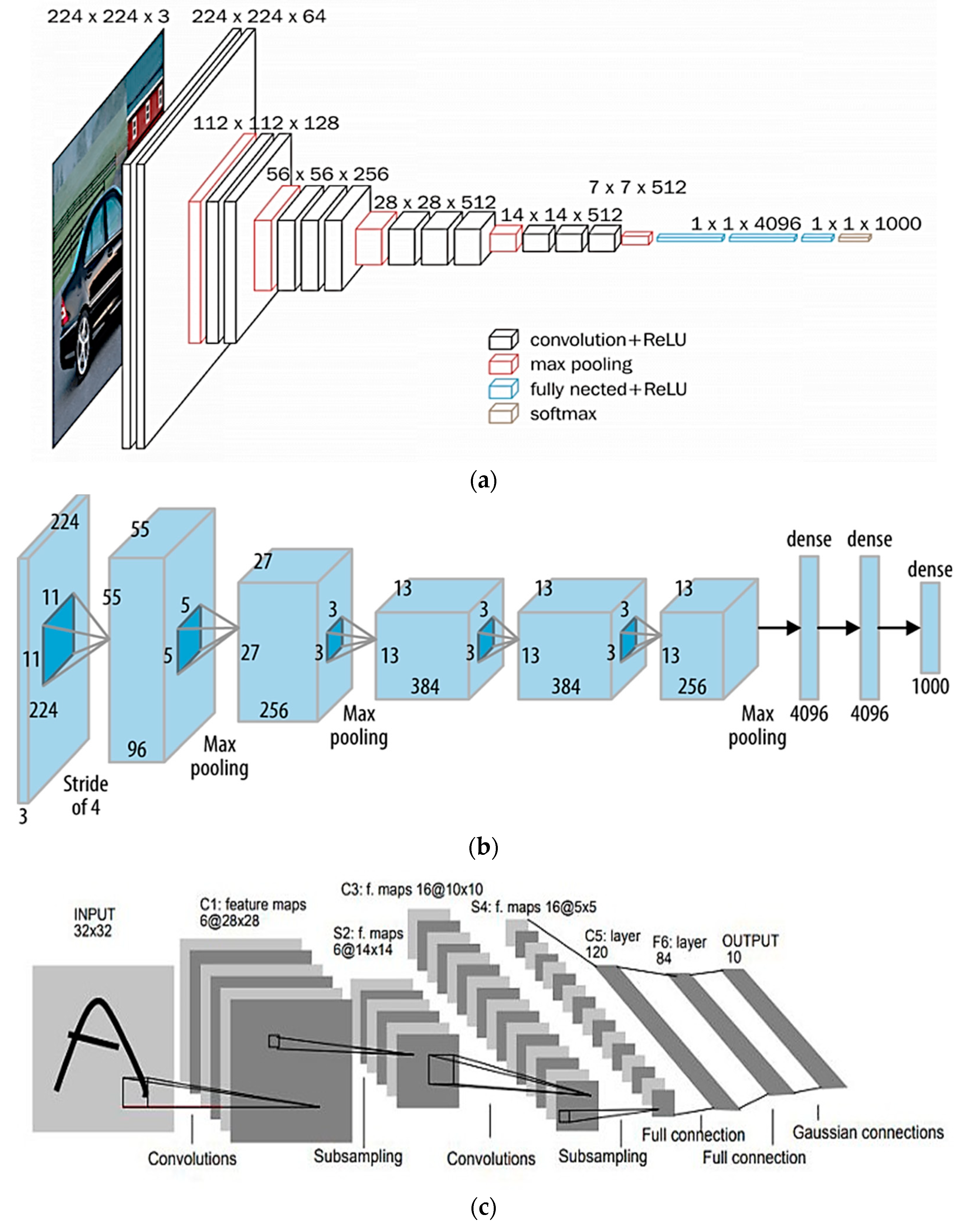
6.1. LeNet5
- This network is very easy to understand and served as a good introduction to the field of neural networks. Character recognition works well.
- Due to the shallowness (not deep enough) of the model, it has a difficult time searching for all features, leading to models with poor performance.
- This model does not work with color images.
6.2. AlexNet
- The first significant CNN model to use GPU training, which leads to faster training, was AlexNet.
- In comparison to another model like LeNet, the AlexNet model has eight layers and a deeper structural design, making it better able to extract important features. It also performed admirably for color images.
- As compared to future models, it takes longer to obtain results with high accuracy with AlexNet.
6.3. VGG Net
- VGG is simple to comprehend and explain.
- A baseline of about 80 percent is recommended for classic problems like classifying cats and dogs.
- A longer inference time is caused by the greater number of weight parameters.
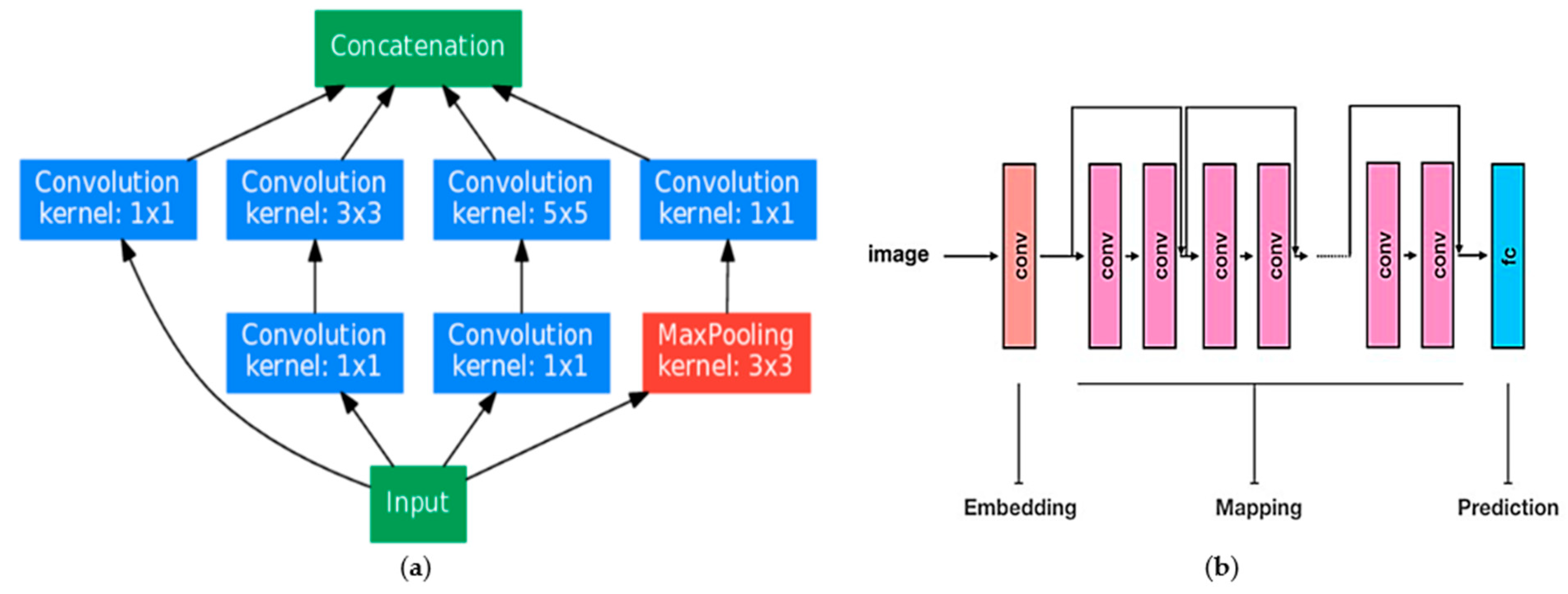
6.4. Inception Net
- As a result of applying multiple convolution filters to the same input in the case of multi-level feature extraction, computational costs are reduced.
- Increased performance can be achieved on this CNN.
- Inception model can be train more quickly than the VGG model and VGG model is relatively bigger in size as compared to LeNet-5.
6.5. ResNet
- Skip-or-shortcut connections aid in addressing the issue of vanishing gradients.
- The structure increases the training pace.
- ResNet provides greater accuracy, particularly in classification.
- It makes an effort to distinguish between learned features, and if a learned feature is not relevant to the decision at hand, its weight is reduced to zero.
- Since it is incorporating skip connections between layers that may take dimensionality into account, it also increases architectural complexity [78].
6.6. DenseNet
- Growth rate: This determines the number of feature maps that are output into individual layers within dense blocks;
- Dense connectivity: Dense connectivity refers to the fact that within a dense block, each successive layer is able to obtain input feature maps from the layer below it [88];
- Composite functions: The following is an explanation of the order in which operations take place within a layer. First, we begin with batch normalization, then move on to applying activation functions (e.g., ReLU), and finally, arrive at the convolution layer [87];
- Transition layers: The transition layers reduce the dimensions of the dense block by aggregating the feature maps that are contained within it. Therefore, maximum pooling has been enabled.
- Each subsequent layer adds only a small number of parameters; for example, only about 12 kernels are learned in each subsequent layer. Therefore, parameter efficiency is achieved.
- Better distribution of the gradient throughout the network for all of the feature maps can enable the CNN to directly access the loss function and its gradient, which gives implicit deep supervision [89].


7. Practical Perspective and Fine-Tuning of Transfer Learning Techniques
- Training the entire model: In this approach, the entire pre-trained model is used as a starting point, and all the parameters of the model are fine-tuned for the new task. This is suitable when the new task is similar to the original task for which the pre-trained model was trained [92].
- Freezing some layers: In this approach, some of the layers in the pre-trained model are frozen and the remaining layers are fine-tuned for the new task. Typically, the lower-level layers of the pre-trained model, which capture low-level features such as edges and corners, are frozen, while the higher-level layers, which capture more complex features, are fine-tuned. This is suitable when the new task is related to the original task but requires some modification of the model [93].
- Fine-tuning some layers: In this approach, some of the layers in the pre-trained model are fine-tuned while the remaining layers are frozen. Typically, the higher-level layers of the pre-trained model, which capture more complex features, are fine-tuned, while the lower-level layers are frozen. This is suitable when the new task is significantly different from the original task, but the higher-level features of the pre-trained model can still be useful [93].
- Freezing the convolutional base: In this approach, the convolutional base of the pre-trained model is frozen, and a new classifier is added on top of it. The new classifier is then trained on the new task [94]. This is suitable when the new task requires a different classification scheme than the original task, but the pre-trained convolutional base can still be used to extract features from the input data [95].
8. Important Things for Consideration
8.1. Generalization: Problems and Key Concepts to Mitigate
- Data augmentation: One approach to avoid overfitting is to simply expand the quantity of data, However, gathering large amounts of data in real-world situations is a laborious and time-consuming task, so collecting new data is not a practical option. Increasing the total size of the dataset [37] used for training is one of the best methods for reducing overfitting. Since we are talking about CNNs for image-based data, the easiest way to add variety to our data and expand it is to add more images to the dataset. This process is referred to as data augmentation [100]. This has potential for narrowing the gap between the training and validation set, as well as between those two sets and any future test sets [98], because the augmented data will represent a comprehensive collection of possible data points. Therefore, augmentation is a highly effective strategy.
- Batch normalization: This approach is the one that is utilized most frequently in deep learning, as it increases the speed at which neural networks learn new information and provides regularization, thereby preventing the problem of overfitting. In CNN convolutions, shared filters follow input feature maps and are the same on every feature map [101]. When this occurs, it is reasonable to normalize the output in the same manner, and then share it across the feature maps. Therefore, each map will have a single standard deviation and mean for all its features [102];
- Dropout: This is a training method in which some neurons are selectively ignored. A model with applied dropout cannot rely on any single feature and must instead learn robust features. This method has been shown to effectively decrease overfitting in numerous issues [103]. Tompson [104] expanded on this concept by applying it to a convolutional neural network using a technique called spatial dropout. This technique eliminates entire feature maps as opposed to individual neurons;
- Weight decay: In model training, large weights mean that the prediction relies heavily on one pixel; therefore, a more interesting method comes to the picture, which is weight decay, which says that large weights are penalized [105]. Intuitively, the classification of an image based on one or a few pixels seems to not make sense;
- Transfer learning: This involves training a machine model on a large amount of data like ImageNet and using those weights in a new classification task [106].
8.2. Computational Accelerators within the Scope of DL
9. Discussion
- Vanishing gradient: Since the derivative of this activation can only be either on the value 0 or 1, it cannot fall within the range [0, 1] [114]. As a consequence of this result, the product of various derivatives would also be either 0 or 1. Therefore, the problem of vanishing gradients does not arise when backpropagation is being performed;
- Sparsity: An ReLU will always produce an output value of 0 in response to negative input. This indicates that a smaller percentage of the network’s neurons are actively firing. As a result, the neural network possesses activations that are both sparse and efficient;
- Speedier training: Better convergence performance is typically demonstrated by networks that have the ReLU function and offer faster training. As a result, our total running time is significantly shorter [111].
- Furthermore, due to the complex structures of data, training a deep learning model is extremely expensive. They often require expensive GPUs and a large number of computers, which raises the cost for users.
- Training performance worsens as a result of the large computational load required by the growing complexity of multiple layers. To tackle the vanishing gradient issue, over-fitting concerns, improved activation, and cost function design, dropout techniques have been employed [113].
- Utilizing hardware with a high degree of parallelism, such as GPUs and normalization techniques, allowed for the large computational-weight issue to be resolved [61].
- Category 1: Large dataset, but different from the pre-trained model’s dataset. Strategy 1 is recommended, which involves training a model from scratch but using the architecture and weights of a pre-trained model to initialize the model.
- Category 2: Large dataset and similar to the pre-trained model’s dataset. Any option can work, but Strategy 2 is the most efficient. This involves training the classifier and top layers of the convolutional base, leveraging previous knowledge.
- Category 3: Small dataset and different from the pre-trained model’s dataset. Strategy 2 is recommended, but it can be challenging to find the right balance between the number of layers to train and freeze. Data augmentation techniques may be necessary.
- Category 4: Small dataset, but similar to the pre-trained model’s dataset. Strategy 3 is the best option, which involves using the pre-trained model as a fixed feature extractor, removing the last fully connected layer, and training a new classifier using the resulting features.
- CPU: It is responsible for achieving the highest FLOPS utilization for Recurrent Neural Networks and is capable of supporting the largest models due to its vast memory capacity;
- GPU: For irregular computations, such as tiny batches and nonMatMul computations, the GPU demonstrates more flexibility and programmability than other processing units;
- TPU: It is highly optimized for large batches and boasts the best possible training throughput.
10. Conclusions
- To make accurate predictions and train deep learning models, these models need access to large datasets, preferably with labels. When processing data in real-time is necessary, to be specific in the case of healthcare data, this problem becomes more difficult. Over the past few years, researchers have investigated potential solutions to this problem, such as data augmentation and pre-trained CNN models.
- Changes to the hyperparameter settings will have a significant impact on the deep learning-based models’ overall performance. Therefore, developing an optimization technique requires careful consideration of parameter choices; for example, there are various techniques to mitigate this problem such as Keras Tuner, Ray Tuner, etc.
- In order to train a CNN model effectively, powerful computational approaches are required like GPUs or TPUs. Therefore, there is a significant amount of ongoing work being conducted to think of ways to speed up these resources.
- Generalizability of the CNN in the case of medical imaging is very important; therefore, concepts like dropout, batch-normalization, weight decay, transfer learning, and data augmentation are presented.
- To find the solution to not having enough data for training, we discussed data augmentation, which is one way to help in the creation of more data from the existing data, and it is likely that different pre-trained CNN models will utilize this solution. For example, a CNN could be trained on a huge amount of unlabeled data, and then that knowledge could be used to train that CNN on a smaller amount of labeled data for the same job.
- It is anticipated that a variety of approaches to learning through transfer will be taken into consideration and choosing the right strategy for utilizing such models in image classification depends on the similarity and the amount of the dataset.
- While utilizing a CNN alone can be computationally costly, using transfer learning with pre-trained CNN models can greatly lower the cost of training a CNN for medical imaging diagnosis while simultaneously enhancing its performance.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cai, L.; Gao, J.; Zhao, D. A review of the application of deep learning in medical image classification and segmentation. Ann. Transl. Med. 2020, 8, 713. [Google Scholar] [CrossRef]
- Chopra, P.; Junath, N.; Singh, S.K.; Khan, S.; Sugumar, R.; Bhowmick, M. Cyclic GAN Model to Classify Breast Cancer Data for Pathological Healthcare Task. BioMed Res. Int. 2022, 2022, 6336700. [Google Scholar] [CrossRef] [PubMed]
- Zhou, S.K.; Greenspan, H.; Davatzikos, C.; Duncan, J.S.; Van Ginneken, B.; Madabhushi, A.; Prince, J.L.; Rueckert, D.; Summers, R.M. A Review of Deep Learning in Medical Imaging: Imaging Traits, Technology Trends, Case Studies with Progress Highlights, and Future Promises. Proc. IEEE 2021, 109, 820–838. [Google Scholar] [CrossRef]
- Dutta, P.; Upadhyay, P.; De, M.; Khalkar, R. Medical Image Analysis using Deep Convolutional Neural Networks: CNN Architectures and Transfer Learning. In Proceedings of the 5th International Conference on Inventive Computation Technologies, ICICT 2020, Coimbatore, India, 26–28 February 2020; pp. 175–180. [Google Scholar] [CrossRef]
- Singh, S.P.; Wang, L.; Gupta, S.; Goli, H.; Padmanabhan, P.; Gulyás, B. 3D Deep Learning on Medical Images: A Review. Sensors 2020, 20, 5097. [Google Scholar] [CrossRef] [PubMed]
- Guezzaz, A.; Azrour, M.; Benkirane, S.; Mohy-Eddine, M.; Attou, H.; Douiba, M. A Lightweight Hybrid Intrusion Detection Framework Using Machine Learning for Edge-Based IIoT Security. Int. Arab. J. Inf. Technol. 2022, 19, 822–830. [Google Scholar] [CrossRef]
- Khan, S. Business Intelligence Aspect for Emotions and Sentiments Analysis. In Proceedings of the 2022 First International Conference on Electrical, Electronics, Information and Communication Technologies (ICEEICT), Trichy, India, 16–18 February 2022; pp. 1–5. [Google Scholar] [CrossRef]
- Khan, S.; Fazil, M.; Sejwal, V.K.; Alshara, M.A.; Alotaibi, R.M.; Kamal, A.; Baig, A.R. BiCHAT: BiLSTM with deep CNN and hierarchical attention for hate speech detection. J. King Saud Univ. Comput. Inf. Sci. 2022, 34, 4335–4344. [Google Scholar] [CrossRef]
- Azrour, M.; Mabrouki, J.; Fattah, G.; Guezzaz, A.; Aziz, F. Machine learning algorithms for efficient water quality prediction. Model. Earth Syst. Environ. 2021, 8, 2793–2801. [Google Scholar] [CrossRef]
- Mutasa, S.; Sun, S.; Ha, R. Understanding artificial intelligence based radiology studies: CNN architecture. Clin. Imaging 2021, 80, 72–76. [Google Scholar] [CrossRef]
- Lee, J.-G.; Jun, S.; Cho, Y.-W.; Lee, H.; Kim, G.B.; Seo, J.B.; Kim, N. Deep Learning in Medical Imaging: General Overview. Korean J. Radiol. 2017, 18, 570–584. [Google Scholar] [CrossRef] [Green Version]
- Bhatt, D.; Patel, C.; Talsania, H.; Patel, J.; Vaghela, R.; Pandya, S.; Modi, K.; Ghayvat, H. CNN Variants for Computer Vision: History, Architecture, Application, Challenges and Future Scope. Electronics 2021, 10, 2470. [Google Scholar] [CrossRef]
- Kim, M.; Yun, J.; Cho, Y.; Shin, K.; Jang, R.; Bae, H.-J.; Kim, N. Deep Learning in Medical Imaging. Neurospine 2019, 16, 657–668. [Google Scholar] [CrossRef] [Green Version]
- Haq, A.U.; Li, J.P.; Khan, I.; Agbley, B.L.Y.; Ahmad, S.; Uddin, M.I.; Zhou, W.; Khan, S.; Alam, I. DEBCM: Deep Learning-Based Enhanced Breast Invasive Ductal Carcinoma Classification Model in IoMT Healthcare Systems. IEEE J. Biomed. Health Inform. 2022, 1–12. [Google Scholar] [CrossRef]
- Abdelhafiz, D.; Yang, C.; Ammar, R.; Nabavi, S. Deep convolutional neural networks for mammography: Advances, challenges and applications. BMC Bioinform. 2019, 20, 281. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Salehi, W.; Gupta, G.; Bhatia, S.; Koundal, D.; Mashat, A.; Belay, A. IoT-Based Wearable Devices for Patients Suffering from Alzheimer Disease. Contrast Media Mol. Imaging 2022, 2022, 3224939. [Google Scholar] [CrossRef] [PubMed]
- IEEE. 2017 IEEE 19th International Conference on e-Health Networking, Applications and Services (Healthcom); IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Kushnure, D.T.; Tyagi, S.; Talbar, S.N. LiM-Net: Lightweight multi-level multiscale network with deep residual learning for automatic liver segmentation in CT images. Biomed. Signal Process. Control. 2023, 80, 104305. [Google Scholar] [CrossRef]
- Haq, A.U.; Li, J.P.; Khan, S.; Alshara, M.A.; Alotaibi, R.M.; Mawuli, C. DACBT: Deep learning approach for classification of brain tumors using MRI data in IoT healthcare environment. Sci. Rep. 2022, 12, 15331. [Google Scholar] [CrossRef] [PubMed]
- Torres-Velazquez, M.; Chen, W.-J.; Li, X.; McMillan, A.B. Application and Construction of Deep Learning Networks in Medical Imaging. IEEE Trans. Radiat. Plasma Med. Sci. 2020, 5, 137–159. [Google Scholar] [CrossRef]
- Mukhlif, A.A.; Al-Khateeb, B.; Mohammed, M.A. An extensive review of state-of-the-art transfer learning techniques used in medical imaging: Open issues and challenges. J. Intell. Syst. 2022, 31, 1085–1111. [Google Scholar] [CrossRef]
- Wiesel, T.N. Receptive fields and functional architecture of monkey striate cortex. J. Physiol. 1968, 195, 215–243. [Google Scholar]
- Ghosh, A.; Sufian, A.; Sultana, F.; Chakrabarti, A.; De, D. Fundamental Concepts of Convolutional Neural Network. In Recent Trends and Advances in Artificial Intelligence and Internet of Things; Springer: Berlin/Heidelberg, Germany, 2019; pp. 519–567. [Google Scholar] [CrossRef]
- Fukushima, K.; Miyake, S. Neocognitron learning by backpropagation. Syst. Comput. Jpn. 1995, 26, 19–28. [Google Scholar] [CrossRef]
- Khan, S.; Kamal, A.; Fazil, M.; Alshara, M.A.; Sejwal, V.K.; Alotaibi, R.M.; Baig, A.R.; Alqahtani, S. HCovBi-Caps: Hate Speech Detection Using Convolutional and Bi-Directional Gated Recurrent Unit with Capsule Network. IEEE Access 2022, 10, 7881–7894. [Google Scholar] [CrossRef]
- Jogin, M.; Mohana; Madhulika, M.S.; Divya, G.D.; Meghana, R.K.; Apoorva, S. Feature Extraction using Convolution Neural Networks (CNN) and Deep Learning. In Proceedings of the 2018 3rd IEEE International Conference on Recent Trends in Electronics, Information and Communication Technology, RTEICT 2018, Bangalore, India, 18–19 May 2018; pp. 2319–2323. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, M.; Ma, S.; Wang, Q.; Qu, Y.; Sun, Z.; Yang, T. Research Progress of Deep Learning in the Diagnosis and Prevention of Stroke. BioMed Res. Int. 2021, 2021, 5213550. [Google Scholar] [CrossRef] [PubMed]
- Brownlee, J. A Gentle Introduction to Pooling Layers for Convolutional Neural Networks. Mach. Learn. Mastery 2019, 22. Available online: https://machinelearningmastery.com/pooling-layers-for-convolutional-neural-networks/ (accessed on 5 December 2022).
- Naranjo-Torres, J.; Mora, M.; Hernández-García, R.; Barrientos, R.J.; Fredes, C.; Valenzuela, A. A Review of Convolutional Neural Network Applied to Fruit Image Processing. Appl. Sci. 2020, 10, 3443. [Google Scholar] [CrossRef]
- Sun, M.; Song, Z.; Jiang, X.; Pan, J.; Pang, Y. Learning Pooling for Convolutional Neural Network. Neurocomputing 2017, 224, 96–104. [Google Scholar] [CrossRef]
- Liu, T.; Fang, S.; Zhao, Y.; Wang, P.; Zhang, J. Implementation of Training Convolutional Neural Networks. arXiv 2015, arXiv:1506.01195, preprint. [Google Scholar]
- Mac, S.; Products, S.; Also, C. Convolutional Kernel Networks Julien. arXiv 2014, arXiv:1406.3332, preprint. [Google Scholar]
- Corvil. The Role of Bias in Neural Networks. 2018. Available online: https://www.pico.net/kb/the-role-of-bias-in-neural-networks/ (accessed on 16 March 2022).
- Skalski, P. Gentle Dive into Math Behind Convolutional Neural Networks. Data Sci. 2019. Available online: https://towardsdatascience.com/https-medium-com-piotr-skalski92-deep-dive-into-deep-networks-math-17660bc376ba (accessed on 20 February 2023).
- Hashemi, M. Enlarging smaller images before inputting into convolutional neural network: Zero-padding vs. interpolation. J. Big Data 2019, 6, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Prabhu. Understanding of Convolutional Neural Network (CNN)—Deep Learning. Medium. 2022. Available online: https://medium.com/@RaghavPrabhu/understanding-of-convolutional-neural-network-cnn-deep-learning-99760835f148 (accessed on 15 February 2023).
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Adrian, G. Dropout in Recurrent Neural Networks. 2018. Available online: https://adriangcoder.medium.com/a-review-of-dropout-as-applied-to-rnns-72e79ecd5b7b (accessed on 12 October 2022).
- Radhakrishnan, P. What are Hyperparameters? And How to tune the Hyperparameters in a Deep Neural Network? Data Sci. 2017. Available online: https://towardsdatascience.com/what-are-hyperparameters-and-how-to-tune-the-hyperparameters-in-a-deep-neural-network-d0604917584a (accessed on 20 February 2023).
- Sharma, S.; Sharma, S.; Anidhya, A. Understanding Activation Functions in Neural Networks. Int. J. Eng. Appl. Sci. Technol. 2020, 4, 310–316. [Google Scholar]
- Nwankpa, C.; Ijomah, W.; Gachagan, A.; Marshall, S. Activation Functions: Comparison of trends in Practice and Research for Deep Learning. arXiv 2018, arXiv:1811.03378. preprint. [Google Scholar]
- Neal, R.M. Connectionist learning of belief networks. Artif. Intell. 1992, 56, 71–113. [Google Scholar] [CrossRef]
- DeepAI. ReLu Definition. In Deep AI Machine Learning Glossary; DeepAI; Available online: https://deepai.org/machine-learning-glossary-and-terms/relu (accessed on 22 February 2023).
- Agostinelli, F.; Hoffman, M.; Sadowski, P.; Baldi, P. Learning activation functions to improve deep neural networks. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015—Workshop Track Proceedings, San Diego, CA, USA, 7–9 May 2015; pp. 1–9. [Google Scholar]
- IEEE. Engineering in Medicine and Biology Society. In Proceedings of the IECBES, IEEE-EMBS Conference on Biomedical Engineering and Science, Kuching, Malaysia, 3–6 December 2018. [Google Scholar]
- Khan, S.; AlSuwaidan, L. Agricultural monitoring system in video surveillance object detection using feature extraction and classification by deep learning techniques. Comput. Electr. Eng. 2022, 102, 108201. [Google Scholar] [CrossRef]
- Boutahir, M.K.; Farhaoui, Y.; Azrour, M. Machine Learning and Deep Learning Applications for Solar Radiation Predictions Review: Morocco as a Case of Study. In Digital Economy, Business Analytics, and Big Data Analytics Applications; Springer: Berlin/Heidelberg, Germany, 2022; pp. 55–67. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef]
- Jain, R.; Jain, N.; Aggarwal, A.; Hemanth, D.J. Convolutional neural network based Alzheimer’s disease classification from magnetic resonance brain images. Cogn. Syst. Res. 2019, 57, 147–159. [Google Scholar] [CrossRef]
- Wu, H.; Yin, H.; Chen, H.; Sun, M.; Liu, X.; Yu, Y.; Tang, Y.; Long, H.; Zhang, B.; Zhang, J.; et al. A Deep Learning, Image Based Approach for Automated Diagnosis for Inflammatory Skin Diseases. Available online: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7290553 (accessed on 5 December 2022).
- Ting, D.S.W.; Cheung, C.Y.-L.; Lim, G.; Tan, G.S.W.; Quang, N.D.; Gan, A.; Hamzah, H.; Garcia-Franco, R.; Yeo, I.Y.S.; Lee, S.Y.; et al. Development and Validation of a Deep Learning System for Diabetic Retinopathy and Related Eye Diseases Using Retinal Images from Multiethnic Populations with Diabetes. JAMA 2017, 318, 2211–2223. [Google Scholar] [CrossRef]
- Gu, H.; Guo, Y.; Gu, L.; Wei, A.; Xie, S.; Ye, Z.; Xu, J.; Zhou, X.; Lu, Y.; Liu, X.; et al. Deep Learning for Identifying Corneal Diseases from Ocular Surface Slit-Lamp Photographs. Available online: https://www.nature.com/articles/s41598-020-75027-3 (accessed on 5 December 2022).
- Bai, X.; Niwas, S.I.; Lin, W.; Ju, B.-F.; Kwoh, C.K.; Wang, L.; Sng, C.C.; Aquino, M.C.; Chew, P.T.K. Learning ECOC Code Matrix for Multiclass Classification with Application to Glaucoma Diagnosis. J. Med. Syst. 2016, 40, 78. [Google Scholar] [CrossRef] [PubMed]
- Xin, M.; Wang, Y. Research on image classification model based on deep convolution neural network. EURASIP J. Image Video Process. 2019, 2019, 40. [Google Scholar] [CrossRef] [Green Version]
- Brown, M.; An, P.E.; Harris, C.J.; Wang, H. How Biased is Your Multi-Layered Perceptron? World Congr. Neural Netw. 1993, 507–511. Available online: https://eprints.soton.ac.uk/250244/ (accessed on 22 February 2023).
- Haq, A.U.H.; Li, J.P.L.; Agbley, B.L.Y.; Khan, A.; Khan, I.; Uddin, M.I.; Khan, S. IIMFCBM: Intelligent Integrated Model for Feature Extraction and Classification of Brain Tumors Using MRI Clinical Imaging Data in IoT-Healthcare. IEEE J. Biomed. Health Inform. 2022, 26, 5004–5012. [Google Scholar] [CrossRef]
- Guezzaz, A.; Benkirane, S.; Azrour, M.; Khurram, S. A Reliable Network Intrusion Detection Approach Using Decision Tree with Enhanced Data Quality. Secur. Commun. Networks 2021, 2021, 1230593. [Google Scholar] [CrossRef]
- ResNet; AlexNet; VGGNet. Inception: Understanding Various Architectures of Convolutional Networks. 2022. Available online: https://cv-tricks.com/cnn/understand-resnet-alexnet-vgg-inception/ (accessed on 23 February 2023).
- Wang, P.; Fan, E.; Wang, P. Comparative analysis of image classification algorithms based on traditional machine learning and deep learning. Pattern Recognit. Lett. 2020, 141, 61–67. [Google Scholar] [CrossRef]
- Suganyadevi, S.; Seethalakshmi, V.; Balasamy, K. A review on deep learning in medical image analysis. Int. J. Multimed. Inf. Retr. 2021, 11, 19–38. [Google Scholar] [CrossRef]
- Shamshirband, S.; Fathi, M.; Dehzangi, A.; Chronopoulos, A.T.; Alinejad-Rokny, H. A review on deep learning approaches in healthcare systems: Taxonomies, challenges, and open issues. J. Biomed. Inform. 2020, 113, 103627. [Google Scholar] [CrossRef] [PubMed]
- Khvostikov, A.; Aderghal, K.; Benois-Pineau, J.; Krylov, A.; Catheline, G. 3D CNN-based classification using sMRI and MD-DTI images for Alzheimer disease studies. arXiv 2018, arXiv:1801.05968, preprint. [Google Scholar]
- Liu, Z.; Lu, H.; Pan, X.; Xu, M.; Lan, R.; Luo, X. Diagnosis of Alzheimer’s disease via an attention-based multi-scale convolutional neural network. Knowl. Based Syst. 2022, 238, 107942. [Google Scholar] [CrossRef]
- Ajagbe, S.A.; Amuda, K.A.; Oladipupo, M.A.; Afe, O.F.; Okesola, K.I. Multi-classification of alzheimer disease on magnetic resonance images (MRI) using deep convolutional neural network (DCNN) approaches. Int. J. Adv. Comput. Res. 2021, 11, 51–60. [Google Scholar] [CrossRef]
- Villa-Pulgarin, J.P.; Ruales-Torres, A.A.; Arias-Garz, D.; Bravo-Ortiz, M.A.; Arteaga-Arteaga, H.B.; Mora-Rubio, A.; Alzate-Grisales, J.A.; Mercado-Ruiz, E.; Hassaballah, M.; Orozco-Arias, S.; et al. Optimized Convolutional Neural Network Models for Skin Lesion Classification. Comput. Mater. Contin. 2022, 70, 2131–2148. [Google Scholar] [CrossRef]
- Hemdan, E.E.-D.; Shouman, M.A.; Karar, M.E. COVIDX-Net: A Framework of Deep Learning Classifiers to Diagnose COVID-19 in X-ray Images. arXiv 2020, arXiv:2003.11055. preprint. [Google Scholar]
- Horry, M.J.; Chakraborty, S.; Paul, M.; Ulhaq, A.; Pradhan, B.; Saha, M.; Shukla, N. COVID-19 Detection through Transfer Learning Using Multimodal Imaging Data. IEEE Access 2020, 8, 149808–149824. [Google Scholar] [CrossRef]
- Joshua, E.S.N.; Bhattacharyya, D.; Chakkravarthy, M.; Byun, Y.-C. 3D CNN with Visual Insights for Early Detection of Lung Cancer Using Gradient-Weighted Class Activation. J. Healthc. Eng. 2021, 2021, 6695518. [Google Scholar] [CrossRef]
- Li, Q.; Cai, W.; Wang, X.; Zhou, Y.; Feng, D.D.; Chen, M. Medical image classification with convolutional neural network. In Proceedings of the 2014 13th International Conference on Control Automation Robotics & Vision (ICARCV), Singapore, 10–12 December 2014; pp. 844–848. [Google Scholar]
- Tiwari, P.; Pant, B.; Elarabawy, M.M.; Abd-Elnaby, M.; Mohd, N.; Dhiman, G.; Sharma, S. CNN Based Multiclass Brain Tumor Detection Using Medical Imaging. Comput. Intell. Neurosci. 2022, 2022, 1830010. [Google Scholar] [CrossRef] [PubMed]
- Yildirim, M.; Cinar, A. Classification with respect to colon adenocarcinoma and colon benign tissue of colon histopathological images with a new CNN model: MA_ColonNET. Int. J. Imaging Syst. Technol. 2021, 32, 155–162. [Google Scholar] [CrossRef]
- Ravi, V.; Narasimhan, H.; Chakraborty, C.; Pham, T.D. Deep learning-based meta-classifier approach for COVID-19 classification using CT scan and chest X-ray images. Multimed. Syst. 2021, 28, 1401–1415. [Google Scholar] [CrossRef]
- Chakraborty, S.; Paul, S.; Hasan, K.M.A. A Transfer Learning-Based Approach with Deep CNN for COVID-19- and Pneumonia-Affected Chest X-ray Image Classification. SN Comput. Sci. 2021, 3, 17. [Google Scholar] [CrossRef] [PubMed]
- Srinivas, C.; Prasad, N.K.S.; Zakariah, M.; Alothaibi, Y.A.; Shaukat, K.; Partibane, B.; Awal, H. Deep Transfer Learning Approaches in Performance Analysis of Brain Tumor Classification Using MRI Images. J. Healthc. Eng. 2022, 2022, 3264367. [Google Scholar] [CrossRef] [PubMed]
- Kumar, N.; Gupta, M.; Gupta, D.; Tiwari, S. Novel deep transfer learning model for COVID-19 patient detection using X-ray chest images. J. Ambient. Intell. Humaniz. Comput. 2021, 14, 469–478. [Google Scholar] [CrossRef]
- Vijaysinh, L. A Comparison of 4 Popular Transfer Learning Models. AIM 2021. Available online: https://arxiv.org/abs/1603.08631 (accessed on 23 February 2023).
- Sarraf, S.; Tofighi, G. Classification of Alzheimer’s Disease Using fMRI Data and Deep Learning Convolutional Neural Networks. arXiv 2016, arXiv:1603.08631. preprint. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- ImageNet Large Scale Visual Recognition Challenge (ILSVRC). Available online: https://www.image-net.org/ (accessed on 24 February 2023).
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. 2017. Available online: https://github.com/liuzhuang13/DenseNet (accessed on 12 December 2022).
- Liu, W.; Zeng, K. SparseNet: A Sparse DenseNet for Image Classification. arXiv 2018, arXiv:1804.05340. preprint. [Google Scholar]
- Introduction to DenseNets (Dense CNN)—Analytics Vidhya. Available online: https://www.analyticsvidhya.com/blog/2022/03/introduction-to-densenets-dense-cnn/ (accessed on 12 December 2022).
- Tra, V.; Kim, J.; Khan, S.A.; Kim, J.-M. Bearing Fault Diagnosis under Variable Speed Using Convolutional Neural Networks and the Stochastic Diagonal Levenberg-Marquardt Algorithm. Sensors 2017, 17, 2834. [Google Scholar] [CrossRef] [Green Version]
- Rousseau, F.; Drumetz, L.; Fablet, R. Residual Networks as Flows of Diffeomorphisms. J. Math. Imaging Vis. 2019, 62, 365–375. [Google Scholar] [CrossRef] [Green Version]
- Marcelino, P. Transfer learning from pre-trained models. Medium 2018. Available online: https://towardsdatascience.com/transfer-learning-from-pre-trained-models-f2393f124751 (accessed on 23 February 2023).
- Taresh, M.M.; Zhu, N.; Ali, T.A.A.; Hameed, A.S.; Mutar, M.L. Transfer Learning to Detect COVID-19 Automatically from X-ray Images Using Convolutional Neural Networks. Int. J. Biomed. Imaging 2021, 2021, 8828404. [Google Scholar] [CrossRef]
- Ezzat, D.; Hassanien, A.E.; Ella, H.A. An optimized deep learning architecture for the diagnosis of COVID-19 disease based on gravitational search optimization. Appl. Soft Comput. 2020, 98, 106742. [Google Scholar] [CrossRef]
- Keykhaie, S. POLYTECHNIQUE MONTRÉAL Affiliée à l’Université de Montréal Secure Authentication for Mobile Users SEPEHR KEYKHAIE Département de Génie Informatique Et Génie Logiciel”. Available online: https://publications.polymtl.ca/5604/ (accessed on 12 December 2022).
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. preprint. [Google Scholar]
- Salman, S.; Liu, X. Overfitting Mechanism and Avoidance in Deep Neural Networks. arXiv 2019, arXiv:1901.06566. preprint. [Google Scholar]
- Guide to Prevent Overfitting in Neural Networks—Analytics Vidhya. Available online: https://www.analyticsvidhya.com/blog/2021/06/complete-guide-to-prevent-overfitting-in-neural-networks-part-1/ (accessed on 13 December 2022).
- Khan, S.; Alqahtani, S. Big Data Application and its Impact on Education. Int. J. Emerg. Technol. Learn. (IJET) 2020, 15, 36–46. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Batch Normalization in Convolutional Neural Networks | Baeldung on Computer Science. Available online: https://www.baeldung.com/cs/batch-normalization-cnn (accessed on 13 December 2022).
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Tompson, J.; Goroshin, R.; Jain, A.; LeCun, Y.; Bregler, C. Efficient object localization using Convolutional Networks. arXiv 2015, arXiv:1411.4280. preprint. [Google Scholar]
- Toronto. Preventing Overfitting. 2022. Available online: https://www.cs.toronto.edu/~lczhang/360/lec/w05/overfit.html (accessed on 13 December 2022).
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar] [CrossRef] [Green Version]
- Premio Inc. What Are Accelerators in the Context of Computing Hardware? Available online: https://premioinc.com/blogs/blog/performance-accelerators-in-the-context-of-computing-hardware (accessed on 12 December 2022).
- Ways AI is Changing our World for the Better. Available online: https://www.salzburgglobal.org/news/latest-news/article/5-ways-ai-is-changing-our-world-for-the-better?gclid=CjwKCAjw-rOaBhA9EiwAUkLV4n43oOgEhJktVevO_iWDnbu-GSMYPvDosnD4Is8nmt76SS_NeHDpFxoCh8wQAvD_BwE (accessed on 18 October 2022).
- Meta AI. Available online: https://ai.facebook.com/#notable-papers (accessed on 12 December 2022).
- DenseNet Explained | Papers with Code. Available online: https://paperswithcode.com/method/densenet (accessed on 12 December 2022).
- Feng, J.; Lu, S. Performance Analysis of Various Activation Functions in Artificial Neural Networks. J. Phys. Conf. Ser. 2019, 1237, 022030. [Google Scholar] [CrossRef]
- Chung, H.; Lee, S.J.; Park, J.G. Deep neural network using trainable activation functions. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 348–352. [Google Scholar] [CrossRef]
- Tan, H.H.; Lim, K.H. Vanishing Gradient Mitigation with Deep Learning Neural Network Optimization. In Proceedings of the 7th International Conference on Smart Computing & Communications (ICSCC), Sarawak, Malaysia, 28–30 June 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Hu, Y.; Huber, A.; Anumula, J.; Liu, S.-C. Overcoming the vanishing gradient problem in plain recurrent networks. arXiv 2018, arXiv:1801.06105. preprint. [Google Scholar]
- Training, Testing & Deploy of Classification Model Using CNN & ML. Available online: https://www.turing.com/kb/training-testing-deployment-of-classification-model-using-convolutional-neural-networks-and-machine-learning-classifiers (accessed on 12 December 2022).
- Akselrod-Ballin, A.; Karlinsky, L.; Alpert, S.; Hasoul, S.; Ben-Ari, R.; Barkan, E. A region based convolutional network for tumor detection and classification in breast mammography. In Deep Learning and Data Labeling for Medical Applications; Springer: Cham, Switzerland, 2016; pp. 197–205. [Google Scholar]
- Anavi, Y.; Kogan, I.; Gelbart, E.; Geva, O.; Greenspan, H. Visualizing and enhancing a deep learning framework using patients age and gender for chest X-ray image retrieval. SPIE 2016, 9785, 249–254. [Google Scholar] [CrossRef]
- Zakharchuk, I. Generalization, Overfitting, and Under-fitting in Supervised Learning | MLearning.ai | Medium. Available online: https://medium.com/mlearning-ai/generalization-overfitting-and-underfitting-in-supervised-learning-a21f02ebf3df (accessed on 13 December 2022).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors | Modalities | Methods | Number of Images | Content | Accuracy |
|---|---|---|---|---|---|
| Alexander et al. [63] | sMRI, DTI | CNN | ADNI (Normal data—214, Augmented data—3240) | Hippocampal ROI | AD-NC—96.7%, AD-MCI—80%, MCI-NC—65.8% |
| Liu et al. [64] | 3D-MRI | MSCNet | GM-AD—160, MCI—200, NC—160 WM-AD—160, MCI—200, NC—160 | Grey matter and white matter | AD-NC—98.96%, AD-MCI—95.37%, MCI-NC—92.59% (GM—98.85% and WM—98. 11%) |
| Ajagbe et al. [65] | MRIs | CNN, VGG16, VGG-19 | Kaggle (6400) | NA | 4 classes-CNN—71%, VGG16—77%, VGG-19—77% |
| Villa—Pulgarin et al. [66] | Dermatoscopic | DenseNet versin 201, Inception-ResNet version 2, Inception version 3 | Human Against Machine (HAM10000) Normal data—10015 Augmented data—42925 | 8 classes—Akiec, bkl, bcc, mel, df, nv, vasc, and scc | DenseNet—98%, Inception ResNet—97%, Inception—96% |
| EI—Din Hemdan et al. n.d. [67] | X-ray | COVIDX-Net | Total—50 (Normal—25, Positive—25) | NA | MobileNetV2—60%, DenseNet-201—90%, ResNetV2—70%, InceptionV3—50%, Xception—80%, VGG-19—90%, InceptionResNetV2—80% |
| Horry et al. [68] | X-ray, ultrasound, and CT scan | VGG-19 | Curated dataset— 729 (X-ray), 746 (CT), 911 (ultrasound) Augmented dataset—11,680 (X-Ray), 12,000 (CT), 10,880 (ultrasound) | Lung | VGG-19—Precision—100% (Ultrasound), 83% (X—Ray), 84% (CT scan) |
| Neal Joshua et al. [69] | CT | 3D-CNN with Grad-CAM images | LUNA 16 database—888 | Lung nodule | 3D-CNN—97.17% |
| Li et al. [70] | HRCT | CNN | Total samples—16,220 (92 HRCT image dataset, 4348 N patches, 1953 G patches, 1047 E patches, 2591 F patches, 6281 M patches) | Lung images | CNN— Precision—76% Recall—77.4% |
| Tiwari et al. [71] | MRIs | CNN | Total—3264 (MRIs) Four classes (training & testing)—glioma—826 and 100, meningioma—822 and 115, no tumor—395 and 105, pituitary tumor—827 and 74. | Brain images | CNN—99% |
| Yildirim et al. [72] | Histopathological images | MA_ColonNET | Total—10,000 Two classes (Colon adenocarcinoma—500, Colon benign tissue—9500) | Colon images | MA_ColonNET—99.75% |
| Ravi et al. [73] | CT scan and Chest X-ray | EfficientNet | Total– CT—8055 (train—5638, test—2417); CXR—9544 (train—6680, test—2864) | Chest | EfficientNet—99% |
| Soarov et al. [74] | X-ray Chest | VGG-19 | COVID-19 (1,184 images) Pneumonia (1294 images) Healthy (1319 images) | Chest | 97.11% accuracy, 97% average precision, 97% average recall |
| Srinivas, C et al. [75] | MRI scans | Classfiers: VGG-16, Inception-v3, ReseNet50 | tumor: 158 malignant tumor: 98 | Brain | VGG—16 accuracy 0.96 Inception-v3 0.78 ResNet50x—0.95 |
| N. Kumar et al. [76] | X-ray | Binary and Multiclass Classification | Two datasets: Source 1: null Source 2: 9300 divided for each four class | Chest | Multiclass accuracy 99.21% Binary accuracy 98.95% |
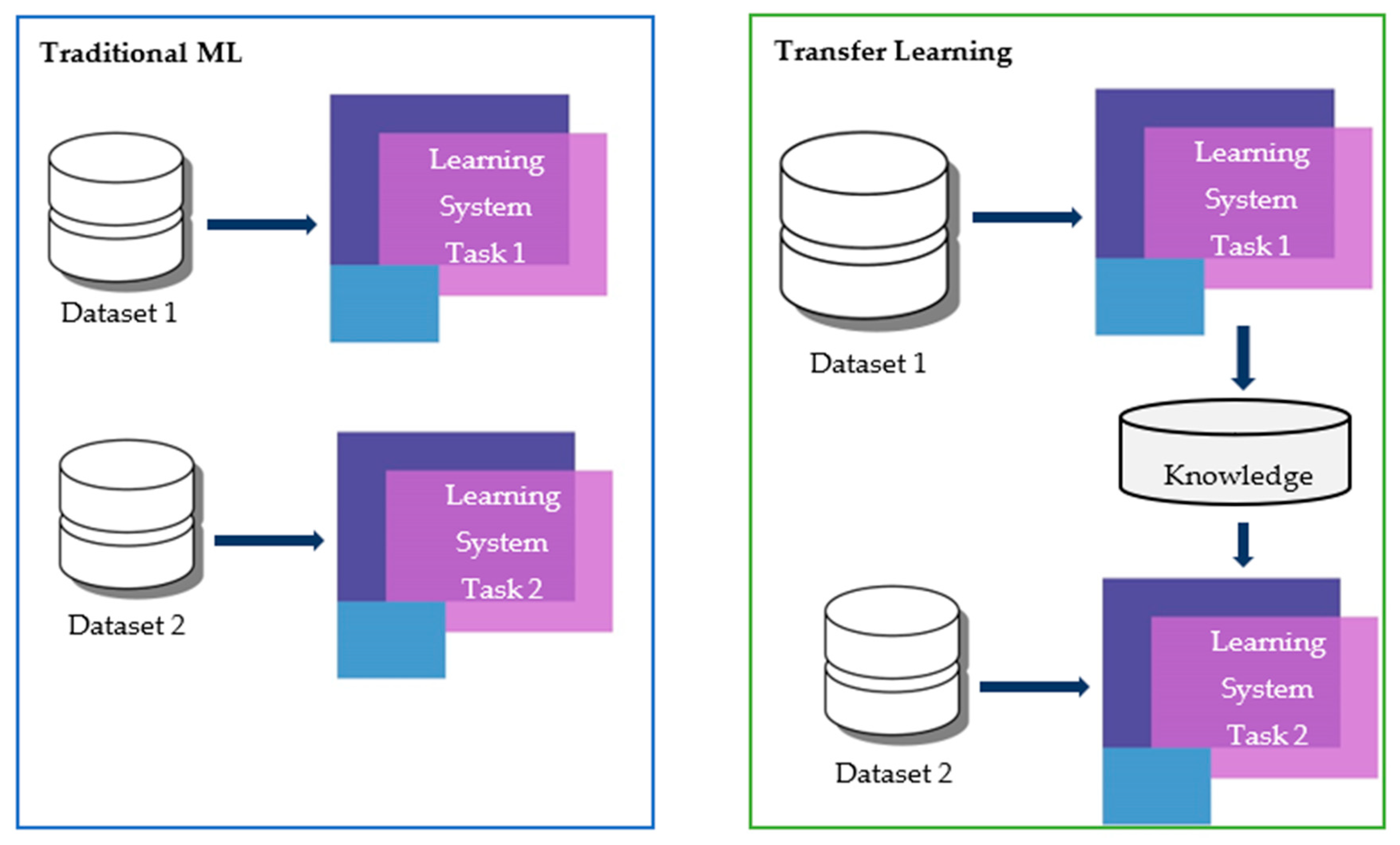
| Traditional ML | Transfer Learning |
|---|---|
|
|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Salehi, A.W.; Khan, S.; Gupta, G.; Alabduallah, B.I.; Almjally, A.; Alsolai, H.; Siddiqui, T.; Mellit, A. A Study of CNN and Transfer Learning in Medical Imaging: Advantages, Challenges, Future Scope. Sustainability 2023, 15, 5930. https://doi.org/10.3390/su15075930
Salehi AW, Khan S, Gupta G, Alabduallah BI, Almjally A, Alsolai H, Siddiqui T, Mellit A. A Study of CNN and Transfer Learning in Medical Imaging: Advantages, Challenges, Future Scope. Sustainability. 2023; 15(7):5930. https://doi.org/10.3390/su15075930
Chicago/Turabian StyleSalehi, Ahmad Waleed, Shakir Khan, Gaurav Gupta, Bayan Ibrahimm Alabduallah, Abrar Almjally, Hadeel Alsolai, Tamanna Siddiqui, and Adel Mellit. 2023. "A Study of CNN and Transfer Learning in Medical Imaging: Advantages, Challenges, Future Scope" Sustainability 15, no. 7: 5930. https://doi.org/10.3390/su15075930