
Mobile Phone Data Feature Denoising for Expressway Traffic State Estimation
Abstract
:1. Introduction
2. Literature Review
3. Data Feature Extraction and Denoising
3.1. Data Preprocessing
- (1)
- Processing of Mobile Identifiers
- (2)
- Processing of Invalid Data
- (3)
- Processing of Duplicate Data
- (4)
- Processing of Ping-Pong Data
- (5)
- Processing of Drift Data
3.2. Feature Extraction
3.3. Origin of Data Noise
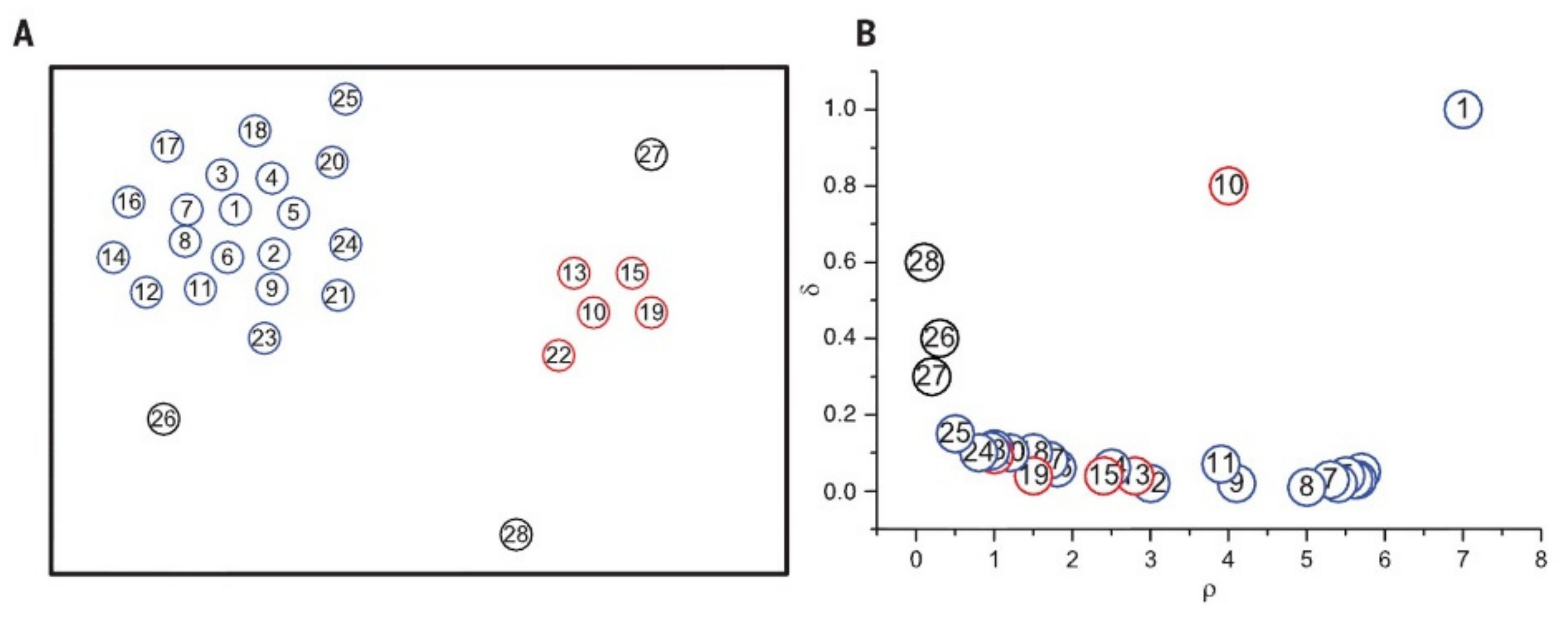
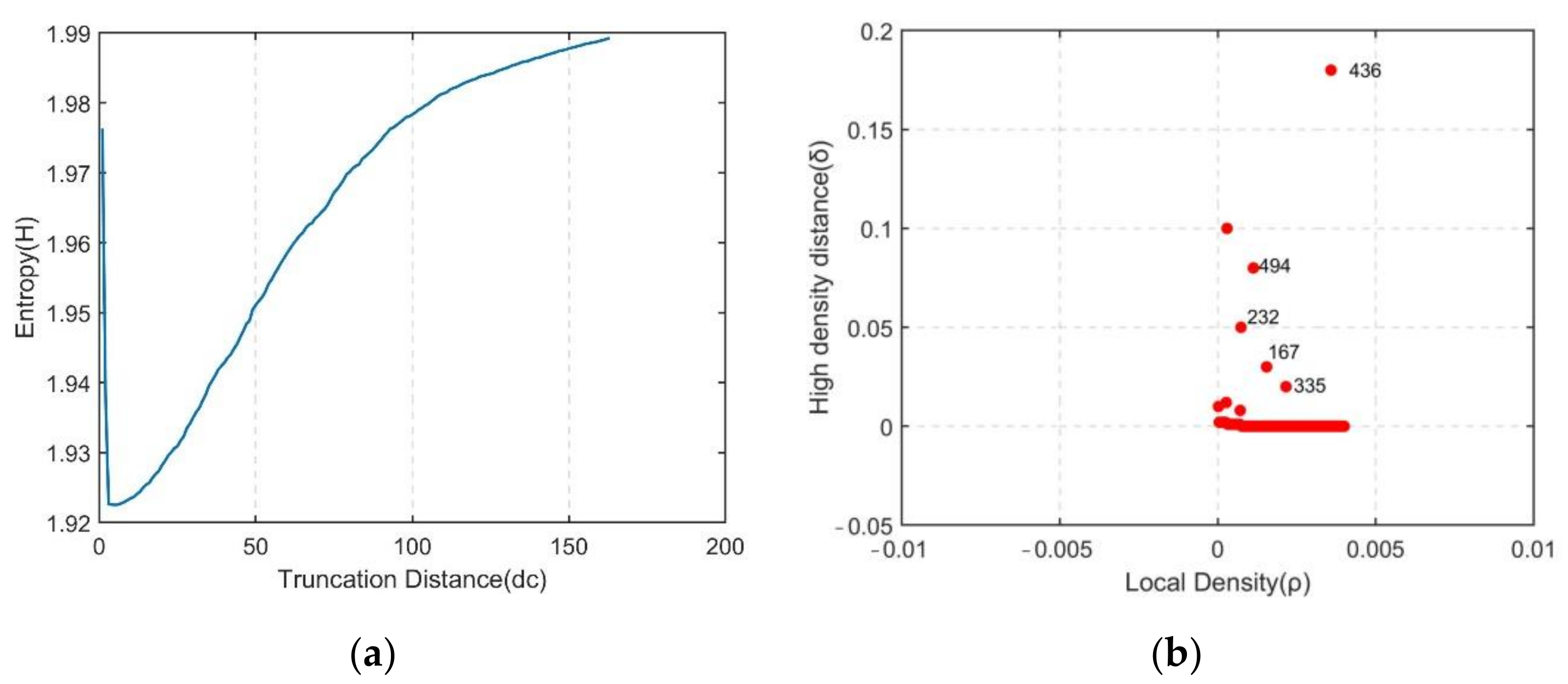
3.4. Feature Data Denoising Method Based on the Improved DPCA
- (1)
- Optimization of the adaptive selection of the cut-off distance
- (2)
- Optimization of the cluster center automatic selection
- (3)
- Optimization of valid data type selection
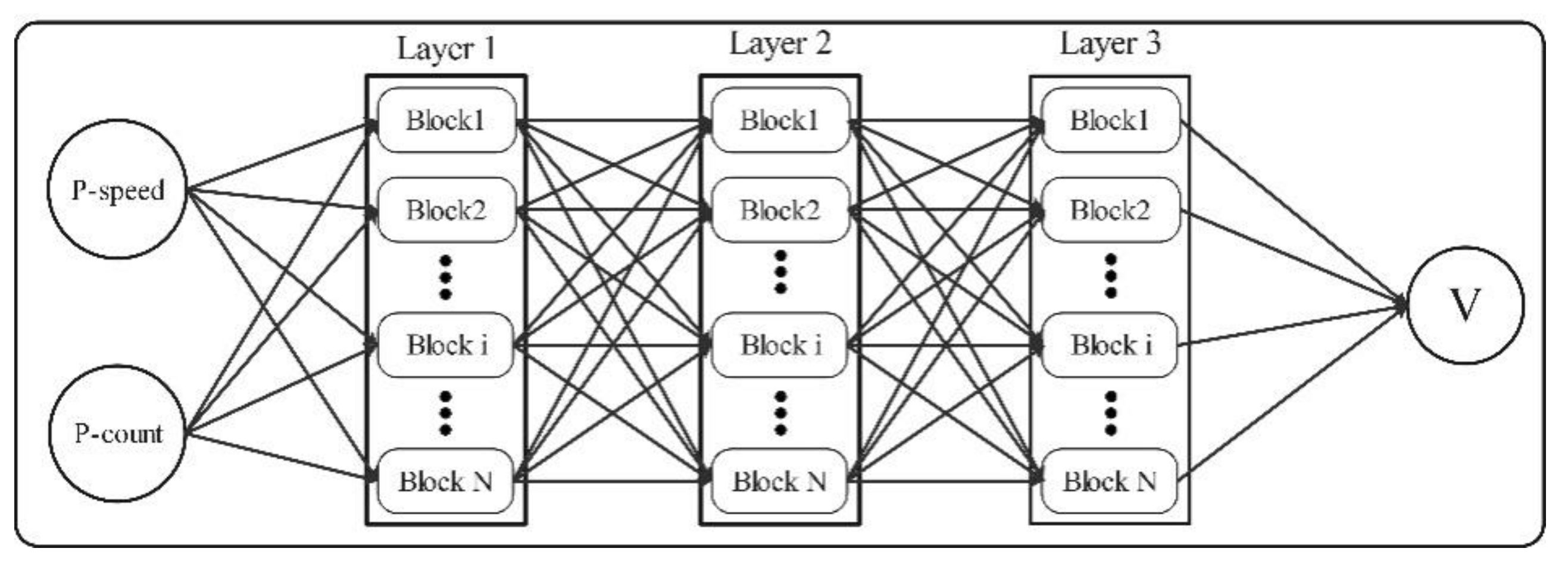
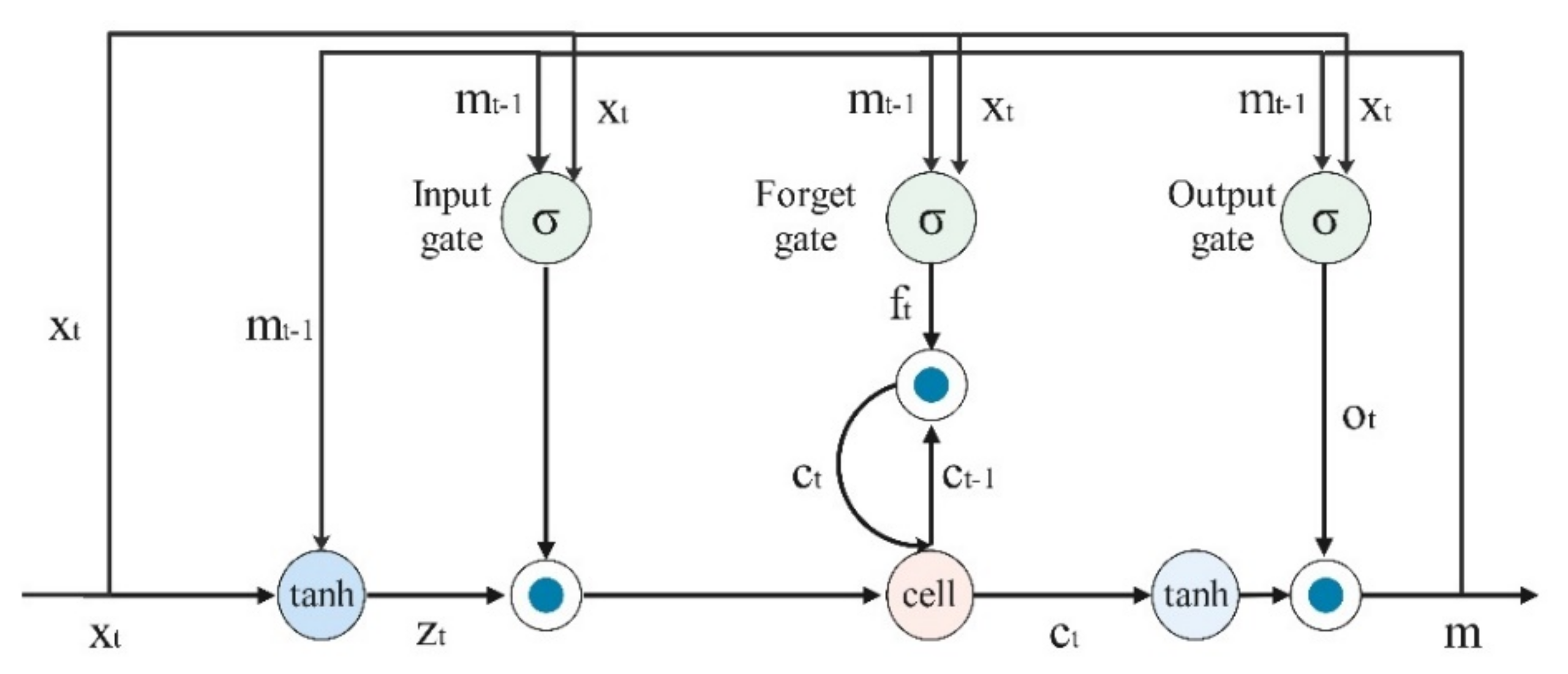
4. Construction of an LSTM-Based Traffic State Estimation Model
5. Case Study
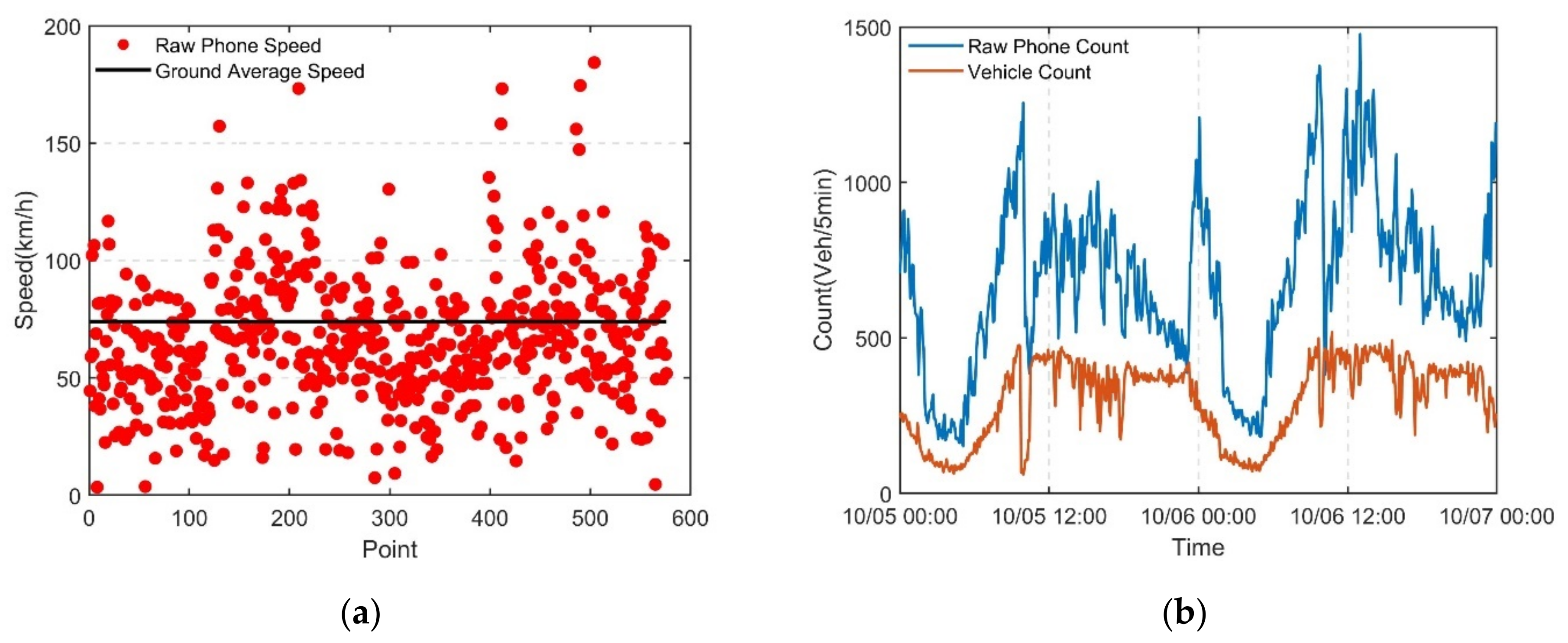
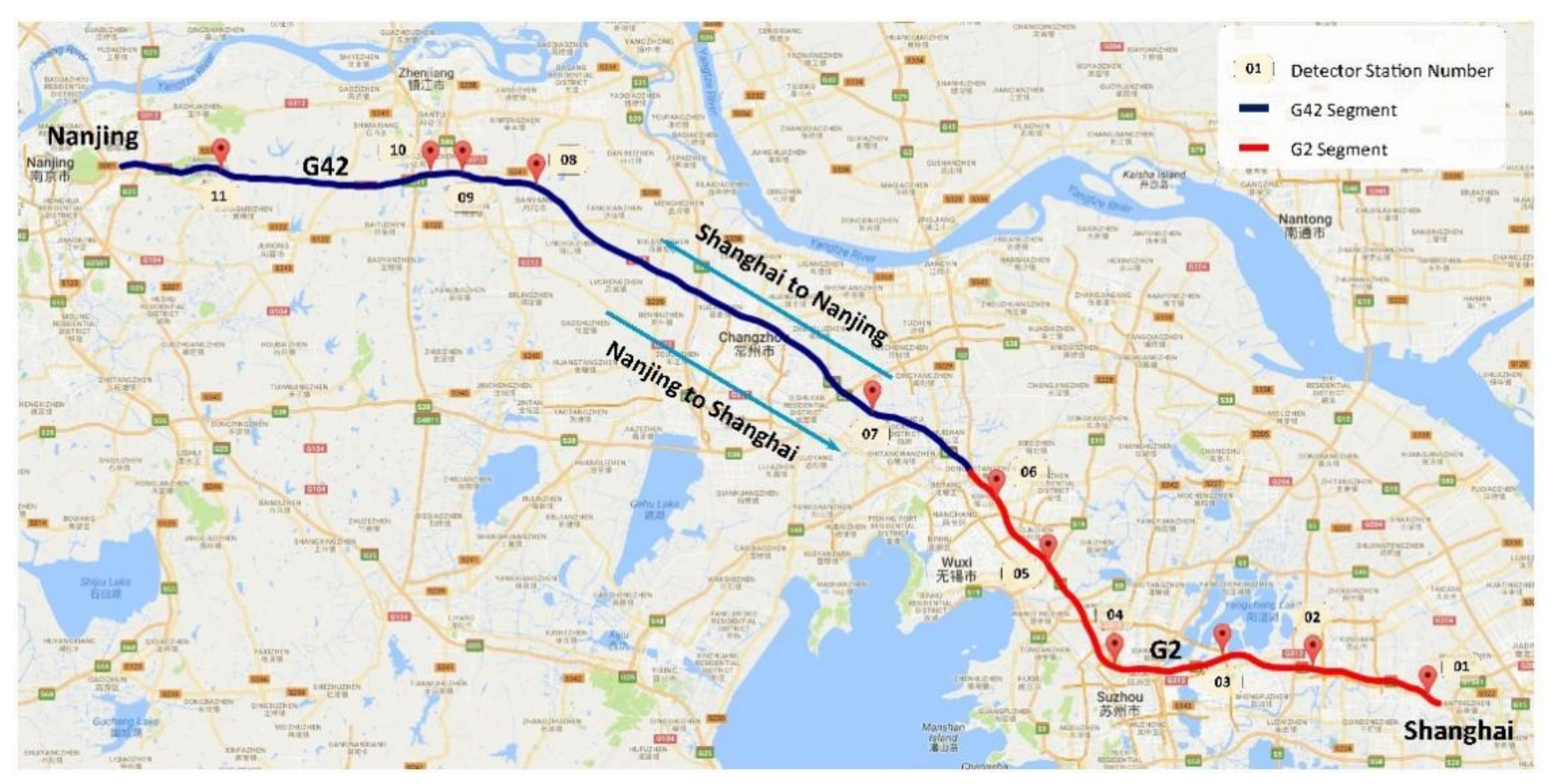
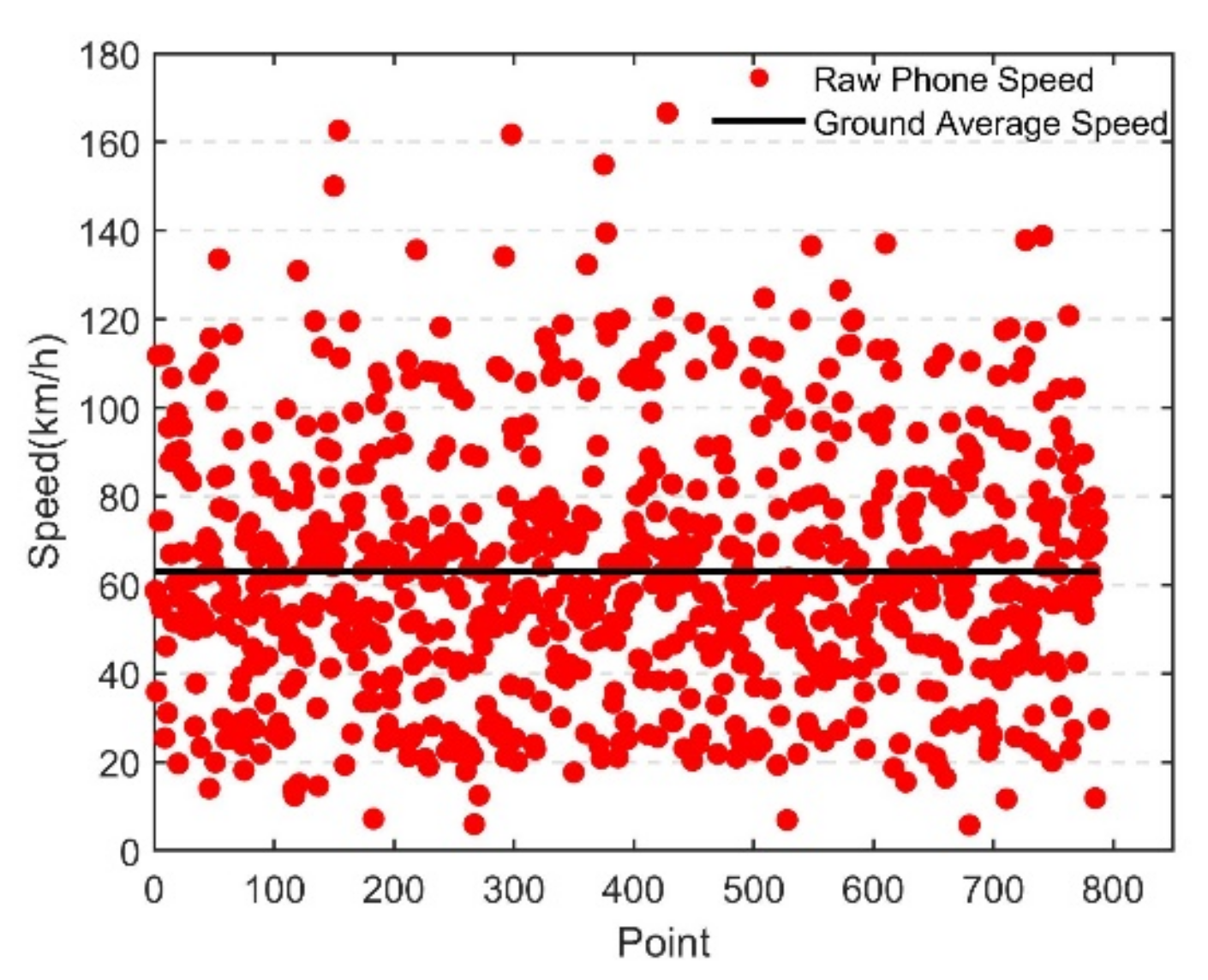
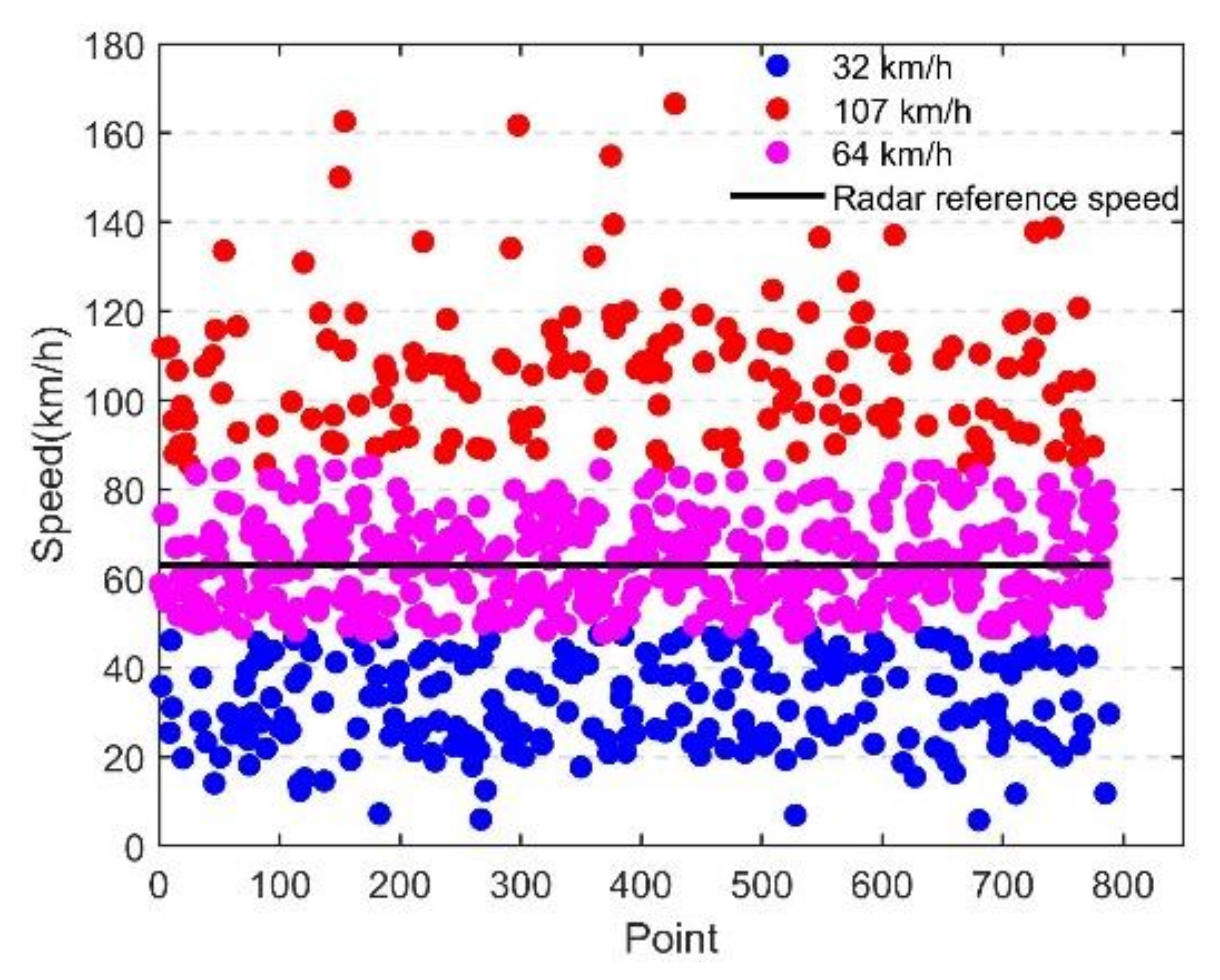
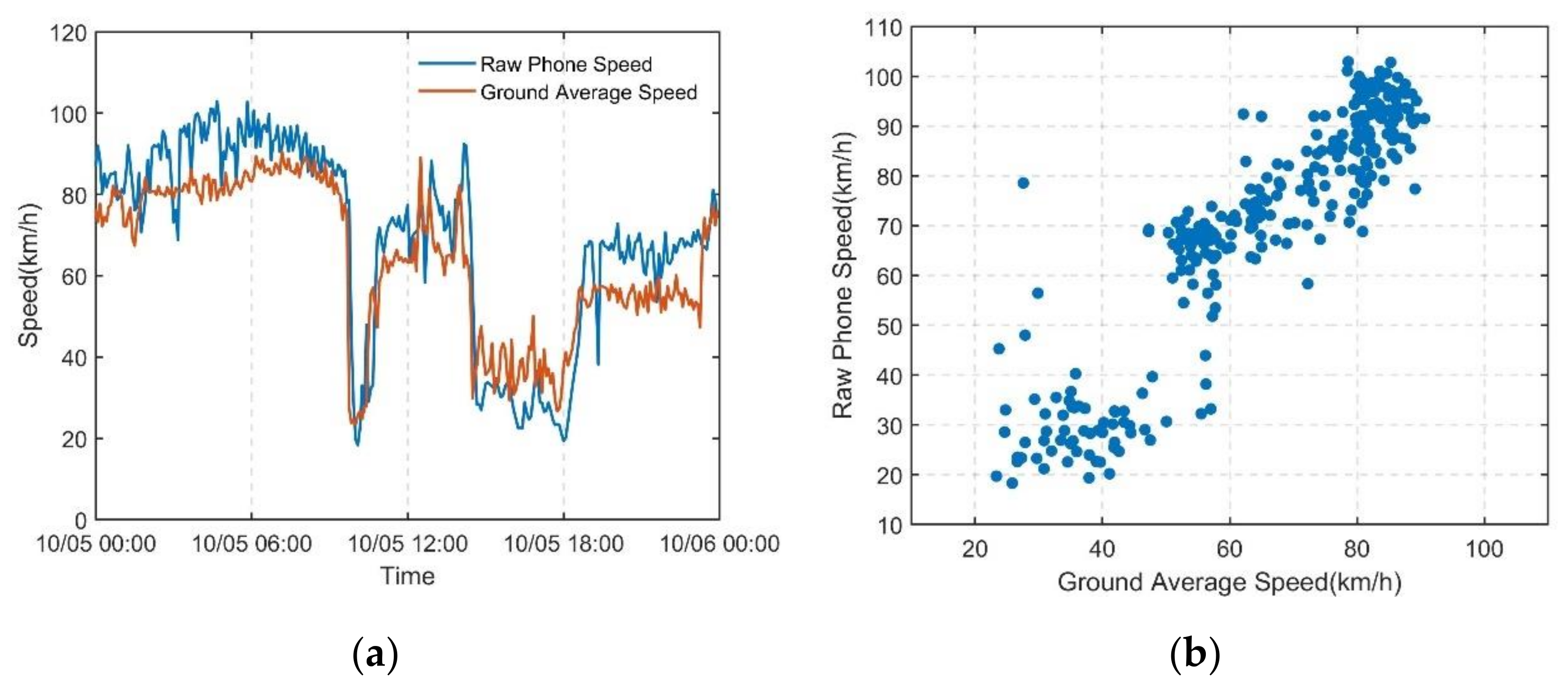
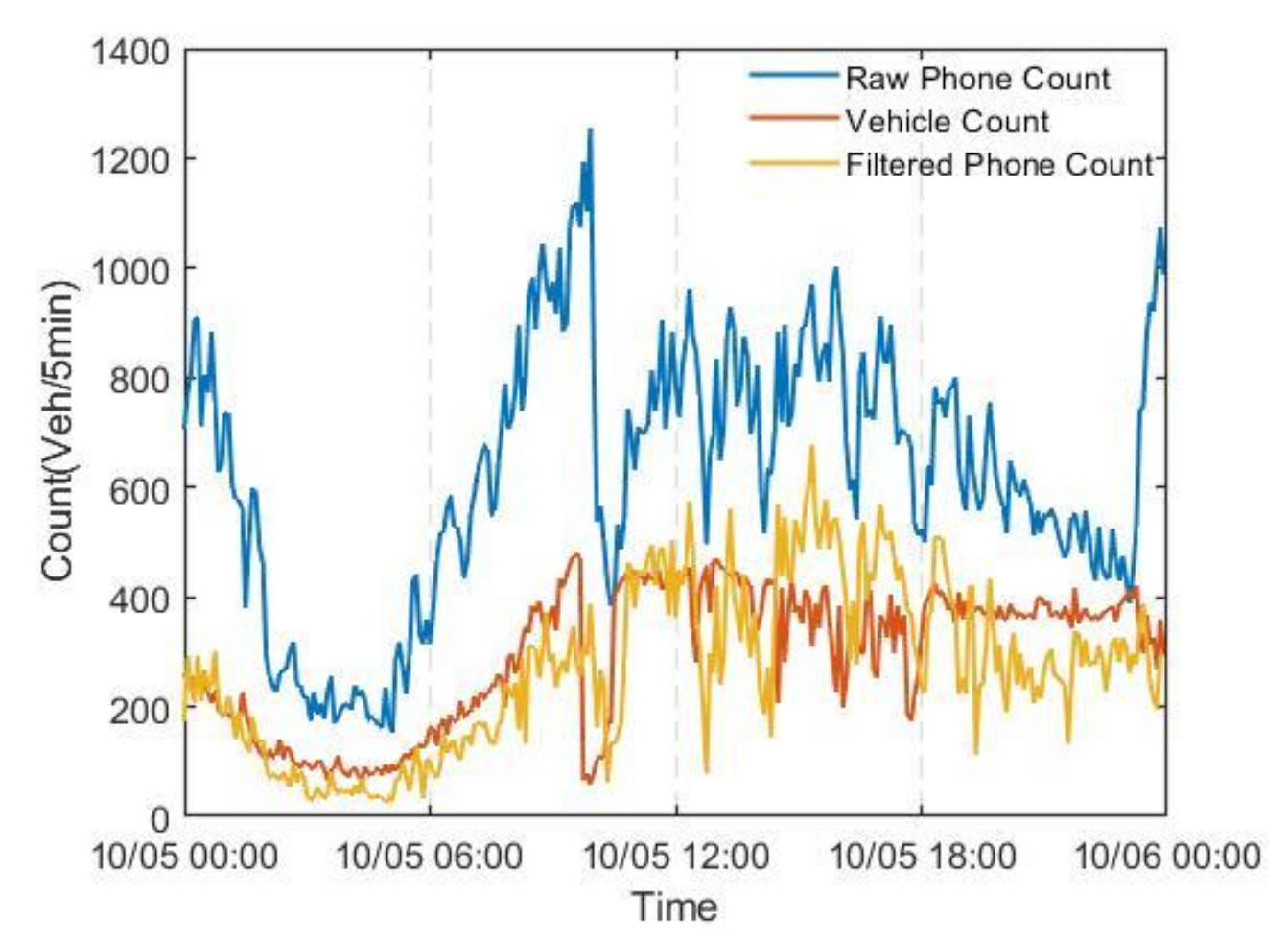
5.1. Source Data
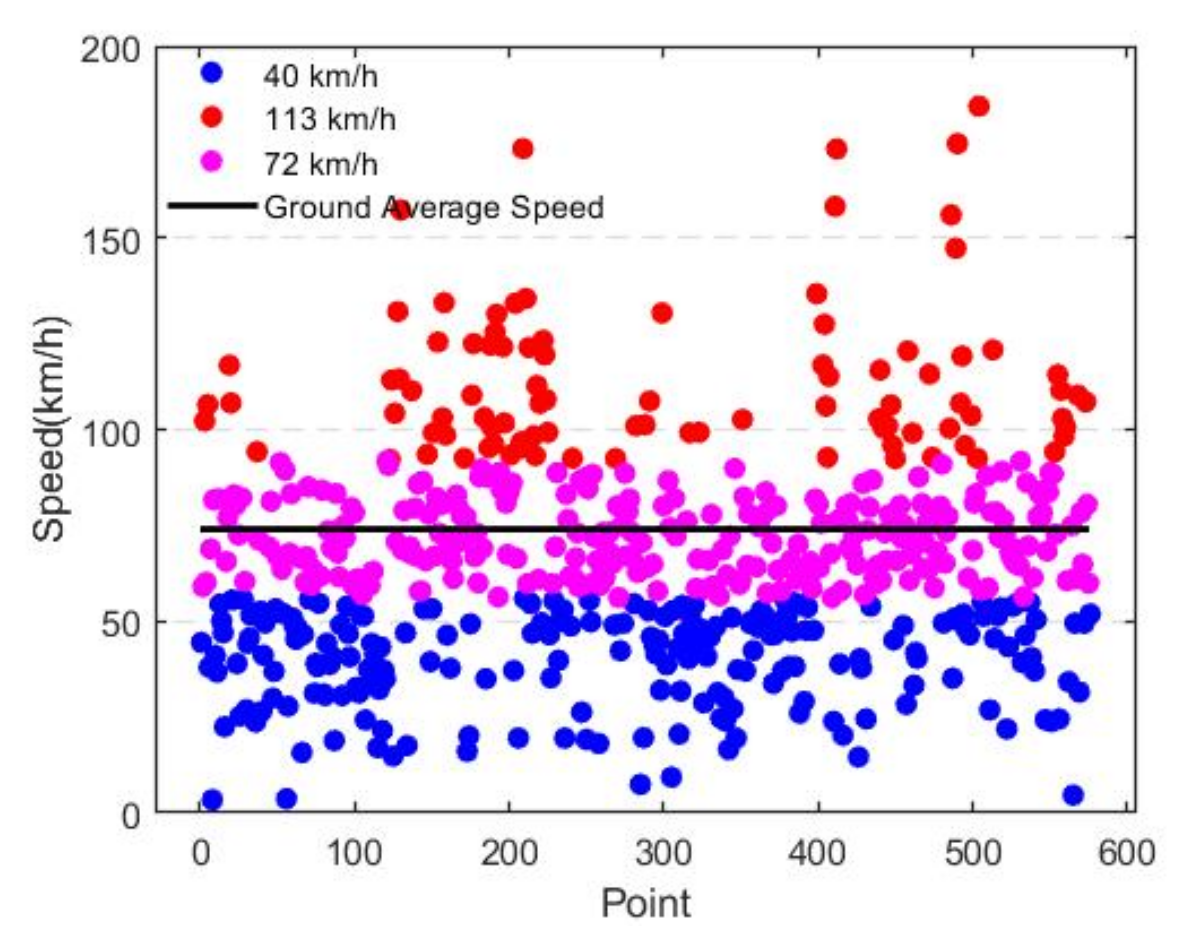
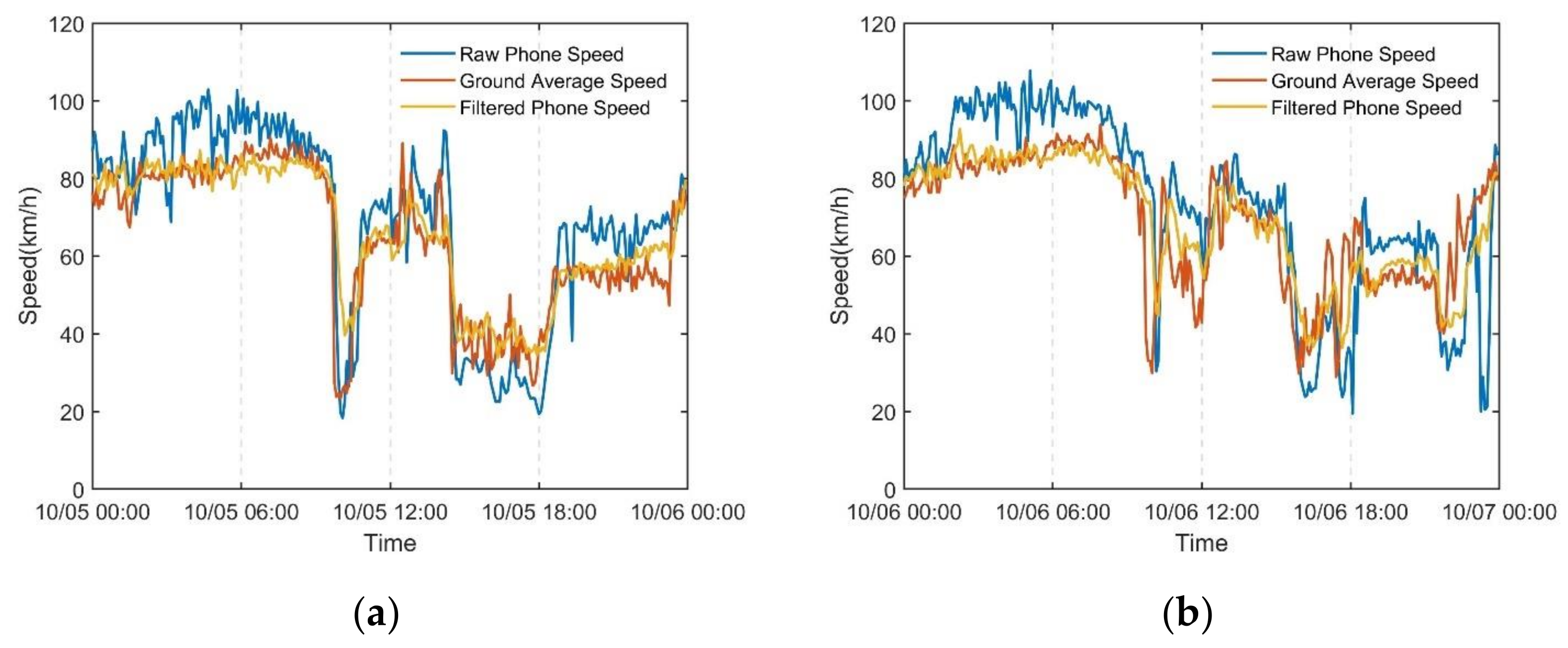
5.2. Mobile Phone Feature Data Denoising Based on the Improved DPCA
Denoising Effect Analysis
5.3. Traffic State Estimation Based on Denoising Data
Accuracy Evaluation of the Traffic State Estimation Model
6. Summary
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Rose, G. Mobile phones as traffic probes: Practices, prospects and issues. Transp. Rev. 2006, 26, 275–291. [Google Scholar] [CrossRef]
- Yarah, B. Travel speed estimation from cellular networks using modified Data Swarm Clustering algorithm. In Proceedings of the ICET 2014-2nd International Conference on Engineering and Technology, Coimbatore, India, 8 July 2014. [Google Scholar]
- Chen, X.; Wan, X.; Ding, F.; Li, Q.; McCarthy, C.; Cheng, Y.; Ran, B. Data-Driven Prediction System of Dynamic People-Flow in Large Urban Network Using Cellular Probe Data. J. Adv. Transp. 2019, 2019, 9401630. [Google Scholar]
- Caceres, N.; Romero, L.M.; Benitez, F.G.; del Castillo, J.M. Traffic Flow Estimation Models Using Cellular Phone Data. IEEE Trans. Intell. Transp. Syst. 2012, 13, 1430–1441. [Google Scholar] [CrossRef]
- Janecek, A.; Valerio, D.; Hummel, K.A.; Ricciato, F.; Hlavacs, H. The Cellular Network as a Sensor: From Mobile Phone Data to Real-Time Road Traffic Monitoring. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2551–2572. [Google Scholar] [CrossRef]
- Huang, Z.; Ling, X.; Wang, P.; Zhang, F.; Mao, Y.; Lin, T.; Wang, F.Y. Modeling real-time human mobility based on mobile phone and transportation data fusion. Transp. Res. Part C Emerg. Technol. 2018, 96, 251–269. [Google Scholar] [CrossRef]
- Hillel, B. Evaluation of a cellular phone-based system for measurements of traffic speeds and travel times: A case study from Israel. Transp. Res. Part C Emerg. Technol. 2007, 15, 380–391. [Google Scholar]
- Li, S.; Li, G.; Cheng, Y.; Ran, B. Urban arterial traffic status detection using cellular data without cellphone GPS information-ScienceDirect. Transp. Res. Part C Emerg. Technol. 2020, 114, 446–462. [Google Scholar] [CrossRef]
- Liu, Q.; Xie, J.; Ding, F. A Data-Driven Feature Based Learning Application to Detect Freeway Segment Traffic Status Using Mobile Phone Data. Sustainability 2021, 13, 7131. [Google Scholar] [CrossRef]
- Wang, F.; Chen, C. On data processing required to derive mobility patterns from passively-generated mobile phone data. Transp. Res. Part C Emerg. Technol. 2018, 87, 58–74. [Google Scholar] [CrossRef] [PubMed]
- Li, G.; Chen, C.-J.; Peng, W.-C.; Yi, C.-W. Estimating crowd flow and crowd density from cellular data for mass rapid transit. In Proceedings of the 6th International Workshop on Urban Computing, Halifax, NS, Canada, 14–17 August 2017. [Google Scholar]
- Kalatian, A.; Shafahi, Y.; Figueira, M. Travel Mode Detection Exploiting Cellular Network Data. MATEC Web Conf. 2016, 81, 03008. [Google Scholar] [CrossRef] [Green Version]
- Horn, C.; Kern, R. Deriving Public Transportation Timetables with Large-Scale Cell Phone Data. Procedia Comput. Sci. 2015, 52, 67–74. [Google Scholar] [CrossRef] [Green Version]
- Horn, C.; Gursch, H.; Kern, R.; Cik, M. QZTool-Automatically Generated Origin-Destination Matrices from Cell Phone Trajectories. Adv. Hum. Asp. Transp. 2017, 484, 823–833. [Google Scholar]
- Horn, C.; Klampfl, S.; Cik, M.; Reiter, T. Detecting Outliers in Cell Phone Data: Correcting Trajectories to Improve Traffic Modeling. Transp. Res. Rec. 2014, 2405, 49–56. [Google Scholar] [CrossRef] [Green Version]
- Grubbs, F.E. Procedures for detecting outlying observations in samples. Technometrics 1969, 11, 1–21. [Google Scholar] [CrossRef]
- Lv, F.; Liang, T.; Zhao, J.; Zhuo, Z.; Wu, J.; Yang, G. Latent Gaussian process for anomaly detection in categorical data. Knowl.-Based Syst. 2021, 220, 106896. [Google Scholar] [CrossRef]
- Zhang, A.; Song, S.; Wang, J. Sequential Data Cleaning: A Statistical Approach. In Proceedings of the 2016 International Conference on Management of Data, San Francisco, CA, USA, 26 June–1 July 2016. [Google Scholar]
- Fang, C.; Wang, F.; Yao, B.; Xu, J. GPSClean: A Framework for Cleaning and Repairing GPS Data. ACM Trans. Intell. Syst. Technol. 2022, 13, 1–22. [Google Scholar] [CrossRef]
- Desforges, M.J.; Jacob, P.J.; Cooper, J.E. Applications of probability density estimation to the detection of abnormal conditions in engineering. Proc. Inst. Mech. Eng. Part C J. Mech. Eng. Sci. 1998, 212, 687–703. [Google Scholar] [CrossRef]
- Song, S.; Li, C.; Zhang, X. Turn Waste into Wealth: On Simultaneous Clustering and Cleaning over Dirty Data. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015. [Google Scholar]
- Houdt, G.V. A review on the long short-term memory model. Artif. Intell. Rev. Int. Sci. Eng. J. 2020, 53, 5929–5955. [Google Scholar] [CrossRef]
- Ding, F.; Zhang, Z.; Zhou, Y.; Chen, X.; Ran, B. Large-Scale Full-Coverage Traffic Speed Estimation under Extreme Traffic Conditions Using a Big Data and Deep Learning Approach: Case Study in China. Transp. Eng. Part A Syst. 2019, 5, 145. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Wu, Y.; Tan, H.; Qin, L.; Ran, B.; Jiang, Z. A hybrid deep learning based traffic flow prediction method and its understanding. Transp. Res. Part C Emerg. Technol. 2018, 90, 166–180. [Google Scholar] [CrossRef]
- Nicholas, G.P.; Vadim, O.S. Deep learning for short-term traffic flow prediction. Transp. Res. Part C Emerg. Technol. 2017, 79, 1–17. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Degree of Congestion | Design Speed (km/h) | ||
|---|---|---|---|
| 120 | 100 | 80 | |
| Free-flowing | [90, max) | [75, max) | [60, max) |
| Smooth | [60, 90) | [50, 75) | [40, 60) |
| Congested | [30, 60) | [25, 50) | [20, 40) |
| Severely congested | [0, 30) | [0, 25) | [0, 20) |
| Evaluation Index | Design Speed (km/h) | |||
|---|---|---|---|---|
| 5 October 2015 | 6 October 2015 | |||
| Raw Data | Filtered Data | Raw Data | Filtered Data | |
| MSE (km2/h2) | 134.41 | 57.34 | 268.61 | 87.59 |
| MAE (km/h) | 9.73 | 4.98 | 13.01 | 6.32 |
| ME (km/h) | −5.16 | −1.61 | −4.78 | −0.52 |
| MAPE (%) | 17.37 | 10.71 | 21.32 | 11.32 |
| Evaluation Index | Design Speed (km/h) | |||||
|---|---|---|---|---|---|---|
| 5 October 2015 | 6 October 2015 | |||||
| Gaussian | k-Means | The Improved DPCA | Gaussian | k-Means | The Improved DPCA | |
| MSE (km2/h2) | 100.60 | 85.67 | 57.34 | 196.80 | 219.18 | 87.59 |
| MAE (km/h) | 8.72 | 7.57 | 4.98 | 12.08 | 11.13 | 6.32 |
| ME (km/h) | −5.18 | −2.16 | −1.61 | −4.85 | −1.78 | −0.52 |
| MAPE (%) | 15.95 | 14.47 | 10.71 | 19.39 | 18.26 | 11.32 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, L.; Shou, G.; Xie, Z.; Jing, P. Mobile Phone Data Feature Denoising for Expressway Traffic State Estimation. Sustainability 2023, 15, 5811. https://doi.org/10.3390/su15075811
Wu L, Shou G, Xie Z, Jing P. Mobile Phone Data Feature Denoising for Expressway Traffic State Estimation. Sustainability. 2023; 15(7):5811. https://doi.org/10.3390/su15075811
Chicago/Turabian StyleWu, Linlin, Guangming Shou, Zaichun Xie, and Peng Jing. 2023. "Mobile Phone Data Feature Denoising for Expressway Traffic State Estimation" Sustainability 15, no. 7: 5811. https://doi.org/10.3390/su15075811