
Increased Digital Resource Consumption in Higher Educational Institutions and the Artificial Intelligence Role in Informing Decisions Related to Student Performance




Abstract
:1. Introduction
- The United Nations Education, Scientific, and Cultural Organization (UNESCO), in collaboration with the United Nations Environment Programme (UNEP), hosted the world’s first intergovernmental conference on environmental education from 14 to 26 October 1977 in Tbilisi, Georgia (USSR).
- The Earth Summit in Rio de Janeiro in 1992 saw the launch of Education for Sustainable Development (ESD): The United Nations Conference on Environment and Development (Rio Summit, Earth Summit) and Agenda 21’s Chapter 36 on Education, Training, and Public Awareness consolidated international discussions on the critical role of education, training, and public awareness in achieving sustainable development.
- In 2002, during the World Summit on Sustainable Development, the Decade for ESD was announced: A proposal for the Decade of Education for Sustainable Development (ESD) was included in the Johannesburg Plan of Implementation. At its 57th session in December 2002, the United Nations General Assembly passed a resolution declaring the UN Decade of Education for Sustainable Development (DESD) to begin in January 2005.
- In 2014, the announcement of the Global Action Programme (GAP) for ESD was introduced during the UNESCO World Conference on ESD.
- In 2015 the World Education Forum in Incheon, Korea R, emphasised the importance of education as a primary driver of development and achievement of the SDGs.
- Analysis and Visualization of Data,
- Providing Feedback for Supporting Instructors,
- Recommendations for Students,
- Predicting Student’s Performance,
- Student Modelling, and
- Social Network Analysis.
- A framework for an AI based student performance predictor is proposed,
- Digital resources are used in informing decisions related to student performance,
- Al prediction for student performance is designed and analyzed for a first-year IT literacy course at The University of the South Pacific (USP).
2. Types of Early Warning Systems
2.1. The Evolution of EWS in Higher Education
2.2. AI in Early Warning Systems

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Feature | Accuracy (%) | Ref. |
|---|---|---|---|
| DNN | External assessment, Student Demographic, High school background | 74 | [47] |
| Student Demographic, High school background | 72 | [48] | |
| CGPA, Student Demographic, High school background, Scholarship, Social network interaction | 71 | [49] | |
| CGPA | 75 | [50] | |
| External assessment | 97 | [51] | |
| Psychometric factors | 69 | [52] | |
| Internal assessments | 81 | [53] | |
| SVM | Internal assessment, CGPA | 80 | [54] |
| Internal assessment, CGPA, Extra-curricular activities | 80 | [55] | |
| Psychometric factors | 83 | [56] | |
| Decision Tree | Psychometric factors, Extra-curricular activities, soft skills | 88 | [57] |
| External assessment, CGPA, Student Demographic, Extra-curricular activities | 90 | [58] | |
| Internal assessment, Student Demographic, Extra-curricular activities | 90 | [59] | |
| Internal assessment, CGPA, Extra-curricular activities | 73 | [55] | |
| CGPA, Student Demographic, High school background, Scholarship, Social network interaction | 73 | [49] | |
| CGPA | 91 | [50] | |
| External assessment | 85 | [60] | |
| Psychometric factors | 65 | [51] | |
| Internal assessments | 76 | [24] |
3. Design and Architecture of Intelligent Early Warning System (iEWS) Model
4. Methodology
4.1. Dataset
4.2. Features
- AvgCompRate—average percentage of online activities completed by students each week,
- AvgLogin—average number of logins by students each week.
- CourseworkScore—the coursework marks for Weeks 6, 8 and 10.
4.3. Reducing the Imbalance between Classes
4.4. Tool
4.5. Classifier
4.6. RF
4.7. Statistical Measures
4.8. Validation Scheme
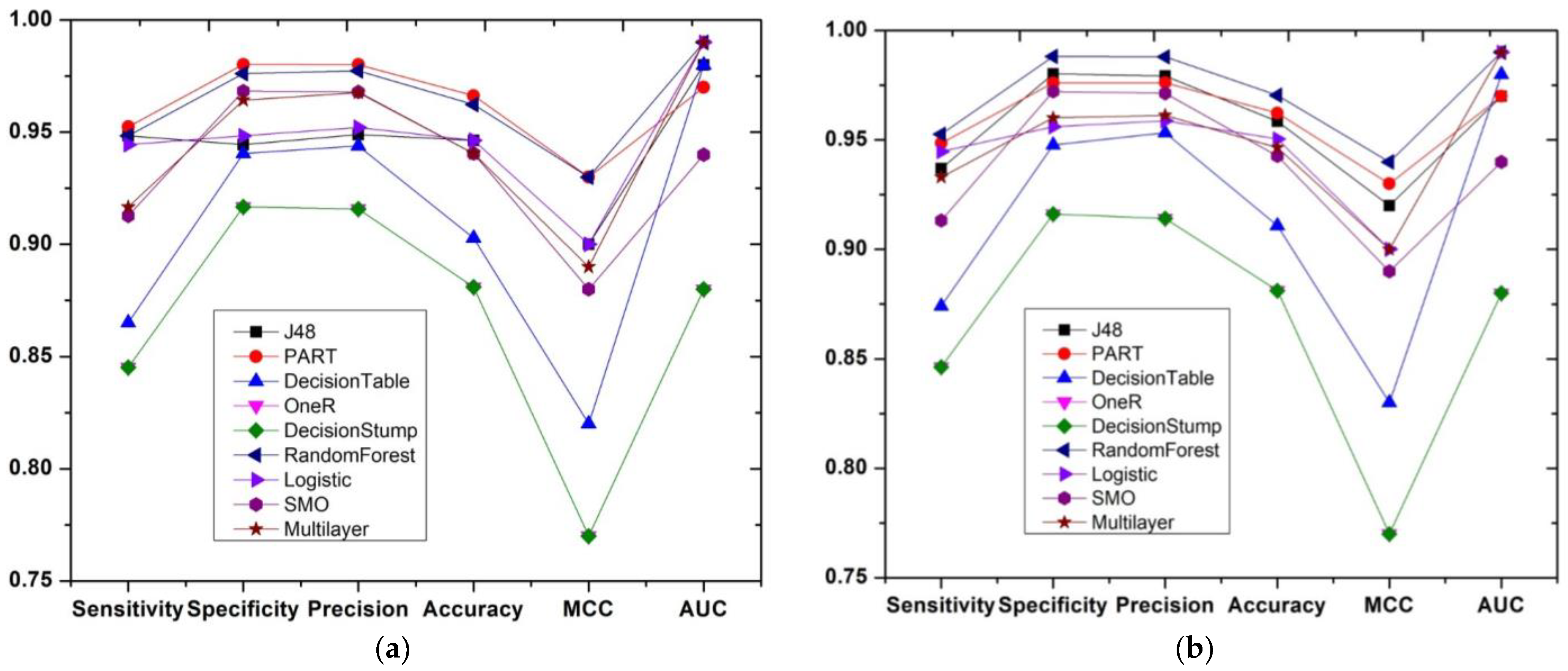
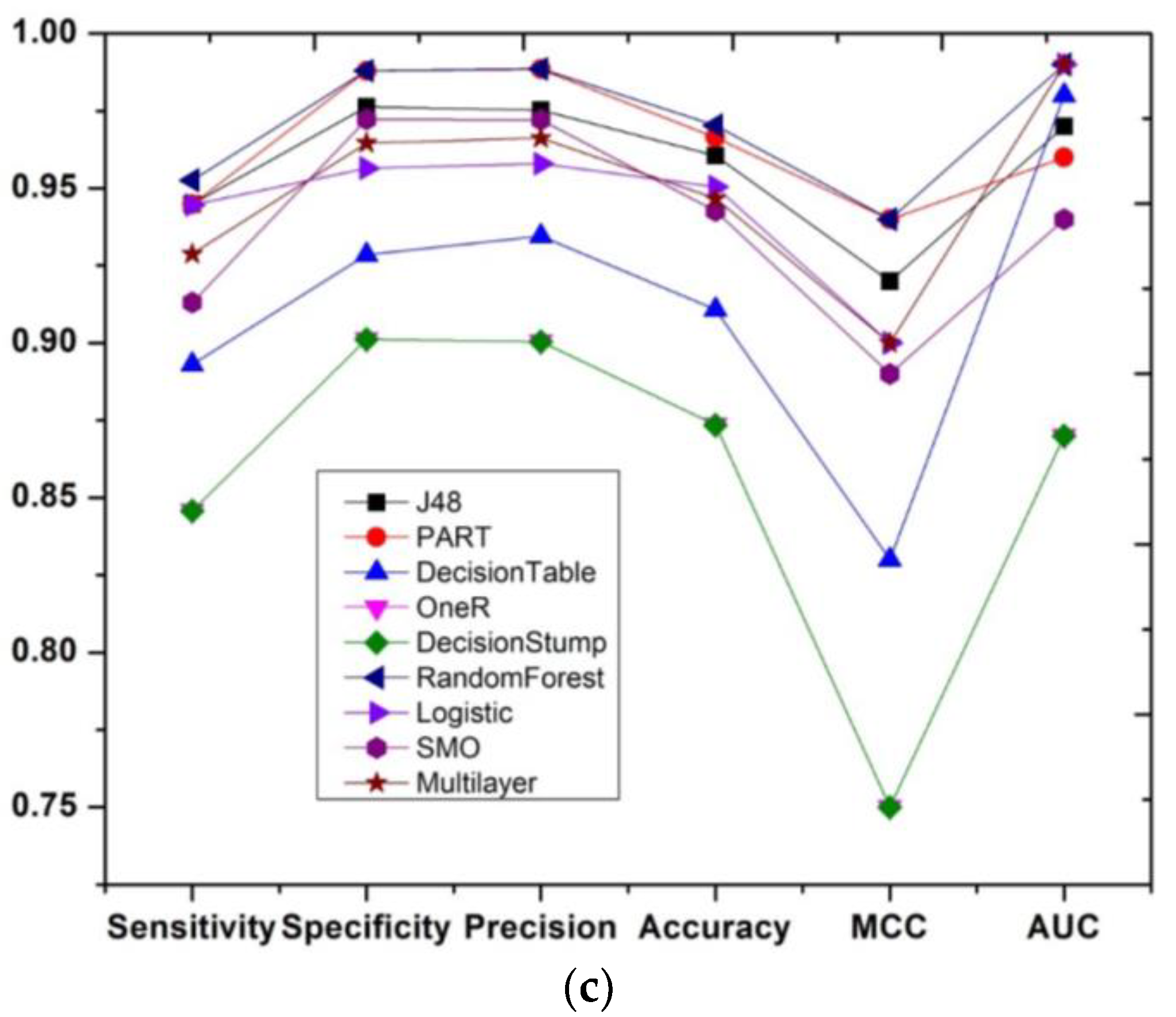
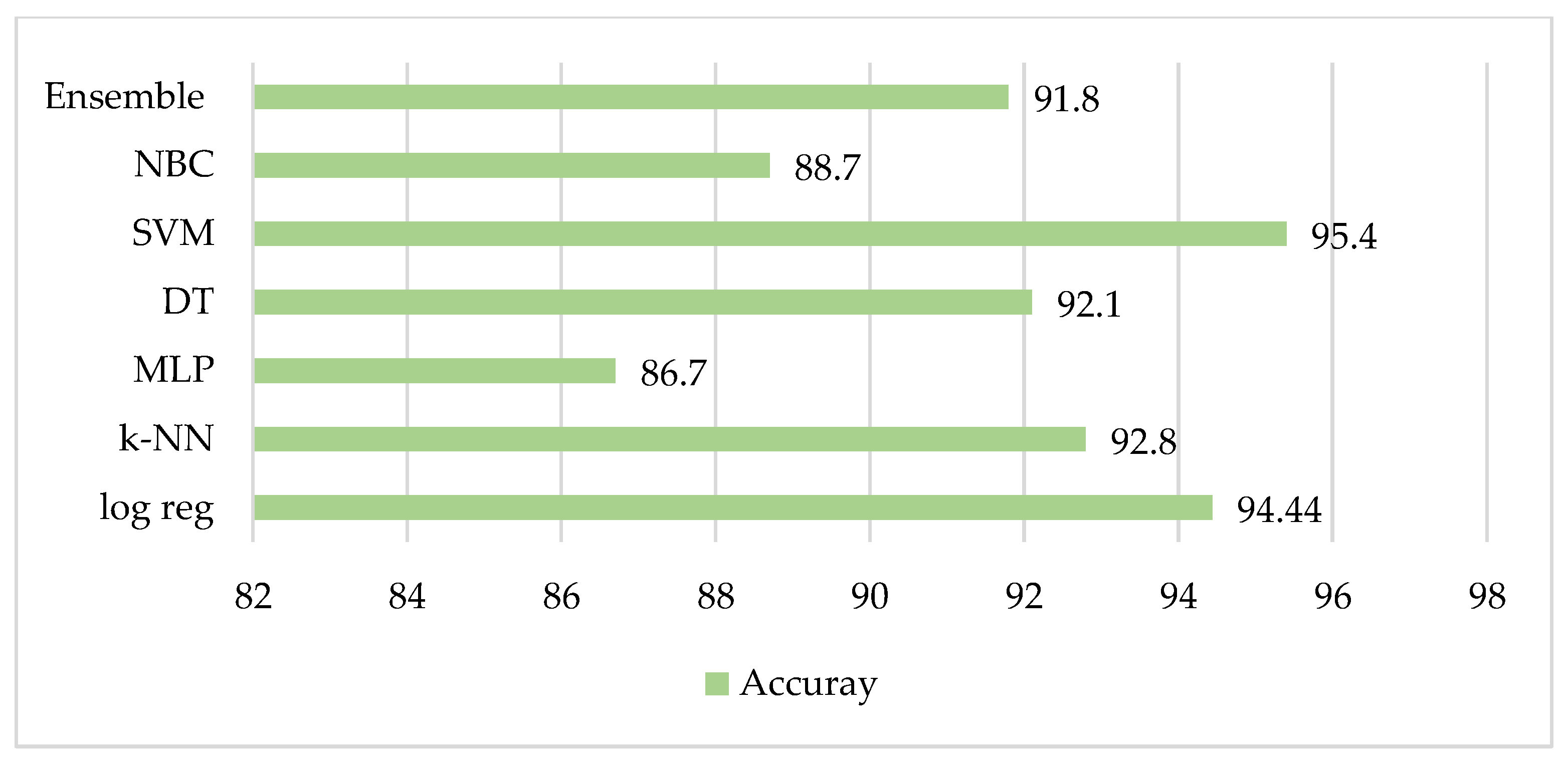
5. Results and Discussion
5.1. Comparison with Statistical Analysis
5.2. iEWS Prediction with RF
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ANN | Artificial Neural Network |
| DM | Data Mining |
| DNN | Deep Neural Network |
| EQE | Equitable Quality Education |
| ESD | Education for Sustainable Development |
| EWS | Early Warning System |
| HEI | Higher Education Institutions |
| iEWS | Intelligent Early Warning System |
| KNN | K-nearest neighbors |
| LMS | Learning Management Systems |
| RF | Random Forest |
| SDGs | Sustainable Development Goals |
| SVM | Support Vector Machine |
References
- United Nations. Sustainable Development Goals. Available online: http://www.undp.org/content/undp/en/home/sustainable-development (accessed on 15 October 2021).
- Messner, D.; Nakicenovic, N.; Zimm, C.; Clarke, G.; Rockström, J.; Aguiar, A.P.; Boza-Kiss, B.; Campagnolo, L.; Chabay, I.; Collste, D.; et al. The Digital Revolution and Sustainable Development: Opportunities and Challenges-Report Prepared by The World in 2050 Initiative; International Institute for Applied Systems Analysis (IIASA): Laxenburg, Austria, 2019. [Google Scholar]
- Kioupi, V.; Voulvoulis, N. Education for sustainable development: A systemic framework for connecting the SDGs to educational outcomes. Sustainability 2019, 11, 6104. [Google Scholar] [CrossRef] [Green Version]
- Jayaprakash, S.M.; Moody, E.W.; Lauría, E.J.; Regan, J.R.; Baron, J.D. Early alert of academically at-risk students: An open source analytics initiative. J. Learn. Anal. 2014, 1, 6–47. [Google Scholar] [CrossRef] [Green Version]
- Petruzzellis, L.; Romanazzi, S. Educational value: How students choose university: Evidence from an Italian university. Int. J. Educ. Manag. 2010, 24, 139–158. [Google Scholar] [CrossRef]
- Young, M.F.; Slota, S.; Cutter, A.B.; Jalette, G.; Mullin, G.; Lai, B.; Simeoni, Z.; Tran, M.; Yukhymenko, M. Our princess is in another castle: A review of trends in serious gaming for education. Rev. Educ. Res. 2012, 82, 61–89. [Google Scholar] [CrossRef] [Green Version]
- Islam, A.A.; Mok, M.M.C.; Gu, X.; Spector, J.; Hai-Leng, C. ICT in higher education: An exploration of practices in Malaysian universities. IEEE Access 2019, 7, 16892–16908. [Google Scholar] [CrossRef]
- Tseng, H.; Yi, X.; Yeh, H.T. Learning-related soft skills among online business students in higher education: Grade level and managerial role differences in self-regulation, motivation, and social skill. Comput. Hum. Behav. 2019, 95, 179–186. [Google Scholar] [CrossRef]
- Sharma, B.; Nand, R.; Naseem, M.; Reddy, E.V. Effectiveness of online presence in a blended higher learning environment in the Pacific. Stud. High. Educ. 2020, 45, 1547–1565. [Google Scholar] [CrossRef]
- Rodrigues, H.; Almeida, F.; Figueiredo, V.; Lopes, S. Mapping key concepts of e-learning and educational-systematic review through published papers. In Proceedings of the 11th Annual International Conference of Education, Research and Innovation, Seville, Spain, 12–14 November 2018; pp. 8949–8952. [Google Scholar]
- Chand, A.A.; Lal, P.P.; Chand, K.K. Remote learning and online teaching in Fiji during COVID-19: The challenges and opportunities. Int. J. Surg. 2021, 92, 106019. [Google Scholar] [CrossRef] [PubMed]
- Sharma, B.N.; Reddy, P.; Reddy, E.; Narayan, S.S.; Singh, V.; Kumar, R.; Naicker, R.; Prasad, R. Use of Mobile Devices for Learning and Student Support in the Pacific Region. In Handbook of Mobile Teaching and Learning; Zhang, Y., Cristol, D., Eds.; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Sharma, B.; Kumar, R.; Rao, V.; Finiasi, R.; Chand, S.; Singh, V.; Naicker, R. A mobile learning journey in Pacific education. In Mobile Learning in Higher Education in the Asia-Pacific Region; Springer: Singapore, 2017; pp. 581–605. [Google Scholar]
- Singh, V. Android based student learning system. In Proceedings of the 2015 2nd Asia-Pacific World Congress on Computer Science and Engineering (APWC on CSE), Suva, Fiji, 2–4 December 2015; IEEE: New York, NY, USA; pp. 1–9. [Google Scholar]
- Denning, P.J.; Lewis, T.G. Intelligence May Not Be Computable: A hierarchy of artificial intelligence machines ranked by their learning power shows their abilities--and their limits. Am. Sci. 2019, 107, 346–350. [Google Scholar] [CrossRef]
- Zhao, Y.; Liu, G. How do teachers face educational changes in artificial intelligence era. Adv. Soc. Sci. Educ. Humanit. Res. 2018, 300, 47–50. [Google Scholar]
- Zawacki-Richter, O.; Marín, V.I.; Bond, M.; Gouverneur, F. Systematic review of research on artificial intelligence applications in higher education–where are the educators? Int. J. Educ. Technol. High. Educ. 2019, 16, 39. [Google Scholar] [CrossRef] [Green Version]
- Kumar, N.M.; Krishna, P.R.; Pagadala, P.K.; Kumar, N.S. Use of smart glasses in education-a study. In Proceedings of the 2018 2nd International Conference on I-SMAC (IoT in Social, Mobile, Analytics and Cloud)(I-SMAC) I-SMAC (IoT in Social, Mobile, Analytics and Cloud)(I-SMAC), Coimbatore, India, 30–31 August 2018; IEEE: New York, NY, USA; pp. 56–59. [Google Scholar]
- Kumar, N.M.; Singh, N.K.; Peddiny, V.K. Wearable smart glass: Features, applications, current progress and challenges. In Proceedings of the 2018 Second International Conference on Green Computing and Internet of Things (ICGCIoT), Bangalore, India, 16–18 August 2018; IEEE: New York, NY, USA; pp. 577–582. [Google Scholar]
- Jokhan, A.; Sharma, B.; Singh, S. Early warning system as a predictor for student performance in higher education blended courses. Stud. High. Educ. 2019, 44, 1900–1911. [Google Scholar] [CrossRef]
- Pierrakeas, C.; Koutsonikos, G.; Lipitakis, A.D.; Kotsiantis, S.; Xenos, M.; Gravvanis, G.A. The variability of the reasons for student dropout in distance learning and the prediction of dropout-prone students. In Machine Learning Paradigms; Springer: Cham, Switzerland, 2020; pp. 91–111. [Google Scholar]
- Hochachka, W.M.; Caruana, R.; Fink, D.; Munson, A.R.T.; Riedewald, M.; Sorokina, D.; Kelling, S. Data-mining discovery of pattern and process in ecological systems. J. Wildl. Manag. 2007, 71, 2427–2437. [Google Scholar] [CrossRef]
- Dutt, A.; Ismail, M.A.; Herawan, T. A systematic review on educational data mining. IEEE Access 2017, 5, 15991–16005. [Google Scholar] [CrossRef]
- Romero, C.; Ventura, S.; Espejo, P.G.; Hervás, C. Data mining algorithms to classify students. In Proceedings of the Educational Data Mining 2008, The 1st International Conference on Educational Data Mining, Montreal, QC, Canada, 20–21 June 2008. [Google Scholar]
- Buenaño-Fernandez, D.; Villegas-CH, W.; Luján-Mora, S. The use of tools of data mining to decision making in engineering education—A systematic mapping study. Comput. Appl. Eng. Educ. 2019, 27, 744–758. [Google Scholar] [CrossRef] [Green Version]
- Buenaño-Fernández, D.; Gil, D.; Luján-Mora, S. Application of machine learning in predicting performance for computer engineering students: A case study. Sustainability 2019, 11, 2833. [Google Scholar] [CrossRef] [Green Version]
- Avramidis, E.; Skidmore, D. Reappraising learning support in higher education. Res. Post-Compuls. Educ. 2004, 9, 63–82. [Google Scholar] [CrossRef]
- Wolff, A.; Zdrahal, Z.; Nikolov, A.; Pantucek, M. Improving retention: Predicting at-risk students by analysing clicking behaviour in a virtual learning environment. In Proceedings of the Third International Conference on Learning Analytics and Knowledge, Leuven, Belgium, 8–13 April 2013; pp. 145–149. [Google Scholar]
- Marbouti, F.; Diefes-Dux, H.A.; Madhavan, K. Models for early prediction of at-risk students in a course using standards-based grading. Comput. Educ. 2016, 103, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Howard, E.; Meehan, M.; Parnell, A. Contrasting prediction methods for early warning systems at undergraduate level. Internet High. Educ. 2018, 37, 66–75. [Google Scholar] [CrossRef] [Green Version]
- Hu, Y.H.; Lo, C.L.; Shih, S.P. Developing early warning systems to predict students’ online learning performance. Comput. Hum. Behav. 2014, 36, 469–478. [Google Scholar] [CrossRef]
- Romero, C.; Ventura, S. Educational data mining: A review of the state of the art. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2010, 40, 601–618. [Google Scholar] [CrossRef]
- Casillas, A.; Robbins, S.; Allen, J.; Kuo, Y.L.; Hanson, M.A.; Schmeiser, C. Predicting early academic failure in high school from prior academic achievement, psychosocial characteristics, and behavior. J. Educ. Psychol. 2012, 104, 407. [Google Scholar] [CrossRef] [Green Version]
- Agaoglu, M. Predicting instructor performance using data mining techniques in higher education. IEEE Access 2016, 4, 2379–2387. [Google Scholar] [CrossRef]
- Gašević, D.; Dawson, S.; Rogers, T.; Gasevic, D. Learning analytics should not promote one size fits all: The effects of instructional conditions in predicting academic success. Internet High. Educ. 2016, 28, 68–84. [Google Scholar] [CrossRef] [Green Version]
- Calvo-Flores, M.D.; Galindo, E.G.; Jiménez, M.P.; Piñeiro, O.P. Predicting students’ marks from Moodle logs using neural network models. Curr. Dev. Technol.-Assist. Educ. 2006, 1, 586–590. [Google Scholar]
- Azcona, D.; Casey, K. Micro-analytics for student performance prediction. Int. J. Comput. Sci. Softw. Eng. 2015, 4, 218–223. [Google Scholar]
- Ognjanovic, I.; Gasevic, D.; Dawson, S. Using institutional data to predict student course selections in higher education. Internet High. Educ. 2016, 29, 49–62. [Google Scholar] [CrossRef] [Green Version]
- Andriessen, J.; Sandberg, J. Where is education heading and how about AI. Int. J. Artif. Intell. Educ. 1999, 10, 130–150. [Google Scholar]
- Vasileva-Stojanovska, T.; Malinovski, T.; Vasileva, M.; Jovevski, D.; Trajkovik, V. Impact of satisfaction, personality and learning style on educational outcomes in a blended learning environment. Learn. Individ. Differ. 2015, 38, 127–135. [Google Scholar] [CrossRef]
- Basavaraju, P.; Varde, A.S. Supervised learning techniques in mobile device apps for Androids. ACM SIGKDD Explor. Newsl. 2017, 18, 18–29. [Google Scholar] [CrossRef]
- Amrieh, E.A.; Hamtini, T.; Aljarah, I. Mining educational data to predict student’s academic performance using ensemble methods. Int. J. Database Theory Appl. 2016, 9, 119–136. [Google Scholar] [CrossRef]
- Bendangnuksung, P.P. Students’ performance prediction using deep neural network. Int. J. Appl. Eng. Res. 2018, 13, 1171–1176. [Google Scholar]
- Okubo, F.; Yamashita, T.; Shimada, A.; Ogata, H. A neural network approach for students’ performance prediction. In Proceedings of the Seventh International Learning Analytics & Knowledge Conference, Vancouver, BC, Canada, 13–17 March 2017; pp. 598–599. [Google Scholar]
- Shahiri, A.M.; Husain, W. A review on predicting student’s performance using data mining techniques. Procedia Comput. Sci. 2015, 72, 414–422. [Google Scholar] [CrossRef] [Green Version]
- Sikder, M.F.; Uddin, M.J.; Halder, S. Predicting students yearly performance using neural network: A case study of BSMRSTU. In Proceedings of the 2016 5th International Conference on Informatics, Electronics and Vision (ICIEV), Dhaka, Bangladesh, 13–14 May 2016; IEEE: New York, NY, USA; pp. 524–529. [Google Scholar]
- Oladokun, V.O.; Adebanjo, A.T.; Charles-Owaba, O.E. Predicting students academic performance using artificial neural network: A case study of an engineering course. Bull. Educ. Res. 2008, 40, 157–164. [Google Scholar]
- Ramesh, V.A.M.A.N.A.N.; Parkavi, P.; Ramar, K. Predicting student performance: A statistical and data mining approach. Int. J. Comput. Appl. 2013, 63, 35–39. [Google Scholar] [CrossRef]
- Osmanbegovic, E.; Suljic, M. Data mining approach for predicting student performance. Econ. Rev. J. Econ. Bus. 2012, 10, 3–12. [Google Scholar]
- Jishan, S.T.; Rashu, R.I.; Haque, N.; Rahman, R.M. Improving accuracy of students’ final grade prediction model using optimal equal width binning and synthetic minority over-sampling technique. Decis. Anal. 2015, 2, 112. [Google Scholar] [CrossRef]
- Arsad, P.M.; Buniyamin, N. A neural network students’ performance prediction model (NNSPPM). In Proceedings of the 2013 IEEE International Conference on Smart Instrumentation, Measurement and Applications (ICSIMA), Kuala Lumpur, Malaysia, 25–27 November 2013; IEEE: New York, NY, USA; pp. 1–5. [Google Scholar]
- Gray, G.; McGuinness, C.; Owende, P. An application of classification models to predict learner progression in tertiary education. In Proceedings of the 2014 IEEE International Advance Computing Conference (IACC), Gurgaon, India, 21–22 February 2014; IEEE: New York, NY, USA; pp. 549–554. [Google Scholar]
- Wang, T.; Mitrovic, A. Using neural networks to predict student’s performance. In Proceedings of the International Conference on Computers in Education, Auckland, New Zealand, 3–6 December 2002; IEEE: New York, NY, USA; pp. 969–973. [Google Scholar]
- Hämäläinen, W.; Vinni, M. Comparison of machine learning methods for intelligent tutoring systems. In Proceedings of the International Conference on Intelligent Tutoring Systems, Jhongli, Taiwan, 26–30 June 2006; Springer: Berlin/Heidelberg, Germany; pp. 525–534. [Google Scholar]
- Mayilvaganan, M.; Kalpanadevi, D. Comparison of classification techniques for predicting the performance of students academic environment. In Proceedings of the 2014 International Conference on Communication and Network Technologies, Sivakasi, India, 18–19 December 2014; IEEE: New York, NY, USA; pp. 113–118. [Google Scholar]
- Sembiring, S.; Zarlis, M.; Hartama, D.; Ramliana, S.; Wani, E. Prediction of student academic performance by an application of data mining techniques. In Proceedings of the International Conference on Management and Artificial Intelligence IPEDR, Bali, Indonesia, 1–3 April 2011; Volume 6, pp. 110–114. [Google Scholar]
- Mishra, T.; Kumar, D.; Gupta, S. Mining students’ data for prediction performance. In Proceedings of the 2014 Fourth International Conference on Advanced Computing & Communication Technologies, Rohtak, India, 8–9 February 2014; pp. 255–262. [Google Scholar]
- Natek, S.; Zwilling, M. Student data mining solution–knowledge management system related to higher education institutions. Expert Syst. Appl. 2014, 41, 6400–6407. [Google Scholar] [CrossRef]
- Naren, J. Application of data mining in educational database for predicting behavioural patterns of the students. Int. J. Comput. Sci. Inf. Technol. 2014, 5, 4649–4652. [Google Scholar]
- Bunkar, K.; Singh, U.K.; Pandya, B.; Bunkar, R. Data mining: Prediction for performance improvement of graduate students using classification. In Proceedings of the 2012 Ninth International Conference on Wireless and Optical Communications Networks (WOCN), Indore, India, 20-22 September 2012; pp. 1–5. [Google Scholar]
- Holmes, G.; Donkin, A.; Witten, I.H. Weka: A machine learning workbench. In ANZIIS’94-Australian New Zealnd Intelligent Information Systems; IEEE: New York, NY, USA, 1994; pp. 357–361. [Google Scholar]
- Witten, I.H.; Frank, E.; Trigg, L.E.; Hall, M.A.; Holmes, G.; Cunningham, S.J. Weka: Practical Machine Learning Tools and Techniques with Java Implementations. In Proceedings of the ICONIP/ANZIIS/ANNES’99 International Workshop “Future Directions for Intelligent Systems and Information Sciences”, Dunedin, New Zealand, 22–23 November 1999; pp. 192–196. [Google Scholar]
- Bhargava, N.; Sharma, G.; Bhargava, R.; Mathuria, M. Decision tree analysis on j48 algorithm for data mining. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 2013, 3, 1114–1119. [Google Scholar]
- Ali, S.; Smith, K.A. On learning algorithm selection for classification. Appl. Soft Comput. 2006, 6, 119–138. [Google Scholar] [CrossRef]
- Qian, Y.; Liang, J.; Li, D.; Zhang, H.; Dang, C. Measures for evaluating the decision performance of a decision table in rough set theory. Inf. Sci. 2008, 178, 181–202. [Google Scholar] [CrossRef]
- Muda, Z.; Yassin, W.; Sulaiman, M.N.; Udzir, N.I. Intrusion detection based on k-means clustering and OneR classification. In Proceedings of the 2011 7th International Conference on Information Assurance and Security (IAS), Melacca, Malaysia, 5–8 December 2011; IEEE: New York, NY, USA; pp. 192–197. [Google Scholar]
- Ayinde, A.Q.; Adetunji, A.B.; Bello, M.; Odeniyi, O.A. Performance Evaluation of Naive Bayes and Decision Stump Algorithms in Mining Students’ Educational Data. Int. J. Comput. Sci. Issues 2013, 10, 147. [Google Scholar]
- Peng, C.Y.J.; Lee, K.L.; Ingersoll, G.M. An introduction to logistic regression analysis and reporting. J. Educ. Res. 2002, 96, 3–14. [Google Scholar] [CrossRef]
- Platt, J. Sequential Minimal Optimization: A Fast Algorithm for Training Support Vector Machines; Microsoft: Washington, DC, USA, 1998; Available online: https://web.iitd.ac.in/~{}sumeet/tr-98-14.pdf (accessed on 15 October 2021).
- Gardner, M.W.; Dorling, S.R. Artificial neural networks (the multilayer perceptron)—A review of applications in the atmospheric sciences. Atmos. Environ. 1998, 32, 2627–2636. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Chan, J.C.W.; Paelinckx, D. Evaluation of Random Forest and Adaboost tree-based ensemble classification and spectral band selection for ecotope mapping using airborne hyperspectral imagery. Remote Sens. Environ. 2008, 112, 2999–3011. [Google Scholar] [CrossRef]
- Ho, T.K. The random subspace method for constructing decision forests. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 832–844. [Google Scholar]
- Xue, Y.; Chen, H.; Jin, C.; Sun, Z.; Yao, X. NBA-Palm: Prediction of palmitoylation site implemented in Naive Bayes algorithm. BMC Bioinform. 2006, 7, 458. [Google Scholar] [CrossRef] [Green Version]
- Paliwal, M.; Kumar, U.A. Neural networks and statistical techniques: A review of applications. Expert Syst. Appl. 2009, 36, 2–17. [Google Scholar] [CrossRef]







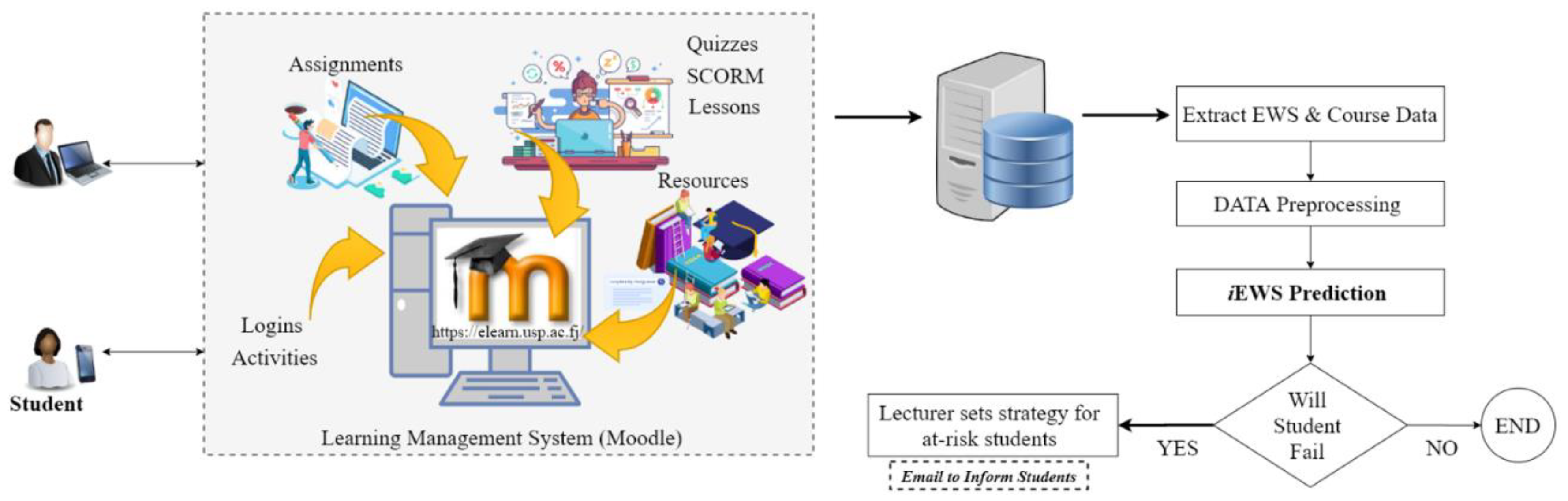
| 1 | Students and teachers interact with the course activities. |
| 2 | All interactions are recorded on Moodle Database. |
| 3 | EWS data are calculated using Moodle DB and recorded in EWS DB. |
| 4 | EWS data are extracted, and data prepressing is done (Data cleaning and EWS features are extracted). |
| 5 | EWS features are used to develop the iEWS predictor. |
| 6 | The iEWS predictor is tested with the test data. |
| 7 | If iEWS predicts a student to fail, then teacher sets strategies for these students. |
| 1 | Split pre-processed data set into n folds of approximately equal sample size with similar positive and negative samples in each. |
| 2 | Separate one of the folds as an independent test set and use the other n-1 folds as training data. |
| 3 | Train the model with training data and adjust the parameters of the predictor |
| 4 | Use the independent test set (2) to validate the predictor by computing all the statistical measures |
| 5 | Repeat steps 1 to 4 for other folds until n folds for validation and calculate the average of each statistical measure for n-folds and record the result |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jokhan, A.; Chand, A.A.; Singh, V.; Mamun, K.A. Increased Digital Resource Consumption in Higher Educational Institutions and the Artificial Intelligence Role in Informing Decisions Related to Student Performance. Sustainability 2022, 14, 2377. https://doi.org/10.3390/su14042377
Jokhan A, Chand AA, Singh V, Mamun KA. Increased Digital Resource Consumption in Higher Educational Institutions and the Artificial Intelligence Role in Informing Decisions Related to Student Performance. Sustainability. 2022; 14(4):2377. https://doi.org/10.3390/su14042377
Chicago/Turabian StyleJokhan, Anjeela, Aneesh A. Chand, Vineet Singh, and Kabir A. Mamun. 2022. "Increased Digital Resource Consumption in Higher Educational Institutions and the Artificial Intelligence Role in Informing Decisions Related to Student Performance" Sustainability 14, no. 4: 2377. https://doi.org/10.3390/su14042377