1. Introduction
Globalization has led to dramatic changes in maritime transport and trade. Containerization with large container vessels has emerged as a major actor in the container shipping industry, provided certain countries with a cooperative advantage in a globalized trading environment [
1]. Modern trade and economic development heavily rely on maritime transport. Asian countries are paying more attention to marine transportation due to the rapid growth in the volume of sea freight [
2]. Indeed, many Asian countries have shown astonishing economic growth in the recent past due to globalization. Particularly, this region has the advantage of being a central location for many manufacturing industries; moreover, Asia has some of the world’s busiest shipping routes connecting America, Africa, and Europe. Some ports offer a high level of connectivity as the primary trans-shipment hubs in the region [
2,
3]. They have built up reliable and densely connected networks. Asian manufacturing and trading networks have become increasingly integrated, which has led to a growth of intra-regional trade. More than 50% of global maritime trade is carried out in Asia, due to fragmented and globalized production processes [
2]. These dramatic changes have put great pressure on developing maritime transport management systems in this nascent region. Especially under the influence of many disruptions in recent times, such as the COVID-19 crisis, the maritime transport system has become highly vulnerable to potential risks.
In its most basic form, port sustainability implies persistence over time by considering the integration of environmentally friendly strategies for port activities, operations, and management [
1,
2,
3,
4]. Port sustainability aims to enhance the productivity and efficiency of port operations, both in the present and for future generations [
5]. The success of contemporary port management relies on embracing environmental, social, and economic goals. The efficiency and sustainability of port operations have been studied in previously. These studies have mostly focused on three perspectives: performance measurement [
3], performance management [
2,
5], and how these aspects are connected in building port resilience by studying the impact of environmental or social management on economic performance [
6,
7]. As an aspect of sustainability, resilience entails maintaining a certain level of functionality or a particular primary goal (e.g., profit, safety, and throughput), despite disruptions. It will help decision makers cope with market changes under the influence of disruptive factors [
6,
7]. It is challenging to ensure the long-term sustainability and productivity of container ports. There is an interconnectedness between individuals, organizations, and communities in complex and stochastic environments [
1]. For port infrastructure investments and construction, container throughput is an important indicator, and it is an irreversible investment [
8]. Port performance and international competitiveness are severely affected when there is an imbalance forecast on trade volume and container throughput. Therefore, a lack of port resilience policy may result in substantial financial losses of revenues and adversely affect global economies. In fact, the global and interconnected nature of today’s business environment poses serious threats to global supply chains.
It is important for port authorities to deal with the external factors that affect port viability, including changes in the technology of ports and transport, as well as the increased competition among ports. A nonlinear phenomenon observed in port ecosystems is called resilience, which was introduced as a descriptive ecological term in [
9]. In the rapidly changing business environment, resilience has been a key factor in achieving business sustainability. These key capabilities have been emphasized in subsequent ecological resilience studies, although they may have used different terms such as recovery and restoration, or defined them in a more specific context [
1,
10,
11,
12,
13]. The term ‘resilience’ is commonly described as the capability of a system to recover stability and performance after some disruptions or perturbations [
14,
15]. Thus, enterprise resilience plays an essential role in guaranteeing enterprises’ long-term continuity against disruptions. This will require the necessity to implement port resilience strategies, especially considering Korea’s strategic location in the Far East [
16].
For port performance indicators, many tools have been presented to explore the resilience and stability of container throughput in port ecosystems, such as control theory [
17], data envelopment analysis [
18], decomposition–ensemble methodology [
19], and stochastic modelling [
20]. Each approach has its own advantages but does not show the typical features of container throughput dynamics. Previous studies fail to provide resilience analysis of their systems under multiple disrupted factors that tend to cause system instability [
1]. In fact, the global COVID-19 pandemic is currently impacting business and investor communities around the world, and conventional resilience planning does not provide efficient strategies for dealing with it. In this paper, a new method is presented to analyse port resilience by combining dynamical analysis and data analytics techniques such as time series investigation, entropy analysis, Lyapunov exponent, and Hurst exponent, with statistical significance tests. The test results show that the presented approaches complement each other to gain more insights into dynamic properties of the port ecosystem.
To make effective management decisions based on liner shipping companies’ preferences, it is important to understand the port-to-port container volume and cargo flows. A literature review indicates that different forecasting methods for container throughput have been presented using a linear system, most of which are extensions of classic time series models. These methods include autoregressive integrated moving averages (ARIMAs), seasonal ARIMAs (SARIMAs), exponential smoothing [
21], optimization by reinforcement technique [
22], Grey forecasting [
23], and deep learning [
24,
25,
26]. Time series forecasting commonly assumes linearity; however, in reality, the systems often have unknown nonlinear structures. The time series data of container throughput show non-stationary characteristics and nonlinear trends, exhibiting highly complex behaviour [
1]. Especially in periods of rapid market changes affecting maritime transportation activities and trade, such as the 2009 financial crisis or the COVID-19 pandemic, powerful strategies based on deep learning algorithms will make port performance forecasting more accurate.
Future data forecasts are typically performed using time-series methods that identify trends and cyclic patterns in the dataset, as well as multivariate methods that establish relationships between the variable of interest and other independent variables [
27]. The methods, however, do not work well when the dependent variable (demand) exhibits trends, cycles, and dependencies on external disrupting factors. Various methods are used to deal with this situation, including hybrid forecasting methods. This paper presents a novel forecasting method in light of the latest stream of data-driven solutions to operations management problems [
28,
29,
30,
31,
32]. The proposed algorithm utilizes state-of-the-art sequential machine learning techniques. A hybrid deep learning method is implemented using LSTM and random forest (RF), a machine learning technique derived from decision trees’ structure. An innovative hybrid method is employed to address the problem when there are additional variables or disruptions in the time series. This technique can be used to model both temporal and correlational information in the dataset, whether the data are available in temporal or correlational format. A time-series data model was developed using deep learning techniques, such as LSTM networks. An in-depth discussion of the architecture and data format of LSTM networks is provided, as well as the optimization of hyperparameters. In addition, our method incorporates random forest after LSTM networks in order to improve accuracy and to better understand the demand behaviour by applying key variables. Additionally, the application of the proposed methodology can improve the forecasting performance for the disrupted throughput data in the container ports. The effectiveness of the proposed method was evaluated by a set of performance indexes and statistical significance tests to demonstrate the robust performance of the new proposed approach. Thus, this study addressed the following research questions against disruptions:
- -
How to build resilience strategies of container ports using the data analytics method?
- -
How to improve port productivity forecasting by utilizing hybrid deep learning methods?
- -
How to assess the effectiveness of hybrid forecasting methods using statistical significance tests?
To summarize, the proposed data analytics is based on time series investigation, entropy analysis, Lyapunov exponent, and Hurst exponent, with statistical significance tests. It will help policymakers understand insights into the system dynamics of port throughput and explain the underlying mechanism of port resilience after periods of volatility. In addition, the proposed methods will help port managers evaluate the predictability of port throughput systems, in addition to managerial implications. Next, the paper presents an advanced data analytics method with machine learning to improve prediction accuracy. The novel architecture, data setup, and hyperparameter optimisation have been presented for successful realization of the LSTM method in detail. Moreover, the random forest (RF) algorithm has been implemented as a supervisory method to improve the forecasting accuracy. The rest of this paper is organised as follows:
Section 2 presents a literature review;
Section 3 presents the resilience analysis using data analytics techniques;
Section 4 deals with the forecasting methods using machine learning; in
Section 5, the forecasting results, statistical analysis, and discussion are presented to validate the current research findings; finally,
Section 6 draws valid conclusions and outlines promising avenues for future research.
4. Deep Learning Approach for Port Productivity Forecasting
Based on the data analytics discussed above, the nature and dynamics of container throughput of Busan port are a complex and nonlinear time series, containing uncertain factors; especially, it is also influenced by many external disturbances. Therefore, building a robust forecasting method is necessary so that decision-makers can rely on it for improving operational efficiency as well as mitigating external shocks, thereby sustaining the growth trend and productivity of port operations. For predicting port throughput, LSTM networks have been shown to be highly effective in time-series forecasting tasks [
27,
29]. The dataset contains several throughput patterns during some volatile periods of international shipping. Therefore, a prediction model based on LSTM is a suitable alternative to handle linear and non-linear data, as well as data fluctuations caused by disruptions. This is the limitation of the LSTM model applied to a highly volatile market caused by external factors. Therefore, random forest (RF) is proposed as a complementary method to mitigate residual errors from the LSTM scheme. Multiple regression could be employed; however, RF is considered due to its superiority over others in prediction accuracy, with wide applicability in supply chain management [
31,
54]. In addition, recent empirical evaluations of the RF strategy show the strategy to be a very competitive advantage when it comes to forecasting performance [
27,
29,
54].
4.1. LSTM Algorithm
In artificial recurrent neural networks (RNNs), LSTM networks are among the most popular [
29,
69,
70,
71]. In time series analyses, RNNs are excellent because they consider the relationship between previous and subsequent data. As with normal neural networks, RNNs are trained by backpropagation and then learn by gradient descent [
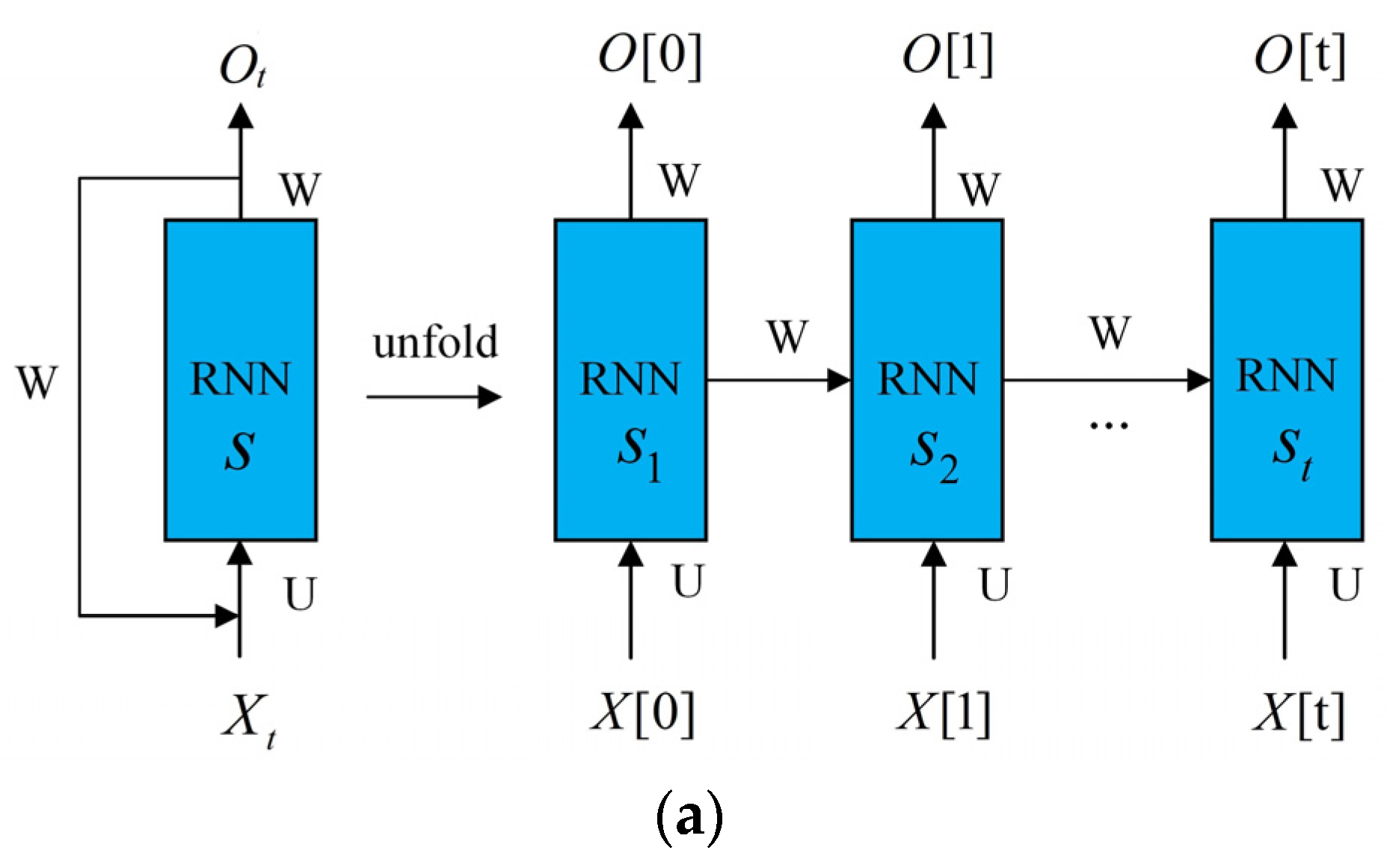
27]. Recurrent neural networks recirculate input data according to layers, in contrast to normal neural networks. In this way, new information is added to the memory and past information is remembered. A generic RNN architecture is shown in
Figure 10a:
X[0],
X[1]…
X[
t] are the data inputs, and
O[0],
O[1]…
O[t] are the data outputs, where
t is the time or order for each vector [
51].
There are three basic layers in LSTM networks: an input layer, one or more hidden layers, and an output layer. Feature space (explanatory variables) is equal to the number of neurons in the input layer. In the hidden layer(s) of LSTM networks, memory cells play a key role in describing their characteristics [
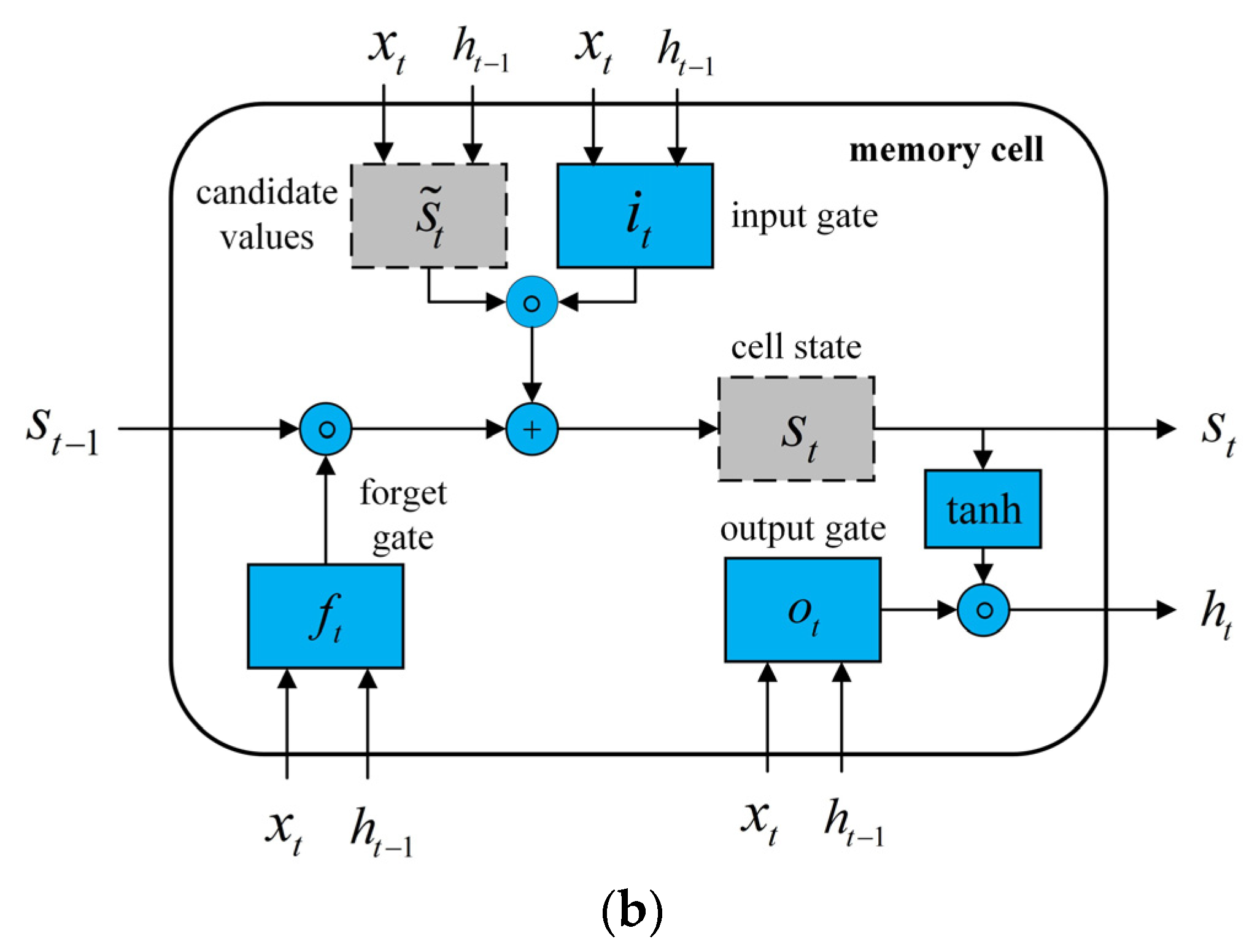
51].
Figure 10b illustrates the structure of a memory cell. LSTM layer memory cells are updated at every time step t according to the equations below. The notations used here are as follows:
is the input vector at time step t.
and are weight matrices.
, and are bias vectors.
, and are vectors for activating the respective gates.
and are vectors for the cell states and candidate values, respectively.
is a vector representing the LSTM layer.
Therefore, the activation values
ft of the forget gates at time step
t are computed based on the current input
xt, the outputs
ht−1 of the memory cells at the previous time step (
t − 1), and the bias terms
bf of the forget gates:
In the second step, the LSTM layer determines which information should be added to the network’s cell states (
). This procedure comprises two operations:
In the third step,
st is calculated based on the results of the previous two steps:
In the last step, the outputs of
ht are derived in the following two equations:
LSTM networks process input sequences by displaying their features timestep by timestep. The network processes the input (in this case, one single standardized return) at each time step t, as given in the equations above. The final output is returned once all elements of the sequence have been processed.
4.2. RF Algorithm
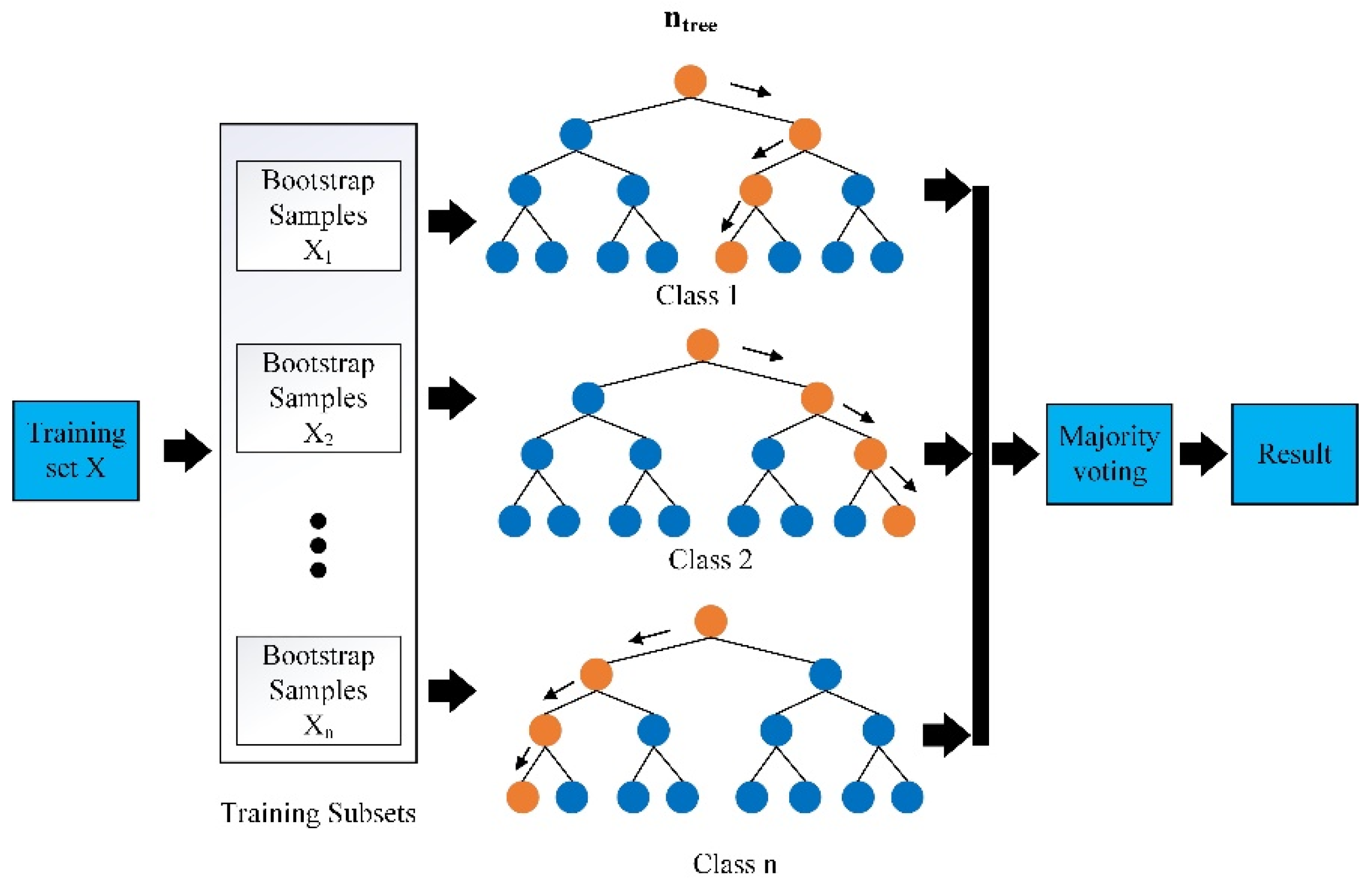
In decision tree modelling, the random forest (RF) algorithm is based on an ensemble classifier. A bootstrap sampling approach is used to generate
n training data subsets from an original dataset. These subsets are then trained to build
n decision trees [
72]. A combination of decision trees is used in the RF algorithm to overcome this shortcoming. When multiple trees are combined, the average of multiple trees will produce the correct results, eliminating the instability of a single tree [
72,
73]. The final classification result is determined based on the votes for each sample of the testing dataset (
Figure 11). Throughput forecasts are performed using RF, with explanatory variables as input variables and residuals from stage 1 as dependent variables [
27]. The proposed tasks would be easier to solve with multiple regression; however, RF is superior in accuracy and has wide applicability, including in retail management [
27,
54], financial management [
29], and supply chain management [
31]. Furthermore, recent empirical evaluations of the RF strategy demonstrate competitive forecasting performance. Due to the large number of trees, it is computationally expensive.
4.3. Hybrid Deep Learning for Forecasting Strategy
Batch size in the LSTM is defined as a set of past values used to predict future values. Batch size ranges from a single sample to a whole training set, but smaller batch sizes enable computing resources to be optimized. In this way, LSTM cannot make use of the data that are available across products to train the model. In contrast, RF can be trained over datasets on all products, thus obtaining more data and obtaining a better model for predicting the relationship between demand and independent variables; however, RF cannot detect trends or cyclicity in demand [
27]. As a result, the proposed method, based on the three-step approach outlined below, overcomes these limitations and presents a complete solution to the problems of modelling the temporal and regression effects of port throughput data.
Combining LSTM with RF enables the proposed forecasting method to take advantage of both methods’ complementary strengths, while avoiding overlapping weaknesses. Thus, the proposed method is the hybrid cooperative schemes from steps (1) and (2). In step (1), LSTM acts as the main algorithm to predict the nonlinear time series. In step (2), RF acts as a supervisory algorithm to predict the errors of step (1); then, step (3) can be used for the final forecasting results. These are errors caused by external shocks as well as serious internal uncertainties that LSTM cannot cover. Thus, the complete algorithm works in this way:
Step (1): The data series Xt is an input of the LSTM network, and forecasting , and the errors are typically generated. The forecasting step (1) is presented in Algorithm 1.
Step (2): The residuals from the first forecast are regressed over independent variables through the RF model and forecasting values for the residuals are determined. This algorithm step can be described in Algorithm 2.
Step (3): The final forecasting is obtained as:
Due to its ability to overcome both LSTM and RF limitations, the hybrid method should be able to predict outcomes better than either algorithm individually. LSTM forecasts future values based on past data, called the batch size. Smaller batch sizes produce better results when compared with larger batch sizes. Therefore, the algorithm cannot be used to train the model based on data from another dataset. Conversely, RF can be trained as a function of data from all training datasets; thus, it has a larger dataset on which to operate. Demand data cannot be modelled using RF, however, because they lack trend and cyclicity. In this regard, a hybrid approach that takes advantage of the combined advantages through three forecasting steps is suggested to overcome those limitations and provide a comprehensive solution to model the temporal and regression effects of demand data [
27,
29].
| Algorithm 1: Forecasting base on LSTM architectures |
| , training data length Ly, an LSTM model with P layers, weight W, and training epoch n | Dataset to be used |
| |
| 1. | | Training data |
| 2. | , do | |
| 3. | | | |
| 4. | | | LSTM input |
| 5. | | | input gate |
| 6. | | | forget gate |
| 7. | | | cell |
| 8. | | | output gate |
| 9. | | | LSTM output |
| 10. | | | |
| 11. | end | |
| | Prediction results: | |
| 12. | | Average Pooling |
| 13. | | |
| 14. | | Index of highest probability |
| 15. | | Predicted output |
| 16. | | Predicted error |
| 17. | End procedure | |
| Algorithm 2: Error forecasting using the RF method |
| dataset to be used |
| |
| 1. | | number of replicate experiments |
| 2. | | number of cross-validation folds |
| 3. | | number of runs per fold |
| 4. | | number of trees in RF |
| 5. | do | |
| 6. | | folds | |
| 7. | | for do | |
| 8. | | | Split dataset into training and test sets according to fold | |
| 9. | | | | initialize empty jungle |
| 10. | | | | initialize empty super-ensemble |
| 11. | | | for run ← 1 to n_runs do | |
| 12. | | | | Train RF with n_trees on training set | |
| 13. | | | | Test resultant RF on test set | |
| 14. | | | | Add all models (decision trees) to jungle | |
| 15. | | | | Add RF to super-ensemble | |
| 16. | | | end | |
| 17. | | | Test jungle | |
| 18. | | | Test super-ensemble | |
| 19. | | | Generate gardens of given sizes using order-based pruning, clustering-based pruning, and lexigarden | |
| 20. | | | Test resultant gardens on test set | |
| 21. | | end | | |
| 22. | end | |
5. Empirical Testing Results
5.1. Experimental Setup
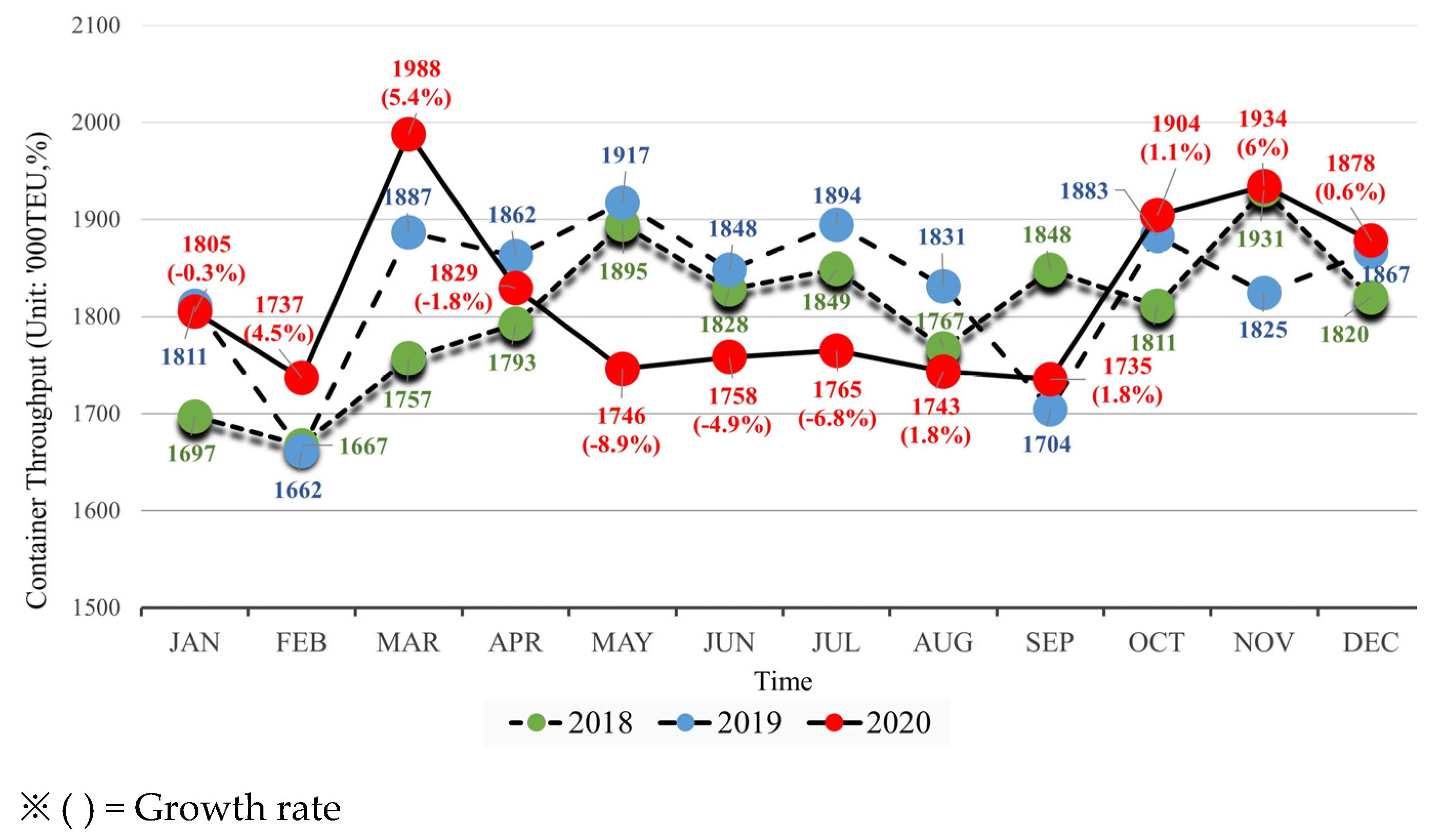
The strategic vision for Busan port has been about ensuring connectivity, productivity, and competitiveness. The dataset was derived from container throughput, which can be expressed as a twenty-foot equivalent unit (TEU) of Busan port in the period of 2001M1 to 2020M12, available in the shipping port logistics information system (PORT-MIS). The monthly data included 240 data points and covered import, export, and trans-shipment containers (
Table 1). The same training and testing datasets were used for all testing methods. The training dataset ranged from 2001M1 of monthly data to 2016M12, including 192 data points; the testing dataset included 48 data point consisting of monthly data from 2017M1 to 2020M12. According to the analysis in
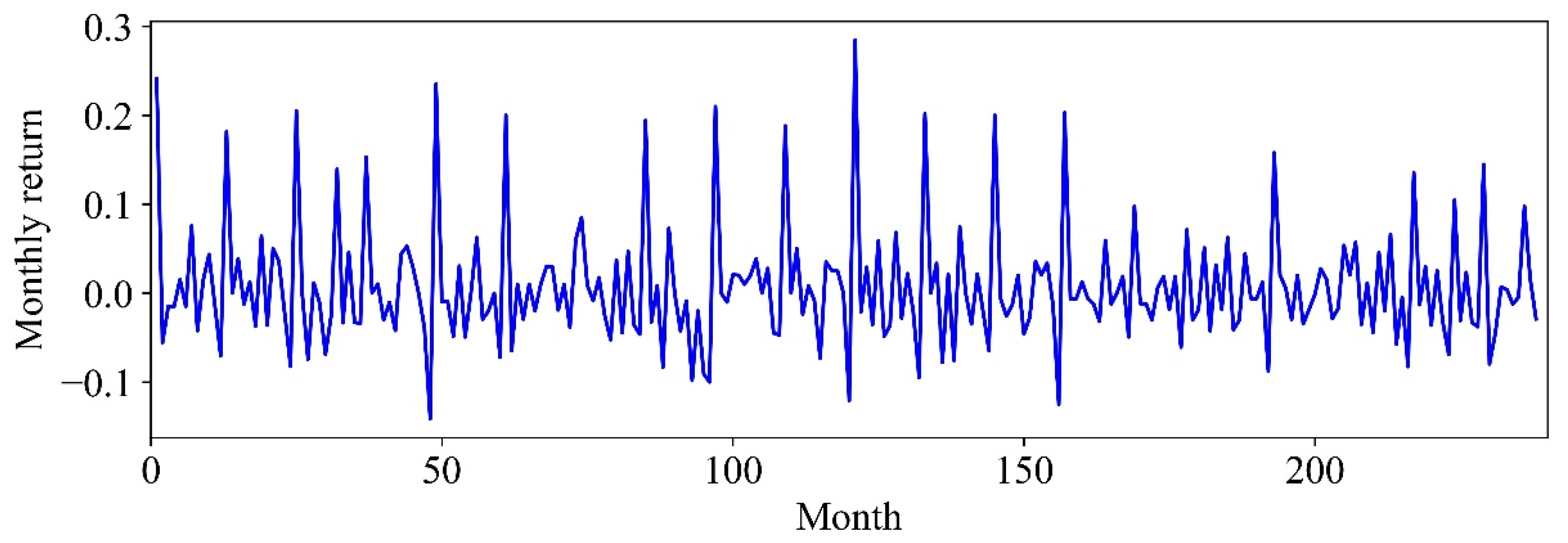
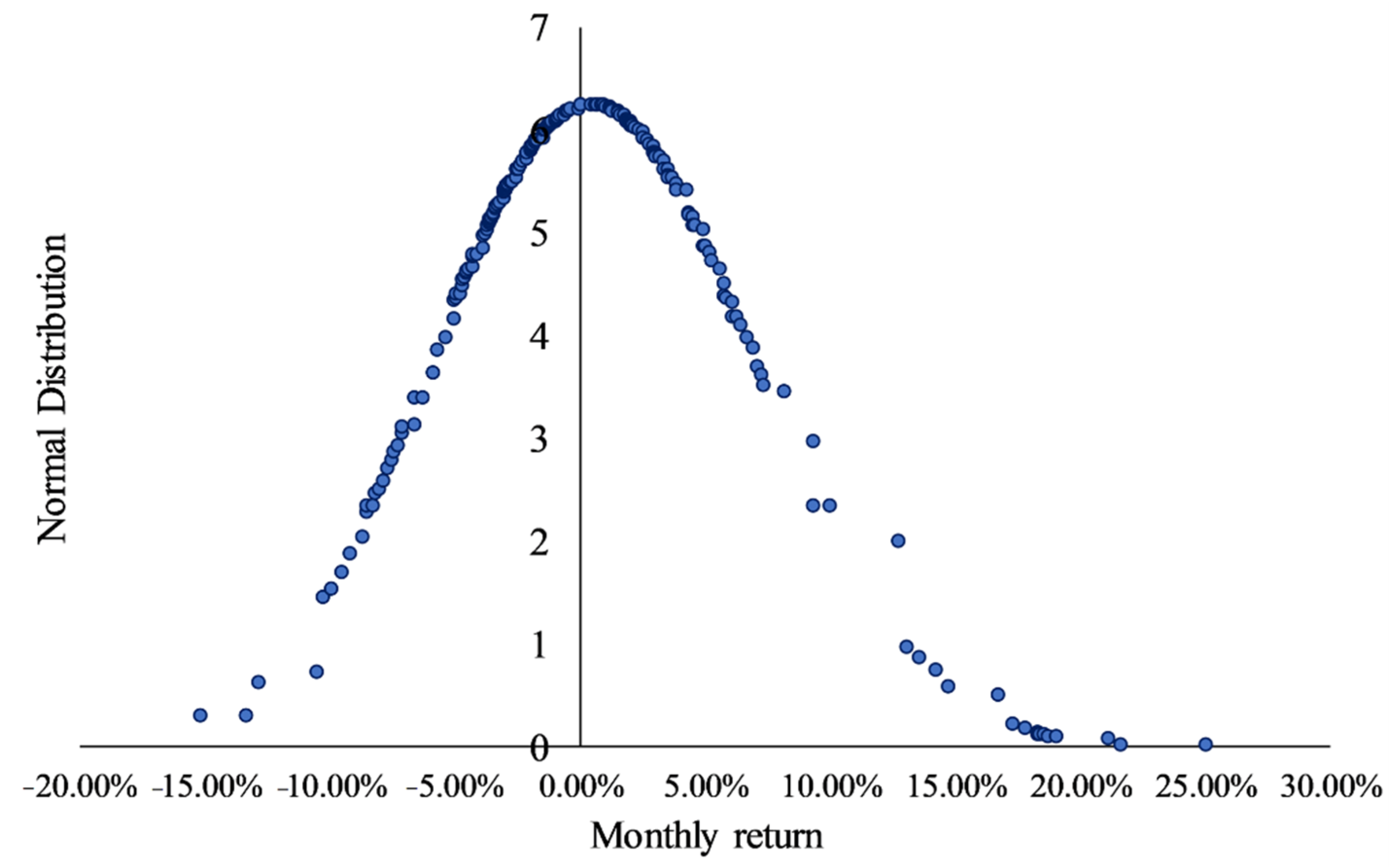
Section 3.2, the dataset (training and testing) followed a normal distribution, and the monthly volatility was around 6.38%.
Two convolutional layers of 64 and 128 filters were used in the RNN and LSTM models, respectively. Using a max pooling layer of 2 and an LSTM layer of 120 units, a fully connected layer of 36 neurons, and a neuron as the output layer, each layer was followed by a max pooling layer. There were 100 runs performed per fold for each training set of 4 folds and the left-out test set of 4 folds. A 100-tree RF was fitted for the training set, and a test set was created from the fitted RF. In addition, all trees were collected into a jungle and all RFs were saved into a super-ensemble.
5.2. Forecasting Performance Criteria
In order to determine a proposed algorithm’s predictive capabilities, four criteria are commonly used: mean squared error (MSE), mean absolute error (MAE), root-mean-square error (RMSE), and root-mean-square logarithmic error (RMSLE). The metric of each method is described in Equations (20)–(25), respectively. MSE, MAE, and RMSE are three well-known statistical measures. These methods were performed in this study for evaluating the deviations of forecasted results from actual values. MSE measures the difference between the original and forecasted values extracted by squaring the average difference over the dataset. MAE represents the deviations of the original and forecasted values extracted by averaging the absolute difference over the dataset. RMSE is obtained by the square root of MSE.
where
and
are the actual and forecasted values, respectively, and
N is the sample size.
A modern statistic evaluation method, the Diebold–Mariano (DM) test, is presented in this paper instead of the traditional evaluation criteria for forecasting performance mentioned previously [
74], which can be used as a quantitative tool to assess forecast accuracy. Using this test, it is possible to determine whether the difference between the forecasts is significant or the result of a specific choice of datasets. According to Diebold and Mariano [
75], the DM test theory originated from them. In fact, the DM test tends to reject the null hypothesis too often for a dataset with a small sample size. A better test procedure is based on the Harvey et al. [
69], or the so-called HLN test method, which is described as follows:
The DM test has been widely used to test for forecast accuracy in large samples. If the forecast samples are small, the HLN test is conveniently used, which is actually a modification of the DM test with a small sample size. In this study, both DM and HLN test methods were used to evaluate the effectiveness of the proposed forecasting algorithms.
5.3. Long-Term Forecasting Results for Container Throughput
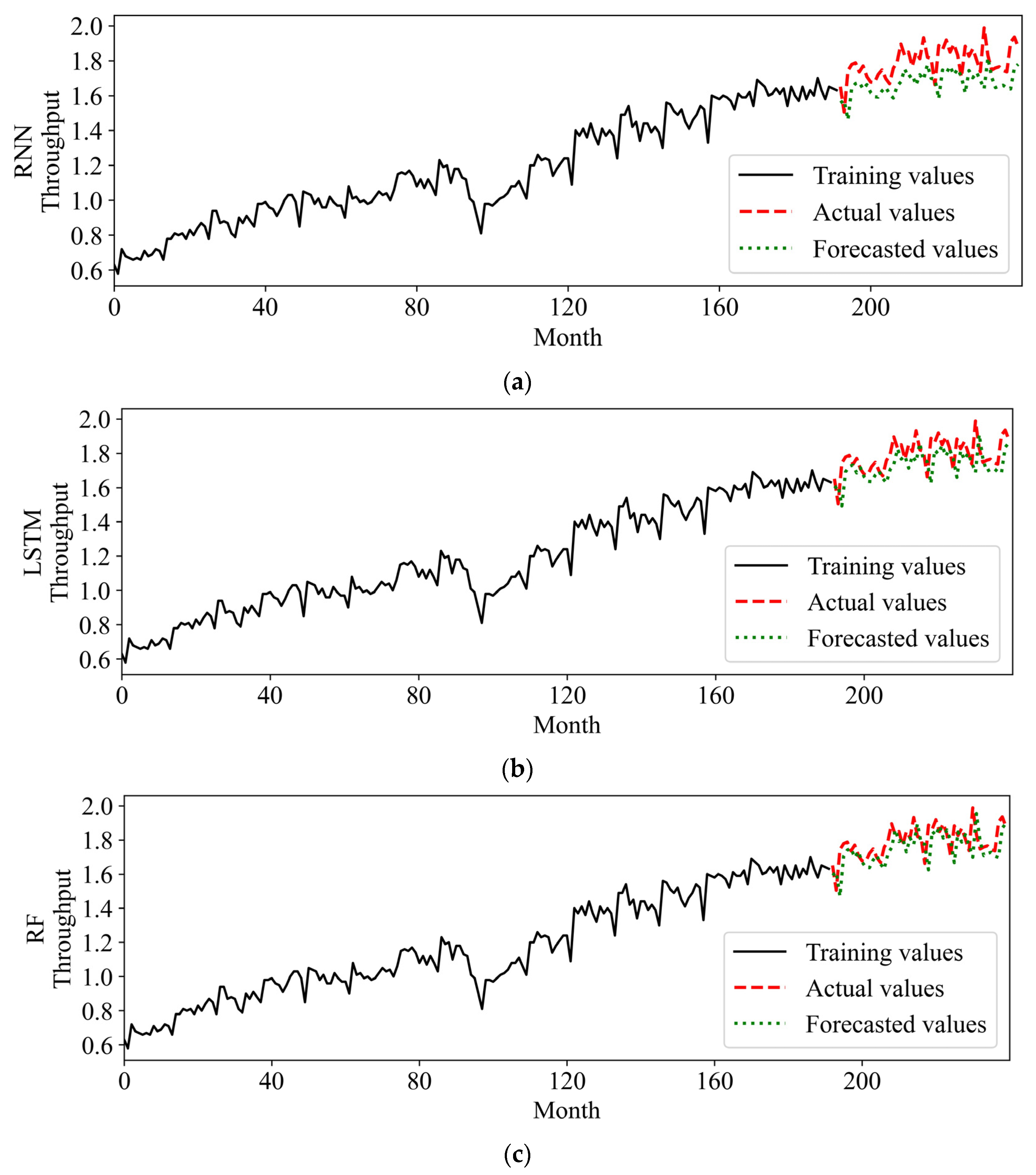
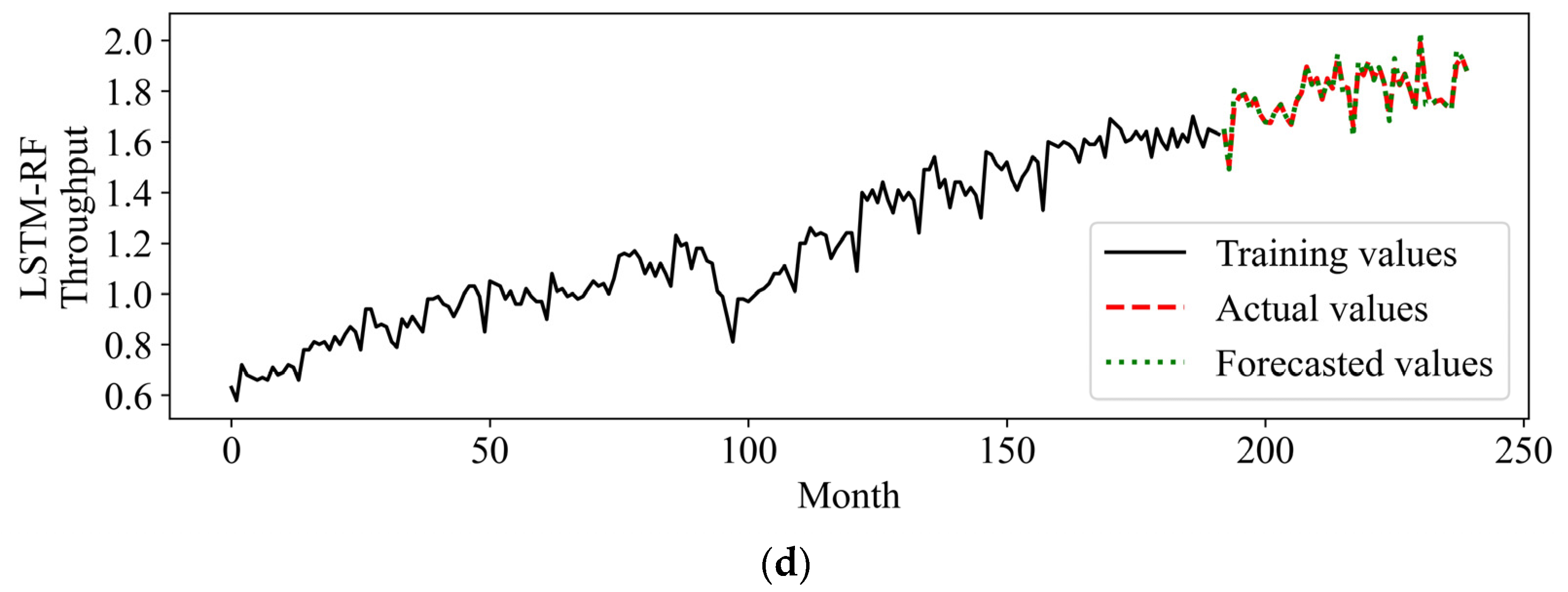
The proposed forecasting method was initially applied for long-term prediction. A forecast of the container throughput volume for the next four years was based on data from the first 16 years for training. Three benchmarking algorithms, RNN, LSTM, and RF, were used to evaluate the effectiveness of the proposed algorithms. The actual extrapolations are shown in
Figure 11. It can be seen in
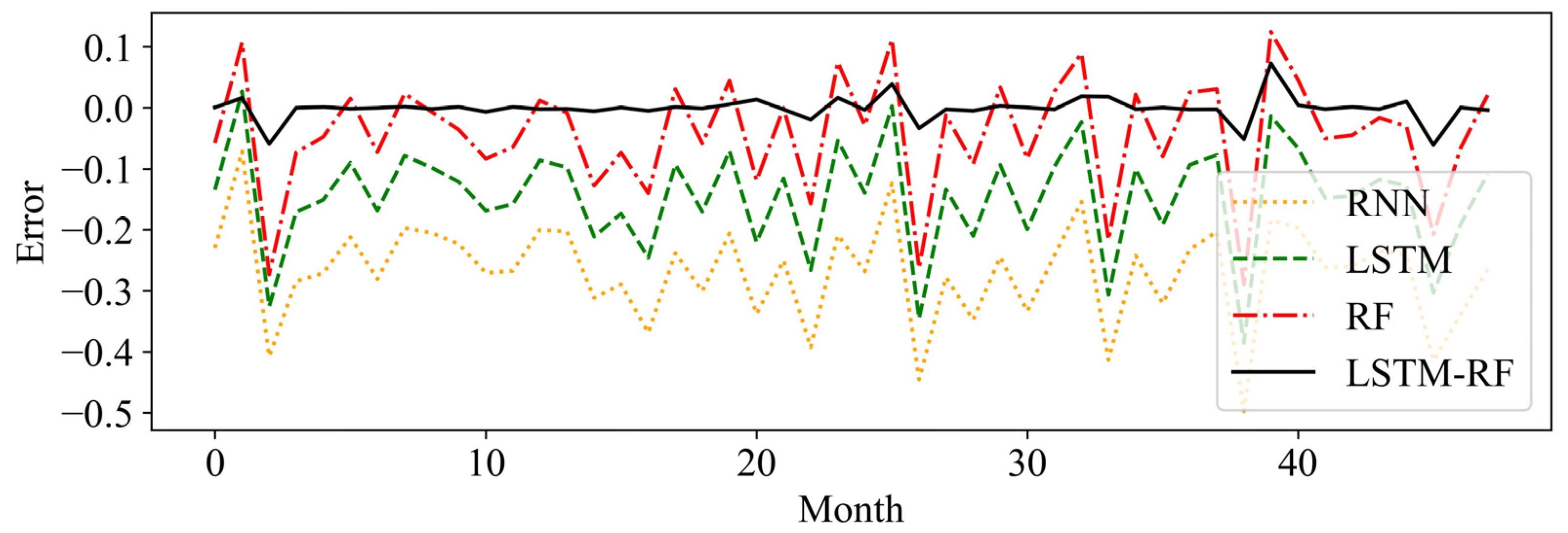
Figure 11 that LSTM, RF, and the proposed methods achieved better forecasting performance than RNN. Moreover, the results show that the new hybrid approach has the best performance where the forecasting data series could converge to the actual data. In more detail, the residual errors of the forecasting methods are shown in
Figure 12. It can be seen that the proposed method performs extremely well compared with other methods, whereas the RNN algorithm yields relatively larger errors than other methods (see
Figure 13).
As shown in
Table 2, throughput forecasts for the next four years are averaged. Results from the proposed method show that forecasts are more accurate. When comparing all methods for forecasting port throughput, the proposed hybrid method outperforms benchmarking methods.
Based on the DM and HLN tests, statistical significance tests were conducted for the empirical evaluation differences between the proposed hybrid method and the aforementioned algorithms (
Table 3). Statistically significant differences in forecasting performance exist at a 95% confidence level between the proposed method and different benchmarking methodologies. For the null hypothesis that paired methods have equal performance, panel A of
Table 3 shows the
p-values from the DM test. A
p-value indicates the confidence that method
i will produce a worse prediction than method
j. Forecasts using the proposed method are superior to benchmarking methods (RNN, LSTM, and RF) because all individual hypotheses are rejected over the 95% significance level. As shown in
Table 3, the HLN test yielded similar results for panel B. Comparing the proposed algorithm with other algorithms, all test results demonstrated optimal performance. Therefore, this hybrid method can be successfully applied for throughput forecasting in a volatile environment with ensuring better performance and higher accuracy compared with conventional methods.
5.4. Short-Term Forecasting Results for Container Throughput
After evaluating long-term forecasting methods, short-term testing could be a more challenging issue because the disruptions would only be of a short duration; therefore, it is very difficult to predict the next trend. The last 10 years of container throughput data are used as training data to forecast the trend over the next 12 months, in which the test setup is described in
Section 5.1. The forecast periods are divided into three periods, covering 2018–2020. The performance evaluation and significance test of each period are presented in
Table 4,
Table 5,
Table 6,
Table 7,
Table 8 and
Table 9. In general, the proposed hybrid algorithm yielded good performance compared with other methods in all the periods of 2018–2020 (
Table 4,
Table 6 and
Table 8, respectively). An important aberration from the short-term prediction is that LSTM exhibited better performance than RF in 2019 and 2020. This is different from the long-term test where RF always performed better than LSTM. Furthermore, DM and HLN tests were performed to evaluate statistical significance for short-term forecasting.
Table 5,
Table 7, and
Table 9 show the test results for monthly predictions for the years 2018, 2019, and 2020, respectively. Similar results were obtained for all tests over time. The proposed hybrid algorithm was the top-performing strategy across all the metrics at a 95% confidence level. The test results confirm the superiority of the proposed hybrid method for throughput prediction against volatile market conditions.
5.5. Discussions
Comprehensive data analytics techniques for analysing nonlinear dynamical behaviour and identifying business disruptions are presented in this study (LE, information entropy, HE, statistical significance with DM and PT evaluation). The accuracy and efficiency of business forecasting have recently been improved, but researchers have spent comparatively little time assessing performance. A biased forecast, however, can lead to higher logistical costs (transportation, carrying, inventory, and warehousing), which directly affects profit margins.
Forecasting algorithms (including the hybrid and three benchmark forecasting models) have been presented to predict the container throughput of Busan port using historical data back to 2001. It shows that for handling a complex and potentially risky system such as port throughput dynamics, effective throughput forecasting is not readily obvious using only conventional benchmark models. Five metrics and two statistical tests have been used to comprehensively prove that the hybrid method outperforms all other benchmarking algorithms. For long-term forecasts, RF is the best performing of the tested prediction models, whereas LSTM is the third best. The case of RF demonstrates the advantage of the decision tree model in long-term prediction over LSTM or RNN. In fact, RNN showed the lowest performance level of the tested prediction models, whereas advanced methods, such as the proposed hybrid method and LSTM, are well-suited for short-term prediction. In particular, for short-term foresting in 2019 and 2020, LSTM provided higher accuracy compared with RF. Notably, the hybrid method performed better than LSTM and RF in both short- and long-term forecasting. This is mainly due to the LSTM network which was first applied to model the temporal characteristics of the time series. The residuals of the LSTM network were then modelled using RF with any exogenous information that differed for each time period. Then, the proposed method was successfully used to predict the real throughput data of Busan port. Finally, the proposed hybrid model focused on building the operational resilience of port management using novel deep learning algorithms against a disruptive market environment.
6. Conclusions, Managerial Insights, and Future Research
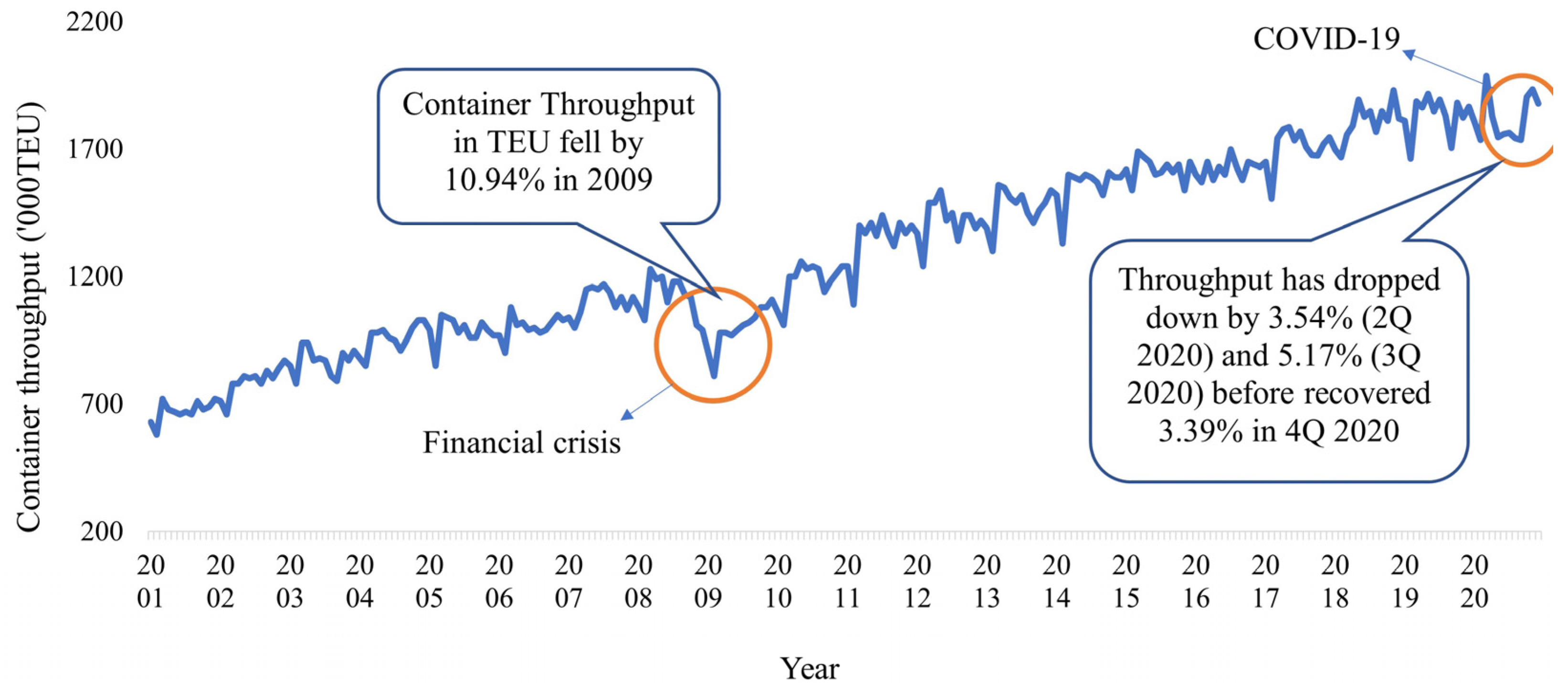
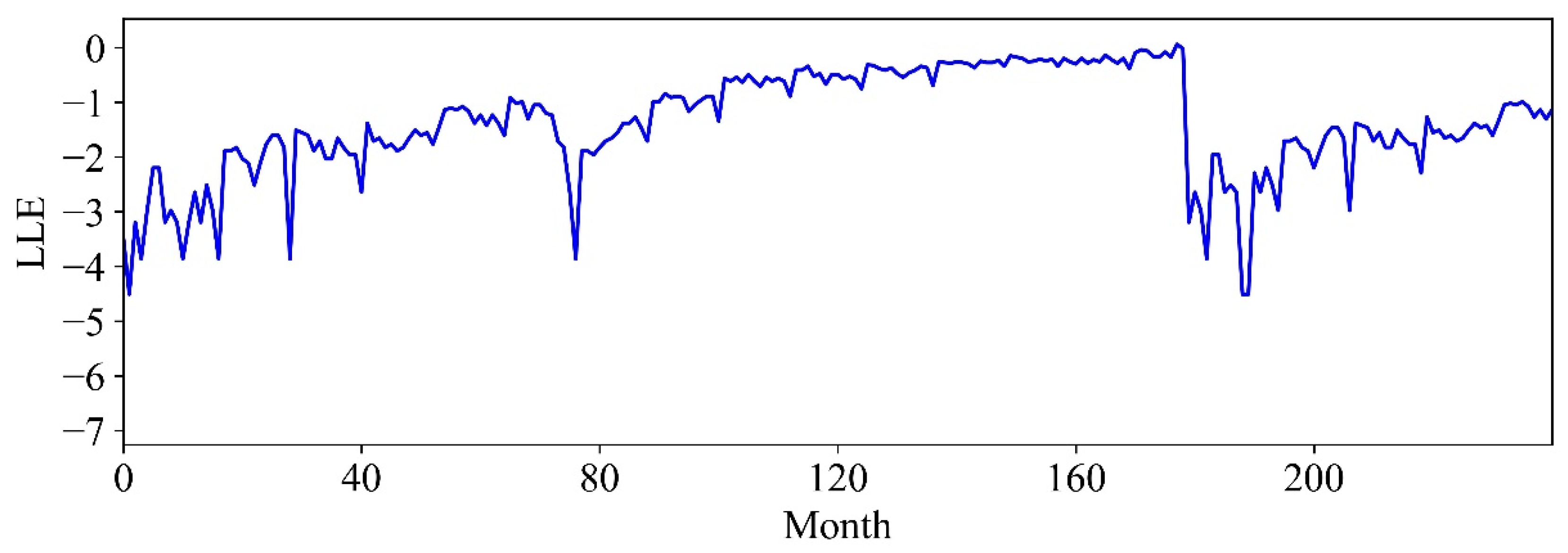
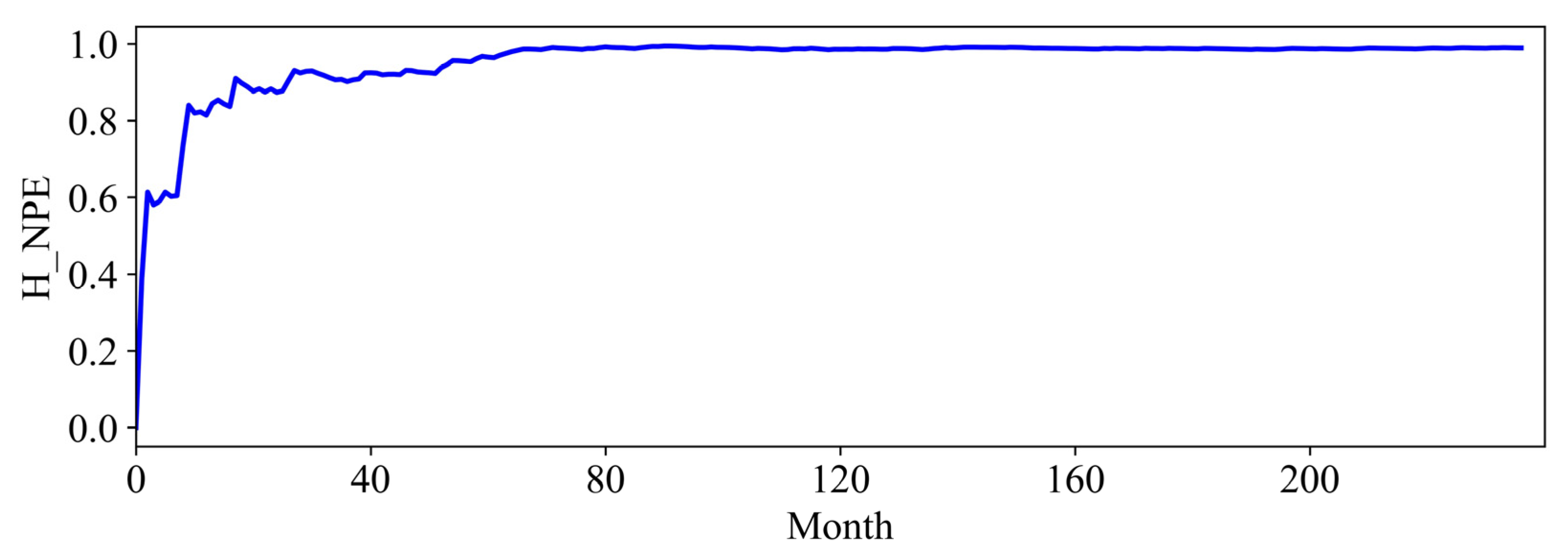
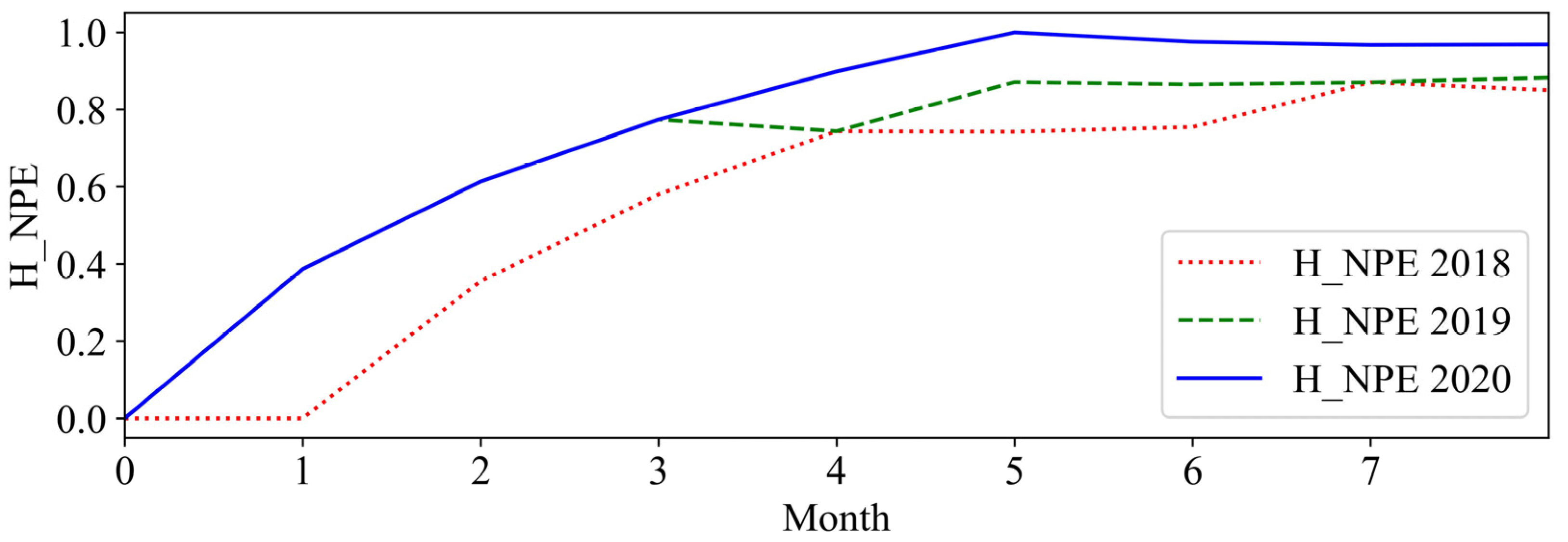
In this paper, comprehensive methods have been proposed for evaluating port resilience and throughput forecasting based on nonlinear time series analysis. The data analytics techniques can provide managerial insights for decision makers in understanding, characterizing, and predicting port productivity. First, the port resilience was evaluated using both nonlinear time-series analysis and statistical methods to help policymakers gain a deeper understanding of the resilience properties of maritime logistics in a disruptive market environment. In particular, the port throughput resilience against disruptions has been investigated through historical events such as the 2009 financial crisis and the COVID-19 pandemic. Nonlinear data analytics techniques for improving decision-making include Lyapunov exponents, entropy analysis, and Hurst exponents, which demonstrated the nonlinearity and chaotic tendency of a dynamic system.
Next, a robust forecasting method has been proposed by combining LSTM and RF to draw on the strengths of each strategy while avoiding their weaknesses. Then, the forecasting performance was extensively evaluated for the proposed hybrid method and a set of well-known algorithms, including RNN, LSTM, and RF. The performance evaluation metrics used were MSE, MAE, MAPE, RMSE, and RMSLE. Furthermore, the DM and HLN statistical significance tests were used to demonstrate the proposed empirical findings. All the evaluation results indicated that the proposed method outperformed all benchmarking models used in this study for both long- and short-term prediction. The proposed hybrid algorithm was the top-performing strategy across all measures at a 95% confidence level. The test results confirmed the superiority of the proposed hybrid method for throughput prediction against market volatility. In addition, the prediction results show that this study has many other possible applications in nonlinear time series forecasting and provides a new paradigm for the development of port productivity forecasting.
In more detail, this study makes major contributions to the theory and practice of both data analytics and dynamical behaviour for port productivity. As part of the first contribution, powerful analysis tools are proposed to investigate complex and nonlinear system behaviour, helping decision makers gain a better understanding of the dynamic behaviour of port productivity; the resilience mechanisms of port operations under external disturbances were explored by data analytics and statistical methods. In addition, a robust forecasting method has been proposed in this paper, which could be used to analyse complex maritime logistics patterns in the event of disruptions. This method employs a hybrid approach: first, an LSTM is applied to represent the temporal characteristics of a time series, followed by an RF for residuals from the model fitting. Therefore, port authorities can better prepare for future planning and operations based on the results obtained in the past through the proposed algorithm. Furthermore, the third contribution is that this study provides new insights into the mechanisms for clarifying system dynamic behaviour via nonlinear time series theory, such as in economic and financial forecasting problems.
In this study, the forecasting method was based on univariate analysis for training on the historical data. However, the expansion of multiple input variables, such as storage capacity of the terminal yard, ship turnaround time, container dwell time, berth/crane productivity, custom declaration time, etc., will make the forecasting method more comprehensive through learning various relationships that affect port productivity. For further studies, nonlinear control techniques could be used to help port authorities make systemic decisions that improve productivity and profitability.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}