1. Introduction
Exchange rate risks are one of the main risks in international trade. It can be defined as losses that are caused by the fluctuation of the local currency relative to the currency of the trading nation. After the collapse of the Bretton Woods system, most governments adopted more flexible exchange rate regimes, which are characterized by unanticipated exchange rate fluctuations [
1]. Exchange rate movements are affected by many complex factors, including political and economic events. The risks of international trade become more accentuated at the same time as the increase of the exchange rates volatility. The exchange rate risks faced by multinational trading firms include transaction risk, translation risk, and economic risk [
2]. For example, related to transaction risk, fluctuations in the exchange rate of the denominated currency caused losses to import and export contracts related to accounts receivable. Also, the risks attract the attention of national policy-makers who need to embrace the challenge related to the exchange rates volatility. To reduce these risks and avoid the returns from overseas trade being eroded, the use of financial market instruments, such as financial derivatives (forward, futures, options, etc.) and foreign currency debt, is the most important way for multinational trading firms to hedge exchange rate risks [
3]. The premise of using these financial market instruments for hedging risk is that the correct measurement of risk has been proven to be difficult by Van Deventer et al. [
4]. Making accurate forecasts and decisions of the direction and magnitude of fluctuations is another more direct and efficient approach for reducing exchange rate risks. This research will propose a new approach to improve the accuracy of short-term exchange rate forecasting for reducing exchange rate risks.
Over the course of the past 40 years, many classical time series analysis models such as AR, ARMA, ARCH, and GARCH have been widely used in financial time series analysis [
5,
6,
7]. The linear autoregressive (AR) model provides the flexibility to model stationary time series. The autoregressive moving average (ARMA) model assumes a linear relationship between the lag variables [
8]. It has poor prediction accuracy for nonlinear and nonstationary time series. Especially when time trends and seasonal features appear in nonstationary time series, the predictive performance of the ARMA model degrades significantly. Box and Jenkins proposed the famous autoregressive integrated moving average (ARIMA) model in the 1970s [
9]. This model eliminates or reduces the first-order nonstationarity by differencing. However, the differencing usually amplifies the high frequency noise in the time series, so much effort is required to determine the order of the ARIMA model. Engle introduced the autoregressive conditional heteroskedasticity (ARCH) model to capture second-order nonstationarity [
10]. The generalized autoregressive conditional heteroskedasticity (GARCH) model is an extension of ARCH that represents the variance of the error term as a function of its autoregressive terms [
11]. However, all these methods tend to be limited for nonlinear and nonstationary time series forecasting.
In the last twenty years, researchers in machine learning have tried to solve the problems of time series forecasting with machine learning methods and achieved certain results. These methods include random forests, support vector machines, Bayesian, and the like. Lin et al. proposed a random forests-based extreme learning machine ensemble model in multiregime time series forecasting [
12]. Cao proposed using the support vector machines (SVMs) experts for time series forecasting [
13]. Balabin and Lomakina proposed a model based on SVM-based generalized regression for time series forecasting, such as support vector regression (SVR) and least-squares support vector machines (LSSVMs). A novel forecasting approach with a Bayesian-regularized artificial neural networks (BR-ANN) was proposed by Yan et al. [
14]. The methods mentioned above play an important role in time series forecasting which have small data size and smooth features. However, the results of predictions are not satisfactory when the data is large, nonstationary, or nonlinear [
15].
In recent years, the research of artificial neural networks has made breakthrough progress. Deep learning can deal with many practical problems that are difficult to solved by conventional methods. It has been widely used in financial time series forecasting [
16,
17,
18,
19,
20]. The neural network models are known to be effective in stock market dynamic predictions [
21,
22]. Studies have shown that the models of deep learning can approximate nonlinear functions with arbitrary precision while there are enough hidden nodes (neurons). The recurrent neural network (RNN), one kind of the deep learning with time series processing capabilities, has naturally become a strong contender for these methods of classic approaches of exchange rate forecasting [
23,
24,
25].
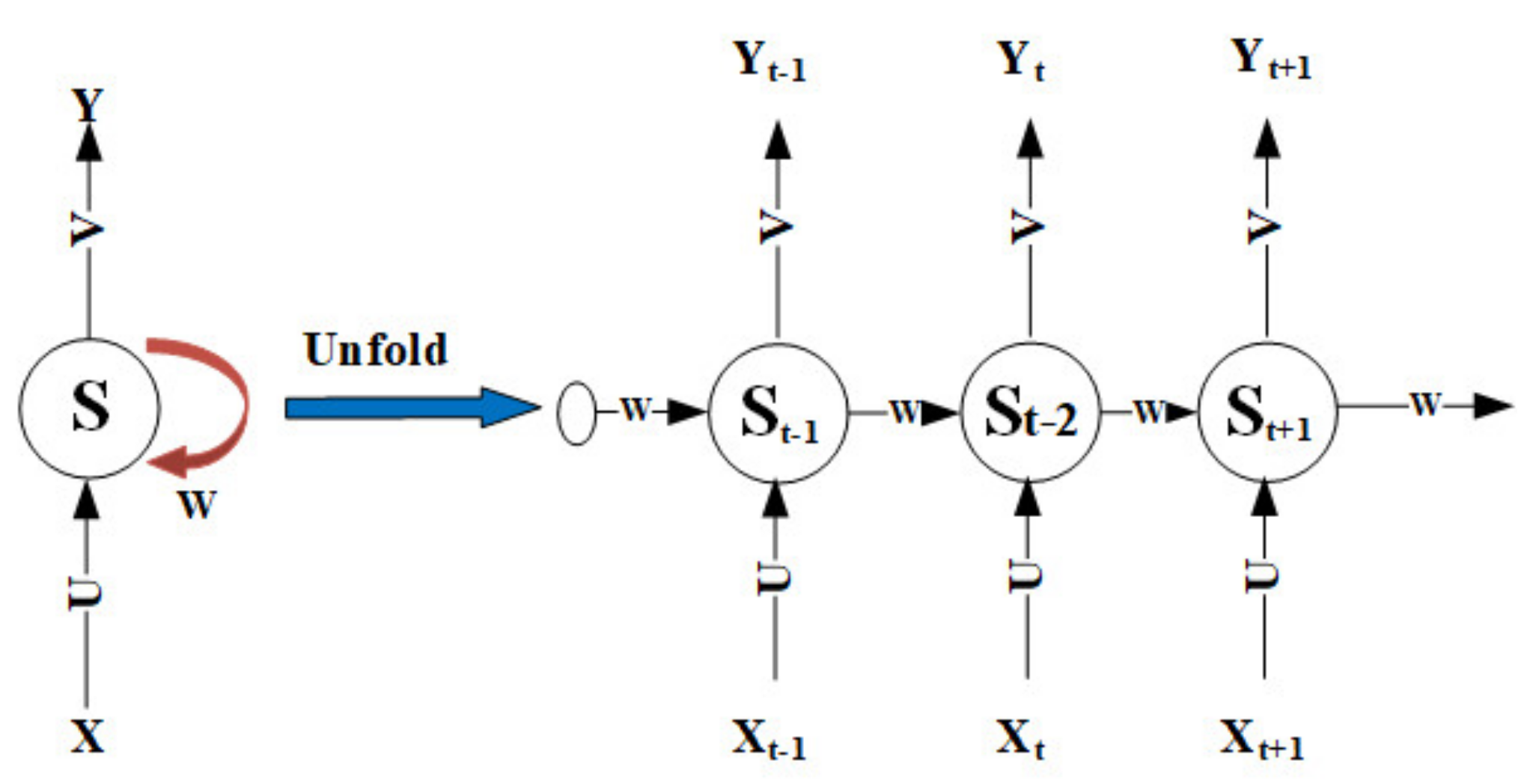
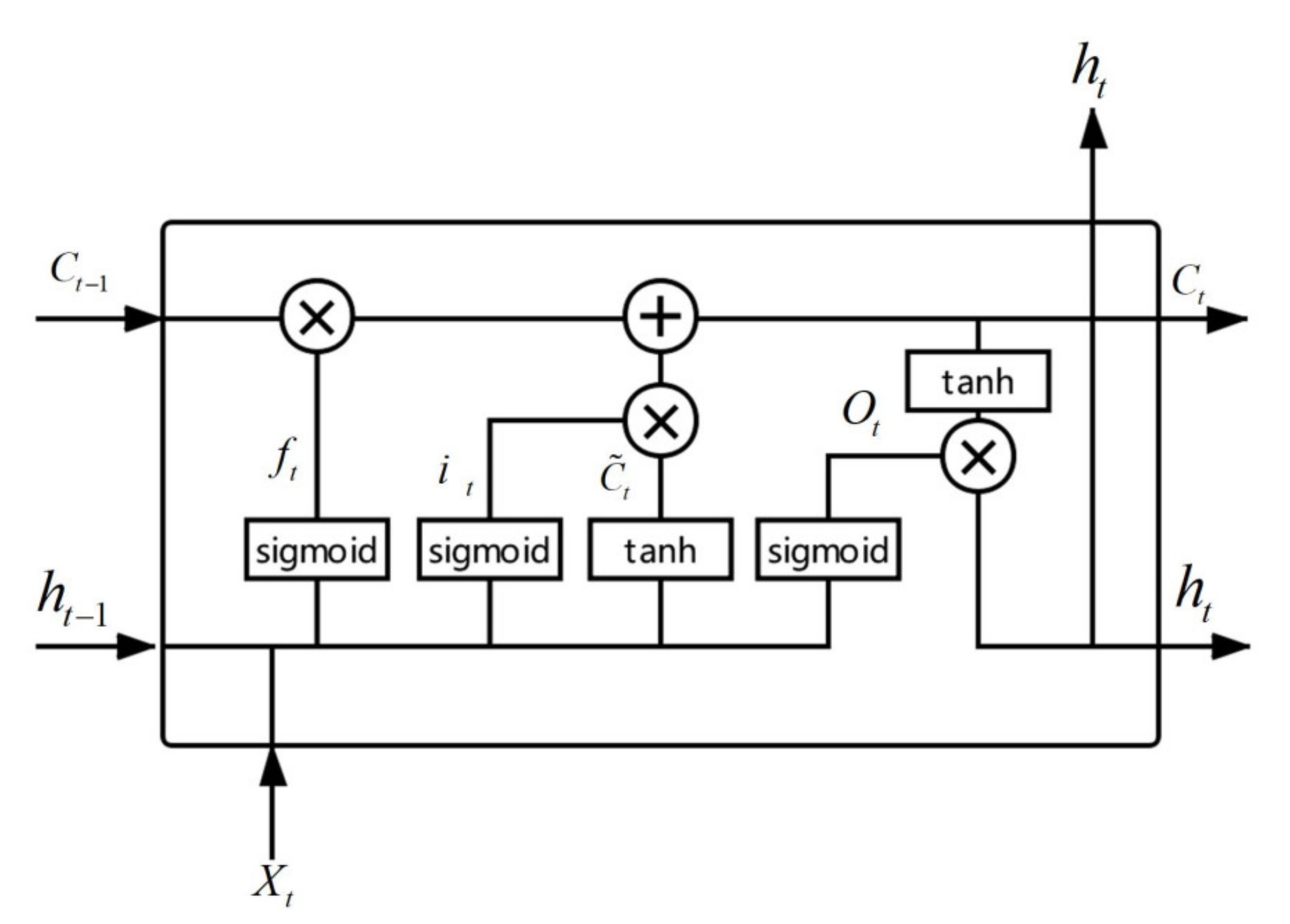
In the classic RNN, the information of each time step is stored in the internal state of the network. When training, it needs to learn in the opposite direction of time. The multiplication of the derivative of the activation function will lead to the disappearance of the gradient or the phenomenon of gradient explosion. The long short-term memory (LSTM) proposed by Hochreiter and Schmidhuber as an extension of RNN can learn the long-term dependence of data, and is widely used for speech recognition, natural language processing, image identification, time series forecasting, and other fields [
26,
27,
28,
29]. Dai et al. proposed trajectory prediction modeling of vehicle interactions through an improved LSTM model [
30]. Hao et al. used an improved LSTM model for pedestrian trajectory prediction [
31], but their performance on financial time series forecasting issues is not satisfactory. This single-layered architecture does not effectively demonstrate the complex features of exchange rate data, especially when trying to deal with nonstationary, nonlinear and long-interval time series data [
32,
33].
Empirical mode decomposition (EMD) is an adaptive signal decomposition algorithm for nonlinear, nonstationary signals [
34]. EMD cannot effectively decompose the nonstationary signals if there are not enough extreme points. In order to solve the mode mixing problem of EMD, Wu and Huang proposed a white-noise-assisted data analysis method called ensemble empirical mode decomposition (EEMD) [
35]. Compared to EMD, EEMD eliminates the influences of mode mixing, but still retains some noise in the intrinsic mode functions (IMFs) [
36]. The complete ensemble empirical mode decomposition with adaptive noise (CEEMDAN) algorithm obtains a set of noise-containing signals by adding multiple sets of independent and identically distributed adaptive white noise with finite variance constraints on the original signal, and then decomposes with EMD [
37]. It can further reduce the number of iterations, compress the frequency aliasing region, and improve the convergence performance. It has better performance than EEMD on decomposition of the nonstationary signal.
Exchange rate forecasting is based on current and past information in the foreign exchange market to predict future exchange rate behavior. As a financial time series, the exchange rate data owns not only the characteristics of general time series such as autocorrelation, trend, seasonality, and random noise, but also features of financial time series such as nonlinearity, nonstationary, and volatility clustering [
38]. Meese and Rogoff compared the out-of-sample forecasting accuracy of exchange rate prediction methods. They found that a random walk model performs as well as other models at exchange rate forecast within 12 months [
39]. Galeshchuk further expanded the set of models to include Taylor rule fundamentals, yield curve factors, and incorporate shadow rates and risk and liquidity factors [
40]. Wright proposed Bayesian Model Averaging and found that the prediction error is smaller than the random walk model [
41].
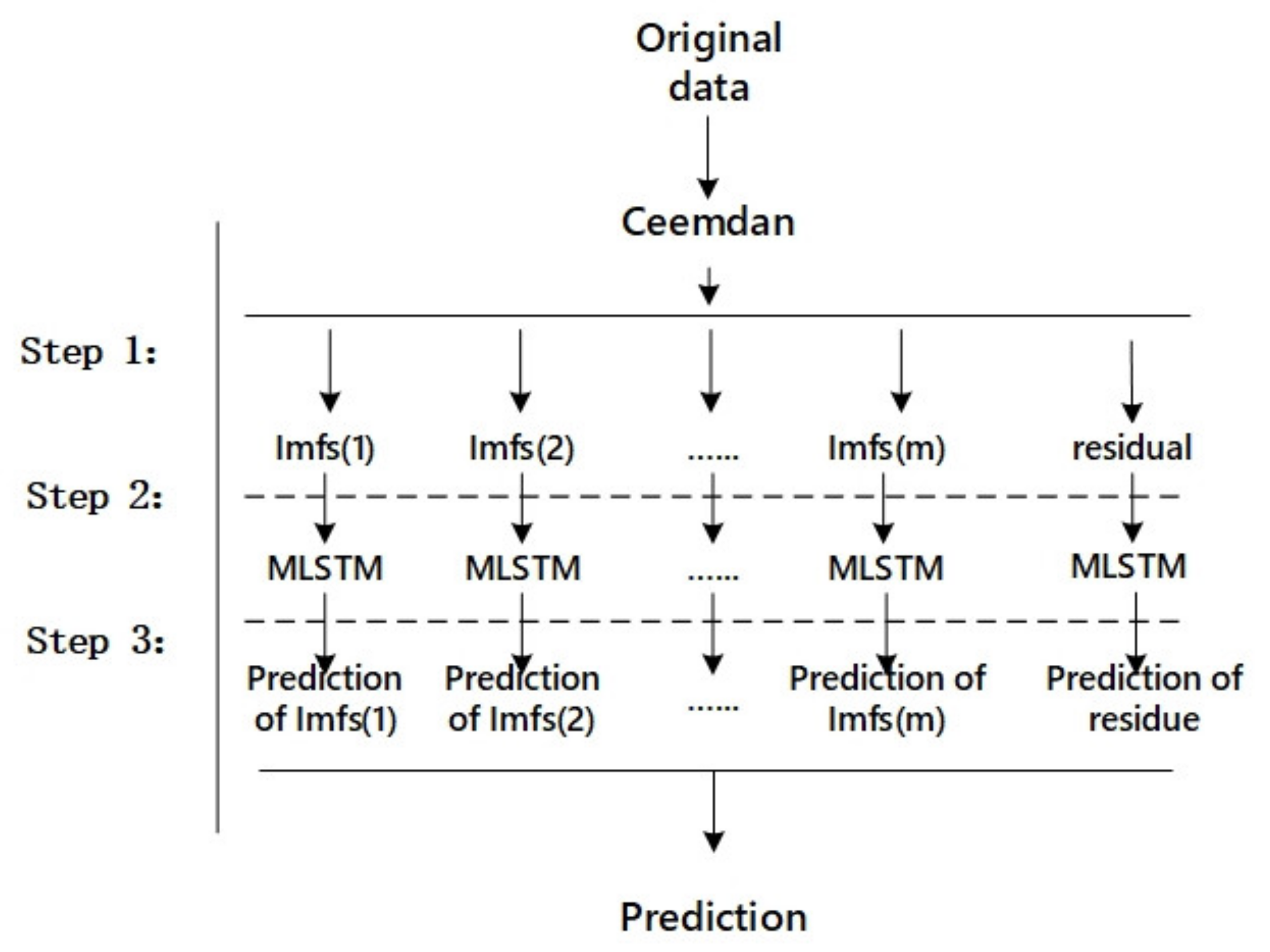
The goal of complete ensemble empirical mode decomposition with adaptive noise based on multilayer long short-term memory (CEEMDAN–MLSTM) proposed in this paper is to achieve better performance on the exchange rate forecasts. The complete ensemble empirical mode decomposition with CEEMDAN is combined with multilayer long short-term memory (MLSTM) to predict the exchange rate. A brief description of its work process is as follows. First, the positive and negative white noise pairs with the same amplitude, and opposite phase are added to the original signal to reduce the non-stationarity of exchange rate data. Then, the data is decomposed through EMD to produce a series of intrinsic mode functions (IMFs) with different characteristic scales. These IMFs represent exchange rate fluctuations caused by different investors at different times. Finally, we input the IMFs data into the LSTM network model and output the results. In order to achieve an objective evaluation, we compared the performance of CEEMDAN–MLSTM with other reference models using the same dataset and the same experimental conditions through different error measurement. The results show that CEEMDAN–MLSTM is more suitable for the analysis of nonlinear nonstationary signals because it signally reduces the number of iterations and increases the reconstruction accuracy. Details on the proposed method are discussed in later sections.
The remainder of this paper is organized as follows. In
Section 2, we introduce the EMD, EEMD, CEEMDAN signal decomposition mechanism and the architecture of the recurrent neural network. Next, we demonstrate how CEEMDAN–MLSTM works for exchange rate forecasting. In
Section 3, we carried out a series of experiments, including data preprocessing, data decomposition, evaluation of indicators, and description and analysis of experimental results. In
Section 4, the last section, the conclusion can be seen.
3. Experiment
To make the evaluation more objective and accurate, we compared the CEEDMAN–MLSTM with other prediction models through a series of experiments on real data sets. We analyzed the effects of deep learning models under different training strategies, network architecture, and network depths.
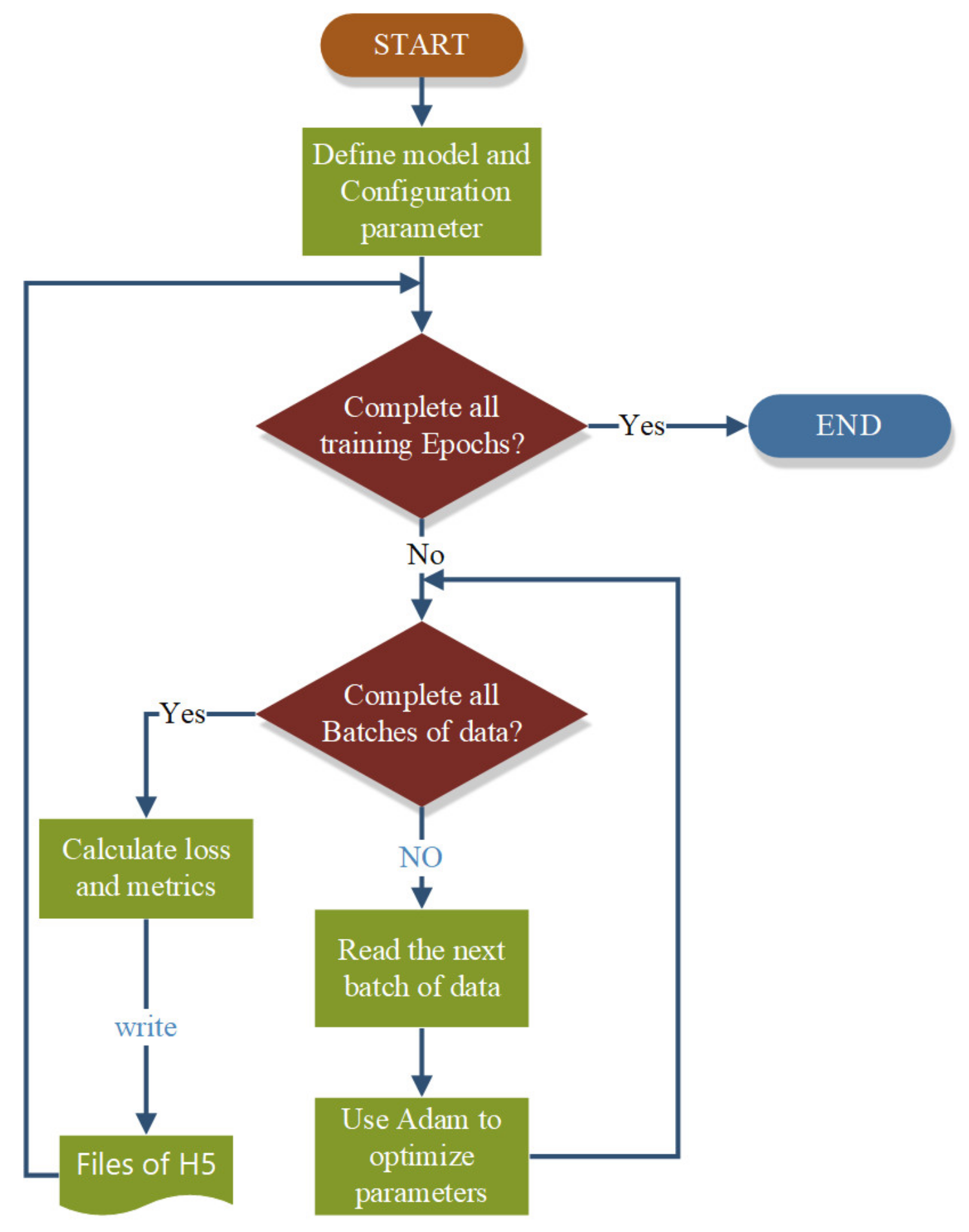
Figure 6 shows the flowchart of multilayer LSTM network training.
3.1. Data Preparing and Description
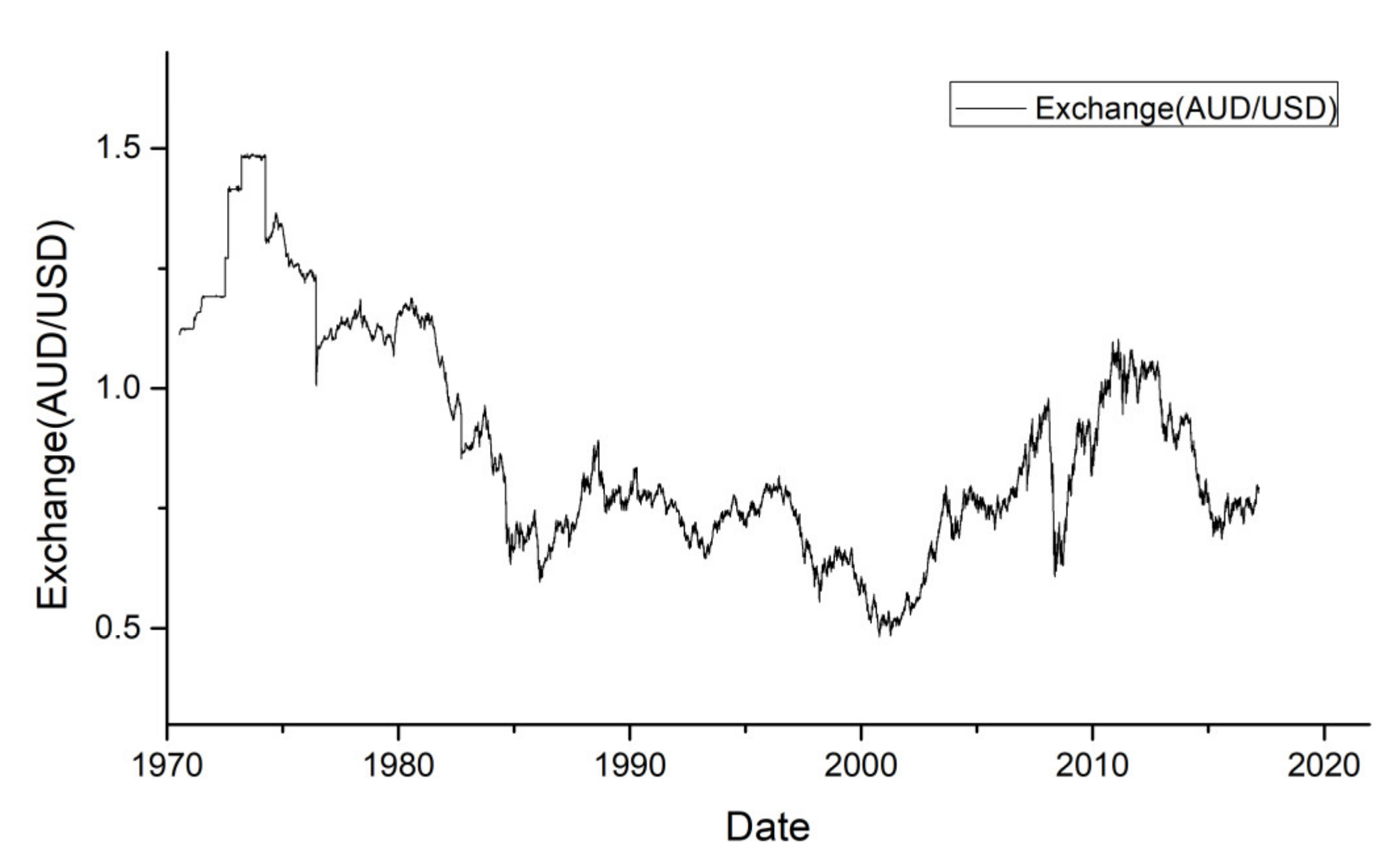
According to previous analysis, we should verify the effectiveness and stability of the proposed approach for the real datasets. Considering two characteristics of convertibility and influence, we chose the real exchange rate data of GBP–USD and USD–AUD from 4 January 1971 to 25 August 2017 for empirical research on exchange rate forecasting. In the subsequent experiments, the trends of exchange rate were analyzed and forecasted.
Figure 7 shows the trend and fluctuation amplitude of the USD–AUD exchange rate.
Data preprocessing is an important step in machine learning tasks. It includes various functions such as filter or extract, scale, normalize, or shuffle. Before these experiments, we did the necessary preprocessing of the initial data. First, we did a preliminary exploration of the initial data and observed the distribution. Secondly, we cleaned the missing values in the data and normalized the data. Finally, we divided the cleaned data into training sets and test sets.
These experiments adopted the n-step-ahead prediction strategy for all models. It made predictions over the latest k days of exchange rate available, always forecasting just one day ahead. After preprocessing, the data set is converted to [(N − k) × (k + 1)] (N: dataset length, k: steps) Matrix. Any row of the matrix represents one of the training samples. The next k of observations for each sample were used as input to the model, and the first data is validation data. In order to evaluate the efficiency of different models in exchange rate forecasting, we divided the data into two parts: training set and test set. In the following experiments, the proportion of training set is 80% of total data, and the remaining 20% belong to the test set.
3.2. Data Decomposition
In order to evaluate the influence of different decomposition methods on prediction, the data sets were decomposed by the EMD, EEMD, and CEEMDAN methods respectively, and three different IMFs were obtained. To investigate the impact of the parameters of CEEMDAN, some experiments were conducted on exchange rate data with one-step-ahead forecasting. We ran the proposed hybrid model with the parameters of ensemble_size in the range of [4 200, 300, 500, 1000, 2000] and noise_strength in the range of [0.01, 0.02, 0.03, 0.05, 0.10]. By synthesizing the metrics, it was finally determined that the parameters of noise strength = 0.05 and ensemble_size = 200. This means that the standard deviation of 0.05 and quantity of 100 white noise data will be added to the exchange rate data. Other parameters have little influence on the model, so we directly adopted the default settings. The parameters description and settings of EMD, EEMD, and CEEMDAN are shown in
Table 1 and
Table 2.
The time–frequency spectrums of IMFs obtained by EEMD, CEEMDAN are shown in
Figure 8.
3.3. Building of MLSTM
The end of the data preprocessing and decomposition means that the data preparation has been completed. Once the model is built, we can feed the data to the model for training. In
Section 2, we have researched the structure and workflow of MLSTM. In this subsection, we will discuss the initialization of several key parameters that directly affect the efficiency of our proposed deep learning model, and briefly illustrate the dependencies of components in MLSTM.
3.3.1. Loss
As with machine learning, deep learning also learns the parameters of complex problems through the loss. In the field of machine learning, with the help of some functions of optimization, the loss can well measure the gap between the model predictions and the actual observations. The essence of training of neural networks is the learned process of weight parameters. The training of neural networks makes the functions of loss gradually converge, and the model is continuously optimized and the prediction error becomes smaller and smaller. The neural network returns the error from the loss through the backpropagation algorithm, and then optimizes the hyperparameters in the network by means like the gradient descent. The experiments in this paper are to evaluate the prediction accuracy of the methods, which is a type of question about regression, so we chose MSE as the loss function.
3.3.2. Learning Rate
Learning rate (LR) refers to the magnitude of the update network weight in the optimization algorithm. The learning rate can be constant, gradually decreasing, momentum-based, or adaptive. Different optimization algorithms determine different learning rates. When the learning rate is too large, the model may not converge, and the loss will continue to fluctuate up and down. If the learning rate is too small, the model will converge slowly and require longer training. These experiments use the optimization algorithm of Adam, which can design an independent adaptive learning rate for different parameters by calculating first-order moment estimation and second-order moment estimation of gradient. For comparison purposes, we set the learning rate of the deep learning models in the experiment to 0.01.
3.3.3. Batch_size
Batch_size is the number of samples that are sent to the neural network model for each training. In neural networks, the larger Batch_size usually makes the network converge faster. However, setting the oversized Batch_size may result in insufficient memory or a program kernel crash. In the experiment, we set the parameters of epochs and batch_size to 100 and 256, respectively.
3.3.4. Optimizer
Since the adaptive optimization algorithm can quickly find the correct target direction in the parameter update, the loss function can converge quickly. The standard stochastic gradient descent (SGD), nesterov accelerated gradient(NAG) and momentum methods are difficult to find the correct direction, so the convergence is slow. Experience has shown that adaptive moment estimation (Adam) has faster convergence and more effective learning effects than the other adaptive learning rate algorithms. Adam solves the problems in other optimization techniques, such as learning rate disappearing, convergence is too slow, and the parameter update of the high variance causes the function of loss to fluctuate greatly. Considering that the convergence of the CEEDMAN–MLSTM model is more complicated than the common neural network, we chose Adam as the optimizer.
3.3.5. Metrics
We chose mean absolute error (MAE), root mean squared error (RMSE) and mean absolute error percentage (MAPE) as the performance metrics to measure a model”s relevance:
MAE can better reflect the actual situation of the error of prediction.
- 2.
RMSE:
RMSE is used to measure the deviation between observations and real values and is the most commonly used indicator of forecasts by machine learning models.
- 3.
MAPE:
MAPE considers not only the absolute error between the predicted and the real value, but also the relative distance between the error and the true value. The letter y in the above formula represents the true value, represents the predicted value, and N is the number of samples.
3.3.6. Dependencies in MLSTM
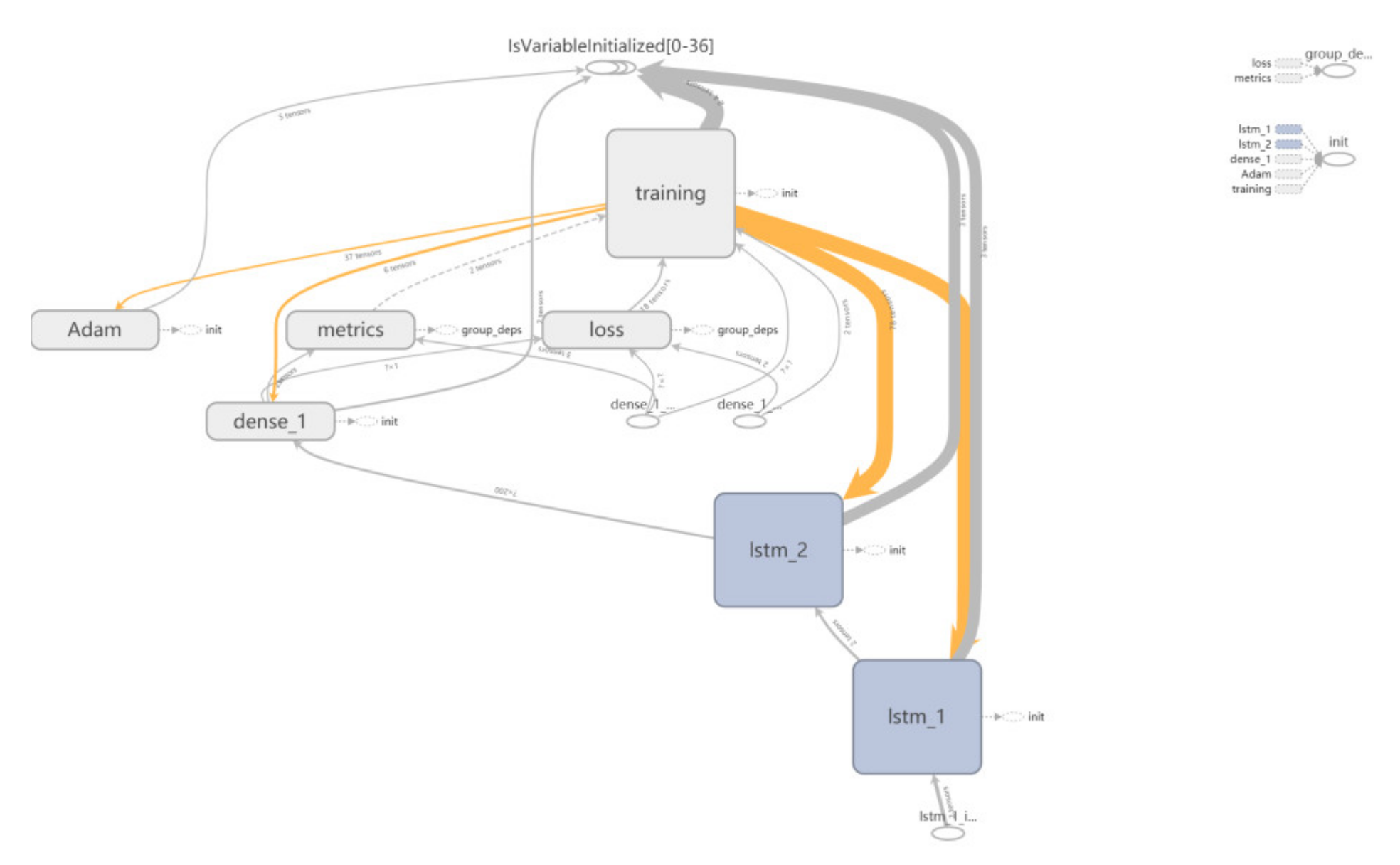
We trace back the dependencies between the internal components of the MLSTM based on the visualization obtained after model training.
Figure 9 is the computation graph containing many nodes and connecting lines. These nodes represent the computations, while the directional lines represent some data flows. Obviously, this MLSTM is a multilayer deep learning model consisting of two LSTM hidden layers, a Dense layer, an input layer and an output layer. The bottom oval section represents the input node. The training data is provided in the form of a tensor to the first hidden layer of the MLSTM through the input nodes. After computation, the output of first hidden layer is converted to the input of the second hidden layer. Finishing calculations of all hidden layers , the dataflow is sent to the dense layer, where the dataflow is compressed into an intermediate prediction and input to the loss node for loss calculation. The orange lines represent the backpropagation of the data flows. Adam is responsible for optimizing the computation of parameters tuning. The updating information of parameters flows from the output layer to the input layer. It is a back propagation process. What has been discussed above is an iteration of MLSTM training.
3.4. Experimental Results and Analysis
We conducted two groups of experiments. In the first group of experiments, the undecomposed data of exchange rates were imported into the models such as ARIMA, Bayesian, SVM, RNN, LSTM, and Multilayer LSTM. In the second group of experiments, we input the decomposed IMFs into the RNN, MRNN, LSTM, and MLSTM for training and evaluation.
3.4.1. Prediction and Analysis Based on Undecomposed Data
We input the cleaned but undecomposed data into several classic models and the proposed model, such as ARIMA, RNN, MRNN (Multilayer RNN), LSTM, and MLSTM (Multilayer LSTM), respectively. Will different models result in a different forecast? Both
Figure 10 and
Table 3 illustrate the answers.
Table 3 shows us that, among the seven methods, the famous ARIMA model has the lowest predictive performance score. It indicates that ARIMA is not suitable for forecasting exchange rate data that is nonlinear and nonstationary. Machine learning algorithms such as support vector machines (SVM), Bayesian, and artificial neural networks (ANN) perform better than ARIMA models. However, they do not perform as well as several deep learning models. The LSTM model has better performance than the classic RNN, even if both of them belong to recurrent neural networks. MLSTM achieves the best performance. This phenomenon indicates that multilayer architecture of LSTM performs better than the single-layer’s. In other words, the multilayer network has better generalization than single in solving complex problems. Yet, the former needs more parameters to be trained than the latter and requires more learning time. From the training time point of view, the more complex the structure of network, the longer the training takes. LSTM training takes 43% more time than RNN. A network with a two-layer LSTM stack structure consumes approximately 40% more time than a single-layer LSTM in training.
3.4.2. Prediction and Analysis Based on Decomposition Data
We conducted another group of experiments, which purpose was to measure the effects of EMD, EEMD, and CEEMDAN methods on improving the accuracy of exchange rate forecasting. The experimental steps were developed as follows:
Decompose the three preprocessed identical exchange rate data by EMD, EEMD, and CEEMDAN methods to obtain three sets of different IMFs.
Divide each group of IMFs into training set and test set, and input the training set into RNN, MRNN, LSTM, and MLSTM models for training.
Enter the test data set and observation values into the trained deep learning model to obtain the final evaluation result.
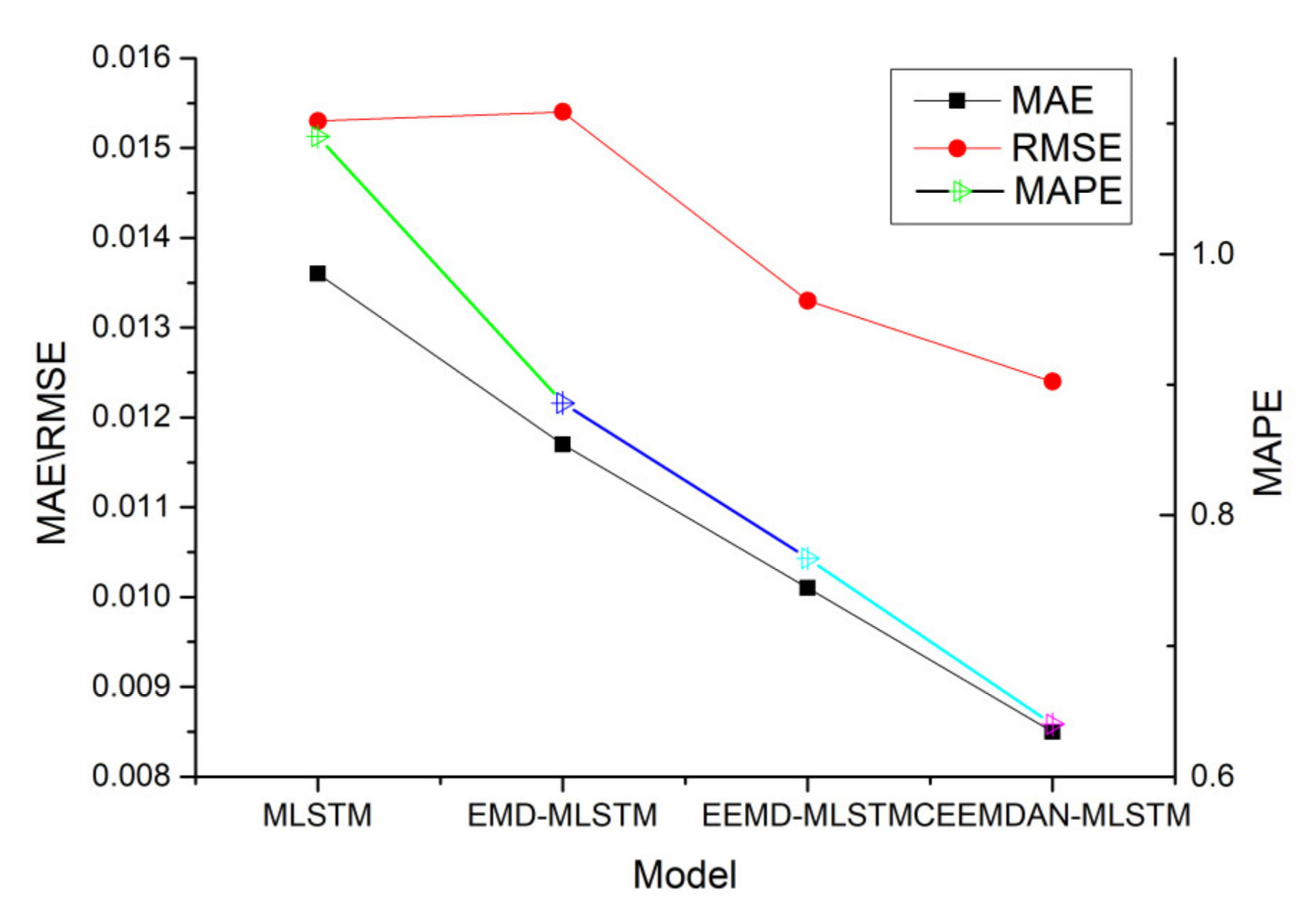
The performance of different methods in the GBP–USD exchange rate forecasting are shown in
Table 4,
Table 5 and
Table 6. As can be seen from
Table 4, the performance of the EMD-LSTM model is better than that of the EMD-RNN. A deep learning model using a multi-layer architecture is better than a model using a single-layer structure. Comparing the previous predictions of single model, it is easy to observe that the predictions based on EMD are better than the undecomposed data.
Obviously,
Table 5 and
Table 6 have some new information besides reaching similar conclusions as
Table 4. The CEEMDAN-based hybrid method performs better than the other two types of hybrid methods in exchange rate prediction tasks.
Figure 10 shows the predictive performance of the three types of hybrid methods.
From the experimental results shown in
Table 4,
Table 5 and
Table 6 and
Figure 10, we can see that models using decomposed data perform better than undecomposed data. It is that the EMD, EEMD, and CEEMD solve the problem of high-volatility, nonstationary exchange rate data, which is difficult to be processed. These methods can decompose the fluctuations and trends of different characteristic scales layer by layer from the original exchange rate data. Then, we integrated each predicted IMF for reconstruction, so a more accurate prediction was obtained.
Table 6 tells us that the CEEMDAN combined deep learning model is used for exchange rate forecasting and has better performance than EMD and EEMD.
Comparing the approach of CEEMDAN–MLSTM with the others, it is found that the loss function converges the fastest during training, because CEEMDAN not only solves the problem of exchange rate data due to nonlinear and nonstationary features, but also solves the problem of frequent appearance of mode mixing. CEEMDAN–MLSTM shows better performance than other methods. We tested the AUD–USD data set and reached the same conclusion.
3.5. Discussion
3.5.1. Performance of Different Step-Ahead Forecasts
Here, we discuss the performance of different step-ahead forecasts. In previous experiments, we verified the effectiveness of our proposed approach in one-step-ahead forecasts. However, in international trade, not only one step in advance is required, but even two, three, and multi-steps ahead are required. Does the proposed method still work? We started a new set of experiments to measure the performance of the proposed method on multistep prediction. We set four horizons in this set of experiments. Horizon = 1, 2, 10, 20 denote the one-day-, two-day-, ten-day-, and thirty-day-ahead forecast, respectively. The results are shown in
Table 7. From this table, we can see that, among these three metrics, MAE and RMSE are used to measure the absolute error between the predictions and the observations, which is closely related to the data scale. As seen from the previous equations, MAPE is a measure of scale-independency and interpretability. Therefore, these metrics should be analyzed together. Overall, our proposed model still achieves the best of all methods on three metrics. The value of metrics is positively related to the level. This shows that our proposed method is still ahead of other methods in multistep prediction. In the multistep forecast of exchange rate based on the daily data, all metrics maintain low values, which shows that multistep forecast of exchange rate is feasible and meaningful. It is easy to observe that, as the step size increases, all metrics increase and the prediction accuracy decreases. It is interesting that the value of MAPE increases faster than the other two metrics. The former phenomenon indicates that the prediction error increases with the number of steps, due to the loss of information and lack of intermediate daily data. The latter is caused by the change in the data. In the observation period, the exchange rate of the British pound to the US dollar showed a downward trend. When the observations go down, MAPE naturally increases.
3.5.2. Impact of Different Lag Orders
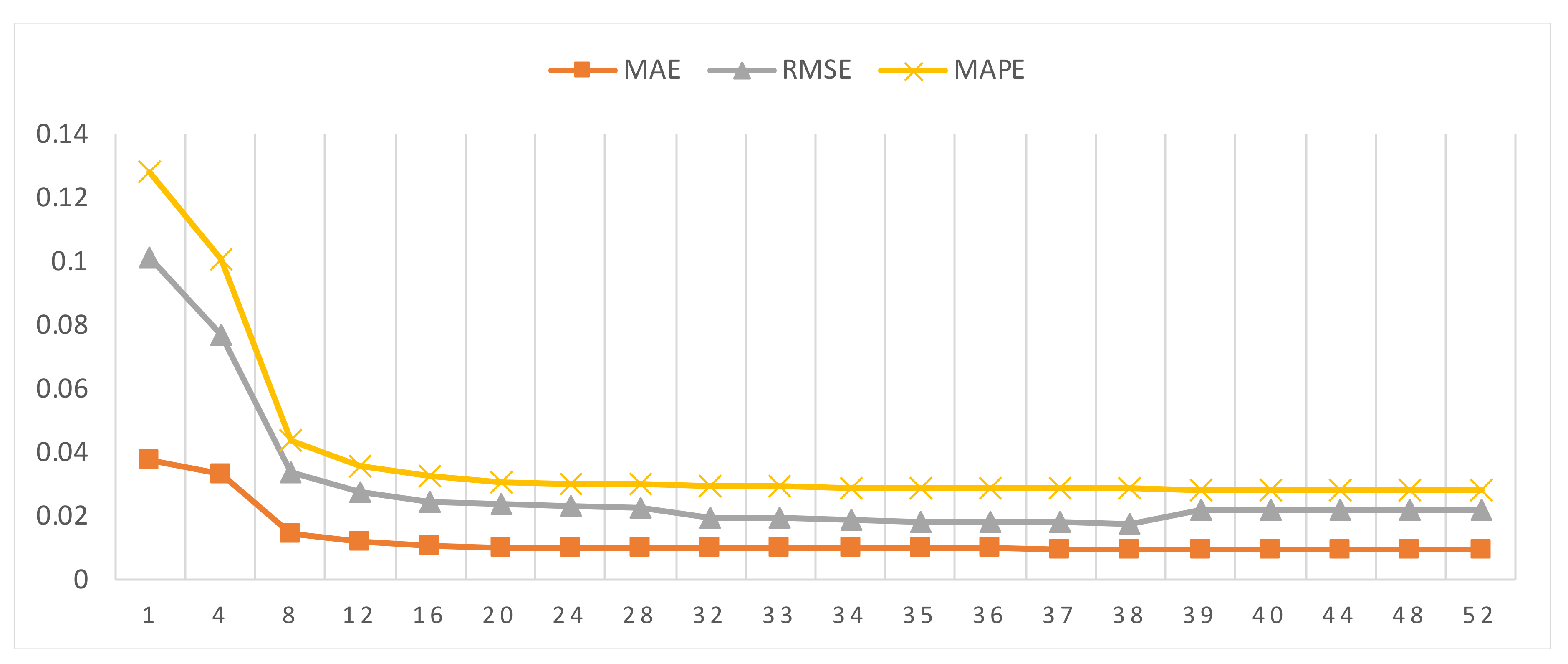
In preceding experiments, we set the proposed model to a fixed number of lag order of 38 by trial and error. Here, we will discuss the impact of different lag orders to the performance of CEEMDAN–MLSTM. We input the exchange rate data organized into different lag orders into CEEMDAN–MLSTM and obtained different outputs, including the metrics mentioned above. All the metrics were used to evaluate the impact of different numbers of lag orders on model performance. We use a segmented strategy to implement our plan. The experiment was conducted in two stages. A total of thirteen experiments were completed in the first stage, and the lag order of these experiments is based on the thirteen numbers of {1, 4, 8, 12, 16, 20, 24, 28, 32, 36, 40, 44, 48}. After completing the first phase of the experiment, a synthetical and optimal solution (lag order = 36) was obtained. In the second phase, we limited the range of lag order from 33 to 39. In this stage, we completed a total of 7 experiments and obtained the optimal solution (lag order = 38). The result is shown in
Figure 11.
From this figure, we can observe that the performance is significantly improved as the lag order increased from 1 to 8. Once the lag order is greater than 16, all these metrics would be stable. RMSE slightly increased with the increase of lag order from 39 to 52, while MAE and MAPE remained stable. These results tell us that the lag order plays an important role in improving forecasting performance.
4. Conclusions
In this paper, we proposed a CEEMDAN-based long short-term memory neural network that adopts the multilayer stacked architecture to forecast the trend of exchange rate. We denoted it as CEEMDAN–MLSTM. The main steps are the following: (1) The exchange is decomposed into several IMFs and one residue by CEEMDAN mode; (2) The IMFs and residue are input into the multilayer LSTM network for forecasts; (3) The prediction of exchange rate data is obtained by summing up the forecast results of each IMF and the residue. We compared the proposed method with ARIMA, Bayesian, SVM, RNN, MRNN, LSTM, MLSTM, and MLSTM–CEEMDAN. The experiment proves that the proposed model has a better predictive performance than the other single models or combined models. This new approach has the following characteristics: (1) CEEMDAN algorithm, which can deeply explore the fluctuation characteristics of different time-scales of exchange rate data; (2) CEEMDAN algorithm solves the problem of mode mixing in empirical mode decomposition and the problem of signal reconstruction error; (3) LSTM adds a gating mechanism based on the classical RNN, so that the model can learn the data dependencies with a longer time span without the problem of gradient disappearance and gradient explosion. LSTM is more suitable for solving exchange rate forecasting problems than RNN. (4) Empirical evidence shows that properly increasing the depth of the neural network will improve the ability of solving the complex problems.
In addition, this hybrid model of CEEMDAN–MLSTM was developed to solve the problems of short-term exchange rate forecasts. Therefore, the factors that affect exchange rate, such as interest rates, balance of payments, economic growth, inflation rates, etc., have not been taken into account. All forecasts are based on historical price data. If the long-term forecasts are required, we should combine our proposed method with economic theory or measurement methods to play a greater role.
In this study, the proposed CEEMDAN–MLSTM was used to improve the accuracy of exchange rate forecasts for reducing the risks of international trade. However, this does not mean that this method can only solve this particular issue. It also can be extended to solve more nonlinear and nonstationary time series problems, such as natural disaster prediction, energy price prediction, financial time series regression problems, risk prediction and decision, etc.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}