Specification Testing of Production in a Stochastic Frontier Model



Abstract
:1. Introduction
2. Test Statistics
2.1. Estimation
2.2. Construction
- Step 1.
- Obtain , , and by using the approach proposed in Section 2.1, and then construct , as in Section 2.2.
- Step 2.
- Generate bootstrap observations, . Here is a sequence of i.i.d. random variables with zero mean, unit variance, and independent of the sequence . Usually, can be chosen to be i.i.d. Bernoulli variates with:
- Step 3.
- Let be defined similarly as , based on the bootstrap sample, .
- Step 4.
- Repeat Steps 2 and 3, B times, and calculate the p-value as .
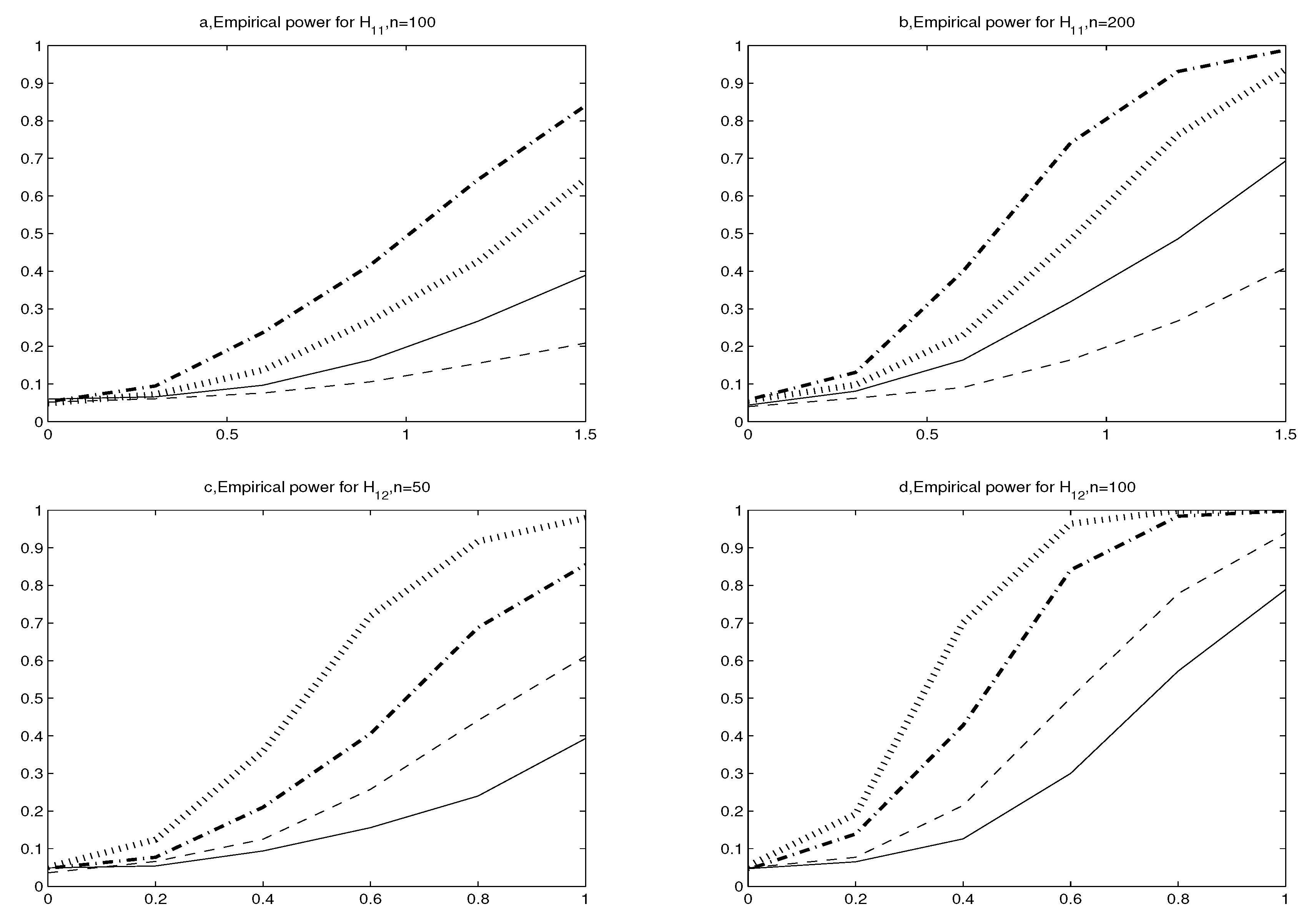
3. Simulations
4. Empirical Application
5. Concluding Remarks
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Aigner, D.J.; Lovell, C.A.K.; Schmidt, P. Formulation and estimation of stochastic frontier models. J. Econom. 1977, 6, 21–37. [Google Scholar] [CrossRef]
- Meeusen, W.; Broeck, J.V.D. Efficiency estimation from Cobb-Douglas production functions with composed error. Int. Econ. Rev. 1977, 18, 435–444. [Google Scholar] [CrossRef]
- Greene, W.H. A Gamma-distributed stochastic frontier model. J. Econom. 1990, 46, 141–163. [Google Scholar] [CrossRef] [Green Version]
- Greene, W.H. Reconsidering heterogeneity in panel data estimators of the stochastic frontier model. J. Econom. 2005, 126, 269–303. [Google Scholar] [CrossRef]
- Kumbhakar, S.; Lovell, C.A.K. Stochastic Frontier Analysis; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Fried, H.; Lovell, C.A.K.; Schmidt, S. The Measurement of Productive Efficiency and Productivity Change; Oxford University Press: New York, NY, USA, 2008. [Google Scholar]
- Simar, L.; Wilson, P. Statistical approaches for nonparametric frontier models: A guided tour. Int. Stat. Rev. 2015, 83, 77–110. [Google Scholar] [CrossRef]
- Wang, W.S.; Amsler, C.; Schmidt, P. Goodness of fit tests in stochastic frontier models. J. Prod. Anal. 2011, 35, 95–118. [Google Scholar] [CrossRef]
- Chen, Y.T.; Wang, H.J. Centered-residuals-based moment tests for stochastic frontier models. Econom. Rev. 2012, 31, 625–653. [Google Scholar] [CrossRef]
- Schmidt, P.; Lin, T.F. Simple tests of alternative specifications in stochastic frontier models. J. Econom. 1984, 24, 349–361. [Google Scholar] [CrossRef]
- Coelli, T.J. Estimators and hypothesis tests for a stochastic frontier function: A Monte Carlo analysis. J. Prod. Anal. 1995, 6, 247–268. [Google Scholar] [CrossRef]
- Lee, L.F. A test for distributional assumptions for the stochastic frontier functions. J. Econom. 1983, 22, 245–267. [Google Scholar] [CrossRef]
- Kopp, R.J.; Mullahy, J. Moment-based estimation and testing of stochastic frontier models. J. Econom. 1990, 46, 165–183. [Google Scholar] [CrossRef]
- Fan, Y.; Li, Q.; Weersink, A. Semiparametric estimation of stochastic production frontier. J. Bus. Econ. Stat. 1996, 14, 460–468. [Google Scholar]
- Kumbhakar, S.C.; Park, B.U.; Simar, L.; Tsionas, E.G. Nonparametric stochastic frontiers: A local likelihood approach. J. Econom. 2007, 137, 1–27. [Google Scholar] [CrossRef]
- Simar, L.; Van Keilegom, I.; Zelenyuk, V. Nonparametric least squares methods for stochastic frontier models. J. Prod. Anal. 2017, 47, 189–204. [Google Scholar] [CrossRef]
- Bonanno, G.; De Giovanni, D.; Domma, F. The ‘wrong skewness’ problem: A re-specification of stochastic frontiers. J. Prod. Anal. 2017, 47, 9–64. [Google Scholar] [CrossRef]
- González-Manteiga, W.; Crujeiras, R.M. An updated review of goodness-of-fit tests for regression models. Test 2013, 22, 361–411. [Google Scholar] [CrossRef]
- Tsekouras, K.; Chatzistamoulou, N.; Kounetas, K. Productive performance, technology heterogeneity and hierarchies: Who to compare with whom. Int. J. Prod. Econ. 2017, 193, 465–478. [Google Scholar] [CrossRef]
- Zheng, J.X. A consistent test of functional form via nonparametric estimation techniques. J. Econom. 1996, 75, 263–289. [Google Scholar] [CrossRef]
- Fan, Y.; Li, Q. Consistent model specification tests: Omitted variables and semiparametric functional forms. Econometrica 1996, 64, 865–890. [Google Scholar] [CrossRef]
- Stute, W. Nonparametric model checks for regression. Ann. Stat. 1997, 25, 613–641. [Google Scholar]
- Stute, W.; Gonzáles-Manteiga, W.; Presedo-Quindimil, M. Bootstrap approximation in model checks for regression. J. Am. Stat. Assoc. 1998, 93, 141–149. [Google Scholar] [CrossRef]
- Coelli, T.J.; Prasada Rao, D.S.; O’Donnell, C.J.; Battese, G.E. An Introduction to Efficiency and Productivity Analysis, 2nd ed.; Springer: New York, NY, USA, 2005. [Google Scholar]
- Guo, X.; Wong, W.K.; Xu, Q.F.; Zhu, L.X. Production and hedging decisions under regret aversion. Econ. Model. 2015, 51, 153–158. [Google Scholar] [CrossRef]
- Moslehpour, M.; Pham, V.K.; Wong, W.K.; Bilgicli, I. E-purchase intention of Taiwanese consumers: Sustainable mediation of perceived usefulness and perceived ease of use. Sustainability 2018, 10, 234. [Google Scholar] [CrossRef]
- Li, C.S.; Wong, W.K.; Peng, S.C.; Tsendsuren, S. The effects of health status on life insurance holding in 16 European countries. Sustainability 2018, in press. [Google Scholar]
- Li, Z.; Li, X.; Hui, Y.C.; Wong, W.K. Maslow portfolio selection for individuals with low financial sustainability. Sustainability 2018, 10, 1128. [Google Scholar] [CrossRef]
- Lai, H.P.; Huang, C.J. Likelihood ratio tests for model selection of stochastic frontier models. J. Prod. Anal. 2010, 34, 3–13. [Google Scholar] [CrossRef]
- Lai, H.P.; Huang, C.J. Estimation of stochastic frontier models based on multimodel inference. J. Prod. Anal. 2012, 38, 273–284. [Google Scholar]
- Parmeter, C.F.; Wan, A.T.; Zhang, X.Y. Model Averaging Estimators for the Stochastic Frontier Model, Working Paper. 2016. Available online: https://www.bus.miami.edu/_assets/files/repec/WP2016-09.pdf (accessed on 27 July 2018).


{kind=link}
| 0.0 | 0.0490 | 0.0530 | ||
| 0.3 | 0.0730 | 0.0950 | ||
| 0.6 | 0.1370 | 0.2370 | ||
| 0.9 | 0.2685 | 0.4170 | ||
| 1.2 | 0.4255 | 0.6430 | ||
| 1.5 | 0.6445 | 0.8400 | ||
| 0.0 | 0.0510 | 0.0480 | 0.0540 | 0.0450 |
| 0.2 | 0.1240 | 0.0770 | 0.1920 | 0.1390 |
| 0.4 | 0.3590 | 0.2100 | 0.7010 | 0.4280 |
| 0.6 | 0.7190 | 0.4060 | 0.9640 | 0.8410 |
| 0.8 | 0.9170 | 0.6880 | 0.9990 | 0.9840 |
| 1.0 | 0.9790 | 0.8550 | 1.0000 | 0.9980 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, X.; Li, G.-R.; McAleer, M.; Wong, W.-K. Specification Testing of Production in a Stochastic Frontier Model. Sustainability 2018, 10, 3082. https://doi.org/10.3390/su10093082
Guo X, Li G-R, McAleer M, Wong W-K. Specification Testing of Production in a Stochastic Frontier Model. Sustainability. 2018; 10(9):3082. https://doi.org/10.3390/su10093082
Chicago/Turabian StyleGuo, Xu, Gao-Rong Li, Michael McAleer, and Wing-Keung Wong. 2018. "Specification Testing of Production in a Stochastic Frontier Model" Sustainability 10, no. 9: 3082. https://doi.org/10.3390/su10093082