
A Two-Stage Pillar Feature-Encoding Network for Pillar-Based 3D Object Detection


Abstract
:1. Introduction
- To solve the problem of under-segmentation due to missing features, compared with other pillar-based approaches that only consider the intra-relational features, we propose Ts-PFE, a feature-encoding network which considers both inter- and intra-relational features among and in the pillars. It improves the distinction between objects and reduces the under-segmentation problems in occluded and overlapping scenes.
- We improved the backbone by integrating SeNet, enhancing key features in pseudo-images, and suppressing irrelevant information to enhance the network’s ability to extract important features of objects to be detected. By leveraging the power of SeNet, the proposed approach exhibits superior performance in object detection compared to prior works.
- Evaluated on the KITTI dataset, the experiments show that the detection accuracy of the proposed approach are significantly improved; the improvement of AP for car, pedestrian, and cyclist 3D detection are 1.1%, 3.78%, and 2.23% over the baseline. The results of qualitative evaluation show that the under-segmentation problem is reduced in the occlusion and overlapping scenes.
2. Related Work
2.1. 3D Object Detection from Point Cloud Based on Voxel/Pillar
2.2. Attention Mechanisms in Object Detection
3. Our Approach
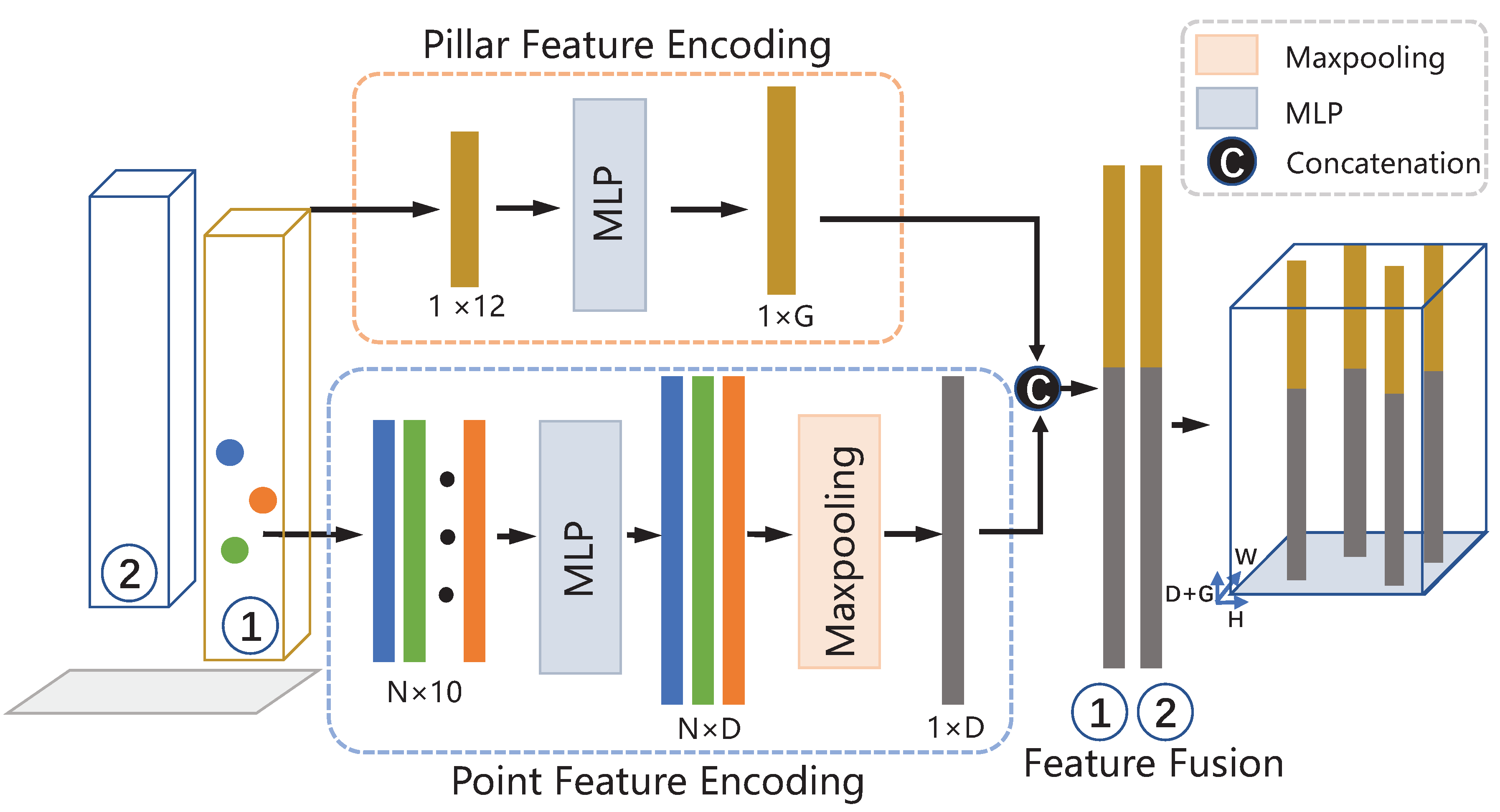
3.1. Two-Stage Pillar Feature Encoding
3.1.1. Point Feature Encoding
3.1.2. Pillar Feature Encoding
3.1.3. Feature Fusion
3.2. Backbone
3.2.1. SeNet
3.2.2. RPN
3.3. Detection Head
3.4. Loss Function
4. Experiment
4.1. Dataset
4.2. Implementation Details
4.3. Result
4.3.1. Quantitative Evaluation
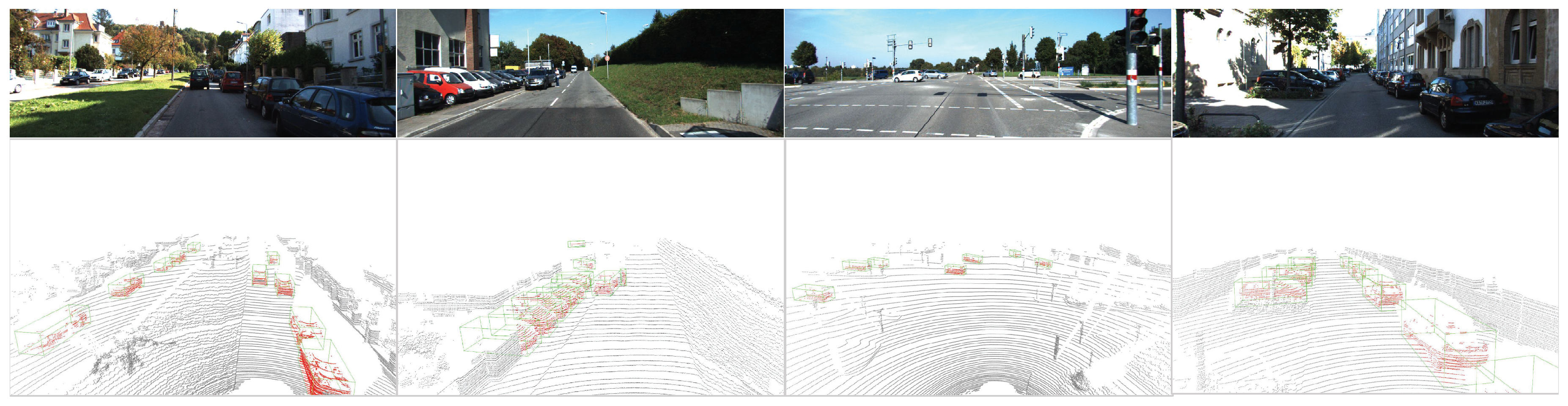
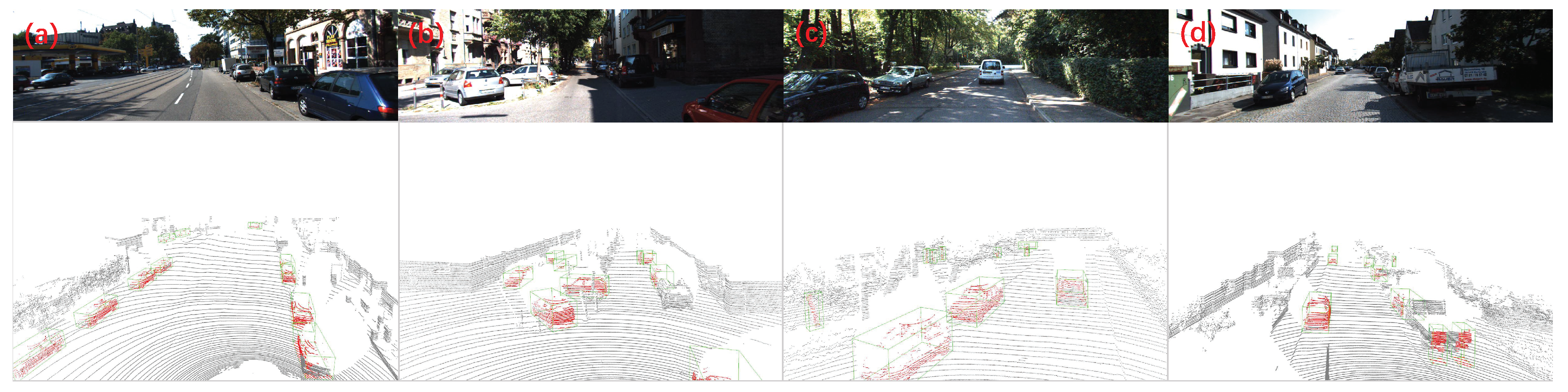
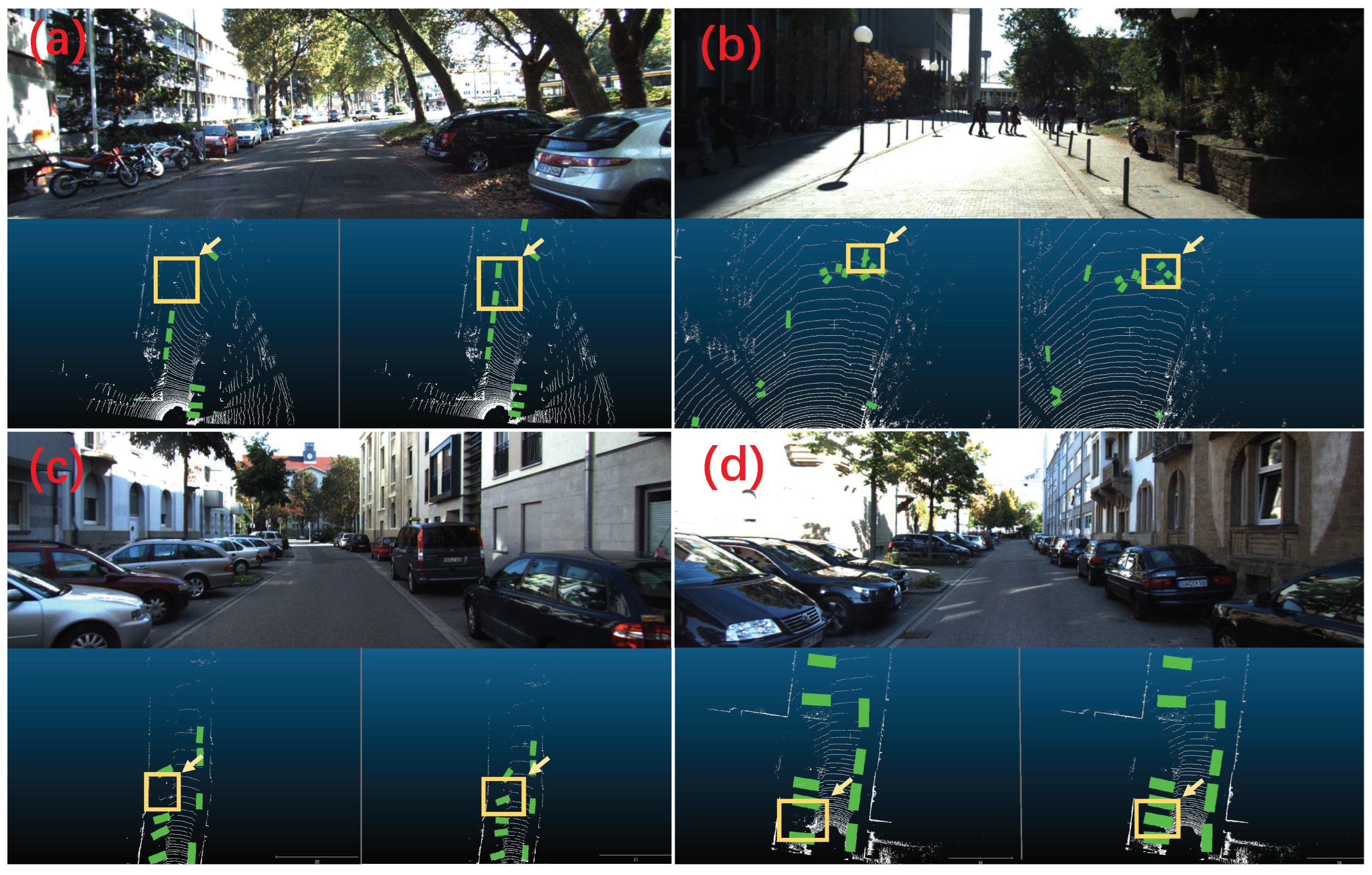
4.3.2. Qualitative Evaluation
4.4. Ablation Experiments
4.4.1. SeNet Backbone Module Analysis
4.4.2. Ts-PFE Module Analysis
4.4.3. Ts-PFE and SeNet Backbone Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, F.; Jin, W.; Fan, C.; Zou, L.; Chen, Q.; Li, X.; Jiang, H.; Liu, Y. PSANet: Pyramid splitting and aggregation network for 3D object detection in point cloud. Sensors 2020, 21, 136. [Google Scholar] [CrossRef]
- Bai, Z.; Wu, G.; Barth, M.J.; Liu, Y.; Sisbot, E.A.; Oguchi, K. Pillargrid: Deep learning-based cooperative perception for 3d object detection from onboard-roadside lidar. In Proceedings of the 2022 IEEE 25th International Conference on Intelligent Transportation Systems (ITSC), Macau, China, 8–12 October 2022; pp. 1743–1749. [Google Scholar]
- Wang, B.; Zhu, M.; Lu, Y.; Wang, J.; Gao, W.; Wei, H. Real-time 3D object detection from point cloud through foreground segmentation. IEEE Access 2021, 9, 84886–84898. [Google Scholar] [CrossRef]
- He, C.; Zeng, H.; Huang, J.; Hua, X.S.; Zhang, L. Structure aware single-stage 3d object detection from point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11873–11882. [Google Scholar]
- Wang, Q.; Chen, J.; Deng, J.; Zhang, X. 3D-CenterNet: 3D object detection network for point clouds with center estimation priority. Pattern Recognit. 2021, 115, 107884. [Google Scholar] [CrossRef]
- Bello, S.A.; Yu, S.; Wang, C.; Adam, J.M.; Li, J. Deep learning on 3D point clouds. Remote Sens. 2020, 12, 1729. [Google Scholar] [CrossRef]
- Yang, B.; Luo, W.; Urtasun, R. Pixor: Real-time 3d object detection from point clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7652–7660. [Google Scholar]
- Alaba, S.Y.; Ball, J.E. A survey on deep-learning-based lidar 3d object detection for autonomous driving. Sensors 2022, 22, 9577. [Google Scholar] [CrossRef] [PubMed]
- Liang, Z.; Zhang, Z.; Zhang, M.; Zhao, X.; Pu, S. Rangeioudet: Range image based real-time 3d object detector optimized by intersection over union. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7140–7149. [Google Scholar]
- Fan, L.; Xiong, X.; Wang, F.; Wang, N.; Zhang, Z. Rangedet: In defense of range view for lidar-based 3d object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 2918–2927. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Adv. Neural Inf. Process. Syst. 2017, 30, 1–14. [Google Scholar]
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3d object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4490–4499. [Google Scholar]
- Xie, J.; Zheng, Z.; Gao, R.; Wang, W.; Zhu, S.C.; Wu, Y.N. Generative VoxelNet: Learning energy-based models for 3D shape synthesis and analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 2468–2484. [Google Scholar] [CrossRef] [PubMed]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. Pointpillars: Fast encoders for object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12697–12705. [Google Scholar]
- Liang, N.; Sun, S.; Zhou, L.; Zhao, N.; Taha, M.F.; He, Y.; Qiu, Z. High-throughput instance segmentation and shape restoration of overlapping vegetable seeds based on sim2real method. Measurement 2023, 207, 112414. [Google Scholar] [CrossRef]
- Wang, Y.; Jiang, Z.; Li, Y.; Hwang, J.N.; Xing, G.; Liu, H. RODNet: A real-time radar object detection network cross-supervised by camera-radar fused object 3D localization. IEEE J. Sel. Top. Signal Process. 2021, 15, 954–967. [Google Scholar] [CrossRef]
- Qi, C.R.; Liu, W.; Wu, C.; Su, H.; Guibas, L.J. Frustum pointnets for 3d object detection from rgb-d data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 918–927. [Google Scholar]
- Fernandes, D.; Silva, A.; Névoa, R.; Simões, C.; Gonzalez, D.; Guevara, M.; Novais, P.; Monteiro, J.; Melo-Pinto, P. Point-cloud based 3D object detection and classification methods for self-driving applications: A survey and taxonomy. Inf. Fusion 2021, 68, 161–191. [Google Scholar] [CrossRef]
- Yan, Y.; Mao, Y.; Li, B. Second: Sparsely embedded convolutional detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yin, T.; Zhou, X.; Krahenbuhl, P. Center-based 3d object detection and tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11784–11793. [Google Scholar]
- Li, J.; Chen, B.M.; Lee, G.H. So-net: Self-organizing network for point cloud analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9397–9406. [Google Scholar]
- Wang, S.; Lu, K.; Xue, J.; Zhao, Y. DA-Net: Density-Aware 3D Object Detection Network for Point Clouds. IEEE Trans. Multimed. 2023. [Google Scholar] [CrossRef]
- Li, C.; Gao, F.; Han, X.; Zhang, B. A New Density-Based Clustering Method Considering Spatial Distribution of Lidar Point Cloud for Object Detection of Autonomous Driving. Electronics 2021, 10, 2005. [Google Scholar] [CrossRef]
- Wang, Z.; Fu, H.; Wang, L.; Xiao, L.; Dai, B. SCNet: Subdivision coding network for object detection based on 3D point cloud. IEEE Access 2019, 7, 120449–120462. [Google Scholar] [CrossRef]
- Bhattacharyya, P.; Huang, C.; Czarnecki, K. Sa-det3d: Self-attention based context-aware 3d object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 3022–3031. [Google Scholar]
- Shi, S.; Guo, C.; Jiang, L.; Wang, Z.; Shi, J.; Wang, X.; Li, H. Pv-rcnn: Point-voxel feature set abstraction for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10529–10538. [Google Scholar]
- Guo, M.H.; Xu, T.X.; Liu, J.J.; Liu, Z.N.; Jiang, P.T.; Mu, T.J.; Zhang, S.H.; Martin, R.R.; Cheng, M.M.; Hu, S.M. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Wu, C.; Zhang, F.; Xia, J.; Xu, Y.; Li, G.; Xie, J.; Du, Z.; Liu, R. Building damage detection using U-Net with attention mechanism from pre-and post-disaster remote sensing datasets. Remote Sens. 2021, 13, 905. [Google Scholar] [CrossRef]
- Zhai, Z.; Wang, Q.; Pan, Z.; Gao, Z.; Hu, W. Muti-Frame Point Cloud Feature Fusion Based on Attention Mechanisms for 3D Object Detection. Sensors 2022, 22, 7473. [Google Scholar] [CrossRef]
- Wang, G.; Zhai, Q.; Liu, H. Cross self-attention network for 3D point cloud. Knowl.-Based Syst. 2022, 247, 108769. [Google Scholar] [CrossRef]
- Han, J.; Zeng, L.; Du, L.; Ye, X.; Ding, W.; Feng, J. Modify Self-Attention via Skeleton Decomposition for Effective Point Cloud Transformer. In Proceedings of the AAAI Conference on Artificial Intelligence, Held Virtually, 22 February–1 March 2022; pp. 808–816. [Google Scholar]
- Zhao, X.; Liu, Z.; Hu, R.; Huang, K. 3D object detection using scale invariant and feature reweighting networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 9267–9274. [Google Scholar]
- Qiu, S.; Wu, Y.; Anwar, S.; Li, C. Investigating attention mechanism in 3d point cloud object detection. In Proceedings of the 2021 International Conference on 3D Vision (3DV), London, UK, 1–3 December 2021; pp. 403–412. [Google Scholar]
- Li, X.; Liang, B.; Huang, J.; Peng, Y.; Yan, Y.; Li, J.; Shang, W.; Wei, W. Pillar-Based 3D Object Detection from Point Cloud with Multiattention Mechanism. Wirel. Commun. Mob. Comput. 2023, 2023, 5603123. [Google Scholar] [CrossRef]
- Chen, S.; Miao, Z.; Chen, H.; Mukherjee, M.; Zhang, Y. Point-attention Net: A graph attention convolution network for point cloud segmentation. Appl. Intell. 2022, 53, 11344–11356. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Liu, Z.; Zhao, X.; Huang, T.; Hu, R.; Zhou, Y.; Bai, X. Tanet: Robust 3d object detection from point clouds with triple attention. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 11677–11684. [Google Scholar]
- Brekke, A.; Vatsendvik, F.; Lindseth, F. Multimodal 3d object detection from simulated pretraining. In Proceedings of the Nordic Artificial Intelligence Research and Development: Third Symposium of the Norwegian AI Society, Trondheim, Norway, 27–28 May 2019; pp. 102–113. [Google Scholar]
- Cao, P.; Chen, H.; Zhang, Y.; Wang, G. Multi-view frustum pointnet for object detection in autonomous driving. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 3896–3899. [Google Scholar]
- Yang, B.; Liang, M.; Urtasun, R. Hdnet: Exploiting hd maps for 3d object detection. In Proceedings of the Conference on Robot Learning, Zürich, Switzerland, 29–31 October 2018; pp. 146–155. [Google Scholar]
- Desheng, X.; Youchun, X.; Feng, L.; Shiju, P. Real-time Detection of 3D Objects Based on Multi-Sensor Information Fusion. Autom. Eng. 2022, 44, 3. [Google Scholar]
- Wang, L.; Song, Z.; Zhang, X.; Wang, C.; Zhang, G.; Zhu, L.; Li, J.; Liu, H. SAT-GCN: Self-attention graph convolutional network-based 3D object detection for autonomous driving. Knowl.-Based Syst. 2023, 259, 110080. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Car | Pedestrian | Cyclist | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Easy | Mod. | Hard | Easy | Mod. | Hard | Easy | Mod. | Hard | |
| PointPillars [15] | 88.35 | 86.10 | 79.83 | 58.66 | 50.23 | 47.19 | 79.14 | 62.25 | 56.00 |
| SECOND [20] | 88.07 | 79.37 | 77.95 | 55.10 | 46.27 | 44.76 | 73.67 | 56.04 | 48.78 |
| VoxelNet [13] | 89.35 | 79.26 | 77.39 | 46.13 | 40.74 | 38.11 | 66.70 | 54.76 | 50.55 |
| TANet [42] | 91.58 | 86.54 | 81.19 | 60.58 | 51.38 | 47.54 | 79.16 | 63.77 | 56.21 |
| AVODFPN [43] | 88.53 | 83.79 | 77.90 | 58.75 | 51.50 | 47.54 | 68.09 | 57.48 | 50.77 |
| FPointNet [44] | 88.70 | 84.00 | 75.33 | 58.09 | 50.22 | 47.20 | 75.38 | 61.96 | 54.68 |
| HDNET [45] | 89.14 | 86.57 | 78.32 | N/A | N/A | N/A | N/A | N/A | N/A |
| PRGBNet [46] | 91.39 | 85.73 | 80.68 | 38.07 | 29.32 | 26.94 | 73.09 | 57.59 | 51.78 |
| Ours | 89.62 | 84.95 | 79.53 | 59.50 | 53.24 | 49.13 | 83.07 | 64.86 | 60.74 |
| Model | Car | Pedestrian | Cyclist | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Easy | Mod. | Hard | Easy | Mod. | Hard | Easy | Mod. | Hard | |
| PointPillars [15] | 79.05 | 74.99 | 68.30 | 52.08 | 43.53 | 41.49 | 75.78 | 59.07 | 52.92 |
| SECOND [20] | 83.13 | 73.66 | 66.20 | 51.07 | 42.56 | 37.29 | 70.51 | 53.85 | 46.90 |
| VoxelNet [13] | 77.47 | 65.11 | 57.73 | 39.48 | 33.69 | 31.50 | 61.22 | 48.36 | 44.37 |
| TANet [42] | 84.39 | 75.94 | 68.82 | 53.72 | 44.34 | 40.49 | 75.70 | 59.44 | 52.53 |
| AVODFPN [43] | 81.94 | 71.88 | 66.38 | 50.80 | 42.81 | 40.88 | 64.00 | 52.18 | 46.61 |
| FPointNet [44] | 81.20 | 70.39 | 62.19 | 51.21 | 44.89 | 40.23 | 71.96 | 56.77 | 50.39 |
| SATGCN [47] | 83.20 | 76.04 | 71.17 | 44.63 | 37.37 | 34.92 | 75.24 | 61.70 | 55.32 |
| PRGBNet [46] | 83.99 | 73.49 | 68.56 | 34.77 | 26.40 | 24.03 | 67.05 | 52.15 | 46.78 |
| Ours | 83.52 | 76.09 | 73.88 | 53.99 | 47.31 | 42.98 | 81.23 | 61.30 | 57.57 |
| Model | Car | Pedestrian | Cyclist | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Easy | Mod. | Hard | Easy | Mod. | Hard | Easy | Mod. | Hard | |
| PointPillars [15] | 88.35 | 86.10 | 79.83 | 58.66 | 50.23 | 49.19 | 79.14 | 62.25 | 56.00 |
| withSeNet | 90.03 | 86.35 | 79.83 | 58.21 | 52.48 | 48.84 | 79.37 | 63.11 | 59.19 |
| withTsPFE | 89.50 | 86.43 | 79.74 | 58.29 | 52.51 | 49.01 | 80.79 | 61.71 | 59.27 |
| withboth | 89.62 | 84.95 | 79.53 | 59.50 | 53.24 | 49.13 | 83.07 | 64.86 | 60.74 |
| Model | Car | Pedestrian | Cyclist | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Easy | Mod. | Hard | Easy | Mod. | Hard | Easy | Mod. | Hard | |
| PointPillars [15] | 79.05 | 74.99 | 68.30 | 52.08 | 43.53 | 41.49 | 75.78 | 59.07 | 52.92 |
| withSeNet | 83.85 | 76.09 | 69.06 | 52.02 | 46.97 | 42.54 | 76.28 | 59.14 | 55.51 |
| withTsPFE | 83.36 | 75.74 | 68.90 | 52.64 | 46.59 | 42.99 | 75.98 | 58.28 | 54.16 |
| withboth | 83.52 | 76.09 | 73.88 | 53.99 | 47.31 | 42.98 | 81.23 | 61.30 | 57.57 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, H.; Dong, X.; Wu, W.; Yu, B.; Zhu, H. A Two-Stage Pillar Feature-Encoding Network for Pillar-Based 3D Object Detection. World Electr. Veh. J. 2023, 14, 146. https://doi.org/10.3390/wevj14060146
Xu H, Dong X, Wu W, Yu B, Zhu H. A Two-Stage Pillar Feature-Encoding Network for Pillar-Based 3D Object Detection. World Electric Vehicle Journal. 2023; 14(6):146. https://doi.org/10.3390/wevj14060146
Chicago/Turabian StyleXu, Hao, Xiang Dong, Wenxuan Wu, Biao Yu, and Hui Zhu. 2023. "A Two-Stage Pillar Feature-Encoding Network for Pillar-Based 3D Object Detection" World Electric Vehicle Journal 14, no. 6: 146. https://doi.org/10.3390/wevj14060146