3.2.1. Basic Concepts
In this section, the Q-learning algorithm is adopted to optimize the overall efficiency and obtain an effective energy management strategy for the WLTP. A series of basic concepts of reinforcement learning need to be introduced hierarchically to define the Q-learning algorithm.
Reinforcement learning solves and improves the control performance of Markov decision problems. Its main architecture revolves around a so-called learning agent, which has access to sensing the environment state and taking actions that conversely affect the controlled environment. To improve control performance, a reward signal is defined that can guide the agent to achieve higher cumulative values through a trial-and-error mechanism. Reinforcement learning can be divided into two categories: model-based learning and model-free learning. In model-based learning, considering the multi-step reinforcement learning task, the machine has modeled the environment, which can simulate the same or similar situation with the environment inside the machine. Regarding model-free learning, in a realistic reinforcement learning task, it is often difficult to know the transition probability and reward function of the environment or even how many states there are in the environment. If the learning algorithm does not depend on environment modeling, it is called model-free learning, which is much more difficult than model-based learning.
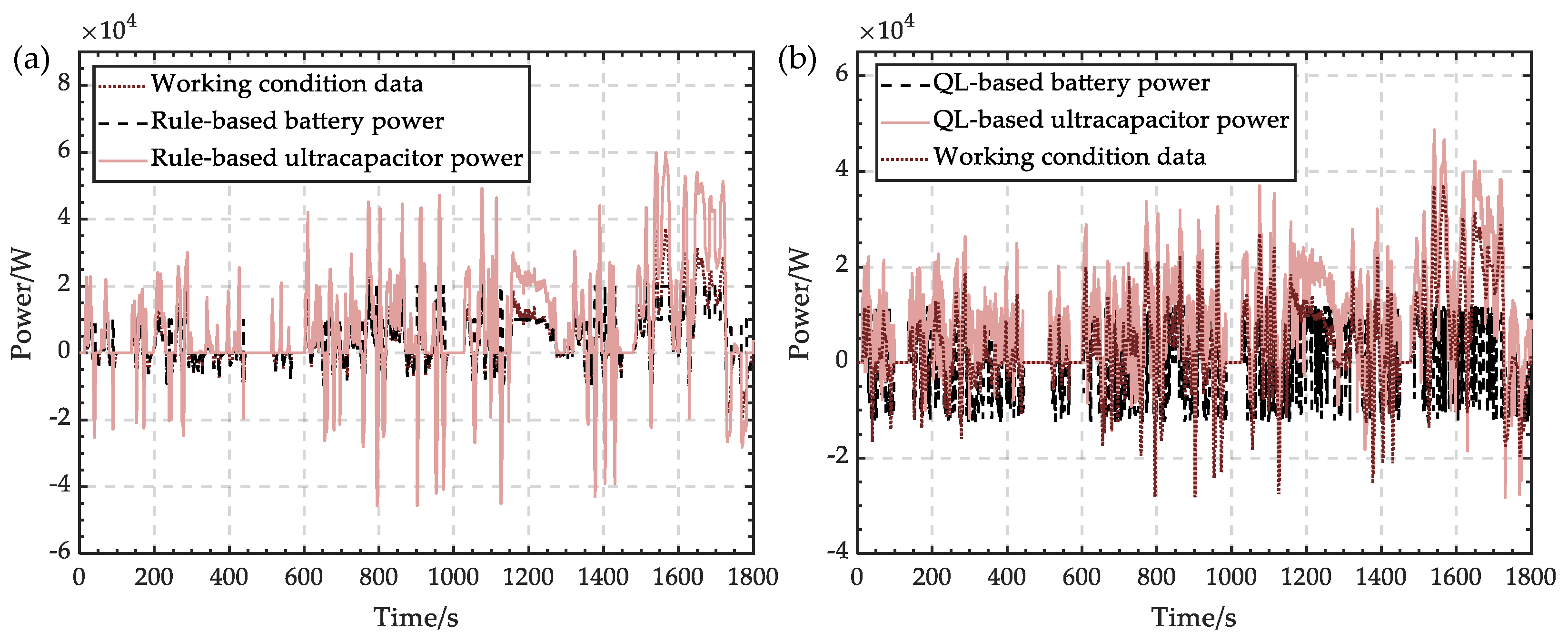
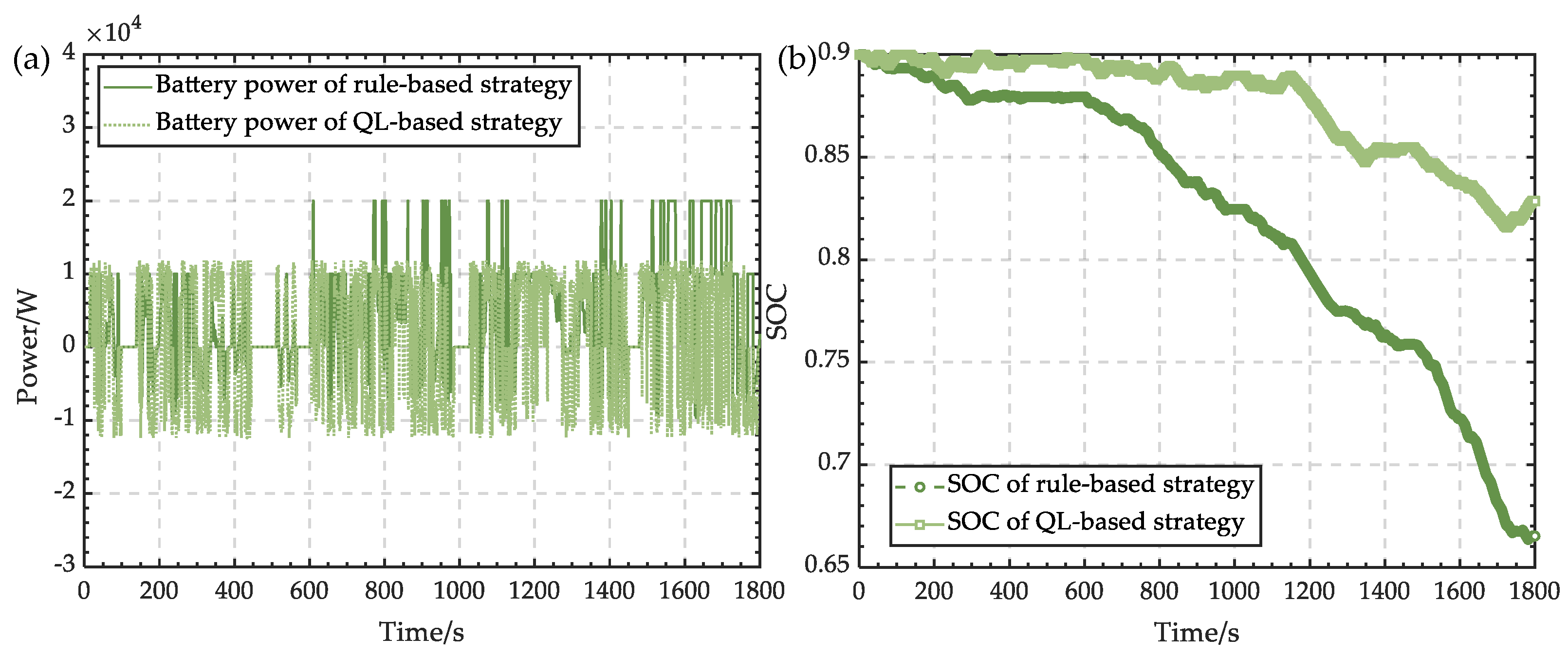
The biggest advantage of model-based learning is that agents can plan in advance, try possible future choices in advance when they go to each step, and then clearly choose from these candidates. The biggest disadvantage is that agents often cannot get the real model of the environment. If the agent wants to use the model in a scene, it must learn completely from experience, which will bring many challenges. The biggest challenge is that there is an error between the model explored by the agent and the real model, which will cause the agent to perform well in the learning model but not well in the real environment. In order to obtain an energy management strategy that can cope with the real environment well, the model-free learning method is used here. There are two kinds of methods in model-free reinforcement learning: the Monte-Carlo update and temporal-difference update. In actual working conditions, the required power is changing every second. According to this characteristic, Q-learning is selected to explore energy management. At the same time, the rule-based method is used to provide another integrated energy management system and be compared with Q-learning to verify its effectiveness.
3.2.2. Power Splitting Based on Q-Learning
Q-learning was proposed for solving Markov decision problems. As one of the most popular off-policy RL methods, Q-learning is expected to maximize the total reward . Consequently, the optimal value function that guides the decision process of the policy can be defined as the distribution over the given current state S(t) and control action A(t).
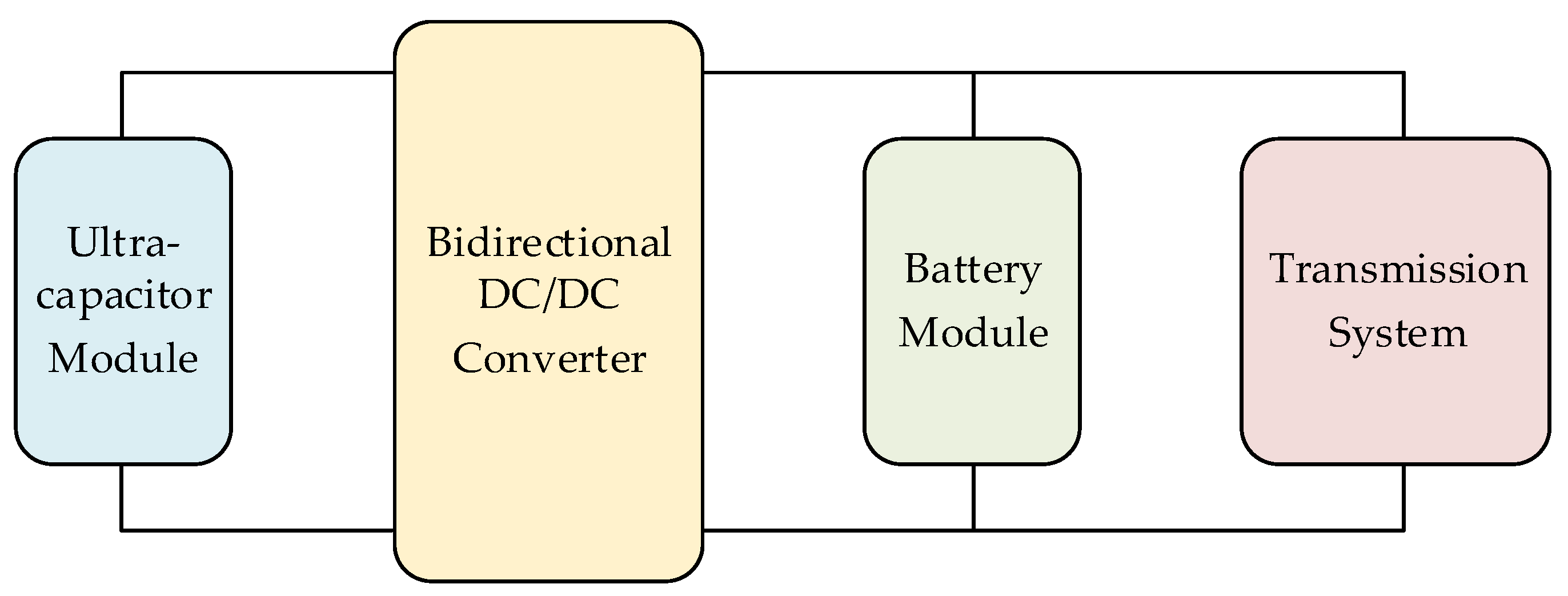
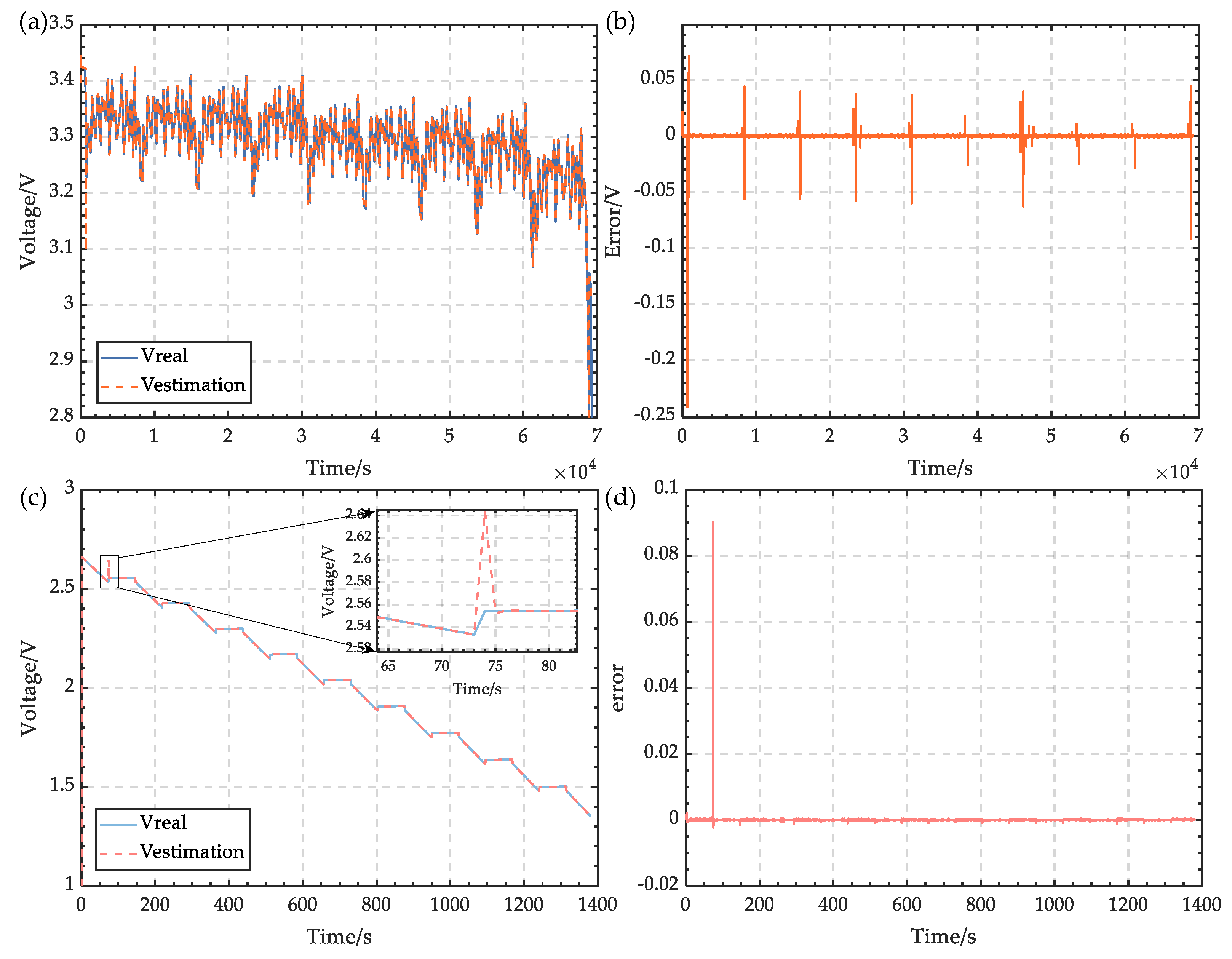
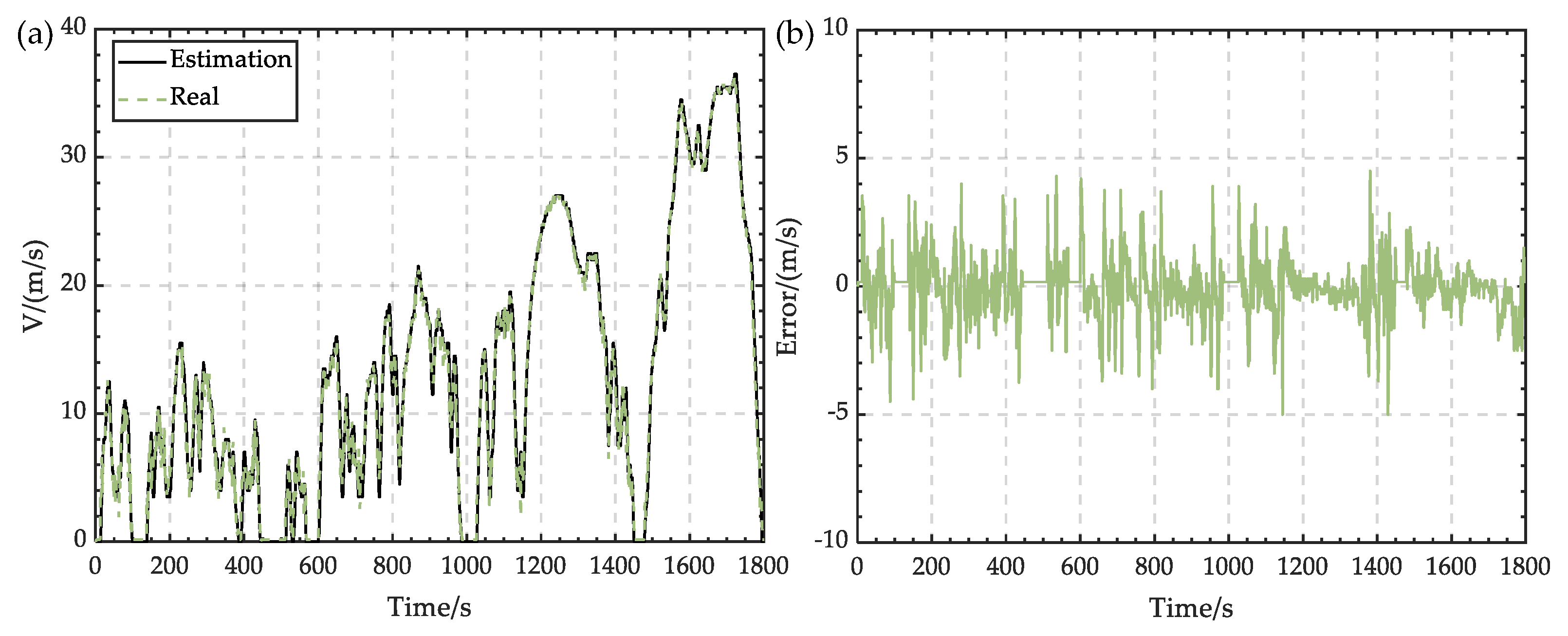
In the integrated energy management system, there are three kinds of changing states: the SOC representing the battery state, state-of-voltage (SOV) representing the capacitor state, and
Pdem representing system output. The constraints of the state variable
S(
t) = {
SOC(
t),
SOV(
t),
Pdem(
t)} can be defined as:
where
Pdem is the required power (unit: kW).
The constraints of the control variable
A(
t) = {
Ic(
t),
Iv(
t)} are defined as:
where
Ic is the battery current, and
Iv is the ultracapacitor current (unit: A).
The reward function is:
where
is a variable; with the size of the total loss value under each second working condition, it is randomly selected in the corresponding interval. When the total loss is less than the required power of 20%,
is 1; otherwise,
is −1.
=
−
, is used to limit the SOC range of battery packs.
Rt is the reward at a single time step
t; for estimating the long-term return, the return
Gt is used to represent the cumulative value of reward
Rt after time
t, and its recursion form is:
where γ∈(0,1) is the discount factor.
Strategy
b is a mapping from the state to the likelihood of selecting each action. The state value function
vb(
s) is defined as the expected return starting from state
s and following strategy
b, expressed as:
where
S(
t) is the state at time
t.
Meanwhile, the action value function
qb(
s,
a) is also defined as the expected return starting from state
s, taking action
a and following strategy
b:
where
A(
t) is the action at time
t. Then, again, the recursive form can be derived:
where
s(
t) and
s(
t + 1) represent specific states at time
t, and
t + 1.
a(
t) and
a(
t + 1) represent the specific actions at time
t and
t + 1.
The optimal action value function
q*(
s,
a) is defined as the maximum action value function in all strategies, and its recursive form can be expressed as:
If q*(s, a) is known, the optimal strategy b* can be obtained by maximizing q*(s, a).
As the real value of the optimal action value function is difficult to obtain, the estimated value of
q*(
S(
t),
A(
t)) −
Q(S(
t),
A(
t)) is used. In a sequential difference method including Q-learning, the difference between the estimated value
Q(
S(
t),
A(
t)) and the better estimated value
R(
t) +
γQ(
S(
t),
A(
t)) is used to update
Q(
S(
t),
A(
t)):
where α is the learning rate.
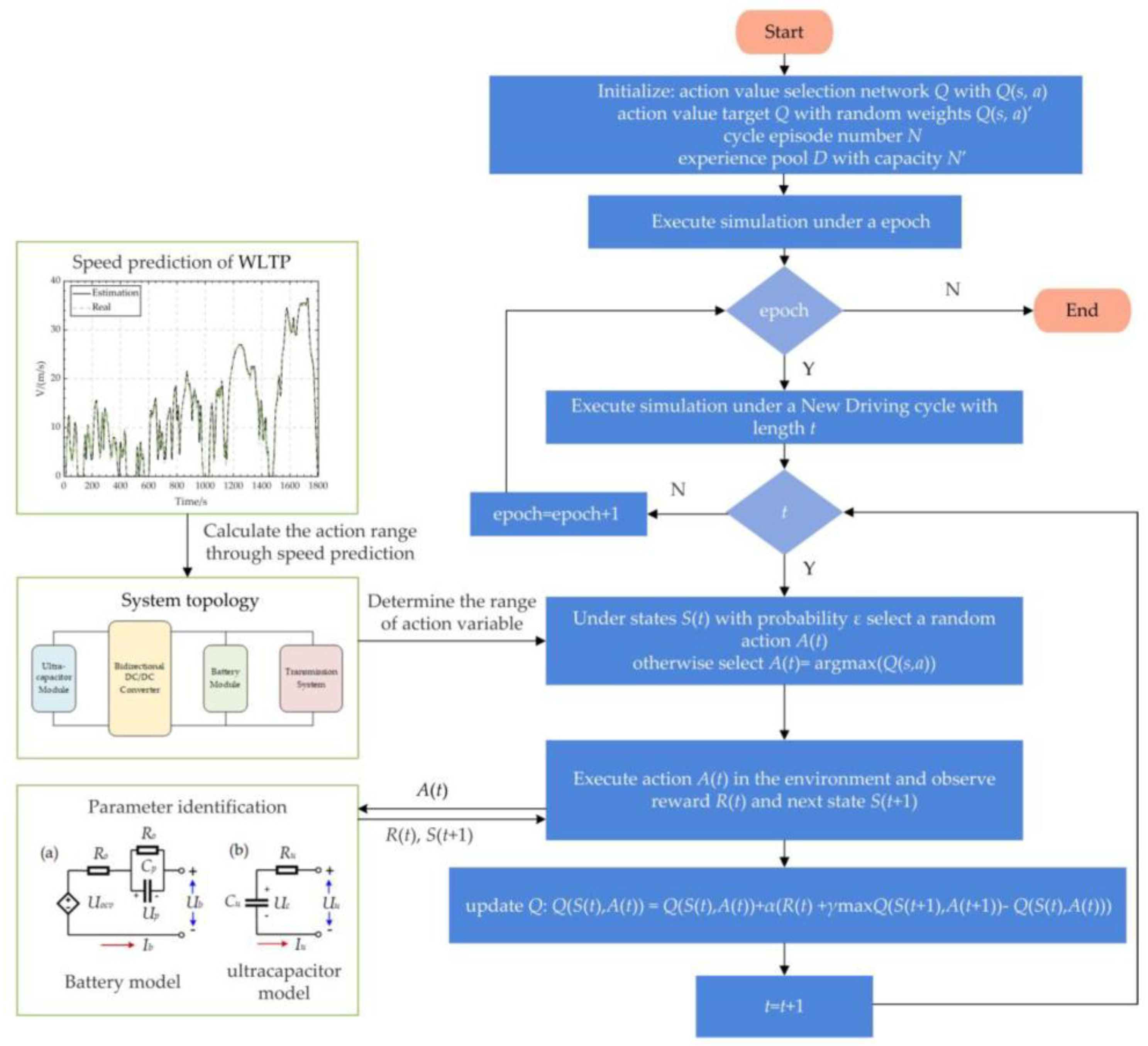
The algorithm block diagram is shown in
Figure 3, which demonstrates the basic method of the algorithm, including the usage of previous work. The exact procedures of the QL algorithm in this article are shown in Algorithm 1.
| Algorithm 1: Q-Learning |
Initialization of Q-learning: Determine algorithm parameter boundary: α∈(0,1), γ∈(0,1), numbers of episodes N, working condition duration T, initialize action value target Q with random weights Q(s, a)’ and experience pool D with capacity N for episode = 1: N do for t = 1:T do With probability π select a random action A(t) Otherwise, select A(t) = arg maxQ(S(t), A(t)) execute action A(t) and observe reward R(t) and next state S(t + 1) update Q follows: Q(S(t), A(t)) = Q(S(t), A(t)) + α[R(t) + γmaxQ(S(t + 1), a) − Q(S(t), A(t))] update S(t) and A(t) end for end for
|











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}