
A DQN-Based Multi-Objective Participant Selection for Efficient Federated Learning
Abstract
:1. Introduction
- We develop a multi-objective node selection optimization model that takes into account accuracy, robustness, and latency simultaneously.
- We formulate the multi-objective node selection as a Markov decision process (MDP), defining the state space, action space, and reward function.
- Based on the multi-objective and deep reinforcement learning, we design a DQN-based algorithm to solve the node selection problem.
2. Related Work
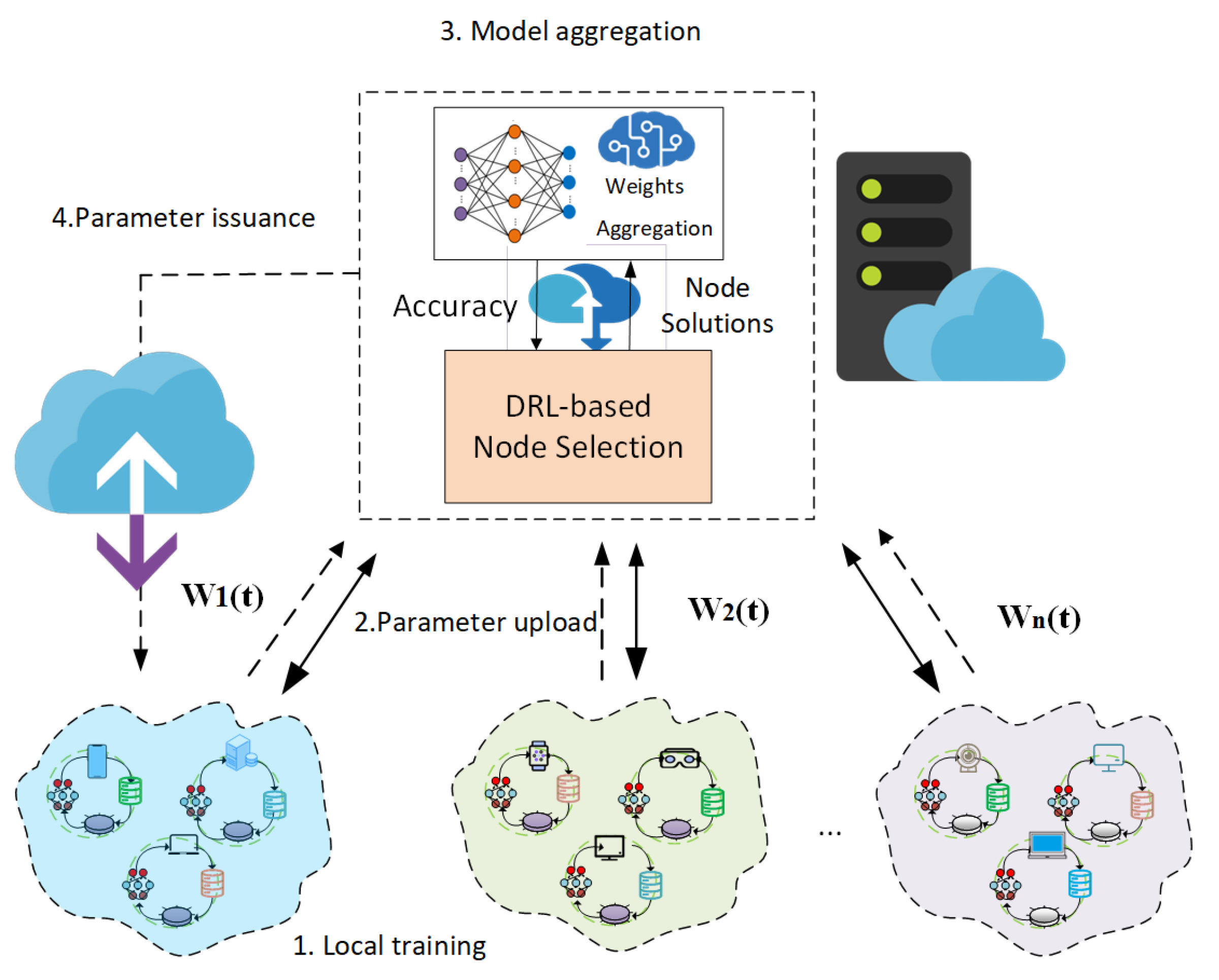
3. System Model
3.1. Network Model
3.2. Workflow for Federated Learning Training
3.3. Problem Formulation for Node Selection
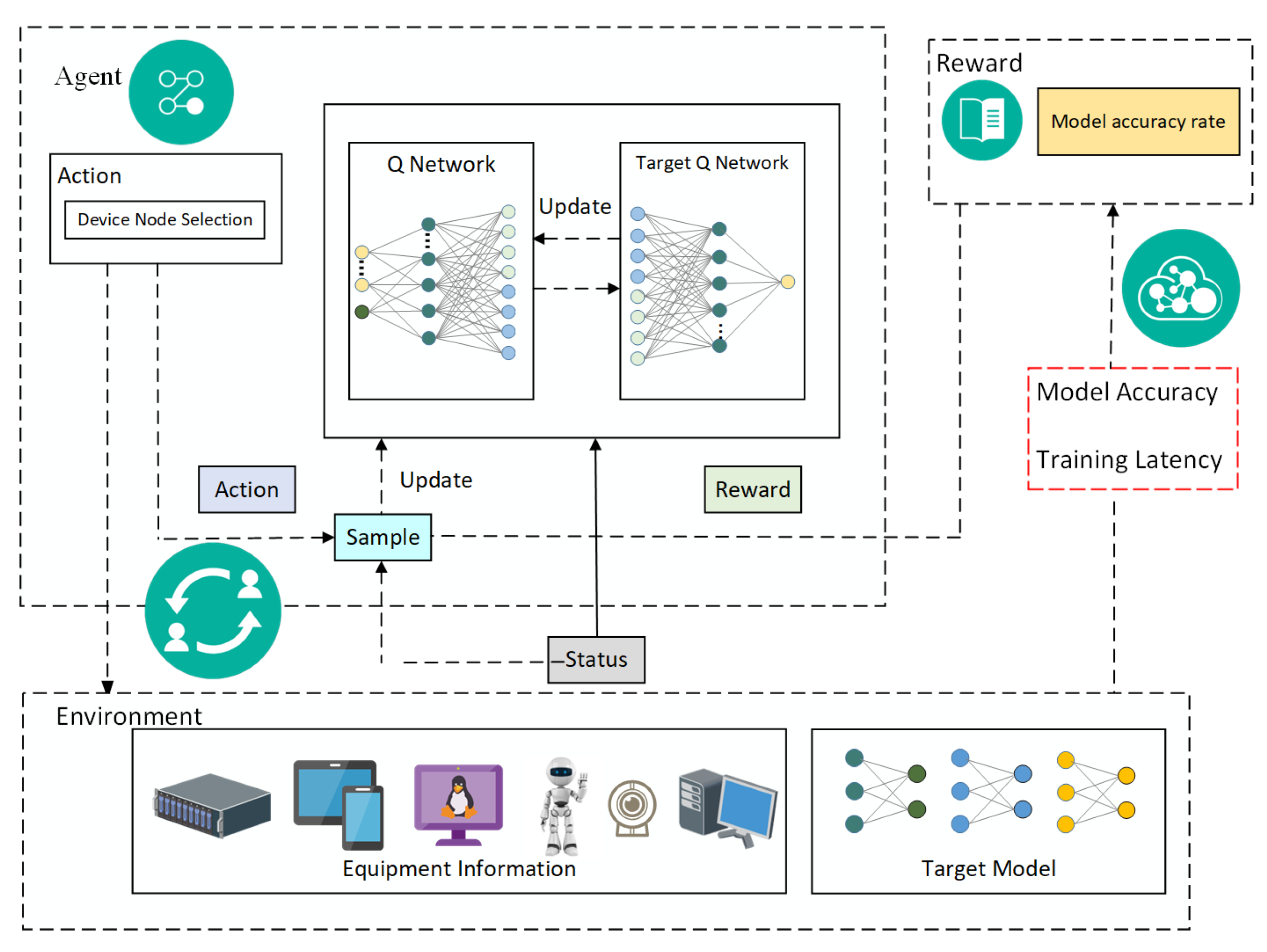
4. FL Node Selection Algorithm Based on DQN
4.1. MDP Model
4.1.1. State Space
4.1.2. Action Space
4.1.3. Reward Function
4.2. DQN-Based Algorithm for FL Node Selection
- (1)
- Multi-threaded interactions
- Step 1
- Each worker thread is assigned a replica of the environment and a local copy of the DQN network. In the context of FL tasks, the environment emulates the behavior and performance of client devices, while the network serves to implement policies within the local environment.
- Step 2
- Each worker thread independently interacts with a replica of its environment to gather empirical data including states, actions, rewards, and new states. This information is used to train the DQN network. Threads can interact concurrently with their assigned environments, thereby speeding up the data collection process.
- Step 3
- The experience data collected by individual threads is stored in a shared experience replay buffer. This buffer can be used to randomly sample batch data.
- (2)
- Global Network Updates
- Step 1
- Upon completing a predetermined number of iterations, the parameters of the global DQN network are synchronized with the local network of each thread, ensuring consistency and updated information across all instances.
- Step 2
- The global DQN network is trained by sampling a random batch of data from the shared experience replay buffer. The training process is executed concurrently, distributing the computational load across multiple threads for increased efficiency.
- Step 3
- Every specified number of steps (circle), update the target network with the parameters of the global DQN network to ensure consistency and continued learning progress.
- Step 4
- Iterate through steps 1 to 3 until the model converges.
| Algorithm 1: DQN-based node selection algorithm |
Input: FL Task Information Q network initial state Output: Node selection scheme Initialize network, edge device and task information, along with system state and experience replay buffers.  |
5. Simulation Analysis
5.1. Experimental Settings
- (1)
- FL-Random: This algorithm does not utilize deep reinforcement learning for node selection during each iteration of FL training. Instead, it selects nodes at random.
- (2)
- FL-Greedy: The algorithm selects all participating nodes for model aggregation in each iteration of the FL training.
- (3)
- Local Training: This approach does not incorporate any FL mechanism, and the model is solely trained on individual local devices [36].
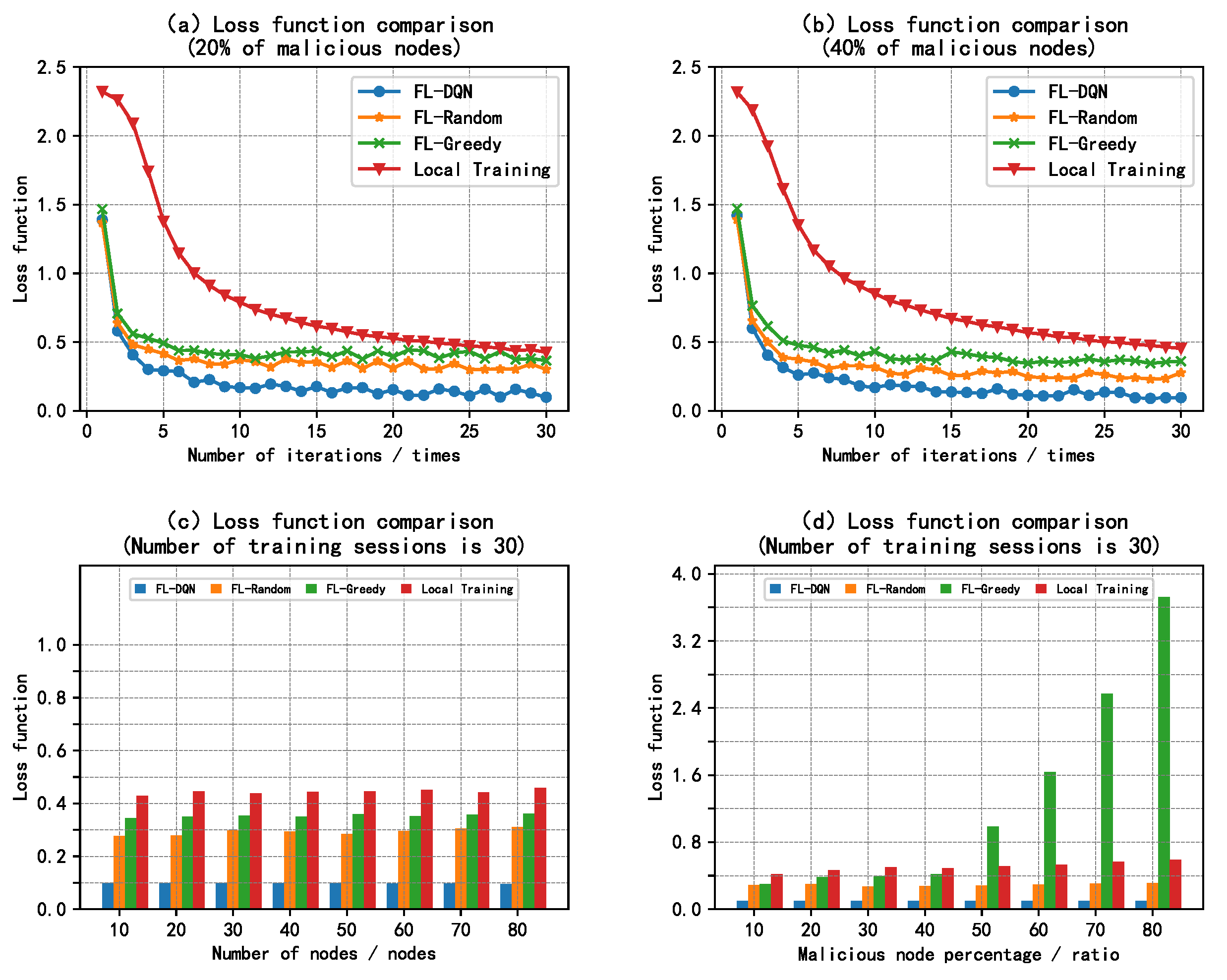
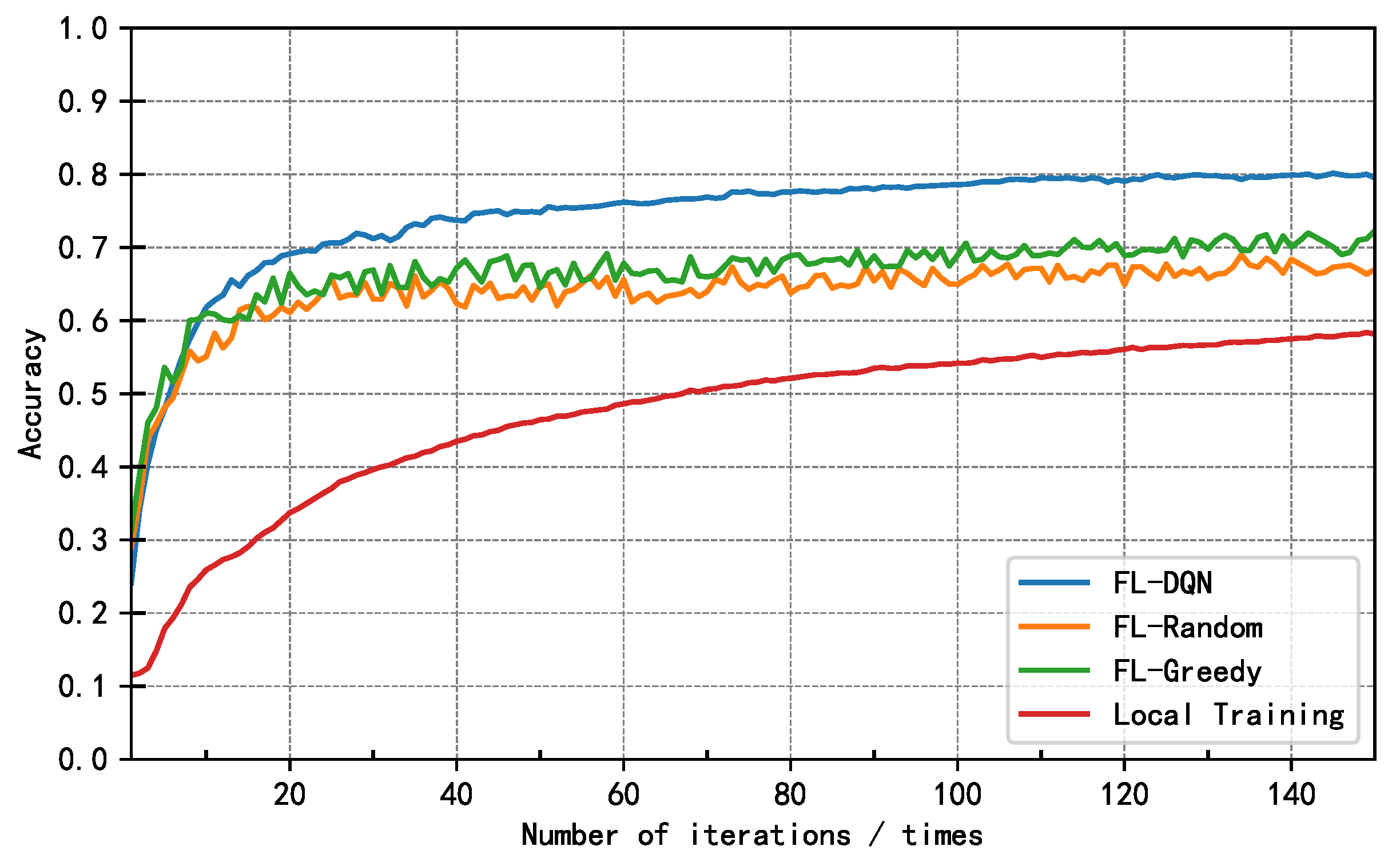
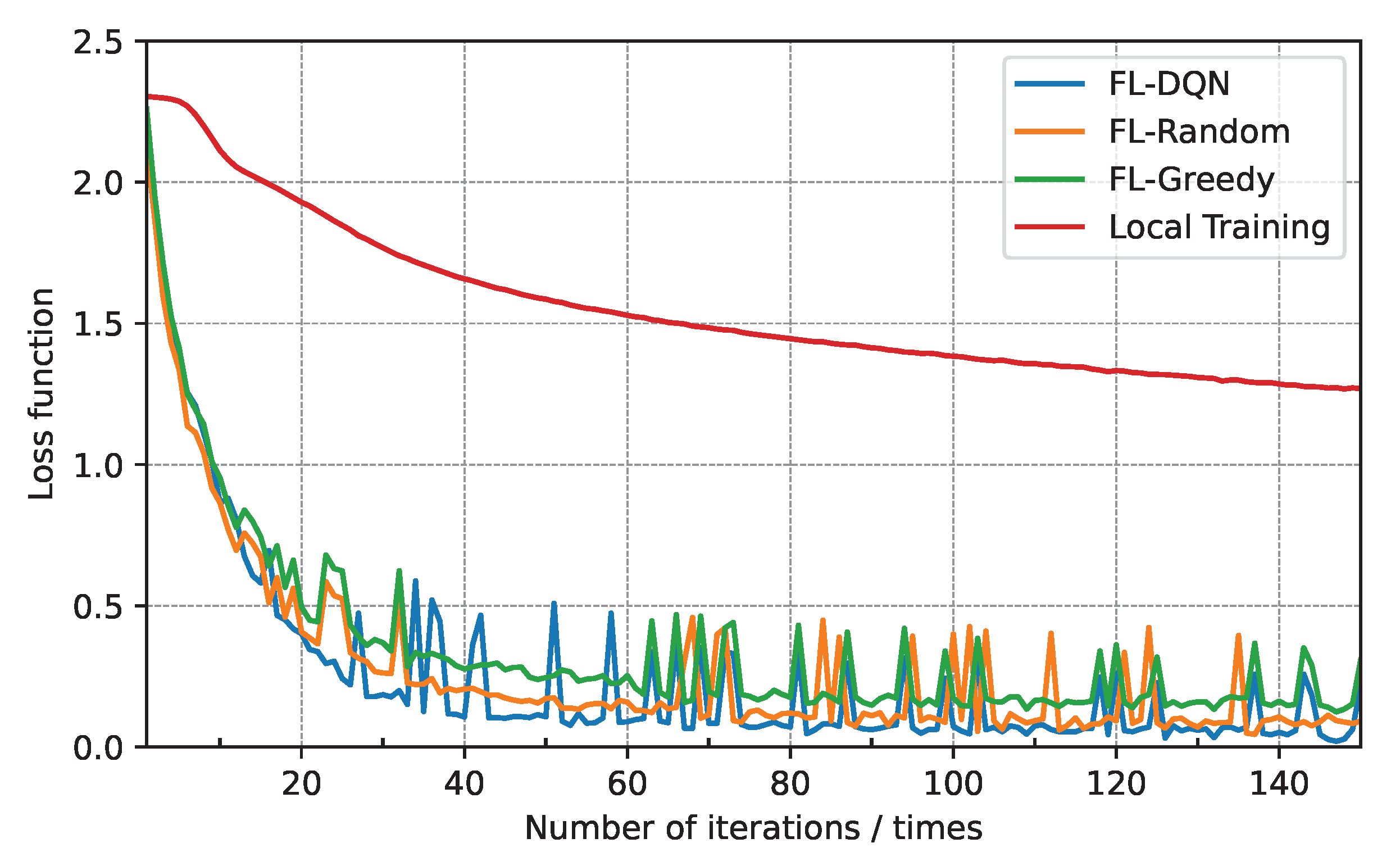
5.2. Analysis of Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| MDP | Markov decision process |
| DQN | Deep Q-Network |
| DRL | Deep Reinforcement Learning |
| SGD | Stochastic Gradient Descent |
| CNN | Convolutional Neural Network |
| MSE | Mean Square Error |
References
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. ACM Trans. Intell. Syst. Technol. (TIST) 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and open problems in federated learning. Found. Trends Mach. Learn. 2021, 14, 1–210. [Google Scholar] [CrossRef]
- Banabilah, S.; Aloqaily, M.; Alsayed, E.; Malik, N.; Jararweh, Y. Federated learning review: Fundamentals, enabling technologies, and future applications. Inf. Process. Manag. 2022, 59, 103061. [Google Scholar] [CrossRef]
- Mora, A.; Fantini, D.; Bellavista, P. Federated Learning Algorithms with Heterogeneous Data Distributions: An Empirical Evaluation. In Proceedings of the 2022 IEEE/ACM 7th Symposium on Edge Computing (SEC), Seattle, WA, USA, 5–8 December 2022; pp. 336–341. [Google Scholar] [CrossRef]
- Chathoth, A.K.; Necciai, C.P.; Jagannatha, A.; Lee, S. Differentially Private Federated Continual Learning with Heterogeneous Cohort Privacy. In Proceedings of the 2022 IEEE International Conference on Big Data (Big Data), Osaka, Japan, 17–20 December 2022; pp. 5682–5691. [Google Scholar] [CrossRef]
- Han, J.; Khan, A.F.; Zawad, S.; Anwar, A.; Angel, N.B.; Zhou, Y.; Yan, F.; Butt, A.R. Heterogeneity-Aware Adaptive Federated Learning Scheduling. In Proceedings of the 2022 IEEE International Conference on Big Data (Big Data), Osaka, Japan, 17–20 December 2022; pp. 911–920. [Google Scholar] [CrossRef]
- Wu, H.; Wang, P. Node selection toward faster convergence for federated learning on non-iid data. IEEE Trans. Netw. Sci. Eng. 2022, 9, 3099–3111. [Google Scholar] [CrossRef]
- Deer, A.; Ali, R.E.; Avestimehr, A.S. On Multi-Round Privacy in Federated Learning. In Proceedings of the 2022 56th Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 31 October–2 November 2022; pp. 764–769. [Google Scholar] [CrossRef]
- Liu, W.; Chen, L.; Zhang, W. Decentralized federated learning: Balancing communication and computing costs. IEEE Trans. Signal Inf. Process. Over Netw. 2022, 8, 131–143. [Google Scholar] [CrossRef]
- Issa, W.; Moustafa, N.; Turnbull, B.; Sohrabi, N.; Tari, Z. Blockchain-based federated learning for securing internet of things: A comprehensive survey. ACM Comput. Surv. 2023, 55, 1–43. [Google Scholar] [CrossRef]
- Chi, J.; Xu, S.; Guo, S.; Yu, P.; Qiu, X. Federated Learning Empowered Edge Collaborative Content Caching Mechanism for Internet of Vehicles. In Proceedings of the NOMS 2022–2022 IEEE/IFIP Network Operations and Management Symposium, Budapest, Hungary, 25–29 April 2022; pp. 1–5. [Google Scholar] [CrossRef]
- Patel, V.A.; Bhattacharya, P.; Tanwar, S.; Gupta, R.; Sharma, G.; Sharma, P.N.; Sharma, R. Adoption of federated learning for healthcare informatics: Emerging applications and future directions. IEEE Access 2022, 10, 90792–90826. [Google Scholar] [CrossRef]
- Moon, S.H.; Lee, W.H. Privacy-Preserving Federated Learning in Healthcare. In Proceedings of the 2023 International Conference on Electronics, Information, and Communication (ICEIC), Singapore, 5–8 February 2023; pp. 1–4. [Google Scholar] [CrossRef]
- Vrind, T.; Pathak, L.; Das, D. Novel Federated Learning by Aerial-Assisted Protocol for Efficiency Enhancement in Beyond 5G Network. In Proceedings of the 2023 IEEE 20th Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 8–11 January 2023; pp. 891–892. [Google Scholar] [CrossRef]
- Zhang, H.; Zhou, H.; Erol-Kantarci, M. Federated deep reinforcement learning for resource allocation in O-RAN slicing. In Proceedings of the GLOBECOM 2022-2022 IEEE Global Communications Conference, Rio de Janeiro, Brazil, 4–8 December 2022; pp. 958–963. [Google Scholar] [CrossRef]
- Guo, X. Implementation of a Blockchain-enabled Federated Learning Model that Supports Security and Privacy Comparisons. In Proceedings of the2022 IEEE 5th International Conference on Information Systems and Computer Aided Education (ICISCAE), Dalian, China, 23–25 September 2022; pp. 243–247. [Google Scholar] [CrossRef]
- Xin, S.; Zhuo, L.; Xin, C. Node Selection Strategy Design Based on Reputation Mechanism for Hierarchical Federated Learning. In Proceedings of the 2022 18th International Conference on Mobility, Sensing and Networking (MSN), Guangzhou, China, 14–16 December 2022; pp. 718–722. [Google Scholar] [CrossRef]
- Li, C.; Wu, H. FedCLS: A federated learning client selection algorithm based on cluster label information. In Proceedings of the 2022 IEEE 96th Vehicular Technology Conference (VTC2022-Fall), London, UK, 26–29 September 2022; pp. 1–5. [Google Scholar] [CrossRef]
- Shen, Y.; Wang, H.; Lv, H. Federated Learning with Classifier Shift for Class Imbalance. arXiv 2023, arXiv:2304. 04972. [Google Scholar] [CrossRef]
- Travadi, Y.; Peng, L.; Bi, X.; Sun, J.; Yang, M. Welfare and Fairness Dynamics in Federated Learning: A Client Selection Perspective. arXiv 2023, arXiv:2302.08976. [Google Scholar] [CrossRef]
- Carey, A.N.; Du, W.; Wu, X. Robust Personalized Federated Learning under Demographic Fairness Heterogeneity. In Proceedings of the 2022 IEEE International Conference on Big Data (Big Data), Osaka, Japan, 17–20 December 2022; pp. 1425–1434. [Google Scholar] [CrossRef]
- Huang, T.; Lin, W.; Shen, L.; Li, K.; Zomaya, A.Y. Stochastic client selection for federated learning with volatile clients. IEEE Internet Things J. 2022, 9, 20055–20070. [Google Scholar] [CrossRef]
- Ami, D.B.; Cohen, K.; Zhao, Q. Client Selection for Generalization in Accelerated Federated Learning: A Bandit Approach. In Proceedings of the ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Eslami Abyane, A.; Drew, S.; Hemmati, H. MDA: Availability-Aware Federated Learning Client Selection. arXiv 2022, arXiv:2211.14391. [Google Scholar] [CrossRef]
- Yin, T.; Li, L.; Lin, W.; Ma, D.; Han, Z. Grouped Federated Learning: A Decentralized Learning Framework with Low Latency for Heterogeneous Devices. In Proceedings of the 2022 IEEE International Conference on Communications Workshops (ICC Workshops), Seoul, Republic of Korea, 16–20 May 2022; pp. 55–60. [Google Scholar] [CrossRef]
- Yin, B.; Chen, Z.; Tao, M. Predictive GAN-powered Multi-Objective Optimization for Hybrid Federated Split Learning. arXiv 2022, arXiv:2209.02428. [Google Scholar] [CrossRef]
- Tu, X.; Zhu, K. Learning-based Multi-Objective Resource Allocation for Over-the-Air Federated Learning. In Proceedings of the GLOBECOM 2022-2022 IEEE Global Communications Conference, Rio de Janeiro, Brazil, 4–8 December 2022; pp. 3065–3070. [Google Scholar] [CrossRef]
- Banerjee, S.; Vu, X.S.; Bhuyan, M. Optimized and Adaptive Federated Learning for Straggler-Resilient Device Selection. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022; pp. 1–9. [Google Scholar] [CrossRef]
- Hu, Z.; Shaloudegi, K.; Zhang, G.; Yu, Y. Federated learning meets multi-objective optimization. IEEE Trans. Netw. Sci. Eng. 2022, 9, 2039–2051. [Google Scholar] [CrossRef]
- Jarwan, A.; Ibnkahla, M. Edge-Based Federated Deep Reinforcement Learning for IoT Traffic Management. IEEE Internet Things J. 2022, 10, 3799–3813. [Google Scholar] [CrossRef]
- Lu, Y.; Huang, X.; Zhang, K.; Maharjan, S.; Zhang, Y. Blockchain empowered asynchronous federated learning for secure data sharing in internet of vehicles. IEEE Trans. Veh. Technol. 2020, 69, 4298–4311. [Google Scholar] [CrossRef]
- Wang, R.; Tsai, W.T. Asynchronous federated learning system based on permissioned blockchains. Sensors 2022, 22, 1672. [Google Scholar] [CrossRef]
- Shen, Y.; Gou, F.; Wu, J. Node screening method based on federated learning with IoT in opportunistic social networks. Mathematics 2022, 10, 1669. [Google Scholar] [CrossRef]
- Neves, M.; Neto, P. Deep reinforcement learning applied to an assembly sequence planning problem with user preferences. Int. J. Adv. Manuf. Technol. 2022, 122, 4235–4245. [Google Scholar] [CrossRef]
- Li, X.; Fang, J.; Du, K.; Mei, K.; Xue, J. UAV Obstacle Avoidance by Human-in-the-Loop Reinforcement in Arbitrary 3D Environment. arXiv 2023, arXiv:2304.05959. [Google Scholar] [CrossRef]
- He, W.; Guo, S.; Qiu, X.; Chen, L.; Zhang, S. Node selection method in federated learning based on deep reinforcement learning. J. Commun. 2021, 42, 62–71. [Google Scholar]
- Xuan, Z.; Wei, G.; Ni, Z. Power Allocation in Multi-Agent Networks via Dueling DQN Approach. In Proceedings of the 2021 IEEE 6th International Conference on Signal and Image Processing (ICSIP), Nanjing, China, 22–24 October 2021. [Google Scholar] [CrossRef]
- Lin, J.; Moothedath, S. Federated Stochastic Bandit Learning with Unobserved Context. arXiv 2023, arXiv:2303.17043. [Google Scholar] [CrossRef]
- Kim, H.; Doh, I. Privacy Enhanced Federated Learning Utilizing Differential Privacy and Interplanetary File System. In Proceedings of the 2023 International Conference on Information Networking (ICOIN), Bangkok, Thailand, 11–14 January 2023; pp. 312–317. [Google Scholar] [CrossRef]
- Zhang, H.; Xie, Z.; Zarei, R.; Wu, T.; Chen, K. Adaptive client selection in resource constrained federated learning systems: A deep reinforcement learning approach. IEEE Access 2021, 9, 98423–98432. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Targets | Research Work | Contribution | Limitation |
|---|---|---|---|
| Signature-based | Xin et al. [17] | Using NSRA to select nodes with high reputation prediction value. | Selecting nodes just by the historical reputation. |
| Li et al. [18] | Optimizing the selection of clients through label information of each cluster. | Obtaining such cluster labels may not always be feasible or may introduce additional computational overhead. | |
| Shen et al. [19] | Applying FedShift to alleviate the negative impact of class imbalance and improve the accuracy of the model. | The approach’s applicability to other forms of non-IID data needs to be further explored. | |
| Fairness | Travadi et al. [20] | Designing an incentive mechanism to remove low-quality clients and ensure a fair reward distribution. | In practice, the cost may not be easily accessible and the utility can be determined by multiple factors. |
| Carey et al. [21] | Utilizing FHN to make clients to personalize the fairness metric enforced during local training freely. | Not all fairness metrics can be formalized. | |
| Huang et al. [22] | Employing E3CS as selection decision under joint consideration of effective participation and fairness. | Real-time contributions of individual clients are not taken into account in the design of fairness factors. | |
| Training time | Ami et al. [23] | Minimize the training latency without harming the ability of the model to generalize through MAB-based approach. | Lack of consideration for client heterogeneity. |
| Abyan et al. [24] | Propose MDA to speed up the learning process. | The generalization capability of the strategy across different FL scenarios should be assessed. | |
| Yin et al. [25] | Accelerating the convergence of the FL model using FGFL. | When the data size is large, the scalability is not good. | |
| Multi-Objective | Chen et al. [26] | Applying GAN to address the conflicting objectives of training time and energy consumption. | Approach has limited generalization to diverse scenarios. |
| Tu et al. [27] | Minimize the AMSE of the aggregation and maximize the long-term energy efficiency of the system via DRL-based framework. | Lack of comprehensive performance evaluation. | |
| Banerjee et al. [28] | Maximize the processing power, memory, and bandwidth capacity of devices by Fed-MOODS. | Lack of simulations with a large number of devices. | |
| Hu et al. [29] | FedMGDA+ is proposed to guarantee fairness among users and robustness against malicious attackers. | Absence of privacy guarantees to ensure the privacy of user data. |
| Parameters | Meaning |
|---|---|
| G | |
| The environmental state at time | |
| Parameter Type | Parameter | Parameter Description | Parameter Value |
|---|---|---|---|
| Equipment and model parameters | Number of terminals | 100 | |
| CPU cycle frequency | [0, 1] | ||
| Wireless Bandwidth | [0, 2] | ||
| Local datasets | 600 | ||
| Local Iteration | 2 | ||
| Minimum sample size | 10 | ||
| Learning Rate | 0.01 | ||
| Node | Number of nodes involved | [10, 80] | |
| Number of CPU cycles required for | 7000 | ||
| training per data bit | |||
| Global Model Size | 20 Mbit | ||
| DQN parament | A | Agents | 4 |
| s | Training steps | 1000 | |
| Target Q | Q Network | 0.0001 | |
| Bonus Discount Factor | 0.9 | ||
| circle | Strategy Update Steps | 100 | |
| Experience replay buffer | 10,000 | ||
| B | Batch-size | 64 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, T.; Liu, Y.; Ma, Z.; Huang, Y.; Liu, P. A DQN-Based Multi-Objective Participant Selection for Efficient Federated Learning. Future Internet 2023, 15, 209. https://doi.org/10.3390/fi15060209
Xu T, Liu Y, Ma Z, Huang Y, Liu P. A DQN-Based Multi-Objective Participant Selection for Efficient Federated Learning. Future Internet. 2023; 15(6):209. https://doi.org/10.3390/fi15060209
Chicago/Turabian StyleXu, Tongyang, Yuan Liu, Zhaotai Ma, Yiqiang Huang, and Peng Liu. 2023. "A DQN-Based Multi-Objective Participant Selection for Efficient Federated Learning" Future Internet 15, no. 6: 209. https://doi.org/10.3390/fi15060209