

Anomaly Detection for Hydraulic Power Units—A Case Study


Abstract
:1. Introduction
- data acquisition;
- data analysis;
- data visualization in MOLOS.CLOUD [1] web SCADA by REDNT S.A.
1.1. Hydraulic Power Unit Description
1.2. Business Needs
1.3. Literature Review
2. Materials and Methods
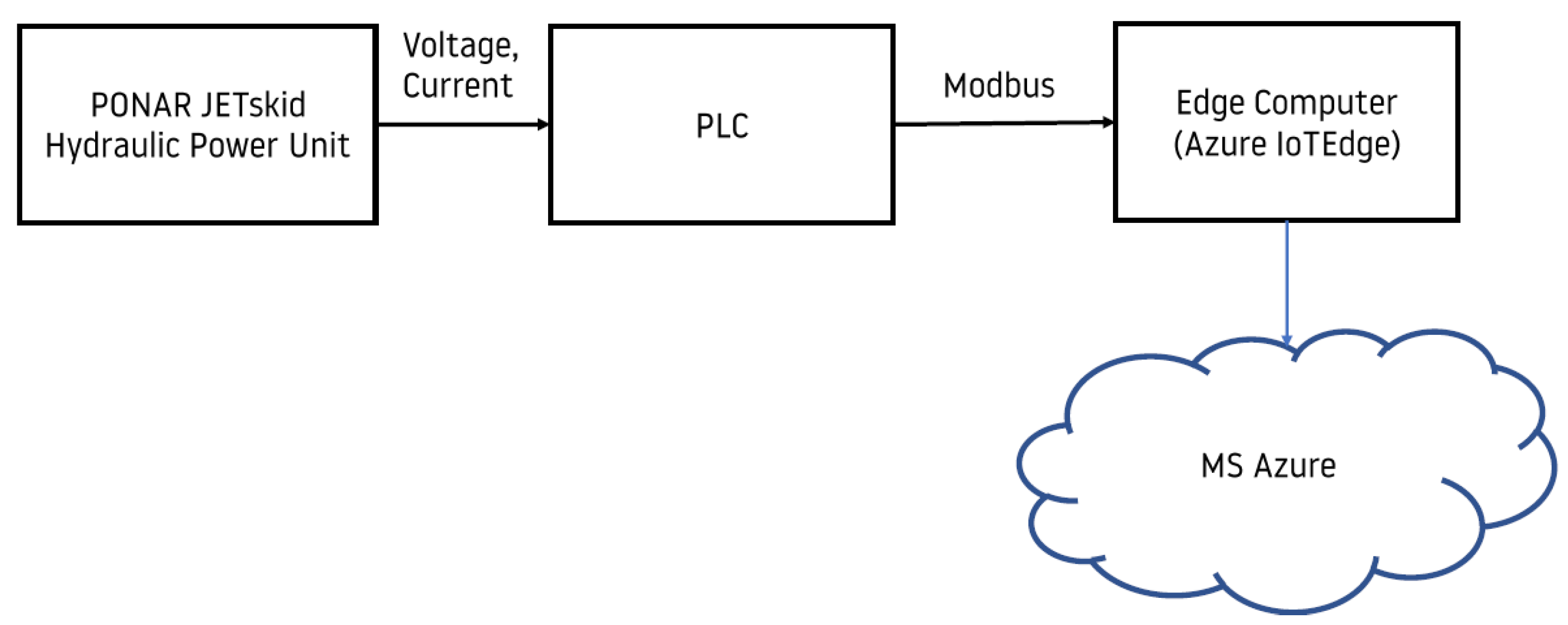
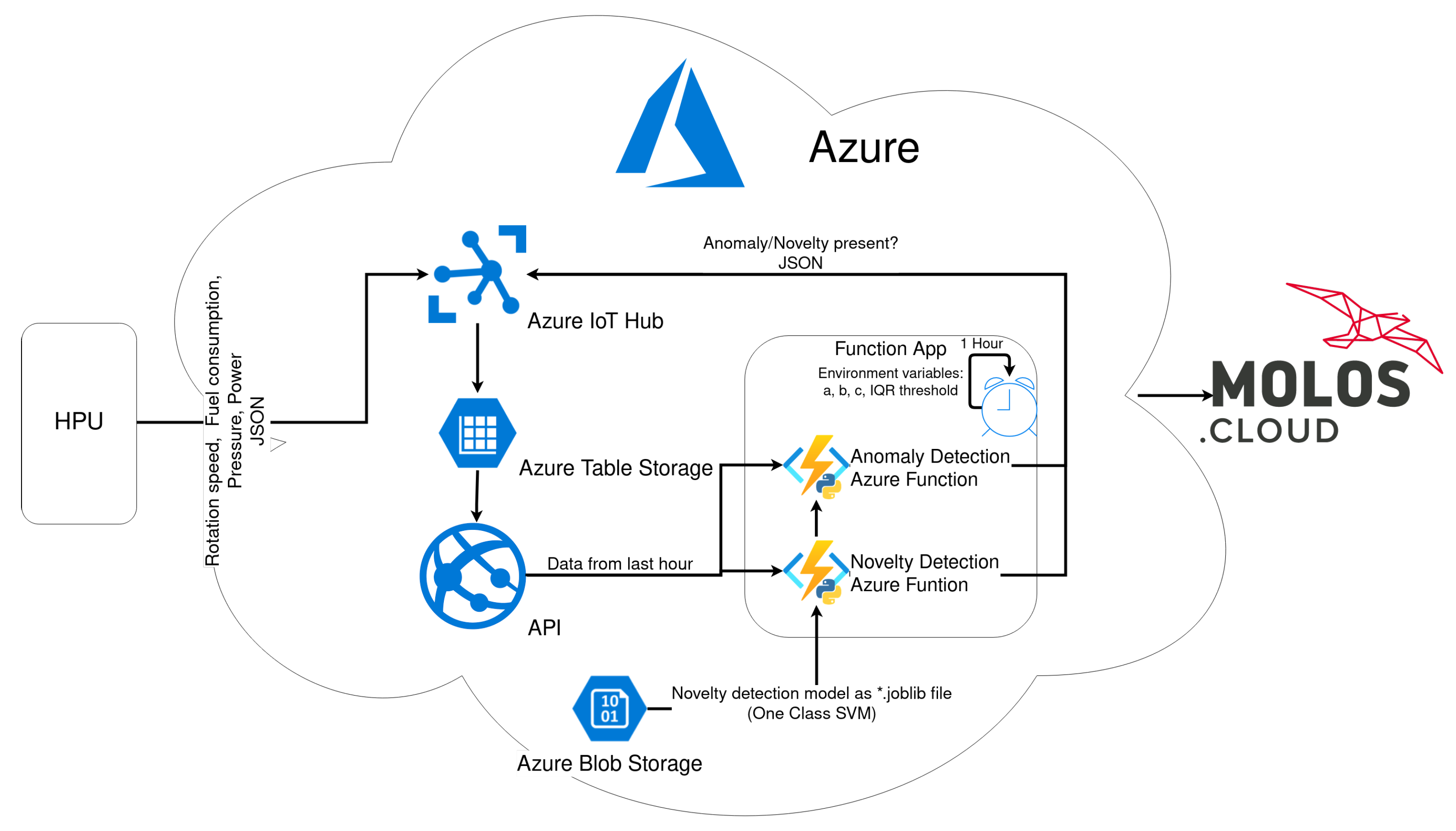
2.1. Data Acquisition and Communication
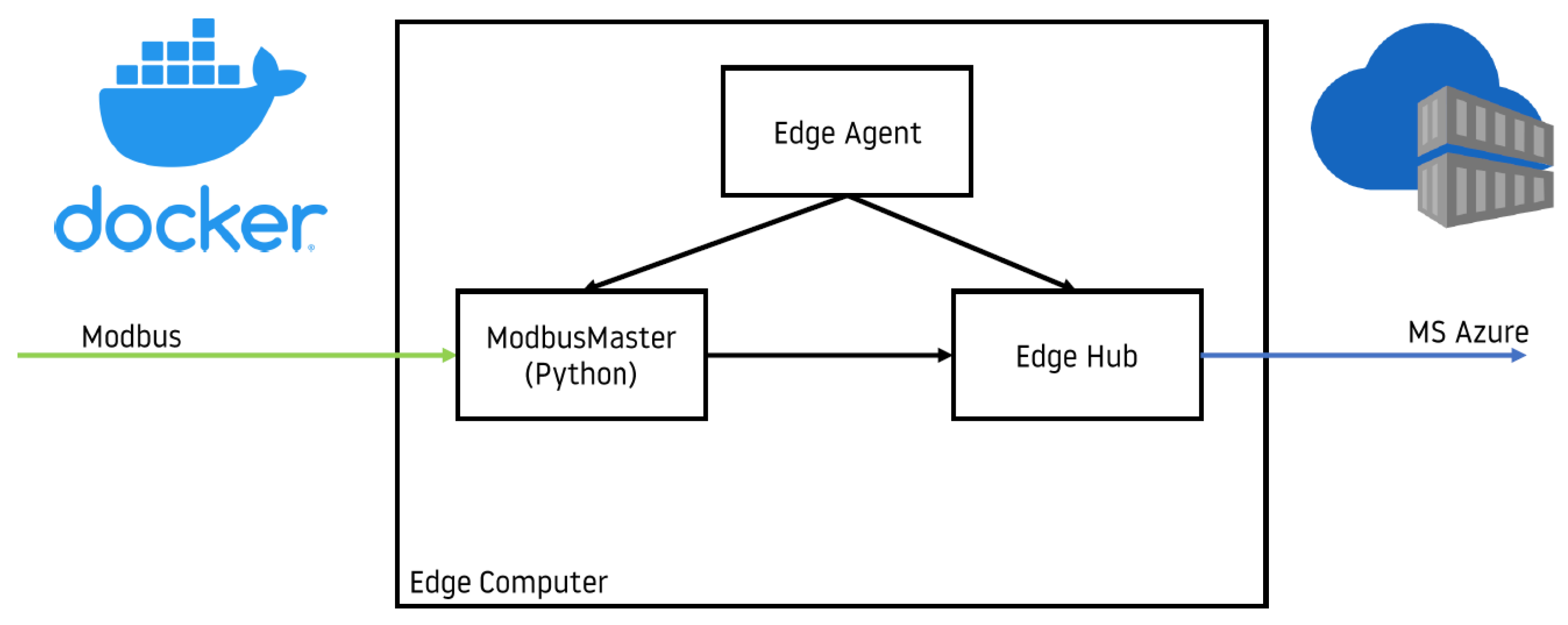
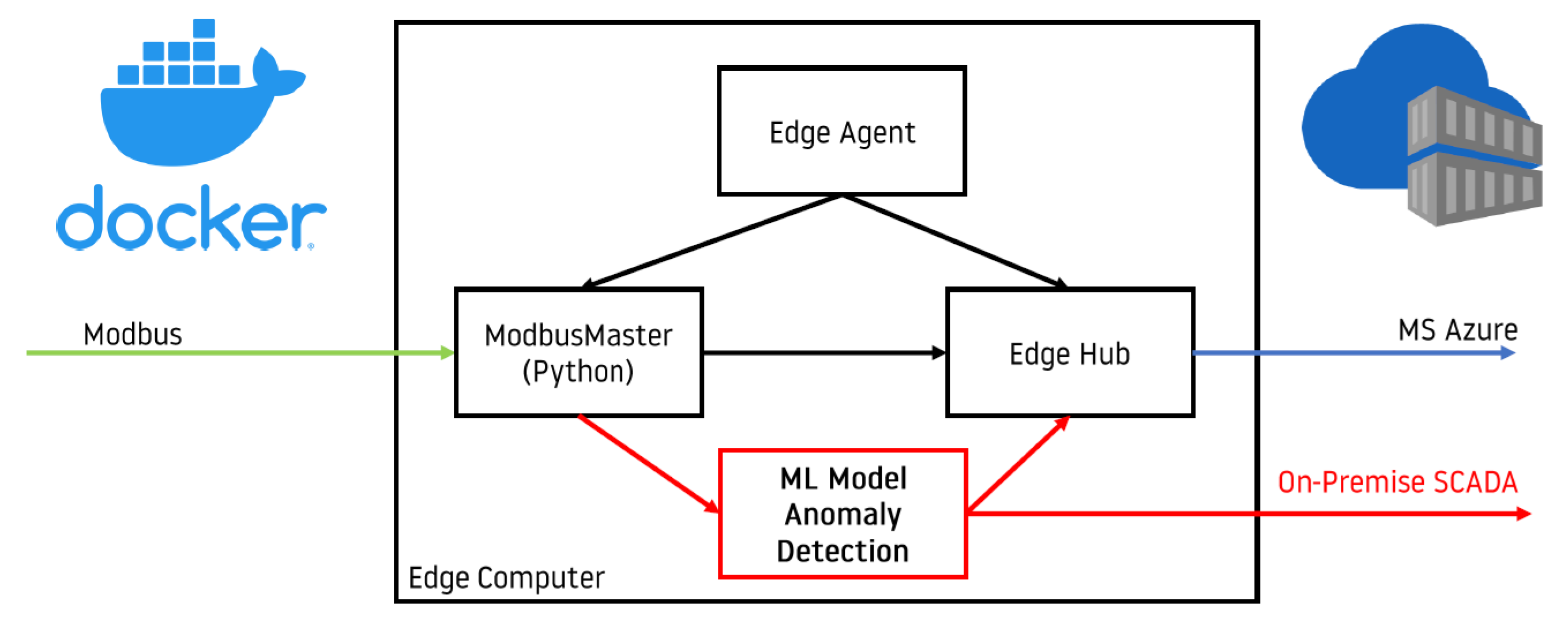
2.1.1. Hardware and Software Architecture
- Pressure behind filter, bar;
- Engine oil pressure, bar;
- Fuel level, %;
- Water level in the tank, %;
- Fuel consumption, L;
- Engine coolant temperature, °C;
- Water temperature in the tank, °C;
- Oil temperature, °C;
- Power, W;
- Rotation speed, ;
- Oil flow, .
- Reading data from Modbus (program acting as Modbus Master);
- Sending data to the cloud in a proper format.
| Algorithm 1 Program for reading measurements from PLC and sending them to the cloud |
|
2.1.2. Azure IoT Edge
- Code development, including implementation of data acquisition presented in Algorithm 1;
- Building Docker container;
- Pushing Docker container to container registry;
2.2. Algorithms Design
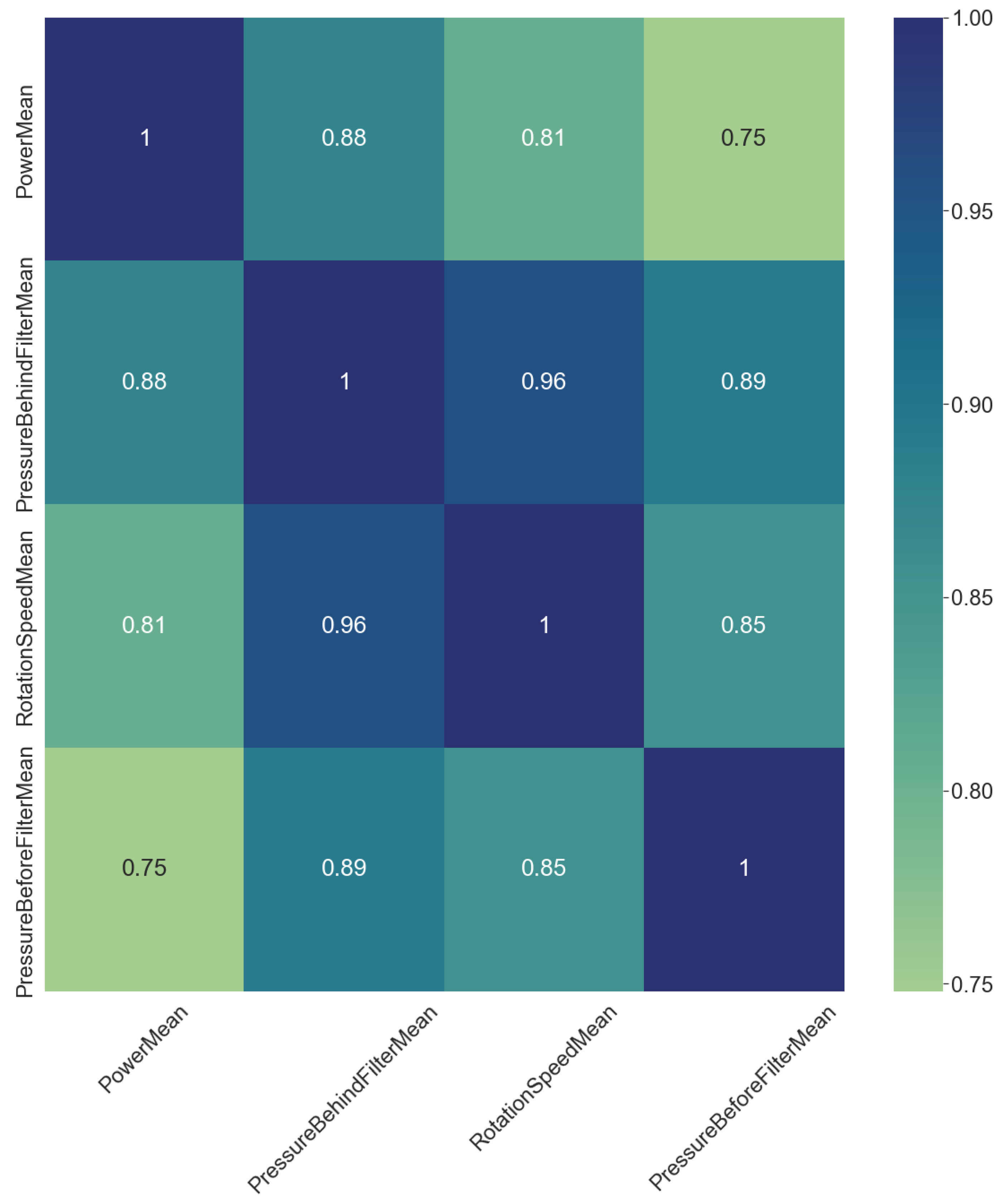
2.2.1. Feature Engineering
- Fuel consumption divided by power;
- Rotation speed divided by pressure behind the filter.
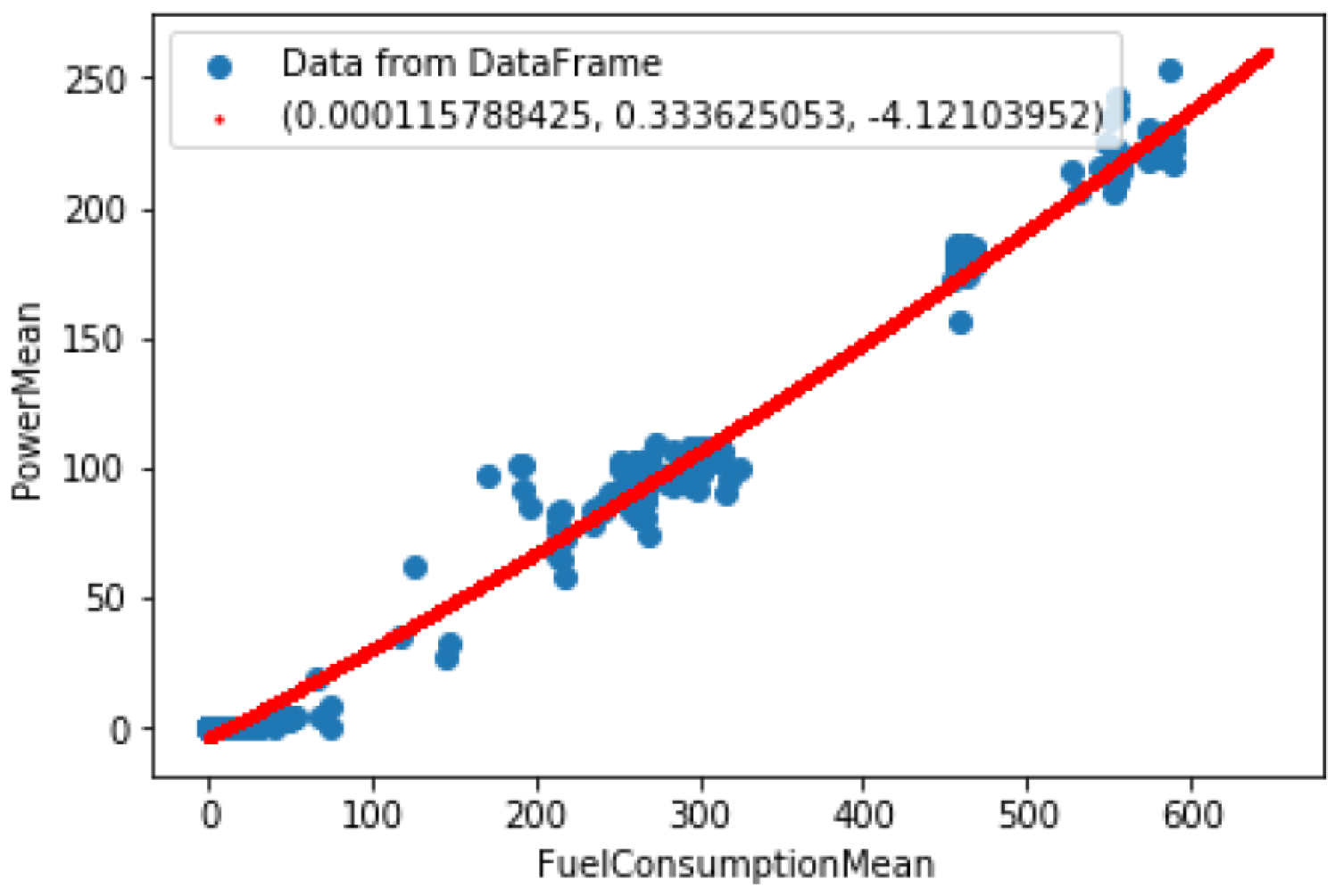
2.2.2. Fitting to Characteristics
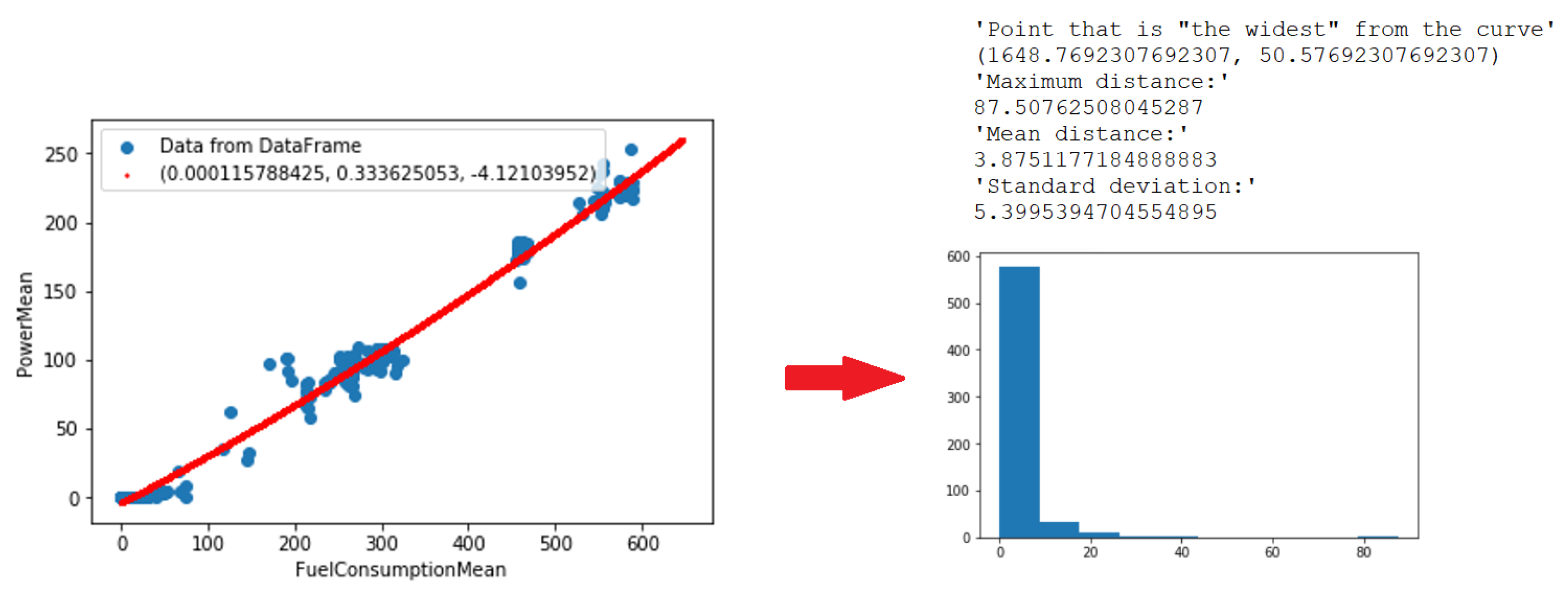
- Power mean due to fuel consumption mean;
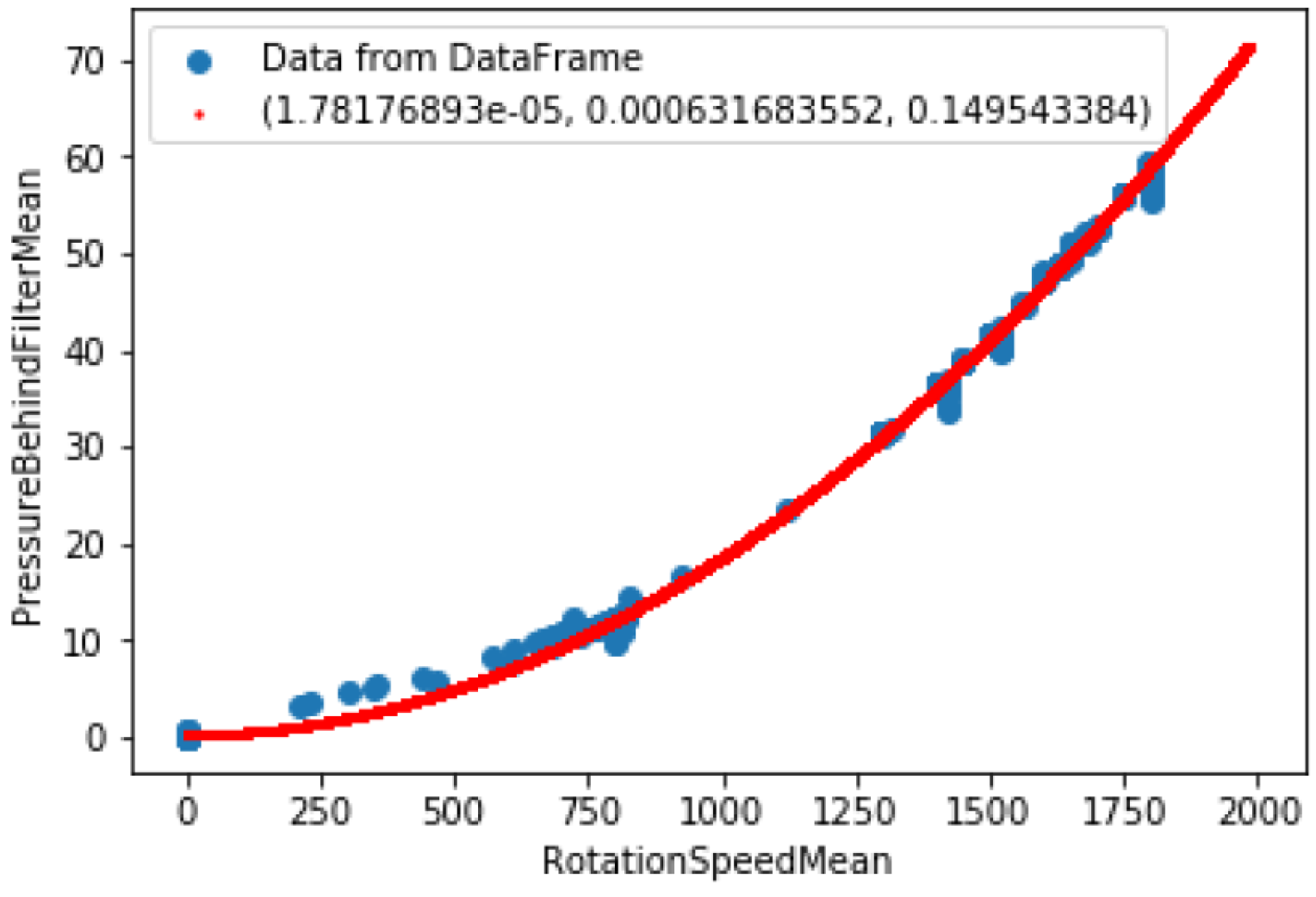
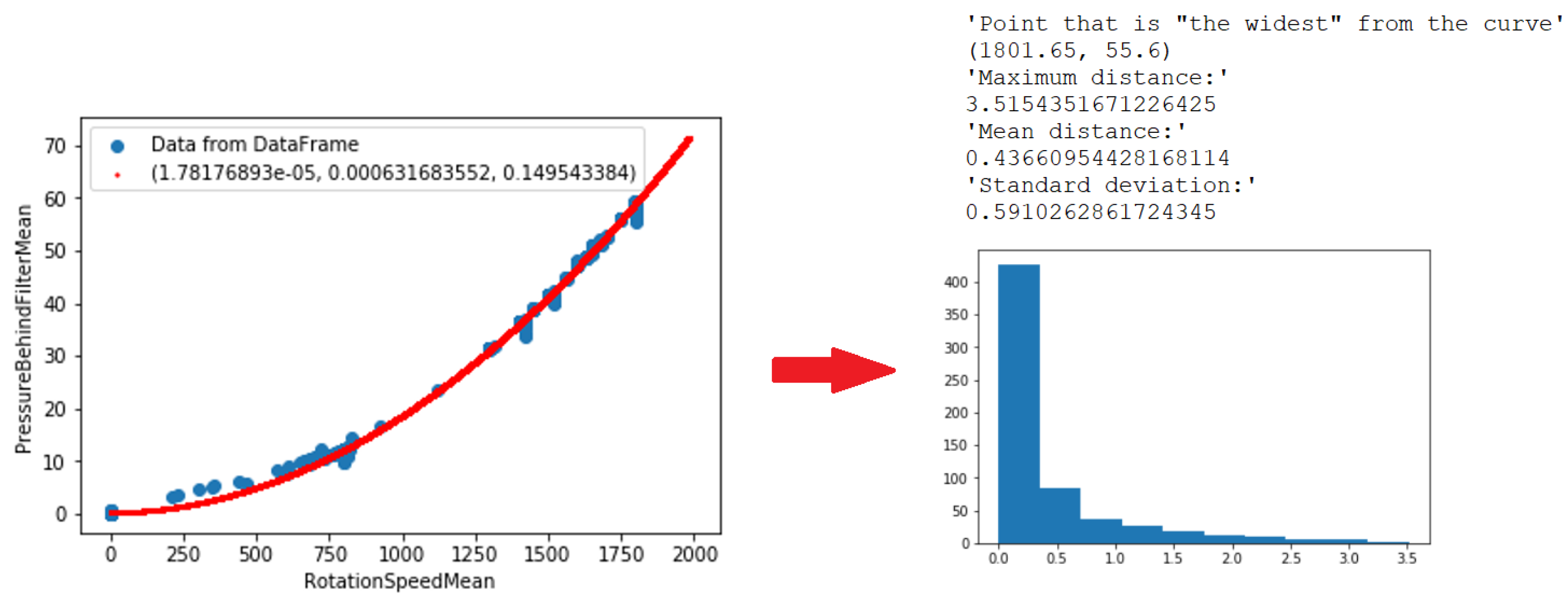
- Pressure behind filter mean due to rotation speed mean.
2.2.3. Anomaly Detection
2.2.4. Novelty Detection
- N is the length of the dataset used for training;
- v is the regularization parameter;
- is the slack variable corresponding to each dataset;
- and are the decision planes that can be decided with participation;
- denotes the way the data are spatially mapped [54].
- PressureBehindFilterMean;
- HighPressureMean;
- RotationSpeedMean;
- PressureBeforeFilterMean.
2.3. Algorithms Deployment
2.3.1. Anomaly Detection
- a, b, c—coefficients for Equation (16). Two sets of parameters, because of two fitted characteristics;
- Interquartile Range (IQR) criterion mentioned in Section 2.2.3. Two parameters, one per each characteristics.
2.3.2. Novelty Detection
2.3.3. Tests Performed before the Solution Was Deployed in Production
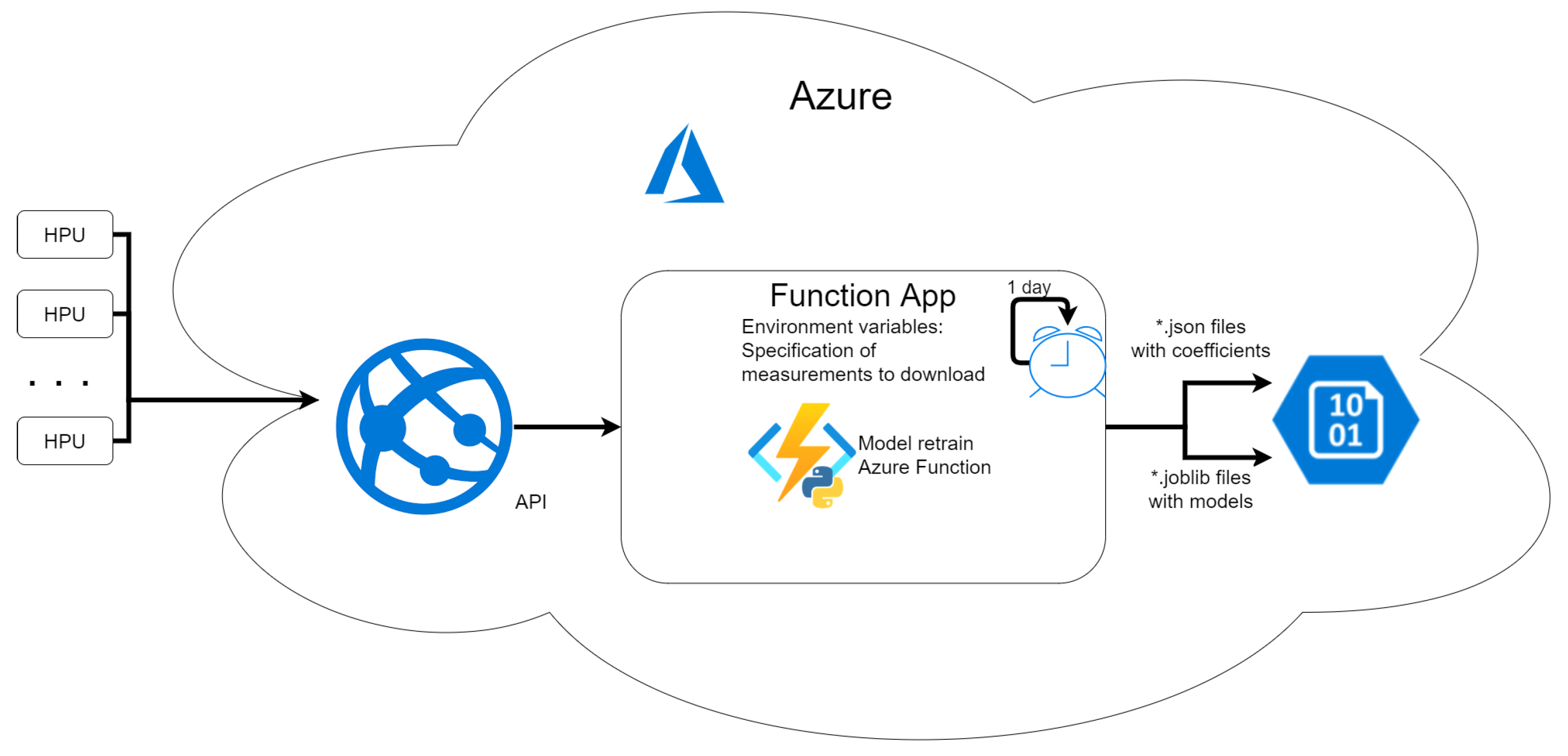
2.3.4. Summary of Algorithms Workflow in Production Environment
- Download required variables time series (power, pressure, fuel consumption, rotation speed) from cloud storage using API from the last hour.
- Determine stable periods.
- Calculate mean for each variable for each stable period.
- Handle anomaly detection:
- (a)
- Calculate point-to-curve distance (PTCD);
- (b)
- Confront PTCD with IQR Criterion.
- Handle novelty detection:
- (a)
- Download model from BLOB storage;
- (b)
- Use model to predict novelty.
- Send feedback to IoTHub on whether an anomaly or novelty was detected or not. MOLOS.CLOUD will raise an alarm if necessary.
- Function App as a consumption plan [61]:
- Costs are generated per Azure Function run;
- In described solution it is 2 .
- Storage:
- Costs are generated by read operations—both volume and quantity of reads;
- Read operations from table storage with time series data for desired variables;
- Read operations BLOB storage with models for anomaly detection;
- Read operations BLOB storage with models for novelty detection.
- API:
- Fee is charged for working hour.
2.4. Cyber Security
3. Results
3.1. Anomaly Detection
- a, b, c are functions coefficients that are real numbers.
3.2. Novelty Detection
4. Discussion
4.1. Algorithms
4.2. Solution Limitations
4.3. Costs of the Solution
4.4. Commercial Applications
4.5. Contributions of the Article
5. Further Research and Improvement Possibilities
5.1. Make HPU More Independent from Cloud
5.2. Algorithms Refinement
5.3. Domain Expertise
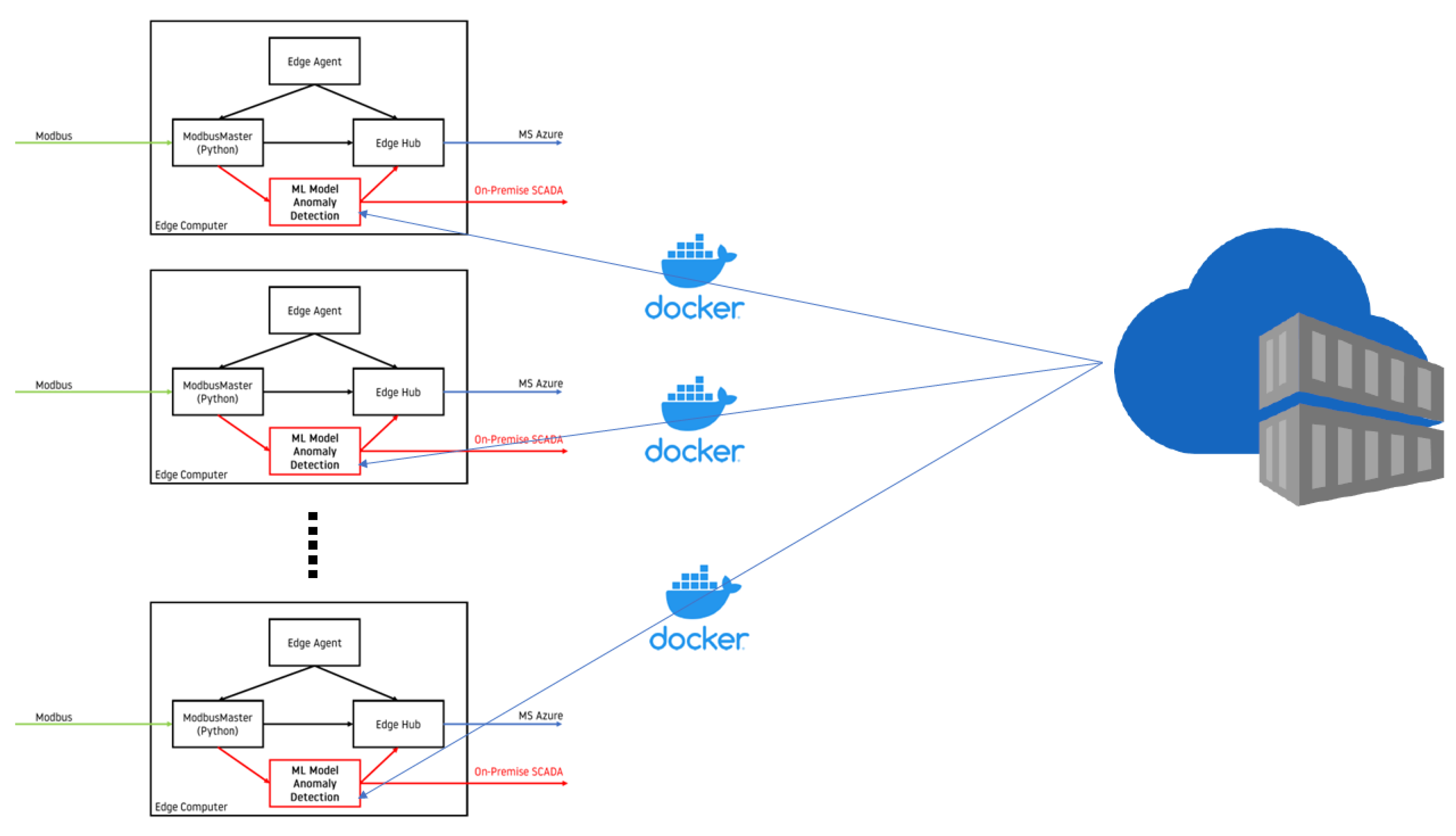
5.4. Azure IoTEdge in Deployment at Scale
- Perform bugfix, implement feature or refine model/algorithm;
- Build Docker container;
- Push container to container repository (ACR or Docker Hub);
- Deploy it using deployment manifest.
6. Conclusions and Final Thoughts
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Rednt, S.A. Web-SCADA. Available online: https://molos.cloud/ (accessed on 23 December 2022).
- Shevlyakov, G.; Andrea, K.; Choudur, L.; Smirnov, P.; Ulanov, A.; Vassilieva, N. Robust versions of the Tukey boxplot with their application to detection of outliers. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 6506–6510. [Google Scholar] [CrossRef]
- Ma, Y.; Hewitt, W.T. Point inversion and projection for NURBS curve and surface: Control polygon approach. Comput. Aided Geom. Des. 2003, 20, 79–99. [Google Scholar] [CrossRef]
- Schölkopf, B.; Williamson, R.; Smola, A.; Shawe-Taylor, J.; Platt, J. Support Vector Method for Novelty Detection. In Proceedings of the 12th International Conference on Neural Information Processing Systems, Cambridge, MA, USA, 29 November–4 December 1999; pp. 582–588. [Google Scholar]
- Satyro, W.C.; Contador, J.C.; Monken, S.F.D.P.; Lima, A.F.D.; Soares Junior, G.G.; Gomes, J.A.; Neves, J.V.S.; do Nascimento, J.R.; de Araújo, J.L.; Correa, E.D.S.; et al. Industry 4.0 Implementation Projects: The Cleaner Production Strategy—A Literature Review. Sustainability 2023, 15, 2161. [Google Scholar] [CrossRef]
- Gomaa, M.; Schade, S.; Bao, D.W.; Xie, Y.M. Automation in rammed earth construction for industry 4.0: Precedent work, current progress and future prospect. J. Clean. Prod. 2023, 398, 136569. [Google Scholar] [CrossRef]
- Ryalat, M.; ElMoaqet, H.; AlFaouri, M. Design of a Smart Factory Based on Cyber-Physical Systems and Internet of Things towards Industry 4.0. Appl. Sci. 2023, 13, 2156. [Google Scholar] [CrossRef]
- Wang, M.; Xu, C.; Lin, Y.; Lu, Z.; Sun, J.; Gui, G. A Distributed Sensor System Based on Cloud-Edge-End Network for Industrial Internet of Things. Future Internet 2023, 15, 171. [Google Scholar] [CrossRef]
- Thayyib, P.V.; Mamilla, R.; Khan, M.; Fatima, H.; Asim, M.; Anwar, I.; Shamsudheen, M.K.; Khan, M.A. State-of-the-Art of Artificial Intelligence and Big Data Analytics Reviews in Five Different Domains: A Bibliometric Summary. Sustainability 2023, 15, 4026. [Google Scholar] [CrossRef]
- Alghamdi, A.S.; Rahman, A. Data Mining Approach to Predict Success of Secondary School Students: A Saudi Arabian Case Study. Educ. Sci. 2023, 13, 293. [Google Scholar] [CrossRef]
- Jedrzykiewicz, Z.; Stojek, J.; Rosikowski, P. Naped i Sterowanie Hydrostatyczne, Monograph; Vist Sp. z o.o.: Dąbrowa Górnicza, Poland, 2017; p. 557. [Google Scholar]
- Chatterjee, A.; Ahmed, B.S. IoT anomaly detection methods and applications: A survey. Internet Things 2022, 19, 100568. [Google Scholar] [CrossRef]
- Belichovski, M.; Stavrov, D.; Donchevski, F.; Nadzinski, G. Unsupervised Machine Learning Approach for Anomaly Detection in E-coating Plant. In Proceedings of the 2022 IEEE 17th International Conference on Control &Automation (ICCA), Naples, Italy, 27–30 June 2022; pp. 992–997. [Google Scholar] [CrossRef]
- Samara, M.A.; Bennis, I.; Abouaissa, A.; Lorenz, P. A Survey of Outlier Detection Techniques in IoT: Review and Classification. J. Sens. Actuator Netw. 2022, 11, 4. [Google Scholar] [CrossRef]
- Wan, X.; Farmani, R.; Keedwell, E. Online leakage detection system based on EWMA-enhanced Tukey method for water distribution systems. J. Hydroinform. 2022, 25, 51–69. [Google Scholar] [CrossRef]
- Beghi, A.; Cecchinato, L.; Corazzol, C.; Rampazzo, M.; Simmini, F.; Susto, G. A One-Class SVM Based Tool for Machine Learning Novelty Detection in HVAC Chiller Systems. IFAC Proc. Vol. 2014, 47, 1953–1958. [Google Scholar] [CrossRef] [Green Version]
- Keleko, A.T.; Kamsu-Foguem, B.; Ngouna, R.H.; Tongne, A. Health condition monitoring of a complex hydraulic system using Deep Neural Network and DeepSHAP explainable XAI. Adv. Eng. Softw. 2023, 175, 103339. [Google Scholar] [CrossRef]
- Wu, Z.Y.; Chew, A.; Meng, X.; Cai, J.; Pok, J.; Kalfarisi, R.; Lai, K.C.; Hew, S.F.; Wong, J.J. High Fidelity Digital Twin-Based Anomaly Detection and Localization for Smart Water Grid Operation Management. Sustain. Cities Soc. 2023, 91, 104446. [Google Scholar] [CrossRef]
- Tziolas, T.; Papageorgiou, K.; Theodosiou, T.; Papageorgiou, E.; Mastos, T.; Papadopoulos, A. Autoencoders for Anomaly Detection in an Industrial Multivariate Time Series Dataset. Eng. Proc. 2022, 18, 23. [Google Scholar] [CrossRef]
- Zhou, B.; Pychynski, T.; Reischl, M.; Kharlamov, E.; Mikut, R. Machine learning with domain knowledge for predictive quality monitoring in resistance spot welding. J. Intell. Manuf. 2022, 33, 1139–1163. [Google Scholar] [CrossRef]
- Voigt, T.; Kohlhase, M.; Nelles, O. Incremental DoE and Modeling Methodology with Gaussian Process Regression: An Industrially Applicable Approach to Incorporate Expert Knowledge. Mathematics 2021, 9, 2479. [Google Scholar] [CrossRef]
- Coelho, D.; Costa, D.; Rocha, E.M.; Almeida, D.; Santos, J.P. Predictive maintenance on sensorized stamping presses by time series segmentation, anomaly detection, and classification algorithms. Procedia Comput. Sci. 2022, 200, 1184–1193. [Google Scholar] [CrossRef]
- Kim, D.; Heo, T.Y. Anomaly Detection with Feature Extraction Based on Machine Learning Using Hydraulic System IoT Sensor Data. Sensors 2022, 22, 2479. [Google Scholar] [CrossRef]
- Maggipinto, M.; Beghi, A.; Susto, G.A. A Deep Convolutional Autoencoder-Based Approach for Anomaly Detection with Industrial, Non-Images, 2-Dimensional Data: A Semiconductor Manufacturing Case Study. IEEE Trans. Autom. Sci. Eng. 2022, 19, 1477–1490. [Google Scholar] [CrossRef]
- Chohra, A.; Shirani, P.; Karbab, E.B.; Debbabi, M. Chameleon: Optimized feature selection using particle swarm optimization and ensemble methods for network anomaly detection. Comput. Secur. 2022, 117, 102684. [Google Scholar] [CrossRef]
- Gong, X.; Yu, L.; Wang, J.; Zhang, K.; Bai, X.; Pal, N.R. Unsupervised feature selection via adaptive autoencoder with redundancy control. Neural Netw. 2022, 150, 87–101. [Google Scholar] [CrossRef]
- Ali, O.; Ishak, M.K.; Bhatti, M.K.L.; Khan, I.; Kim, K.I. A Comprehensive Review of Internet of Things: Technology Stack, Middlewares, and Fog/Edge Computing Interface. Sensors 2022, 22, 995. [Google Scholar] [CrossRef] [PubMed]
- Kumar, A.; Saha, R.; Alazab, M.; Kumar, G. A Lightweight Signcryption Method for Perception Layer in Internet-of-Things. J. Inf. Secur. Appl. 2020, 55, 102662. [Google Scholar] [CrossRef]
- SIMATIC S7-400 Documentation. Available online: https://new.siemens.com/global/en/products/automation/systems/industrial/plc/simatic-s7-400.html (accessed on 13 May 2023).
- SIEMENS S7 Comparison. Available online: https://cache.industry.siemens.com/dl/files/648/109797648/att_1067421/v1/s71500_compare_table_en.pdf (accessed on 14 May 2023).
- SIEMENS MindSphere. Available online: https://www.plm.automation.siemens.com/global/pl/products/mindsphere/ (accessed on 14 May 2023).
- MOXA Industrial Linux. Available online: https://www.moxa.com/en/products/industrial-computing/system-software/moxa-industrial-linux (accessed on 11 May 2022).
- Python Package for Modbus Handling. Version: 2.5.3. Available online: https://pymodbus.readthedocs.io/en/latest/index.html (accessed on 4 December 2022).
- Azure IoT-SDK-Python. Available online: https://github.com/Azure/azure-iot-sdk-python (accessed on 16 March 2022).
- Docker-Based Ecosystem for Deploying Software on Edge Devices. Available online: https://azure.microsoft.com/en-us/services/iot-edge/ (accessed on 4 December 2022).
- Docker Official Website. Available online: https://docker.com/ (accessed on 22 December 2022).
- Azure-CLI. Available online: https://docs.microsoft.com/en-us/cli/azure/ (accessed on 22 December 2022).
- Portal Azure. Available online: https://portal.azure.com/ (accessed on 22 December 2022).
- Docker CLI. Available online: https://docs.docker.com/engine/reference/commandline/cli/ (accessed on 16 December 2022).
- Docker Hub. Available online: https://hub.docker.com/_/registry (accessed on 22 December 2022).
- Azure Container Registry. Available online: https://azure.microsoft.com/en-us/services/container-registry/ (accessed on 22 December 2022).
- Basseville, M.; Nikiforov, I.V. Detection of abrupt changes: Theory and application. Technometrics 1993, 36, 550. [Google Scholar]
- Deshcherevskii, A.V.; Sidorin, A.Y. Iterative algorithm for time series decomposition into trend and seasonality: Testing using the example of CO2 concentrations in the atmosphere. Izv. Atmos. Ocean. Phys. 2021, 57, 813–836. [Google Scholar] [CrossRef]
- Talagala, P.; Hyndman, R.; Smith-Miles, K.; Kandanaarachchi, S.; Muñoz, M. Anomaly detection in streaming nonstationary temporal data. J. Comput. Graph. Stat. 2020, 29, 13–27. [Google Scholar] [CrossRef]
- Schmidl, S.; Wenig, P.; Papenbrock, T. Anomaly Detection in Time Series: A Comprehensive Evaluation. Proc. VLDB Endow. PVLDB 2022, 15, 1779–1797. [Google Scholar] [CrossRef]
- Akoglu, H. User’s guide to correlation coefficients. Turk. J. Emerg. Med. 2018, 18, 91–93. [Google Scholar] [CrossRef]
- Harris, C.R.; Millman, K.J.; van der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J.; et al. Array programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef]
- Linear Regression Explanation. Available online: http://www.stat.yale.edu/Courses/1997-98/101/linreg.htm (accessed on 16 March 2022).
- Torabi, H.; Mirtaheri, S.L.; Greco, S. Practical autoencoder based anomaly detection by using vector reconstruction error. Cybersecurity 2023, 6, 1. [Google Scholar] [CrossRef]
- Hosseinzadeh, M.; Rahmani, A.M.; Vo, B.; Bidaki, M.; Masdari, M.; Zangakani, M. Improving security using SVM-based anomaly detection: Issues and challenges. Soft Comput. 2021, 25, 3195–3223. [Google Scholar] [CrossRef]
- Miljkovic, D. Review of novelty detection methods. In Proceedings of the 33rd International Convention MIPRO, Opatija, Croatia, 24–28 May 2010; pp. 593–598. [Google Scholar]
- One Class SVM in Scikit-Learn Python Package. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.svm.OneClassSVM.html (accessed on 16 April 2022).
- Huang, G.; Chen, J.; Liu, L. One-Class SVM Model-Based Tunnel Personnel Safety Detection Technology. Appl. Sci. 2023, 13, 1734. [Google Scholar] [CrossRef]
- Chen, L.; Buhong, W.; Jiwei, T.; Rongxiao, G. Anomaly detection method for UAV sensor data based on LSTM-OCSVM. J. Chin. Comput. Syst. 2021, 42, 700–705. [Google Scholar]
- Peng, T.; Li, C.; Zhou, X. Application of machine learning to laboratory safety management assessment. Saf. Sci. 2019, 120, 263–267. [Google Scholar] [CrossRef]
- Azure Functions Description. Available online: https://azure.microsoft.com/en-us/services/functions/ (accessed on 22 December 2022).
- Hassan, H.B.; Barakat, S.A.; Sarhan, Q.I. Survey on serverless computing. J. Cloud Comput. Adv. Syst. Appl. 2021, 10, 39. [Google Scholar] [CrossRef]
- Ways of Triggering Azure Functions. Available online: https://docs.microsoft.com/en-us/learn/modules/execute-azure-function-with-triggers/ (accessed on 22 December 2022).
- Exporting and Importing Model as *.joblib File. Available online: https://scikit-learn.org/stable/model_persistence.html (accessed on 12 April 2022).
- Documentation of ModbusSlave Software. Version: 9. Available online: https://www.modbustools.com/modbus_slave.html (accessed on 15 March 2023).
- Description of Azure Function App as Consumpion Plan. Available online: https://docs.microsoft.com/en-us/azure/azure-functions/consumption-planl (accessed on 22 December 2022).
- Available online: https://learn.microsoft.com/en-us/azure/network-watcher/traffic-analytics (accessed on 15 May 2023).
- Available online: https://stackoverflow.com/questions/70501366/azure-pricing-calculator-for-hours-in-cloud-service (accessed on 15 May 2023).
- Azure-Stream-Analytics. Available online: https://azure.microsoft.com/en-us/services/stream-analytics/ (accessed on 16 December 2022).
- Available online: https://www.microsoft.com/en-us/download/details.aspx?id=56519 (accessed on 15 May 2023).
- Available online: https://learn.microsoft.com/en-us/azure/iot-hub/iot-hub-mqtt-support (accessed on 15 May 2023).
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; p. 117. Available online: http://www.deeplearningbook.org (accessed on 29 December 2022).
- Sun, C.; He, Z.; Lin, H.; Cai, L.; Cai, H.; Gao, M. Anomaly detection of power battery pack using gated recurrent units based variational autoencoder. Appl. Soft Comput. 2023, 132, 109903. [Google Scholar] [CrossRef]
- Saha, S.; Sarkar, J.; Dhavala, S.; Sarkar, S.; Mota, P. Quantile LSTM: A Robust LSTM for Anomaly Detection In Time Series Data. arXiv 2023, arXiv:2302.08712. [Google Scholar]
- Park, M.H.; Chakraborty, S.; Vuong, Q.D.; Noh, D.H.; Lee, J.W.; Lee, J.U.; Choi, J.H.; Lee, W.J. Anomaly Detection Based on Time Series Data of Hydraulic Accumulator. Sensors 2022, 22, 9428. [Google Scholar] [CrossRef]
- Kang, H.S.; Choi, Y.S.; Yu, J.S.; Jin, S.W.; Lee, J.M.; Kim, Y.J. Hyperparameter Tuning of OC-SVM for Industrial Gas Turbine Anomaly Detection. Energies 2022, 15, 8757. [Google Scholar] [CrossRef]
- Guan, S.; Zhao, B.; Dong, Z.; Gao, M.; He, Z. GTAD: Graph and Temporal Neural Network for Multivariate Time Series Anomaly Detection. Entropy 2022, 24, 759. [Google Scholar] [CrossRef]
- Perez-Padillo, J.; García Morillo, J.; Ramirez-Faz, J.; Torres Roldán, M.; Montesinos, P. Design and Implementation of a Pressure Monitoring System Based on IoT for Water Supply Networks. Sensors 2020, 20, 4247. [Google Scholar] [CrossRef]
- Anton, A.A.; Cococeanu, A.; Muntean, S. Software for Monitoring the In-Service Efficiency of Hydraulic Pumps. Appl. Sci. 2022, 12, 11450. [Google Scholar] [CrossRef]
- Robyns, S.; Helsen, S.; Weckx, S.; Bhoi, S.K.; Baghdadi, M.E.; Hegazy, O.; De Smet, J. An intelligent data capturing framework to improve condition monitoring and anomaly detection for industrial machines. Procedia Comput. Sci. 2023, 217, 709–719. [Google Scholar] [CrossRef]
- Derse, C.; El Baghdadi, M.; Hegazy, O.; Sensoz, U.; Gezer, H.N.; Nil, M. An Anomaly Detection Study on Automotive Sensor Data Time Series for Vehicle Applications. In Proceedings of the 2021 Sixteenth International Conference on Ecological Vehicles and Renewable Energies (EVER), Monte-Carlo, Monaco, 5–7 May 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Motulsky, H.J.; Brown, R.E. Detecting outliers when fitting data with nonlinear regression—A new method based on robust nonlinear regression and the false discovery rate. BMC Bioinform. 2006, 7, 123. [Google Scholar] [CrossRef] [Green Version]
- Pang, J.; Pu, X.; Li, C. A Hybrid Algorithm Incorporating Vector Quantization and One-Class Support Vector Machine for Industrial Anomaly Detection. IEEE Trans. Ind. Inform. 2022, 18, 8786–8796. [Google Scholar] [CrossRef]
- Arunthavanathan, R.; Khan, F.; Ahmed, S.; Imtiaz, S. Autonomous Fault Diagnosis and Root Cause Analysis for the Processing System Using One-Class SVM and NN Permutation Algorithm. Ind. Eng. Chem. Res. 2022, 61, 1408–1422. [Google Scholar] [CrossRef]
- Li, X.; Xu, Y.; Li, N.; Yang, B.; Lei, Y. Remaining Useful Life Prediction With Partial Sensor Malfunctions Using Deep Adversarial Networks. IEEE/CAA J. Autom. Sin. 2023, 10, 121–134. [Google Scholar] [CrossRef]
- Li, D.; Zhou, Y.; Hu, G.; Spanos, C.J. Handling Incomplete Sensor Measurements in Fault Detection and Diagnosis for Building HVAC Systems. IEEE Trans. Autom. Sci. Eng. 2020, 17, 833–846. [Google Scholar] [CrossRef]
- Perales Gómez, Á.L.; Maimó, L.F.; Celdrán, A.H.; Clemente, F.J.G. SUSAN: A Deep Learning based anomaly detection framework for sustainable industry. Sustain. Comput. Inform. Syst. 2023, 37, 100842. [Google Scholar] [CrossRef]
- Peco Chacón, A.M.; Segovia Ramirez, I.; García Márquez, F.P. False alarm detection in wind turbine by classification models. Adv. Eng. Softw. 2023, 177, 103409. [Google Scholar] [CrossRef]
- ELMARK MOXA. Available online: https://www.elmark.com.pl/sklep/moxa/uc-8100-me-t (accessed on 14 May 2023).
- TIBCO. Available online: https://community.tibco.com/s/article/anomaly-detection-and-root-cause-analysis-using-tibco-analytics-and-microsoft-cognitive (accessed on 14 May 2023).
- Crosser. Available online: https://crosser.io/resources/webinars-and-videos/webinars/iot/anomaly-detection-with-crossers-low-code-platform/?gclid=CjwKCAjwjYKjBhB5EiwAiFdSfircXqSPDMpjlZqzmzRIQ5DWH3if7I1KbGS236n9Bmf2jmSHuLuffxoCuwYQAvD_BwE (accessed on 14 May 2023).
- Bowen, C.L.; Buennemeyer, T.; Thomas, R. Next generation SCADA security: Best practices and client puzzles. In Proceedings of the Sixth Annual IEEE SMC Information Assurance Workshop, West Point, NY, USA, 15–17 June 2005; pp. 426–427. [Google Scholar]
- Available online: https://docs.microsoft.com/en-us/azure/machine-learning/\v1/how-to-deploy-azure-container-instance (accessed on 22 December 2022).
- Holzinger, A. Interactive machine learning for health informatics: When do we need the human-in-the-loop? Brain Inform. 2016, 3, 119–131. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Way of Deploying IoTEdge Containers at Scale. Available online: https://docs.microsoft.com/en-us/azure/iot-edge/module-deployment-monitoring?view=iotedge-2020-11 (accessed on 11 May 2022).
- PONAR Wadowice S.A. Webpage. Available online: https://www.ponar-wadowice.pl/ (accessed on 4 December 2022).
- REDNT S.A. Webpage. Available online: https://rednt.eu (accessed on 21 December 2022).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristics | a | b | c |
|---|---|---|---|
| Power mean vs. fuel consumption mean | −4.1 | ||
| Pressure behind filter vs. rotation speed mean | 1.8 |
| Characteristics | Error Threshold |
|---|---|
| Power mean vs. fuel consumption mean | 10.4 |
| Pressure behind filter vs. rotation speed mean | 0.998 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fic, P.; Czornik, A.; Rosikowski, P. Anomaly Detection for Hydraulic Power Units—A Case Study. Future Internet 2023, 15, 206. https://doi.org/10.3390/fi15060206
Fic P, Czornik A, Rosikowski P. Anomaly Detection for Hydraulic Power Units—A Case Study. Future Internet. 2023; 15(6):206. https://doi.org/10.3390/fi15060206
Chicago/Turabian StyleFic, Paweł, Adam Czornik, and Piotr Rosikowski. 2023. "Anomaly Detection for Hydraulic Power Units—A Case Study" Future Internet 15, no. 6: 206. https://doi.org/10.3390/fi15060206