
Methods of Annotating and Identifying Metaphors in the Field of Natural Language Processing

Abstract
:1. Introduction
2. Theories of the Metaphor
2.1. Conceptual Metaphor
- Theory of conflation [8] which proposes that children combine sensory and non-sensory experiences from a very early age, resulting in later understandings of metaphors such as “close friend”, “warm smile” and “big problem”.
- Neural theory of metaphor [9] that claims that the associations created during the conflation period are realized through permanent neural connections in the neural network that defines the conceptual domains.
- Theory of conceptual blending [10] which states that distant domains can be connected and create new deductions.
2.2. Linguistic Metaphor
3. Annotating Metaphors
3.1. Annotating Linguistic Metaphors
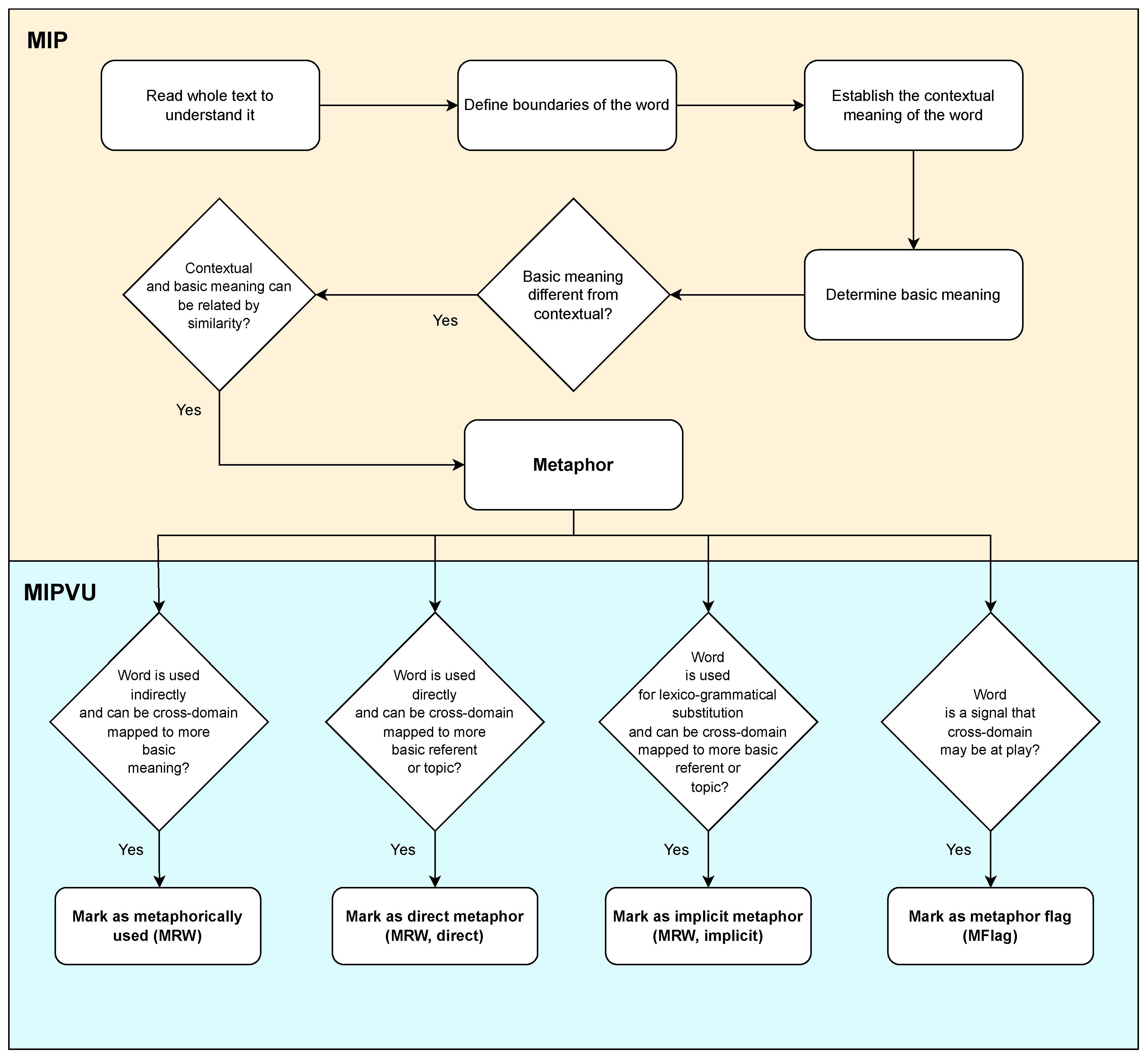
- Read the whole text or transcript to understand what it is about.
- Decide about the boundaries of words.
- Establish the contextual meaning of the examined word.
- a.
- Determine the basic meaning of the word (most concrete, human-oriented and specific).
- b.
- Decide whether the basic meaning of the word is sufficiently distinct from the contextual meaning.
- c.
- Decide whether the contextual meaning of the word can be related to the more basic meaning by some form of similarity.
- Find metaphor-related words (MRWs) by examining the text on a word-by-word basis.
- When a word is used indirectly and that use may potentially be explained by some form of cross-domain mapping from a more basic meaning of that word, mark the word as metaphorically used (MRW).
- When a word is used directly and its use may potentially be explained by some form of cross-domain mapping to a more basic referent or topic in the text, mark the word as direct metaphor (MRW, direct).
- When words are used for the purpose of lexico-grammatical substitution, such as third person personal pronouns, or when ellipsis occurs where words may be seen as missing, as in some forms of co-ordination, and when a direct or indirect meaning is conveyed by those substitutions or ellipses that may potentially be explained by some form of cross-domain mapping from a more basic meaning, referent, or topic, insert a code for implicit metaphor (MRW, implicit).
- When a word functions as a signal that a cross-domain mapping may be at play, mark it as a metaphor flag (MFlag).
- When a word is a new-formation coined, examine the distinct words that are its independent parts according to steps 2 through 5.

{kind=link}
| Data Set | Procedure | Data Set Size |
|---|---|---|
| VUA [16,17] | MIPVU | 186,695 words |
| TroFi [22] | Sentences containing 50 selected verbs | Total 6435 sentences, 2740 metaphorical |
| TSV [23] | Metaphors expressed by adjectives and nouns | 995 metaphorical, 995 literal expressions |
| MOH-X [24] | 440 verbs with >3 and <10 meanings in WordNet | Total 647 sentences, 315 metaphorical |
| KOMET 1.0 [25] | MIPVU | 218,730 words |
3.2. Lists and Databases of Metaphorical Concepts
3.3. Metaphor Annotation for Natural Language Processing
4. Identifying Metaphors
- Hand coded knowledge and use of lexical resources
- Statistical and machine learning methods
- Neural networks and word embeddings
4.1. Hand Coded Knowledge and Use of Lexical Resources
4.2. Statistical and Machine Learning Methods
| Paper | Data Set | Methodology | Results |
|---|---|---|---|
| Birke and Sarkar [22] | TroFi | Clustering | F1 0.538 |
| Turney et al. [28] | TroFi | Calculating abstractness, classification | F1 0.68 |
| Neuman et al. [61] | Five concepts extracted from the Reuters and New Yor Times archive | Concrete Category Overlap (CCO) algorithm, Selectional preferences | Precision 0.72 |
| Tsvetkov et al. [23] | TroFi, TSV | Classification, word embedding | F1 for TroFi 0.79, F1 for TSV 0.85 |
| Li and Sporleder [32] | 17 phrases extracted from Gigaword | Clustering, classification | Accuracy 0.9 |
| Shutova [30] | Subset of the British National Corpus | Clustering (by association) | Precision 0.79 |
| Heintz et al. [31] | 60 concepts from newspapers and blogs in English and Spanish | Topic modeling with Latent Dirichlet Allocation | Evaluation 1: F1 score 0.59, Evaluation 2: Average value of 0.41 for English, 0.33 for Spanish |
| Mohler et al. [29] | Domain of governance extracted from Wikipedia | TF-IDF, classification | Precision 0.561, F1 score 0.70 |
4.3. Neural Networks and Word Embeddings
4.3.1. Overview of Static Word Embeddings
4.3.2. Overview of Contextual Word Embeddings
4.4. Metaphor Identification with the Use of Word Embeddings
4.4.1. Metaphor Identification Using Static Word Embeddings
4.4.2. Metaphor Identification Using Contextual Word Embeddings
| Paper | Data | Methodology | Approach | Word Embeddings | F1 Score |
|---|---|---|---|---|---|
| Do Dinh and Gurevych [33] | VUA | Multi layer perceptron | Sequence labeling | word2vec | VUA news 0.6385, VUA academic 0.5618 |
| Shutova et al. [34] | MOH-X, TSV | Skip-gram, CNN, Cosine similarity | Enriching word embeddings with visual embeddings | Word and visual embeddings | 0.75, 0.79 |
| Rei et al. [35] | MOH-X, TSV | Cosine similarity, gating function | Supervised version of cosine similarity | Skip-gram | 0.699, 0.811 |
| Mykowiecka et al. [36] | VUA | BiLSTM | Sequence labeling | GloVe | VUA all 0.583, VUA verbs 0.619 |
| Swarnkar and Singh [37] | VUA | LSTM | Sequence labeling | GloVe | VUA all 0.570, VUA verbs 0.605 |
| Wu et al. [38] | VUA | BiLSTM, CNN | Sequence labeling | word2vec | VUA all 0.651, VUA verbs 0.671 |
| Gao et al. [39] | VUA | BiLSTM | Sequence labeling, Classification of verbs | ELMo | VUA verbs classification 0.704 |
| Mao et al. [40] | TroFi, MOH-X, VUA | BiLSTM | Implementing linguistic theories (MIP, SPV) | GloVe, ELMO | 0.724, 0.80, VUA all 0.743, VUA verbs 0.708 |
| Su et al. [41] | TroFi, MOH-X, VUA, TOEFL | Transformers | Reading comprehension | BERT, RoBERTa | 0.761, 0.918, VUA all 0.769, VUA verbs 0.804, TOEFL all 0.715, TOEFL verbs 0.749 |
| Gong et al. [42] | VUA, TOEFL | Feed Forward Network | Sequence labeling | RoBERTa | VUA verbs 0.771, TOEFL verbs 0.719 |
| Chen et al. [43] | VUA, TOEFL | BERT | Learning from another type of figurative language | BERT | VUA verbs 0.775, VUA all 0.734, TOEFL all 0.692, TOEFL verbs 0.702, |
| Dankers et al. [44] | VUA | BERT, Hierarchical Attention | Broader discourse of the sentence | BERT | 0.715 |
| Lin et al. [45] | TroFi, MOH-X, VUA | CATE | Contrastive Learning, Classification of the target word | RoBERTa | 0.745, 0.847, VUA all 0.79, VUA verbs 0.756 |
| Song et al. [51] | VUA | Transformers, MrBERT | Relation extraction problem | BERT | VUA verbs 0.759, VUA all 0.772 |
| Choi et al. [46] | VUA | Transformers, MelBERT | Implementing linguistic theories (MIP, SPV) | RoBERTa | VUA-18 0.785, VUA-20 0.723, VUA verbs 0.757 |
| Maudslay and Teufel [50] | MML | Transformers, Word sense disambiguation, MPD | Implementing linguistic theories (MIP), Word sense disambiguation | BERT | 0.60 Relative metaphori-city measure 0.78 |
| Zhang and Liu [49] | VUA, MOH-X | Transformers, MisNet | Implementing linguistic theories (MIP, SPV) | BERT | VUA all 0.794, VUA Verb 0.759, MOH-X 0.834 |
| Li et al. [47] | VUA, MOH-X, TroFi | Transformers, FrameBERT | Implementing linguistic theories (MIP, SPV), External knowlesge of concepts | RoBERTa | VUA-18 0.788, VUA-20 0.73, MOH-X 0.838, TroFi 0.742 |
| Ge et al. [48] | TSV, MOH-X, GUT | Transformers, Dependent word pairs | Implementing linguistic theories (CMT) | RoBERTa | TSV 0.866, MOH-X 0.756, GUT 0.925 |
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
| Year | Paper |
|---|---|
| 1975 | Wilks [53] |
| 1978 | Wilks [54] |
| 1991 | Fass [55] |
| 2004 | Mason [57] |
| 2007 | Krishnakumaran and Zhu [59] |
| 2006 | Birke and Sarkar [22] |
| 2009 | Li and Sporleder [32] |
| 2010 | Shutova [30] |
| 2011 | Turney et al. [28] |
| 2013 | Neuman et al. [61], Heintz et al. [31], Mohler et al. [29], Wilks et al. [56] |
| 2014 | Tsvetkov et al. [23] |
| 2016 | Do Dinh and Gurevych [33] |
| 2017 | Rei et al. [35] |
| 2018 | Mykowiecka et al. [36], Swarnkar and Singh [37], Wu et al. [38], Gao et al. [39] |
| 2019 | Mao et al. [40] |
| 2020 | Su et al. [41], Gong et al. [42], Chen et al. [43], Dankers et al. [44] |
| 2021 | Lin et al. [45], Song et al. [51], Choi et al. [46] |
| 2022 | Maudslay and Teufel [50], Zhang and Liu [49], Ge et al. [48] |
| 2023 | Li et al. [47] |
References
- Lakoff, G.; Johnson, M. Metaphors We Live By; University of Chicago Press: Chicago, IL, USA, 1980. [Google Scholar]
- Despot Štrkalj, K. Konceptualna metafora i dijakronija: O evoluciji metaforičkog uma u hrvatskom jeziku. In Metafore Koje istražujemo: Suvremeni Uvidi u Konceptualnu Metaforu, by Mateusz-Milan Stanojević; Srednja Europa: Zagreb, Croatia, 2014; pp. 63–89. [Google Scholar]
- Croft, W.; Cruse, D.A. Cognitive Linguistics; University Press: Cambridge, UK, 2004. [Google Scholar]
- Sulivan, K. Conceptual Metaphor. In The Cambridge Handbook of Cognitive Linguistics; Dancygier, B., Ed.; Cambridge University Press: Cambridge, UK, 2017; pp. 385–406. [Google Scholar]
- Grady, J. Foundations of Meaning: Primary Metaphors and Primary Scenes; University of California: Berkeley, CA, USA, 1997. [Google Scholar]
- Grady, J. Metaphor. In The Oxford Handbook of Cognitive Linguistics, by Dirk Geeraerts and Hubert Cuyckens; Oxford University Press: New York, NY, USA, 2010; pp. 188–213. [Google Scholar]
- Lakoff, G.; Johnson, M. Philosophy in the Flesh: The Embodied Mind and Its Challenge to Western Thought; Basic Books: New York, NY, USA, 1999; ISBN 0465056741. [Google Scholar]
- Johnson, C.R. Metaphor vs. Conflation in the Acquisition of Polysemy. In Proceedings of the Cultural, Psychological and Typological Issues in Cognitive Linguistics: Selected Papers of the Bi-Annual ICLA Meeting in Albuquerque; Hiraga, M.K., Sinha, C., Wilcox, S., Eds.; John Benjamins: Amsterdam, The Netherlands, 1999. [Google Scholar]
- Feldman, J.; Narayanan, S. Embodied meaning in a neural theory of language. Brain Lang. 2004, 89, 385–392. [Google Scholar] [CrossRef]
- Fauconnier, G.; Turner, M. The Way We Think: Conceptual Blending and the Mind’s Hidden Complexities; Basic Books: New York, NY, USA, 2002. [Google Scholar]
- Shutova, E. Annotation of Linguistic and Conceptual Metaphor. In Handbook of Linguistic Annotation; Ide, N., Pustejovsky, J., Eds.; Springer Science + Business Media: Dordrecht, The Netherlands, 2017; pp. 1073–1100. [Google Scholar]
- Cameron, L. Metaphor in Educational Discourse; Continuum: London, UK; New York, NY, USA, 2003. [Google Scholar]
- Shutova, E.; Teufel, S. Metaphor Corpus Annotated for Source—Target Domain Mappings. In Proceedings of the Seventh International Conference on Language Resources and Evaluation (LREC’10); European Language Resources Association (ELRA): Valletta, Malta, 2010. [Google Scholar]
- Shutova, E. Design and Evaluation of Metaphor Processing Systems. Comput. Linguist. 2015, 41, 579–623. [Google Scholar] [CrossRef]
- Pragglejaz Group. MIP: A Method for Identifying Metaphorically Used Words in Discourse. Metaphor. Symb. 2007, 22, 1–39. [Google Scholar] [CrossRef]
- Steen, G.J.; Dorst, A.G.; Herrmann, J.B.; Kaal, A.A.; Krennmayr, T.; Pasma, T. A Method for Linguistic Metaphor Identification; John Benjamins: Amsterdam, The Netherlands, 2010; ISBN 9789027239044. [Google Scholar]
- Krennmayr, T.; Steen, G. VU Amsterdam Metaphor Corpus. In Handbook of Linguistic Annotation; Ide, N., Pustejovsky, J., Eds.; Springer Science + Business Media: Dordrecht, The Netherlands, 2017; pp. 1053–1071. [Google Scholar]
- Nacey, S.; Dorst, A.G.; Krennmayr, T.; Reijnierse, W.G. Metaphor Identification in Multiple Languages; John Benjamins: Amsterdam, The Netherlands, 2019; ISBN 9789027204721. [Google Scholar]
- Bogetić, K.; Bročić, A.; Rasulić, K. Linguistic Metaphor Identification in Serbian. In Metaphor Identification in Multiple Languages; Nacey, S., Dorst, A.G., Krennmayr, T., Reijnierse, W.G., Eds.; John Benjamins: Amsterdam, The Netherlands, 2019; pp. 203–226. [Google Scholar]
- Lakoff, G.; Espenson, J.; Schwartz, A. Master Metaphor List; Cognitive Linguistics Group, University of California at Berkeley: Berkeley, CA, USA, 1991. [Google Scholar]
- Wallington, A.M.; Barnden, J.A.; Buchlovsky, P.; Fellows, L.; Glasbey, S.R. Metaphor Annotation: A Systematic Study; Technical Report CSRP-03-04; University of Birmingham: Birmingham, UK, 2003. [Google Scholar]
- Birke, J.; Sarkar, A. A Clustering Approach for Nearly Unsupervised Recognition of Nonliteral Language. In Proceedings of the EACL 2006, 11st Conference of the European Chapter of the Association for Computational Linguistics, Trento, Italy, 3–7 April 2006; pp. 329–336. [Google Scholar]
- Tsvetkov, Y.; Boytsov, L.; Gershman, A.; Nyberg, E.; Dyer, C. Metaphor Detection with Cross-Lingual Model Transfer. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, Baltimore, MD, USA, 22–27 June 2014; Association for Computational Linguistics: Stroudsburg, PA, USA, 2004; pp. 248–258. [Google Scholar]
- Mohammad, S.; Shutova, E.; Turney, P. Metaphor as a Medium for Emotion: An Empirical Study. In Proceedings of the Fifth Joint Conference on Lexical and Computational Semantics, Berlin, Germany, 11–12 August 2016; Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 23–33. [Google Scholar]
- Miller, G.A. WordNet: A lexical database for English. Commun. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- Fellbaum, C. WordNet: An Electronic Lexical Database; MIT Press: Cambridge, MA, USA, 1998; ISBN 9780262061971. [Google Scholar]
- Antloga, Š. Metaphor Corpus KOMET 1.0. Clarin.si. 2020. Available online: https://www.clarin.si/repository/xmlui/handle/11356/1293 (accessed on 8 January 2023).
- Turney, P.; Neuman, Y.; Assaf, D.; Cohen, Y. Literal and Metaphorical Sense Identification through Concrete and Abstract Context. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, Edinburgh, Scotland, UK, 27–31 July 2011; Association for Computational Linguistics: Stroudsburg, PA, USA, 2011; pp. 680–690. [Google Scholar]
- Mohler, M.; Bracewell, D.; Tomlinson, M.; Hinote, D. Semantic Signatures for Example-Based Linguistic Metaphor Detection. In Proceedings of the First Workshop on Metaphor in NLP, Atlanta, Georgia, 13 June 2013; Association for Computational Linguistics: Stroudsburg, PA, USA, 2013; pp. 27–35. [Google Scholar]
- Shutova, E.; Sun, L.; Korhonen, A. Metaphor Identification Using Verb and Noun Clustering. In Proceedings of the 23rd International Conference on Computational Linguistics, Beijing, China, 23–27 August 2010; Association for Computational Linguistics: Stroudsburg, PA, USA, 2010; pp. 1002–1010. [Google Scholar]
- Heintz, I.; Gabbard, R.; Srivastava, M.; Barner, D.; Black, D.; Friedman, M.; Weischedel, R. Automatic Extraction of Linguistic Metaphors with LDA Topic Modeling. In Proceedings of the First Workshop on Metaphor in NLP, Atlanta, Georgia, 13 June 2013; Association for Computational Linguistics: Stroudsburg, PA, USA, 2013; pp. 58–66. [Google Scholar]
- Li, L.; Sporleder, C. Classifier Combination for Contextual Idiom Detection Without Labelled Data. In Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–7 August 2009; Association for Computational Linguistics: Stroudsburg, PA, USA, 2009; pp. 315–323. [Google Scholar]
- Do Dinh, E.-L.; Gurevych, I. Token-Level Metaphor Detection Using Neural Networks. In Proceedings of the Fourth Workshop on Metaphor in NLP, San Diego, CA, USA, 17 June 2016; Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 28–33. [Google Scholar]
- Shutova, E.; Kiela, D.; Maillard, J. Black Holes and White Rabbits: Metaphor Identification with Visual Features. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 160–170. [Google Scholar]
- Rei, M.; Bulat, L.; Kiela, D.; Shutova, E. Grasping the Finer Point: A Supervised Similarity Network for Metaphor Detection. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; Association for Computational Linguistics: Stroudsburg, PA, USA, 2017; pp. 1537–1546. [Google Scholar]
- Mykowiecka, A.; Wawer, A.; Marciniak, M. Detecting Figurative Word Occurrences Using Recurrent Neural Networks. In Proceedings of the Workshop on Figurative Language Processing, New Orleans, LA, USA, 6 June 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 124–127. [Google Scholar]
- Swarnkar, K.; Singh, A.K. Di-LSTM Contrast: A Deep Neural Network for Metaphor Detection. In Proceedings of the Workshop on Figurative Language Processing, New Orleans, LA, USA; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 115–120. [Google Scholar]
- Wu, C.; Wu, F.; Chen, Y.; Wu, S.; Yuan, Z.; Huang, Y. Neural Metaphor Detecting with CNN-LSTM Model. In Proceedings of the Workshop on Figurative Language Processing, New Orleans, LA, USA, 6 June 2018; Association for Computational Linguistics: New Orleans, LA, USA, 2018; pp. 110–114. [Google Scholar]
- Gao, G.; Choi, E.; Choi, Y.; Zettlemoyer, L. Neural Metaphor Detection in Context. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 607–613. [Google Scholar]
- Mao, R.; Lin, C.; Guerin, F. End-to-End Sequential Metaphor Identification Inspired by Linguistic Theories. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 3888–3898. [Google Scholar]
- Su, C.; Fukumoto, F.; Huang, X.; Li, J.; Wang, R.; Chen, Z. DeepMet: A Reading Comprehension Paradigm for Token-Level Metaphor Detection. In Proceedings of the Second Workshop on Figurative Language Processing, Online, 9 July 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 30–39. [Google Scholar]
- Gong, H.; Gupta, K.; Jain, A.; Bhat, S. IlliniMet: Illinois System for Metaphor Detection with Contextual and Linguistic Information. In Proceedings of the Second Workshop on Figurative Language Processing, Online, 9 July 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 146–153. [Google Scholar]
- Chen, X.; Leong, C.W.; Flor, M.; Klebanov, B.B. Go Figure! Multi-Task Transformer-Based Architecture for Metaphor Detection Using Idioms: ETS Team in 2020 Metaphor Shared Task. In Proceedings of the Second Workshop on Figurative Language Processing, Online, 9 July 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 235–243. [Google Scholar]
- Dankers, V.; Malhotra, K.; Kudva, G.; Medentsiy, V.; Shutova, E. Being Neighbourly: Neural Metaphor Identification in Discourse. In Proceedings of the Second Workshop on Figurative Language Processing, Online, 9 July 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 227–234. [Google Scholar]
- Lin, Z.; Ma, Q.; Yan, J.; Chen, J. CATE: A Contrastive Pre-Trained Model for Metaphor Detection with Semi-Supervised Learning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Online and Punta Cana, Dominican Republic, 7–11 November 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 3888–3898. [Google Scholar]
- Choi, M.; Lee, S.; Choi, E.; Park, H.; Lee, J.; Lee, D.; Lee, J. MelBERT: Metaphor Detection via Contextualized Late Interaction Using Metaphorical Identification Theories. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Stroudsburg, PA, USA, 6–11 June 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 1763–1773. [Google Scholar]
- Li, Y.; Wang, S.; Lin, C.; Guerin, F.; Barrault, L. FrameBERT: Conceptual Metaphor Detection with Frame Embedding Learning. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, Dubrovnik, Croatia, 9 February 2023; Association for Computational Linguistics: Stroudsburg, PA, USA, 2023; pp. 1558–1563. [Google Scholar]
- Ge, M.; Mao, R.; Cambria, E. Explainable Metaphor Identification Inspired by Conceptual Metaphor Theory. Proc. Conf. AAAI Artif. Intell. 2022, 36, 10681–10689. [Google Scholar] [CrossRef]
- Zhang, S.; Liu, Y. Metaphor Detection via Linguistics Enhanced Siamese Network. In Proceedings of the 29th International Conference on Computational Linguistics, Gyeongju, Republic of Korea, 12–17 October 2022; International Committee on Computational Linguistics: Stroudsburg, PA, USA, 2022; pp. 4149–4159. [Google Scholar]
- Maudslay, R.H.; Teufel, S. Metaphorical Polysemy Detection: Conventional Metaphor Meets Word Sense Disambiguation. In Proceedings of the 29th International Conference on Computational Linguistics, Gyeongju, Republic of Korea, 12–17 October 2022; International Committee on Computational Linguistics: Stroudsburg, PA, USA, 2022; pp. 65–77. [Google Scholar]
- Song, W.; Zhou, S.; Fu, R.; Liu, T.; Liu, L. Verb Metaphor Detection via Contextual Relation Learning. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Stroudsburg, PA, USA, 1–6 August 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 4240–4251. [Google Scholar]
- Katz, J.J.; Fodor, J.A. The Structure of a Semantic Theory. Language 1963, 39, 170. [Google Scholar] [CrossRef]
- Wilks, Y. A preferential, pattern-seeking, Semantics for natural language inference. Artif. Intell. 1975, 6, 53–74. [Google Scholar] [CrossRef]
- Wilks, Y. Making preferences more active. Artif. Intell. 1978, 11, 197–223. [Google Scholar] [CrossRef]
- Fass, D. Met*: A Method for Dicriminating Metonymy and Metaphor by Computer. Comput. Linguist. 1991, 17, 49–90. [Google Scholar]
- Wilks, Y.; Dalton, A.; Allen, J.; Galescu, L. Automatic Metaphor Detection Using Large-Scale Lexical Resources and Conventional Metaphor Extraction. In Proceedings of the First Workshop on Metaphor in NLP, Atlanta, GA, USA, 13 June 2013; Association for Computational Linguistics: Atlanta, GA, USA, 2013; pp. 36–44. [Google Scholar]
- Mason, Z.J. CorMet: A Computational, Corpus-Based Conventional Metaphor Extraction System. Comput. Linguist. 2004, 30, 23–44. [Google Scholar] [CrossRef]
- Resnik, P.S. Selection and Information: A Class-Based Approach to Lexical Relationships; Technical Report No. IRCS-93-42; University of Pennsylvania: Philadelphia, PA, USA, 1993. [Google Scholar]
- Krishnakumaran, S.; Zhu, X. Hunting Elusive Metaphors Using Lexical Resources. In Proceedings of the Workshop on Computational Approaches to Figurative Language, Rochester, NY, USA, 26 April 2007; Association for Computational Linguistics: Stroudsburg, PA, USA, 2007; pp. 13–20. [Google Scholar]
- Karov, Y.; Edelman, S. Similarity-Based Word Sense Disambiguation. Comput. Linguist. 1998, 24, 41–59. [Google Scholar]
- Neuman, Y.; Assaf, D.; Cohen, Y.; Last, M.; Argamon, S.; Howard, N.; Frieder, O. Metaphor Identification in Large Texts Corpora. PLoS ONE 2013, 8, e62343. [Google Scholar] [CrossRef] [PubMed]
- Tsvetkov, Y.; Mukomel, E.; Gershman, A. Cross-Lingual Metaphor Detection Using Common Semantic Features. In Proceedings of the First Workshop on Metaphor in NLP, Atlanta, GA, USA, 13 June 2013; Association for Computational Linguistics: Stroudsburg, PA, USA, 2013; pp. 45–51. [Google Scholar]
- Sporleder, C.; Li, L. Unsupervised Recognition of Literal and Non-Literal Use of Idiomatic Expressions. In Proceedings of the 12th Conference of the European Chapter of the ACL (EACL 2009), Athens, Greece, 30 March–3 April 2009; Association for Computational Linguistics: Stroudsburg, PA, USA, 2009; pp. 754–762. [Google Scholar]
- Jurafsky, D.; Martin, J.H. Speech and Language Processing. 2023. Available online: https://web.stanford.edu/~jurafsky/slp3/ (accessed on 26 December 2022).
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. 2013. Available online: https://arxiv.org/pdf/1301.3781.pdf (accessed on 25 December 2022).
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed Representations of Words and Phrases and Their Compositionality. 2013. Available online: https://arxiv.org/pdf/1310.4546.pdf (accessed on 25 December 2022).
- Pennington, J.; Socher, R.; Manning, C. GloVe: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Association for Computational Linguistics: Stroudsburg, PA, USA, 2014; pp. 1532–1543. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep Contextualized Word Representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 2–4 June 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; Volume 1, pp. 2227–2237. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the NAACL-HLT 2019, Minneapolis, MA, USA, 2–7 June 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 4171–4186. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. 2019. Available online: https://arxiv.org/pdf/1907.11692.pdf (accessed on 25 December 2022).
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Neural Information Processing Systems: Long Beach, CA, USA, 2017; pp. 6000–6010. [Google Scholar]
- Jozefowicz, R.; Vinyals, O.; Schuster, M.; Shazeer, N.; Wu, Y. Exploring the Limits of Language Modeling. 2016. Available online: https://arxiv.org/pdf/1602.02410.pdf (accessed on 22 December 2022).
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation Applied to Handwritten Zip Code Recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Conneau, A.; Khandelwal, K.; Goyal, N.; Chaudhary, V.; Wenzek, G.; Guzmán, F.; Grave, E.; Ott, M.; Zettlemoyer, L.; Stoyanov, V. Unsupervised Cross-Lingual Representation Learning at Scale. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 8440–8451. [Google Scholar]
- Lample, G.; Conneau, A. Cross-Lingual Language Model Pretraining. 2019. Available online: https://arxiv.org/pdf/1901.07291.pdf (accessed on 5 January 2023).
- Brysbaert, M.; Warriner, A.B.; Kuperman, V. Concreteness ratings for 40 thousand generally known English word lemmas. Behav. Res. Methods 2013, 46, 904–911. [Google Scholar] [CrossRef] [PubMed]
- Bulat, L.; Clark, S.; Shutova, E. Modeling Metaphor with Attribute-Based Semantics. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, Valencia, Spain, 3–7 April 2017; Association for Computational Linguistics: Stroudsburg, PA, USA, 2017; Volume 2, pp. 523–528. [Google Scholar]
- Gutiérrez, E.D.; Shutova, E.; Marghetis, T.; Bergen, B. Literal and Metaphorical Senses in Compositional Distributional Semantic Models. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 183–193. [Google Scholar]
- Stone, P.J.; Hunt, E.B. A Computer Approach to Content Analysis: Studies Using the General Inquirer System. In Proceedings of the AFIPS ’63 (Spring): Proceedings of the May 21–23, 1963, Spring Joint Computer Conference, New York, NY, USA, 21–23 May 1963; Association for Computing Machinery: New York, NY, USA, 1963; pp. 241–256. [Google Scholar]
- Leong, C.W.; Klebanov, B.B.; Shutova, E. A Report on the 2018 VUA Metaphor Detection Shared Task. In Proceedings of the Workshop on Figurative Language Processing, New Orleans, LA, USA, 6 June 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 56–66. [Google Scholar]
- Leong, C.W.; Klebanov, B.B.; Hamill, C.; Stemle, E.; Ubale, R.; Chen, X. A Report on the 2020 VUA and TOEFL Metaphor Detection Shared Task. In Proceedings of the Second Workshop on Figurative Language Processing, Online, 9 July 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 18–29. [Google Scholar]
- Bevilacqua, M.; Navigli, R. Breaking Through the 80% Glass Ceiling: Raising the State of the Art in Word Sense Disambiguation by Incorporating Knowledge Graph Information. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Stroudsburg, PA, USA, 5–10 July 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 2854–2864. [Google Scholar]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ptiček, M.; Dobša, J. Methods of Annotating and Identifying Metaphors in the Field of Natural Language Processing. Future Internet 2023, 15, 201. https://doi.org/10.3390/fi15060201
Ptiček M, Dobša J. Methods of Annotating and Identifying Metaphors in the Field of Natural Language Processing. Future Internet. 2023; 15(6):201. https://doi.org/10.3390/fi15060201
Chicago/Turabian StylePtiček, Martina, and Jasminka Dobša. 2023. "Methods of Annotating and Identifying Metaphors in the Field of Natural Language Processing" Future Internet 15, no. 6: 201. https://doi.org/10.3390/fi15060201