
Creation, Analysis and Evaluation of AnnoMI, a Dataset of Expert-Annotated Counselling Dialogues †
 , ,
, ,  , ,
, ,  and
and 
Abstract
:1. Introduction
- 1.
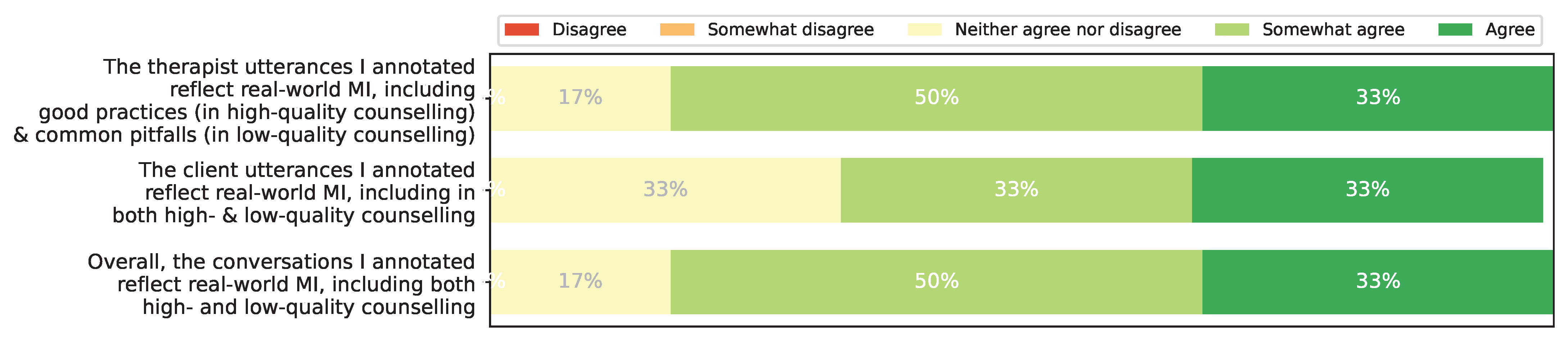
- We release the full version of AnnoMI, which has several fine-grained additional attributes. We also elaborate on the details of data collection and processing, including the results of a post-annotation survey for the annotators, which suggest that the dataset reflects real-world high- and low-quality MI even though its dialogues are from demonstration videos.
- 2.
- We present detailed, visualised statistical analyses of the expanded dataset to examine its patterns and properties.
- 3.
- We establish two AnnoMI-based utterance-level classification tasks with potential for real-world applications: therapist behaviour prediction and client talk type prediction. We also experiment with various machine learning models as baselines for these tasks to facilitate comparison with future methods.
- 4.
- We explore the performance of these models on different topics, as well as their generalisability to new topics.
2. Background and Related Work
2.1. MI Coding
2.2. Available Resources
2.3. Text-Based Approaches to MI Analysis
2.4. Speech-Based and Multimodal Methods for MI Analysis
3. Creating AnnoMI
3.1. MI Demonstration Videos
3.2. Transcription
3.3. Expert Annotators and Workload Assignment
3.4. AnnoMI and “Real-World” MI
4. Annotation Scheme
4.1. Therapist Utterance Attributes
4.1.1. (Main) Behaviour
4.1.2. Question
4.1.3. Input
4.1.4. Reflection
4.2. Client Utterance Attribute (Talk Type)
5. Inter-Annotator Agreement (IAA)
5.1. Default Measure: Fleiss’ Kappa at Utterance Level
5.2. Results of Default IAA Measure
5.3. Supplementary IAA Measure: Intraclass Correlation
5.4. IAA and Full Dataset Release
- Question: {Open question, Closed question, No question}
- Input: {Information, Advice, Options, Negotiation/Goal-Setting, No input}
- Reflection: {Simple reflection, Complex reflection, No reflection}
- (Main) Behaviour: {Question, Input, Reflection, Other}
- Talk Type: {Change, Neutral, Sustain}
6. Dataset Analysis
6.1. General (Main) Behaviour and Talk Type Distributions
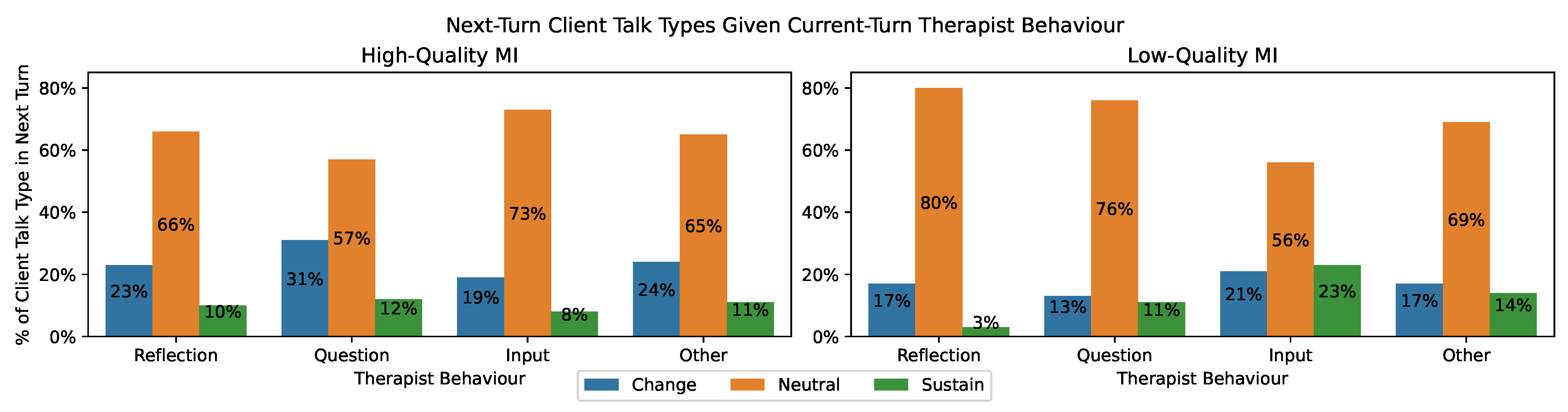
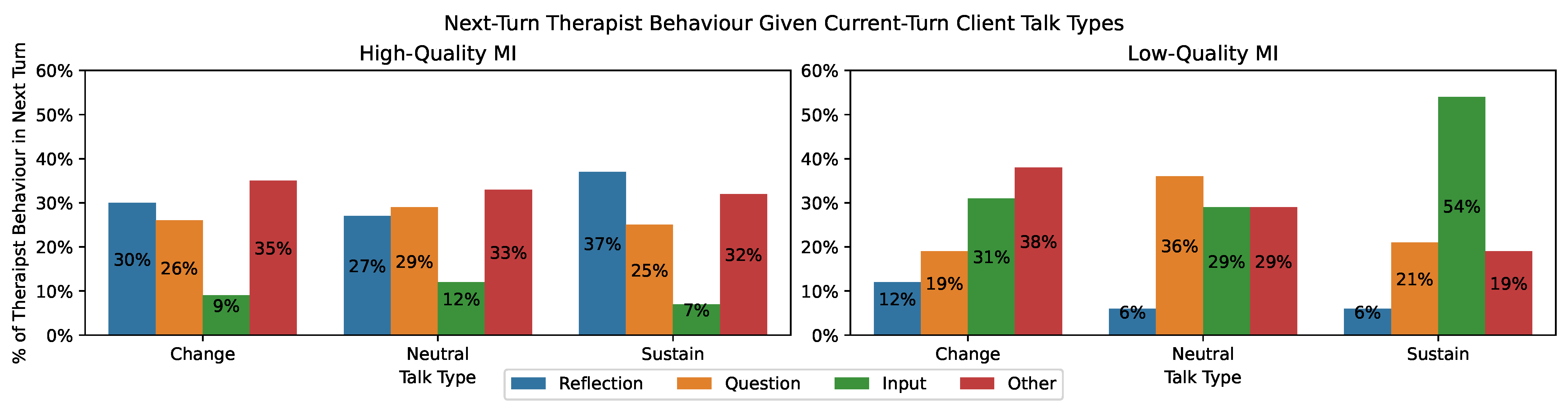
6.2. Posterior (Main) Behaviour and Talk Type Distributions
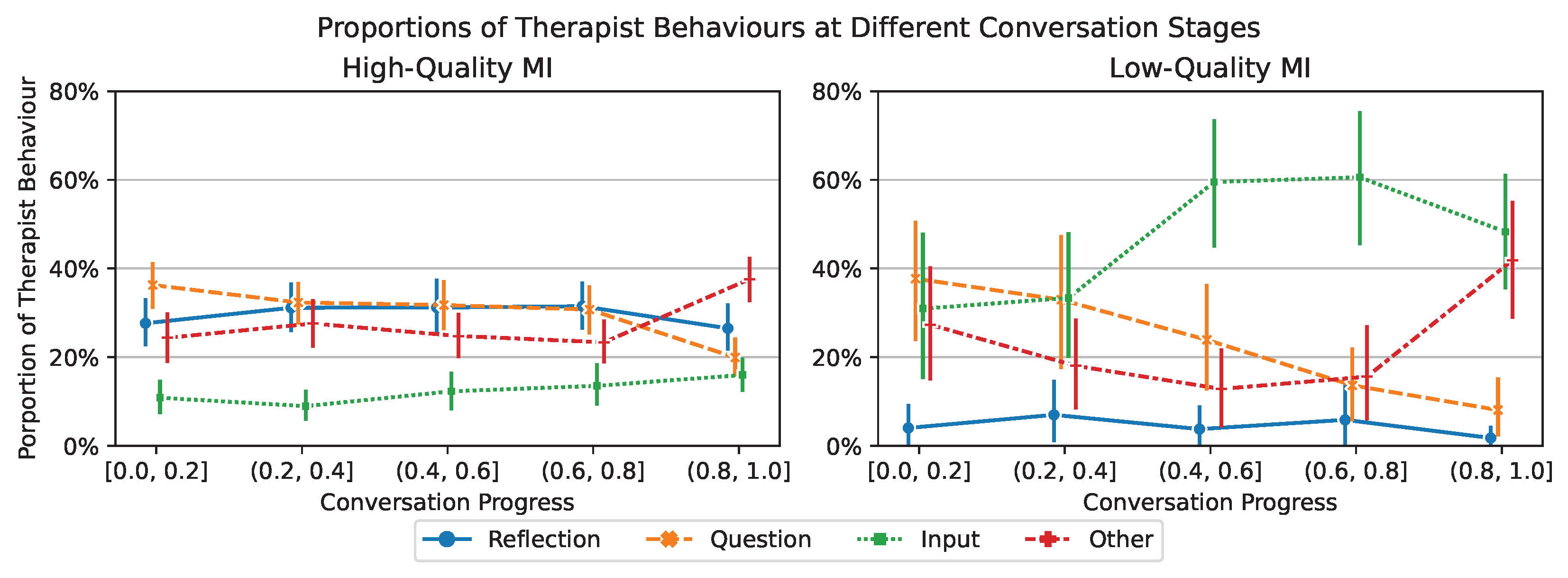
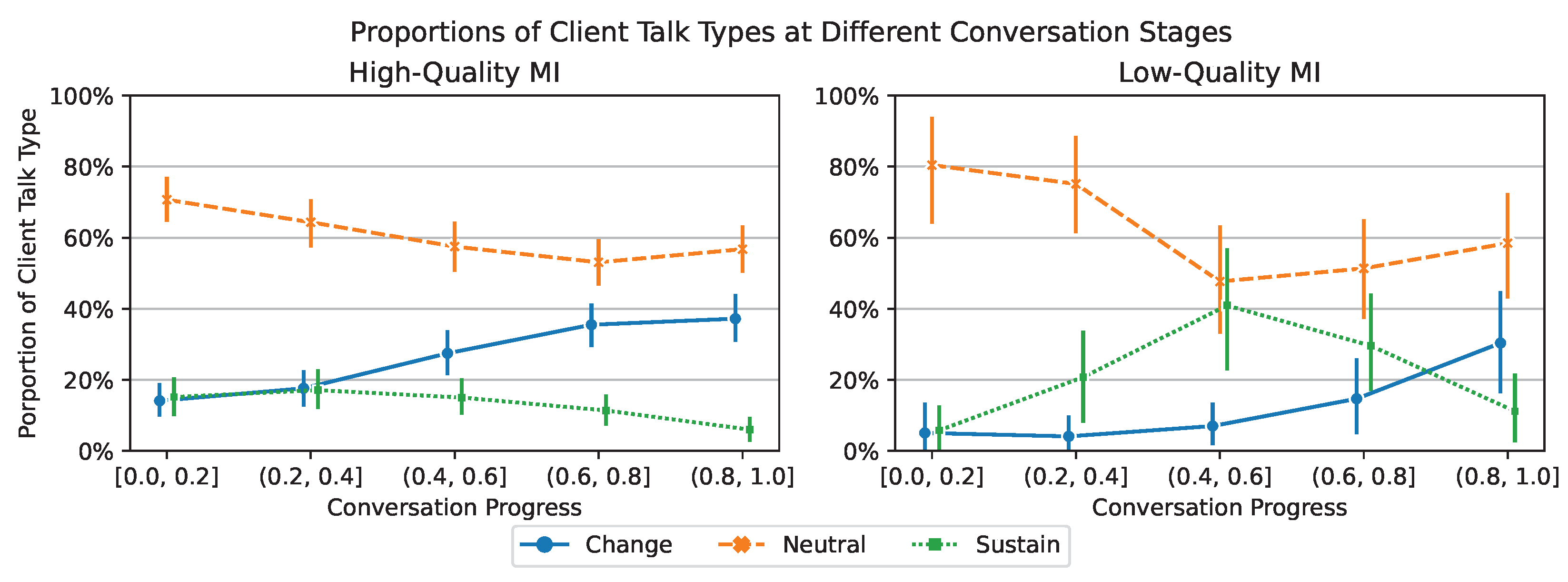
6.3. (Main) Behaviour and Talk Type as Conversation Proceeds
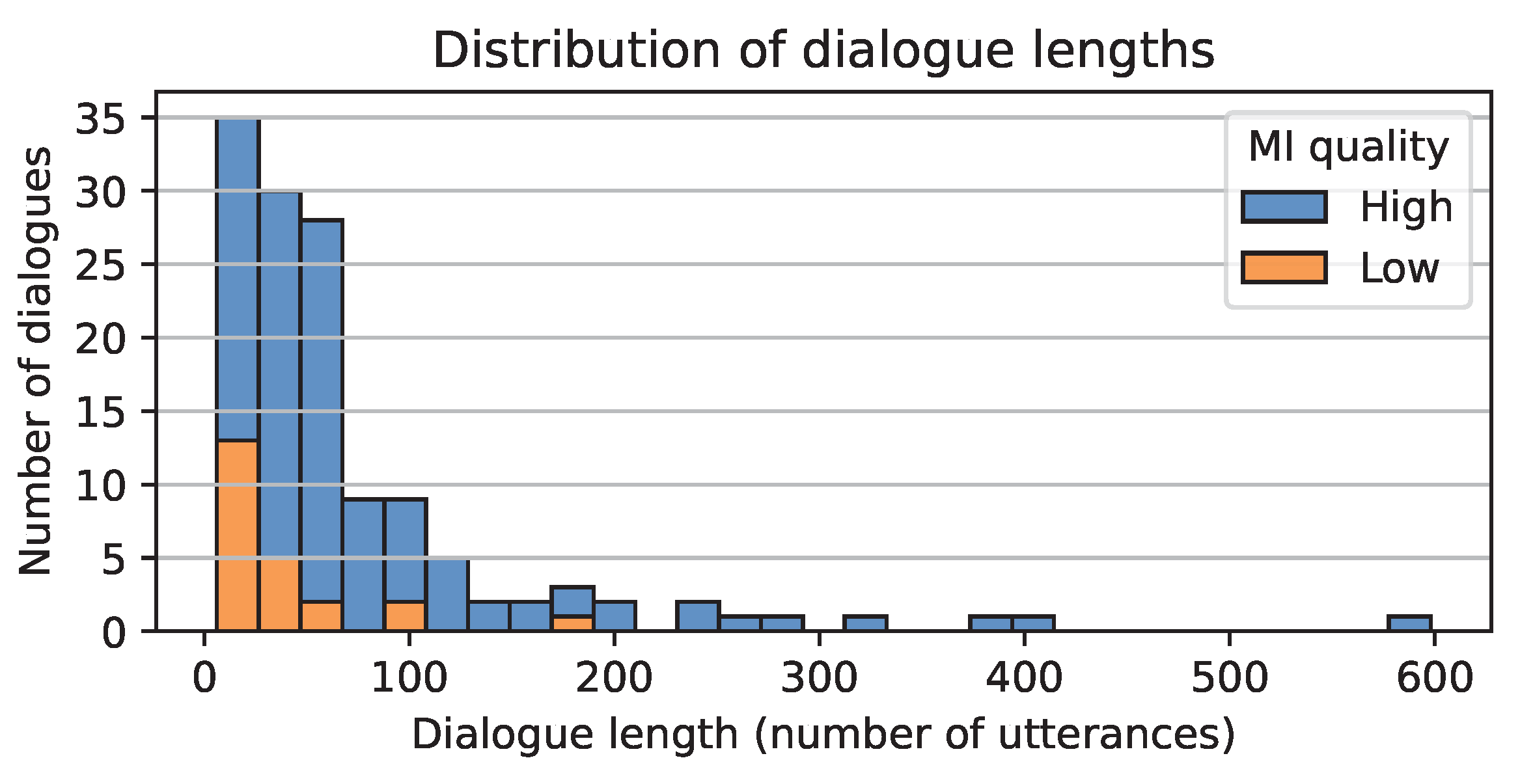
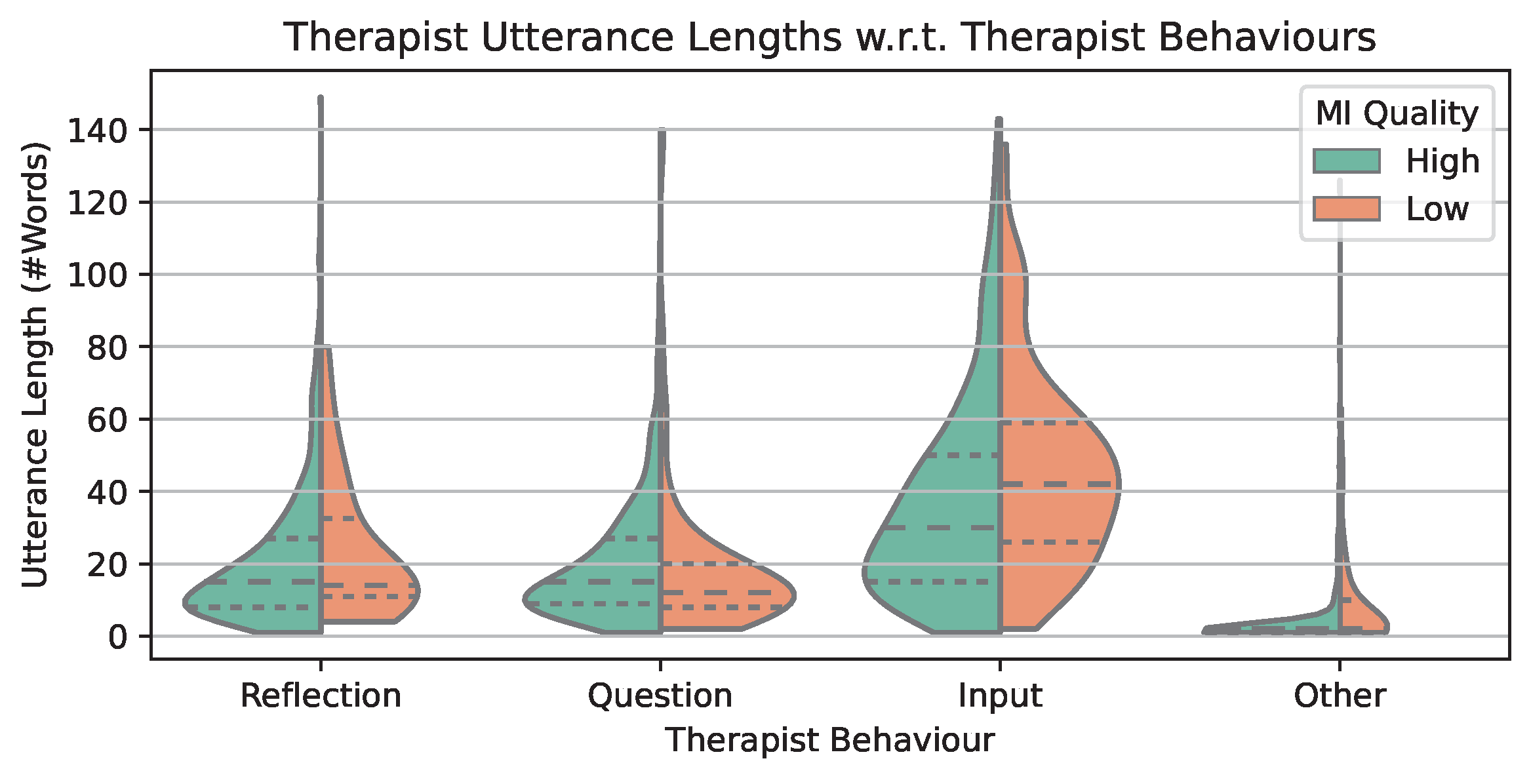
6.4. Utterance Length Distributions
6.5. Frequent 3-Grams
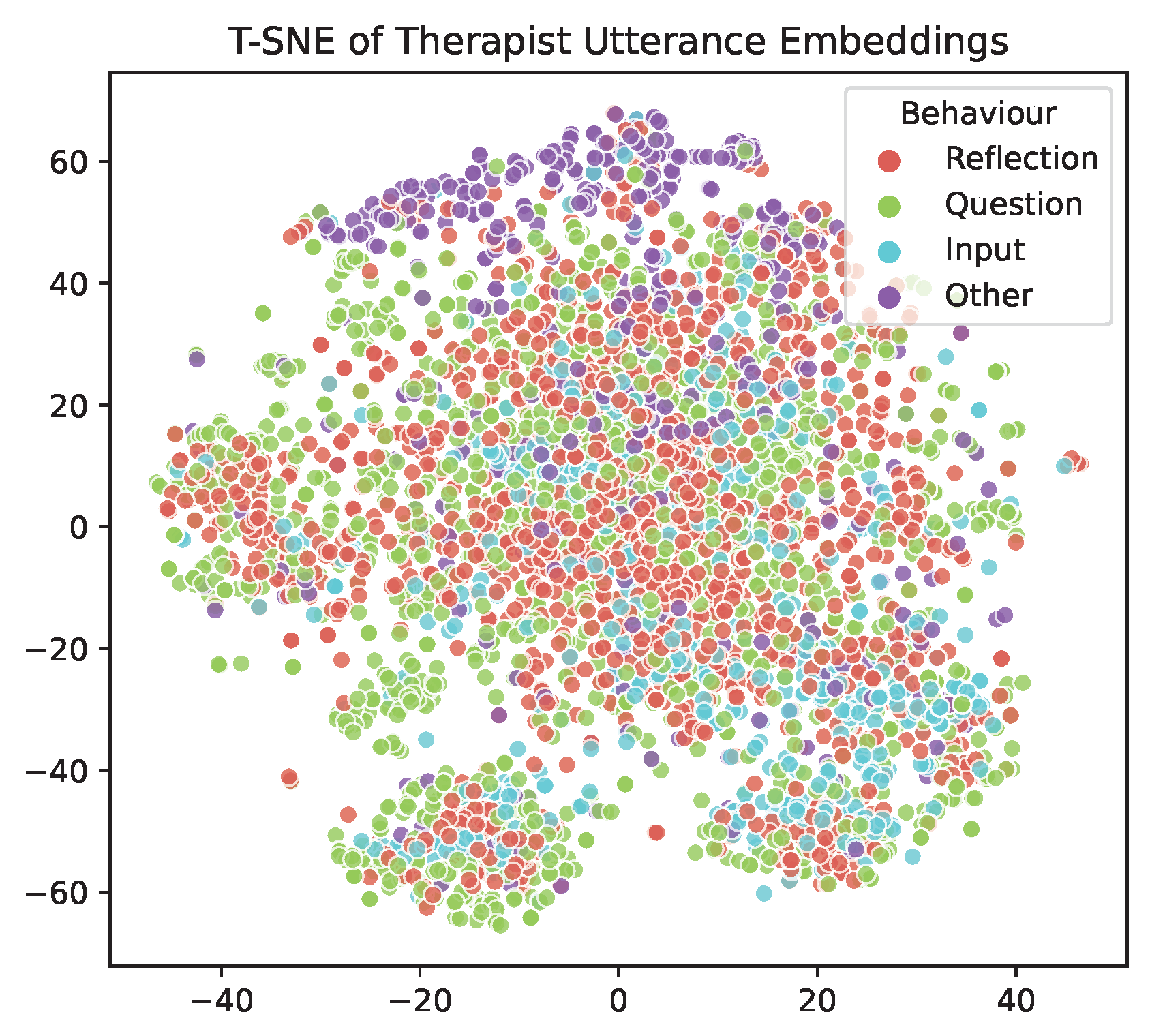
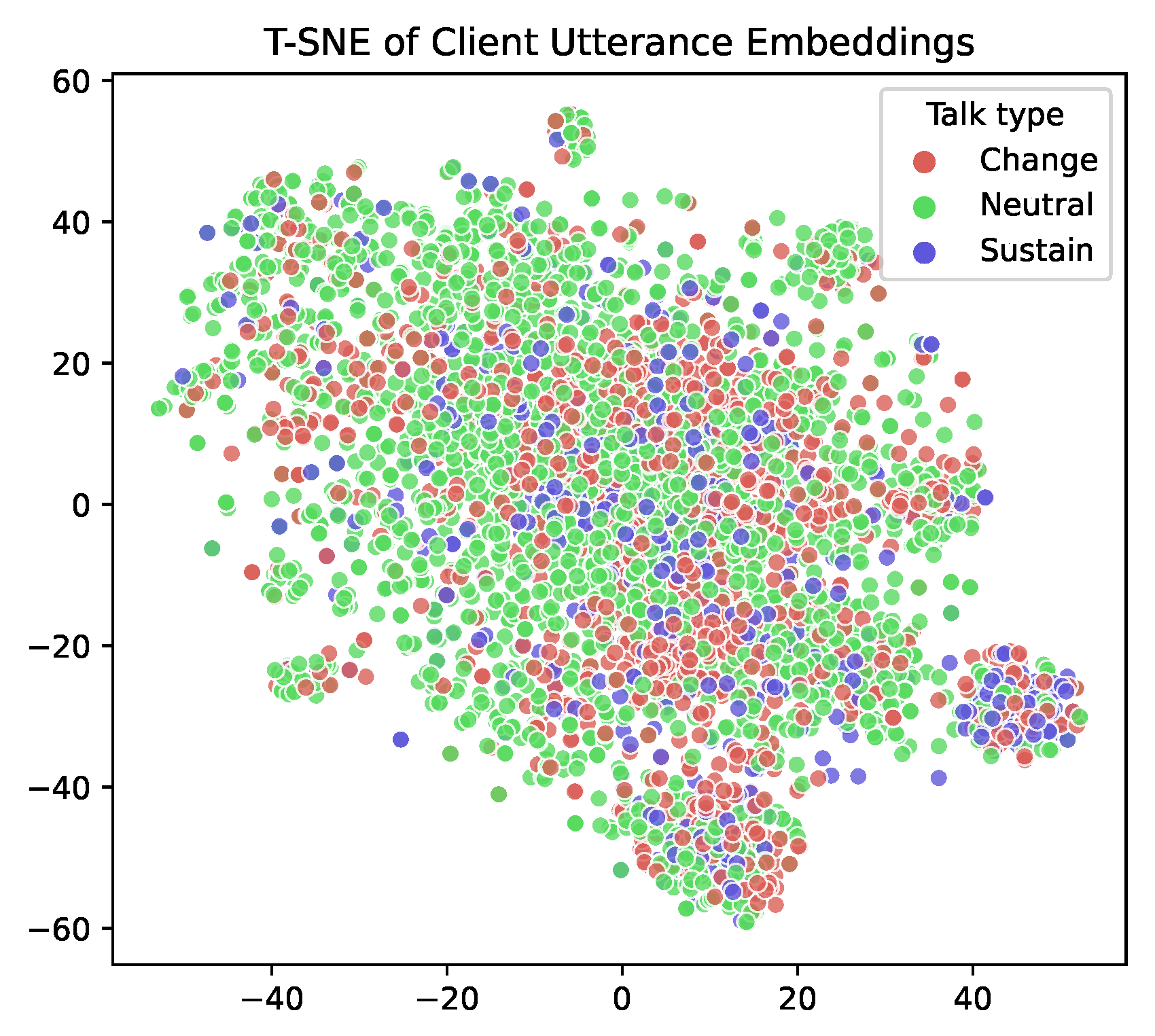
6.6. Utterance Embedding Distribution
7. Utterance-Level Prediction Experiments
- BERT w/o Adapters: BERT-base-uncased [40] fine-tuned on AnnoMI.
- CNN: convolutional neural networks initialised with word2vec embeddings [43] and fine-tuned on AnnoMI.
- Random Forest: random forest with tf-idf features.
- Prior: random prediction based on the class distribution in the training set;
- Uniform: random prediction based on the uniform distribution of the classes.
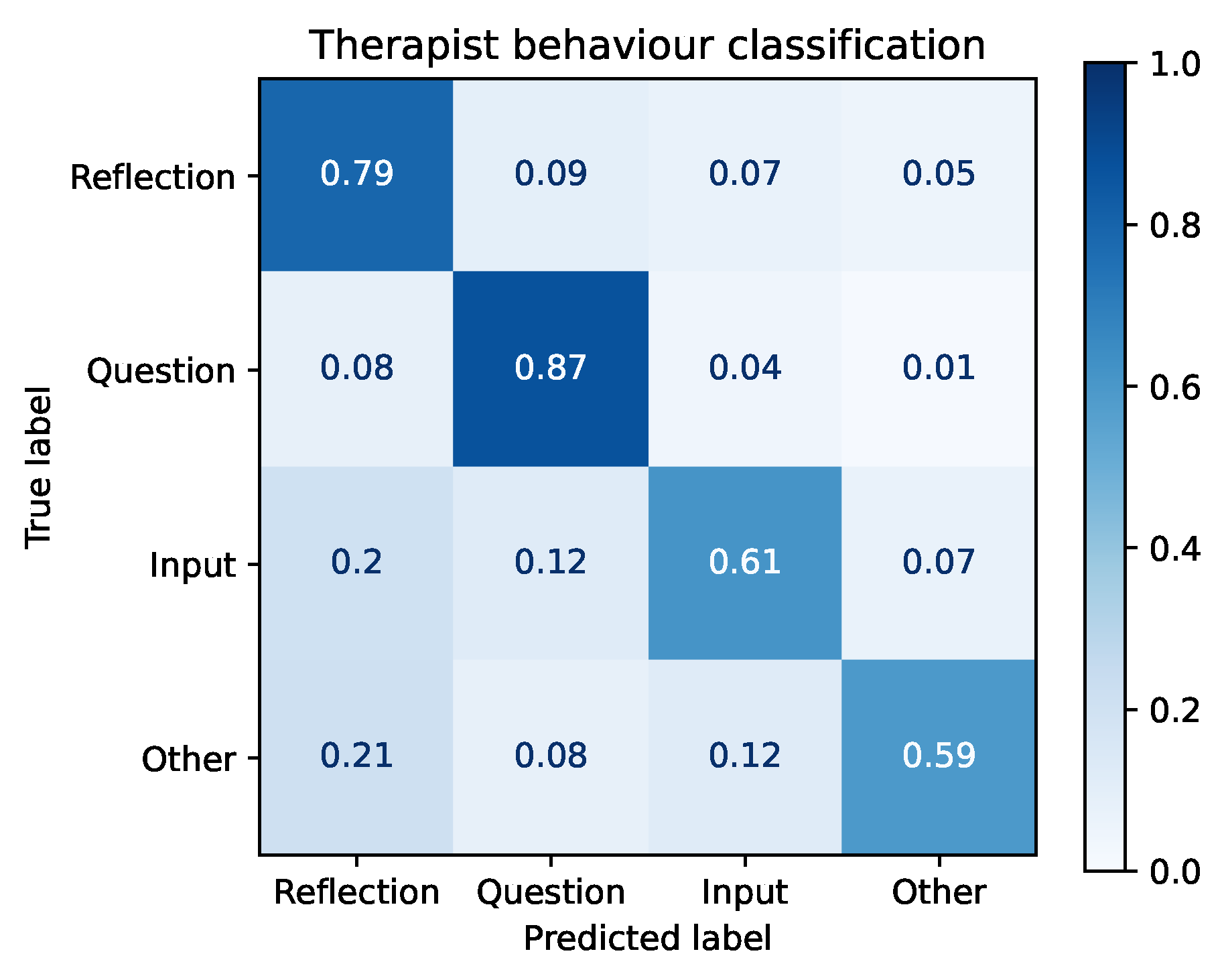
7.1. Task 1: Therapist Behaviour Prediction
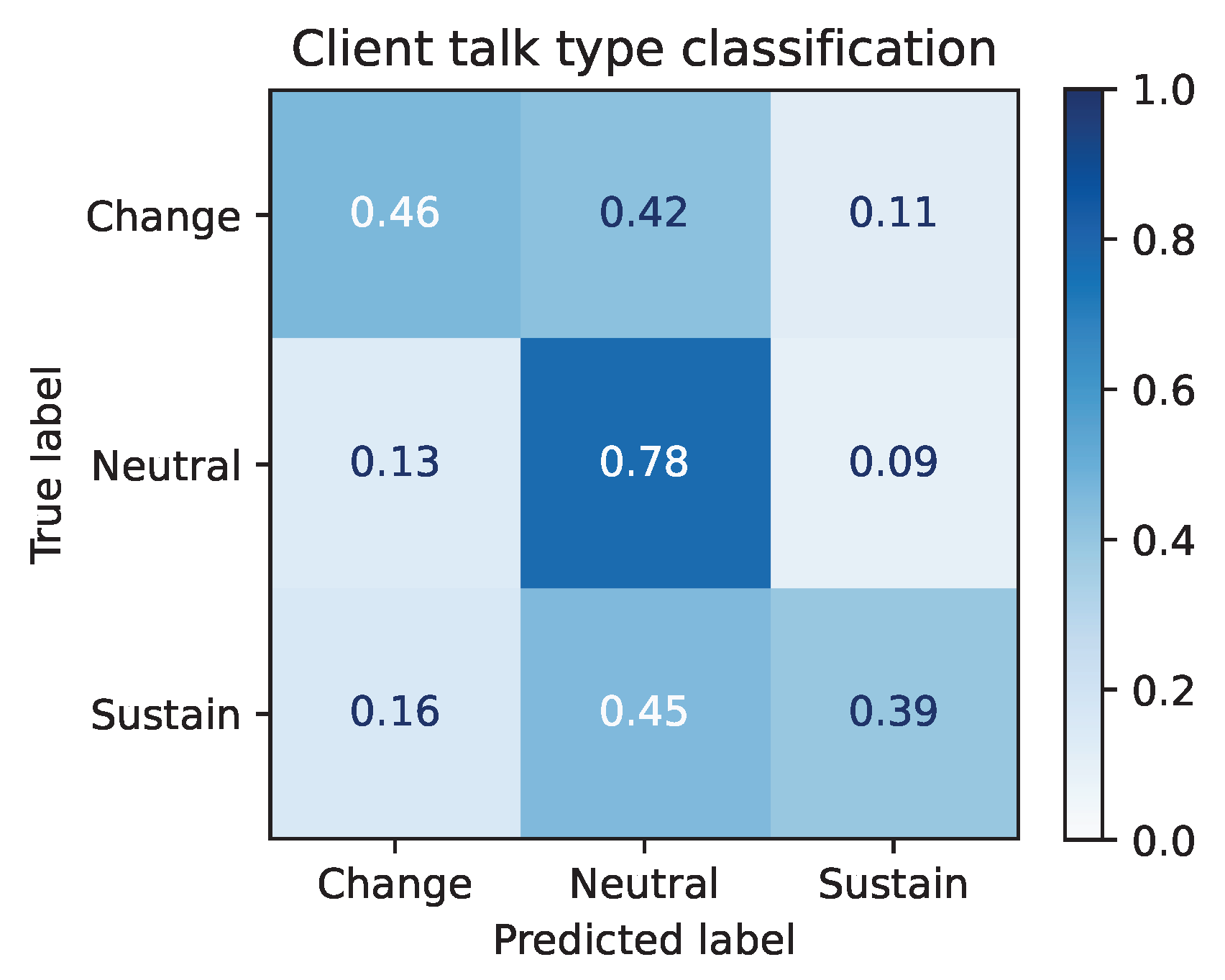
7.2. Task 2: Client Talk Type Prediction
8. Topic-Specific and Cross-Topic Performance
8.1. Topic-Specific Performance
- Therapist Behaviour Prediction: reducing alcohol consumption > smoking cessation > reducing recidivism;
- Client Talk Type Prediction: reducing alcohol consumption ≈ smoking cessation > reducing recidivism.
8.2. Cross-Topic Performance
9. Discussion
10. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Rollnick, S.; Miller, W.R.; Butler, C. Motivational Interviewing in Health Care: Helping Patients Change Behavior; Guilford Press: New York, NY, USA, 2008. [Google Scholar]
- Miller, W.R.; Rollnick, S. Motivational Interviewing: Helping People Change; Guilford Press: New York, NY, USA, 2012. [Google Scholar]
- Miller, W.R. (University of New Mexico, Albuquerque, New Mexico, USA); Moyers, T.B. (University of New Mexico, Albuquerque, New Mexico, USA); Ernst, D. (Denise Ernst Training and Consultation, Portland, Oregon, USA); Amrhein, P. (Montclair State University, Montclair, New Jersey, USA) Manual for the motivational interviewing skill code (MISC). 2003; Unpublished Manuscript.
- Moyers, T.B.; Rowell, L.N.; Manuel, J.K.; Ernst, D.; Houck, J.M. The motivational interviewing treatment integrity code (MITI 4): Rationale, preliminary reliability and validity. J. Subst. Abus. Treat. 2016, 65, 36–42. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Can, D.; Georgiou, P.G.; Atkins, D.C.; Narayanan, S.S. A case study: Detecting counselor reflections in psychotherapy for addictions using linguistic features. In Proceedings of the Thirteenth Annual Conference of the International Speech Communication Association, Portland, OR, USA, 9–13 September 2012. [Google Scholar]
- Xiao, B.; Can, D.; Georgiou, P.G.; Atkins, D.; Narayanan, S.S. Analyzing the language of therapist empathy in motivational interview based psychotherapy. In Proceedings of the 2012 Asia Pacific Signal and Information Processing Association Annual Summit and Conference, Hollywood, CA, USA, 3–6 December 2012; pp. 1–4. [Google Scholar]
- Atkins, D.C.; Steyvers, M.; Imel, Z.E.; Smyth, P. Scaling up the evaluation of psychotherapy: Evaluating motivational interviewing fidelity via statistical text classification. Implement. Sci. 2014, 9, 1–11. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gibson, J.; Malandrakis, N.; Romero, F.; Atkins, D.C.; Narayanan, S.S. Predicting therapist empathy in motivational interviews using language features inspired by psycholinguistic norms. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Gibson, J.; Can, D.; Xiao, B.; Imel, Z.E.; Atkins, D.C.; Georgiou, P.; Narayanan, S.S. A Deep Learning Approach to Modeling Empathy in Addiction Counseling. In Proceedings of the 17th Annual Conference of the International Speech Communication Association, San Francisco, USA, 8–12 September 2016; pp. 1447–1451. [Google Scholar] [CrossRef] [Green Version]
- Xiao, B.; Can, D.; Gibson, J.; Imel, Z.E.; Atkins, D.C.; Georgiou, P.G.; Narayanan, S.S. Behavioral Coding of Therapist Language in Addiction Counseling Using Recurrent Neural Networks. In Proceedings of the 17th Annual Conference of the International Speech Communication Association, San Francisco, CA, USA, 8–12 September 2016; pp. 908–912. [Google Scholar]
- Gibson, J.; Atkins, D.; Creed, T.; Imel, Z.; Georgiou, P.; Narayanan, S. Multi-label multi-task deep learning for behavioral coding. IEEE Trans. Affect. Comput. 2019, 13, 508–518. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cao, J.; Tanana, M.; Imel, Z.; Poitras, E.; Atkins, D.; Srikumar, V. Observing Dialogue in Therapy: Categorizing and Forecasting Behavioral Codes. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 5599–5611. [Google Scholar]
- Pérez-Rosas, V.; Wu, X.; Resnicow, K.; Mihalcea, R. What makes a good counselor? learning to distinguish between high-quality and low-quality counseling conversations. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 926–935. [Google Scholar]
- Wu, Z.; Balloccu, S.; Kumar, V.; Helaoui, R.; Reiter, E.; Recupero, D.R.; Riboni, D. Anno-MI: A Dataset of Expert-Annotated Counselling Dialogues. In Proceedings of the ICASSP 2022–2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 6177–6181. [Google Scholar]
- Bakeman, R.; Quera, V. Behavioral observation. In APA Handbook of Research Methods in Psychology, Vol 1: Foundations, Planning, Measures, and Psychometrics; APA Handbooks in Psychology®; American Psychological Association: Washington, DC, USA, 2012; pp. 207–225. [Google Scholar] [CrossRef]
- Pérez-Rosas, V.; Mihalcea, R.; Resnicow, K.; Singh, S.; An, L. Building a motivational interviewing dataset. In Proceedings of the Third Workshop on Computational Linguistics and Clinical Psychology, San Diego, CA, USA, 16 June 2016; pp. 42–51. [Google Scholar]
- Pérez-Rosas, V.; Mihalcea, R.; Resnicow, K.; Singh, S.; An, L.; Goggin, K.J.; Catley, D. Predicting counselor behaviors in motivational interviewing encounters. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, Valencia, Spain, 3–7 April 2017; Volume 1, Long Papers. pp. 1128–1137. [Google Scholar]
- Pérez-Rosas, V.; Mihalcea, R.; Resnicow, K.; Singh, S.; An, L. Understanding and predicting empathic behavior in counseling therapy. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1426–1435. [Google Scholar]
- Tanana, M.; Hallgren, K.A.; Imel, Z.E.; Atkins, D.C.; Srikumar, V. A comparison of natural language processing methods for automated coding of motivational interviewing. J. Subst. Abus. Treat. 2016, 65, 43–50. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wu, Z.; Helaoui, R.; Recupero, D.R.; Riboni, D. Towards Low-Resource Real-Time Assessment of Empathy in Counselling. In Proceedings of the Seventh Workshop on Computational Linguistics and Clinical Psychology: Improving Access, Online, 11 June 2021; pp. 204–216. [Google Scholar]
- Wu, Z.; Helaoui, R.; Kumar, V.; Reforgiato Recupero, D.; Riboni, D. Towards Detecting Need for Empathetic Response in Motivational Interviewing. In Proceedings of the Companion Publication of the 2020 International Conference on Multimodal Interaction, Utrecht, The Netherlands, 26–29 October 2020; pp. 497–502. [Google Scholar]
- Singla, K.; Chen, Z.; Atkins, D.; Narayanan, S. Towards end-2-end learning for predicting behavior codes from spoken utterances in psychotherapy conversations. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 3797–3803. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.; Singla, K.; Gibson, J.; Can, D.; Imel, Z.E.; Atkins, D.C.; Georgiou, P.; Narayanan, S. Improving the prediction of therapist behaviors in addiction counseling by exploiting class confusions. In Proceedings of the ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 6605–6609. [Google Scholar]
- Singla, K.; Chen, Z.; Flemotomos, N.; Gibson, J.; Can, D.; Atkins, D.C.; Narayanan, S.S. Using Prosodic and Lexical Information for Learning Utterance-level Behaviors in Psychotherapy. In Proceedings of the 19th Annual Conference of the International Speech Communication Association, Hyderabad, India, 2–6 September 2018; pp. 3413–3417. [Google Scholar]
- Xiao, B.; Bone, D.; Segbroeck, M.V.; Imel, Z.E.; Atkins, D.C.; Georgiou, P.G.; Narayanan, S.S. Modeling therapist empathy through prosody in drug addiction counseling. In Proceedings of the Fifteenth Annual Conference of the International Speech Communication Association, Singapore, 14–18 September 2014. [Google Scholar]
- Xiao, B.; Imel, Z.E.; Atkins, D.C.; Georgiou, P.G.; Narayanan, S.S. Analyzing speech rate entrainment and its relation to therapist empathy in drug addiction counseling. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Flemotomos, N.; Martinez, V.R.; Chen, Z.; Singla, K.; Ardulov, V.; Peri, R.; Caperton, D.D.; Gibson, J.; Tanana, M.J.; Georgiou, P.; et al. Automated evaluation of psychotherapy skills using speech and language technologies. Behav. Res. Methods 2022, 54, 690–711. [Google Scholar] [CrossRef] [PubMed]
- Reforgiato Recupero, D.; Cambria, E. ESWC’14 challenge on Concept-Level Sentiment Analysis. Commun. Comput. Inf. Sci. 2014, 475, 3–20. [Google Scholar] [CrossRef]
- Dridi, A.; Reforgiato Recupero, D. Leveraging semantics for sentiment polarity detection in social media. Int. J. Mach. Learn. Cybern. 2019, 10, 2045–2055. [Google Scholar] [CrossRef]
- Recupero, D.R.; Alam, M.; Buscaldi, D.; Grezka, A.; Tavazoee, F. Frame-based detection of figurative language in tweets [application notes]. IEEE Comput. Intell. Mag. 2019, 14, 77–88. [Google Scholar] [CrossRef]
- Fleiss, J.L. Measuring nominal scale agreement among many raters. Psychol. Bull. 1971, 76, 378. [Google Scholar] [CrossRef]
- Landis, J.R.; Koch, G.G. The measurement of observer agreement for categorical data. Biometrics 1977, 33, 159–174. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cicchetti, D.V.; Sparrow, S.A. Developing criteria for establishing interrater reliability of specific items: Applications to assessment of adaptive behavior. Am. J. Ment. Defic. 1981, 86, 127–137. [Google Scholar] [PubMed]
- Wang, W.; Wei, F.; Dong, L.; Bao, H.; Yang, N.; Zhou, M. Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers. Adv. Neural Inf. Process. Syst. 2020, 33, 5776–5788. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Pfeiffer, J.; Rücklé, A.; Poth, C.; Kamath, A.; Vulić, I.; Ruder, S.; Cho, K.; Gurevych, I. AdapterHub: A Framework for Adapting Transformers. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020; pp. 46–54. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. HuggingFace’s Transformers: State-of-the-art natural language processing. arXiv 2019, arXiv:1910.03771. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Houlsby, N.; Giurgiu, A.; Jastrzebski, S.; Morrone, B.; De Laroussilhe, Q.; Gesmundo, A.; Attariyan, M.; Gelly, S. Parameter-efficient transfer learning for NLP. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 2790–2799. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Zhang, J.; Zhao, Y.; Saleh, M.; Liu, P. Pegasus: Pre-training with extracted gap-sentences for abstractive summarization. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 11328–11339. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| High-Quality MI |
|---|
| T: Um, I did wanna talk to you though. I’m a little bit concerned looking through his chart of how many ear infections he’s had recently. And I-I noticed that you had checked the box that someone’s smoking in the home. So I was wondering if you can tell me a little more about that. |
| C: Well, um, It’s just me and him and I do smoke. Um, I try really hard not to smoke around him, but I-I’ve been smoking for 10 years except when I was pregnant with him. But it– everything is so stressful being a single mom and-and my having a full-time job. And so it’s just—that’s why I started smoking again. |
| T: You have a lot of things going on and smoking’s kind of a way to relax and destress. |
| C: Yeah. Some people have a glass of wine. I have a cigarette. |
| T: Sure. And it sounds like you’re trying not to smoke around him. Why did you make that decision? |
| Low-Quality MI |
| T: Well, now’s the time to quit. It’s really gotten to the point where you can’t keep smoking. Not only for him, like I said, but also for you. You’re putting yourself at risk for lung cancer, for emphysema, for oral cancers, for heart disease, for all kinds of things- |
| C: I know, I know. I’ve heard– People have told me before, I’ve heard all that. I just don’t know how to do it. How am I supposed to quit? It’s-it’s so hard. |
| T: Well, there’s all kinds of things you can use now. It’s not as hard as it used to be. You can use nicotine replacement. There’s patches, there’s lozenges, there’s gum, there’s the inhaler, there’s nasal spray. We can talk about medications. You can try Chantix, you can try Zyban, there’s quit smoking groups you can go to, there’s hotlines you can call. |
| C: I just don’t have time for any of that. |
| AnnoMI |
|---|
| C: Right. Well, it would be good if I knew, you know, that my kids are taken care of too- |
| T: Yeah. |
| C: - so I’m not worried about them while I’m at work. |
| T: Right. Yeah. Because you’re- you’re the kind of parent that wants to make sure your kids are doing well. |
| C: Right. |
| T: Yeah. Um, so tell me, what would it take to get you to like a five in confidence, to feel a little bit more confident about getting work? |
| C: Well, I mean, being able to make the interviews would be the priority. |
| T: Okay, Yeah. |
| C: Um, so chi- you know, taking care, having some childcare, having- |
| T: Mm-hmm. |
| C: - having someone I trust that I can call when I know I’ve got an interview. |
| T: Yeah. Because you definitely need to go to an interview in order to get the job. |
| C: Right. Yeah. |
| T: So having taken care of that part, having some reliable childcare would definitely help. |
| C: Yeah. |
| [13] |
| C: one it would be good if I knew you know that my kids are taking care of (“too”) - yeah so I’m not worried about them law in the work right yeah |
| T: because you’re you’re the kind of parent that wants to make sure your kids are doing well great({C}) yeah um so tell me what would it take to get you to like a five in confidence to feel a little bit more confident (“about”) getting work |
| C: well I mean being able to make the interviews would be the priority again({T}) um so try you know taking care having some child care I mean having ({T}) someone I trust that I can call when I you know what that interview because you definitely need to go to an interview in order to get (“the job”) |
| T: yeah so having taken care of that part having some reliable child care (“would definitely help”) |
| C: yeah definitely not |
| Topic | Dialogues |
|---|---|
| Reducing alcohol consumption | 28 (21.1%) |
| Smoking cessation | 21 (15.8%) |
| Weight loss | 9 (6.8%) |
| Taking medicine/following medical procedure | 9 (6.8%) |
| More exercise/increasing activity | 9 (6.8%) |
| Reducing drug use | 8 (6.0%) |
| Reducing recidivism | 7 (5.3%) |
| Compliance with rules | 5 (3.8%) |
| Asthma management | 5 (3.8%) |
| Diabetes management | 5 (3.8%) |
| Other | 33 (24.8%) |
| Topic | Utterances |
| Reducing alcohol consumption | 1914 (19.7%) |
| Reducing recidivism | 1303 (13.4%) |
| Smoking cessation | 1106 (11.4%) |
| Diabetes management | 709 (7.3%) |
| Reducing drug use | 578 (6.0%) |
| Taking medicine/following medical procedure | 574 (5.9%) |
| More exercise/increasing activity | 525 (5.4%) |
| Weight loss | 396 (4.1%) |
| Avoiding DUI | 394 (4.1%) |
| Changing approach to disease | 315 (3.2%) |
| Other | 2107 (21.7%) |
| Therapist Utterance Attributes | Label |
|---|---|
| (Main) Behaviour | Question |
| Input | |
| Reflection | |
| Other | |
| Question | Open question (+) |
| Closed question (+) | |
| No question (-) | |
| Input | Information (+) |
| Advice (+) | |
| Options (+) | |
| Negotiation/goal setting (+) | |
| No input (-) | |
| Reflection | Simple reflection (+) |
| Complex reflection (+) | |
| No reflection (-) | |
| Client Utterance Attribute | Label |
| Talk Type | Change |
| Neutral | |
| Sustain |
| Utterance | Question Type |
|---|---|
| Do you have children in your house? | Closed (Yes/No answer) |
| How much does it actually cost you a week? | Closed (Number) |
| Okay. What kind of alcohol do you drink at parties? | Closed (Specific fact) |
| So what is a typical week for you as far as your alcohol use is concerned? | Open (Seek information) |
| Okay. So how do you feel about being here today? | Open (Invite client’s perspective) |
| So, when you think about what you like and don’t like about your drinking, where do you wanna go from here? | Open (Encourage self-exploration) |
| Utterance | Input Type |
|---|---|
| You’re not alone in feeling that way. Binge drinking can feel normal to some people. | Information |
| So that’s a hormone that allows you to utilise sugar in your body. | Information |
| I want you to be healthy. And I don’t want to see you coming back in here for something else. So I’m really gonna recommend that you try to cut down to that amount. | Advice |
| That’s why I recommend that all my adolescent patients not drink at all. | Advice |
| So, what have you looked into about, um, you know, advocacy in that area or expungement or anything like that? | Options |
| Okay. So, exploring some yoga classes. Is doing yoga in your living room appealing to you at all? | Options |
| So for you being in your class, when that bell rings, then you know, this is the goal. | Negotiation/goal setting |
| Do you think you could go two months without drinking? | Negotiation/goal setting |
| Scenario 1—Smoking Cessation | ||
|---|---|---|
| Speaker | Utterance | Reflection Type |
| Client | Um, I try really hard not to smoke around him, but I-I’ve been smoking for 10 years except when I was pregnant with him. But it– everything is so stressful being a single mom and-and my having a full-time job. And so it’s just– that’s why I started smoking again. | |
| Therapist 1 | Things are very stressful for you right now. | Simple |
| Therapist 2 | You have a lot of things going on and smoking’s kind of a way to relax and de-stress. | Complex |
| Scenario 2—Reducing Alcohol Consumption | ||
| Speaker | Utterance | Reflection Type |
| Client | Um, I’ve been really trying not to, but, you know, weekends come around, and, um, all my friends are kind of partying and stuff, and it’s been hard to, like, break that habit. | |
| Therapist 1 | It’s quite a challenge for you. | Simple |
| Therapist 2 | Mm-hmm. So, there’s this external pressure coming from the people you care about to sort of stay in the scene. | Complex |
| Utterance | Talk Type |
|---|---|
| Yeah, I just want to do what’s right. | Change |
| Well, that was fine until I came here, um, but now that I know about the health risk, um, I have something I gotta think about. | Change |
| Um, I mean, the 10 drinks seems like not a lot for me and my tolerance. | Sustain |
| Yeah, whatever. I Know you got to do your job, but I don’t care. | Sustain |
| Yeah, I would like to play soccer in college. | Neutral |
| And um, I think she used to look after me because she used to do the cooking and stuff like that. | Neutral |
| Therapist Utterance Attribute | IAA Setting | IAA |
|---|---|---|
| Input | All(Strict) | 0.34 |
| All | 0.51 | |
| Binary | 0.64 | |
| Reflection | All(Strict) | 0.32 |
| All | 0.50 | |
| Binary | 0.66 | |
| Question | All(Strict) | 0.54 |
| All | 0.74 | |
| Binary | 0.87 | |
| (Main) Behaviour | All | 0.74 |
| Client Utterance Attribute | IAA Setting | IAA |
| Talk Type | All | 0.47 |
| (Main) Therapist Behaviour | ICC |
|---|---|
| Input | 0.975 |
| Reflection | 0.991 |
| Question | 0.997 |
| Other | 0.996 |
| Client Talk Type | ICC |
| Change | 0.916 |
| Neutral | 0.986 |
| Sustain | 0.890 |
| High-Quality MI | Low-Quality MI | |
|---|---|---|
| Reflection | 28% | 7% |
| Question | 28% | 32% |
| Input | 11% | 33% |
| Other | 33% | 28% |
| High-Quality MI | Low-Quality MI | |
|---|---|---|
| Change | 25% | 17% |
| Neutral | 64% | 68% |
| Sustain | 11% | 15% |
| Therapist | Client | ||||
|---|---|---|---|---|---|
| High-Quality MI | Low-Quality MI | High-Quality MI | Low-Quality MI | ||
| Reflection | “it sounds like” (78) “sounds like you” (56) “a little bit” (51) “you do n’t” (43) “a lot of” (39) | “’re gon na” (4) “you do n’t” (3) “you ’re here” (3) “you ’re gon” (3) “you ’ve already” (2) | Change Talk | “I do n’t” (188) “do n’t know” (68) “I ’m not” (42) “do n’t want” (30) “I think I” (30) | “I do n’t” (8) “I guess I” (6) “I think I” (5) “do n’t know” (4) “I-I guess I” (4) |
| Question | “do you think” (91) “a little bit” (62) “me a little” (35) “little bit about” (33) “I ’m wondering” (30) | “do you think” (11) “you think you” (6) “a lot of” (5) “that you ’re” (5) “you ’re not” (5) | Neutral Talk | “I do n’t” (261) “do n’t know” (142) “I ’m not” (53) “do n’t really” (47) “I did n’t” (27) | “I do n’t” (27) “I ’m not” (7) “do n’t know” (7) “I ’ve been” (6) “I have n’t” (5) |
| Input | “a lot of” (32) “a little bit” (27) “one of the” (16) “that you ’re” (13) “you ’d be” (13) | “a lot of” (15) “you need to” (11) “that you ’re” (9) “’s gon na” (8) “that you ’ve” (7) | Sustain Talk | “I do n’t” (135) “do n’t know” (57) “I ’m not” (28) “it ’s not” (23) “do n’t really” (23) | “I do n’t” (14) “I ’m not” (8) “do n’t know” (5) “It ’s just” (5) “I just need” (4) |
| Other | “for coming in” (12) “that you ’re” (8) “a little bit” (8) “coming in today” (7) “I do n’t” (7) | “that ’s certainly” (2) “so it ’s” (2) “you ’re not” (2) “you ’re still” (2) “be able to” (2) | |||
| (Main) Behaviour | Talk Type | |||||
|---|---|---|---|---|---|---|
| Reflection | Question | Input | Other | Change Talk | Neutral Talk | Sustain Talk |
| 34% | 36% | 16% | 14% | 29% | 57% | 14% |
| Result Format | Original Unbalanced (Augmented Balanced) | ||||
|---|---|---|---|---|---|
| (Main) Therapist Behaviour Prediction | |||||
| Model | F1-Macro | F1-Reflection | F1-Question | F1-Input | F1-Other |
| BERT w/ Adapters | 0.72 (0.70↓) | 0.77 (0.75↓) | 0.86 (0.84↓) | 0.63 (0.60↓) | 0.64 (0.62↓) |
| BERT w/o Adapters | 0.72 (0.70↓) | 0.77 (0.75↓) | 0.85 (0.85) | 0.63 (0.60↓) | 0.64 (0.62↓) |
| CNN | 0.60 (0.58↓) | 0.64 (0.63↓) | 0.70 (0.70) | 0.50 (0.48↓) | 0.56 (0.52↓) |
| Random Forest | 0.50 (0.50) | 0.56 (0.53↓) | 0.58 (0.54↓) | 0.41 (0.45↑) | 0.46 (0.46) |
| Prior | 0.25 (0.24↓) | 0.34 (0.29↓) | 0.36 (0.30↓) | 0.16 (0.20↑) | 0.14 (0.18↑) |
| Uniform | 0.24 (0.24) | 0.29 (0.29) | 0.30 (0.29↓) | 0.20 (0.20) | 0.18 (0.18) |
| Result Format | Original Unbalanced (Augmented Balanced) | |||
|---|---|---|---|---|
| Client Talk Type Prediction | ||||
| Model | F1-Macro | F1-Change Talk | F1-Neutral Talk | F1-Sustain Talk |
| BERT w/ Adapters | 0.55 (0.53↓) | 0.51 (0.53↑) | 0.74 (0.67↓) | 0.39 (0.37↓) |
| BERT w/o Adapters | 0.53 (0.52↓) | 0.49 (0.51↑) | 0.71 (0.67↓) | 0.39 (0.39) |
| CNN | 0.47 (0.46↓) | 0.45 (0.44↓) | 0.65 (0.63↓) | 0.31 (0.31) |
| Random Forest | 0.39 (0.44↑) | 0.38 (0.40↑) | 0.71 (0.65↓) | 0.10 (0.26↑) |
| Prior | 0.33 (0.31↓) | 0.29 (0.31↑) | 0.57 (0.42↓) | 0.14 (0.20↑) |
| Uniform | 0.31 (0.31) | 0.31 (0.31) | 0.42 (0.42) | 0.20 (0.20) |
| Result Format | Topic-Specific → Cross-Topic | ||
|---|---|---|---|
| Topic | Reducing Alcohol Consumption | Reducing Recidivism | Smoking Cessation |
| (Main) Therapist Behaviour Prediction | |||
| BERT w/ Adapters | 0.74 → 0.74 | 0.63 → 0.62↓ | 0.70 → 0.72↑ |
| BERT w/o Adapters | 0.72 → 0.75↑ | 0.65 → 0.66↑ | 0.72 → 0.70↓ |
| CNN | 0.59 → 0.55↓ | 0.50 → 0.52↑ | 0.64 → 0.60↓ |
| Random Forest | 0.49 → 0.49 | 0.40 → 0.36↓ | 0.53 → 0.48↓ |
| Client Talk Type Prediction | |||
| BERT w/ Adapters | 0.55 → 0.52↓ | 0.41 → 0.43↑ | 0.56 → 0.51↓ |
| BERT w/o Adapters | 0.54 → 0.52↓ | 0.41 → 0.42↑ | 0.55 → 0.50↓ |
| CNN | 0.47 → 0.45↓ | 0.39 → 0.39 | 0.50 → 0.43↓ |
| Random Forest | 0.42 → 0.38↓ | 0.33 → 0.34↑ | 0.37 → 0.32↓ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Z.; Balloccu, S.; Kumar, V.; Helaoui, R.; Reforgiato Recupero, D.; Riboni, D. Creation, Analysis and Evaluation of AnnoMI, a Dataset of Expert-Annotated Counselling Dialogues. Future Internet 2023, 15, 110. https://doi.org/10.3390/fi15030110
Wu Z, Balloccu S, Kumar V, Helaoui R, Reforgiato Recupero D, Riboni D. Creation, Analysis and Evaluation of AnnoMI, a Dataset of Expert-Annotated Counselling Dialogues. Future Internet. 2023; 15(3):110. https://doi.org/10.3390/fi15030110
Chicago/Turabian StyleWu, Zixiu, Simone Balloccu, Vivek Kumar, Rim Helaoui, Diego Reforgiato Recupero, and Daniele Riboni. 2023. "Creation, Analysis and Evaluation of AnnoMI, a Dataset of Expert-Annotated Counselling Dialogues" Future Internet 15, no. 3: 110. https://doi.org/10.3390/fi15030110