


Design and Conceptual Development of a Novel Hybrid Intelligent Decision Support System Applied towards the Prevention and Early Detection of Forest Fires
 , , and
, , and
Abstract
:1. Introduction
1.1. Intelligent Firefighting Systems
2. Materials and Methods
2.1. Definition of the System
2.1.1. Database Usage
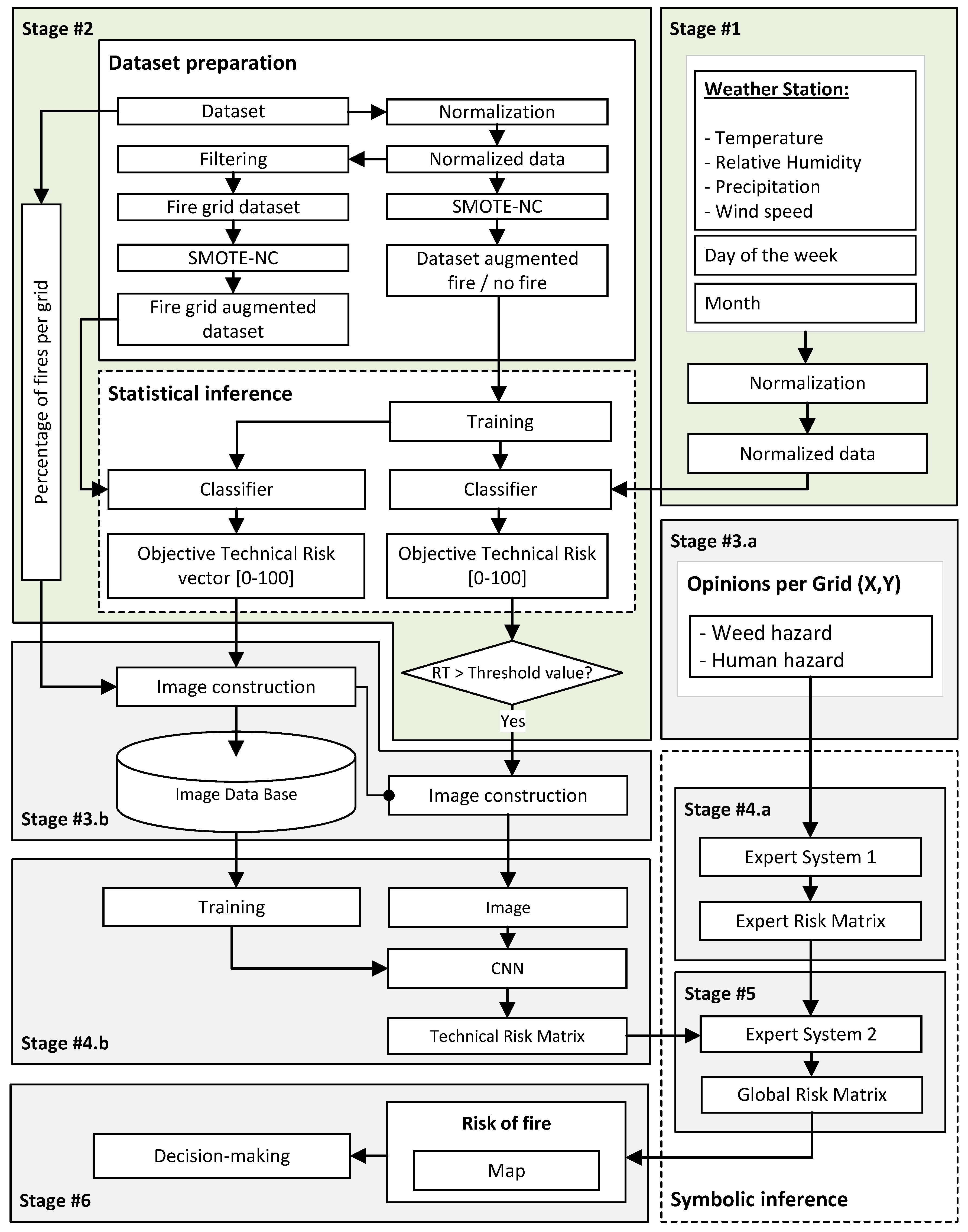
2.1.2. Conceptual Design and Description of the System
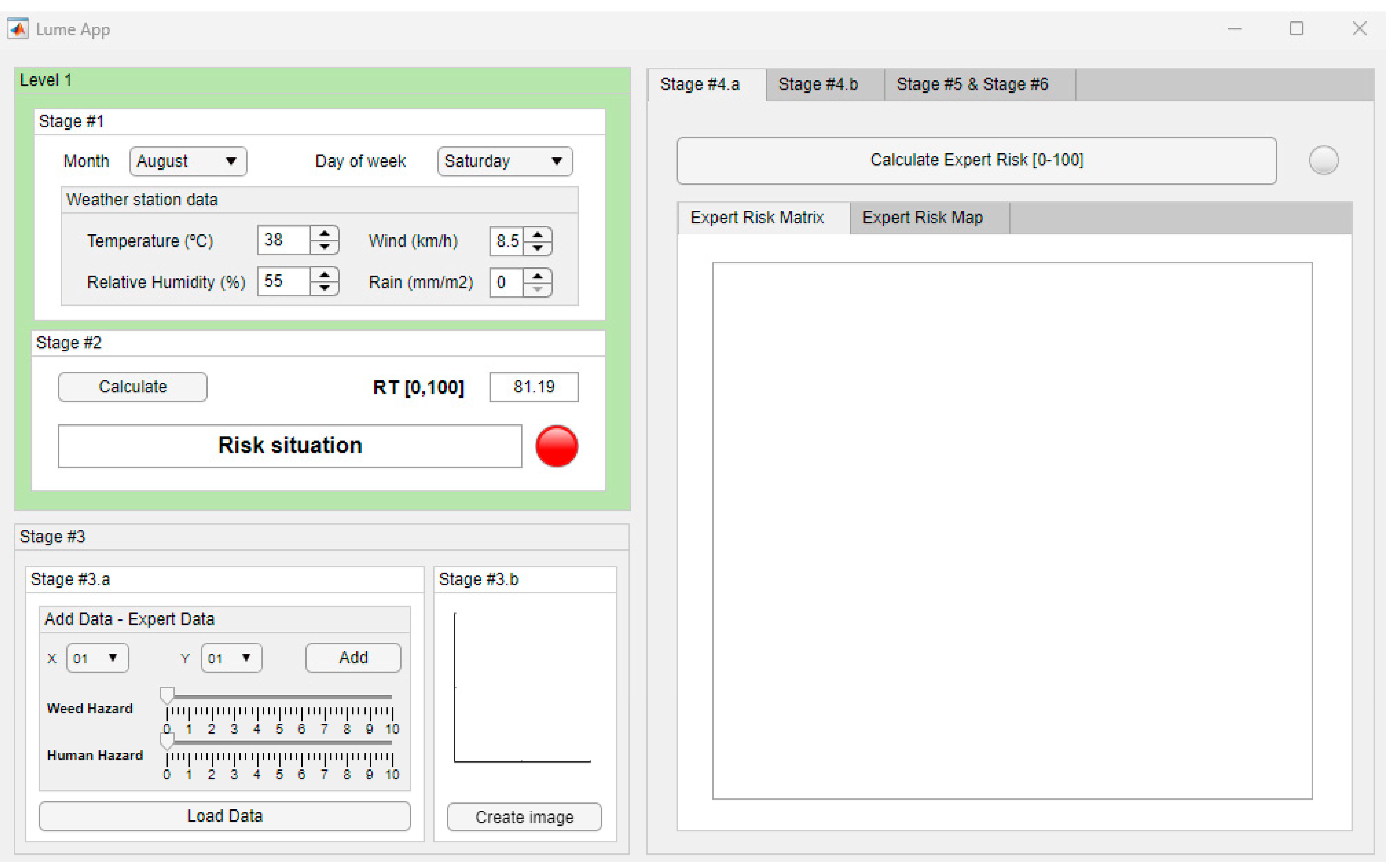
- Stage 1—Information collection from the weather station: In this stage, the atmospheric variables (temperature, relative humidity, wind speed, and precipitation) from the weather station are gathered, as well as the day of the week and month. Once all the initial information has been collected, it is analyzed and normalized, discarding strange values or those far from the average. Then, the data are processed and interpreted.
- Stage 2—Calculation of the risk level in the study area: In the second stage, the aim is to determine whether a fire could occur in the natural park based on the historical dataset, taking into account the data collected in the previous stage. For this, a classification machine learning algorithm will be used [22]. This employs an approach that can be understood as a statistical inference process where a reasonable data distribution is determined. The use of such algorithms, dependent on training in the search for relationships, obeys the basic assumption that some kind of distribution or pattern exists that can relate the variables under study taken within a period of time. As can be deduced, this is a naive and certainly questionable estimate because the start of a fire will be influenced by very diverse variables.
- Stage 3—Collection and adaptation of information: During this stage, the information needed to determine in which area of the study region the fire could occur is compiled and adapted. This stage is a necessary step prior to approaching the inferential process of fire detection in a given area. Any algorithm with inference capabilities must have data to support this knowledge generation. These data can be expressed in different ways and constitute, in themselves, an ontology characterized by classes, relations, axioms, and instances [28,29,30,31]. However, this ontology of knowledge will have a different structure depending on its purpose and application in the inferential process and, of course, will adopt a particular form in each of these applications.
- —
- Stage 3.a—Compilation of expert opinions and evaluations: In this sub-stage, the opinions and evaluations of an expert on each of the different study region zones are collected. The expert will answer a series of questions in pairs, which are summarized in Table 2. The expert must answer each of the questions indicating on a ten-point Likert scale with a step of one the fire danger value associated with both the undergrowth and the human presence. These questions must be based on an unambiguous definition of the term ‘hazardousness’ to avoid cognitive biases on the part of the expert.
- —
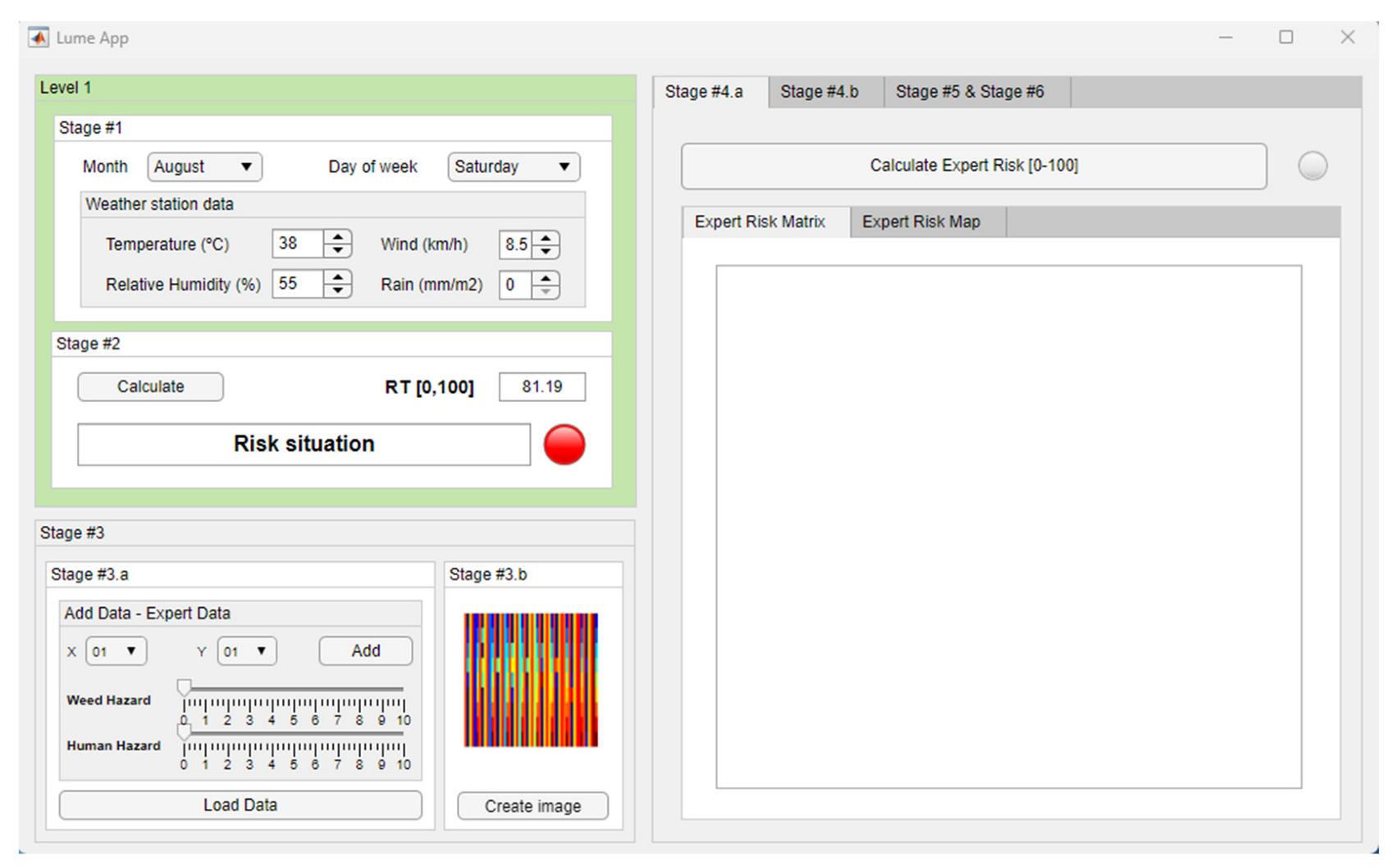
- Stage 3.b—Image generation: In this sub-stage, images are composed that are characteristic and representative of the objective data. In the previous stage, a knowledge base was created from the experience, training, and intuition of the forest fire expert. Undoubtedly, this is a way of limiting the uncertainty present in multivariate problems [32,33] such as this one without addressing them in the way argued above. However, there is a fact associated with knowledge bases that conditions their validity, and it is none other than the presence of false witnesses in the construction of logical constructs. How is the veracity of the expert’s reasoning evaluated? It is not a matter, in this case, of questioning the reliability of the data or environments being analyzed but of evaluating the degree of certainty, replicability, and formalization of the expert’s knowledge in order to avoid false judgments and therefore imprecise syllogisms. For this reason, at the same time as the knowledge base discussed in Stage 3.a is constructed, Stage 3.b sees the construction of an image that represents a fire risk situation in each of the areas being analyzed in the study.
- Stage 4—Determination of risk matrices: Once the information has been collected and the images have been generated, which constitute the knowledge bases of the problem, the next step is to process the information, which is done through two sub-stages running concurrently [23,24,25,26]. In this stage, the concept of risk matrix is introduced, understood to be a representation of the set of fire risks associated with each zone of the study map represented in the form of a matrix. Taking the knowledge bases created above, two types of matrices associated with their respective resolution approaches will be determined.
- —
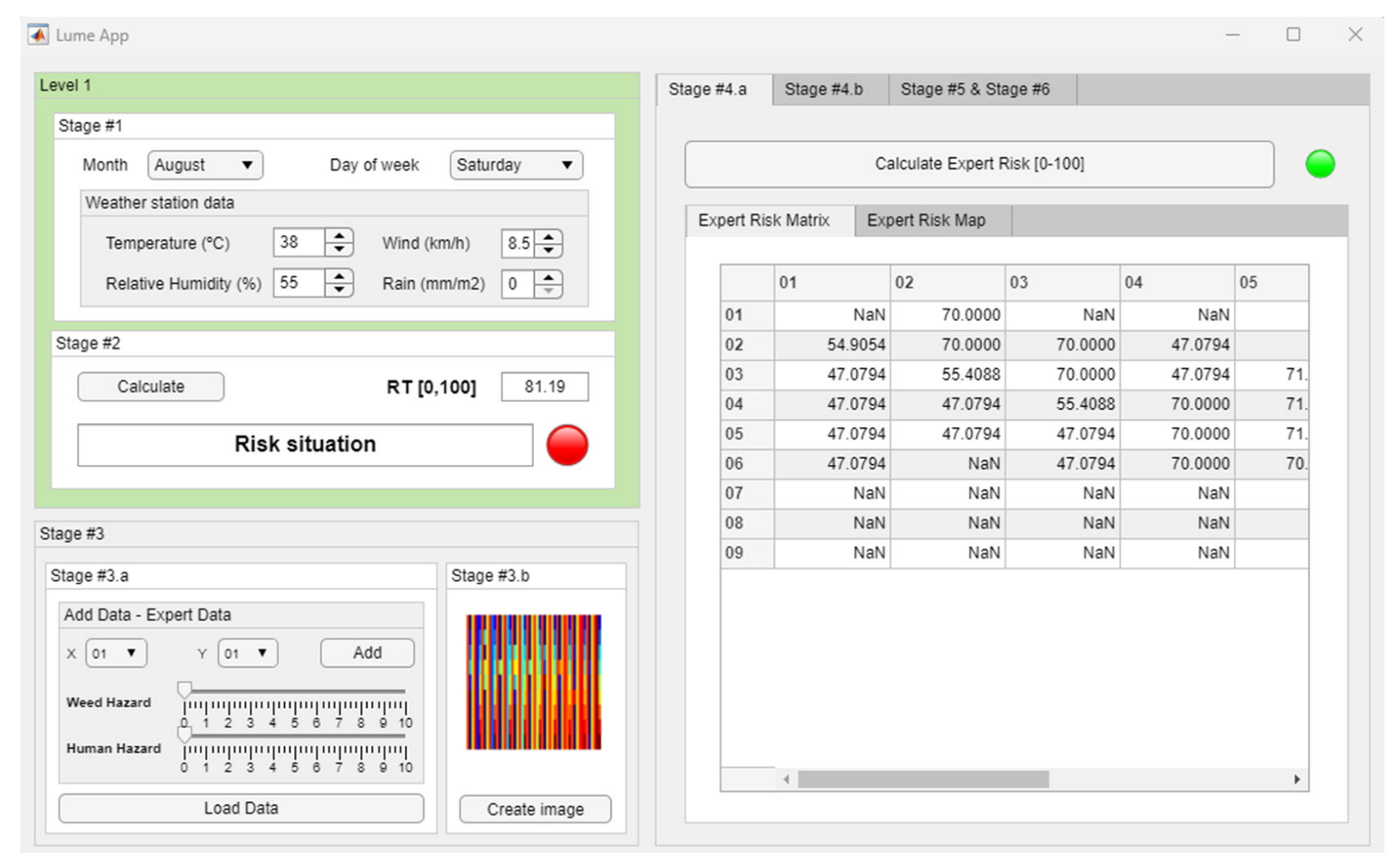
- Stage 4.a—Determination of the Expert Risk Matrix: The expert’s opinions and assessments collected in Stage 3.a will be processed by an expert system based on fuzzy logic, which allows a risk value for each zone to be determined and represented in each quadrant, giving rise to the Expert Risk Matrix. The choice of expert system is no trivial matter. In this case, given the nature of the knowledge base, it is not a question of finding distributions, relationships, or patterns that relate fire risk with variables that could be defined to describe undergrowth or human presence. The problem is reduced to analyzing the syllogisms that make up the knowledge base and, from them, inferring an explicit and deductive reasoning, in accordance with the expert’s experience.
- —
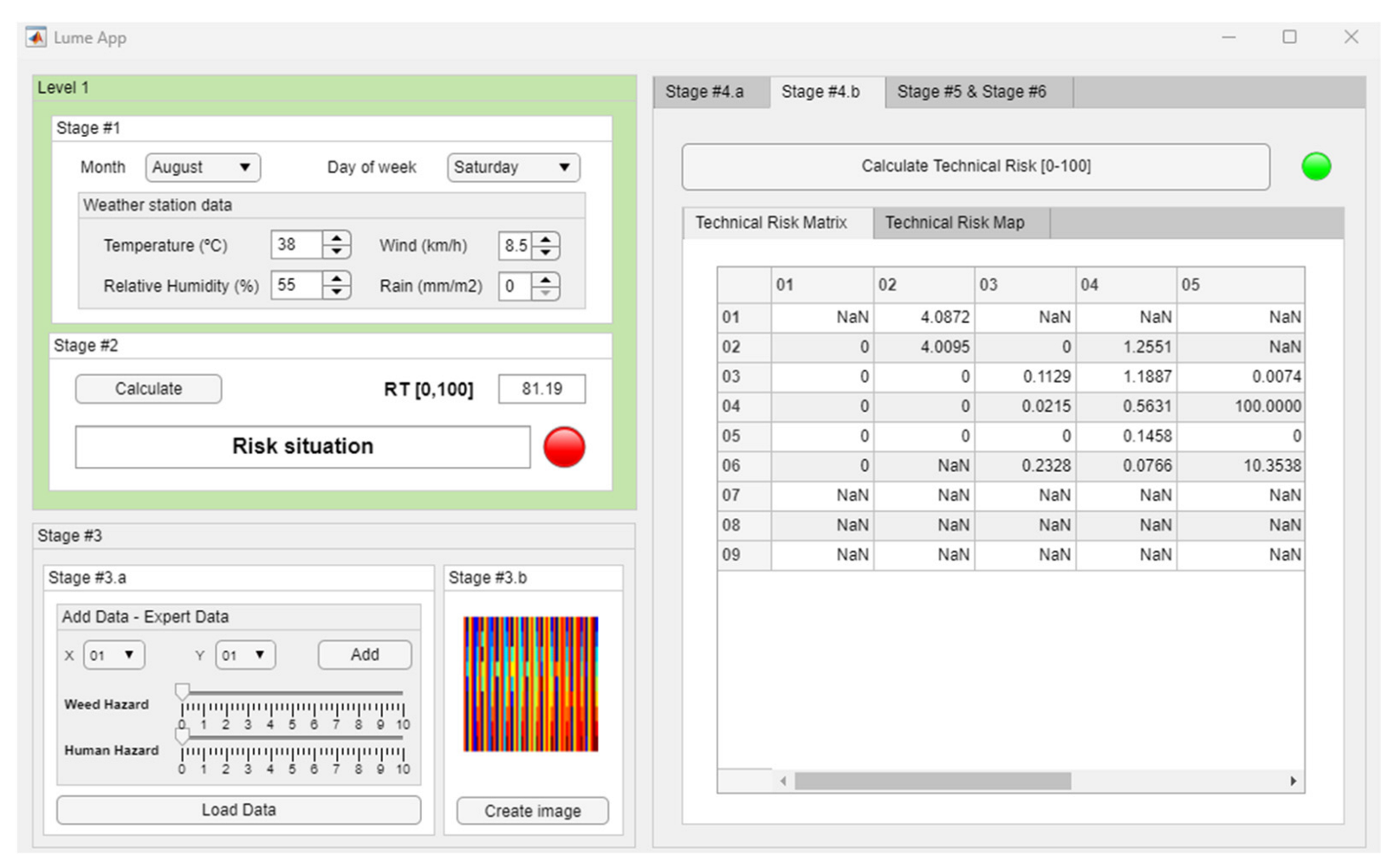
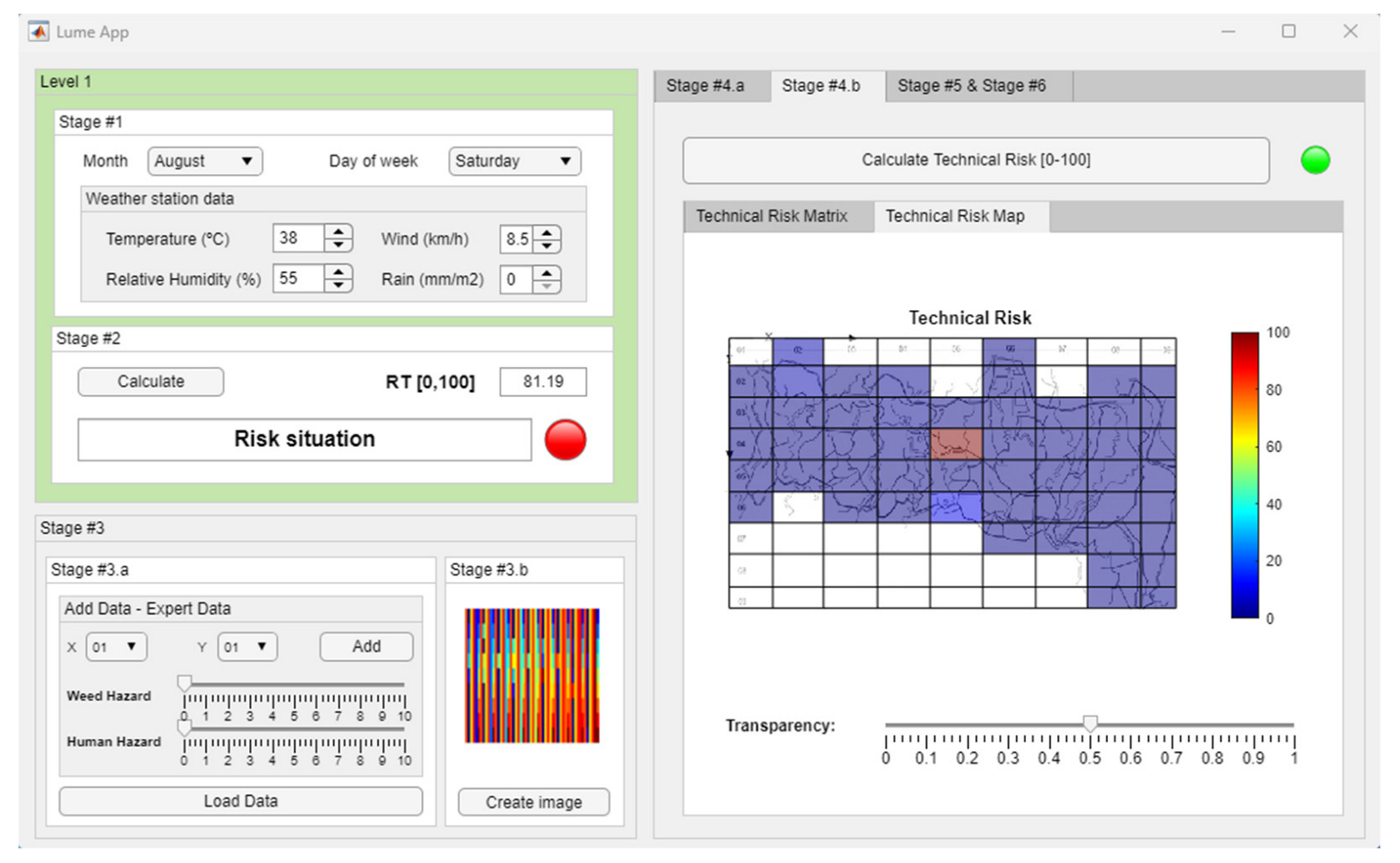
- Stage 4.b—Determination of the Technical Risk Matrix: Concurrently to Stage 4.a, in Stage 4.b, the image is processed by a convolutional neural network through which it is possible to determine a series of scores that make it possible to point towards those areas in which, based on the historical data, it is plausible that a fire may occur. From these scores, it is possible to build a matrix that collects them, called the Technical Risk Matrix, associating each position to each of the zones or quadrants of the map. As before, the choice of a convolutional neural network is not arbitrary. When the knowledge base can be understood as a grouping of data arrays, which is, in essence, what the image represents, the identification of distributions of the explained variables is a process implicit to supervised learning algorithms.
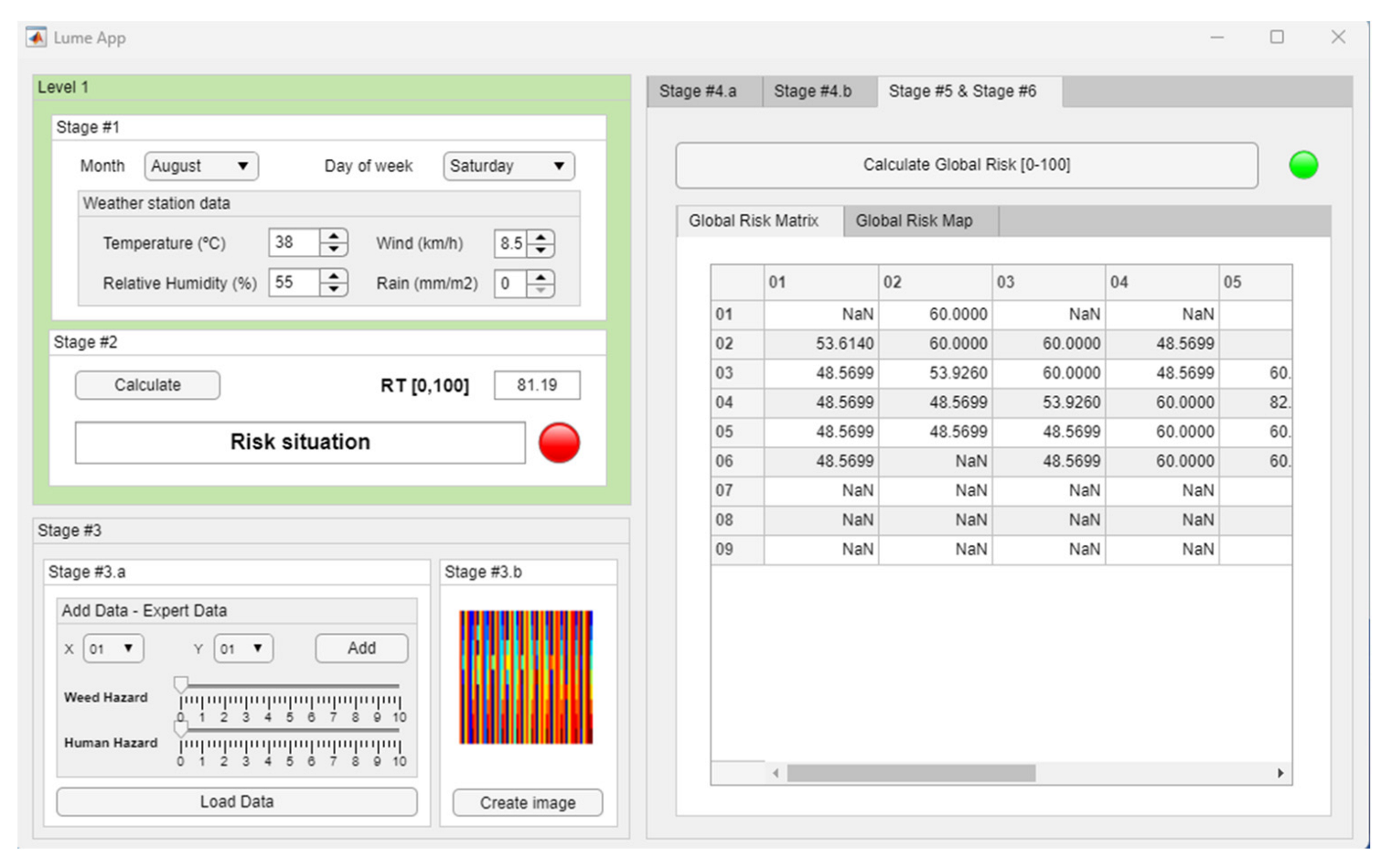
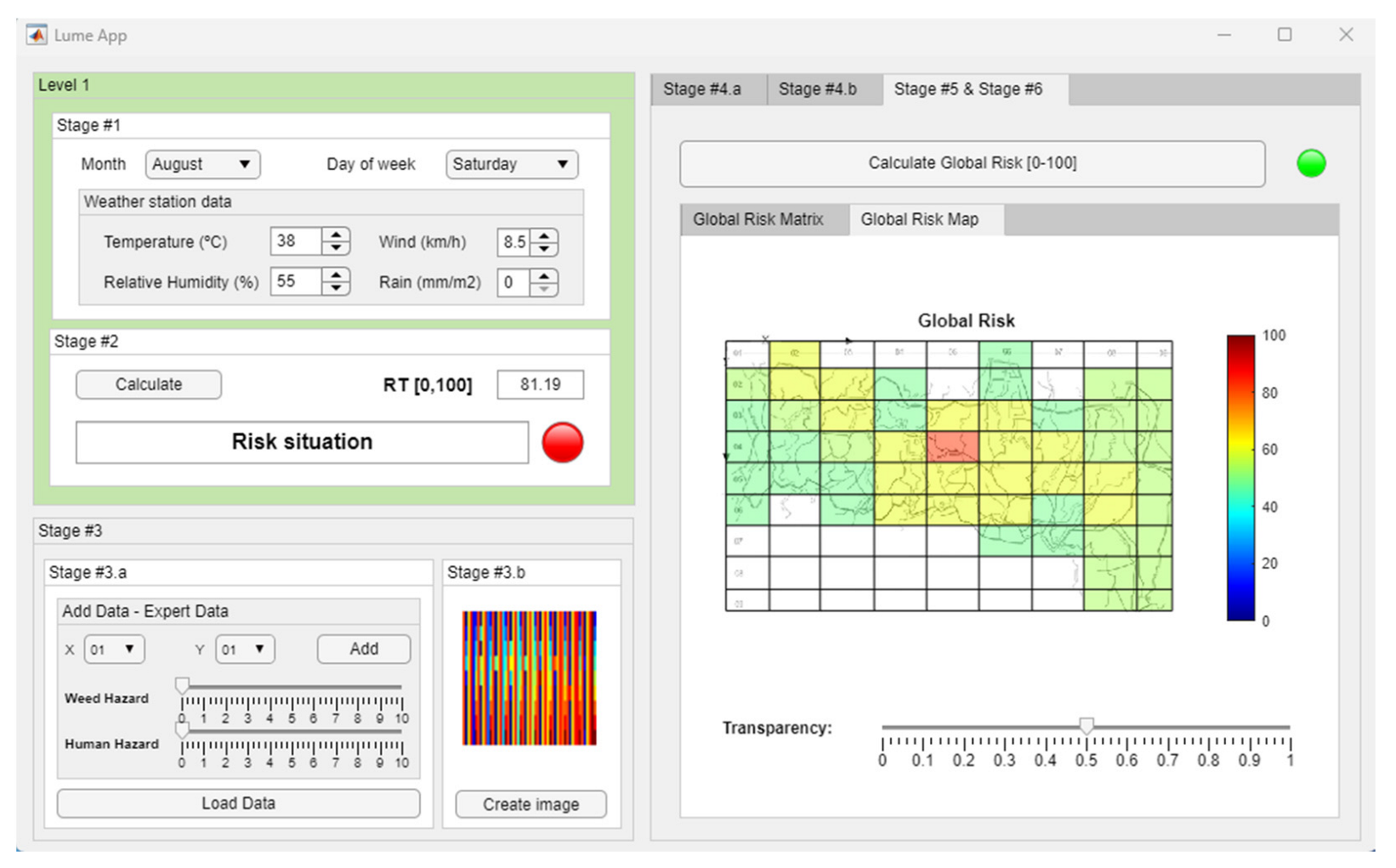
- Stage 5—Determination of the Global Risk Matrix: Once the risk matrices associated with the opinions and assessments of the expert and the image have been determined, they are then aggregated using an expert system based on fuzzy logic that makes it possible to determine a third matrix, called the Global Risk Matrix. It is significant that both the Expert and Technical Risk refer to the same prevention problem and therefore make use of joint knowledge that has been expressed, even though this expression uses different grounds. Joining the two allows effective and complete control of the different sources of uncertainty present to detect not only imprecision or vagueness in the starting data and the creation of the image, but also false or incorrect judgments in the wording of the rules in the expert systems. This control is exemplified by risk linking or aggregation.
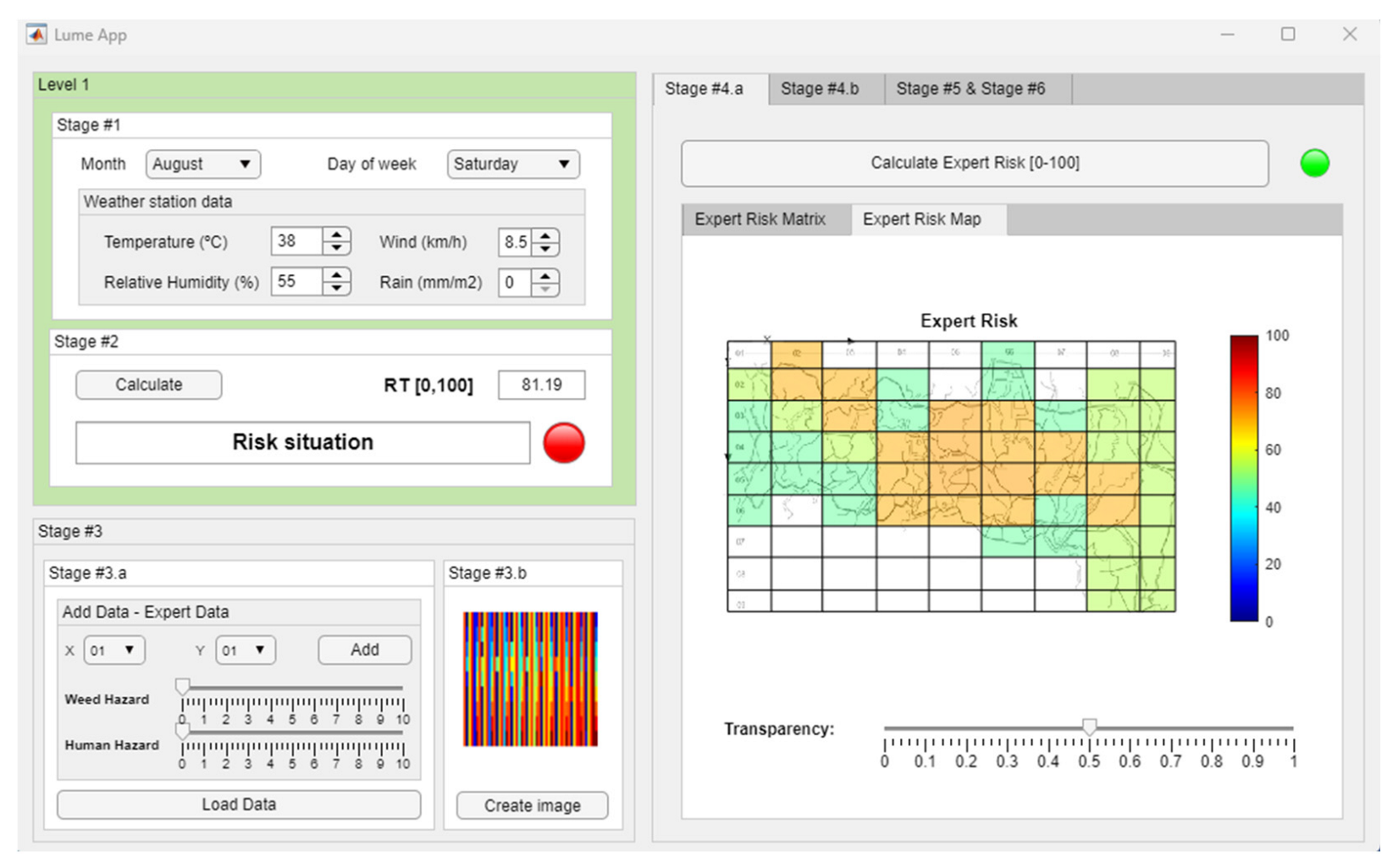
- Stage 6—Alert Generation and Decision Making: Taking the Global Risk Matrix, it is possible to build a color map, which, when superimposed on the study region map, makes it possible to determine those places where a fire could occur on that day. This makes it easier for those responsible for that region to define strategies for surveillance, prevention, and action. In this case, the color scale is subjective and is used as a graphic support for the previously calculated Global Risk values. This scale does not introduce apparent subjectivity in the methodology or in its results since it only affects the way they are shown, serving as a support for decision making.
2.2. Implementation of the System
- Collection and adaptation of the information, which would cover Stages 1, 3.a and 3.b;
- Processing of this information, covering Stage 2;
- Inferential determination of risks, covering Stages 4.a, 4.b and 5;
- Generation of alerts, covered in Stage 6.
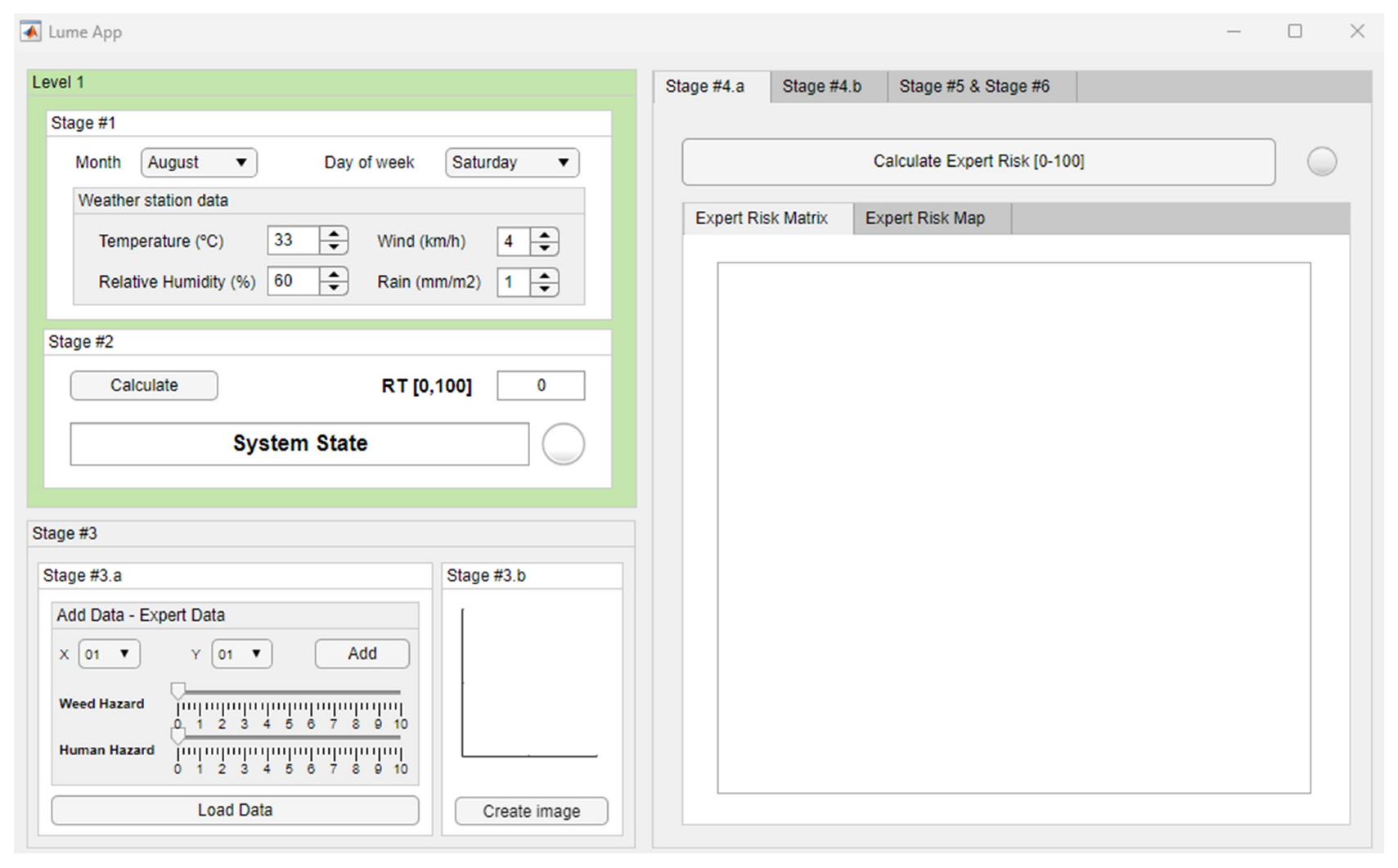
2.2.1. First Level of the Methodology
Data Preparation: Data Normalization and Augmentation
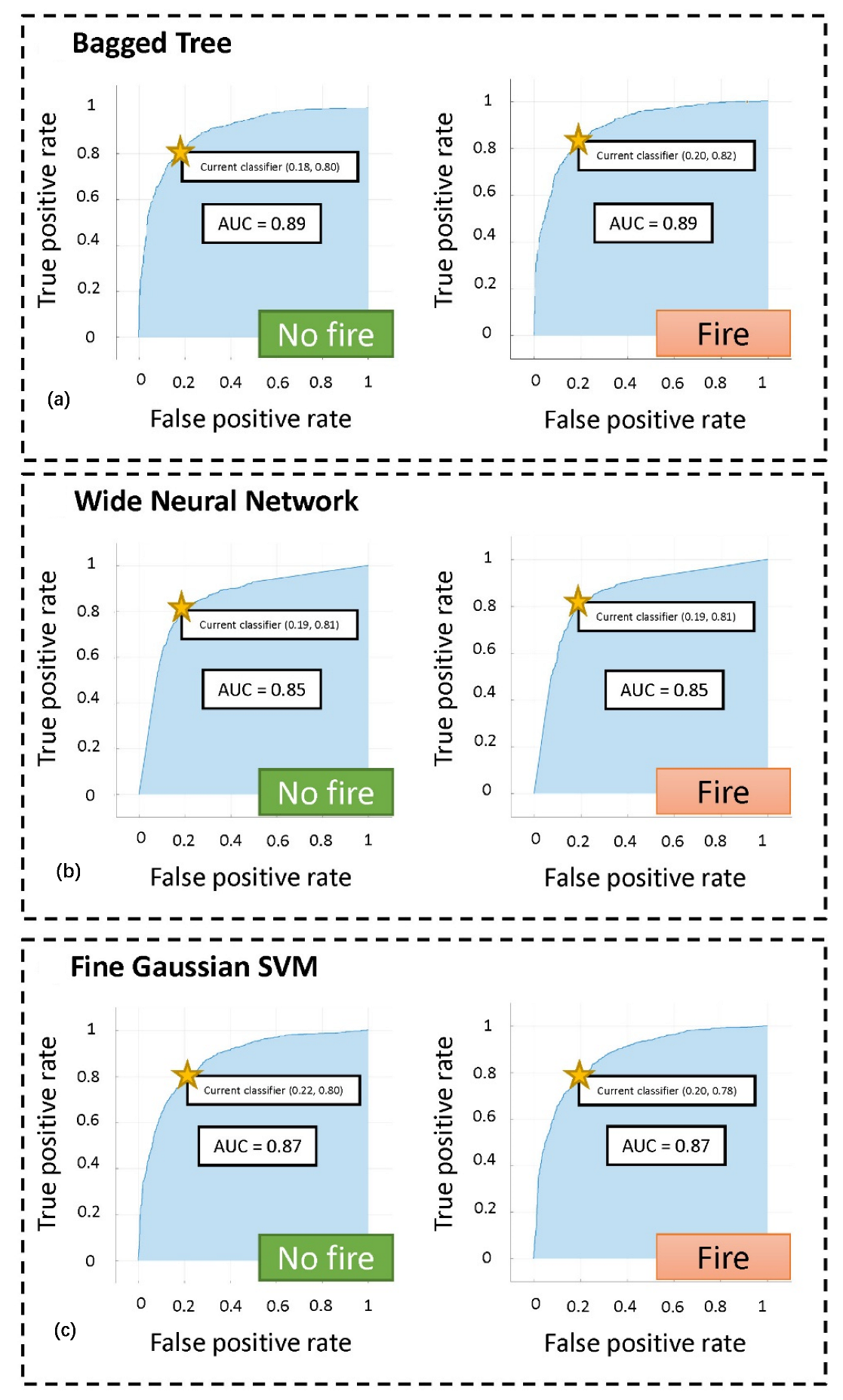
Classification Algorithm Based on Machine Learning
- Decision Tree (Fine, Medium, and Coarse Tree models);
- Logistic Regression;
- Naïve Bayes (Gaussian and Kernel models);
- Support Vector Machine (Linear, Quadratic, Cubic, Fine Gaussian, Medium Gaussian, and Coarse Gaussian Support Vector Machine models);
- Bagged Trees;
- RUSBoosted Trees;
- Neural Network (Narrow, Medium, Wide, Bilayered, and Trilayered Neural Networks models).
- If RT < 40, it is considered that there is no risk of fire, which means that in principle there is no need to advance to the second level of the methodology.
- If RT ϵ [40, 60], it is considered that there is a situation of doubt, which means the responsibility for deciding falls to the user of the methodology who must assess whether to generate the map of risks associated with the second level of the methodology.
- If RT > 60, it is considered that there is a risk, and so there is a move to the second level of the methodology to generate the risk map.
2.2.2. Second Level of the Methodology
First Expert System: Expert Risk Matrix
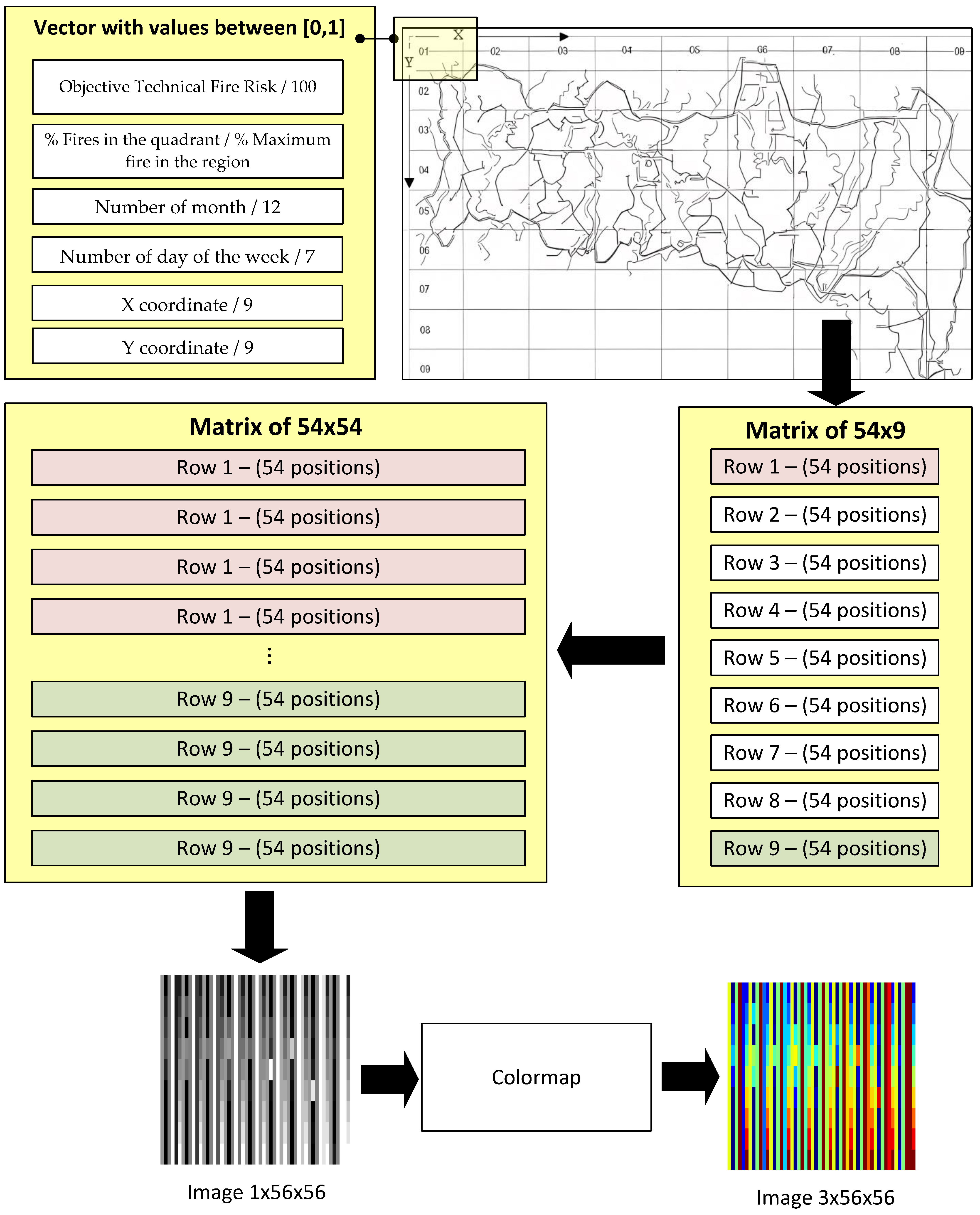
Image Construction
- Objective Technical Fire Risk/100;
- % Fires in the quadrant/Maximum % of fires in the region;
- Number of month/12;
- Number of day of the week/7;
- X-coordinate/n;
- Y-coordinate/m.
Convolutional Neuronal Network: Technical Risk Matrix
Second Expert System: Global Risk Matrix
Color Map Generation and Decision Making
3. Case Study
3.1. First Level
3.2. Second Level
3.2.1. Generation of the Image and Compilation of the Expert’s Assessments
3.2.2. Calculation of Matrices and Risk Maps
Expert Risk Matrix
Technical Risk
Global Risk
4. Discussion
- Creation of knowledge bases: In this case, two actions are proposed: on the one hand, preparing the initial data and, on the other, creating the expert and technical knowledge bases. In the former, the use of SMOTE-NC allows the binary categories of the data to be balanced, while the Z-score normalizes their representation. This combination makes it possible to have a coherent and adequate data set, which guarantees the subsequent adjustment of robust statistical classifiers. Based on these data, an image is elaborated which, acting in a structural way, allows the incorporation of not only the reflected data but also other additional data and even intrinsic data not identified at the beginning. Although in the preprocessing of data neither the dimensionality was reduced nor the uncertainty restricted—indeed, it was necessary to rely on these data to create the image—in the creation of the image there is an effective and clear reduction. Images are defined that group the features of the data, which, moreover, are related to the classification of each image into ‘fire’/’no-fire’. The data are no longer statistically linked to the categories; it is now the features implicit in them, enriched within the image, that are so linked. Dimensions are reduced in the problem but also uncertainty is reduced by not having to define, identify, or name these features. Finally, the expert knowledge base contemplates the context not only of all the data but also of new variables that directly or indirectly include those same data. The dimensionality of the data here is represented by common language structures, syllogisms, which shape causality and deductive reasoning. The problem is bounded by the knowledge required for its solution. Formal logic, of statements and predicates, is used to understand the way to solve the problem, not the problem itself, and thus, in turn, the uncertainty of the resolution is restricted since the term becomes part of the reasoned explanation. It is not necessary then to quantify the uncertainty by indicating its probability, although that would be possible, but rather to evaluate to which qualifier of the language a variable belongs to a greater extent. The creation and definition of knowledge bases, data, and syllogisms is one of the crucial steps of a hybrid system and constitutes a quantitative and qualitative difference from other intelligent systems.
- Determination of fire risks: Three different risks are defined and calculated in the methodology. On the one hand, the Objective Technical Risk is derived from the application of a machine learning algorithm taking the initial data, preprocessed with Z-score and SMOTE-NC. Its relevance is questionable as it is based on assumptions that are not always true. However, it is useful as a first discriminator. As already mentioned, the limitations of this approach are clear, but within a hybrid model, it serves as a scale to assess the steps to be followed, in general terms and taking into account the distributions identified by the algorithm among variables. From this first risk, the Expert Risk Matrix is determined, on the one hand, using expert systems, and on the other, the Technical Risk Matrix is determined using convolutional neural networks. Both start from knowledge bases that represent the same reality, the same context, but are formally very different. Expert systems have increased the applicability of decision support systems and incorporated formal logic and deductive and inductive reasoning in the field of artificial intelligence. Their structure allows them to diversify knowledge since the rules that compose their knowledge bases allow the chain of reasoning to be understood and formalized in a common language. This usually employs some kind of logical approach, both probabilistic, such as Bayesian networks, and non-probabilistic, such as fuzzy systems. The Expert Risk derived from these expert systems is calculated taking into consideration a formal representation of knowledge and therefore is a measure of the experience and even the intuition of the experts in fire detection. At the same time, convolutional neural networks have a proven ability to find features in arrays of data, such as images. This allows them to see underlying relationships between large volumes of data as long as these volumes can be represented as an image without any loss of information in the process. The idea then is to reduce the dimensionality of the starting data not by finding groupings or common factors but through the arrangement of that data. It is, as can be seen, a new formalization of the data, a link between both inferences which are, in fact, two sides of the same coin since both decide on the basis of analogous knowledge. Therefore, both risks, expert and technical, skillfully complement each other. Both are formal representations of the fire hazard. Both are calculated using tools that reduce the initial dimension of the problem and limit the uncertainty, either by reasoning or by repositioning the data. Both, when compared, increase the decision-support capability of the system. The only thing left to do is to unite them, which is proposed with a new expert system. However, this is not a potential differentiator of the current methodology, as argued in the description of Stage 5 in Section 2.1.2, but a linking mechanism for the purpose of determining a Global Risk that allows a fire map to be shown over the area being studied. Its relevance and usefulness are limited to this, so the linkage is, in reality, meaningless.
Relevance in the Field of Study
- Internal architecture: it aims to assess the reliability of the results, based on the management of uncertainty and the percentages of accuracy obtained.
- Scalability: it assesses the ability to add or remove computational blocks from the system.
- Inference: it assesses the system’s ability to use symbolic reasoning approaches.
- Learning: it tries to evaluate the capacity of the system to incorporate approaches based on machine learning.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Goldammer, J.; Mitsopoulos, I.; Mallinis, G.; Woolf, M. Wildfire Hazard and Risk Assessment. In Words into Action Guidelines-National Disaster Risk Assessment; United Nations Office for Disaster Risk Reduction: Geneva, Switzerland, 2017. [Google Scholar]
- San-Miguel-Ayanz, J.; Durrant, T.; Boca, R.; Maianti, P.; Libertá, G.; Artés-Vivancos, T.; Oom, D.; Branco, A.; de Rigo, D.; Ferrari, D.; et al. Forest Fires in Europe Middle East and North Africa 2020; Publications Office of the European Union: Luxembourg, 2021; ISBN 978-92-76-42351-5. [Google Scholar]
- Abid, F. A Survey of Machine Learning Algorithms Based Forest Fires Prediction and Detection Systems. Fire Technol. 2021, 57, 559–590. [Google Scholar] [CrossRef]
- Woźniak, M.; Graña, M.; Corchado, E. A Survey of Multiple Classifier Systems as Hybrid Systems. Inf. Fusion 2014, 16, 3–17. [Google Scholar] [CrossRef] [Green Version]
- Da Silva, S.S.; Fearnside, P.M.; de Graça, P.M.L.A.; Brown, I.F.; Alencar, A.; de Melo, A.W.F. Dynamics of Forest Fires in the Southwestern Amazon. For. Ecol. Manag. 2018, 424, 312–322. [Google Scholar] [CrossRef]
- Korovin, G.N. Analysis of the Distribution of Forest Fires in Russia; Springer: Dordrecht, The Netherlands, 1996; pp. 112–128. [Google Scholar] [CrossRef]
- Fiorucci, P.; Gaetani, F.; Minciardi, R.; Trasforini, E. Forest fire dynamic hazard assessment and pre-operational resource allocation. IFAC Proc. Vol. 2005, 38, 91–96. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.; Kim, A.K. A Review of Water Mist Fire Suppression Systems—Fundamental Studies. J. Fire Prot. Eng. 1999, 10, 32–50. [Google Scholar] [CrossRef] [Green Version]
- Mawhinney, J.R.; Back, G.G. Water Mist Fire Suppression Systems. In SFPE Handbook of Fire Protection Engineering, 5th ed.; Hurley, M.J., Ed.; Springer: New York, NY, USA, 2016. [Google Scholar]
- Martin, D.; Tomida, M.; Meacham, B. Environmental Impact of Fire. Fire Sci. Rev. 2016, 5, 1. [Google Scholar] [CrossRef] [Green Version]
- Giménez, A.; Pastor, E.; Zárate, L.; Planas, E.; Arnaldos, J.; Giménez, A.; Pastor, E.; Zárate, L.; Planas, E.; Arnaldos, J. Long-Term Forest Fire Retardants: A Review of Quality, Effectiveness, Application and Environmental Considerations. Int. J. Wildl. Fire 2004, 13, 1–15. [Google Scholar] [CrossRef]
- Fowler, C.T. Human Health Impacts of Forest Fires in the Southern United States: A Literature Review. J. Ecol. Anthropol. 2003, 7, 39–63. [Google Scholar] [CrossRef] [Green Version]
- Finlay, S.E.; Moffat, A.; Gazzard, R.; Baker, D.; Murray, V. Health Impacts of Wildfires. PLoS Curr. 2012, 4, e4f959951cce2c. [Google Scholar] [CrossRef]
- House of Representatives Committee on Science, Space, and Technology. Science and Technology. From the Lab Bench to the Marketplace: Improving Technology Transfer: Hearing Charter; U.S. House of Representatives Committee on Science and Technology, Subcommittee on Research and Science Education: Washington, DC, USA, 2010. [Google Scholar]
- Alonso-Betanzos, A.; Fontenla-Romero, O.; Guijarro-Berdiñas, B.; Hernández-Pereira, E.; Paz Andrade, M.I.; Jiménez, E.; Soto, J.L.L.; Carballas, T. An Intelligent System for Forest Fire Risk Prediction and Fire Fighting Management in Galicia. Expert Syst. Appl. 2003, 25, 545–554. [Google Scholar] [CrossRef]
- Bisquert, M.; Caselles, E.; Sánchez, J.M.; Caselles, V.; Bisquert, M.; Caselles, E.; Sánchez, J.M.; Caselles, V. Application of Artificial Neural Networks and Logistic Regression to the Prediction of Forest Fire Danger in Galicia Using MODIS Data. Int. J. Wildl. Fire 2012, 21, 1025–1029. [Google Scholar] [CrossRef]
- Cortez, P.; Morais, A. A Data Mining Approach to Predict Forest Fires Using Meteorological Data. In Proceedings of the 13th Portuguese Conference on Artificial Intelligence, Guimarães, Portugal, 3–7 December 2007; pp. 512–523. [Google Scholar]
- Pham, B.T.; Jaafari, A.; Avand, M.; Al-Ansari, N.; Du, T.D.; Hai Yen, H.P.; van Phong, T.; Nguyen, D.H.; van Le, H.; Mafi-Gholami, D.; et al. Performance Evaluation of Machine Learning Methods for Forest Fire Modeling and Prediction. Symmetry 2020, 12, 1022. [Google Scholar] [CrossRef]
- Nebot, À.; Mugica, F. Forest Fire Forecasting Using Fuzzy Logic Models. Forests 2021, 12, 1005. [Google Scholar] [CrossRef]
- Jaafari, A.; Razavi Termeh, S.V.; Bui, D.T. Genetic and Firefly Metaheuristic Algorithms for an Optimized Neuro-Fuzzy Prediction Modeling of Wildfire Probability. J. Environ. Manag. 2019, 243, 358–369. [Google Scholar] [CrossRef]
- Lai, C.; Zeng, S.; Guo, W.; Liu, X.; Li, Y.; Liao, B. Forest Fire Prediction with Imbalanced Data Using a Deep Neural Network Method. Forests 2022, 13, 1129. [Google Scholar] [CrossRef]
- Wasserman, L. All of Statistics: A Concise Course in Statistical Inference; Springer: New York, NY, USA, 2004; Volume 26, ISBN 978-0-387-21736-9. [Google Scholar]
- Casal-Guisande, M.; Comesaña-Campos, A.; Cerqueiro-Pequeño, J.; Bouza-Rodríguez, J.-B. Design and Development of a Methodology Based on Expert Systems, Applied to the Treatment of Pressure Ulcers. Diagnostics 2020, 10, 614. [Google Scholar] [CrossRef]
- Comesaña-Campos, A.; Casal-Guisande, M.; Cerqueiro-Pequeño, J.; Bouza-Rodríguez, J.B. A Methodology Based on Expert Systems for the Early Detection and Prevention of Hypoxemic Clinical Cases. Int. J. Environ. Res. Public Health 2020, 17, 8644. [Google Scholar] [CrossRef] [PubMed]
- Cerqueiro-Pequeño, J.; Comesaña-Campos, A.; Casal-Guisande, M.; Bouza-Rodríguez, J.-B. Design and Development of a New Methodology Based on Expert Systems Applied to the Prevention of Indoor Radon Gas Exposition Risks. Int. J. Environ. Res. Public Health 2020, 18, 269. [Google Scholar] [CrossRef] [PubMed]
- Casal-Guisande, M.; Comesaña-Campos, A.; Dutra, I.; Cerqueiro-Pequeño, J.; Bouza-Rodríguez, J.-B. Design and Development of an Intelligent Clinical Decision Support System Applied to the Evaluation of Breast Cancer Risk. J. Pers. Med. 2022, 12, 169. [Google Scholar] [CrossRef] [PubMed]
- UCI Machine Learning Repository: Forest Fires Data Set. Available online: http://archive.ics.uci.edu/ml/datasets/Forest+Fires (accessed on 16 March 2022).
- Gruber, T.R. Ontolingua: A Mechanism to Support Portable Ontologies; Technical report KSL-91-66; Stanford University: Stanford, CA, USA, 1992. [Google Scholar]
- Gruber, T.R. A Translation Approach to Portable Ontology Specifications. Knowl. Acquis. 1993, 5, 199–220. [Google Scholar] [CrossRef]
- Grüninger, M.; Fox, M.S. Methodology for the Design and Evaluation of Ontologies. In Proceedings of the IJCAI95 Workshop on Basic Ontological Issues in Knowledge, Montreal, Canada, 13 April 1995. Montreal, QC, Canada, 13 April 1995; pp. 6.1–6.10. [Google Scholar]
- Lenat, D.B.; Guha, R.V. Building Large Knowledge-Based Systems; Representation and Inference in the Cyc Project; Addison-Wesley Longman Publishing Co., Inc.: Boston, MA, USA, 1989. [Google Scholar]
- Tabachnick, B.G.; Fidell, L.S.; Ullman, J.B. Using Multivariate Statistics; Pearson: Boston, MA, USA, 2007; Volume 5. [Google Scholar]
- Harris, R.J. A Primer of Multivariate Statistics; Psychology Press: London, UK, 2001. [Google Scholar]
- Castillo, E.; Gutiérrez, J.M.; Hadi, A.S. Expert Systems and Probabilistic Network Models; Monographs in Computer Science; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Hair, J.F.; Black, W.C.; Babin, B.J.; Anderson, R.E. Multivariate Data Analysis; Prentice Hall: Upper Saddle River, NJ, USA, 2009; Volume 87, ISBN 9780138132637. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2323. [Google Scholar] [CrossRef] [Green Version]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Conneau, A.; Schwenk, H.; le Cun, Y.; Barrault, L. Very Deep Convolutional Networks for Text Classification. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 1, Long Papers, Valencia, Spain, 3–7 April 2017; pp. 1107–1116. [Google Scholar] [CrossRef]
- MATLAB App Designer—MATLAB & Simulink. Available online: https://es.mathworks.com/products/matlab/app-designer.html (accessed on 10 August 2022).
- Fuzzy Logic Toolbox—MATLAB. Available online: https://es.mathworks.com/products/fuzzy-logic.html (accessed on 10 August 2022).
- App Classification Learner—MATLAB & Simulink—MathWorks España. Available online: https://es.mathworks.com/help/stats/classification-learner-app.html (accessed on 10 August 2022).
- Deep Learning Toolbox—MATLAB. Available online: https://es.mathworks.com/products/deep-learning.html (accessed on 10 August 2022).
- Imbalanced-Learn Documentation—Version 0.9.1. Available online: https://imbalanced-learn.org/stable/ (accessed on 10 August 2022).
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority over-Sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Mohammed, A.J.; Hassan, M.M.; Kadir, D.H. Improving Classification Performance for a Novel Imbalanced Medical Dataset Using Smote Method. Int. J. Adv. Trends Comput. Sci. Eng. 2020, 9, 3161–3172. [Google Scholar] [CrossRef]
- Kumari, R.; Srivastava, S. Machine Learning: A Review on Binary Classification. Int. J. Comput. Appl. 2017, 160, 11–15. [Google Scholar] [CrossRef]
- Duda, R.O.; Hart, P.E.; Stork, D.G. Pattern Classification; Wiley: Hoboken, NJ, USA, 2000. [Google Scholar]
- Mamdani, E.H. Advances in the Linguistic Synthesis of Fuzzy Controllers. Int. J. Man Mach. Stud. 1976, 8, 669–678. [Google Scholar] [CrossRef]
- Mamdani, E.H. Application of Fuzzy Logic to Approximate Reasoning Using Linguistic Synthesis. IEEE Trans. Comput. 1977, C–26, 1182–1191. [Google Scholar] [CrossRef]
- Mamdani, E.H.; Assilian, S. An Experiment in Linguistic Synthesis with a Fuzzy Logic Controller. Int. J. Man Mach. Stud. 1975, 7, 1–13. [Google Scholar] [CrossRef]
- Ross, T.J. Fuzzy Logic with Engineering Applications, 3rd ed.; John Wiley & Sons, Ltd.: Chichester, UK, 2010; ISBN 9781119994374. [Google Scholar]
- Jet Colormap Array—MATLAB Jet—MathWorks España. Available online: https://es.mathworks.com/help/matlab/ref/jet.html (accessed on 12 August 2022).
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Rodriguez, A. Deep Learning Systems: Algorithms, Compilers, and Processors for Large-Scale Production. In Synthesis Lectures on Computer Architecture; Morgan & Claypool Publishers: San Rafael, CA, USA, 2021; Volume 15, pp. 1–265. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Wang, L.X.; Mendel, J.M. Generating Fuzzy Rules by Learning from Examples. IEEE Trans. Syst. Man Cybern. 1992, 22, 1414–1427. [Google Scholar] [CrossRef] [Green Version]
- Cooper, J.C.B. Artificial Neural Networks versus Multivariate Statistics: An Application from Economics. J. Appl. Stat. 2010, 26, 909–921. [Google Scholar] [CrossRef]
- Wang, C.Y.; Lee, T.F.; Fang, C.H.; Chou, J.H. Fuzzy Logic-Based Prognostic Score for Outcome Prediction in Esophageal Cancer. IEEE Trans. Inf. Technol. Biomed. 2012, 16, 1224–1230. [Google Scholar] [CrossRef] [PubMed]
- Yazdanbakhsh, O.; Dick, S. Forecasting of Multivariate Time Series via Complex Fuzzy Logic. IEEE Trans. Syst. Man Cybern. Syst. 2017, 47, 2160–2171. [Google Scholar] [CrossRef]
- Egrioglu, E.; Aladag, C.H.; Yolcu, U.; Uslu, V.R.; Basaran, M.A. A New Approach Based on Artificial Neural Networks for High Order Multivariate Fuzzy Time Series. Expert Syst. Appl. 2009, 36, 10589–10594. [Google Scholar] [CrossRef]
- Smithson, M. Multivariate Analysis Using ‘and’ and ‘Or’. Math. Soc. Sci. 1984, 7, 231–251. [Google Scholar] [CrossRef]
- Porzel, R. Contextual Computing: Models and Applications; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Casal-Guisande, M.; Comesaña-Campos, A.; Pereira, A.; Bouza-Rodríguez, J.-B.; Cerqueiro-Pequeño, J. A Decision-Making Methodology Based on Expert Systems Applied to Machining Tools Condition Monitoring. Mathematics 2022, 10, 520. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variables | |
|---|---|
| Data collected by the warden responsible for the natural park | Month |
| Day of the week | |
| X-coordinate | |
| Y-coordinate | |
| Burnt area | |
| Data come from a weather station | Temperature (°C) |
| Relative humidity (%) | |
| Wind speed (km/h) | |
| Precipitation (mm/m2) |
| Explanatory Variable-Antecedent | Valuation Scale (0–10) |
|---|---|
| Assess the hazard associated with undergrowth in quadrant (X,Y). | 0-1-2-3-4-5-6-7-8-9-10 |
| The expert must assess the presence of undergrowth in the study region, as well as how this situation might affect the potential beginning of a fire. | |
| Assess the hazard associated with the presence of humans in quadrant (X,Y) | 0-1-2-3-4-5-6-7-8-9-10 |
| The expert must assess the human presence and activity in the study region, as well as how these might affect the potential beginning of a fire. |
| Independent Variables of the Starting Dataset | Independent Variables of the Machine Learning Dataset | Independent Variables of the Deep Learning Dataset | Independent Variables of the Expert System Dataset |
|---|---|---|---|
| Temperature | Temperature | Temperature | Undergrowth |
| Relative humidity | Relative humidity | Relative humidity | Human activity |
| Wind speed | Wind speed | Wind speed | |
| Rainfall | Rainfall | Rainfall | |
| Month | Month | Month | |
| Day of the week | Day of the week | Day of the week | |
| X-coordinate | - | ||
| Y-coordinate | - | ||
| Dependent Variable of the Initial Dataset | Dependent Variable of the Machine Learning Dataset | Dependent Variable of the Deep Learning Dataset | Dependent Variable of the Expert System Dataset |
| Burnt area per quadrant | Objective Technical Fire Risk in the zone | Objective Technical Fire Risk per quadrant | Expert Risk of fire per quadrant |
| Summary of the Classification Algorithm |
|---|
| Bagged Trees Model |
| Ensemble aggregation method: Bag |
| Number of ensemble learning cycles: 130 |
| Learners: Decision tree |
| Maximum number of splits: 1316 |
| Number of learners: 237 |
| Inference System for the Calculation of the Expert Risk Matrix | |||
|---|---|---|---|
| Input Data | Range | Output Data | Range |
| Undergrowth | 0–10 | Expert Risk | 0–100 |
 |  | ||
| Human activity | 0–10 | Initial configuration | |
 | Fuzzy structure: Mamdani-type. Membership function type: trapezoidal. Defuzzification method: centroid. Implication method: MIN. Aggregation method: MAX. Number of fuzzy rules: 21 | ||
| 21 rules of the system | |||
| |||
| Surface | |||
 | |||
| Parameter | Value |
|---|---|
| Mini-Batch Size | 10 |
| Epochs | 297 |
| Learning Rate | 0.0001 |
| Validation frequency | 3 epochs |
| Total time | 160 min |
| Inference System for the Calculation of the Global Risk | |||
|---|---|---|---|
| Input Data | Range | Output Data | Range |
| Technical Risk | 0–100 | Global Risk | 0–100 |
 |  | ||
| Expert Risk | 0–100 | Initial configuration | |
 | Fuzzy structure: Mamdani-type. Membership function type: trapezoidal. Defuzzification method: centroid. Implication method: MIN. Aggregation method: MAX. Number of fuzzy rules: 21 | ||
| 21 rules of the system | |||
| |||
| Surface | |||
 | |||
| Variables | Values |
|---|---|
| Month | August |
| Day of the week | Saturday |
| Temperature (°C) | 38 |
| Relative humidity (%) | 55% |
| Wind speed (km/h) | 8.5 |
| Rainfall (mm/m2) | 0 |
| X/Y | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 7 | 0 | 0 | 0 | 2 | 0 | 0 | 0 |
| 2 | 3 | 6 | 4 | 2 | 0 | 2 | 0 | 3 | 3 |
| 3 | 2 | 4 | 6 | 2 | 6 | 4 | 2 | 3 | 3 |
| 4 | 2 | 2 | 5 | 5 | 7 | 6 | 5 | 3 | 3 |
| 5 | 2 | 2 | 2 | 5 | 7 | 7 | 4 | 4 | 3 |
| 6 | 2 | 0 | 2 | 6 | 7 | 5 | 2 | 4 | 3 |
| 7 | 0 | 0 | 0 | 0 | 0 | 2 | 2 | 3 | 3 |
| 8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 3 |
| 9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 3 |
| X/Y | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 4 | 0 | 0 | 0 | 2 | 0 | 0 | 0 |
| 2 | 3 | 5 | 4 | 2 | 0 | 2 | 0 | 3 | 3 |
| 3 | 2 | 2 | 4 | 2 | 7 | 4 | 2 | 3 | 3 |
| 4 | 2 | 2 | 2 | 5 | 7 | 6 | 5 | 3 | 3 |
| 5 | 2 | 2 | 2 | 5 | 7 | 7 | 4 | 4 | 3 |
| 6 | 2 | 0 | 2 | 5 | 6 | 5 | 2 | 4 | 3 |
| 7 | 0 | 0 | 0 | 0 | 0 | 2 | 2 | 3 | 3 |
| 8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 3 |
| 9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 3 |
| Method/System | Internal Architecture | Scalability | Inference | Learning |
|---|---|---|---|---|
| Amparo Alonso-Betanzos et al. [15] | The proposed system has several modules. The module aimed for the prevention of fires is based in the use of a neural network that manages the uncertainty with a probabilistic approach. The system includes other modules aimed to the extinction and recuperation of burnt areas which will not be taken in consideration for this comparison. | The system is not scalable. | The system uses statistical inference instead of symbolic reasoning. | The system incorporates new knowledge in the process of training the architecture |
| - | - | - | - | |
| Mar Bisquert et al. [16] | The system uses models based on logistic regression and neural networks. It manages the uncertainty with a probabilistic approach. | The system is not scalable. | The system uses statistical inference instead of symbolic reasoning. | The system incorporates new knowledge in the process of training the architecture. |
| - | - | = | - | |
| Paulo Cortez y Aníbal Morais [17] | The authors propose the use of support vector machines for the prediction of the burnt area. A probabilistic approach is applied to uncertainty control. | The system is not scalable. | The system uses statistical inference instead of symbolic reasoning. | The system incorporates knowledge in a subsidiary way to its classification process. |
| - | - | - | - | |
| Binh Thai Pham et al. [18] | The authors use different approaches of machine learning for the prediction of fire, obtaining the best results using a Bayes network. An implicit management of uncertainty is used, based in the calculation of probabilities. | The system is not scalable, as it is associated to the network model. | Statistical inference is used instead of symbolic reasoning. | The system incorporates knowledge in a way that is subsidiary to the Bayesian network. |
| - | - | - | - | |
| Àngela Nebot y Francisco Mugica [19] | The authors use a neuro-fuzzy system, which does manage uncertainty. | The system is not scalable. | It uses statistical inference and symbolic reasoning. | The system incorporates knowledge by means of a training process. |
| = | - | = | - | |
| Abolfazl Jaafari et al. [20] | The authors use a neuro-fuzzy system, which does manage uncertainty. | The system is not scalable. | It uses statistical inference and symbolic reasoning. | The system incorporates knowledge by means of a training process. |
| = | - | = | - | |
| Can Lai et al. [21] | The authors use a sparse autoencoder-based deep neural network, so a probabilistic management of uncertainty is used. | The system is not scalable. | The system uses statistical inference instead of symbolic reasoning. | The system incorporates new knowledge in the process of training the architecture. |
| - | - | - | - | |
| Proposed system | The proposed system manages the uncertainty using probabilistic and non-probabilistic approaches. | The proposed system is scalable. It is possible to modify the calculation and inference modules. | The system uses deductive symbolic reasoning methods and statistical inference models. | The system has capabilities to model and incorporate new knowledge and to learn across the process. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Casal-Guisande, M.; Bouza-Rodríguez, J.-B.; Cerqueiro-Pequeño, J.; Comesaña-Campos, A. Design and Conceptual Development of a Novel Hybrid Intelligent Decision Support System Applied towards the Prevention and Early Detection of Forest Fires. Forests 2023, 14, 172. https://doi.org/10.3390/f14020172
Casal-Guisande M, Bouza-Rodríguez J-B, Cerqueiro-Pequeño J, Comesaña-Campos A. Design and Conceptual Development of a Novel Hybrid Intelligent Decision Support System Applied towards the Prevention and Early Detection of Forest Fires. Forests. 2023; 14(2):172. https://doi.org/10.3390/f14020172
Chicago/Turabian StyleCasal-Guisande, Manuel, José-Benito Bouza-Rodríguez, Jorge Cerqueiro-Pequeño, and Alberto Comesaña-Campos. 2023. "Design and Conceptual Development of a Novel Hybrid Intelligent Decision Support System Applied towards the Prevention and Early Detection of Forest Fires" Forests 14, no. 2: 172. https://doi.org/10.3390/f14020172