

Unsupervised Domain Adaptation for Forest Fire Recognition Using Transferable Knowledge from Public Datasets

Abstract
:1. Introduction
- UDA is applied to fire recognition for the first time, which transfers the knowledge learned from labeled public fire datasets to unlabeled ones in specific application scenarios.
- The Fire-DA dataset for transfer learning is constructed for validation in the hope that it can serve as a benchmark for future work.
- The performance of the traditional handcrafted feature-based methods, supervised CNNs, and DSAN is compared based on the FLAME and FD-dataset. The feasibility of our UDA-based approach for fire recognition is verified.
2. Related Work
2.1. DNNs in Fire Detection
2.2. UDA and Its Application
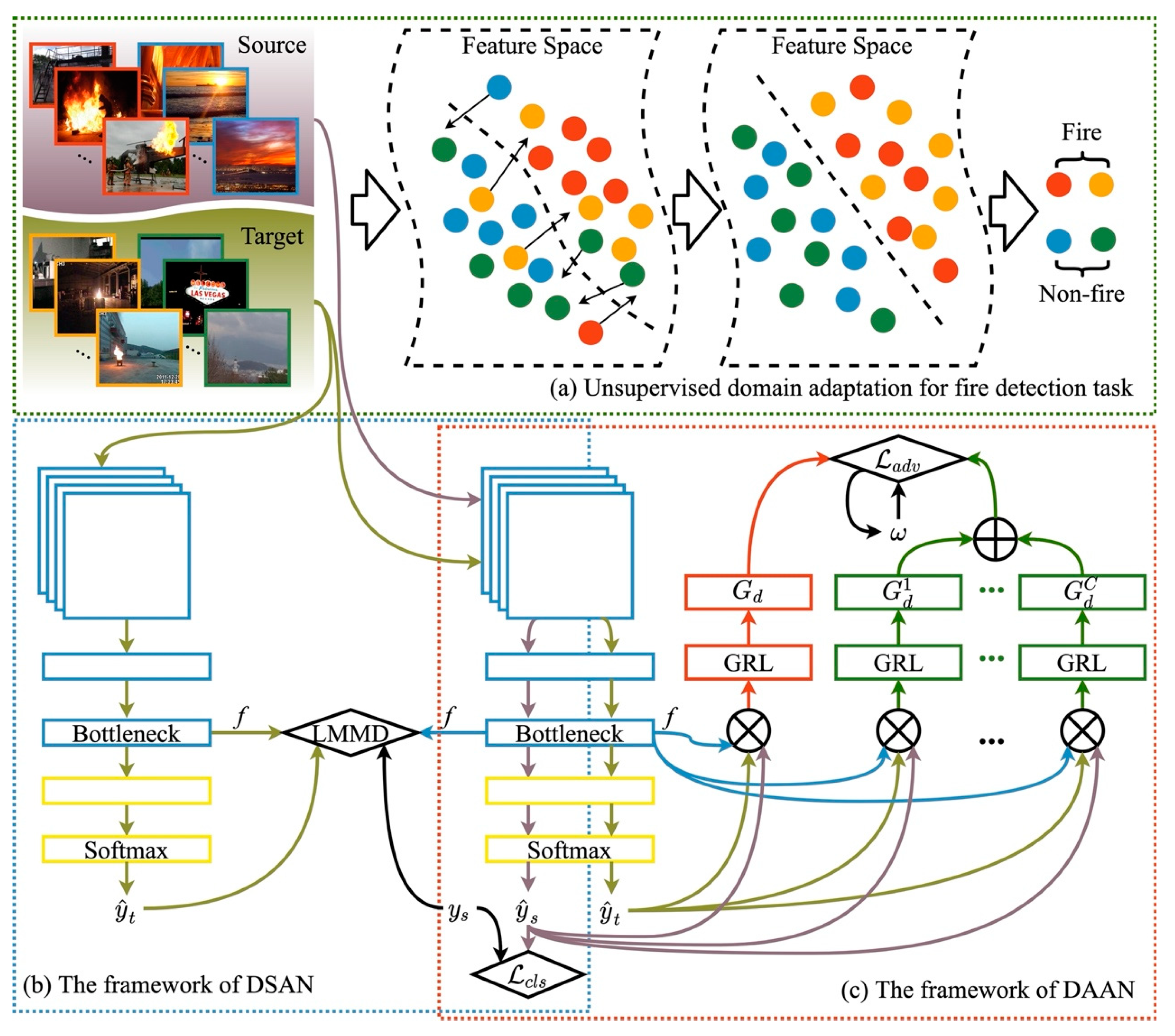
3. Materials and Methods
3.1. Problem Definition
3.2. DSAN
3.3. DAAN
3.4. Fire-DA Dataset
4. Experiments
4.1. Experiment I: Transferability Research on Fire-DA Based on UDA
4.1.1. Implementation Details
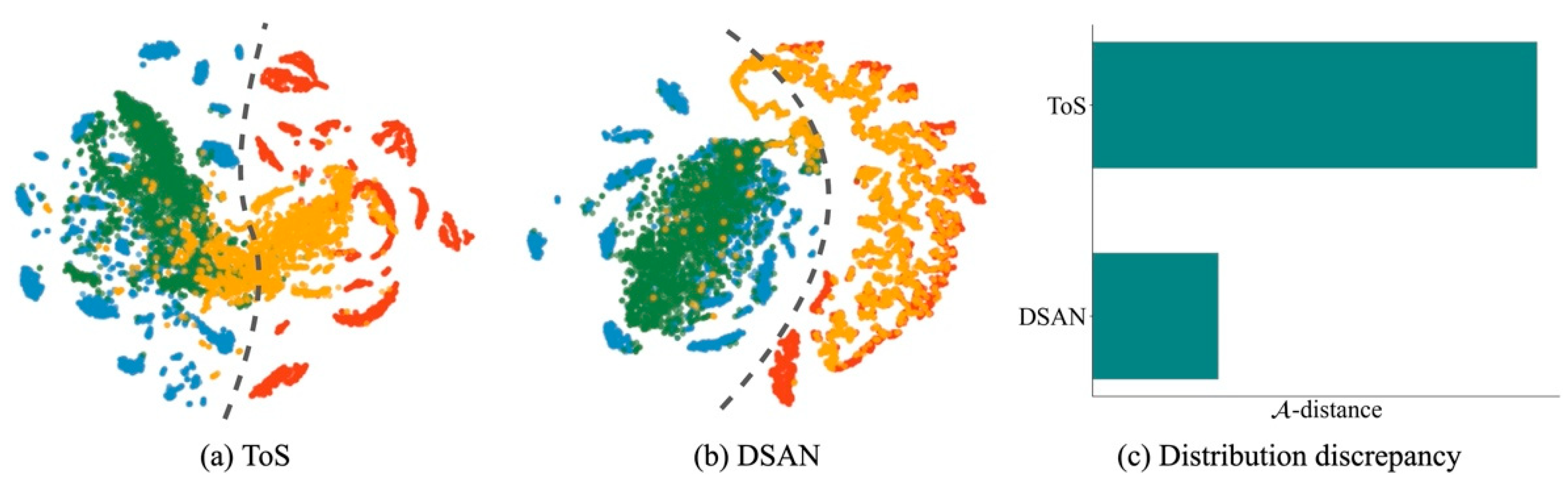
4.1.2. Results and Analysis
4.2. Experiment II: Comparison of Different Fire Recognition Methods on FLAME and FD-Dataset
4.2.1. Dataset
4.2.2. Implementation Details
4.2.3. Evaluation Metrics
4.2.4. Results and Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Discussion of Table 6
References
- Available online: https://www.119.gov.cn/article/46TiYamnnrs (accessed on 1 August 2022).
- Ahrens, M.; Evarts, B. Fire Loss in the United States During 2021. Available online: https://www.nfpa.org/News-and-Research/Data-research-and-tools/US-Fire-Problem/Fire-loss-in-the-United-States (accessed on 1 August 2022).
- Çelik, T.; Demirel, H. Fire detection in video sequences using a generic color model. Fire Saf. J. 2009, 44, 147–158. [Google Scholar] [CrossRef]
- Borges, P.V.K.; Izquierdo, E. A probabilistic approach for vision-based fire detection in videos. IEEE Trans. Circuits Syst. Video Technol. 2010, 20, 721–731. [Google Scholar] [CrossRef]
- Qiu, T.; Yan, Y.; Lu, G. An autoadaptive edge-detection algorithm for flame and fire image processing. IEEE Trans. Instrum. Meas. 2012, 61, 1486–1493. [Google Scholar] [CrossRef] [Green Version]
- Günay, O.; Taşdemir, K.; Töreyin, B.U.; Çetin, A.E. Fire detection in video using LMS based active learning. Fire Technol. 2010, 46, 551–577. [Google Scholar] [CrossRef]
- Verstockt, S.; Van Hoecke, S.; Tilley, N.; Merci, B.; Sette, B.; Lambert, P.; Hollemeersch, C.-F.J.; Van De Walle, R. FireCube: A multi-view localization framework for 3D fire analysis. Fire Saf. J. 2011, 46, 262–275. [Google Scholar] [CrossRef]
- Foggia, P.; Saggese, A.; Vento, M. Real-Time Fire Detection for Video-Surveillance Applications Using a Combination of Experts Based on Color, Shape, and Motion. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 1545–1556. [Google Scholar] [CrossRef]
- Stadler, A.; Windisch, T.; Diepold, K. Comparison of intensity flickering features for video based flame detection algorithms. Fire Saf. J. 2014, 66, 1–7. [Google Scholar] [CrossRef]
- Dimitropoulos, K.; Barmpoutis, P.; Grammalidis, N. Spatio-temporal flame modeling and dynamic texture analysis for automatic video-based fire detection. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 339–351. [Google Scholar] [CrossRef]
- Qureshi, W.S.; Ekpanyapong, M.; Dailey, M.N.; Rinsurongkawong, S.; Malenichev, A.; Krasotkina, O. QuickBlaze: Early Fire Detection Using a Combined Video Processing Approach. Fire Technol. 2016, 52, 1293–1317. [Google Scholar] [CrossRef]
- Gong, F.; Li, C.; Gong, W.; Li, X.; Yuan, X.; Ma, Y.; Song, T. A real-time fire detection method from video with multifeature fusion. Comput. Intell. Neurosci. 2019, 2019, 1939171. [Google Scholar] [CrossRef]
- Ko, B.; Cheong, K.-H.; Nam, J.-Y. Early fire detection algorithm based on irregular patterns of flames and hierarchical Bayesian Networks. Fire Saf. J. 2010, 45, 262–270. [Google Scholar] [CrossRef]
- Kong, S.G.; Jin, D.; Li, S.; Kim, H. Fast fire flame detection in surveillance video using logistic regression and temporal smoothing. Fire Saf. J. 2016, 79, 37–43. [Google Scholar] [CrossRef]
- Mueller, M.; Karasev, P.; Kolesov, I.; Tannenbaum, A. Optical flow estimation for flame detection in videos. IEEE Trans. Image Process. 2013, 22, 2786–2797. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Muhammad, K.; Ahmad, J.; Baik, S.W. Early fire detection using convolutional neural networks during surveillance for effective disaster management. Neurocomputing 2018, 288, 30–42. [Google Scholar] [CrossRef]
- Sharma, J.; Granmo, O.-C.; Goodwin, M.; Fidje, J.T. Deep convolutional neural networks for fire detection in images. Commun. Comput. Inf. Sci. 2017, 744, 183–193. [Google Scholar] [CrossRef]
- Muhammad, K.; Ahmad, J.; Mehmood, I.; Rho, S.; Baik, S.W. Convolutional Neural Networks Based Fire Detection in Surveillance Videos. IEEE Access 2018, 6, 18174–18183. [Google Scholar] [CrossRef]
- Muhammad, K.; Ahmad, J.; Lv, Z.; Bellavista, P.; Yang, P.; Baik, S.W. Efficient Deep CNN-Based Fire Detection and Localization in Video Surveillance Applications. IEEE Trans. Syst. Man Cybern. Syst. 2019, 49, 1419–1434. [Google Scholar] [CrossRef]
- Shamsoshoara, A.; Afghah, F.; Razi, A.; Zheng, L.; Fulé, P.Z.; Blasch, E. Aerial imagery pile burn detection using deep learning: The FLAME dataset. Comput. Netw. 2021, 193, 108001. [Google Scholar] [CrossRef]
- Li, S.; Yan, Q.; Liu, P. An Efficient Fire Detection Method Based on Multiscale Feature Extraction, Implicit Deep Supervision and Channel Attention Mechanism. IEEE Trans. Image Process. 2020, 29, 8467–8475. [Google Scholar] [CrossRef]
- Zhu, Y.; Zhuang, F.; Wang, J.; Ke, G.; Chen, J.; Bian, J.; Xiong, H.; He, Q. Deep subdomain adaptation network for image classification. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 1713–1722. [Google Scholar] [CrossRef] [PubMed]
- Yu, C.; Wang, J.; Chen, Y.; Huang, M. Transfer learning with dynamic adversarial adaptation network. In Proceedings of the 2019 IEEE International Conference on Data Mining (ICDM), Beijing, China, 8–11 November 2019; pp. 778–786. [Google Scholar] [CrossRef] [Green Version]
- Gaur, A.; Singh, A.; Kumar, A.; Kumar, A.; Kapoor, K. Video Flame and Smoke Based Fire Detection Algorithms: A Literature Review. Fire Technol. 2020, 56, 1943–1980. [Google Scholar] [CrossRef]
- Hu, C.; Tang, P.; Jin, W.; He, Z.; Li, W. Real-Time Fire Detection Based on Deep Convolutional Long-Recurrent Networks and Optical Flow Method. In Proceedings of the 2018 37th Chinese Control Conference (CCC), Wuhan, China, 25–27 July 2018; pp. 9061–9066. [Google Scholar] [CrossRef]
- Dunnings, A.J.; Breckon, T.P. Experimentally defined convolutional neural network architecture variants for non-temporal real-time fire detection. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 1358–1362. [Google Scholar] [CrossRef] [Green Version]
- Huang, L.; Liu, G.; Wang, Y.; Yuan, H.; Chen, T. Fire detection in video surveillances using convolutional neural networks and wavelet transform. Eng. Appl. Artif. Intell. 2022, 110, 104737. [Google Scholar] [CrossRef]
- Majid, S.; Alenezi, F.; Masood, S.; Ahmad, M.; Gündüz, E.S.; Polat, K. Attention based CNN model for fire detection and localization in real-world images. Expert Syst. Appl. 2022, 189, 116114. [Google Scholar] [CrossRef]
- Xu, R.; Lin, H.; Lu, K.; Cao, L.; Liu, Y. A forest fire detection system based on ensemble learning. Forests 2021, 12, 217. [Google Scholar] [CrossRef]
- Muhammad, K.; Khan, S.; Elhoseny, M.; Ahmed, S.H.; Baik, S.W. Efficient Fire Detection for Uncertain Surveillance Environment. IEEE Trans. Ind. Inform. 2019, 15, 3113–3122. [Google Scholar] [CrossRef]
- Li, P.; Zhao, W. Image fire detection algorithms based on convolutional neural networks. Case Stud. Therm. Eng. 2020, 19, 100625. [Google Scholar] [CrossRef]
- Park, M.; Ko, B.C. Two-step real-time night-time fire detection in an urban environment using static elastic-yolov3 and temporal fire-tube. Sensors 2020, 20, 2202. [Google Scholar] [CrossRef]
- Barmpoutis, P.; Stathaki, T.; Dimitropoulos, K.; Grammalidis, N. Early fire detection based on aerial 360-degree sensors, deep convolution neural networks and exploitation of fire dynamic textures. Remote Sens. 2020, 12, 3177. [Google Scholar] [CrossRef]
- Choi, H.-S.; Jeon, M.; Song, K.; Kang, M. Semantic Fire Segmentation Model Based on Convolutional Neural Network for Outdoor Image. Fire Technol. 2021, 57, 3005–3019. [Google Scholar] [CrossRef]
- Yang, Z.; Wang, T.; Bu, L.; Ouyang, J. Training with Augmented Data: GAN-based Flame-Burning Image Synthesis for Fire Segmentation in Warehouse. Fire Technol. 2021, 58, 183–215. [Google Scholar] [CrossRef]
- Kou, L.; Wang, X.; Guo, X.; Zhu, J.; Zhang, H. Deep learning based inverse model for building fire source location and intensity estimation. Fire Saf. J. 2021, 121, 103310. [Google Scholar] [CrossRef]
- Qin, K.; Hou, X.; Yan, Z.; Zhou, F.; Bu, L. FGL-GAN: Global-Local Mask Generative Adversarial Network for Flame Image Composition. Sensors 2022, 22, 6332. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Wang, M.; Fu, Y.; Ding, Y. A Forest Fire Recognition Method Using UAV Images Based on Transfer Learning. Forests 2022, 13, 975. [Google Scholar] [CrossRef]
- Shahid, M.; Virtusio, J.J.; Wu, Y.-H.; Chen, Y.-Y.; Tanveer, M.; Muhammad, K.; Hua, K.-L. Spatio-Temporal Self-Attention Network for Fire Detection and Segmentation in Video Surveillance. IEEE Access 2022, 10, 1259–1275. [Google Scholar] [CrossRef]
- Jeon, M.; Choi, H.-S.; Lee, J.; Kang, M. Multi-Scale Prediction For Fire Detection Using Convolutional Neural Network. Fire Technol. 2021, 57, 2533–2551. [Google Scholar] [CrossRef]
- Zhong, Z.; Wang, M.; Shi, Y.; Gao, W. A convolutional neural network-based flame detection method in video sequence. Signal Image Video Process. 2018, 12, 1619–1627. [Google Scholar] [CrossRef]
- Xie, Y.; Zhu, J.; Cao, Y.; Zhang, Y.; Feng, D.; Zhang, Y.; Chen, M. Efficient video fire detection exploiting motion-flicker-based dynamic features and deep static features. IEEE Access 2020, 8, 81904–81917. [Google Scholar] [CrossRef]
- Zhao, Y.; Ma, J.; Li, X.; Zhang, J. Saliency detection and deep learning-based wildfire identification in uav imagery. Sensors 2018, 18, 712. [Google Scholar] [CrossRef] [Green Version]
- Tzeng, E.; Hoffman, J.; Zhang, N.; Saenko, K.; Darrell, T. Deep Domain Confusion: Maximizing for Domain Invariance. arXiv 2014, arXiv:1412.3474. [Google Scholar]
- Long, M.; Cao, Y.; Wang, J.; Jordan, M.I. Learning transferable features with deep adaptation networks. In Proceedings of the 32nd International Conference on Machine Learning, ICML, Lille, France, 7 July 2015; pp. 97–105. [Google Scholar]
- Sun, B.; Saenko, K. Deep CORAL: Correlation Alignment for Deep Domain Adaptation. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berliln, Germany, 2016; Volume 9915, pp. 443–450. [Google Scholar] [CrossRef] [Green Version]
- Ganin, Y.; Lempitsky, V. Unsupervised domain adaptation by backpropagation. In Proceedings of the 32nd International Conference on Machine Learning, ICML, Lille, France, 7 July 2015; Volume 2, pp. 1180–1189. [Google Scholar]
- Pei, Z.; Cao, Z.; Long, M.; Wang, J. Multi-Adversarial Domain Adaptation. In Proceedings of the AAAI Conference on Artificial Intelligence 2018, New Orleans, LA, USA, 2–7 February 2018; pp. 3934–3941. [Google Scholar]
- Wang, M.; Deng, W.; Liu, C.-L. Unsupervised Structure-Texture Separation Network for Oracle Character Recognition. IEEE Trans. Image Process. 2022, 31, 3137–3150. [Google Scholar] [CrossRef]
- Zhao, T.; Shen, Z.; Zou, H.; Zhong, P.; Chen, Y. Unsupervised adversarial domain adaptation based on interpolation image for fish detection in aquaculture. Comput. Electron. Agric. 2022, 198, 107004. [Google Scholar] [CrossRef]
- Liu, W.; Luo, Z.; Cai, Y.; Yu, Y.; Ke, Y.; Junior, J.M.; Gonçalves, W.N.; Li, J. Adversarial unsupervised domain adaptation for 3D semantic segmentation with multi-modal learning. ISPRS J. Photogramm. Remote Sens. 2021, 176, 211–221. [Google Scholar] [CrossRef]
- Wang, W.; Zhao, F.; Liao, S.; Shao, L. Attentive WaveBlock: Complementarity-Enhanced Mutual Networks for Unsupervised Domain Adaptation in Person Re-Identification and Beyond. IEEE Trans. Image Process. 2022, 31, 1532–1544. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2012, 6, 84–90. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Ben-David, S.; Blitzer, J.; Crammer, K.; Pereira, F. Analysis of representations for domain adaptation. Adv. Neural Inf. Process. Syst. 2007, 19, 137–144. [Google Scholar] [CrossRef]
- Celik, T.; Ozkaramanli, H.; Demirel, H. Fire pixel classification using fuzzy logic and statistical color model. In Proceedings of the 2007 IEEE International Conference on Acoustics, Speech and Signal Processing—ICASSP ’07, Honolulu, HI, USA, 15–20 April 2007; Volume 1, pp. I-1205–I-1208. [Google Scholar] [CrossRef]
- Zhang, D.; Han, S.; Zhao, J.; Zhang, Z.; Qu, C.; Ke, Y.; Chen, X. Image based Forest fire detection using dynamic characteristics with artificial neural networks. In Proceedings of the 2009 International Joint Conference on Artificial Intelligence, Hainan, China, 25–26 April 2009; pp. 290–293. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Raw Data | Sampled Images | ||||
|---|---|---|---|---|---|---|
| Format | Fire | Non-Fire | Downloading Links (Accessed on 1 November 2022) | Fire | Non-Fire | |
| BoWFire (B) | Image | 119 | 107 | https://bitbucket.org/gbdi/bowfire-dataset | 119 | 107 |
| FIRESENSE (F) | Video | 11 | 16 | http://doi.org/10.5281/zenodo.836749 | 1000 | 1000 |
| MIVIA (M) | Video | 14 | 17 | http://mivia.unisa.it | 1000 | 1000 |
| KMU (K) | Video | 22 | 16 | https://cvpr.kmu.ac.kr | 1000 | 1000 |
| VisiFire | Video | 15 | 24 | http://signal.ee.bilkent.edu.tr/VisiFire | - | - |
| Method | B→F | F→B | B→M | M→B | B→K | K→B | F→M | M→F | F→K | K→F | M→K | K→M | Avg |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ToS + AlexNet | 89.9 ± 2.1 | 70.4 ± 1.4 | 70.9 ± 3.1 | 65.3 ± 2.2 | 55.0 ± 2.4 | 63.1 ± 0.7 | 78.4 ± 0.2 | 87.0 ± 1.0 | 51.2 ± 0.8 | 70.0 ± 1.8 | 72.9 ± 0.7 | 74.3 ± 2.3 | 70.7 |
| DAAN + AlexNet | 91.0 ± 1.8 | 75.0 ± 3.4 | 79.8 ± 2.5 | 65.1 ± 1.3 | 87.1 ± 0.8 | 66.4 ± 1.9 | 82.3 ± 1.5 | 89.3 ± 1.2 | 74.4 ± 0.7 | 77.6 ± 3.0 | 74.6 ± 4.0 | 76.2 ± 1.0 | 78.2 |
| DSAN + AlexNet | 94.9 ± 3.3 | 71.9 ± 1.9 | 78.6 ± 2.8 | 73.4 ± 1.7 | 81.6 ± 1.7 | 66.0 ± 0.9 | 79.0 ± 1.2 | 88.3 ± 1.2 | 74.1 ± 0.7 | 77.3 ± 1.3 | 75.4 ± 0.4 | 79.0 ± 1.7 | 78.3 |
| ToS + ResNet50 | 87.4 ± 1.5 | 78.1 ± 1.6 | 86.3 ± 1.3 | 74.1 ± 1.4 | 57.3 ± 3.1 | 68.5 ± 1.1 | 80.1 ± 0.7 | 83.8 ± 1.8 | 48.0 ± 1.1 | 76.7 ± 3.2 | 71.6 ± 1.8 | 80.5 ± 2.2 | 74.4 |
| DAAN + ResNet50 | 91.5 ± 1.8 | 79.9 ± 1.9 | 88.0 ± 1.4 | 78.9 ± 2.6 | 69.1 ± 2.0 | 71.2 ± 1.1 | 81.7 ± 1.4 | 87.8 ± 3.2 | 46.9 ± 2.5 | 80.3 ± 3.6 | 78.4 ± 3.6 | 82.1 ± 2.1 | 78.0 |
| DSAN + ResNet50 | 91.0 ± 2.8 | 84.4 ± 3.9 | 89.7 ± 1.6 | 74.7 ± 1.8 | 95.3 ± 3.1 | 83.0 ± 0.9 | 81.9 ± 0.8 | 90.1 ± 1.2 | 62.3 ± 1.4 | 83.8 ± 2.2 | 97.1 ± 1.6 | 89.5 ± 2.3 | 85.2 |
| Transfer Task | Data Division | Fire Images | Non-Fire Images | Labels | |
|---|---|---|---|---|---|
| Fire-DA→FLAME | Training | Fire-DA (source) | 3119 | 3107 | √ |
| The training set of FLAME (target) | 25,018 | 14,357 | × | ||
| Testing | The testing set of FLAME | 5137 | 3480 | √ | |
| Fire-DA→FD-dataset | Training | Fire-DA (source) | 2654 | 3107 | √ |
| The training set of FD-dataset (target) | 17,500 | 17,500 | × | ||
| Testing | The testing set of FD-dataset | 2500 | 2500 | √ | |
| The challenging testing set of FD-dataset | 250 | 250 | √ | ||
| Method | Recall | Precision | Accuracy | F1-Score | |
|---|---|---|---|---|---|
| Supervised CNNs | Xception [20] | 76.2 | |||
| ResNet50 w/SA [38] | 82.0 | 80.6 | 77.5 | 0.813 | |
| ToT + ResNet50 (Upper bound) | 86.5 | 68.3 | 67.5 | 0.761 | |
| Unsupervised DSAN (Ours) | ToS + ResNet50 (Lower bound) | 8.3 | 98.3 | 45.2 | 0.152 |
| DSAN + ResNet50 | 60.7 | 78.2 | 63.9 | 0.662 | |
| Method | Recall | Precision | Accuracy | F1-Score | |
|---|---|---|---|---|---|
| Traditional | [57] | 99.9 | 52.0 | 53.9 | 0.684 |
| [3] | 90.0 | 63.9 | 69.6 | 0.747 | |
| [58] | 73.2 | 71.1 | 71.7 | 0.721 | |
| Supervised CNNs | [16] | 93.2 | 83.3 | 87.2 | 0.879 |
| [18] | 98.0 | 88.0 | 92.3 | 0.928 | |
| [19] | 91.3 | 84.6 | 87.3 | 0.879 | |
| [30] | 98.7 | 88.3 | 92.8 | 0.932 | |
| [17] | 97.6 | 84.8 | 90.0 | 0.907 | |
| [21] | 97.4 | 93.5 | 95.3 | 0.954 | |
| ToT + AlexNet (Upper bound) | 97.2 | 92.3 | 94.6 | 0.947 | |
| ToT + ResNet50 (Upper bound) | 98.8 | 96.3 | 97.5 | 0.976 | |
| Unsupervised DSAN (Ours) | ToS + AlexNet (Lower bound) | 75.1 | 95.3 | 85.7 | 0.840 |
| ToS + ResNet50 (Lower bound) | 69.2 | 98.1 | 83.9 | 0.812 | |
| DSAN + AlexNet | 93.5 | 92.4 | 92.8 | 0.929 | |
| DSAN + ResNet50 | 93.6 | 98.0 | 95.8 | 0.957 | |
| Method | Recall | Precision | Accuracy | F1-Score | |
|---|---|---|---|---|---|
| Supervised CNNs | [16] | 82.8 | 57.7 | 61.0 | 0.680 |
| [18] | 84.8 | 72.9 | 76.6 | 0.784 | |
| [19] | 87.6 | 62.0 | 67.0 | 0.726 | |
| [30] | 85.2 | 75.8 | 79.0 | 0.802 | |
| [17] | 89.6 | 72.7 | 78.0 | 0.803 | |
| [21] | 86.4 | 78.5 | 81.4 | 0.823 | |
| ToT+ AlexNet (Upper bound) | 89.6 | 78.4 | 82.5 | 0.836 | |
| ToT + ResNet50 (Upper bound) | 92.1 | 88.2 | 89.9 | 0.901 | |
| Unsupervised DSAN (Ours) | ToS + AlexNet (Lower bound) | 30.0 | 75.0 | 60.0 | 0.428 |
| ToS + ResNet50 (Lower bound) | 30.3 | 92.3 | 63.9 | 0.456 | |
| DSAN + AlexNet | 77.3 | 78.2 | 77.7 | 0.777 | |
| DSAN + ResNet50 | 72.8 | 92.7 | 83.5 | 0.815 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, Z.; Wang, L.; Qin, K.; Zhou, F.; Ouyang, J.; Wang, T.; Hou, X.; Bu, L. Unsupervised Domain Adaptation for Forest Fire Recognition Using Transferable Knowledge from Public Datasets. Forests 2023, 14, 52. https://doi.org/10.3390/f14010052
Yan Z, Wang L, Qin K, Zhou F, Ouyang J, Wang T, Hou X, Bu L. Unsupervised Domain Adaptation for Forest Fire Recognition Using Transferable Knowledge from Public Datasets. Forests. 2023; 14(1):52. https://doi.org/10.3390/f14010052
Chicago/Turabian StyleYan, Zhengjun, Liming Wang, Kui Qin, Feng Zhou, Jineng Ouyang, Teng Wang, Xinguo Hou, and Leping Bu. 2023. "Unsupervised Domain Adaptation for Forest Fire Recognition Using Transferable Knowledge from Public Datasets" Forests 14, no. 1: 52. https://doi.org/10.3390/f14010052