1. Introduction
Forest resources are essential for the global environment and human society. In addition to improving the quality of the atmospheric environment, forests also play a crucial role in the global carbon cycle, soil properties, and climate regulation [
1]. The increasing occurrence of forest fires is destroying the world’s forest resources and impacting human society in terms of considerable losses in human lives and public properties [
2,
3]. Due to forest fires being too difficult to rapidly control and extinguish once they occur, effective detection of early forest fires is an urgent need. The characteristics of smoke are more obvious, always appearing earlier than fires when a forest fire breaks out. It is of great significance for fire detection if forest fire smoke can be detected quickly and accurately.
Traditional forest fire smoke monitoring is based on manual inspection and smoke sensor monitoring [
4]. However, manual inspection consumes substantial human and material resources with low efficiency and unsatisfactory results. Various sensors have been used to detect fire and smoke in the last two decades. Point sensors [
5,
6] obtain remarkable results indoors, but the investment of a fire smoke wireless sensor network over an entire forest is too expensive, and sensors are easily interfered with and damaged. Smoke sensors require close proximity to the forest fire because the alarm needs particles to trigger. However, when the particle concentration reaches the threshold, the forest fire might be too strong to be controlled. Unmanned Aerial Vehicles (UAVs) can collect important visual information on early forest fire smoke detection during patrols [
7]. Satellite sensors [
8] have been used widely in forest fire smoke detection, and are not affected by various environmental factors, but can only monitor large-scale fires. Due to infrequent periods and resolution limitations, satellite sensors cannot immediately detect forest fires. Currently, with the development of computer vision technology, video surveillance systems that can be installed in forests have become a suitable alternative to previous detection methods and have lower cost, convenient deployment, and high detection efficiency. Watchtowers [
9] and UAVs [
4] equipped with cameras are appropriate for automatically monitoring forest fire smoke. Previous forest fire smoke detection methods based on computer vision technology usually make use of color and motion characteristics of the pixels from surveillance video frames. They mostly adopt pattern recognition processes, including feature extraction and classification, which are human-designed. After the candidate areas are extracted, static and dynamic smoke features are used for smoke recognition. Gubbi et al. [
10] used wavelets to extract smoke characteristics and then classified them by using SVM (Support Vector Machines). ByoungChul et al. [
11] trained two random forests for wildfire smoke classification using RGB (Red Green Blue) color, wavelets coefficients, motion orientation and a histogram of oriented gradients as independent temporal and spatial feature vectors. Prema et al. [
12] proposed an image-processing approach using YUV color space, wavelet energy, and correlation and contrast of smoke to detect smoke. However, such methods are heavily dependent on human prior knowledge and are limited in various scenarios due to complex changeable forest environments, small-target smoke, and low-contrast flame and smoke.
Deep learning methods have attracted more attention in recent years than traditional image processing methods. Compared with traditional fire smoke detection methods, the fire smoke detection methods based on deep learning could extract more abstract and high-level features, and have the advantages of fast speed, high accuracy and strong robustness in complex forest environments. Convolutional neural networks (CNNs) have become prevalent object detection methods due to their outstanding performance in image recognition [
13]. Frizzi et al. [
14] proposed a CNN for fire and smoke detection and classification by extracting features in video. Wu et al. [
15] used classical object detection models to detect forest fires. The adopted models contained You Only Look Once (YOLO) [
16], Single Shot multi-box Detector (SSD) [
17] and Faster Region-CNN (R-CNN) [
18,
19], and the experiments showed that an improved YOLO model could detect early forest fires efficiently. Semantic segmentation is also a common method to detect smoke. The task of semantic segmentation is to classify the input image pixel by pixel and mark the pixel-level objects. Pan et al. [
20] introduced a collaborative region detection and grading framework for forest fire and smoke using a weakly supervised fine segmentation and a lightweight Faster R-CNN. Frizzi et al. [
21] showed the comparison of network performance on two smoke semantic segmentation databases. Semantic segmentation and object detection, which have similar task objectives, mark objects and specific classification information of objects. The difference is that the object marked by semantic segmentation is at the pixel level, while the object marked by target detection is its bounding box. When preparing the smoke dataset, there is no need for tedious pixel-level marking operation, nor to classify every pixel in the image during detection, which leads to great optimization in running speed.
There is a transformer [
22] model which has become a preferred settlement for machine translation, text generation, etc. [
23,
24,
25] with the development of natural language processing (NLP). The self-attention mechanism could gather global information and pay attention to important elements more quickly and efficiently. Inspired by the success of transformer model and self-attention mechanism, Dosovitskiy et al. [
26] proposed Vision Transformer (ViT) for image recognition. The first end-to-end object detection method based on transformer (DETR) demonstrated higher accuracy and speed on par with the previous well-established Faster R-CNN on COCO dataset [
27]. DETR has a simple architecture with a CNN backbone and transformer encoder–decoders. However, DETR needs more epochs than Faster R-CNN to converge and shows low performance in detecting small targets. Deformable DETR [
28], which is modified from DETR by using a deformable attention module, obtains satisfactory results in object detection tasks, especially in detecting small targets. Here, we set deformable DETR as our baseline for forest fire smoke detection and demonstrate its efficiency through experiments.
In previous studies of forest fire smoke detection, many detection models have been used and have obtained good results. However, there are many existing problems for early forest fire smoke detection in forest environments due to the complex background and the difficulty of extracting smoke features. Firstly, forest images usually contain not only smoke but other irrelevant background information with similar characteristics to smoke, such as clouds, lake surface, fog, etc. The light change in the natural environment will also cause interference, resulting in the change of some image features, affecting the subsequent feature extraction and recognition. Secondly, it is challenging to detect early smoke precisely with their dynamic characteristics and small fuzzy shape. Therefore, in this paper, we aim to address this critical issue by improving feature extraction and small object detecting abilities using a Multi-scale Context Contrasted Local Feature module (MCCL), Dense Pyramid Pooling module (DPPM) [
29,
30,
31], and iterative bounding box combination method.
The contributions of our paper are as follows:
We propose an improved deformable DETR model to detect forest fire smoke which involves a Multi-scale Context Contrasted Local Feature module (MCCL) and Dense Pyramid Pooling module (DPPM). The modules enhance low contrast smoke for detecting small and inconspicuous smoke by capturing locally discriminative features.
An iterative bounding box combination method is proposed to obtain precise boxes for smoke objects to obtain more accurate localization and bounding boxes of semitransparent blurred smoke.
In order to evaluate our model, we build a forest fire smoke dataset from public resources, including various kinds of smoke and smoke-like objects in complex forest environments.
The rest of the paper is organized as follows.
Section 2 describes our dataset and the details of the improved deformable DETR model,
Section 3 presents the experimental results and performance analysis, the discussion is given in
Section 4, and finally
Section 5 concludes this paper.
2. Materials and Methods
2.1. Dataset and Annotation
It is well-known that the quality and size of a dataset are essential for a deep learning model’s performance. However, there are few public datasets about forest fire smoke or smoke datasets suitable for forest environments. Therefore, we proposed a forest fire smoke dataset (FFS dataset) by collecting forest fire smoke images (JPG format) from crawling open data on the Internet. Our self-built dataset contained different views and scales of forest fire smoke images. We manually labeled smoke areas in images and converted them to COCO [
32] format. The dataset contained 10,250 images total, and we randomly divided them by 9:1; thus, 90% of the dataset was used as a training set and 10% as a validation set. Some sample images are shown in
Figure 1.
2.2. Deformable DETR
Recently, DETR has demonstrated very competitive performance in the object detection field as a real end-to-end detector. In contrast to other modern object detect models, it does not need any hand-crafted components such as anchor generation and non-maximum suppression (NMS) and has a very simple architecture: a CNN backbone and an encoder–decoder transformer model. However, DETR has its own issues. Firstly, DETR need more epochs to converge, which is mainly due to the difficulty of processing image features to train for the attention module. While the model is initializing, the cross-attention module gives average attention to the whole feature map. After training, the attention module gives attention to feature maps sparsely. Secondly, it is hard for DETR to detect small objects. The self-attention module in the encoder part of the transformer cannot handle high-resolution feature maps with unacceptable complexity. Zhu et al. [
28] proposed a deformable DETR, which achieved satisfactory results in small object detection, and training epochs were reduced by almost a factor of 10. Authors provided the deformable attention module on each query to pay attention to the more meaningful locations that the network thought contained more local information, which were fewer in number, and a fixed number of locations as keys. This alleviated the problem of large computation requirements caused by high-resolution feature maps.
The deformable attention feature was calculated by:
In the formula, x is the input feature map, q represents the query element with content feature zq and 2-d reference point pq, k indexes the sampled keys with the sampling offset Δmqk and normalized attention weight Amqk of the k sampling point in m attention head. In addition, Wm represents attention weights after linear transformation from different heads and K sampling offsets Δmqk are calculated according to the linear layer, then K sampling offsets and pq determine the selected points in the neighborhood.
Furthermore, a deformable attention module could be extended to a multi-scale deformable attention module in the deformable DETR’s encoder part. Output feature maps of the encoder have the same resolution with the input feature maps. The input feature maps
of the encoder are extracted from the backbone’s output feature maps of stages C
3 to C
5 (such as ResNet [
33], transformed by 1 × 1 convolution). Every resolution of C
l is 2
l lower than the input images. Authors proposed C
6 stage, which was obtained by 3 × 3 stride 2 convolution from C
5 stage. For clarity of each query pixel’s location, scale-level embedding is used for feature representation.
Then, the multi-scale deformable attention module is applied as:
On the basis of the deformable attention module, l indexes input feature level, are input feature maps which are divided by different levels, pq are normalized coordinates which are not equivalent to reference points pq in deformable attention module, function rescales normalized coordinates at every feature layer to locate points that are sampled at different levels, and the remaining elements are similar to Equation (1) except for an additional l element.
The network structure of the deformable DETR is shown in
Figure 2.
By replacing the traditional transformer attention module, deformable DETR used a multi-scale deformable attention module to process feature maps which could be extended by aggregating multi-scale features naturally.
2.3. Multi-Scale Context Contrasted Local Feature Module
As we know, context information can improve performance through scene labeling. CNN provides high-level context features which contain abstract and global information on the whole image for object recognition [
31,
33]. However, there are many inconspicuous targets in complex natural environments. Those context features from CNN usually focus on the dominated objects in the image and cannot make sure that they are useful for inconspicuous objects recognition. The Context Contrasted Local Feature (CCL) module solves this problem well by computing the contrast of local context information, which not only makes full use of context but foregrounds the local information. This is an imitation of human behavior. Human beings concentrate on an object while we pay attention to its surrounding context. The contrast is computed by:
where
CL indexes the context contrasted local features,
Cl and
Cc are the local convolution block and context convolution block, respectively,
F is the input features and
denotes respective parameters. The CCL module obtains context-local information from different levels by several chained context-local blocks. Each block contains dilated convolution blocks with dilation rate = 1 and rate = 5 to integrate multi-level context aware local features.
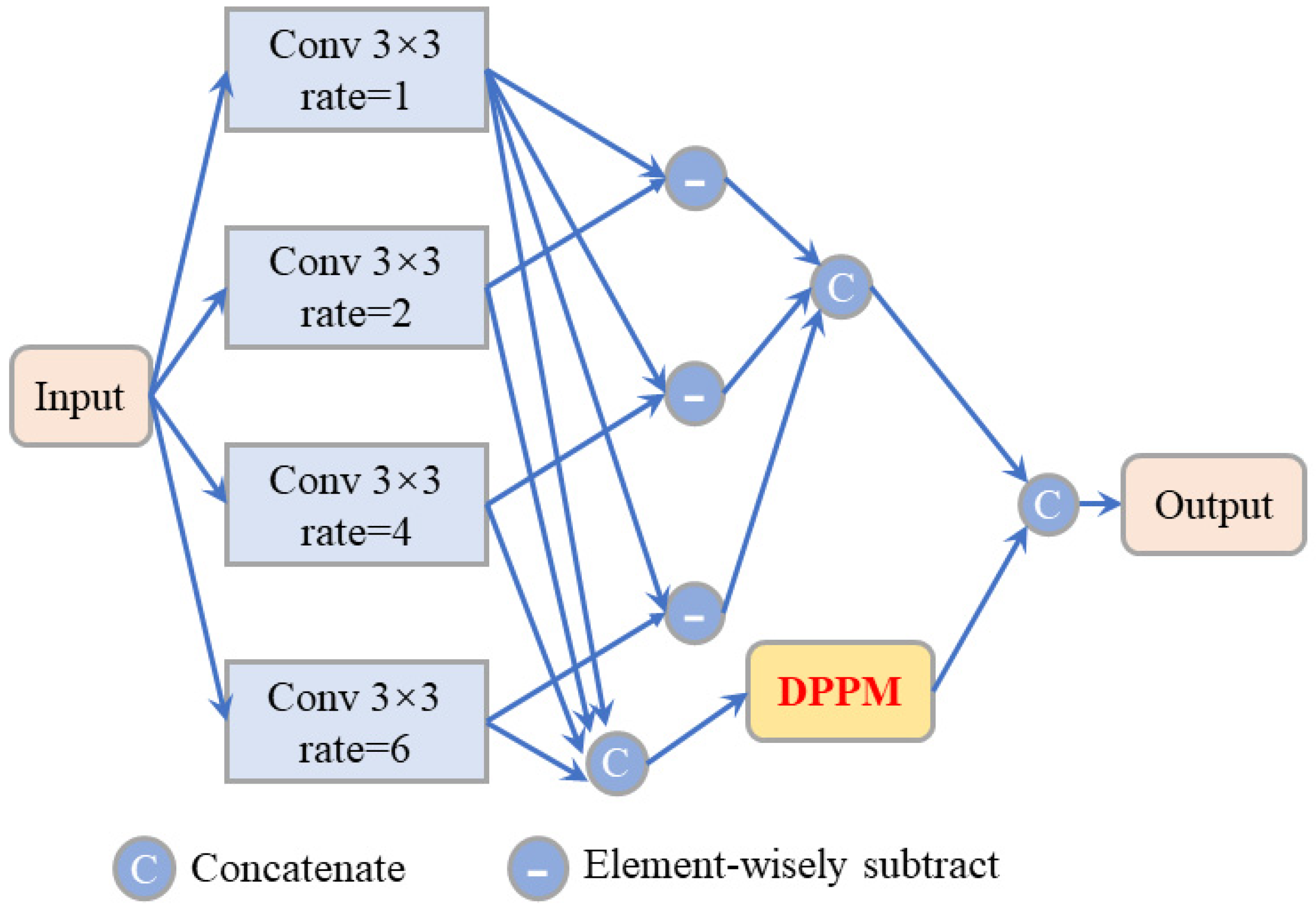
Early forest fire smoke can usually be considered as inconspicuous and blurred objects with low contrast and the CCL module cannot obtain satisfactory results for this task. To obtain more multi-scale features of inconspicuous smoke objects effectively, we use the Multi-scale Context Contrasted Local Feature module in our model, which is modified from a previous module. The MCCL module is shown in
Figure 3.
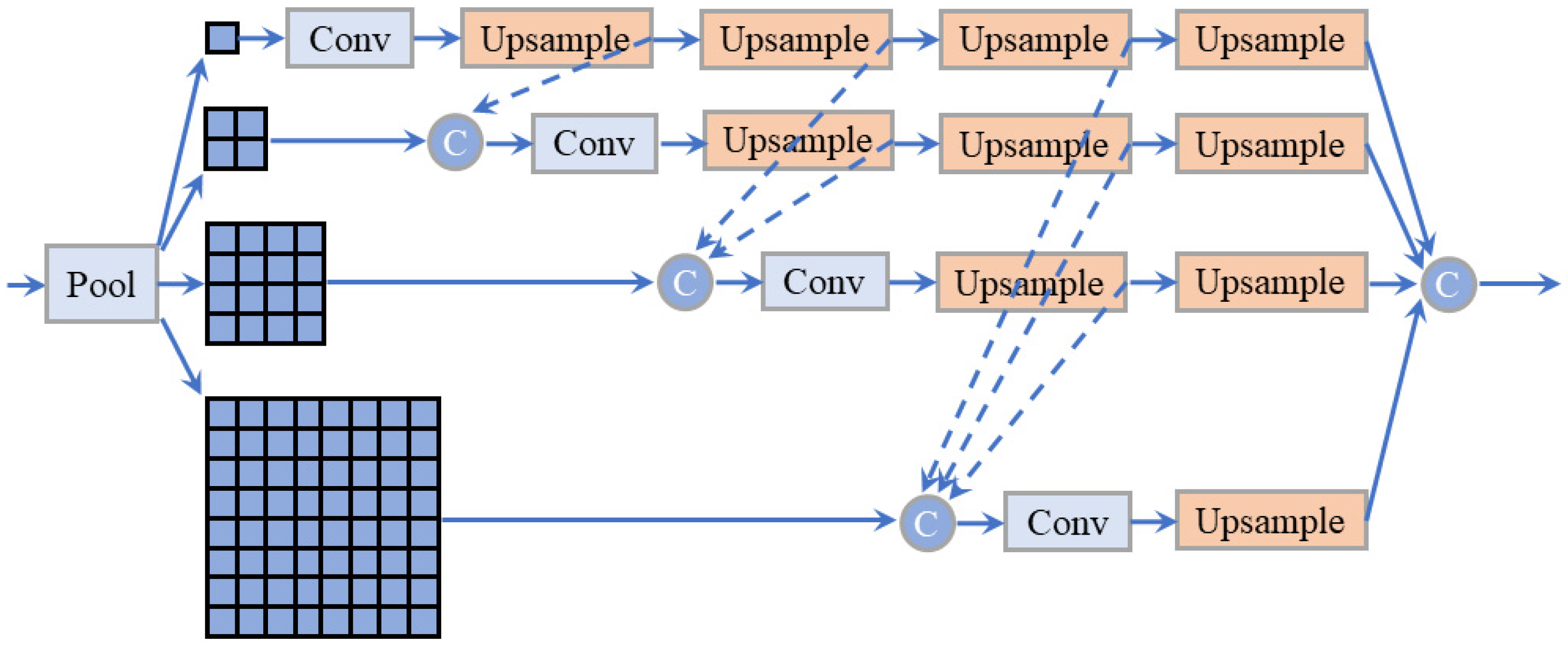
To process subsequent high-level feature maps conveniently, we resize the input features as 16 × 16 and restore them at the output block. This module contains 4 different levels of dilated convolution blocks with dilation rates = 1, 2, 4 and 6, respectively. Then we concatenate their output feature maps from each of the two blocks. We use a Dense Pyramid Pooling Module (DPPM) to extract more abstract information from the concatenated multi-scale feature maps. Confusion categories are a common problem in classification. It is an enormous challenge to distinguish between smoke and smoke-like objects such as clouds and haze. Zhao et al. [
34] proposed a Pyramid Pooling Module (PPM) for global scene prior construction upon the high-level feature maps, and this obtains context information between sub-regions efficiently. Furthermore, the Dense Pyramid Pooling Module (DPPM) is used to process feature maps efficiently with fewer parameters and a larger size of the receptive field, as shown in
Figure 4.
The module contains features under four different scales. We use four average pooling layers with different kernels and strides to generate feature maps (size 1 × 1, 2 × 2, 4 × 4 and 8 × 8, respectively) into different sub-regions. After that, we use a 1 × 1 convolution layer to reduce the dimension of features which could keep the weights of global feature consistent. Then we concatenate multi-scale feature maps from different pyramid levels and upsample several times directly to obtain the same size between input and output features via bilinear interpolation. Finally, we concatenate these feature maps as multi-scale features.
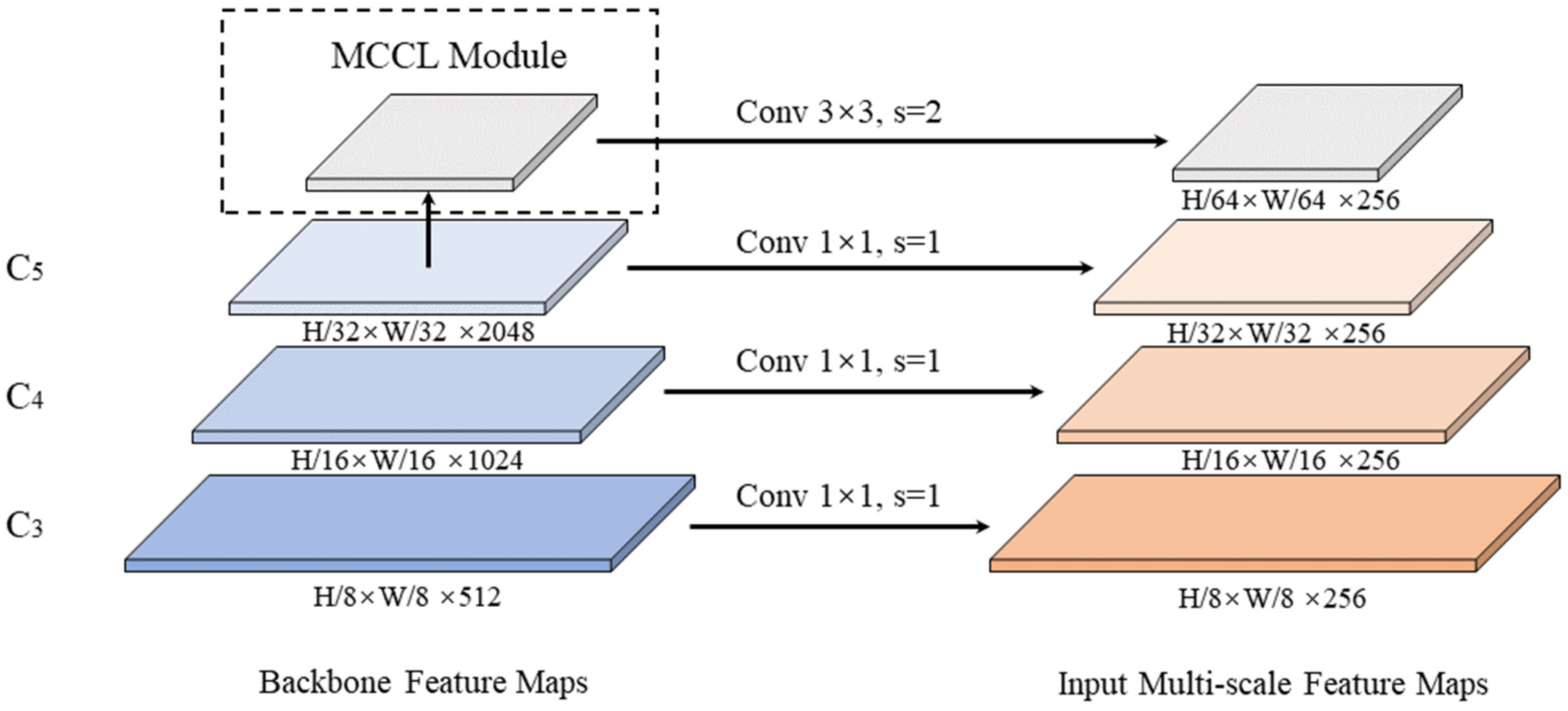
As we discussed in
Section 2.2, the input feature maps
of the encoder are extracted from the backbone’s output feature maps of stages C
3 to C
5 (such as ResNet [
33], transformed by 1 × 1 convolution). The input multi-scale feature maps are obtained via 1 × 1 stride 1 convolution on C
3, C
4 and C
5 stage. In addition, we use the MCCL module to process the lowest-resolution feature maps on final C
5 stage, then use 3 × 3 stride 2 convolution to get the highest-dimensional feature maps as illustrated in
Figure 5. The numbers below each layer represent the size and dimension of the feature maps.
2.4. Iterative Bounding Box Combination Method
Forest fire smoke is easily affected by complex forest environments, and its characteristics change easily. Early smoke usually represents a semitransparent characteristic which leads to a blurred boundary. Unlike general object detection, it is difficult to obtain a precise bounding box for smoke. These uncertain elements inevitably lead to missed and false detections, as shown in
Figure 6. In the previous object detection model, Non-Maximum Suppression (NMS) is proposed to obtain bounding boxes based on their scores. However, NMS is not necessary for DETR which lowers AP (Average Precision) in final layers and only improves AP
50 (AP at IoU = 0.5) slightly [
27]. Deformable DETR uses iterative bounding box refinement to obtain precise bounding boxes based on predictions from each layer and different layers compute parameters independently [
28]; each decoder layer predicts bounding boxes based on the predictions from the previous layer. As shown in Equation (4), for the boxes from the
d-th decoder layer, the key elements are sampled to boxes predicted from the (
d-1)-th decoder layer and the new reference points are set as
,
. Additionally, these methods are not suitable for blurred smoke box proposals. Considering that our ideal goal is to detect early smoke rapidly and obtain an accurate position in images, we propose an iterative bounding box combination method based on NMS and iterative bounding box refinement to obtain satisfactory results and decrease the occurrence of missed and false detections. Our algorithm generates bounding boxes that do not overlap with each other, and where the whole smoke objects are surrounded by bounding boxes. Ablation experimental results are shown in
Figure 6.
Firstly, we set
D numbers of deformable DETR decoder layers (e.g.,
D = 6) and the predictions of bounding boxes
boxj from every decoder layer are sorted by their confidences. The
boxj is defined as:
where
d = {1, 2, …,
D},
bdj{x, y, w, h} are the predictions of the
d-th decoder layer, and
boxj is relevant to the predictions of
d-1-th layer. The
σ (·) and
σ−1 (·) represent sigmoid function and inverse sigmoid function, respectively.
Secondly, we delete the
boxj whose confidences are lower than 0.01. Then we calculate the Intersection over Union (IoU) between
boundingboxi and
boxj:
We keep the boxj as a new bounding box if its IoU equals to zero.
Moreover, we combine
bounding boxi and
boxj as a new
bounding boxi+1 if the
boxj only coincides with one bounding box and the IoU between two boxes is less than 0.7. We also need to keep the new boxes independent from other bounding boxes. Based on these, we improve the bounding box generation algorithm and our iterative bounding box combination algorithm is shown in Algorithm 1.
| Algorithm 1 Iterative Bounding Box Combination |
| Input: bbox = {bbox1, …, bboxI}, box = {box1, …, boxJ}, D = {1, …, d, …, D} |
| bbox is the bounding boxes. |
| box is the box predictions from each decoder layers. |
| D is a list of decoder layers. |
| Begin: |
| Ford in D do |
| Rank box by confidence |
| While confidence of boxj < 0.01 do |
| delete boxj |
| If = 0 do |
| bbox ← boxj |
| Else If ≤ 0.7 && = 0 do |
| bbox ← bboxi U boxj |
| End |
| End |
| End |
| Returnbbox |
| End |
2.5. Loss Function
In terms of loss function, our model follows the function of deformable DETR. Therefore, we totally set three components to the loss, classification loss, bounding box distance loss and GIoU loss [
35]. The classification loss is necessary for the training model and classification task, which are represented as cross-entropy loss. The bounding box distance loss is set as L1 loss, which calculates the distance between prediction box and the ground truth then propagates gradients. Furthermore, we use
GIoU loss to make the prediction box closer to the ground truth:
where
A,
B and
C represent prediction box, ground truth and smallest closing box between
A and
B, respectively. Thus, our total loss is weighed sum of three loss:
4. Discussion
It is very important to detect forest fires quickly and accurately. Smoke, as a significant feature of early fires, should be paid more attention to during detection. However, objects such as smoke and flames have irregular shapes and are easily disturbed by complex forest environments. Delayed or even missed detection of forest fire smoke can lead to the rapid spread of fire, which causes immeasurable losses. The development of computer vision has made it possible for high-precision automatic inspection to replace manual inspection in the last two decades. Because of the translucency and blurred boundary of smoke, it is easily influenced by other factors such as light and wind. Previous smoke detection methods based on deep learning have mainly studied the texture and spatio-temporal characteristics from smoke videos to achieve more accurate smoke detection results [
36,
37,
38]. Smoke detection can also adopt another strategy, that is, paying attention to data re-processing such as dark channel prior, optical flow, and super-pixel segmentation of images [
20,
39].
Our improved deformable DETR model concentrates on feature extraction in order to obtain higher accuracy of smoke detection. Through these comparisons and ablation experiments, we found that our model is more suitable for early forest fire smoke detection tasks compared with other common models, as shown in
Table 3. The MCCL module provides precise multi-scale features of small and inconspicuous smoke objects for high-level feature processing and the module has more dilated convolution blocks and fewer parameters than CCL. We used the DPPM module, which is expanded from the Pyramid Pooling Module to generate more features with fewer parameters than the Pyramid Pooling Module. As shown in
Figure 4, our DPPM module computes multi-scale features naturally by upsampling at each stage. The module we used combines efficient feature extraction with fewer calculation parameters. In
Figure 12, we visualize sampling points and attention weights of the last layer in the encoder, and our improved model can focus more precisely on smoke objects while the MCCL module extracts more useful features for subsequent feature learning and detection modules. Compared with the original model, more accurate sampling points and attention weights show the advantages of our method in feature extraction. Additionally, the detection performance of our model also demonstrates advantages in this task (as shown in
Figure 7,
Figure 8,
Figure 9,
Figure 10 and
Figure 11). Our detection samples contain ultra-small smoke objects with strong inference (such as strong direct sunlight and smoke-like clouds in
Figure 11). Due to the further processing of high-dimensional feature maps by the MCCL module and DPPM greatly reducing the possibility of misclassification, this model can more accurately obtain inconspicuous smoke features and distinguish the smoke from smoke-like objects. In the field of vision-based target detection, small target detection has always been a difficult problem. Mis-detection of our model occurs when detecting small targets. Early small smoke targets tend to be easily covered by trees and dissipate quickly. Limited pixel representations of early smoke flow and the interference from smoke-like objects usually lead to the problem of mis-detection in the original model. In order to improve the detection performance of inconspicuous smoke targets, we propose using several dilated convolutions with different rates to obtain useful context information, and also pay attention to local information of inconspicuous targets. The proposed improvement strategy obtained satisfactory result in detecting early smoke targets and improved the
APS metric by 5.1% (compared with the original model).
The previous bounding box generation method is obviously suitable for smoke in forest fire smoke detection tasks; the generated bounding box always has a smaller or larger offset to the ground truth, which leads to high training loss. Considering this situation, we used an iterative bounding box combination method to generate bounding boxes more consistently with ground truth which reduced the occurrences of false and missed detections and improved
mAP by 4.2%. With the addition of our bounding box generation method, the detection results become more accurate than the baseline in
Figure 6. Furthermore, we constructed a large forest fire smoke dataset to evaluate our method. Four common object detection models were obtained in the experiments with good performance on forest fire smoke detection, which made it possible to detect the forest fire smoke in the wild.
However, our model still has some disadvantages to improve. Small object detection is not only the detection of forest fire smoke but also one of the difficulties of computer vision. We extracted features from high dimensions to detect small smoke, which will still be limited by the lack of small target pixel information. Complex environments, such as foggy weather, greatly affect the detection of our model, but smoke sensors still have high accuracy in detecting smoke. Therefore, combining computer vision with traditional smoke sensor networks may make smoke detection more accurate.
5. Conclusions
In this paper, we propose an improved end-to-end deformable DETR model for forest fire smoke detection. Firstly, in order to capture the information of small and inconspicuous smoke, a feature extraction module with Multi-scale Context Contrasted Local Feature module and Dense Pyramid Pooling module is used. Several dilated convolutions with different rates make full use of context information and local information of inconspicuous objects, which improves the performance of early forest fire smoke detection. Secondly, we propose an iterative bounding box combination method to reduce the occurrences of false and missed detections and generate a bounding box for forest fire smoke more accurately to the ground truth. Lastly, due to the lack of relevant public datasets, we established a quantitative and qualitative forest fire smoke dataset to verify the performance of our model. Ablation experiments show that our improved model for detecting forest fire smoke is superior to the mainstream detection model in most metrics. Our model not only achieves high detection accuracy of smoke but can detect early forest fire smoke which is too small and inconspicuous to be detected by common models.
In the next stage, we plan to conduct joint detection of early fire and smoke, then prune and distill the knowledge for our improved model so that it can be deployed to edge devices such as UAVs and watchtowers for real-time detection with fewer parameters and higher processing speed.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}