1. Introduction
Wild forest fires occur frequently all over the world. Forest fires usually have the characteristics of high risk and strong destructive potential, and pose a great harm to social and economic development, environmental protection and ecosystems. Different from other fires, forest fires present specific damage modes due to their environment. In the open environment and with sufficient oxygen, fires are more likely to occur and spread in forests, causing serious personal safety risks and economic losses. Early fire detection is the only effective way to reduce the harm of forest fires [
1]. Therefore, research on forest fire identification and early warning has attracted extensive attention.
At present, forest fire detection is mainly realized through monitoring towers, aviation and satellite systems, optical sensors, digital cameras and wireless sensor networks [
2,
3]. However, forest fire detection methods based on monitoring towers largely depend on the experience of observers, and it is difficult for the monitoring range to cover a large area of wild forest. Satellite remote sensing is very effective for detecting large-scale forest fires, but it is limited by the difficulty in effectively identifying early regional fires [
4,
5]. Fire detection systems based on sensor networks have good identification performance in indoor spaces, but are difficult to install and maintain in wild forest areas due to high hardware costs [
6,
7]. In addition, due to the limitations of sensor materials, interference from the environment may lead to false positives. At the same time, wireless sensor networks are unable to provide important visual information to help firefighters track the fire scene. In recent years, with the development of machine vision technology, researchers have proposed various fire detection models based on image processing [
8,
9]. However, image processing methods based on fixed cameras are limited by the field of view, which leads to poor monitoring ability for large scenes. In addition, undulating terrain in forests may block the scenes of some fires. Different from the above forest fire detection methods, unmanned aerial vehicles (UAVs) equipped with cameras can solve the problems of fixed position cameras, can cover a larger monitoring range, and are not limited by the installation angle [
10,
11]. Therefore, UAV images are especially suitable for early recognition of forest fire.
Many countries have carried out relevant research and practical activities for forest fire monitoring and identification based on UAVs [
12]. Fire identification technology based on UAV images is usually developed based on the color, motion and geometric features of the images [
13]. Jiao et al. proposed a forest fire detection algorithm using YOLOv3 to extract color and shape features from aerial images taken by unmanned aircraft [
14]. Anh et al. proposed a method based on RGB color space to distinguish fire pixels and background [
15]. Yuan et al. used median filter, color space conversion, Otsu threshold segmentation, morphological operations and blob counter to detect and track potential fires in sequence [
16].
With the successful application of deep learning technology in the fields of intelligent transportation systems [
17], indoor target positioning [
18], and intelligent agriculture [
19], researchers have also introduced deep learning technology into the field of forest fire detection to improve the accuracy of forest fire identification by extracting deep semantic features from images. Hu et al. proposed the MVMNet model to improve the accuracy and effectiveness of forest fire smoke target detection [
20]. Guan et al. proposed a FireColorNet model based on color attention to extract color feature information from forest fire images [
21]. Li et al. proposed an adversarial fusion network to extract abstract features for forest fire smoke detection [
22]. Fan et al. proposed YOLOv4-Light, a lightweight network structure for forest fire detection. YOLOv4-Light uses MobileNet to replace the backbone feature extraction network of YOLOv4, and deep separable convolution to replace the standard convolution of PANet [
23]. Federico et al. developed a deep learning model for forest fire detection, obtained from transfer-learning of pre-trained RetinaNet, and established a Faster R-CNN model for object detection [
24]. However, the images captured by UAVs were overhead images. In the early detection of forest fires, the forest fire target is very small, and the color and shape characteristics are not obvious. Therefore, the above fire detection models based on color and shape features cannot be directly applied to UAV images. This brings great challenges for research into forest fire early recognition based on UAV images. In addition the lack of sufficient labeled UAV fire image samples directly affects the accuracy of forest fire recognition based on UAV images. At the same time, the lack of sufficient fire annotation image samples makes it difficult effectively to introduce deep learning methods into UAV image recognition, because these methods require large quantities of high-quality annotation data to obtain satisfactory recognition results.
In order to extract deeper abstract features from images, it is necessary to construct a deep-level network model, and the training of a deep neural network is a time-consuming and complex process. In addition, the training of a deep model needs a large number of labeled samples. This has become the bottleneck in the task of forest fire identification based on UAV images, and the emergence of transfer learning technology provides an opportunity to solve this problem. Transfer learning [
25,
26] refers to transferring the trained model to a new task, and realizing the modeling of the new task by fine-tuning the model parameters. When there are insufficient labeled samples, transfer learning can solve the problem of overfitting training caused by too few labeled samples.
In this paper, the idea of transfer learning is introduced into the research of forest fire recognition based on UAV images, and a new forest fire recognition model is proposed: FT-ResNet50, based on transfer learning. The Ft-ResNet50 model is based on the transfer learning method, and ResNet50 pre-trained on the ImageNet dataset is used as the backbone framework for forest fire recognition. The pre-trained weights are used as initialization parameters for the backbone network, and the original network is improved by optimizing network structure parameters. Finally, the optimized network is applied to the data-enhanced UAV forest fire dataset realize the effective identification of forest fire. The main contributions of this paper are:
- (1)
The FT-ResNet50 model adopted transfer learning to solve the problem of insufficient labeled samples of UAV forest fire images. This model can also realize high-performance forest fire recognition when UAV labeled samples are limited in size and uneven in sample distribution.
- (2)
The FT-ResNet50 selected ResNet50 as the basic network to realize transfer learning through experimental results. By fixing the shallow layers of ResNet50 and fine tuning its deep layers, we obtained the optimal configuration of ResNet50 suitable for the target dataset. The FT-ResNet50 model could successfully extract deep semantic features from UAV images, thus improving the accuracy of the model for forest fire recognition.
- (3)
The FT-ResNet50 model combined the mixup-based sample enhancement method with the traditional sample enhancement method to expand the sample size of UAV images, so as to enhance the generalization ability of the model.
The structure of this paper is organized as follows. In
Section 2, the dataset used in the experiments is presented, and the structure of the FT-ResNet50 model is discussed in detail.
Section 3 introduces the configuration of the experiment, and experimentally verifies the influence on forest fire identification of configuration parameters such as network depth, loss function, activation function, and optimizer, to explain the framework of the FT-ResNet50 model. In
Section 4, the experimental results are discussed in depth and analyzed;
Section 5 summarizes the full work.
2. Materials and Methods
2.1. Dataset
The FLAME (Fire Luminosity Airborne-based Machine learning Evaluation) dataset is a dataset of fire images collected by UAV in an Arizona pine forest [
27]. The dataset used different UAVs and cameras to collect image samples of forest fires.
Table 1 describes the technical specifications of UAVs and cameras used in the FLAME dataset, and the resolution of the collected samples. The dataset includes video recording and heat maps taken by infrared camera. Each frame of the video is labeled as an image. In this paper, 31501, 7874 and 8617 image samples were extracted from the FLAME data set as the training set, verification set and test set of this experiment, respectively.
Figure 1 shows some examples of typical forest fire images in the FLAME dataset.
2.2. Mixup
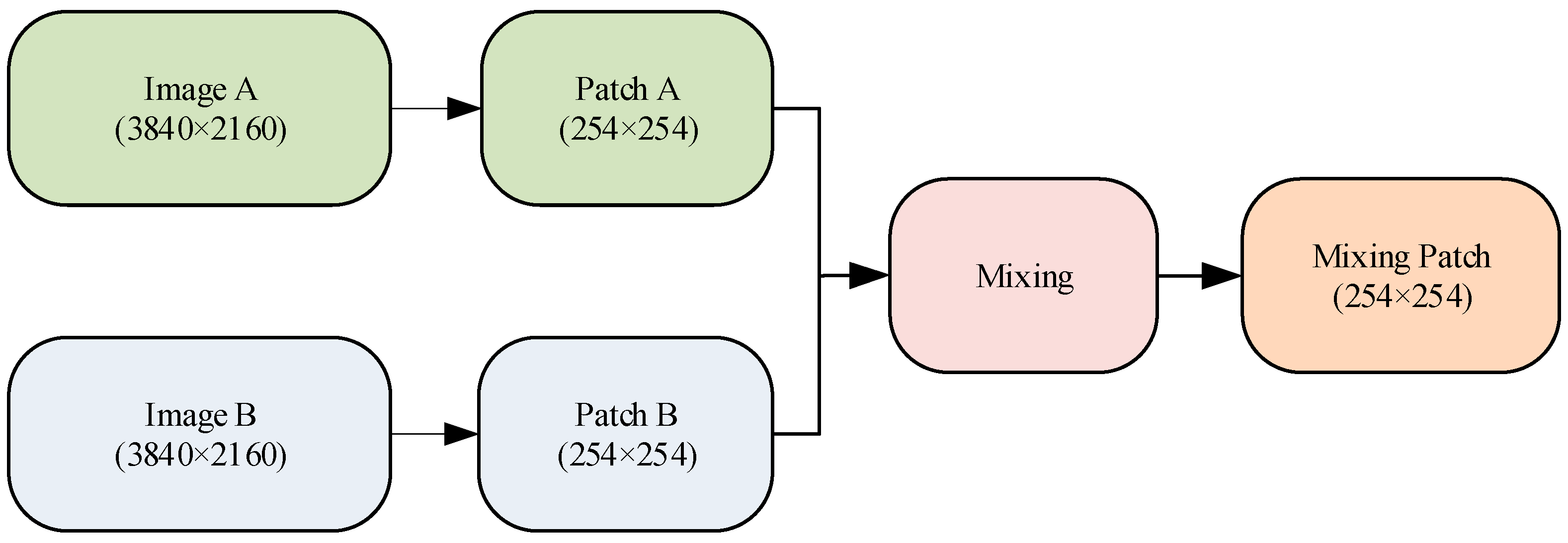
In order to give the forest fire recognition model better generalization ability, this paper presents an expansion strategy for the forest fire image training samples. By increasing the number of training samples, the distribution of training samples can be improved and the robustness of the model to noise can be improved.
Zhang et al. [
28] proposed a sample enhancement method based on mixup. This method is a sample expansion algorithm for computer vision, which can expand the size of a dataset by mixing different types of images. Two image samples are randomly selected from the training dataset, and the pixel values and labels of the two image samples are weighted according to a certain weight. Specifically, the mixup builds virtual training samples in the following ways:
where
and
are the two random examples extracted from training sample data, and
[0, 1].
follows a Beta distribution, namely
. This mixup-based data enhancement method has the advantages of processing decision boundary blurring, providing smoother predictions, and enhancing the prediction ability of the model beyond the scope of training dataset.
Figure 2 shows the process of mixup-based image sample augmentation. The experiment shows that when
= 0.5,
, the best data-fusion effect is achieved.
2.3. Residual Network (ResNet-50)
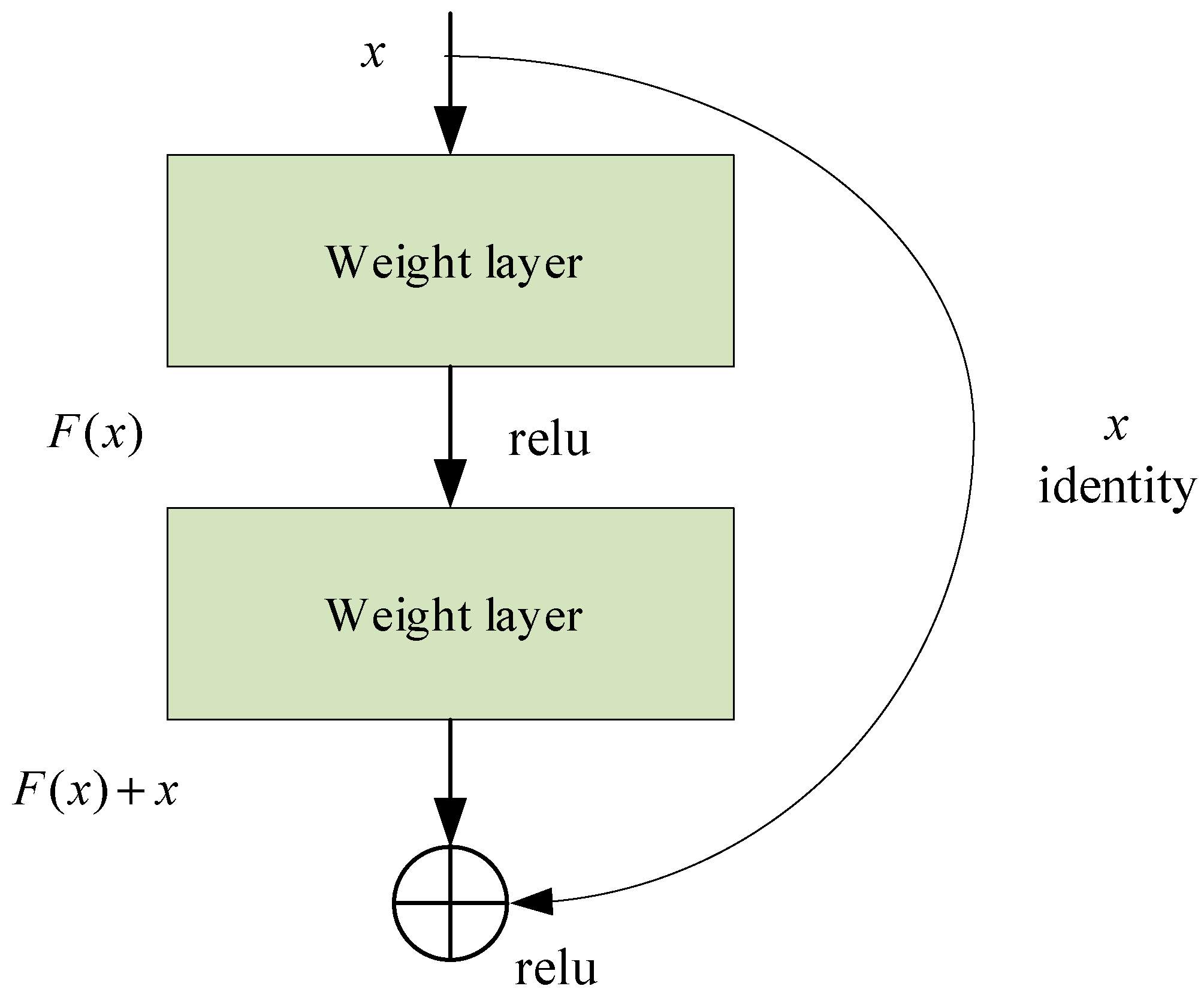
Following the success of VGGNet architectures [
29], researchers believe that deeper models outperform shallower models. However, as the number of model layers increases, the complexity and training difficulty of the model also increases, and the accuracy decreases. In 2016, Kaiming He and colleagues at Microsoft Research solved the problem of gradient disappearance and gradient explosion by building ResNet, making feasible deeper network training. They introduced a new learning framework to simplify the training of deeper networks [
30], and called the framework residual learning; accordingly, the model using this framework is called residual network (ResNet). ResNet allows original input information to be directly connected to subsequent neurons, and takes as its goal minimization of the difference (residual) between input and output. Specifically, the original input to the network is set to
x and the final desired output is set to
. When the original input
is passed directly to the tail of the network as the initial result, the objective to be learned in this case becomes
.
Figure 3 illustrates the principle of residual learning in ResNet.
This paper is devoted to extracting deeper semantic information from forest fire images, beyond color and structural features, so the ResNet-50 network was selected as the backbone network of our model.
Table 2 lists the architecture of ResNet-50. ResNet-50 contains 49 convolution layers, one of which is 3 × 3, an average pool layer, and a fully connected layer. The classical ResNet-50 model involves 25.56 million parameters, of which the rectification nonlinearity (ReLU) activation function and batch normalization (BN) function are applied to the back of all convolution layers in the “Bottle-neck” block, and the softmax function is applied to the full connection layer.
2.4. Transfer Learning
The idea of transfer learning was introduced to solve the problem of limited sample size of UAV forest fire images. In this study, the ResNet50 network trained on ImageNet dataset [
31] was migrated to the experimental dataset of UAV forest fires. The ImageNet dataset contains about 1.2 million images in 1000 categories. Using the network model pre-trained on such a large dataset, it can be effectively migrated to classification tasks of various images [
32]. The ResNet50 network was trained on the Imagenet dataset, taken as the preliminary training model, and the optimal configuration of the ResNet50 network was realized by fixing the convolution block of shallow feature extraction, fine-tuning the convolution block of deep feature extraction, and adjusting the Mish and Adam parameters, to complete feature extraction and recognition based on UAV forest fire images.
2.5. Adam Optimizer
In this study, an Adam optimizer was used to accelerate the convergence of the FT-ResNet50 model. Adam is a first-order gradient-based stochastic objective function optimization algorithm [
33]. Adam combines the advantages of the AdaGrad [
34] and RMSProp [
35] algorithms; the former is used for sparse gradient problems, and the latter is used for nonlinear and unfixed optimization objective problems. Adam has the advantages of easy implementation, high computing efficiency and low memory requirements [
36]. Its gradient diagonal scaling is invariant, so it is suitable for solving problems with large-scale data or parameters. For different parameters, Adam can adaptively adjust the learning rate and iteratively update the weights of the neural network according to the training data [
37,
38]. The calculation process and pseudocode of the Adam algorithm are shown in Algorithm 1.
| Algorithm 1. The calculation process and pseudocode of Adam algorithm. |
| indicates the elementwise square (⊙). Good default settings for the tested machine learning problems are = 0.001, = 0.9, = 0.999, = 10−8. All operations on vectors are element-wise. With and we denote and to the power t: |
| Require: α: Stepsize |
| Require: , [0, 1): Exponential decay rates for the moment estimates |
| Require:f(θ): Stochastic objective function with parameters θ |
| Require: : Initial parameter vector |
| ← 0 (Initialize 1st moment vector) |
| ← 0 (Initialize 2nd moment vector) |
| t ← 0 (Initialize timestep) |
| while not converged do |
| t ← t + 1 |
| (Get gradient w.r.t stochastic objective at timestep t) |
| (Update biased first moment estimate) |
| (Update biased second raw moment estimate) |
| (Compute bias-corrected first moment estimate) |
| (Compute bias-corrected second raw moment estimate) |
| (Update parameters) |
| end while |
| return (Resulting parameters) |
2.6. Focal Loss
Focal Loss function [
39] is mainly used to solve problems such as unbalanced sample number and sample difficulty. When training the FT-ResNet50 model, Focal Loss was used as a loss function to update ω and b. The Focal Loss function is defined as follows:
reflects the proximity to ground truth. The larger is, the closer it is to the ground truth, i.e., the more accurate the classification. is the adjustable factor. Focal Loss’s modulation factor is ; for the accurately classified sample , modulating factor approaches 0; for the inaccurately classified sample , modulating factor approaches 1. Compared with traditional cross entropy loss, Focal Loss does not change for samples with inaccurate classification, and for samples with accurate classification, loss decreases. On the whole, it is equivalent to increasing the weight of the inaccurately classified samples in the loss function.
also reflects the difficulty of classification. The larger , the higher the confidence of classification, and the easier it is to divide the sample. The smaller is, the lower the confidence of classification, and the more difficult it is to distinguish the sample. Therefore, Focal Loss increases the weight of difficult samples in the loss function, making the loss function tend towards the difficult samples, which helps to improve the accuracy of difficult samples and improve the learning ability of the network for the current task.
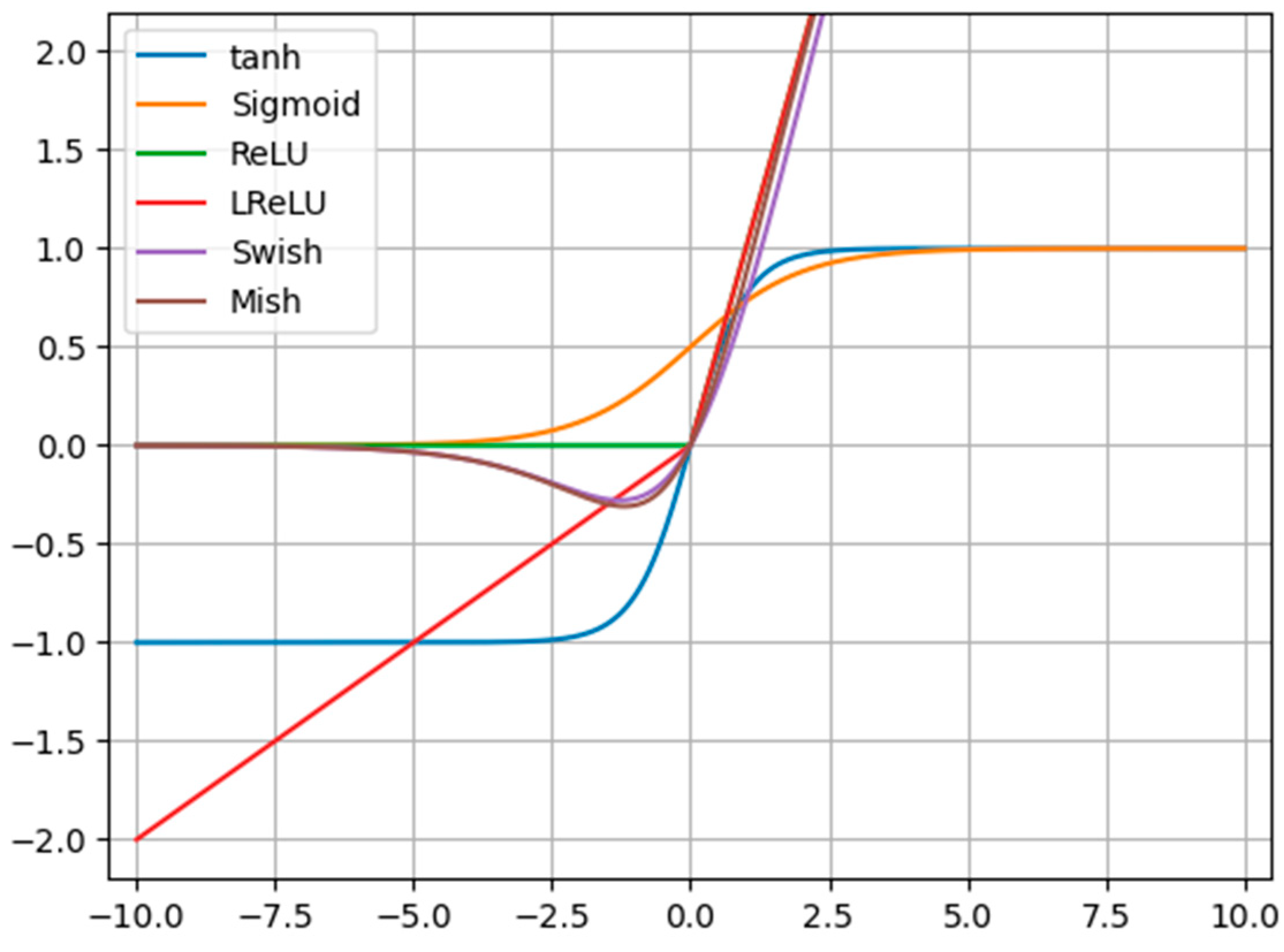
2.7. Mish
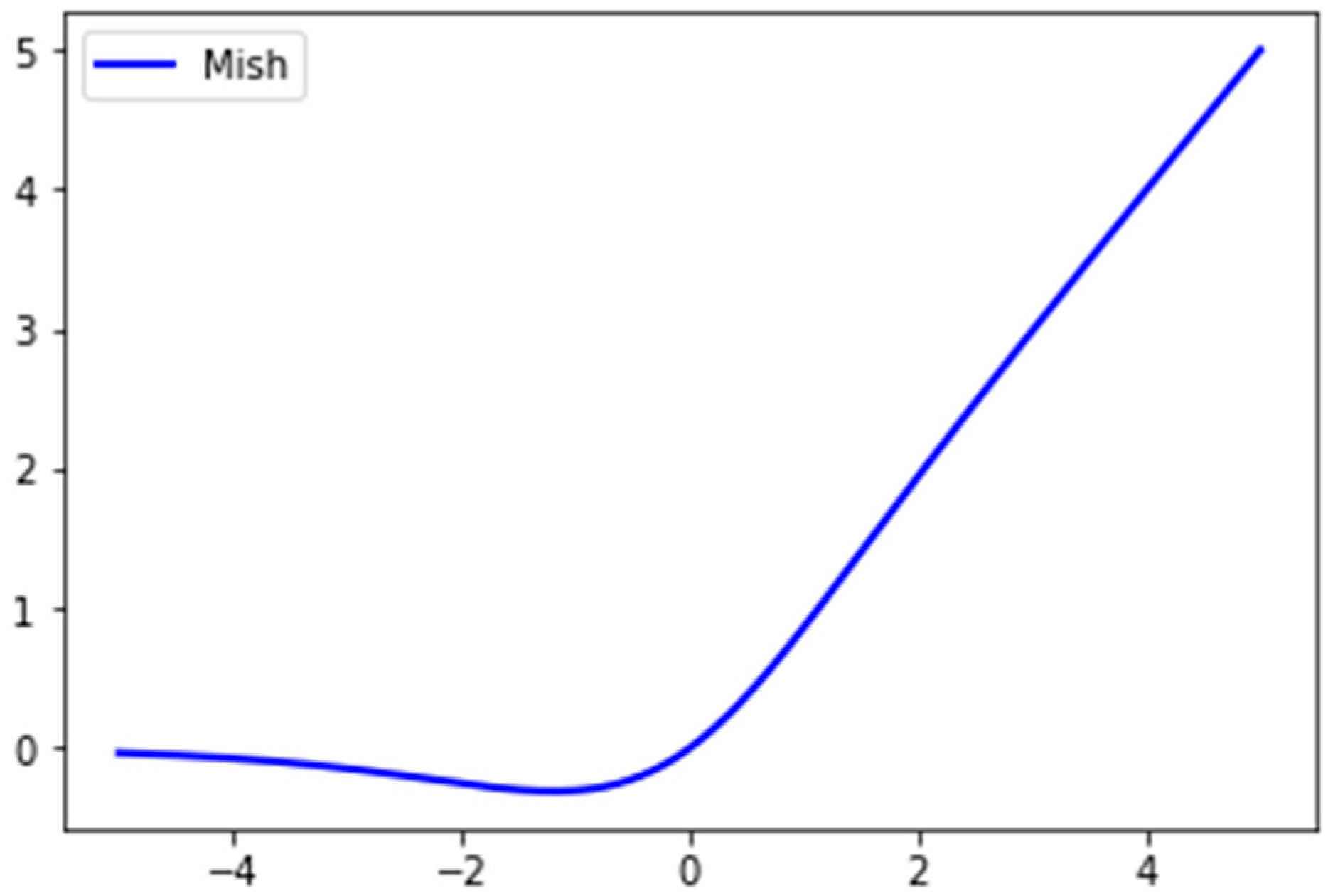
Mish function [
40] is a novel self-regularized non-monotonic activation function. Its shape and properties are similar to those of Swish. It plays an important role in the performance and training dynamics of neural networks. The Mish activation function can be expressed as follows:
Compared with the ReLU function, which is the common activation function in the neural network, Mish is differentiable anywhere in its domain, so there is no hard turning point at zero.
Figure 4 shows the curve of the Mish function.
2.8. The Proposed Forest Fire Identification Model—FT-ResNet50
This section introduces the FT-ResNet50 model in detail.
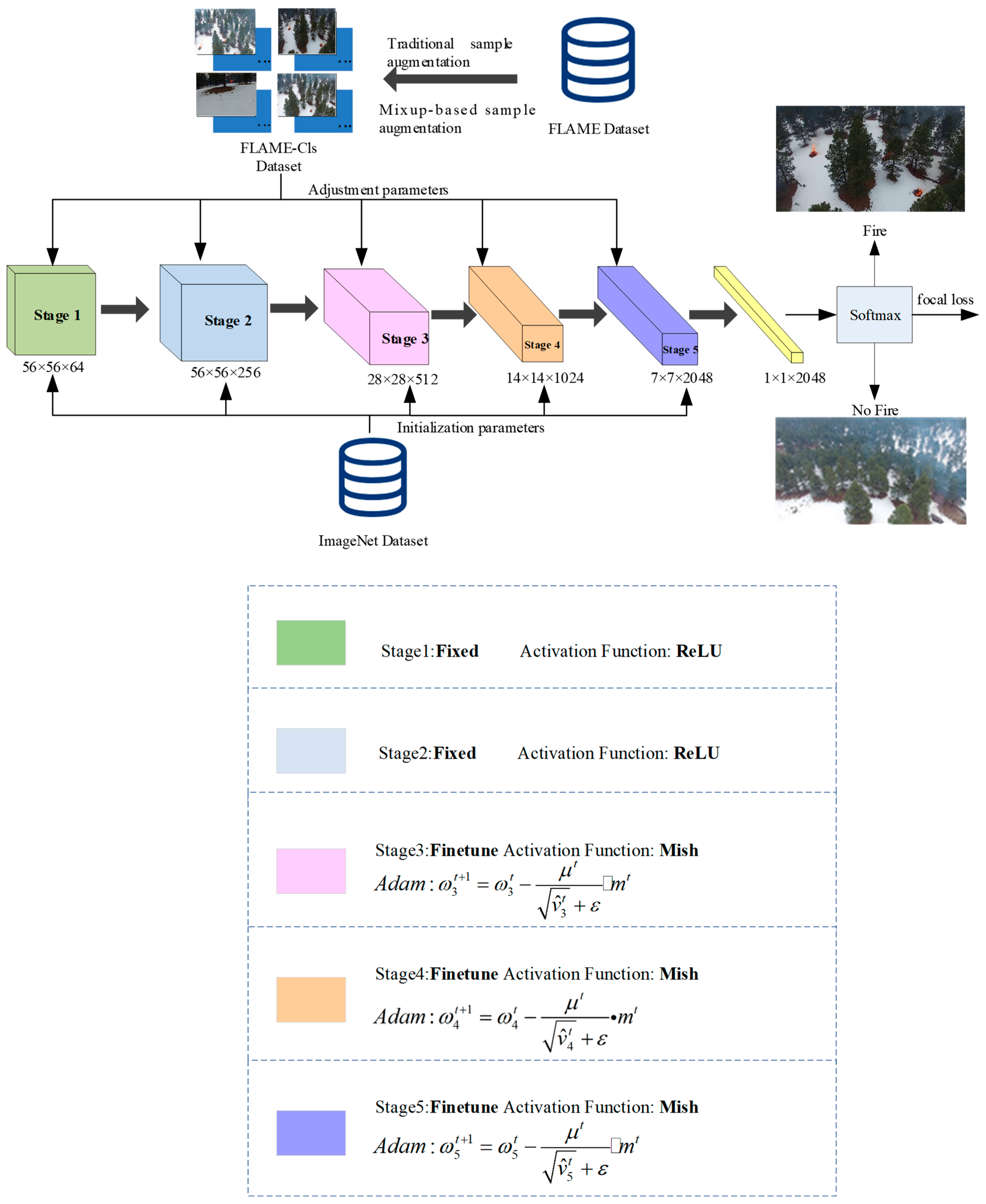
Figure 5 shows the architecture of the FT-ResNet50 model.
FLAME-Cls is the extended data set after sample enhancement. The FT-ResNet50 model uses five-level residual blocks for feature extraction. The first two residual blocks are mainly used to extract the edge, texture and color features of the image. Because the extraction process of these features is highly universal for all types of images, the structure of the first two-stage residual block is the same as that of ResNet50 in the FT-ResNet50 model. The next three-level residual block mainly extracts the abstract semantic features of the image, which is the key to improving the accuracy of forest fire recognition. The FT-ResNet50 model adjusts the last three residual blocks of the ResNet50 network, and adds the Adam random gradient descent algorithm to residual blocks 3, 4 and 5 to avoid training falling into local optimization, and to ensure that the model can obtain more accurate recognition results. The feature map output from the last convolution layer of the FT-ResNet50 model is converted into a 2048-dimensional vector through the global average pool, and the forest fire identification results are output in the form of probability through the SoftMax function.
Meanwhile, in the FT-ResNet50 model, the original activation function ReLu was replaced by the Mish function to improve the gradient vanishing problem in model training. In addition, the Focal Loss s was employed to replace the traditional binary cross-entropy loss. Focal Loss pays more attention to the training of difficult samples, which is more helpful for improving the learning ability of the model.
4. Discussion
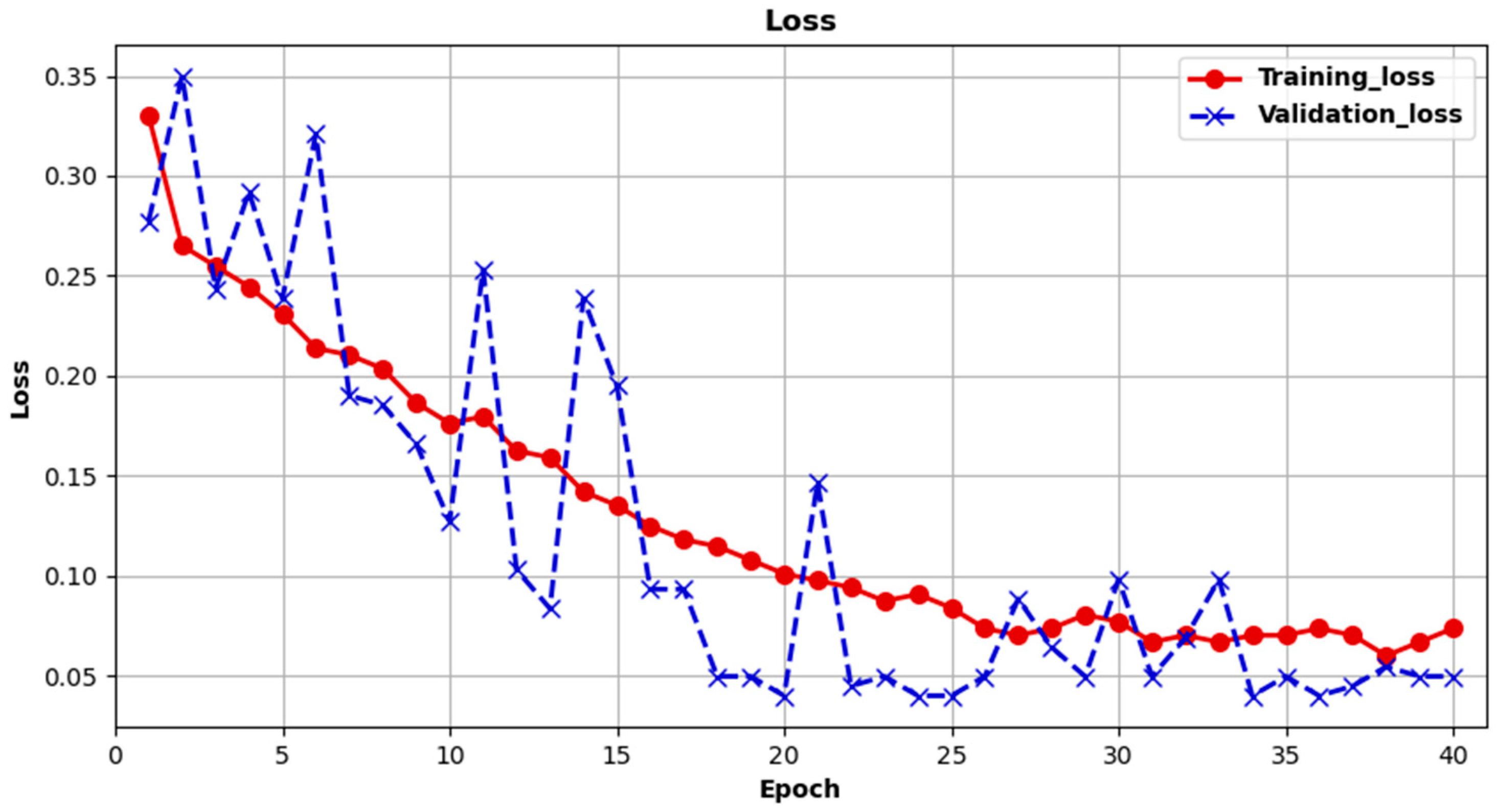
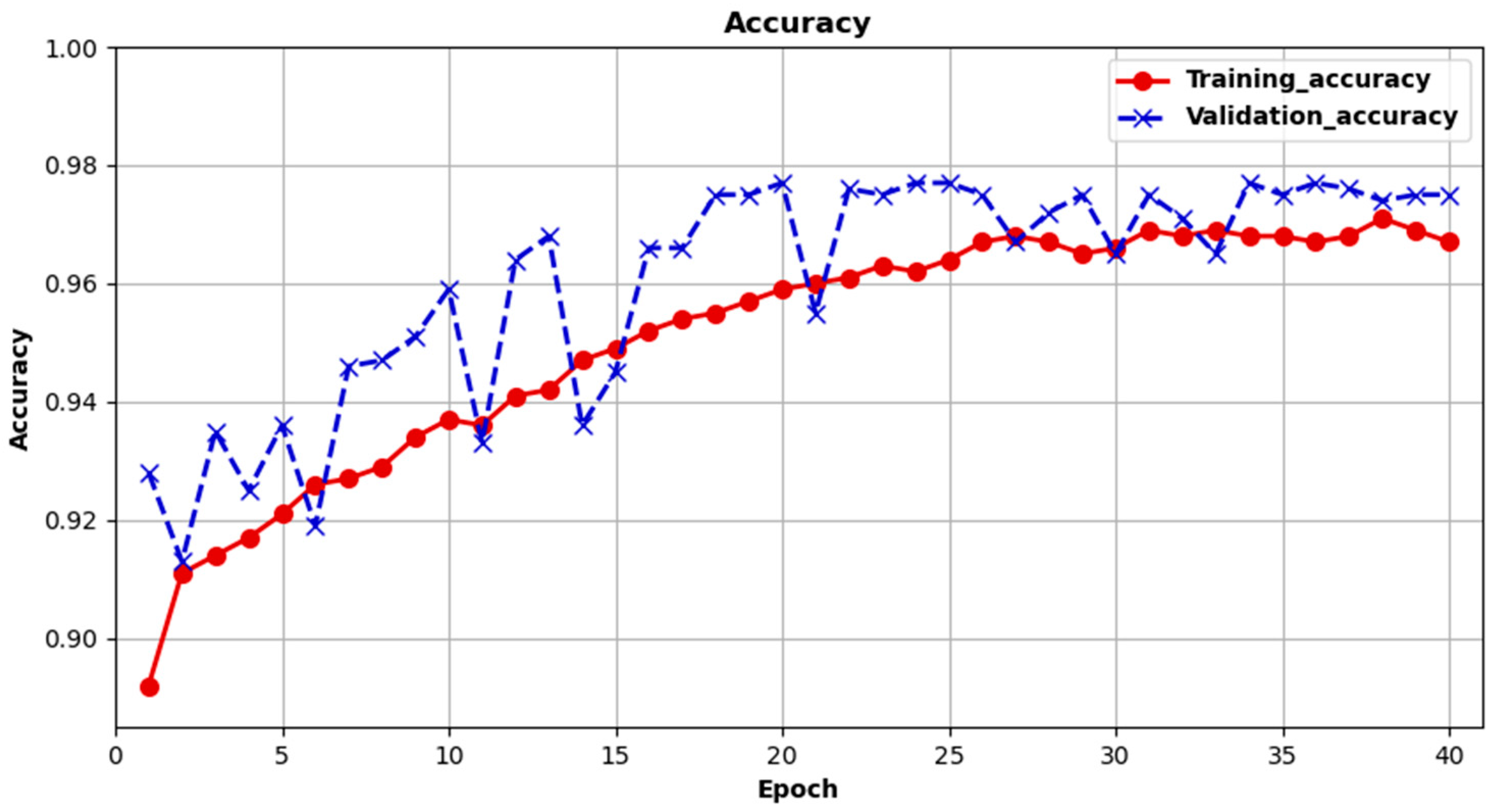
The experimental results in
Table 5 show that the proposed sample expansion strategy had a positive impact on improving the accuracy of forest fire identification. The expansion of the sample size made the training data more diversified, which can reduce the field transfer of training and testing to a certain extent. Therefore, compared with the dataset before the sample expansion, the expanded dataset achieved higher forest fire recognition accuracy.
The choice of loss function also affects the accuracy of forest fire identification. The experimental results in
Table 6 and
Table 7 show that, compared with the traditional cross-entropy loss function, the Focus Loss function focused more on the training of difficult samples, which helped to improve the learning ability of the network.
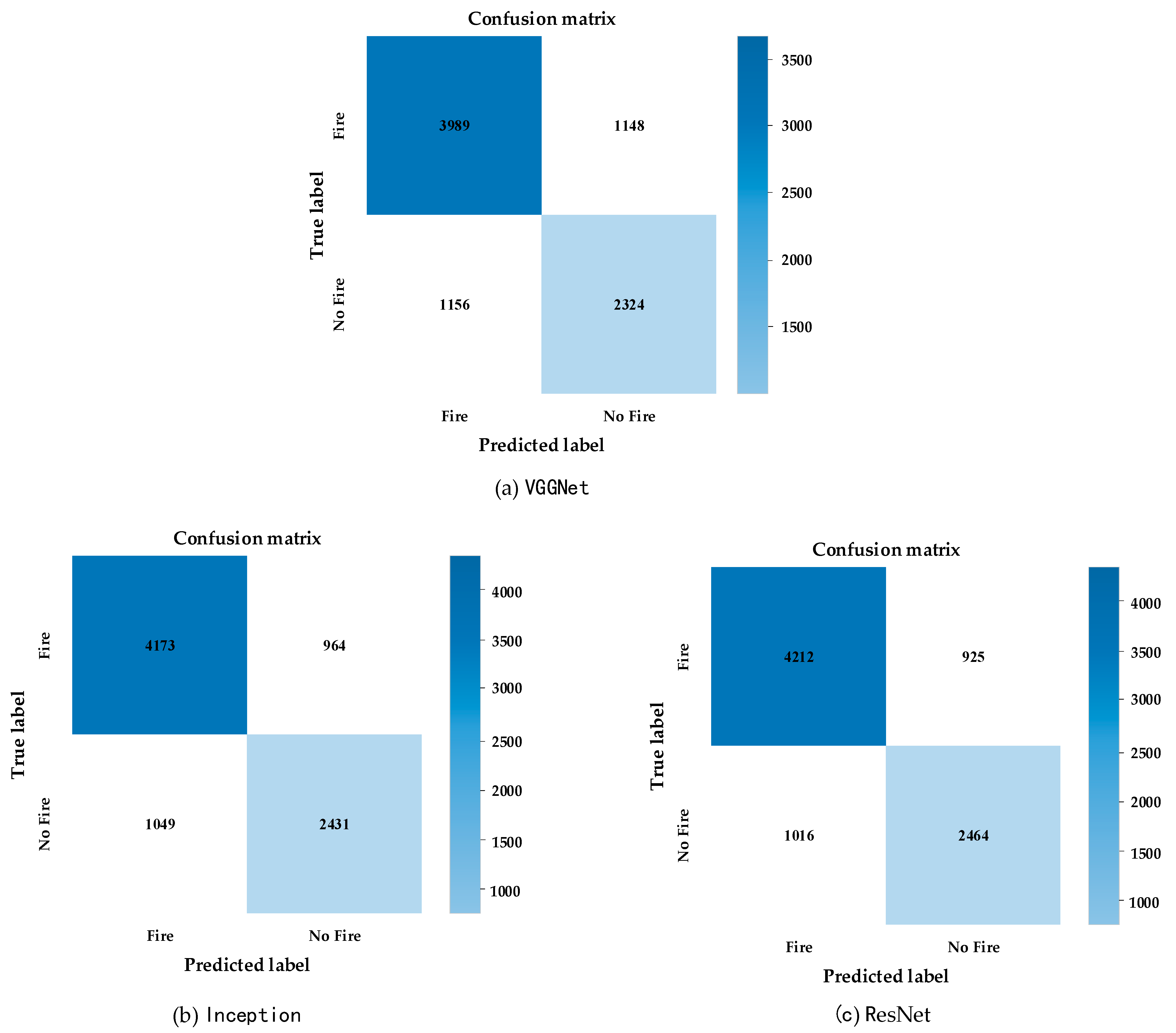
The experimental results shown in
Table 8 indicate that different depths of the ResNet network affect the recognition accuracy and operational performance of the model. With the deepening of network layers, although the accuracy of forest fire identification is improved, the time consumption of operations also increases. After weighing the model complexity, training cost, test accuracy and other factors, this study finally selected ResNet 50 as the backbone network for feature extraction.
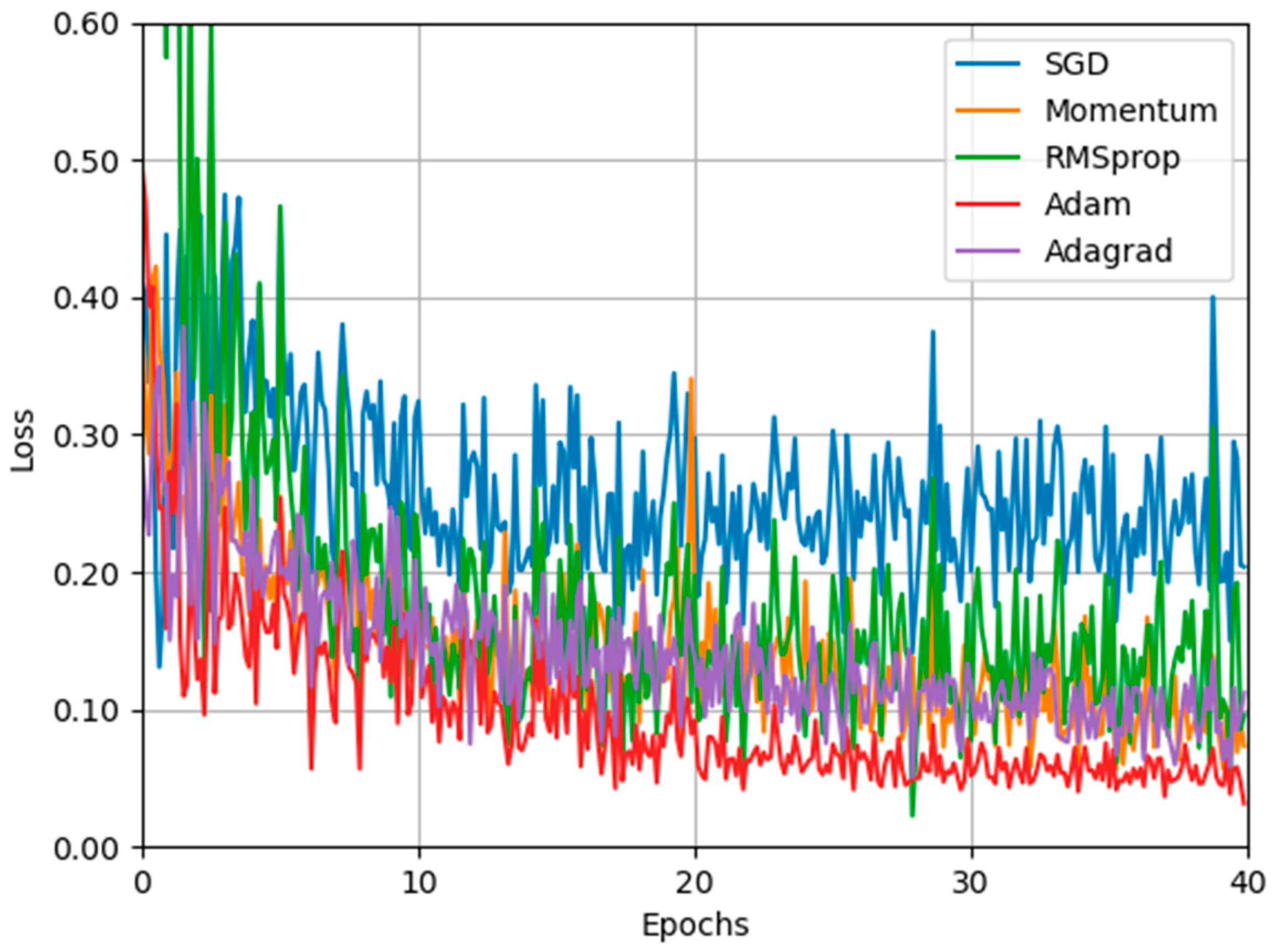
The selection of activation function and optimizer affects forest fire recognition accuracy. The experimental results shown in
Table 9 show that better recognition results can be obtained by fine-tuning the convolution block with Mish as the activation function and Adam as the optimizer. This is because the Mish activation function can effectively improve the gradient loss in network training. The Adam optimizer can avoid the model falling into local optimization during training.
In this study, six transfer learning schemes were designed for each network model, given in the second column of
Table 10. Specifically, “Scheme 0” represents the base scheme baseline in which the pre-training weights of all five convolutional blocks were fixed, and the network did not require fine-tuning during the training; “Scheme 1” to “Scheme 4” indicate the fine-tuning scheme from deep to shallow layers respectively, which gradually unlocked the fine-tuning operation of the deep layer network; “Scheme 5” indicates the fine-tuning of all the pre-training parameters. Observing the results in
Table 10, we can see that the ReNet50 network achieved the highest recognition accuracy by fixing the first two and fine-tuning the last three ConvBlocks, while the VGG16 network achieved a higher detection result by fixing the first three and fine-tuning the last two ConvBlocks. The accuracy of “Scheme 1” and of “Scheme 7”, which only fine-tuned the last convolutional block, is lower than that of schemes that fine-tuned the last two convolutional blocks; e.g., in the ResNet architecture “Scheme 1” was reduced by 0.81 percentage points compared with “Scheme 2”, and by 2.5 percentage points compared with “Scheme 3”. This is because features acquired by deeper networks are often abstract and have strong category correlation, therefore, fixed parameter information inhibits to a certain extent the ability of the network to capture discriminant information for the current task. In other words, the images in the ImageNet dataset tend to depict natural landscapes, animals, plants, etc., with low applicability after training on these images for transferring high-level semantic information obtained by the backbone network to the current forest fire image task. Low-level information such as edge, texture, color, etc., is often universal, and no matter the type of image it will cover similar features to a certain extent. Transferring and fixing trained shallow network weights to the proposed model will help improve the network convergence performance and prevent the deterioration of training. However, the parameters before which convolution blocks are to be fixed need specific analysis for different problems, so it is difficult to identify from the theoretical level the specific level most beneficial to the migration effect, and the situation is different for different models. For example, for the current forest fire image recognition problem, it is better to use ResNet50 to fix the first two convolution blocks, and VGG16 to fix the first three convolution blocks. “Scheme 5” and “Scheme 11” provide a training scheme for fine-tuning all migration parameters. It can be seen from the results that this training method achieved relatively good performance. “Scheme 5” and “Scheme 11” are poor than “Scheme 3” and “Scheme 8” because fine tune all parameters are prone to large fluctuations, especially in the initial stage, the training of the layered transmission characteristics influence each other, more “error” may occur between to optimize parameters of cumulative phenomenon, resulting in instability in the process of training. Finally, we selected “Scheme 3” as the fine-tuning method for the transfer learning strategy in the subsequent experimental process.
In order to verify that the FT-ResNet50 model can effectively extract image features, this paper visually displays the features captured by FT-ResNet50. The results in
Figure 13 show that with the increase of network depth, the extracted feature level also increases. Low-level features initially extracted from Convblock1 and Convblock2, such as edge, texture and color, are transformed in Convblock3 and subsequent convolution blocks into high-level abstract features with stronger task relevance. The results shown in
Figure 14 show that different convolution kernels also help to obtain different features of the image. The more types of convolution kernels, the better the feature extraction ability. Therefore, the FT-ResNet50 model proposed in this paper can extract more abundant features from fire images, and can better improve the accuracy of forest fire classification by combining low-level edge information with high-level semantic information.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}