1. Introduction
Facial recognition biometrics is one of the most popular uses of AI today [
1]. First-generation uses include unlocking and mobile phone payment [
2]; second-generation uses include camera monitoring and security systems [
3]. However, as the COVID-19 pandemic spread, mask use became commonplace, and many people put on masks to stay safe and avoid infection. As the world fought the heinous COVID-19 pandemic, traditional face-to-face engagements such as board meetings, press conferences, product introductions, and even family reunions have shifted to a more digital presence through video conversations based on the Internet. However, the use of masks has negatively affected the performance of existing face-based identification systems, as these systems have not been trained on masked face images [
4].
Facial recognition has become increasingly used by police in their investigations and responses. The Detroit Police Department used “facial recognition” to make 42 arrests; of these, only eight were valid [
5]. This rate is quite low, and some individuals may even be questioned as a result of the police force’s errors. There are, however, two primary causes: First, the cameras captured tens of millions of faces across the city of Detroit over a period of time, which is an enormous order of magnitude. Second, the main cause of this low accuracy rate is that in some environments, surveillance can record the criminal content of the offender, but routine crime is generally not recorded [
6]. The reason for the incredibly poor angle is that criminals frequently bow their heads, avoid looking directly into any camera equipment, and cover their face and facial characteristics, as well as the light and darkness. Therefore, light, angle, and causes of visual occlusion are the main limitations of face recognition technology. Finding ways to more effectively detect faces in specific scenarios is also the study focus of our project (wearing a mask).
Several fascinating studies have pointed out the limitations of currently available face recognition software. In one set of experiments, for example, it was discovered that most data packets tend to be more accurate for white male faces than for faces of people of color or females. In particular, there was a 10–100 times higher rate of false positives for Asian and African American faces than white ones in the database. Additionally, women are more likely than men to be misidentified [
7]. Although deep learning-based algorithms have reached great performance, large-scale annotated data are difficult to obtain, and the enormous parameters make model implementation in embedded systems problematic. To overcome this, a dissimilarity-based strategy [
8] that selects few but representative samples while taking data variety into account might be utilized.
Obviously, recent advances in this area have focused on trying to recognize an obscured face [
9]. The technical requirements for these two cases could not be more dissimilar [
10]. High requirements for AI recognition accuracy, typically beginning at four nines, are necessary in consumer scenarios with a focus on technical accuracy, such as unlocking mobile phones that involve financial payments [
11]. For example, the Ruyi Pay PAD is a face-swiping payment device that has a cloud slave enhanced liveness detection module that has achieved 99.99% precision in the anti-living attack, as certified by the Bank Card Testing Centre [
12]. In terms of security, the scope of available tech is now more of a priority [
13]. To avoid being tracked by CCTV, for example, when captured by law enforcement and subsequently escaping from their custody, the vast majority of criminal suspects choose to cover some of their faces with hats or masks [
14]. Several researchers have studied face occlusion technology for quite some time [
15] with an eye on meeting the needs of real-world security scenarios [
16,
17], and have made several different attempts to make the technology more user-friendly, as the ethical use of face recognition in areas such as law enforcement investigations requires a set of clear criteria to ensure that this technology is trustworthy and safe [
18]. Deep forgery detection techniques are learning-based systems that rely on data to a certain degree. Enhancing facial anti-spoofing databases is an excellent way to address the aforementioned issue. Yang et al. [
19] proposed a face swapping system based on StyleGAN based on a feature pyramid network to obtain facial features and map them to the latent space of StyleGAN for whole face swapping while offering accurate information for deep forgery detection for ensuring the security of audiovisual systems. Their alternative strategy [
20] included post-processing to improve the image’s authenticity. To demonstrate the advantages of our proposed technique. Experiments demonstrated the usefulness of identity latent space and controllability, and the suggested network was able to deliver photo-level results while outperforming previous face swapping approaches.
As part of our study, we investigated the following scientific complexities. Preprocessing data and its effect on facial recognition systems: although many face recognition algorithms are “squealed down” on various evaluation lists [
21], Google’s brilliant FaceNet maintains a high accuracy rate in this area [
22]. With FaceNet, the precision was 99.63% in the LFW dataset and 95.12% in the YouTube Faces DB dataset. Therefore, today due to COVID-19, everyone is required to wear protective masks. In this case, we are making changes to the structure and parameters, and adapting the dataset and image preprocessing of the FaceNet method, which previously had a very high accuracy rate in face recognition. The masked face dataset should be just as successful and find use in a wide range of contexts. It helps law enforcement identify criminals hiding behind masks. Since we are attempting to recognize faces while they are obscured by masks, we need to be able to do so with less information than is available in the standard face dataset. Since there are fewer data to learn from, accurate subject recognition becomes more difficult when the faces of the subjects being studied are obscured or masked [
23]. Therefore, it is necessary to identify an appropriate model and approach for this. Evaluations of recognition algorithms conducted after the pandemic reveal that the vast majority suffer from a decline in performance when faces are concealed. To this end, we plan to work on better masked-face models. There are numerous varieties of masks, each with its own level of occlusion. Another factor is the question of how to make better use of the data gathered from non-occlusion regions. Furthermore, when both the training and test images are masked, recognition performance decreases. This issue will be resolved soon.
The novelty of this paper is that it addresses a new challenge in face recognition technology caused by the widespread use of masks during the COVID-19 pandemic. With an increasing demand for technology that can identify individuals while wearing masks, this paper provides an overview of various standard face recognition technologies and the latest models for masked and unmasked face recognition.
The contribution of this paper is that it evaluates and compares the accuracy of these technologies and models and concludes that the best model to recognize individuals while wearing masks is FaceNet. The paper also presents a novel approach of using data preprocessing techniques such as ‘CutMix’ and ‘mixup’ and making changes to the model’s parameters and structure to improve the accuracy of FaceNet. This research is a significant step forward in the field of face recognition technology and its application in the era of mask wear.
To further guide our research, we introduce the following research questions.
How can facial recognition algorithms, particularly FaceNet, be improved to accurately recognize faces that are partially or fully obscured by masks?
What techniques can be used to effectively utilize data from non-occluded regions of masked faces to improve recognition performance?
What approaches and models are most appropriate for recognizing masked faces?
How can recognition performance be improved in masked face datasets, including in scenarios where both training and test images are masked?
What solutions can be implemented to overcome the decline in recognition performance when faces are concealed?
The remainder of the paper is organized as follows.
Section 2 presents an overview of the state-of-the-art.
Section 3 discusses the methods for masked face detection, describes the construction of the datasets, explains the image augmentation methods, and describes the proposed method.
Section 4 presents the results of experiments and presents the results of the ablation study.
Section 5 provides answers to research questions and discusses the limitations of the study. Finally,
Section 6 presents the conclusions.
2. State-of-the-Art Overview
This section first introduces some of the popular methods proposed for regular face recognition. Then, the state-of-the-art overview continues with masked face recognition.
In general, the techniques to be applied in face recognition are quite simple [
24]. Face characteristics can be extracted using principal component analysis or linear discriminant analysis, and then for example basic Euclidean distance with a backpropagated neural network can be employed to categorize face subjects [
25]. Often, such facial recognition algorithms are subject to face-presenting assaults (face-PA), including print, video playback, and rubber masks [
26]. To address the aforementioned issues, Shekel et al. [
27] built a unique deep neural network to deep-encode face areas. Others used PCA to minimize the dimensionality of feature representation while eliminating redundant and contaminated visual information [
28]. Damer et al. [
17] investigated the accuracy of face recognition and proposed the use of evolutionary algorithms to maximize the selection and prioritization of test cases, while machine learning guided the search for successful test cases. Yu et al. [
29] built a face detection and recognition system based on neural computing paradigms and artificial neural methods. The research findings indicated that the approach had a greater detection accuracy and a faster computation. Tavakolian’s team [
30] suggested a technique based on multiscale facial components and the characteristics of the Eigen/Fisher artificial neural network, aiming to reduce the components of the face of various resolutions, such as eyes, nose, mouth, and the complete face, according to their saliency, and then apply the principal component analysis of the subspace or linear analysis to generate a vector of facial characteristics. Soni et al. [
31] suggested using preprocessing, cascade feature extraction, optimal feature extraction, and recognition as the four basic phases in convolutional processing. Deotale et al. [
32] suggested an unsupervised neural network for the analysis of human activity as well as capturing faces. Gao et al. [
33] established the idea of candidate areas for faces. Thilapi et al. [
34] used the Ada boost face recognition system to scrutinize and retain all candidate regions. In [
35], the candidate area was then classified using a small-scale CNN to determine whether it is a face and a medium-scale CNN to complete the categorization of all candidate regions. Moghadam et al. [
36] introduced a new deep dynamic neural network to assess and extract three key aspects of facial expression movies. The suggested model of [
37] had recurrent network benefits and can be used to assess the sequence and dynamics of information in moving faces.
Table 1 presents the recognition rate of different methods, tested on a regular face (without mask) dataset.
Face recognition algorithms have evolved rapidly over the years due to a variety of causes [
48]. Researchers have researched and created a variety of algorithms for occluded face identification in response to the unexpected aspects encountered in real world circumstances [
49]. Zhao suggested a consistent subdecision network to obtain subdecisions that correspond to different facial areas and constraining subdecisions using weighted bidirectional KL divergence to focus the network on the upper faces without occlusion [
50]. Fine-tuning current face recognition models on a dataset of masked faces is one of the most prevalent ways for masked face identification [
51]. This strategy has been shown to improve the accuracy of masked face recognition, but it depends on the availability of a large and diverse collection of masked faces [
52]. In [
53], for example, scientists fine-tuned a face recognition model using a dataset of masked faces and reached a recognition accuracy of 92.5%.
A multitask learning architecture, in which a single network is trained to perform mask classification and face recognition tasks, is another technique successfully applied to mask recognition [
54]. This strategy has also been found to increase the precision of mask face recognition by using mask information to aid in the recognition process [
55]. For example, in [
56], the authors suggested a multitask learning architecture and attained a recognition accuracy of 96.2%. Another approach is to employ generative models, such as Generative Adversarial Networks (GANs) [
57] or Variational Autoencoders (VAEs) [
58], to generate a varied set of masked faces for fine-tuning or training new models. A similar VAE-based method has also been shown to improve the accuracy of masked face recognition, although it depends on the availability of a large and diverse collection of unmasked faces [
59]. For example, in [
60], the authors used a GAN to generate masked faces and attained a recognition accuracy of 94.5%. A popular strategy is to remove the mask from the face before applying a facial recognition model to the unmasked face [
61]. This is accomplished by training the deep learning model to create an unmasked face from the input masked face. For example, Liu et al. [
62] explored facial action recognition and face identification applications and discovered that both benefit from the encoding of face photos using Gabor wavelets. They performed dimensionality reduction and a linear discriminant analysis on the down-sampled data. Gabor wavelet faces can help to enhance discrimination. The closest feature space is expanded using several similarity measures. Hao et al. [
63] proposed a uniform framework to identify both masked and unmasked faces. They proposed rectification blocks to correct features extracted by a cutting-edge classification method in both the spatial and channel dimensions to reduce the distance in the corrected feature space between a masked face and its mask-free equivalent.
Other approaches, such as Region-based CNN, Two-stream CNN, and 3D CNN, have been proven to increase the recognition accuracy of masked faces. Ref. [
64] used a Region-based CNN to extract characteristics from the masked face, which were subsequently put into a fully connected layer for classification. On a masked face dataset, their approach achieved an accuracy of 96.2%. In [
65], a 3D CNN was used to learn spatial–temporal information from the masked face, which was subsequently input into a fully connected layer for classification. On a masked face dataset, the approach attained an accuracy of 98.5%.
Although these approaches have increased masked face recognition accuracy, they still depend on the availability of a large and diverse collection of masked faces. In [
66], to recognize faces of persons in mines, avalanches, under water, or other hazardous settings where their face may not be highly visible over the surrounding background, a lightweight CNN architecture was presented. The created model supports mobile devices as easily as possible. A box is displayed on the device’s screen as the processing output at the face location. The findings demonstrate that the proposed lightweight CNN recognized human faces over a range of textures with an accuracy of more than 95%. In [
67], face verification was performed using a hybrid method based on SURF and a neural network classifier. The entire system can be applied in real time to confirm individuals’ IDs in congested areas such as airports. To boost overall performance, Fadi presented the Embedding Unmasking Model, which works on top of current face recognition algorithms [
68]. The authors of [
69] presented a dual-branch training technique to direct the model’s attention to the top half of the face in order to extract strong features for masked face recognition. During training, the characteristics gained at the global branch’s intermediate layers are supplied into the suggested attention module, which functions as a local branch and aids in resilience. The Masked Face Detection Dataset (MFDD), the Real-World Masked Face Recognition Dataset (RMFRD), and the Synthetic Masked Face Recognition Dataset (SMFRD) are the three types of masked face dataset proposed by Huang et al. [
70], allowing for a more realistic evaluation of face classification algorithms. Cao et al. [
71] proposed a new dataset called Diverse Masked Faces and advised that the YOLOX model be modified with a new composite loss that combines CIoU and alpha-IoU losses and retains both benefits. Wang’s mask creation module [
72], on the other hand, used facial landmarks to generate more realistic and reliable masked faces for training in addition to using existing datasets. The loss function search module aimed to find the best loss function for face recognition. Boutros et al. [
68] presented an Embedding Unmasking Model (EUM) that would work over current face recognition methods. They also provided an innovative loss function, the Self-Restrained Triplet (SRT), which allowed the EUM to generate embeddings that resembled those of unmasked faces of the same individuals.
Table 2 presents the comparison of recognition accuracy of different methods, tested on a masked face dataset.
In summary, biometric face recognition systems have gained widespread use in various applications such as security, access control, and identification [
83]. However, there are several challenges and limitations that affect their performance and accuracy. One major challenge is the variability of lighting conditions, which can cause shadows, reflections, and other distortions that can affect the quality of captured images. This can lead to poor recognition performance, especially in outdoor environments [
84]. Another challenge is the change in facial appearance over time, such as aging, hairstyles, glasses, and makeup. These variations can cause problems for systems that are trained on a single image of a person, leading to poor recognition accuracy [
85]. Additionally, facial recognition systems can be affected by the presence of occlusions such as masks, hats, and scarfs, which can make it difficult to accurately identify a person [
86].
3. Materials and Methods
3.1. Datasets Characteristics
This research conducted its experiments on a combination of two original datasets. The first dataset is CASIA [
87,
88], which contains 492,832 face images with 10,585 identities.
Figure 1 illustrates samples of masked faces in the CASIA dataset.
The second dataset is a VGG-Face [
87] dataset. It contains 2,024,897 images of 8631 identities. Examples for images of the VGG-Face are presented in
Figure 2. The VGG-Face dataset was combined with the CASIA dataset used for the training, validation, and testing phases.
This combined dataset as shown in
Figure 3 is used for the training, validation, and testing phases.
3.2. Image Augmentation
Image augmentation is a technique used to increase the diversity of a dataset by applying various types of image transformation to existing images [
89]. This technique is particularly useful in the face recognition task, as it helps to improve the robustness and generalization of a model by exposing it to a wider range of variations in the input data. The benefits of image enhancement for the face recognition task are as follows. Brightness and contrast adjustments can help a model handle variations in lighting conditions, which can be a major challenge in face recognition. Rotation, scaling, and flipping can help a model handle variations in pose, which can make it difficult for a model to recognize a face from different angles. Image warping can help a model to handle variations in facial expressions, which can make it difficult for a model to recognize a face with different emotions. Adding masks or glasses can help a model to handle variations in occlusion, which can make it difficult for a model to recognize a face with masks or glasses on. By exposing a model to a wider range of variations in the input data, image augmentation can help to improve the generalization of the model and make it more robust to unseen variations.
First, we removed the data without masks from the dataset. Image augmentation is a very important step in our image preprocessing step. Unlike other projects, the purpose is to enhance the recognition ability of the image, such as strengthening the contrast and strengthening the light to make the image clearer. We aimed at making the image difficult to recognize, such as flipping the image, reducing the light intensity, etc., so that the image is not easy to recognize. Only in this way could we verify whether our face recognition algorithm can actually detect the part of the face and mask.
Image enhancement was performed using the Albumentation library [
90] using functions such as transpose, horizontal flip, vertical flip, shift scale rotation, change in hue and saturation, and random adjustment of brightness and contrast.
Figure 4 illustrates sample training images after augmentation.
In order to better improve the performance of the model, we also added the CutMix and mixup augmentation so as to perform some additional data preprocessing steps before actually training the model. We clipped and pasted random patches between the training images while using the CutMix augmentation. Depending on the size of the patches in the photos, the ground truth labels were blended. By forcing the model to concentrate on less discriminative aspects of the object being classified, CutMix improves the localization ability and is thus also well suited for tasks like object identification.
In Mixup augmentation, the pictures and labels of two samples are linearly interpolated to combine them. Mixup samples are poor at tasks such as image localization and object detection due to their unrealistic output and label ambiguity. Furthermore, a random patch from an image is zeroed out in a localized dropout technique known as “cutout augmentation” (replaced with black pixels). Reduced information and regularization capacity affect cutout samples.
Figure 5 shows a sample of images from our dataset after CutMix and Mixup augmentation.
3.3. Denoising of Images
The goal of denoising is to remove the noise from the image and recover the original image. This can be achieved by using a denoising model, which is trained to remove the noise added during the noise injection step. Image noise, which is usually electrical noise, is a random variation in the brightness or color information in photographs. It can be produced by the image sensor and circuitry of a scanner or digital camera [
90]. Noise invariably reduces the quality of images, resulting in a decrease in visual image quality [
91]. It should be noted that the impact of image noise manipulation on gaze distribution was mainly determined by noise intensity rather than noise type [
92].
There are several types of noise models that can be used to add noise to images in deep learning, such as Gaussian noise, salt and pepper noise, and Poisson noise.
Gaussian noise is the most used noise model, which is characterized by a normal distribution with a mean of zero and a standard deviation of
. It can be mathematically represented as follows:
where
x is the original image and
y is the noisy image.
Salt and pepper noise is a type of noise that randomly sets certain pixels to the minimum or maximum value. The mathematical representation of salt and pepper noise can be represented as:
where
x is the original image,
y is the noisy image,
p is the probability of noise, and
is a random number between 0 and 1.
Poisson noise is a type of noise that is typically added to images taken by sensors such as cameras. Poisson noise can be mathematically represented as:
where
x is the original image,
y is the noisy image, and
is the intensity of the noise.
To test for model robustness, we added Gaussian noise from the Albumentations library to the training dataset to reduce the image features and see how well our model performs. Noise was added to the images during the training phase and this was usually performed by applying a noise model to each image in the training dataset. The noise model was usually applied to each pixel of the image, with the goal of simulating the noise that would be present in real-world scenarios.
A loss function was used to measure the difference between the denoised image and the original image. The most commonly used loss function for image denoising is the mean squared error (MSE), which is defined as:
where
y is the original image,
is the image denoised, and
n is the number of pixels in the image.
Finally, the denoising model was optimized by minimizing the loss function using gradient descent, a method for finding the minimum of a function by iteratively moving in the direction of steepest descent as defined by the negative of the gradient:
where
is the parameter to optimize,
is the loss function,
is the learning rate, and
is the loss function gradient with respect to the parameters. The negative of the gradient is used to find the steepest descent direction, and the learning rate
determines the step size to take in that direction. The process is repeated until the function reaches a minimum.
In general, the goal of adding noise to images in deep learning is to improve the robustness of the model by making it more resistant to the noise present in real-world scenarios. This is achieved by training the model on noisy images and by using denoising techniques to remove the noise during the testing phase. The mathematical formulas and optimization techniques used in this process help minimize the difference between the denoised image and the original image, thus recovering the original image.
3.4. Up-Scaling of the Resolution
We have used a model called a “super-resolution generative adversarial network” (SRGAN) to evaluate the effects of higher resolution. The loss function in this model consists of two components: adversarial loss and content loss. Adversarial loss aims to produce realistic images that resemble the original, while content loss makes sure that the generated image has the same features as the low-resolution original. The loss function incorporates both adversarial and content loss using a perceptual loss function. A discriminator network, trained to differentiate between high-resolution images generated and true photorealistic images, drives the solution towards the manifold of natural images through adversarial loss [
92].
In SR-GAN, a generator network is trained to learn the mapping between LR and HR images. The generator network is a convolutional neural network (CNN) that takes an LR image as input and produces an SR image as output. A discriminator network is also trained to distinguish the SR image generated by the generator from the HR image. The generator and discriminator networks are trained simultaneously in an adversarial manner. The generator network is trained to minimize the difference between the SR image and the HR image, while the discriminator network is trained to maximize this difference.
The adversarial loss function used for this purpose is typically the binary cross-entropy loss function, given by:
where
represents the generated SR image,
represents the output of the discriminator network for the HR image, and
y is the label (1 for real images and 0 for generated images).
Additionally, a Mean Square Error (MSE) loss function is also used to measure the difference between the generated image and the original image:
where
represents the original HR image and
represents the LR input image. These two loss functions are combined to create a total loss function, which is used to train the generator network. An optimizer algorithm such as Adam, SGD, or RMSprop is used to adjust the parameters of the generator and discriminator networks during training.
The hyperparameters of SR-GAN are summarized in
Table 3. The performance of SR-GAN was evaluated on several publicly available datasets. The results show that SR-GAN was able to produce SR images with a significant improvement in quality compared to We implemented the SRGAN tensorflow model used in [
92] and trained it on our commercial dataset of VGG-masking face and the CASIA masking face dataset to further improve the resolution of the images and obtain a better generalization and performance of the model.
3.5. FaceNet Architecture
The original FaceNet architecture is a convolutional neural network (CNN), which has been trained to map face images to a compact and meaningful representation in Euclidean space, where the distances between points indicate the similarity between faces [
60].
The architecture of FaceNet can be divided into three main parts: The first part of the model is the convolutional neural network (CNN) that is used to extract features from the input face image. This CNN is typically based on an architecture called Inception, which is a variant of GoogleNet. The Inception architecture uses a combination of 1 × 1, 3 × 3, and 5 × 5 convolutional filters, as well as max pooling layers, to extract features from the input image. The output of the Inception CNN is a 512-dimensional feature vector. The second part of the model is the embedding layer, which is a fully connected (FC) layer that maps the 512-dimensional feature vector to a 128-dimensional embedding vector. The embedding vector is used to calculate the distance between faces. The embedding layer is defined as:
where
x is the 512-dimensional feature vector,
and
are the weight matrices, and
and
are the bias vectors.
The third part of the model is the triplet loss function, which is used to train the model. The triplet loss function is defined as:
where
A,
P, and
N are anchor, positive, and negative images, respectively,
,
, and
are embedding vectors of anchor, positive, and negative images, respectively, and
is a margin constant. The triplet loss function is used to ensure that the embedding vectors of the same person are closer to each other than the embedding vectors of different people.
3.6. Pareto-Optimized FaceNet Architecture
The Pareto-optimized FaceNet architecture is a variant of the original FaceNet model, which seeks to balance multiple objectives, such as accuracy, computational complexity, and memory requirements. To achieve this balance, the Pareto-optimized FaceNet architecture is designed based on a Pareto frontier, which is the set of solutions that cannot be further improved in one objective without degrading another objective.
Let
be the set of all possible architectures for FaceNet, and let
,
, and
be the accuracy, computational complexity, and memory requirements of the architecture
, respectively. An architecture
is said to dominate another architecture
if
,
, and
, with at least one inequality being strict. The Pareto-optimized FaceNet architecture is obtained from the set of Pareto optimal solutions, defined as:
The algorithm for Pareto optimization of the FaceNet architecture (see Algorithm 1) is based on the concept of multi-objective optimization using genetic algorithms. Note that this is just one possible approach to Pareto optimization, and other optimization algorithms may be used as well.
| Algorithm 1 Pareto optimization of FaceNet architecture |
- Require:
, , , - 1:
Initialize - 2:
- 3:
while do - 4:
Evaluate the objectives , , and for all - 5:
- 6:
- 7:
while do - 8:
- 9:
- 10:
- 11:
- 12:
Add to - 13:
end while - 14:
- 15:
- 16:
end while - 17:
return
|
The algorithm starts by initializing a random population of FaceNet architectures (line 2). Then, for a predefined number of generations (lines 3–14), the algorithm evaluates the objectives for each architecture (line 4) and computes the Pareto front (line 5). It generates offspring through selection, crossover, and mutation operations (lines 7–12), and the offspring become the new population for the next generation (line 13). Once the algorithm reaches the maximum number of generations, it returns the final Pareto front (line 15).
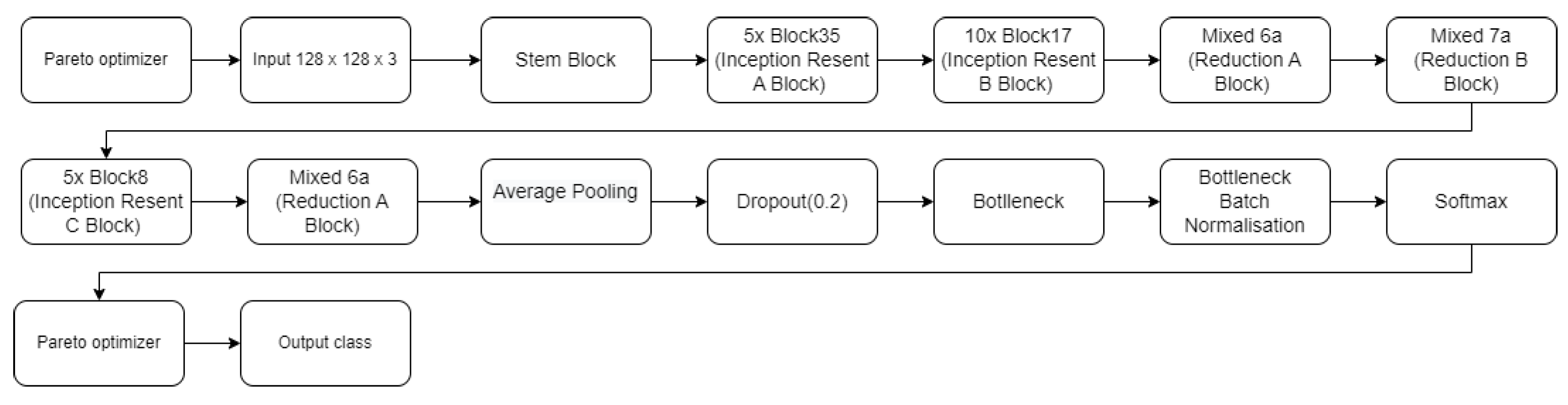
The Pareto-optimized FaceNet architecture includes the components from the original FaceNet architecture, such as the Inception CNN, the embedding layer, and the triplet loss function. However, the specific structure of the Inception CNN and the embedding layer may be altered to achieve a balance between the objectives. For example, a Pareto-optimized FaceNet architecture (see
Figure 6) might have a reduced number of layers, filters, or neurons in the Inception CNN and the embedding layer. This would result in a trade-off between accuracy, computational complexity, and memory requirements, achieving a balance that is optimal according to the Pareto frontier.
4. Results
4.1. Experimental Results
All experimental trials have been conducted on an Apple macbook pro M1 device equipped with the M1 8 core processor and 8 GB of RAM. The Jupyter Notebook software was chosen for conducting experiments and implementing them in this research. In addition, the models were trained and tested using the tensorflow and keras python packages. As described in
Section 3, the datasets used are a combination of the CASIA-WebFace+masks image dataset, which contains 492,832 face images with 10,585 identities (10,585 different classes), and the VGG-Face dataset, which included a total of 16,903 masked facial images (2622 identity classes).
The models were split into training, validation, and test sets using stratified K-folds cross-validation and the 60%-20%-20% rule. The training set was first preprocessed using Albumentations and then CutMix and MixUp to further improve the accuracy of the model.
To evaluate the performance, size, and computation time of the different algorithms, performance metrics had to be investigated through this research. The performance metrics used in this research are accuracy, flopping, and model size.
Classification Report: A classification algorithm’s predictive accuracy can be evaluated with the use of a classification report. It shows the ratio of accurate to inaccurate forecasts. In particular, the metrics of a categorization report can be predicted using True Positives (TP), False Positives (FP), True Negatives (TN), and False Negatives (FN).
Accuracy: The ratio of correctly classified data instances over all data instances is known as accuracy.
FLOPS, or floating-point operations per second, is a metric that determines a microprocessor’s capability to carry out floating-point calculations in one second.
Model size: Model size (number of parameters) is related to performance, and it is the size of the model after training. In this research, our model was measured in megabytes (MB).
4.2. Model Analysis and Comparison
The initial experiments performed involved six different models, namely: Arc-Face ResNet50, Inception ResnetV1, tensorflow densenet, vision transformer, and FaceNet keras models pre-trained on the imagenet dataset, and, finally, the Pareto-optimized FaceNet model.
All of the above models have been implemented and tested in detail. After training the models over 30 epochs, the results in
Table 4 show the performance of the models in all the different performance metrics. After comparing the different models, the Inception ResnetV1 model and the Densenet model had a precision of 60% and 66% in the test set, respectively, which is quite low. This shows an underperforming model compared to the rest. The vision transformer that had the worst performance, highest model size and flops after 30 epochs required a lot of computation power to train the model and increasing the number of epochs might have resulted in a higher accuracy.
The ArcFace ResNet50 and FaceNet models were more accurate in the test dataset, although they had more computation time compared to the rest. However, the best performance was obtained by the Pareto-optimized FaceNet model.
4.2.1. GradCam HeatMap
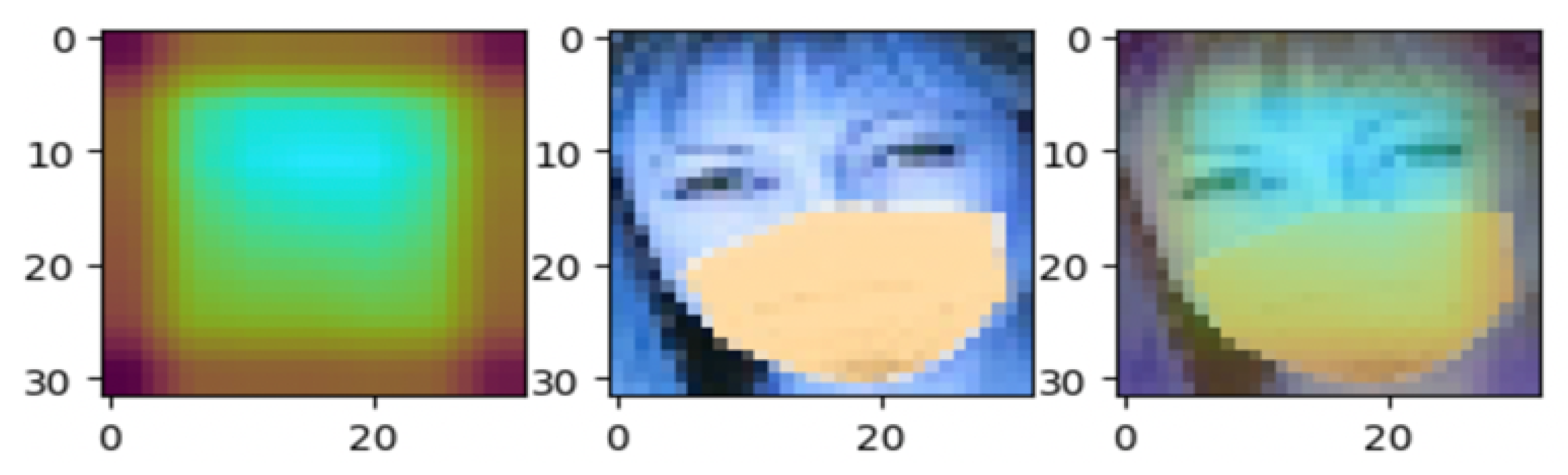
One of the most popular methods for computer vision interpretability is Grad-CAM. A saliency map weight feature map, resembling a heat map, can be created by multiplying the target feature map obtained by forward propagation by the gradient of the fully connected layer obtained by backward propagation on the target feature map and then passing a ReLU activation function. This identifies the critical receptive field for task execution. Grad-CAM is a classic method of CNN interpretability. Compared to CAM (class activation map), it can generate a heatmap without changing the model, which is very convenient and flexible [
93]. The implementation of this Grad-Cam heatmap to recognize our masked face dataset could help us increase the accuracy. The images in
Figure 7 are examples of the test results.
4.2.2. Accuracy and Loss Curves
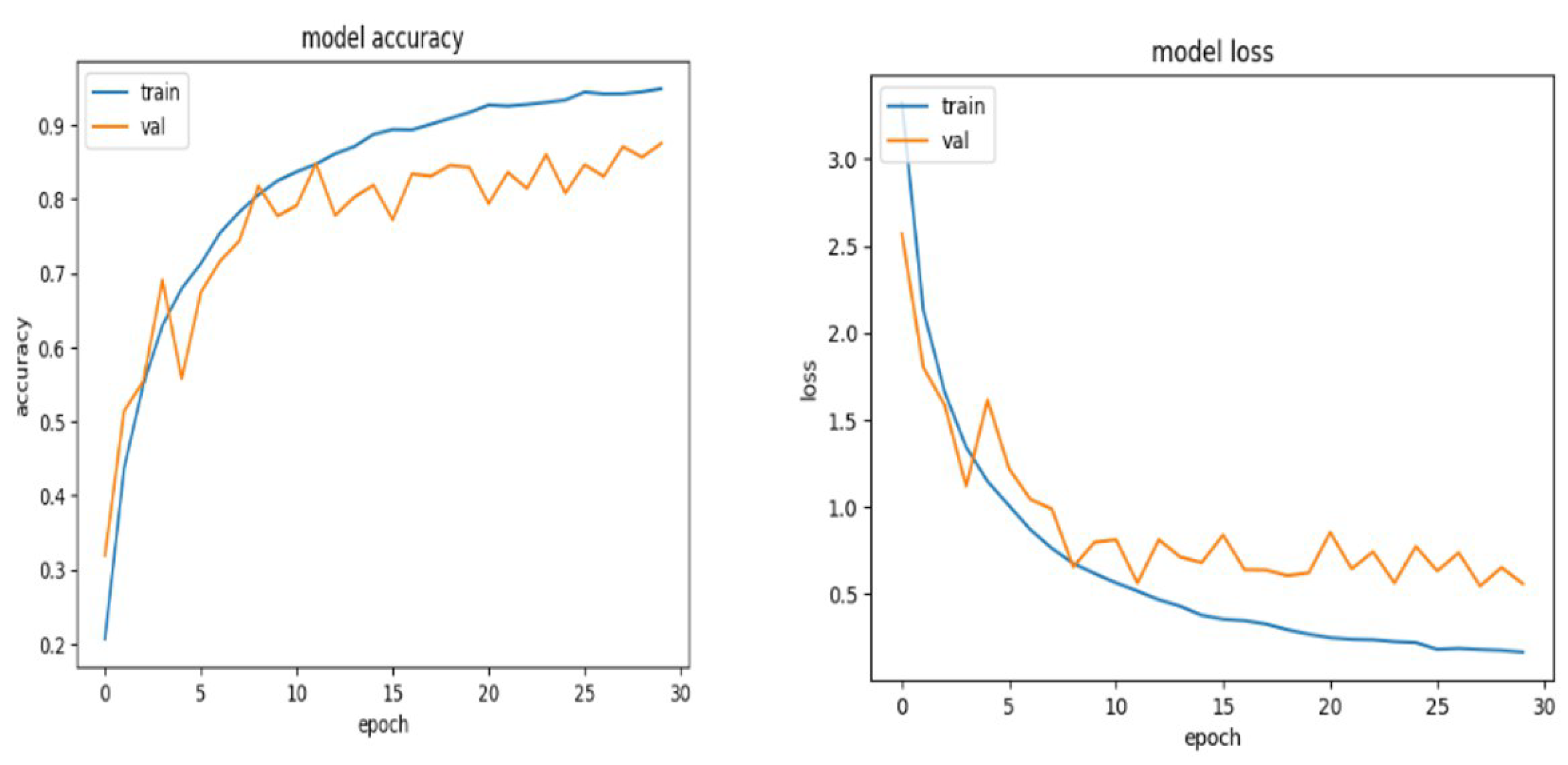
As seen in
Figure 8 below, after training the FaceNet model over 30 epochs, the validation accuracy of the model increased along with the training accuracy. This means that our model made better prediction increases as the epochs increased.
In addition, the training and validation loss value decreased, which means that the model was constantly learning. However, since the loss decreased in both the training set and the validation set, but there was a noticeable difference, the model could be improved in this case, which is the reason why we used GAN.
4.2.3. Classification Report
Class-by-class, the report in
Table 5 below displays the precision, recall, and F1 score of the primary classification metrics. True positives, false negatives, and everything in between were used to determine these measures. The predicted classes are simply referred to here as “positive” or “negative”.
4.2.4. Model Robustness
The robustness of the model is very important for a model. A good model should not cause huge deviations in results due to changes in values or data. Basically, programmers check the performance of the model by using new versus training data to determine the robustness of the model [
94].
The simplest way to check whether our model is robust is to add noise to the test data. In this case, we added noise to our dataset to test our model.
A method to determine whether models are change-resistant is to introduce noise into the test data. When we vary the amplitude of the noise, we can infer the model’s performance with new data and other noise sources.
In our test set, we have introduced Gaussian noise from the Albumentations library discussed in
Section 3.1 above. Means ranging from 10 to 50 were used, in order to see the performance of the mean changes.
Table 6 shows the performance of the model; as the mean of the Gaussian noise increased from 10 to 50, the model performance on the test set reduced from 89% to 82%.
After adding different intensities of noise, through step-by-step testing, we obtained the results in
Table 6. The data in the results can be stabilized to more than 80%, indicating that the stability of our model is quite good.
4.2.5. SR-GAN Result
Super-Resolution Generative Adversarial Networks (SRGANs) are a class of deep learning models that are used to increase the resolution of images. The goal of an SRGAN implementation is to generate high-resolution images from low-resolution inputs while maintaining the visual quality and realism of the output. In this paper, we present an SRGAN implementation that achieved an accuracy of 94% in generating high-resolution images.
The SRGAN model architecture consists of two main components: a generator and a discriminator. The generator is responsible for generating high-resolution images, while the discriminator is used to evaluate the realism of the generated images. Both the generator and the discriminator are deep neural networks that are trained using a variant of the Generative Adversarial Networks (GAN) training algorithm.
The generator network is based on a U-Net architecture, which is a type of convolutional neural network that uses skip connections to propagate information from the contracting path to the expanding path. This allows for the preservation of fine details in the generated images. Additionally, the generator uses a Residual-in-Residual Dense Block (RRDB) architecture to increase the capacity of the network, which improves the quality of the generated images.
The discriminator network is a PatchGAN, which classifies whether each NxN patch in an image is real or fake. This allows for the evaluation of the entire image, rather than just a single output. The discriminator uses a multi-scale discriminator architecture, which evaluates the image at multiple scales to improve the realism of the generated images.
During training, the generator and discriminator networks are optimized in an adversarial manner. The generator aims to generate high-resolution images that are indistinguishable from real images, while the discriminator aims to correctly classify the generated images as fake. The two networks are trained together, with the generator being updated to improve the realism of its output and the discriminator being updated to better classify the generated images.
The SRGAN implementation was trained on a dataset of low-resolution images and their corresponding high-resolution versions. The model was trained for 200 epochs, with a batch size of 16. The Adam optimizer was used for optimization, with a learning rate of 0.0001 and a beta value of 0.9.
The results of the SRGAN implementation show that it is capable of generating high-resolution images with a high degree of visual realism. The generated images have a resolution that is four times higher than the input images, and the accuracy of the model in generating high-resolution images was 95%. These results demonstrate the effectiveness of SRGANs in image super-resolution tasks and the potential for their use in various applications such as medical imaging, surveillance, and video compression.
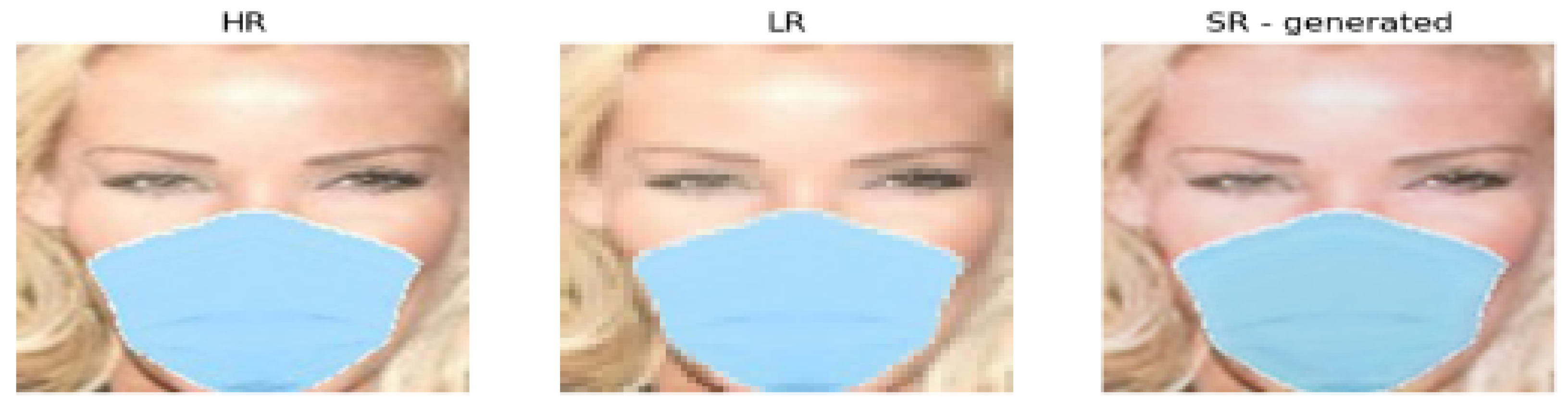
In conclusion, in our model, the Super Resolution GAN was used to denoise and also increase the resolution of images in the training dataset, as seen in
Figure 9 below. After the implementation of the SR-GAN, the performance of the model was improved to 94% in the test set.
Table 7 shows the result of the model after training the model with the SR-GAN generated images.
4.3. Ablation Study
FaceNet’s InceptionResnetV2 backbone is used for its quick learning time. This course serves as an ablation test bed for us to determine which components are most effective.
The effects of various convolutional blocks were investigated in this study by omitting or altering individual blocks progressively, and the results are summarized in
Table 8. We can see from the table that removing the bottleneck block resulted in a 6.4% performance drop, that Mixed 7a (Reduction-B block) decreased accuracy by 15% to 72%, and that all other techniques improved performance by 0.2% to 0.3%, with the exception of removing the dropout and bottleneck simultaneously, resulting in a 1% performance drop. This resulted in a 67.8% accuracy rate and highlights the vital role these components play in the overall structure of the model. The results of the evaluations are consistent with each other and do not indicate any significant progress.
We also investigated our approach on unmasked faces (see
Table 9. The baseline FaceNet model achieved a test accuracy of 92.25% with an evaluation time of 36.2 s, showcasing its strong performance. Various ablations were conducted to examine the effects of specific components on model performance. Notably, removing the bottleneck and certain Inception Resnet C Blocks (Block 8, Block 17, and Block 35) led to decreased test accuracies ranging from 46.61% to 83.26% and slightly affected the evaluation time. The inclusion of Dropout in conjunction with the bottleneck resulted in a lower test accuracy of 54.50%, indicating that this combination did not contribute positively to smoke detection. Furthermore, the Mixed 7a (Reduction-B block) ablation achieved a test accuracy of 74.25%, showing a moderate impact on model performance.
6. Conclusions
This research paper presents a novel hybrid model for the purpose of recognizing masked faces, which combines deep learning techniques with traditional machine learning methods. Our own Pareto-optimized FaceNet model was proposed as the main model for this task. This model is widely used in deep learning for facial recognition and has proven to be effective. The study utilized a mixture of two datasets consisting of 100 labels and various training and testing procedures. The dataset was divided into training, validation, and test sets using stratified K-Fold cross-validation, and the proposed model was trained and tested on these sets. The results of this study show that the Pareto optimization allowed improving the overall accuracy, over the 94% achieved by the original FaceNet variant, which also performed similarly to the arcface model during testing. Furthermore, the Pareto-optimized model no longer has a limitation of the model size and is a much smaller and more efficient version than the original FaceNet and its derivatives, helping to reduce its inference time and making it more practical for use in real-life applications.
Future work on FaceNet and facial recognition technology, in general, will focus on several key areas to address current limitations, improve performance, and explore new applications. We will continue exploring alternative network architectures that provide better trade-offs between accuracy, computational complexity, and memory requirements. This may involve designing novel layers, activation functions, or loss functions, as well as utilizing techniques such as network pruning, quantization, or knowledge distillation.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}