1. Introduction
First introduced by Fonseca and Fleming [
1], attainment surfaces provide researchers in multi-objective optimization with a means to accurately visualize the region dominated by a Pareto-optimal front (POF). In many studies, approximated Pareto optimal fronts (POFs) are shown by joining the non-dominated solutions using a curve. Fonseca and Fleming reasoned that it is not correct to use a curve to join these non-dominated solutions. The use of a curve creates a false impression that intermediate solutions exist between any two non-dominated solutions. In reality, there is no guarantee that any intermediate solutions exist. Fonseca and Fleming suggested that, instead of a curve, the non-dominated solutions can be used to create an envelope that separates the dominated and non-dominated spaces. The envelope formed by the non-dominated solutions is referred to as an attainment surface.
Despite being proposed in 1995, attainment surfaces have not seen wide use in the comparison of multi-objective algorithms (MOAs). Instead, the well-known hypervolume [
2,
3], inverted generational distance [
4,
5] and its improvements [
6], and spread [
7] measures are frequently used to quantify and to compare the quality of approximated POFs. This study provides an analysis of the shortcomings of attainment surfaces as a multi-objective performance measure. Specifically, the attainment-surface-based measure proposed by Knowles and Corne [
8] is analyzed. Improvements to Knowles and Corne’s approach for bi-objective optimization problems are developed and analyzed in this paper. Additionally, an
M-dimensional (where
M is the number of objectives) attainment-surface-based quantitative measure, named the porcupine measure, is proposed and analyzed.
The porcupine measure provides a way to quantify the ratio of the Pareto front when one algorithm performs statistically significantly better than another algorithm. The objective of this paper is to introduce this new attainment-surface-based measure and to illustrate its applicability. For this purpose, the measure is applied to compare the performance of arbitrary selected MOAs on a set of multi-objective optimization benchmark problems. Note that the focus is not on an extensive comparison of multi-objective algorithms but rather on validating the use of the porcupine measure as a statistically sound mechanism to compare MOAs.
The remainder of this paper is organized as follows.
Section 2 introduces multi-objective optimization along with the definitions used throughout this paper.
Section 3 presents the background and related work. Next, 2-dimensional attainment surfaces are introduced in
Section 4, followed by a weighted approach to produce attainment surfaces in
Section 5. The generalization to
M dimensions is provided in
Section 6. Finally, the conclusions are given in
Section 7.
2. Definitions
Without loss of generality, assuming minimization, a multi-objective optimization problem (MOP) with
M objectives is of the form
with
,
for all
, and where
is the feasible space as determined by constraints;
n is the dimension of the search space, and
M is the number of objective functions.
The following definitions are used throughout this paper.
Definition 1. (Domination): A decision vector dominates a decision vector (denoted by ) if and only if and such that .
Definition 2. (Pareto optimal): A decision vector is said to be Pareto optimal if no decision vector exists such that .
Definition 3. (Pareto-optimal set): A set , where , is referred to as the Pareto-optimal solutions (POS).
Definition 4. (Approximated Pareto-optimal front): A set , where , is referred to as an approximation for the true POF.
Definition 5. (Nadir objective vector): A vector that represents the upper bound of each objective in the entire POF is referred to as a nadir point.
3. Background and Related Work
Fonseca and Fleming [
1] suggested that the non-dominated solutions that make up the approximated POF be used to construct an attainment surface. The attainment surface’s envelope is defined as the boundary in the objective space that separates those points that are dominated by, or equal to, at least one of the non-dominated solutions that make up the approximated POF from those points for which no non-dominated solution dominates or equals.
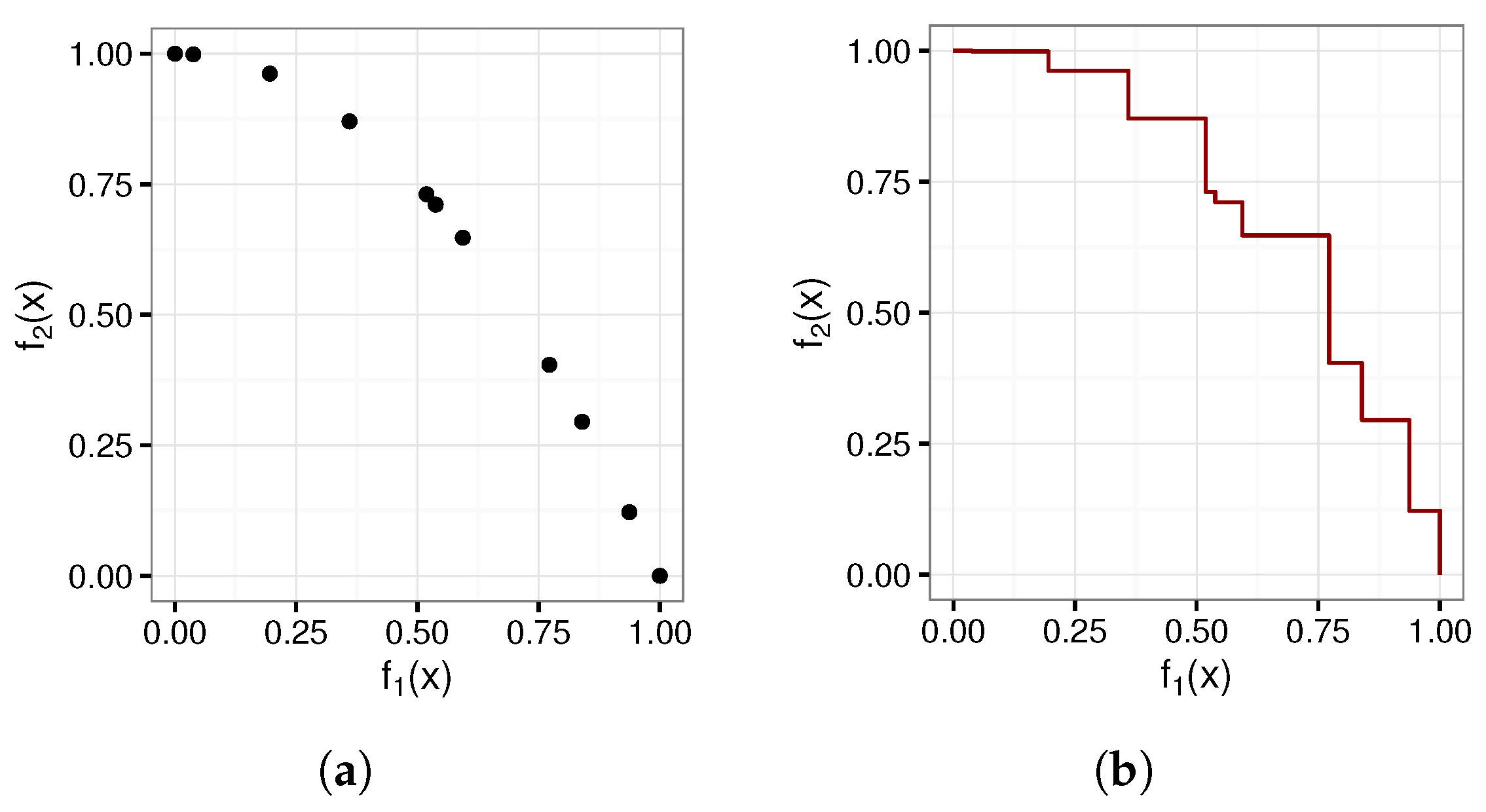
Figure 1 depicts an attainment surface and the corresponding approximated POF.
The attainment surface envelope is identical to the envelope used during the calculation of the hypervolume metric [
2,
3]. In contrast to the hypervolume calculation, in the case of an attainment surface, the envelope is not used directly in the calculation of a performance metric. Instead, the attainment surface can be used to visually compare algorithms’ performance by plotting the attainment surfaces for both algorithms.
For stochastic algorithms, variations in the performance over multiple runs (also referred to as samples) are expected. Fonseca and Fleming [
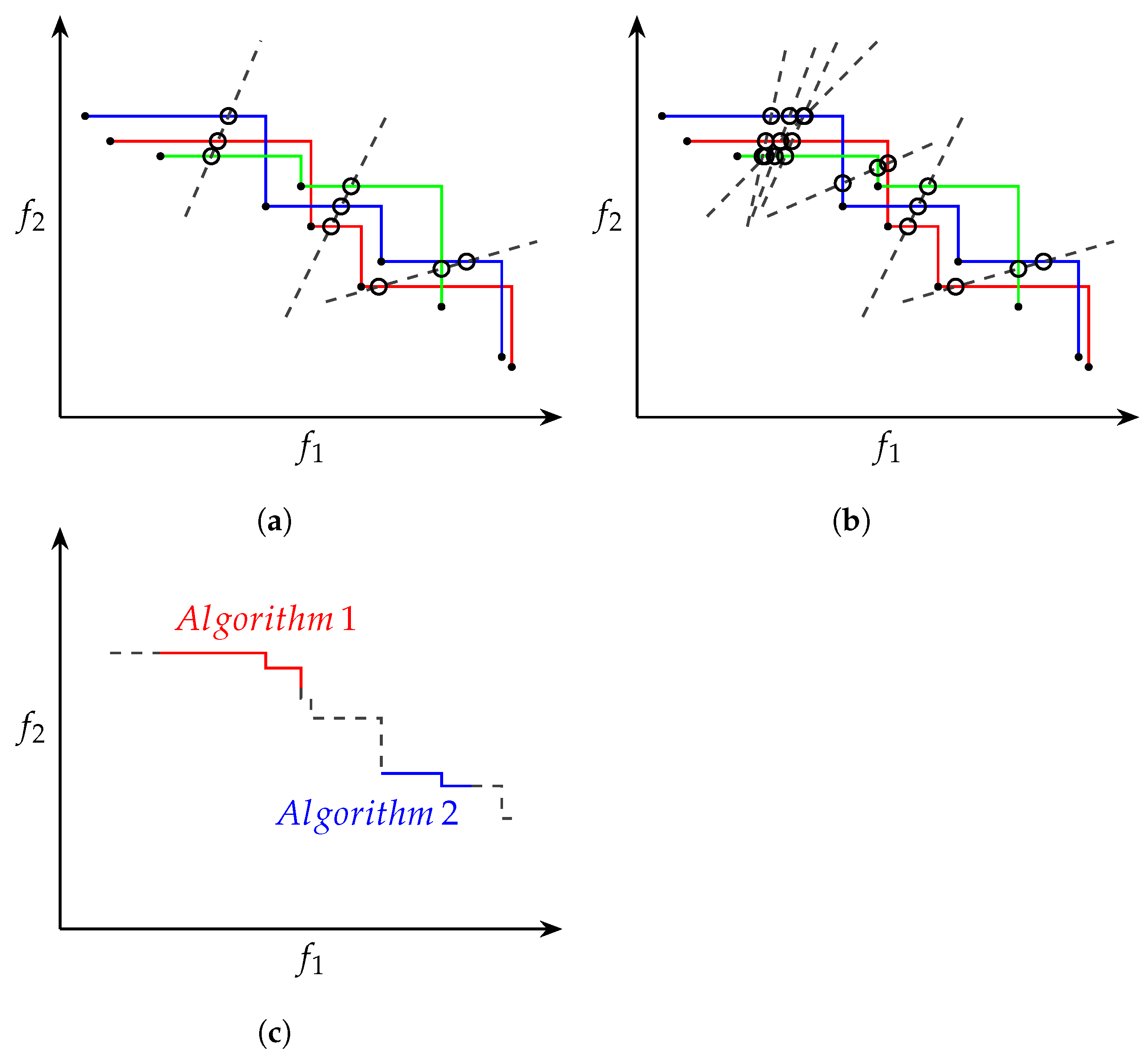
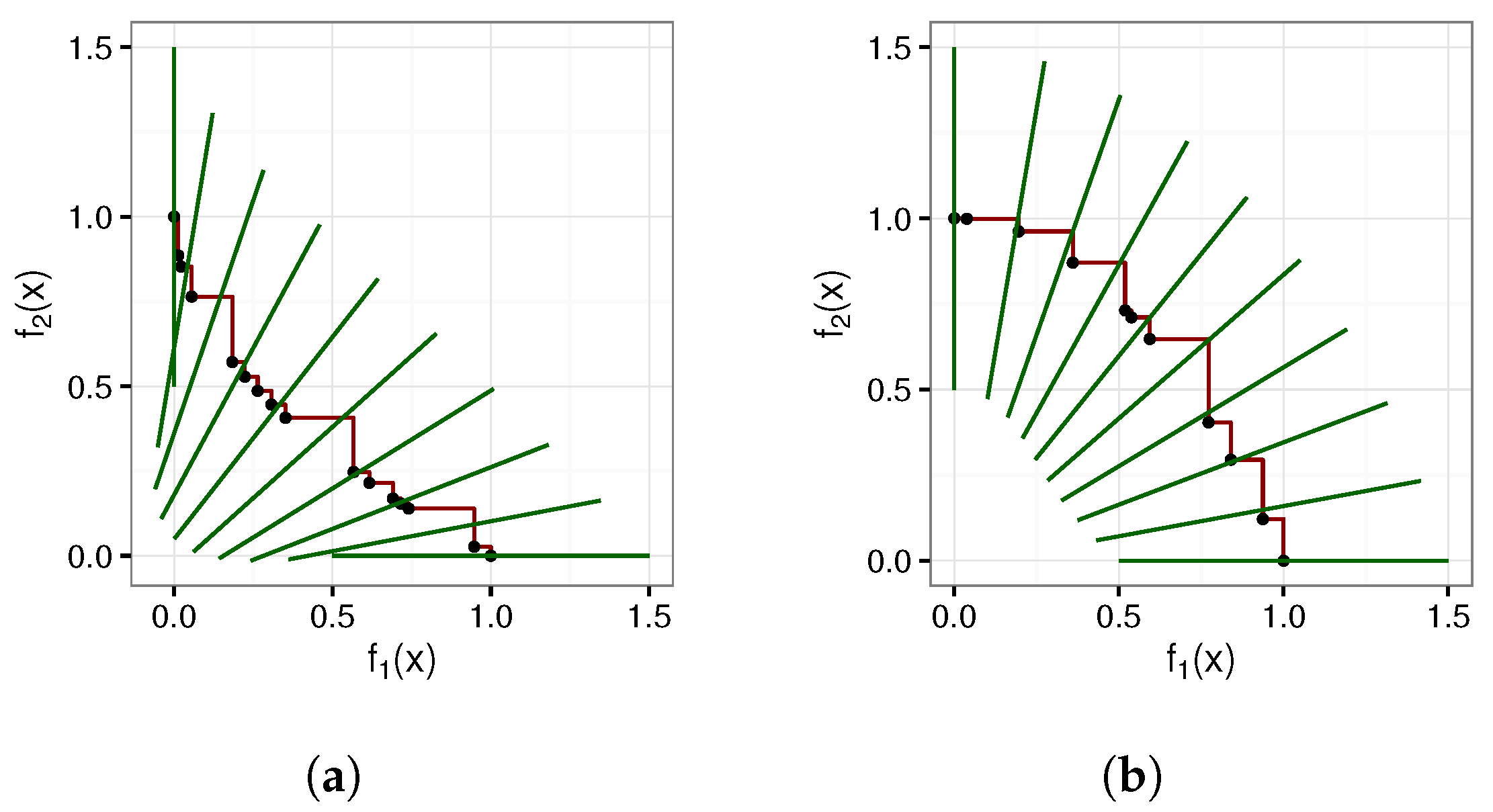
1] described a procedure to generate an attainment surface that represents a given algorithm’s performance over multiple independent runs. The attainment surface for multiple independent runs is computed by first determining the attainment surface for each run’s approximated POF. Next, a number of random imaginary lines is chosen, pointing in the direction of improvement for all the objectives. For each line, the points of intersection with each of the lines and the attainment surfaces are calculated.
Figure 2a,b depict three attainment surfaces with intersection lines and intersection points.
For each line, the intersection points can be seen as a sample distribution that is uni-dimensional and can thus be strictly ordered. By calculating the median for each of the sample distributions, the objective vectors that are likely to be attained in exactly of the runs can be identified. The envelope formed by the median points is known as the grand attainment surface. Similar to how the median is used to construct the grand attainment surface, the lower and upper quantiles (25th and 75th percentiles) are used to construct the and grand attainment surfaces.
The sample distribution approach can also be used to compare performance between algorithms. In order to compare two algorithms, two sample distributions—one for each of the algorithms—are calculated per intersection line. Standard non-parametric statistical test procedures can then be used to determine if there is a statistically significant difference between the two sample distributions. Using the statistical test results, a combined grand attainment surface, as depicted in
Figure 2c, can be constructed, showing the regions where each of the algorithms outperforms the other. Fonseca and Fleming [
1] suggested that suitable test procedures include the median test, its extensions to other quantiles, and tests of the Kolmogorov–Smirnov type [
9].
Knowles and Corne [
8] extended the work carried out by Fonseca and Fleming and used attainment surfaces to quantify the performance of their Pareto archives evolution strategy (PAES) algorithm. Knowles and Corne identified four variables in the approach proposed by Fonseca and Fleming, namely:
How many comparison lines should be used;
Where the comparison lines should go;
Which statistical test should be used to compare the univariate distribution;
In what form should the results be presented.
From their empirical analysis, Knowles and Corne found that at least 1000 lines should be used. In order to generate the intersection lines, the minimum and maximum values for each objective over the non-dominated solutions were found. The objective values were then normalized according to the minimum and maximum values into the range . Intersection lines were then generated as equally spread lines from the origin rotated from to , effectively rotating 90°, covering the complete approximated POF.
For M-dimensional problems, where the number of objectives is , Knowles and Corne suggested using a grid-based approach where points are spread equally on the M, -dimensional hyperplanes. Each hyperplane corresponds to an objective value fixed at the value . The intersection lines are drawn from the origin to these equally distributed points. In the case of 3-dimensional problems, a grid would result in 108 () points and, thus, 108 intersection lines. Similarly, using a grid on a 3-dimensional problem would result in 768 intersection lines, and so forth.
For statistical significance testing, Knowles and Corne used the Mann–Whitney U test [
9] with a significance level of
.
Finally, Knowles and Corne found that a convenient way to report the comparison results was to use simple value pairs , hereafter referred to as the Knowles-Corne measure (KC), where a gives the percentage of space for which algorithm A was found to be statistically superior to algorithm B, and b gives the percentage where algorithm B was found to be statistically superior to algorithm A. It can be noted that gives the percentage where neither algorithm was found to be statistically superior to the other.
Knowles and Corne [
8] generalized the definition of the comparison to compare more than two algorithms. For
K algorithms, the above comparison is carried out for all
algorithm pairs. For each algorithm,
k, two percentages are reported:
, which is the region where algorithm
k was not worse than any other algorithm, and
, which is the region where algorithm
k performed better than all the other
algorithms. Note that
because the region described by
is contained in the region described by
.
Knowles and Corne [
10] found that visualization of attainment surfaces in three dimensions is difficult due to the intersection lines not being evenly spread. As an alternative, Knowles presented an algorithm inspired by the work conducted by Smith et al. [
11] to visually draw summary attainment surfaces using axis-aligned lines. The algorithm was found to be particularly well suited for drawing 3-dimensional attainment surfaces.
Fonseca et al. [
12] continued work on attainment surfaces by introducing the empirical attainment function (EAF). The EAF is a mean-like, first-order moment measure of the solutions found by a multi-objective optimiser. The EAF allows for intuitive visual comparisons between bi-objective optimization algorithms by plotting the solution probabilities as a heat map [
13]. Fonseca et al. [
14] studied the use of the second-order EAF, which allows for the pairwise relationship between random Pareto-set approximations to be studied.
It should be noted that calculation of the EAF for three or more dimensions is not trivial [
15]. Efficient algorithms to calculate the EAF for two and three dimensions have been proposed in [
15]. Tušar and Filipič [
16] developed approaches to visualize the EAFs in two and three dimensions.
4. Regarding 2-Dimensional Attainment Surfaces
The attainment surface calculation approach developed by Fonseca and Fleming [
1] did not describe in detail how the intersection lines should be generated. Instead, it was only stated that a random number of intersection lines, each pointing in the direction of improvement for all the objectives, should be used. This approach worked well to construct a visualization of the attainment surface.
When Knowles and Corne [
8] extended the intersection line approach to develop a quantitative comparison measure, they needed the lines to be equally distributed. If the lines were not equally distributed, as depicted in
Figure 2b, certain regions of the attainment surface would contribute more than others, leading to misleading results.
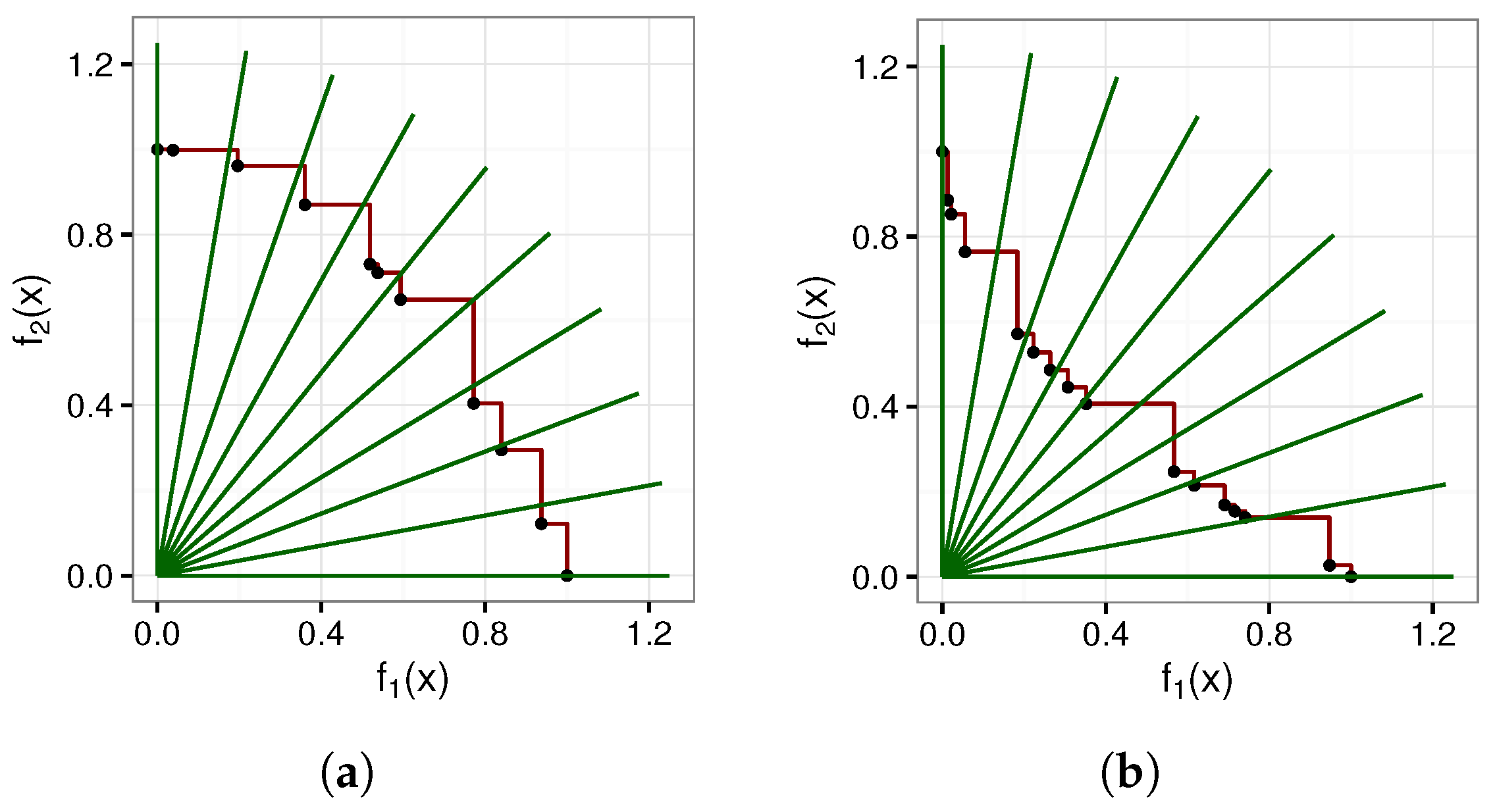
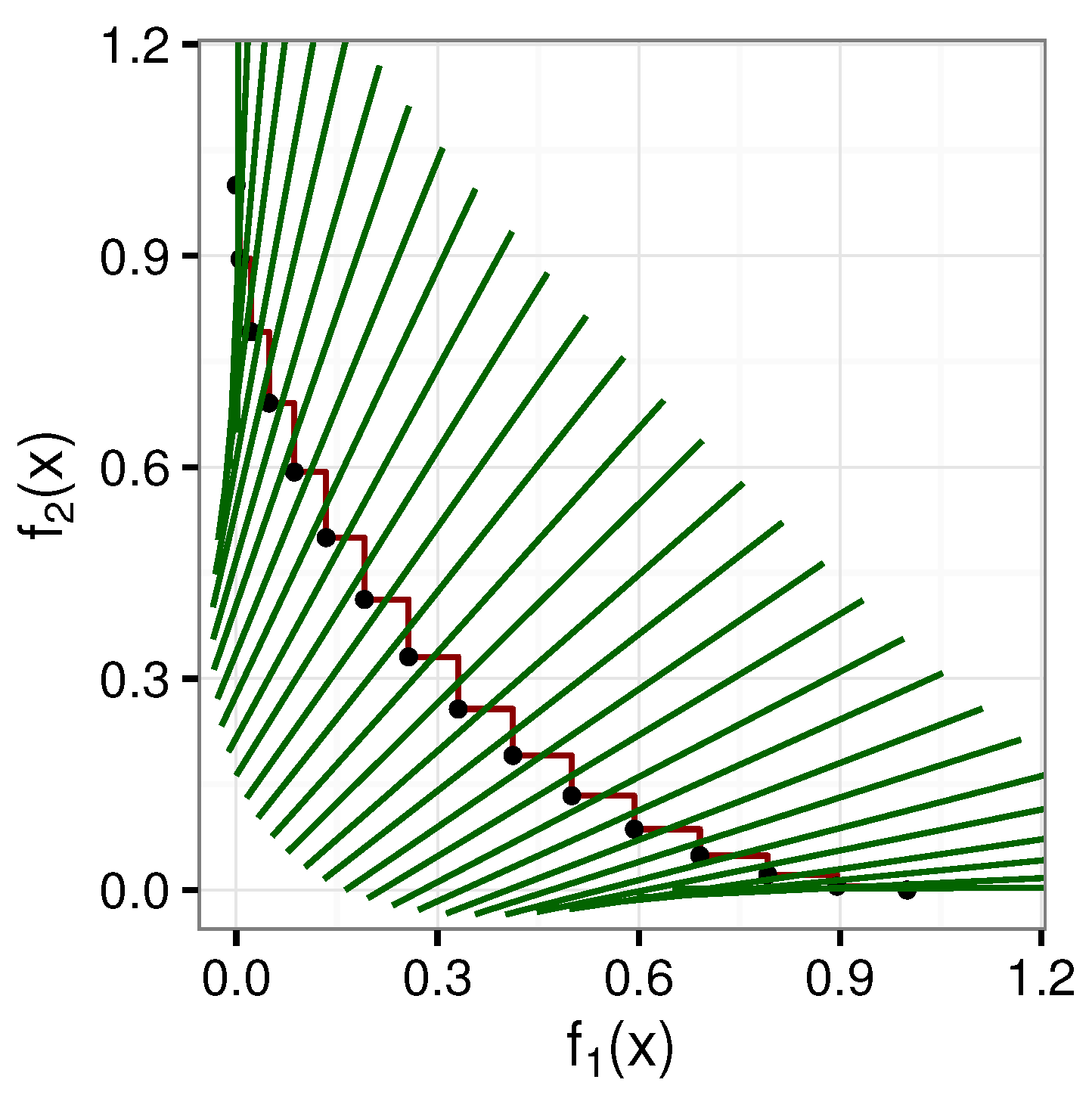
Figure 3 depicts two example attainment surfaces with rotation-based intersection lines.
Figure 3a depicts a concave attainment surface. Visually, the rotation-based intersection lines look to be equally distributed.
Figure 3b, however, depicts a convex attainment surface. Visually, the length of the attainment surface between the intersection lines is larger in the regions closer to the objective axis than in the middle regions. Clearly, the rotation-based intersection lines are not equally spaced for convex-shaped fronts when comparing the length of the attainment surface represented by each intersection line.
In order to address the unequal spacing of the rotation-based intersection lines, a new approach to placing the intersection lines is proposed in this paper. To compensate for the shape of the front, the intersection lines can be generated either inwardly or outwardly positioned on a line, running from the extreme values of the attainment surface, based on the shape of the attainment surfaces being compared.
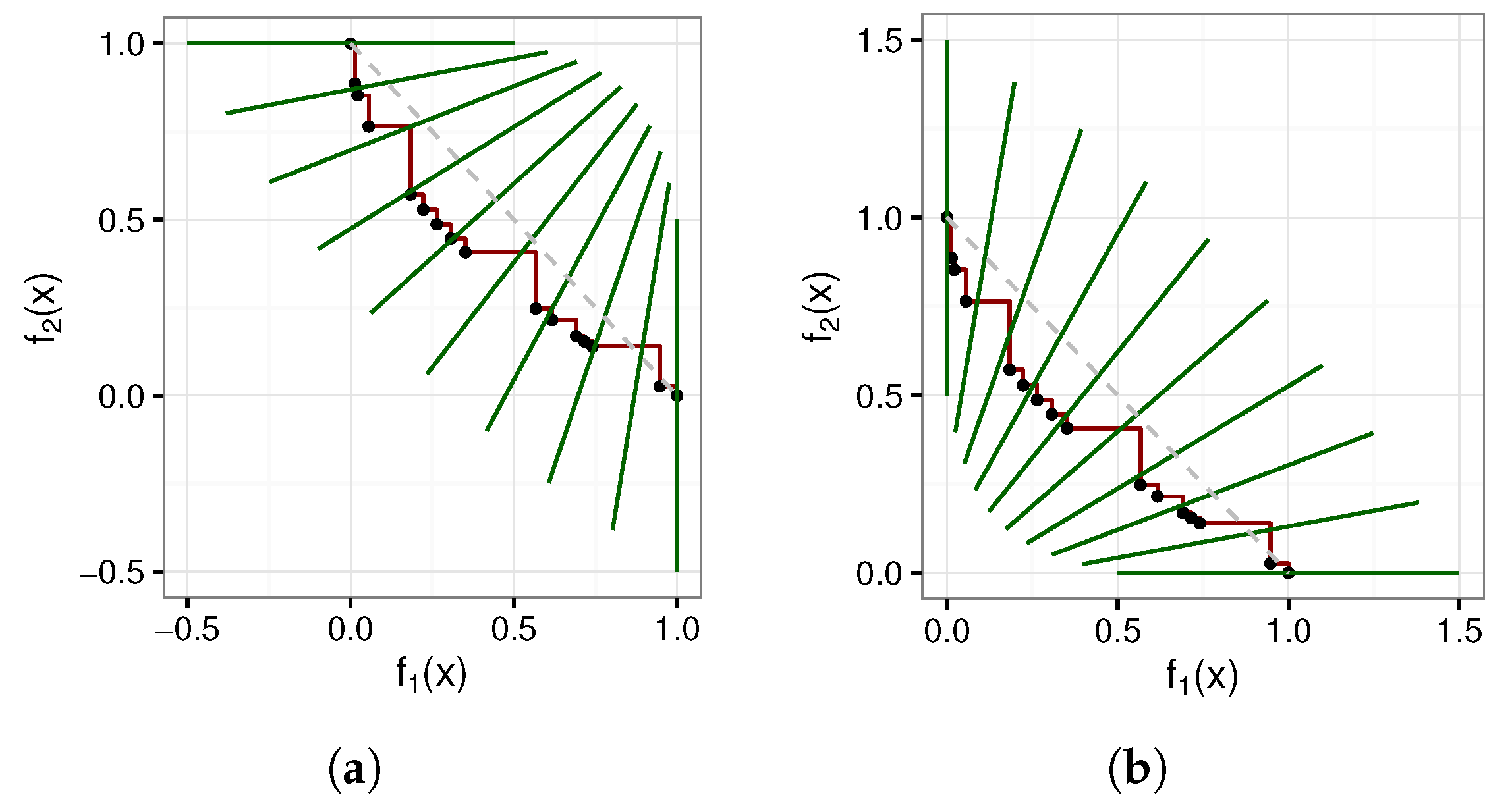
Figure 4 depicts the inward and outward intersection line approaches for a convex shaped front. The regions are clearly more equally spread for the inward intersection line approach.
However, the direction of the intersection lines is less desirable for comparison purposes. At the edges, the intersection lines are parallel with the opposite objective’s axis. Intuitively, it is more desirable that the intersection lines should be parallel to the closest objective’s axis. Another disadvantage of the inward and outward approaches is that the approach to be selected depends on the shape of the front, which is typically unknown. For attainment surfaces that are not fully convex or concave, neither approach is suitable.
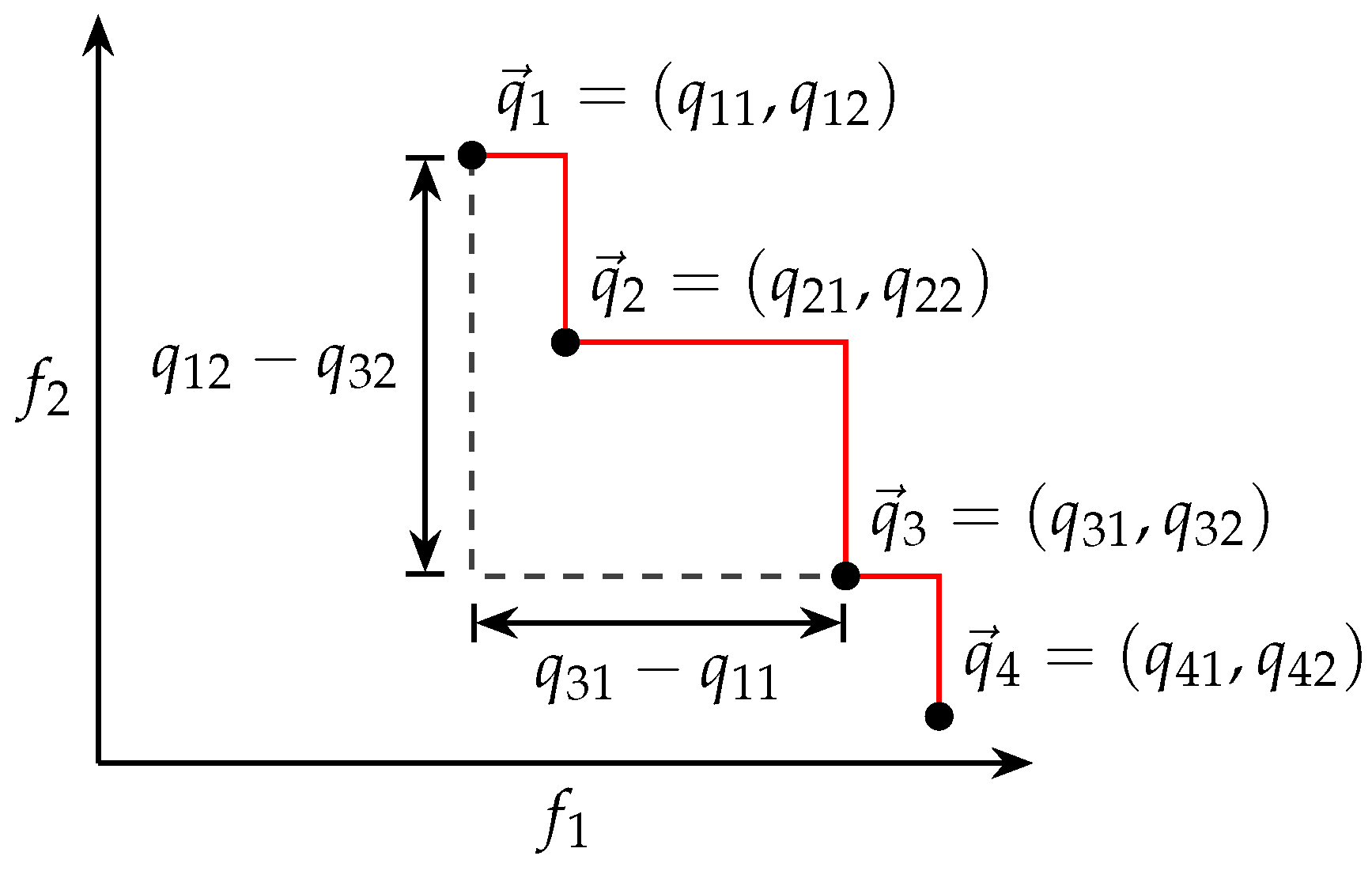
An alternative approach, referred to as attainment-surface-shaped intersection lines (ASSIL) in this paper, is to generate the intersection lines along the shape of the attainment surface. In order to equally spread the intersection lines, the Manhattan distance is used to calculate equal spacings for the intersection lines along the attainment surface.
Figure 5 depicts the Manhattan distance calculation between two points on the approximated POF, which is
and
in this case. ASSIL can be generated using Algorithm 1.
| Algorithm 1 Attainment-surface-shaped intersection line (ASSIL) generation. |
- 1:
Input: The optimal POF, with I solutions and - 2:
Output: An attainment surface - 3:
Sort Q in ascending order by - 4:
- 5:
Let N be the desired number of intersection lines - 6:
for do - 7:
- 8:
while do - 9:
- 10:
end while - 11:
if then - 12:
- 13:
else if then - 14:
- 15:
else - 16:
- 17:
end if - 18:
- 19:
- 20:
- 20:
// Finally, draw the generated intersection line - 21:
drawIntersectionLine(, ) - 22:
end for
|
Intersection lines are spaced equally along the attainment surface. The intersection lines are rotated incrementally such that the intersection lines at the ends of the attainment surface are parallel to the objective axis.
Figure 6 depicts the attainment-surface-shaped intersection line approach. The generation of the intersection lines along the shape of the attainment surface allows for an equal spacing of the intersection lines independent of the shape of the front. For all shapes that the attainment surface can assume, whether convex, concave, or mixed, the intersection lines are equally spread out.
The KC measure is calculated as shown in Algorithm 2.
| Algorithm 2 Algorithm for the calculation of the KC measure. |
- 1:
Input: Intersection lines for algorithms A and B to be compared - 2:
Output: The KC measure - 3:
Let - 4:
Let - 5:
Let - 6:
for each intersection line l do - 7:
Let O be the strict ordering of the intersection points for algorithms A and B on intersection line l - 8:
Let be the ordering of the intersection points for algorithm A on intersection line l - 9:
Let be the ordering of the intersection points for algorithm B on intersection line l - 10:
if is statistically significantly less than then - 11:
- 12:
else if is statistically significantly less than then - 13:
- 14:
end if - 15:
- 16:
end for - 17:
Return
|
An evaluation of the rotation-based and random intersection line approaches is presented using six artificially generated POF test cases based on those used by Knowles and Corne [
8].
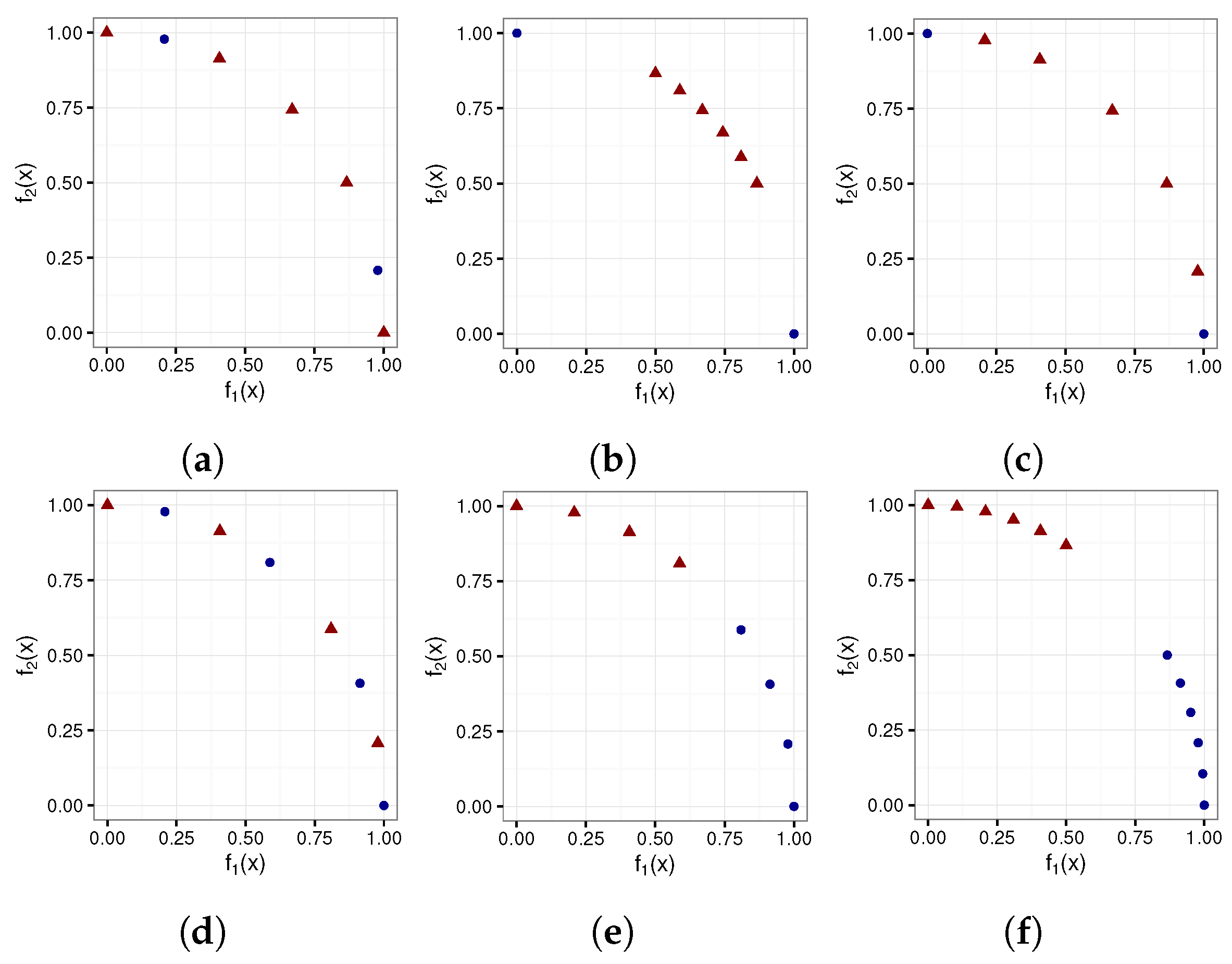
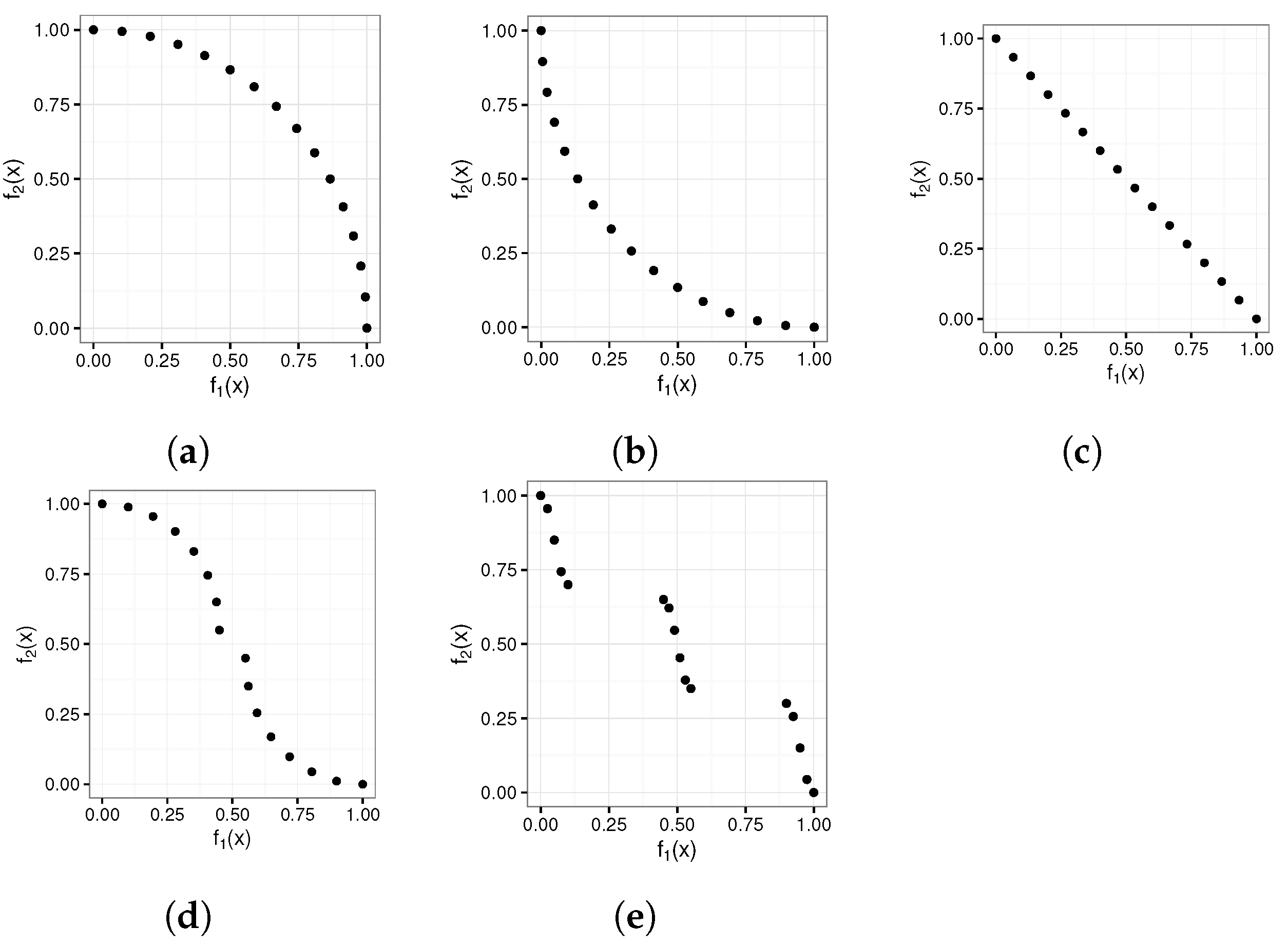
Figure 7 depicts the six artificially generated POF test cases. Each of these artificially generated POF test cases was tested using six pof shape geometries, namely concave, convex, linear, mixed, and disconnected geometries.
Figure 8 depicts the five POF shape geometries.
Table 1 summarises the true KC, the KC with rotation-based and random intersection lines, and the KC with ASSIL results. Values in red indicate attainment surfaces obtained that outperformed the control method (i.e., the true KC measure) by more than 5%, while values in blue indicate attainment surfaces that were found that were 5% worse than the control method. For each of the approaches, 1000 intersection lines were used for the calculation.
As expected, the ASSIL generation approach produced results much closer to the true KC measure: the closer the POFs being compared are to the true POF, the more accurate the comparison using the ASSIL generation approach becomes.
Table 2 and
Table 3 present a comparison of the varying results obtained from using the various intersection line generation approaches. Results comparing the vector evaluated particle swarm optimization (VEPSO) [
17], optimized multi-objective particle swarm optimization (OMOPSO) [
18], and speed-constrained multi-objective particle swarm optimization (SMPSO) [
19] algorithms using the Zitzler-Deb-Thiele (ZDT) [
20] and Walking Fish Group (WFG) [
21] test sets are presented. The choice of algorithms was arbitrary and only for illustrative purposes. Results were obtained over 30 independent runs. For more details on the algorithms and parameters used, the interested reader is referred to [
22]. The characteristics of the problems are summarized in
Table 4.
Variations in the results between the different intersection line generation approaches can be seen. ZDT1, ZDT3, ZDT4, and ZDT6 all show variations in the results greater than for each of the comparisons. WFG1, WFG2, WFG5, WFG6, and WFG9 all show variations in the results greater than for at least one of the comparisons. The variations are indicative of the bias towards certain attainment surface shapes shown by the various intersection line generation approaches.
5. Weighted 2-Dimensional Attainment-Surface-Shaped Intersection Lines
As an alternative to the equally spread intersection lines used by ASSIL, intersection lines can be generated along the shape of the POF, with at least one intersection line per attainment surface line segment. Because the attainment surface segments are not all of equal lengths, a weight is associated with each intersection line to balance the KC measure result. The weighted attainment-surface-shaped intersection lines (WASSIL) generation algorithm is given in Algorithm 3.
Figure 9 depicts a convex POF with WASSIL-generated intersection lines. The figure clearly shows that the intersection lines are positioned along the attainment surface, and due to the positioning, the lines are angled slightly differently from the intersection lines in
Figure 3b. The WASSIL algorithm should, for the test cases, result in a weighted KC measure result that matches the true KC measure result.
Note that the weighted KC measure is calculated as shown in Algorithm 4.
Table 5 summarises the true KC measure, the KC measure with rotation-based and random intersection lines, the KC measure with ASSIL, and the KC measure with WASSIL results. For each of the approaches, 1000 intersection lines were used for the calculation.
| Algorithm 3 Weighted attainment-surface-shaped intersection line (WASSIL) generation. |
- 1:
Input: The optimal POF, with I solutions and - 2:
Output: An attainment surface - 3:
for each attainment line segment do - 4:
Let - 5:
Let be the center of - 6:
Let , for - 7:
Let - 8:
//Draw the generated intersection line - 9:
drawIntersectionLineWithWeight(from=,to=,weight=) - 10:
end for
|
For POF test cases 1 through 3, only 2 of the 15 measurements using the random intersection line generation approach had a deviation from the true KC of less than . Overall, of the measurements using the random intersection line generation approach had a deviation greater than . This confirms that the random intersection line generation approach is not well suited for the KC calculation.
The rotation-based intersection line generation approach presented by Knowles and Corne fared better than the random intersection line generation approach. Only 7 of the 30 measurements using the rotation-based intersection line generation approach had a deviation greater than . Case 1 with a convex POF fared worse with a deviation of almost for both algorithms. Four of the five case 2 measurements using the rotation-based intersection line generation approach had a deviation greater than . For the remaining case 2 measurement, a deviation of at least is noted. The results indicate the rotation-based intersection line generation approach outperformed the random intersection line generation approach with respect to accuracy. However, the results also indicate that the rotation-based intersection line generation approach is not well suited for the KC calculation and that the results vary based on the POF shape and the spread of the solutions.
As expected, the WASSIL generation approach produced results much closer to the true KC: the closer the approximated POFs being compared are to the true POF, the more accurate the comparison using the WASSIL generation approach becomes.
| Algorithm 4 Weighted KC measure algorithm |
- 1:
Input: Intersection lines for algorithms A and B to be compared - 2:
Output: The weighted KC measure - 3:
Let - 4:
Let - 5:
Let - 6:
for each intersection line l do - 7:
Let be the weight associated with l - 8:
Let O be the strict ordering of the intersection points for algorithms A and B on intersection line l - 9:
Let be the ordering of the intersection points for algorithm A on intersection line l - 10:
Let be the ordering of the intersection points for algorithm B on intersection line l - 11:
if is statistically significantly less than then - 12:
- 13:
else if is statistically significantly less than then - 14:
- 15:
end if - 16:
- 17:
end for - 18:
Return
|
6. -Dimensional Attainment Surfaces
For
M-dimensional problems, Knowles and Corne [
8] recommended that a grid-based intersection line generation approach, as explained in
Section 3, be used. Similar to the rotational approach for 2-dimensional problems, the grid-based approach would lead to unbalanced intersection lines when measuring irregularly shaped POFs.
Figure 10 shows an example of an irregularly shaped 3-dimensional attainment surface.
Section 6.1 discusses the challenges that need to be addressed in order to generate intersection lines for
M-dimensional attainment surfaces.
Section 6.2 and
Section 6.3 introduce two algorithms to generate
M-dimensional attainment surface intersection lines. The first uses a naive (and computationally expensive) approach that produces all possible intersection lines. The second is computationally more efficient, considering a minimal set of intersection lines.
Section 6.4 presents a stability analysis of the two proposed algorithms to show that the computationally efficient approach performs similarly to the naive approach with respect to comparison accuracy.
6.1. Generalizing Attainment Surface Intersection Line Generation to M Dimensions
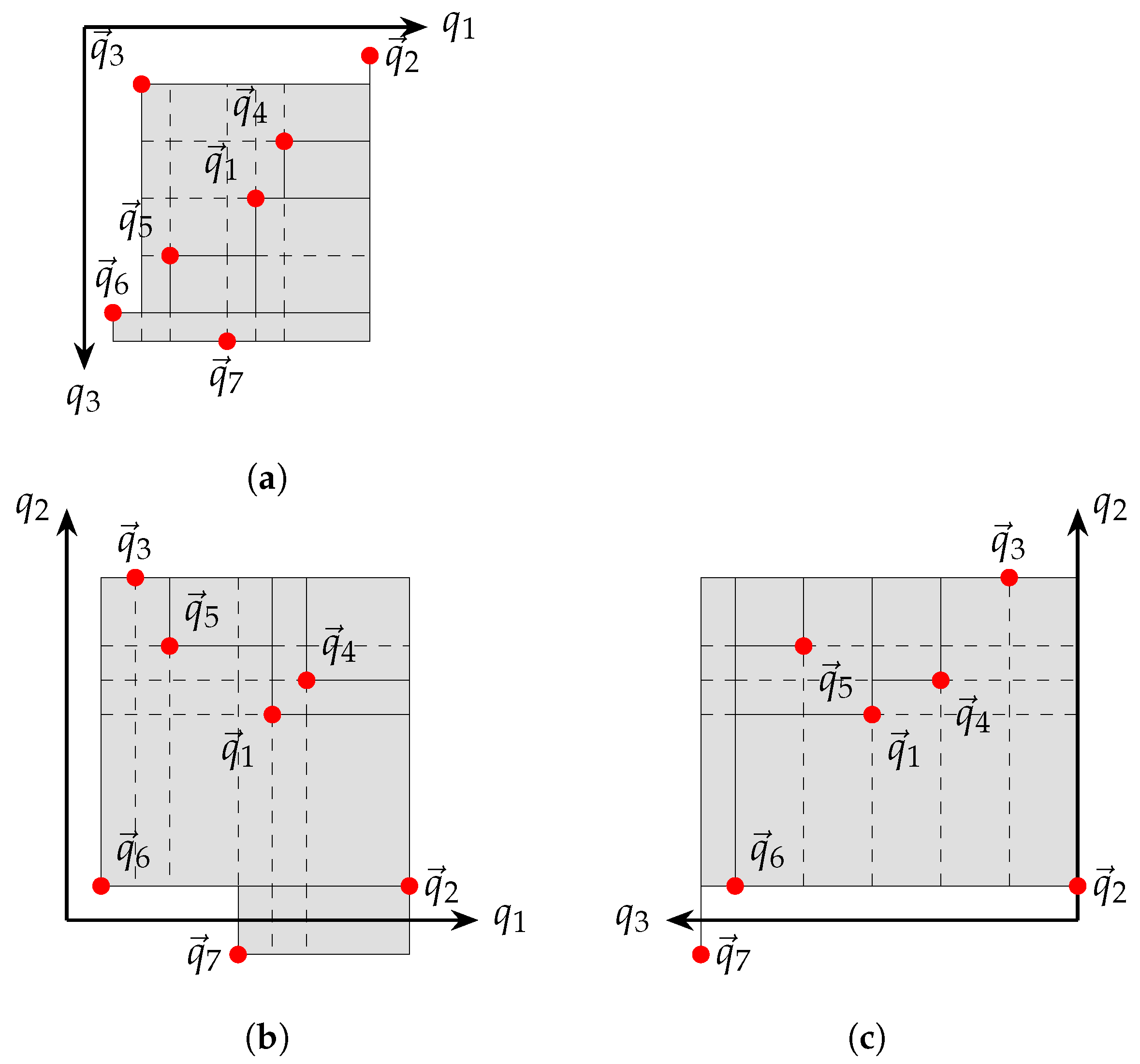
For 2-dimensional problems, the ASSIL approach generates equally spread intersection lines. Intuitively, generalization of the assil approach for M dimensions requires the calculation of equally spread points over the M-dimensional attainment surface.
The calculation of equally spread points requires that the surface is divided into equally sized -dimensional hypercubes. For the 3-dimensional case, this would require dividing the attainment surface into equally sized squares. The intersection vectors would be positioned from the middle of each square. The length of the edges would need to be set to the greatest common divider of the lengths of the edges that make up the attainment surface. Even for simple cases, this would lead to an excessive number of squares. The more squares, the higher the computational cost of the measure.
In order to lower the computational cost of the measure, the number of squares needs to be reduced. Because the square edge lengths are based on the greatest common divider, there is no way to reduce the number of squares as long as the squares must be equal in size. If the square sizes differ, the measure will be biased to areas with smaller squares. Areas with smaller squares will carry more weight in the calculation because there will be more of them.
In contrast to the ASSIL approach, the WASSIL approach does not require the intersection lines to be equally spread; instead, only a weight factor must be known for each intersection line. For the 3-dimensional case, the weight factor for each intersection line is calculated as the area of the squares that make up the attainment surface. The weight factor for each intersection line is calculated as the area of the square by multiplying the edge lengths. The weight factor also allows use of rectangles in the 3-dimensional case (hyper-rectangles in the M-dimensional case) instead of equally sized squares.
6.2. Porcupine Measure (Naive Implementation)
This section presents the naive implementation for the
n-dimensional attainment-surface-based quantitative measurement named the porcupine measure. The naive implementation uses each of the
n-dimensional values from each Pareto-optimal point to subdivide the attainment surface in each of the dimensions.
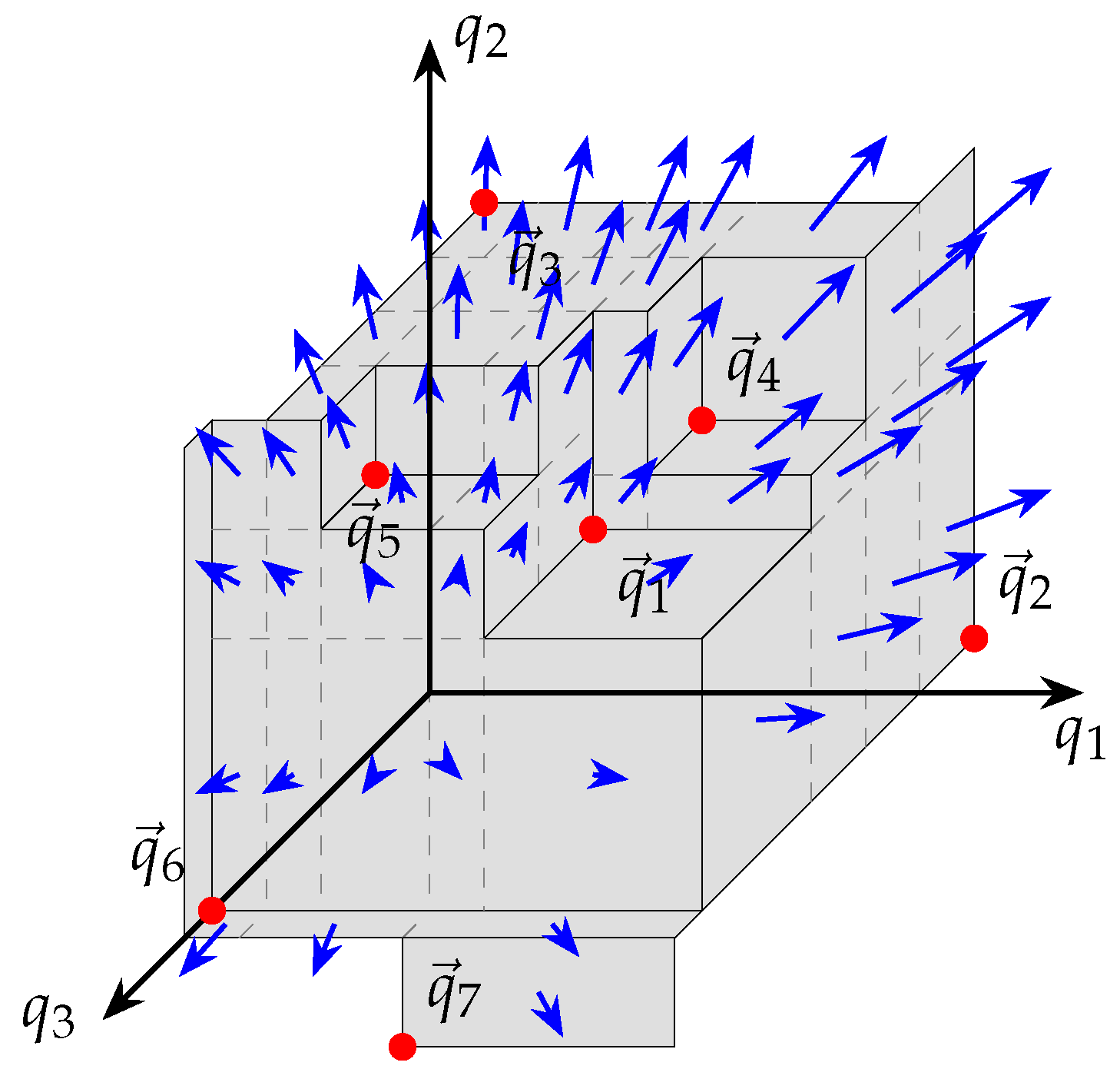
Figure 11 depicts an example of the subdivision approach for each of the three dimensions, considering all intersection lines.
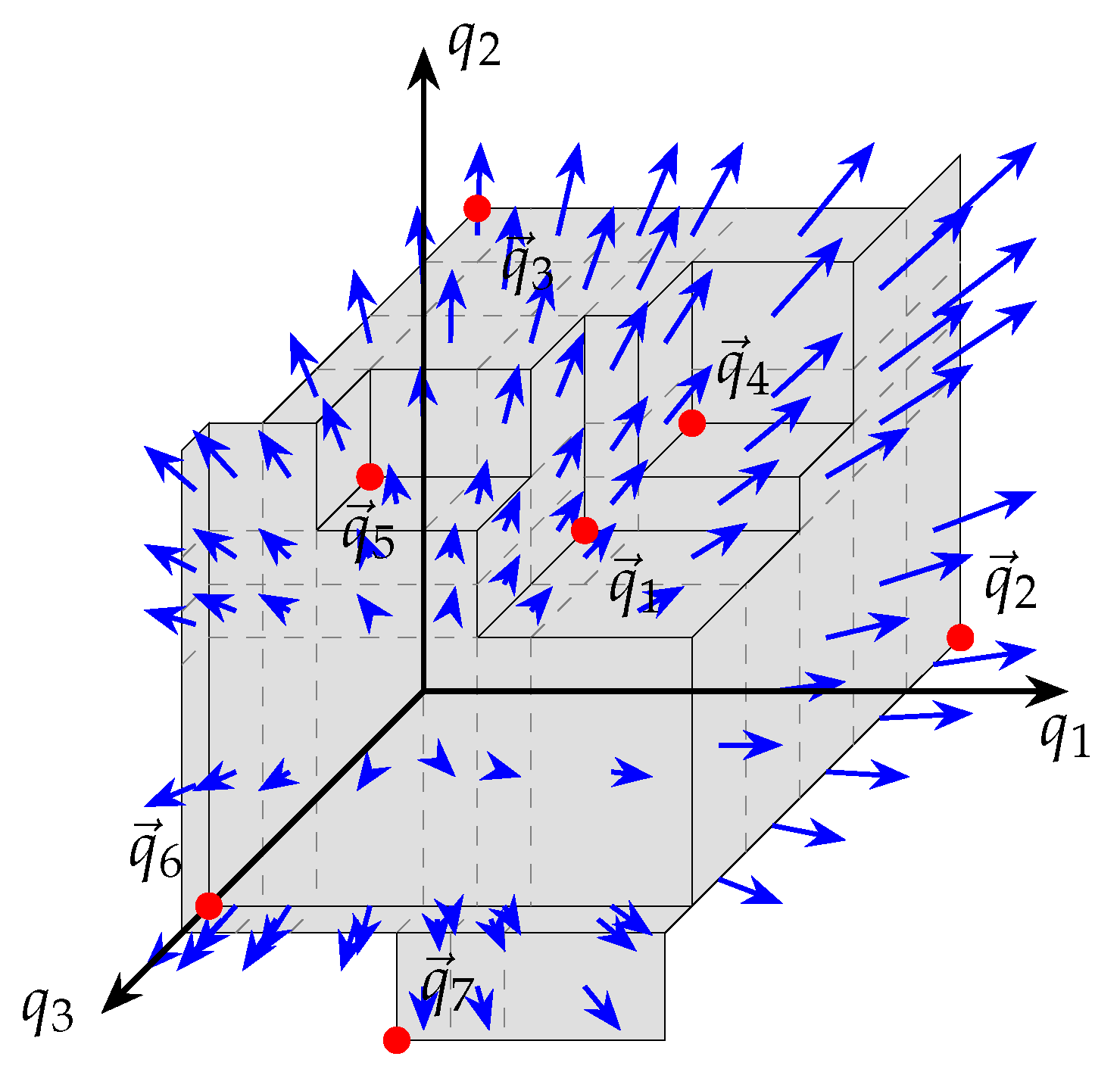
Figure 12 depicts the attainment surface, in 3-dimensional space, with the subdivisions visible.
In addition to the calculation of the hyper-rectangles, the center point and intersection vector need to be calculated. The naive implementation of the porcupine measure is summarized in Algorithm 5. For a more detailed algorithm listing, please refer to
Appendix A.
Using the intersection lines generated by the above algorithm, two algorithms can now be compared using a nonparametric statistical test, such as the Mann–Whitney U test [
9]. The porcupine measure is defined, similar to the weighted KC measure, as the weighted sum of the intersection lines where a statistically significant difference exists over the sum of all the weights (i.e., the percentage of the surface area of the attainment surface, as determined by the weights, where one algorithm statistically performs superior to another).
| Algorithm 5 Porcupine measure (naive implementation). |
- 1:
Input: The found POF - 2:
Output: The porcupine attainment surface - 3:
for each of the objective space basis vectors, , do - 4:
Project the attainment surface parallel to the basis vector, , onto the orthogonal -dimensional subspace - 5:
Subdivide the projected attainment surface, in each dimension at every Pareto-optimal point’s dimensional value, into hyper-rectangles - 6:
for each hyper-rectangle do - 7:
Let be the center point of the hyper-rectangle - 8:
Let w be the weight of the hyper-rectangle, equal to the product of the hyper-rectangle’s edge lengths - 9:
for each dimension in objective space do - 10:
Let be the smallest of the mth-dimensional values of all the Pareto-optimal points where at least one other dimensional value is less than or equal to that of the corresponding center vector’s dimensional value - 11:
Let be the largest of the mth-dimensional values of all the Pareto-optimal points - 12:
end for - 13:
Let be the intersection vector, calculated as , where is the mth component of the vector , corresponding to the mth objective function - 14:
drawIntersectionLineWithWeight (from = , to = , weight = w) - 15:
end for - 16:
end for
|
Figure 13 depicts an attainment surface with subdivisions and intersection vectors generated using the naive approach. The porcupine measure’s name is derived from the fact that the intersection vectors resembles the spikes of a porcupine.
6.3. Porcupine Measure (Optimized Implementation)
The large number of subdivisions that result from using the naive implementation of the porcupine measure creates a computationally complex problem when performing the statistical calculations required by the porcupine measure. To reduce the computational cost of the porcupine measure, the naive implementation can be optimized by subdividing the attainment surface only as necessary to accommodate the shape of the attainment surface.
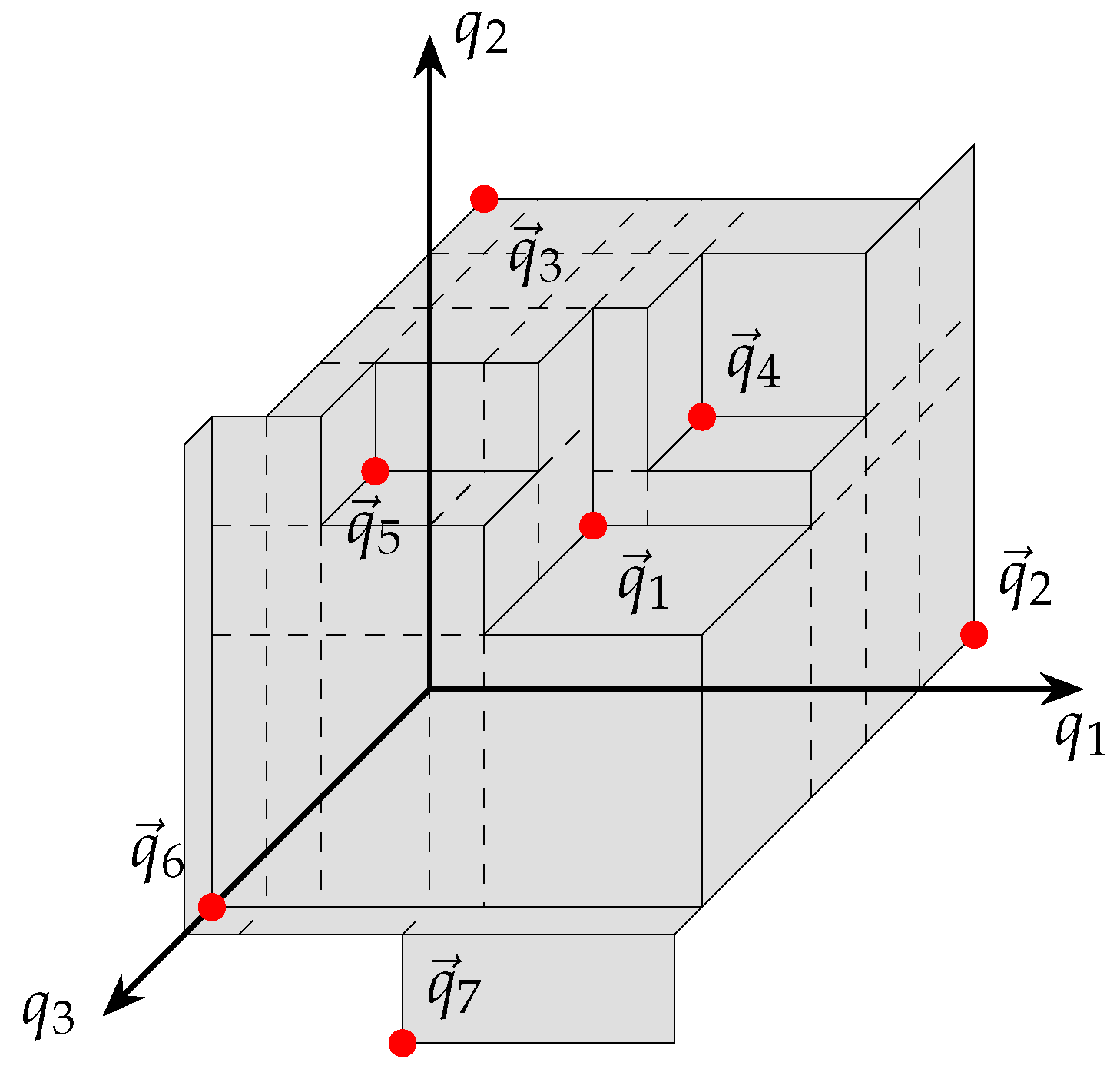
Figure 14 depicts an attainment surface with the subdivision lines (dashed) as generated by the optimized implementation.
Note that the algorithm yields the minimum number of subdivisions such that the results are independent of the dimension ordering of the Pareto-optimal points. This is by design to allow for the reproducibility and increased stability of the results.
The optimized implementation of the porcupine measure is summarized in Algorithm 6. For a more detailed algorithm listing, please refer to
Appendix B.
Similar to the naive implementation, the porcupine measure is defined as the weighted sum of the intersection lines where a statistically significant difference exists over the sum of all the weights (the percentage of the surface area of the attainment surface, as determined by the weights, where one algorithm statistically performs superior to another).
Figure 15 depicts an attainment surface with subdivisions and intersection vectors generated using the optimized implementation. As can be seen in the figure, the optimized implementation resulted in notably fewer subdivisions and intersection vectors. The lower number of intersection vectors considerably reduces the computational complexity of the measure.
6.4. Stability Analysis
In order to show that the optimized implementation provides results similar to the naive implementation, 30 independent runs of each measure were executed. Each measurement run calculated the porcupine measure using the approximated POFs as calculated by 30 independent runs of each of the algorithms being compared. A total of runs were executed for each algorithm being compared.
Table 6 lists the results for the algorithm pairs that were compared. The algorithm pairs are listed without a separator line between them. The results should thus be interpreted by looking at both lines of the comparison. For each algorithm, the mean, standard deviation (
), minimum, and maximum for the naive and optimized implementations of the porcupine measure with a maximum side length of
are listed.
The experimental results in [
22] show that a maximum side length of
for the optimized implementation yielded a good trade-off between accuracy of the results and performance when compared with the naive implementation.
Statistical testing was performed to determine if there were any statistically significant differences between the naive and optimized implementations’ results. The Mann–Whitney U test was used at a significance level of
. The purpose of the statistical testing was to determine if there was any information loss due to using the optimized implementation compared to the naive implementation. The results indicated that for 52 out of the 54 measurements, or
, there were no statistically significant differences. Only for two cases, namely the OMOPSO in the WFG3 OMOPSO vs. VEPSO comparison and the SMPSO in the WFG3 VEPSO vs. SMPSO comparison, was a statistically significant difference noted. In spite of the statistical difference, the ranking of the algorithms did not change. Based on the results, it can, therefore, be concluded that the optimized implementation yielded the same results as the naive implementation and no information was lost. Because no information was lost when using the optimized implementation, it can be concluded that the optimized implementation, with less computational complexity when compared to the naive implementation, can be used when conducting comparisons of multi-objective algorithms.
| Algorithm 6 Porcupine measure (optimized implementation). |
- 1:
Input: The found POF - 2:
Output: The porcupine attainment surface - 3:
Let be the nadir vector defined as for each of the known Pareto-optimal points, , of dimension M - 4:
for each of the objective space basis vectors, , do - 5:
Project the attainment surface parallel to the basis vector, , onto the orthogonal -dimensional subspace - 6:
for each of the Pareto-optimal points, do, - 7:
Let be the vector with dimensional values set to the minimum dimensional values that are dominated or the corresponding value if no minimum exists - 8:
Let be the set of all points that dominate but not , filtered for non-dominance - 9:
for each dimension m do, - 10:
Let be the set of all the m’th dimensional values of the points in that fall inside the range - 11:
end for - 12:
Let be the set of all the minimum points that will affect the calculation of - 13:
Let be the set of all the maximum points that will affect the calculation of - 14:
Add all dimensional values of the points in and that fall inside the range to the corresponding set - 15:
Add additional values to the sets to limit the side lengths to - 16:
Subdivide the projected attainment surface in each of the m dimensions at every value in the set into hyper-rectangles - 17:
for each hyper-rectangle do, - 18:
Let be the center point of the hyper-rectangle - 19:
Let w be the weight of the hyper-rectangle, equal to the product of the hyper-rectangle’s edge lengths - 20:
for each dimension m do - 21:
Let be the smallest of the mth-dimensional values of all the Pareto-optimal points where at least one other dimensional value is less than or equal to that of the corresponding center vector’s dimensional value - 22:
Let is the largest of the mth-dimensional values of all the Pareto-optimal points - 23:
end for - 24:
Let be the intersection vector, calculated as , where is the mth component of the vector - 25:
drawIntersectionLineWithWeight (from = , to = , weight = w) - 26:
end for - 27:
end for - 28:
end for
|
The mean standard deviation was , and the maximum standard deviation was . The conclusion that can be drawn from the data is that the optimized implementation of the porcupine measure is very robust because measurement values for each of the samples were close to the average.
For the experimentation that was carried out for this study, the runtime of the optimized implementation was notably faster than that of the naive implementation. A difference on the orders of a few magnitudes was noticeable.
The computational complexity of the naive implementation is directly proportional to the size of the sets. It should be noted that, for the tested algorithms with an approximated POF size of 50 points tested over 30 independent samples, the optimal POF had a typical size of 1250 points. The size of the sets were thus approximately 1250 points. For three dimensions, this resulted in a minimum computational complexity of at least , or rather 1,953,125,000 (almost two billion). The optimized implementation resulted in much-reduced computational complexity because only the necessary subdivisions were made. The size of the sets were much smaller. For the three-dimensional case, the maximum edge length leads to a minimum complexity of at least , or rather 1000 times lower than that of the naive version.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}