

Iterative Oblique Decision Trees Deliver Explainable RL Models
 , , , and
, , , and
Abstract
:1. Introduction
- It is conceptually simple, as it translates the problem of explainable RL into a supervised learning setting.
- DTs are fully transparent and (at least for limited depth) offer a set of easily understandable rules.
- The approach is oracle-agnostic: it does not rely on the agent being trained by a specific RL algorithm, as only a training set of state–action pairs is required.
2. Related Work
3. Methods
3.1. Environments
3.2. Deep Reinforcement Learning
3.3. Decision Trees
3.4. DT Training Methods
3.4.1. Episode Samples (EPS)
- A DRL agent (“oracle”) is trained to solve the problem posed by the studied environment.
- The oracle acting according to its trained policy is evaluated for a set number of episodes. At each time step, the state of the environment and action of the agent are logged until a total of samples are collected.
- A decision tree (CART or OPCT) is trained from the samples collected in the previous step.
3.4.2. Bounding Box (BB)
- The oracle is evaluated for a certain number of episodes. Let and be the lower and upper bound of the visited points in the ith dimension of the observation space and their interquartile range (difference between the 75th and the 25th percentile).
- Based on the statistics of visited points in the observation space from the previous step, we take a certain number of samples from the uniform distribution within a hyperrectangle of side lengths . The side length is clipped, should it exceed the predefined boundaries of the environment.
- For all investigated depths d, OPCTs are trained from the dataset consisting of the samples and the corresponding actions predicted by the oracle.
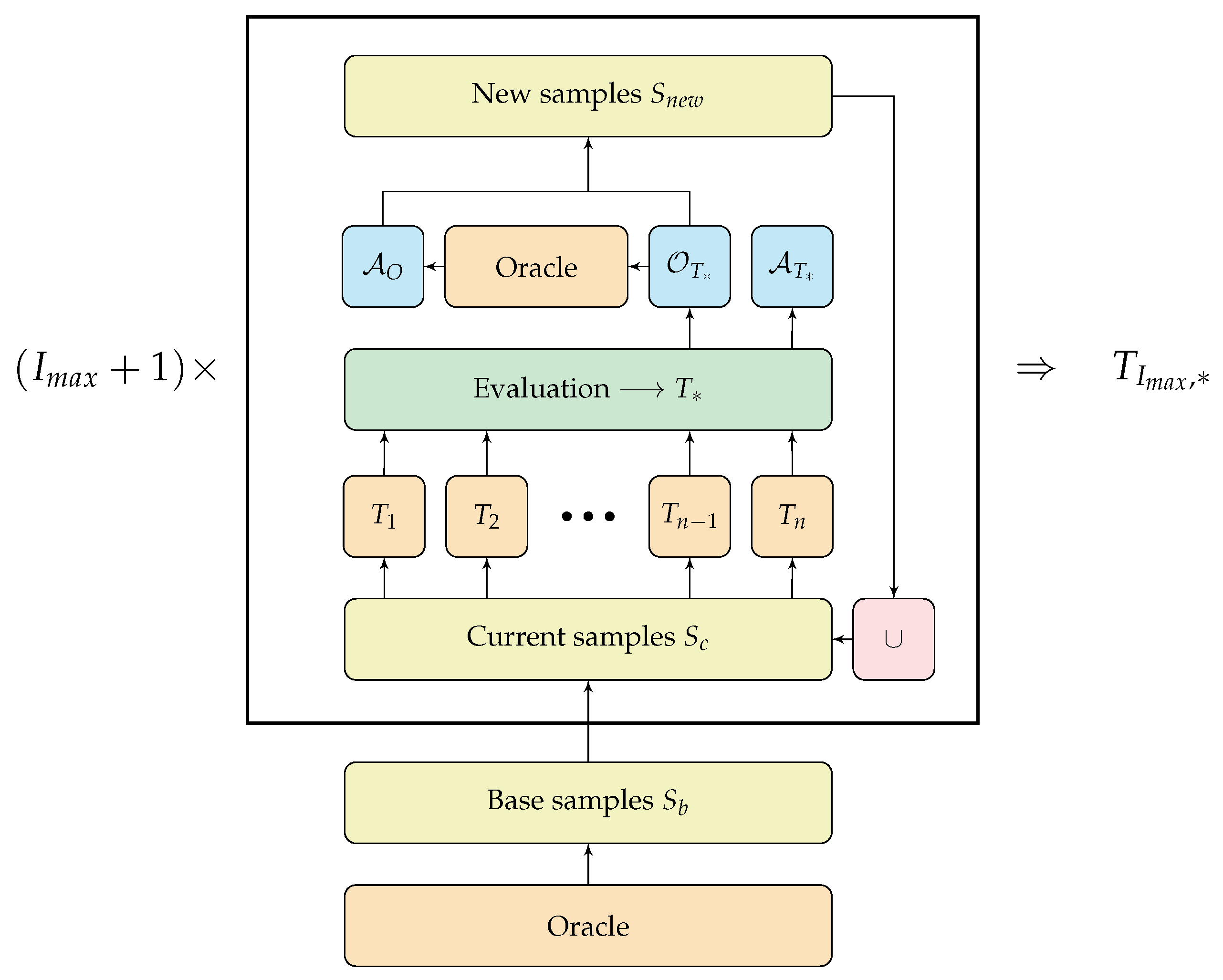
3.4.3. Iterative Training of Explainable RL Models (ITER)
| Algorithm 1 Iterative Training of Explainable RL Models (ITER) | |
| Require:
Oracle policy , maximum iteration , number of base samples, number of trees , evaluation episodes , DT depth d, number of samples added in each iteration . : observations, : actions. | |
| 1: | ▹ collect samples by running in environment |
| 2: | ▹ the set collects triples for each tree |
| 3: for do | |
| 4: for do | |
| 5: | ▹ tree |
| 6: | ▹ triple (eval_tree returns ) |
| 7: | |
| 8: end for | |
| 9: | ▹ pick triple with highest reward |
| 10: | ▹ pick random observations |
| 11: | |
| 12: | |
| 13: end for | |
| 14: return | ▹ return the best tree from all iterations |
3.5. Experimental Setup
4. Results
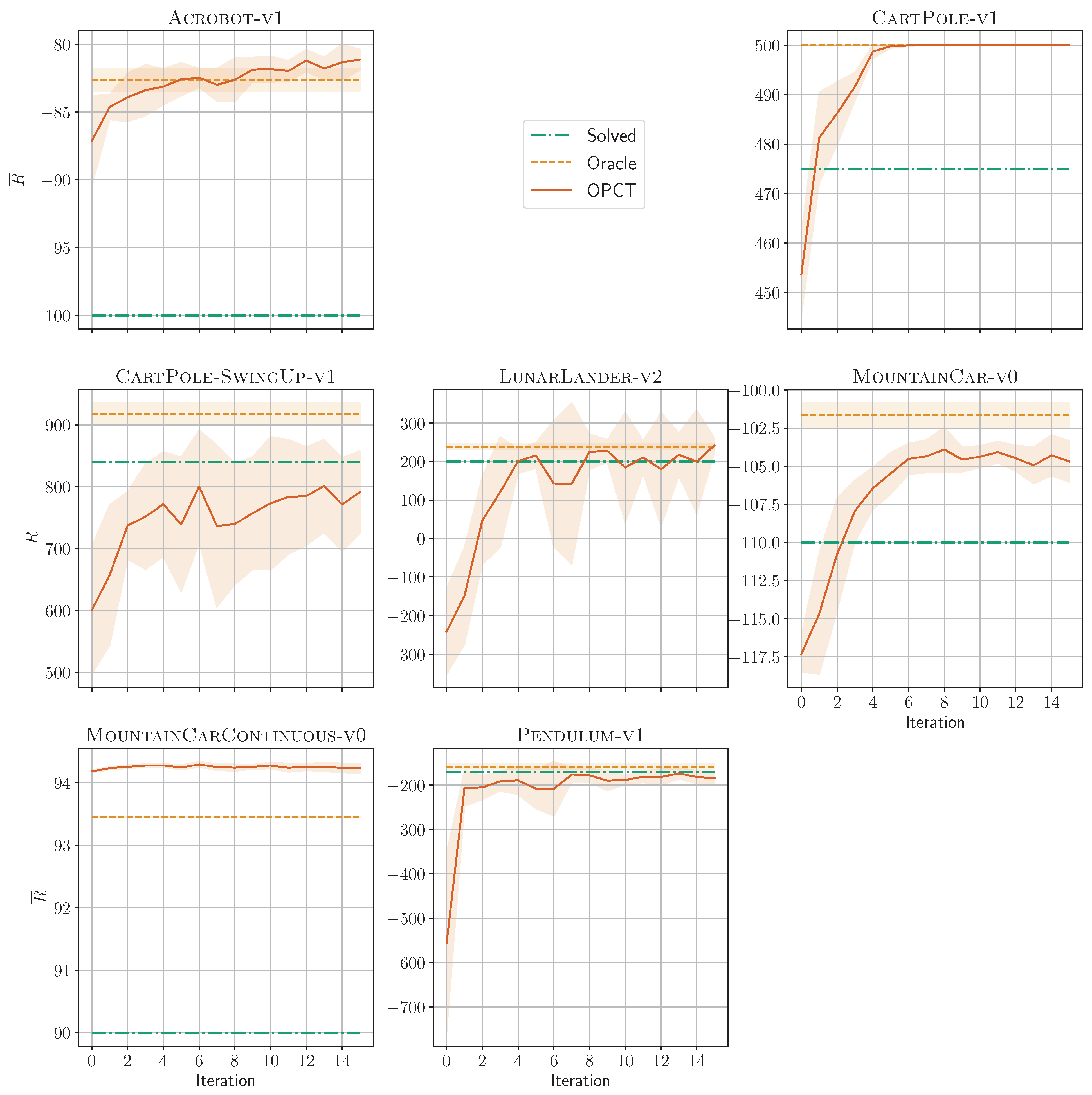
4.1. Solving Environments
4.2. Computational Complexity
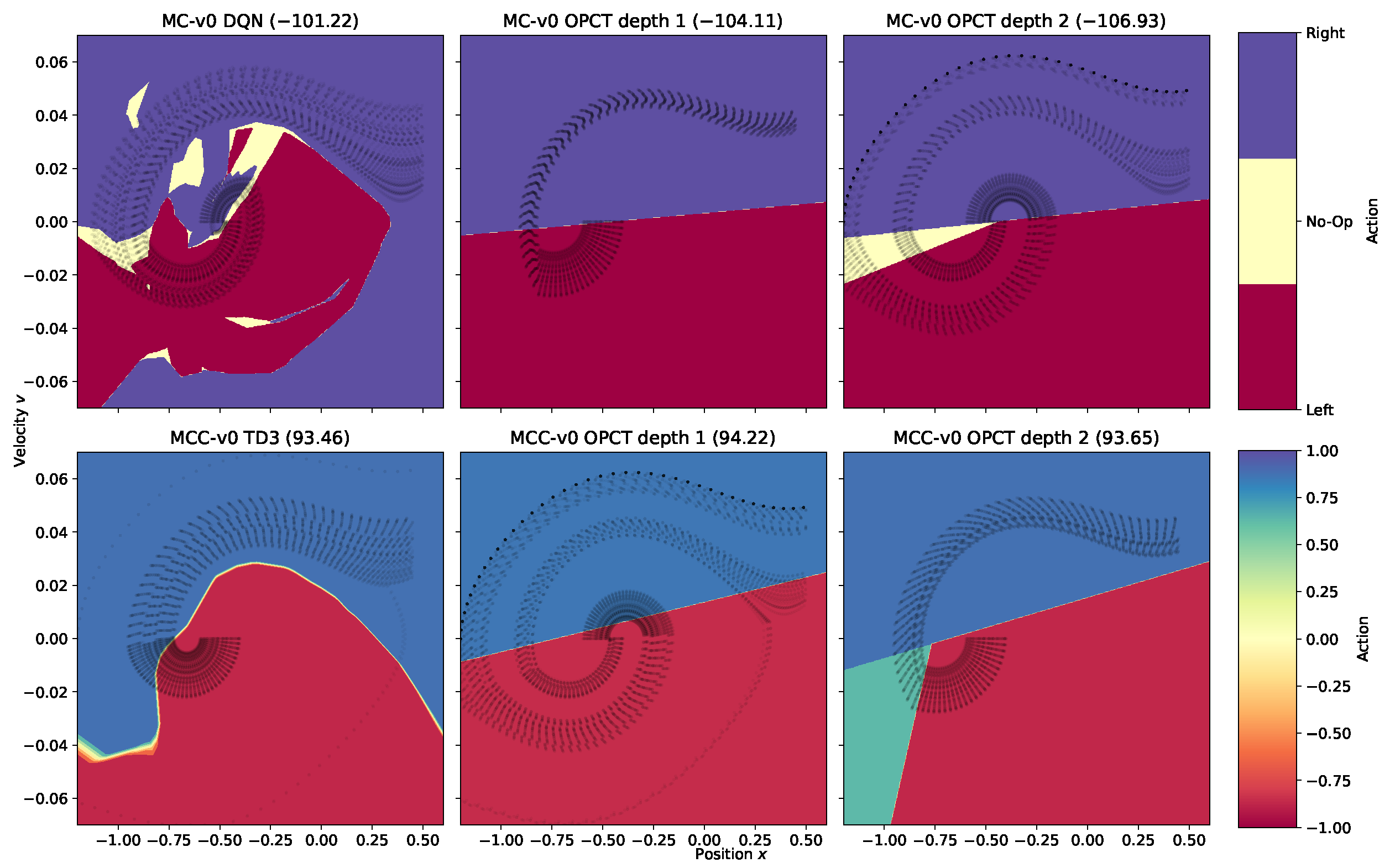
4.3. Decision Space Analysis
4.4. Explainability for Oblique Decision Trees in RL
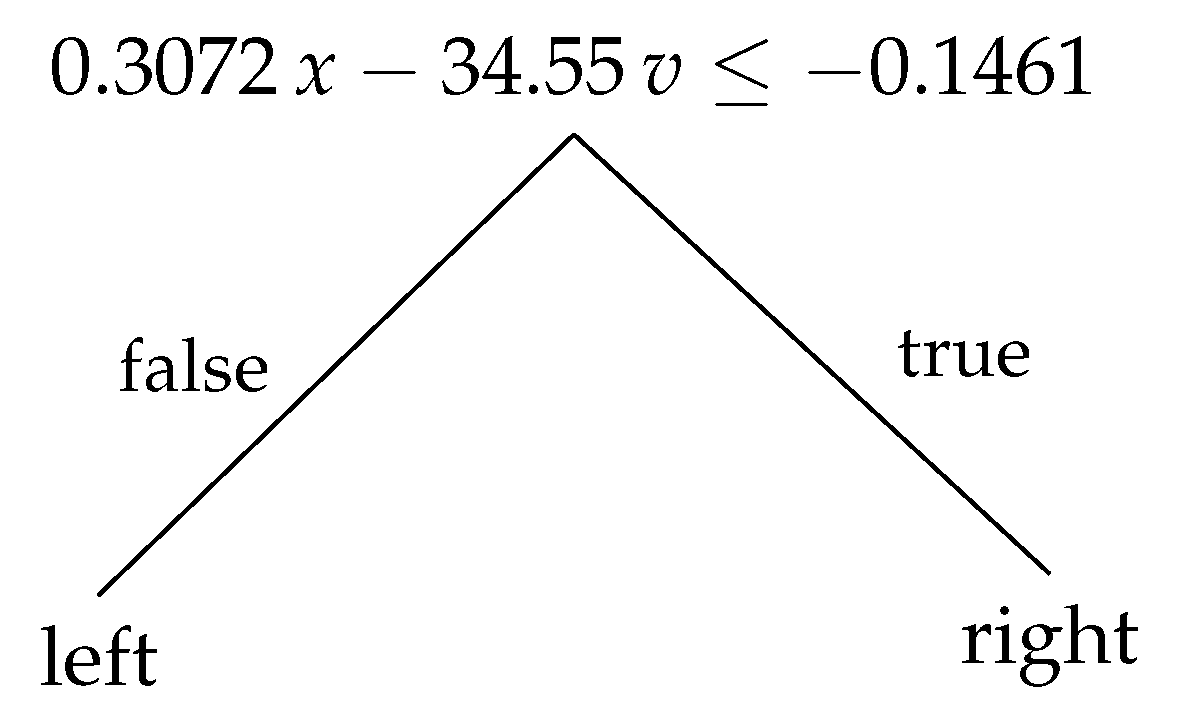
4.4.1. Decision Trees: Compact and Readable Models
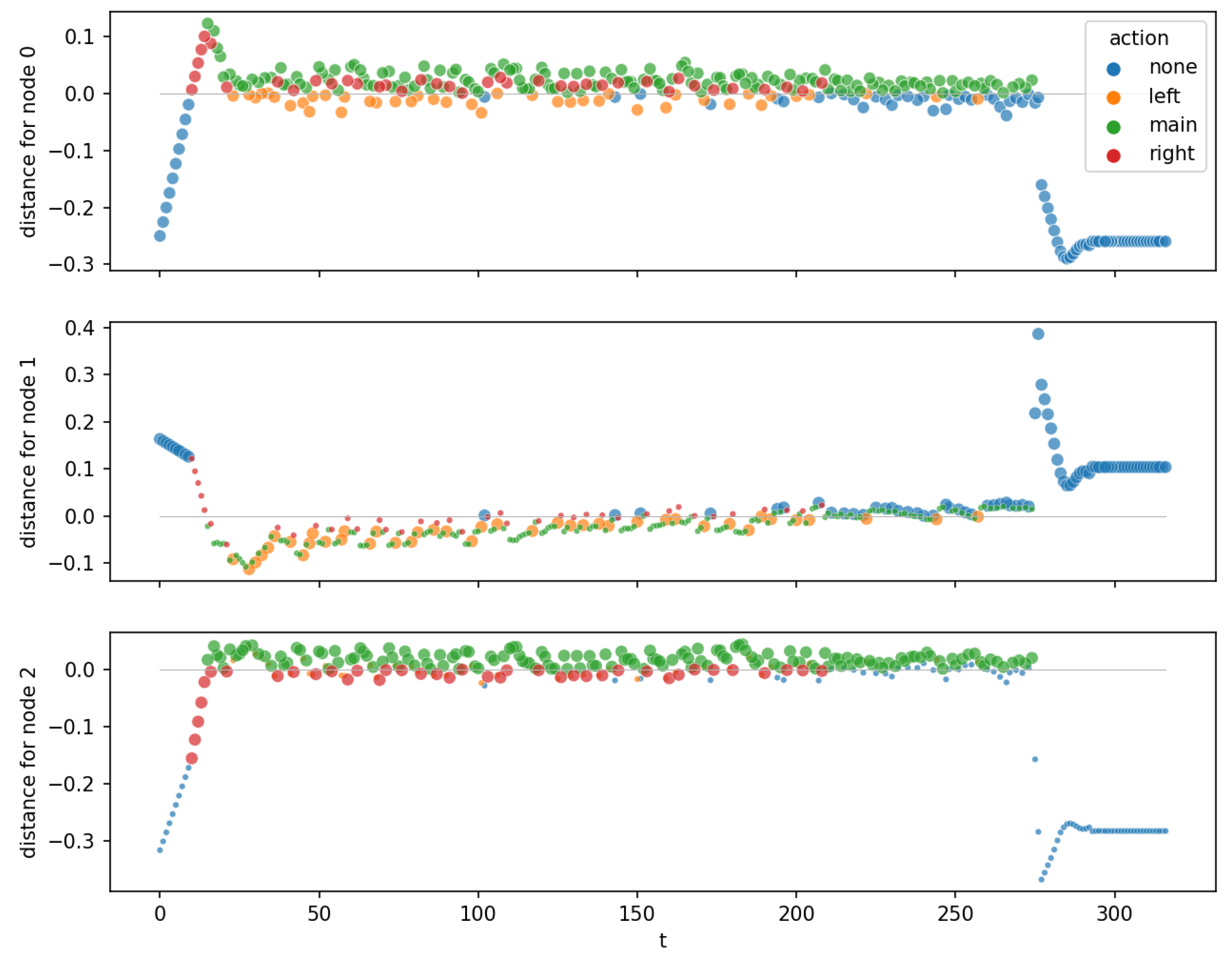
4.4.2. Distance to Hyperplanes
- Equilibrium nodes (or attracting nodes): nodes with distance near to zero for all observation points after a transient period. These nodes occur only in those environments where an equilibrium has to be reached.
- Swing-up nodes: nodes that do not stabilize at a distance close to zero. These nodes are responsible for swing-up, for bringing energy into a system. The trees for environments MountainCar, MountainCarContinuous, and Acrobot consist only of swing-up nodes because, in these environments, the goal state to reach is not an equilibrium.
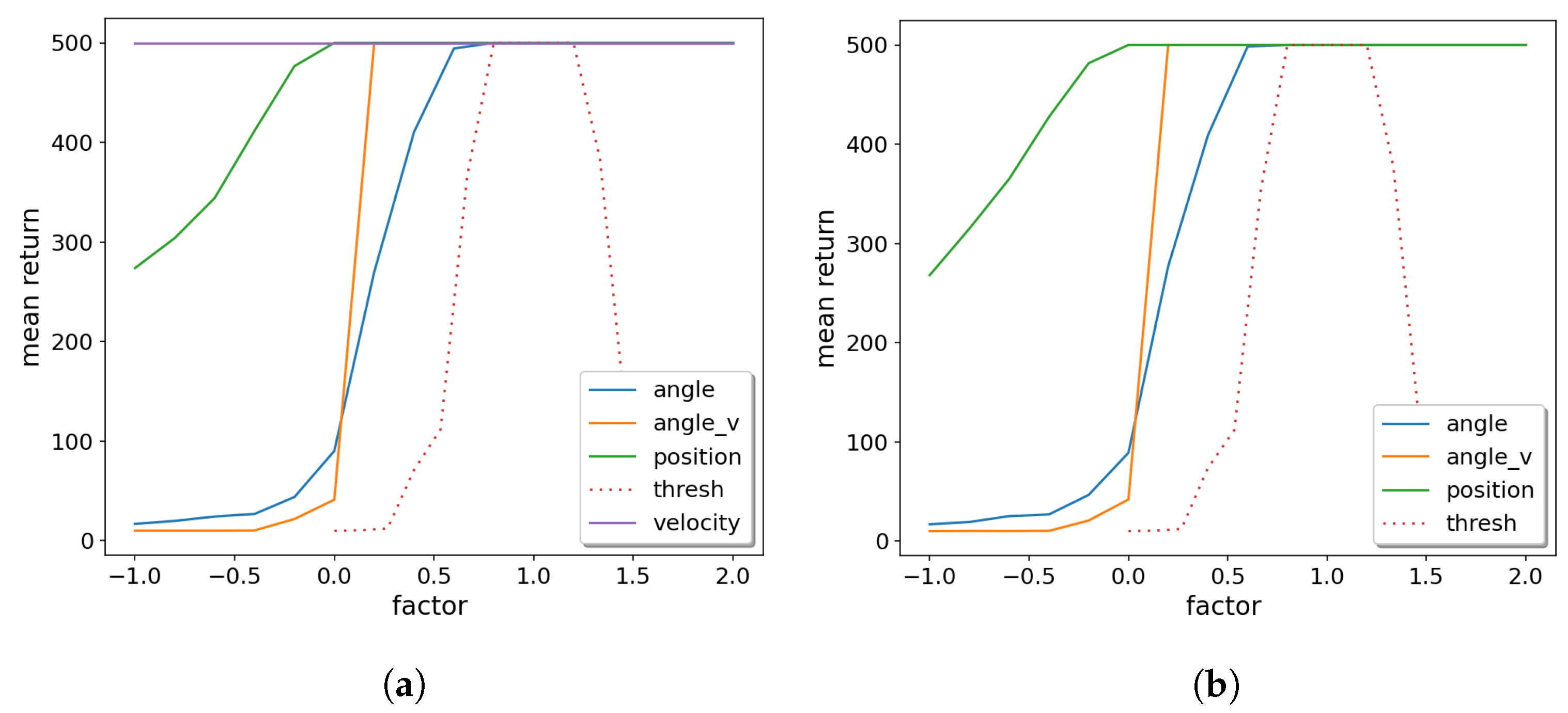
4.4.3. Sensitivity Analysis
5. Discussion
- To align our work in the context of XAI, we may use the guidance of the taxonomy proposed by (Schwalbe and Finzel [35], Section 5):
- The problem definition: The task consists of a classification or regression (for discrete or continuous actions, respectively) of tabular, numerical data (observations). We intend a post hoc explanation of DRL oracles, by finding decision trees described that are inherently transparent and simulatable in that a human can follow the simple mathematical and hierarchical structure of a DT’s decision-making process.
- Our algorithm as an explanator requires a model (the oracle and also the environment’s dynamics) as input, while still being portable by not relying on a specific type of oracle. The output data of our algorithm are shallow DTs as surrogate models mimicking the decision-making process of the DRL oracles. This leads to a drastic reduction of model parameters (see Table 4). Given their simple and transparent nature, DTs lend themselves to rule-based output and to further explanations by example or by counterfactuals, and analysis of feature importance (as we showed in Section 4.4.3).
- As the fundamental functionally grounded metric of our algorithm, we compare the DT’s average return in the RL environment with the oracle’s performance. This measures the fidelity to the oracle in the regions relevant to successfully solve the environment and the accuracy with respect to the original task of the environment. We do not evaluate human-grounded metrics. (Human-grounded metrics are defined by Schwalbe and Finzel [35] as metrics involving human judgment of the explainability of the constructed explanator (here: DT): how easy is it for humans to build a mental model of the DT, how accurately does the mental model approximate the explanator model, and so on.) Instead, we trust that the simple structure and mathematical expressions used in the DTs generated by our algorithms, as well as the massively reduced number of model parameters, lead to an interpretability and effectiveness of predictions that could not be achieved with DRL models. In Section 4.4, we have explained aspects connected to this in more detail.
- Can we understand why the combination ITER + OPCT is successful, while the combination EPS + OPCT is not? We have no direct proof, but from the experiments conducted, we can share these insights: Firstly, equilibrium problems such as CartPole or Pendulum exhibit a severe oversampling of some states (i.e., the upright pendulum state). If, as a consequence, the initial DT is not well-performing, ITER allows to add the correct oracle actions for problematic samples and to improve the tree in critical regions of the observation space. Secondly, for environment Pendulum we observed that the initial DT was “bad” because it learned only from near-perfect oracle episodes. It had not seen any samples outside the near-perfect episode region and hypothesized the wrong actions in the outside regions (see Figure 3). Again, ITER helps; a “bad” DT is likely to visit these outside regions and then add samples combined with the correct oracle actions to its sample set.We conclude that algorithm ITER is successful because it strikes the right balance between being too exploratory, like algorithm BB (which might sample from constraint-violating regions or from regions unknown to the oracle), and not exploratory enough, like algorithm EPS (which might sample only from the narrow region of successful oracle trajectories). Algorithm ITER solves the sampling challenges mentioned in Section 1. It works well based on its iterative nature, which results in self-correction of the tree. At every iteration, the trajectories generated by the tree form a dataset of state–action pairs. The oracle corrects the wrong actions, and the tree can improve its behavior based on the enlarged dataset.
- We investigated another possible variant of an iterative algorithm. In this variant, observations were sampled while the oracle was training (and probably also visited unfavorable regions of the observation space). After the oracle had completed its training, the samples were labeled with the action predictions of the fully trained oracle. These labeled samples were presented to DTs in a similar iterative algorithm as described above. However, this algorithm was not successful.
- A striking feature of our results is that DTs (predominantly those trained with ITER) can outperform the oracle they were trained from. This seems paradoxical at first glance, but the decision space analysis for MountainCar in Section 4.3 has shown the likely reason. In Figure 5, the decision spaces of the oracles are overly complex (similar to overfitted classification boundaries, although overfitted is not the proper term in the RL context). With their significantly reduced degrees of freedom, the DTs provide simpler, better generalizing models. Since they do not follow the “mistakes” of the overly complex DRL models, they exhibit a better performance. It fits to this picture that the MountainCarContinuous results in Figure 2 are best at (better than oracle) and slowly degrade towards the oracle performance as d increases; the DT obtains more degrees of freedom and mimics the (slightly) non-optimal oracle better and better. The fact that DTs can be better than the DRL model they were trained on is compatible with the reasoning of Rudin [20], who stated that transparent models are not only easier to explain but often also outperform black box models.
- We applied algorithm ITER to OPCTs. Can CARTs also benefit from ITER? The solved-depths shown in column ITER + CART of Table 2a add up to , which is nearly as bad as EPS + CART (). Only the solved-depth for Pendulum improved somewhat from to 7. We conclude that the expressive power of OPCTs is important for being successful in creating shallow DTs with ITER.
- What are the limitations of our algorithms? In principle, the three algorithms EPS, BB, and ITER are widely applicable since they are model-agnostic concerning the DRL and DT methods used and applicable to any RL environment. However, the limitation of the current work is that, so far, we have only tested environments with one-dimensional action spaces (discrete or continuous). There is no principled reason why the algorithms should not be applicable to multi-dimensional action spaces (OPCTs can be trained for multi-dimensional outputs as well). Still, the empirical demonstration of successful operation in multi-dimensional action spaces is a topic for future work. One obvious limitation of the three algorithms is that they need a working oracle. A less obvious limitation is that algorithm EPS only needs static, pre-collected samples from oracle episodes (in other applications, these might be “historical” samples). In contrast, the algorithms BB and ITER really need an oracle function to query for the right action at arbitrary points in the observation space. Which points are needed is not known until the algorithms BB and ITER are run.
- A last point worth mentioning is the intrinsic trustworthiness of DTs. They partition the observation space in a finite (and often small) set of regions, where the decision is the same for all points. (This feature includes smooth extrapolation to yet-unknown regions.) DRL models, on the other hand, may have arbitrarily complex decision spaces. If such a model predicts action a for point x, it is not known which points in the neighborhood of x will have the same action.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Reproduction of PIRL via NDPS Results

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Verma et al. [13] | Our Reproduction | ||
|---|---|---|---|
| Environment | |||
| Acrobot-v1 | −93.29 ± 25.19 | ||
| CartPole-v0 | 46.66 ± 15.34 | ||
| MountainCar-v0 | −163.02 ± 3.48 |
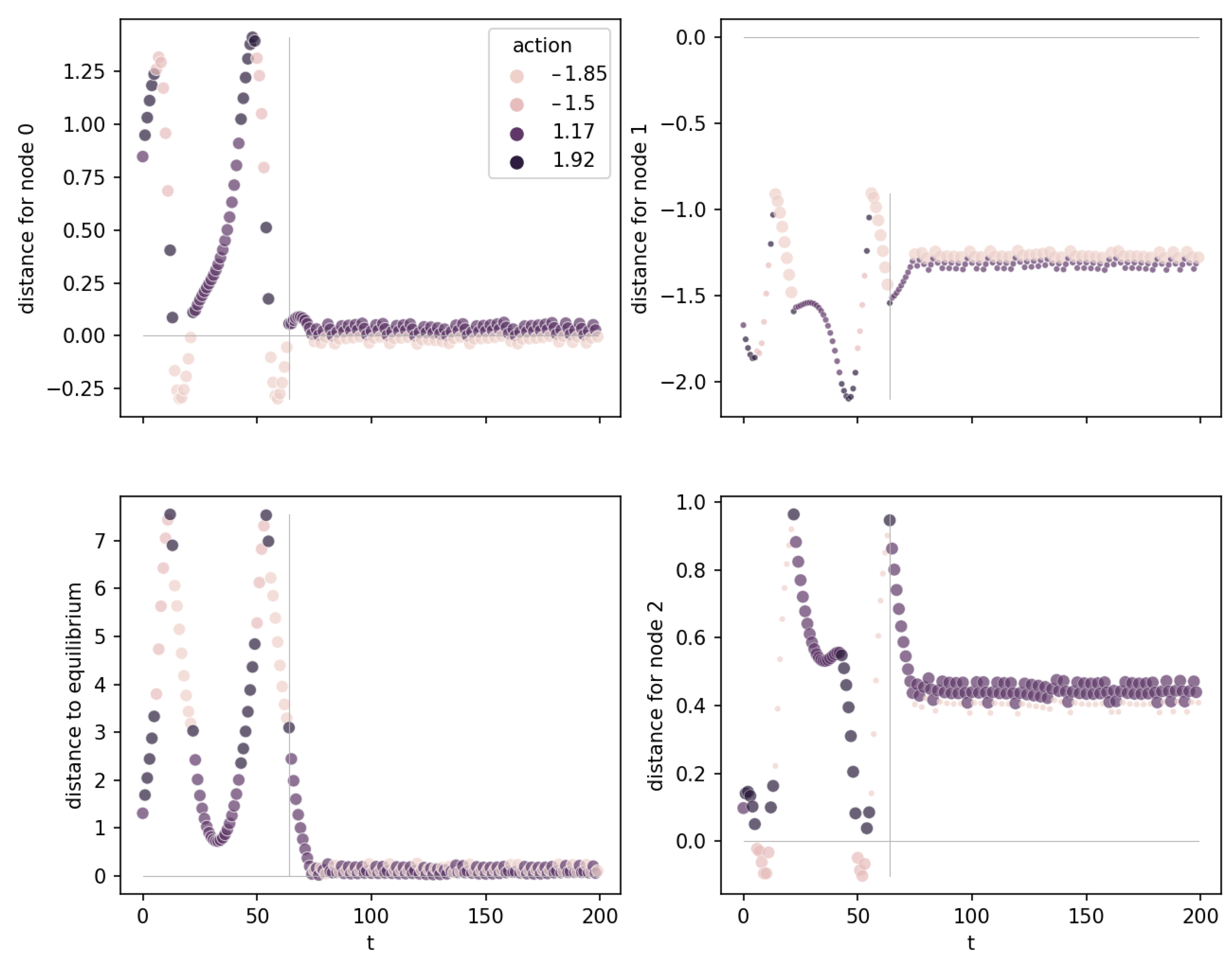
Appendix B. Effect of Observation Space Normalization on the Distances to Hyperplane
Abbreviations
| BB | Bounding Box algorithm |
| CART | Classification and Regression Trees |
| DRL | Deep Reinforcement Learning |
| DQN | Deep Q-Network |
| DT | Decision Tree |
| EPS | Episode Samples algorithm |
| ITER | Iterative Training of Explainable RL models |
| OPCT | Oblique Predictive Clustering Tree |
| PPO | Proximal Policy Optimization |
| RL | Reinforcement Learning |
| SB3 | Stable-Baselines3 |
| TD3 | Twin Delayed Deep Deterministic Policy Gradient |
References
- Engelhardt, R.C.; Lange, M.; Wiskott, L.; Konen, W. Sample-Based Rule Extraction for Explainable Reinforcement Learning. In Proceedings of the Machine Learning, Optimization, and Data Science, Certosa di Pontignano, Italy, 18–22 September 2022; Nicosia, G., Ojha, V., La Malfa, E., La Malfa, G., Pardalos, P., Fatta, G.D., Giuffrida, G., Umeton, R., Eds.; Springer: Cham, Switzerland, 2023; Volume 13810, pp. 330–345. [Google Scholar] [CrossRef]
- Adadi, A.; Berrada, M. Peeking inside the black-box: A survey on explainable artificial intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Molnar, C.; Casalicchio, G.; Bischl, B. Interpretable Machine Learning—A Brief History, State-of-the-Art and Challenges. In Proceedings of the ECML PKDD 2020 Workshops, Ghent, Belgium, 14–18 September 2020; Koprinska, I., Kamp, M., Appice, A., Loglisci, C., Antonie, L., Zimmermann, A., Guidotti, R., Özgöbek, Ö., Ribeiro, R.P., Gavaldà, R., Eds.; Springer: Cham, Switzerland, 2020; pp. 417–431. [Google Scholar] [CrossRef]
- Molnar, C. Interpretable Machine Learning: A Guide for Making Black Box Models Explainable. 2022. Available online: https://christophm.github.io/interpretable-ml-book (accessed on 25 May 2023).
- Puiutta, E.; Veith, E.M.S.P. Explainable Reinforcement Learning: A Survey. In Proceedings of the Machine Learning and Knowledge Extraction, Dublin, Ireland, 25–28 August 2020; Holzinger, A., Kieseberg, P., Tjoa, A.M., Weippl, E., Eds.; Springer: Cham, Switzerland, 2020; pp. 77–95. [Google Scholar] [CrossRef]
- Heuillet, A.; Couthouis, F.; Díaz-Rodríguez, N. Explainability in deep reinforcement learning. Knowl.-Based Syst. 2021, 214, 106685. [Google Scholar] [CrossRef]
- Milani, S.; Topin, N.; Veloso, M.; Fang, F. A survey of explainable reinforcement learning. arXiv 2022, arXiv:2202.08434. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Erion, G.; Chen, H.; DeGrave, A.; Prutkin, J.M.; Nair, B.; Katz, R.; Himmelfarb, J.; Bansal, N.; Lee, S.I. From local explanations to global understanding with explainable AI for trees. Nat. Mach. Intell. 2020, 2, 56–67. [Google Scholar] [CrossRef] [PubMed]
- Liu, G.; Schulte, O.; Zhu, W.; Li, Q. Toward Interpretable Deep Reinforcement Learning with Linear Model U-Trees. In Proceedings of the Machine Learning and Knowledge Discovery in Databases, Dublin, Ireland, 10–14 September 2018; Berlingerio, M., Bonchi, F., Gärtner, T., Hurley, N., Ifrim, G., Eds.; Springer: Cham, Switzerland, 2019; Volume 11052, pp. 414–429. [Google Scholar] [CrossRef] [Green Version]
- Mania, H.; Guy, A.; Recht, B. Simple random search of static linear policies is competitive for reinforcement learning. In Advances in Neural Information Processing Systems; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2018; Volume 31. [Google Scholar]
- Coppens, Y.; Efthymiadis, K.; Lenaerts, T.; Nowé, A.; Miller, T.; Weber, R.; Magazzeni, D. Distilling deep reinforcement learning policies in soft decision trees. In Proceedings of the IJCAI 2019 Workshop on Explainable Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 1–6. [Google Scholar]
- Frosst, N.; Hinton, G.E. Distilling a Neural Network Into a Soft Decision Tree. In Proceedings of the First International Workshop on Comprehensibility and Explanation in AI and ML, Bari, Italy, 16–17 November 2017. [Google Scholar]
- Verma, A.; Murali, V.; Singh, R.; Kohli, P.; Chaudhuri, S. Programmatically Interpretable Reinforcement Learning. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; Proceedings of Machine Learning Research; Dy, J., Krause, A., Eds.; PMLR: New York, NY, USA, 2018; Volume 80, pp. 5045–5054. [Google Scholar]
- Qiu, W.; Zhu, H. Programmatic Reinforcement Learning without Oracles. In Proceedings of the Tenth International Conference on Learning Representations, ICLR, Virtual, 25–29 April 2022. [Google Scholar]
- Ross, S.; Gordon, G.; Bagnell, D. A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Ft. Lauderdale, FL, USA, 11–13 April 2011; Proceedings of Machine Learning Research; Gordon, G., Dunson, D., Dudík, M., Eds.; PMLR: New York, NY, USA, 2011; Volume 15, pp. 627–635. [Google Scholar]
- Bastani, O.; Pu, Y.; Solar-Lezama, A. Verifiable Reinforcement Learning via Policy Extraction. In Advances in Neural Information Processing Systems; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2018; Volume 31. [Google Scholar]
- Zilke, J.R.; Loza Mencía, E.; Janssen, F. DeepRED—Rule Extraction from Deep Neural Networks. In Proceedings of the Discovery Science, Bari, Italy, 19–21 October 2016; Calders, T., Ceci, M., Malerba, D., Eds.; Springer: Cham, Switzerland, 2016; Volume 9956, pp. 457–473. [Google Scholar] [CrossRef]
- Schapire, R.E. The strength of weak learnability. Mach. Learn. 1990, 5, 197–227. [Google Scholar] [CrossRef] [Green Version]
- Freund, Y.; Schapire, R.E. A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Rudin, C. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nat. Mach. Intell. 2019, 1, 206–215. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. OpenAI Gym. arXiv 2016, arXiv:1606.01540. [Google Scholar] [CrossRef]
- Lovatto, A.G. CartPole Swingup—A Simple, Continuous-Control Environment for OpenAI Gym. 2021. Available online: https://github.com/0xangelo/gym-cartpole-swingup (accessed on 25 May 2023).
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing Atari with Deep Reinforcement Learning. arXiv 2013, arXiv:1312.5602. [Google Scholar] [CrossRef]
- Fujimoto, S.; van Hoof, H.; Meger, D. Addressing Function Approximation Error in Actor-Critic Methods. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; Proceedings of Machine Learning Research; Dy, J., Krause, A., Eds.; PMLR: New York, NY, USA, 2018; Volume 80, pp. 1587–1596. [Google Scholar]
- Raffin, A.; Hill, A.; Gleave, A.; Kanervisto, A.; Ernestus, M.; Dormann, N. Stable-Baselines3: Reliable Reinforcement Learning Implementations. J. Mach. Learn. Res. 2021, 22, 12348–12355. [Google Scholar]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification And Regression Trees; Routledge: New York, NY, USA, 1984. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Stepišnik, T.; Kocev, D. Oblique predictive clustering trees. Knowl.-Based Syst. 2021, 227, 107228. [Google Scholar] [CrossRef]
- Alipov, V.; Simmons-Edler, R.; Putintsev, N.; Kalinin, P.; Vetrov, D. Towards practical credit assignment for deep reinforcement learning. arXiv 2021, arXiv:2106.04499. [Google Scholar] [CrossRef]
- Woergoetter, F.; Porr, B. Reinforcement learning. Scholarpedia 2008, 3, 1448. [Google Scholar] [CrossRef]
- Roth, A.E. (Ed.) The Shapley Value: Essays in Honor of Lloyd S. Shapley; Cambridge University Press: Cambridge, UK, 1988. [Google Scholar] [CrossRef]
- Bach, S.; Binder, A.; Montavon, G.; Klauschen, F.; Müller, K.R.; Samek, W. On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation. PLoS ONE 2015, 10, e0130140. [Google Scholar] [CrossRef] [Green Version]
- Montavon, G.; Binder, A.; Lapuschkin, S.; Samek, W.; Müller, K.R. Layer-Wise Relevance Propagation: An Overview. In Explainable AI: Interpreting, Explaining and Visualizing Deep Learning; Samek, W., Montavon, G., Vedaldi, A., Hansen, L.K., Müller, K.R., Eds.; Springer: Cham, Switzerland, 2019; pp. 193–209. [Google Scholar] [CrossRef]
- Schwalbe, G.; Finzel, B. A comprehensive taxonomy for explainable artificial intelligence: A systematic survey of surveys on methods and concepts. Data Min. Knowl. Discov. 2023, 1–59. [Google Scholar] [CrossRef]











| Environment | Observation Space () | Action Space () | |
|---|---|---|---|
| Acrobot-v1 | First angle , First angle , Second angle , Second angle , Angular velocity , Angular velocity | Apply torque{-1 (0), 0 (1), 1 (2)} | |
| CartPole-v1 | Position cart , Velocity cart , Angle pole , Velocity pole | Accelerate{left (0), right (1)} | 475 |
| CartPole- SwingUp-v1 | Position cart , Velocity cart , Angle pole , Angle pole , Angular velocity pole | Accelerate{left (0), not (1), right (2)} | undef. |
| LunarLander-v2 | Position , Position , Velocity , Velocity , Angle , Angular velocity , Contact center leg , Contact right leg | Fire{not (0), left engine (1), main engine (2), right engine (3)} | 200 |
| MountainCar-v0 | Position , Velocity | Accelerate{left (0), not (1), right (2)} | |
| MountainCar Continuous-v0 | Same as MountainCar-v0 | Accelerate | 90 |
| Pendulum-v1 | Angle , Angle , Angular velocity | Apply torque | undef. |
| (a) Solving an environment | ||||||
|---|---|---|---|---|---|---|
| Algorithms | ||||||
| EPS | EPS | BB | ITER | ITER | ||
| Environment | Model | CART | OPCT | OPCT | CART | OPCT |
| Acrobot-v1 | DQN | 1 | 1 | 1 | 1 | |
| CartPole-v1 | PPO | 3 | 3 | 1 | 3 | 1 |
| CartPole-SwingUp-v1 | DQN | 10 | 10 | 10 | 10 | 7 |
| LunarLander-v2 | PPO | 10 | 10 | 2 | 10 | 2 |
| MountainCar-v0 | DQN | 3 | 3 | 5 | 3 | 1 |
| MountainCarContinuous-v0 | TD3 | 1 | 1 | (1) | 1 | 1 |
| Pendulum-v1 | TD3 | 10 | 9 | 6 | 7 | 5 |
| Sum | 38 | 37 | 35 | 35 | 18 | |
| (b) Surpassing the oracle | ||||||
| Acrobot-v1 | DQN | 3 | 3 | 2 | 1 | |
| CartPole-v1 | PPO | 5 | 6 | 1 | (3) | 1 |
| CartPole-SwingUp-v1 | DQN | |||||
| LunarLander-v2 | PPO | 2 | 3 | |||
| MountainCar-v0 | DQN | 3 | 5 | 6 | 3 | 4 |
| MountainCarContinuous-v0 | TD3 | 1 | 4 | 2 | 1 | |
| Pendulum-v1 | TD3 | 9 | 8 | 10 | 6 | |
| Sum | 44 | 41 | 26 | |||
| Environment | dim D | Algorithm | |||
|---|---|---|---|---|---|
| Acrobot-v1 | 6 | EPS | 124.82 ± 1.96 | 11.71 ± 0.95 | 30,000 |
| BB | 477.70 ± 7.89 | 47.56 ± 2.92 | 30,000 | ||
| ITER | 1189.14 ± 28.70 | 10.76 ± 1.02 | 30,000 | ||
| CartPole-v1 | 4 | EPS | 187.39 ± 3.64 | 18.06 ± 2.29 | 30,000 |
| BB | 202.65 ± 1.26 | 19.11 ± 1.13 | 30,000 | ||
| ITER | 2040.16 ± 21.46 | 18.50 ± 1.64 | 30,000 | ||
| MountainCar-v0 | 2 | EPS | 85.39 ± 1.50 | 7.93 ± 0.57 | 30,000 |
| BB | 104.92 ± 2.05 | 10.27 ± 0.54 | 30,000 | ||
| ITER | 849.90 ± 19.79 | 7.68 ± 0.61 | 30,000 |
| Number of Parameters | |||||
|---|---|---|---|---|---|
| Environment | Dim D | Model | Oracle | ITER | Depth d |
| Acrobot-v1 | 6 | DQN | 136,710 | 9 | 1 |
| CartPole-v1 | 4 | PPO | 9155 | 7 | 1 |
| CartPole-SwingUp-v1 | 5 | DQN | 534,534 | 890 | 7 |
| LunarLander-v2 | 8 | PPO | 9797 | 31 | 2 |
| MountainCar-v0 | 2 | DQN | 134,656 | 5 | 1 |
| MountainCarContinuous-v0 | 2 | TD3 | 732,406 | 5 | 1 |
| Pendulum-v1 | 3 | TD3 | 734,806 | 156 | 5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Engelhardt, R.C.; Oedingen, M.; Lange, M.; Wiskott, L.; Konen, W. Iterative Oblique Decision Trees Deliver Explainable RL Models. Algorithms 2023, 16, 282. https://doi.org/10.3390/a16060282
Engelhardt RC, Oedingen M, Lange M, Wiskott L, Konen W. Iterative Oblique Decision Trees Deliver Explainable RL Models. Algorithms. 2023; 16(6):282. https://doi.org/10.3390/a16060282
Chicago/Turabian StyleEngelhardt, Raphael C., Marc Oedingen, Moritz Lange, Laurenz Wiskott, and Wolfgang Konen. 2023. "Iterative Oblique Decision Trees Deliver Explainable RL Models" Algorithms 16, no. 6: 282. https://doi.org/10.3390/a16060282