4.2. Task Assignment and Sequencing
We present in Listing 2 an encoding for assigning and sequencing tasks.
| Listing 2. Task assignment and sequencing. |
- 1
1 { assign(R,T) : robot(R) } 1 :- task(T,_), not depends(deliver,_,T). - 2
assign(R,T') :- assign(R,T), depends(deliver,T,T').
- 4
0 { task_sequence(T,T') : task(T',_), T!=T', not depends(deliver,_,T') } 1
- 5
:- task(T,_), not depends(deliver,T,_).
- 6
task_sequence(T,T') :- depends(deliver,T,T').
- 8
same_robot(T,T') :- assign(R,T), assign(R,T'), T < T',
- 9
not depends(deliver,T,T').
- 10
same_robot(T,T') :- depends(deliver,T,T').
- 12
:- task_sequence(T,T'), not depends(deliver,T,T'),
- 13
not same_robot(T,T'), not same_robot(T',T).
- 14
:- task(T,_), 2 #count{ T' : task_sequence(T',T) }.
- 15
:- assign(R,_), not #count{ T : assign(R,T), not task_sequence(_,T) } = 1.
|
More precisely, a complete and non-overlapping task sequence assignment to robots is established. This part is common to both the step- and path-based approach introduced in the following two sections. In what follows, we draw on the components of a fixed warehouse (V,E,,C,R,,) and a task execution graph (T,D,,).
A task sequence assignment allots each robot a sequence of tasks; it is represented by atoms over predicates assign/2 and task_sequence/2. An atom assign(r,t) represents that for robot r and task t. Furthermore, an atom task_sequence(t,) signifies that there is a task assignment with two consecutive tasks for some robot .
Lines 1–2 deal with task assignments and enforce that the task sequence assignment is complete and non-overlapping, as spelled out in Condition 6 and 7. In Line 1, we assign each task t without any delivery dependency, or formally, where there is no such that , to exactly one robot in R. Line 2 ensures that tasks that are in a delivery dependency are assigned to the same robot. That is, once a robot r is assigned a task t that is part of a delivery dependency , then r must also be assigned task .
The remainder of Listing 2 is dedicated to sequencing the assigned tasks. In Line 4, a task can be chosen as succeeding a task t, by means of task_sequence(t,), so long as has no other task as a delivery dependency and t is not a delivery dependent of some other task. That is, for any task t without a subsequent delivery dependency, we may choose a succeeding task having no preceding delivery dependency. On the other hand, whenever two tasks are in a delivery dependency, viz. and , we enforce their succession by deriving task_sequence(t,) in Line 6.
Lines 8–10 identify tasks assigned to the same robot. We separate this into two cases. Line 8 deals with tasks that are not in a delivery dependency but happen to be assigned to the same robot. This information is dynamic and can only be determined at solving time from the identity of the assigned robots. Note, clingo’s grounder guarantees a total ordering over terms; and we rely on this ordering by using the condition T < T′ to avoid the generation of redundant ground rules resulting from the symmetry between the tasks T and T′. In contrast, Line 10 directly asserts the static fact that a pair of tasks in a delivery dependency is necessarily assigned to the same robot. This static information is independent of the identity of the assigned robots and can be determined at grounding time. Consequently, separating the two cases results in a (slight) reduction of the size of the resulting grounding and results in fewer choices that need to be made by the solver. The resulting information is then used in Line 12 to ensure that all pairs of ordered tasks, expressed by task_sequence(t,), are assigned to the same robot. Line 14 forbids that a task has several predecessors and Line 15 requires that a robot’s task sequence has a unique beginning.
Note that the encoding in Listing 2 cannot rule out that the obtained instances of predicate task_sequence/2 form disconnected cycles. This is because it only enforces that each such task sequence has a unique start and there is no task with several predecessors. For instance, given the robot assignments assign(r1,t1), assign(r1,t2), assign(r1,t3), and assign(r1,t4), Lines 4–15 could potentially generate the linear sequence task_sequence(t1,t2) in combination with the circular sequence consisting of task_sequence(t3,t4) and task_sequence(t4,t3). Fortunately, while Listing 2 by itself is not ruling out such incorrect sequences, they are discarded when scheduling information is added. This is an implicit consequence of assigning time points to tasks which rule out cyclic time sequences. However, scheduling is handled differently for the step and path encodings, and we therefore differ the discussion of its application to the following subsections.
Nevertheless, while the scheduling process implicitly removes any disconnected cycles, it is also possible, and potentially beneficial, to enforce this explicitly. We introduce two distinct mechanisms for doing this. The first way of removing cyclic task sequences without scheduling is via a reachability encoding. The encoding in Listing 3 ensures that all tasks on a task sequence are reachable from the start of a sequence.
| Listing 3. Task sequence reachability. |
- 1
task_reachable(T) :- task_sequence(T,_), not task_sequence(_,T). - 2
task_reachable(T') :- task_reachable(T), task_sequence(T,T').
- 3
:- task_sequence(T,_), not task_reachable(T).
|
First, Line 1 identifies the start of a sequence and determines that it is reachable, then, Line 2 propagates that a task is also reachable if it is connected to some other reachable task on a task sequence. Finally, Line 3 ensures that a task sequence may only continue from a reachable task. This discards the cyclic example from above, as neither t3 nor t4 are reachable from the start of a task sequence. In fact, the reachability between t3 and t4 forms an unfounded set and is discarded by the unfounded set checker of clingo.
A second, and easy, alternative to explicitly eliminating cyclic task sequences is by using clingo’s builtin acyclicity checker. This can be accomplished by using the #edge directive with atoms over predicate task_sequence/2 as shown in Listing 4.
| Listing 4. Task sequence acyclicity via #edge directives. |
| #edge(T,T') : task_sequence(T,T'). |
The advantages of combining Listings 2 with either 3 or 4 are twofold. First, the stable models of both listings combined yield all correct possible task sequence assignments, and second, although redundant when scheduling is added, it may improve solving performance by immediately discarding cyclic task sequences. We empirically investigate this in
Section 5.
Beyond individually correct task sequences, we can also employ acyclicity detection to prematurely discard more complex sequences that are unschedulable. For instance, we may have the single acyclic sequence
task_sequence(t3,t4),
task_sequence(t4,t1), and
task_sequence(t1,t2), where all tasks are assigned to the same robot (e.g.,
assign(r1,t1),
assign(r1,t2),
assign(r1,t3), and
assign(r1,t4)). While this task sequence itself is not cyclic, nevertheless there is a cycle introduced through wait dependencies over multiple task sequences. In this example, there is a wait dependency
depends(wait,t1,t4) because
t1 is the full pallet pickup task at location
l1 while
t4 is its corresponding empty pallet putdown task (see
Figure 2). Essentially
t1 must be executed before
t4, and so this sequence is not schedulable despite the fact that the task sequence itself is acyclic. Listing 5 eliminates such cycles by adding the wait dependencies, via the edge directive, to the acyclicity detection. However, it is important to note that this encoding has no effect individually and needs to be used in tandem with Listing 4.
| Listing 5. Acyclicity between task sequences via #edge directives. |
| #edge(T,T') : depends(D,T,T'), D != deliver. |
Our example yields 120 (acyclic) task sequence assignments, among them the one in
Table 1, represented by
assign(r1,t1) assign(r2,t5)
assign(r1,t2) assign(r2,t6)
assign(r1,t3) assign(r2,t7)
assign(r1,t4) assign(r2,t8)
task_sequence(t1,t2) task_sequence(t5,t6)
task_sequence(t2,t3) task_sequence(t6,t7)
task_sequence(t3,t4) task_sequence(t7,t8)
4.3. Step-Based Encoding
In this section, we address routing and scheduling aspects of our application via an encoding closely following our formalization. In doing so, we separately describe the parts of the encoding capturing walk assignments, conflict detection and resolution, projections, and scheduling. Finally, we discuss the correspondence of the resulting stable models to the solutions of warehouse delivery problems.
4.3.1. Walk Assignment
We start by providing an encoding capturing (non-timed) walks satisfying starting and homing conditions in Listing 6; timing constraints addressing arrival and exit times are addressed in
Section 4.3.4.
| Listing 6. Assign a walk to each robot. |
- 1
step(0..maxstep). - 3
vertex(V) :- edge(V,_,_).
- 4
vertex(V') :- edge(_,V',_).
- 5
0 { walk(R,S,V) : vertex(V) } 1 :- robot(R), step(S).
- 7
:- walk(R,S,_), not walk(R,S-1,_), S>0.
- 8
:- walk(R,S,V), walk(R,S+1,V'), not edge(V,V',_).
- 10
:- walk(R,0,V), not start(R,V).
- 11
:- walk(R,S,V), not walk(R,S+1,_), not home(R,V).
- 12
:- start(R,V), home(R,V'), V != V', not walk(R,_,_).
|
To begin with, we introduce a horizon limiting the maximum length of any walk. The corresponding parameter is introduced in Line 1 and controls how many instances of predicate step/1 are introduced.
A robot’s walk is a sequence of vertices; it is represented via the ternary predicate
walk/3. The walk in
Table 2 is captured by the following atoms.
walk(r1,0,h1) walk(r2,0,h2)
walk(r1,1,w3) walk(r2,1,w4)
walk(r1,2,w2) walk(r2,2,w8)
walk(r1,3,w1) walk(r2,3,l2)
walk(r1,4,l1) walk(r2,4,w8)
walk(r1,5,w1) walk(r2,5,w7)
walk(r1,6,w5) walk(r2,6,w6)
walk(r1,7,s1) walk(r2,7,s2)
walk(r1,8,w5) walk(r2,8,w6)
walk(r1,9,w6) walk(r2,9,w2)
walk(r1,10,w2) walk(r2,10,p1)
walk(r1,11,p1) walk(r2,11,w2)
walk(r1,12,w2) walk(r2,12,w1)
walk(r1,13,w1) walk(r2,13,w5)
walk(r1,14,l1) walk(r2,14,w6)
walk(r1,15,w1) walk(r2,15,w7)
walk(r1,16,w2) walk(r2,16,w8)
walk(r1,17,w3) walk(r2,17,l2)
walk(r1,18,h1) walk(r2,18,w8)
walk(r2,19,w4)
walk(r2,20,h2)
Each instance walk(r,s,v) expresses that robot r is at step at vertex v. Accordingly, Line 5 allows every robot in every step to be at any vertex, while the remaining integrity constraints make sure that walks are feasible (except for timing constraints) and respect the starting and homing conditions.
Firstly, the integrity constraint at Line 7 excludes walks with gaps. This ensures a canonical representation making sure that subsequently visited vertices also have subsequent step numbers. Next, since walks have to respect the warehouse’s structure, vertices with successive step numbers must be connected via an edge in the warehouse graph. This is enforced by the integrity constraint in Line 8.
Up to this point, the encoding produces (non-timed) feasible walks with up to maxstep vertices for each robot in the warehouse at hand. Next, we add additional constraints to ensure Conditions 8 and 9, warranting a starting and homing walk. Line 10 ensures that the walk of each robot begins at its starting location. Then, Line 11 requires each walk to end at the robot’s home location. Furthermore, finally, Line 12 enforces that the walk is non-empty if the robot does not start at its home location. This is necessary to deal with the special case of a robot that does not start at its home location but also has no assigned tasks. Without this constraint it would be possible for there to be no walk/3 instances generated for this robot, which in turn would mean that the homing constraint at Line 11 would not ensure that the robot finished its walk at its home location.
4.3.2. Conflict Detection and Resolution
Having assigned robots to walks, we now turn to detecting and resolving any potential conflicts between these walks. Rather than explicitly ruling out conflicting situations, Listing 7 relies on the predicate before/2 to indicate which robot is to proceed first whenever two robots travel over conflicting vertices.
| Listing 7. Resolve conflicts for robots visiting conflicting vertices. |
- 1
{ before((R,S),(R',S')) } :- walk(R,S,V), walk(R',S',V'), - 2
conflict(V,V'), R < R'.
- 3
before((R',S'),(R,S)) :- walk(R,S,V), walk(R',S',V'),
- 4
conflict(V,V'), R < R',
- 5
not before((R,S),(R',S')).
- 7
:- start(R,V), not walk(R,_,_), walk(_,_,V).
- 8
:- walk(R,0,_), before((_,_),(R,0)).
- 9
:- walk(R,S,_), not walk(R,S+1,_), before((R,S),(_,_)).
- 11
:- walk(R,S,V1), walk(R,S+1,V2), walk(R',S',V1'), walk(R',S'+1,V2'),
- 12
conflict(V1,V1'), conflict(V2,V2'), before((R,S),(R',S')),
- 13
not before((R,S+1),(R',S'+1)).
- 14
:- walk(R,S,V1), walk(R,S+1,V2), walk(R',S',V1'), walk(R',S'+1,V2'),
- 15
conflict(V1,V2'), conflict(V2,V1'), before((R,S),(R',S'+1)),
- 16
not before((R,S+1),(R',S')).
|
More specifically, an atom of the form before((r,s),(,)) indicates that robot r in its step s precedes robot in its steps . The underlying conflicting vertices remain implicit. The actual detection and resolution of conflicts is done in Lines 1–5. To reduce grounding, we only make a choice whenever the robots’ names are strictly smaller. We derive the opposite ordering, if the robot with the smaller name was not chosen to advance first.
The rest of the encoding adds constraints for a conflict-free routing that are expressible without the need of timing constraints. In the initial situation, robots are located at their starting positions, and therefore, no other robot could pass through there first. Line 7 forbids any robot to pass through the starting point of another robot that never moves. A similar constraint is expressed in Line 8, denying robots precedence over other robots at the starting step no matter where this step takes place. Finally, Line 9 imposes a constraint for the end of each robot’s walk. In particular, for the final vertex of a given robot’s walk, all other robots need to have passed through any conflicting vertices first, before the given robot is allowed to arrive at its destination. Note, since our solutions are restricted to homing walks, this constraint covers the corner-case where a robot visits another robot’s home vertex. This would only happen if the robot’s home vertex happened to also be a waypoint to some other vertex, or if a robot needed to detour to this vertex to allow some other robot to pass, such as along a narrow corridor. However, both these situations are potential indicators of a poorly designed warehouse, and are therefore unlikely to occur in practice.
Finally, the integrity constraints in Lines 11 and 14 handle robots following or facing each other in a group of conflicting vertices. The idea is that in both situations, whatever decision was made to order a pair of robots with respect to a pair of conflicting vertices, that same decision has to be maintained throughout the rest of the group of conflicting vertices. As a consequence, overtaking or colliding head-on is impossible since the robots remain in the same order or let the other robot pass completely before entering the critical part of the warehouse.
Continuing our example, the following facts capture part of the conflict resolution for the walks of robots r1 and r2. To help illustrate this scenario ASP comments also show the underlying warehouse conflict atoms.
before((r2,6),(r1,6)) before((r2,6),(r1,8))
before((r2,6),(r1,9)) before((r2,7),(r1,7))
before((r2,8),(r1,6)) before((r2,8),(r1,8))
before((r2,8),(r1,9))
before((r1,6),(r2,13)) before((r1,6),(r2,14))
before((r1,8),(r2,13)) before((r1,8),(r2,14))
before((r1,9),(r2,13)) before((r1,9),(r2,14))
These atoms address the conflicts on the two pairs of conflict vertices
(w5,w6), and
(s1,s2), discussed in
Section 3 and shown in
Figure 1. Robot
r2 passes through these conflict vertices twice; once on its way to dropping off a full pallet at
s2 and a second time on its way to dropping off an empty pallet at
l2. In contrast, robot
r1 only passes through the vertices once on its way to dropping off a full pallet at
s1. In combination, there are two sets of occasions requiring conflict resolution, and we have therefore presented these facts in two distinct blocks.
Firstly, when r2 is at its step 6 it passes through vertex w6 on its way to dropping off the pallet at s2. The first fact states that r2 must do this before r1 passes through vertices w5 at its own step 6. In fact, the subsequent facts in this block show that because of the adjacency of these conflict pairs, r2 must complete the full sequence of moves from w5 to s2, back to w5 and then leave w5 before r1 is able to travel through w5 on its way to s1 and back to w5 and then to w6.
The second block of facts deals with r2’s second visit to w5 and w6 as it passes through these vertices on its way to dropping off an empty pallet at vertex l2. However, unlike the first case where r2 was given precedence over robot r1, in this case r1 is given precedence.Intuitively, this is the preferred scenario as the overall delay would have been much greater if r1 had to wait for r2 to pass through twice before it could finish its first delivery task.
Finally, it is worthwhile observing that the
before/2 facts only establish a qualitative ordering without providing any assignment of specific timings. For instance,
before((r2,6),(r1,8)) only expresses that the passage of
r2 in its sixth step must precede that of
r1 in its eighth step. As shown in
Section 3.1.2, in an ultimate solution of our example, this is refined by letting
r1 pass at time point 215 and
r2 at 120.
4.3.3. Projection
Next, we form projections for checking whether task assignments, sequences and walks are executable, still without considering timing constraints. For this, we derive in Listing 8 atoms of the form proj(t,s) to indicate that task t is executed during some walk at step s.
| Listing 8. Choose a projection for each walk. |
- 1
1 { proj(T,S) : step(S) } 1 :- task(T,_). - 3
:- #count{ T : proj(T,S), assign(R,T) } > 1, step(S), robot(R).
- 5
:- proj(T,S), task(T,V), assign(R,T), not walk(R,S,V).
- 6
:- proj(T,S), proj(T',S'), task_sequence(T,T'), S > S'.
|
Specifically, we project in Line 1 each task onto exactly one step. In contrast to Condition 13, this abstracts from the specific robot and vertex; which allows for a more compact encoding that scales independently of the number of robots and vertices. Rather, we represent the actual projection points implicitly and enforce the connection to the specific robot and vertex via the integrity constraints in Lines 3 to 5. Line 3 makes sure that at most one task per robot and step is projected, given that robots cannot execute several tasks simultaneously. The constraint in Line 5 enforces that there actually is a robot assigned with the specific task at its target vertex in the projected step. In detail, for proj(t,s), it is required that we have walk(r,s,v) with t ∊ fT(r) and fV(t) = v, or assign(r,t) and task(t,v), respectively. This establishes Condition k. in the definition of projections and selects the relevant vertices from the robot’s walk. Finally, Line 6 ensures that projections respect the order of the task sequences, fT. Together the rules in Listing 8 make sure that there is a non-timed projection of each robot’s walk onto its task sequence. This establishes the qualitative aspects of Condition 13.
As an example, the representation of the two projections in
Table 3 is given below.
proj(t1,4) proj(t5,3)
proj(t2,7) proj(t6,7)
proj(t3,11) proj(t7,10)
proj(t4,14) proj(t8,17)
Note that the respective step indicates the position in the timed walks in
Table 2, which are in turn represented by the following instances of
walk/3 (cf. end of
Section 4.3.1):
walk(r1,4,l1) walk(r2,3,l2)
walk(r1,7,s1) walk(r2,7,s2)
walk(r1,11,p1) walk(r2,10,p1)
walk(r1,14,l1) walk(r2,17,l2)
4.3.4. Scheduling
Up to now, we have ignored all timing constraints. In fact, so far our encoding has only dealt with walks rather than timed walks, making up an actual walk assignment. Recall that the walk assignment of a robot r is a sequence of route points being feasible in the underlying warehouse. Each route point represents the arrival and exit time at a vertex. We represent a route point at position of the timed walk of a robot r by means of an atom walk(r,s,v) along with two terms a and e acting as integer variables. The actual timing constraints are expressed as difference constraints among these integer variables.
Listing 9 poses timing constraints based on the robots’ walks, resolved conflicts, and projections. These constraints are encoded using integer variables that correspond to the arrival and exit times of specific robots at specific steps of their walks. These variables are represented by the terms arrive(r,s) and exit(r,s) for any robot r at step of walk assignment . Note, the arrival and exit of a robot at a specific step maps directly to specific vertices, so we can think of the constraints as determining the arrival and exit times of robots at vertices. The purpose of the difference constraints in Listing 9 is then to check whether an integer assignment to these variables exists that warrants a feasible timed walk in view of the constraints posed by the other parts of the encoding.
| Listing 9. Derive timing constraints to obtain a valid schedule. |
- 1
&diff{ arrive(R,S) - exit(R,S) } <= 0 :- walk(R,S,_). - 3
&diff{ exit(R,S) - arrive(R,S+1) } <= -W :- walk(R,S,V), walk(R,S+1,V'),
- 4
edge(V,V',W).
- 6
&diff{ arrive(R,0) - 0 } <= 0 :- walk(R,0,_).
- 7
&diff{ 0 - arrive(R,0) } <= 0 :- walk(R,0,_).
- 9
&diff{ arrive(R,S) - bound } <= 0 :- walk(R,S,_), not walk(R,S+1,_).
- 10
&diff{ exit(R,S) - bound } <= 0 :- walk(R,S,_), not walk(R,S+1,_).
- 11
&diff{ bound - exit(R,S) } <= 0 :- walk(R,S,_), not walk(R,S+1,_).
- 14
&diff{ arrive(R,S+1) - arrive(R',S') } <= 0 :- before((R,S),(R',S')). - 16
#const kappa=10. - 18
&diff{ arrive(R,S) - exit(R,S) } <= -kappa :-
- 19
proj(T,S), assign(R,T).
- 20
&diff{ arrive(R,S) - arrive(R',S') } <= -kappa :-
- 21
proj(T,S), assign(R,T),
- 22
proj(T',S'), assign(R',T'),
- 23
depends(D,T,T'), D != deliver,
- 24
R != R'.
|
Line 1 ensures that the exit time of a robot at a vertex, as represented by the robot’s step count, does not precede its arrival at that vertex, while Line 3 ensures that the travel time between vertices is respected. Together, this corresponds to the feasibility requirements (2) and (3) on timed walks. Next, Lines 6 and 7 force each robot’s arrival time at its starting vertex, represented by the step count 0, to a time of 0 as stipulated in 10.
Lines 9 to 11 impose constraints on each robot at its terminal vertex. In particular, the constraints ensure that for any robot r at its terminating step s, we have that arrive(r,s) ≤ bound and exit(r,s) = bound. Note, bound here is an integer variable, so the value of bound is an upper bound on all robots’ arrival times at their last steps. In fact, clingo[dl] yields the least upper bound, which corresponds to the last of these arrival times, because the assignment returned by clingo[dl] contains the lowest possible positive integer values that satisfy all difference constraints. Furthermore, the exit times of all last steps are set to this value. Hence, the exit times of all robots at their corresponding home vertices are equal, which also constitutes the makespan of the solution to the warehouse delivery problem. The advantage of this technique is two-fold. First, if a home vertex of a robot can be in the walk of another robot, we ensure that finished robots remain in place until the entire execution is completed. Second, the variable bound gives us an easy access to the makespan of the solution. This can be utilized to either minimize or restrict the execution time. Note, that we use the variable bound for the exit times at terminal vertices rather than the constant ∞, as stipulated by the homing Condition 11. However, since bound is the common exit time of all terminal vertices it is easy to see the direct mapping between the two.
The combination of the constraints from Lines 1 to 11 ensures that the obtained robot arrival and exit times result in a timed walk that is feasible in the given warehouse. We now turn to the remaining constraints that address the timing of conflict resolution and task execution.
Condition 12 requires the robot assignment to be collision-free. Line 14 addresses this condition by imposing a difference constraint to ensure that two robots visiting conflicting vertices at certain steps do not collide. That is, whenever a robot r has been granted precedence over another robot by virtue of before((r,s),(,)), then the relationship arrive(r,) ≤ arrive(,) must hold. This relationship ensures that enters the conflict zone only once r has already moved outside the conflict zone to its next vertex (this vertex is guaranteed to exist due to Line 9 in Listing 7). To further elaborate on how the difference constraint satisfies the collision-free condition, we start by noting that the above robot-step pairs, and , are associated with vertices and by atoms ( see Listing 7). walk(r,s,v), walk(,,), as well as walk(r,,). The actual conflict concerns route points and with . Given walk , the difference constraint in Line 14 requires . Furthermore, the non-zero travel time of r between v and implies that , namely that r arrives at s before arrives at . Note that if we also have conflict , the integrity constraints in Lines 11 and 14 in Listing 7 ensure that before((r,),(,)) also holds. This then further delays the entry of to vertex in the same manner as above.
Moving on to task timing, the rule at Line 18 enforces that when a robot arrives at a vertex to execute a given task, it must remain at that vertex long enough for it to actually complete the task’s execution. To this end, the constraint
arrive(r,s) +
≤
exit(r,s) is imposed whenever
assign(r,t) and
proj(t,s) hold. However, note, by virtue of Line 5 in Listing 8, whenever
assign(r,t) and
proj(t,s) hold, then we also conclude
walk(r,s,v) for vertex
. So we know that robot
r is at the correct location
v, and time step
s, required to execute the task
t to which it has been assigned. So the difference constraint at Line 18 simply ensures that the duration of
r’s stay at
v does indeed satisfy the minimum timing requirement given by the definition of a projection (i.e., Condition l.). Together with the earlier result in
Section 4.3.3 that Listing 8 satisfies the qualitative aspect of Condition 13, the result of this timing constraint is to satisfy the quantitative aspect of this same condition.
Finally, Line 20 establishes the satisfaction of Condition 14 by enforcing the timing constraint that arrive(r,s) + ≤ arrive(,) for any two robots that are assigned, respectively, to the two tasks t and in a pair of dependent tasks, where s and are the projections points corresponding to these two tasks. Similarly to the explanation for Line 14, the rule’s precondition implies the existence of the two route points and that serve as the projection points s and of the tasks t and . The given timing constraint thus amounts to the one required in Condition 14, namely, . Finally, note that the rule’s precondition includes the requirement that D != deliver, thus limiting its application to non-delivery dependent tasks. The reason for this restriction is simply that this rule is redundant for a pair of delivery dependent tasks. Delivery dependent tasks can only be assigned to the same robot and since the task sequencing for that robot guarantees the correct task execution order, the correctness of the timing is implicitly guaranteed by this ordering.
This completes the explanation of the difference constraints and variables defined in Listing 9. The assignment to these integer variables in our example is output by using the binary predicate
dl/2 in
clingo[
dl]. The following expressions capture the arrival and exit times in the timed walks in
Table 2.
dl(arrive(r1,0),0) dl(exit(r1,0),0) dl(arrive(r2,0),0) dl(exit(r2,0),0)
dl(arrive(r1,1),15) dl(exit(r1,1),15) dl(arrive(r2,1),15) dl(exit(r2,1),15)
dl(arrive(r1,2),45) dl(exit(r1,2),45) dl(arrive(r2,2),30) dl(exit(r2,2),30)
dl(arrive(r1,3),65) dl(exit(r1,3),65) dl(arrive(r2,3),45) dl(exit(r2,3),55)
dl(arrive(r1,4),80) dl(exit(r1,4),90) dl(arrive(r2,4),70) dl(exit(r2,4),70)
dl(arrive(r1,5),105) dl(exit(r1,5),105) dl(arrive(r2,5),100) dl(exit(r2,5),100)
dl(arrive(r1,6),175) dl(exit(r1,6),175) dl(arrive(r2,6),120) dl(exit(r2,6),120)
dl(arrive(r1,7),190) dl(exit(r1,7),200) dl(arrive(r2,7),135) dl(exit(r2,7),145)
dl(arrive(r1,8),215) dl(exit(r1,8),215) dl(arrive(r2,8),160) dl(exit(r2,8),160)
dl(arrive(r1,9),225) dl(exit(r1,9),225) dl(arrive(r2,9),175) dl(exit(r2,9),175)
dl(arrive(r1,10),240) dl(exit(r1,10),240) dl(arrive(r2,10),190) dl(exit(r2,10),200)
dl(arrive(r1,11),255) dl(exit(r1,11),265) dl(arrive(r2,11),215) dl(exit(r2,11),215)
dl(arrive(r1,12),280) dl(exit(r1,12),280) dl(arrive(r2,12),235) dl(exit(r2,12),235)
dl(arrive(r1,13),300) dl(exit(r1,13),300) dl(arrive(r2,13),253) dl(exit(r2,13),253)
dl(arrive(r1,14),315) dl(exit(r1,14),325) dl(arrive(r2,14),263) dl(exit(r2,14),263)
dl(arrive(r1,15),340) dl(exit(r1,15),340) dl(arrive(r2,15),283) dl(exit(r2,15),283)
dl(arrive(r1,16),360) dl(exit(r1,16),360) dl(arrive(r2,16),313) dl(exit(r2,16),313)
dl(arrive(r1,17),390) dl(exit(r1,17),390) dl(arrive(r2,17),328) dl(exit(r2,17),338)
dl(arrive(r1,18),405) dl(exit(r1,18),405) dl(arrive(r2,18),353) dl(exit(r2,18),353)
dl(arrive(r2,19),368) dl(exit(r2,19),368)
dl(bound,405) dl(arrive(r2,20),383) dl(exit(r2,20),405)
Note that ∞ is replaced by the makespan, viz. the value of variable bound.
4.3.5. Stable Models of the Step-Based Encoding and Solutions to the Warehouse Delivery Problem
After examining the individual parts of our step-based encoding of the warehouse delivery problem, we now describe how the resulting stable models relate to solutions of the warehouse delivery problem. This is not meant as a formal correctness proof but rather an informal account providing a broader perspective.
To this end, let
F be the set of facts obtained from a given warehouse (
V,
E,
,
C,
R,
,
) and task execution graph (
T,
D,
,
), as described in
Section 4.1, and let
P be the combined set of rules from Listings 2 to 9.
A stable model X of logic program induces the candidate robot assignment in the following way for , , , and .
If assign(r,t) , then ;
If {assign(r,t),assign(r,),task_sequence(t,), then ;
If {walk(r,s,v),dl(arrive(r,s),a),dl(exit(r,s),e) and
walk(r,,) , then route point is at position of ;
If {walk(r,s,v),dl(arrive(r,s),a),dl(exit(r,s),e) and
walk(r,,) , then route point is at position of ;
If there are no walk/3 atoms for r in X, then .
Given a stable model X of logic program , we now establish step by step why the induced robot assignment meets all required conditions of a solution to the warehouse delivery problem.
We begin with the basic properties of robot assignments.
Condition 4: is a task sequence over for every robot . As described in
Section 4.2, atoms over predicates
assign/2 and
task_sequence/2 are established in a way that all tasks are assigned to exactly one robot (Lines 1 and 2 in Listing 2), tasks are indeed arranged in sequences with a single beginning (Line 15 in Listing 2), no branching (Line 14 in Listing 2), or cycles (either Listing 4 or timing constraints induced by Listing 9), and, finally, tasks connected via a task sequence are assigned to the same robot (Line 12 in Listing 2), Then, by construction, this carries over to
and makes each a task sequence for any
.
Note, there are two implicit consequences of the above construct of from X. Firstly, if there are no assign/2 atoms for r in X then . Secondly, if there does exist some assign(r,t) but t does not exist either as the first or second parameter of some task_sequence/2 atom, then assign(r,t) is guaranteed to be the only assign/2 atom for r and .
Condition 5: is a timed walk feasible in (,,,,,,) for every robot . This is achieved by the rules in Lines 5, 7, and 8 in Listing 6 and Lines 1 and 3 in Listing 9.
The construction of along with the consecutive numbering of steps enforced in Line 7 of Listing 6, ensures that any atom walk(r,s,v) indicates a route point at position in the timed walk of robot r for and . We rely upon their consecutive step numbering in the following.
For Condition 1, we observe that for two successive route points and in , the integrity constraint in Line 8 of Listing 6 makes sure that there exists an edge . Condition 2 is captured in Line 1 of Listing 9: For any route point in a timed walk , the robot’s exit time is at least as large as its arrival time, viz. we have . Line 3 of Listing 9 enforces Condition 3; it requires for any successive route points and in .
Note that Line 5 of Listing 6 does not guarantee that instances of predicate walk/3 are generated for every robot. This leaves us with the corner case that there may be no such atoms in X for a given robot r. This corresponds to the timed walk . In this case, Condition 1 and 2 are trivially satisfied in the presence of a single route point and satisfies Condition 3.
Condition 6–7: Complete and Non-Overlapping Assignment. As already mentioned, Lines 1 and 2 of Listing 2 assign each task t to exactly one robot r. Thus, all tasks are assigned and no task is assigned twice in .
Condition 8–11: Starting and Homing Assignment. Line 10 of Listing 6 ensures that each robot is initially at its starting vertex; and Line 11 of Listing 6 guarantees that they finish at their respective home docking vertices. Clearly, this establishes Condition 8 and 9 for .
In terms of timing, the difference constraints in Lines 6 and 7 of Listing 9 set the arrival times at the starting vertices to 0, and thus fulfill Condition 10. Similarly, Lines 9 to 11 of Listing 9 set the exit time at the last position of each walk to the makespan in view of all timed walks. While this does not satisfy Condition 11 in an exact manner, the replacement of ∞ by the makespan amounts to the same condition, since the makespan is greater than or equal to any other time point in the timed walks. It is also, clearly, more informative.
Condition 12: Collision-free Assignment. Listing 7 is dedicated to detecting conflicts, and in particular deciding whether Condition 12a or 12b is used to resolve a conflict. More precisely, for distinct robots with route points , at steps s and , respectively, facing a conflict at , we have that either before((r,s),(,)) or before((,),(r,s)) . Then, in Line 14 of Listing 9, we use this decision to derive difference constraints either expressing that arrive(r,) ≤ arrive(,) or arrive(,) ≤ arrive(r,s). If and are the route points following and in and , respectively, then the difference constraints enforce either or , thus establishing Condition 12.
Condition 13–15: Executable Assignment. A pivotal concept for establishing a solution is the set of projections on the robots walks warranting that all tasks can be executed. In the step-based encoding, we do not explicitly represent the projection for every robot but rather rely upon atoms over predicate proj/2. Specifically, an atom proj(t,s) represents that task t is projected on some walk at position s. We can retrieve the projected walk via atoms assign(r,t) and walk(r,s,v) telling us that we project on the walk of robot r. This, as well as task(t,v), also provides the task’s action execution vertex v. Note that encoding projections in this way reduces the number of ground atoms compared to a more direct representation with proj(r,s,v).
A stable model X of logic program induces a set of projections in the following way for , , , and .
If {proj(t,s),assign(r,t),walk(r,s,v),dl(arrive(r,s),a),dl(exit(r,s),e),
{proj(,),assign(r,),walk(r,,)
and {dl(arrive(r,),),dl(exit(r,),)
such that , and there exists no {proj(,),assign(r,),walk(r,,)
such that and , , ,
then for some .
If {proj(t,s),assign(r,t),walk(r,s,v),dl(arrive(r,s),a),dl(exit(r,s),e),
and there exists no {proj(,),assign(r,),walk(r,,)
such that and , ,
then for some .
If {proj(t,s),assign(r,t),walk(r,s,v),dl(arrive(r,s),a),dl(exit(r,s),e), and there exists no {proj(,),assign(r,),walk(r,,)
such that and , ,
then for some .
We start with Condition 13. First, Line 5 of Listing 8 ensures a non-timed candidate projection on the robots’ walks. That is, for each robot r and (timed) walk , we have a projection in such that only if for any and task . Then, Line 6 of Listing 8 accounts for the correct order within the projections in view of the task sequences. In detail, for any robot r with task sequence , we have a corresponding projection in with and . Finally, Line 18 of Listing 9 ensures that a robot stays on the projection point of a given task for at least its execution time . Specifically, for every robot r, task and corresponding projection , we have a projection point satisfying .
Condition 14 is addressed in Line 20 of Listing 9 by ensuring that the task execution time is respected for tasks in a dependency. Note that we only need to pose a timing constraint if interdependable tasks are assigned to different robots. If we have two distinct tasks with and for some robot r, then there is a projection in of form , comprising the projection points and of t and in the given order, respectively. This is the case, first, because respects dependencies by construction, and second, as established above, there has to be a projection on the walk of r in . Then, by the properties of projections, we have that , and thus . Otherwise, if we have two distinct tasks with and two distinct robots with and , we pose the timing constraint which implies on the projection points and of tasks t and , respectively.
To address Condition 15, Line 6 of Listing 2 makes sure that tasks in a delivery dependency are assigned to the same task sequence, and Line 10 in the same listing that they are assigned to the same robot. Then, Line 6 of Listing 8 demands their successive execution. Note that it is enough to require that there exists a projection such that for two adjacent tasks in a task sequence the latter one is executed at a strictly larger step number. This is because a task may have at most one successor and predecessor in a task sequence due to Lines 4 and 14 of Listing 2. That means, if such a projection exists, the tasks in a task sequence are strictly ordered by the step they are executed in. Of course, this also holds for deliver dependencies. In detail, for distinct tasks with , there exists a projection in such that and p and are the projection points of t and , respectively.
4.4. Path-Based Encoding
In this section, we present an encoding to the warehouse delivery problem that solves the routing and scheduling of robots through a series of discrete acyclic paths. This approach contrasts to the step-based encoding, presented in the previous section, that explicitly assigns timed walks to individual robots. While a timed walk pertains to the entire movement of a single robot, from its starting vertex through to its final arrival at its home vertex, we use the graph theoretic notion of (acyclic) paths at a more fine-grained level of abstraction.
In particular, in our encoding we generate an individual path for each task. The start of the path is the vertex of the assigned robot at the point that it starts fulfilling that task, and the path’s destination is the task’s execution vertex. A path is also generated for each robot that needs to return to its home location. For any robot assigned a sequence of tasks, the corresponding path sequence is constructed so that the starting and ending vertices of each path align with the task sequence. Consequently, the series of paths are generated so as to fulfill all tasks and return all robots to their home stations.
For example, the walk of robot
is given by the sequence in
Table 2; where the robot visits a series of vertices starting and finishing at its home location
. The actual task execution for tasks
through to
is determined by
Table 3 showing the projection of the walk onto
’s task sequence. In contrast, for the path-based approach we view this walk as being composed of a sequence of five distinct paths; the first path
is associated with task
, the second
is associated with task
, and the final path
is associated with robot
’s journey back to its home vertex. Note, that while each individual path is acyclic, nevertheless
still visits some vertices multiple times, but it does so only when fulfilling different paths.
4.4.1. Advantages and Limitations
The path-based encoding has a number of key advantages over the step-based encoding. In the first place, it does not require a step horizon; the step horizon is instance specific and has to be determined on a case-by-case basis. The lack of a horizon also means that there is no step counter for tracking each robot’s walk through the warehouse, which has important consequences for scalability and the size of the ground instances produced by the encoding. A second advantage of the path-based encoding is that by introducing an explicit notion of a path it allows for specific path-based optimizations. In particular it allows for pre-computed shortest-paths that can be used to calculate timing lower-bounds, determine movement corridors, and specify domain-based move heuristics.
Despite the advantages of the path-based encoding, restricting each task to a single acyclic path does limit the allowable moves that a robot can make, whereas the step-based encoding permits arbitrary movements. This limitation can be easily observed in the example outlined in
Figure 3. In this scenario each robot needs to swap sides in order to execute its assigned task;
needs to travel to
while
needs to travel to
. The step-based encoding is able to calculate an optimal solution of 90 s, where both robots start moving at the same time with robot
deviating to vertex
to allow the robot
to pass (
Figure 3 left). In contrast with the step-based encoding robot
is not able to deviate to
as it would then have to visit vertex
twice, which would break the path acyclicity requirement. Instead, one of the robots has to wait until the other robot arrives at its destination before starting its journey (
Figure 3 right); with the resulting non-optimal minimal makespan of 120 s.
The observant reader may also notice that it would be easy to generate a variant of
Figure 3 where the path encoding admits no solutions at all. In particular, if robot
starts at
and
starts at
then neither robot will be able to break the deadlock by moving to
.
While the lack of completeness of the path encoding with respect to the formalization is important to appreciate, nevertheless, in practice it is not a serious limitation. The main reason for this is that in practice warehouse graphs are designed by domain experts, and a well-designed warehouse rarely contains artefacts that would lead to these types of scenarios. This is borne out in
Section 5, where this restriction has no practical impact when applied to our real-world warehouse scenarios.
Finally, it should also be noted that even in cases where such a narrow corridor is unavoidable, it is possible for the path encoding to avoid such deadlocks through the careful introduction of
mirrored vertices and edges. In
Figure 3, it would be possible to introduce an extra vertex
, setting a conflict with
, and with edges to both
and
. In this modified scenario, robot
could then travel along the (acyclic) path sequence
allowing it to use the passing vertex
and find an optimal plan.
4.4.2. Outline
As in
Section 4.3, we start by discussing individual encoding components, namely, path creation, routing, conflict resolution and scheduling. Finally, we relate the answer sets of the path-based encoding to the ones of the step-based encoding, and discuss the relation to the problem formalization.
Recall that both the step- and path-based encoding rely upon Listing 2, optionally with Listings 3–5, for assigning and sequencing tasks. It provides task sequence assignments allotting each robot a sequence of tasks; they are represented by atoms assign(r,t), representing that for robot r and task t, and task_sequence(t,), capturing that there is a task assignment with two consecutive tasks for some robot r.
4.4.3. Path Creation
Knowing task assignment and sequences provides us with the necessary information about paths to be routed and their order. That is, there needs to be a path addressing each task, whereby the set of paths are ordered so as to match the task sequences, and an additional path has to be routed to return each robot to its home station. The latter applies to robots having been assigned a task or not having started from their home station.
Looking at the warehouse delivery problem in terms of necessary paths has the advantage that a lot of relevant information is static, since the tasks’ target vertices are known in advance. Hence, the routing problem is no longer being solved in a somewhat indirect manner, by shaping the meandering timed walks of individual robots to fit their assigned tasks. Instead routing becomes focused on the individual paths themselves, where only the starting location of each path can be subject to change based on the assigned robot.
Listing 10 identifies how the necessary paths are constructed.
| Listing 10. Create necessary paths and path sequences. |
- 1
path(T,V) :- task(T,V). - 2
path(R,V) :- assign(R,_), home(R,V).
- 3
path(R,V) :- not start(R,V), home(R,V).
- 5
path_assign(R,T) :- assign(R,T).
- 6
path_assign(R,R) :- assign(R,_).
- 7
path_assign(R,R) :- not start(R,V), home(R,V).
- 9
path_sequence(T,T’) :- task_sequence(T,T’).
- 10
path_sequence(T,R) :- assign(R,T), not task_sequence(T,_).
|
Lines 1–3 define atoms over predicate path/2, where the first argument can be seen as the name of a path and the second as its destination. More precisely, we have path(t,v) for every task t and , and path(r,v) for every robot r that needs to return to its home station, either because it has assigned tasks or because it did not start at its home station, viz. .
Analogously, we assign paths to robots in Lines 5–7. We have path_assign(r,t) whenever assign(r,t) and path_assign(r,r) for any robot r having a task assignment or not having started at its home station. Here the first argument identifies the robot while the second identifies the path.
Lines 9 and 10 build path sequences from task sequences. Line 9 aligns path sequences with task sequences. That is, we have path_sequence(t,) whenever task_sequence(t,) for all tasks . Furthermore, we have to route a way home once a robot has executed its final assigned task. For this, we add path_sequence(t,r) in Line 10, where t is the final task assigned to robot r. Here, t is identifiable as a final task as it has no successor task in any task sequence. Note, that Line 10 covers two cases: one where there exists a fact task_sequence(,t) for some , and one where there is no such fact. The latter is a corner-case that does not occur in our specific application setting, since every delivery job consists of both a pickup and a putdown task, guaranteeing that any robot having a task assignment is assigned more than one task.
We get the following atoms in our example in
Table 1.
path(t1,l1) path(t2,s1) path(t3,p1) path(t4,l1)
path(t5,l2) path(t6,s2) path(t7,p1) path(t8,l2)
path(r1,h1) path(r2,h2)
path_assign(r1,t1) path_assign(r2,t5)
path_assign(r1,t2) path_assign(r2,t6)
path_assign(r1,t3) path_assign(r2,t7)
path_assign(r1,t4) path_assign(r2,t8)
path_assign(r1,r1) path_assign(r2,r2)
path_sequence(t1,t2) path_sequence(t5,t6)
path_sequence(t2,t3) path_sequence(t6,t7)
path_sequence(t3,t4) path_sequence(t7,t8)
path_sequence(t4,r1) path_sequence(t8,r2)
The first eight atoms over path/2 identify paths associated with specific tasks, while the last two care about the return of both robots to their home station. In turn, robot is assigned plus its return home; analogously, is assigned and its return. The given list of tasks also corresponds to the order of the paths to be executed by each robot.
4.4.4. Routing
Listing 11 determines routes for the paths created in Listing 10. The individual moves along a path are represented by atoms over predicate move/3, where the first argument is the path’s name, and the second and third are vertices belonging to an edge on the path. Note that there is no time step associated with a move. This abolishes the need for a horizon and yields, a priori, a smaller problem representation. The drawback is, however, that each path needs to be acyclic since there is no way to distinguish between multiple visits to a vertex. In contrast, with a step-based encoding, distinct time steps allow for multiple visits of vertices. Having said that, the combination of the distinct paths that form the overall walk of any given robot may itself contain cycles, it is only the paths themselves that must be acyclic.
| Listing 11. Route necessary paths. |
- 1
0 { move(T,V,V') : edge(V,V',_) } 1 :- task(T,_), edge(V,_,_). - 2
0 { move(T,V,V') : edge(V,V',_) } 1 :- task(T,_), edge(_,V',_).
- 4
0 { move(R,V,V') : edge(V,V',_) } 1 :- robot(R), edge(V,_,_).
- 5
0 { move(R,V,V') : edge(V,V',_) } 1 :- robot(R), edge(_,V',_).
- 6
:- robot(R), not path(R,_), move(R,_,_).
- 8
first_visit(P,V) :- move(P,V,_), not move(P,_,V).
- 9
last_visit(P,V) :- move(P,_,V), not move(P,V,_).
- 10
:- #count{ V : last_visit(P,V) } > 1, path(P,_).
- 12
first_visit(P,V) :- path(P,V), not move(P,_,_).
- 13
last_visit(P,V) :- path(P,V), not move(P,_,_).
- 15
:- start(R,V), path(R,_), not assign(R,_), not first_visit(R,V). - 16
:- start(R,V), path_assign(R,P), - 17
path_sequence(P,_), not path_sequence(_,P), not first_visit(P,V).
- 18
:- path_sequence(P,P'), path(P,V), not first_visit(P',V).
- 19
:- path(P,V), not last_visit(P,V).
|
Lines 1–6 allow for traversing every vertex on each path in at most one way, namely, along an incoming and an outgoing edge. The definition of predicate move/3 is separated into four choice rules, two for each task and two for homing each robot. In each case, the first rule handles moves over outgoing edges while the second handles moves over incoming edges.
The encoding of the move choices in this way introduces two forms of redundancy. Firstly, rather than explicitly dealing with paths, we encode separate choice rules for tasks and robots. This allows rule bodies to be dissolved during grounding, since task/2 and robot/1 are input predicates, while path/2 is not. For the solver, this eliminates the need to first derive instances of path/2 before making the respective move choices. Secondly, while the duplication of choice rules for incoming and outgoing moves allows the same move to be selected by each rule, it also allows for solver propagation along both directions along a path. In particular, since there is at most one incoming and one outgoing move to any vertex, the solver can generate a chain of moves, propagating either from a vertex back to some source for forward to some destination. Consequently, while these choice rules encode some redundancy, this redundancy allows for improved propagation during solving.
Finally, note that the constraint in Line 6 simply ensures that homing moves are created only when a robot needs it; a robot that starts at its home location and has no assigned tasks has no need to be homed.
While the choice rules in Lines 1–6 ensure that each vertex along a path has at most one incoming and one outgoing edge, nevertheless, moves may still be disconnected and may not match a task’s or robot’s location. Ensuring these restrictions is addressed through the addition of integrity constraints. The rules in Lines 8–10 identify the first and last vertex in each path via atoms over first_visit/2 and last_visit/2, respectively. Such atoms are used to ensure that paths form connected sequences of moves. Specifically, Line 10 expresses that there cannot be paths with more than one end vertex. Additionally, Lines 12 and 13 define the first and last vertex of a path without movement. This is the case if the robot starts on a vertex where it also executes a task. Then, the path only consists of the single vertex, the target vertex of the task.
Finally, the integrity constraints in Lines 15–19 align paths with robot and task locations. Line 15 ensures that a robot without any assigned tasks begins its homing path at its start location. The integrity constraint in Line 16 enforces a similar arrangement for the opposite case of robots that have assigned tasks. It requires that a path addressing the first task assigned to a robot needs to begin at the robot’s starting location.
Next, Line 18 connects paths being adjacent in a path sequence. In detail, the target vertex of the preceding path needs to be the first vertex of the following path. Finally, Line 19 enforces that the last vertex of a path is indeed its target vertex. This is either a task’s destination or a robot’s home location.
Up to this point, the path routing has ensured that there is a connected sequence of moves for each path that is aligned with the relevant task and robot locations. However, similar to the sequencing of tasks detailed in
Section 4.2, this does not exclude the possibility of disconnected cyclic moves. As with task sequencing, we may employ three alternative techniques to ensure acyclicity: scheduling via difference constraints, a reachability encoding, and an edge directive. Since we detail the former approach in
Section 4.4.6, we focus below on the two latter; also because they allow for routing valid paths independently. The encoding of reachability is given in Listing 12.
| Listing 12. Path reachability. |
- 1
vertex_reachable(P,V) :- path(P,V). - 2
vertex_reachable(P,V) :- vertex_reachable(P,V'), move(P,V,V').
- 3
:- move(P,_,V), not vertex_reachable(P,V).
|
In contrast to the reachability encoding for task sequencing, we establish reachability for move sequencing from a path’s destination vertex, because this target vertex is known statically. First, Line 1 declares that target vertices of each path are reachable, then, Line 2 propagates that vertices are reachable by a path, if they are connected with a reachable vertex via an outgoing move, and, finally, Line 3 checks that all moves along a path end in a reachable vertex. As an easy alternative, we may also use an edge directive to enforce acyclicity, as shown in Listing 13.
| Listing 13. Path acyclicity via #edge directives. |
| #edge((P,V),(P,V')) : move(P,V,V'). |
Concluding the routing of paths, Listing 11, combined with cyclic move detection, ensures a sequence of moves for each path that satisfies all tasks and homes all robots. The moves of the example timed walk in
Table 2 is captured by the following atoms.
move(t1,h1,w3) move(t1,w3,w2) move(t1,w2,w1) move(t1,w1,l1)
move(t2,l1,w1) move(t2,w1,w5) move(t2,w5,s1)
move(t3,s1,w5) move(t3,w5,w6) move(t3,w6,w2) move(t3,w2,p1)
move(t4,p1,w2) move(t4,w2,l1)
move(r1,l1,w1) move(r1,w1,w2) move(r1,w2,w3) move(r1,w3,h1)
move(t5,h2,w4) move(t5,w4,w8) move(t5,w8,l2)
move(t6,l2,w8) move(t6,w8,w7) move(t6,w7,w6) move(t6,w6,s2)
move(t7,s2,w6) move(t7,w6,w2) move(t7,w2,p1)
move(t8,p1,w2) move(t8,w2,w1) move(t8,w1,w5) move(t8,w5,w6)
move(t8,w6,w7) move(t8,w7,w8) move(t8,w8,l2)
move(r2,l2,w8) move(r2,w8,w4) move(r2,w4,h2)
The first block of moves corresponds to the walk for robot . Task is the first task assigned to so the path for begins at ’s starting location, , and ends at ’s target location . Task is the second task assigned to , so the path for begins at and ends at its target location . The astute reader may note that these moves correspond to robot first moving to the pallet pickup location and then delivering the pallet to the storage location . This pattern is then repeated for the subsequent tasks and , where the final task corresponds to the delivery of the replacement (empty) pallet to . Finally, the homing path for begins at ’s target location and ends back at ’s home location .
An identical pattern of moves applies to the second block, corresponding to the walk for robot . It starts at ’s home location , successively traveling to the target locations for , , , and , and finishing back at .
4.4.5. Conflict Detection and Resolution
Having routed the paths that the robots must follow, we can now turn to dealing with conflict detection and resolution. Similar to the step-based approach in
Section 4.3.2, we refrain from explicitly ruling out conflicting situations, and rather rely on the binary predicate before/2 for expressing precedences. In contrast to
Section 4.3.2, however, these precedences are now established among paths rather than robots.
The encoding in Listing 14 derives either the fact before((p,v),(,)) or the fact before((,),(p,v)). This represents that vertex v is visited on path p before vertex is visited on path or vice versa, whenever paths p and contain conflicting vertices v and and are assigned to different robots.
| Listing 14. Resolve conflicts for paths visiting conflicting vertices and edges. |
- 1
visit(P,V) :- path(P,V). - 2
visit(P,V) :- move(P,V,_).
- 3
same_robot(R,T) :- assign(R,T).
- 5
{ before((P,V),(P',V')) } :- visit(P,V), visit(P',V'),
- 6
conflict(V,V'), P < P',
- 7
not same_robot(P,P'),
- 8
not same_robot(P',P).
- 9
before((P',V'),(P,V)) :- visit(P,V), visit(P',V'),
- 10
conflict(V,V'), P < P',
- 11
not same_robot(P,P'),
- 12
not same_robot(P',P),
- 13
not before((P,V),(P',V')).
- 15
:- start(R,V), not path(R,_), { move(_,V,_); move(_,_,V) } 1.
- 16
:- start(R,V), path(R,_), not assign(R,_), before((_,_),(R,V)).
- 17
:- start(R,V), path_assign(R,P),
- 18
path_sequence(P,_), not path_sequence(_,P), before((_,_),(P,V)).
- 19
:- before((P,V),(P',V')), path(P,V), path_sequence(P,P''),
- 20
not before((P'',V),(P',V')). - 21
:- robot(R), path(R,V), before((R,V),(_,_)). - 24
:- move(P,V1,V2), move(P',V1',V2'),
- 25
conflict(V1,V1'), conflict(V2,V2'), before((P,V1),(P',V1')),
- 26
not before((P,V2),(P',V2')).
- 27
:- move(P,V1,V2), move(P',V1',V2'),
- 28
conflict(V1,V2'), conflict(V2,V1'), before((P,V1),(P',V2')),
- 29
not before((P,V2),(P',V1')).
|
To this end, Lines 1 to 2 provide predicate visit/2 to capture which vertices are visited on each path; the first argument is the name of the path and the second argument is a vertex belonging to the path. Note that the rule in Line 1 uses static information since the endpoint of each path is known beforehand. Then, Line 2 only needs to collect the first vertex from each path’s moves, which is dynamic information.
Predicate same_robot/2 is already defined in Listing 2 to indicate which tasks are executed by the same robot. Line 3 extends this to paths by stating that for every robot r that is assigned a task t, the path named r and the path named t is executed by the same robot. This extends to paths since path names are task names.
With these auxiliary predicates, lines 5 to 13 use visit and path assignments to detect and resolve conflicts as indicated above. Note that we are only allowed to choose before((p,v),(,)) whenever path p is alphanumerically smaller than path . If this atom is not chosen, we derive the opposite ordering before((,),(p,v)). This enhances propagation because we only need half the choices and reduces the problem size since the additional constraint that only one ordering can be chosen becomes unnecessary.
Integrity constraints in Lines 15 to 21 avoid invalid moves and address the part of conflict resolution discernible without precise scheduling. Line 15 states that no move is possible through a robot’s starting location if it has no path assigned and thus never leaves this location. Both Lines 16 and 17 focus on the first path assigned to a robot. The former addresses paths to home nodes where no further tasks are assigned; the latter deals with the first task in the path sequence. In both cases, the integrity constraints ensure that no other path is given priority over the robots’ starting positions, which constitutes the first vertex of the respective initial paths. Since each robot can be viewed as “arriving” at its starting location at time point zero, therefore, no path assigned to a different robot containing this starting location, or a vertex in conflict with it, could arrive there first.
Line 19 aligns conflict resolution at the transition between two adjacent paths in a sequence. This transition is reflected in the target vertex v of a path p, expressed by path(p,v). If path p is followed immediately by path then v is both the final vertex for p and the starting vertex for . Since the robot remains on v during this path transition, therefore, the same conflict resolution that applied between p and must also apply between and . That is, since p had precedence over in accessing v therefore must also precede in accessing v.
Finally, integrity constraints in Lines 24 and 27 align conflict resolution whenever paths follow or cross each other with respect to adjacent pairs of conflicting vertices. In essence, if path p contains a move from vertex to vertex , path contains a move from vertex to vertex , and we have that and , then whatever conflict resolution is applied to and must also carry over to and . Intuitively, in this situation, two robots would follow each other through narrow terrain, so overtaking would not be possible, whoever starts going first, continues doing so. Similarly, if instead and , that is, distinct robots traveling along paths p and that cross in a tight corridor, the robot to enter the corridor first must also exit the corridor before the second robot can enter, resulting in the same conflict resolution for and and for and .
Our running example in
Table 2 exhibits the following conflict resolution.
before((t1,w2),(t7,w2)) before((t7,w2),(t3,w2))
before((t1,w2),(t8,w2)) before((t8,w2),(t3,w2))
before((t1,w1),(t8,w1)) before((t7,p1),(t3,p1))
before((t2,w1),(t8,w1)) before((t7,w2),(t4,w2))
before((t2,w5),(t8,w5)) before((t8,w2),(t4,w2))
before((t3,w5),(t8,w5)) before((t8,w1),(t4,w1))
before((t6,w6),(t3,w6)) before((t8,w1),(r1,w1))
before((t3,w6),(t8,w6)) before((t7,w2),(r1,w2))
before((t8,w2),(r1,w2))
4.4.6. Scheduling
Once the paths have been routed and the potential conflicts have been resolved, the next step is deal with scheduling. Listing 15 handles scheduling for the path-based encoding.
| Listing 15. Derive timing constraints to obtain a valid schedule. |
- 1
&diff{ arrive(P,V) - exit(P,V) } <= 0 :- visit(P,V). - 2
&diff{ exit(P,V) - arrive(P,V’) } <= -W :- move(P,V,V’), edge(V,V’,W).
- 4
&diff{ 0 - arrive(P,V) } <= 0 :- path(P,_), not path_sequence(_,P),
- 5
path_assign(R,P), start(R,V).
- 6
&diff{ arrive(P,V) - 0 } <= 0 :- path(P,_), not path_sequence(_,P),
- 7
path_assign(R,P), start(R,V).
- 8
&diff{ exit(P,V) - arrive(P’,V) } <= 0 :- path_sequence(P,P’),
- 9
path(P,V).
- 10
&diff{ arrive(R,V) - bound } <= 0 :- home(R,V).
- 11
&diff{ exit(R,V) - bound } <= 0 :- home(R,V).
- 12
&diff{ bound - exit(R,V) } <= 0 :- home(R,V).
- 14
&diff{ arrive(P,V'') - arrive(P',V') } <= 0 :-
- 15
before((P,V),(P',V')), move(P,V,V'').
- 17
#const kappa=10.
- 18
&diff{ arrive(T,V) - exit(T,V) } <= -kappa :- task(T,V).
- 19
&diff{ exit(T,V) - exit(T’,V’)} <= -kappa :- depends(D,T,T’),
- 20
D != deliver, - 21
task(T,V), task(T’,V’), - 22
not same_robot(T,T’),
- 23
not same_robot(T’,T).
|
Similarly to the step-based encoding, difference constraints over integer variables are used to derive the arrival and exit times at vertices. More specifically, variables arrive(p,v) and exit(p,v) represent the arrival and exit times, respectively, at a vertex v for path p. Note that, in contrast to the step-based encoding, we no longer have a step associated with variable names. This has the advantage that variables describing arrival and exit times on target vertices for tasks are known apriori, and the number of possible variables scales with the number of paths and vertices instead of the number of robots and chosen horizon. The drawback, as already discussed, is that there is no mechanism to distinguish multiple visits to a vertex, and therefore, there cannot be cyclic movement within a single path. The structure of the scheduling for the path-based encoding is very similar to the scheduling for the step-based encoding, detailed in Listing 4.3.4. We first create a valid schedule for the individual paths, then handle conflict resolution between paths, and finally address task executions and dependencies.
Line 1 reuses predicate
visit/2, described in
Section 4.4.5, to derive difference constraints stating that the exit time at each vertex on a path is greater than or equal to the arrival time. Line 2 ensures that the schedule of each path respects durations stemming from the warehouse layout. That is, whenever there is a move from
v to
on path
p, then a difference constraint enforces that
exit(p,v) +
arrive(p,). The two rules in Lines 4 to 7 deal with the first vertex on the first path in a path sequence and set the corresponding arrival time to zero. Line 8 deals with scheduling of the transition between paths. This is, for a path
that immediately follows path
p in a path sequence, such that the target vertex of
p is
v, then we stipulate that
exit(p,v) ≤
arrive(,v), Note that here the exit time of path
p at vertex
v should be understood as the end of the assigned robot’s execution of
p. It does not indicate that the robot itself has left the vertex, only that
p is finished and that any corresponding task has been executed. Similarly, the arrival time of path
at vertex
v marks the beginning of the execution of path
p by the assigned robot, and not the robot’s physical arrival at vertex
v.
Analogously to the step-based encoding, Lines 10–12 add difference constraints to set the variable bound to the makespan, and align it with the final paths’ exit times. Note that this is made possible by selecting the home vertex of each robot, because the last path in a path sequence is always identified by the name of a robot, and the last vertex of this path is the home vertex of that robot. Naming the homing path with the identifier of the corresponding robot has the added advantage that home/2 is known statically so these atoms is dissolved during grounding.
Line 14 deals with conflict resolution. Whenever we have before((p,v),(,)), we add a difference constraint expressing the condition that arrive(p,) ≤ arrive(,), where is the vertex immediately following vertex v along path p. Intuitively, this constraint ensures that the robot following path p has moved on to the vertex past the conflict before the robot tasked with may arrive at the vertex in conflict. This removes any possibility of a collision. There are a number of points worth noting here. Firstly, if vertex is also in conflict with , then the fact before((p,),(,)) would also be derived. Hence a matching difference constraint regarding the followup vertex of in path p and vertex in path would also be derived, essentially delaying the robot that is assigned to until the whole conflict zone is cleared. Secondly, the corner case where path p has no move after vertex v, since v is its target vertex, is covered by the constraints in Lines 17 to 21 of Listing 14. In this case, the conflict resolution has been propagated to path p’s successor and the appropriate difference constraint is derived. Furthermore, in this case p is guaranteed to have a successor path, since if p were a final homing path then the constraint at Line 21 of Listing 14 would have prevented before((p,v),(,)) from being derived.
Finally, it is worth noting that there are alternative ways of addressing conflict resolution. Here, we take a conservative approach by tracking the time when a robot arrives at a location outside of the conflict area. This might be too strict if one faces edges with large durations: The robot might already be out of the way before actually arriving at its next location. In such a case, alternative conflict strategies could be considered. For example, one could introduce a safety period after the exit at the conflict vertex to more closely fit real-world conditions.
The final aspect of scheduling is to deal with task execution and dependencies. This is handled by the difference constraints at Lines 18 and 19. Line 18 ensures that the assigned robot remains at the target vertex long enough for the task to be executed. That is, for every task t and , we require that arrive(t,v) + exit(t,v). This constraint only requires that a path overlaps at least the execution time with its task’s target location; it would be a valid assignment to the integer variables if the exit time were larger than necessary. In practice, however, the difference constraint solver generates an assignment that schedules everything as early as possible, meaning that the exit time of a path is equal to the arrival time at the task location plus the execution time. However, this does not force the robot to physically move locations at this time; it simply transitions to the successor path which has its own arrival and exit variables at that same vertex. This may be necessary, for instance, to delay the starting movement of the robot to let another robot pass.
It is worth highlighting an important performance consideration of this constraint. Since each task has an identically named path, the arrival and exit times of the path at its target vertex can be simply identified by the static fact task(t,v). This means that this constraint can be applied unconditionally by the solver. In contrast, scheduling of task execution for the step-based encoding is dependent on the projection of the task over the assigned robot’s walk (see Line 18 of Listing 9). This means that its application is conditional on both the task assignment choice as well as the projection choice. Consequently, task execution scheduling for the step-based encoding is a significantly more complicated, and potentially costly, process.
Finally, the rule starting at Line 19 addresses task interdependencies. We add a timing constraint whenever the paths associated with dependent tasks are assigned to different robots. More precisely, for two tasks with and distinct robots such that and , we impose the timing constraint exit(t,v) + exit(,) with and . Recall that exit(t,v) marks the end of path t and not necessarily r’s physical departure from vertex v, and due to the difference constraint in Line 18, we know that task t must be executed by the time point exit(t,v). Hence, the earliest time point that task could be finished is exit(t,v) + . Again, combined with Line 18, this means that the execution time of is after t has finished. However, the constraint does not require that task be executed the instant after t is finished, and it is of course possible for there to be an arbitrary delay following t’s completion.
This dependency constraint is only enforced when the paths are assigned to distinct robots. For paths that are assigned to the same robot this constraint is redundant, since the correctness of the scheduling is enforced implicitly by the path sequencing. However, here we have also imposed the additional restriction that the tasks are in a non-delivery dependency. Delivery dependencies are a special case of tasks that are assigned to the same robot, since they are known statically. This means that not only is the rule redundant for delivery dependencies, but specifying it explicitly means that its application to delivery dependencies is removed completely during grounding. In our application setting, this is the only special case we need to consider. However, in a different application setting with other dependency types that can only be executed by the same robot, we could derive a specific static predicate to capture these cases.
As was the case for scheduling in the step-based encoding (
Section 4.3.4), we use the binary predicate
dl/2 to express the assignment of arrival and exit times. The paths corresponding to the timed walks in
Table 2 are scheduled as follows.
dl(arrive(t1,h1),0) dl(exit(t1,h1),0) dl(arrive(t5,h2),0) dl(exit(t5,h2),0)
dl(arrive(t1,w3),15) dl(exit(t1,w3),15) dl(arrive(t5,w4),15) dl(exit(t5,w4),15)
dl(arrive(t1,w2),45) dl(exit(t1,w2),45) dl(arrive(t5,w8),30) dl(exit(t5,w8),30)
dl(arrive(t1,w1),65) dl(exit(t1,w1),65) dl(arrive(t5,l2),45) dl(exit(t5,l2),55)
dl(arrive(t1,l1),80) dl(exit(t1,l1),90) dl(arrive(t6,l2),55) dl(exit(t6,l2),55)
dl(arrive(t2,l1),90) dl(exit(t2,l1),90) dl(arrive(t6,w8),70) dl(exit(t6,w8),70)
dl(arrive(t2,w1),105) dl(exit(t2,w1),105) dl(arrive(t6,w7),100) dl(exit(t6,w7),100)
dl(arrive(t2,w5),175) dl(exit(t2,w5),175) dl(arrive(t6,w6),120) dl(exit(t6,w6),120)
dl(arrive(t2,s1),190) dl(exit(t2,s1),200) dl(arrive(t6,s2),135) dl(exit(t6,s2),145)
dl(arrive(t3,s1),200) dl(exit(t3,s1),200) dl(arrive(t7,s2),145) dl(exit(t7,s2),145)
dl(arrive(t3,w5),215) dl(exit(t3,w5),215) dl(arrive(t7,w6),160) dl(exit(t7,w6),160)
dl(arrive(t3,w6),225) dl(exit(t3,w6),225) dl(arrive(t7,w2),175) dl(exit(t7,w2),175)
dl(arrive(t3,w2),240) dl(exit(t3,w2),240) dl(arrive(t7,p1),190) dl(exit(t7,p1),200)
dl(arrive(t3,p1),255) dl(exit(t3,p1),265) dl(arrive(t8,p1),200) dl(exit(t8,p1),200)
dl(arrive(t4,p1),265) dl(exit(t4,p1),265) dl(arrive(t8,w2),215) dl(exit(t8,w2),215)
dl(arrive(t4,w2),280) dl(exit(t4,w2),280) dl(arrive(t8,w1),235) dl(exit(t8,w1),235)
dl(arrive(t4,w1),300) dl(exit(t4,w1),300) dl(arrive(t8,w5),253) dl(exit(t8,w5),253)
dl(arrive(t4,l1),315) dl(exit(t4,l1),325) dl(arrive(t8,w6),263) dl(exit(t8,w6),263)
dl(arrive(r1,l1),325) dl(exit(r1,l1),325) dl(arrive(t8,w7),283) dl(exit(t8,w7),283)
dl(arrive(r1,w1),340) dl(exit(r1,15),340) dl(arrive(t8,w8),313) dl(exit(t8,w8),313)
dl(arrive(r1,w2),360) dl(exit(r1,16),360) dl(arrive(t8,l2),328) dl(exit(t8,l2),338)
dl(arrive(r1,w3),390) dl(exit(r1,17),390) dl(arrive(r2,l2),338) dl(exit(r2,l2),338)
dl(arrive(r1,h1),405) dl(exit(r1,18),405) dl(arrive(r2,w8),353) dl(exit(r2,w8),353)
dl(arrive(r2,w4),368) dl(exit(r2,w4),368)
dl(bound,405) dl(arrive(r2,h2),383) dl(exit(r2,h2),405)
4.4.7. Stable Models of the Path-Based and Step-Based Encodings
In this section, we show how the stable models of a path-based encoding correspond to the models of a step-based encoding, and thus also constitute solutions to the warehouse delivery problem in view of
Section 4.3.5.
In general the opposite is not the case and the solution of a step-based encoding may not have a corresponding path-based solution. To see this, consider a possible stable model of the step-based encoding for our running example in which robot r1 walks back and forth at its home station. This stable model may contain atoms walk(r1,0,h1), walk(r1,1,w3), and walk(r1,2,h1). Since no task is executed, the moves had to belong to the same path in a stable model of the path-based encoding which is impossible since each path must be acyclic.
In what follows, let
F be the set of facts obtained from a warehouse (
V,
E,
,
C,
R,
,
) and a task execution graph (
T,
D,
,
) as described in
Section 4.1, and let
P be the combined set of rules from Listings 2 and 10 to 15.
To associate a stable model of the path-based encoding to one of the step-based encoding, we trace moves on paths, such that each move in the former corresponds to a move in the latter along with an increasing step counter. We make this precise by mapping paths and vertices to steps as follows: Given a stable model
X of logic program
, we define the function
recursively in the following way:
for some
and
in each case. The three cases address the respective positions in a sequence of paths. The first case reflects the first position in the first path of a sequence, which means that it is the starting vertex for the corresponding robot. The second deals with intermediate moves on paths. Furthermore, the third case carries over the step count of the last vertex of the previous path to the first vertex of the current path. Note, that this last case does not increment the step count, since the transition between paths does not involve any change of location from the assigned robot.
Now, let P be the logic program defined above and its step-based counterpart, that is, the combined set of rules from Listings 2 to 9. Then, a stable model X of logic program is mapped into a stable model Y of logic program . For , , , , and , we have
assign(r,t) if assign(r,t)
{assign(r,t),assign(r,),task_sequence(t,) if
{assign(r,t),assign(r,),task_sequence(t,)
same_robot(t,) if same_robot(t,)
{walk(r,,v),walk(r,,)
{dl(arrive(r,),a),dl(exit(r,),e)
{dl(arrive(r,),),dl(exit(r,),)
if
{move(p,v,),move(p,,),path_assign(r,p)
{dl(arrive(p,v),a),dl(exit(p,v),e)
{dl(arrive(p,),),dl(exit(p,),)
{walk(r,,)
{dl(arrive(r,),a),dl(exit(r,),e)
if
{move(p,v,),path_assign(r,p)
{dl(arrive(p,),a),dl(exit(p,),e)
provided that move(p,,) and path_sequence(p,)
{walk(r,,), proj(p,)
{dl(arrive(r,),a),dl(exit(r,),e)
if
{move(p,v,),move(,,)
{path_sequence(p,),path_assign(r,p)
{dl(arrive(p,),a),dl(exit(,),e)
provided that move(p,,)
{before((r,),(,))
{before((p,v),(,)),path_assign(r,p),path_assign(,)
We first establish that task assignment and task sequences function in the same way in both settings. Then, for intermediate moves along a path, we determine the timed walk for both vertices in 4. That is, we identify the robot assigned to the path and add both vertices to its walk at the step provided by function as well as the arrival and exit times.
The next two cases deal with the end of a path. If we have reached the final vertex, i.e., there are no more paths in the path sequence, we add the information provided by stable model X as is. If another path follows, we combine the duration of both paths on their shared vertex to define the timed walk.
Looking at 6 in more detail. If robot r is assigned to paths p and , with immediately following on from p, and where vertex is the target vertex of p, then we add atoms representing that robot r visits vertex at step , arriving at path p’s arrival time at and departing at path ’s exit time from . Furthermore, since p identifies a task, and not just a path, and is its target location, we can add the projection of task p on step . Note that the step count is the same for paths p and on vertex .
Finally, we deal with conflict resolution in 7. If vertex v on path p precedes vertex on path , then the robot, r, assigned to path p also precedes the robot, , assigned to path on these vertices. Recall that conflict resolution in the step-based encoding is expressed via the step and not the vertex. It is mapped to the correct vertices via atoms walk(r,,v) and walk(,,).
4.5. Performance Enhancement via Shortest Path Information
To this point, we have provided two different encodings that generate solutions to the warehouse delivery problem. The step-based encoding closely matches the formalization of the warehouse delivery problem, so the mapping from a stable model of the step-based encoding to a solution of the problem was relatively straightforward. In contrast, the link from the path-based encoding to the problem formalization was less immediate. So instead, we showed how a path-based solution maps directly to a step-based solution (but not vice versa), and hence, by implication, the stable models of a path-based encoding also correspond to solutions of the warehouse delivery problem.
We now go beyond the basic encodings to develop enhancements that can be added to improve solver performance, and also solution quality, when searching for solutions to the warehouse delivery problem. The enhancements that we introduce are based around pre-computing shortest path information for a given warehouse graph. This type of pre-processing is tractable and needs only be done once for a graph at hand. The shortest path information is used in three key ways: to calculate timing lower-bounds to improve solver propagation, to implement domain heuristics to prefer routes along shortest paths, and finally to define corridors for limiting the choice of robot moves.
It is worth pointing out that we do not consider performance enhancements for the step-based encoding. There are two reasons for this. Firstly, the need to apply a step horizon means that grounding problem instances for the step-based encoding is highly dependent on the size of the warehouse graph. As will be clear from our experimental results (
Section 5), this issue alone negatively impacts the viability of the step-based encoding for many realistic warehouse graphs. The second reason is that it is significantly more challenging to apply shortest path techniques to the step-based encoding. This encoding deals with the entire walk of a robot as a single unit, from its starting vertex to its final arrival at its home vertex. In order to apply shortest path information in such a setting it would be necessary to first segment a robot’s walk into sub-parts for which shortest path information would be relevant. In contrast, this is something that comes for free with the path-based encoding, shortest path information can be applied directly to the paths of the path-based encoding.
The underlying shortest path information is provided at the outset by pre-computing all shortest paths from every vertex on the graph to every
endpoint vertex. By endpoint vertex we simply mean all possible task target vertices as well as the robot home vertices. For a warehouse (
V,
E,
,
C,
R,
,
), this results in facts of the form
shortest_path(,,,).
for every
,
, and
. Such a fact represents that there is a shortest path from
v to
of length
l that follows edge
. Note that there might be several such shortest paths.
The idea is now to use this information to calculate shortest paths that are relevant for a given set of tasks. This is done in Listing 16.
| Listing 16. Calculate static and dynamic shortest path information for relevant vertices. |
- 1
static_shortest_path(T’,V) :- depends(deliver,T,T’), task(T,V). - 2
static_shortest_path(T,V'') :- static_shortest_path(T,V), task(T,V'),
- 3
shortest_path(V,V',_,V'').
- 5
possible_shortest_path(R,R,V) :- start(R,V).
- 6
possible_shortest_path(T,R,V) :- robot(R), not depends(deliver,T,_),
- 7
task(T,V).
- 8
possible_shortest_path(P,R,V'') :- possible_shortest_path(P,R,V),
- 9
home(R,V’),
- 10
shortest_path(V,V',_,V'').
- 11
possible_shortest_path(R,T,V) :- start(R,V), task(T),
- 12
not depends(deliver,_,T).
- 13
possible_shortest_path(T,T',V') :- task(T,_), task(T',V'), T != T',
- 14
not depends(deliver,T,T’).
- 15
possible_shortest_path(P,T,V'') :- possible_shortest_path(P,T,V),
- 16
task(T,V’),
- 17
shortest_path(V,V',_,V'').
- 19
dynamic_shortest_path(R,V) :- possible_shortest_path(R,R,V),
- 20
not assign(R,_), path(R,_). - 21
dynamic_shortest_path(R,V) :- possible_shortest_path(T,R,V), - 22
path_sequence(T,R), not path_sequence(R,_).
- 23
dynamic_shortest_path(T,V) :- possible_shortest_path(R,T,V), assign(R,T),
- 24
task_sequence(T,_), not task_sequence(_,T).
- 25
dynamic_shortest_path(T’,V) :- possible_shortest_path(T,T’,V),
- 26
task_sequence(T,T'), task(T',_).
|
To begin with, in Lines 1 to 3 we capture the shortest paths that are relevant irrespective of the task assignment or the sequencing. To this end, atoms of the form
static_shortest_path(t,v) collect vertices,
v, belonging to shortest paths among the start and end node of task of
t. In fact, whenever two tasks
t and
are in a delivery dependency with their respective target vertices
v and
, then
v must be the start of the path to
for the path of
, since both
t and
have to be executed by the same robot and one immediately after the other. We then use the pre-computed shortest path information to complete the shortest paths from
v to
for the path of
. For instance, in our running example, we get
static_shortest_path(t2,l1) static_shortest_path(t2,w1)
static_shortest_path(t2,w5) static_shortest_path(t2,s1)
because path
t2 must begin at vertex
l1 and end at
s1.
From Lines 5 to 17, we define all possible relevant shortest paths depending on what paths and robots are present. An atom possible_shortest_path(x,p,v) states that vertex v belongs to the shortest path p if x is a path and precedes p in the path sequence or x is a robot and p is its first path. Then, Lines 19 to 26 check the actual task assignment and path sequencing and determine the shortest paths for each path. The multitude of rules in both cases stems from case discrimination.
For instance, if we consider the path for task
t1 in our example, we have the following possibilities among others:
possible_shortest_path(r1,t1,h1) possible_shortest_path(r1,t1,w3)
possible_shortest_path(r1,t1,w2) possible_shortest_path(r1,t1,w1)
possible_shortest_path(r1,t1,l1)
possible_shortest_path(r2,t1,h2) possible_shortest_path(r2,t1,w4)
possible_shortest_path(r2,t1,w3) possible_shortest_path(r2,t1,w2)
possible_shortest_path(r2,t1,w1) possible_shortest_path(r2,t1,l1)
possible_shortest_path(t6,t1,s2) possible_shortest_path(t6,t1,w6)
possible_shortest_path(t6,t1,w5) possible_shortest_path(t6,t1,w1)
possible_shortest_path(t6,t1,l1)
The three blocks of atoms tell us what vertices belong to path t1 depending on whether task t1 is assigned first to robot r1, first to robot r2, or is preceded by task t6 in the path sequence.
For the solution in
Table 2, we then get the following atoms for path
t1 that determine the vertices on its shortest path
dynamic_shortest_path(t1,h1) dynamic_shortest_path(t1,w3)
dynamic_shortest_path(t1,w2) dynamic_shortest_path(t1,w1)
dynamic_shortest_path(t1,l1)
They correspond to the first block of atoms since task t1 is the first task assigned to robot r1.
4.5.1. Lower-Bound Propagation
The first application of the shortest path information is to impose lower bounds on travel times for all paths. Although these lower bound constraints are redundant, their addition may improve propagation and therefore decrease solving time. The lower bound information can quickly prune invalid variable assignments that could never be part of a satisfiable solution. This can be especially performant for detecting unsatisfiable problem instances.
We express this by means of difference constraints in Listing 17.
| Listing 17. Add difference constraint representing lower bound on travel time. |
- 1
-
&diff{ exit(R,V) - arrive(R,V') } <= -N :-
- 2
-
start(R,V), home(R,V'), V != V',
- 3
-
not assign(R,_), shortest_path(V,V',N,_).
- 4
-
&diff{ exit(T,V) - arrive(T,V') } <= -N :-
- 5
-
start(R,V), not task_sequence(_,T), task(T,V'),
- 6
-
assign(R,T), shortest_path(V,V',N,_).
- 7
-
&diff{ exit(P',V) - arrive(P',V') } <= -N :-
- 8
-
path_sequence(P,P'), path(P,V), path(P',V'),
- 9
-
shortest_path(V,V',N,_).
|
Whenever we have a path p with start vertex v and end vertex , and a shortest path among them of length n, we add a difference constraint requiring that the arrival time at on p is at least n time units after the exit of v on p. For instance, in our running example, we would add the difference constraint &diff { exit(t2,l1) - arrive(t2,s1) } <= -48 for the path for t2.
As above, case discrimination results in the three different rules for identifying the respective start and end vertex of each path. Line 1 captures the situation where a robot has no work assigned but is not at its home vertex; the start of the path is thus the start of the robot and the end is its home vertex. Line 4 identifies the first task in a task sequence. The start of the path is the start of its associated robot, and the end is the target vertex of the task. Furthermore, finally, Line 7 handles two subsequent paths in a path sequence. The target vertex of the first path is the start and the target vertex of the second path the end.
4.5.2. Domain-Specific Heuristics
The second application of shortest path information is to use it to encode domain-specific heuristics to prefer moves on shortest paths as well as to avoid moves that are off the shortest paths. We use the two heuristic modifiers [1,sign] and [1,false] to specify these preferences; where the modifier [1,false] is a shorthand for the combination of [-1,sign] and [1,level].
The heuristic directives in Line 1 and Line 4 in Listing 18 prefer atoms over move/3 to be assigned true, at the default assignment level of 0, whenever they are on statically and dynamically determined shortest paths, respectively. Note that Line 1 is determined before solving, while Line 4 is evaluated during solving, since it depends on task assignments and sequencing.
| Listing 18. Domain-specific heuristics avoiding moves not a shortest path and preferring moves on
the shortest path. |
- 1
-
#heuristic move(P,V,V') : static_shortest_path(P,V), path(P,V''),
- 2
-
shortest_path(V,V'',_,V'), V != V'.
[1,sign]
- 4
-
#heuristic move(P,V,V') : dynamic_shortest_path(P,V), path(P,V''),
- 5
-
shortest_path(V,V'',_,V'), V != V'.
[1,sign]
- 7
-
#heuristic move(P,V,V') : edge(V,V',_), path(P,V''),
- 8
-
not shortest_path(V,V'',_,V').
[1,false]
|
Finally, the statement in Line 7 prefers choosing and falsifying atoms, at the higher assignment level of 1, for moves that are not on a shortest path.
While all three directives express preferences on the assigned truth values, the latter is assigned first and is therefore the stronger preference. In this way, we use a weaker form of heuristics for moves on the shortest path. This is because there might be several shortest paths spread over different vertices, and so heuristically modifying all of them has no focusing effect. On the other hand, if a move is not on any shortest path, it is clearly preferable to avoid it.
We verify these hypotheses empirically in
Section 5.
For instance, in our running example, we would add the directives (after grounding):
#heuristic move(t1,w1,w5). [1,sign]
#heuristic move(t1,w1,w2). [1,false]
4.5.3. Corridor-Based Routing
Last but not least, the final application of shortest path information is to define corridors and to restrict robot moves accordingly. Unlike the previous applications of shortest path information, restricting robot moves to defined corridors actually restricts the solution space of the problem. While the path-based encoding has already been shown to be incomplete with respect to the formalization (
Section 4.4.1), the introduction of corridor-based routing adds a second source of incompleteness. Candidate models that deviate from the corridors will no longer be acceptable as solutions. On the other hand, the corridor restriction decreases the problem size, and therefore the overall size of the ground instance, which is an important consideration when dealing with large warehouse graphs. This is borne out in
Section 5 where the experimental results show that a significant number problem instances simply fail to ground without the addition of corridor-based routing. Furthermore, with some caveats that we discuss at the end of this section, the set of solutions often have shorter makespans, even in the absence or other performance enhancements, such as domain heuristics, since detours are avoided.
In the same way that there can be multiple shortest paths between any two vertices, there can also be multiple corridor between any two vertices. To define the corridors between two vertices we first ensure that the shortest paths between these vertices are part of some corridor. We then expand each corridor to include vertices that are directly connected to a shortest path vertex that is already on that corridor. Optionally this expansion can be restricted only to cases where the new vertex does not increase the distance to the target goal vertex.
Listing 19 shows the creation of corridors from the shortest paths.
| Listing 19. Calculate an immediate corridor around the shortest paths.
1 corridor |
- 1
-
corridor(T,V) :- static_shortest_path(T,V).
- 2
-
corridor(T,V') :- static_shortest_path(T,V),
- 3
-
edge(V,V',_), task(T,V''),
- 4
-
shortest_path(V,V'',N,_),
- 5
-
shortest_path(V',V'',N',_), N' <= N.
- 7
-
corridor(P,P',V) :- possible_shortest_path(P,P',V).
- 8
-
corridor(P,T,V') :- corridor(P,T,V),
- 9
-
edge(V,V',_), task(T,V''),
- 10
-
shortest_path(V,V'',N,_),
- 11
-
shortest_path(V',V'',N',_), N' <= N.
- 12
-
corridor(P,R,V') :- corridor(P,R,V),
- 13
-
edge(V,V',_), home(R,V''),
- 14
-
shortest_path(V,V'',N,_),
- 15
-
shortest_path(V',V'',N',_), N' <= N.
|
Lines 1 and 7 make the shortest paths part of the corridors. The rules in Lines 2, 8 and 12 extend the corridor with vertices if the aforementioned conditions are fulfilled. The three different cases are necessary because of different sources of shortest path information. We have to differentiate whether a path is associated with a task or a robot to know its target location. Note that all corridors are established after grounding.
Listing 19 only shows the case where the expansion is restricted to vertices where the distance to the target vertex is not increased. However in the experimental results (
Section 5) we also consider the case where the expansion is not restricted by this requirement, essentially removing the
N’ <= N restriction from each rule and requiring only that a vertex in a corridor either is a vertex on the shortest path or is directly connected to such a vertex.
We ensure in the adapted routing encoding in Listing 20 that the correct corridors are traversed depending on task assignment and sequencing.
As an example, we have the following corridor for path t2 in our example.
corridor(t2,l1) corridor(t2,w1)
corridor(t2,w5) corridor(t2,s1)
This corridor is identical to the only shortest path because all alternative routes would increase the distance to the target vertex s1. On the other hand, a corridor that is unequal to a shortest path in our running example is the following one.
corridor(r1,t1,h1) corridor(r1,t1,w3)
corridor(r1,t1,w2) corridor(r1,t1,w7)
corridor(r1,t1,w1) corridor(r1,t1,w6)
corridor(r1,t1,l1) corridor(r1,t1,w5)
Here the corridor includes the shortest path vertices h1, w3, w2, and l1, as well as the vertices w7, w1, w6, and w5, that are directly connected to one of these shortest path vertices. If we consider the case of vertex w7, it is directly connected to w3 and from w7 the minimum travel time to the target l1 is 63 s, which is less than the 65 s from w3 to l1. In contrast w4 is also directly connected to w3, but has a minimum travel time of 85 s to w7 and hence fails the N’ <= N restriction.
To integrate the corridor information, we need to replace the choice rules in Lines 1 to 6 in Listing 11 by the ones in Lines 1 to 10 in Listing 20.
| Listing 20. Only allow moves along corridors. |
- 1
-
0 { move(P,V,V') : edge(V,V',_), corridor(P,V') } 1 :-
- 2
-
corridor(P,V), edge(V,_,_).
- 3
-
0 { move(P,V,V') : edge(V,V',_), corridor(P,V) } 1 :-
- 4
-
corridor(P,V'), edge(_,V',_).
- 6
-
0 { move(P,V,V') : edge(V,V',_), corridor(_,P,V') } 1 :-
- 7
-
corridor(_,P,V), edge(V,_,_).
- 8
-
0 { move(P,V,V') : edge(V,V',_), corridor(_,P,V) } 1 :-
- 9
-
corridor(_,P,V'), edge(_,V',_).
- 10
-
:- robot(R), not path(R,_), move(R,_,_).
- 12
-
:- move(P',V,V'), path_sequence(P,P'),
- 13
-
not corridor(P,P',V), not corridor(P,P',V').
- 15
-
:- move(R,V,V'), robot(R), not assign(R,_),
- 16
-
not corridor(R,R,V), not corridor(R,R,V').
|
This only allows moves along corridors. Furthermore, recall that corridors are decided at grounding time, so we keep the desired property that the choices do not depend on any non-domain atom.
Finally, the integrity constraints in Lines 12 and 15 ensure that only moves are made on corridors applicable to the path sequencing and task assignments.
Although corridor-based routing restricts the set of possible solutions, its advantages are twofold. Firstly, the problem size is reduced, and secondly, the first solution found by the solver is likely to have a relatively high quality with respect to the set of all possible solutions. What we mean by this is that the pool of solutions without a corridor-based restriction will include circuitous paths that can range over the entire warehouse graph. If the solver is simply trying to find a single satisfying solution then it is difficult to guarantee that it will not fix on one of these poor quality solutions. In contrast the solutions returned by the corridor-based restriction will all have the basic level of route quality guaranteed by the corridor definition.
In this section, we have described the details of corridor-based routing and highlighted its many advantages. Nevertheless this approach also has some important limitations that need to be considered. As was mentioned earlier, applying corridor-based routing introduces a source of incompleteness to the encoding. It is relatively easy to construct an example where the use of corridor-based routes can rule out an optimal solution or even fail to admit any solution. In
Figure 4, corridor-free routing allows robot
to take a longer path that avoids conflicts with the path of robot
. In so doing it is able to find an optimal makespan of 70 s. In contrast, with corridor-based routing the longer path is no longer an option, which makes the problem highly sensitive to timing so that robot
has to reach its destination before
can even start its journey. This results in a non-optimal makespan of 80 s. Furthermore, as with the scenario in
Figure 3 it is also possible to create an alternative scenario with robot
starting at
and
starting at
that makes the corridor-based routing fail to admit a solution.
Nevertheless, as with the discussion of the trade-offs between the step and path-based encodings, there are measures that can be taken to minimize any potential negative effects of employing corridor-based routing. Firstly, and most importantly, as we have already outlined in
Section 4.4.1, good warehouse design is crucial. The artefacts that can lead to poor solutions, such as narrow corridors with no room for passing or over-taking, do not typically occur in well designed real-world warehouses.
Secondly, where necessary it is also possible to consider different corridor definitions. Here, we have only considered the case of expanding the corridor with vertices that are directly connected to some shortest path vertex, optionally only if they do not increase the distance to the final destination. However, this expansion could be generalized to some arbitrary distance from the shortest path. We did not consider this generalization since our corridor definition worked well for our application setting and our warehouse configurations. However, alternative corridor definitions could certainly be considered for different application and warehouse settings.

 ,
, 







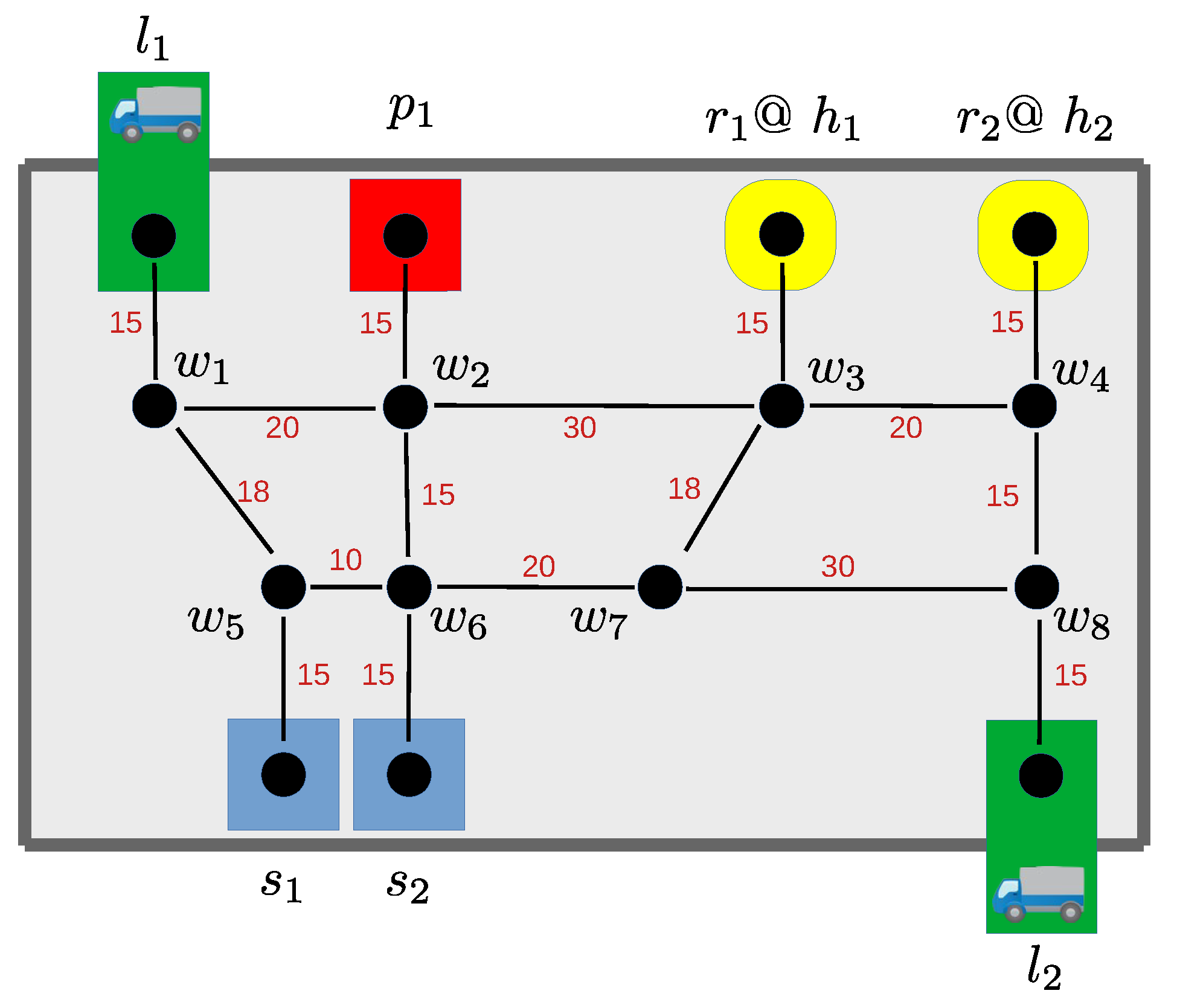{kind=link}
{kind=link}
{kind=link}
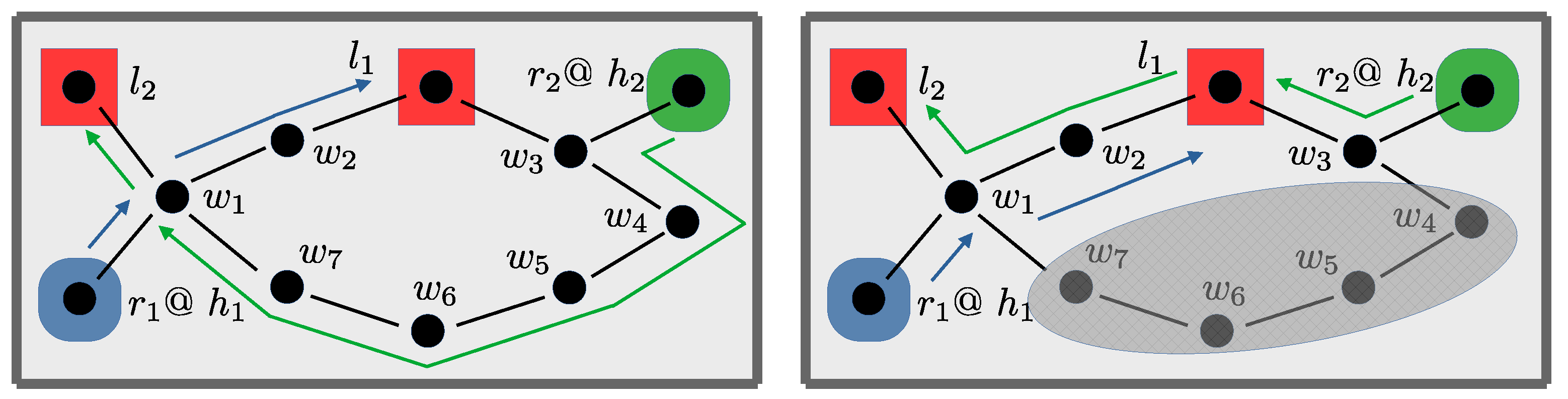{kind=link}
{kind=link}
{kind=link}
{kind=link}