
Evolutionary System Design with Answer Set Programming

Abstract
:1. Introduction
2. Answer Set Programming
- a1;…;am :- am+1,…,an,not an+1,…,not ao
- 1 { bind(T,R) : mapping(R,T) } 1 :- task(T).
- #minimize{w1@l1,t11,…,tk1:b11,…,bl1;…;wn@ln,t1n,…,tkn:b1n,…,bln}.
- #heuristic a:b1,…,bm. [w,m]
- #edge (u,v):b1,…,bm.
- &diff { u-v } <= d
3. Evolutionary Design Space Exploration
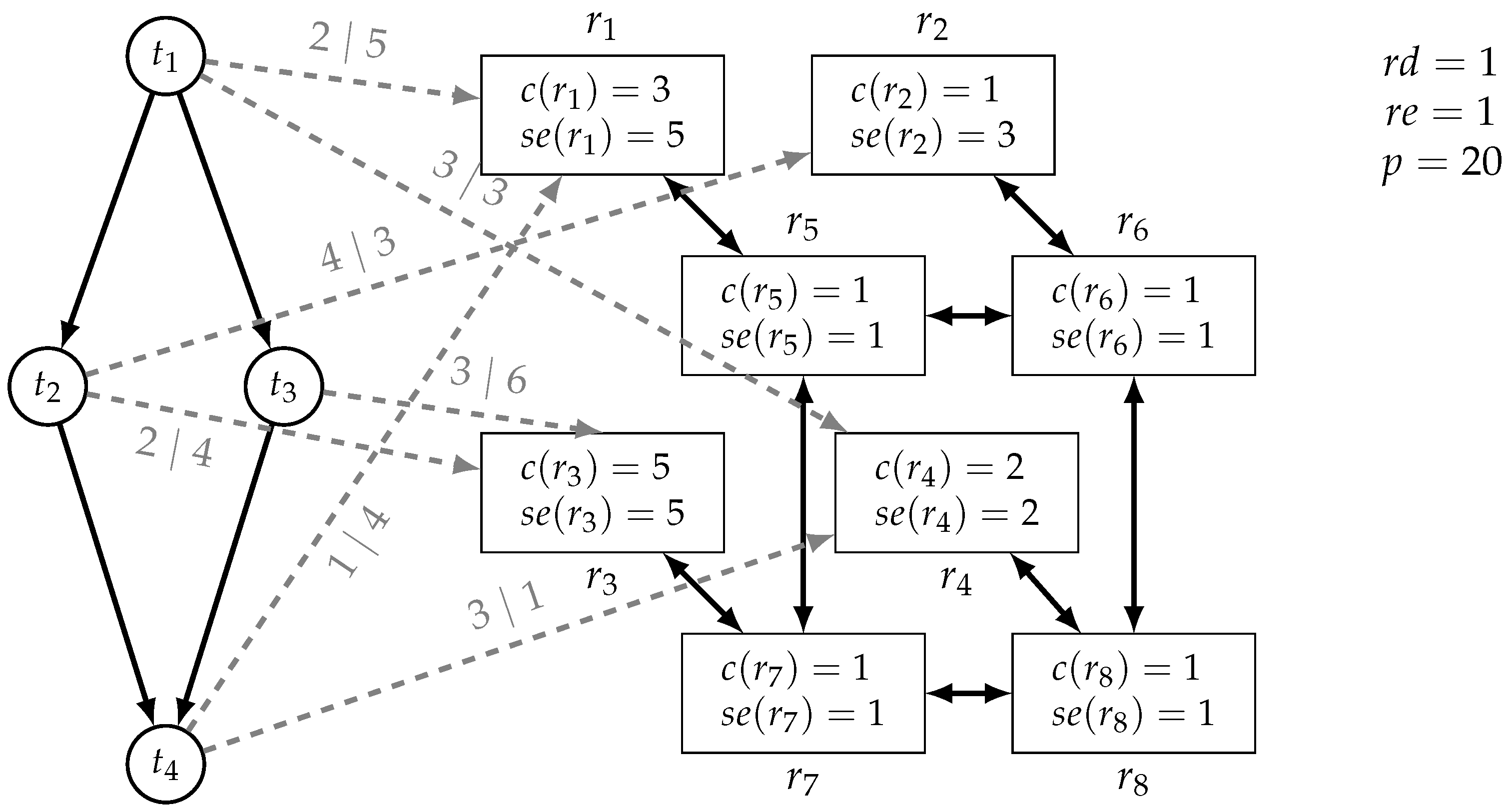
3.1. System Synthesis Problem
- is a directed graph consisting of resources R, i.e., either routers, computational, or memory resources, and links L between resources describing the network;
- is the (uniform) routing delay, i.e., the time it takes for a communication to traverse a link;
- is a total function that gives the cost of a resource;
- is a total function that gives the static energy consumption of a resource;
- is the (uniform) routing energy, i.e., the energy used whenever a link is used by a communication;
- is a total function that gives the set of tasks that may be executed on a resource;
- is the (uniform) period in which applications have to be executed, i.e., the deadline of all tasks;
- is a partial function that gives the execution time of tasks;that is, is defined if for resource and task ;
- is a partial function giving the dynamic energy consumption that is dependent on what specific task is executed on what resource;as above, is defined if for resource and task .
3.2. Implementations of a System Synthesis Problem
- 1.
- if , then for all ;
- 2.
- if , then for ;
- 3.
- if , then for .
- 1.
- for ;
- 2.
- for ;
- 3.
- for ;
- 4.
- if , then for and , either
- (a)
- ; or
- (b)
- ;
- 5.
- if and , thenfor , and , either
- (a)
- ; or
- (b)
- .
3.3. Implementation Quality and Pareto Front
- Cost
- Energy consumption
- Latency
- 1.
- for all ; and
- 2.
- for some .
3.4. Distance between Implementations
- For two bindings b and and , we define
- For two routings r and and , we define
- For two schedulings s and and , we define
- Binding distance
- Routing distance
- Scheduling distance
- Overall distance
4. Encoding the System Synthesis Problem with ASP Modulo Difference Constraints
4.1. Fact Format
- task(t), send(,) for , and ;
- link(r,) for ;
- cost(r,) for ;
- static_energy(r,) for ;
- mapping(r,t), execution(r,t,); and dynamic_energy(r,t,)for and ;
- routing_delay(), routing_energy(), and period(p)
4.2. General Problem Encoding

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 1 | task (t1). task (t2). task (t3). task (t4). |
| 2 | send (t1,t2). send (t1,t3). send (t2,t4). send (t3,t4). |
| 4 | link (r1,r5). link (r5,r1). link (r2,r6). link (r6,r2). |
| 5 | link (r3,r7). link (r7,r3). link (r4,r8). link (r8,r4). |
| 6 | link (r5,r6). link (r6,r5). link (r5,r7). link (r7,r5). |
| 7 | link (r6,r8). link (r8,r6). link (r7,r8). link (r8,r7). |
| 9 | cost (r1,3). cost (r2,1). |
| 10 | cost (r3,5). cost (r4,2). |
| 11 | cost (r5,1). cost (r6,1). |
| 12 | cost (r7,1). cost (r8,1). |
| 14 | static_energy (r1,5). static_energy (r2,3). |
| 15 | static_energy (r3,5). static_energy (r4,2). |
| 16 | static_energy (r5,1). static_energy (r6,1). |
| 17 | static_energy (r7,1). static_energy (r8,1). |
| 19 | mapping (r1,t1). mapping (r1,t4). |
| 20 | mapping (r2,t2). |
| 21 | mapping (r3,t2). mapping (r3,t3). |
| 22 | mapping (r4,t1). mapping (r4,t4). |
| 24 | execution (r1,t1,2). execution (r1,t4,1). |
| 25 | execution (r2,t2,2). |
| 26 | execution (r3,t2,2). execution (r3,t3,3). |
| 27 | execution (r4,t1,3). execution (r4,t4,1). |
| 29 | dynamic_energy (r1,t1,5). dynamic_energy (r1,t4,4). |
| 30 | dynamic_energy (r2,t2,3). |
| 31 | dynamic_energy (r3,t2,4). dynamic_energy (r3,t3,6). |
| 32 | dynamic_energy (r4,t1,3). dynamic_energy (r4,t4,1). |
| 34 | routing_delay (1). |
| 35 | routing_energy (1). |
| 36 | period (20). |
| 1 | 1 { bind (T,R) : mapping (R,T) } 1 :- task (T). |
| 1 | resource (R;R’) :- link (R,R’). |
| 3 | { route ((T,T’),R,R’) : link (R,R’) } 1 :- resource (R), send (T,T’). |
| 4 | { route (( T,T’),R,R’) : link (R,R’) } 1 :- resource (R’), send (T,T’). |
| 6 | visit (( T,T’),R) :- send (T,T ’), bind (T,R). |
| 7 | visit (C,R’) :- visit (C,R), route (C,R,R’). |
| 8 | :- route (C,_,R), not visit (C,R ). |
| 9 | :- send (T,T’), bind (T’,R), not visit ((T,T’),R ). |
| 10 | :- send (T,T’), bind (T’,R), route (( T,T’) ,R,_). |
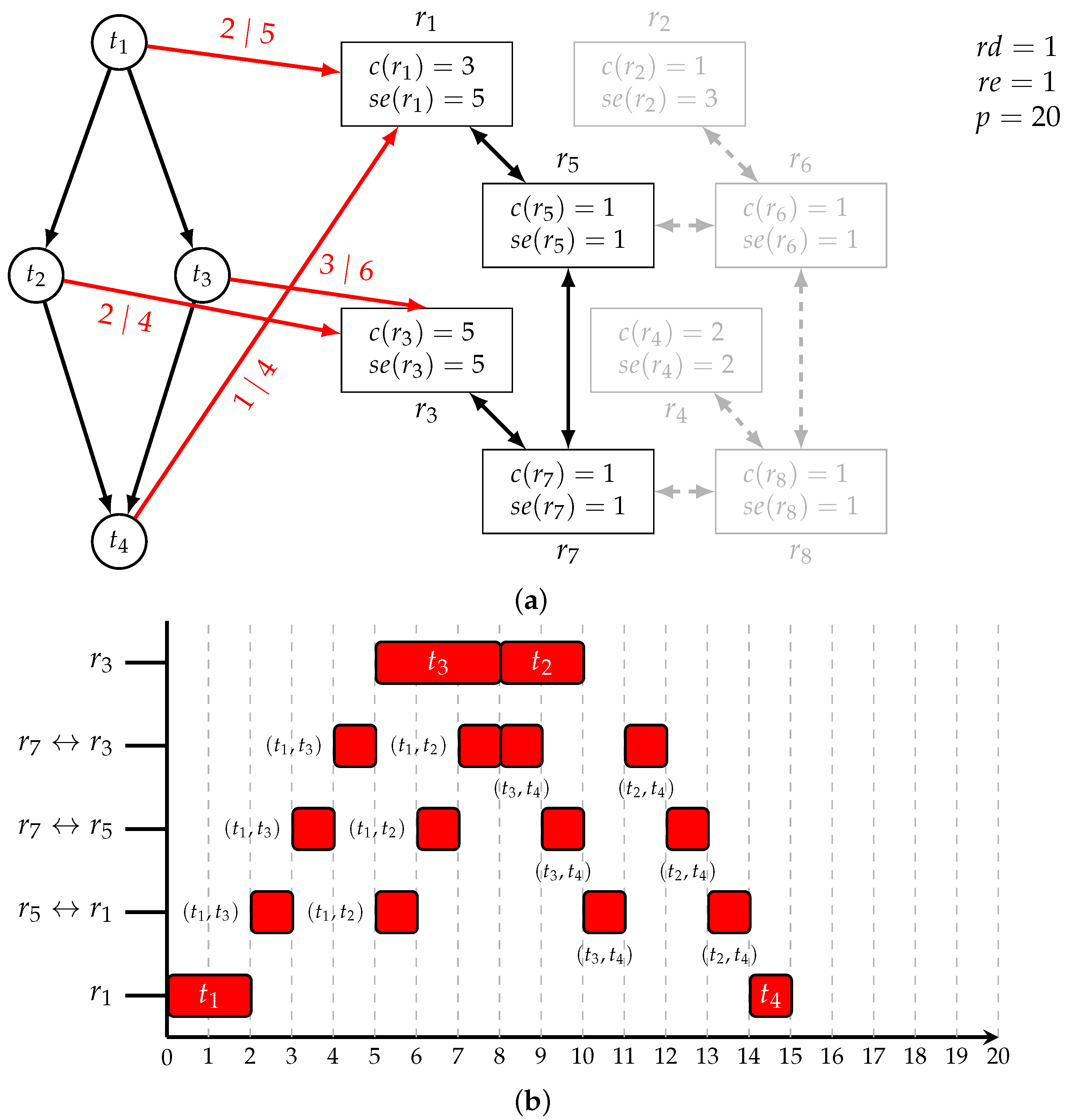
- route((t1,t2),r1,r5) route((t2,t4),r3,r7)
- route((t1,t2),r5,r7) route((t2,t4),r7,r5)
- route((t1,t2),r7,r3) route((t2,t4),r5,r1)
- route((t1,t3),r1,r5) route((t3,t4),r3,r7)
- route((t1,t3),r5,r7) route((t3,t4),r7,r5)
- route((t1,t3),r7,r3) route((t3,t4),r5,r1)
| 1 | nr_links (NR) :- NR=#count { link (N,N’) : link (N,N’) }. |
| 2 | hops ((T,T’),R,0) :- send (T,T’), bind (T,R). |
| 3 | hops (C,R’,H+1) :- hops (C,R,H), route (C,R,R’), |
| 4 | H< NR, nr_links (NR). |
| 5 | hops (C,H) :- hops (C,R,H), send (T,T’), bind (T’,R). |
| 1 | depends (T,T’) :- send (T,T’). |
| 2 | depends (( T,T’),(T’,T’’)) :- send (T,T’), send (T’,T’’). |
| 4 | depends_trans (T,T’) :- depends (T,T’). |
| 5 | depends_trans (T,T’) :- depends_trans (T,T’), depends (T,T’). |
| 7 | conflict (T,T’) :- task (T), task (T’), T < T’, |
| 8 | bind (T,R), bind (T’,R), |
| 9 | not depends_trans (T’,T), |
| 10 | not depends_trans (T,T’). |
| 12 | conflict ((T,T’),(T’’,T’’’)) :- send (T,T’), send (T’’,T’’’), |
| 13 | (T,T’) < (T’’,T’’’), |
| 14 | 1 #sum { 1 : route ((T,T’),R,R’), |
| 15 | route ((T’’,T’’’),R,R’)}, |
| 16 | not depends_trans ((T,T’),(T’’,T’’’)), |
| 17 | not depends_trans ((T’’,T’’’),(T,T’)). |
| 19 | { priority (C,C’)} :- conflict (C,C’). |
| 1 | &diff { 0-T } <= 0 :- task (T). |
| 2 | &diff { T -0 } <= V :- period (P), bind (T,R), execution (R,T,E), V=P-E. |
| 4 | &diff { T-( T,T’) } <= -E :- send (T,T’), bind (T,R), execution (R,T,E). |
| 5 | &diff { (T,T’)-T’} <= -S :- send (T,T’), hops (C,N), routing_delay (D), |
| 6 | S=N∗D. |
| 8 | &diff { T-T’} <= -E :- conflict (T,T’), priority (T,T’), |
| 9 | task (T), task (T’), |
| 10 | execution (R,T,E). |
| 11 | &diff { T’-T} <= -E :- conflict (T,T’), not priority (T,T’), |
| 12 | task (T), task (T’), |
| 13 | execution (R,T’,E ). |
| 15 | &diff { C-C’ } <= -S :- conflict (C,C’), priority (C,C’), |
| 16 | hops (C,N), routing_delay (D), S=N∗D. |
| 17 | &diff { C’-C } <= -S :- conflict (C,C’), not priority (C,C’), |
| 18 | hops (C’,N), routing_delay (D), S=N∗D. |
- dl(t1,0) dl(t2,8) dl(t3,5) dl(t4,14)
- dl((t1,t2),5) dl((t1,t3),2) dl((t2,t4),11) dl((t3,t4),8)
4.2.1. Routing Variants
| 1 | location (r1, (0,1,0)). location (r2, (1,1,0)). |
| 2 | location (r3, (0,0,0)). location (r4, (1,0,0)). |
| 3 | location (r5, (0,1,0)). location (r6, (1,1,0)). |
| 1 | location (r7, (0,0,0)). location (r8, (1,0,0)). |
Bound Routing
| 1 | hops ((T,T’),N) :- bind (T,R), bind (T’,R’), R!=R’, send (T,T’), |
| 2 | location (R,(X,Y,Z)), location (R’,(X’,Y’,Z’)), |
| 3 | N = |X-X’|+|Y-Y’|+|Z-Z’|+2. |
| 4 | hops ((T,T’),0) :- bind (T,R), bind (T’,R), send (T,T’). |
| 5 | :- hops (C,N), not N { route (C,_,_) : route (C,_,_) } N. |
Dimension-Ordered Routing
4.2.2. Preference Encoding
| 1 | coord (X,Y,Z) :- location (_,(X,Y,Z)). |
| 2 | next ((X,Y,Z),(X’,Y’,Z’),(X+1,Y,Z)) :- coord (X,Y,Z), coord (X’,Y’,Z’), |
| 3 | coord (X+1,Y,Z), X < X’. |
| 4 | next ((X,Y,Z),(X’,Y’,Z’),(X-1,Y,Z)) :- coord (X,Y,Z), coord (X’,Y’,Z’), |
| 5 | coord (X-1,Y,Z), X > X’. |
| 6 | next ((X,Y,Z),(X,Y’,Z’),(X,Y +1,Z)) :- coord (X,Y,Z), coord (X,Y’,Z’), |
| 7 | coord (X,Y+1,Z), Y < Y’. |
| 8 | next ((X,Y,Z),(X,Y’,Z’),(X,Y-1,Z)) :- coord (X,Y,Z), coord (X,Y’,Z’), |
| 9 | coord (X,Y-1,Z), Y > Y’. |
| 10 | next ((X,Y,Z),(X,Y,Z’),(X,Y,Z+1)) :- coord (X,Y,Z), coord (X,Y,Z’), |
| 11 | coord (X,Y,Z+1), Z < Z’. |
| 12 | next ((X,Y,Z),(X,Y,Z’),(X,Y,Z-1)) :- coord (X,Y,Z), coord (X,Y,Z’), |
| 13 | coord (X,Y,Z-1), Z > Z’. |
| 14 | route ((T,T’),R,R’) :- bind (T,R), bind (T’,R’), send (T,T’), |
| 15 | location (R,C), location (R’,C), R!=R’. |
| 16 | route ((T,T’),R,R’’) :- route ((T,T’),_,R), bind (T’,R’), |
| 17 | location (R,C), location (R’,C’), |
| 18 | next (C,C’,C’’), location (R’’,C’’), |
| 19 | not bind (T’,R’’). |
| 20 | route ((T,T’),R’,R) :- bind (T’,R), send (T,T’), |
| 21 | location (R,C), location (R’,C), R!=R’. |
| 1 | allocated (R) :- bind (T,R). |
| 3 | allocated (R) :- route (_,R,_). |
| 4 | allocated (R) :- route (_,_,R). |
| 1 | preference (cost,sum). |
| 2 | preference (cost,(1,1),1,for(atom(allocated(R))),(C)) |
| 3 | :- cost(R,C). |
| 4 | holds(atom(allocated(R)),0) :- allocated(R). |
| 6 | preference(energy,sum). |
| 7 | preference(energy,(2,1),1,for(atom (allocated(R))),(S)) |
| 8 | :- static_energy(R,S). |
| 9 | holds(atom(allocated(R)),0) |
| 10 | :- allocated(R). |
| 11 | preference(energy,(2,2),1,for(atom (route((T,T’),R,R’))),(E)) |
| 12 | :- link(R,R’), send (T,T’), routing_energy(E). |
| 13 | holds(atom(route((T,T’),R,R’)),0) |
| 14 | :- route((T,T’),R,R’). |
| 15 | preference(energy,(2,3),1,for(atom( bind(T,R))),(D)) |
| 16 | :- mapping(R,T), dynamic_energy(R,T,D). |
| 17 | holds(atom(bind(T,R)),0) |
| 18 | :- bind(T,R ). |
| 20 | preference(latency,max ). |
| 21 | preference(latency,(3,1),1,for(atom (bind(T,R))),(T,E)) |
| 22 | :- mapping(R,T), execution(R,T,E). |
| 23 | holds(atom(bind(T,R)),0) |
| 24 | :- bind(T,R). |
5. Encoding Evolutionary Design Space Exploration
5.1. Encoding the Similarity Measure
- unequal(route((t1,t2),r1,r5)) unequal(route((t1,t2),r5,r7))
- unequal(route((t1,t2),r7,r3)) unequal(route((t1,t3),r1,r5))
- unequal(route((t1,t3),r5,r7)) unequal(route((t1,t3),r7,r3))
5.2. Strategies
| 1 | parent(send(t1,t2)). parent(send(t1,t3)). |
| 2 | parent(send(t2,t4)). parent(send(t3,t4)). |
| 4 | parent(link(r1,r5)). parent(link(r5,r1)). |
| 5 | parent(link(r2,r6)). parent(link(r6,r2)). |
| 6 | parent(link(r3,r7)). parent(link(r7,r3)). |
| 7 | parent(link(r4,r8)). parent(link(r8,r4)). |
| 8 | parent(link(r5,r6)). parent(link(r6,r5)). |
| 9 | parent(link(r5,r7)). parent(link(r7,r5)). |
| 10 | parent(link(r6,r8)). parent(link(r8,r6)). |
| 11 | parent(link(r7,r8)). parent(link(r8,r7)). |
| 13 | parent(mapping(r1,t1)). parent(mapping(r1,t4)). |
| 14 | parent(mapping(r2,t2)). |
| 15 | parent(mapping(r3,t2)). parent(mapping(r3,t3)). |
| 16 | parent(mapping(r4,t1)). parent(mapping(r4,t4)). |
| 18 | parent(bind(t1,r1)). |
| 19 | parent(bind(t2,r3)). |
| 20 | parent(bind(t3,r3)). |
| 21 | parent(bind(t4,r1)). |
| 22 | parent(route((t1,t2),r1,r5)). |
| 23 | parent(route((t1,t2),r5,r7)). |
| 24 | parent(route((t1,t2),r7,r3)). |
| 25 | parent(route((t1,t3),r1,r5)). |
| 26 | parent(route((t1,t3),r5,r7)). |
| 27 | parent(route((t1,t3),r7,r3)). |
| 28 | parent(route((t2,t4),r3,r7)). |
| 29 | parent(route((t2,t4),r5,r1)). |
| 30 | parent(route((t2,t4),r7,r5)). |
| 31 | parent(route((t3,t4),r3,r7)). |
| 32 | parent(route((t3,t4),r5,r1)). |
| 33 | parent(route((t3,t4),r7,r5)). |
| 1 | equal(bind(T,R)) :- bind(T,R), parent(bind(T,R)). |
| 2 | equal(bind(T,R)) :- not bind(T,R), not parent(bind(T,R)), |
| 3 | mapping(R,T). |
| 4 | equal(bind(T,R)) :- not bind(T,R), not parent(bind(T,R)), |
| 5 | parent(mapping(R,T)). |
| 6 | unequal(bind(T,R)) :- bind(T,R), mapping(R,T), |
| 7 | not parent(mapping(R,T)). |
| 8 | unequal(bind(T,R)) :- parent(bind(T,R)), not mapping(R,T), |
| 9 | parent(mapping(R,T)). |
| 10 | unequal(bind(T,R)) :- bind(T,R), not parent(bind(T,R)), |
| 11 | mapping(R,T’), parent(mapping(R,T’)). |
| 12 | unequal(bind(T,R)) :- not bind(T,R), parent(bind(T,R)), |
| 13 | mapping(R,T’), parent(mapping(R,T’)). |
| 15 | equal(route((T,T’),R,R’)) :- route((T,T’),R,R’), |
| 16 | parent(route((T,T’),R,R’)). |
| 17 | equal(route((T,T’),R,R’)) :- not route((T,T’),R,R’), |
| 18 | not parent(route((T,T’),R,R’)), |
| 19 | send(T,T’), link(R,R’). |
| 20 | equal(route((T,T’),R,R’)) :- not route((T,T’),R,R’), |
| 21 | not parent(route((T,T’),R,R’)), |
| 22 | parent(send(T,T’)), parent(link(R,R’)). |
| 23 | unequal(route((T,T’),R,R’)) :- route((T,T’),R,R’), |
| 24 | not parent(send(T,T’)), send(T,T’). |
| 25 | unequal(route((T,T’),R,R’)) :- parent(route((T,T’),R,R’)) , |
| 26 | parent(send(T,T’)), not send(T,T’). |
| 27 | unequal(route((T,T’),R,R’)) :- route((T,T’),R,R’), |
| 28 | not parent(route((T,T’),R,R’)), |
| 29 | send(T,T’), parent(send(T,T’)). |
| 30 | unequal(route((T,T’),R,R’)) :- not route(( T,T’),R,R’), |
| 31 | parent(route((T,T’),R,R’)), |
| 32 | send(T,T’), parent(send(T,T’)). |
| 1 | :- unequal(bind(T,R)). |
| 2 | :- unequal(route((T,T’),R,R’)). |
| 1 | :- not equal(bind(T,R)), mapping(R,T). |
| 2 | :- not equal(bind(T,R)), parent(mapping(R,T)). |
| 4 | :- not equal(route((T,T’),R,R’)), send(T,T’), link(R,R’). |
| 5 | :- not equal(route((T,T’),R,R’)), parent(send(T,T’)), parent(link(R,R’)). |
5.3. Preferences
| 1 | preference(dist,sum). |
| 3 | preference(dist,(4,1),1,for(atom(unequal(bind(T,R)))) , (1)) |
| 4 | :- mapping(R,T). |
| 5 | preference(dist,(4,2),1,for(atom(unequal(bind(T,R)))), (1)) |
| 6 | :- parent(mapping(R,T)). |
| 7 | holds(atom(unequal(bind(T,R))),0) |
| 8 | :- unequal(bind(T,R)). |
| 10 | preference(dist,(4,3),1,for(atom(unequal(route((T,T’),R,R’)))), (1)) |
| 11 | :- send(T,T’), link(R,R’). |
| 12 | preference(dist,(4,4),1,for(atom(unequal(route((T,T’),R,R’)))), (1)) |
| 13 | :- parent(send(T,T’)), parent(link(R,R’)). |
| 14 | holds(atom(unequal(route((T,T’),R,R’))),0) |
| 15 | :- unequal(route((T,T’),R,R’)). |
| 1 | preference(dist,sum). |
| 3 | preference(dist,(4,1),1,for(atom(equal(bind(T,R)))), (-1)) |
| 4 | :- mapping(R,T). |
| 5 | preference(dist,(4,2),1,for(atom(equal(bind(T,R)))), (-1)) |
| 6 | :- parent(mapping(R,T)). |
| 7 | holds(atom(equal(bind(T,R))),0) |
| 8 | :- equal(bind(T,R)). |
| 10 | preference(dist,(4,3),1,for(atom(equal(route((T,T’),R,R’)))), (-1)) |
| 11 | :- send(T,T’), link(R,R’). |
| 12 | preference(dist,(4,4),1,for(atom(equal(route((T,T’),R,R’)))), (-1)) |
| 13 | :- parent(send(T,T’)), parent(link(R,R’)). |
| 14 | holds(atom(equal(route((T,T’),R,R’))),0) |
| 15 | :- equal(route((T,T’),R,R’)). |
5.4. Domain-Specific Heuristics
| 1 | #heuristic equal(bind(T,R)). [value, modifier] |
| 2 | #heuristic equal(route((T,T’),R,R’)). [value, modifier] |
| 3 | #heuristic equal(bind(T,R)). [sign, 1] |
| 4 | #heuristic equal(route((T,T’),R,R’)). [sign, 1] |
| 1 | #heuristic unequal(bind(T,R)). [value, modifier] |
| 2 | #heuristic unequal(route((T,T’),R,R’)). [value, modifier] |
| 3 | #heuristic unequal(bind(T,R)). [sign, -1] |
| 4 | #heuristic unequal(route((T,T’),R,R’)). [sign, -1] |
6. Experiments
- 1.
- Are the solutions found in a short amount of time similar to the parent implementation when using similarity techniques?
- 2.
- Is the quality of the solutions found in a short amount of time better when using similarity information?
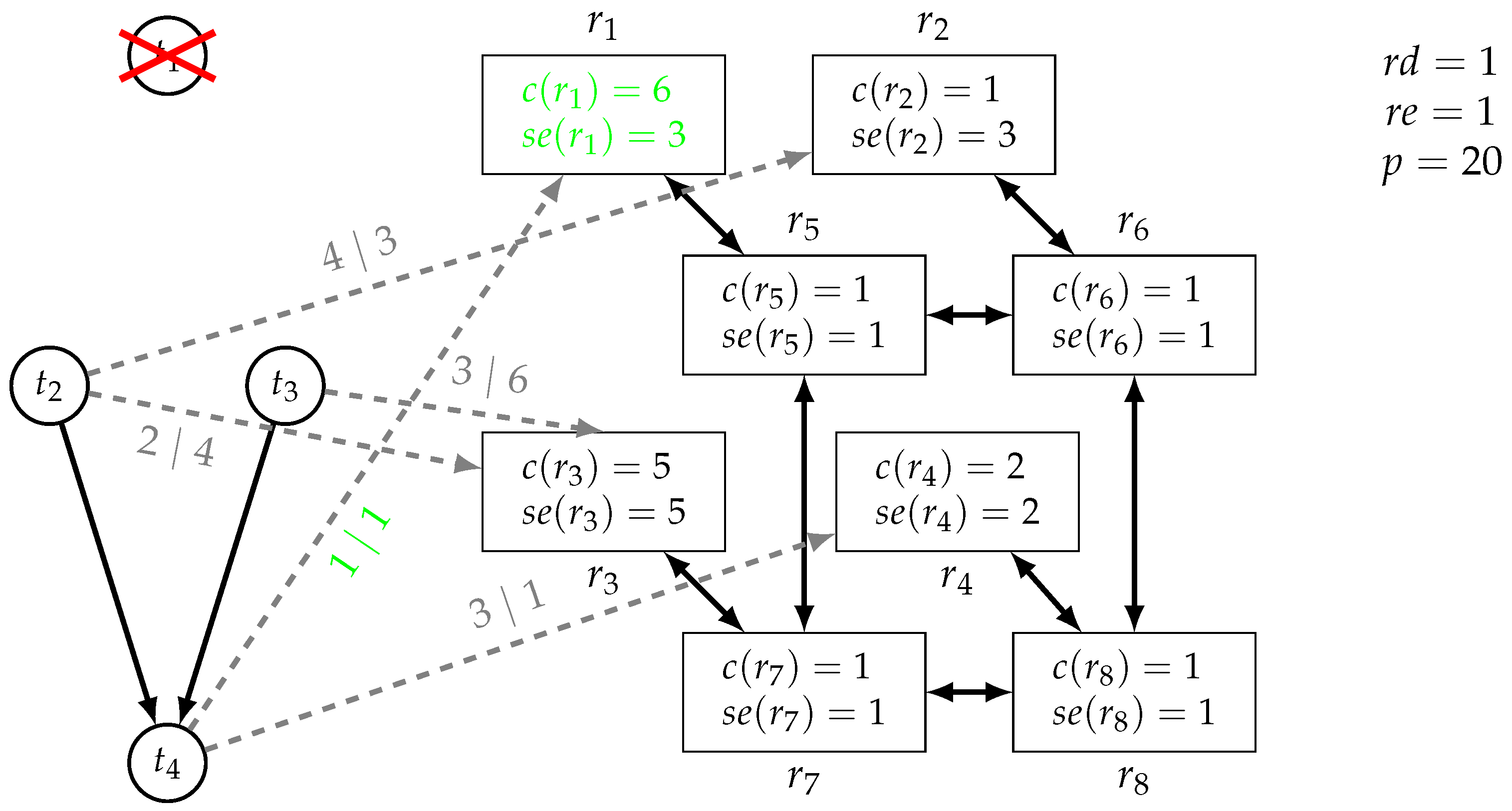
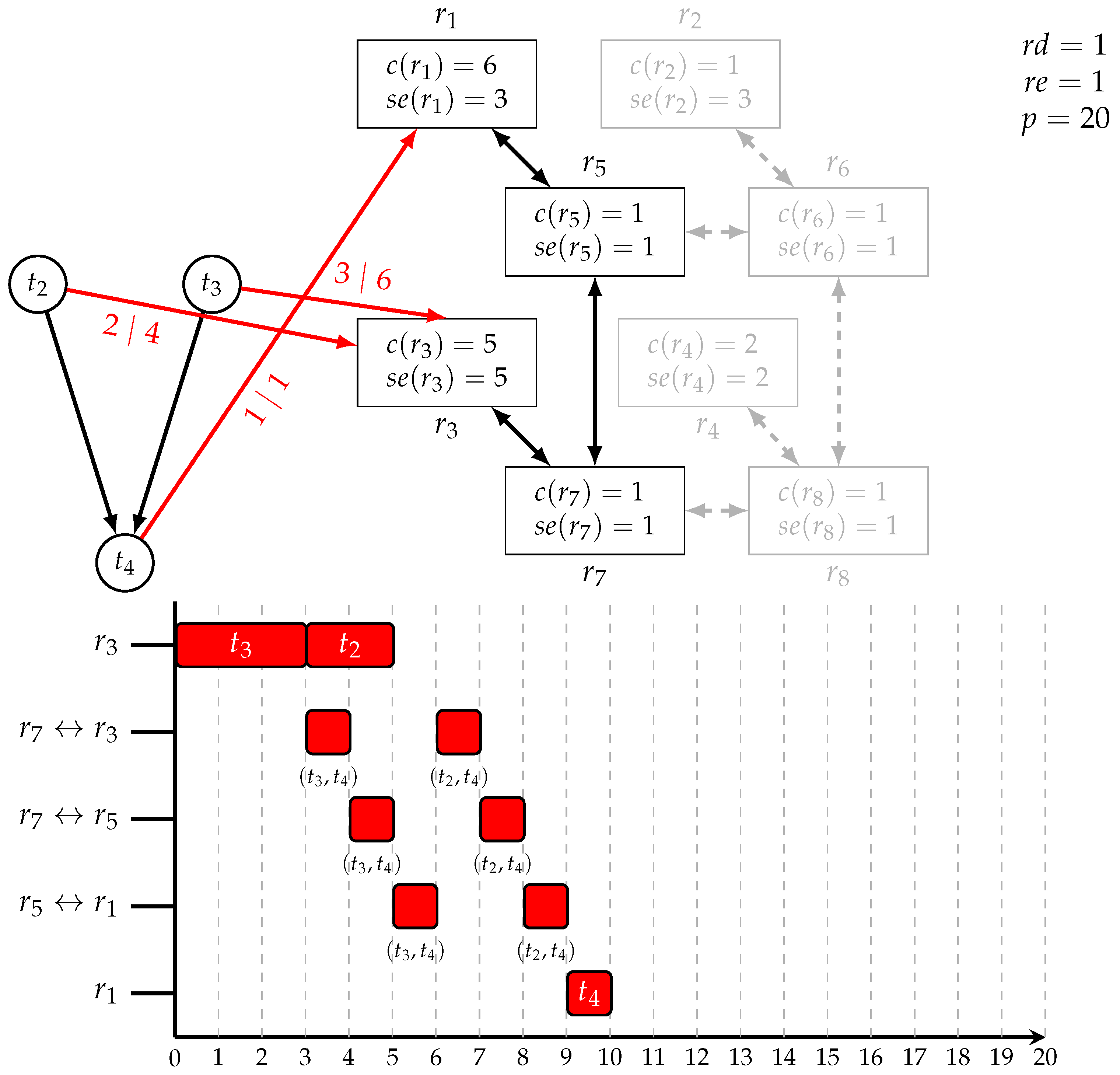
6.1. Experimental Setup
- 1.
- Perform an extensive Pareto optimization on the instance set and select a non-dominated solution as the parent implementation;
- 2.
- Obtain child specifications by slightly changing the instances and perform a low-timeout Pareto optimization with and without our various similarity techniques.
- Routing variants:
- Similarity techniques:
- −
- Strategies
- s1
- forbid unequal implementations (Listing 14)
- s2
- enforce equal implementations (Listing 15)
- −
- Preferences
- p1
- discourage unequal implementations (Listing 16)
- p2
- encourage equal implementations (Listing 17)
- −
- Heuristics
- h1
- heuristics discouraging unequal implementations (Listing 18)
- h2
- heuristics encouraging equal implementations (Listing 19)
- *
- additional modifiers for importance are f (factor) with value 2,4, and 8, and l (level) with value 1
- Part of implementation:
- b
- binding only
- br
- binding plus routing
6.2. Experimental Evaluation
7. Summary
- 1.
- Perform design space exploration for a system synthesis problem and obtain and implement a high-quality solution;
- 2.
- Perform design space exploration for a similar system synthesis problem while maximizing similarity to the previously obtained high quality solution.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gebser, M.; Kaminski, R.; Kaufmann, B.; Ostrowski, M.; Schaub, T.; Wanko, P. Theory Solving Made Easy with Clingo 5. In Proceedings of the Technical Communications of the Thirty-Second International Conference on Logic Programming (ICLP’16), New York, NY, USA, 16–21 October 2016; Carro, M., King, A., Eds.; OpenAccess Series in Informatics (OASIcs). Schloss Dagstuhl–Leibniz-Zentrum fuer Informatik: Dagstuhl, Germany, 2016; Volume 52, pp. 2:1–2:15. [Google Scholar]
- Neubauer, K.; Wanko, P.; Schaub, T.; Haubelt, C. Exact Multi-Objective Design Space Exploration using ASPmT. In Proceedings of the Twenty-first Conference on Design, Automation and Test in Europe (DATE’18), Dresden, Germany, 19–23 March 2018; Madsen, J., Coskun, A., Eds.; IEEE Computer Society Press: Piscataway Township, NJ, USA, 2018; pp. 257–260. [Google Scholar]
- Albers, A.; Bursac, N.; Wintergerst, E. Product Generation Development—Importance and Challenges from a Design Research Perspective. In Proceedings of the International Conference on Mechanical Engineering (ME 2015); Proceedings of the International Conference on Theoretical Mechanics and Applied Mechanics (TMAM 2015), Vienna, Austria, 15–17 March 2015; Volume 13, pp. 16–21. [Google Scholar]
- Müller, L.; Neubauer, K.; Haubelt, C. Exploiting Similarity in Evolutionary Product Design for Improved Design Space Exploration. In Embedded Computer Systems: Architectures, Modeling, and Simulation. SAMOS 2021; Springer International Publishing: Cham, Switzerland, 2022; pp. 33–49. [Google Scholar]
- Gelfond, M.; Lifschitz, V. Logic Programs with Classical Negation. In Proceedings of the Seventh International Conference on Logic Programming (ICLP’90), Jerusalem, Israel, 18–22 June 1990; Warren, D., Szeredi, P., Eds.; MIT Press: Cambridge, MA, USA, 1990; pp. 579–597. [Google Scholar]
- Simons, P.; Niemelä, I.; Soininen, T. Extending and implementing the stable model semantics. Artif. Intell. 2002, 138, 181–234. [Google Scholar] [CrossRef] [Green Version]
- Gebser, M.; Kaminski, R.; Kaufmann, B.; Lindauer, M.; Ostrowski, M.; Romero, J.; Schaub, T.; Thiele, S. Potassco User Guide, 2nd ed.; University of Potsdam: Potsdam, NY, USA, 2015. [Google Scholar]
- Gebser, M.; Kaufmann, B.; Otero, R.; Romero, J.; Schaub, T.; Wanko, P. Domain-specific Heuristics in Answer Set Programming. In Proceedings of the Twenty-Seventh National Conference on Artificial Intelligence (AAAI’13), Bellevue, WA, USA, 14–18 July 2013; desJardins, M., Littman, M., Eds.; AAAI Press: Palo Alto, CA, USA, 2013; pp. 350–356. [Google Scholar]
- Bomanson, J.; Gebser, M.; Janhunen, T.; Kaufmann, B.; Schaub, T. Answer Set Programming Modulo Acyclicity. Fundam. Informaticae 2016, 147, 63–91. [Google Scholar] [CrossRef]
- Janhunen, T.; Kaminski, R.; Ostrowski, M.; Schaub, T.; Schellhorn, S.; Wanko, P. Clingo goes Linear Constraints over Reals and Integers. Theory Pract. Log. Program. 2017, 17, 872–888. [Google Scholar] [CrossRef] [Green Version]
- Benini, L.; De Micheli, G. Networks on Chips—Technology and Tools; The Morgan Kaufmann Series in Systems on Silicon; Elsevier Morgan Kaufmann: Burlington, VT, USA, 2006. [Google Scholar]
- Pareto, V. Cours D’economie Politique; Librairie Droz: Geneva, Switzerland, 1964. [Google Scholar]
- Brewka, G.; Delgrande, J.; Romero, J.; Schaub, T. asprin: Customizing Answer Set Preferences without a Headache. In Proceedings of the Twenty-Ninth National Conference on Artificial Intelligence (AAAI’15), Austin, TX, USA, 25–30 January 2015; Bonet, B., Koenig, S., Eds.; AAAI Press: Palo Alto, CA, USA, 2015; pp. 1467–1474. [Google Scholar]
- Kaminski, R.; Romero, J.; Schaub, T.; Wanko, P. How to Build Your Own ASP-based System?! Theory Pract. Log. Program. 2023, 23, 299–361. [Google Scholar] [CrossRef]
- Zitzler, E.; Thiele, L.; Laumanns, M.; Fonseca, C.; da Fonseca, V. Performance assessment of multiobjective optimizers: An analysis and review. IEEE Trans. Evol. Comput. 2003, 7, 117–132. [Google Scholar] [CrossRef] [Green Version]
- Neubauer, K.; Haubelt, C.; Wanko, P.; Schaub, T. Utilizing quad-trees for efficient design space exploration with partial assignment evaluation. In Proceedings of the Twenty-Third Asia and South Pacific Design Automation Conference (ASP-DAC’18), Jeju, Republic of Korea, 22–25 January 2018; Shin, Y., Ed.; IEEE: New York, NY, USA, 2018; pp. 434–439. [Google Scholar]
- Andres, B.; Gebser, M.; Glaß, M.; Haubelt, C.; Reimann, F.; Schaub, T. Symbolic System Synthesis Using Answer Set Programming. In Proceedings of the Twelfth International Conference on Logic Programming and Nonmonotonic Reasoning (LPNMR’13), Corunna, Spain, 15–19 September 2013; Cabalar, P., Son, T., Eds.; Lecture Notes in Artificial Intelligence. Springer: Berlin/Heidelberg, Germany, 2013; Volume 8148, pp. 79–91. [Google Scholar]
- Andres, B.; Gebser, M.; Glaß, M.; Haubelt, C.; Reimann, F.; Schaub, T. A Combined Mapping and Routing Algorithm for 3D NoCs Based on ASP. In Sechzehnter Workshop für Methoden und Beschreibungssprachen zur Modellierung und Verifikation von Schaltungen und Systemen (MBMV’13); Haubelt, C., Timmermann, D., Eds.; Institut für Angewandte Mikroelektronik und Datentechnik, Universität Rostock: Rostock, Germany, 2013; pp. 35–46. [Google Scholar]
- Andres, B.; Biewer, A.; Romero, J.; Haubelt, C.; Schaub, T. Improving Coordinated SMT-based System Synthesis by Utilizing Domain-specific Heuristics. In Proceedings of the Thirteenth International Conference on Logic Programming and Nonmonotonic Reasoning (LPNMR’15), Lexington, KY, USA, 27–30 September 2015; Calimeri, F., Ianni, G., Truszczyński, M., Eds.; Lecture Notes in Artificial Intelligence. Springer: Cham, Switzerland, 2015; Volume 9345, pp. 55–68. [Google Scholar]
- Biewer, A.; Andres, B.; Gladigau, J.; Schaub, T.; Haubelt, C. A symbolic system synthesis approach for hard real-time systems based on coordinated SMT-solving. In Proceedings of the Eighteenth Conference on Design, Automation and Test in Europe (DATE’15), Grenoble, France, 9–13 March 2015; Nebel, W., Atienza, D., Eds.; ACM Press: New York, NY, USA, 2015; pp. 357–362. [Google Scholar]
- Neubauer, K.; Wanko, P.; Schaub, T.; Haubelt, C. Enhancing symbolic system synthesis through ASPmT with partial assignment evaluation. In Proceedings of the Twentieth Conference on Design, Automation and Test in Europe (DATE’17), Lausanne, Switzerland, 27–31 March 2017; Atienza, D., Di Natale, G., Eds.; IEEE Computer Society Press: New York, NY, USA, 2017; pp. 306–309. [Google Scholar]
- Abels, D.; Jordi, J.; Ostrowski, M.; Schaub, T.; Toletti, A.; Wanko, P. Train scheduling with hybrid ASP. Theory Pract. Log. Program. 2021, 21, 317–347. [Google Scholar] [CrossRef]
- El-Kholany, M.; Gebser, M.; Schekothin, K. Problem Decomposition and Multi-shot ASP Solving for Job-shop Scheduling. Theory Pract. Log. Program. 2022, 22, 623–639. [Google Scholar] [CrossRef]
- Biere, A.; Heule, M.; van Maaren, H.; Walsh, T. (Eds.) Handbook of Satisfiability; Frontiers in Artificial Intelligence and Applications; IOS Press: Amsterdam, The Netherlands, 2009; Volume 185. [Google Scholar]
- Thompson, M.; Pimentel, A.D. Exploiting domain knowledge in system-level MPSoC design space exploration. J. Syst. Archit. 2013, 59, 351–360. [Google Scholar] [CrossRef]
- Ferrandi, F.; Lanzi, P.; Pilatp, C.; Sciuto, D.; Tumeo, A. Ant Colony Heuristic for Mapping and Scheduling Tasks and Communications on Heterogeneous Embedded Systems. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2010, 29, 911–924. [Google Scholar] [CrossRef] [Green Version]
- Lukasiewycz, M.; Glaß, M.; Haubelt, C.; Teich, J. Efficient symbolic multi-objective design space exploration. In Proceedings of the 13th Asia and South Pacific Design Automation Conference (ASP-DAC’08), Seoul, Republic of Korea, 21–24 March 2008; pp. 691–696. [Google Scholar] [CrossRef] [Green Version]
- Khalilzad, N.; Rosvall, K.; Sander, I. A modular design space exploration framework for multiprocessor real-time systems. In Proceedings of the Forum on Specification and Design Languages (FDL’16), Bremen, Germany, 14–16 September 2016; pp. 1–7. [Google Scholar] [CrossRef]
- Neubauer, K.; Haubelt, C.; Glaß, M. Supporting composition in symbolic system synthesis. In Proceedings of the International Conference on Embedded Computer Systems: Architectures, Modeling and Simulation (SAMOS’16), Agios Konstantinos, Greece, 17–21 July 2016; pp. 132–139. [Google Scholar]
- Schlichter, T.; Lukasiewycz, M.; Haubelt, C.; Teich, J. Improving system level design space exploration by incorporating SAT-solvers into multi-objective evolutionary algorithms. In Proceedings of the IEEE Computer Society Annual Symposium on Emerging VLSI Technologies and Architectures (ISVLSI’06), Karlsruhe, Germany, 2–3 March 2006; pp. 309–316. [Google Scholar]
- Barták, R.; Müller, T.; Rudová, H. A New Approach to Modeling and Solving Minimal Perturbation Problems. In Recent Advances in Constraints; Apt, K., Fages, F., Rossi, F., Szeredi, P., Váncza, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2004; pp. 233–249. [Google Scholar]
- Banbara, M.; Inoue, K.; Kaufmann, B.; Okimoto, T.; Schaub, T.; Soh, T.; Tamura, N.; Wanko, P. teaspoon: Solving the Curriculum-Based Course Timetabling Problems with Answer Set Programming. Ann. Oper. Res. 2019, 275, 3–37. [Google Scholar] [CrossRef]
- Alviano, M.; Dodaro, C.; Maratea, M. Nurse (re) scheduling via answer set programming. Intell. Artif. 2018, 12, 109–124. [Google Scholar]




| sat | sat+to | unsat | |
|---|---|---|---|
| arb | 1 | 14 | 0 |
| arb-s | 1 | 11 | 9 |
| arb-p | 1 | 6 | 0 |
| arb-h | 1 | 22 | 0 |
| bou | 4 | 23 | 0 |
| bou-s | 5 | 12 | 18 |
| bou-p | 4 | 13 | 0 |
| bou-h | 4 | 27 | 0 |
| xyz | 6 | 27 | 0 |
| xyz-s | 9 | 8 | 18 |
| xyz-p | 6 | 19 | 0 |
| xyz-h | 6 | 28 | 0 |
| hd | d | hd×d | |||
|---|---|---|---|---|---|
| c | avg-r | c | avg-r | c | avg-r |
| bou-br-h1-l | 8.3 | xyz-br-h2 | 17.4 | bou-br-h2-l | 14.1 |
| bou-br-h2-l | 8.5 | xyz-b-h1-l | 18.1 | bou-br-h1-f-8 | 14.3 |
| bou-br-h1-f-8 | 10.5 | xyz-b-h2-l | 18.1 | bou-br-h1-l | 14.3 |
| bou-br-h2-f-8 | 10.8 | xyz-br-h2-f-4 | 19.2 | bou-br-h1-f-2 | 14.4 |
| bou-br-h1-f-2 | 12.3 | xyz-br-h2-f-2 | 19.4 | bou-br-h2-f-8 | 14.8 |
| bou-br-h2-f-4 | 13.0 | xyz-br-h2-l | 19.4 | bou-br-h2-f-2 | 16.7 |
| bou-br-h1-f-4 | 13.4 | xyz-br-h1 | 19.8 | xyz-b-h1-l | 17.1 |
| bou-br-h2-f-2 | 13.7 | xyz-br-h1-f-2 | 19.9 | xyz-b-h2-l | 17.1 |
| xyz-br-h1-l | 14.9 | xyz-br-h2-f-8 | 20.0 | bou-br-h1-f-4 | 17.9 |
| xyz-b-h1-l | 15.3 | bou-br-h1-f-8 | 20.2 | bou-br-h2-f-4 | 18.0 |
| xyz-b-h2-l | 15.3 | xyz-br-h1-f-8 | 20.3 | xyz-br-h1-l | 18.8 |
| xyz-br-h2-l | 17.1 | bou-b-h1-f-4 | 20.4 | xyz-br-h2-l | 18.9 |
| bou-b-h1-l | 18.7 | bou-b-h2-f-4 | 20.4 | xyz-br-h1-f-8 | 21.3 |
| bou-b-h2-l | 18.7 | xyz-br-h1-f-4 | 20.4 | xyz-br-h2-f-8 | 21.3 |
| xyz-br-h1-f-8 | 19.6 | xyz-br-h1-l | 20.7 | bou-br-h1 | 21.6 |
| xyz-br-h2-f-8 | 20.8 | bou-br-h2-f-8 | 21.0 | xyz-br-h2-f-2 | 21.9 |
| xyz-br-h1-f-4 | 21.0 | xyz-b-h1-f-8 | 21.2 | xyz-br-h1-f-4 | 22.4 |
| bou-br-h1 | 22.1 | xyz-b-h2-f-8 | 21.2 | bou-br-h2 | 22.7 |
| bou-br-h2 | 22.1 | bou-br-h1-f-2 | 21.4 | bou-b-h1-f-4 | 22.7 |
| arb-br-h2-l | 23.1 | bou-br-h1-l | 21.7 | bou-b-h2-f-4 | 22.7 |
| bou-b-h1-f-8 | 23.4 | bou-b-h1-f-2 | 21.9 | xyz-br-h2-f-4 | 22.9 |
| bou-b-h2-f-8 | 23.4 | bou-b-h2-f-2 | 21.9 | xyz-br-h1-f-2 | 23.0 |
| xyz-b-h1-f-4 | 23.4 | bou-br-h2-l | 22.0 | bou-b-h1-l | 23.3 |
| xyz-b-h2-f-4 | 23.4 | xyz | 22.3 | bou-b-h2-l | 23.3 |
| xyz-br-h2-f-4 | 23.4 | bou-br-h1 | 22.3 | xyz-br-h2 | 23.5 |
| xyz-b-h1-f-8 | 23.5 | bou-b-h1-f-8 | 22.5 | xyz-b-h1-f-8 | 23.8 |
| xyz-b-h2-f-8 | 23.5 | bou-b-h2-f-8 | 22.5 | xyz-b-h2-f-8 | 23.8 |
| xyz-br-h2-f-2 | 23.8 | bou-b-h1-l | 23.1 | xyz-br-h1 | 24.1 |
| arb-br-h1-l | 24.0 | bou-b-h2-l | 23.1 | bou-b-h1-f-8 | 24.3 |
| xyz-br-h1-f-2 | 25.5 | bou-br-h2 | 23.4 | bou-b-h2-f-8 | 24.3 |
| bou-b-h1-f-4 | 25.6 | xyz-b-h1-f-2 | 23.6 | xyz-b-h1-f-4 | 25.1 |
| bou-b-h2-f-4 | 25.6 | xyz-b-h2-f-2 | 23.6 | xyz-b-h2-f-4 | 25.1 |
| xyz-b-h1-f-2 | 25.7 | xyz-b-h1-f-4 | 23.9 | bou-b-h1-f-2 | 25.3 |
| xyz-b-h2-f-2 | 25.7 | xyz-b-h2-f-4 | 23.9 | bou-b-h2-f-2 | 25.3 |
| bou-b-h1-f-2 | 26.3 | bou-br-h2-f-2 | 23.9 | xyz-b-h1-f-2 | 25.9 |
| bou-b-h2-f-2 | 26.3 | bou-b-h1 | 24.2 | xyz-b-h2-f-2 | 25.9 |
| xyz-br-h1 | 28.6 | bou-b-h2 | 24.2 | bou-b-h1 | 28.9 |
| xyz-br-h2 | 29.7 | bou-br-h2-f-4 | 24.3 | bou-b-h2 | 28.9 |
| xyz-b-s2 | 29.8 | bou-br-h1-f-4 | 24.5 | xyz-b-h1 | 29.6 |
| bou-b-s2 | 31.5 | xyz-b-h1 | 25.3 | xyz-b-h2 | 29.6 |
| arb-br-h2-f-8 | 31.6 | xyz-b-h2 | 25.3 | xyz-b-s2 | 30.0 |
| arb-br-h1-f-8 | 31.8 | bou | 25.3 | bou-b-s2 | 32.2 |
| xyz-b-h1 | 31.8 | xyz-b-p2 | 26.2 | arb-br-h1-l | 34.3 |
| xyz-b-h2 | 31.8 | xyz-b-s2 | 30.1 | xyz | 34.6 |
| arb-br-h2-f-4 | 32.6 | xyz-b-p1 | 31.6 | arb-br-h2-l | 35.2 |
| bou-b-h1 | 34.0 | bou-b-s2 | 31.6 | bou | 35.6 |
| bou-b-h2 | 34.0 | xyz-br-p1 | 33.1 | arb-br-h2-f-4 | 36.5 |
| arb-br-h1-f-4 | 34.5 | xyz-br-p2 | 33.1 | arb-br-h2-f-8 | 37.1 |
| arb-br-h2-f-2 | 35.9 | bou-b-p2 | 33.8 | arb-br-h1-f-8 | 37.2 |
| arb-br-h1-f-2 | 37.6 | bou-b-p1 | 34.5 | xyz-b-p2 | 37.3 |
| bou | 43.2 | arb | 42.5 | arb | 51.1 |
| xyz | 43.3 | ||||
| arb | 52.2 |
| avg-hd | max-hd | ||
|---|---|---|---|
| c | avg-r | c | avg-r |
| bou-br-h1-l | 9.7 | bou-br-h1-l | 8.4 |
| bou-br-h2-l | 9.9 | bou-br-h2-l | 8.6 |
| bou-br-h1-f-8 | 10.9 | bou-br-h1-f-8 | 10.4 |
| bou-br-h2-f-8 | 11.3 | bou-br-h2-f-8 | 10.7 |
| bou-br-h2-f-4 | 12.4 | bou-br-h2-f-4 | 12.1 |
| bou-br-h1-f-4 | 13.0 | bou-br-h1-f-4 | 12.7 |
| bou-br-h1-f-2 | 14.6 | bou-br-h1-f-2 | 13.3 |
| bou-br-h2-f-2 | 15.9 | bou-br-h2-f-2 | 14.7 |
| bou-b-h1-l | 18.6 | xyz-br-h1-l | 16.0 |
| bou-b-h2-l | 18.6 | xyz-b-h2-l | 16.8 |
| arb-br-h2-l | 20.1 | xyz-b-h1-l | 16.9 |
| xyz-br-h1-l | 20.5 | bou-b-h1-l | 17.5 |
| arb-br-h1-l | 20.7 | bou-b-h2-l | 17.5 |
| xyz-b-h2-l | 21.0 | xyz-br-h2-l | 17.8 |
| xyz-b-h1-l | 21.1 | xyz-br-h1-f-8 | 20.3 |
| bou-br-h1 | 22.2 | bou-br-h2 | 20.5 |
| bou-br-h2 | 22.3 | bou-br-h1 | 20.6 |
| xyz-br-h2-l | 22.8 | bou-b-h1-f-8 | 20.7 |
| bou-b-h1-f-8 | 22.8 | bou-b-h2-f-8 | 20.7 |
| bou-b-h2-f-8 | 22.8 | arb-br-h2-l | 21.7 |
| xyz-br-h1-f-8 | 25.1 | bou-b-h1-f-4 | 22.1 |
| bou-b-h1-f-4 | 25.9 | bou-b-h2-f-4 | 22.1 |
| bou-b-h2-f-4 | 25.9 | arb-br-h1-l | 22.4 |
| bou-b-h1-f-2 | 26.0 | xyz-br-h2-f-8 | 22.9 |
| bou-b-h2-f-2 | 26.0 | xyz-b-h1-f-4 | 23.2 |
| xyz-b-s2 | 27.0 | xyz-b-h2-f-4 | 23.2 |
| xyz-b-h1-f-4 | 27.4 | xyz-br-h1-f-2 | 23.4 |
| xyz-b-h2-f-4 | 27.4 | bou-b-h1-f-2 | 23.5 |
| bou-b-s2 | 27.6 | bou-b-h2-f-2 | 23.5 |
| xyz-br-h2-f-8 | 27.8 | xyz-br-h2-f-4 | 23.6 |
| xyz-br-h1-f-4 | 28.2 | xyz-br-h1-f-4 | 23.7 |
| xyz-br-h1-f-2 | 28.3 | xyz-br-h2-f-2 | 24.2 |
| xyz-br-h2-f-4 | 28.6 | xyz-b-h1-f-8 | 24.9 |
| arb-br-h1-f-8 | 28.9 | xyz-b-h2-f-8 | 24.9 |
| xyz-b-h1-f-8 | 28.9 | xyz-b-h1-f-2 | 26.1 |
| arb-br-h2-f-8 | 28.9 | xyz-b-h2-f-2 | 26.1 |
| xyz-b-h2-f-8 | 28.9 | bou-b-h1 | 26.5 |
| xyz-br-h2-f-2 | 29.5 | bou-b-h2 | 26.5 |
| bou-b-h1 | 29.7 | xyz-br-h1 | 28.2 |
| bou-b-h2 | 29.7 | xyz-br-h2 | 28.7 |
| xyz-b-h2-f-2 | 30.4 | xyz-b-h2 | 29.0 |
| xyz-b-h1-f-2 | 30.4 | xyz-b-h1 | 29.1 |
| arb-br-h2-f-4 | 32.4 | xyz-b-s2 | 29.5 |
| xyz-br-h2 | 33.5 | bou-b-s2 | 30.1 |
| xyz-br-h1 | 33.6 | arb-br-h1-f-8 | 30.2 |
| arb-br-h1-f-4 | 34.1 | arb-br-h2-f-8 | 30.3 |
| xyz-b-h2 | 34.2 | arb-br-h2-f-4 | 32.4 |
| xyz-b-h1 | 34.3 | arb-br-h1-f-4 | 34.2 |
| arb-br-h2-f-2 | 35.1 | xyz | 35.8 |
| arb-br-h1-f-2 | 36.5 | arb-br-h2-f-2 | 36.1 |
| xyz | 41.1 | bou | 38.5 |
| bou | 42.5 | arb | 50.5 |
| arb | 50.5 |
| d | hd×d | ||
|---|---|---|---|
| c | avg-r | c | avg-r |
| xyz-b-h1-l | 3.9 | bou-br-h1-l | 12.1 |
| xyz-b-h2-l | 3.9 | bou-br-h2-l | 13.1 |
| xyz-br-h1-l | 4.7 | xyz-b-h2-l | 13.6 |
| xyz-br-h2-f-8 | 6.1 | xyz-b-h1-l | 13.7 |
| xyz-br-h1-f-2 | 6.5 | xyz-br-h1-l | 14.4 |
| xyz-br-h2-l | 6.6 | bou-br-h1-f-8 | 15.9 |
| xyz-br-h2-f-4 | 6.9 | xyz-br-h2-l | 16.9 |
| xyz-br-h1-f-8 | 6.9 | xyz-br-h1-f-8 | 17.8 |
| xyz-br-h2-f-2 | 7.1 | bou-br-h2-f-8 | 18.1 |
| xyz-br-h1-f-4 | 7.3 | xyz-br-h1-f-2 | 18.8 |
| xyz-b-h2-f-4 | 8.0 | xyz-b-h2-f-4 | 19.1 |
| xyz-b-h1-f-4 | 8.1 | xyz-br-h1-f-4 | 19.2 |
| xyz-br-h2 | 8.5 | xyz-b-h1-f-4 | 19.4 |
| xyz-b-h1-f-2 | 9.3 | xyz-br-h2-f-4 | 19.5 |
| xyz-b-h2-f-2 | 9.3 | xyz-br-h2-f-8 | 19.8 |
| xyz | 9.5 | bou-br-h1-f-4 | 20.3 |
| xyz-b-h1-f-8 | 10.1 | bou-br-h1-f-2 | 20.6 |
| xyz-b-h2-f-8 | 10.1 | xyz-br-h2-f-2 | 20.6 |
| xyz-b-h1 | 10.7 | xyz-b-h1-f-8 | 20.7 |
| xyz-b-h2 | 10.7 | xyz-b-h2-f-8 | 20.7 |
| xyz-br-h1 | 11.3 | bou-br-h2-f-4 | 20.8 |
| xyz-b-p2 | 13.0 | xyz-b-h2-f-2 | 21.8 |
| bou-br-h1-l | 14.8 | xyz-b-h1-f-2 | 21.8 |
| bou-br-h2-l | 15.5 | xyz-br-h2 | 22.7 |
| bou-b-h1-f-4 | 19.1 | bou-br-h2-f-2 | 23.1 |
| bou-b-h2-f-4 | 19.1 | xyz-br-h1 | 24.3 |
| bou-br-h1-f-8 | 19.6 | bou-br-h2 | 24.4 |
| bou-br-h2-f-8 | 20.7 | bou-br-h1 | 24.7 |
| xyz-b-p1 | 21.1 | bou-b-h1-f-4 | 26.0 |
| bou-b-h1-f-2 | 21.6 | bou-b-h2-f-4 | 26.0 |
| bou-b-h2-f-2 | 21.6 | xyz-b-h2 | 26.1 |
| xyz-br-p1 | 22.3 | bou-b-h1-l | 26.2 |
| xyz-br-p2 | 22.3 | bou-b-h2-l | 26.2 |
| bou-br-h1 | 22.3 | xyz-b-h1 | 26.2 |
| bou | 22.4 | bou-b-h1-f-2 | 26.9 |
| bou-br-h2 | 22.6 | bou-b-h2-f-2 | 26.9 |
| bou-b-h1-l | 22.8 | bou-b-h1-f-8 | 27.0 |
| bou-b-h2-l | 22.8 | bou-b-h2-f-8 | 27.0 |
| bou-br-h1-f-4 | 22.8 | bou-b-h1 | 29.0 |
| bou-br-h1-f-2 | 23.1 | bou-b-h2 | 29.1 |
| bou-b-h1-f-8 | 23.4 | xyz-b-s2 | 30.9 |
| bou-b-h2-f-8 | 23.4 | xyz | 32.0 |
| bou-b-h1 | 23.5 | arb-br-h2-l | 33.4 |
| bou-b-h2 | 23.5 | arb-br-h1-l | 33.5 |
| bou-br-h2-f-4 | 24.2 | xyz-b-p2 | 35.5 |
| bou-br-h2-f-2 | 25.7 | bou-b-s2 | 35.7 |
| bou-b-p2 | 29.2 | bou | 37.1 |
| bou-b-p1 | 29.3 | xyz-b-p1 | 37.5 |
| bou-br-p1 | 29.3 | xyz-br-p1 | 38.1 |
| bou-br-p2 | 30.4 | arb-br-h1-f-8 | 39.2 |
| arb | 44.3 | arb | 50.1 |
| hd | d | hd×d | |||
|---|---|---|---|---|---|
| c | avg-r | c | avg-r | c | avg-r |
| bou-br-h1-f-8 | 6.9 | xyz-b-s2 | 17.2 | bou-br-h1-f-2 | 12.2 |
| bou-br-h2-l | 7.4 | xyz-br-h2 | 17.8 | bou-br-h2-l | 12.8 |
| bou-br-h2-f-8 | 7.7 | bou-b-s2 | 20.2 | bou-br-h1-f-8 | 13.2 |
| bou-br-h1-l | 8.1 | bou-br-h1 | 20.2 | bou-br-h1-l | 13.6 |
| bou-br-h1-f-2 | 8.4 | bou-br-h1-f-2 | 21.1 | bou-br-h2-f-8 | 14.0 |
| bou-br-h2-f-4 | 9.6 | bou-b-h1-f-4 | 21.2 | bou-br-h2-f-4 | 14.5 |
| arb-br-h2-l | 10.4 | bou-b-h2-f-4 | 21.2 | bou-br-h1-f-4 | 15.4 |
| bou-br-h1-f-4 | 10.5 | xyz-br-h1 | 21.8 | xyz-b-s2 | 16.9 |
| bou-br-h2-f-2 | 11.4 | bou-b-h1-f-2 | 21.9 | bou-br-h2-f-2 | 17.4 |
| arb-br-h1-l | 12.1 | bou-b-h2-f-2 | 21.9 | bou-br-h1 | 18.0 |
| xyz-b-s2 | 16.5 | xyz-br-h1-f-8 | 22.1 | bou-br-h2 | 20.5 |
| bou-br-h1 | 18.7 | bou-b-h1-f-8 | 22.5 | bou-b-s2 | 21.4 |
| bou-br-h2 | 18.8 | bou-b-h2-f-8 | 22.5 | xyz-br-h2-l | 23.4 |
| xyz-b-h1-l | 19.8 | bou-br-h1-f-8 | 22.8 | xyz-b-h1-l | 23.5 |
| xyz-b-h2-l | 19.8 | bou-br-h1-l | 22.9 | xyz-b-h2-l | 23.5 |
| bou-b-s2 | 20.0 | bou-br-h2 | 23.1 | xyz-br-h2 | 24.6 |
| bou-b-h1-l | 20.9 | xyz-br-h1-f-2 | 23.1 | xyz-br-h1-l | 24.8 |
| bou-b-h2-l | 20.9 | xyz-br-h1-f-4 | 23.3 | bou-b-h1-f-8 | 25.4 |
| xyz-br-h1-l | 21.3 | xyz-b-h1-l | 23.6 | bou-b-h2-f-8 | 25.4 |
| xyz-br-h2-l | 21.8 | xyz-b-h2-l | 23.6 | bou-b-h1-f-4 | 25.6 |
| xyz-br-h1-f-8 | 26.1 | bou-br-h2-l | 23.8 | bou-b-h2-f-4 | 25.6 |
| bou-b-h1-f-8 | 26.3 | bou-br-h2-f-4 | 23.8 | xyz-br-h1-f-8 | 25.8 |
| bou-b-h2-f-8 | 26.3 | xyz-br-h2-f-4 | 23.9 | xyz-br-h1-f-4 | 27.0 |
| arb-br-h2-f-8 | 28.0 | bou-br-h2-f-8 | 24.1 | bou-b-h1-f-2 | 28.0 |
| xyz-br-h1-f-4 | 28.1 | xyz-br-h2-f-2 | 24.4 | bou-b-h2-f-2 | 28.0 |
| xyz-br-h2-f-8 | 28.2 | xyz-br-h2-l | 24.5 | xyz-br-h1 | 28.1 |
| arb-br-h1-f-8 | 28.4 | xyz-br-h2-f-8 | 25.0 | xyz-br-h1-f-2 | 28.4 |
| arb-br-h2-f-4 | 29.6 | xyz-b-h1 | 25.2 | xyz-br-h2-f-8 | 28.5 |
| bou-b-h1-f-4 | 30.1 | xyz-b-h2 | 25.2 | bou-b-h1-l | 28.5 |
| bou-b-h2-f-4 | 30.1 | bou-br-h1-f-4 | 25.4 | bou-b-h2-l | 28.5 |
| xyz-br-h2-f-4 | 30.8 | xyz-br-h1-l | 25.4 | xyz-br-h2-f-4 | 29.4 |
| xyz-br-h1-f-2 | 32.0 | bou | 26.5 | xyz-br-h2-f-2 | 29.5 |
| xyz-b-h1-f-8 | 32.1 | bou-br-h2-f-2 | 27.5 | arb-br-h1-l | 30.6 |
| xyz-b-h2-f-8 | 32.1 | bou-b-h1 | 27.5 | xyz-b-h1-f-2 | 31.8 |
| xyz-b-h1-f-4 | 32.5 | bou-b-h2 | 27.5 | xyz-b-h2-f-2 | 31.8 |
| xyz-b-h2-f-4 | 32.5 | xyz-b-h1-f-2 | 27.8 | arb-br-h2-l | 32.5 |
| bou-b-h1-f-2 | 32.6 | xyz-b-h2-f-2 | 27.8 | xyz-b-h1-f-8 | 33.1 |
| bou-b-h2-f-2 | 32.6 | xyz-b-h1-f-8 | 28.0 | xyz-b-h2-f-8 | 33.1 |
| xyz-br-h2-f-2 | 32.6 | xyz-b-h2-f-8 | 28.0 | xyz-b-h1-f-4 | 33.4 |
| xyz-b-h1-f-2 | 32.6 | xyz | 28.1 | xyz-b-h2-f-4 | 33.4 |
| xyz-b-h2-f-2 | 32.6 | bou-b-h1-l | 29.1 | bou-b-h1 | 33.5 |
| arb-br-h1-f-4 | 33.5 | bou-b-h2-l | 29.1 | bou-b-h2 | 33.5 |
| arb-br-h2-f-2 | 34.3 | xyz-b-h1-f-4 | 30.0 | xyz-b-h1 | 33.7 |
| xyz-br-h1 | 34.4 | xyz-b-h2-f-4 | 30.0 | xyz-b-h2 | 33.7 |
| xyz-br-h2 | 34.7 | xyz-b-p2 | 31.5 | arb-br-h2-f-8 | 36.4 |
| arb-br-h1-f-2 | 37.8 | arb-br-h1-l | 34.8 | arb-br-h1-f-8 | 36.5 |
| xyz-b-h1 | 39.2 | arb-br-h1-f-8 | 35.8 | arb-br-h2-f-4 | 37.1 |
| xyz-b-h2 | 39.2 | arb-br-h2-f-8 | 36.2 | arb-br-h1-f-4 | 39.1 |
| bou-b-h1 | 40.2 | arb-br-h2-l | 36.7 | bou | 40.5 |
| bou-b-h2 | 40.2 | arb-br-h2-f-4 | 38.1 | arb-br-h2-f-2 | 41.1 |
| bou | 52.8 | arb | 46.5 | xyz | 45.9 |
| xyz | 56.5 | arb | 61.8 | ||
| arb | 63.8 |
| avg-hd | max-hd | ||
|---|---|---|---|
| c | avg-r | c | avg-r |
| arb-br-h2-l | 9.1 | bou-br-h1-f-8 | 7.9 |
| bou-br-h1-f-8 | 10.1 | bou-br-h2-l | 8.2 |
| arb-br-h1-l | 10.2 | bou-br-h2-f-8 | 8.3 |
| bou-br-h2-l | 10.3 | bou-br-h2-f-4 | 8.8 |
| bou-br-h2-f-4 | 10.6 | bou-br-h1-l | 8.8 |
| bou-br-h2-f-8 | 10.8 | bou-br-h1-f-2 | 9.5 |
| bou-br-h1-f-2 | 11.0 | bou-br-h1-f-4 | 9.9 |
| bou-br-h1-l | 11.1 | arb-br-h2-l | 10.9 |
| xyz-b-s2 | 11.4 | arb-br-h1-l | 12.2 |
| bou-br-h1-f-4 | 11.9 | bou-br-h2-f-2 | 12.6 |
| bou-b-s2 | 12.6 | bou-b-h1-l | 15.4 |
| bou-br-h2-f-2 | 13.8 | bou-b-h2-l | 15.4 |
| bou-b-h1-l | 18.1 | xyz-b-s2 | 16.5 |
| bou-b-h2-l | 18.1 | bou-b-s2 | 17.8 |
| bou-br-h1 | 22.8 | bou-b-h1-f-8 | 18.4 |
| bou-br-h2 | 22.9 | bou-b-h2-f-8 | 18.4 |
| bou-b-h1-f-8 | 23.1 | bou-br-h2 | 18.8 |
| bou-b-h2-f-8 | 23.1 | bou-br-h1 | 19.0 |
| arb-br-h1-f-8 | 23.8 | xyz-b-h2-l | 21.0 |
| arb-br-h2-f-8 | 23.9 | xyz-b-h1-l | 21.1 |
| bou-b-h1-f-2 | 27.6 | bou-b-h1-f-4 | 22.0 |
| bou-b-h2-f-2 | 27.6 | bou-b-h2-f-4 | 22.0 |
| xyz-b-h2-l | 28.2 | xyz-br-h1-l | 22.1 |
| xyz-b-h1-l | 28.4 | xyz-br-h2-l | 22.5 |
| arb-br-h2-f-4 | 29.3 | bou-b-h1-f-2 | 23.4 |
| bou-b-h2-f-4 | 29.4 | bou-b-h2-f-2 | 23.4 |
| bou-b-h1-f-4 | 29.4 | arb-br-h1-f-8 | 26.4 |
| xyz-br-h1-l | 30.4 | arb-br-h2-f-8 | 26.6 |
| xyz-br-h2-l | 30.8 | xyz-br-h1-f-8 | 28.3 |
| arb-br-h1-f-4 | 32.7 | bou-b-h1 | 28.7 |
| bou-b-h1 | 33.5 | bou-b-h2 | 28.7 |
| bou-b-h2 | 33.5 | arb-br-h2-f-4 | 29.2 |
| arb-br-h2-f-2 | 34.2 | xyz-br-h2-f-8 | 30.2 |
| xyz-br-h1-f-8 | 36.4 | xyz-br-h1-f-4 | 31.9 |
| arb-br-h1-f-2 | 37.1 | arb-br-h1-f-4 | 32.9 |
| xyz-br-h2-f-8 | 38.2 | xyz-b-h1-f-4 | 32.9 |
| xyz-br-h1-f-4 | 39.4 | xyz-b-h2-f-4 | 32.9 |
| xyz-b-h1-f-4 | 40.0 | xyz-br-h2-f-4 | 33.1 |
| xyz-b-h1-f-8 | 40.0 | xyz-b-h1-f-8 | 33.3 |
| xyz-b-h2-f-4 | 40.1 | xyz-b-h2-f-8 | 33.3 |
| xyz-b-h2-f-8 | 40.1 | xyz-br-h2-f-2 | 33.3 |
| xyz-br-h2-f-4 | 40.6 | arb-br-h2-f-2 | 33.9 |
| xyz-b-s1 | 41.3 | xyz-br-h1-f-2 | 34.2 |
| bou-b-s1 | 41.5 | xyz-b-h1-f-2 | 34.8 |
| xyz-br-h1-f-2 | 41.8 | xyz-b-h2-f-2 | 34.8 |
| xyz-b-h1-f-2 | 42.1 | xyz-br-h1 | 35.6 |
| xyz-b-h2-f-2 | 42.1 | xyz-br-h2 | 35.9 |
| xyz-br-h2-f-2 | 42.6 | arb-br-h1-f-2 | 37.1 |
| xyz-br-h2 | 43.1 | xyz-b-h2 | 37.7 |
| xyz-br-h1 | 43.3 | xyz-b-h1 | 37.9 |
| bou | 50.6 | bou | 44.5 |
| xyz | 54.1 | xyz | 45.5 |
| arb | 60.9 | arb | 60.8 |
| d | hd×d | ||
|---|---|---|---|
| c | avg-r | c | avg-r |
| xyz-br-h1-l | 3.2 | bou-br-h1-l | 6.9 |
| xyz-b-h1-l | 3.6 | bou-br-h2-l | 8.2 |
| xyz-b-h2-l | 3.6 | bou-br-h1-f-8 | 14.2 |
| xyz-br-h1-f-8 | 3.8 | xyz-b-h2-l | 17.6 |
| xyz-br-h1-f-2 | 4.9 | xyz-b-h1-l | 17.6 |
| xyz-br-h2-l | 4.9 | bou-br-h2-f-8 | 18.1 |
| xyz-br-h2-f-8 | 5.9 | bou-br-h1-f-2 | 18.3 |
| xyz-br-h2-f-4 | 6.6 | bou-br-h1-f-4 | 18.5 |
| xyz-br-h1-f-4 | 7.2 | bou-br-h2-f-4 | 19.2 |
| xyz-br-h2 | 8.4 | xyz-b-s2 | 19.5 |
| xyz-b-h1 | 8.8 | xyz-br-h1-l | 19.6 |
| xyz-b-h2-f-4 | 8.8 | xyz-br-h2-l | 20.2 |
| xyz-b-h2 | 8.8 | xyz-br-h1-f-8 | 21.2 |
| xyz-b-h1-f-4 | 8.9 | bou-br-h2-f-2 | 23.9 |
| bou-br-h1-l | 9.0 | xyz-br-h2-f-8 | 24.8 |
| xyz | 9.3 | bou-br-h1 | 25.7 |
| bou-br-h2-l | 9.5 | xyz-br-h1-f-2 | 25.9 |
| xyz-br-h2-f-2 | 10.4 | bou-b-h1-f-2 | 26.0 |
| xyz-b-h1-f-8 | 12.1 | bou-b-h2-f-2 | 26.0 |
| xyz-b-h2-f-8 | 12.1 | xyz-br-h1-f-4 | 26.0 |
| xyz-br-h1 | 12.2 | xyz-br-h2-f-4 | 26.3 |
| xyz-b-h1-f-2 | 12.6 | bou-b-h2-f-4 | 26.8 |
| xyz-b-h2-f-2 | 12.6 | bou-b-h1-f-4 | 26.8 |
| xyz-b-p2 | 12.8 | xyz-b-h2-f-4 | 26.8 |
| bou-b-h1-f-4 | 17.6 | bou-br-h2 | 27.1 |
| bou-b-h2-f-4 | 17.6 | xyz-b-h1-f-4 | 27.4 |
| xyz-b-s2 | 18.8 | xyz-br-h2 | 27.7 |
| bou-br-h1-f-8 | 19.5 | bou-b-h1-l | 27.9 |
| bou | 20.0 | bou-b-h2-l | 27.9 |
| bou-br-h1-f-4 | 21.0 | xyz-b-h1-f-8 | 28.2 |
| bou-b-h1-f-2 | 21.1 | xyz-b-h2-f-8 | 28.2 |
| bou-b-h2-f-2 | 21.1 | arb-br-h2-l | 28.3 |
| bou-br-h2-f-8 | 21.4 | arb-br-h1-l | 28.5 |
| bou-br-h1-f-2 | 22.3 | bou-b-h1-f-8 | 28.6 |
| bou-br-h1 | 22.5 | bou-b-h2-f-8 | 28.6 |
| bou-br-h2-f-4 | 23.7 | xyz-br-h1 | 29.2 |
| bou-b-h1-f-8 | 24.4 | bou-b-s2 | 29.4 |
| bou-b-h2-f-8 | 24.4 | xyz-br-h2-f-2 | 29.9 |
| bou-br-h2 | 25.3 | xyz-b-h1-f-2 | 30.5 |
| bou-b-h1 | 25.9 | xyz-b-h2-f-2 | 30.5 |
| bou-b-h2 | 25.9 | bou-b-h1 | 32.6 |
| bou-b-h1-l | 26.2 | bou-b-h2 | 32.6 |
| bou-b-h2-l | 26.2 | xyz-b-h2 | 33.8 |
| xyz-b-p1 | 26.8 | xyz-b-h1 | 33.8 |
| bou-br-h2-f-2 | 28.0 | bou | 40.8 |
| arb-br-h1-l | 29.1 | xyz | 41.6 |
| xyz-br-p2 | 29.3 | arb-br-h1-f-8 | 42.9 |
| xyz-br-p1 | 29.5 | xyz-b-p2 | 43.5 |
| bou-b-s2 | 30.5 | bou-b-p2 | 44.0 |
| arb-br-h2-l | 31.4 | arb-br-h2-f-8 | 44.3 |
| arb | 49.5 | arb | 60.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Haubelt, C.; Müller, L.; Neubauer, K.; Schaub, T.; Wanko, P. Evolutionary System Design with Answer Set Programming. Algorithms 2023, 16, 179. https://doi.org/10.3390/a16040179
Haubelt C, Müller L, Neubauer K, Schaub T, Wanko P. Evolutionary System Design with Answer Set Programming. Algorithms. 2023; 16(4):179. https://doi.org/10.3390/a16040179
Chicago/Turabian StyleHaubelt, Christian, Luise Müller, Kai Neubauer, Torsten Schaub, and Philipp Wanko. 2023. "Evolutionary System Design with Answer Set Programming" Algorithms 16, no. 4: 179. https://doi.org/10.3390/a16040179