1. Introduction
In the daily communication process, the background noise of the surrounding environment has a great impact on it, especially on the noisy roadside, near construction sites, train waiting rooms, and other places. The military communication field also needs to remove all kinds of noises. Therefore, improving the voice quality is very important for improving the quality of life. Environmental noise not only affects voice communication in daily life but also needs to be removed in military communication, fire rescue communication, and other fields. In the field of military communications, many places need to use voice to transmit information, and voice quality is crucial. If the voice quality is poor, the transmitted information may not be obtained correctly, resulting in very significant losses. Speech enhancement is an important technical means of reducing noise interference in speech communication. At present, speech enhancement technology has made great progress. Traditional speech enhancement methods [
1,
2] and depth-learning-based enhancement methods [
3,
4] emerge endlessly, which can achieve good enhancement effects when dealing with stationary noise. However, when the noise environment is very complex, the effect of existing speech enhancement methods will be greatly reduced. Ordinary air conduction (AC) microphones transmit information by capturing voice signals in the air, so they are very vulnerable to various environmental noises. However, it is precisely because of the unique transmission channel of its speech signal that the speech signal captured by the bone-conducted (BC) equipment can completely shield the background noise, separate the noise from the transmitted speech information from the sound source, and prevent the noise from interfering with the speech signal.
To fundamentally solve the problem of environmental noise [
5], people began to use BC microphones for speech communication in some strong noise environments, such as military aircraft and tanks, where the background noise in the cockpit is very strong. In addition, the BC communication equipment is small in size, easy to carry, and can communicate normally in water. It can also be used as speech recognition under strong noise. Generally, the BC microphone with good universality mainly collects signals from sensors. The sensors are close to the skin, which can sense the vibration signals of the bones driven by human speech. Then, the collected signals are converted into formats to form BC speech signals. Different from traditional AC microphones, BC microphones only collect vibration information and will not be affected by background noise. They shield noise interference from the sound source to obtain relatively pure speech signals. This is also an important feature of BC microphones in practical applications and has important application value in complex noise environments.
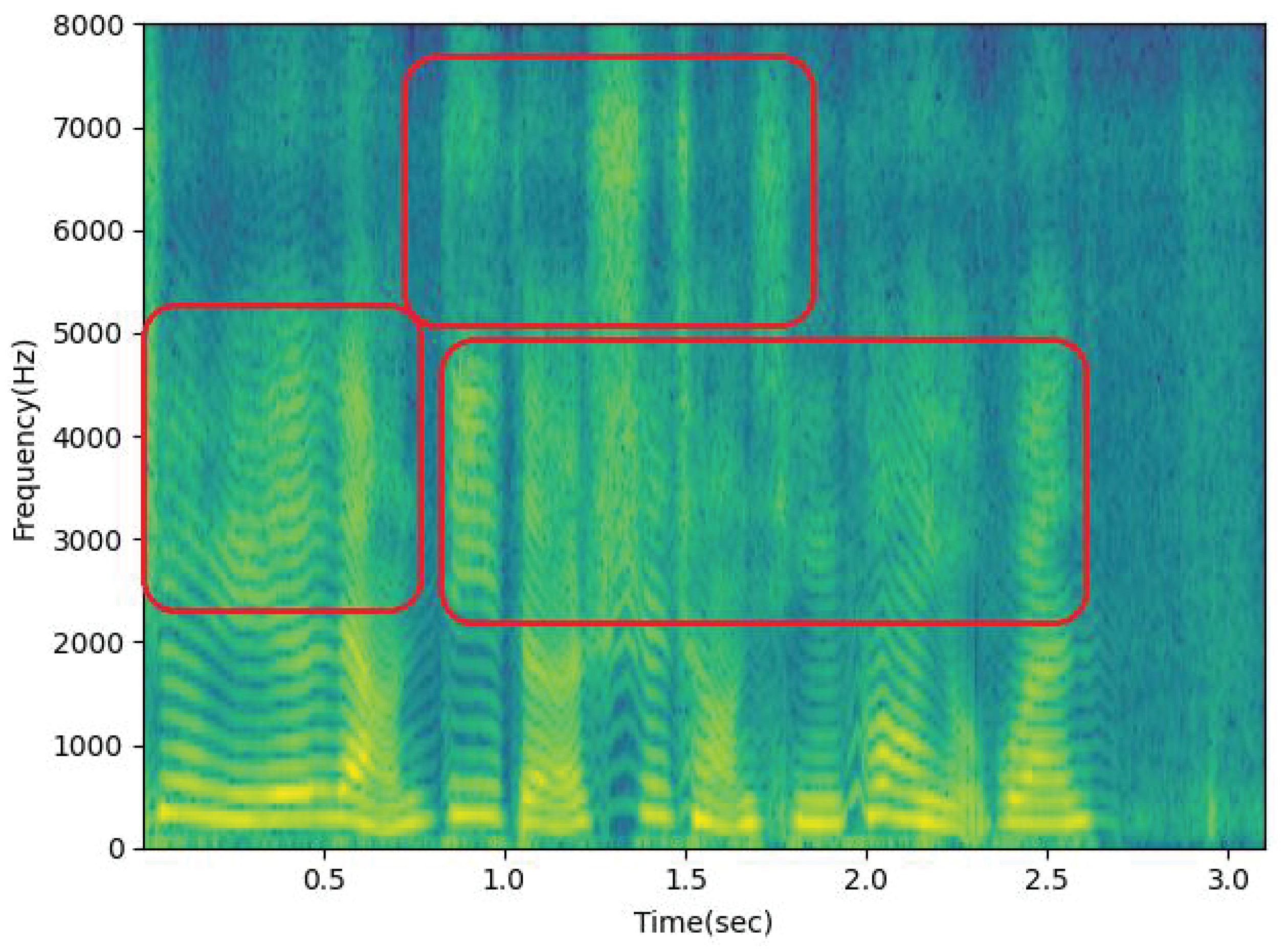
BC speech can effectively resist the interference of environmental noise; however, due to the change in the sound transmission path and the limitation of the human voice generation mechanism, the BC microphone will lose some signals, especially important high-frequency voice signal information, which makes the comfort experience of the BC microphone for users unfriendly. High-frequency information of BC speech is lost, some unvoiced syllables are missing, and the sense of hearing is dull and not clear enough, so the speech intelligibility is low, and it is difficult to directly apply to normal communication [
5]. These shortcomings also seriously restrict the development of BC communication.
Compared with the acoustic characteristics of AC speech, the biggest problem of BC speech is the loss of high-frequency information components. Different from the multi-sensor fusion enhancement algorithm, blind enhancement of BC speech only has BC speech information in the enhancement phase and does not need to be supplemented by AC speech features. At the same time, this process is called Blind Restoration [
6]. Therefore, the difficulty of blind enhancement is to infer and recover high-frequency information based on limited information in the middle and low-frequency bands.
At present, BC speech enhancement methods include traditional methods and depth learning methods. Traditional BC speech enhancement methods are based on the Gaussian mixture model, the least mean-square error method, and other statistical methods. The traditional blind BC speech enhancement method analyzes the spectrum characteristics of BC speech from many aspects, finds the correlation between AC and BC speech, and lays a good foundation for the follow-up work. Recently, with the rapid development of deep learning technology, it has been widely used in various fields. Compared with traditional methods, the method based on deep learning can better learn the spectral characteristics of bone and air conduction speech and obtain a better enhancement effect [
7,
8,
9]. DNN is gradually applied to learning the nonlinear conversion relationship between spectral envelope features [
9,
10]. Because the deep neural network has a good characterization ability for high-dimensional data, Liu et al. have used the deep denoising autoencoder (DDAE) to model the transformational relation of the high-dimensional Mel-amplitude spectrum features [
8]. Changyan et al. [
7] regarded the BC speech spectrum as a two-dimensional image, and proposed a bidirectional long short-term memory (attention-based BLSTM, ABBLSTM) on the basis of using the structural similarity (SSIM) loss function and achieved certain results. At present, most neural network enhancement frameworks are based on short-time Fourier characteristics. Most of the research inputs the spectrum into the network and thinks that the short-term phase is not important for speech enhancement. However, Paliwal et al. found through experiments that when the phase spectrum of the enhanced speech is effectively restored, the quality of speech enhancement will be significantly improved [
11].
The BC speech enhancement method based on deep learning can infer high-frequency information by analyzing the low-frequency spectrum signal information composition of BC speech, reconstructing the full band speech, and improving the quality and intelligibility of the generated speech. However, the deep neural network currently used in BC speech enhancement methods is difficult to fully learn the characteristics of BC speech in the case of limited BC speech samples and is not robust to speaker-independent speech data sets.
Recently, the authors of [
12] used generative adversarial networks (GAN) to conduct in-depth learning and training of data through game learning of generators and discriminators. In theory, it has a strong generating ability. It has been widely used in many fields, such as image processing [
13,
14], video generation, speech synthesis [
15], and so on. In particular, it has achieved considerable success in generating realistic images and solving complex data distribution problems [
12]. Q. Pan et al. [
16] proposed a method that can reconstruct the high-frequency part of BC speech without using the dynamic integration algorithm (DTW) for feature alignment, and the enhanced BC speech is clear.
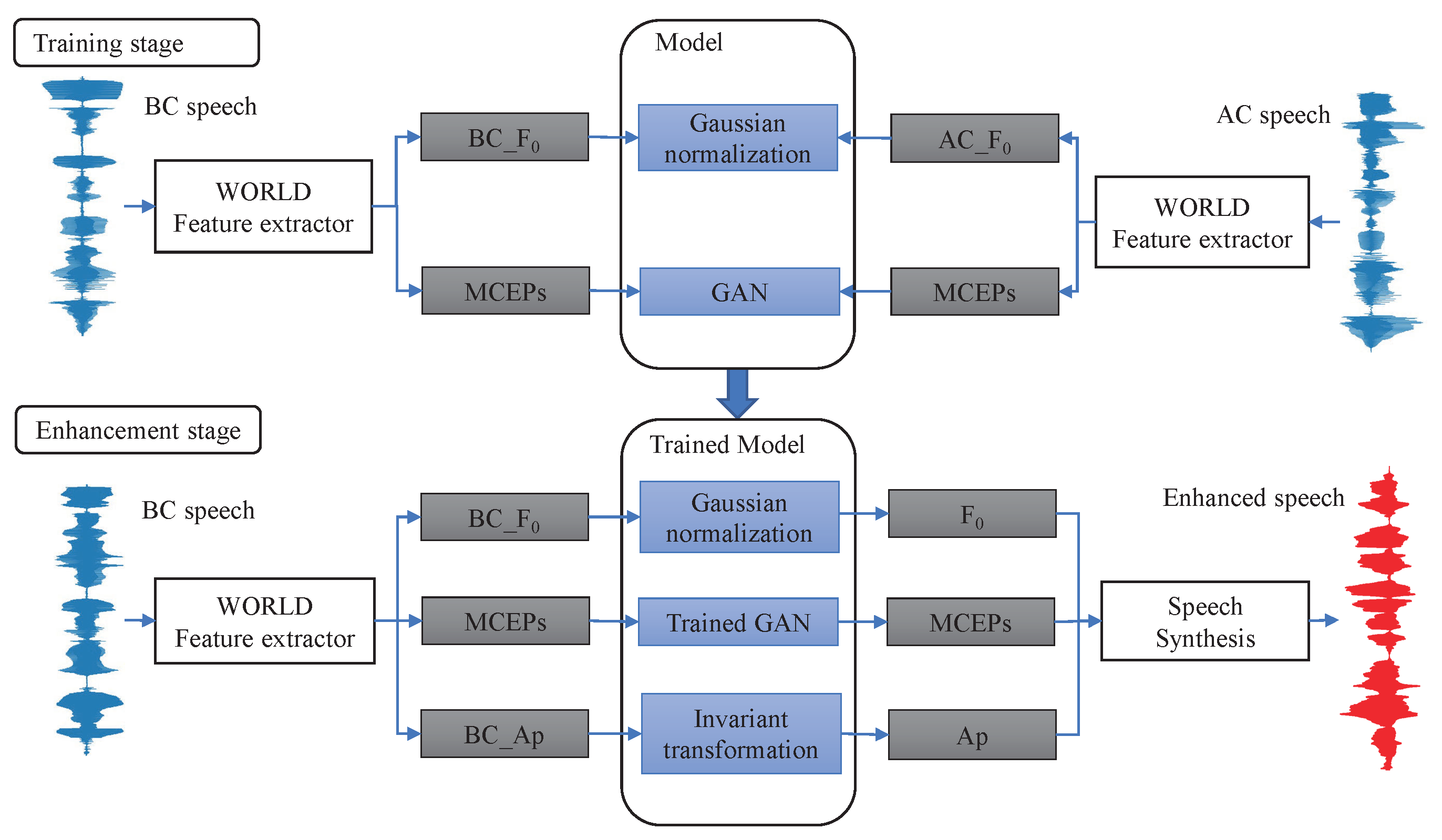
Aiming at the problem of BC speech enhancement for speaker-independent systems, to pay full attention to the information of BC speech, we make full use of the existing features in the case of fewer training data. The BC speech enhancement generative adversarial networks for speaker-independent (BSEGAN-SI) method is proposed in this paper. In view of the shortcomings of the original GAN, this paper selects a reasonable generator and discriminator structure to build a BC speech blind enhancement architecture and directly learns the mapping relationship between BC speech and pure AC speech. This paper discusses and studies the blind enhancement methods of BC speech for speaker-independent systems, mainly to solve the problems of dull and unclear speech caused by serious high-frequency attenuation of BC speech and consonant loss and promote the practical popularization of BC speech technology. The model adopts convolutional encoder–decoder [
17] architecture. Due to the convolutional shared parameters, the model can rapidly enhance BC speech. The main contributions of this paper are summarized as follows:
The BSEGAN-SI method proposed in this paper does not need to align features and learns a priori knowledge from a small amount of data. By establishing the mapping relationship between BC and AC, the high-frequency components of BC speech can be recovered better without the assistance of AC speech in the enhancement phase.
We add a spectral distance (L1 regularization factor) constraint to the generator to further reduce the training error, better recover the missing components of the BC speech spectrum and improve the enhancement effect so that the enhanced BC speech signal is more similar to the clear AC speech signal.
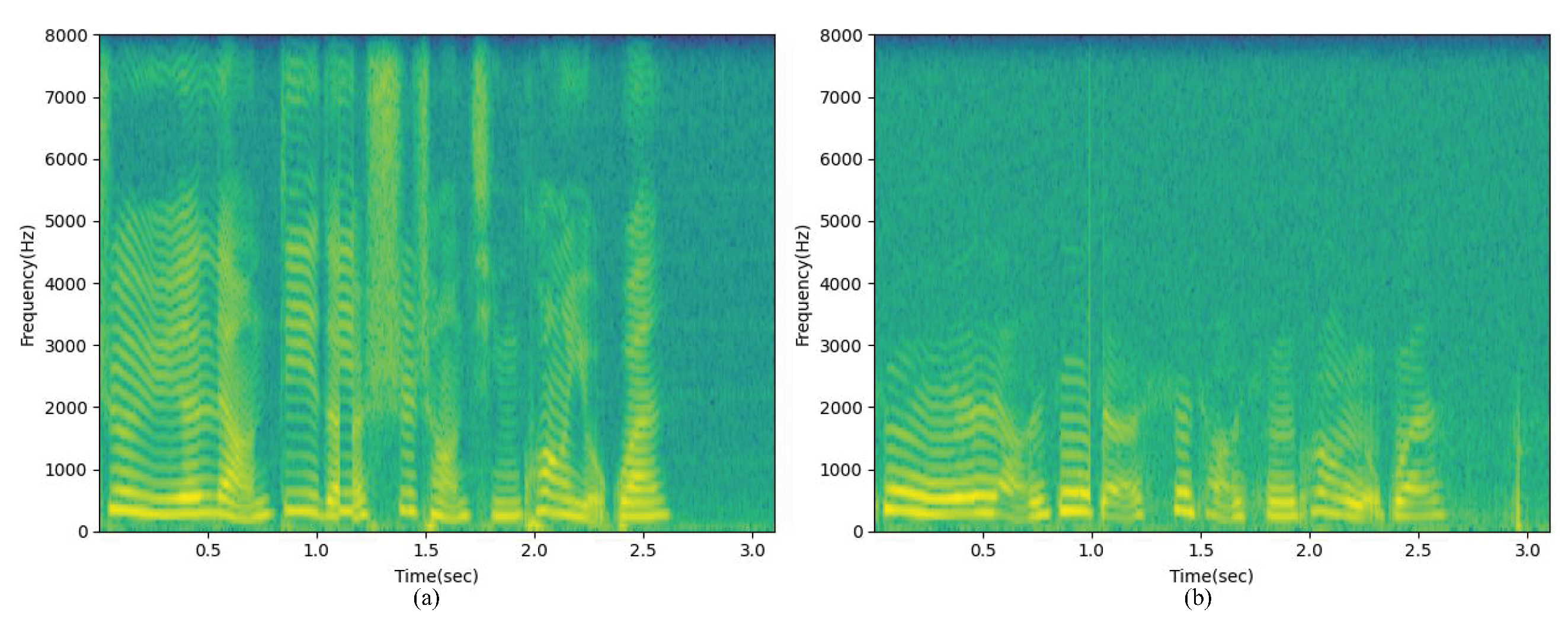
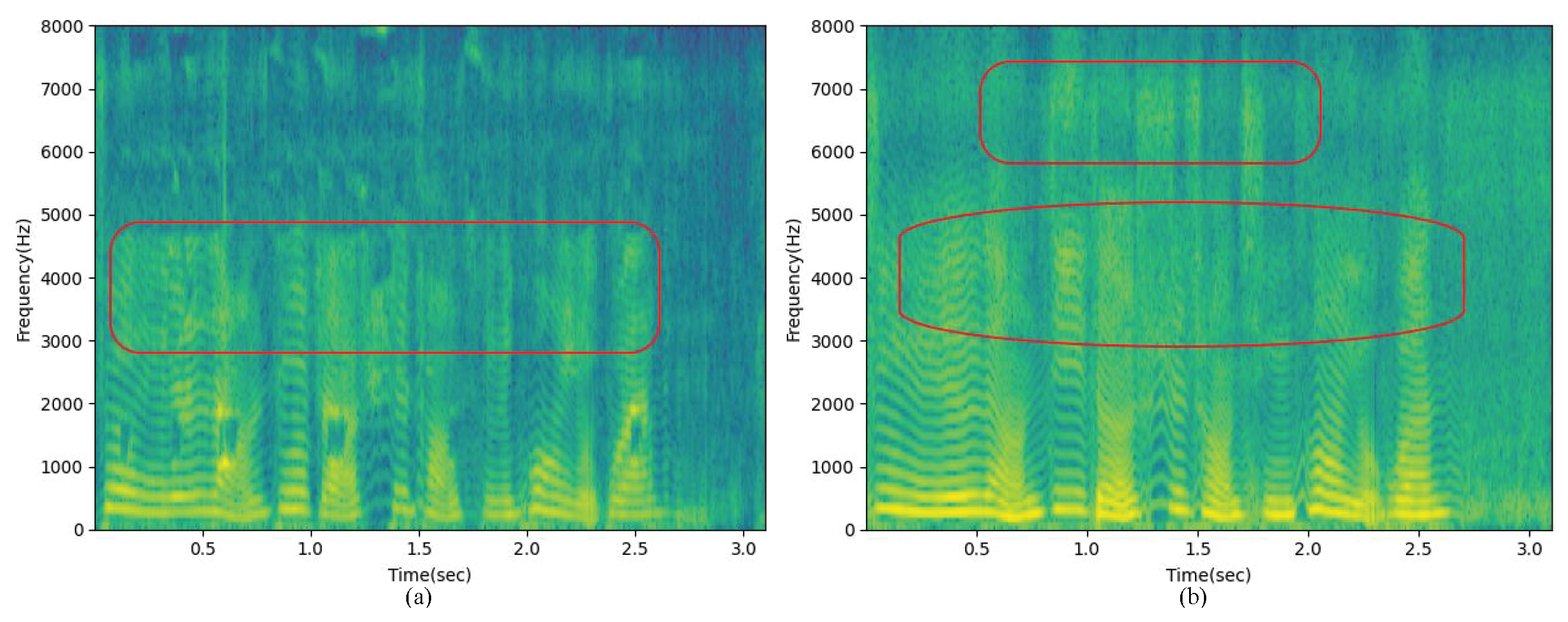
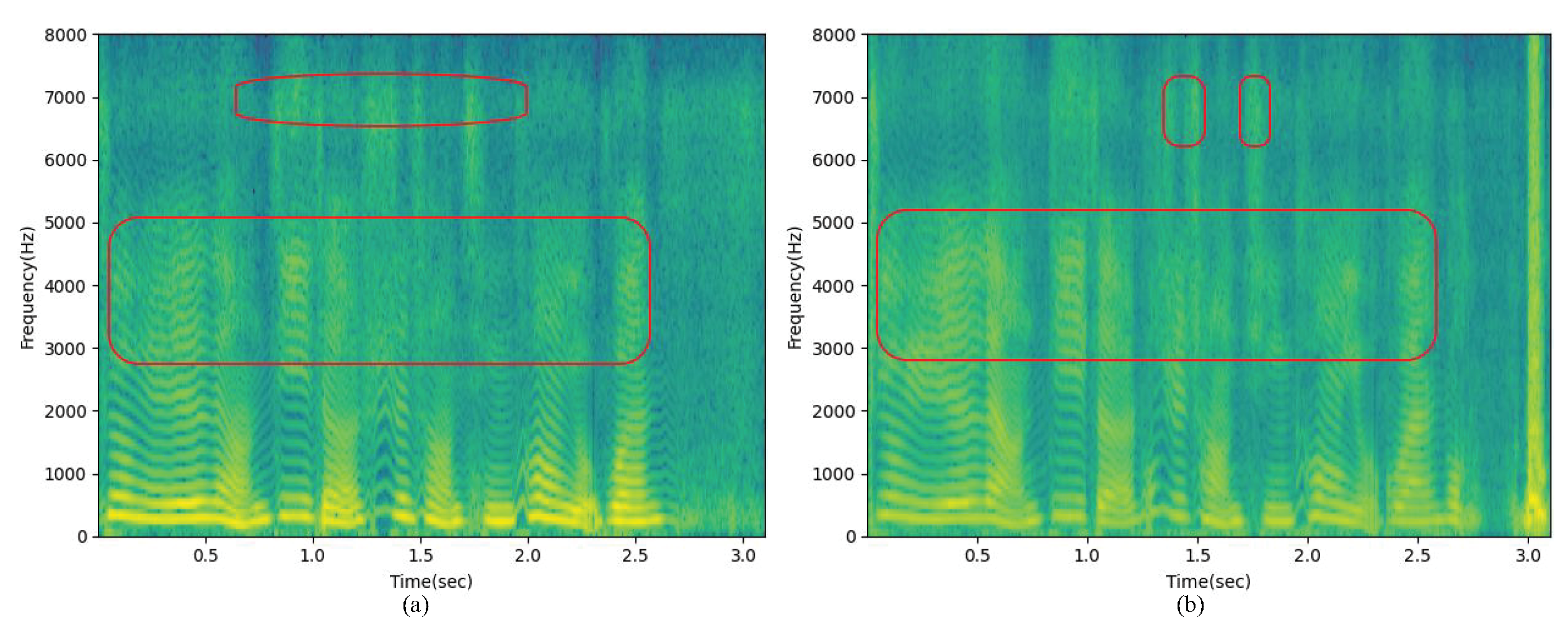
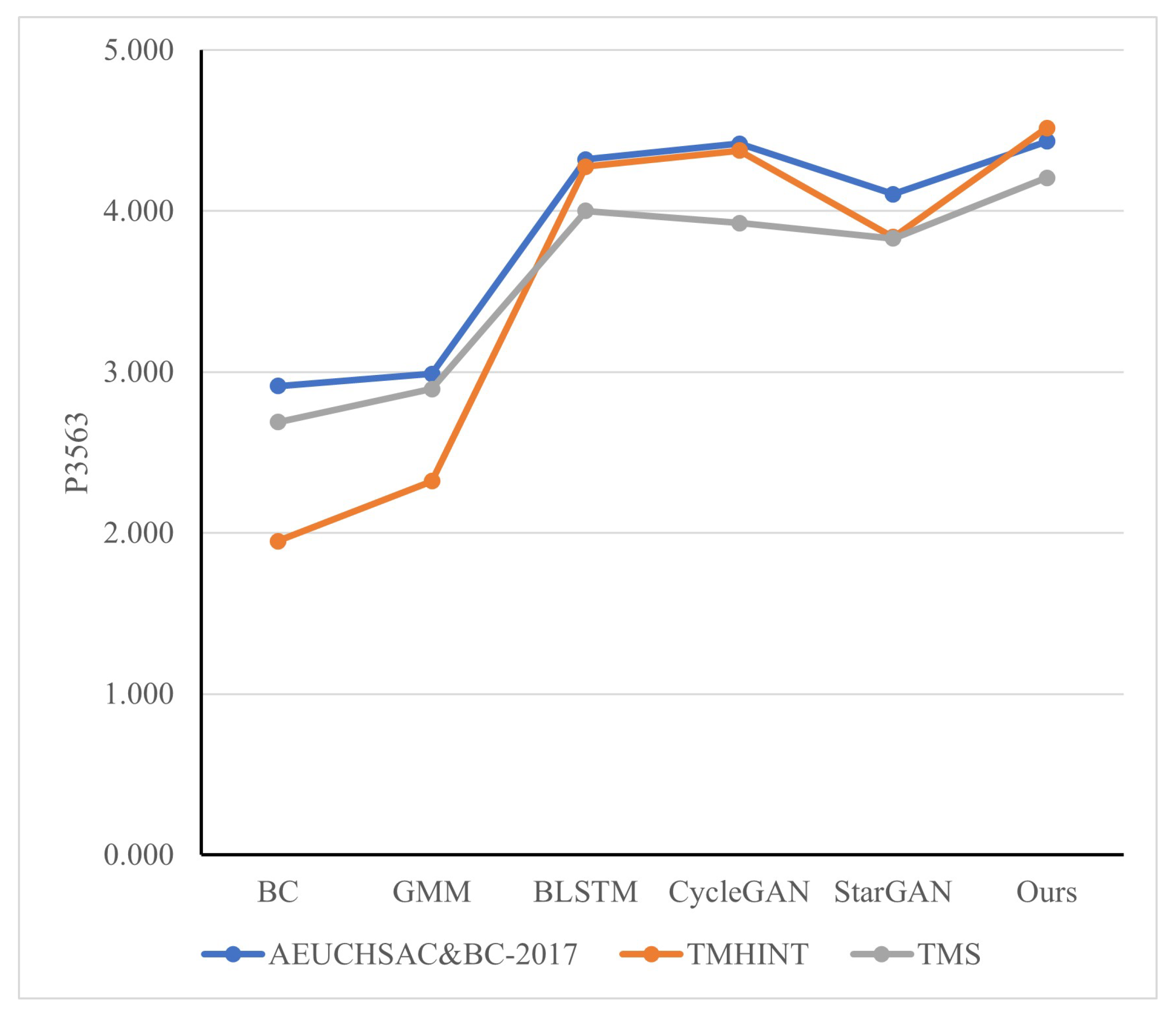
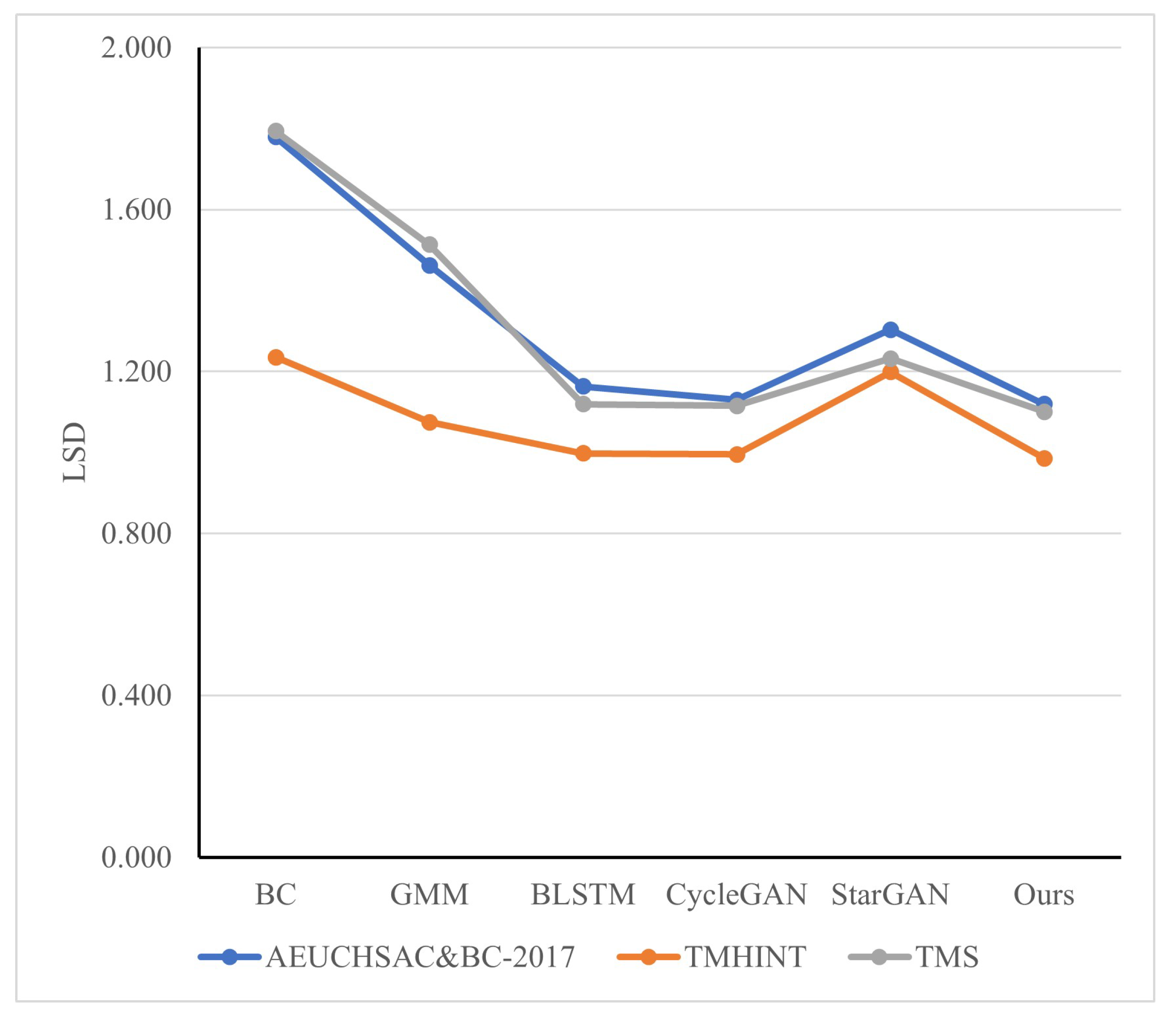
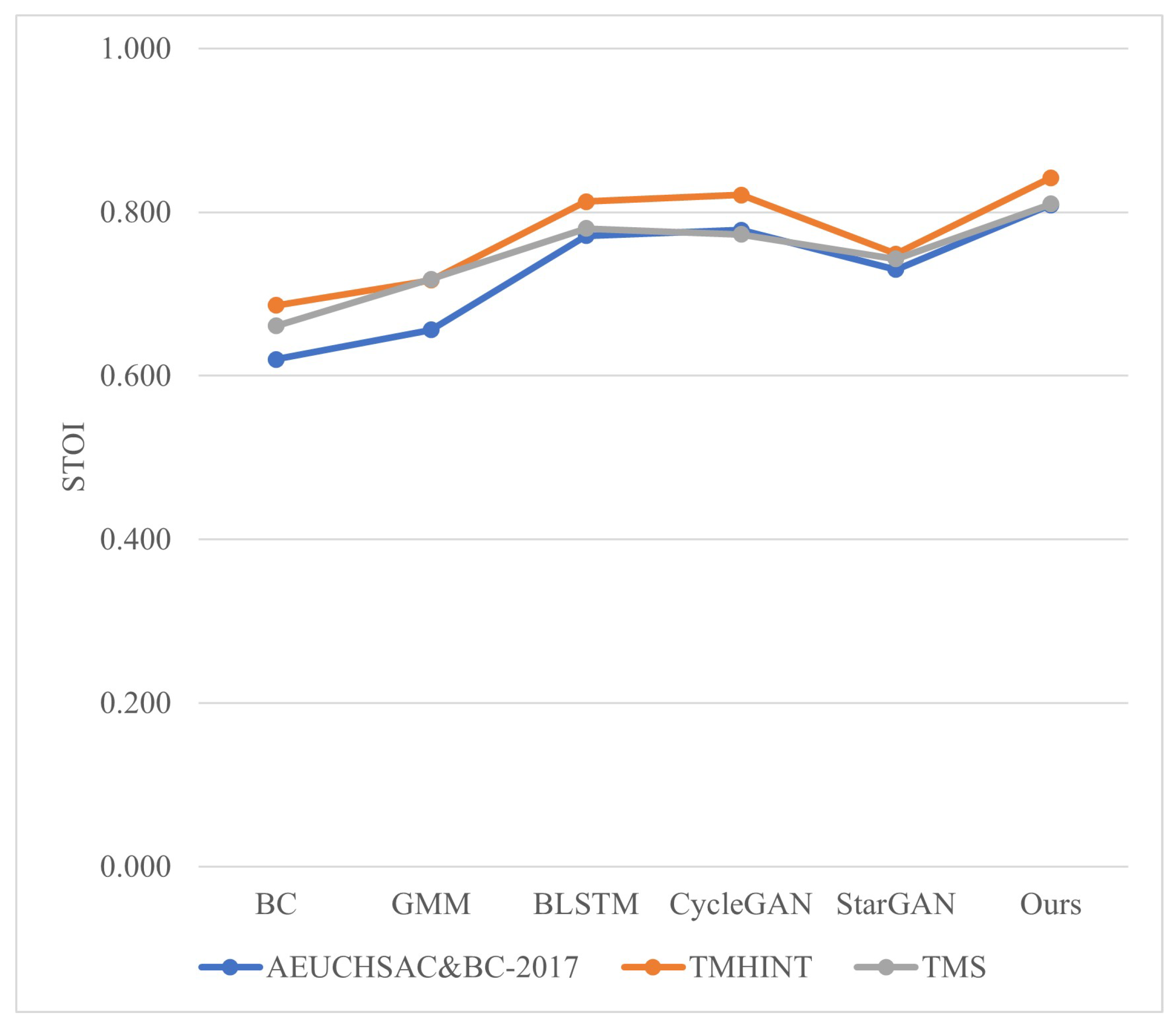
The proposed BSEGAN-SI method only uses BC speech information in the enhancement phase and does not need AC speech features. Experimental results show that this method can better perform speaker-independent BC speech enhancement in limited data sets.
The structure of subsequent papers is as follows:
Section 2 introduces the blind enhancement technology of BC speech;
Section 3 introduces the method of speaker-independent BC speech enhancement;
Section 4 carries out the simulation experiment and presents the results from the analysis;
Section 5 summarizes the whole work.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}