
Comparison of Standalone and Hybrid Machine Learning Models for Prediction of Critical Heat Flux in Vertical Tubes

 ,
,
Abstract
:1. Introduction
2. Materials and Methods
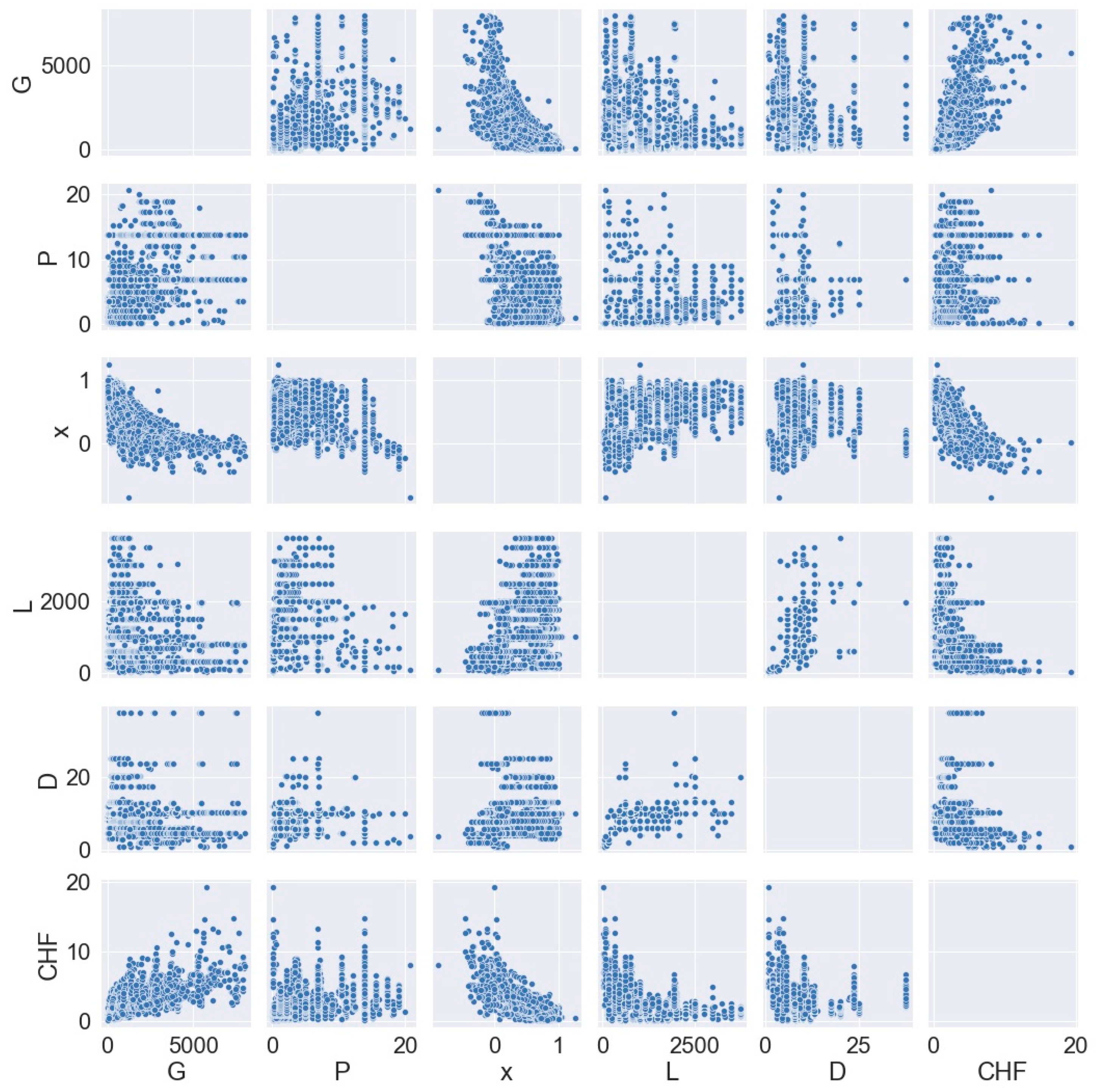
2.1. Dataset Generation
2.2. Methodology
2.2.1. Look-Up Table (LUT) Method
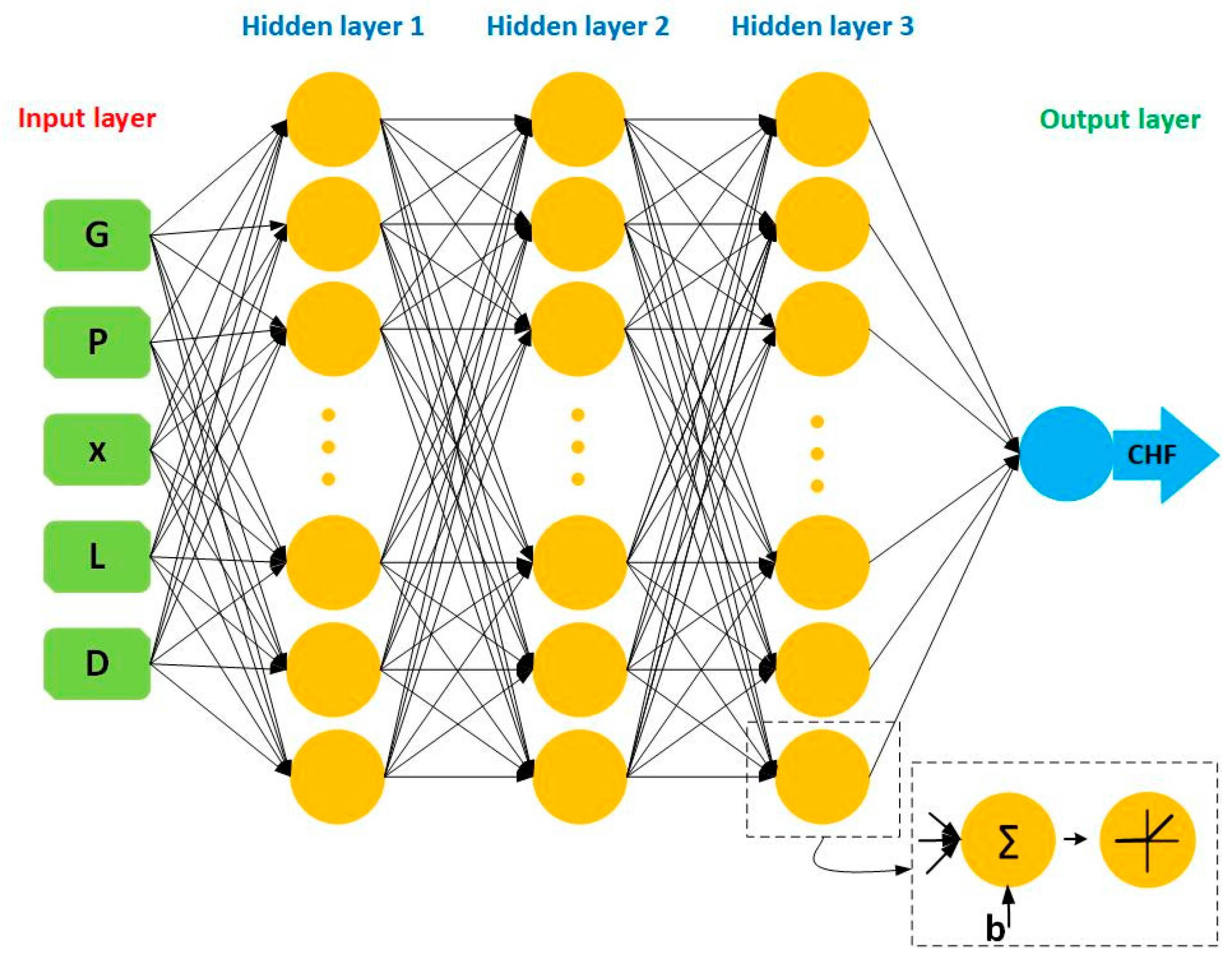
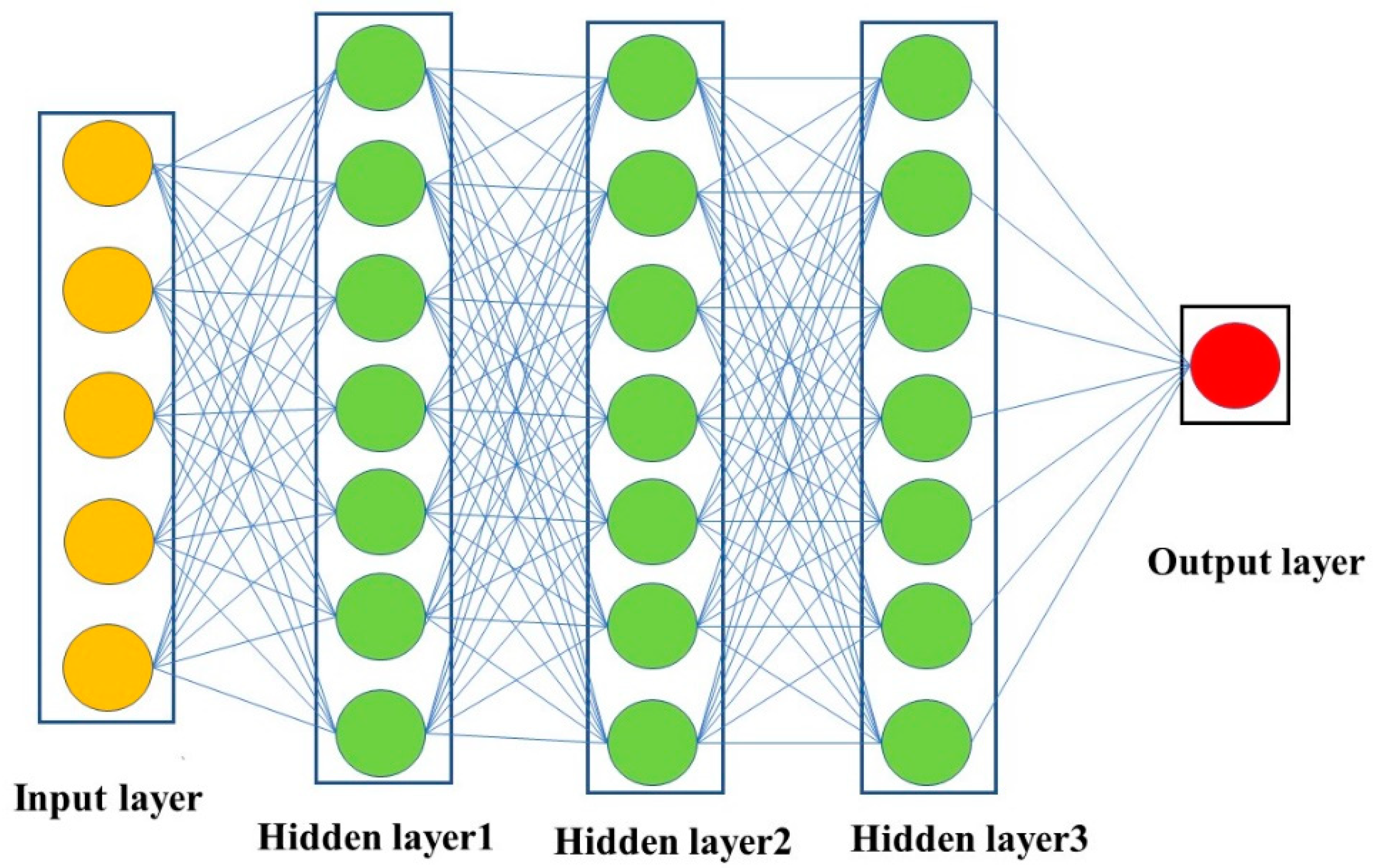
2.2.2. Artificial Neural Network (ANN)
2.2.3. Support Vector Regression (SVR)
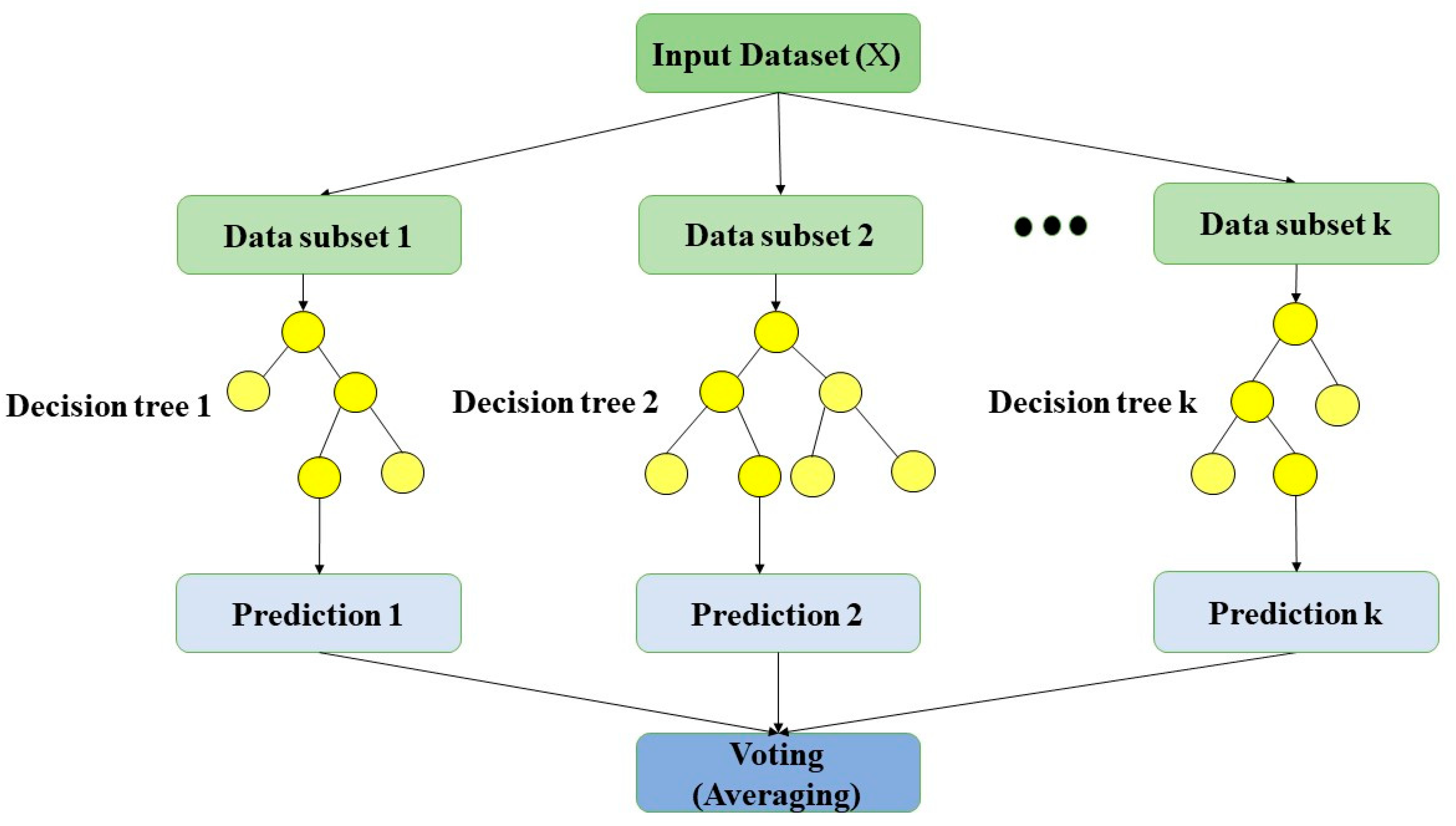
2.2.4. Random Forest (RF)
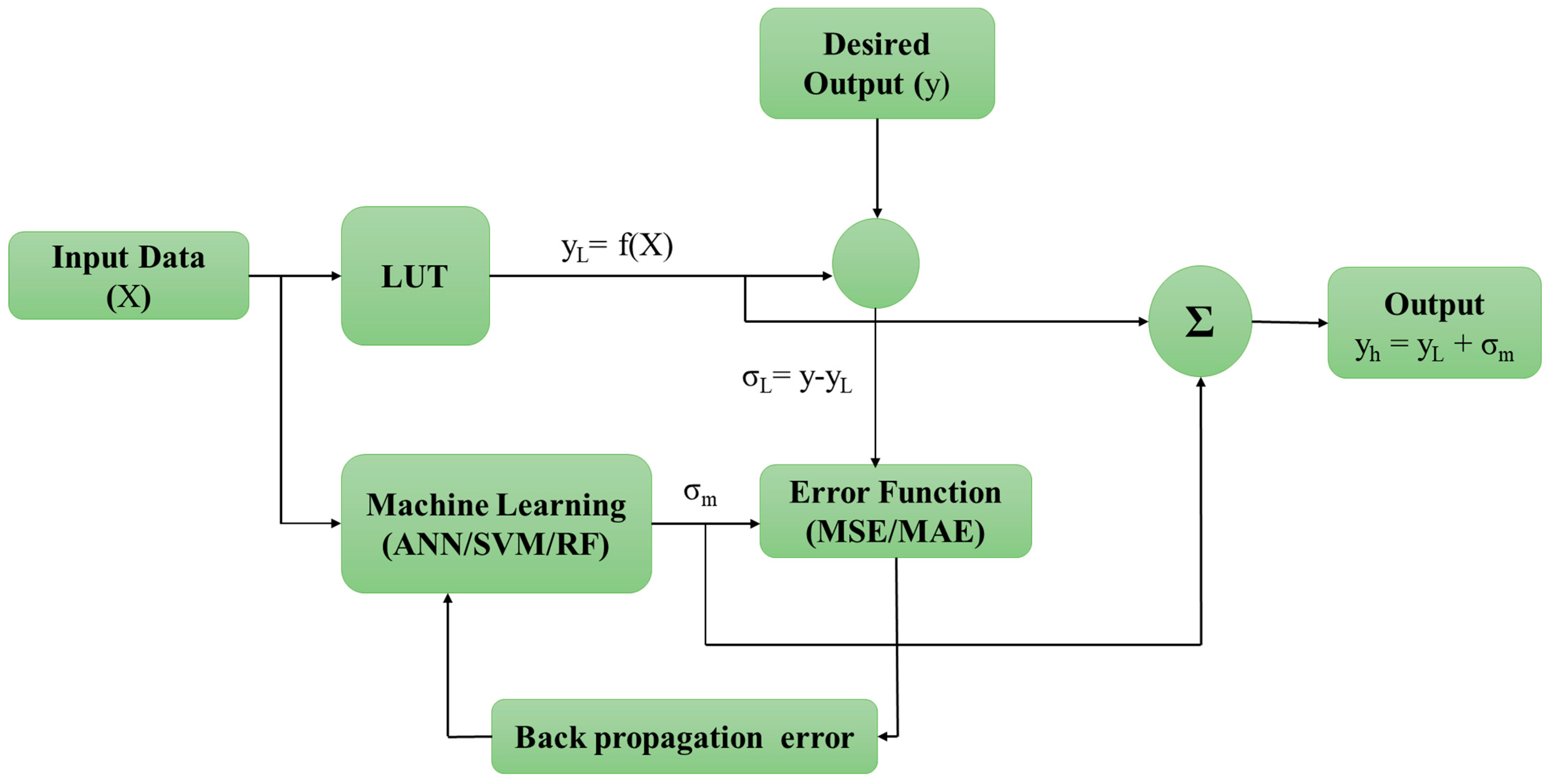
2.2.5. Data-Driven Hybrid Model
3. Simulation Settings
4. Performance Evaluations
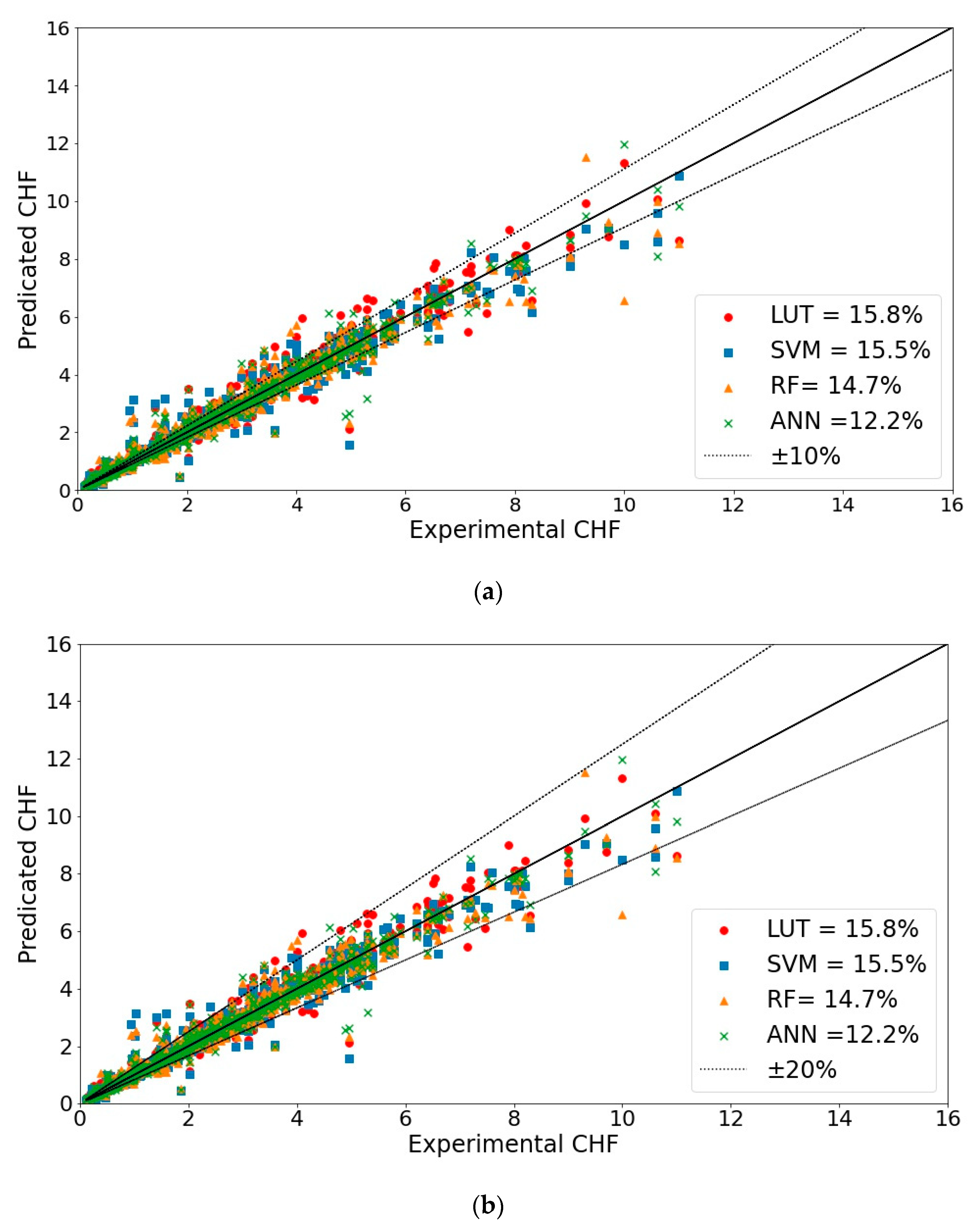
4.1. Standalone ML Models (ANN vs. SVM vs. RF vs. LUT)
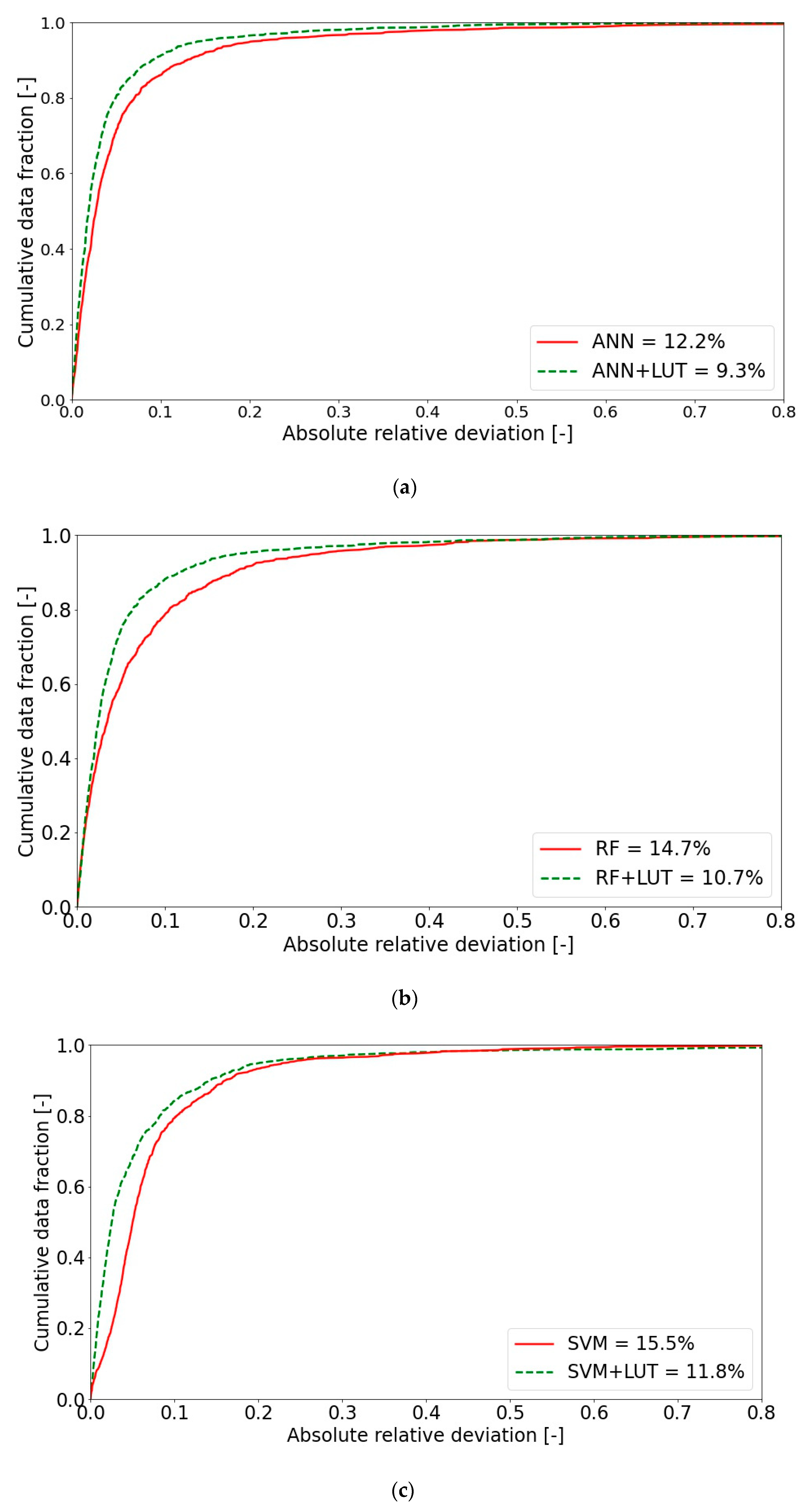
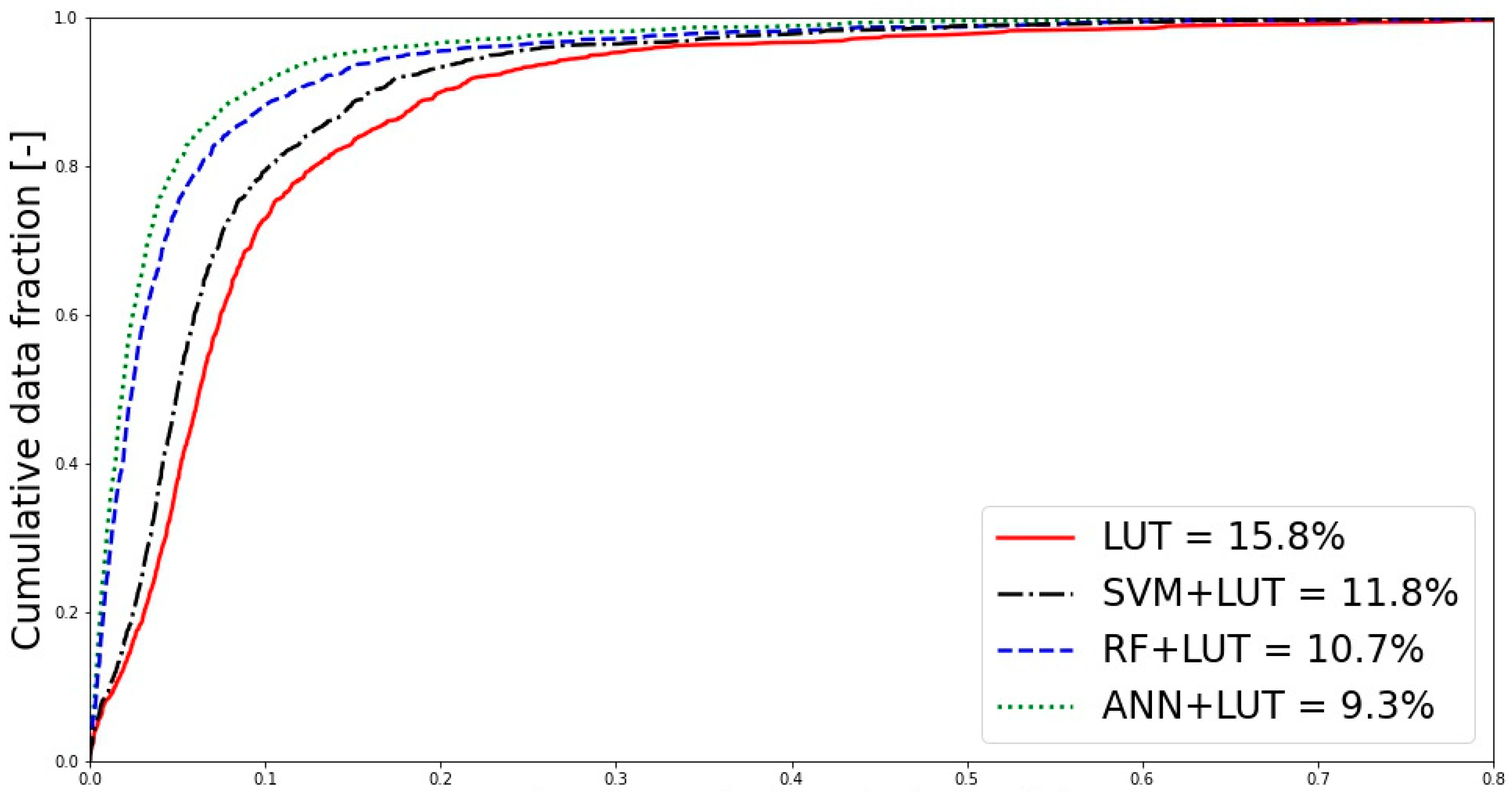
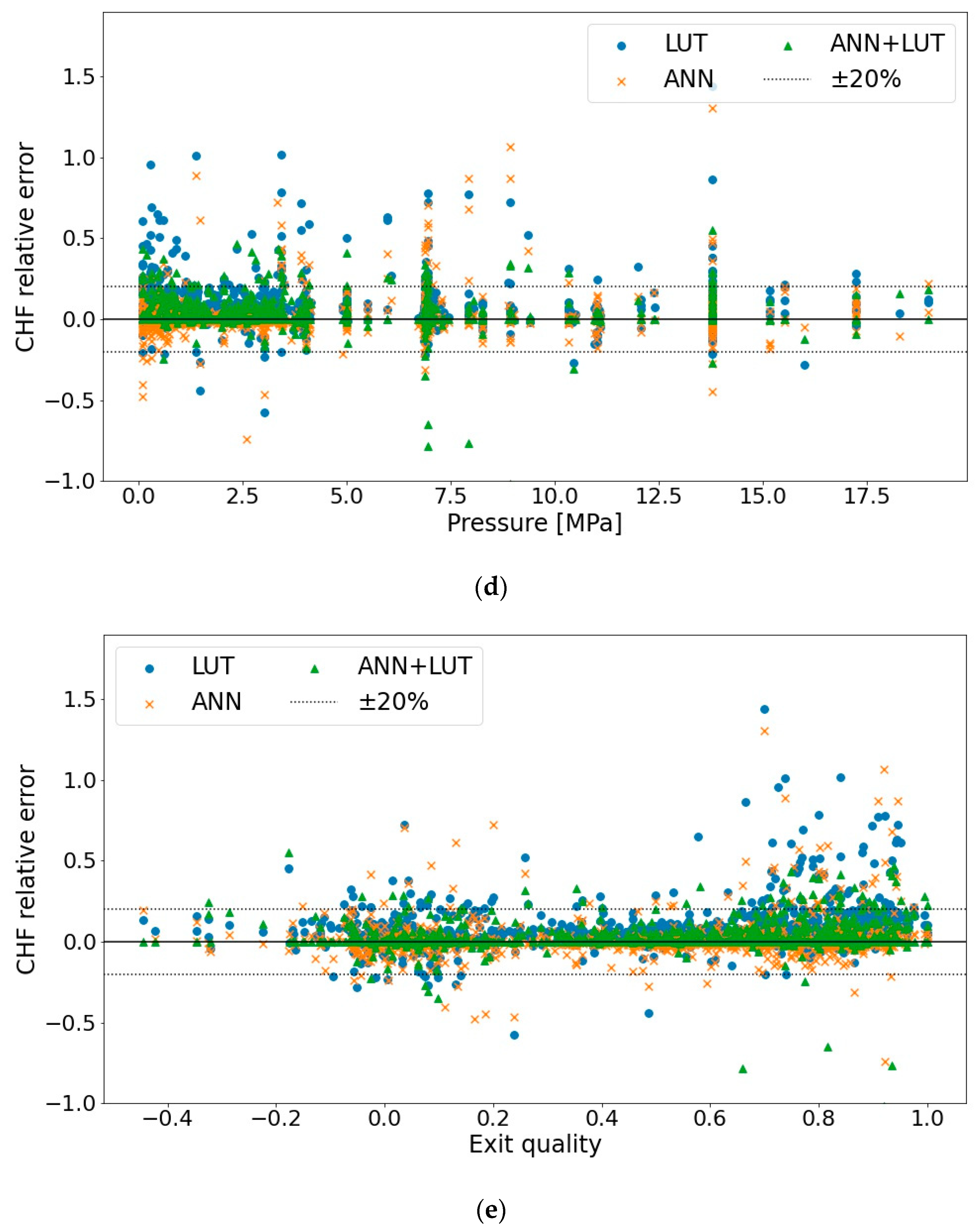
4.2. Comparison of Hybrid and Standalone Approaches
4.3. Sensitivity Analysis
5. Conclusions
- ○
- The hybrid approach using ANN outperforms both traditional ML techniques and the conventional LUT technique when it comes to predicting accuracy.
- ○
- Although standalone ML-based models performed better than the widely used conventional LUTs, the hybrid model greatly outperforms standalone ML models for prediction of CHF in vertical tubes for diverse set of operating parameters, with lower dispersion and non-biased parametric patterns.
- ○
- ML architecture can be greatly simplified in the hybrid framework as compared to its standalone version to reduce computing costs when working with big databases.
- ○
- From the parametric analysis in this work, it is confirmed that standalone ANN and hybrid (ANN + LUT) models have more suitable regression features between input and output than conventional LUT.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Nomenclature
| AI | Artificial Intelligence |
| ANN | Artificial neural network |
| b | Bias term |
| BPN | Backpropagation neural network |
| C | Kernel function |
| CHF | Critical heat flux |
| D | Heated diameter |
| DNB | Departure from nucleate boiling |
| DNBR | Departure from nucleate boiling ratio |
| DNN | Deep neural networks |
| DT | Decision tree |
| EPRI | Electric Power Research Institute |
| f | Unknown function |
| FNN | Feed-forward neural network |
| G | Mass flux |
| HONN | Higher order neural network |
| L | Heated length |
| LUT | Look-up table |
| MAE | Mean absolute error |
| MDNBR | Minimum value of DNBR |
| MLP | Multi-layer perceptron |
| MSE | Mean square error |
| ML | Machine learning |
| m | Number of data points |
| P | Pressure |
| PWR | Pressurized water reactor |
| RBF | Radial basis function |
| ReLU | Rectified Linear unit |
| RF | Random Forest |
| rRMSE | relative Root mean squared error |
| SVR | Support Vector Regression |
| w | Weight factor |
| x | Local equilibrium/exit quality |
| X | Input matrix |
| y | Desired output |
| yh | Hybrid model output |
| ξ | Slack in SVR |
| σ | Error |
| σm | ML predicated error |
References
- Pérez, F.I. Writing ‘usable’nuclear power plant (NPP) safety cases using bowtie methodology. Process Saf. Environ. Prot. 2021, 149, 850–857. [Google Scholar] [CrossRef]
- Bruder, M.; Bloch, G.; Sattelmayer, T. Critical heat flux in flow boiling—Review of the current understanding and experimental approaches. Heat Transf. Eng. 2017, 38, 347–360. [Google Scholar] [CrossRef]
- Baglietto, E.; Demarly, E.; Kommajosyula, R. Boiling crisis as the stability limit to wall heat partitioning. Appl. Phys. Lett. 2019, 114, 103701. [Google Scholar] [CrossRef]
- Ghiaasiaan, S.M. Two-Phase Flow, Boiling, and Condensation: In Conventional and Miniature Systems; Cambridge University Press: Cambridge, UK, 2007. [Google Scholar]
- Moreira, T.A.; Lee, D.; Anderson, M.H. Critical heat flux on zircaloy and accident tolerant fuel cladding under prototypical conditions of pressurized and boiling water reactors. Appl. Therm. Eng. 2022, 213, 118740. [Google Scholar] [CrossRef]
- International Atomic Energy Agency. Operational Limits and Conditions and Operating Procedures for Research Reactors; Draft Safety Guide; International Atomic Energy Agency: Vienna, Austria, 2021. [Google Scholar]
- Todreas, N.E.; Kazimi, M.S. Nuclear Systems Volume I: Thermal Hydraulic Fundamentals; CRC Press: Boca Raton, FL, USA, 2021. [Google Scholar]
- Celata, G.P.; Cumo, M.; Mariani, A.; Simoncini, M.; Zummo, G. Rationalization of existing mechanistic models for the pre-diction of water subcooled flow boiling critical heat flux. Int. J. Heat Mass Transf. 1994, 37, 347–360. [Google Scholar] [CrossRef]
- Bucci, M. Advanced diagnostics to resolve long-lasting controversies in boiling heat transfer. In Proceedings of the 13th In-ternational Conference on Heat Transfer, Fluid Mechanics and Thermodynamics, Portoroz, Slovenia, 17–19 July 2017. [Google Scholar]
- Kandlikar, S.G. Critical heat flux in subcooled flow boiling—An assessment of current understanding and future directions for research. Multiph. Sci. Technol. 2001, 13, 26. [Google Scholar] [CrossRef] [Green Version]
- Biasi, L.; Clerici, G.; Garribba, S.; Sala, R.; Tozzi, A. Studies on Burnout. Part a New Correlation for Round Ducts and Uniform Heating and Its Comparison with World Data; ARS, SpA and University of Milan: Milan, Italy, 1967. [Google Scholar]
- Bowring, R. A Simple but Accurate Round Tube, Uniform Heat Flux, Dryout Correlation over the Pressure Range 0.7–17 MN/m2 (100–2500 PSIA); UKAEA Reactor Group: Oxfordshire, UK, 1972. [Google Scholar]
- Tong, L. Heat transfer in water-cooled nuclear reactors. Nucl. Eng. Des. 1967, 6, 301–324. [Google Scholar] [CrossRef]
- Katto, Y. A generalized correlation of critical heat flux for the forced convection boiling in vertical uniformly heated round tubes. Int. J. Heat Mass Transf. 1978, 21, 1527–1542. [Google Scholar] [CrossRef]
- Groeneveld, D.; Shan, J.; Vasić, A.; Leung, L.; Durmayaz, A.; Yang, J.; Cheng, S.; Tanase, A. The 2006 CHF look-up table. Nucl. Eng. Des. 2007, 237, 1909–1922. [Google Scholar] [CrossRef]
- Reddy, D. Parametric study of CHF data, volume 2, A generalized subchannel CHF correlation for PWR and BWR fuel assemblies. EPRI-NP-2609 1983, 2, 1983. [Google Scholar]
- Tong, L.S.; Tang, Y.S. Boiling Heat Transfer and Two-Phase Flow; Routledge: Boca Raton, FL, USA, 2018. [Google Scholar] [CrossRef]
- Xie, C.; Yuan, Z.; Wang, J. Artificial neural network-based nonlinear algebraic models for large eddy simulation of turbulence. Phys. Fluids 2020, 32, 115101. [Google Scholar] [CrossRef]
- Abu Saleem, R.; Radaideh, M.I.; Kozlowski, T. Application of deep neural networks for high-dimensional large BWR core neutronics. Nucl. Eng. Technol. 2020, 52, 2709–2716. [Google Scholar] [CrossRef]
- Hedayat, A.; Davilu, H.; Barfrosh, A.A.; Sepanloo, K. Estimation of research reactor core parameters using cascade feed forward artificial neural networks. Prog. Nucl. Energy 2009, 51, 709–718. [Google Scholar] [CrossRef]
- Hedayat, A.; Davilu, H.; Barfrosh, A.A.; Sepanloo, K. Optimization of the core configuration design using a hybrid artificial intelligence algorithm for research reactors. Nucl. Eng. Des. 2009, 239, 2786–2799. [Google Scholar] [CrossRef]
- Zubair, R.; Ullah, A.; Khan, A.; Inayat, M.H. Critical heat flux prediction for safety analysis of nuclear reactors using machine learning. In Proceedings of the 2022 19th International Bhurban Conference on Applied Sciences and Technology (IBCAST), Bhurban, Pakistan, 16–20 August 2022; pp. 314–318. [Google Scholar] [CrossRef]
- Faria, E.F.; Pereira, C. Nuclear fuel loading pattern optimisation using a neural network. Ann. Nucl. Energy 2003, 30, 603–613. [Google Scholar] [CrossRef]
- Kim, H.G.; Chang, S.H.; Lee, B.H. Optimal Fuel Loading Pattern Design Using an Artificial Neural Network and a Fuzzy Rule-Based System. Nucl. Sci. Eng. 1993, 115, 152–163. [Google Scholar] [CrossRef]
- Desterro, F.S.; Santos, M.C.; Gomes, K.J.; Heimlich, A.; Schirru, R.; Pereira, C.M. Development of a Deep Rectifier Neural Network for dose prediction in nuclear emergencies with radioactive material releases. Prog. Nucl. Energy 2020, 118, 103110. [Google Scholar] [CrossRef]
- Yong, S.; Linzi, Z. Robust deep auto-encoding network for real-time anomaly detection at nuclear power plants. Process. Saf. Environ. Prot. 2022, 163, 438–452. [Google Scholar] [CrossRef]
- Saeed, H.A.; Peng, M.-J.; Wang, H.; Zhang, B.-W. Novel fault diagnosis scheme utilizing deep learning networks. Prog. Nucl. Energy 2020, 118, 103066. [Google Scholar] [CrossRef]
- Guo, Z.; Wu, Z.; Liu, S.; Ma, X.; Wang, C.; Yan, D.; Niu, F. Defect detection of nuclear fuel assembly based on deep neural network. Ann. Nucl. Energy 2020, 137, 107078. [Google Scholar] [CrossRef]
- Yiru, P.; Yichun, W.; Fanyu, W.; Yong, X.; Anhong, X.; Jian, L.; Junyi, Z. Safety analysis of signal quality bits in nuclear power plant distributed control systems based on system-theoretic process analysis method. Process. Saf. Environ. Prot. 2022, 164, 219–227. [Google Scholar] [CrossRef]
- Bae, H.; Chun, S.-P.; Kim, S. Predictive Fault Detection and Diagnosis of Nuclear Power Plant Using the Two-Step Neural Network Models. Int. Symp. Neural Netw. 2006, 3973, 420–425. [Google Scholar] [CrossRef]
- Adali, T.; Bakal, B.; Sönmez, M.; Fakory, R.; Tsaoi, C. Modeling nuclear reactor core dynamics with recurrent neural networks. Neurocomputing 1997, 15, 363–381. [Google Scholar] [CrossRef]
- Koo, Y.D.; An, Y.J.; Kim, C.-H.; Na, M.G. Nuclear reactor vessel water level prediction during severe accidents using deep neural networks. Nucl. Eng. Technol. 2019, 51, 723–730. [Google Scholar] [CrossRef]
- Bildirici, M.; Ersin, Ö.Ö. Regime-Switching Fractionally Integrated Asymmetric Power Neural Network Modeling of Nonlinear Contagion for Chaotic Oil and Precious Metal Volatilities. Fractal Fract. 2022, 6, 703. [Google Scholar] [CrossRef]
- Bildirici, M.; Ersin, Ö. Markov-switching vector autoregressive neural networks and sensitivity analysis of environment, economic growth and petrol prices. Environ. Sci. Pollut. Res. 2018, 25, 31630–31655. [Google Scholar] [CrossRef]
- Yapo, T. Prediction of critical heat fluex using a hybrid kohonen-backpropagation neural network. Intelligent Engineering Systems through Artificial Neural Networks-Proc. Artif. Neural Netw. Eng. (ANNIE’92) 1992, 2, 853–858. [Google Scholar]
- Moon, S.K.; Baek, W.-P.; Chang, S.H. Parametric trends analysis of the critical heat flux based on artificial neural networks. Nucl. Eng. Des. 1996, 163, 29–49. [Google Scholar] [CrossRef]
- Mazzola, A. Integrating artificial neural networks and empirical correlations for the prediction of water-subcooled critical heat flux. Rev. Générale Therm. 1997, 36, 799–806. [Google Scholar] [CrossRef]
- Lee, Y.H.; Baek, W.-P.; Chang, S.H. A correction method for heated length effect in critical heat flux prediction. Nucl. Eng. Des. 2000, 199, 1–11. [Google Scholar] [CrossRef]
- Kim, S.H.; Bang, I.-C.; Baek, W.-P.; Chang, S.H.; Moon, S.K. CHF detection using spationtemporal neural network and wavelet transform. Int. Commun. Heat Mass Transf. 2000, 27, 285–292. [Google Scholar] [CrossRef]
- Su, G.; Fukuda, K.; Jia, D.; Morita, K. Application of an artificial neural network in reactor thermohydraulic problem: Prediction of critical heat flux. J. Nucl. Sci. Technol. 2002, 39, 564–571. [Google Scholar] [CrossRef]
- Guanghui, S.; Morita, K.; Fukuda, K.; Pidduck, M.; Dounan, J.; Miettinen, J. Analysis of the critical heat flux in round vertical tubes under low pressure and flow oscillation conditions. Applications of artificial neural network. Nucl. Eng. Des. 2003, 220, 17–35. [Google Scholar] [CrossRef]
- Zaferanlouei, S.; Rostamifard, D.; Setayeshi, S. Prediction of critical heat flux using ANFIS. Ann. Nucl. Energy 2010, 37, 813–821. [Google Scholar] [CrossRef]
- Cong, T.; Chen, R.; Su, G.; Qiu, S.; Tian, W. Analysis of CHF in saturated forced convective boiling on a heated surface with impinging jets using artificial neural network and genetic algorithm. Nucl. Eng. Des. 2011, 241, 3945–3951. [Google Scholar] [CrossRef]
- Jiang, B.; Zhao, F. Combination of support vector regression and artificial neural networks for prediction of critical heat flux. Int. J. Heat Mass Transf. 2013, 62, 481–494. [Google Scholar] [CrossRef]
- Aldrees, A.; Awan, H.H.; Javed, M.F.; Mohamed, A.M. Prediction of water quality indexes with ensemble learners: Bagging and boosting. Process. Saf. Environ. Prot. 2022, 168, 344–361. [Google Scholar] [CrossRef]
- Inasaka, F.; Nariai, H. Critical heat flux of subcooled flow boiling for water in uniformly heated straight tubes. Fusion Eng. Des. 1992, 19, 329–337. [Google Scholar] [CrossRef]
- Williams, C.; Beus, S. Critical Heat Flux Experiments in a Circular Tube with Heavy Water and Light Water; AWBA Development Program; Bettis Atomic Power Lab.: West Mifflin, PA, USA, 1980. [Google Scholar] [CrossRef] [Green Version]
- Kim, H.C.; Baek, W.-P.; Chang, S.H. Critical heat flux of water in vertical round tubes at low pressure and low flow conditions. Nucl. Eng. Des. 2000, 199, 49–73. [Google Scholar] [CrossRef]
- Becker, K.M.; Hernborg, G.; Bode, M.; Eriksson, O. Burnout Data for Flow of Boiling Water in Vertical Round Ducts, Annuli and Rod Clusters; AB Atomenergi: Nyköping, Sweden, 1965. [Google Scholar]
- Lowdermilk, W.H.; Weiland, W.F. Some Measurements of Boiling Burn-Out; National Advisory Committee for Aeronautics: Langley Field, VA, USA, 1955; Volume 16.
- Clark, J.A.; Rohsenow, W.M. Local boiling heat transfer to water at low Reynolds numbers and high pressures. Trans. Am. Soc. Mech. Eng. 1954, 76, 553–561. [Google Scholar] [CrossRef]
- Reynolds, J.M. Burnout in Forced Convection Nucleate Boiling of Water; Massachusetts Institute of Technology: Cambridge, MA, USA, 1957. [Google Scholar]
- Peskov, O.; Subbotin, V.; Zenkevich, B.; Sergeyev, N. The critical heat flux for the flow of steam–water mixtures through pipes. In Problems of Heat Transfer and Hydraulics of Two Phase Media; Pergamon Press: Oxford, UK, 1969; pp. 48–62. [Google Scholar] [CrossRef]
- Thompson, B.; Macbeth, R. Boiling Water Heat Transfer Burnout in Uniformly Heated round Tubes: A Compilation of World Data with Accurate Correlations; Reactor Group, United Kingdom Atomic Energy Authority: Oxfordshire, UK, 1964.
- Tanase, A.; Cheng, S.; Groeneveld, D.; Shan, J. Diameter effect on critical heat flux. Nucl. Eng. Des. 2009, 239, 289–294. [Google Scholar] [CrossRef]
- Ansari, H.; Zarei, M.; Sabbaghi, S.; Keshavarz, P. A new comprehensive model for relative viscosity of various nanofluids using feed-forward back-propagation MLP neural networks. Int. Commun. Heat Mass Transf. 2018, 91, 158–164. [Google Scholar] [CrossRef]
- Qing, H.; Hamedi, S.; Eftekhari, S.A.; Alizadeh, S.; Toghraie, D.; Hekmatifar, M.; Ahmed, A.N.; Khan, A. A well-trained feed-forward perceptron Artificial Neural Network (ANN) for prediction the dynamic viscosity of Al2O3–MWCNT (40:60)-Oil SAE50 hybrid nano-lubricant at different volume fraction of nanoparticles, temperatures, and shear rates. Int. Commun. Heat Mass Transf. 2021, 128, 105624. [Google Scholar] [CrossRef]
- Mohanraj, M.; Jayaraj, S.; Muraleedharan, C. Applications of artificial neural networks for refrigeration, air-conditioning and heat pump systems—A review. Renew. Sustain. Energy Rev. 2012, 16, 1340–1358. [Google Scholar] [CrossRef]
- Haykin, S.; Network, N. A comprehensive foundation. Neural Netw. 2004, 2, 41. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Varol, Y.; Oztop, H.F.; Avci, E. Estimation of thermal and flow fields due to natural convection using support vector machines (SVM) in a porous cavity with discrete heat sources. Int. Commun. Heat Mass Transf. 2008, 35, 928–936. [Google Scholar] [CrossRef]
- Kwon, B.; Ejaz, F.; Hwang, L.K. Machine learning for heat transfer correlations. Int. Commun. Heat Mass Transf. 2020, 116, 104694. [Google Scholar] [CrossRef]
- Friedman, J.; Hastie, T.; Tibshirani, R. The Elements of Statistical Learning; Springer Series in Statistics; Springer: Cham, Switzerland, 2001; Volume 1. [Google Scholar]
- Hanin, B. Universal Function Approximation by Deep Neural Nets with Bounded Width and ReLU Activations. Mathematics 2019, 7, 992. [Google Scholar] [CrossRef] [Green Version]
- Li, K.-Q.; Liu, Y.; Kang, Q. Estimating the thermal conductivity of soils using six machine learning algorithms. Int. Commun. Heat Mass Transf. 2022, 136, 106139. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Mass-Flux (G) [kg/m2s] | Pressure (P) [MPa] | Equilibrium Quality (x) [-] | Heated Length (L) [mm] | Heated Diameter (D) [mm] | CHF [MW/m2] | No. of Samples |
|---|---|---|---|---|---|---|---|
| Inasaka [46] | 4300–6700 | 0.31–0.64 | −0.11 to −0.05 | 100 | 3 | 7.3–12.8 | 6 |
| Williams [47] | 325–4683 | 2.7–15.2 | −0.02 to 0.92 | 1840 | 9.5 | 0.39–4.1 | 129 |
| Kim [48] | 20–277 | 0.11–0.95 | 0.32 to 1.2 | 300–1770 | 6–12 | 0.12–1.6 | 512 |
| Becker [49] | 100–5450 | 0.22–9.9 | 0 to 0.99 | 400–3750 | 3.9–25 | 0.28–7.5 | 3473 |
| Lowdermilk [50] | 60–597 | 3.4 | 0.71 to 0.94 | 152 | 3 | 0.47–3.3 | 21 |
| Clark [51] | 28–102 | 3.4–13.8 | 0.66 to 0.99 | 239 | 4.6 | 0.23–1.2 | 67 |
| Reynold [52] | 1166–2889 | 3.6–10.7 | 0 to 0.47 | 229 | 4.6 | 3.6–9 | 67 |
| Peskov [53] | 750–5361 | 10–20 | −0.23 to 0.13 | 400–1650 | 10 | 0.9–4.3 | 17 |
| Thompson [54] | 542–7975 | 0.1–20.7 | −0.86 to 0.21 | 25–3048 | 1–37.5 | 1–19.3 | 1585 |
| Total | 20–7975 | 0.1–20.7 | −0.86 to 1.2 | 25–3750 | 1–37.5 | 0.12–19.3 | 5877 |
| Data-Driven Model | LUT |
|---|---|
| ML Approach | ANN, SVR, RF |
| Best-estimate ANN approach | |
| 5/50/50/50/1 (5/100/100/100/50/1 if standalone ANN) |
| Adam |
| ReLU (Rectified Linear unit) |
| 0.001 |
| Best-estimate SVR approach | |
| Kernel: Rbf, C: 100, Nu: 0.9 (Kernel: Rbf, C: 100, Nu: 1 if standalone SVR) |
| Best-estimate RF approach | |
| 100 (300 if standalone RF) |
| Approach | Test rRMSE (%) | Data-Points within ±10% Error | Data-Points within ±20% Error |
|---|---|---|---|
| LUT | 15.8 | 68% | 85% |
| SVM | 15.5 | 72% | 86% |
| RF | 14.7 | 80% | 89% |
| ANN | 12.2 | 87% | 95% |
| Hybrid SVM + LUT | 11.8 | 87% | 97% |
| Hybrid RF + LUT | 10.7 | 89% | 99% |
| Hybrid ANN + LUT | 9.3 | 91% | 100% |
| Sensitivity Analysis Technique | Test RMSE (%) | Test Samples within ±10% Error |
|---|---|---|
| 80% train + 20% test | 9.30 | 91% |
| 5-fold cross-validation | 9.15 | 89% |
| 10-fold cross-validation | 8.90 | 91% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khalid, R.Z.; Ullah, A.; Khan, A.; Khan, A.; Inayat, M.H. Comparison of Standalone and Hybrid Machine Learning Models for Prediction of Critical Heat Flux in Vertical Tubes. Energies 2023, 16, 3182. https://doi.org/10.3390/en16073182
Khalid RZ, Ullah A, Khan A, Khan A, Inayat MH. Comparison of Standalone and Hybrid Machine Learning Models for Prediction of Critical Heat Flux in Vertical Tubes. Energies. 2023; 16(7):3182. https://doi.org/10.3390/en16073182
Chicago/Turabian StyleKhalid, Rehan Zubair, Atta Ullah, Asifullah Khan, Afrasyab Khan, and Mansoor Hameed Inayat. 2023. "Comparison of Standalone and Hybrid Machine Learning Models for Prediction of Critical Heat Flux in Vertical Tubes" Energies 16, no. 7: 3182. https://doi.org/10.3390/en16073182