1. Introduction
Renewable energy sources are fluctuant, stochastic, and uncontrollable [
1,
2]. The impact of large-scale renewable energy integration on the power system is becoming more and more obvious, and the risks of system operation are increasing [
3,
4,
5]. The accurate scenarios of wind, solar, and load can provide the basis for power system dispatch and reduce the curtailment of renewable energies, which is significant for grid flexibility improvement [
6,
7]. The scenario generation methods can be classified into short-term, medium-term, and long-term methods, according to the length of time scale [
8]. A probabilistic model of the dataset based on the Copula function is used to generate experimental scenarios that guarantee the autocorrelation of the data [
9]. The literature [
10] extracts key features of weather factors and uses the gated recurrent unit (GRU)-convolutional neural network (CNN) method to generate scenarios. The literature [
11] utilizes the generative moment matching network (GMMN) and the optimization strategy to extract the typical wind power generation scenario. The wind and solar output probability densities are con-structed based on the non-parametric kernel density estimation and Frank-Copula functions, and the wind and solar scenarios are generated by using the spline interpolation method [
12].
When modeling based on the time series analysis, the autocorrelation can provide enough information, and a high-accuracy model can be built based on the limited sample number of time series without the need to make predictions based on other conditions. The main methods for the analysis of time series are the wavelet analysis method [
13], Kalman filter method [
14,
15], and autoregressive integrated moving average (ARIMA) model [
16]. In [
17], the ARIMA model and the identification of the model parameters are explained. The ARIMA model needs to be improved to adopt characteristics of wind, solar, and other renewable energies. The literature [
18] combines the modified ensemble empirical mode decomposition (MEEMD) with the ARIMA model, and uses the MEEMD to process the data to improve accuracy. The literature [
19] introduces frequency decomposition method to decompose the wind speed data and constructs the ARIMA model for the decomposed data. The non-smoothness factors of time series are eliminated by constructing seasonal-ARIMA based on stochastic probability analysis methods [
20,
21]. The literature [
22] proposed a hybrid model of the ARIMA and triple exponential smoothing to achieve a real-time prediction of linear and nonlinear data. The literature [
23] uses the combined method of wavelet transform and the ARIMA model to improve the accuracy of the ARIMA model. The data feature extraction method proposed in the literature [
24] can capture data characteristics by using the correlation feature selection (CFS). The characteristics of the above methods are summarized in
Table 1.
The accuracy of the scenario generation method is closely related to the dataset, and the analysis process of datasets is a nondeterministic polynomial (NP) problem. The NP problem can be solved using optimization algorithms, with the genetic algorithm (GA) being one of the key methods to solving the optimal problem. The traditional GA has defects, such as falling into local optimal solution and early convergence [
25]. Many researches have been conducted to eliminate these defects. The search condition constraints are set up to improve the search speed of using GA to search for gene fragments [
26]. The mixed-integer nonlinear programming (MINLP) is transformed into a linear programming problem by using the Chu–Beasley GA (CBGA) [
27]. The literature [
28] uses a pruning operator to improve the GA and increase the convergence of the algorithm. The literature [
29,
30] solve stochastic programming problems using GA. The former uses the biased random key genetic algorithm (BKAGA) and the latter uses the grid-oriented genetic algorithm (GOGA).
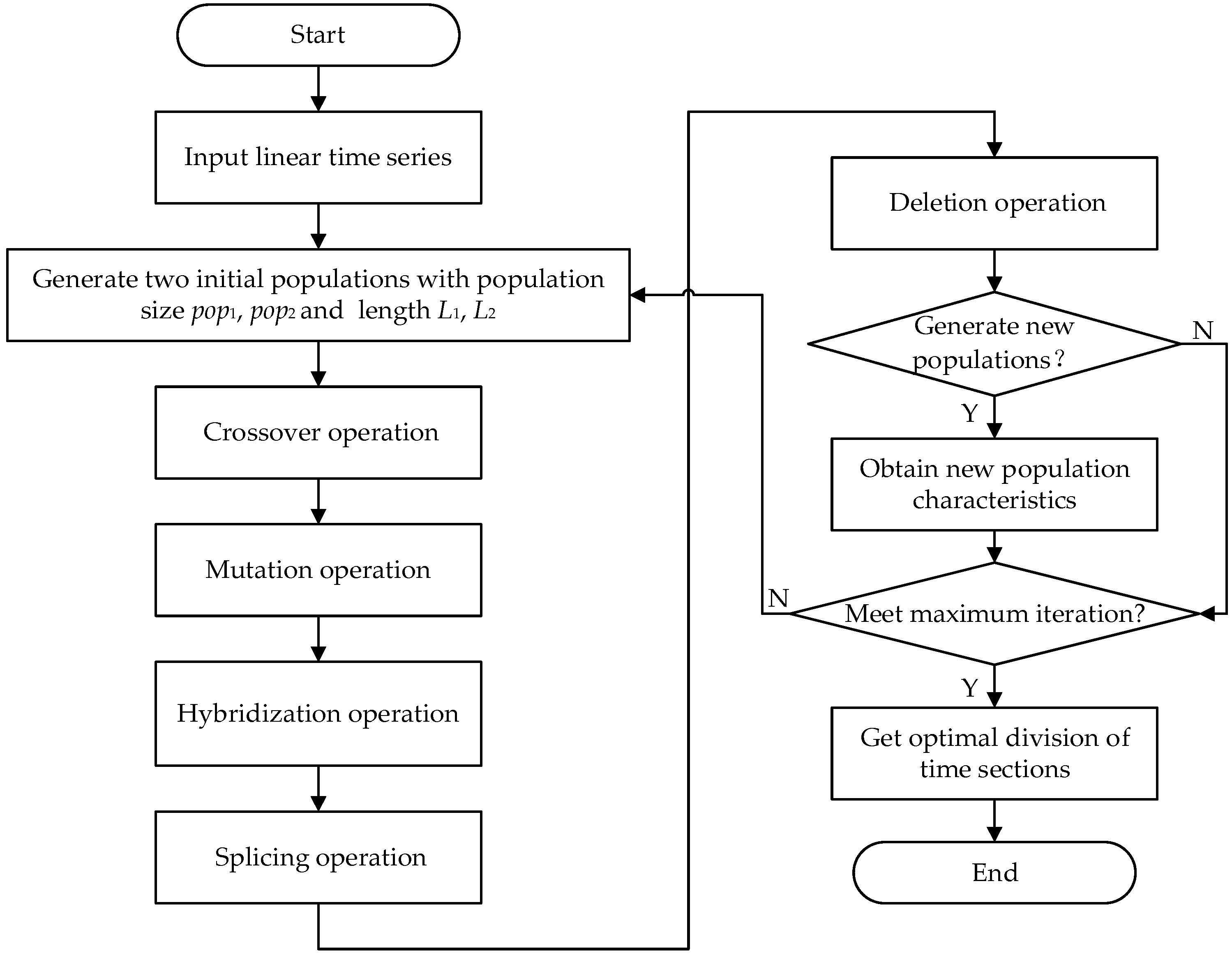
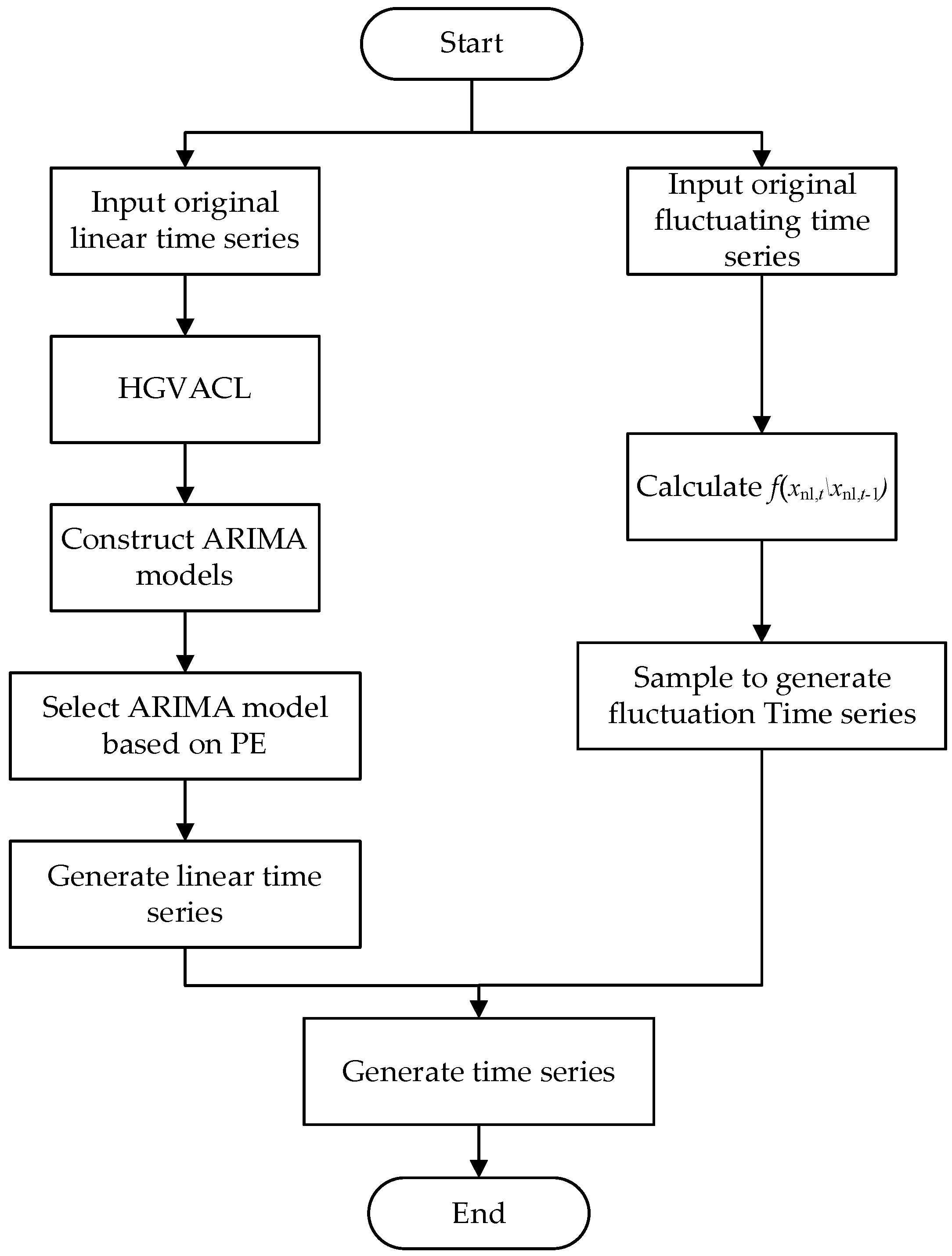
The above scenario generation methods also have defects, such as heavy calculation burden and complex calculation process. The complexity of the time series has an important impact on the scenario generation results. Therefore, this paper proposes a renewable scenario generation method that decomposes the original time series to decrease the complexity. The proposed approach can generate scenario results with a high amount of accuracy and has a superior performance in reflecting the characteristics of original data. The contributions can be listed as: (1) according to the time scales, the original data are divided into linear and fluctuant parts by the discrete wavelet transform (DWT); (2) a hybrid genetic algorithm with variable chromosome length (HGAVCL) is presented to optimally divide the linear part into different time sections; (3) the ARIMA model and Copula joint probability density function are, respectively, adopted to depict the linear and fluctuant parts.
The rest of this paper is organized as follows:
Section 2 presents the decomposition of original time series. Additionally, the HGCVCL and renewable energy scenario generation method are presented in
Section 3.
Section 4 gives the steps of renewable energy scenario generation method and the assessment indexes. The case study is carried out in
Section 5. Finally, conclusions are drawn in
Section 6.
5. Case Study
The minimum value of chromosome fragment length is 128. The value is determined by the experiment, which shows that 128 is the minimum to ensure the performance of solution algorithm. Additionally, the chromosome individual constraints are set up to ensure the accuracy of ARIMA model building. Two initial populations are set up. The population I with chromosome length is 5 and population II is 10. The number of iterations is 200, and the pop1 and pop2 are 40.
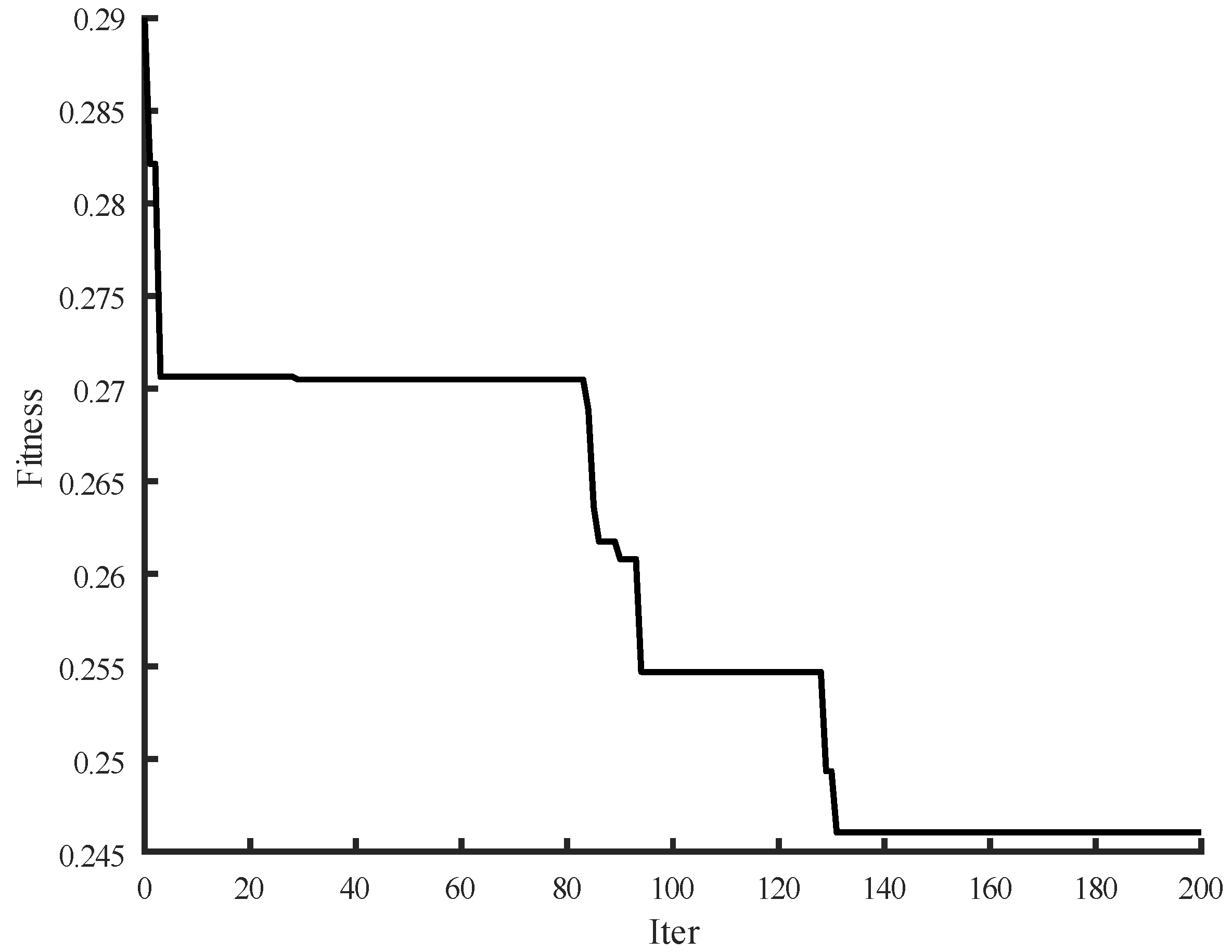
The PE of original linear time series is 3.46. Additionally, the PE is normalized and the value is 0.76. The fitness curve during the iterative process is shown in
Figure 3.
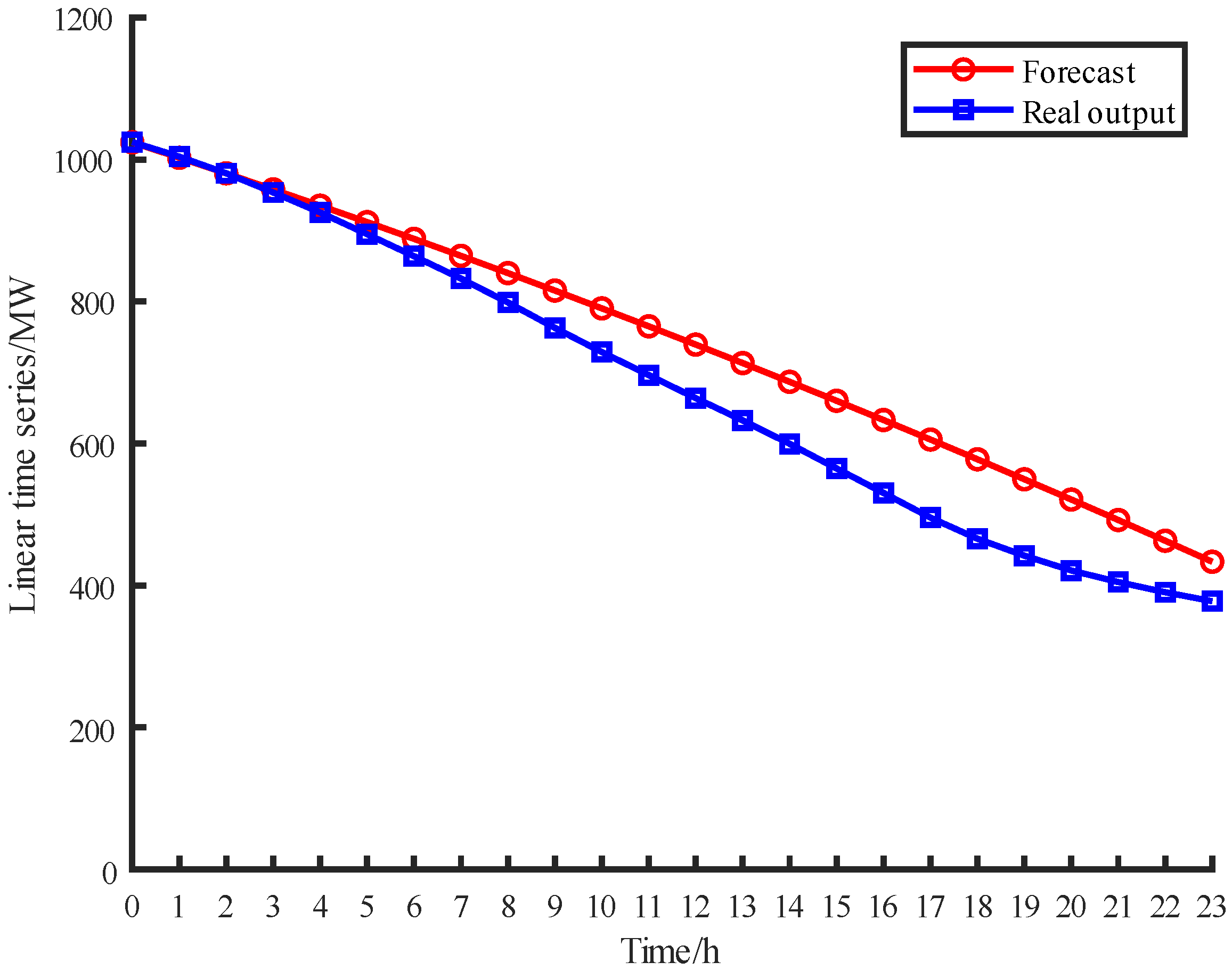
The results converge after 172 times and the chromosome length of optimal solution is 6. The original linear time series is divided into six zones. The ARIMA model is constructed for dividing the linear series. According to the existing research, the
p and
q orders of the ARIMA model are usually small, and this paper sets the maximum
p and
q order to 5. The fourth zone is analyzed as an example, and the construction series results of the ARIMA model are shown in
Figure 4. The ADF results are shown in
Table 2, and the AIC results are shown in
Table 3. The ARIMA model parameters are shown in
Table 4.
Additionally, the values of length, PE and MAPE of each time section, are shown in
Table 5. The results verify that the length of time sections affects the accuracy of the ARIMA model and the correlation between the distribution of PE and MAPE is positive. The smaller MAPE indicate that the constructed ARIMA is more accurate.
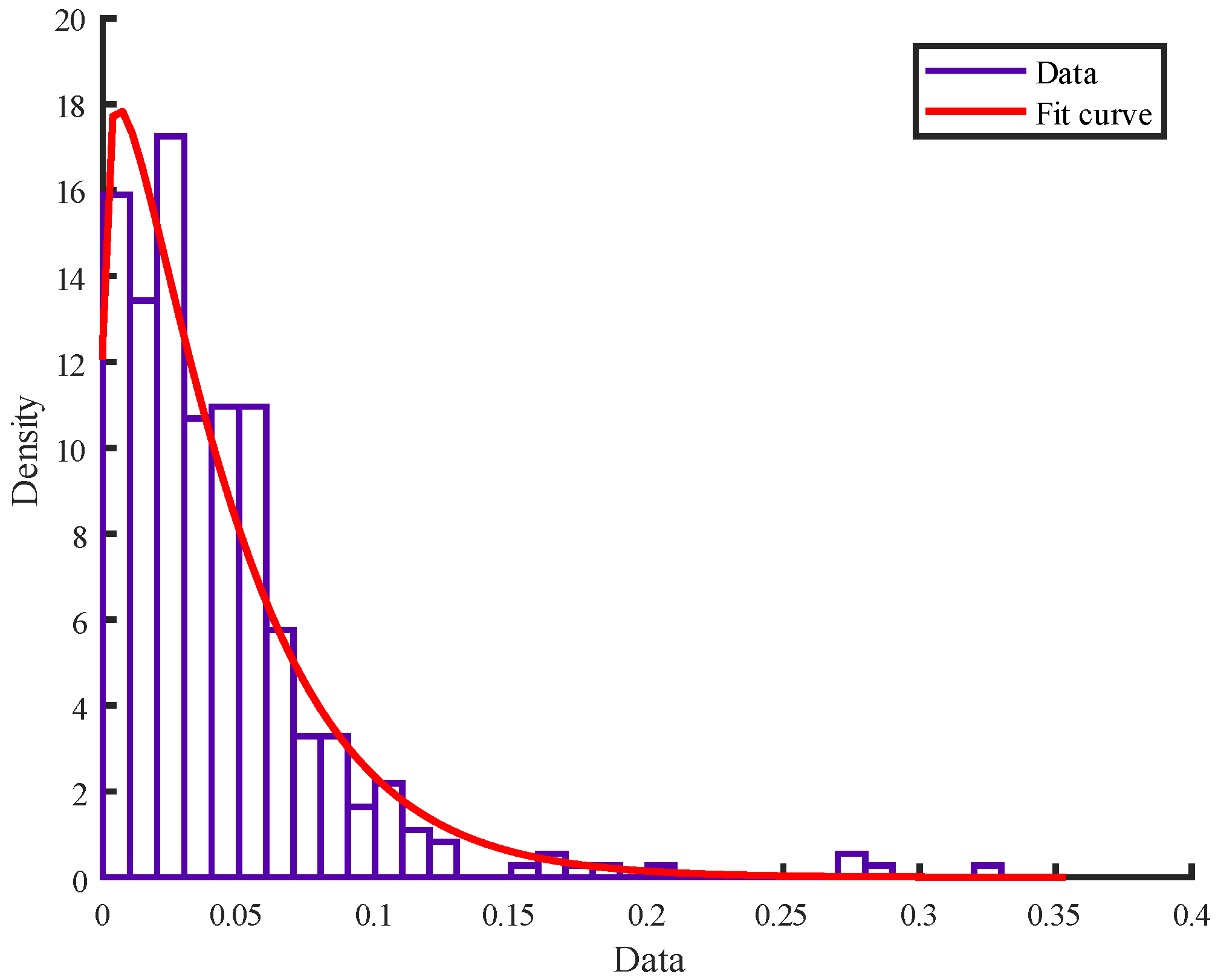
The value of net load ratio output at moment 1 and 2 is taken as an example, and the marginal distribution of net load ratio at moment 1 is shown in
Figure 5. The marginal distribution is consistent with the Weibull distribution.
The Kendall correlation coefficient and Spearman rank correlation coefficient are used to compare the fitting effect of various types of Copula functions. The normal Copula function fitted well. Hence, it was used. The results are shown in
Figure 6.
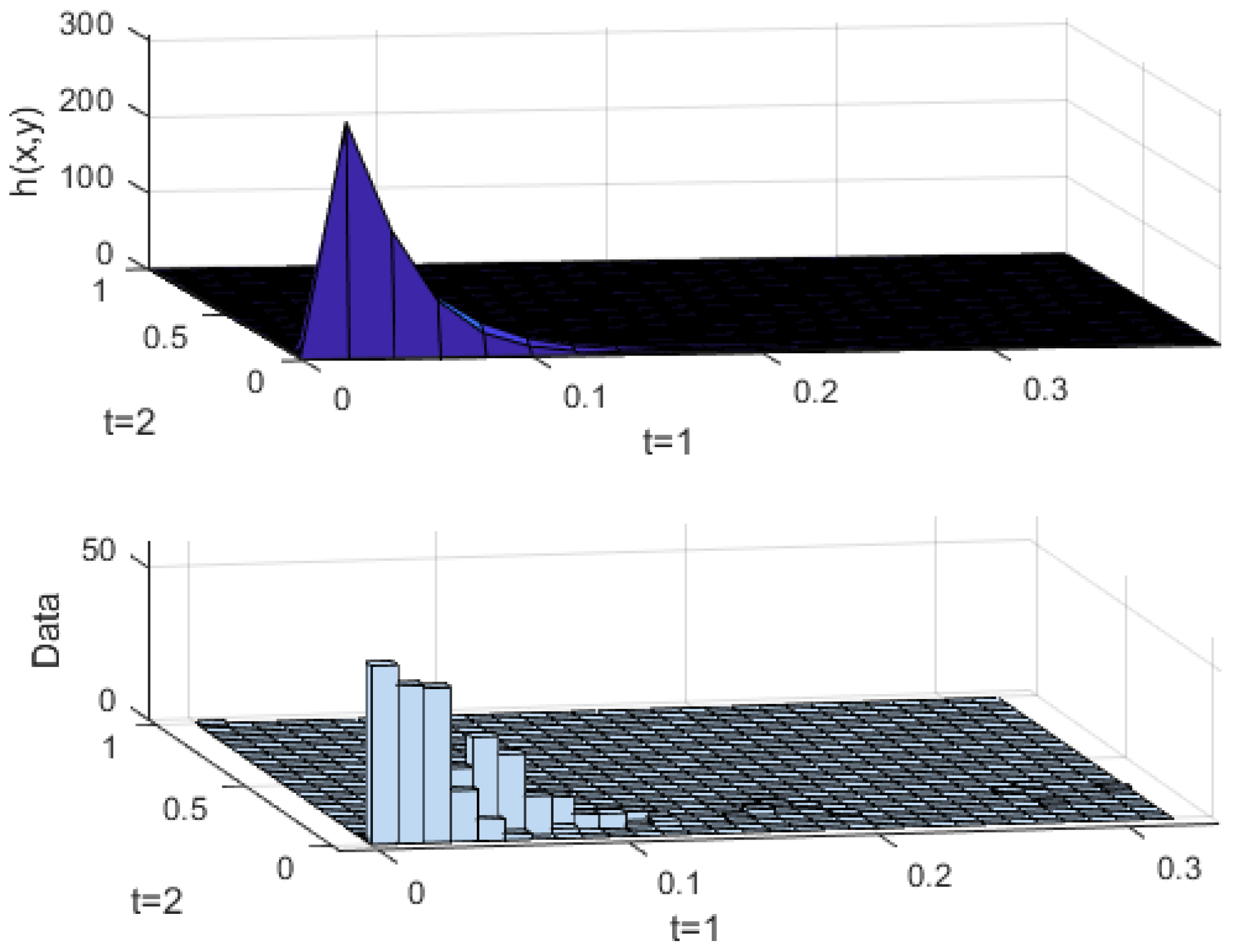
According to
Figure 6, the shape of the fitted joint probability density is the same as the frequency histogram. The solutions of other adjacent moments joint probability densities are the same as in moment 1 and 2. The
h(
x,
y) is solved according to the Bayesian formula to obtain the probability model of the fluctuant time series. The net load fluctuant time series is obtained based on the probability model. A set of scenarios are generated and shown in
Figure 7.
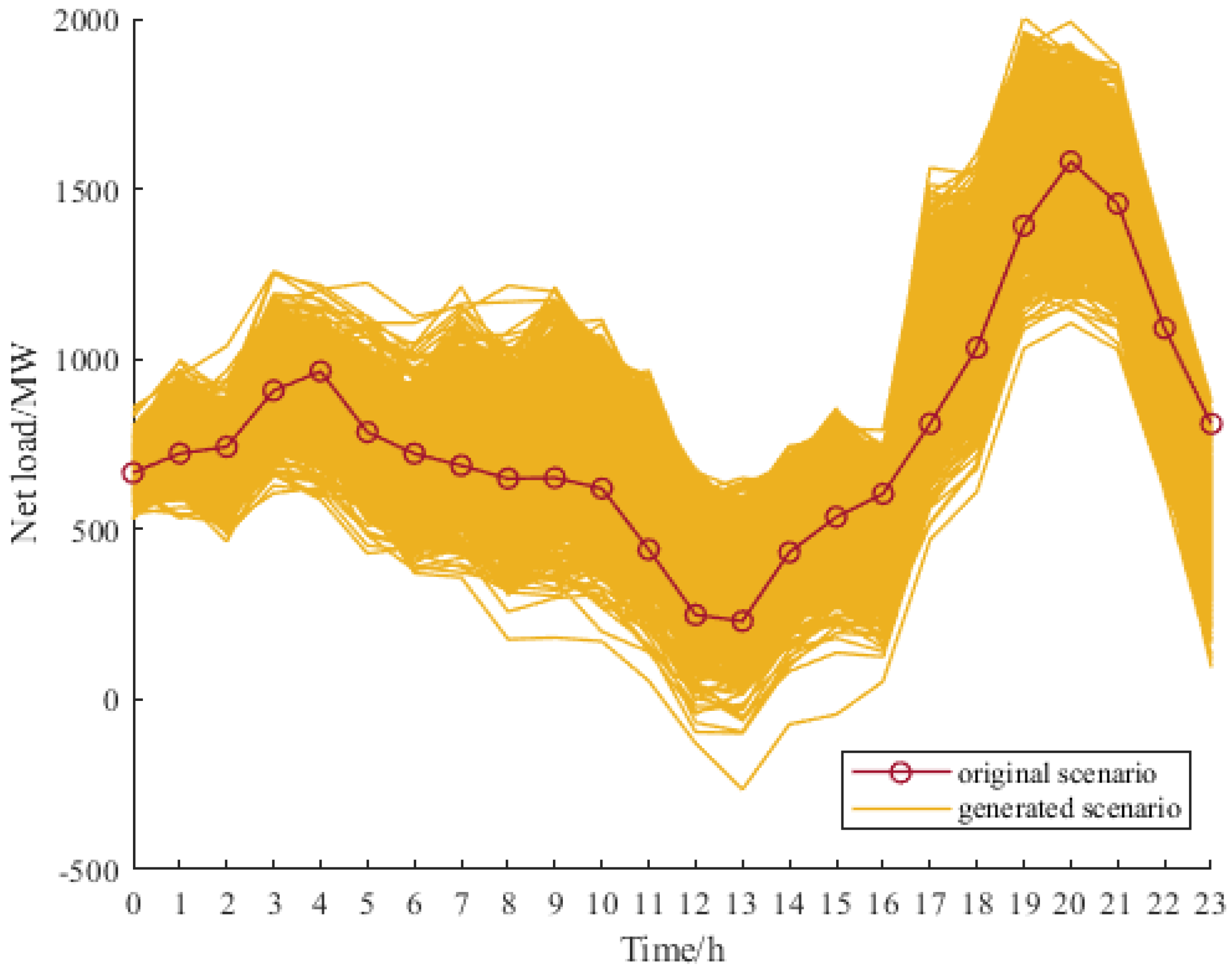
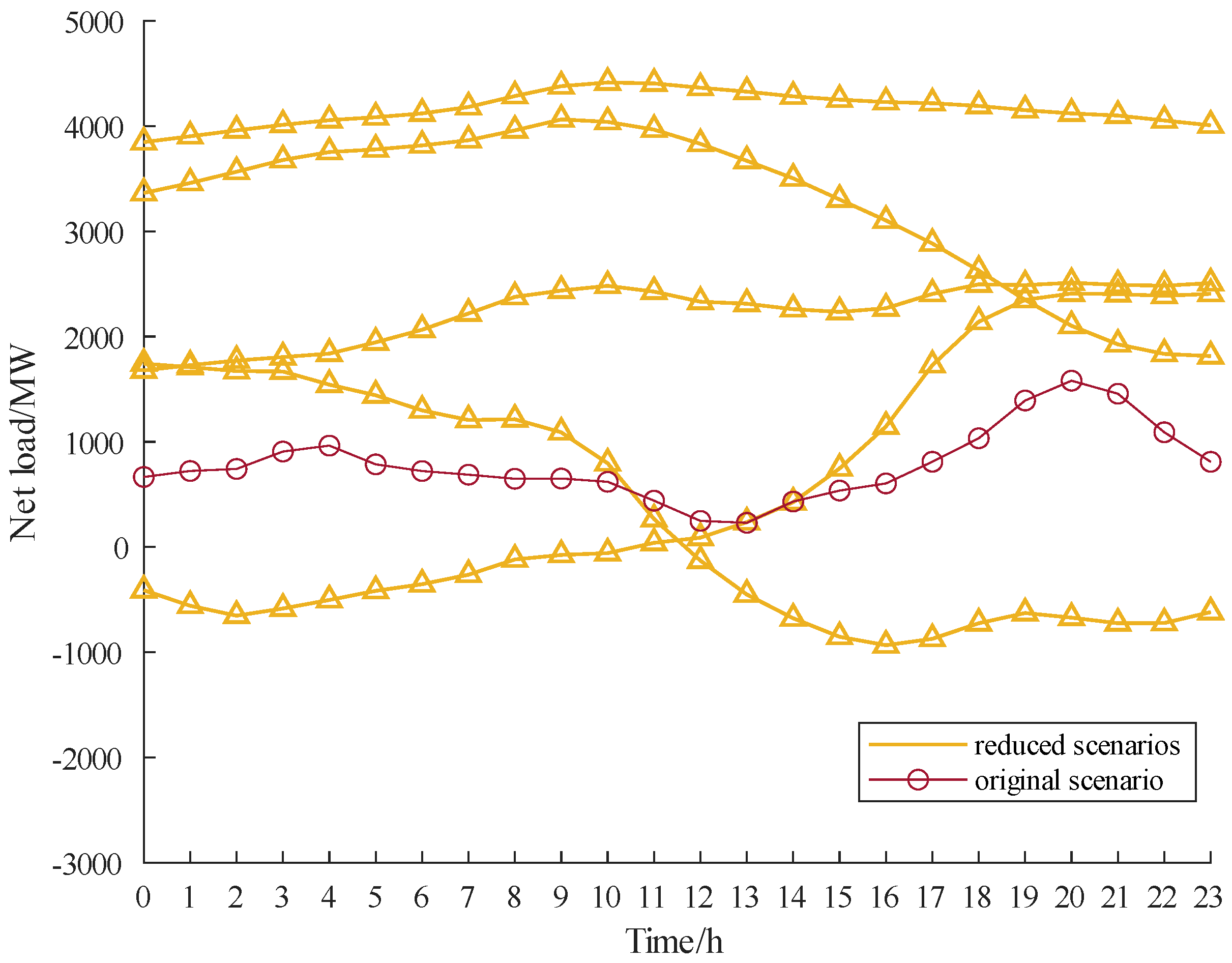
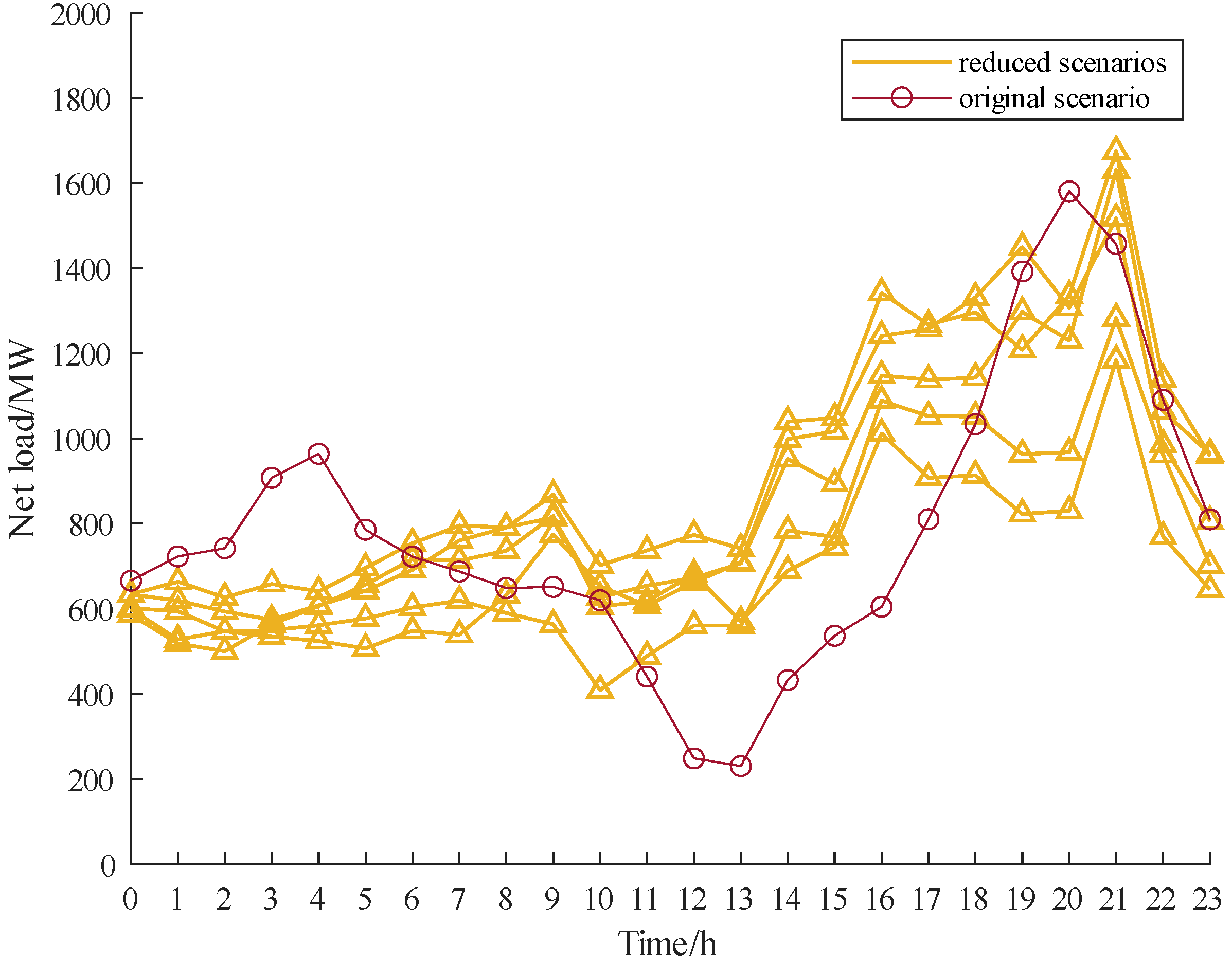
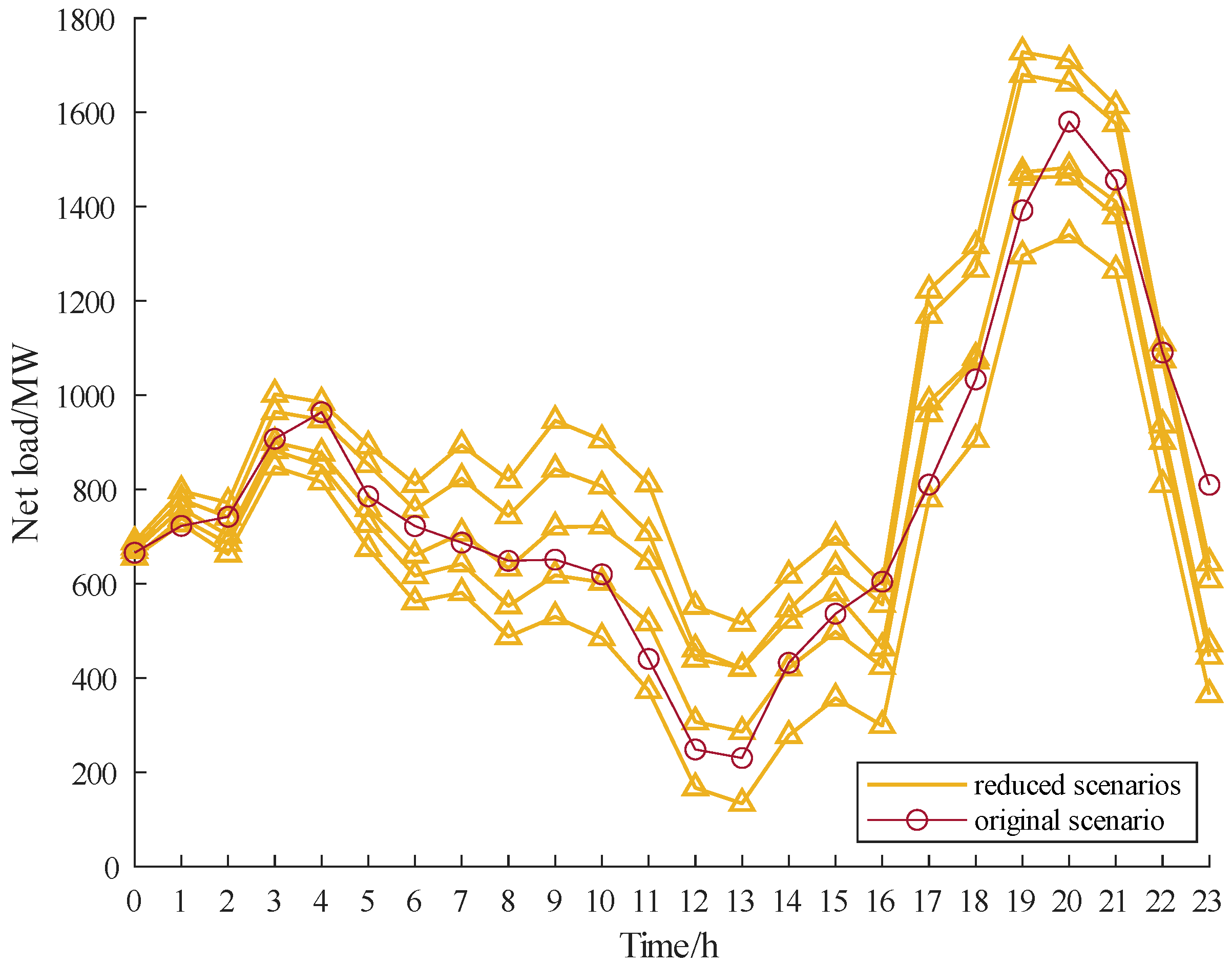
The Monte Carlo method, based on historical data, Copula function generation scenario method, and the proposed approach are compared. The number of generated scenarios is 1000. The k-means algorithm is used for scenario reduction and the results are shown in
Figure 8,
Figure 9 and
Figure 10.
In order to illustrate the advantages of the proposed approach, the Monte Carlo sampling (MCS) method is carried out. The time autocorrelation
σ, average offset rate
μ, and climbing similarity
Pe of the two methods are calculated, as shown in
Table 6.
As for the time autocorrelation
σ, the MCS method with the smaller value has little similarity to that of the generated and original data. In contrast, the proposed approach can better track the characteristics of original data. Additionally,
Table 6 shows that the average offset rate
μ of the proposed approach is smaller than the MCS method, which verifies the higher accuracy of the proposed approach. Furthermore, the proposed approach has better performance in climbing similarity
Pe when compared to the MCS method. The scenarios generation method of Copula function satisfies the requirement of temporal correlation of adjacent moments and the requirement of climbing similarity, but the resultant offset of its generated scene is still not very satisfactory. Therefore, the proposed approach can generate scenario results with the highest amount of accuracy and the corresponding climbing similarity, which shows superior performance in reflecting the real situation of the net load scenario.
6. Conclusions
This paper proposes a renewable scenario generation approach based on the HGAVCL. With the use of the DWT, the original data are divided into the linear and fluctuant parts. For the linear part, the HGAVCL is used to minimize the PE and divide the time series into different time sections. This is modeled by the ARIMA. Additionally, the Copula joint probability density function is used to model the fluctuant part. The scenarios are generated by the Monte Carlo method, and the quantitative indices are established. The comparative analysis is conducted to demonstrate the advantages of the proposed approach. The proposed approach can improve the time autocorrelation σ and climbing similarity Pe, and reduce the average offset rate μ. The results show that the proposed approach better reflects the real situation of original data.
In future research, the optimal dispatching scheme for renewable energy sources, based on the proposed scenario generation approach, will be presented.

 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}