
Power-Load Forecasting Model Based on Informer and Its Application
Abstract
:1. Introduction
- (1)
- To address the squared increase of memory overhead in the computation of self-attentive weights in the Transformer model, this paper reduces the complexity of each layer from O(L2) to O(L lnL) by sparsifying the self-attentive matrix and optimizes the memory overhead of the self-attentive weight matrix.
- (2)
- To address the problem that the Transformer model encoder–decoder does not adapt to long-time series power-load prediction, this paper optimizes the feature-map generation method of the encoder and the output structure of the decoder, which reduces the memory overhead of the encoder and improves the output speed of the decoder.
- (3)
- In this paper, we experimentally investigate the optimal solutions of the main parameters in the sparse self-attentive model and compare the optimized parameters with several other common power-load forecasting models using the Nanchang Taoyuan substation dataset. The results of the measured data show that the model based on the sparse self-attentive mechanism has obvious advantages in terms of prediction accuracy and training efficiency compared with the recurrent neural-network-type model, which provides a real case reference under a new solution idea for solving the long-time series power-load forecasting problem.
2. Informer Model
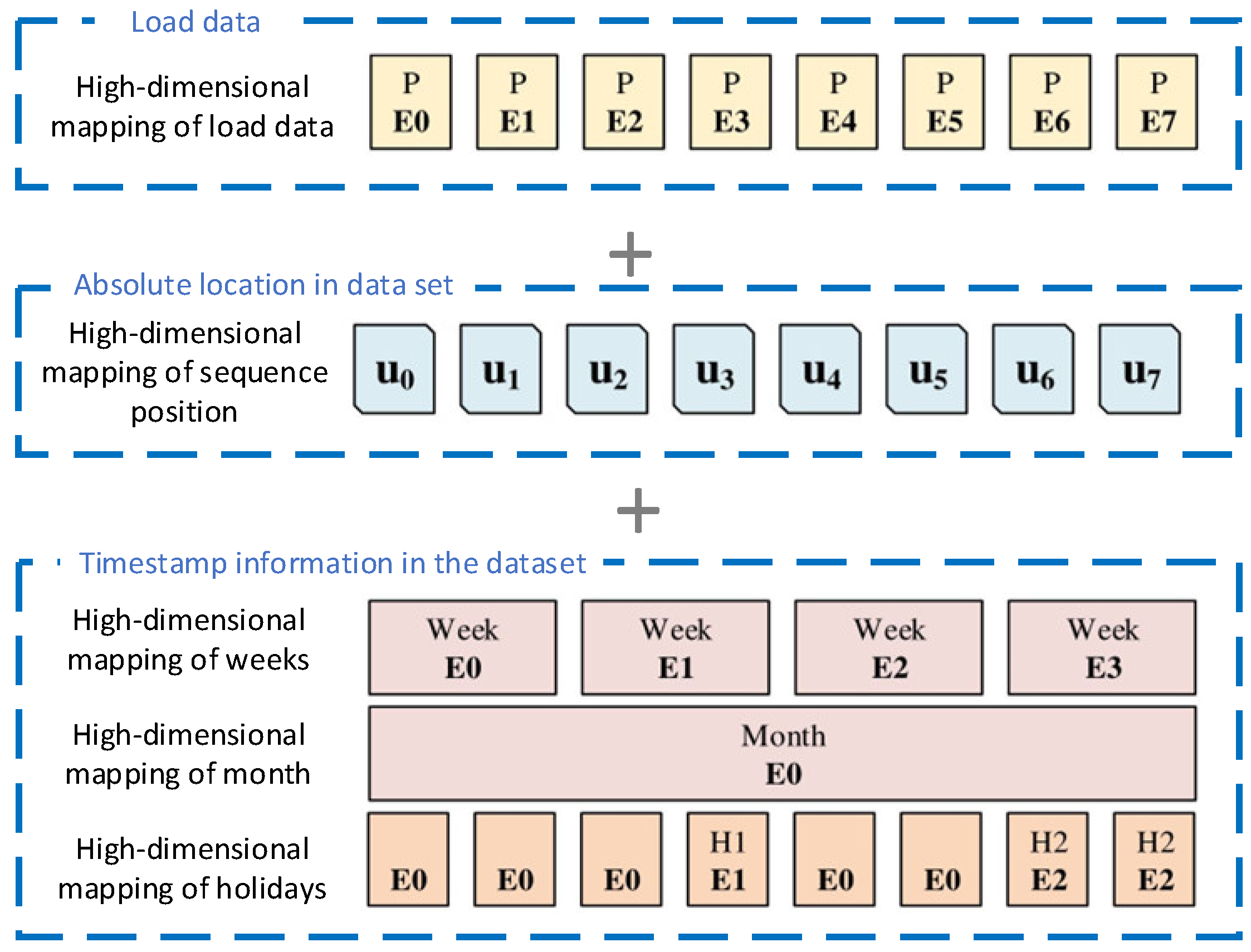
2.1. Input Structure of Informer
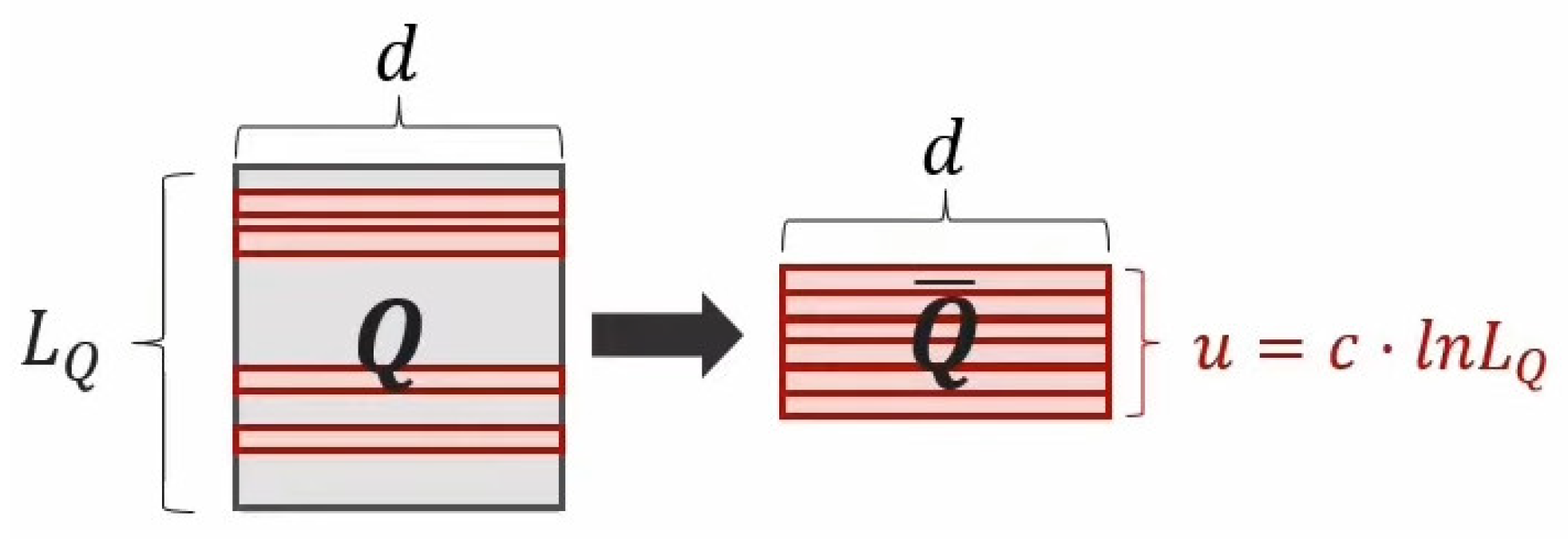
2.2. Self-Attention Mechanism
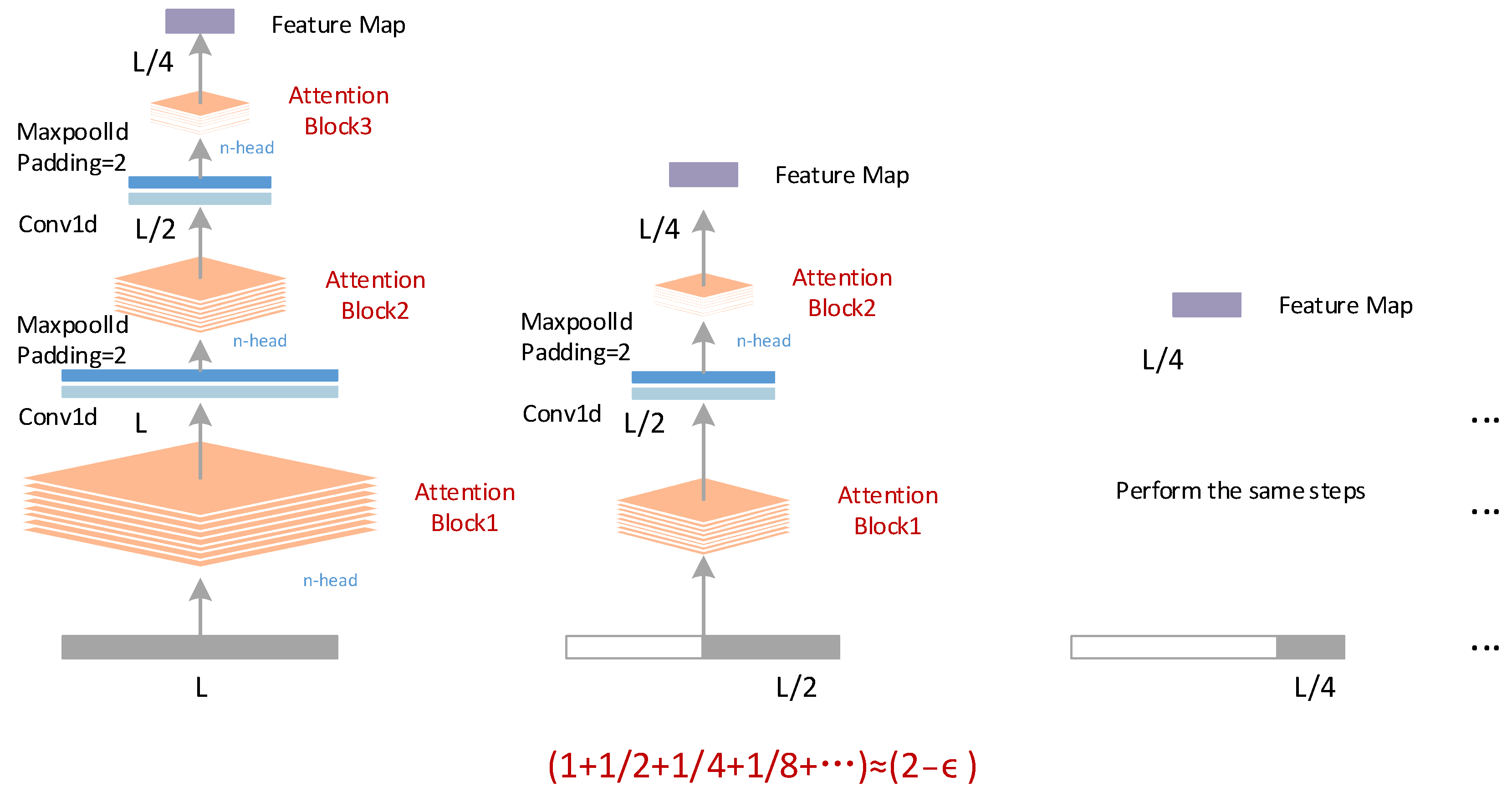
2.3. Distillation Mechanism in the Encoder
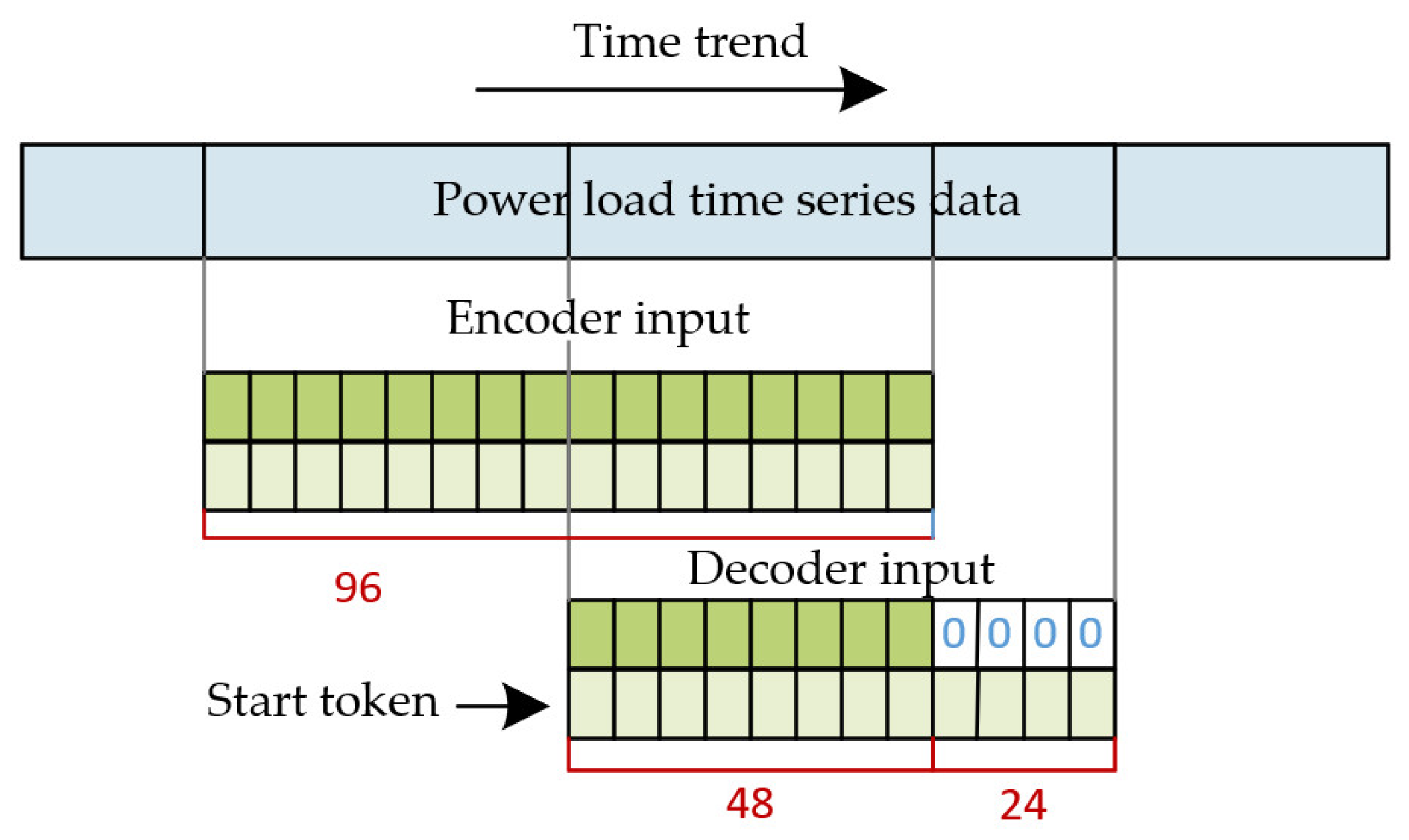
2.4. One-Step Generative Decoder
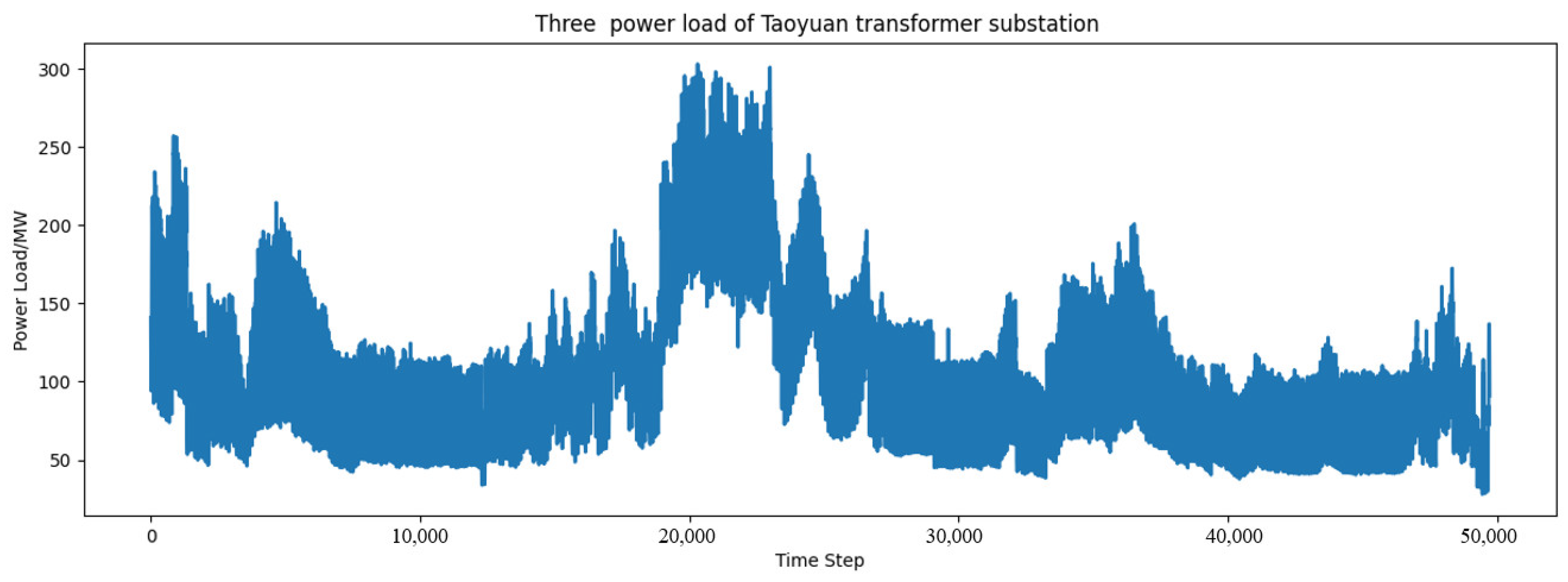
3. Data Correlation Analysis
4. Example Analysis
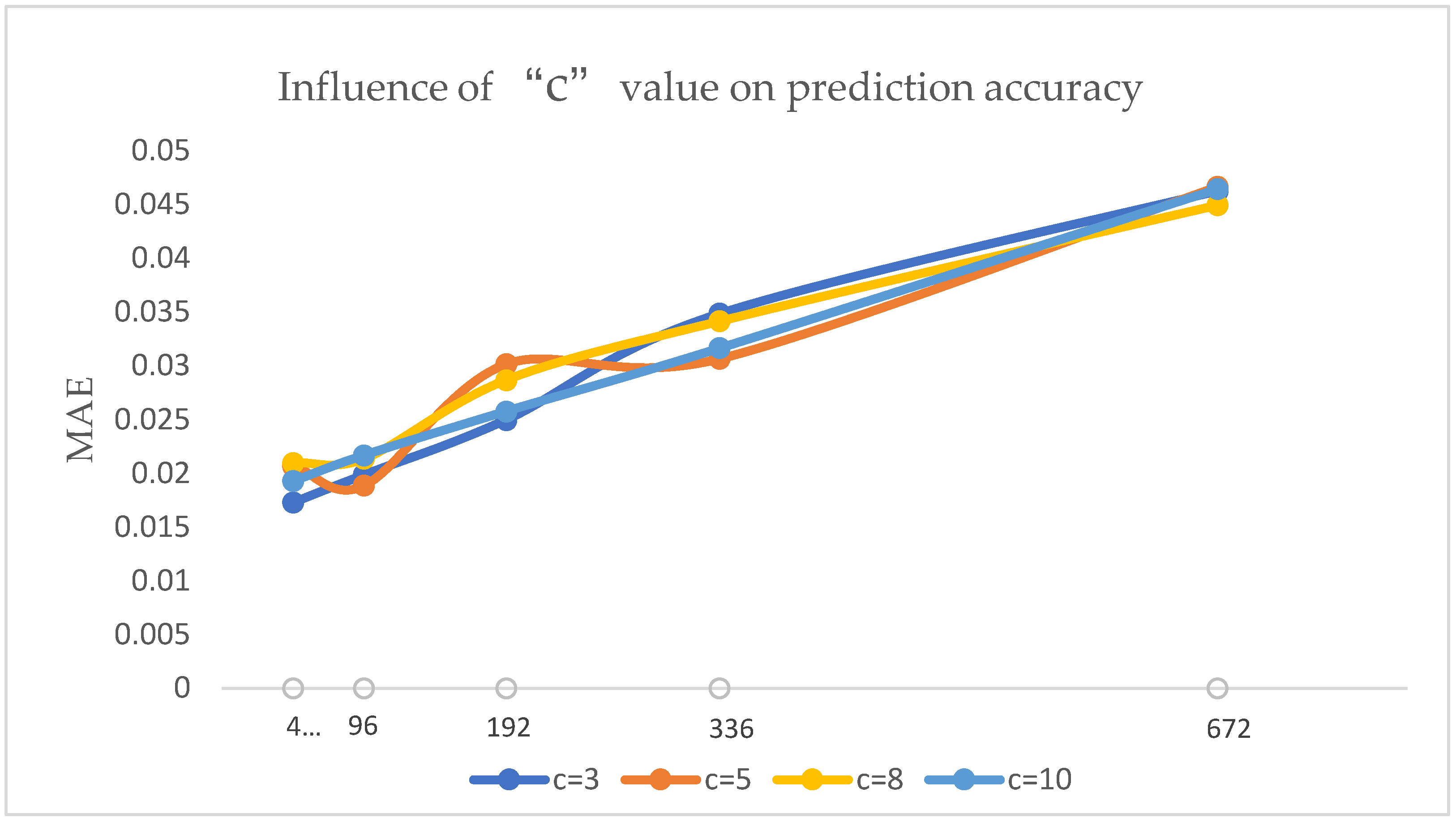
4.1. Model Parameter Optimization
- (1)
- The effect of the length of the input data on the prediction results
- (2)
- The effect of hyperparameter c on the experiment
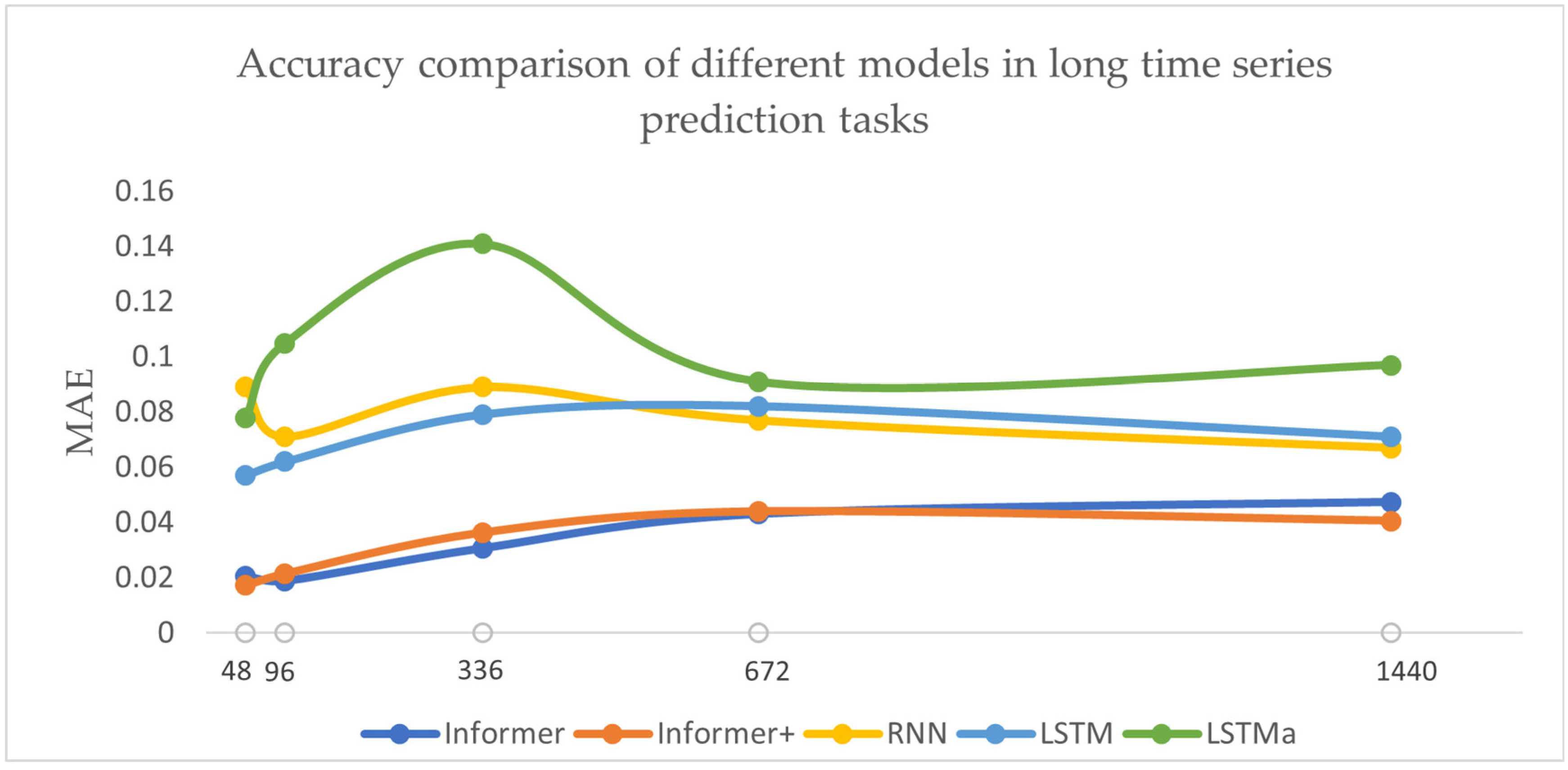
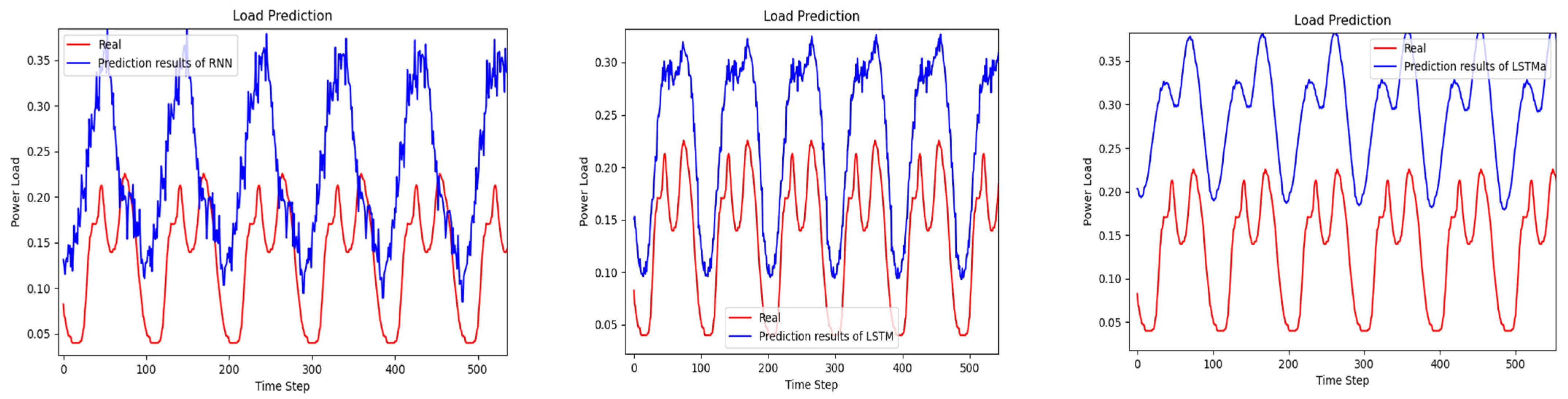
4.2. Experimental Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhu, J.C.; Yang, Z.L.; Guo, Y.J.; Yu, K.J.; Zhang, J.K.; Mu, X.M. A review on the application of deep learning in power load forecasting. J. Zhengzhou Univ. 2019, 40, 13–22. [Google Scholar]
- Li, Y.; Jia, Y.J.; Li, L.; Hao, J.; Zhang, X. Short-term electric load forecasting based on random forest algorithm. Power Syst. Prot. Control. 2020, 48, 117–124. [Google Scholar]
- Zhuang, S.J.; Yu, Z.Y.; Guo, W.Z.; Huang, F.W. Cross-scale recurrent neural network based on Zoneout and its application in short-term power load forecasting. Comput. Sci. 2020, 47, 105–109. [Google Scholar]
- Jingliang, Y.; Linhai, Q.; Shun, T.; Hong, W. Attention LSTM-based optimization of on-load tap-changer operation. Power Grid Technol. 2020, 44, 2449–2456. [Google Scholar]
- Lv, H.C.; Wang, W.F.; Zhao, B.; Zhang, Y.; Guo, Q.T.; Hu, W. Short-term station load forecasting based on Wide&Deep LSTM model. Power Grid Technol. 2020, 44, 428–436. [Google Scholar]
- Kong, W.; Dong, Z.Y.; Jia, Y.; Hill, D.J.; Xu, Y.; Zhang, Y. Short-term residential load forecasting based on LSTM recurrent neural network. IEEE Trans. Smart Grid 2017, 10, 841–851. [Google Scholar] [CrossRef]
- Lee, C.M.; Ko, C.N. Short-term load forecasting using lifting scheme and ARIMA models. Expert Syst. Appl. 2011, 38, 5902–5911. [Google Scholar] [CrossRef]
- Fan, C.; Ding, Y. Cooling load prediction and optimal operation of HVAC systems using a multiple nonlinear regression model. Energy Build. 2019, 197, 7–17. [Google Scholar] [CrossRef]
- Zheng, T.; Girgis, A.A.; Makram, E.B. A hybrid wavelet-Kalman filter method for load forecasting. Electr. Power Syst. Res. 2000, 54, 11–17. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Jingbo, M.; Honggeng, Y. Application of adaptive Kalman filtering in short-term load forecasting of power systems. Power Grid Technol. 2005, 29, 75–79. [Google Scholar]
- Quan, L. Adaptive Kalman filter-based load forecasting under meteorological influence. Comput. Meas. Control. 2020, 28, 156–159 + 165. [Google Scholar]
- Xu, W.; Peng, H.; Zeng, X.; Zhou, F.; Tian, X.; Peng, X. A hybrid modelling method for time series forecasting based on a linear regression model and deep learning. Appl. Intell. 2019, 49, 3002–3015. [Google Scholar] [CrossRef]
- Liu, L.; Liu, J.; Zhou, Q.; Qu, M. An SVR-based Machine Learning Model Depicting the Propagation of Gas Explosion Disaster Hazards. Arab. J. Sci. Eng. 2021, 46, 10205–10216. [Google Scholar] [CrossRef]
- Ning, Y.; Yong, L.; Yong, W. Short-term power load forecasting based on SVM. In Proceedings of the World Automation Congress 2012, Puerto Vallarta, Mexico, 24–28 June 2012. [Google Scholar]
- Che, J.; Wang, J. Short-term load forecasting using a kernel-based support vector regression combination model. Appl. Energy 2014, 132, 602–609. [Google Scholar] [CrossRef]
- Hsu, Y.Y.; Ho, K.L. Fuzzy linear programming: An application to short-term load forecasting. Gener. Transm. Distrib. IEEE Proc. C 1992, 139, 471–477. [Google Scholar] [CrossRef] [Green Version]
- Zhaoyu, P.; Shengzhu, L.; Hong, Z.; Nan, Z. The application of the PSO based BP network in short-term load forecasting. Phys. Procedia 2012, 24, 626–632. [Google Scholar] [CrossRef] [Green Version]
- Bashir, Z.A.; El-Hawary, M.E. Applying waveletsto short-term load forecasting using PSO-based neural networks. IEEE Trans. Power Syst. 2009, 24, 20–27. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Yao, L.; Jie, Y.; Zhijuan, S.; Congcong, Z. Robust PM2.5 prediction based on stage-based time-series attention network. Environ. Eng. 2021, 39, 93–100. [Google Scholar] [CrossRef]
- Kitaev, N.; Kaiser, Ł.; Levskaya, A. Reformer: The Efficient Transformer [EB/OL]. Available online: https://arxiv.org/pdf/2001.04451.pdf (accessed on 11 March 2020).
- Child, R.; Gray, S.; Radford, A.; Sutskever, I. Generating Long Sequences with Sparse Transformers. arXiv 2019, arXiv:1904.10509. [Google Scholar]
- Beltagy, I.; Peters, M.E.; Cohan, A. Longformer: The Long-Document Transformer. arXiv 2020, arXiv:2004.05150. [Google Scholar]
- Li, S.; Jin, X.; Xuan, Y.; Zhou, X.; Chen, W.; Wang, Y.; Yan, X. Enhancing the Locality and Breaking the Memory Bottleneck of Transformer on Time Series Forecasting. Adv. Neural Inf. Process. Syst. 2019, 32, abs/1907.00235. [Google Scholar]
- Zhang, H.; Jiang, Y. Axle temperature prediction model for urban rail vehicles based on sparse attention mechanism. Technol. Innov. 2021, 3, 1–4. [Google Scholar] [CrossRef]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting. Proc. AAAI Conf. Artif. Intell. 2020, 35, 11106–11115. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V.; Funkhouser, T. Dilated residual networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 472–480. [Google Scholar]
- Lindberg, K.B.; Seljom, P.; Madsen, H.; Fischer, D.; Korpås, M. Long-term electricity load forecasting: Current and future trends. Util. Policy 2019, 58, 102–119. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Delay | Autocorrelation | True Value | Ljung-Box Test |
|---|---|---|---|
| 1 | 0.995 | 140.83 | 1429.059 |
| 2 | 0.984 | 133.18 | 2826.708 |
| 3 | 0.966 | 127.61 | 4176.199 |
| 4 | 0.943 | 023.99 | 5462.566 |
| 5 | 0.915 | 119.26 | 6673.302 |
| Encoder | N | ||
|---|---|---|---|
| Input | 1 × 3 Conv1d | Embedding (d = 512) | 6 |
| Sparse self-attention blocks | Multi-head Sparse Attention (h = 16, d = 32) | ||
| Add, LayerNorm, Dropout (p) | |||
| Pos-wise FFN (), GELU | |||
| Add, LayerNorm, Dropout (p ) | |||
| Distillation layer | 1 × 3 Conv1d | ||
| Max pooling (stride = 2) | |||
| Decoder | N | ||
| Input | 1 × 3 Conv1d | Embedding (d = 512) | 6 |
| Masked SAB | Add a mask to the Attention Block | ||
| Self-attention block | Multi-head Sparse Attention (h = 8, d = 64) | ||
| Add, LayerNorm, Dropout (p ) | |||
| Pos-wise FFN (), GELU | |||
| Add, LayerNorm, Dropout (p ) | |||
| Distillation layer | 1 × 3 Conv1d | ||
| Max pooling (stride = 2) | |||
| Output | FCN () | ||
| Predicted Length | 288 | 672 | ||||
|---|---|---|---|---|---|---|
| Input Length | 288 | 576 | 1152 | 672 | 1344 | 2688 |
| RMSE | 0.044 | 0.046 | 0.060 | 0.079 | 0.073 | 0.070 |
| MAE | 0.032 | 0.033 | 0.037 | 0.047 | 0.046 | 0.049 |
| Time | 312 | 770 | 2613 | 930 | 3510 | 13,384 |
| C | Metric | 48 | 96 | 192 | 336 | 672 |
|---|---|---|---|---|---|---|
| 3 | RMSE | 0.0262 | 0.0320 | 0.0366 | 0.0479 | 0.0691 |
| MAE | 0.0173 | 0.0199 | 0.0250 | 0.0349 | 0.0463 | |
| Time | 196 | 205 | 243 | 342 | 916 | |
| 5 | RMSE | 0.0289 | 0.0307 | 0.04060 | 0.0441 | 0.0786 |
| MAE | 0.0207 | 0.0189 | 0.0302 | 0.0307 | 0.0467 | |
| Time | 197 | 209 | 246 | 365 | 938 | |
| 8 | RMSE | 0.0306 | 0.0333 | 0.0402 | 0.0495 | 0.0725 |
| MAE | 0.0210 | 0.0214 | 0.0287 | 0.0342 | 0.0450 | |
| Time | 199 | 212 | 249 | 376 | 961 | |
| 10 | RMSE | 0.0275 | 0.0344 | 0.0379 | 0.0458 | 0.0814 |
| MAE | 0.0193 | 0.0217 | 0.0258 | 0.0317 | 0.0465 | |
| Time | 200 | 210 | 246 | 376 | 849 |
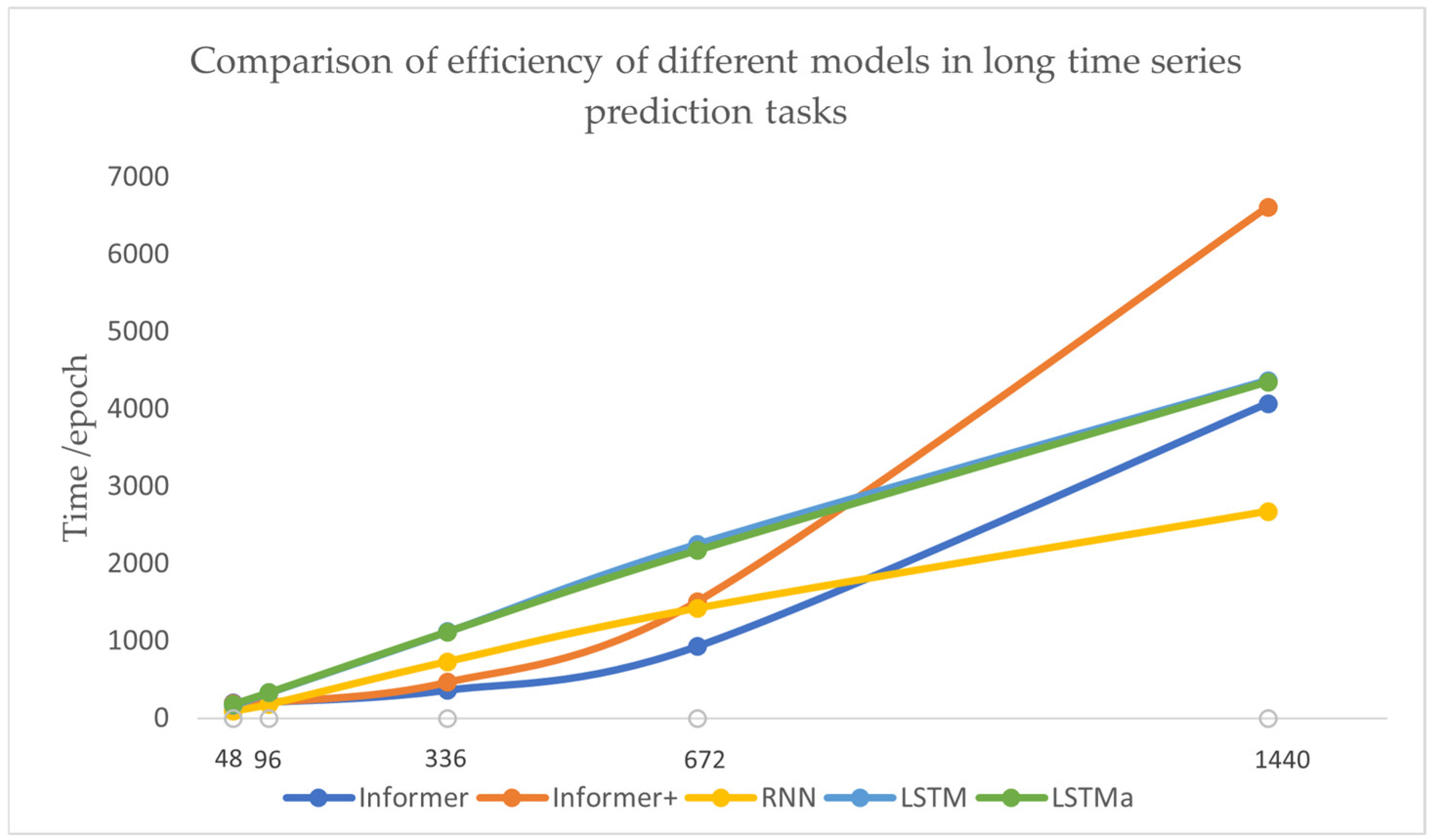
| Methods | Metric | 48 | 96 | 336 | 672 | 1440 |
|---|---|---|---|---|---|---|
| Informer | RMSE | 0.0289 | 0.0307 | 0.0441 | 0.0714 | 0.0670 |
| MAE | 0.0207 | 0.0189 | 0.0307 | 0.0431 | 0.0474 | |
| Time | 197 | 209 | 365 | 930 | 4070 | |
| Informer+ | RMSE | 0.0255 | 0.0303 | 0.0508 | 0.0748 | 0.0583 |
| MAE | 0.0173 | 0.0216 | 0.0364 | 0.0440 | 0.0406 | |
| Time | 186 | 204 | 463 | 1508 | 6610 | |
| RNN | RMSE | 0.108 | 0.090 | 0.108 | 0.093 | 0.084 |
| MAE | 0.089 | 0.071 | 0.089 | 0.077 | 0.067 | |
| Time | 92 | 176 | 730 | 1421 | 2674 | |
| LSTM | RMSE | 0.069 | 0.072 | 0.089 | 0.093 | 0.081 |
| MAE | 0.057 | 0.062 | 0.079 | 0.082 | 0.071 | |
| Time | 166 | 330 | 1117 | 2249 | 4365 | |
| LSTMa | RMSE | 0.095 | 0.124 | 0.169 | 0.103 | 0.122 |
| MAE | 0.078 | 0.105 | 0.141 | 0.091 | 0.097 | |
| Time | 181 | 331 | 1116 | 2169 | 4346 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, H.; Peng, Q.; Wang, Y.; Zhan, Z. Power-Load Forecasting Model Based on Informer and Its Application. Energies 2023, 16, 3086. https://doi.org/10.3390/en16073086
Xu H, Peng Q, Wang Y, Zhan Z. Power-Load Forecasting Model Based on Informer and Its Application. Energies. 2023; 16(7):3086. https://doi.org/10.3390/en16073086
Chicago/Turabian StyleXu, Hongbin, Qiang Peng, Yuhao Wang, and Zengwen Zhan. 2023. "Power-Load Forecasting Model Based on Informer and Its Application" Energies 16, no. 7: 3086. https://doi.org/10.3390/en16073086