
Probabilistic Decline Curve Analysis: State-of-the-Art Review



Abstract
:1. Introduction
1.1. Overview of DCA Models

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | (q) versus (t) * | Reference |
|---|---|---|
| Exponential Arps (1945) | [6] | |
| Hyperbolic Arps (1945) | [6] | |
| Harmonic Arps (1945) | [6] | |
| Modified Arps approach (2008) | [21,22] | |
| [23,24] | ||
| SEPD (2010) | [25,26] | |
| Duong (2010, 2011) | [27,28] | |
| LGM (2011) | [29] | |
| EEDCA (2015) | [30] | |
| Pan (2017) | [31] |
1.2. Uncertainties Related to DCA
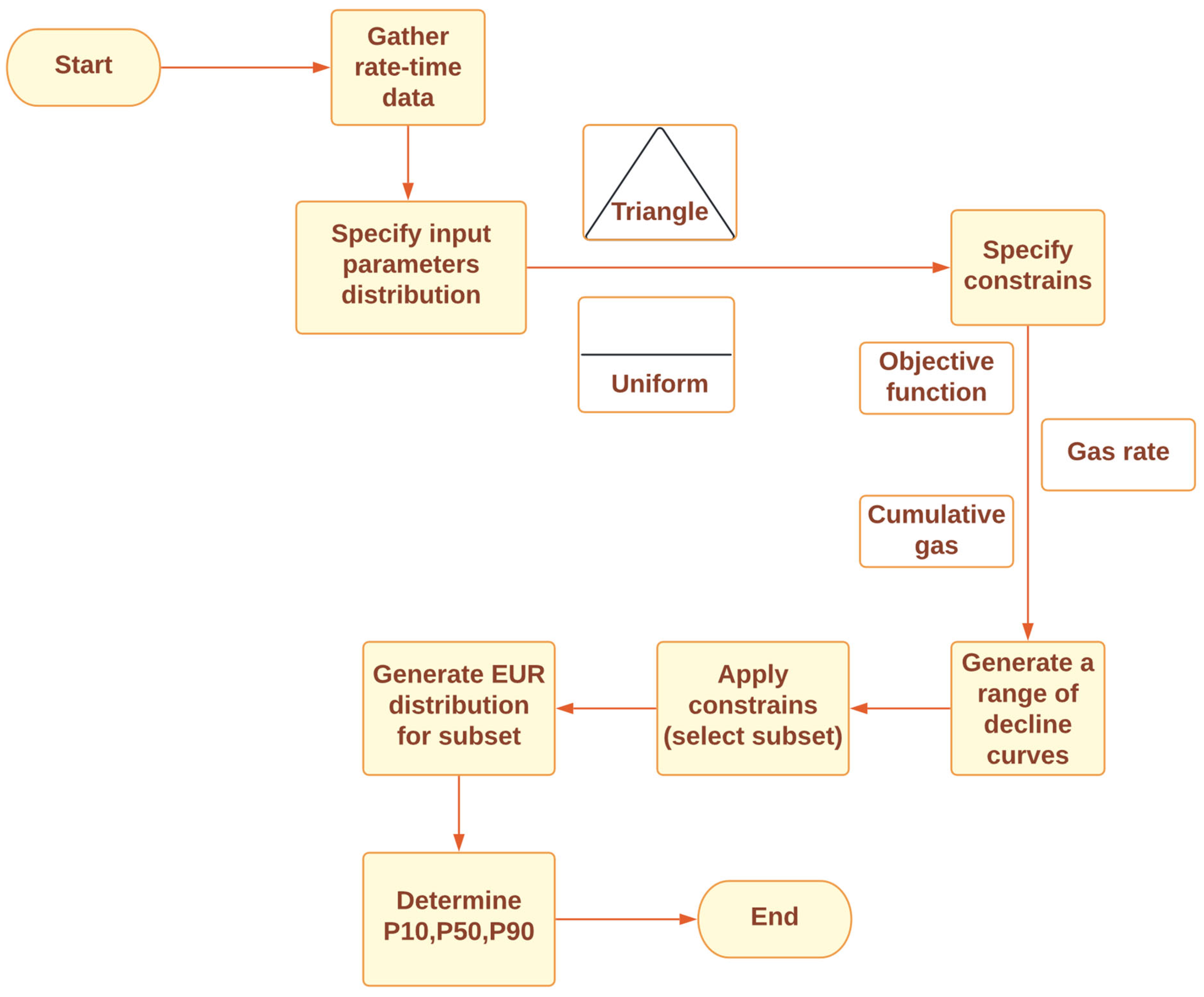
1.3. Probabilistic DCA (pDCA)
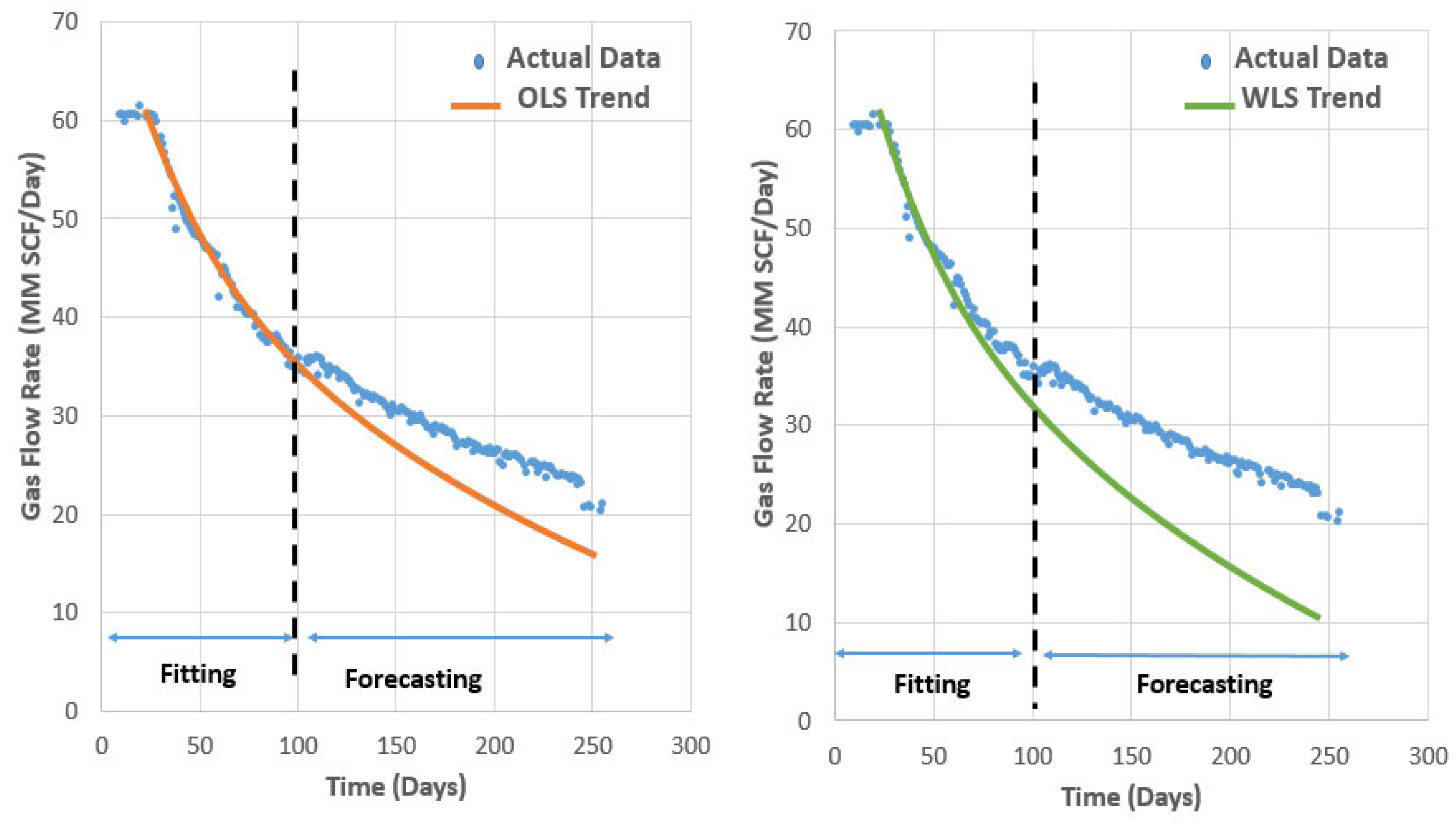
1.4. Types of Statistical Analysis
1.5. Resampling Techniques
2. pDCA Approaches
2.1. Jochen’s Approach (1996) [54]
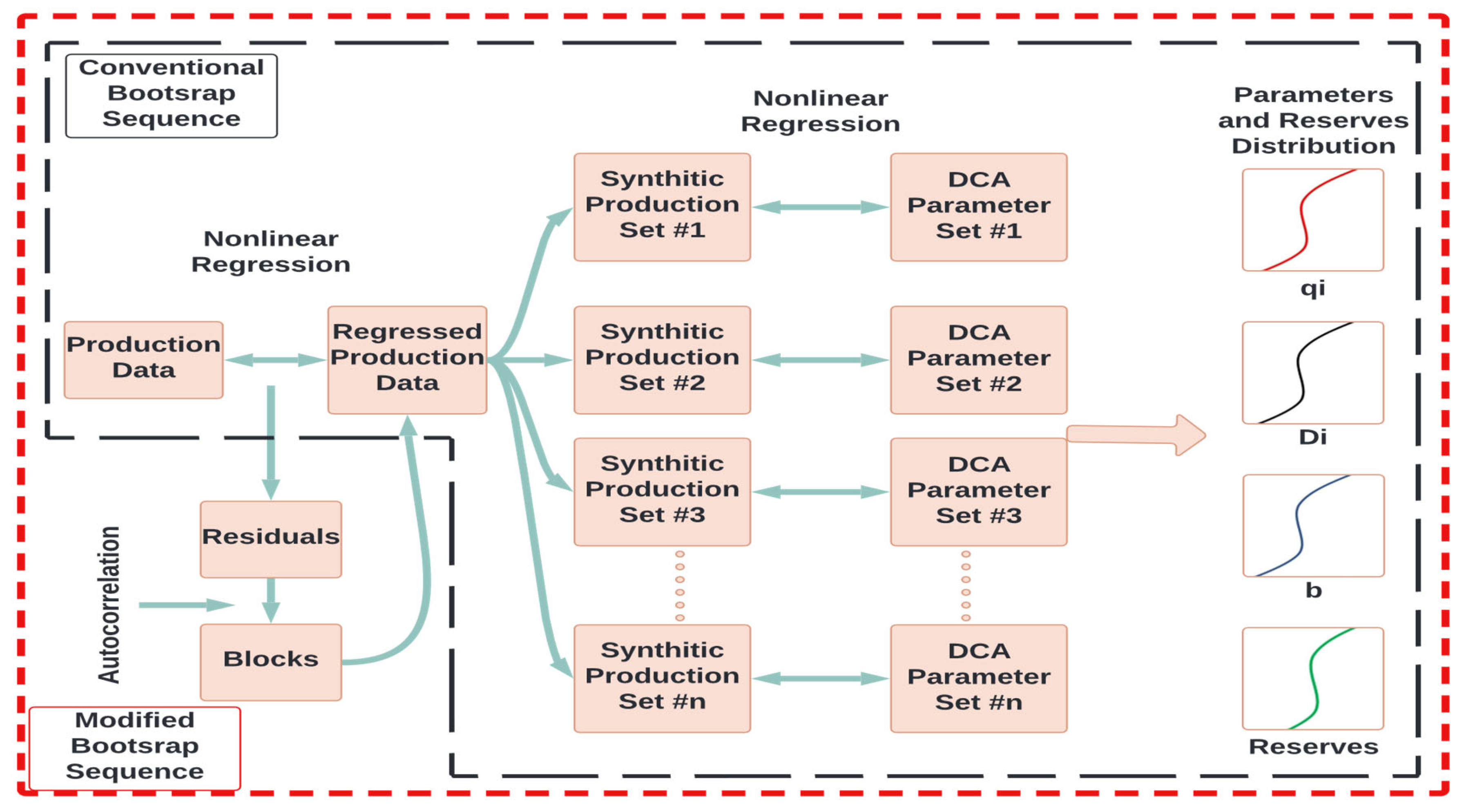
2.2. Cheng’s Approach (2010) [55]
2.3. Minin’s Approach (2011) [57]
2.4. Gong’s Approach (2011) [56]
2.5. Brito’s Approach (2012) [58]
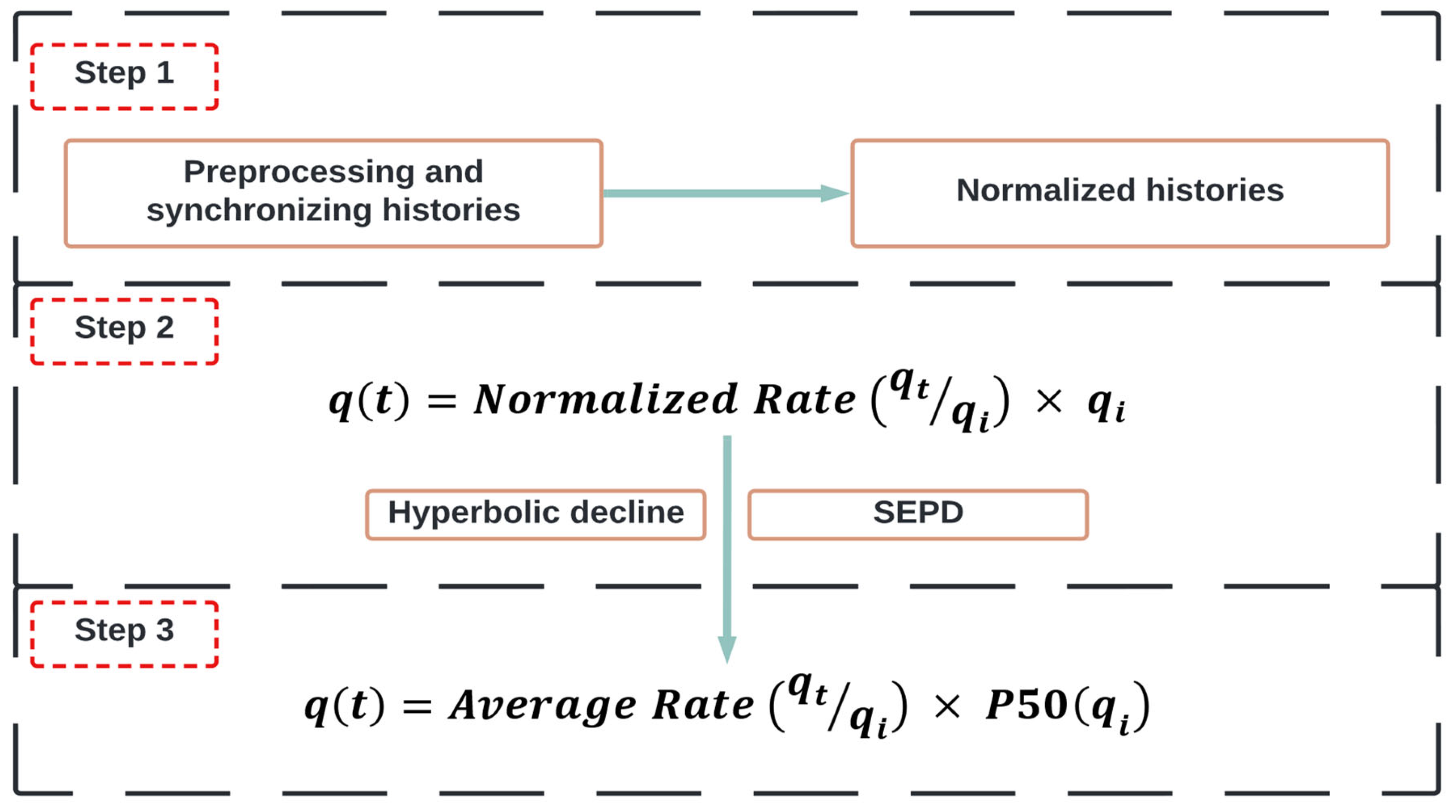
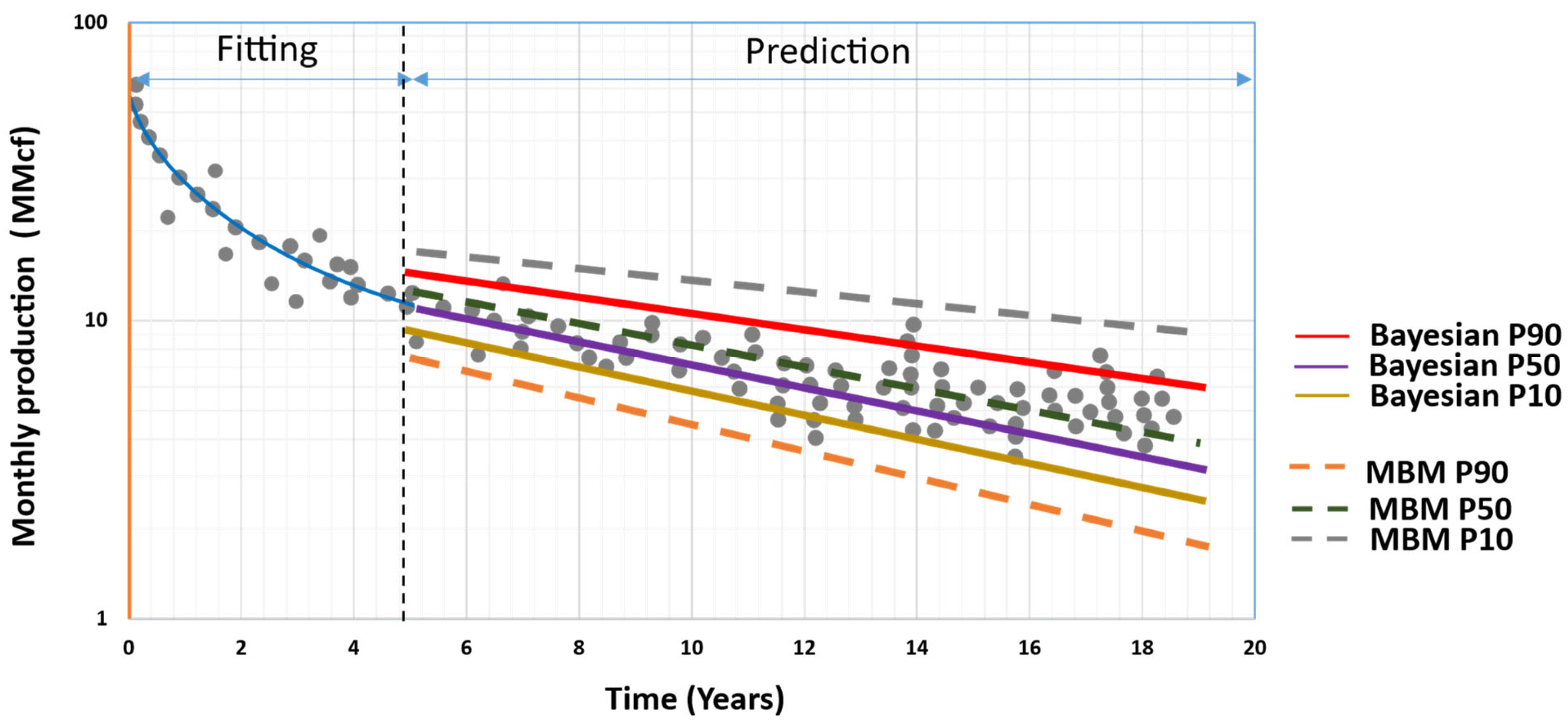
2.6. Gonzalez’s Approach (2012) [5]
2.7. Fanchi’s Approach (2013) [60]
2.8. Kim’s Approach (2014) [61]
2.9. Zhukovsky Approach (2016) [62]
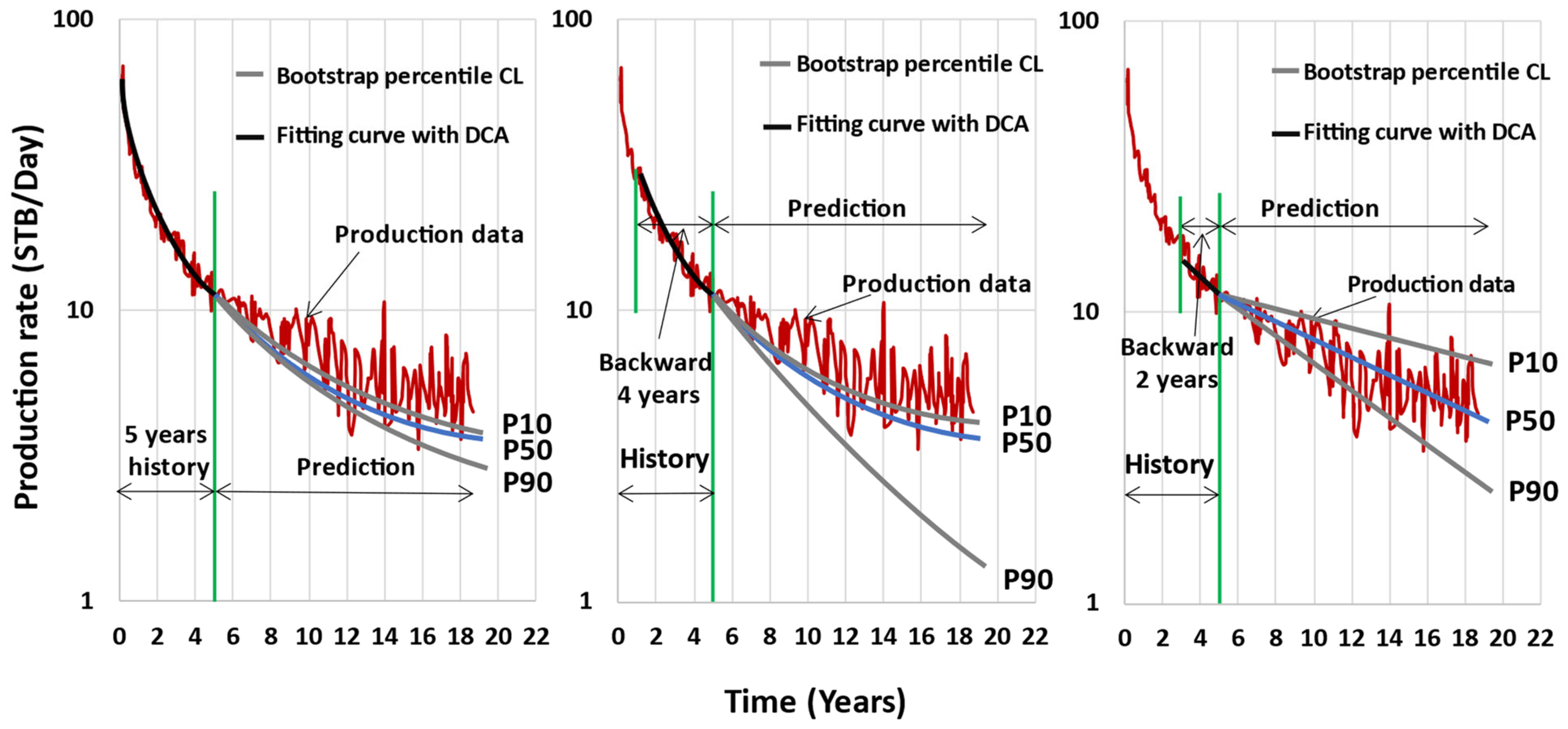
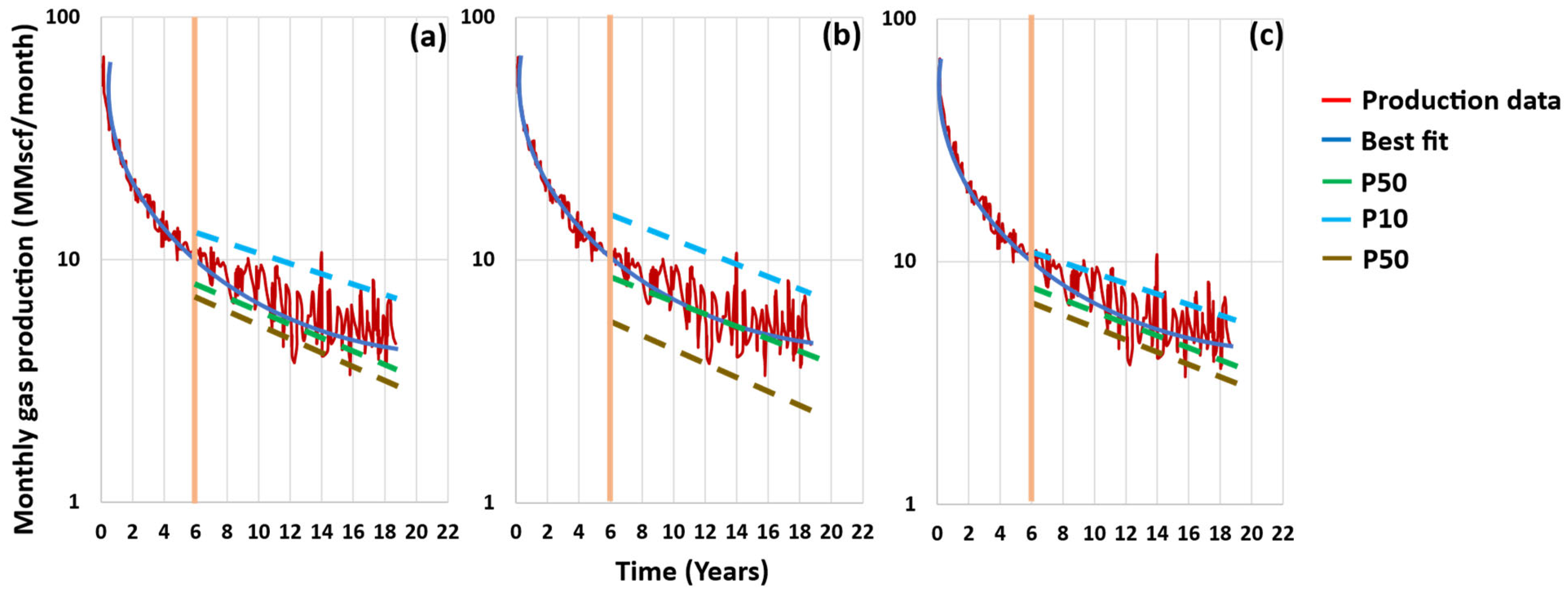
2.10. Paryani’s Approach (2017) [63]
2.11. Jimenez’s Approach (2017) [65]
2.12. Joshi’s Approach (2018) [34]
2.13. Hong’s Approach (2019) [66]
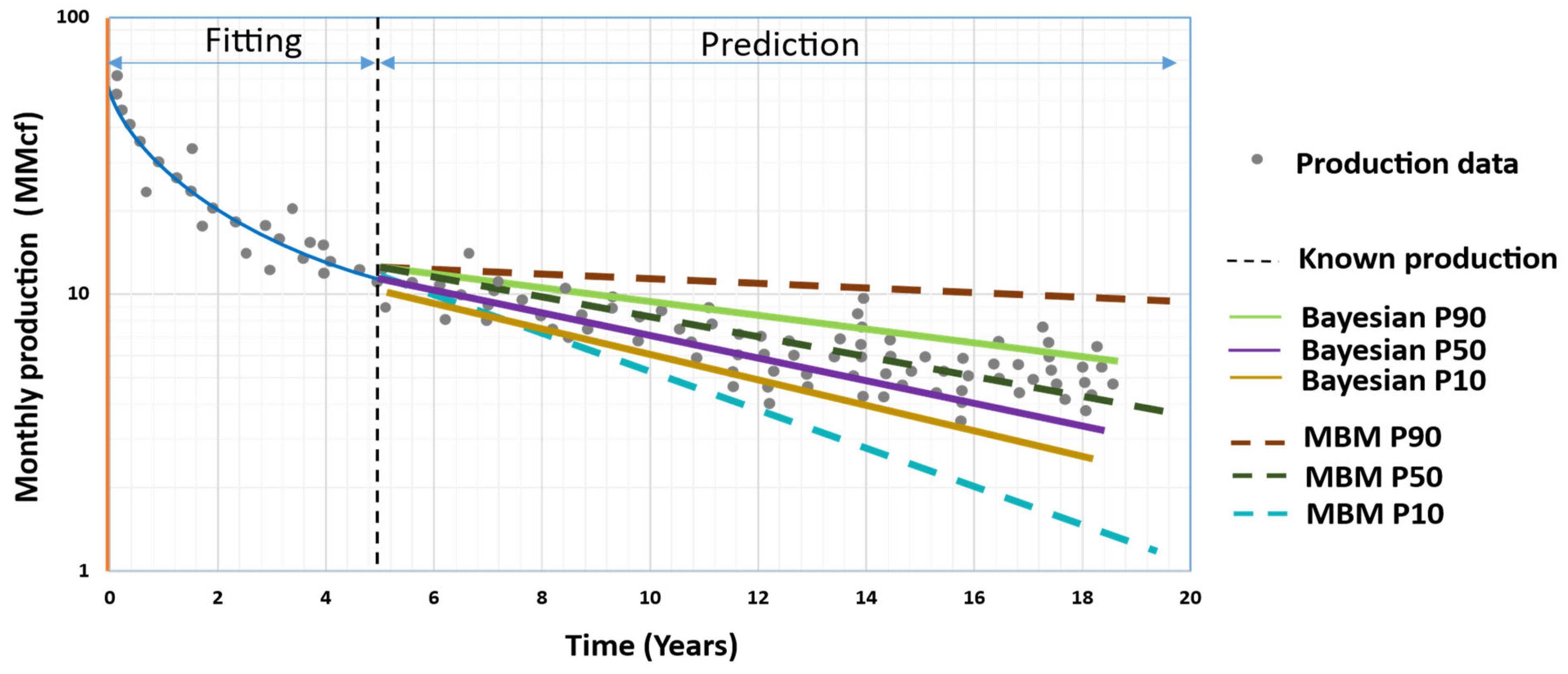
2.14. Fanchi’s New Approach (2020) [67]
2.15. Korde’s Approach (2021) [68]
3. Conclusions and Recommendations
- The main differences among them are: (1) the selected DCA model(s) combined with the pDCA approach, (2) the used sampling technique and the assumed probability distributions of the model’s parameters, (3) the domain of the study, and (4) the computational time for each approach.
- The probability techniques of the approaches are mainly Bayesian analyses and only a few approaches are frequentist analyses. A frequentist analysis has a larger computational time than a Bayesian one. In addition, a Bayesian analysis is more effective, given narrower CIs than in a frequentist one.
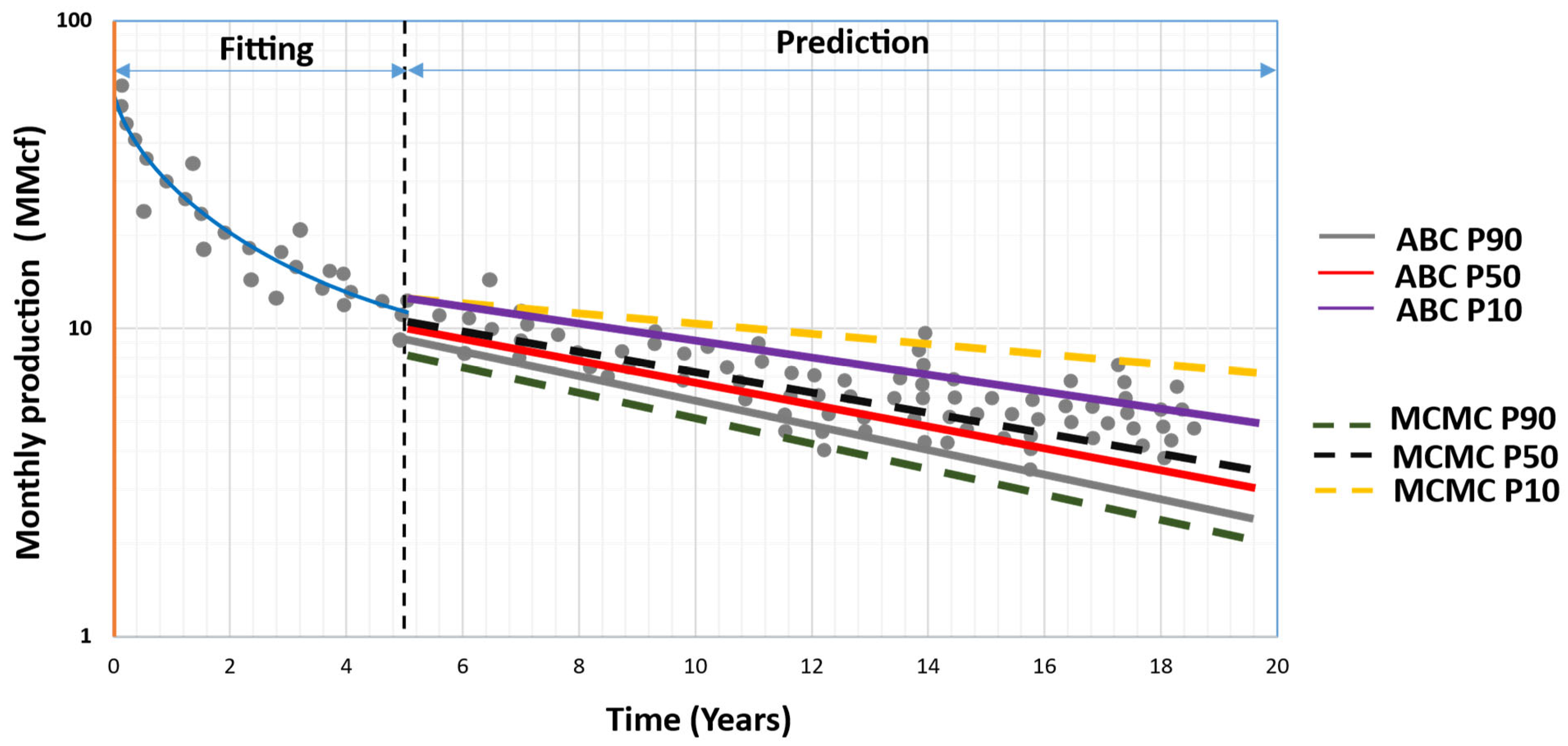
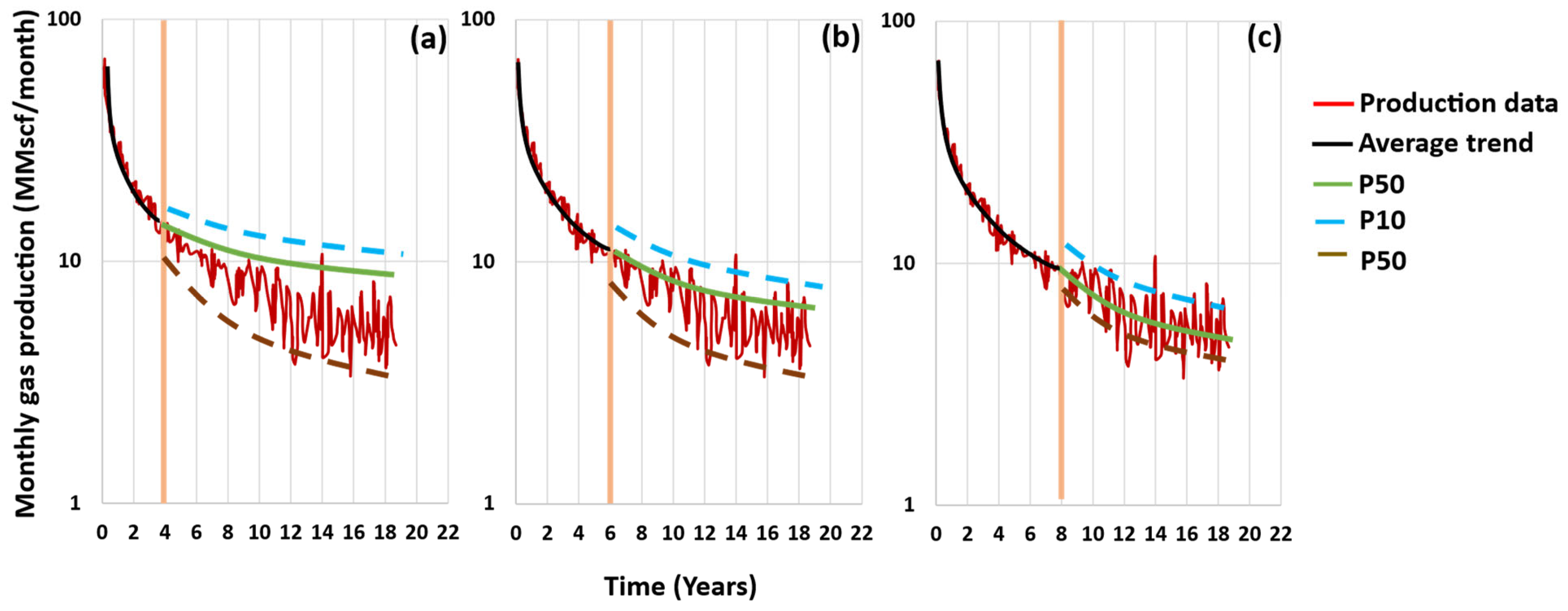
- The bounds of the CIs and the CR change when using a different decline curve model(s) and when using different sampling algorithms. The ABC algorithm was the best at bounding the CIs when it was used with the Arps’s model. The assumption that the parameters that undergo sampling follow a certain probability distribution is important. The uniform distribution was the most common among the various approaches. Other assumptions such as posterior approximation and maximum likelihood are highly recommended.
- pDCA helps in quantifying the uncertainties related to DCA. Ranges of the EUR with a certain level of confidence are better than one deterministic EUR value that might be over- or under-estimated. The narrower the CIs, the more effective the pDCA approach. The computational time is critical, especially with approaches such as those of Cheng and Gong. The number of iterations in sampling is critical. As the number of iterations increases, the uncertainties decrease, but the computational time increases.
- As a recommendation, the larger the production history, the narrower the CI. In addition, improving data quality before an analysis by removing the outlier from the production data will reduce uncertainties and improve forecasting. Using more than one DCA model can also help in improving accuracy.
4. Suggestions for Future Research and Development
- Data size and data quality are crucial for any analysis. Therefore, testing the sensitivity of some of the proposed approaches to different data sizes and data qualities is recommended to gain deep insights into their performance under such conditions.
- Data of the early production period have a great impact on the whole analysis for two main reasons: (1) at an early time, especially in shale hydrocarbons, changes in flow regimes are severe, and (2) the flowback period is too noisy and could last for a long time. As result, further investigations of the impacts of this period of data on pDCA are recommended in order to develop more robust approaches.
- Computational time is critical for such analysis and is greatly affected by the number of iterations, the data size, and the used sampling algorithm. Based on this, more investigation is recommended about: (1) the sampling techniques and their effectiveness, (2) which critical parameters of a model should undergo probability distribution, and (3) which is the most effective and reliable distribution for each parameter.
- It is recommended to comprehensively use the new advancements in machine learning algorithms and supercomputing, which are capable of dealing with pDCA and include other production records such as pressure, water cut, chock size, periodic liquid loading, etc. in the analysis, which could lead to great improvements in production forecasting.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Nomenclature
| ABC | Approximate Bayesian Computation |
| ARIMA | Auto-Regressive Integrated Moving Average |
| BDF | Boundary Dominated Flow |
| BHP | Bottom Hole Pressure |
| CDF | Cumulative Distribution Functions |
| CI | Confidence Interval |
| CR | Coverage Range |
| DCA | Decline Curve Analysis |
| EEDCA | Extended Exponential Decline Curve |
| EUR | Estimated Ultimate Recovery |
| IW | Interval Width |
| LGM | Logistic Growth Model |
| MBM | Modified Bootstrap Method |
| MC | Monte Carlo |
| MCMC | Marcov Chain Monte Carlo |
| MH | Metropolis-Hasting |
| OLS | Ordinary Least Squares |
| pDCA | Probabilistic Decline Curve Analysis |
| PDE | Production Decline Envelopes |
| PLE | Power Law Equation |
| SEPD | Stretched Exponential Decline Model |
| WLS | Weighted Least Squares |
| b | Decline-Curve Exponent |
| D | Decline Rate (Day−1) |
| Di | Initial Decline Rate (Day−1) |
| qi | Initial Flow Rate (bbl/D or scf/D) |
| t | Time (day) |
References
- Liang, H.-B.; Zhang, L.-H.; Zhao, Y.-L.; Zhang, B.-N.; Chang, C.; Chen, M.; Bai, M.-X. Empirical Methods of Decline-Curve Analysis for Shale Gas Reservoirs: Review, Evaluation, and Application. J. Nat. Gas Sci. Eng. 2020, 83, 103531. [Google Scholar] [CrossRef]
- Joshi, K.; Lee, J. Comparison of Various Deterministic Forecasting Techniques in Shale Gas Reservoirs. In Proceedings of the SPE Hydraulic Fracturing Technology Conference, The Woodlands, TX, USA, 4–6 February 2013; OnePetro: Richardson, TX, USA, 2013. [Google Scholar]
- Chen, Q.; Wang, N.; Ruan, K.; Zhang, M. Selection of Production Decline Analysis Method of Shale Gas Well. Reserv. Eval. Dev. 2018, 8, 76–79. [Google Scholar]
- Yuan, J.; Luo, D.; Feng, L. A Review of the Technical and Economic Evaluation Techniques for Shale Gas Development. Appl. Energy 2015, 148, 49–65. [Google Scholar] [CrossRef]
- Gonzalez, R.; Gong, X.; McVay, D. Probabilistic decline curve analysis reliably quantifies uncertainty in shale gas reserves regardless of stage of depletion. In Proceedings of the SPE Eastern Regional Meeting, Lexington, KY, USA, 3–5 October 2012. [Google Scholar] [CrossRef]
- Arps, J.J. Analysis of Decline Curves. Trans. AIME 1945, 160, 228–247. [Google Scholar] [CrossRef]
- Ahmed, T. Analysis of Decline and Type Curves. In Reservoir Engineering Handbook; Elsevier: Amsterdam, The Netherlands, 2019; pp. 1227–1310. ISBN 978-0-12-813649-2. [Google Scholar]
- Fetkovich, M.J. Decline-Curve Analysis Using Type Curves. SPE Form. Eval. 1980, 2, 637–656. [Google Scholar] [CrossRef]
- Rongze, Y.; Wei, J.; Xiaowei, Z.; Wei, G.; Li, W.; Jingping, Z.; Meizhu, W. A Review of Empirical Production Decline Analysis Methods for Shale Gas Reservoir. China Pet. Explor. 2018, 23, 9. [Google Scholar]
- Mahmoud, O.; Ibrahim, M.; Pieprzica, C.; Larsen, S. EUR Prediction for Unconventional Reservoirs: State of the Art and Field Case. In Proceedings of the SPE Trinidad and Tobago Section Energy Resources Conference, Port of Spain, Trinidad and Tobago, Virtual, 25 June 2018; OnePetro: Richardson, TX, USA, 2018. [Google Scholar]
- Mostafa, S.; Hamid, K.; Tantawi, M. Studying Modern Decline Curve Analysis Models for Unconventional Reservoirs to Predict Performance of Shale Gas Reservoirs. JUSST 2021, 23, 36. [Google Scholar]
- Yehia, T.; Khattab, H.; Tantawy, M.; Mahgoub, I. Improving the Shale Gas Production Data Using the Angular- Based Outlier Detector Machine Learning Algorithm. JUSST 2022, 24, 152–172. [Google Scholar]
- Ibrahim, M.; Mahmoud, O.; Pieprzica, C. A New Look at Reserves Estimation of Unconventional Gas Reservoirs. In Proceedings of the SPE/AAPG/SEG Unconventional Resources Technology Conference, Houston, TX, USA, 23 July 2018; OnePetro: Richardson, TX, USA, 2018. [Google Scholar]
- Zhang, R.; Zhang, L.; Tang, H.; Chen, S.; Zhao, Y.; Wu, J.; Wang, K. A Simulator for Production Prediction of Multistage Fractured Horizontal Well in Shale Gas Reservoir Considering Complex Fracture Geometry. J. Nat. Gas Sci. Eng. 2019, 67, 14–29. [Google Scholar] [CrossRef]
- You, X.-T.; Liu, J.-Y.; Jia, C.-S.; Li, J.; Liao, X.-Y.; Zheng, A.-W. Production Data Analysis of Shale Gas Using Fractal Model and Fuzzy Theory: Evaluating Fracturing Heterogeneity. Appl. Energy 2019, 250, 1246–1259. [Google Scholar] [CrossRef]
- Nwaobi, U.; Anandarajah, G. A Critical Review of Shale Gas Production Analysis and Forecast Methods. Saudi J. Eng. Technol. (SJEAT) 2018, 5, 276–285. [Google Scholar]
- Brantson, E.T.; Ju, B.; Ziggah, Y.Y.; Akwensi, P.H.; Sun, Y.; Wu, D.; Addo, B.J. Forecasting of Horizontal Gas Well Production Decline in Unconventional Reservoirs Using Productivity, Soft Computing and Swarm Intelligence Models. Nat. Resour. Res. 2019, 28, 717–756. [Google Scholar] [CrossRef]
- Wahba, A.; Khattab, H.; Gawish, A. A Study of Modern Decline Curve Analysis Models Based on Flow Regime Identification. JUSST 2022, 24, 26. [Google Scholar]
- Wahba, A.M.; Khattab, H.M.; Tantawy, M.A.; Gawish, A.A. Modern Decline Curve Analysis of Unconventional Reservoirs: A Comparative Study Using Actual Data. J. Pet. Min. Eng. 2022, 24, 51–65. [Google Scholar] [CrossRef]
- Yehia, T.; Khattab, H.; Tantawy, M.; Mahgoub, I. Removing the Outlier from the Production Data for the Decline Curve Analysis of Shale Gas Reservoirs: A Comparative Study Using Machine Learning. ACS Omega 2022, 7, 32046–32061. [Google Scholar] [CrossRef]
- Ahmed, T. Modern Decline Curve Analysis. In Reservoir Engineering Handbook; Elsevier: Amsterdam, The Netherlands, 2019; pp. 1389–1461. ISBN 978-0-12-813649-2. [Google Scholar]
- Cheng, Y. Improving Reserves Estimates From Decline-Curve Analysis of Tight and Multilayer Gas Wells. SPE Reserv. Eval. Eng. 2008, 11, 912–920. [Google Scholar] [CrossRef]
- Ilk, D.; Rushing, J.A.; Perego, A.D.; Blasingame, T.A. Exponential vs. Hyperbolic Decline in Tight Gas Sands: Understanding the Origin and Implications for Reserve Estimates Using Arps’ Decline Curves. In Proceedings of the SPE Annual Technical Conference and Exhibition, Denver, CO, USA, 21 September 2008; p. SPE-116731-MS. [Google Scholar]
- Ilk, D.; Perego, A.D.; Rushing, J.A.; Blasingame, T.A. Integrating Multiple Production Analysis Techniques To Assess Tight Gas Sand Reserves: Defining a New Paradigm for Industry Best Practices. In Proceedings of the CIPC/SPE Gas Technology Symposium 2008 Joint Conference, Calgary, AB, Canada, 16 June 2008; p. SPE-114947-MS. [Google Scholar]
- Valko, P.P. Assigning Value to Stimulation in the Barnett Shale: A Simultaneous Analysis of 7000 plus Production Hystories and Well Completion Records. In Proceedings of the SPE hydraulic fracturing technology conference, The Woodlands, TX, USA, 19 January 2009; OnePetro: Richardson, TX, USA, 2009. [Google Scholar]
- Valkó, P.P.; Lee, W.J. A Better Way to Forecast Production from Unconventional Gas Wells. In Proceedings of the SPE Annual Technical Conference and Exhibition, Florence, Italy, 19 September 2010; p. SPE-134231-MS. [Google Scholar]
- Duong, A.N. An Unconventional Rate Decline Approach for Tight and Fracture-Dominated Gas Wells. In Proceedings of the Canadian Unconventional Resources and International Petroleum Conference, Calgary, AB, Canada, 19 October 2010; p. SPE-137748-MS. [Google Scholar]
- Duong, A.N. Rate-Decline Analysis for Fracture-Dominated Shale Reservoirs. SPE Reserv. Eval. Eng. 2011, 14, 377–387. [Google Scholar] [CrossRef]
- Clark, A.J.; Lake, L.W.; Patzek, T.W. Production Forecasting with Logistic Growth Models. In Proceedings of the SPE Annual Technical Conference and Exhibition, Denver, CO, USA, 30 October 2011; p. SPE-144790-MS. [Google Scholar]
- Zhang, H.; Cocco, M.; Rietz, D.; Cagle, A.; Lee, J. An Empirical Extended Exponential Decline Curve for Shale Reservoirs. In Proceedings of the SPE Annual Technical Conference and Exhibition, Houston, TX, USA, 28 September 2015; p. D031S031R007. [Google Scholar]
- Wattenbarger, R.A.; El-Banbi, A.H.; Villegas, M.E.; Maggard, J.B. Production Analysis of Linear Flow Into Fractured Tight Gas Wells. In Proceedings of the SPE Rocky Mountain Regional/Low-Permeability Reservoirs Symposium, Denver, CO, USA, 5 April 1998; OnePetro: Richardson, TX, USA, 1998. [Google Scholar] [CrossRef]
- Mahmoud, O.; Elnekhaily, S.; Hegazy, G. Estimating Ultimate Recoveries of Unconventional Reservoirs: Knowledge Gained from the Developments Worldwide and Egyptian Challenges. Int. J. Ind. Sustain. Dev. 2020, 1, 60–70. [Google Scholar] [CrossRef]
- Yehia, T.; Wahba, A.; Mostafa, S.; Mahmoud, O. Suitability of Different Machine Learning Outlier Detection Algorithms to Improve Shale Gas Production Data for Effective Decline Curve Analysis. Energies 2022, 15, 8835. [Google Scholar] [CrossRef]
- Joshi, K.G.; Awoleke, O.O.; Mohabbat, A. Uncertainty Quantification of Gas Production in the Barnett Shale Using Time Series Analysis. In Proceedings of the SPE Western Regional Meeting, Garden Grove, CA, USA, 22 April 2018; OnePetro: Richardson, TX, USA, 2018. [Google Scholar]
- Yehia, T.; Abdelhafiz, M.M.; Hegazy, G.M.; Elnekhaily, S.A.; Mahmoud, O. A Comprehensive Review of Deterministic Decline Curve Analysis for Oil and Gas Reservoirs. Geoenergy Sci. Eng. 2023, 226, 211775. [Google Scholar] [CrossRef]
- Manda, P.; Nkazi, D.B. The Evaluation and Sensitivity of Decline Curve Modelling. Energies 2020, 13, 2765. [Google Scholar] [CrossRef]
- Martyushev, D.A.; Ponomareva, I.N.; Galkin, V.I. Conditions for Effective Application of the Decline Curve Analysis Method. Energies 2021, 14, 6461. [Google Scholar] [CrossRef]
- Maraggi, L.M.R.; Lake, L.W.; Lake, L.W.; Walsh, M.P. Bayesian Predictive Performance Assessment of Rate-Time Models for Unconventional Production Forecasting. In Proceedings of the 82nd EAGE Annual Conference & Exhibition, Amsterdam, The Netherlands, 18–21 October 2021. [Google Scholar] [CrossRef]
- Capen, E.C. Probabilistic Reserves! Here at Last? SPE Reserv. Eval. Eng. 2001, 4, 387–394. [Google Scholar] [CrossRef]
- Egbe, U.C.; Awoleke, O.O.; Olorode, O.; Goddard, S.D. On the Application of Probabilistic Decline Curve Analysis to Unconventional Reservoirs. SPE Reserv. Eval. Eng. 2022, 26, 1–17. [Google Scholar] [CrossRef]
- Asante, J.; Ampomah, W.; Rose-Coss, D.; Cather, M.; Balch, R. Probabilistic Assessment and Uncertainty Analysis of CO2 Storage Capacity of the Morrow B Sandstone—Farnsworth Field Unit. Energies 2021, 14, 7765. [Google Scholar] [CrossRef]
- Gelman, A.; Vehtari, A.; Simpson, D.; Margossian, C.C.; Carpenter, B.; Yao, Y.; Kennedy, L.; Gabry, J.; Bürkner, P.-C.; Modrák, M. Bayesian Workflow. arXiv 2020, arXiv:2011.01808. [Google Scholar] [CrossRef]
- Baluev, R.V. Comparing the Frequentist and Bayesian Periodic Signal Detection: Rates\n of Statistical Mistakes and Sensitivity to Priors. Mon. Not. R. Astron. Soc. 2022, 512, 5520–5534. [Google Scholar] [CrossRef]
- Yuhun, P.; Awoleke, O.O.; Goddard, S.D. Using Rate Transient Analysis and Bayesian Algorithms for Reservoir Characterization in Unconventional Gas Wells during Linear Flow. SPE Reserv. Eval. Eng. 2021, 24, 733–751. [Google Scholar] [CrossRef]
- Lambert, B. A Student’s Guide to Bayesian Statistics; Sage: Newcastle, UK, 2018; pp. 1–520. [Google Scholar]
- Maior, C.B.S.; Macedo, J.B.; Lins, I.D.; Moura, M.C.; Azevedo, R.V.; De Santana, J.M.M.; da Silva, M.J.; da Silva, M.F.; Magalhães, M.V.C. Bayesian Prior Distribution Based on Generic Data and Experts’ Opinion: A Case Study in the O&G Industry. J. Pet. Sci. Eng. 2021, 210, 109891. [Google Scholar] [CrossRef]
- Maraggi, L.M.R.; Lake, L.W.; Walsh, M.P. Using Bayesian Leave-One-Out and Leave-Future-Out Cross-Validation to Evaluate the Performance of Rate-Time Models to Forecast Production of Tight-Oil Wells. SPE Reserv. Eval. Eng. 2022, 25, 730–750. [Google Scholar] [CrossRef]
- Cummings, M.P.; Handley, S.A.; Myers, D.S.; Reed, D.L.; Rokas, A.; Winka, K. Comparing Bootstrap and Posterior Probability Values in the Four-Taxon Case. Syst. Biol. 2003, 52, 477–487. [Google Scholar] [CrossRef] [PubMed]
- Qian, S.S.; Stow, C.A.; Borsuk, M.E. On Monte Carlo Methods for Bayesian Inference. Ecol. Model. 2003, 159, 269–277. [Google Scholar] [CrossRef]
- Tillé, Y. Sampling Algorithms; Springer Series in Statistics; Springer: New York, NY, USA, 2006; ISBN 978-0-387-30814-2. [Google Scholar]
- Makarova, A.A.; Mantorova, I.V.; Kovalev, D.A.; Kutovoy, I.N. The Modeling of Mineral Water Fields Data Structure. In Proceedings of the 2021 IEEE Conference of Russian Young Researchers in Electrical and Electronic Engineering (ElConRus), St. Petersburg, Russia, 26–29 January 2021; pp. 517–521. [Google Scholar]
- Makarova, A.A.; Kaliberda, I.V.; Kovalev, D.A.; Pershin, I.M. Modeling a Production Well Flow Control System Using the Example of the Verkhneberezovskaya Area. In Proceedings of the 2022 Conference of Russian Young Researchers in Electrical and Electronic Engineering (ElConRus), Saint Petersburg, Russia, 25–28 January 2022; pp. 760–764. [Google Scholar]
- Martirosyan, A.V.; Ilyushin, Y.V. Modeling of the Natural Objects’ Temperature Field Distribution Using a Supercomputer. Informatics 2022, 9, 62. [Google Scholar] [CrossRef]
- Jochen, V.A.; Spivey, J.P. Probabilistic Reserves Estimation Using Decline Curve Analysis with the Bootstrap Method. In Proceedings of the SPE Annual Technical Conference and Exhibition, Denver, CO, USA, 6 October 1996; OnePetro: Richardson, TX, USA, 1996. [Google Scholar]
- Cheng, Y.; Wang, Y.; McVay, D.A.A.; Lee, W.J.J. Practical Application of a Probabilistic Approach to Estimate Reserves Using Production Decline Data. SPE Econ. Manag. 2010, 2, 19–31. [Google Scholar] [CrossRef]
- Gong, X.; Gonzalez, R.; McVay, D.A.; Hart, J.D. Bayesian Probabilistic Decline-Curve Analysis Reliably Quantifies Uncertainty in Shale-Well-Production Forecasts. SPE J. 2014, 19, 1047–1057. [Google Scholar] [CrossRef]
- Minin, A.; Guerra, L.; Colombo, I. Unconventional Reservoirs Probabilistic Reserve Estimation Using Decline Curves. In Proceedings of the International Petroleum Technology Conference, Bangkok, Thailand, 15 November 2011; p. IPTC-14801-MS. [Google Scholar]
- Brito, L.E.; Paz, F.; Belisario, D. Probabilistic Production Forecasts Using Decline Envelopes. In Proceedings of the SPE Latin America and Caribbean Petroleum Engineering Conference, Mexico City, Mexico, 16 April 2012; p. SPE-152392-MS. [Google Scholar]
- Gong, X.; Gonzalez, R.; McVay, D.; Hart, J. Bayesian Probabilistic Decline Curve Analysis Quantifies Shale Gas Reserves Uncertainty. In Proceedings of the Canadian Unconventional Resources Conference, Calgary, AB, Canada, 15 November 2011; p. SPE-147588-MS. [Google Scholar]
- Fanchi, J.R.; Cooksey, M.J.; Lehman, K.M.; Smith, A.; Fanchi, A.C.; Fanchi, C.J. Probabilistic Decline Curve Analysis of Barnett, Fayetteville, Haynesville, and Woodford Gas Shales. J. Pet. Sci. Eng. 2013, 109, 308–311. [Google Scholar] [CrossRef]
- Kim, J.-S.; Shin, H.-J.; Lim, J.-S. Application of a Probabilistic Method to the Forecast of Production Rate Using a Decline Curve Analysis of Shale Gas Play. In Proceedings of the Twenty-Fourth International Ocean and Polar Engineering Conference, Busan, Republic of Korea, 15–20 June 2014; p. ISOPE-I-14-158. [Google Scholar]
- Zhukovsky, I.D.; Mendoza, R.C.; King, M.J.; Lee, W.J. Uncertainty Quantification in the EUR of Eagle Ford Shale Wells Using Probabilistic Decline-Curve Analysis with a Novel Model. In Proceedings of the Abu Dhabi International Petroleum Exhibition & Conference, Abu Dhabi, United Arab Emirates, 7 November 2016; p. D021S049R005. [Google Scholar]
- Paryani, M. Approximate Bayesian Computation for Probabilistic Decline Curve Analysis in Unconventional Reservoirs. Master’s Thesis, University of Alaska Fairbanks, College, AK, USA, 2015. Available online: https://hdl.handle.net/11122/6383 (accessed on 15 December 2022).
- Paryani, M.; Awoleke, O.O.; Ahmadi, M.; Hanks, C.; Barry, R. Approximate Bayesian Computation for Probabilistic Decline-Curve Analysis in Unconventional Reservoirs. SPE Reserv. Eval. Eng. 2017, 20, 478–485. [Google Scholar] [CrossRef]
- Jiménez, E.T.; Cervantes, R.J.; Magnelli, D.E.; Dabrowski, A. Probabilistic Approach of Advanced Decline Curve Analysis for Tight Gas Reserves Estimation Obtained from Public Data Base. In Proceedings of the SPE Latin America and Caribbean Petroleum Engineering Conference, Buenos Aires, Argentina, 17 May 2017; p. D021S009R006. [Google Scholar]
- Hong, A.; Bratvold, R.B.; Lake, L.W.; Ruiz Maraggi, L.M. Integrating Model Uncertainty in Probabilistic Decline-Curve Analysis for Unconventional-Oil-Production Forecasting. SPE Reserv. Eval. Eng. 2019, 22, 861–876. [Google Scholar] [CrossRef]
- Fanchi, J. Decline Curve Analysis of Shale Oil Production Using a Constrained Monte Carlo Technique. J. Basic Appl. Sci. 2020, 16, 61–67. [Google Scholar] [CrossRef]
- Korde, A.; Goddard, S.D.; Awoleke, O.O. Probabilistic Decline Curve Analysis in the Permian Basin Using Bayesian and Approximate Bayesian Inference. SPE Reserv. Eval. Eng. 2021, 24, 536–551. [Google Scholar] [CrossRef]










| Simulation Technique | Types of Statistic Analysis | Sampling Algorithms | |
|---|---|---|---|
| MC | Frequentist |
| |
| Bayesian |
| ||
| MCMC | Bayesian | Posterior sampling | |
| Likelihood-based | Nonlikelihood-based | ||
|
| ||
| Jochen’s Approach | Cheng’s Approach |
|---|---|
| Uses bootstrap as a sampling technique | |
| Uses Arps’ models as the DCA model | |
| Assumes no correlation between the data points | Assumes a time-series-data structure |
| Resampled the original data | Resampled the fitted data obtained from a DCA model (Arps) |
| Random samples from the original data are generated | Samples are generated based on autocorrelated residual blocks |
| pDCA Model | Probabilistic Technique | Sampling Technique(s) | No. of Integrations | Computational Time | Used Probability Distribution |
|---|---|---|---|---|---|
| Jochen (1996) | Frequentist Analysis | MC Bootstrap | >100 | 6.5 h | - |
| Cheng (2010) | Frequentist Analysis | MC Bootstrap | More than 6.5 h | - | |
| Minin (2011) | Bayesian Analysis | MC Latin Hypercube | - | - | Uniform |
| Brito (2012) | Bayesian Analysis | MC | - | - | Uniform |
| Gong (2011) | Bayesian Analysis | MCMC MH | 2000 | 25 min | Approximate posterior |
| Gonzalez (2012) | Bayesian Analysis | MCMC MH | 1000 | 25 min | Approximate posterior |
| Fanchi (2013) | Bayesian Analysis | MC | 1000 | - | Uniform |
| Kim (2014) | Bayesian Analysis | MC | 5000 | - | Triangle |
| Zhukovsky (2016) | Bayesian Analysis | MCMC MH | 100,000 | 25 min | Approximate posterior |
| Paryani (2017) | Bayesian Analysis | MCMC ABC MC ABC Rejection ABC | 10,000 | Faster than Gong (2011) | Likelihood-free approximation |
| Jimenez (2017) | Bayesian Analysis | MC | - | - | Chi-square |
| Joshi (2018) | Frequentist Analysis | Time series | |||
| Hong (2019) | Bayesian Analysis | MC | - | - | Uniform |
| Fanchi (2020) | Bayesian Analysis | MC | 1000 | - | Uniform |
| Korde (2021) | Bayesian Analysis | MCMC Gibbs MH ABC | 20,000 | 5–25 s | Likelihood |
| pDCA Model | The Study Domain | The Combined DCA Model(s) | Reference | ||
| Jochen (1996) | Conventional oil wells, two different fields | Arps | [54] | ||
| Cheng (2010) | Conventional mature oil and gas wells; 100 wells | Arps | [55] | ||
| Minin (2011) | Shale gas reservoirs; 150 gas wells | Arps | [57] | ||
| Brito (2012) | Conventional oil wells | PDE | [58] | ||
| Gong (2011) | Shale gas reservoirs; 197 gas wells | Arps | [56] | ||
| Gonzalez (2012) | Shale gas reservoirs; 197 gas wells | Arps, PLE, SEPD, and Duong | [5] | ||
| Fanchi (2013) | Shale gas reservoirs; 110 gas wells | Arps and SEPD | [60] | ||
| Kim (2014) | Shale gas reservoirs; 4 gas wells | Arps, SEPD, and PDE | [61] | ||
| Zhukovsky Approach (2016) | Shale reservoirs; 199 shale oil wells | EEDCA | [62] | ||
| Paryani (2017) | Unconventional reservoirs; 21 oil wells (Eagle Ford) and 100 gas wells (Barnett Shale) | Arps and LGM | [63,64] | ||
| Jimenez Approach (2017) | Tight gas reservoir; 1 gas well | Arps, SEPD, PLE, LGM, and Duong | [65] | ||
| Joshi Approach (2018) | Shale reservoirs; 100 shale gas wells | LGM and SEPD | [34] | ||
| Hong (2019) | Unconventional shale oil; Bakken field, 28 wells, and Midland field, 31 wells | Arps, SEPD, LGM, and Pan | [66] | ||
| Fanchi (2020) | Unconventional shale oil; Bakken field, 9 wells, and Eagle Ford, 6 wells | Arps and SEPD | [67] | ||
| Korde (2021) | Conventional and unconventional reservoirs; 23 oil wells and 51 gas wells | Arps, SEPD, PLE, Duong, and LGM | [68] | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yehia, T.; Naguib, A.; Abdelhafiz, M.M.; Hegazy, G.M.; Mahmoud, O. Probabilistic Decline Curve Analysis: State-of-the-Art Review. Energies 2023, 16, 4117. https://doi.org/10.3390/en16104117
Yehia T, Naguib A, Abdelhafiz MM, Hegazy GM, Mahmoud O. Probabilistic Decline Curve Analysis: State-of-the-Art Review. Energies. 2023; 16(10):4117. https://doi.org/10.3390/en16104117
Chicago/Turabian StyleYehia, Taha, Ahmed Naguib, Mostafa M. Abdelhafiz, Gehad M. Hegazy, and Omar Mahmoud. 2023. "Probabilistic Decline Curve Analysis: State-of-the-Art Review" Energies 16, no. 10: 4117. https://doi.org/10.3390/en16104117